In this section, we set up the formal framework for our results and give more complete definitions for our objects of study as follows: stationary processes, hidden Markov models, and -machines.
3.1. Processes
There are several ways to define a stochastic process. Perhaps the most traditional definition is simply as a sequence of random variables on some common probability space . However, in the following discussion, it will be convenient to use a slightly different but equivalent construction in which a process is itself a probability space whose sample space consists of bi-infinite sequences . Of course, on this space we have random variables defined by the natural projections , which we will at times employ in our proofs. However, for most of our development and, in particular, for defining history -machines, it will be more convenient to adopt the sequence-space viewpoint.
Throughout, we restrict our attention to processes over a finite alphabet . We denote by the set of all words w of finite positive length consisting of symbols in and, for a word , we write for its length. Note that we deviate slightly from the standard convention here and explicitly exclude the null word from .
Definition 1. Let be a finite set. A process over the alphabet is a probability space where the following stand:
is the set of all bi-infinite sequences of symbols in : .
is the σ-algebra generated by finite cylinder sets of the form .
is a probability measure on the measurable space .
For each symbol , we assume implicitly that for some . Otherwise, the symbol x is useless and the process can be restricted to the alphabet . In the following, we will be primarily interested in stationary, ergodic processes.
Let be the right shift operator. A process is stationary if the measure is shift invariant as follows: , for any measurable set A. A process is ergodic if every shift invariant event A is trivial. That is, for any measurable event A such that A and are a.s. equal, the probability of A is either 0 or 1. A stationary process is defined entirely by the word probabilities , , where is the shift invariant probability of cylinder sets for the word w. Ergodicity is equivalent to the almost sure convergence of empirical word probabilities in finite sequences to their true values , as .
For a stationary process
and words
with
, we define
as the probability where the word
w is followed by the word
v in a bi-infinite sequence
as follows:
The following facts concerning word probabilities and conditional word probabilities for a stationary process come directly from the definitions. They will be used repeatedly throughout our development, without further mention. For any words
, the following stand:
.
and .
If , .
If , .
If and , .
3.2. Hidden Markov Models
There are two primary types of hidden Markov models as follows:
state-emitting (or
Moore) and
edge-emitting (or
Mealy). The state-emitting type is the simpler of the two and, also, the more commonly studied and applied [
29,
30]. However, we focus on edge-emitting hidden Markov models here, since
-machines are edge-emitting. We also restrict our development to the case where the hidden Markov model has a finite number of states and output symbols, although generalizations to countably infinite and even uncountable state sets and output alphabets are certainly possible.
Definition 2. An edge-emitting hidden Markov model (HMM) is a triple model where the following stand:
is a finite set of states.
is a finite alphabet of output symbols.
are symbol-labeled transition matrices. represents the probability of transitioning from state σ to state on symbol x.
In what follows, we normally take the state set to be and denote simply as . We also denote the overall state-to-state transition matrix for an HMM as T: . is the overall probability of transitioning from state to state , regardless of symbol. The matrix T is stochastic as follows: , for each i.
Pictorially, an HMM can be represented as a directed graph with labeled edges. The vertices are the states and, for each with , there is a directed edge from state to state , labeled for the symbol x and transition probability . The transition probabilities are normalized so that their sum on all outgoing edges from each state is 1.
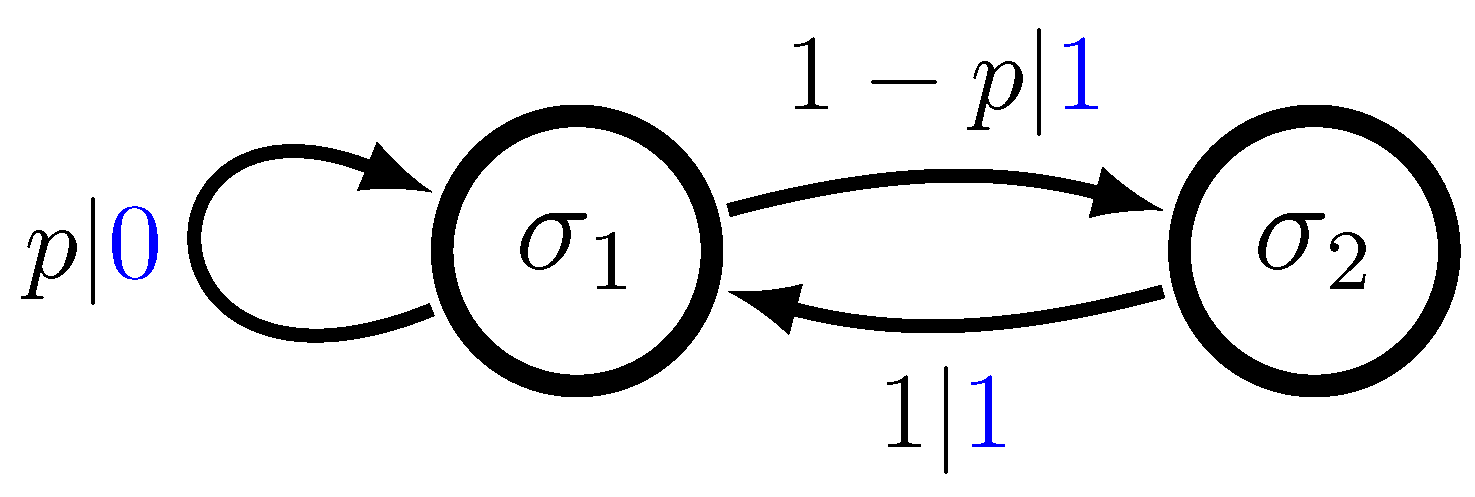
Figure 1 depicts an HMM for the Even Process. The support for this process consists of all binary sequences in which blocks of uninterrupted 1 s are even in length, bounded by 0 s. After each even length is reached, there is a probability
p of breaking the block of 1 s by inserting a 0. The HMM has two states
and symbol-labeled transitions matrices as follows:
The operation of an HMM may be thought of as a weighted random walk on the associated directed graph. That is, from the current state , the next state is determined by selecting an outgoing edge from according to their relative probabilities. Having selected a transition, the HMM then moves to the new state and outputs the symbol x labeling this edge. The same procedure is then invoked repeatedly to generate future states and output symbols.
The state sequence determined in such a fashion is simply a Markov chain with transition matrix T. However, we are interested not simply in the HMM’s state sequence, but rather the associated sequence of output symbols it generates. We assume that an observer of the HMM has direct access to this sequence of output symbols, but not to the associated sequence of “hidden” states.
Formally, from an initial state
, the probability that the HMM next outputs symbol
x and transitions to state
is expressed as follows:
Furthermore, the probability of longer sequences is computed inductively. Thus, for an initial state
, the probability the HMM outputs a length-
l word
while following the
state path in the next
l steps is expressed as follows:
If the initial state is chosen according to some distribution
rather than as a fixed state
, we obtain the following by linearity:
The overall probabilities of next generating a symbol
x or word
from a given state
are computed by summing over all possible associated target states or state sequences as follows:
respectively, where
is the
standard basis vector in
and
Finally, the overall probabilities of next generating a symbol
x or word
from an initial state distribution
are, respectively, expressed as follows:
If the graph
G associated with a given HMM is strongly connected, then the corresponding Markov chain over states is irreducible and the state-to-state transition matrix
T has a unique
stationary distribution satisfying
[
31]. In this case, we may define a stationary process
by the word probabilities obtained from choosing the initial state according to
. That is, for any word
as follows:
Strong connectivity also implies the process
is ergodic, as it is a pointwise function of the irreducible Markov chain over edges, which is itself ergodic [
31]. That is, at each time step, the symbol labeling the edge is a deterministic function of the edge.
We denote the corresponding (stationary, ergodic) process over bi-infinite symbol-state sequences by . That is, where the following stand:
.
is the -algebra generated by finite cylinder sets on the bi-infinite symbol-state sequences.
The (stationary) probability measure
on
is defined by Equation (8) with
. Specifically, for any length-
l word
w and length-
l state sequence
s we have the following:
By stationarity, this measure may be extended uniquely to all finite cylinders and, hence, to all
-measurable sets. Furthermore, this is consistent with the measure
as follows:
for all
.
Two HMMs are said to be
isomorphic if there is a bijection between their state sets that preserves edges, including the symbols and probabilities labeling the edges. Clearly, any two isomorphic, irreducible HMMs generate the same process, but the converse is not true. Nonisomorphic HMMs may also generate equivalent processes. In
Section 4, we will be concerned with isomorphism between generator and history
-machines.
3.3. Generator -Machines
Generator -machines are irreducible HMMs with two additional important properties as follows: unifilarity and probabilistically distinct states.
Definition 3. A generator ϵ-machine is an HMM with the following properties:
- 1.
Irreducibility: The graph G associated with the HMM is strongly connected.
- 2.
Unifilarity: For each state and each symbol , there is at most one outgoing edge from state labeled with symbol x.
- 3.
Probabilistically distinct states: For each pair of distinct states , there exists some word such that .
Note that all three of these properties may be easily checked for a given HMM. Irreducibility and unifilarity are immediate. The probabilistically distinct states’ condition can (if necessary) be checked by inductively separating distinct pairs with an algorithm similar to the one used to check for topologically distinct states in [
15].
By irreducibility, there is always a unique stationary distribution
over the states of a generator
-machine, so we may associate to each generator
-machine
a unique stationary, ergodic process
, with word probabilities defined as in Equation (
14). We refer to
as
the process generated by the generator
-machine
. The transition function for a generator
-machine or, more generally, any unifilar HMM, is denoted by
. That is, for
i and
x with
,
, where
is the (unique) state to which state
transitions on symbol
x.
In a unifilar HMM, for any given initial state
and word
, there can be at most one associated state path
such that the word
w may be generated following the state path
s from
. Moreover, the probability
of generating
w from
is nonzero if and only if there is a path
s. In this case, the states
are defined inductively by the relations
with
, and the probability
is simply expressed as follows:
Slightly more generally, Equation (
15) holds as long as there is a well defined path
upon which the subword
may be generated starting in
. Though, in this case,
may be 0 if state
has no outgoing transition on symbol
. This formula for word probabilities in unifilar HMMs will be useful in establishing the equivalence of generator and history
-machines in
Section 4.
3.4. History -Machines
The history
-machine
for a stationary process
is, essentially, just the hidden Markov model whose states are the equivalence classes of infinite past sequences defined by the equivalence relation
of Equation (
1). Two pasts
and
are considered equivalent if they induce the same probability distribution over future sequences. However, it takes some effort to make this notion precise and specify the transitions. The formal definition itself is quite lengthy, so, for clarity, the verification of many technicalities is deferred to the appendices. We recommend first reading through this section in its entirety without reference to the appendices for an overview and then reading through the appendices separately afterward for the details. The appendices are entirely self-contained in that, except for the notation introduced here, none of the results derived in the appendices rely on the developments in this section. As noted before, our focus is restricted to ergodic, finite-alphabet processes to parallel the generator definition. However, neither of these requirements is strictly necessary. Only stationarity is actually needed.
Let be a stationary, ergodic process over a finite alphabet , and let be the corresponding probability space over past sequences . The following stand:
is the set of infinite past sequences of symbols in : .
is the -algebra generated by finite cylinder sets on past sequences as follows: , where and .
is the probability measure on the measurable space , which is the projection of to past sequences as folllows: , for each .
For a given past
, we denote the last
t symbols of
as
. A past
is said to be
trivial if
for some finite
t and is otherwise
nontrivial. If a past
is nontrivial, then for each
,
is well defined for each
t, Equation (
4), and one may consider
. A nontrivial past
is said to be
w-regular if
exists and
regular if it is
w-regular for each
.
Appendix A shows that the set of trivial pasts
is a null set and that the set of regular pasts
has full measure. That is,
and
.
For a word
, the function
is defined as follows:
Intuitively,
is the conditional probability of
w given
. However, this probability is technically not well defined in accordance with Equation (
4), since the probability of each past
is normally 0. Furthermore, we do not want to define
in terms of a formal conditional expectation, because such a definition is only unique up to a.e. equivalence, while we would like its value on individual pasts to be uniquely determined. Nevertheless, intuitively speaking,
is the conditional probability of
w given
, and this intuition should be kept in mind as it will provide insights for what follows. Indeed, if one does consider the conditional probability
as a formal conditional expectation, any version of it will be equal to
for a.e.
. So, this intuition is justified.
The central idea in the construction of the history
-machine is the following equivalence relation on the set of regular pasts:
That is, two pasts
and
are ∼ equivalent if their predictions are the same. Conditioning on either past leads to the same probability distribution over the future words of all lengths. This is simply a more precise definition of the equivalence relation
of Equation (
1) (we drop the subscript
, as this is the only equivalence relation we will consider from here on).
The set of the equivalence classes of regular pasts under the relation ∼ is denoted as
, where
B is simply an index set. In general, there may be finitely many, countably many, or uncountably many such equivalence classes. Examples with finite and countably infinite
are given in
Section 3.5. For uncountable
, see Example 3.26 in [
16].
For an equivalence class
and word
we define the probability of
w given
as follows:
By construction of the equivalence classes this definition is independent of the representative
, and
Appendix B shows that these probabilities are normalized, so that for each equivalence class
the following stands:
Appendix B also shows that the equivalence-class-to-equivalence-class transitions for the relation ∼ are well defined, so that the following stand:
For any regular past and symbol with , the past is also a regular.
If and are two regular pasts in the same equivalence class and , then the two pasts and must also be in the same equivalence class.
So, for each
and
with
, there is a unique equivalence class
to which equivalence class
transitions on symbol
x.
According to Point 2 above, this definition is again independent of the representative
.
The subscript h in indicates that it is a transition function between equivalence classes of pasts or histories, . Formally, it is to be distinguished from the transition function between the states of a unifilar HMM. However, the two are essentially equivalent for a history -machine.
Appendix C shows that each equivalence class
is an
measurable set, so we can meaningfully assign a probability as follows:
to each equivalence class
. We say a process
is
finitely characterized if there is a finite number of positive probability equivalence classes
that together comprise a set of full measure as follows:
, for each
and
. For a finitely characterized process
, we will also occasionally say, by a slight abuse of terminology, that
is the set of equivalence classes of pasts and ignore the remaining measure-zero subset of equivalence classes.
Appendix E shows that for any finitely characterized process
, the transitions from the positive probability equivalence classes
all go to other positive probability equivalence classes. That is, if
, then the following stands:
As such, we define the symbol-labeled transition matrices
between the equivalence classes
. A component
of the matrix
gives the probability that equivalence class
transitions to equivalence class
on symbol
x as follows:
where
is the indicator function of the transition from
to
on symbol
x as follows:
This follows from Equations (
19) and (
22), where the matrix
is stochastic. (See also Claim 17 in
Appendix E).
Definition 4. Let be a finitely characterized, stationary, ergodic, finite-alphabet process. The history ϵ-machine is defined as the triple .
Note that is a valid HMM since T is stochastic.
3.5. Examples
In this section, we present several examples of irreducible HMMs and the associated -machines for the processes that these HMMs generate. This should hopefully provide some useful intuition for the definitions. For the sake of brevity, descriptions of the history -machine constructions in our examples will be less detailed than in the formal definition given above, but the ideas should be clear. In all cases, the process alphabet is the binary alphabet .
The first example we consider, shown in
Figure 2, is the generating HMM
M for the Even Process previously introduced in
Section 3.2. It is easily seen that this HMM is both irreducible and unifilar and, also, that it has probabilistically distinct states. State
can generate the symbol 0, whereas state
cannot.
M is therefore a generator
-machine, and by Theorem 1 below, the history
-machine
for the process
that
M generates is isomorphic to
M. The Fischer cover for the sofic shift
is also isomorphic to
M, if probabilities are removed from the edge labels in
M.
More directly, the history
-machine states for
can be deduced by noting that 0 is a
synchronizing word for
M [
15]; it synchronizes the observer to state
. Thus, for any nontrivial past
terminating in
, the initial state
must be
. By unifilarity, any nontrivial past
terminating in a word of the form
for some
also uniquely determines the initial state
. For
n even, we must have
and, for
n odd, we must have
. Since a.e. infinite past
generated by
M contains at least one 0 and the distributions over future sequences
are distinct for the two states
and
, the process
is finitely characterized with exactly two positive probability equivalence classes of infinite pasts as follows:
and
. These correspond to the states
and
of
M, respectively. More generally, a similar argument holds for any
exact generator
-machine; that is, any generator
-machine having a finite synchronizing word
w [
15].
Example 2. Alternating Biased Coins Machine
Figure 3 depicts a generating HMM
M for the Alternating Biased Coins (ABC) Process. This process may be thought of as being generated by alternately flipping two coins with different biases
. The phase—
p-bias on odd flips or
p-bias on even flips—is chosen uniformly at random.
M is again, by inspection, a generator
-machine that is irreducible and unifilar with probabilistically distinct states. Therefore, by Theorem 1 below, the history
-machine
for the process
that
M generates is again isomorphic to
M. However, the Fischer cover for the sofic shift
is not isomorphic to
M. The support of
is the full shift
, so the Fischer cover consists of a single state transitioning to itself on both symbols 0 and 1.
In this simple example, the history -machine states can also be deduced directly, despite the fact that the generator M does not have a synchronizing word. If the initial state is , then by the strong law of large numbers, the limiting fraction of 1s at odd time steps in finite-length past blocks converges a.s. to q, whereas if the initial state is , then the limiting fraction of 1s at odd time steps converges a.s. to p. Therefore, the initial state can be inferred a.s. from the complete past , so the process is finitely characterized with two positive probability equivalence classes of infinite pasts and , corresponding to the two states and . Unlike the exact case, however, arguments like this do not generalize as easily to other nonexact generator -machines.
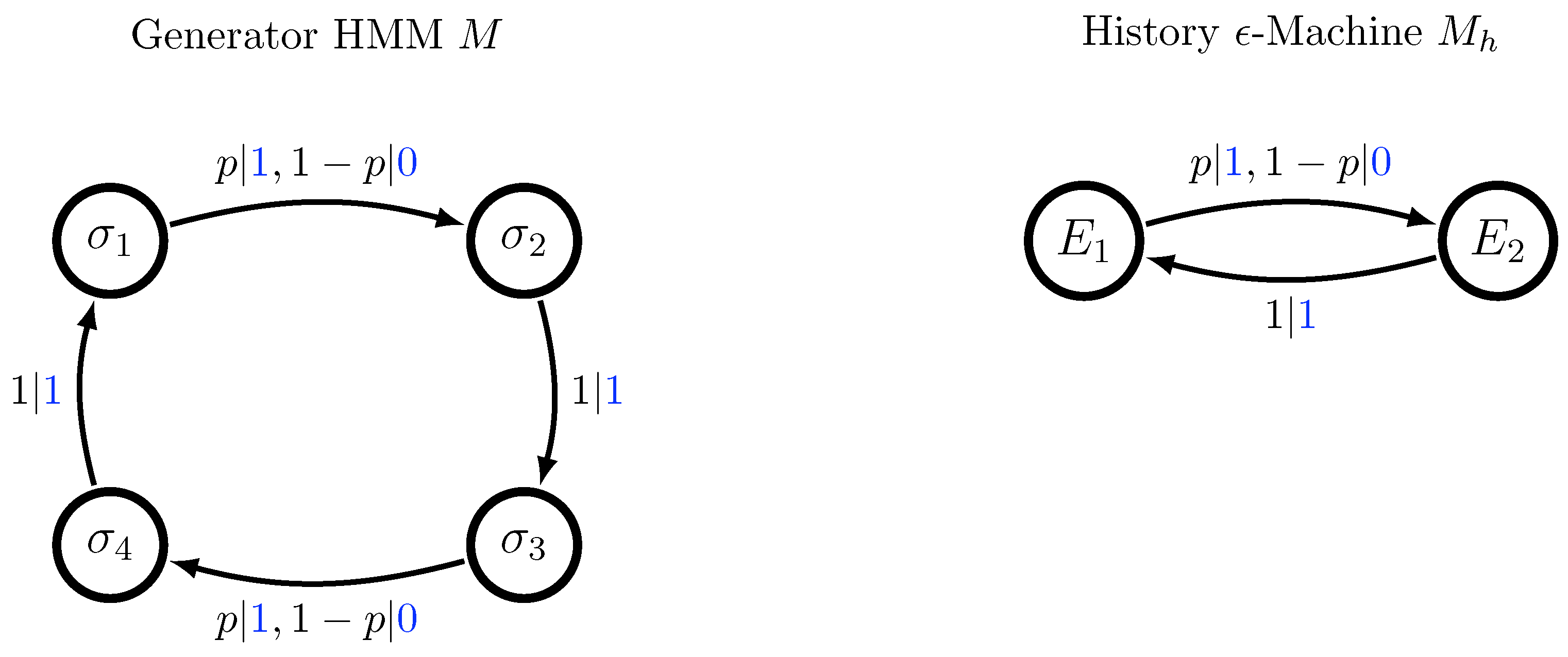
Example 3. Nonminimal Noisy Period-2 Machine
Figure 4 depicts a nonminimal generating HMM
M for the Noisy Period-2 (NP2) Process
in which 1s alternate with random symbols.
M is again unifilar, but it does not have probabilistically distinct states and is, therefore, not a generator
-machine. States
and
have the same probability distribution over future output sequences, as do states
and
.
There are two positive probability equivalence classes of pasts for the process , those containing 0s at a subset of the odd time steps, and those containing 0s at a subset of the even time steps. Those with 0s at odd time steps induce distributions over future output equivalent to that from states and , while those with 0s at even time steps induce distributions over future output equivalent to that from states and . Thus, the -machine for consists of just two states, and . In general, for a unifilar HMM without probabilistically distinct states, the -machine is formed by grouping together equivalent states in a similar fashion.
Example 4. Simple Nonunifilar Source
Figure 5 depicts a generating HMM
M known as the Simple Nonunifilar Source (SNS) [
7]. The output process
generated by
M consists of long sequences of 1s broken by isolated 0s. As its name indicates,
M is nonunifilar, so it is not an
-machine.
Symbol 0 is a synchronizing word for
M, so all pasts
ending in a 0 induce the same probability distribution over future output sequences
: Namely, the distribution over futures is given by starting
M in the initial state
. However, since
M is nonunifilar, an observer does not remain synchronized after seeing a 0. Any nontrivial past of the form
induces the same distribution over the initial state
as any other. However, for
, there is some possibility of being in both
and
at time 0. A direct calculation shows that the distributions over
and, hence, the distributions over future output sequences
are distinct for different values of
n. Thus, since a.e. past
contains at least one 0, it follows that the process
has a countable collection of positive probability equivalence classes of pasts, comprising a set of full measure as follows:
where
. This leads to a
countable-state history ϵ-machine as depicted on the right of
Figure 5. We will not address countable-state machines further here, as other technical issues arise in this case. Conceptually, however, it is similar to the finite-state case and may be depicted graphically in an analogous fashion.


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}