

MSWSR: A Lightweight Multi-Scale Feature Selection Network for Single-Image Super-Resolution Methods

Abstract
1. Introduction
- We propose a lightweight multi-scale feature selection network (MSWSR) for efficient feature fusion and modeling. Through modular design and multi-scale feature extraction strategies, MSWSR effectively balances model performance and computational complexity.
- We propose two key components: MFM and GAU. MFM enhances multi-scale feature modeling through a multi-branch structure, while GAU combines spatial attention with the gating mechanism to optimize feature representation through their synergistic interaction.
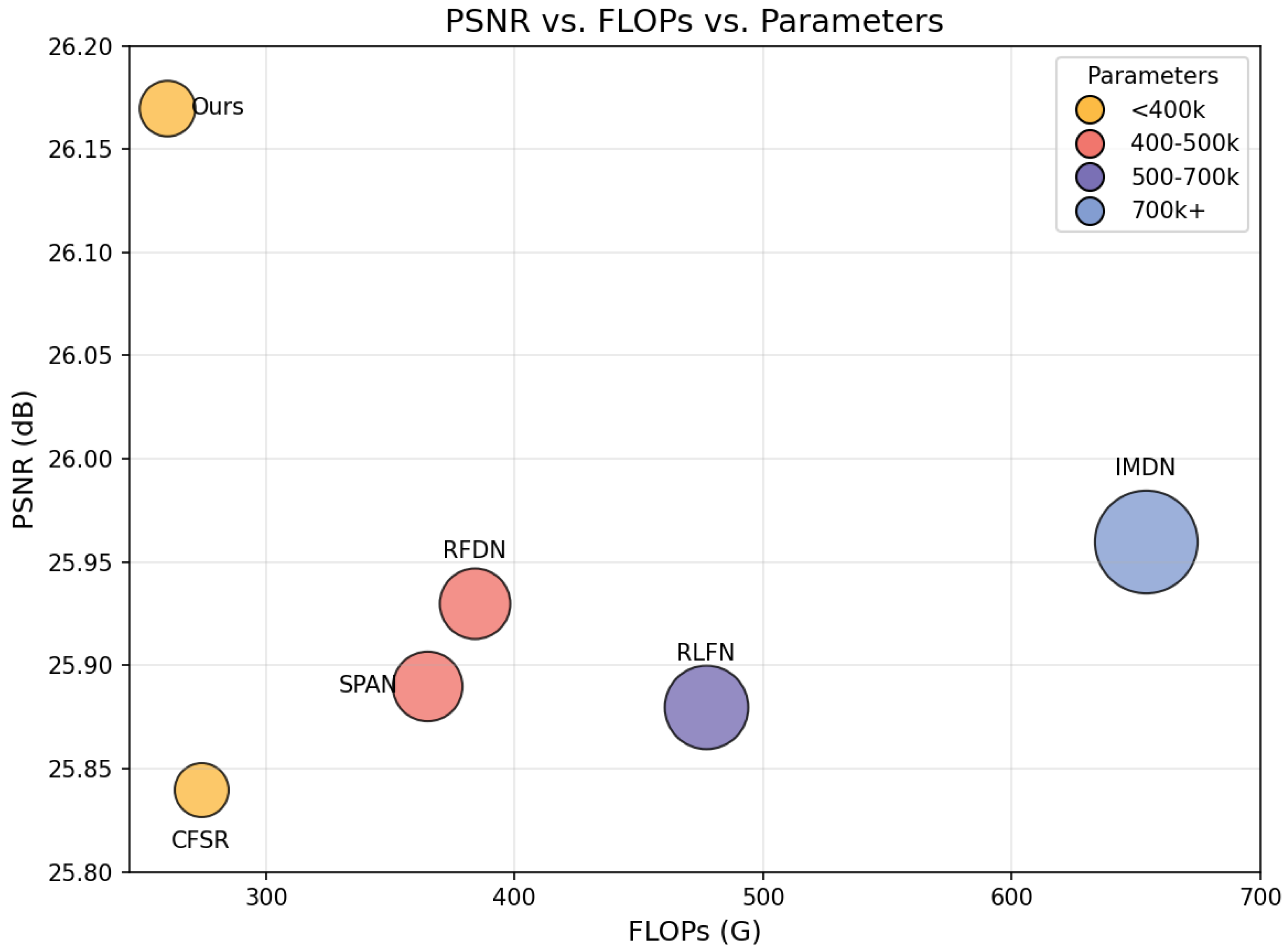
- Extensive experiments demonstrate MSWSR’s superior performance on benchmark datasets. With only 316K parameters, it achieves PSNR improvements of 0.22 dB and 0.26 dB on Urban100 and Manga109 datasets for ×4 super-resolution methods, validating its effectiveness in resource-constrained scenarios.
2. Related Work
2.1. CNN-Based SR Methods
2.2. Transformer-Based Architectures
2.3. Lightweight SR Models
3. Materials and Methods
3.1. Architecture Overview
3.2. Multi-Scale Wavelet Block
3.3. Spatial Selection Attention Module
4. Experiments and Results
4.1. Experimental Settings
4.2. Comparison with Other Network Architectures
4.2.1. Quantitative Analysis
4.2.2. Visual Comparison
4.3. Ablation Studies
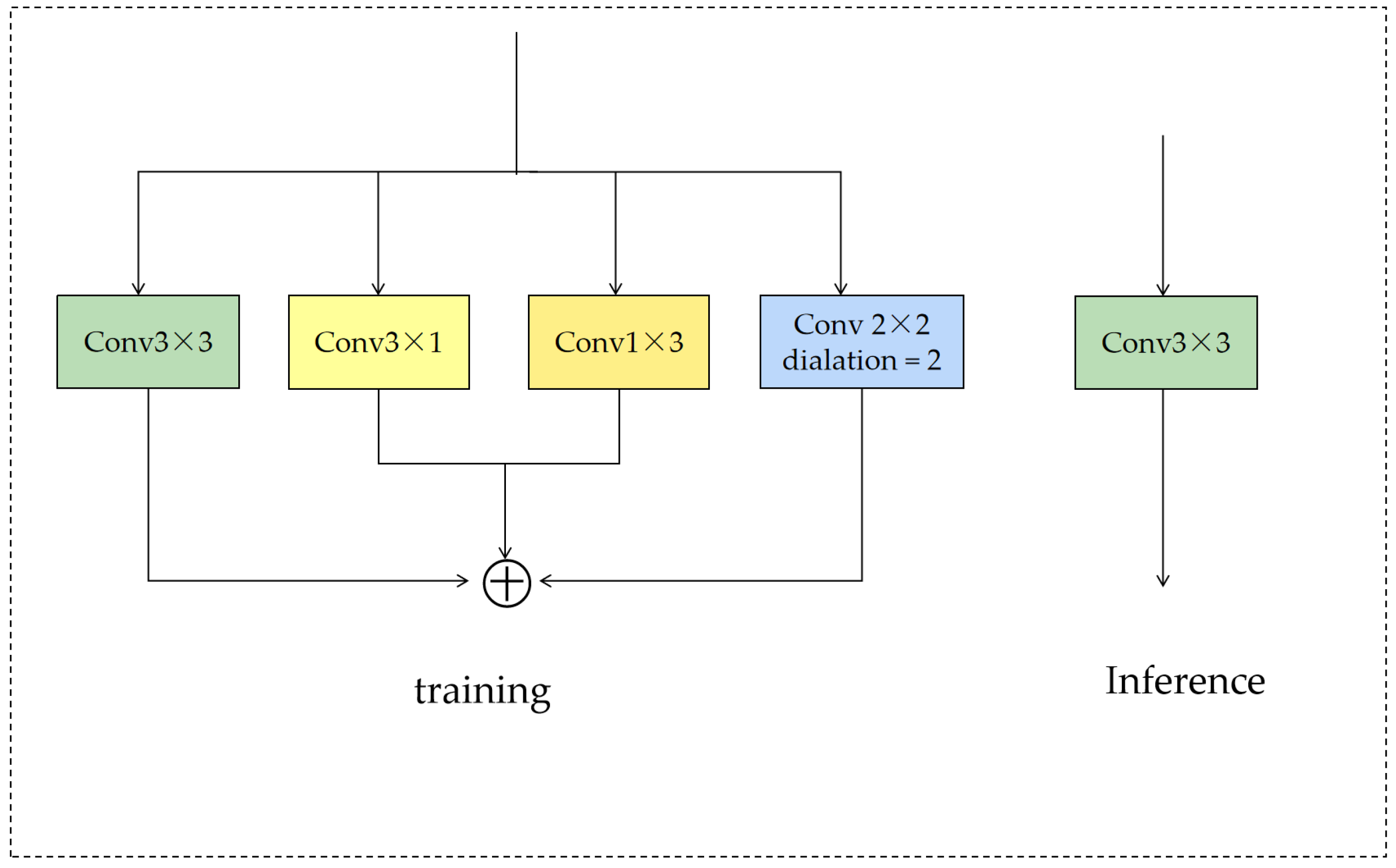
4.3.1. Effects of RepConv and WTConv
4.3.2. Effects of SSA
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Wang, Z.; Chen, J.; Hoi, S.C. Deep learning for image super-resolution: A survey. IEEE Trans. Pattern Anal. Mach. Intell. 2020, 43, 3365–3387. [Google Scholar] [CrossRef] [PubMed]
- Yue, T.; Lu, X.; Cai, J.; Chen, Y.; Chu, S. YOLO-MST: Multiscale deep learning method for infrared small target detection based on super-resolution and YOLO. arXiv 2024, arXiv:2412.19878. [Google Scholar]
- Zhang, J.; Lei, J.; Xie, W.; Fang, Z.; Li, Y.; Du, Q. SuperYOLO: Super resolution assisted object detection in multimodal remote sensing imagery. IEEE Trans. Geosci. Remote Sens. 2023, 61, 1–15. [Google Scholar] [CrossRef]
- Dong, C.; Loy, C.C.; He, K.; Tang, X. Image super-resolution using deep convolutional networks. IEEE Trans. Pattern Anal. Mach. Intell. 2015, 38, 295–307. [Google Scholar] [CrossRef] [PubMed]
- Kim, J.; Lee, J.K.; Lee, K.M. Accurate image super-resolution using very deep convolutional networks. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 1646–1654. [Google Scholar]
- Lim, B.; Son, S.; Kim, H.; Nah, S.; Lee, K.M. Enhanced deep residual networks for single image super-resolution. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops, Honolulu, HI, USA, 10 July 2017; pp. 136–144. [Google Scholar]
- Zhang, Y.; Li, K.; Li, K.; Wang, L.; Zhong, B.; Fu, Y. Image super-resolution using very deep residual channel attention networks. In Proceedings of the European Conference on Computer Cision (ECCV), Munich, Germany, 8–14 September 2018; pp. 286–301. [Google Scholar]
- Li, J.; Fang, F.; Mei, K.; Zhang, G. Multi-scale residual network for image super-resolution. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 7 October 2018. [Google Scholar]
- Li, M.; Zhao, Y.; Zhang, F.; Luo, B.; Yang, C.; Gui, W.; Chang, K. Multi-scale feature selection network for lightweight image super-resolution. Neural Netw. 2024, 169, 352–364. [Google Scholar] [CrossRef] [PubMed]
- Guo, Y.; Tian, C.; Liu, J.; Di, C.; Ning, K. HADT: Image super-resolution restoration using Hybrid Attention-Dense Connected Transformer Networks. Neurocomputing 2025, 614, 128790. [Google Scholar] [CrossRef]
- Chen, X.; Wang, X.; Zhou, J.; Qiao, Y.; Dong, C. Activating more pixels in image super-resolution transformer. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Vancouver, BC, Canada, 17–24 June 2023; pp. 22367–22377. [Google Scholar]
- Li, W.; Lu, X.; Qian, S.; Lu, J.; Zhang, X.; Jia, J. On efficient transformer-based image pre-training for low-level vision. arXiv 2021, arXiv:2112.10175. [Google Scholar]
- Liang, J.; Cao, J.; Sun, G.; Zhang, K.; Van Gool, L.; Timofte, R. Swinir: Image restoration using swin transformer. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Montreal, BC, Canada, 24 November 2021; pp. 1833–1844. [Google Scholar]
- Niu, B.; Wen, W.; Ren, W.; Zhang, X.; Yang, L.; Wang, S.; Zhang, K.; Cao, X.; Shen, H. Single image super-resolution via a holistic attention network. In Computer Vision—ECCV. Proceedings of the 16th European Conference, Glasgow, UK, 23–28 August 2020; Part XII 16; Springer: Berlin/Heidelberg, Germany, 2020; pp. 191–207. [Google Scholar]
- Dai, T.; Cai, J.; Zhang, Y.; Xia, S.T.; Zhang, L. Second-order attention network for single image super-resolution. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 11065–11074. [Google Scholar]
- Ray, A.; Kumar, G.; Kolekar, M.H. CFAT: Unleashing Triangular Windows for Image Super-resolution. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 16–22 June 2024; pp. 26120–26129. [Google Scholar]
- Wu, G.; Jiang, J.; Jiang, J.; Liu, X. Transforming image super-resolution: A ConvFormer-based efficient approach. arXiv 2024, arXiv:2401.05633. [Google Scholar] [CrossRef] [PubMed]
- Xie, C.; Zhang, X.; Li, L.; Meng, H.; Zhang, T.; Li, T.; Zhao, X. Large kernel distillation network for efficient single image super-resolution. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Vancouver, BC, Canada, 17–24 June 2023; pp. 1283–1292. [Google Scholar]
- Wang, Y.; Li, Y.; Wang, G.; Liu, X. Multi-scale attention network for single image super-resolution. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 16–22 June 2024; pp. 5950–5960. [Google Scholar]
- Ding, X.; Zhang, X.; Han, J.; Ding, G. Scaling up your kernels to 31x31: Revisiting large kernel design in cnns. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 18–24 June 2022; pp. 11963–11975. [Google Scholar]
- Finder, S.E.; Amoyal, R.; Treister, E.; Freifeld, O. Wavelet convolutions for large receptive fields. In Computer Vision—ECCV 2024, Proceeding of the European Conference on Computer Vision, Milan, Italy, 29 September–4 October 2024; Springer: Cham, Switzerland, 2025. [Google Scholar]
- Daubechies, I. Ten Lectures on Wavelets; SIAM: Philadelphia, PA, USA, 1992. [Google Scholar]
- Yu, W.; Luo, M.; Zhou, P.; Si, C.; Zhou, Y.; Wang, X.; Feng, J.; Yan, S. Metaformer is actually what you need for vision. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 18–24 June 2022. [Google Scholar]
- Dong, C.; Loy, C.C.; Tang, X. Accelerating the super-resolution convolutional neural network. In Computer Vision–ECCV 2016, Proceeding of the 14th European Conference, Amsterdam, The Netherlands, 11–14 October 2016; Part II 14; Springer International Publishing: Cham, Switzerland, 2016. [Google Scholar]
- Zhang, Y.; Tian, Y.; Kong, Y.; Zhong, B.; Fu, Y. Residual dense network for image super-resolution. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018. [Google Scholar]
- Hui, Z.; Gao, X.; Yang, Y.; Wang, X. Lightweight image super-resolution with information multi-distillation network. In Proceedings of the 27th ACM International Conference on Multimedia, Nice, France, 21–25 October 2019; pp. 2024–2032. [Google Scholar]
- Liu, J.; Tang, J.; Wu, G. Residual feature distillation network for lightweight image super-resolution. In Computer Vision–ECCV 2020 Workshops. Proceeding of the ECCV 2020, Glasgow, UK, 23–28 August 2020; Springer International Publishing: Cham, Switzerland, 2020. [Google Scholar]
- Li, Z.; Liu, Y.; Chen, X.; Cai, H.; Gu, J.; Qiao, Y.; Dong, C. Blueprint separable residual network for efficient image super-resolution. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 18–22 June 2022; pp. 833–843. [Google Scholar]
- Sun, L.; Pan, J.; Tang, J. Shufflemixer: An efficient convnet for image super-resolution. Adv. Neural Inf. Process. Syst. 2022, 35, 17314–17326. [Google Scholar]
- Wang, Z.; Gao, G.; Li, J.; Yan, H.; Zheng, H.; Lu, H. Lightweight feature de-redundancy and self-calibration network for efficient image super-resolution. ACM Trans. Multimed. Comput. Commun. Appl. 2023, 19, 1–15. [Google Scholar] [CrossRef]
- Li, Y.; Deng, Z.; Cao, Y.; Liu, L. GRFormer: Grouped Residual Self-Attention for Lightweight Single Image Super-Resolution. In Proceedings of the 32nd ACM International Conference on Multimedia, New York, NY, USA, 28 October–1 November 2024; ACM: New York, NY, USA, 2024; pp. 9378–9386. [Google Scholar]
- Kim, J.; Nang, J.; Choe, J. LMLT: Low-to-high Multi-Level Vision Transformer for Image Super-Resolution. arXiv 2024, arXiv:2409.03516. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep residual learning for image recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016. [Google Scholar]
- Shi, W.; Caballero, J.; Huszár, F.; Totz, J.; Aitken, A.P.; Bishop, R.; Rueckert, D.; Wang, Z. Real-time single image and video super-resolution using an efficient sub-pixel convolutional neural network. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016. [Google Scholar]
- Yu, J.; Fan, Y.; Yang, J.; Xu, N.; Wang, Z.; Wang, X.; Huang, T. Wide activation for efficient and accurate image super-resolution. arXiv 2018, arXiv:1808.08718. [Google Scholar]
- Hu, J.; Shen, L.; Sun, G. Squeeze-and-excitation networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018. [Google Scholar]
- Agustsson, E.; Timofte, R. Ntire 2017 challenge on single image super-resolution: Dataset and study. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition Workshops, Honolulu, HI, USA, 21–26 July 2017; pp. 126–135. [Google Scholar]
- Bevilacqua, M.; Roumy, A.; Guillemot, C.; Alberi-Morel, M.L. Low-complexity single-image super-resolution based on nonnegative neighbor embedding. In BMVC; BMVA Press: Survery, UK, 2012; pp. 1–10. [Google Scholar]
- Martin, D.R.; Fowlkes, C.C.; Tal, D.; Malik, J. A database of human segmented natural images and its application to evaluating segmentation algorithms and measuring ecological statistics. In Proceedings of the ICCV, Vancouver, BC, Canada, 7–14 July 2001; pp. 416–423. [Google Scholar]
- Huang, J.B.; Singh, A.; Ahuja, N. Single image super-resolution from transformed self-exemplars. In Proceedings of the CVPR, Boston, MA, USA, 7–12 June 2015; pp. 5197–5206. [Google Scholar]
- Matsui, Y.; Ito, K.; Aramaki, Y.; Fujimoto, A.; Ogawa, T.; Yamasaki, T.; Aizawa, K. Sketch-based manga retrieval using manga109 dataset. Multimed. Tools Appl. 2017, 76, 21811–21838. [Google Scholar] [CrossRef]
- Xie, X.; Zhou, P.; Li, H.; Lin, Z.; Yan, S. Adan: Adaptive nesterov momentum algorithm for faster optimizing deep models. IEEE Trans. Pattern Anal. Mach. Intell. 2024, 46, 9508–9520. [Google Scholar] [CrossRef] [PubMed]






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Scale | Method | #Param | FLOPS | Set5 | Set14 | BSDS100 | Urban100 | Manga109 | |||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| PSNR | SSIM | PSNR | SSIM | PSNR | SSIM | PSNR | SSIM | PSNR | SSIM | ||||
| X2 | IMDN | 694K | 635.4G | 37.89 | 0.9606 | 33.51 | 0.9169 | 32.12 | 0.8990 | 32.00 | 0.9267 | 38.61 | 0.9770 |
| RFDN | 417 K | 365.3G | 37.78 | 0.9606 | 33.35 | 0.9166 | 32.09 | 0.8991 | 31.79 | 0.9254 | 38.29 | 0.9764 | |
| RLFN | 526K | 461.7G | 37.88 | 0.9606 | 33.44 | 0.9168 | 32.13 | 0.8991 | 31.88 | 0.9259 | 38.39 | 0.9766 | |
| CFSR | 298K | 260.2G | 37.86 | 0.9605 | 33.44 | 0.9169 | 32.12 | 0.8992 | 31.77 | 0.9352 | 38.31 | 0.9764 | |
| SPAN | 410K | 377.5G | 37.94 | 0.9608 | 33.47 | 0.9165 | 32.14 | 0.8993 | 31.92 | 0.9265 | 38.30 | 0.9765 | |
| Ours | 312K | 243.3G | 38.01 | 0.9610 | 33.71 | 0.9193 | 32.22 | 0.9003 | 32.29 | 0.9301 | 38.86 | 0.9774 | |
| X3 | IMDN | 703K | 643.4G | 34.36 | 0.9272 | 30.28 | 0.8412 | 29.05 | 0.8045 | 28.09 | 0.8504 | 33.48 | 0.9438 |
| RFDN | 424K | 371.4G | 34.18 | 0.9260 | 30.23 | 0.8406 | 29.02 | 0.8037 | 27.90 | 0.8475 | 33.23 | 0.9422 | |
| RLFN | 533K | 468.2G | 34.24 | 0.9266 | 30.26 | 0.8412 | 29.04 | 0.8412 | 27.99 | 0.8489 | 33.28 | 0.9426 | |
| CFSR | 294K | 266.2G | 34.23 | 0.9262 | 30.25 | 0.8406 | 29.04 | 0.8044 | 27.90 | 0.8475 | 33.30 | 0.9428 | |
| SPAN | 417K | 383.5G | 34.28 | 0.9268 | 30.27 | 0.8417 | 29.06 | 0.8049 | 28.04 | 0.8499 | 33.39 | 0.9436 | |
| Ours | 307K | 249.6G | 34.40 | 0.9277 | 30.35 | 0.8437 | 29.12 | 0.8067 | 28.22 | 0.8548 | 33.68 | 0.9454 | |
| X4 | IMDN | 715K | 654.5G | 32.09 | 0.8942 | 28.54 | 0.7810 | 27.52 | 0.7340 | 25.96 | 0.7819 | 30.33 | 0.9063 |
| RFDN | 433 K | 380.2G | 32.13 | 0.8943 | 28.50 | 0.7795 | 27.51 | 0.7339 | 25.92 | 0.7803 | 30.20 | 0.9051 | |
| RLFN | 543K | 477.3G | 31.97 | 0.8931 | 28.47 | 0.7795 | 27.51 | 0.7342 | 25.88 | 0.7803 | 30.12 | 0.9035 | |
| CFSR | 303K | 274.6G | 32.00 | 0.8930 | 28.49 | 0.7797 | 27.52 | 0.7343 | 25.84 | 0.7781 | 30.15 | 0.9045 | |
| SPAN | 426.3K | 391.9G | 32.08 | 0.8942 | 28.53 | 0.7810 | 27.55 | 0.7351 | 25.95 | 0.7812 | 30.34 | 0.9064 | |
| Ours | 316K | 257.6G | 32.26 | 0.8966 | 28.67 | 0.7843 | 27.62 | 0.7379 | 26.17 | 0.7896 | 30.60 | 0.9092 | |
| WtConv | RepConv | BSDS100 | Urban100 | Manga109 | |||
|---|---|---|---|---|---|---|---|
| PSNR | SSIM | PSNR | SSIM | PSNR | SSIM | ||
| √ | 27.57 | 0.7365 | 26.00 | 0.7844 | 30.39 | 0.9076 | |
| √ | 27.54 | 0.7349 | 25.94 | 0.7811 | 30.30 | 0.9061 | |
| √ | √ | 27.62 | 0.7379 | 26.17 | 0.7896 | 30.60 | 0.9092 |
| SSA | BSDS100 | Urban100 | Manga109 | |||
|---|---|---|---|---|---|---|
| PSNR | SSIM | PSNR | SSIM | PSNR | SSIM | |
| 27.54 | 0.7351 | 25.91 | 0.7801 | 30.27 | 0.9057 | |
| √ | 27.62 | 0.7379 | 26.17 | 0.7896 | 30.60 | 0.9092 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Song, W.; Yan, X.; Guo, W.; Xu, Y.; Ning, K. MSWSR: A Lightweight Multi-Scale Feature Selection Network for Single-Image Super-Resolution Methods. Symmetry 2025, 17, 431. https://doi.org/10.3390/sym17030431
Song W, Yan X, Guo W, Xu Y, Ning K. MSWSR: A Lightweight Multi-Scale Feature Selection Network for Single-Image Super-Resolution Methods. Symmetry. 2025; 17(3):431. https://doi.org/10.3390/sym17030431
Chicago/Turabian StyleSong, Wei, Xiaoyu Yan, Wei Guo, Yiyang Xu, and Keqing Ning. 2025. "MSWSR: A Lightweight Multi-Scale Feature Selection Network for Single-Image Super-Resolution Methods" Symmetry 17, no. 3: 431. https://doi.org/10.3390/sym17030431
APA StyleSong, W., Yan, X., Guo, W., Xu, Y., & Ning, K. (2025). MSWSR: A Lightweight Multi-Scale Feature Selection Network for Single-Image Super-Resolution Methods. Symmetry, 17(3), 431. https://doi.org/10.3390/sym17030431