
Functional Time Series Analysis Using Single-Index L1-Modal Regression


Abstract
1. Introduction
2. Robust Estimator of the Modal-Regression in FSI Structure
3. Main Results
- (AS1)
- . Furthermore, as .
- (AS2)
- The functions is of class and such that the following Lipschitz’s condition is satisfied:
- (AS3)
- The sequence satisfies and
- (AS4)
- is a function with support such that .
- (AS5)
- There exists such thatwhere
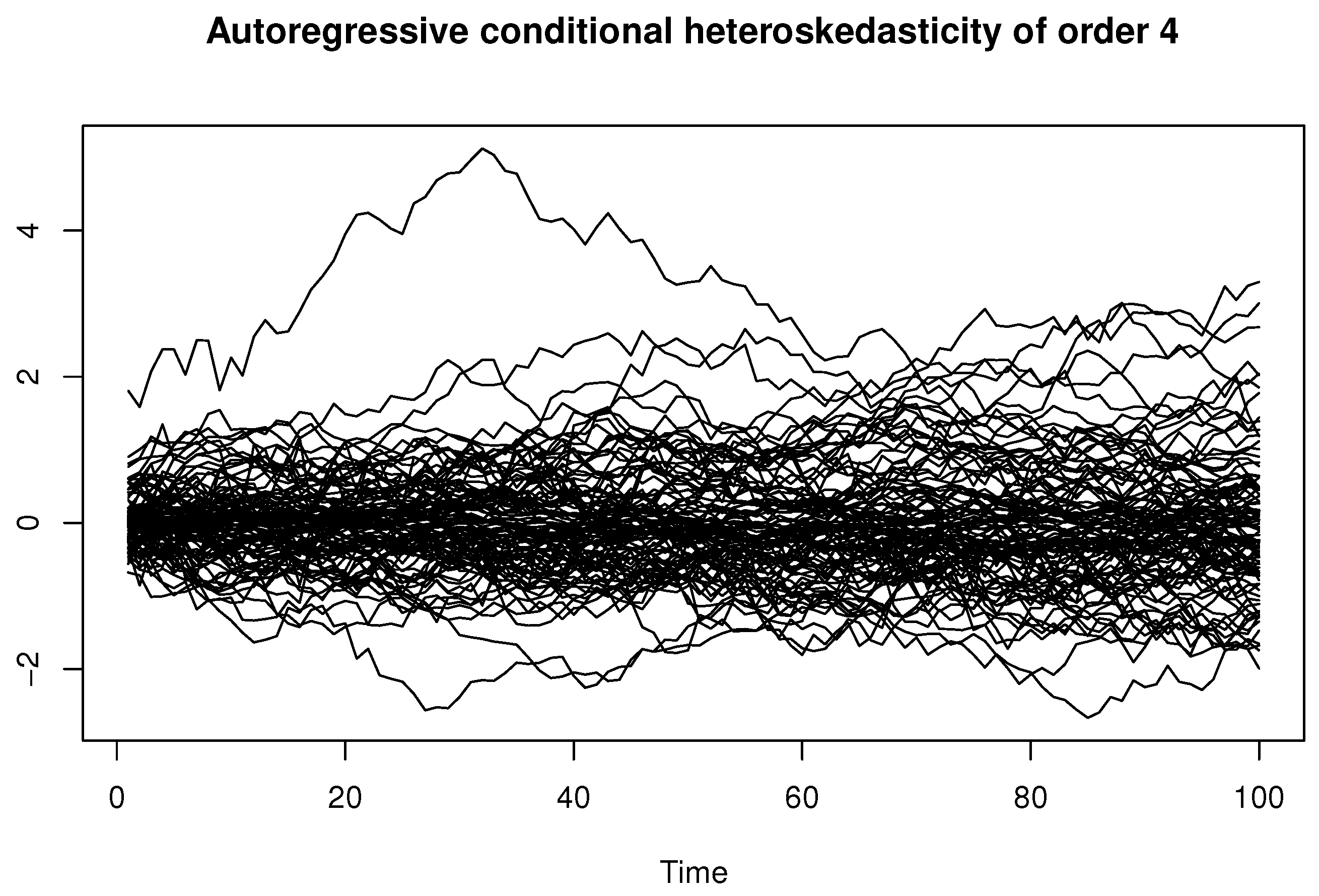
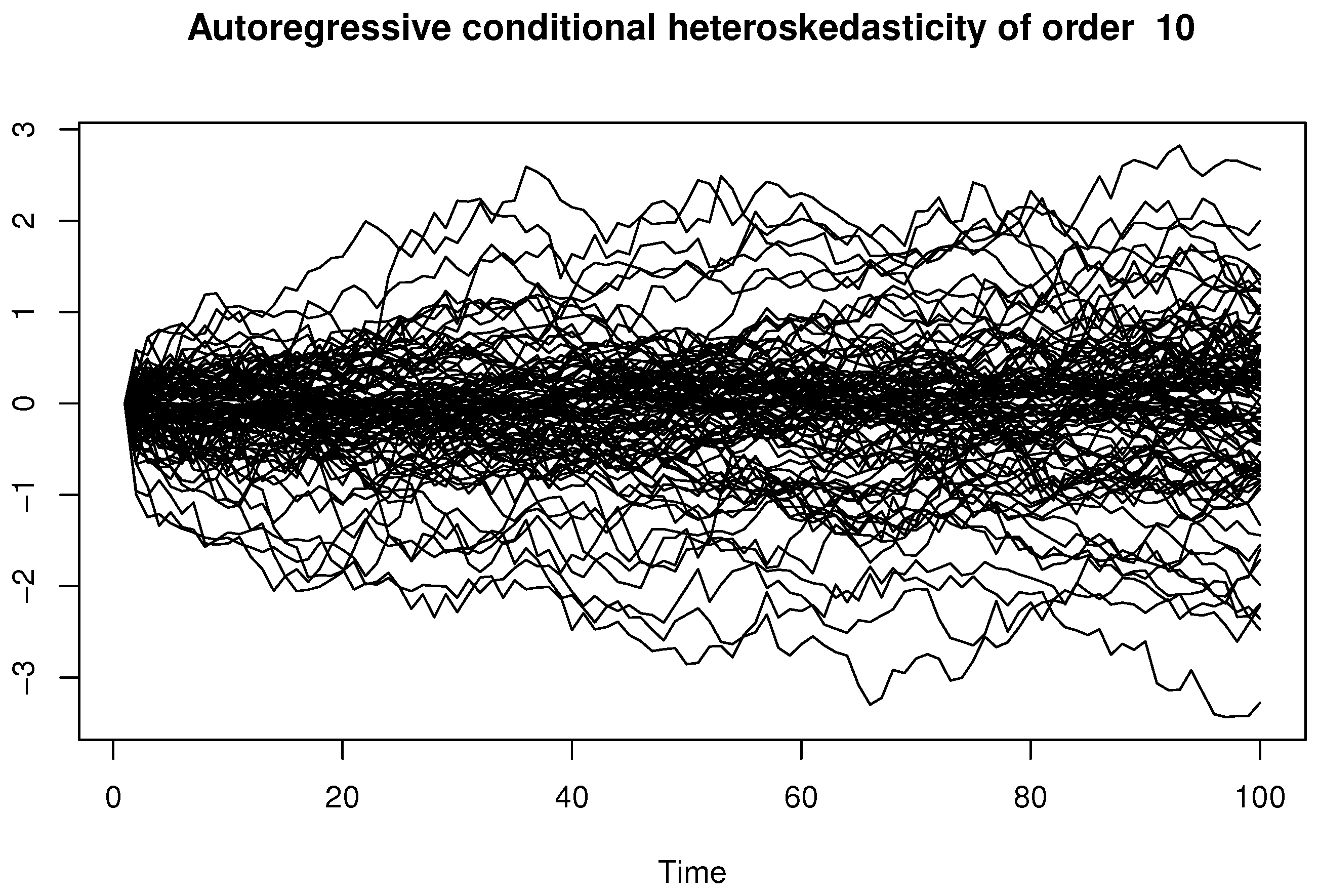
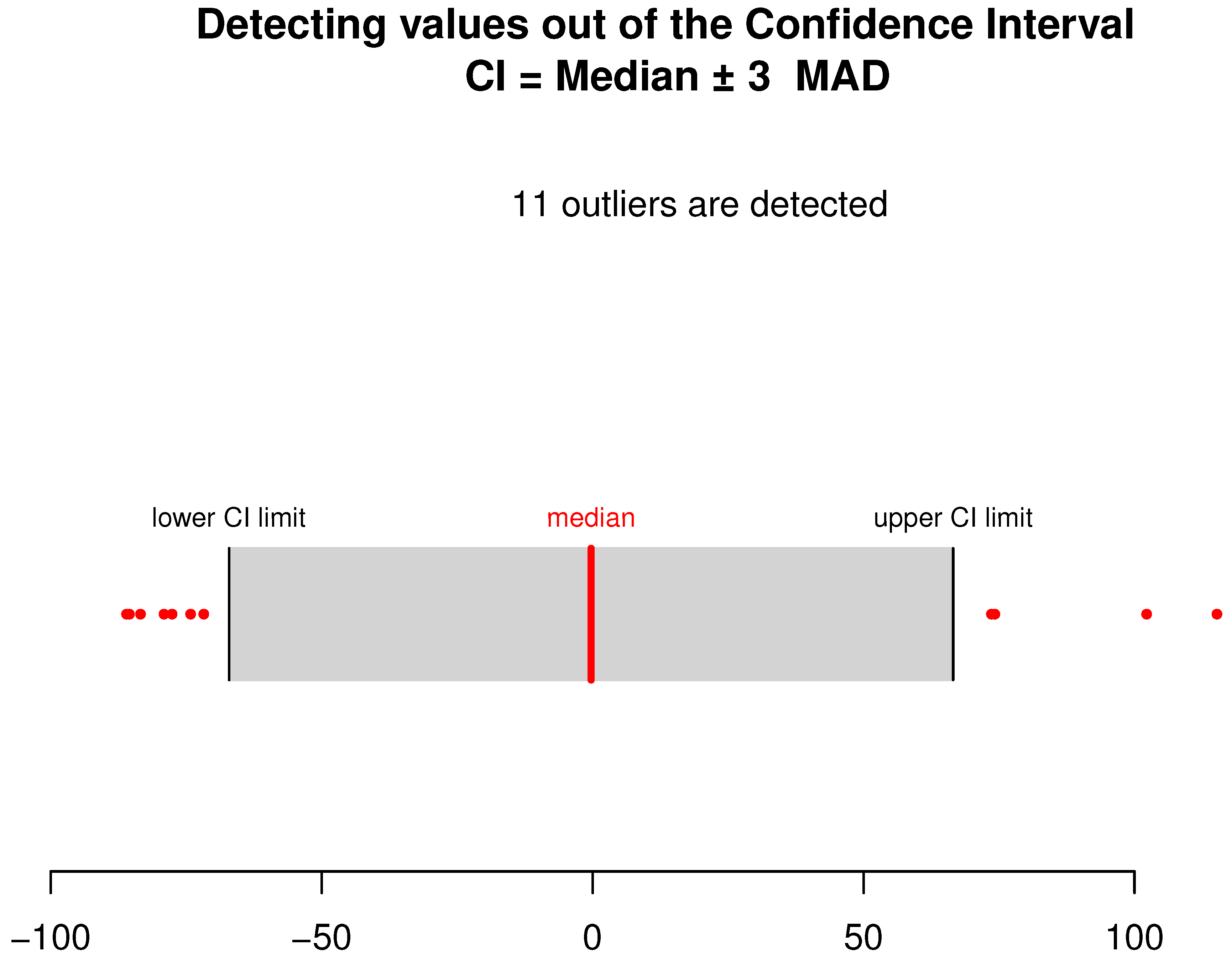
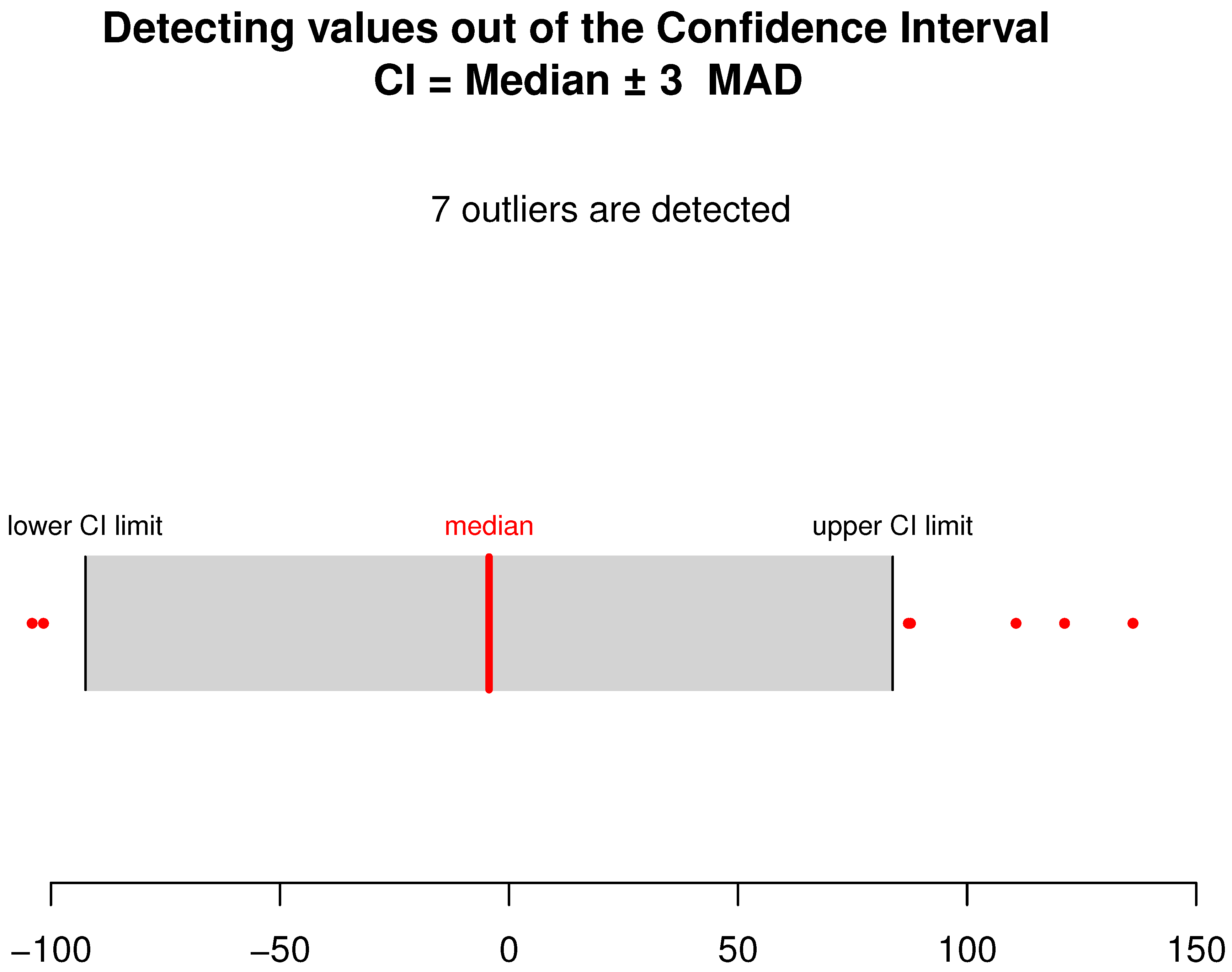
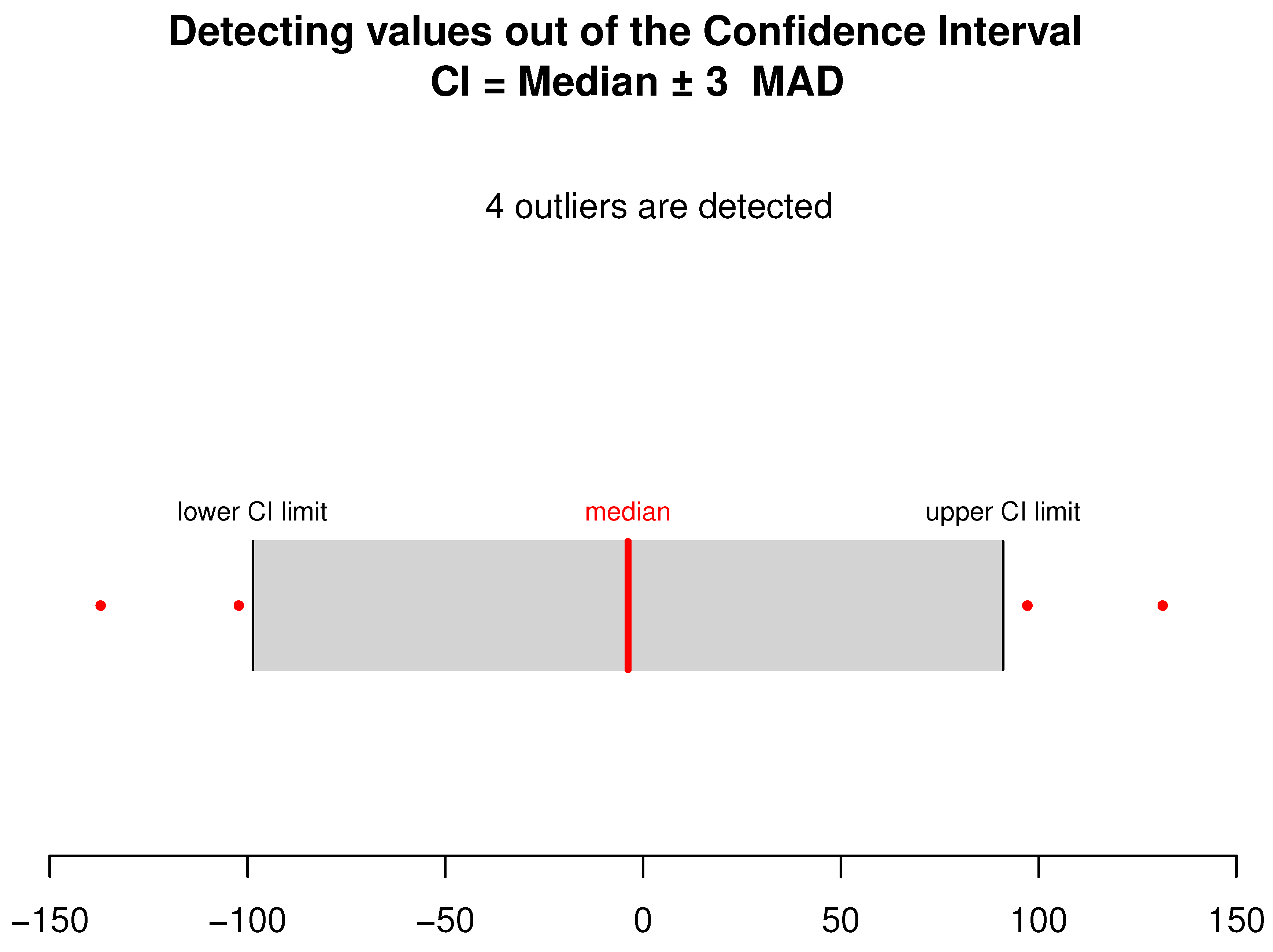
4. Computational Study
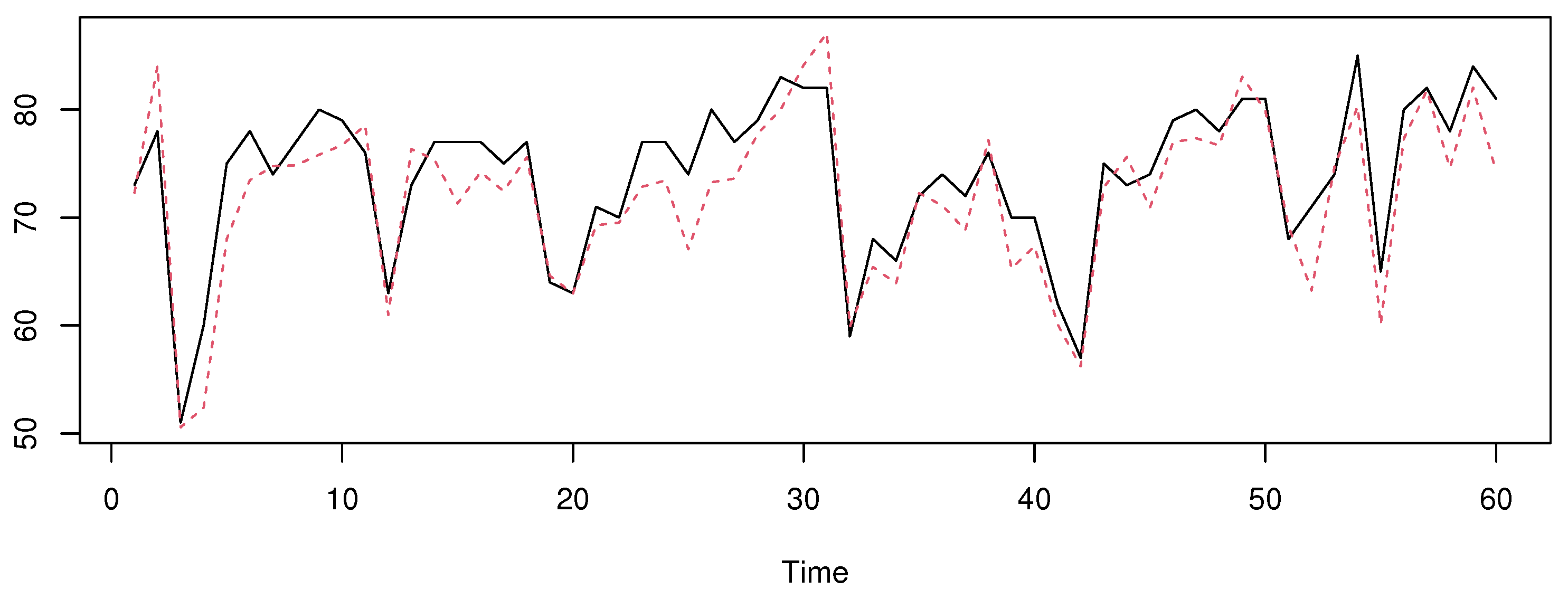
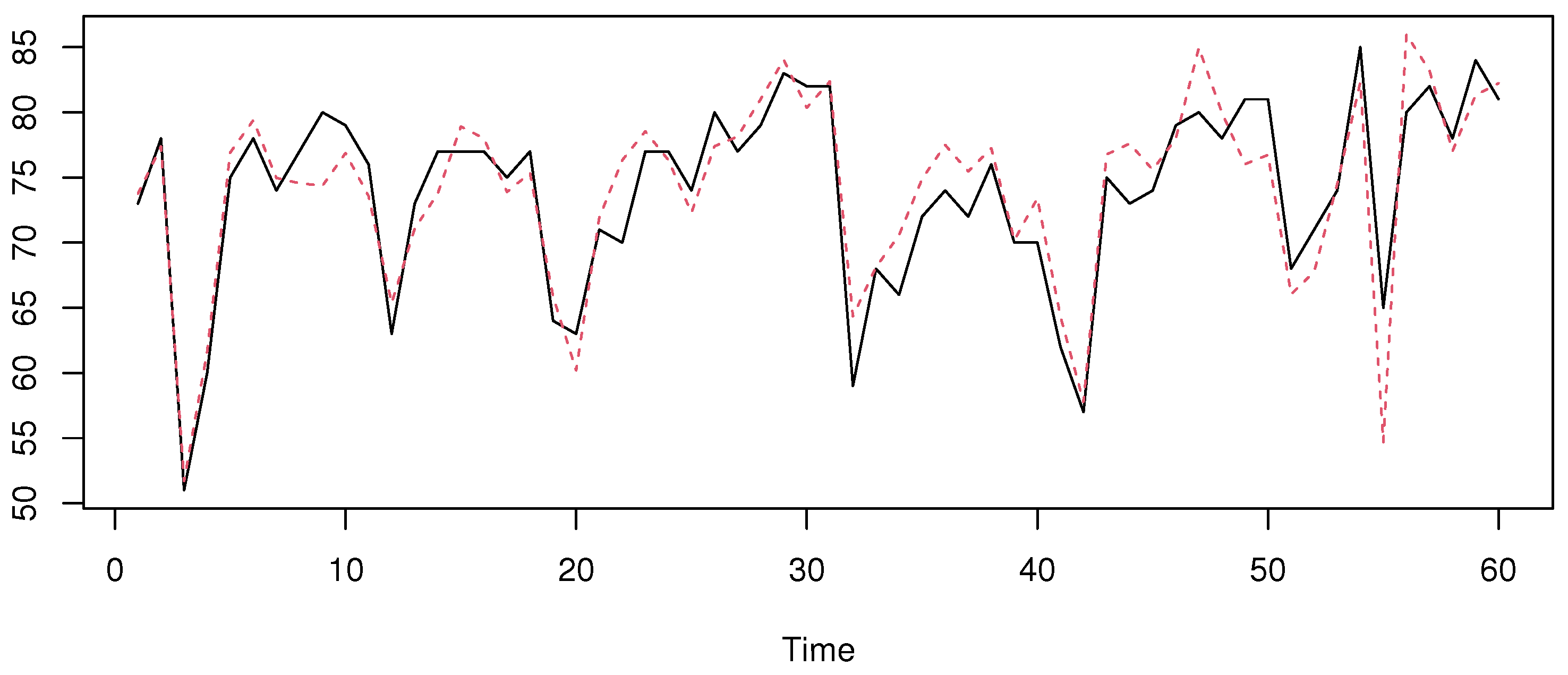
5. Real Data Example
6. Conclusions and Prospects
7. The Mathematical Development
Author Contributions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Collomb, G.; Härdle, W.; Hassani, S. A note on prediction via estimation of conditional mode function. J. Statist. Plan. Inf. 1987, 15, 227–236. [Google Scholar] [CrossRef]
- Härdle, W.; Hall, P.; Ichimura, H. Optimal smoothing in single-index models. Ann. Statist. 1993, 21, 157–178. [Google Scholar] [CrossRef]
- Stute, W.; Zhu, L.-X. Nonparametric checks for single-index models. Ann. Statist. 2005, 33, 1048–1083. [Google Scholar] [CrossRef]
- Tang, Q.; Kong, L.; Rupper, D.; Karunamuni, R.J. Partial functional partially linear single-index models. Statist. Sin. 2021, 31, 107–133. [Google Scholar] [CrossRef]
- Zhou, W.; Gao, J.; Harris, D.; Kew, H. Semi-parametric single-index predictive regression models with cointegrated regressors. J. Econom. 2024, 238, 105577. [Google Scholar] [CrossRef]
- Zhu, H.; Zhang, R.; Liu, Y.; Ding, H. Robust estimation for a general functional single index model via quantile regression. J. Korean Stat. Soc. 2022, 51, 1041–1070. [Google Scholar] [CrossRef]
- Ferraty, F.; Peuch, A.; Vieu, P. Modèle à indice fonctionnel simple. Comptes Rendus Math. 2003, 336, 1025–1028. [Google Scholar] [CrossRef]
- Ait-Saïdi, A.; Ferraty, F.; Kassa, R.; Vieu, P. Cross-validated estimations in the single-functional index model. Statistics 2008, 42, 475–494. [Google Scholar] [CrossRef]
- Jiang, Z.; Huang, Z.; Zhang, J. Functional single-index composite quantile regression. Metrika 2023, 86, 595–603. [Google Scholar] [CrossRef]
- Nie, Y.; Wang, L.; Cao, J. Estimating functional single index models with compact support. Environmetrics 2023, 34, e2784. [Google Scholar] [CrossRef]
- Chen, D.; Hall, P.; Müller, H.-G. Single and multiple index functional regression models with nonparametric link. Ann. Statist. 2011, 39, 1720–1747. [Google Scholar] [CrossRef]
- Ling, N.; Xu, Q. Asymptotic normality of conditional density estimation in the single index model for functional time series data. Statist. Probab. Lett. 2012, 82, 2235–2243. [Google Scholar] [CrossRef]
- Attaoui, S. On the nonparametric conditional density and mode estimates in the single functional index model with strongly mixing data. Sankhya A 2014, 76, 356–378. [Google Scholar] [CrossRef]
- Han, Z.-C.; Lin, J.-G.; Zhao, Y.-Y. Adaptive semiparametric estimation for single index models with jumps. Comput. Stat. Data Anal. 2020, 151, 107013. [Google Scholar] [CrossRef]
- Hao, M.; Liu, K.Y.; Su, W.; Zhao, X. Semiparametric estimation for the functional additive hazards model. Can. J. Stat. 2024, 52, 755–782. [Google Scholar] [CrossRef]
- Kowal, D.R.; Canale, A. Semiparametric Functional Factor Models with Bayesian Rank Selection. Bayesian Anal. 2023, 18, 1161–1189. [Google Scholar] [CrossRef]
- Ferraty, F.; Vieu, P. Nonparametric Functional Data Analysis; Springer: New York, NY, USA, 2006. [Google Scholar]
- Azzedine, N.; Laksaci, A.; Ould-Saïd, E. On robust nonparametric regression estimation for functional regressor. Stat. Probab. Lett. 2008, 78, 3216–3221. [Google Scholar] [CrossRef]
- Barrientos-Marin, J.; Ferraty, F.; Vieu, P. Locally modelled regression and functional data. J. Nonparametric Stat. 2010, 22, 617–632. [Google Scholar] [CrossRef]
- Demongeot, J.; Hamie, A.; Laksaci, A.; Rachdi, M. Relative-error prediction in nonparametric functional statistics: Theory and practice. J. Multivar. Anal. 2016, 146, 261–268. [Google Scholar] [CrossRef]
- Ezzahrioui, M.; Ouldsaïd, E. Asymptotic normality of a nonparametric estimator of the conditional mode function for functional data. J. Nonparametric Stat. 2008, 20, 3–18. [Google Scholar] [CrossRef]
- Ezzahrioui, M.; Ould-Said, E. Some asymptotic results of a non-parametric conditional mode estimator for functional time-series data. Stat. Neerl. 2010, 64, 171–201. [Google Scholar] [CrossRef]
- Dabo-Niang, S.; Laksaci, A. Estimation non paramétrique du mode conditionnel pour variable explicative fonctionnelle. Pub. Inst. Stat. Univ. Paris 2007, 3, 27–42. [Google Scholar] [CrossRef]
- Dabo-Niang, S.; Kaid, Z.; Laksaci, A. Asymptotic properties of the kernel estimate of spatial conditional mode when the regressor is functional. AStA Adv. Stat. Anal. 2015, 99, 131–160. [Google Scholar] [CrossRef]
- Ling, N.; Liu, Y.; Vieu, P. Conditional mode estimation for functional stationary ergodic data with responses missing at random. Statistics 2016, 50, 991–1013. [Google Scholar] [CrossRef]
- Bouanani, O.; Rahmani, S.; Laksaci, A.; Rachdi, M. Asymptotic normality of conditional mode estimation for functional dependent data. Indian J. Pure Appl. Math. 2020, 51, 465–481. [Google Scholar] [CrossRef]
- Engle, R.F. Autoregressive conditional heteroskedasticity with estimates of the variance of U.K. inflation. Econometrica 1982, 50, 987–1007. [Google Scholar] [CrossRef]
- Jones, D.A. Nonlinear autoregressive processes. Proc. Roy. Soc. A 1978, 360, 71–95. [Google Scholar]
- Bollerslev, T. General autoregressive conditional heteroskedasticity. J. Econom. 1986, 31, 307–327. [Google Scholar] [CrossRef]
- Leys, C.; Ley, C.; Klein, O.; Bernard, P.; Licata, L. Detecting outliers: Do not use standard deviation around the mean, use absolute deviation around the median. J. Exp. Soc. Psychol. 2013, 49, 764–766. [Google Scholar] [CrossRef]
- Febrero, M.; Galeano, P.; González-Manteiga, W. Outlier detection in functional data by depth measures with application to identify abnormal NOx levels. Environmetrics 2008, 19, 331–345. [Google Scholar] [CrossRef]
- Azzi, A.; Belguerna, A.; Laksaci, A.; Rachdi, M. The scalar-on-function modal regression for functional time series data. J. Nonparametric Stat. 2024, 36, 503–526. [Google Scholar] [CrossRef]





{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| The White Noise Distribution | n | p | Outliers Case | ||
|---|---|---|---|---|---|
| Laplace distribution | 50 | 1 | with outliers | 2.43 | 1.37 |
| 1 | without outliers | 1.06 | 0.51 | ||
| 4 | with outliers | 7.92 | 2.29 | ||
| 4 | without outliers | 1.41 | 0.39 | ||
| 10 | with outliers | 7.82 | 2.92 | ||
| 10 | without outliers | 1.95 | 0.52 | ||
| 100 | 1 | with outliers | 2.36 | 1.29 | |
| 1 | without outliers | 0.98 | 0.43 | ||
| 4 | with outliers | 7.61 | 2.17 | ||
| 4 | without outliers | 1.32 | 0.28 | ||
| 10 | with outliers | 7.66 | 2.84 | ||
| 10 | without outliers | 1.89 | 0.39 | ||
| 250 | 1 | with outliers | 2.17 | 1.07 | |
| 1 | without outliers | 0.84 | 0.32 | ||
| 4 | with outliers | 7.43 | 2.06 | ||
| 4 | without outliers | 1.11 | 0.12 | ||
| 10 | with outliers | 7.32 | 2.52 | ||
| 10 | without outliers | 1.72 | 0.25 | ||
| Weibull distribution | 50 | 1 | with outliers | 4.54 | 2.95 |
| 1 | without outliers | 1.81 | 0.77 | ||
| 4 | with outliers | 4.82 | 3.23 | ||
| 4 | without outliers | 2.43 | 1.03 | ||
| 10 | with outliers | 5.91 | 3.48 | ||
| 10 | without outliers | 2.46 | 1.05 | ||
| 100 | 1 | with outliers | 4.32 | 2.88 | |
| 1 | without outliers | 1.63 | 0.69 | ||
| 4 | with outliers | 4.53 | 3.02 | ||
| 4 | without outliers | 2.01 | 0.85 | ||
| 10 | with outliers | 5.78 | 3.34 | ||
| 10 | without outliers | 2.26 | 0.92 | ||
| 250 | 1 | with outliers | 4.14 | 2.63 | |
| 1 | without outliers | 1.32 | 0.43 | ||
| 4 | with outliers | 4.25 | 2.98 | ||
| 4 | without outliers | 1.93 | 0.71 | ||
| 10 | with outliers | 5.49 | 3.11 | ||
| 10 | without outliers | 2.01 | 0.74 | ||
| Log-normal distribution | 50 | 1 | with outliers | 6.53 | 1.32 |
| 1 | without outliers | 2.50 | 0.79 | ||
| 4 | with outliers | 5.42 | 2.54 | ||
| 4 | without outliers | 2.62 | 1.12 | ||
| 10 | with outliers | 6.61 | 2.66 | ||
| 10 | without outliers | 3.08 | 1.48 | ||
| 100 | 1 | with outliers 2 | 6.36 | 1.19 | |
| 1 | without outliers | 2.04 | 0.67 | ||
| 4 | with outliers | 5.13 | 2.33 | ||
| 4 | without outliers | 2.39 | 0.98 | ||
| 10 | with outliers | 6.44 | 2.59 | ||
| 10 | without outliers | 2.95 | 1.23 | ||
| 250 | 1 | with outliers 2 | 6.11 | 1.02 | |
| 1 | without outliers | 1.82 | 0.51 | ||
| 4 | with outliers | 5.02 | 2.07 | ||
| 4 | without outliers | 2.14 | 0.71 | ||
| 10 | with outliers | 6.36 | 2.28 | ||
| 10 | without outliers | 2.77 | 1.09 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Alamari, M.B.; Almulhim, F.A.; Kaid, Z.; Laksaci, A. Functional Time Series Analysis Using Single-Index L1-Modal Regression. Symmetry 2025, 17, 460. https://doi.org/10.3390/sym17030460
Alamari MB, Almulhim FA, Kaid Z, Laksaci A. Functional Time Series Analysis Using Single-Index L1-Modal Regression. Symmetry. 2025; 17(3):460. https://doi.org/10.3390/sym17030460
Chicago/Turabian StyleAlamari, Mohammed B., Fatimah A. Almulhim, Zoulikha Kaid, and Ali Laksaci. 2025. "Functional Time Series Analysis Using Single-Index L1-Modal Regression" Symmetry 17, no. 3: 460. https://doi.org/10.3390/sym17030460
APA StyleAlamari, M. B., Almulhim, F. A., Kaid, Z., & Laksaci, A. (2025). Functional Time Series Analysis Using Single-Index L1-Modal Regression. Symmetry, 17(3), 460. https://doi.org/10.3390/sym17030460