1. Introduction
Massive amounts of high-dimensional data, such as text, image, video frame and biological information, are broadly used in our daily lives and in scientific research. However, direct processing of such extensive high-dimensional data can lead to a severe problem, known as the “curse of dimensionality”. Therefore, feature extraction from high-dimensional data has become a prominent research topic in recent years. Over the past few decades, a number of feature extraction methods have been proposed, among which principle component analysis (PCA) [
1] is particularly noteworthy. As an unsupervised feature extraction method, PCA seeks a low-dimensional orthogonal projection matrix via minimizing reconstruction errors. However, PCA can barely process data that are heavily corrupted by complex noise [
2]. The proposal of low-rank representation (LRR) [
3,
4] effectively solved this problem by better-capturing the global structure within the original data while removing noise and outliers. Recently, LRR has received much attention in machine learning and computer vision, and its variants have been successfully applied to different scenarios, including feature selection [
5,
6,
7] and subspace clustering [
8,
9]. However, the absence of a projection matrix limits LRR’s ability to effectively deal with feature extraction tasks, and recent research has focused mainly on three strategies to address this limitation:
(1) The first strategy extracts intrinsic features by employing a low-rank projection matrix, with latent low-rank representation (LatLRR) [
10] and double low-rank representation (DLRR) [
11] being representative examples. However, the feature dimensions of the projection matrices obtained through LatLRR, DLRR and their variants [
12,
13,
14] remain identical to the original data, and their efficiency in handling high-dimensional data is thereby severely limited. Approximate low-rank projection learning (ALPL) [
15] and its variants [
16,
17] have effectively solved this problem by decomposing the low-rank projection matrix into an orthogonal transformation matrix and a low-dimensional projection matrix, thus realizing the projection of high-dimensional features into lower-dimensional subspaces. Nonetheless, these methods tend to overlook the manifold structure of the original data, which is essential to preserving the distribution of data that belong to the same class in the low-dimensional subspaces. In addition, the norm type used to constrain the projection matrix (such as Frobenius norm and
norm) has a significant impact on the feature extraction performance, requiring the assumption of coefficient distribution in the model’s construction process.
(2) The second strategy is to introduce sparse constraint into the low-rank representation model, extracting local features from the original data by the self-representation property of sparse matrices. Low-rank sparse representation (LRSR) [
18] is a prominent method primarily utilized in subspace clustering and segmentation, which has been successfully extended to feature extraction [
19,
20]. However, sparse representation may result in feature loss, to some extent, and the feature extraction methods based on this strategy still cannot fully consider the manifold structure of the original data samples. Recently, a discriminative feature extraction method (DFE) [
21] proposed by Liu et al. enhanced LRSR by introducing a low-dimensional projection matrix to solve the out-of-sample problem and a discriminative term to minimize the reconstruction error of the original data. However, the learning of a projection matrix does not facilitate a mutual reinforcement of the learning of a sparse low-rank coefficient matrix.
(3) The third strategy focuses on non-linear and manifold structures, employing local preserving projection (LPP) [
22] or graph learning to preserve the intrinsic structures of the original data. Low-rank preserving projection (LRPP) [
23] and low-rank representation with adaptive graph regularization (LRR_AGR) [
24] are representatives, which are capable of identifying the intrinsic manifold structure of the data and retaining local information. Low-rank preserving projection via graph regularized reconstruction (LRPP_GRR) [
25] combines graph constraint on the reconstruction error of data with projection learning to further improve its classification accuracy and robustness against noise. However, most graph matrix-based learning methods typically preconstruct affinity or
k-nearest neighbor graphs using original data samples, which often contain noise corruption and outliers in real-world applications. Furthermore, since Euclidean distances are sensitive to noise corruption, the preconstructed graph matrices often fail to accurately capture the correlation between two data samples.
Recently, a number of studies have integrated and improved upon these strategies, and more effective methods have been proposed to address the limitations and enhance the performance of feature extraction. For example, robust latent discriminative adaptive graph preserving learning (RLDAGP) [
26] integrates adaptive graph learning with dimensionality reduction, meanwhile incorporating an adaptive regularizer to better-accommodate data sets with diverse characteristics. Moreover, adaptive graph embedding preserving projection learning (AGE_PPL) [
27] combines adaptive sparse graph learning, global structure preservation and projection learning, thereby preserving both the global and local structures of data, which significantly improves the effectiveness of feature extraction. However, several drawbacks remain despite the success of the existing methods for feature extraction tasks. Firstly, most feature extraction methods ignore the significant role that a low-rank coefficient matrix with favorable properties can play in learning projection matrices. Theoretically, a well-structured graph matrix
should facilitate projection matrix learning. Secondly, many adaptive graph learning-based methods still rely on the preconstruction of graph matrices, and the accuracy of the graph depends on the size of the predetermined neighborhood
k, which cannot adequately meet the diverse requirements of different image data sets. Last but not least, the objective functions of these models are specially designed and tend to be more complex, making it difficult for these models to scale among different learning scenarios. For example, in practical applications, there are several internal parameters that require additional adjustment (such as
in [
26]) in addition to the regularization parameters, greatly increasing the effort required to find an optimal parameter combination.
In order to address these drawbacks, a novel method, i.e., the robust discriminative non-negative and symmetric low-rank projection learning method (RDNSLRP), is proposed. RDNSLRP optimizes low-rank representation to non-negative symmetric low-rank representation, and it applies block-diagonal properties to construct a low-rank coefficient matrix with better properties to improve the interpretability of the model. By integrating non-negative symmetric low-rank representation and adaptive graph learning into a unified framework, RDNSLRP can extract more geometric intrinsic features from the original data. Meanwhile, the projection matrix learned from a low-rank coefficient matrix with better properties (such as non-negative, symmetric and block diagonal) is expected to be more discriminative than that from the unconstrained matrix. In addition, a discriminant term based on the projection error of each class is also introduced to increase intra-class divergence while decreasing inter-class divergence, thereby learning a more discriminative projection matrix. The main contributions of this paper are summarized as follows:
RDNSLRP introduces a low-dimensional projection matrix and adaptive graph learning to low-rank representation, enabling the local geometric structures of the original data to be projected to lower-dimensional subspaces while extracting both the global and intrinsic features.
A low-rank coefficient matrix with better properties, such as non-negative, symmetric and block-diagonal, is introduced as a graph matrix for adaptive graph learning to enhance interpretability and achieve mutual promotion during the learning process between the graph matrix and the projection matrix.
A discriminant term based on the projection error of each sample class is designed and utilized to further enhance the discriminability of feature extraction.
To resolve the RDNSLRP model, an alternating iteration algorithm based on the augmented Lagrange multiplier method with alternating direction strategy is designed, and a restrictive method is used to ensure the block-diagonal property of the graph matrix.
Comprehensive experiments conducted on benchmark data sets have proved the effectiveness and practicality of the RDNSLRP model.
The remainder of this paper consists of the following sections. In
Section 2 , the notations are introduced and related methods are briefly discussed.
Section 3 introduces the formulation of the RDNSLRP model, and its optimization procedure and application of feature extraction are given.
Section 4 proves the convergence and discusses the complexities of the proposed model. Our experimental results and correlation analyses are presented in
Section 5.
Section 6 lists some limitations of the proposed method and looks forward to possible future work.
Section 7 summarizes the contents of the paper.
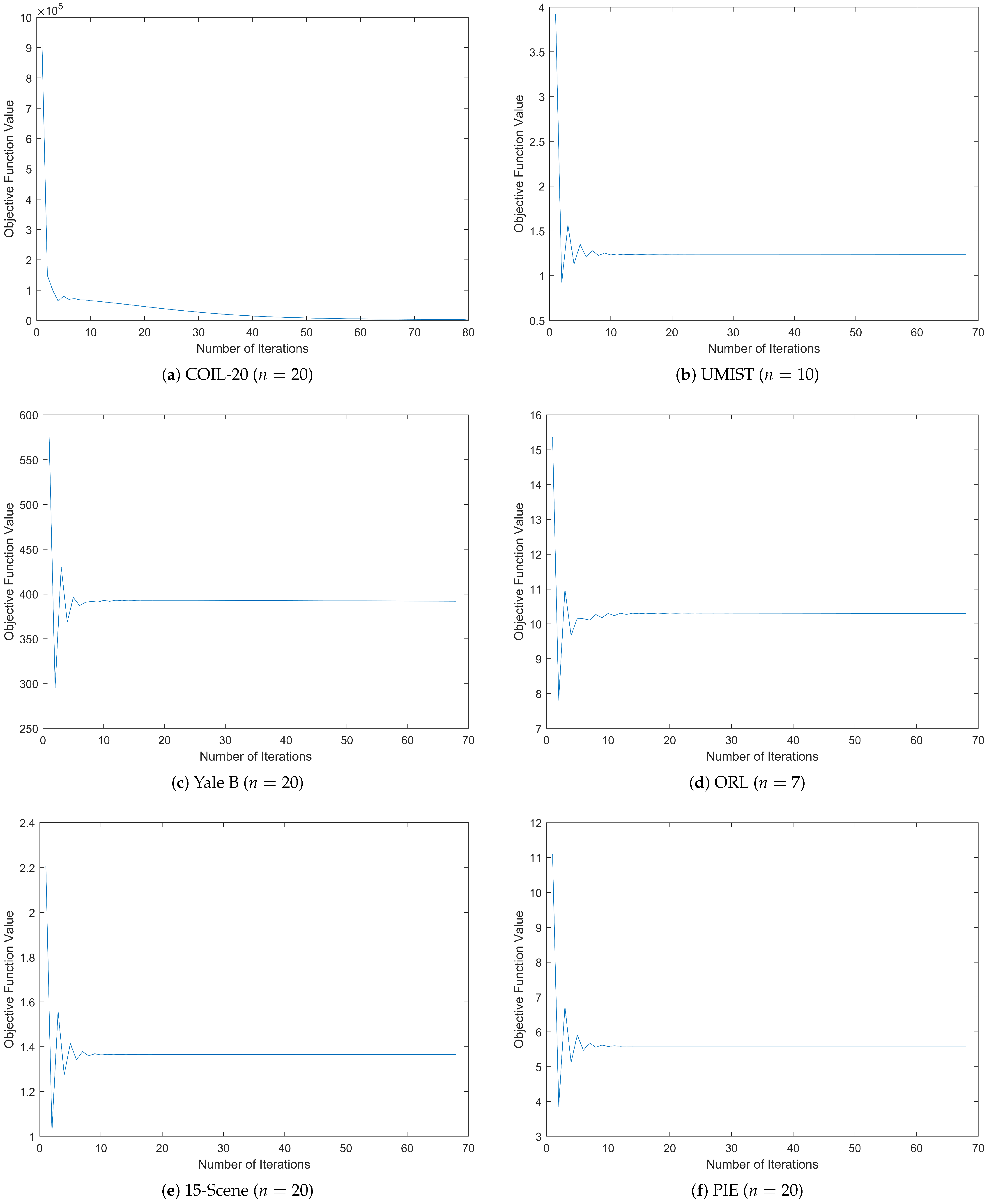
4. Convergence and Complexity
This section proves the convergence of the RDNSLRP model and discusses the computational complexity theoretically.
4.1. Convergence
The objective function of RDNSLRP (
11) is a non-convex constrained optimization problem, and its convergence is difficult to be proved directly. However, by employing the ALM–ADM strategy, the whole algorithm is divided into six sub-problems aimed at updating four variables (
,
,
and
) and two Lagrange multipliers (
and
). Therefore, the convergence of overall objective function (
11) can be derived by proving the convergence of all the sub-problems.
Firstly, the method for updating
by objective function (
19) is obtained by the singular value thresholding (SVT) method, and its convergence has been proved in [
35]. Secondly, it can be proved through the auxiliary function strategy [
37] that objective function (
25) monotonically decreases and is lower-bounded, so the sub-problem for updating
is convergent according to the monotone bounded theorem. Then, the objective function of updating
is an unconstrained optimization problem, and its KKT conditions are as follows:
Let
and
represent the updated values of variables
and
after a new iteration, respectively, and the following equations can be obtained based on their respective update formulas:
Assuming that both sides of the equations approach zero when the number of iterations
t is large enough, the following trend can be obtained:
Therefore, according to (
38), if the variable
converges to a fixed point, i.e.,
then the fixed point satisfies the KKT condition, thereby proving the convergence of the updating rules of
. The convergence of updating Lagrange multipliers
and
can also be proved by a similar analytical method. Finally, for the sub-problem of updating
, the objective function (
14) is bounded, due to the existence of orthogonal and non-negative constraints. In conclusion, since the objective functions of the six sub-optimization problems are all convergent, the total convergence of the objective function of the RDNSLRP method can be derived.
4.2. Complexity
This subsection discusses the computational complexity of Algorithm 1, which mainly consists of two parts, namely, time complexity and space complexity.
For time complexity, according to Algorithm 1, the optimization process of solving problem (
13) can be divided into several independent sub-problems, among which updating variables
,
,
and
are time-consuming. When updating the projection matrix
, the most time-consuming part is the eigenvalue decomposition of temporary variable
, whose time complexity is
. Therefore, the time complexity of updating
is about
. Similarly, updating
involves the singular-value decomposition of the temporary variable
, whose time complexity is
, so the time complexity is nearly
. The construction process of both matrix
and
costs
, from which it can be inferred that the time complexity of updating
is
. It should be noted that since the construction of matrix
involves matrix multiplication the time consumption of this step is greater than that of updating
during iterations. The process of updating
can be divided into two parts. The first part is to calculate every sub-matrix
, whose time complexity is about
[
38], and the second part is to merge all sub-matrices to a block-diagonal matrix
with the total time complexity of
. Therefore, the time complexity of updating
is around
. In summary, the total time complexity of RDNSLRP approximates
if the number of iterations
t is given. In our experiment, the maximum number of iterations was set to 100 to avoid overfitting and reduce time consumption.
For space complexity, due to the introduction of other temporary variables in the iterative process of Algorithm 1, its space complexity depends on the dimensions of the block variables and the introduced temporary variables. When updating , three temporary variables are introduced, i.e., , and . Therefore, the space complexity of updating is . Updating involves the calculation of r positive singular values and the introduction of temporary variables , , , and , which leads to the total space complexity of . Updating involves constructing temporary variables and , and two other temporary variables, namely, and , need to be calculated, respectively, based on , so its space complexity is . Updating does not entail the introduction of temporary variables and merely occupies a space complexity of . For updating , and , no temporary variable is introduced, so their space complexities are , and , respectively. In summary, the maximum space complexity of RDNSLRP is . However, in practical applications, the space consumption can be reduced through pre-computation (such as in updating ), re-usage of temporary variables and other methods, thereby reducing the space complexity of the proposed algorithm.
7. Conclusions
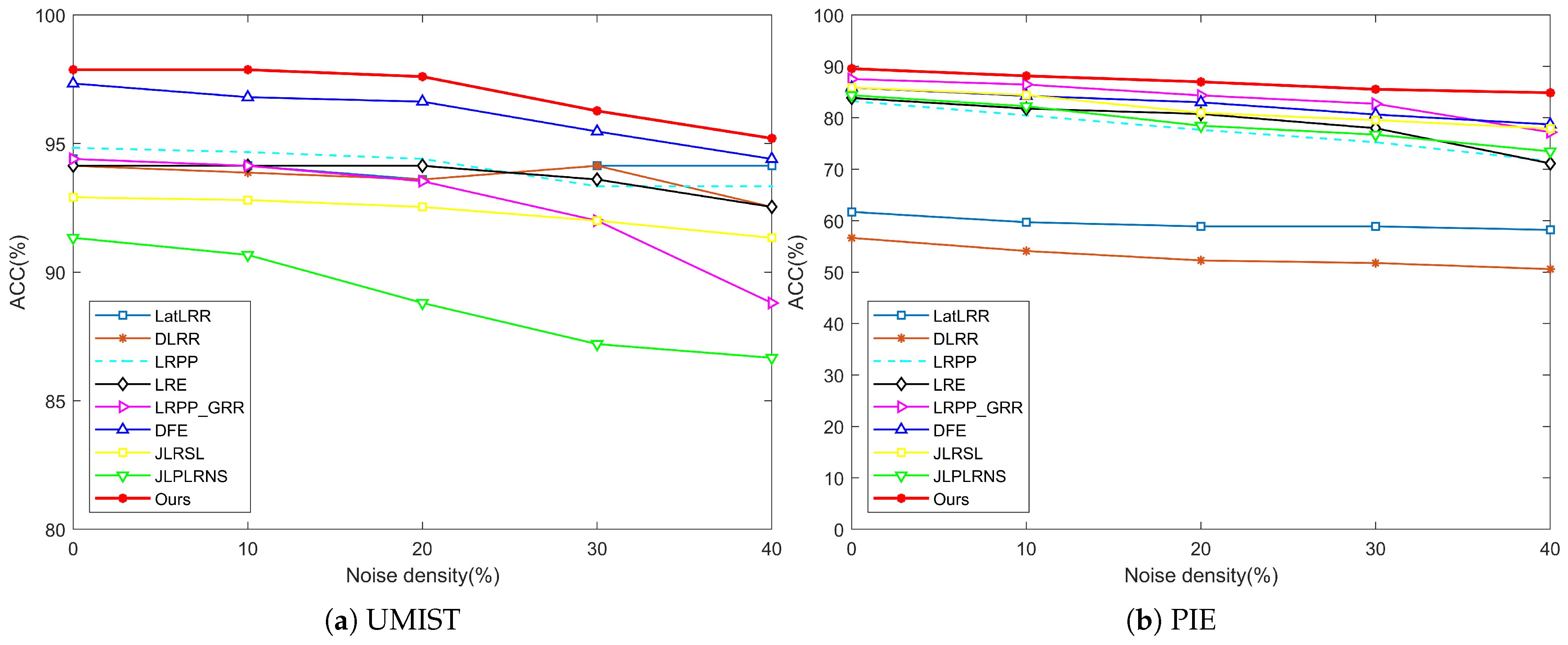
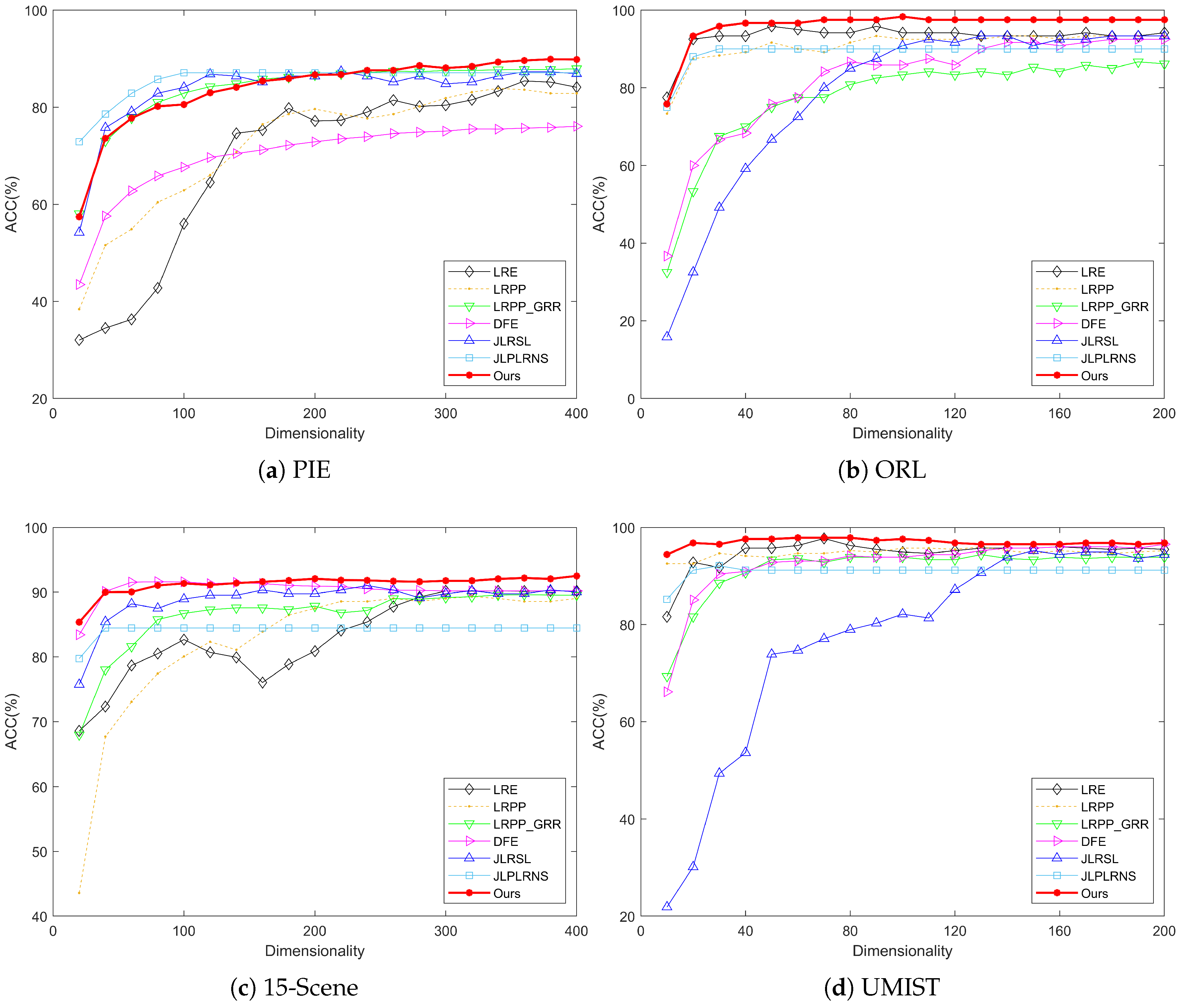
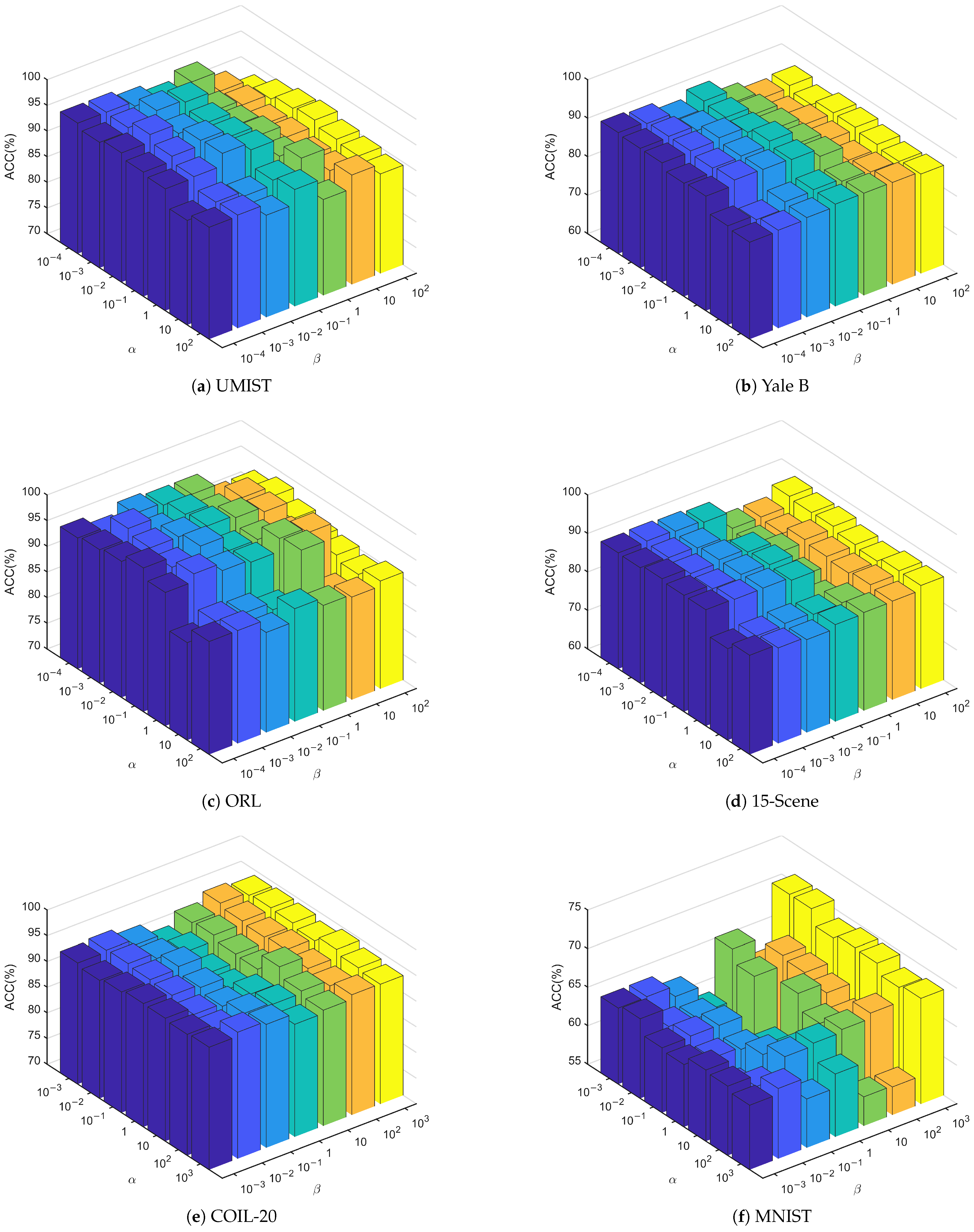
In this paper, a novel model, RDNSLRP, has been proposed for unsupervised feature extraction. A low-rank coefficient matrix with better properties is utilized as the graph matrix for learning the projection matrix, and a discriminant term is introduced to enhance the robustness of the model against noise, as well as the discriminant of extracted features. Therefore, the RDNSLRP model not only makes full use of both the global and the intrinsic structures of the original data, but also effectively separates the impact of noise and outliers; thereby, the performance of feature extraction and image recognition can be improved. A large number of experimental results on several benchmark data sets proved the usability, practicability and performance to be superior to other existing methods, such as in the 8.556% improvement on the PIE data set and the 4.547% improvement on the UMIST data set.
However, RDNSLRP is not flawless, and some limitations exist, including insufficiency in maintaining global structural information and an inability to handle data sets of extremely large scale or complex structure, etc. Therefore, the methods to address these issues, including improving low-rank representation and combining with deep learning methods, are worthy of further study.




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}