1. Introduction
Recommender systems (RSs) are major components in various domains such as e-commerce, search engines, and financial services. They bridge the gap between users and products by presenting personalized content, ensuring a harmonious and symmetric user experience. RSs not only aid customers in finding relevant items efficiently but also directly influence their decision-making processes by providing tailored suggestions. However, growing concerns about RSs may compromise users’ trust due to vulnerabilities such as non-transparency, unfair treatment among different users or groups, extensive use of private user data, and the provision of tampered content guided by attackers or fake users.
A holistic definition of a robust RS encompasses several perspectives of robustness, including robustness with respect to sub-populations, distributional shifts, sparsity, and attacks that corrupt features of items, users, and interactions [
1]. This research focuses on the robustness of an RS against attacks on its content data and interactions.
Even if an RS ethically collects and employs user data, privacy concerns remain if external attackers breach the system or expose crucial system details such as log data. On the one hand, inadequate security measures and data anonymization within the RS could allow adversaries to retrieve user data and system information through hacking or inference [
2]. On the other hand, attackers could impersonate users or trusted third parties interacting with the recommendation system to manipulate its decision-making process. For instance, a fake user might intentionally inject biased data to deceive the RS, thereby steering the recommendation results to favor specific items or business entities while suppressing others [
3].
This research examines two main types of attacks against RSs: (1) shilling attacks, and (2) adversarial attacks on content data. Shilling attacks aim to manipulate the user–item interaction matrix by adding fake interactions to influence the predicted ratings [
4]. On the other hand, adversarial attacks target the content data related to users and items in an RS.
The majority of research on adversarial attacks against content data has focused on visual information (images) in RSs. However, modern RSs utilize various information sources such as user profiles, user comments, social connections, and textual item information. Therefore, ensuring the robustness of an RS against adversarial attacks on any of these different data sources is an open problem [
5]. Additionally, existing methods are only robust against specific types of adversarial attacks, leading to an endless cycle of attacks and defenses [
6]. Recently, PORE [
6] proposed a solution for this challenge, but it is limited to
untargeted adversarial attacks against the interaction matrix,
not content data. Furthermore, there is still room for improvement in the robustness of RSs against novel (unseen) attack types. Some studies, such as [
7], focus on enhancing system robustness against multiple simultaneous attacks; however, these approaches are outside the scope of the RS domain.
To address these challenges, this research presents a novel method called Unified input/target Attack Purifier and Detector (UAPD), which unifies adversarial and shilling attack detection and purification, as well as fake user detection in RSs, by utilizing diffusion networks and employing a self-supervised strategy.
Specifically, to detect and purify adversarial examples, we pass each input through a diffusion network that gradually submerges the adversarial perturbations by adding Gaussian noise and then simultaneously removes both types of noise following a guided denoising process. To enhance the purification and detection capabilities of the diffusion network, we first identify the adversarial directions for a set of clean examples and then train the network to generate a symmetric clean variant of each example, regardless of whether it receives an adversarial or clean input.
Additionally, to enhance the robustness of a baseline RS against possibly
malicious user–item interactions, UAPD adapts the
self-adaptive training strategy [
8], enabling our model to detect and refine the attacked targets during the training process using the model’s own predictions. To detect fake user profiles, we first identify potential target items by comparing the outputs of the self-adaptive training for each item with their initial interactions. Items whose updated interactions are significantly different from their initial values are identified as candidate target items. Then, the profiles of users whose behavior on this target set differs significantly from that of other users are classified as fake profiles.
UAPD offers high generalizability against unseen adversarial and shilling attacks due to the following points:
We conducted extensive experiments on three large-scale RS benchmarks to assess the effectiveness of UAPD. The results demonstrate that our approach effectively purifies adversarial perturbations from both image and text inputs in RSs, achieving substantial improvements over current state-of-the-art methods. Moreover, it can identify noisy interactions and detect fake user profiles under various shilling attacks. Notably, it outperformed other methods in three out of five evaluated shilling attack scenarios. Furthermore, under attacks with realistic intensity, our method preserves the baseline RS performance even when multiple attacks are applied concurrently.
The main contributions of this paper can be summarized as follows:
The proposed method unifies adversarial attack detection and purification, as well as fake user detection in RSs.
It can handle most adversarial attacks on inputs and noisy interactions simultaneously.
UAPD can identify and purify both known and unknown adversarial attack types in content-based or hybrid RSs.
Table 1 and
Table 2 present the main abbreviations and notations used throughout this paper. The remainder of this paper is organized as follows:
Section 2 reviews related work on adversarial and shilling attacks in RSs.
Section 3 provides background information on diffusion networks and the self-adaptive training method.
Section 4 presents the proposed method, including training, detection steps, and implementation details.
Section 5 presents and analyzes experimental results, compares the proposed method’s performance with other methods, and examines various aspects of UAPD through an ablation study. Finally,
Section 6 concludes the paper by summarizing the key findings and discussing potential future research directions.
4. The Proposed Method
4.1. Formalizing the Problem
Let be the list of users, denote the item set including items, and the matrix be the user–item interaction matrix, where a nonzero denotes the rating or interest of user for item scaled to the range (0,1]. denotes the set of items toward which user has positive interactions (e.g., 4 or 5, or items purchased by ).
For simplicity, we assume that each user is represented by a unique identifier, and each item, in addition to a unique identifier, is associated with multi-modal information: and which represent the item’s description and image, respectively. However, our method can be extended to capture other sources of information, such as item reviews and user comments.
The target of an RS is typically a score value
, indicating the interest of a given user
in item
. We assume that the target is scaled in the range
. A rating or ranking-based RS predicts the rating or interest
of a user
u in an item
where
denotes the model’s prediction for the given inputs. Moreover, we can encode the target similar to one-hot encoding as follows:
We assume that the elements of matrix (targets) or any of the recommender system’s inputs, like an item’s image or description, can be changed or perturbed by attackers for unknown adversarial objectives.
4.2. Overview of the Proposed Method
The proposed method enhances the robustness of a baseline RS, which could be any existing multi-modal RS, such as those introduced in refs. [
9,
10,
40].
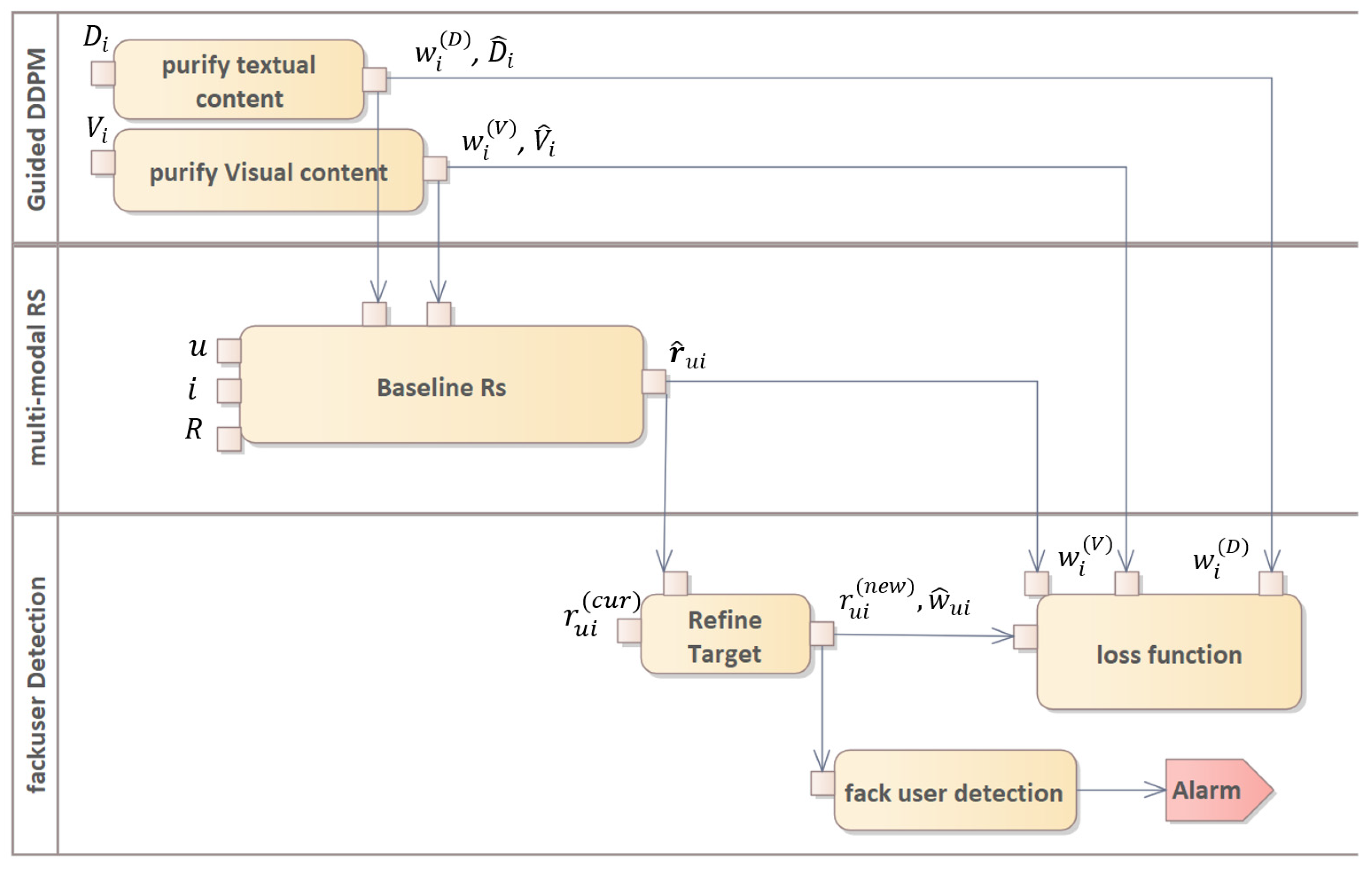
Figure 1 illustrates the architecture and the main training stages of the proposed method. Prior to training the baseline RS, our approach performs a novel pretraining step that fits two guided DDPMs, thereby enhancing their ability to remove adversarial perturbations from their respective inputs.
Given , UAPD first purifies the textual content and the visual content using the pretrained DDPMs, producing purified contents and along with corresponding weights, and , that quantify the likelihood of adversarial attacks on the item’s textual and visual information. Subsequently, UAPD provides the purified input and the weights and to the baseline RS, obtaining , which estimates the interest of user u in item .
The target is then modified by the self-adaptive training mechanism, which also assigns a weight that estimates the probability that is clean. Finally, the loss function of the baseline RS is computed using the modified target , the weights , , and , and the model’s estimation . The resulting gradient is then propagated to update the baseline RS’s parameters.
Additionally, we introduce a fake user detection module that identifies fake users by comparing modified and initial target values for each user. In the following sections, we describe each stage of UAPD in detail.
4.3. Training DDPMs
The proposed method trains a DDPM for each modality of input data (item description and item image). Let
denote an input from an arbitrary modality (i.e.,
x =
). To enhance the purification power of the DDPM, we pretrain it on a clean dataset so that it learns to generate a sample similar to the clean input
by receiving either
or an adversarially perturbed variant of
, denoted as
. This process is illustrated in
Figure 2.
More precisely, we obtain an adversarial direction
by solving the following optimization problem:
where
measures the distance between the model’s predictions on
and
. In practice,
can be modeled by a regression loss such as MSE, Huber loss, or the Binary Cross Entropy classification loss. The adversarial perturbation
can be approximated by ref. [
41]:
This approximation follows the linearization of the loss function
around
. It assumes that
is small, allowing higher-order terms in the Taylor expansion to be neglected [
41].
Subsequently, we obtain
and pass both
and
to the network to optimize its parameters using the proposed hybrid loss, which is composed of a reconstruction loss term such as
Mean Square Error (MSE) and a prediction’s consistency term
:
To train the DDPM using
, we first generate a random timestep
and sample a Gaussian noise
. Then, we diffuse
for t steps and obtain
:
Then, the network estimates the noise
and reconstructs
using the estimated noise
as follows:
Afterward, the loss is computed between and , which encourages the DDPM to eliminate both the added Gaussian noise and the adversarial perturbation simultaneously.
4.4. Adversarial Purification and Detection
A DDPM can naturally eliminate any adversarial perturbation in the diffusion phase by gradually adding Gaussian noises to the input data. Then, it can achieve a symmetric clean input from the output of the diffusion phase through the reverse process. Specifically, given an adversarial example
with adversarial perturbation
, if we diffuse
for
steps, we observe the following:
As increases, the coefficient decreases and increases. Moreover, , since δ should be perceptually indistinguishable. Therefore, we can select such that the added Gaussian noise becomes large enough to submerge the weakened adversarial perturbation , while the main content of the input data is preserved simultaneously.
As seen, a trade-off exists between the purification effect and consistency with the original clean input data. If we use a large value for , the purified data will deviate from the original data. Moreover, a small value for causes the adversarial perturbation to remain in the purified data. This implies the need for an approach that allows us to use a large number of diffusion steps () to achieve effective purification while still generating purified data close to the original data.
To achieve this, we use the input data to guide the reverse process to generate a sample similar to the original data. In particular, we condition each reverse denoising step on
the input data by changing the distribution
to
, where
is obtained by applying
diffusion steps to the original input data (i.e.,
):
For brevity, let
and
. Similarly to ref. [
42],
can be expressed as follows:
where
The proof is presented in
Appendix A. Similarly to ref. [
43], we can approximate
:
Here, is a distance measure like , is the normalizing constant, and is the guidance scale at time step . Consequently, we can approximate the conditional distribution with a normal distribution like the standard DDPM. The key difference is that the mean is shifted by .
After purifying the input data using the guided DDPM, we can detect the existence of adversarial attacks on the input. Our detection mechanism relies on the observation that the predictions for adversarial data differ significantly from those for the corresponding clean data.
Let
be the purified version of the input
. We compute the model’s predictions,
and
, for
and
, respectively. The prediction consistency loss
between
and
(i.e.,
) measures the difference between the predictions. Thus, we assign a weight to the input
from a text or visual modality (i.e.,
D or
) as follows:
where
denotes the modality of the input
, and the hyperparameter
controls the exponential decay rate.
4.5. Refining Targets
In addition to the inputs of an RS, its targets, such as the rating matrix, can be manipulated by malicious users to achieve their own goals. To effectively train the model with potentially noisy targets and restore the true value of these noisy targets, we extend the
self-adaptive training strategy [
8] to recommender systems, allowing the model to progressively refine noisy targets by using its own predictions as guidance during training.
Let
be the target of the RS,
denote the corresponding prediction (output) of the model, and
represent the modified target initially set equal to
. At each training iteration, we update the target by using the
Exponential Moving Average (EMA) mechanism as follows:
where the momentum coefficient
controls the weight of the model’s predictions.
The EMA scheme mitigates the instability of the predictions and smoothly changes the targets if necessary. Moreover, we assign a weight to each target as follows:
The value of reveals the confidence of the corresponding target. Intuitively, during the initial epochs, all examples are treated with equal importance. As the target value is updated, our method reduces its attention to potentially erroneous data and attends more to the potentially clean data. This approach also permits incorrect targets to regain attention if they are confidently refined.
4.6. Loss Function
The loss function plays a key role in the success of our method. It should encourage the model to accurately predict the refined targets. Many SOTA recommender systems such as [
9,
10,
40] sample triplets in the form
from the training set, where
denotes a positive pair and
represents a negative pair typically obtained by random sampling from the set of unobserved items (
). In this research, we sample a negative item j from either unobserved items or items explicitly rated lower by the user.
The loss function of SOTA RSs [
9,
40] is commonly either the pairwise loss (
) originally introduced in
Bayesian Personal Ranking (BPR) [
44] or
Binary Cross Entropy (BCE) loss (
) [
10]:
Let
be the loss function of a baseline recommender system, which is either
or
. In the proposed method, we extend this loss by incorporating the weights obtained from the purification module
,
) and the self-adaptive training mechanism (
for the positive pair. Furthermore, we pass the purified contents
and
to the baseline RS. The final loss function is defined as follows:
We experimentally found that combining the weight values using the product rule is more effective than weighted averaging. The product rule assigns a high weight to an interaction when both the inputs and target values of the interaction are detected as clean. Additionally, it avoids introducing extra hyperparameters to control the relative importance of the weights, unlike weighted averaging.
4.7. Detecting Fake Users
The amount of change in a target variable during the target refinement process can serve as a key metric for distinguishing erroneous targets from clean ones. We extend this concept to detect fake users, as we expect that the amount of change in the target values of these users will be much larger than that of normal users.
To this end, we first identify potential target items by comparing the outputs of the
self-adaptive training strategy for each item with their initial interactions. Specifically, let
and
be the set of original and refined target values of item
, respectively. We identify potential target items by computing the prediction consistency loss
between corresponding targets in two sets, that is,
We then label any item with
greater than threshold
as a target item. Subsequently, user profiles whose behavior on this target set deviates significantly from others are classified as fake profiles. Specifically, let
be the set of identified target items. Moreover, let
and
represent the set of original and refined target values of user
over the potential target items, respectively. We quantify the fakeness of user
by computing the prediction consistency loss
between the corresponding targets in these sets, that is,
We identify malicious users using an appropriate threshold value. Specifically, any user with exceeding threshold is labeled as a fake user, and their interactions are excluded from subsequent training epochs. The threshold is set as the radius of the minimum hypersphere that encloses at least 95% of the normal user profiles from the validation set. This approach reduces false positives while allowing for the robust detection of fake user profiles.
Algorithm 1 summarizes the main steps of UAPD.
| Algorithm 1. UAPD’s Training Algorithm |
Input: Train-Set, : Trained DDPMs, : Baseline RS
Output: : Trained Baseline RS
begin
Initialize modified targets equal to original
for do
for each minibatch in Train-Set do
{Extract user ids, positive item ids, and modified targets from B}
purify()
purify()
Backpropagate to update ’s parameters
end for
end for
return |
4.8. Computational and Space Overhead
To reduce the computational overhead of UADP, we purify the image and description of any item only once and store the purified contents. This increases the space required for storing items by a factor of two. The purification time of images due to the iterative denoising process in DDPMS is relatively time-consuming. However, it demands much less computational time compared to the image generation process by DDPMs. While the number of denoising steps in the DDPM [
42] (
https://openaipublic.blob.core.windows.net/diffusion/march-2021/imagenet64_cond_270M_250K.pt (accessed on 2 January 2025)) used in our work is 1000 (T = 1000), for purifying images, we set the number of denoising steps (
) to 36. In our experiments, the required time for purifying a minibatch of images using a single T4 GPU by the pretrained DDPM [
42] was about 2.371 s, which could be significantly decreased by increasing the number of GPUs and using more powerful GPUs.
The self-supervised target refinement process needs a lower computational overhead because it only includes the weighting and updating of targets using Equations (19) and (20), adding a small constant to the processing time of a minibatch in the training phase. However, this process requires saving the refined targets, which imposes a space complexity of order because each user interacts positively with only a fixed number of items.
5. Experimental Results
This section describes the experiments conducted to evaluate the effectiveness of the proposed defense method against various adversarial attacks on both the content and interaction matrix of selected baseline RSs, including
Visual Bayesian Personalized Ranking (VBPR) [
9], the
visual DSSM modality-based recommender system (DSSM-Vis) [
10], and the
textual DSSM modality-based recommender system (DSSM-Text) [
10].
We also compare our work with peer defense methods on several real-world datasets: the clothing purchase dataset from the H&M platform (HM) (
https://www.kaggle.com/competitions/h-and-m-personalized-fashion-recommendations/overview (accessed on 2 January 2025)), the news clicks dataset from the Microsoft news recommendation platform (MIND) [
45], and the Amazon Men dataset, which is a subset of the larger Amazon Reviews dataset, focusing on men-related products [
9].
5.1. Datasets
HM is a large-scale personalized fashion recommendations dataset. The dataset provides color, category, and image data for each product, as well as the age, loyalty status, and purchase history for each user.
MIND is a large-scale dataset from Microsoft used for the news recommendation task. It contains news articles and user interactions, such as clicks and browsing behavior. The dataset provides title, abstract, category, subcategory, and text content for each news article.
The Amazon Men dataset, a subset of the larger Amazon Reviews dataset, includes items specifically targeted toward men, such as clothing, accessories, and grooming items. It contains 34,212 users, 100,654 items, and 260,352 interactions. This dataset is commonly used to evaluate visual recommender system models.
Following ref. [
10], we randomly selected 500 K and 630 K users from the HM and MIND datasets, along with their referenced items. Users with fewer than 10 interactions were removed from the datasets to filter out extremely sparse user profiles. To construct the interaction matrix, we considered the last 13 and 23 interactions for each selected user in HM and MIND, respectively, to emphasize the most relevant user behavior. We chose to limit the interactions to the last 13 in HM because the task of encoding images demands significantly higher GPU resources. Following ref. [
9], users with fewer than ten interactions were also excluded from the Amazon Men dataset, and only the most recent 20 interactions for each user were considered.
For each user, the last and second-to-last referenced items were selected for test and validation purposes, and the remaining referenced items were used for the training set. In HM and Amazon Men, we represented items by images, while in MIND, we represented items by their titles. We considered only the user ID to represent users.
5.2. Evaluation Metrics
We evaluated competing methods using two standard top-K ranking metrics: Hit Ratio (HR)@K and Normalized Discounted Cumulative Gain (NDCG)@K, where .
HR@K measures the proportion of times the true relevant item appears within the top-K recommended items. Specifically, let
be the ground truth item for user
. HR@K can be expressed as follows:
Let
indicate the binary relevance score of position
, which is 1 if
appears at position k and 0 otherwise. NDCG@K evaluates the ranking quality of the recommended items by examining the positions of relevant items within the top-K list. It assigns higher scores to hits that appear earlier in the ranking.
where
represents the highest possible DCG that can be achieved for the top K ranked items for user
.
In some experiments, we measured the performance of RSs using
robustness improvement (RI) [
18]. For a metric
, such as
and
, let
,
, and
denote the value of
in standard (no attack), defense, and attack without defense settings, respectively. Then,
is defined as follows:
An value closer to 1 indicates better robustness of the defense method.
5.3. Experimental Setup
We implemented the proposed method using the PyTorch version 2.2.0 deep learning framework. For the DSSM-Vis and VBPR, we used ResNet-50 as a feature extractor and a pretrained DDPM provided by ref. [
42] for purifying the images. This DDPM is based on a U-Net architecture [
46], which predicts the
and
for the denoising backward distribution at each time step. For the DSSM-Text, we used RoBERTa as a text encoder. The DDPM used in DSSM-Text is also based on a U-Net architecture; however, it is applied to the output of the RoBERTa encoder.
The denoising process was performed with
and the hyperparameters
were adjusted using a linear scheduling with
and
. We optimized the hyperparameters of the visual RSs (i.e., DSSM-Vis and VBPR) and DSSM-Text, as specified in ref. [
10].
We preprocessed the images in HM and Amazon Men by resizing them to and scaling their pixel values to the range . Moreover, we normalized the images to have a zero mean and a standard deviation of one before passing them to the baseline RSs. The images were rescaled to the range [−1, +1] before being passed to the DDPM. We considered a maximum of 30 tokens for news titles in the MIND dataset, covering 99% of the total tokens.
We evaluated the performance of defense methods in both standard and robust settings. The standard setting evaluates the performance of defense methods on a clean, unaltered test set. On the other hand, the robust setting assesses their performance on an attacked test set. This shows how effectively defense methods can handle adversarial attacks.
5.4. Adversarial Attacks on Images
To estimate the effectiveness of the proposed method against adversarial attacks on images in visual RSs, we selected VBPR and DSSM-Vis as baseline RSs and evaluated our method against advanced threat models, including
Fast Gradient Sign Method (FGSM),
Projected Gradient Descent (PGD), and
Carlini & Wagner (C&W). We also compared our method with SOTA defense methods, including
Adversarial Training (AT) [
11],
Free Adversarial Training (FAT) [
11],
Adversarial Image Denoiser (AiD) [
12], and
Adversarial Multimedia Recommendation (AMR) [
13].
FGSM is a white box attack in which the adversary has complete access to the baseline RS. It is a simple and efficient single-step attack, which generates adversarial examples by adding perturbations aligned with the loss gradient. In contrast, PGD is a stronger, iterative attack. It applies small, repeated perturbations over multiple steps. PGD also projects the perturbed input back into the allowed perturbation space. While PGD is more effective than FGSM, it is computationally more expensive due to its iterative nature. These attacks were performed with an ball of radius = 8/255 in our experiments.
The C&W is a powerful adversarial attack that generates adversarial examples using an optimization problem. It minimizes the perturbation required to mislead a model while ensuring the perturbed input remains close to the original.
Table 4 presents the performance of the competing defense methods against different attacks on the VBPR over the Amazon Men dataset. Additionally,
Table 5 presents the performance of these methods versus different attacks on the DSSM-Vis over the HM dataset.
The results highlight the effectiveness of various defense methods against different attacks in both experiments. For instance, under the PGD attack, the HR@20 and NDCG@20 of VBPR dropped to 10.19% and 5.87%, respectively. However, with Adversarial Training (AT), VBPR attained an HR@20 and NDCG@20 of 17.64% and 9.50%.
Additionally, the proposed method consistently outperformed other defense methods across different metrics. For example, under the PGD attack on the DSSM-Vis, UAPD achieved an HR@10 and NDCG@10 of 17.17% and 10.36%, respectively, while the second-best method, FAT, attained an HR@10 and NDCG@10 of 14.67% and 8.90%, respectively. Similarly, under the FGSM and C&W attacks, UAPD maintained superior performance, with the HR@20 reaching up to 22.76% and the NDCG@20 up to 12.22%.
Furthermore, we observe that UAPD’s results across different attacks were almost stable, mainly due to the diffusion-based purification method in UAPD that can naturally eliminate any adversarial perturbation in the diffusion phase, irrespective of the attack type (refer to
Section 4.4 for more details).
These findings show that the proposed DDPM training approach, guided denoising process, and detection mechanism can effectively remove adversarial perturbations generated by these advanced attacks. In the ablation study, we investigated the contribution of each mechanism to the overall performance of the proposed method.
We also examined the standard performance of the defense methods on the baseline RSs.
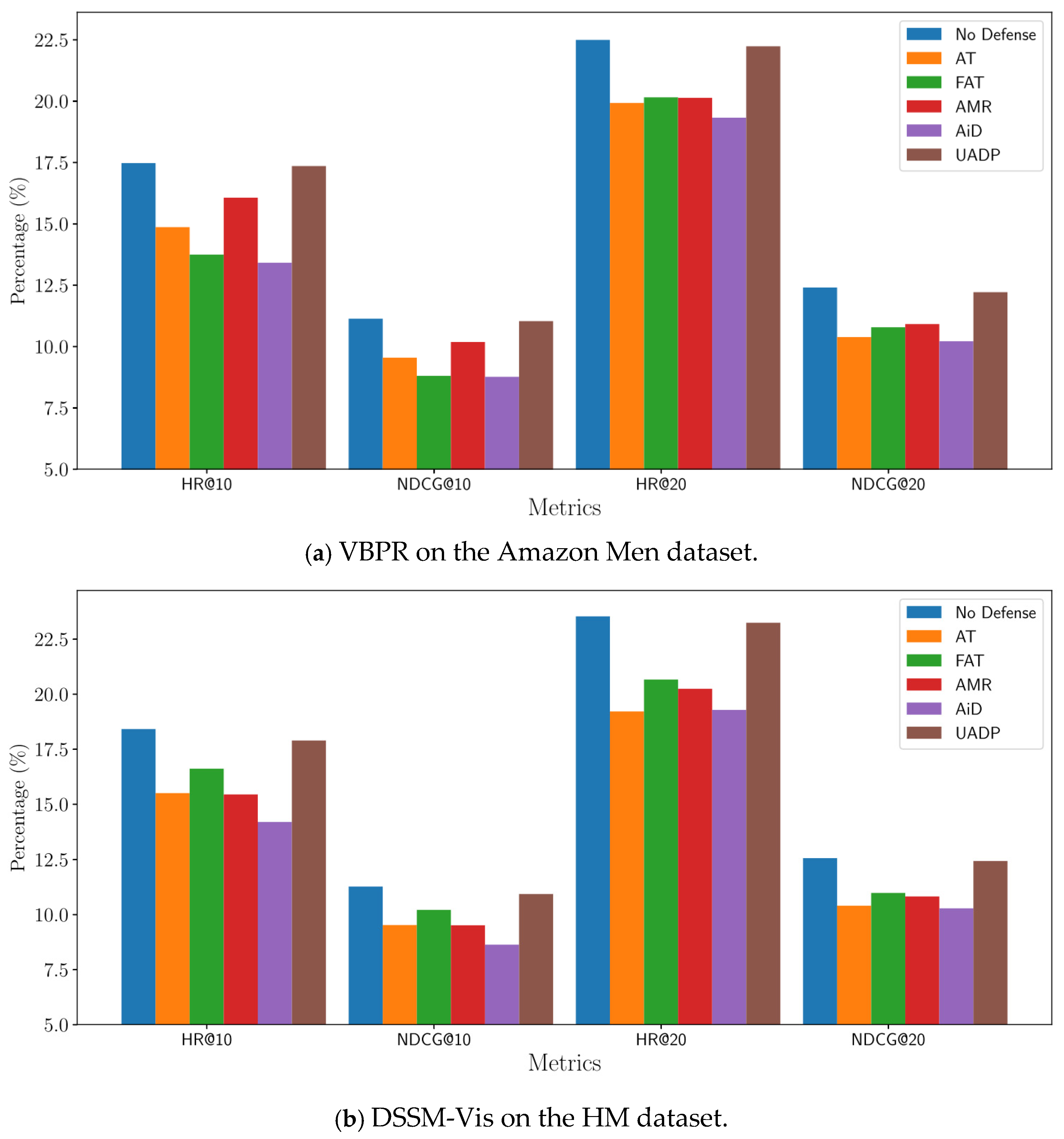
Figure 3 presents the results.
The results shed light on the standard performance—i.e., performance without any adversarial attacks—of different defense methods applied to the DSSM-Vis model on the HM dataset and the VBPR model on the Amazon Men dataset. The baseline models, DSSM-Vis and VBPR, exhibited the highest standard performance across all metrics. Specifically, DSSM-Vis achieved an HR@10 of 18.41% and an NDCG@10 of 11.27%, while VBPR achieved an HR@10 of 17.47% and an NDCG@10 of 11.13%.
The defense methods resulted in noticeable declines in both HR and NDCG metrics. For instance, the DSSM-Vis using AT achieved an HR@10 of 15.50% and an NDCG@10 of 9.52%, which was a significant drop from the baseline. Additionally, both baseline RSs using UAPD maintained performance levels much closer to the baseline. For instance, the DSSM-Vis using UAPD achieved an HR@10 of 17.89% and an NDCG@10 of 10.93%, which are only marginally lower than the baseline DSSM-Vis. Moreover, the VBPR using UAPD achieved an HR@10 of 17.35% and an NDCG@10 of 11.03%, nearly matching the baseline VBPR’s performance. This minimal degradation indicates that UAPD effectively balances the trade-off between enhancing robustness against adversarial attacks and preserving standard recommendation accuracy.
5.5. Adversarial Attacks on Textual Information
We also evaluated UAPD against adversarial attacks on the textual contents of an RS. To this end, we chose the DSSM-Text as the baseline RS. The performance of DSSM-Text with our defense method was assessed against PGD, FGSM, and C&W attacks. These attacks were applied to the output of the RoBERTa text encoder in the DSSM-Text. Additionally, we compared UAPD with peer defense methods including AT, FAT, and AMR. The perturbation size of PGD and FGSM was limited to
in our experiments.
Table 6 presents the performance of the DSSM-Text using the competing defense methods on the MIND dataset. Additionally,
Figure 4 compares the standard performance of the DSSM-Text using different defense methods.
The results show that all attacks successfully degraded the performance of the RS with no defense strategy. Among them, PGD was identified as the most effective threat model. For instance, without any defense, PGD decreased the HR@10 and NDCG@10 of the RS to 6.11% and 3.83%.
Additionally, all defense strategies substantially reduced the impact of the attack. For instance, the DSSM-Text with AT achieved an HR@10 of 12.01% under the PGD attack, far better than the 6.11% achieved by DSSM-Text with no defense method. However, the results show a noticeable drop compared to the standard performance of the DSSM-Text with an HR@10 of 15.17%.
Among the defense methods, UAPD consistently outperformed others across various metrics. For example, UAPD achieved an HR@10 and NDCG@10 of 13.54% and 8.5% under the C&W threat model, showing an improvement of 1.56% and 0.85% compared to AT, the second-best method, under the same attack.
As the results in
Figure 4 indicate, all defense methods had side effects on the standard performance of the baseline RS. For instance, the NDCG@10 of the DSSM-Text decreased from 9.52% to 7.87% when using the FAT. However, the proposed method consistently showed the minimum side effects among the defense methods.
The results of this experiment are consistent with previous findings regarding adversarial attacks on images. The results confirm that UAPD effectively balances the trade-off between enhancing robustness against adversarial attacks and preserving standard recommendation accuracy in the context of adversarial attacks in both image and textual modalities.
5.6. Shilling Attacks
This section presents experiments conducted to evaluate the performance of the proposed defense method against various shilling attacks. To this end, we considered random and bandwagon attacks [
4],
Poisoning Recommender Systems (PoisonRec) [
14],
Deep learning (DL)_Attack [
15], and
Robust Adversarial Poisoning with Uncertainty (RAPU) [
16] attacks on two baseline RSs: the DSSM-Vis and the DSSM-Text. These attacks were implemented using the
Library for Attacks against Recommendation (ARLib) [
17]. We also compared our work with state-of-the-art defense methods, including
Adversarial Training (AT) [
47],
Adversarial Poisoning Training (APT) [
18], Bagging [
19], and PORE [
6].
We set the
fake user fraction parameter to 5% for these attacks, the
target ratio (the proportion of target items relative to the total item count) to 10%, and the
target item selection strategy to “Unpopular”. The malicious rate size (the fraction of total items rated by fake users) was set to the average fraction of total items rated by real users. The hyperparameters of the competing methods were set according to their recommended settings.
Table 7 presents the hyperparameters of the competing methods and their adjustment ranges.
Our experimental results showed that the specified shilling attacks were ineffective in terms of the global performance of the baseline RS. For example, the HR@10 and NDCG@10 of DSSM-Vis only decreased by 0.01% and 0.03% when applying the DL_Attack. Conversely, these attacks significantly manipulated the ranking of target items. For instance, the HR@10 and NDCG@10 of the target items increased by 25.22% and 239.06%, respectively, when we applied the DL_Attack. Therefore, we measured the performance of defense methods using the rate of increase in HR@k and NDCG@k of the target items (k ∈ {10, 20}), where a lower rate indicates a better defense.
Table 8 presents the performance of the DSSM-Vis using these defense methods under the specified attacks on the HM dataset. Additionally,
Table 9 provides the results of the DSSM-Text using these defense methods on the MIND dataset.
As the results indicate, without any defense strategy, all attacks significantly enhanced the ranking of target items. Among these attacks, RAPU—formulated as a bi-level optimization problem—was the most effective threat model. For example, it increased the HR@10 and NDCG@10 of target items by 31.15% and 293.13% when the DSSM-Vis was used as the baseline RS and no defense method was adopted.
Additionally, all defense methods substantially alleviated the effects of the specified attacks. Among them, UAPD was the best defense strategy against many of these attacks. For example, DSSM-Vis using UAPD achieved the best results in 3 of 5 attack scenarios. It reduced the increase rate of NDCG@10 for target items from 293.13% to 19.28% under the RAPU attack. Note that given the original NDCG@10 of target items was a low value of 0.0038, the remaining increase rate had a minimal impact in this case.
Among the adversarial methods (i.e., AT and APT), APT provided a better defense in most attack scenarios. For instance, DSSM-Text using APT decreased the increase rate of NDCG@10 for target items to 27.57% under the DL_Attack, whereas this rate decreased to 30.47% with AT. However, no defense strategy consistently outperformed the others across all attacks, and the performance of the defense methods was competitive in many of these attack scenarios. Therefore, it seems that a combination of these defense methods could lead to a more robust and comprehensive defense.
5.7. Ablation Study
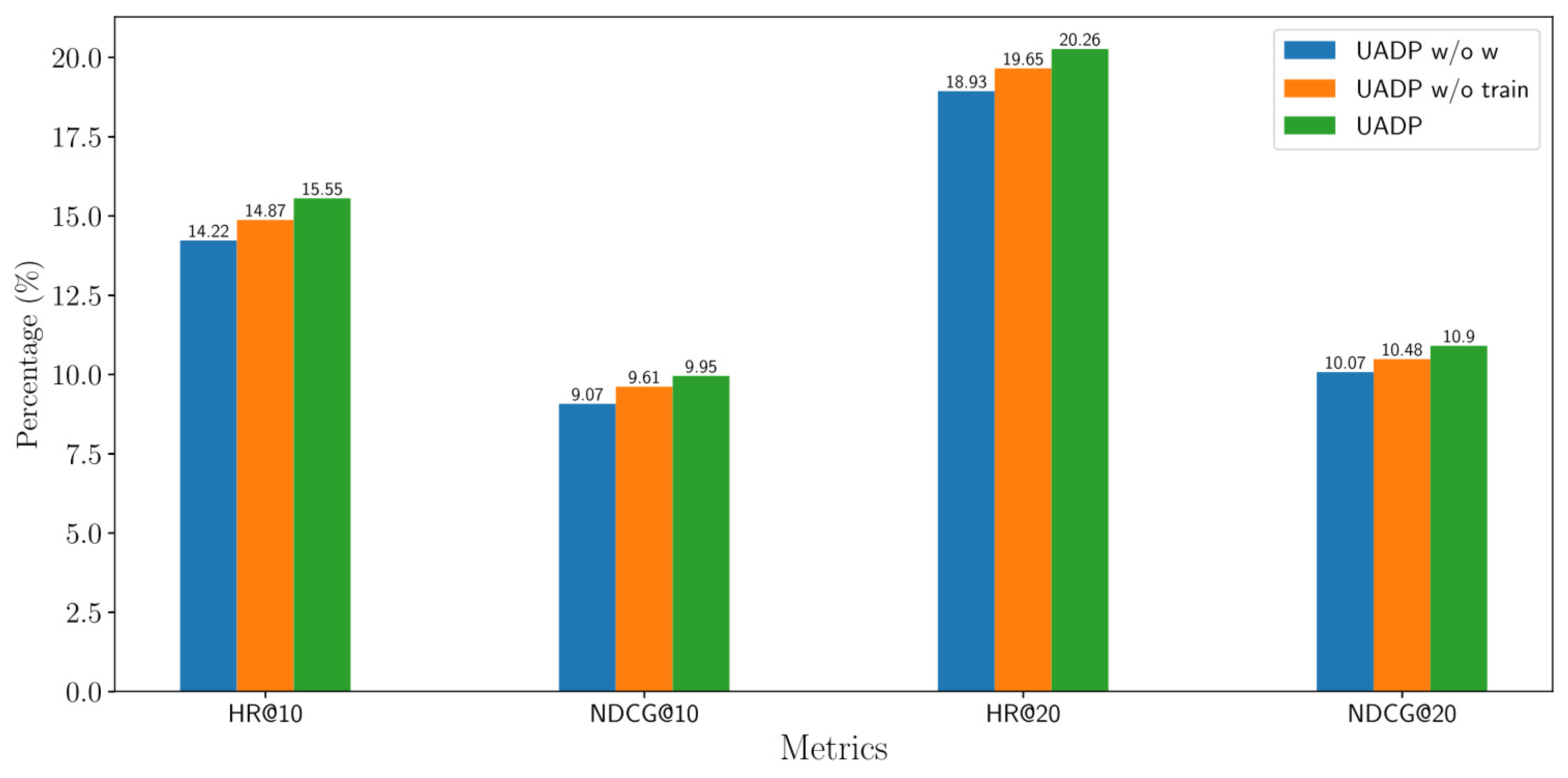
This experiment examined the contribution of the proposed weighting scheme and training process of the DDPM to the overall performance of the proposed method. To this end, we chose the DSSM-Vis as the baseline RS and derived two variants of the proposed method:
We applied a PGD attack with an
ball of radius = 8/255 on the images from the HM dataset and measured the performance of these variants under this attack.
Figure 5 illustrates the results.
The results show that both the weighting scheme and the training process of the DDPM were effective and positively impacted the overall performance of UAPD. The weighting scheme had a greater positive impact compared to the training process. This was mainly due to the purification power of the pretrained DDPM, which could effectively eliminate adversarial noise without a fine-tuning step. However, the training process is necessary for other modalities like text. Moreover, this process noticeably boosts the purification power of the DDPM on images.
5.8. Hyperparameter Analysis
This section explores two hyperparameters of the proposed method: and . The parameter determines the number of purification steps, whereas the parameter controls the update rate of interaction labels in the self-adaptive process.
In the first experiment, we chose the DSSM-Vis as the baseline RS, randomly selected 50% of the HM’s images, and then applied a PGD attack with an
norm ball of
. Then, we measured the RI(HR@10) and RI(NDCG@10) of UAPD by varying the value of
in {20, 30, 36, 40, 50, 60, 70, 100}. The results are illustrated in
Figure 6.
The results indicate that as the value of increases, the effectiveness of the purification improves, reaching peak performance in the range (30, 40). In this range, UAPD achieved a RI(HR@10) over 85%, indicating strong resistance to the attack. Afterward, the performance of the proposed method smoothly declined, mainly due to the side effects of excessive purification of the clean images.
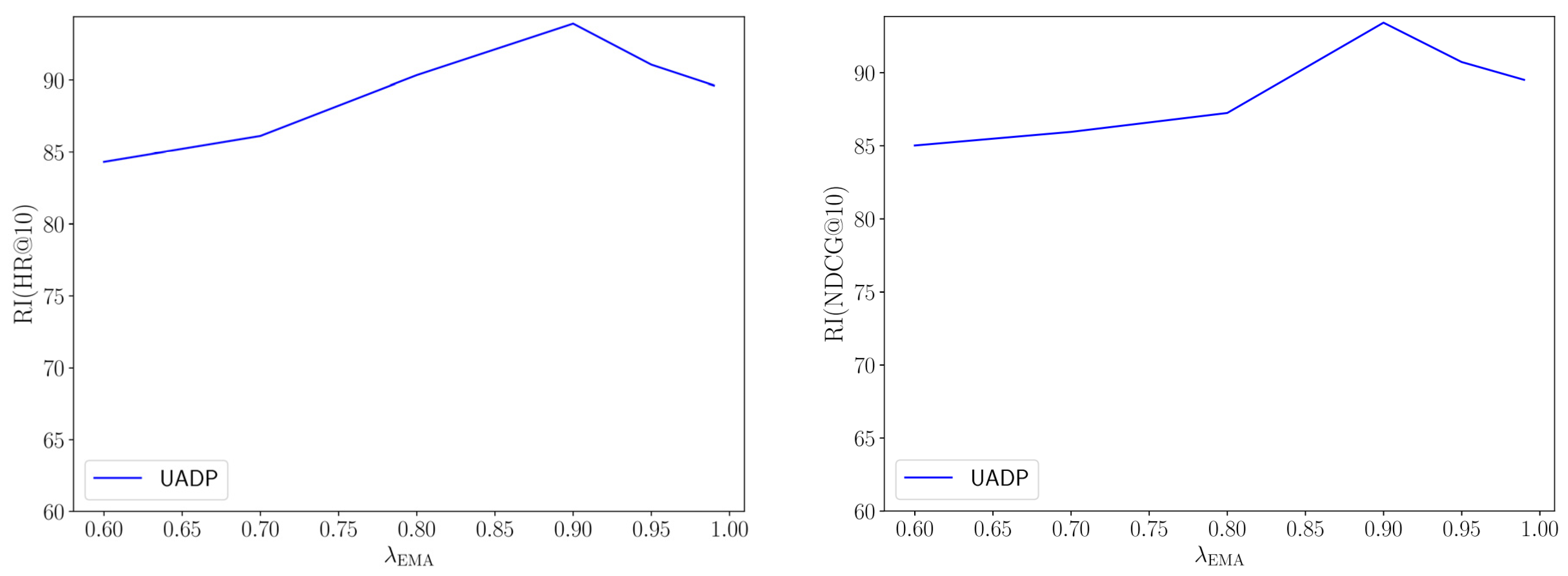
In the second experiment, we applied a RAPU attack on the DSSM-Vis using UAPD as the defense method with the following parameters:
fake user fraction = 5%,
target ratio = 10%, and
target item selection strategy = “Unpopular.” The malicious rate size was also set to the average fraction of total items rated by real users. Then, we measured the RI(HR@10) and RI(NDCG@10) of the
target items by varying the value of
in {0.6, 0.7, 0.8, 0.9, 0.95, 0.99}.
Figure 7 shows the results.
The outcomes reveal that the performance of UAPD against this attack gradually improved as the value of increased from 0.60 to 0.90. The peak performance was observed at 0. At this point, UAPD achieved an RI(NDCG@10) of 93.42%. Afterward, the performance of UAPD gradually declined. Moreover, the high performance of UAPD in the wide range indicates the low sensitivity of our method to specific values of this hyperparameter.
5.9. Robustness
To evaluate the robustness of the proposed method, we applied PGD attacks with different perturbation sizes () to the HM’s images and assessed the decline in the performance of the DSSM-Vis with UAPD. Similarly, adversarial perturbations of varying magnitudes were applied to the MIND’s item descriptions and the decline in the performance of the DSSM-Text with UAPD was measured.
A smaller decrease indicates greater robustness.
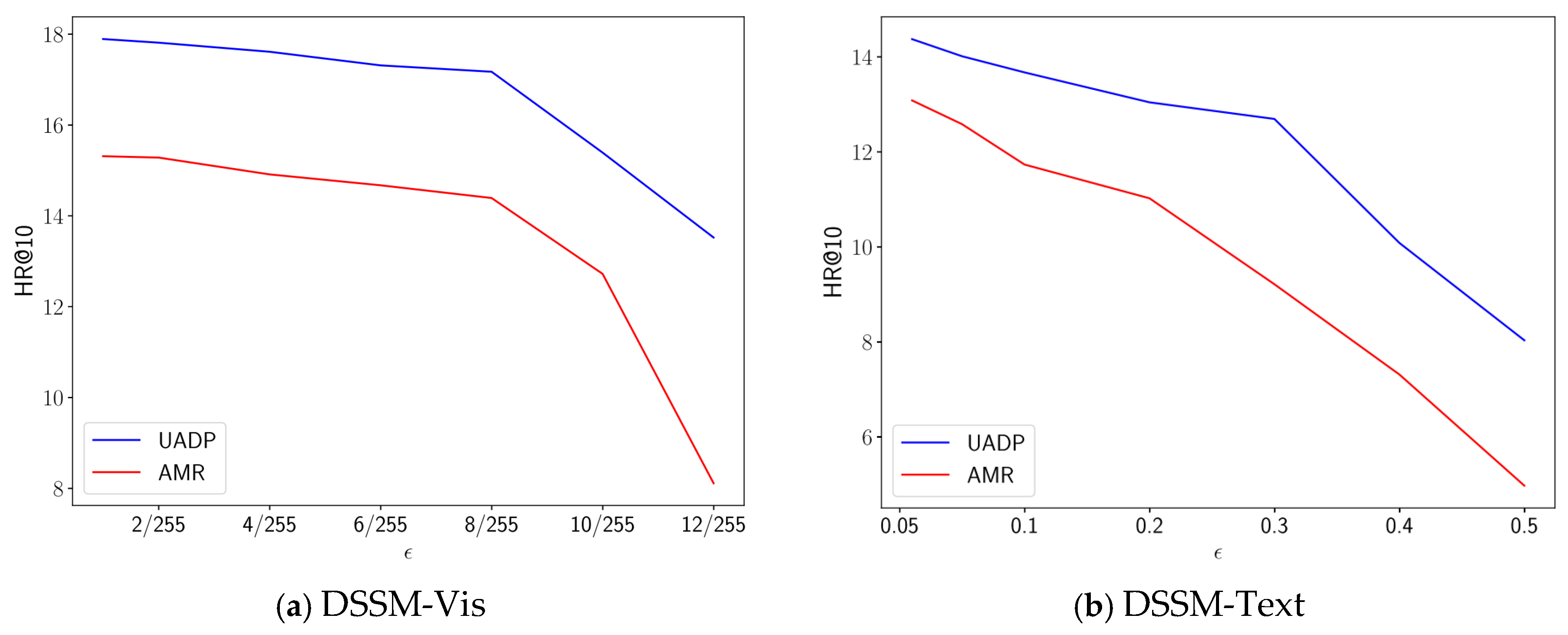
Figure 8 compares the robustness of UAPD with that of AMR on the DSSM-Vis and DSSM-Text, under various levels of adversarial perturbation.
We can observe that for different values of , UAPD outperformed AMR by a relatively large margin when DSSM-Vis was selected as the baseline RS. Moreover, the DSSM-Vis achieved strong robustness under this attack using both defense methods when . For greater perturbation sizes, which may become noticeable to the human eye, there were considerable performance drops. However, UAPD had a much smaller performance drop than AMR, highlighting its superior robustness under more intense attack scenarios.
The results on the text modality were consistent with the outcomes of adversarial attacks on images. UAPD consistently provided higher performance for the DSSM-Text compared to AMR. For perturbation sizes exceeding 0.2, both defense methods experienced a substantial performance decline. However, UAPD showed a significantly smaller performance decline compared to AMR.
The results on both modalities provide empirical evidence of the robustness of UAPD. UAPD is less vulnerable to adversarial attacks compared to Adversarial Training methods because of the purification capabilities of the DDPM and the weighting scheme in the proposed method.
In the second experiment, we evaluated the robustness of UAPD against shilling attacks. To this end, we chose the DSSM-Vis as the baseline and applied the RAPU attack with the following parameters:
target ratio = 10% and
target item selection strategy = “Unpopular.” The number of ratings provided by malicious users was set to match the average fraction of total items that genuine users rate. Then, we measured the RI(HR@10) and RI(NDCG@10) of
target items by varying the value of the
fake user fraction (
) in {5%, 7%, 10%, 12%, 15%, 20%}.
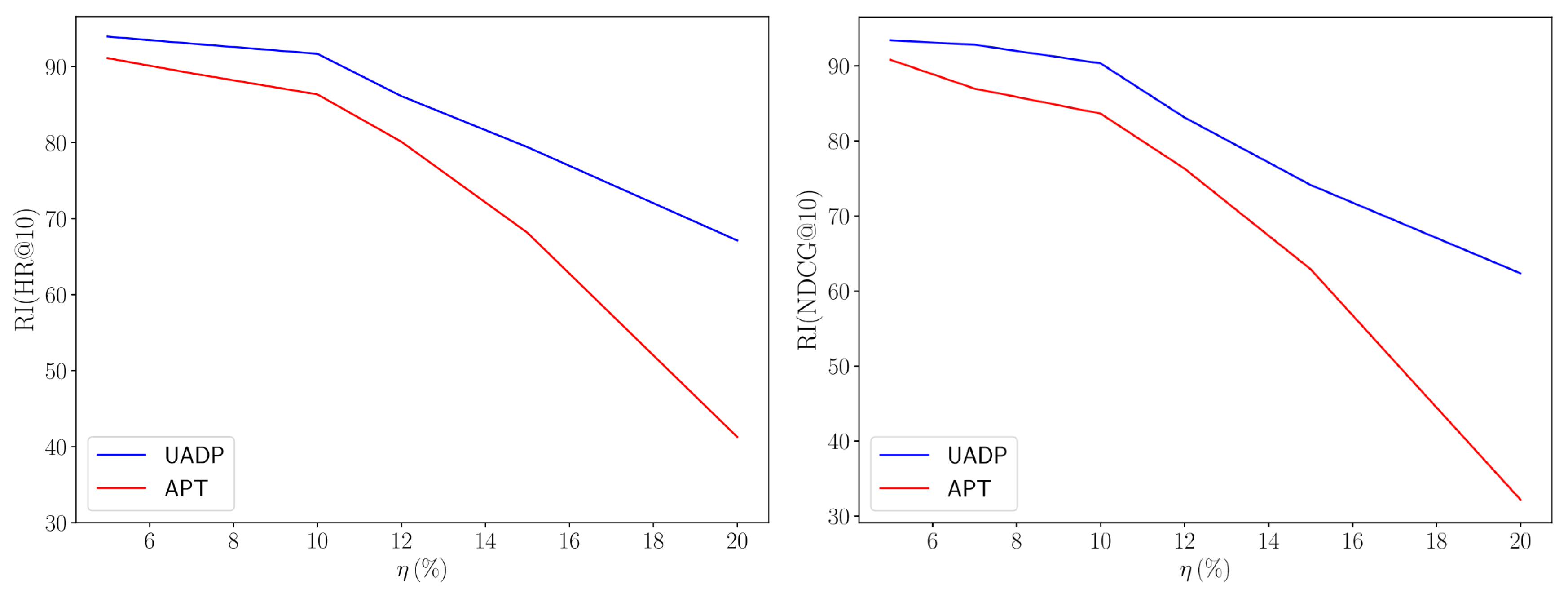
Figure 9 compares the results of UAPD with those of APT.
The results indicate that for realistic values of (i.e., η ≤ 10%), UAPD consistently maintains high robustness against the RAPU attack. In this range, UAPD shows minimal variance in performance metrics, maintaining an RI(HR@10) of over 90%, which suggests that UAPD effectively mitigates the impact of adversarial users under plausible attack scenarios. For larger values of , which may be unrealistic in a real-world situation, the RI(HR@10) of UAPD drops slightly. For instance, the RI(HR@10) of UAPD declines to 79.41% when the value of increases to 18%. In contrast, APT experiences a significantly larger performance drop compared to our method, as its RI(HR@10) declines to 68.15% for Thus, we can conclude that UAPD is robust against advanced shilling attacks such as RAPU, especially when the fake user fraction is limited to 10%.
We also evaluated the performance of UAPD against simultaneous attacks on both the inputs and interaction matrix of the DSSM-Vis. To this end, we simultaneously applied the PGD attack to 50% of the HM’s input images and the RAPU attack to the interaction matrix of the dataset. The PGD attack reduces the global performance of the RS, whereas the RAPU attack mainly affects the ranking metrics of the target items. Here, we set
and
and evaluated the
global HR@10 of the RS, along with the RI(HR@10) of the
target items by varying the intensity of the attacks. Specifically, we measured the HR@10 of UAPD by varying the value of
parameter of the PGD attack in the range {2/255, 4/255, 8/255, 10/255} and the
parameter of the RAPU attack within the range {5%, 10%, 15%}. Moreover, we evaluated the RI(HR@10) of the
target items by varying the value of
in the range {5%, 7%, 10%, 12%, 15%, 20%} and
within the range {4/255, 8/255, 10/255}.
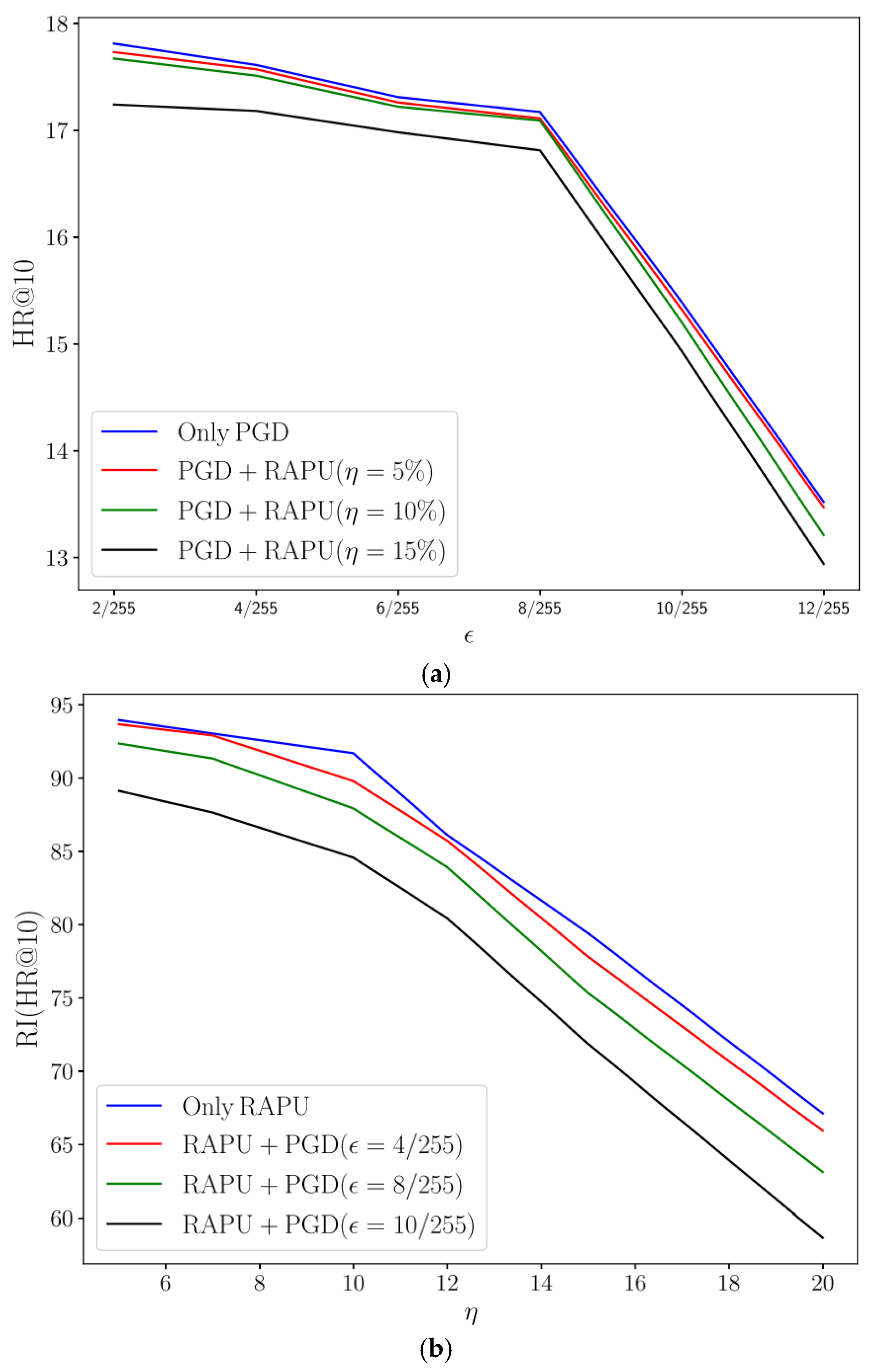
Figure 10 illustrates the results.
The results show that for realistic values of and (i.e., ϵ ≤ 8/255 and ), the global HR@10 of DSSM-Vis using UAPD as the defense method is largely preserved under the combined attack. In this range, the performance of UAPD under the combined attack is comparable to its performance under the PGD attack alone. For instance, the HR@10 of the DSSM-Vis slightly declines from 17.17% to 17.09% when and increases from 0% to 10%. For larger values of , the RAPU attack influences the performance of the RS to a greater extent; however, the performance remains within an acceptable range even in this extreme scenario. For example, applying the RAPU attack with reduces the HR@10 of the RS from 17.17% to 16.81%. Only at extreme values of and do we observe a considerable performance drop. Therefore, we can conclude that UAPD maintains the performance of the RS under simultaneous attacks, particularly for realistic attack sizes.
Additionally, we observe that for realistic values of and (i.e., ϵ ≤ 8/255 and ), the RI(HR@10) of target items remains largely preserved. For instance, the RI(HR@10) of target items under only the RAPU () attack is 93.94%. When the PGD () attack is applied simultaneously with the RAPU attack, the RI(HR@10) of target items declines slightly to 92.34%. However, the RI(HR@10) of target items shows a greater decline for the extreme value of (i.e., ϵ=10/255) and . By simultaneously applying the PGD () and the RAPU () attacks, the RI(HR@10) of target items is significantly dropped and reaches 58.65%. Thus, we can conclude that UAPD is robust against targeted shilling attacks even when it simultaneously faces a strong adversarial attack like PGD. However, a combined attack of extreme sizes can significantly weaken this robustness.







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}