1. Introduction
Many complex systems in reality can be modeled as a complex network, such as power networks, aviation networks, transportation networks, social networks, etc. [
1,
2]. For undirected networks, this relationship satisfies transitivity and symmetry. Complex networks often exhibit obvious structural properties, such as small-world properties, scale-free properties and community structure properties [
3]. Detecting the community structure of the network is important to help study its organizational functions and uncover the hidden inner connections between nodes [
4].
Community detection is to partite the entire network into some sub-networks such that each sub-network is tightly connected to the others internally and sparsely connected between different sub-networks [
5]. Community detection has very important applications in many fields, such as identifying criminal gangs [
6] and product recommendation [
7]. Although the community-detection problem of complex networks has been widely studied and a variety of classical algorithms have emerged [
8,
9], the quality of community detection of many existing methods largely depends on the selection of seed nodes, i.e., community centers. The search for more efficient and accurate community-detection methods is still a hot issue of research.
Generally speaking, the central nodes of communities should be individuals with high influence in the community. If influential nodes of the network can be identified, then the community centers can be determined based on these influential nodes, which is expected to greatly improve the efficiency and accuracy of community detection.
In view of this, this paper proposes a community-detection method of complex networks based on node influence analysis. Firstly, the influence of a node is represented by a vector consisting of three indicators. Then, Pareto dominance is used to divide the nodes into several levels. After that, the community centers are selected taking into account the node influence and the crowding degree. Finally, a labeling algorithm is proposed to partition nodes into various communities. The comparison results with other methods have verified the effectiveness of our method.
This paper has the following three-fold innovations and contributions:
A node impact-ranking method based on Pareto dominance is proposed, which comprehensively considers multiple node influence indicators. We also propose a concept of neighborhood degree centrality, which is more suitable for detecting community centers than conventional degree centrality.
A community-detection method based on node influence and crowding degree is presented. The algorithm first comprehensively considers node influence and crowding degree to determine community centers, and then assigns nodes to different communities by a label method.
The proposed method is applied to different types of actual networks, and the experimental results demonstrate the superiority of the proposed method.
The remainder of this paper is organized as follows:
Section 2 gives the related work; the node influence-ranking method based on Pareto dominance is presented in
Section 3; Based on the node influence analysis,
Section 4 proposes the community-detection method. The experiment to validate the proposed method is put forward in
Section 5. Finally,
Section 6 shortly summarizes the work of this paper.
2. Related Work
Since Girven and Newman introduced the concept of community in 2002 [
8], many community-detection methods have been proposed [
10]. Among them, the community-detection methods for undirected complex networks have been widely studied, which can be broadly classified into graph-partitioning methods [
11,
12], clustering methods [
13,
14] and methods based on heuristic algorithms [
15,
16]. Some of these methods require early identification of community centers, while others do not. In general, people mainly use the influence of nodes to determine the community centers [
17]. Therefore, we will elaborate on the related work for both general community-detection methods and node influence-based community-detection methods.
2.1. Graph-Partitioning Method
The graph-partitioning method divides the nodes of a network into groups of subgraphs with the rule that the number of connected edges between the subgraphs is minimal, the most famous of which is the GN (Girvan–Newman) algorithm proposed by Girven and Newman [
8]. This type of algorithm requires the number of communities to be specified in advance and is not applicable to community detection in general networks. Belim and Larionov [
18] used a modularity function to evaluate the quality of community-partitioning and proposed a greedy algorithm to find communities. Mourchid et al. [
19] proposed a new community-partitioning algorithm by maximizing a new centrality metric, local Fiedler vector centrality (LFVC), at each stage. Most graph-partitioning problems are NP-hard, and therefore, efforts have been devoted to finding algorithmic designs that are closer to the optimal solution. Zhang et al. [
20] proposed a large-scale community-detection method based on core node and layer-by-layer label propagation (CNLP).
2.2. Clustering Method
The clustering method mainly clusters nodes based on some kind of metric that measures the result of community partition. The most commonly used metric is the modularity function proposed by Newman and Girvan [
21]. Newman [
22] first proposed a community-detection algorithm based on modularity optimization, i.e., fast Newman. Blondel et al. [
23] proposed the Louvain algorithm based on hierarchical clustering, which is divided into two stages: the first stage forms the initial community by merging nodes, and the second stage obtains the final community-detection result by merging the initial community. Both stages use modularity as the optimization function. Besides modularity, some scholars also use other improved similarity functions for node clustering. Lv et al. [
24] proposed a community-detection algorithm based on proximity ranking and signal transmission, which ranks nodes by proximity centrality, calculates the similarity between nodes based on the idea of signal transmission and then assigns each node to a candidate community.
2.3. Heuristic Algorithm-Based Method
The heuristic algorithm-based approach regards the community-detection problem as an optimization one and then solves it using some heuristic algorithm. The classical heuristic algorithms are genetic algorithm [
25], particle swarm algorithm [
26], simulated annealing algorithm [
27], label propagation algorithm (CIDLPA) [
28], etc. In terms of objective function construction, there is no widely accepted criterion for community quality evaluation, and most optimization objectives are to minimize or maximize some structural metrics, such as modularity, triangle participation ratio or conductivity of the community [
29].
2.4. Node Influence-Based Method
In actual complex networks, the influences of different individuals varies. The nodes with high influence are often the leaders of various communities. Therefore, it is natural to first determine the community centers based on the influence of nodes, and then assign other nodes to the community centers.
Zhao et al. [
30] introduced an algorithm for detecting overlapping communities by utilizing node influence propagation. Node influence refers to a node’s capacity to impact other nodes, which is determined by both the node’s location and its activity behavior. Liu et al. [
31] proposed an algorithm for discovering communities that integrates the influence of seed nodes and the similarity of neighborhoods. Xu et al. [
32] introduced a community-detection algorithm that utilizes node influence and node similarity for clustering. The algorithm comprises three fundamental steps: identification of the central nodes based on node influence, selection of candidate neighbors based on node similarity to expand the community and merging of small communities based on community similarity. Ma et al. [
33] put forward a new method to identify the most influential nodes which are considered as cores of communities and achieve the initial communities. Subsequently, through an expansion strategy, unassigned nodes are incorporated into the initial communities to facilitate their growth and enlargement. In order to maximize modularity, Boroujeni and Soleimani [
34] attempted to identify influential nodes, and then detect communities by estimating their influence domains.
The above research results have provided various ideas and methods for the community-detection problem of complex networks, which greatly enriched the theory of complex networks and effectively improved the accuracy of community detection. However, the search for more efficient and accurate community-detection methods is still the focus of attention in the field of complex network, and the in-depth research in this popular direction will continue to be promoted on the basis of the existing research results.
3. Analysis of Node Influence Based on Pareto Dominance
We first provide some basic knowledge on networks that need to be used. Then, the node’s influence vector is constructed. Finally, the node influence-ranking method based on Pareto dominance is presented.
3.1. Basic Concepts on Network
Generally, a network can be represented by a graph , where is the node set of the network, and n is the number of nodes in the network; E is called the edge set of the network, and represents the number of edges in the network.
If there is an edge between and , then one of them is called a neighbor of the other one. The edge is said to be incident with and . The neighbor set of is denoted as . The degree of refers to the number of edges of G incident with , denoted as . For a graph without loops, .
A path
P in
G is a non-null sequence
, in which all nodes are distinct.
k is called the length of
P. Nodes
and
are said to be connected if there is a
path in
G. Distance
of
and
in
G is the smallest length of the
path. If there is no path between
and
, then it is specified that
. The distance between all nodes can form a matrix called the distance matrix
, where
. We can use the Dijkstra’ algorithm to find the shortest path from any node to all other nodes in a network [
35].
3.2. Node’s Influence Vector
Some nodes play a vital role in the complex network. The influential and important nodes have a great impact on the structure and function of the network. Therefore, it has important theoretical significance and application value to evaluate the node influence of complex networks, and then explore the key nodes.
This paper synthesizes three commonly used indicators to evaluate the node influence of complex networks. In fact, there are many indicators that can measure the centrality of nodes. We have comprehensively considered the focus and computational cost of different indicators and selected three measurement methods, i.e., neighborhood degree centrality, closeness centrality and clustering coefficient.
3.2.1. Neighborhood Degree Centrality
Generally speaking, in social networks, the greater the influence of an individual, the stronger his social relationships, and therefore the greater its degree will be. So, people measure the influence of nodes based on degrees. The degree centrality of node
is defined as [
36]:
Degree centrality measures the degree of connection between a node and all other nodes in the network. However, some communities contain large number of nodes, and the degrees of core nodes are relatively high. But some communities have fewer nodes, and the degrees of core nodes are relatively small. Therefore, it is unreasonable to analyze the influence of nodes using traditional degree centrality. To address this issue, we propose the concept of neighborhood degree centrality, which is defined as follows:
where
, and
is the neighbor set of
. Relative degree centrality measures the relative size of a node’s degree within its neighborhood. If a node has significant influence, its relative degree centrality tends to be closer to 1; conversely, the relative degree centrality approaches 0 if its influence is small.
3.2.2. Betweenness Centrality
Betweenness centrality quantifies the number of times a node acts as a bridge along the shortest path between two other nodes. The betweenness centrality of node
is defined as [
36]:
where
represents the number of shortest paths between
i and
that pass
, and
refers to the number of all shortest paths between
i and
.
Nodes with high betweenness centrality have significant influence over the flow of information in the network, as many shortest paths pass through them.
3.2.3. Clustering Coefficient
Clustering coefficient is the quantity that represents the aggregation degree of nodes in the network. Let
, which refers to the number of neighbors of
. Let
be the number of edges between all nodes of
. Then, the clustering coefficient of
is defined as [
36]:
The clustering coefficient can quantitatively describe the probability that any two neighbors of a node in a network are also neighbors with each other. The larger the clustering coefficient, the higher the degree of aggregation between the neighbors of the node.
3.2.4. Influence Vector
The above three indicators of node influence can be regarded as a three-dimensional vector, called the influence vector, denoted as , i.e., , and .
3.3. Node Influence Ranking Based on Pareto Dominance
The above three indicators can reflect the influence of nodes from different aspects, and each have its own advantages and disadvantages. Some works combine different indicators into one indicator by weighting [
37]. Although this kind of method can integrate the advantages of each indicator, the weights of different indicators has a great impact on the evaluation results. In addition, it is easy to ignore which nodes are particularly prominent in some aspects. Therefore, this paper uses Pareto dominance to sort the influence of different nodes.
Definition 1 ([
38]).
For nodes and , if the following two relationships are satisfied:- 1.
, ;
- 2.
, .
it is said that node dominates , denoted as , which means that node has greater influence than node . If a node is not dominated by any node, it is called a non-dominated node. We can sort all nodes based on their dominance relationship.
The set consisting of all non-dominated nodes in V is recorded as . The nodes in set have the highest level of influence.
Then, let . The set consisting of all non-dominated nodes in is recorded as . The nodes in set have the second level of influence.
This process continues, and we can divide all nodes into several layers. Assuming that a total of l layers are obtained in the end, then . We can also set the number of layers l in advance as needed. After obtaining the first layers, assign the remaining nodes to l-layer.
The process for sorting all nodes is shown as Algorithm 1. From line 1 to 2, the relativity degree centrality, closeness centrality and clustering coefficient of each node are calculated, respectively. In line 4, these three indicators are stitched together to form a matrix of size
. Each row of this matrix represents the influence vector of a node. Lines 5–22 are to sort all nodes into several layers. To obtain the final set of non-dominant nodes, add an attribute called “WND” to each node in Line 8. First assume that all nodes are not dominated, i.e., WND =
true. From line 9 to 16, the algorithm traverses all nodes
in
V and compares its influence vector with all other nodes. If there exists another node
that dominates
, then set WND[
] =
false. If the attribute WND of node
does not change after the loop, then it belongs to the set
. In this way, all nodes can be divided into
l layers.
| Algorithm 1 Influence Ranking |
Input: .
Output: .
- 1:
for node do - 2:
Calculate ; - 3:
end for - 4:
append(); - 5:
let ; - 6:
if then - 7:
let - 8:
WNDtrue, ; - 9:
for do - 10:
for do - 11:
if then - 12:
WND] ← false; - 13:
break; - 14:
end if - 15:
end for - 16:
end for - 17:
[]; - 18:
for do - 19:
if WND == true then - 20:
.append() - 21:
end if - 22:
end for - 23:
- 24:
end if - 25:
Output .
|
4. Community-Detection Method Based on Node Influence and Crowding Degree
This section provides specific community division, including the determination of community centers, process of community detection, algorithm refinement and time complexity.
4.1. Determination of Community Center
In the real world, community centers are generally individuals with high influence. Therefore, it is reasonable to detect the communities of the network with influential nodes as the centers. However, there may also be more than one influential node within the same community, and in general, these two nodes are closely connected. Additionally, it is also possible that some community center has the highest influence in its own community, but is relatively weak compared to the centers of other communities. In view of this, we consider both node influence and crowding degree to determine the community center.
The crowding degree of nodes
and
is defined as follows:
The crowding degree is only between 0 and 1. The greater the crowding degree, the more likely two nodes are to be in the same community; otherwise, they are more likely to belong to different communities.
We first consider the nodes in the first layer . Each node in has the highest influence. First, a node is randomly selected in as the first community center, recorded as . Then, and the nodes whose crowding degree with is less than a given threshold are removed from . The above process repeats until is empty.
We then consider the nodes in the second layer . The selection process of the center nodes is similar to .
In order to ensure that the community center has a high level of influence, this paper only selects nodes from the first or second layers as community centers.
The value of threshold will have a certain impact on the selection of community centers. Generally speaking, the smaller the threshold, the larger the number of community centers; conversely, the larger the threshold, the smaller the number of community centers. Because the influence of the first layer individuals is higher than that of the first layer individuals, the threshold should be set lower than that of the second layer, which is conducive to selecting more individuals from the second layer as community centers.
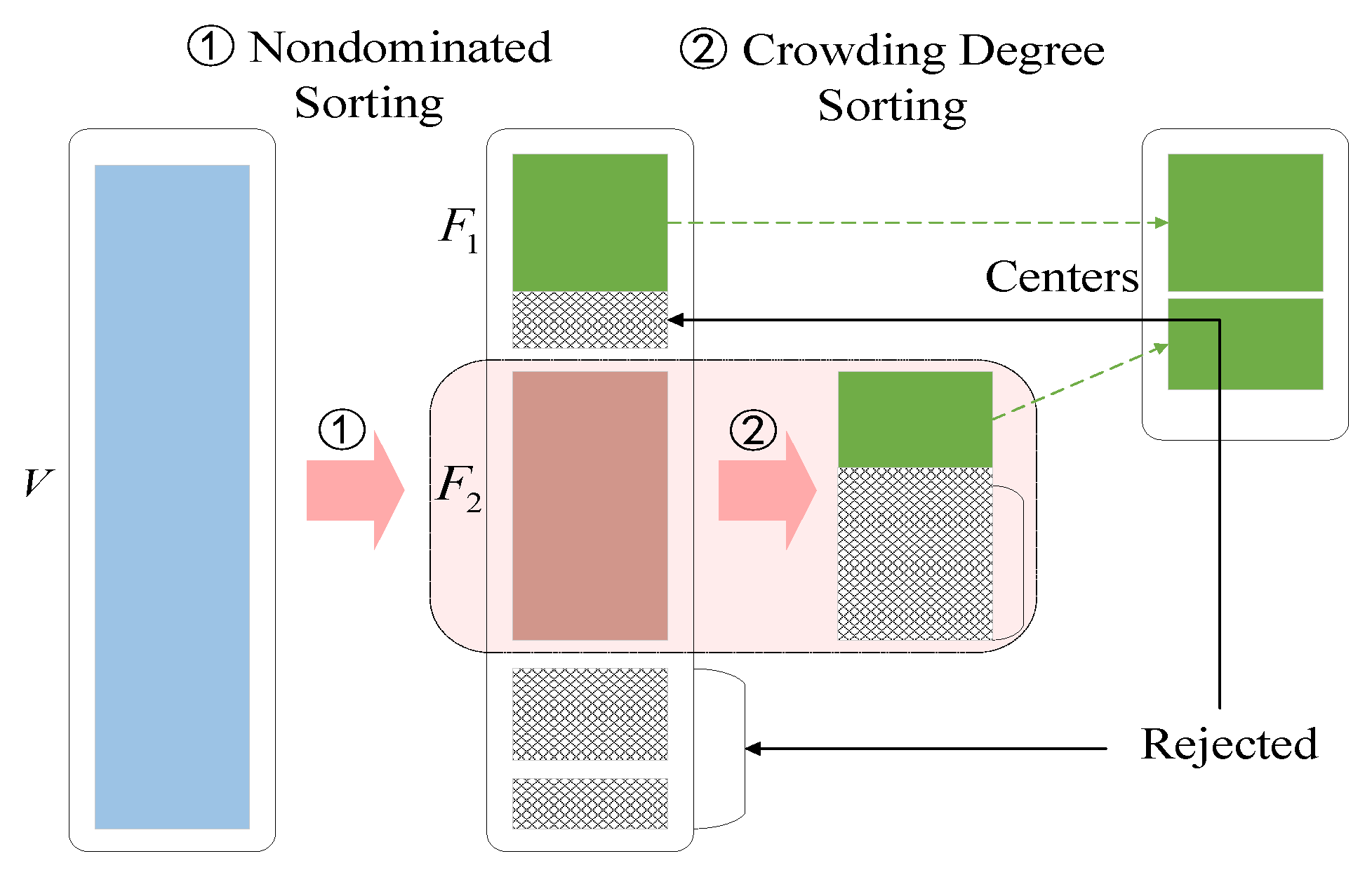
The specific selection process is shown in
Figure 1. Firstly, based on non-dominated sorting, non-dominated sets for different layers are obtained. Then, when screening community centers, crowding non-dominated sorting method is used. Through two different sorting processes, all community centers are ultimately obtained.
4.2. Process of Community Detection
After the community centers are determined, other nodes will be allocated to the center node a labeling algorithm. The community with center is denoted as , . To achieve this, two parameters are defined to determine which set would be most suitable for a node to add in among .
Suppose that v is a node, H is a subset of V. The distance between v and H is defined as . If , then v has at least one neighbor node in H. Also note that for , .
If , let , which is called the attachment of v at H. is called the fitness of node v to set H, indicating the number of neighbors of node v in H. The greater the fitness, the tighter the connection between node v and set H.
The process of generating is shown as Algorithm 2, which is mainly implemented through a labeling process. The input of the algorithm is graph G and the set of community centers .
The label represents the minimum distance from v to all communities. First, lines 1–8 regard each central node as a community and set the label values of the center nodes as 1, and that of other nodes as ∞.
Lines 9–24 assign all other nodes to the community with the highest fitness. records the community code with the highest fitness for each node. Lines 20–22 update the label values of the neighbor nodes.
Theorem 1. Suppose that G is a connected network. In Algorithm 1, if , there is at least one and , so that .
Proof. Assume that the theorem does not hold. For any , let . According to the assumption, . So there is a path of length d, denoted as , such that . Then, contradicts the hypothesis. □
| Algorithm 2 Community Detection |
Input: , C
Output: Community division result .
- 1:
, ; - 2:
for to s do - 3:
= {; - 4:
; - 5:
for do - 6:
; - 7:
end for - 8:
end for - 9:
; - 10:
while do - 11:
for do - 12:
; - 13:
for to s do - 14:
if then - 15:
; - 16:
end if - 17:
; - 18:
end for - 19:
; - 20:
for do - 21:
; - 22:
end for - 23:
end for - 24:
end while - 25:
Output .
|
Theorem 1 guarantees that the algorithm will not fall into a dead cycle for a connected graph. After the algorithm, all nodes are divided into s sets, that is, s communities are obtained. But when the network is disconnected, it is difficult to guarantee. In general, determining whether a network is connected also requires a lot of computation. So, we proposed a refinement for the algorithm.
4.3. Algorithm Refinement
In many cases, community-detection algorithms deal with networks that are not connected. If none of the nodes in a certain connected component is selected as the center of community, the nodes in that connected component cannot be classified into any community. At the same time, the algorithm will be stuck in a dead loop because there are always nodes that have not been classified into communities. In response to this scenario, algorithm augmentation and refinement have been undertaken. The fundamental idea involves recursively decomposing subgraphs not assigned to communities using the same method.
Firstly, the initial graph is subjected to community detection using Algorithm 2. After the number of iterations in Algorithm 2 exceeds the number of nodes, which means the algorithm enters a dead cycle, the algorithm terminates and outputs the set of undivided nodes, denoted as R. Take the nodes in R and edges between nodes to form a subgraph and apply Algorithm 2 for community detection within this subgraph. This process will continue recursively until all nodes are assigned to communities.
4.4. Overall Process
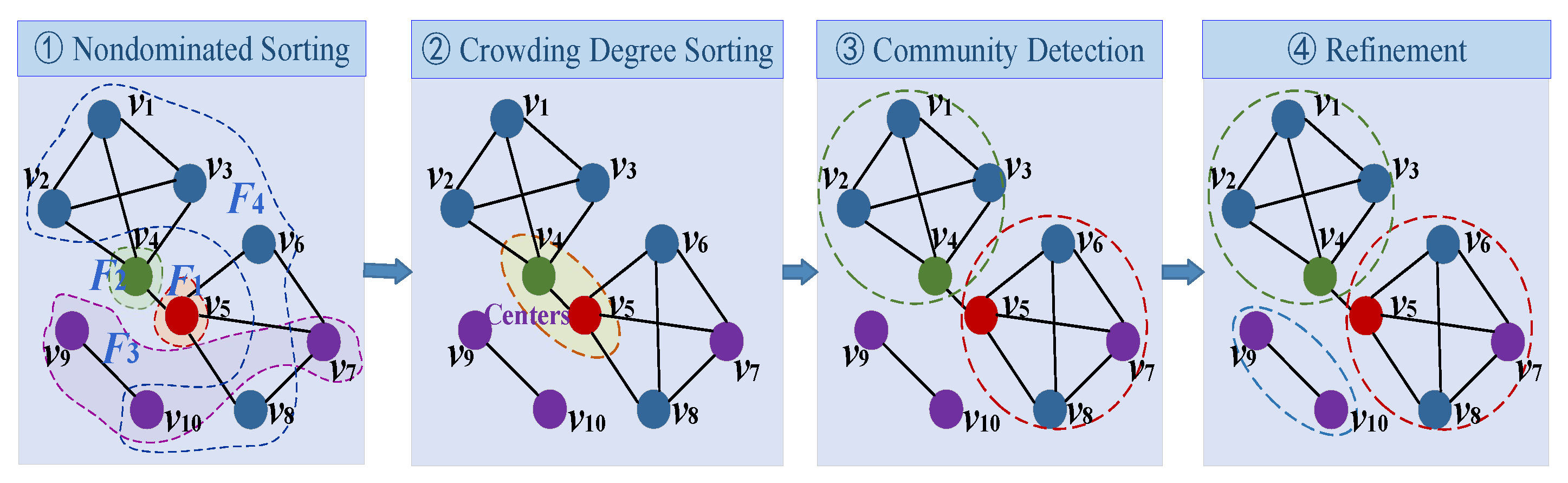
At this point, all the steps of this community-detection algorithm have been designed. The entire algorithm process includes four steps: node influence ranking, community center determination, community division and algorithm refinement. Given this, we denote the method proposed in this paper as the ICDR. The overall process of the proposed method is shown in
Figure 2.
Step 1 divides the nodes in
V into several layers according the influence vector. The influence matrix of the 10 nodes in the mini network shown in
Figure 1 is as follows:
As can be seen from matrix , is a non-dominated node in V. So . After removing from V, the non-dominated node in is . So . Similarly, . If we intend to divide all nodes into four layers, then .
Step 2 determines the community centers by simultaneously considering node influence and crowding degree. First,
is selected as the first center from
. Because
only has one node, then we will consider
. Thus,
is selected as the second center. If we only consider the non-dominated nodes in the first two layers, the selection process of community centers is over. If we consider the third layer of non-dominated nodes,
or
will be selected as the third center. The result in
Figure 1 only considers the first two layers.
Step 3 divides the remaining nodes into various communities in sequence using the labeling algorithm. From
Figure 1, we can see that
and
. However, because nodes
and
are not connected to the other nodes, they will not be assigned to the above two communities.
Step 4 will modify the results if there are nodes that have not been divided into any community. We can see from
Figure 1 that nodes
and
form a subgraph. Applying the same method, these two nodes will be divided into the same community.
In the above example, if we use the first three layers of nodes to determine the community centers, the refinement process will not be used, because we can run the algorithm to partition all nodes at one time.
4.5. Case Study
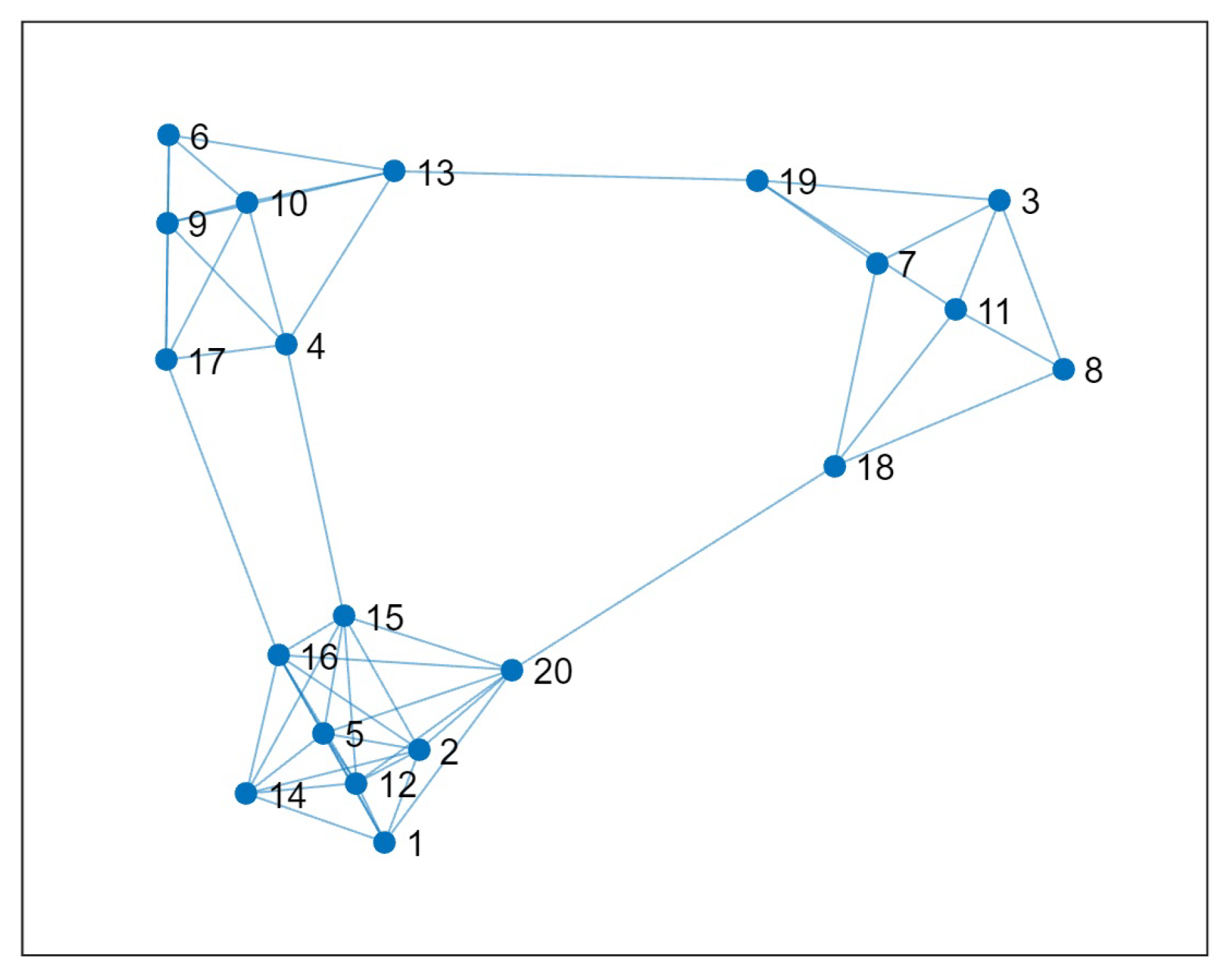
Random networks are also commonly used as test objects to evaluate algorithm performance [
10]. We used a random network to illustrate the implementation process of our method and preliminarily verified its effectiveness. The network is shown in
Figure 3, which contains 20 vertices and has three distinct community structures.
Firstly, using node influence analysis, we can obtain the first layer of non-dominated nodes as
. From
Figure 3, we can see that these three nodes do occupy important positions in the network. Similarly, the second layer of non-dominated nodes is
. The remaining nodes form the third layer
.
Using the selection method of community centers in this paper, we first select node 13 from
as the community center. Since the crowding degree of nodes 16 and 20 is 0.5, we chose one of them as the community center. Suppose that we chose node 20. Next, we will make the selection in the second layer
. Taking into account both node influence and crowding degrees, we ultimately chose node 11 as the third community center. We can see from
Figure 3 that these three nodes are exactly located in different communities, so the selected result is reasonable.
Then, we use labeling algorithms to sequentially partition all vertices into different communities.
Through this example, we can see that using only the nodes in the first layer to select community centers may result in biased results. Neglecting crowded degree can also lead to the consequences of having too many community centers.
6. Conclusions
Community structure is an important feature of complex networks. Mining communities can help analyze the structural features and functions of complex networks, and therefore has important theoretical and practical significance. Although various community-partitioning methods have been proposed, most of them often rely on the selection of seed nodes.
In view of this, this article proposes a complex network community-partitioning method based on node influence analysis. Firstly, this article uses Pareto dominance to divide nodes into several Zeng. Then, we use node influence and crowding to determine the community center. Finally, we use a labeling algorithm to divide the network into several communities. Finally, the method proposed in this article is applied to several practical networks. The comparison results with other methods demonstrate the effectiveness of this method.
Although the proposed method can effectively improve the efficiency and accuracy of community detection, there are also some insufficiencies. Firstly, the determination of some parameters involved in the algorithm still needs to be carefully studied. At present, we mainly rely on experimental analysis to determine these parameters, and have not conducted an in-depth analysis from a theoretical perspective. Secondly, the effectiveness of the proposed method still needs to be promoted and applied in more practical networks in order to comprehensively verify its performance.








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}