Abstract
In this article, we introduce and study a new kind of multiparty session type for a probabilistic process calculus that incorporates two forms of choice: probabilistic and nondeterministic. The main novelty of our approach is the use of interval probabilities in a type system in order to deal with uncertainty in a probabilistic process calculus. We present a decidable proof system that ensures deadlock freedom, type preservation and type safety, even when several types can be assigned to a process. The new typing system represents a conservative extension of the standard typing system based on multiparty session types (removing the probabilities from processes does not affect their well-typedness). We also define a probabilistic bisimulation between processes that are typed by using the same sorting and typing.
1. Introduction
Session types represent a type discipline used to describe communication-centric systems in the framework of process calculi. Involving concurrent processes, session types guarantee that message-passing communication follows predefined protocols, implementing given (multiparty) session protocols without errors. In this way, the session types describe statically the communication protocols, and well-typedness ensures that the behavior is in accordance with these protocols at runtime.
The theory of session types operates under the assumption of no system errors (e.g., failure at transport level), and does not account for tolerance of interactions or variability of parameters in a communication protocol [1]. In fact, most of the work on session types has focused on error-free (and non-probabilistic) scenarios; only recently were published some papers focusing on failures [2,3,4,5,6,7]. However, many real-life communication and concurrent message-passing systems involve various uncertainties, and so they are generally probabilistic. In the real world, these systems involving network and embedded equipment exhibit different kinds of uncertainty in their behavior as a result of some random physical parameters. Probability theory and stochastic processes provide the mathematical foundation for analyzing uncertain and random phenomena. The use of a probabilistic approach can be more realistic and helpful in analyzing the communication-centric systems. The use of probabilities in session types was presented recently in some articles [8,9,10,11,12,13,14].
In this article, we introduce new multiparty session types for a probabilistic process calculus that incorporates two forms of choice: probabilistic and nondeterministic. The main novelty of our approach is the use of interval probabilities in a type system in order to deal with uncertainty in a probabilistic process calculus; in this way, several processes can be well-typed by the same type and several types can be assigned to the same process. We present a decidable proof system that ensures deadlock freedom, type preservation and type safety.
The concept of interval probability is introduced to generalize classical probability for describing uncertainty in general. Such intervals of probabilities are mentioned in early articles [15,16]. More recently, interval probability has been used in [17] for stochastic hybrid systems to manage uncertainty and to develop an efficient formal analysis and control synthesis of (discrete-time) stochastic hybrid systems with linear dynamics. Using the Interval Markov Decision Processes (labelling transitions by intervals of probabilities) as an abstract model, the authors present a robust strategy against the uncertainties of the real-world hybrid systems. The uncertainties are viewed as the nondeterministic choice of a feasible transition probability from one state to another (under a given action); in this way, specific reachability and safety problems are solved.
As usual for multiparty session types, we consider a top-down approach where we utilize global types (that describe the interactions among distributed processes) to enforce communication safety and the local types (obtained by projection from global types) to statically type-check the processes. If processes are well-typed, then they correctly interact as prescribed by a multiparty session protocol. To formally describe these systems, we use interval probabilities in our type system in order to deal with uncertainty in the probabilistic process calculus. In this way, we obtain a formal model for complex communication-centric protocols to describe and analyze their behavior by involving tolerance to inherent uncertainties provided by certain random physical parameters. We use local and global types that incorporate interval probabilities, and allow processes to incorporate two forms of choice: probabilistic internal and nondeterministic external. Note that, in general, the deterministic behavior cannot be replaced by a probabilistic behavior (only in some cases is valid to assume that a probabilistic mechanism governs a nondeterministic choice). This is also due to the fact that the behavior produced by nondeterministic choices is unpredictable, while the one produced by probabilistic is predictable in the long run. Thus, the probabilistic and nondeterministic choices need to be treated separately [18].
The paper follows the standard way of dealing with session types. Section 2 presents the syntax and semantics of our probabilistic calculus incorporating two types of choice (probabilistic and nondeterministic); we use a running example to illustrate the key aspects. Section 3 introduces the global and local types, together with their connection established by a projection. Section 4 presents the new probabilistic typing system that ensures deadlock freedom, type preservation and type safety, even when several types can be assigned to a process. The new typing system represents a conservative extension; removing the probabilities from processes does not affect their well-typedness. Section 4 also defines the probabilistic relations between processes that are typed according to specific sorting and typing, and a bisimulation between processes that are typed under the same sorting and typing. Section 5 presents the conclusions, and discusses other approaches that used probabilities in typing systems.
This is a revised and extended version of [19]. In addition to some improvements in motivation, related work and by including the missing proofs, the most significant technical differences between this article and its conference version are as follows: (i) defining a probabilistic relation between processes that are typed under the same sorting and typing and corresponding definitions when the probabilities are erased; (ii) proving that the previous relation is an equivalence and that there exist several such relations that can relate two processes; (iii) defining and studying bisimulations between processes by also taking into account their types and interval probability.
2. Probabilistic Multiparty Session Calculus
Using similar notations as for the calculus presented in [20], we propose a probabilistic extension of a synchronous multiparty session process calculus. However, taking inspiration from [21], we simplify the syntax by omitting session initiations and dedicated input/output prefixes. Our calculus allows processes to incorporate two forms of choice: probabilistic internal choice and nondeterministic external choice.
2.1. Syntax
A session between multiple parties is basically a series of their interactions. In order to establish a session, the involved parties should use a shared public name that is employed to create fresh session channels that will be used only for communication between them. Table 1 presents the syntax of our probabilistic calculus, where we use p for probabilities, c and s for channels, v for values, x for variables, l for labels, r for roles and X for the process variables appearing in recursive processes.

Table 1.
Syntax of the probabilistic multiparty session calculus.
The selection process uses channel c to send with probability towards role r the labelled value , and then it behaves according to process . Since all the labels in the set are unique by construction, the selection process has I possible continuations. We only impose that the sum of probabilities appearing in a selection is 1, without further constraints or connections with other probabilities appearing in a process. In a similar manner, the branching process uses channel c to receive from role r a labelled value. If the value received has label , the branching process behaves according to process in which the received value replaces all free occurrences of the variable . Note that the branching process is the only one that bounds variables, namely each variable is bound within the scope of . The set of free channels and free variables of a process P (namely those not bound in the branching process) are denoted by and , respectively, while the set of all processes is denoted by .
The restriction process represents a process P to which the scope of session s is constrained. Process definition and process call are used to define recursive behaviors. If D from the process definition has the form , then the process call behaves as P in which are used to replace the variables . Similar to the approach of [20], we allow only closed process declarations in which the process declaration is such that and . The inaction process is a process that does nothing, while the parallel process allows the concurrent processes P and Q to communicate on a shared channel. The error process err marks the fact that we have an unsuccessful communication. Processes containing holes are used as evaluation contexts, while a communication channel c is either a variable x or a channel for role r in a session s, as in [22]. Values v used in processes can be Boolean, integers or strings.
Example 1.
In what follows, we describe a process that outlines a straightforward survey poll in which either answers ’s questions or opts out. can conclude the poll if satisfied with the responses received or proceed with additional polling questions. Similar to the scenario described in [23], and express their preferences and receive others’ choices, each accompanied by numerical probabilities. These probabilities establish a clear numerical scale for responses.
The starting system is as follows:
The session that involves the parallel processes of and is denoted by . This session encompasses two roles: assigned to and assigned to . Thus, within this session, and communicate by using channels identified by roles and , respectively. Additionally, and are sessions in which and can interact; these sessions can be established by performing communications within session . It is important to note that initially the scopes of and are limited to , as is informed later if he needs to join one of these sessions. The variable appearing in of is used to wait for a question from to which she can answer or not.
, where the definitions of and are as follows:
, where the definitions of and are as follows:
The concurrent behavior of processes and is explained through their interaction.
- Initial decision: uses the channel with role in order to decide how to respond to the poll: by phone, instant messaging or by deferring the response. Probabilities are assigned to each option, indicating ’s choice.
- Phone communication: If chooses the option, communication occurs through a unique session channel () representing ’s phone number.
- ’s interaction: initiates the interaction by invoking , where becomes after communication. Here, represents the first question for to answer using the following labels: , no, or . excludes the option for this question, as she considers it inapplicable to the question at hand.
- Question–answer sequence: After receiving an answer, proceeds to the next question in the list (represented by ).
- Exiting the poll: Both processes are able to get out of the poll by selecting either the or label. These options have low probabilities, indicating a low likelihood of being chosen during the survey poll.
2.2. Operational Semantics
If a name s is not in , then we cannot find any role r such that exists within . Additionally, we use to represent all process variables that are declared in D and to represent all process variables that appear as free variables in P.
Operational semantics is defined by using the structural congruence as its foundation:
| 1ex |
| implies . |
For our probabilistic calculus, operational semantics is defined inductively according to Table 2, incorporating the previously defined structural congruence ≡ and also -conversion. A process P is considered erroneous if and only if there exists a context such that .
Table 2.
Operational semantics of the probabilistic multiparty session calculus.
The communication between a probabilistic selection process (with role ) and a branching process (with role ) inside a session s is modelled using rule (Comm). When the process selects with probability a branch with label , the corresponding branch with label is also selected in the process . The probabilistic selection process behaves afterwards as , while the branching process behaves afterwards as , where the communicated value replaces the variable . It is important to note that the options provided by the probabilistic selection process may be fewer than those offered by the branching process, since the latter must account for all potential continuations based on different scenarios. However, all options in the selection set J must be present in the branching set I (i.e., ) to ensure no branch is chosen without a corresponding match. If an option k from the selection set J is absent in the branching set I (i.e., and ) and branch k is chosen without a match, an error is produced (according to rule (Err)).
Rule (Call) initiates a process call by utilizing its definition in which the actual parameters are used to substitute the formal parameters . The side condition from rule (Call) is used to ensure an equal number of variables and values appearing in the definition and process call, respectively. Rule (Struct) asserts that the transition relation is invariant under structural congruence. Rule (Ctxt) specifies that a transition can occur under various evaluation contexts. The newly obtained value associated with the reduction arrow is a normalized version of the original probability value p, adjusted according to the total number of rules applicable to both process P and process . The function is used to determine the number of rules applicable to a process P. Since the function is only relevant when applying rule (Ctxt), it implies that and , as both P and are capable of performing at least one reduction step.
The function is defined as follows:
The necessity of this function will become clear in the next example.
Example 2.
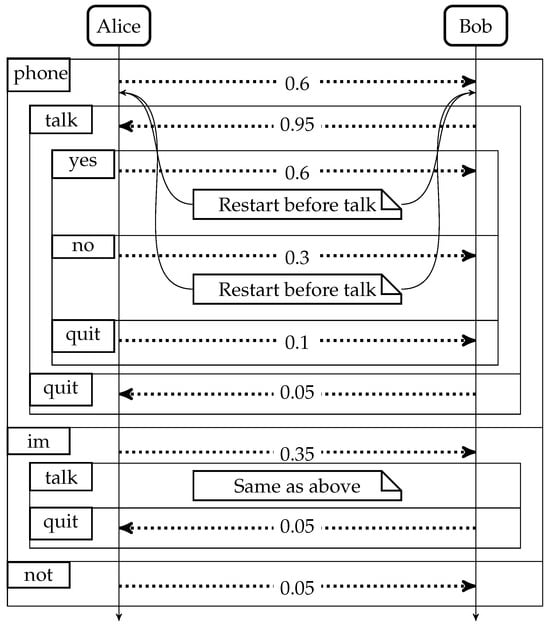
This example presents how the semantics is working. To improve readability, the parts of the processes that are used in the reduction are underlined. Consequently, the initial process can be rewritten as follows:
Note that the first applied rule is (Com), while the second one is (Ctxt) with the context = = in. The uniqueness of the next applied rule for is captured by the fact that . Suppose selects (with probability ) her to respond to the survey poll:
Observe that the rule (Call) is applied to two distinct process calls; subsequently, the (Ctxt) rule is applied. This is caught by . Thus, the probability that the rule (Ctxt) is applied equals the probability that the rule (Call) is applied divided by two. Suppose the process definition = is executed inside the context = in , namely
The evolution continues by applying the rules of Table 2.
The evolution of the system can be presented as a sequence diagram (see Figure 1).
Figure 1.
Dotted lines stand for probabilistic choices and contain the probability associated with a choice; rectangles with names in their left top corners stand for chosen labels.
3. Global and Local Types Using Interval Probability
For describing typed systems with probabilistic behavior given by interval probabilities instead of precise probabilities, we use interval probability for both global and local types of our process calculus with nondeterministic external choices and probabilistic internal choices. We validate the probabilistic behaviors in session types by defining a decidable proof system in which the concept of interval probability is used to express uncertainty in the evaluation of complex concurrent processes. Interval probabilities provide a more general framework for describing uncertainty than classical probability; classical probability, as a special case, is fully compatible with the theory of interval probability [24]. We use probability intervals given by lower and upper bounds; such an interval describes the uncertainty in the behavior of the systems involving nondeterminism and probabilistic interactions. Further details on the probability intervals and operations over them are presented in [25].
The global types shown in Table 3 describe the global behavior of a probabilistic multiparty session process. We represent the probability interval as , where and . If , we use the shorthand notation . The bounds of the intervals appearing in the global types are not randomly selected, but can be found statistically to contain initially the set of most possible values according to our belief/understanding (similar to Bayesian interval estimation in statistics) [26]. These probability intervals can be changed (narrowed) a posteriori.
Table 3.
Global types of the session typing.
The type indicates that a participant with role uses label to send a message of type to a participant with role , with a probability in the interval ; the subsequent interactions are described by . Each is unique, as assumed when defining the processes. The type is recursive; we consider only non-contractive recursion, namely is not allowed. We take the equi-recursive viewpoint [27]; i.e., we identify with .
Example 3.
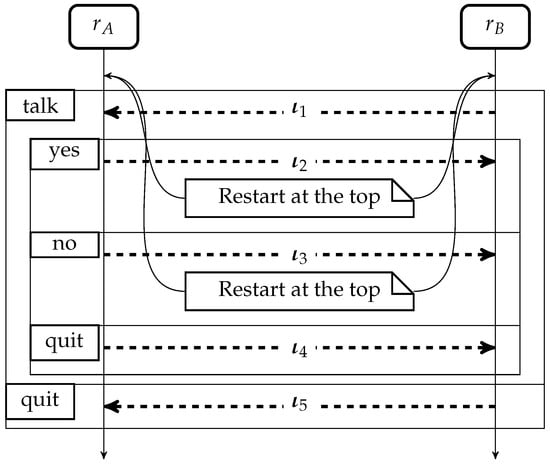
The global type of the session from Example 1 is:
If , it means that (the person responsible for conducting the poll) is more likely to quit than to finish the poll (as intended). However, if we want a minimal chance for to stop the polling, this can be done by imposing .
The global type of this example can be presented as a sequence diagram (see Figure 2).
Figure 2.
Dashed lines stand for interval probabilistic choices and contain the probability interval associated with the choice; rectangles with names in their left top corners stand for chosen labels.
In the global type , one should not assign arbitrarily the bounds of the probability interval for , but must instead adhere to certain constraints [25].
Definition 1.
Consider a set of probability intervals of the form .
The set is called proper if
while the set is called reachable if for all it holds that
Example 4.
Consider the set of probability intervals , where . Note that is not proper (since ). This means that if we choose any , there is no such that . Thus, by defining a set to be proper, we avoid a situation in which we cannot choose a probability from each probability interval such that the sum of the chosen probabilities is 1.
If we modify the intervals with just at the upper part, then the set of probability intervals , where , is proper (since ). This is due to the fact that there exist at least a pair, e.g., and , such that their sum is 1. However, since , this set is not reachable, meaning that it is not the case that for any , there exists a such that their sum is 1. For example, if there is no such that their sum is 1.
Defining a probability interval as proper and reachable prevents scenarios in which for all there does not exist such that .
The local types shown in Table 4 describe the local behavior of processes, and also serve as a link between the global types and the processes of our calculus.
Table 4.
Local types of the session typing.
The selection type represents a channel that can choose a label with a probability belonging to the probability interval (for any ), send it to r along with a variable of type and then proceed as . The branching type represents a channel that can receive a label from role r (for some , chosen by r), along with a variable of type and then proceed as . In both selection and branching types, the labels are distinct and their order does not matter. The recursive type and type variable t model infinite behaviors. Type end represents a terminated channel (and it is often omitted). The base types can include types such as , , and others.
We define the projection of a global type onto its corresponding local types.
Definition 2.
The projection for a participant with role r appearing in a global type G is inductively defined as:
- ;
- ;
- ;
- .
If none of the conditions are satisfied, the projection is undefined.
Example 5.
Consider the global type of Example 3:
The local types obtained from the global type by using the projection of Definition 2 for each of the two roles are as follows:
In order to state subject reduction (a property that ensures that the type of a process is preserved during its evaluation), we need to formalize how global types are modified when multiparty sessions evolve.
Definition 3
(Global type consumption). If G is a global type, then denoting that G is reduced by consumption of a communication between roles and is defined inductively as follows:
- if s.t. , ;
- if and .
Example 6.
Since we take the equi-recursive viewpoint [27], i.e., we identify with , it follows that can be written as:
Then, by Definition 3, type can be reduced as follows:
Consider the global type of Example 3:
Following the methodology presented in [1], we design a distributed system in terms of global types which is then implemented as a set of processes that adhere to local types, local types derived as projections of the global types.
Given a global type G, in what follows denotes the set of participants in G.
Definition 4.
A global type G is said to be well-formed if:
- for all , the projection is defined;
- in all its subterms of the form , the set of intervals is proper and reachable.
Example 7.
Consider the global type of Example 3:
in which for all it holds that and also . As seen in Example 5, is defined for all roles. Moreover, since , the set is proper (there exist at least a probability in each probability interval such that their sum is 1: e.g., , and ) and since , then the set is reachable (for all by choosing there exists such that , and ).
Also, since , the set is proper (there exist at least a probability in each probability interval such that their sum is 1: e.g., and ), while, since , the set is not reachable (for , there does not exists such that ).
Thus, having a proper and reachable set of probabilities is often a desirable requirement; it can serve as a sanity check for a specification.
4. Interval Probability for Multiparty Session Types
4.1. Typing System
We present how the notions defined in Section 2 and Section 3 (namely, the probabilistic processes and the global/local types using probability intervals) are connected. To achieve this, we introduce sortings and typings , specifically
The typing system uses a map from shared names to their sorts . A sorting is a finite map that associates names with sorts, and process variables with sequences of sorts and types. A typing tracks the usage of session channels. The disjoint union of two typings and is defined only if the sets of channels contained in the domains of these two typings are distinct. In what follows, we denote by and the set of all sortings and typings, respectively.
The dynamics of the types of the interacting processes is defined as in [1] by a labelled type reduction relation on typing that respects the following rules:
- ,, for ;
- ;
- whenever .
The first rule indicates two participants with roles and that use a label to communicate on the session channel s a value of type . Notice that the reduction arrow is decorated with the probability interval of the sending type; this would be useful when proving type preservation under evolution. The second rule describes the unfolding of local types with probability interval , while the third rule refers to the composition of two typings when only one of them is evolving.
We describe that a typing is safe as in [28]; this property is independent of the probability intervals present in .
Definition 5.
φ is a safety property of typing contexts if and only if:
- , implies ;
- implies ;
- and implies .
We say Δ is safe if for some safety property φ. The fact that Δ is safe is denoted by .
If the safety property is not explicitly instantiated, then, as in [28], we consider (i.e., the largest safety property, cf. Definition 5).
Example 8.
Consider the local types and from Example 5 and the typing:
We can verify that holds by checking its reductions.
Note that the safety of disjoint unions of typings is preserved by each of these disjoint typings.
Proposition 1.
If , then .
Proof.
By contradiction, assume that it is not the case that holds. Then, by Definition 5 (last clause), there is such that , and violates the first clause of Definition 5 (possibly after applying the second clause if some unfolding is needed). However, by the last clause of the definition of the labelled type reduction relation , it holds that and it is not the case that holds. This means the disjoint union violates the first clause of Definition 5 and therefore it is not the case that holds, which represents a contradiction. Thus, we conclude that holds. □
Example 9.
Consider from Example 8 the typing:
Then Δ can be written as a disjoint union of two typings, namely , where and . From Example 8, holds; according to Proposition 1, and also hold.
In order to establish a connection between the global types G and typings , being inspired by [29], we define the full projection of a global type as a typing. This full projection is useful in defining the typing system and proving the subject reduction.
Definition 6
(Full projection). If G is the global type of a session s such that and where for all it holds that =, then the full projection of G on s is given by .
Example 10.
Consider the global type of Example 3, the local types and obtained from in Example 5 and the safe typing obtained in Example 9. Then, by Definition 6, the full projection of on is .
The connection between the evolution of global types and that of the corresponding typings can be expressed as in the following result.
Proposition 2.
If and , then there exist such that and , where .
Proof.
Since and , then the associated redex is in , where . Due to Proposition 1, it holds that , and thus we can write as for some well-formed global type G. By taking the preimage of the associated redex in , reducing G by corresponds to eliminating its preimage from G to obtain , whose projection precisely gives the result of reducing to , and thus . □
Example 11.
Consider the global type of Example 3, the local types and obtained from in Example 5 and the safe typing obtained in Example 9 such that as obtained in Example 10.
By using the labelled type reduction relation on typing , we have that , where . Since holds from Exercise 9, then by Definition 5 also holds. From Example 6, it holds that . By Definition 2, the local types and are obtained from . Thus, by Definition 6, the full projection on is , and so the result of Proposition 2 holds.
The type-assignment system for processes is given in Table 5. We use the judgement saying that “under the sorting , process P has typing ”. Actually, we have two types of rules: some rules using only and others using both and . We use the rules (TVar) and (TVal) for typing variables and values (using only the sorting ). (TSelect) and (TBranch) are the rules for typing selection and branching, respectively. Just like in [30], the (TSelect) rule states that the selection process is well-typed if has a compatible selection (branching) type and the continuations (for all ) are well-typed with respect to the session types. Since rule (TSelect) types the selection process by using probability intervals, it should verify that the probabilities fall within the corresponding probability interval. Instead, the (TBranch) rule states that the branching process is well-typed if each from the branching type has a compatible branching process and the continuations (for all ) are well-typed with respect to the session types; thus, it allows more branches in the process than in the global type, just mimicking the subtyping for session types [31]. Rule (TEnd) is standard; “” means that contains only end as session types. Rule (TConc) is composed of two processes if their local types are disjoint. (TRes) is the restriction rule for session names, claiming that is well-typed in ; this happens if the full projection of the global type G associated with the session s appears in the typing associated with process P. (TDef) says that a process definition is well-typed if both P and Q are well-typed in their typing contexts. Rule (TCall) says that a process call is well-typed if the actual parameters have compatible types with respect to X.
Table 5.
Typing system for processes in probabilistic multiparty sessions.
Example 12.
Consider from Example 2 the process
, and the safe typing obtained in Example 9.
By using the rules of Table 5, we can type the process with the typing and the empty sorting ∅, namely .
4.2. Behavioral Properties of Typed Processes
We can prove that our probabilistic typing system is sound, meaning that its term-checking rules admit only consistent terms with respect to the structural congruence and operational semantics.
A subject reduction property ensures that the type of an expression is preserved during its evaluation. For proving this property, we need the following substitution, weakening and strengthening results.
Lemma 1.
- (substitution) If and then .
- (type weakening) If and is only end, then .
- (type strengthening) If and , then .
- (sort weakening) If and , then .
- (sort strengthening) If and , then .
Proof.
The proofs are rather standard, by induction on the derivations on the premise, following those presented in [1]. □
The next result states that if under the sorting , a process P has typing , then rearranging the process P into process by using the structural congruence ≡, then the process is typed using the same sorting and the same typing .
Theorem 1
(Subject equivalence). and imply .
Proof.
The proof is by induction on ≡, showing that if one side has a typing, then the other side has the same typing. The probability intervals in the involved types remain unchanged because the structural congruence ≡ does not consume or modify the selection processes.
- Case .⇒ Assume . By inverting the rule (TConc), we obtain and , where . By inverting the rule (TEnd), is only end and is such that . Then, by type weakening, we obtain that , where .⇐ Assume . By rule (TEnd), it holds that , where is only end and . By applying the rule (TConc), we obtain and since , by type strengthening, we obtain , as required.
- Case .⇒ Assume . By inverting the rule (TRes), we obtain where . By inverting the rule (TEnd), is only end, namely is only end. Using the rule (TEnd), we obtain .⇐ Assume . By rule (TRes), it holds that where , and . Then, by type weakening, we obtain that , as required.
- Case⇒ Assume . By inverting the rule (TConc), we obtain and , where . Using the rule (TConc), we obtain .⇐ It follows in a similar way (actually, symmetric to ⇒).
- Case⇒ Assume . By inverting the rule (TConc), we obtain , and , where . Using the rule (TConc), we obtain .⇐ It follows in a similar way (actually, symmetric to ⇒).
- Case⇒ Assume . By inverting the rule (TRes) twice, we obtain where and . Using the rule (TRes), we obtain .⇐ Proof is similar (actually, symmetric to ⇒).
- Case⇒ Assume . Since and , if (by using type weakening), then such that , and is only end. By type strengthening, we obtain . By inverting the rule (TConc), we obtain and , where . By inverting the rule (TRes), we obtain where . Using the rule (TConc), we obtain . Since , it means that does not contain types for s; from with , by using the rule (TRes) we obtain , where . Since is only end, by using type weakening we obtain .⇐ Assume . By inverting rule (TRes), we obtain , where . Since , by inverting the rule (TConc), we obtain and , where . Using rule (TRes), we obtain . By using rule (TConc), we obtain , as required.
- Case⇒ Assume . By inverting rule (TDef), we obtain and , where . By inverting rule (TEnd) we obtain that is only end. Applying rule (TEnd), we obtain .⇐ Assume . By inverting rule (TEnd), we obtain that is only end. Applying rule (TEnd), we obtain . Consider a typable process P such that . By applying rule (TDef) we obtain that , namely , as required.
- Case⇒ Assume . By inverting rule (TDef), we obtain and , where . By inverting the rule (TRes), we obtain where . Using rule (TDef), we obtain , while using rule (TRes), we obtain .⇐ Assume . By inverting rule (TRes), we obtain where . By inverting rule (TDef), we obtain and , where . Using rule (TRes), we obtain . By applying rule (TDef) we obtain that , namely , as required.
- Case⇒ Assume . By inverting the rule (TDef), we obtain and , where . By inverting the rule (TConc), we obtain and , where . By applying the rule (TDef), we obtain that , namely . Since and , then and so by sort strengthening we obtain . By applying the rule (TConc), we obtain that .⇐ Assume . By inverting rule (TConc), we obtain and , where . By inverting rule (TDef), we obtain and , where and . Since , by sort weakening we obtain . By applying rule (TConc), we obtain that . By using rule (TDef), we obtain , namely , as required.
- Case⇒ Assume . By inverting rule (TDef), we obtain and , where . By inverting rule (TDef), we obtain and , where . Since , it means that X and are different. Applying rule (TDef) twice, we obtain .⇐ It follows in a similar way (actually, symmetric to ⇒).
- implies . Let and .The proof is by structural induction on .
- –
- Case . This case is trivial, as is in fact .
- –
- Case . By assumption, . By inverting the rule (TRes), we obtain that . By structural congruence, implies . By induction, . By structural congruence, implies . By using the rule (TRes), we obtain , as required.
- –
- Case . By assumption, . By inverting rule (TDef), we obtain and , where . By structural congruence, implies . By induction, . By structural congruence, implies . By using the rule (TDef), we obtain .
- –
- Case . By assumption, . By inverting rule (TConc), we obtain and , where . By structural congruence, implies . By induction, . By structural congruence, implies . By using the rule (TConc), we obtain , as required.
□
Example 13.
Consider from Example 12 the process
, where . If there exists a process such that , then (by Theorem 1) it also holds that .
The next result states that if under the sorting , a process P has the safe typing , by reducing the process P to process , then the process is typed using the same sorting and a typing obtained from the typing .
Theorem 2
(Subject reduction). , and imply , where = or with .
Proof.
The proof is by induction on the derivation of . There is a case for each operational semantics rule, and for each such rule we consider the typing system rule generating . Since the reduction relations and track the consumed probabilities in processes and probability intervals in types, this result provides a relation between the consumed probabilities and probability intervals at each reduction step.
- Case (Com): .By assumption, . By inverting the rule (TConc), we obtain and with . Since these can be inferred only from (TSelect) and (TBranch), we know that and . By inverting the rules (TSelect) and (TBranch), we obtain that , , and . Since , from and , by applying the substitution part of Lemma 1, we obtain that . By applying the rule (TConc), we obtain . By using the type reduction relation, we obtain , where and .
- Case (Call):By assumption, . By inverting rule (TDef), we obtain and . By inverting the rule (TConc), we obtain and , where . By inverting the rule (TCall), we obtain and is end only. Applying substitution (Lemma 1), we obtain . Since is end only, then by type weakening (Lemma 1) we obtain that . Applying rule (TConc), we obtain . Applying rule (TDef), we obtain , as desired.
- Case (Ctxt): implies , where p = . Let , . Proof is by structural induction on .
- –
- Case . This case is trivial, as is in fact .
- –
- Case . By assumption, . By inverting rule (TRes), we obtain that . By applying rule (Ctxt), implies , where . By induction, , where or , with either or and . By applying rule (Ctxt), implies , where . By using the rule (TRes), we obtain , where or and , as required.
- –
- Case . By assumption, . By inverting rule (TDef), we obtain and , where . By applying rule (Ctxt), implies , where . By induction, , where or and . By applying rule (Ctxt), implies , where . By using rule (TDef), we obtain , where or and , as required.
- –
- Case . By assumption, . By inverting rule (TConc), we obtain and , where . By applying rule (Ctxt), implies , where . By induction, , with or and . By applying rule (Ctxt), implies , where . By using the rule (TConc), we obtain , with or and , as required.
- Case (Struct): and and implies . We use Theorem 1.
□
Example 14.
Consider from Example 12 the process
, where . If , then:
The next result states that if under the sorting , a process P has the safe typing , then by reducing the process P we can never reach the process.
Corollary 1
(Type safety). If , and , then has no error.
Proof.
By induction on the number of performed derivations. By using Theorem 2, from and we obtain such that =Δ or . If there exists a context such that , then is untypable because is untypable. Hence, has no error. □
The next result states that if under the sorting , a process P has the safe typing , then by reducing the process P we ensure the positivity of the on process P.
Corollary 2
(Positivity of ). If , and , then .
Proof.
By induction on the derivation of . There is a case for each operational semantics rule, and for each operational semantics rule we consider the typing system rule generating .
- Case (Com): .This means that and thus , as desired.
- Case (Call): . This means that and thus . Since , then , as desired.
- Case (Ctxt): implies , with . This means that and thus . From and , it holds from the rules of Table 5 that there exists and such that and . By induction, since , and , it holds that and thus , as desired.
- Case (Struct): and and implies . From and , by using Theorem 1, it holds that . By induction, since , and , it holds that . Also, from , it holds that and thus , as desired.
- Case (Err): (if and ). This means that . Since , and , by Corollary 1, has no error. This contradicts the assumption that and thus there is no P with , and such that rule (Err) is applicable.
□
As in [1], an annotated process P is the result of annotating the bound names of P, e.g., , and . Notice that some rules without variables are the same as the ones of Table 5 and that type checking of annotated processes is decidable whenever the safety property is decidable (this follows because typings have finite-state transition systems).
Theorem 3.
Given an annotated process and a sorting Γ, it is decidable even if is derivable or not.
Proof.
An algorithm for deriving can be straightforwardly obtained by inverting the annotated rules obtained from the rules of Table 5, noticing that:
- All typing rules are deterministically invertible—i.e., at most one typing rule can be applied for any arbitrary given well-typed process;
- At each invert, the typing contexts, sortings and type annotations in the process in conclusion determine how typing contexts, sortings and type annotations in the process in premises are generated; note that in the worst case, when splitting a typing context , one might need to try all possible typing contexts and such that ;
- Each rule invert guarantees that the premises contain smaller subterms of the term in the conclusion and so the recursive derivation eventually terminates.
□
As in many approaches on multiparty session types, our approach makes sure that a typed ensemble of processes interacting on a single annotated session (namely, a process typed with each () interacting only on ) is deadlock free. From now on, means that a process Q cannot evolve by means of any rule ( i.e., Q is a stable process).
Theorem 4
(Deadlock freedom). Let , where and each () interacts only on of type , where . Then P is deadlock free, i.e.,
Proof.
By inverting the rule (TRes), it holds that , while by inverting the rule (TConc) it holds that . Since , then reduces as prescribed by G. The proof proceeds by cases depending on the structure of G.
- Case . Then there exist processes and and also, in , the terms and such that and . By inverting the rules (TSelect) and (TBranch), we obtain that and . According to rule (Com), there exist and and a probability p such that ; by using rule (Ctxt), it holds that , as desired.
The remaining cases are proved in a similar manner. □
4.3. Properties Preserved by Removing Probabilities
As can be noticed from the rules of Table 5, the obtained types are not unique. This is due to the fact that we use probability intervals allowing the processes to be considered well-typed within the interval defined by lower and upper probabilities. Having several types for the same process, we can obtain some refinements of these typings. Inspired by [32], we use an erase function that removes the probability annotations when it is applied to a process or a type.
Example 15.
Consider the global type of Example 3:
By using the erase function we obtain the global type
The operational semantics without probabilities is similar to the one from Table 2, while the typing system without probabilities is similar to the one from Table 5. In order to distinguish between the rules of Table 2 and Table 5 and those with probabilities erased, we add an S (from simple) in front of the name of the rules with probabilities erased. E.g., for the rule (Com) of Table 2:
its corresponding rule with probabilities erased is (SCom):
Since probabilities do not influence the evolution, we obtain the following two results. The first one states that if a probabilistic process can perform an evolution step, then an evolution step can be also performed by the process with all the probabilities erased, while the second one states that if a process with all the probabilities erased can perform an evolution step, then an evolution step can be performed also by the process with probabilities.
Proposition 3.
If , then .
Proof.
By induction on the derivation .
There is a case for each operational semantics rule of Table 2.
- Case (Com): . Using the definition of the erase function, we obtain that.By using rule (SCom), it holds that .Since , then it results that , as required.
The remaining cases can be proved in a similar manner. □
Proposition 4.
If , then there exists p such that .
Proof.
The proof is similar to that of the previous result (Proposition 3). □
A process remains well-typed after eliminating probabilities in processes, and probability intervals in types.
Proposition 5.
If , then .
Proof.
The proof is by induction on the structure of process P and by using the rules of Table 5.
- . Assume that for all it holds that there exist and such that . There exists such that and according to rule (TSelect) of Table 5 it holds that , where . Since by induction for all it holds that and , then . According to rule (TSelect), it holds that . Since and , it implies that , as desired.
The remaining cases can be proved in a similar manner. □
4.4. Typed Probabilistic Equivalence
Since in the type system we use probability intervals, several processes (more than one) can be considered well-typed with respect to the same type. However, such well-typed processes are connected, as they can be related by using the function, namely they would be equal by erasing all probabilities.
Proposition 6.
If and Δ contains at least one probability interval of the form in which and , then there exists a process Q such that , and .
Proof.
The proof is by induction on the structure of process P, by using the rules of Table 5.
- . Assume that for all it holds that there exist and such that . There exist such that and according to rule (TSelect) of Table 5 it holds that , where . From the assumption that contains at least one probability interval of the form in which and , one can construct a Q such that by considering , where for all it holds that and for at least one we have . Thus, by construction, it holds that . Since by induction for all it holds that , it implies that also , as desired.
The remaining cases are proved in a similar manner. □
However, the reverse direction of this result does not work: if there exists a process Q such that , and , this does not imply that . Consider as a counterexample the process and . Then the process is such that and , but it does not hold that .
Proposition 6 pushes us to consider a probabilistic relation between processes that are typed under the same sorting and typing and also have equal definitions when their probabilities are erased. Formally, such a relation is defined as follows.
Definition 7.
We say that two processes P and Q are related by a sorting Γ and a typing Δ, denoted by , if , and .
Example 16.
Consider from Example 13 the process
, where and a process such that and . Then, according to Definition 7, it also holds that .
It is not difficult to note that for any sorting and any typing , the relation is an equivalence relation (it is reflexive, symmetric and transitive).
Proposition 7.
For any sorting Γ and typing Δ, the relation is an equivalence.
Proof.
The fact that the relation is an equivalence follows from:
- Reflexivity: Consider . Since , from Definition 7 it follows that , as desired.
- Symmetry: Consider . According to Definition 7, it holds that , and and thus .
- Transitivity: Consider and . According to Definition 7, it holds that , , , and and thus .
□
If two typings and differ only by means of probability intervals, namely , then it is natural to define their intersection:
Since the intersection of probability intervals is associative, then this property is naturally extended to the intersection of typings; thus, the intersection of typings is also associative.
Proposition 8.
.
Proof.
By induction on the structure of the local types appearing in , and , considered whenever their intersection is defined. Assume that for . Notice that if one of (for ) is or t, then we have and so conclude the proof. Otherwise, we have the following cases:
- , for .By induction and by the associativity of interval intersections, we obtain that , as requested.
- , for .By induction, we obtain that , as requested.
- , for .By induction, we obtain that .
□
It is worth noting that if a process is well-typed with different types and such that , then it remains well-typed when we consider the intersection of typings and . This means that if a selection process has a probability p, there exist two well-formed types with different probability intervals and such that the selection process remains well-typed when we consider the intersection of the intervals and .
Theorem 5.
If , and , then .
Proof.
The proof is by induction on the structure of process P and by using the rules of Table 5.
- . Assume that for all it holds that there exist , , and such that and . There exist and such that and . According to rule (TSelect) of Table 5, it holds that and , where and together with . Since for all it holds that and , then also holds. By induction for all , it holds that . By applying the rule (TSelect) of Table 5, it holds that . Since , then , as desired.
The remaining cases are proved in a similar manner. □
The next result shows that if between two processes there exists a probabilistic relation under a sorting and two typings and that are different only in the probability intervals they use (i.e., ), then between the two processes there exists a probabilistic relation under the sorting and the typing . This means that if two processes can be related under the same sorting but at least two different typings, then more typings can be created to relate the two processes.
Proposition 9.
If , and , then .
Proof.
From and , according to Definition 7, it holds that , , , and . Since , and , then by using Theorem 5 it results that . Similarly, since , and , then by using Theorem 5 it results that . From , and , by using Definition 7, it results that , as desired. □
By defining the union operator ⊔ for typings in a similar way to the intersection operator ⊓, since the union of probability intervals is associative, we obtain that this property is naturally extended to the union of typings, and so the union of typings is associative.
Proposition 10.
Proof.
Similar to the proof of Proposition 8. □
It is worth noting that a well-typed process with a type remains well-typed when we consider the union of typing with another typing such that . This means that if a selection process has a probability p, there exists a well-formed type with probability interval such that the selection process remains well-typed when we consider the union of the interval with the probability interval appearing in .
Theorem 6.
If and there is such that =, then .
Proof.
The proof is by induction on the structure of process P, using the rules of Table 5.
- . Assume that for all it holds that there exist and such that . There exist such that and according to rule (TSelect) of Table 5, it holds that , where . If there exists such that , then it implies that . Since for all it holds that , then also holds. By induction for all it holds that . By applying the rule (TSelect) of Table 5, it holds that . Since , then , as desired.
The remaining cases are proved in a similar manner. □
The next result shows that if between two processes there exists a probabilistic relation under one sorting and two typings and that are different only in the probability intervals they use (namely ), then between the two processes there exists a probabilistic relation under the sorting and the typing . This means that two processes can be related under the same sorting, but their typings different only in the probability intervals they use.
Proposition 11.
If and exists such that , then .
Proof.
From , according to Definition 7, it holds that , and . Since and exists such that , then by using Theorem 6 it results that . Similarly, since and exists such that , then by using Theorem 6 it results that . From , and , by using Definition 7, it results that , as desired. □
Usually, an equivalence relation requires an exact match of transitions of two processes. Sometimes this requirement is too strong and this is why in what follows, inspired by [33], we define and study bisimulations between processes by taking into account also their types with probability intervals. We present some notations used in the remaining of the paper.
- A typed probabilistic relation over the set of processes, the set of sortings and the set of typings is any relation .
- The identity typed probabilistic relation is
- The inverse of a typed probabilistic relation is
- The composition of typed probabilistic relations and is
Definition 8
(Typed Probabilistic Bisimulation). Let be a symmetric typed probabilistic relation.
- 1.
- is a typed probabilistic bisimulation if and implies that exists and such that and .
- 2.
- The typed probabilistic bisimilarity is the union ≃ of all typed probabilistic bisimulations .
In what follows, we prove some properties of the typed probabilistic bisimulations and the typed probabilistic bisimilarity.
Proposition 12.
- 1.
- Identity, inverse, composition and union of typed probabilistic bisimulations are typed probabilistic bisimulations.
- 2.
- ≃ is the largest typed probabilistic bisimulation.
- 3.
- ≃ is an equivalence.
Proof.
- We treat each relation separately, showing that it respects the conditions from Definition 8 for being a typed probabilistic bisimulation.
- (a)
- The identity relation is a typed probabilistic bisimulation. Assume ; then and . Consider ; according to Theorem 2, there exists and such that and or . Since , according to Definition 5, it also holds that . According to Proposition 7, by reflexivity, it holds that . Thus, it results that , as desired.
- (b)
- The inverse of a typed probabilistic bisimulation is a typed probabilistic bisimulation. Assume , namely . Consider ; then for some and we have and , namely . By similar reasoning, if then we can find and such that and .
- (c)
- The composition of typed probabilistic bisimulations is a typed probabilistic bisimulation. Assume . Then for some R we have and . Consider ; then for some and , since , we have and . Also, since we have for some that and . Thus, . By similar reasoning, if then we can find and such that and .
- (d)
- The union of typed probabilistic bisimulations is a typed probabilistic bisimulation. Assume . Then for some we have . Consider ; then for some and , since , we have and . Thus, . By similar reasoning, if then we can find such that and , namely .
- Since the union of typed probabilistic bisimulations is a typed probabilistic bisimulation, ≃ is a typed probabilistic bisimulation and it includes any other typed probabilistic bisimulation.
- Proving that relation ≃ is an equivalence requires to show that it satisfies reflexivity, symmetry and transitivity. We consider each of them in what follows:
- (a)
- Reflexivity: For any process P, results from the fact that the identity relation is a typed probabilistic bisimulation.
- (b)
- Symmetry: If , then exists and such that for some typed probabilistic bisimulation . Hence and so because the inverse relation is a typed probabilistic bisimulation.
- (c)
- Transitivity: If and then and for some typed probabilistic bisimulations and . Thus, and so due to the fact that the composition relation is a typed probabilistic bisimulation.
□
4.5. Probabilistic Properties of Typed Processes
In what follows, we associate with each execution path (starting from a process P and leading to a process Q) an execution probability of going along the path. This probability is computed by using the operational semantics presented in Table 2.
Definition 9
(Evolution paths). A sequence of evolution transitions provides an evolution path . Two evolution paths and are identical if and for all we have and .
Definition 10
(Evolution probability). The probability of reaching a process starting from a process (with ) along the evolution path is denoted by . The evolution probability of reaching starting from a process (with ) taking all the possible evolution paths (without considering identical paths) is denoted by .
For any process P, we can define the sets of processes reached in k steps starting from P by using the rules of Table 2.
Definition 11
(Reachable sets). .
For , .
Example 17.
Consider from Example 13 the process
, and from Example 14 the process obtained from after a one step reduction. Then, according to Definition 11, it holds that .
The following result makes sure that for each well-typed restricted process, the sum of the probabilities of all possible transitions is 1. The restriction ensures that the types are derived from some well-formed global types.
Theorem 7.
Given a well-typed process such that for all , then
Proof.
By induction on the number k of the evolution steps.
- Case . The proof proceeds by cases depending on the value of .
- –
- . We have only one subcase:
- ∗
- . Since , then and the sum is not computed.
- ∗
- Since is well-typed, this means that , and also that .
- –
- . We have two subcases:
- ∗
- . Since , it means that R is unable to evolve and only could evolve by applying the rule (Call). Thus, by also using rule (Ctxt), it holds that evolves with probability 1 to . This means that (as desired).
- ∗
- , where and , meaning that the rules (Com) and (Ctxt) are applied and evolves with probability (with ) to . From the definition of , it follows that . Thus, (as desired).
- –
- , with . In this case, there is able to perform at least a (Call) or (Com) rule such that and , where . Since , then by removing from P, what remains (namely ) is such that . Since is well-typed, then . Thus, .The normalization appears due to the application of rule (Ctxt).
- Case . Since , this means that . By considering the inductive step, we obtain that . Let us consider that another evolution step is performed, namely k steps starting from process . This means that can be broken into two parts: one computing the probability for the first () steps and another one using the probabilities obtained in the additional step k. Thus, it holds that . Since we have , thenAlso, since we have , then
□
5. Conclusions and Related Work
The non-probabilistic approach of multiparty session types [1] could become more realistic when dealing with various uncertainties by considering the use of probabilities in processes and types. In our approach, we introduced a new kind of multiparty session type for a probabilistic process calculus that incorporates two forms of choice: probabilistic choice and nondeterministic choice. The main novelty of this approach is the use of interval probabilities in the type system in order to deal with uncertainty in the probabilistic process calculus, thus allowing several processes to be considered well-typed with respect to the same type and also several types to be assigned to a process. We also define a probabilistic bisimulation between processes that are typed by using the same sorting and typing. In our approach, the use of interval probabilities is such that the axioms appearing in the theory of probability are satisfied. The new typing system represents a conservative extension of the standard typing system based on multiparty session types: removing the probabilities from processes does not affect their well-typedness. Moreover, the new typing system preserves deadlock freedom, type preservation and type safety.
The idea of interval probability is not new: the axioms of Kolmogorov [34] together with the other three axioms represent the foundations for the theory of interval probabilities. This probabilistic approach adheres to the standard axioms when dealing with the probability of an event [24]: the probabilities are real values from the closed interval , while the sum of all probabilities is 1. A different approach to dealing with uncertainty is the use of lower and upper probabilities in the Dempster–Shafer theory [35]. Also, when Keynes proposed dealing with probabilities by using intervals [36], B. Russell stated about the work that it is “undoubtedly the most important work on probability that has appeared for a very long time”. It is worth noting that in analytic philosophy, interval-valued functions [37] and lower/upper probabilities [38] were used in probabilistic judgements. A discussion on the differences between these two approaches (classic Bayesian and interval probability) is available in [39].
Regarding the use of probabilities in session types, there are only a few articles to mention. According to the authors of a recent article [14]: “To the best of our knowledge, Aman and Ciobanu [8,19] are the only ones who studied the concept of choreography and probabilities”. In [9], other authors present a probabilistic variant of binary session types by enriching the type system with fixed probabilities. The authors of [10] developed probabilistic binary session types to be used for the runtime analysis of communicating processes, while those of [12] developed a meta theory of probabilistic session types to be used in the automatic expected resource analysis. The authors of [11] enriched session typing with probabilistic choices for modelling cryptographic experiments, while in [13] they investigated the termination problem in a calculus of sessions with probabilistic choices.
On the other hand, there exist several articles presenting probabilistic process calculi (see [40] and its references). In probabilistic -calculus [41], the defined types are useful in identifying nondeterministic probabilistic behaviors such that in the framework of event structures the compositionality of the parallel operator is preserved. The authors propose an initial step toward developing an effective typing discipline that incorporates probabilistic name passing by utilizing Segala automata [42] and probabilistic event structures. In comparison with this work, we simplify the approach and work directly with processes, providing a probabilistic typing in the context of multiparty session types. Additionally, we introduce the interval probability in the framework of multiparty session types.
Author Contributions
These authors contributed equally to this work. Conceptualization, G.C.; formal analysis, B.A.; investigation, B.A. and G.C.; writing—original draft preparation, B.A.; writing—review and editing, G.C. All authors have read and agreed to the published version of the manuscript.
Funding
This research received no external funding.
Data Availability Statement
No new data were created.
Acknowledgments
The authors are grateful to the anonymous reviewers for their careful reading of our manuscript, their insightful comments and suggestions that improved the manuscript.
Conflicts of Interest
The authors declare no conflicts of interest.
References
- Honda, K.; Yoshida, N.; Carbone, M. Multiparty Asynchronous Session Types. J. ACM 2016, 63, 9:1–9:67. [Google Scholar] [CrossRef]
- Fowler, S.; Lindley, S.; Morris, J.G.; Decova, S. Exceptional asynchronous session types: Session types without tiers. Proc. ACM Program. Lang. 2019, 3, 28:1–28:29. [Google Scholar] [CrossRef]
- Viering, M.; Hu, R.; Eugster, P.; Ziarek, L. A multiparty session typing discipline for fault-tolerant event-driven distributed programming. Proc. ACM Program. Lang. 2021, 5, 1–30. [Google Scholar] [CrossRef]
- Barwell, A.D.; Scalas, A.; Yoshida, N.; Zhou, F. Generalised Multiparty Session Types with Crash-Stop Failures. In Proceedings of the 33rd International Conference on Concurrency Theory, CONCUR, LIPIcs, Warsaw, Poland, 12–16 September 2022; Klin, B., Lasota, S., Muscholl, A., Eds.; Schloss Dagstuhl-Leibniz-Zentrum für Informatik: Wadern, Germany, 2022; Volume 243, pp. 35:1–35:25. [Google Scholar] [CrossRef]
- Barwell, A.D.; Hou, P.; Yoshida, N.; Zhou, F. Designing Asynchronous Multiparty Protocols with Crash-Stop Failures. In Proceedings of the 37th European Conference on Object-Oriented Programming, ECOOP, LIPIcs, Seattle, WA, USA, 17–21 July 2023; Ali, K., Salvaneschi, G., Eds.; Schloss Dagstuhl-Leibniz-Zentrum für Informatik: Wadern, Germany, 2023; Volume 263, pp. 1:1–1:30. [Google Scholar] [CrossRef]
- Brun, M.A.L.; Dardha, O. MAGπ: Types for Failure-Prone Communication. In Proceedings of the 32nd European Symposium on Programming on Programming Languages and Systems, ESOP 2023, Held as Part of the European Joint Conferences on Theory and Practice of Software, ETAPS, Paris, France, 22–27 April 2023; Wies, T., Ed.; Lecture Notes in Computer Science. Springer: Berlin/Heidelberg, Germany, 2023; Volume 13990, pp. 363–391. [Google Scholar] [CrossRef]
- Pears, J.; Bocchi, L.; King, A. Safe Asynchronous Mixed-Choice for Timed Interactions. In International Conference on Coordination Languages and Models, Proceedings of the 25th IFIP WG 6.1 International Conference, COORDINATION 2023, Held as Part of the 18th International Federated Conference on Distributed Computing Techniques, DisCoTec 2023, Lisbon, Portugal, 19–23 June 2023; Jongmans, S., Lopes, A., Eds.; Lecture Notes in Computer Science; Springer: Cham, Switzerland, 2023; Volume 13908, pp. 214–231. [Google Scholar] [CrossRef]
- Aman, B.; Ciobanu, G. Probabilities in Session Types. In Proceedings of the Third Symposium on Working Formal Methods, FROM 2019, EPTCS, Timişoara, Romania, 3–5 September 2019; Marin, M., Craciun, A., Eds.; Volume 303, pp. 92–106. [Google Scholar] [CrossRef]
- Inverso, O.; Melgratti, H.C.; Padovani, L.; Trubiani, C.; Tuosto, E. Probabilistic Analysis of Binary Sessions. In Proceedings of the 31st International Conference on Concurrency Theory, CONCUR 2020, LIPIcs, Vienna, Austria (Virtual Conference), 1–4 September 2020; Konnov, I., Kovács, L., Eds.; Schloss Dagstuhl-Leibniz-Zentrum für Informatik: Wadern, Germany, 2020; Volume 171, pp. 14:1–14:21. [Google Scholar] [CrossRef]
- Burlò, C.B.; Francalanza, A.; Scalas, A.; Trubiani, C.; Tuosto, E. Towards Probabilistic Session-Type Monitoring. In International Conference on Coordination Languages and Models, Proceedings of the 23rd IFIP WG 6.1 International Conference, COORDINATION 2021, Held as Part of the 16th International Federated Conference on Distributed Computing Techniques, DisCoTec 2021, Valletta, Malta, 14–18 June 2021; Damiani, F., Dardha, O., Eds.; Lecture Notes in Computer Science; Springer: Cham, Switzerland, 2021; Volume 12717, pp. 106–120. [Google Scholar] [CrossRef]
- Dal Lago, U.; Giusti, G. On Session Typing, Probabilistic Polynomial Time and Cryptographic Experiments. In Proceedings of the 33rd International Conference on Concurrency Theory, CONCUR 2022, LIPIcs, Warsaw, Poland, 12–16 September 2022; Klin, B., Lasota, S., Muscholl, A., Eds.; Schloss Dagstuhl-Leibniz-Zentrum für Informatik: Wadern, Germany, 2022; Volume 243, pp. 37:1–37:18. [Google Scholar] [CrossRef]
- Das, A.; Wang, D.; Hoffmann, J. Probabilistic Resource-Aware Session Types. Proc. ACM Program. Lang. 2023, 7, 1925–1956. [Google Scholar] [CrossRef]
- Lago, U.D.; Padovani, L. On the Almost-Sure Termination of Binary Sessions. In Proceedings of the 26th International Symposium on Principles and Practice of Declarative Programming, PPDP 2024, Milano, Italy, 9–11 September 2024; Bruni, A., Momigliano, A., Pradella, M., Rossi, M., Cheney, J., Eds.; ACM: New York, NY, USA, 2024; pp. 9:1–9:12. [Google Scholar] [CrossRef]
- Carbone, M.; Veschetti, A. A Probabilistic Choreography Language for PRISM. In International Conference on Coordination Models and Languages, Proceedings of the 26th IFIP WG 6.1 International Conference, COORDINATION 2024, Held as Part of the 19th International Federated Conference on Distributed Computing Techniques, DisCoTec 2024, Groningen, The Netherlands, 17–21 June 2024; Castellani, I., Tiezzi, F., Eds.; Lecture Notes in Computer Science; Springer: Cham, Switzerland, 2024; Volume 14676, pp. 20–37. [Google Scholar] [CrossRef]
- Jonsson, B.; Larsen, K.G. Specification and Refinement of Probabilistic Processes. In Proceedings of the 1991 Sixth Annual IEEE Symposium on Logic in Computer Science, Amsterdam, The Netherlands, 15–18 July 1991; pp. 266–277. [Google Scholar] [CrossRef]
- Yi, W. Algebraic Reasoning for Real-Time Probabilistic Processes with Uncertain Information. In Proceedings of the International Symposium on Formal Techniques in Real-Time and Fault-Tolerant Systems, Third International Symposium Organized Jointly with the Working Group Provably Correct Systems-ProCos, Lübeck, Germany, 19–23 September 1994; Langmaack, H., de Roever, W.P., Vytopil, J., Eds.; Lecture Notes in Computer Science. Springer: Cham, Switzerland, 1994; Volume 863, pp. 680–693. [Google Scholar] [CrossRef]
- Cauchi, N.; Laurenti, L.; Lahijanian, M.; Abate, A.; Kwiatkowska, M.; Cardelli, L. Efficiency through uncertainty: Scalable formal synthesis for stochastic hybrid systems. In Proceedings of the 22nd ACM International Conference on Hybrid Systems: Computation and Control, HSCC 2019, Montreal, QC, Canada, 16–18 April 2019; Ozay, N., Prabhakar, P., Eds.; ACM: New York, NY, USA, 2019; pp. 240–251. [Google Scholar] [CrossRef]
- Stoelinga, M. An Introduction to Probabilistic Automata. Bull. EATCS 2002, 78, 176–198. [Google Scholar]
- Aman, B.; Ciobanu, G. Interval Probability for Sessions Types. In Logic, Language, Information and Computation, Proceedings of the 28th International Workshop, WoLLIC 2022, Iaşi, Romania, 20–23 September 2022; Ciabattoni, A., Pimentel, E., de Queiroz, R.J.G.B., Eds.; Lecture Notes in Computer Science; Springer: Cham, Switzerland, 2022; Volume 13468, pp. 123–140. [Google Scholar] [CrossRef]
- Scalas, A.; Dardha, O.; Hu, R.; Yoshida, N. A Linear Decomposition of Multiparty Sessions for Safe Distributed Programming. In Proceedings of the 31st European Conference on Object-Oriented Programming, ECOOP 2017, LIPIcs, Barcelona, Spain, 18–23 June 2017; Müller, P., Ed.; Schloss Dagstuhl-Leibniz-Zentrum für Informatik: Wadern, Germany, 2017; Volume 74, pp. 24:1–24:31. [Google Scholar] [CrossRef]
- Ghilezan, S.; Jaksic, S.; Pantovic, J.; Scalas, A.; Yoshida, N. Precise subtyping for synchronous multiparty sessions. J. Log. Algebr. Methods Progr. 2019, 104, 127–173. [Google Scholar] [CrossRef]
- Coppo, M.; Dezani-Ciancaglini, M.; Yoshida, N.; Padovani, L. Global progress for dynamically interleaved multiparty sessions. Math. Struct. Comput. Sci. 2016, 26, 238–302. [Google Scholar] [CrossRef]
- Wallsten, T.S.; Budescu, D.V.; Zwick, R.; Kemp, S.M. Preferences and reasons for communicating probabilistic information in verbal or numerical terms. Bull. Psychon. Soc. 1993, 31, 135–138. [Google Scholar] [CrossRef]
- Weichselberger, K. The theory of interval-probability as a unifying concept for uncertainty. Int. J. Approx. Reason. 2000, 24, 149–170. [Google Scholar] [CrossRef]
- de Campos, L.M.; Huete, J.F.; Moral, S. Probability Intervals: A Tool for uncertain Reasoning. Int. J. Uncertain. Fuzziness Knowl.-Based Syst. 1994, 2, 167–196. [Google Scholar] [CrossRef]
- Lee, P.M. Bayesian Statistics: An Introduction, 4th ed.; Wiley: Hoboken, NJ, USA, 2012. [Google Scholar]
- Pierce, B.C. Types and Programming Languages; MIT Press: Cambridge, MA, USA, 2002. [Google Scholar]
- Scalas, A.; Yoshida, N. Less is more: Multiparty session types revisited. Proc. ACM Program. Lang. 2019, 3, 30:1–30:29. [Google Scholar] [CrossRef]
- Bejleri, A.; Yoshida, N. Synchronous Multiparty Session Types. In Proceedings of the First Workshop on Programming Language Approaches to Concurrency and Communication-cEntric Software, PLACES@DisCoTec, Oslo, Norway, 7 June 2008; Vasconcelos, V.T., Yoshida, N., Eds.; Electronic Notes in Theoretical Computer Science. Elsevier: Amsterdam, The Netherlands, 2008; Volume 241, pp. 3–33. [Google Scholar] [CrossRef]
- Dagnino, F.; Giannini, P.; Dezani-Ciancaglini, M. Deconfined Global Types for Asynchronous Sessions. Log. Methods Comput. Sci. 2023, 19. [Google Scholar] [CrossRef] [PubMed]
- Demangeon, R.; Honda, K. Nested Protocols in Session Types. In Proceedings of the 23rd International Conference on Concurrency Theory, CONCUR 2012, Newcastle upon Tyne, UK, 4–7 September 2012; Koutny, M., Ulidowski, I., Eds.; Lecture Notes in Computer Science. Springer: Cham, Switzerland, 2012; Volume 7454, pp. 272–286. [Google Scholar] [CrossRef]
- Bocchi, L.; Honda, K.; Tuosto, E.; Yoshida, N. A Theory of Design-by-Contract for Distributed Multiparty Interactions. In Proceedings of the 21th International Conference on Concurrency Theory, CONCUR 2010, Paris, France, 31 August–3 September 2010; Gastin, P., Laroussinie, F., Eds.; Lecture Notes in Computer Science. Springer: Cham, Switzerland, 2010; Volume 6269, pp. 162–176. [Google Scholar] [CrossRef]
- Berger, M.; Yoshida, N. Timed, Distributed, Probabilistic, Typed Processes. In Programming Languages and Systems, Proceedings of the 5th Asian Symposium, APLAS 2007, Singapore, 29 November–1 December 2007; Shao, Z., Ed.; Lecture Notes in Computer Science; Springer: Cham, Switzerland, 2007; Volume 4807, pp. 158–174. [Google Scholar] [CrossRef]
- Kolmogorov, A. Foundations of the Theory of Probability; Chelsea Pub Co.: New York, NY, USA, 1950. [Google Scholar]
- Dempster, A.P. Upper and Lower Probabilities Induced by a Multivalued Mapping. In Classic Works of the Dempster–Shafer Theory of Belief Functions; Yager, R.R., Liu, L., Eds.; Studies in Fuzziness and Soft Computing; Springer: Berlin/Heidelberg, Germany, 2008; Volume 219, pp. 57–72. [Google Scholar] [CrossRef]
- Keynes, J.M. A Treatise on Probability; Macmillan and Co.: New York, NY, USA, 1921. [Google Scholar]
- Levi, I. On Indeterminate Probabilities. J. Philos. 1974, 71, 391–418. [Google Scholar] [CrossRef]
- Wolfenson, M.; Fine, T.L. Bayes-like Decision Making with Upper and Lower Probabilities. J. Am. Stat. Assoc. 1982, 77, 80–88. [Google Scholar] [CrossRef]
- Halpern, J.Y. Reasoning About Uncertainty; MIT Press: Cambridge, MA, USA, 2005. [Google Scholar]
- Bernardo, M.; De Nicola, R.; Loreti, M. Revisiting bisimilarity and its modal logic for nondeterministic and probabilistic processes. Acta Inform. 2015, 52, 61–106. [Google Scholar] [CrossRef][Green Version]
- Varacca, D.; Yoshida, N. Probabilistic pi-Calculus and Event Structures. Electron. Notes Theor. Comput. Sci. 2007, 190, 147–166. [Google Scholar] [CrossRef]
- Segala, R.; Lynch, N.A. Probabilistic Simulations for Probabilistic Processes. Nord. J. Comput. 1995, 2, 250–273. [Google Scholar]
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).