
Local Time-Frequency Feature Fusion Using Cross-Attention for Acoustic Scene Classification
Abstract
1. Introduction
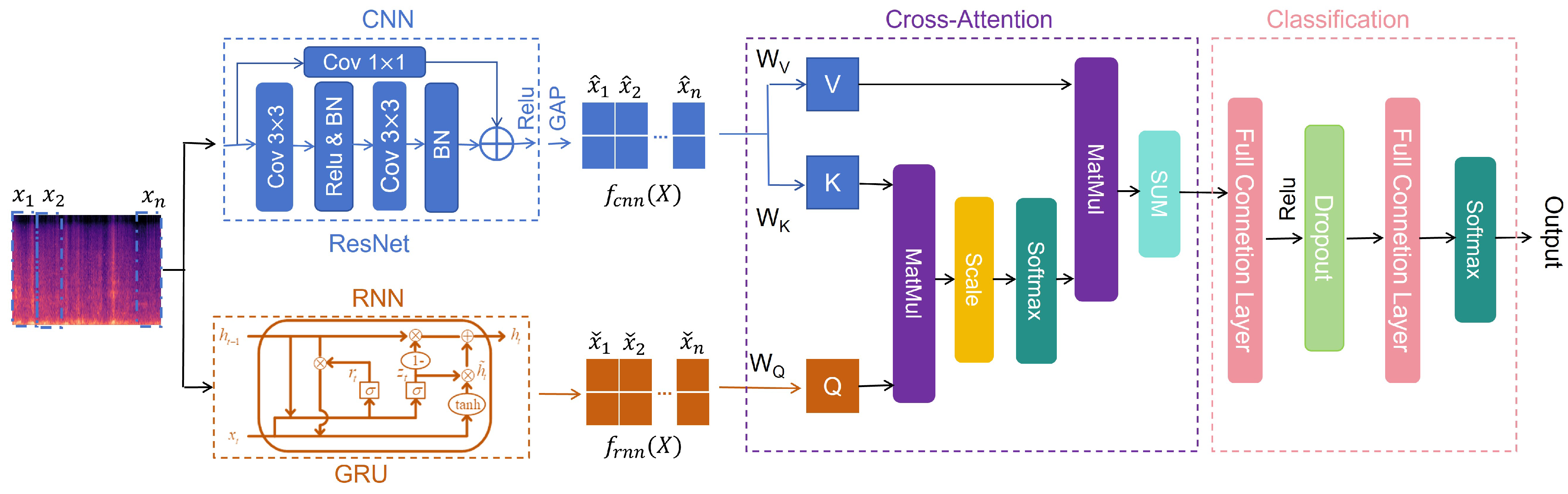
2. Network Structure
3. Algorithm
3.1. Segment-Level Features
3.2. Residual Convolution
3.3. Gated Recurrent Unit
3.4. Cross-Attention
4. Experiments and Discussion
4.1. Datasets
4.2. The Impact of Time Segmentation
- CNN+SA: An independent CNN model followed by self-attention;
- GRU+SA: An independent GRU model followed by self-attention;
- CNN-GRU+CA: A proposed parallel CNN and GRU model followed by cross-attention.
4.3. Confusion Matrix
4.4. Feature Fusion
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Surendiran, J.; Prabhakar, P.B.E.; Ibrahim, M.M.; Saritha, G.; K, S.; Vijayan, V.B. A Systemic Review on Automatic Acoustic Scene Classification. In Proceedings of the 2024 International Conference on Power, Energy, Control and Transmission Systems (ICPECTS), Chennai, India, 8–9 October 2024; pp. 1–6. [Google Scholar]
- Clarkson, B.; Sawhney, N.; Pentland, A. Auditory context awareness via wearable computing. Energy 1998, 400, 20. [Google Scholar]
- Couvreur, C.; Fontaine, V.; Gaunard, P.; Mubikangiey, C.G. Automatic classification of environmental noise events by hidden Markov models. Appl. Acoust. 1998, 54, 187–206. [Google Scholar] [CrossRef]
- Abuirbaiha, R.A.A.; Lee, C.-H.; Lien, C.C. Acoustic Scene Classification Using Perceptually Weighted Log Mel Spectrogram and Buttom-Up Broadcast Neural Network. In Proceedings of the 2024 International Conference on Consumer Electronics-Taiwan (ICCE-Taiwan), Taichung, Taiwan, 9–11 July 2024; pp. 643–644. [Google Scholar]
- Eronen, A.; Tuomi, J.; Klapuri, A.; Fagerlund, S.; Sorsa, T.; Lorho, G.; Huopaniemi, J. Audio-based context awareness-acoustic modeling and perceptual evaluation. In Proceedings of the 2003 IEEE International Conference on Acoustics, Speech, and Signal Processing, 2003. Proceedings. (ICASSP ’03), Hong Kong, China, 6–10 April 2003; p. V-529. [Google Scholar] [CrossRef]
- Heittola, T.; Mesaros, A.; Eronen, A.J.; Virtanen, T. Audio context recognition using audio event histogram. In Proceedings of the 2010 18th European Signal Processing Conference, Aalborg, Denmark, 23–27 August 2010. [Google Scholar]
- Valenti, M.; Diment, A.; Parascandolo, G.; Squartini, S.; Virtanen, T. DCASE 2016 acoustic scene classification using convolutional neural network. In Proceedings of the Detection and Classification of Acoustic Scenes and Events 2016, Budapest, Hungary, 3 September 2016. [Google Scholar]
- Xu, Y.; Huang, Q.; Wang, W.; Plumbley, M.D. Hierarchical learning for DNN-based acoustic scene classification. In Proceedings of the Detection and Classification of Acoustic Scenes and Events 2016, Budapest, Hungary, 3 September 2016. [Google Scholar]
- Basbug, A.M.; Sert, M. Acoustic Scene Classification Using Spatial Pyramid Pooling with Convolutional Neural Networks. In Proceedings of the 2019 IEEE 13th International Conference on Semantic Computing (ICSC), Newport Beach, CA, USA, 30 January–1 February 2019; pp. 128–131. [Google Scholar]
- Zhang, L.; Han, J.; Shi, Z. Learning Temporal Relations from Semantic Neighbors for Acoustic Scene Classification. IEEE Signal Process. Lett. 2020, 27, 950–954. [Google Scholar] [CrossRef]
- Cai, Y.; Zhang, P.; Li, S. TF-SepNet: An Efficient 1D Kernel Design in Cnns for Low-Complexity Acoustic Scene Classification. In Proceedings of the ICASSP 2024—2024 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Seoul, Republic of Korea, 14–19 April 2024; pp. 821–825. [Google Scholar]
- Zöhrer, M.; Pernkopf, F. Gated recurrent networks applied to acoustic scene classification and acoustic event detection. In Proceedings of the Detection and Classification of Acoustic Scenes and Events 2016, Budapest, Hungary, 3 September 2016. [Google Scholar]
- Li, Y.; Li, X.; Zhang, Y.; Wang, W.; Liu, M.; Feng, X. Acoustic Scene Classification Using Deep Audio Feature and BLSTM Network. In Proceedings of the 2018 International Conference on Audio, Language and Image Processing (ICALIP), Shanghai, China, 16–17 July 2018; pp. 371–374. [Google Scholar]
- Vij, D.; Aggarwal, N. Performance evaluation of deep learning architectures for acoustic scene classification. In Proceedings of the Detection and Classification of Acoustic Scenes and Events 2017, Munich, Germany, 16 November 2017. [Google Scholar]
- Hao, W.; Zhao, L.; Zhang, Q.; Zhao, H.; Wang, J. DCASE 2018 task 1a: Acoustic scene classification by bi-LSTM-CNN-net multichannel fusion. In Proceedings of the Detection and Classification of Acoustic Scenes and Events 2018, Surrey, UK, 19–20 November 2018. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep Residual Learning for Image Recognition. In Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778. [Google Scholar]
- Cho, K.; Van Merriënboer, B.; Gulcehre, C.; Bahdanau, D.; Bougares, F.; Schwenk, H.; Bengio, Y. Learning Phrase Representations using RNN Encoder-Decoder for Statistical Machine Translation. arXiv 2014, arXiv:1406.1078. [Google Scholar]
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N.; Kaiser, Ł.; Polosukhin, I. Attention is all you need. In Proceedings of the 31st International Conference on Neural Information Processing Systems (NIPS’17), Long Beach, CA, USA, 4–9 December 2017; Curran Associates Inc.: Red Hook, NY, USA, 2017; pp. 6000–6010. [Google Scholar]
- Stowell, D.; Giannoulis, D.; Benetos, E.; Lagrange, M.; Plumbley, M.D. Detection and classification of acoustic scenes and events. IEEE Trans. Multimed. 2015, 17, 1733–1746. [Google Scholar] [CrossRef]
- Naranjo-Alcazar, J.; Perez-Castanos, S.; Zuccarello, P.; Cobos, M. DCASE 2019: CNN Depth Analysis with Different Channel Inputs for Acoustic Scene Classification. DCASE2019 Challenge, Tech. Rep. June 2019. Available online: https://dcase.community/documents/challenge2019/technical_reports/DCASE2019_Naranjo-Alcazar_13.pdf (accessed on 24 October 2024).
- Wang, Y.; Feng, C.; Anderson, D.V. A Multi-Channel Temporal Attention Convolutional Neural Network Model for Environmental Sound Classification. In Proceedings of the ICASSP 2021—2021 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Toronto, ON, Canada, 6–11 June 2021; pp. 930–934. [Google Scholar]
- Shim, H.J.; Jung, J.W.; Kim, J.H.; Yu, H.J. Capturing scattered discriminative information using a deep architecture in acoustic scene classification. arXiv 2020, arXiv:2007.0463. [Google Scholar]
- Vilouras, K. Acoustic Scene Classification Using Fully Convolutional Neural Networks and Per-Channel Energy Normalization. DCASE 2020 Challenge, Tech. Rep. June 2020. Available online: https://dcase.community/documents/challenge2020/technical_reports/DCASE2020_Vilouras_3.pdf (accessed on 24 October 2024).
- Hasan, N.W.; Saudi, A.S.; Khalil, M.I.; Abbas, H.M. A Genetic Algorithm Approach to Automate Architecture Design for Acoustic Scene Classification. IEEE Trans. Evol. Comput. 2023, 27, 222–236. [Google Scholar] [CrossRef]





{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Predict | Airport | Bus | Subway | Subway Station | Urban Park | Public Square | Indoor Shopping Mall | Pedestrian Street | Traffic Street | Tram | |
|---|---|---|---|---|---|---|---|---|---|---|---|
| Label | |||||||||||
| Airport | 82.55 | 0 | 0 | 12.3 | 0 | 0 | 1.98 | 2.38 | 0.79 | 0 | |
| Bus | 0 | 63.02 | 12.3 | 0.4 | 0.79 | 0 | 0 | 0 | 0 | 23.49 | |
| Subway | 0 | 0.79 | 80.16 | 7.54 | 0 | 0 | 0 | 0.4 | 0.4 | 10.71 | |
| Subway Station | 3.17 | 0 | 3.97 | 90.87 | 0 | 0 | 0.4 | 1.19 | 0 | 0.4 | |
| Urban Park | 0.4 | 0 | 0 | 1.99 | 83.67 | 6.37 | 0.8 | 4.38 | 1.99 | 0.4 | |
| Public Square | 2.38 | 0 | 0 | 1.98 | 6.75 | 60.37 | 0 | 13.89 | 14.23 | 0.4 | |
| Indoor Shopping Mall | 22.72 | 0 | 0 | 1 | 0 | 1.19 | 69.14 | 5.95 | 0 | 0 | |
| Pedestrian Street | 7.57 | 0 | 0 | 0.79 | 0 | 12.35 | 0.79 | 75.32 | 3.17 | 0 | |
| Traffic Street | 0 | 0 | 0 | 0.4 | 0.79 | 2.78 | 0 | 5.56 | 90.47 | 0 | |
| Tram | 0 | 2.39 | 16.73 | 0.4 | 0.4 | 0 | 0 | 0 | 0.8 | 79.28 | |
| Predict | Airport | Bus | Subway | Subway Station | Urban Park | Public Square | Indoor Shopping Mall | Pedestrian Street | Traffic Street | Tram | |
|---|---|---|---|---|---|---|---|---|---|---|---|
| Label | |||||||||||
| Airport | 79.65 | 0.19 | 0.19 | 8.25 | 0.77 | 0.58 | 9.02 | 0.77 | 0.58 | 0 | |
| Bus | 0 | 88.34 | 2.3 | 0.19 | 0.57 | 0 | 0 | 0 | 0.19 | 8.41 | |
| Subway | 0 | 5.94 | 77.01 | 4.21 | 0 | 0.96 | 0.19 | 0 | 0 | 11.69 | |
| Subway Station | 1.15 | 0.19 | 6.5 | 85.09 | 0 | 0.38 | 2.3 | 0.38 | 0.57 | 3.44 | |
| Urban Park | 0 | 0 | 0 | 1.34 | 88.88 | 3.07 | 0.77 | 0.38 | 4.6 | 0.96 | |
| Public Square | 1.34 | 0.77 | 0.19 | 1.34 | 6.72 | 71.69 | 0.67 | 7.68 | 7.87 | 1.73 | |
| Indoor Shopping Mall | 15.08 | 0 | 0.04 | 5.36 | 0 | 4.2 | 66.6 | 7.42 | 0.19 | 1.11 | |
| Pedestrian Street | 4.4 | 0 | 0 | 1.34 | 1.34 | 36.4 | 2.11 | 52.3 | 2.11 | 0 | |
| Traffic Street | 0 | 0.77 | 0 | 0.77 | 0.77 | 6.9 | 0 | 0.96 | 89.25 | 0.58 | |
| Tram | 0 | 5.36 | 7.85 | 0.96 | 0.19 | 0 | 0 | 0 | 0 | 85.64 | |
| Predict | Airport | Bus | Subway | Subway Station | Urban Park | Public Square | Indoor Shopping Mall | Pedestrian Street | Traffic Street | Tram | |
|---|---|---|---|---|---|---|---|---|---|---|---|
| Label | |||||||||||
| Airport | 63.1 | 0.34 | 0.67 | 7.07 | 0.34 | 1.35 | 17.52 | 9.27 | 0 | 0.34 | |
| Bus | 0 | 85.52 | 5.05 | 0.34 | 0.67 | 0 | 0 | 0 | 0 | 8.42 | |
| Subway | 0 | 3.7 | 71.38 | 7.41 | 0 | 0.67 | 0.34 | 0.67 | 0 | 15.82 | |
| Subway Station | 3.37 | 0.67 | 7.07 | 70.37 | 0.34 | 0.34 | 11.11 | 2.36 | 1.01 | 3.37 | |
| Urban Park | 0.67 | 0.67 | 2.02 | 0 | 87.88 | 2.02 | 1.35 | 1.01 | 4.04 | 0.34 | |
| Public Square | 0 | 1.01 | 0.05 | 3.7 | 12.12 | 58.89 | 1.01 | 9.76 | 12.79 | 0.67 | |
| Indoor Shopping Mall | 15.15 | 0.34 | 0.34 | 5.39 | 0.34 | 0.34 | 69.02 | 9.09 | 0 | 0 | |
| Pedestrian Street | 7.74 | 0.67 | 0.34 | 3.37 | 1.35 | 16.5 | 14.14 | 48.48 | 7.07 | 0.34 | |
| Traffic Street | 0.34 | 0.34 | 0 | 1.01 | 2.36 | 7.41 | 3.03 | 1.01 | 84.51 | 0 | |
| Tram | 0.34 | 7.41 | 9.09 | 2.36 | 0.34 | 1.35 | 0 | 0.67 | 0.34 | 78.11 | |
| Model | TUT2018 | TAU2019 | TAU2020 |
|---|---|---|---|
| DCASE [19] | 59.7 | 62.5 | 51.6 |
| BiLSTM-CNN [15] | 73.6 | - | - |
| Visualfy [20] | - | 76.8 | - |
| MCTA-CNN [21] | 72.4 | 75.71 | - |
| LCNN [22] | - | - | 70.4 |
| VilEnsemb3 [23] | - | - | 70.3 |
| GA [24] | 76.7 | 78.2 | 71.3 |
| CNN+GRU+SA | 74.86 | 76.83 | 68.75 |
| GRU+CNN+SA | 73.92 | 76.26 | 68.06 |
| CNN-GRU+CO+SA | 75.34 | 77.38 | 69.86 |
| CNN-GRU+CA | 77.48 | 78.45 | 71.73 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Huang, R.; Xie, Y.; Jiang, P. Local Time-Frequency Feature Fusion Using Cross-Attention for Acoustic Scene Classification. Symmetry 2025, 17, 49. https://doi.org/10.3390/sym17010049
Huang R, Xie Y, Jiang P. Local Time-Frequency Feature Fusion Using Cross-Attention for Acoustic Scene Classification. Symmetry. 2025; 17(1):49. https://doi.org/10.3390/sym17010049
Chicago/Turabian StyleHuang, Rong, Yue Xie, and Pengxu Jiang. 2025. "Local Time-Frequency Feature Fusion Using Cross-Attention for Acoustic Scene Classification" Symmetry 17, no. 1: 49. https://doi.org/10.3390/sym17010049
APA StyleHuang, R., Xie, Y., & Jiang, P. (2025). Local Time-Frequency Feature Fusion Using Cross-Attention for Acoustic Scene Classification. Symmetry, 17(1), 49. https://doi.org/10.3390/sym17010049