1. Introduction
The automation and intelligent control of the entire sintering production process has become a prevailing trend [
1]. The iron-sintering process involves mixing iron ore, fluxes and fuels in specific proportions and adding the appropriate amount of water [
2]. The water content during the sintering process not only significantly affects the quality of the sintered ore but also impacts the production efficiency [
3]. The traditional sintering process primarily relies on manual estimation by employees to control the water injection, leading to high variations in moisture content [
4]. Since the empirical model is influenced by manual operation parameters, it is important to establish a more optimized water-adding volume control model to realize the automation and intelligent control of the water addition process.
In some study on the intelligent control of the sintering process, Li and Gong [
5] proposed an adaptive fuzzy PID control system to address the time lag phenomenon and parameter uncertainty of the sintering process. However, the adaptive fuzzy PID model is sensitive to the selection of fuzzy sets and relies on manual experience. Giri and Roy [
6] introduced a sintering process control system based on genetic algorithms to optimize the parameters of the PID model, but the complexity of the energy balance calculation makes the model challenging to apply. Artificial neural networks have been widely utilized in the field of sintering moisture prediction due to their ability to recognize nonlinear relationships. Cai [
7] proposed a feedforward water addition model based on the least squares method to control the material balance, which can control the moisture content of the mixture during the sintering process; however, under the given mixed ore structure, the water absorption capacity of the mixture and the role of moisture in the granulation effect were ignored. Jiang et al. [
8] proposed a NARX control system based on the combination of offline and online approaches, but there is room for improvement in the prediction accuracy of the model. Ren et al. [
9] utilized the KPCA-GA model based on the BP neural network, which had better prediction accuracy compared to the traditional neural network model. But the model lacks interpretation and numerical prediction, and it is difficult to achieve the precise control of moisture.
In recent years, deep neural network architectures have been gradually applied in various fields, and the LSTM model is widely used in the field of time series prediction. The Transformer model, on the other hand, due to its stronger long-term memory capability and nonlinear mapping advantage, has also been successfully applied to many fields such as image recognition [
10,
11], medical data processing [
12,
13], and text processing [
14,
15], etc. However both models suffer from defects that are difficult to interpret. In 2021, Google proposed an improved Temporal Fusion Transformer (TFT) model [
16], which improves on the Transformer model. The adequate consideration of different types of inputs makes the model more accurate in the prediction of nonlinear relationships, and it utilizes the attention mechanism to make the model interpretable. This paper argues that the symmetry of TFT is reflected in three aspects: time, characteristics and attention. Time series can be divided into past and future parts by symmetry in time because past events affect the occurrence of future events; our hypothesis is that the features in the time series are symmetrical and therefore the same in the choice of encoder and decoder. The symmetry of the self-attention mechanism is understood in this paper to mean that it is possible to focus on both past and future features, and the dependence between such data features can be captured. From this point of view, it can be argued that TFT captures the long-term dependencies between the past and the future in the data, making more accurate predictions, and the same decoder and encoder can reduce the complexity of the model. The advantages of the TFT model for nonlinear systems and the recognition of unexpected events by its attention mechanism make it possible to deal with sintering and water addition processes with transient on–off phenomena.
Therefore, in this study, a real-time prediction and control model for the addition of water to sintering is developed, and the results of the model are interpretable based on the attention mechanism from three perspectives: input characteristics, time, and abnormal working conditions. The main contributions of this paper are as follows:
1. A novel model for predicting sintering water addition parameters is proposed for the intelligent control of water addition in the sintering process, which combines multi-horizon forecasting with interpretability into temporal dynamics and utilizes the gating layers to suppress unnecessary components;
2. Interpretability analyses are conducted for the water addition model to investigate the effects of different materials, time of day, and contingencies on the amount of water added.
2. Sintering and Water Addition Process Mechanism
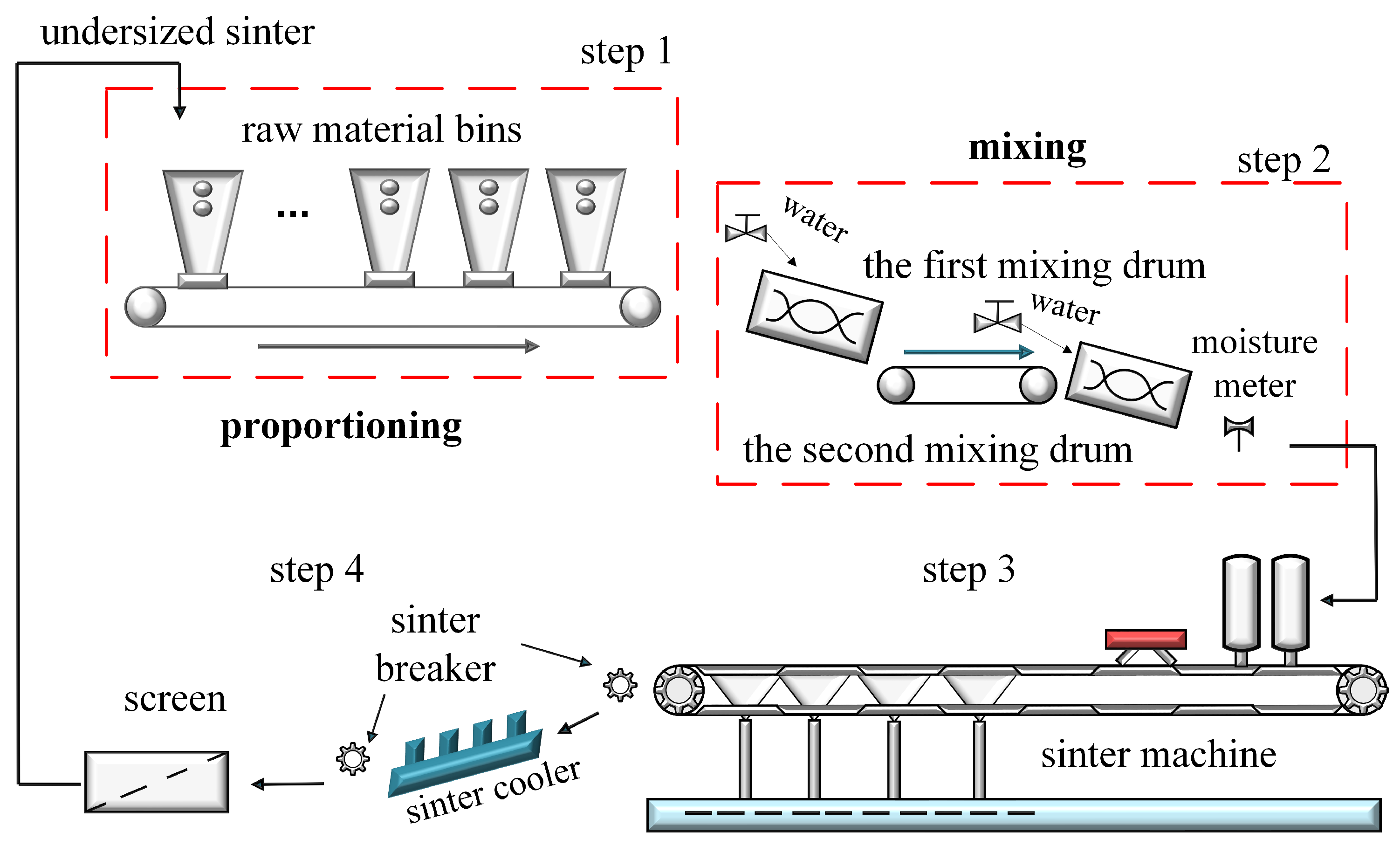
In the sintering process, the model of the actual mixer is shown in
Figure 1. The whole sintering process can be divided into four steps: the first part is the batching, the second part is the mixing, the third part is the ignition high-temperature sintering, and the fourth part is the crushing, screening and cooling of the material. In the first step, various raw materials are placed in different containers, and the required raw materials are taken out in proportion to the conveyor belt under computer control, such as iron ore, dolomite, quicklime, etc. Then, enter the second step, the process can be divided into two mixing steps; this paper will mainly introduce and study this step. In the third step, the mixed raw material continues through the sintering machine for a series of operations, and the sintering process ends when the reaction in the unit reaches the end. In the fourth step, the sintered ore is crushed and sieved according to size and cooled in a cooler. After screening, the qualified sinter is sent to the blast furnace to make iron, while the unqualified part is returned to the batching area of step 1 for the next round of sintering. This paper focuses on the second step of the whole sintering process: mixing.
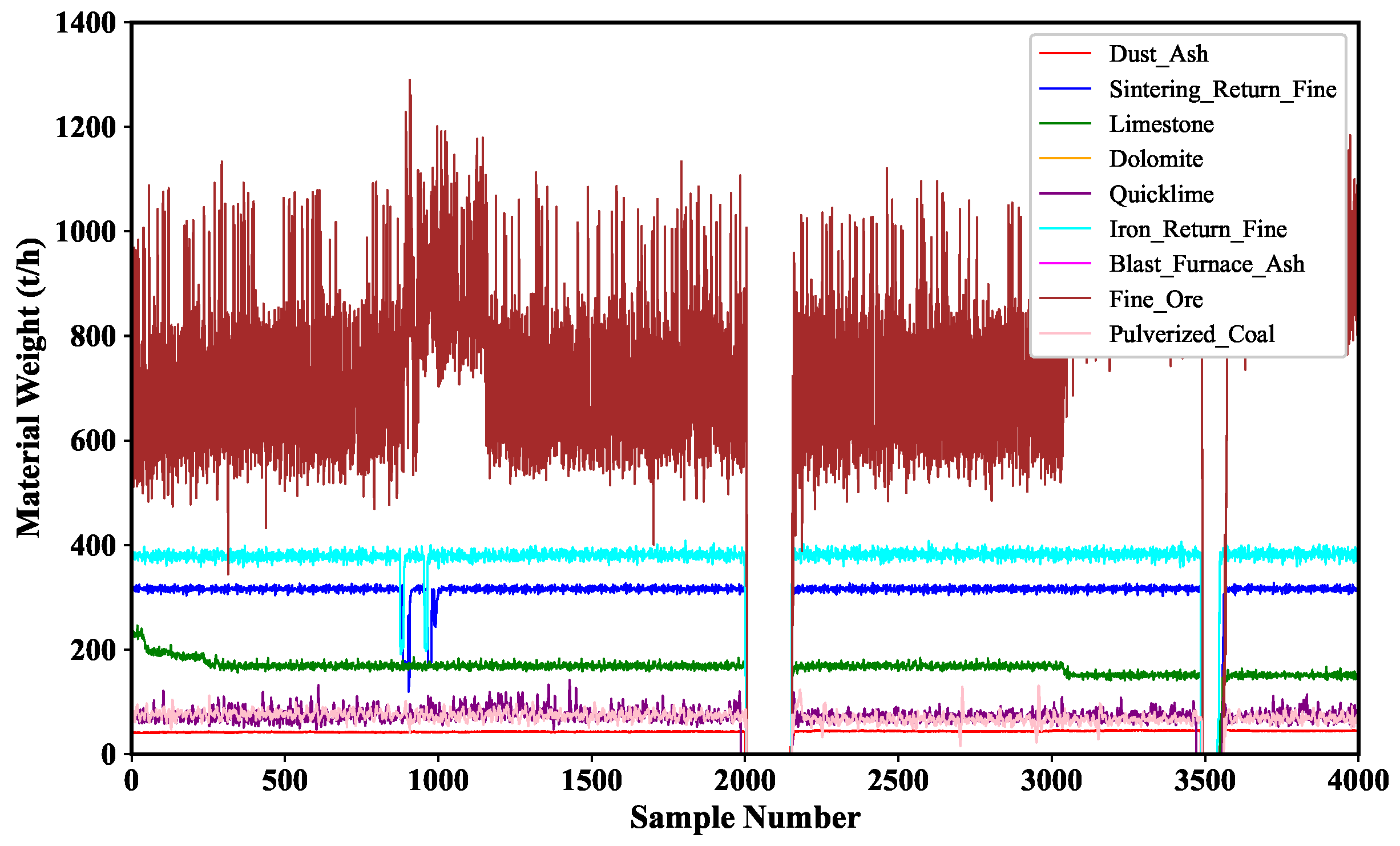
In the second step, there are two mixing drums, and various raw materials are first introduced into the first mixing drum, at which time the inlet valve adds water to the raw material mixture and mixes it fully to form the raw material mixture. The initial addition of materials includes sintered return ore, limestone, quicklime, dolomite, iron ore, etc. The raw materials are then transferred to a second mixing drum for mixing, and the second mixing is for granulation. The inlet valve also adds water to the raw material mixture and mixes it. There is a moisture meter at the end of both mixing drums to measure the moisture content in the mixture. The operator will dynamically adjust the amount of water added in the second inlet valve according to the quantity of raw materials and moisture content measured by the moisture meter so that the moisture content of the mixture coming out of the second mixing drum can reach the standard [
8].
During the sintering process, various materials are introduced into the sintering machine, which then enter the mixer and combine with water to create a raw material mixture. Initially the added materials include sintered ore return, limestone, quicklime, dolomite, iron ore return, etc. After the raw materials are mixed, the water content in the mixture is measured at two points where water is added. At this stage, the worker will adjust the amount of water to be added based on the quantity of material and the moisture content measured by the hydrometer [
8].
The water content of the raw material mixture is theoretically calculated as follows:
where
M represents the water content of the mixture,
denotes the weight of each raw material in the mixture,
and
indicate the weight and water content of the sintered ore,
U signifies the amount of artificially added water, and
represents the water content of the material. The units for
M,
,
and
are
, and the unit for
is %. Therefore, it can be concluded that the quantity of artificially added water should be:
The amount of water added is controlled so that the water content of the mixture meets the optimal demand, and the amount of water added to the mixer at a given moment correlates with the amount added in the previous period. This correlation allows for controlling the water addition in the sintering process based on the previous amount added and the measured material quantity:
The control system for adding water during sintering becomes a complex nonlinear system due to the delay between measuring the material quantity and the actual fabric in the sintering process, and the influence of the raw material water content and moisture measurement values by the ambient temperature and humidity. The main objective of this study is to analyze and predict the complex nonlinear system using the Temporal Fusion Transformers (TFTs).
3. Model Architecture
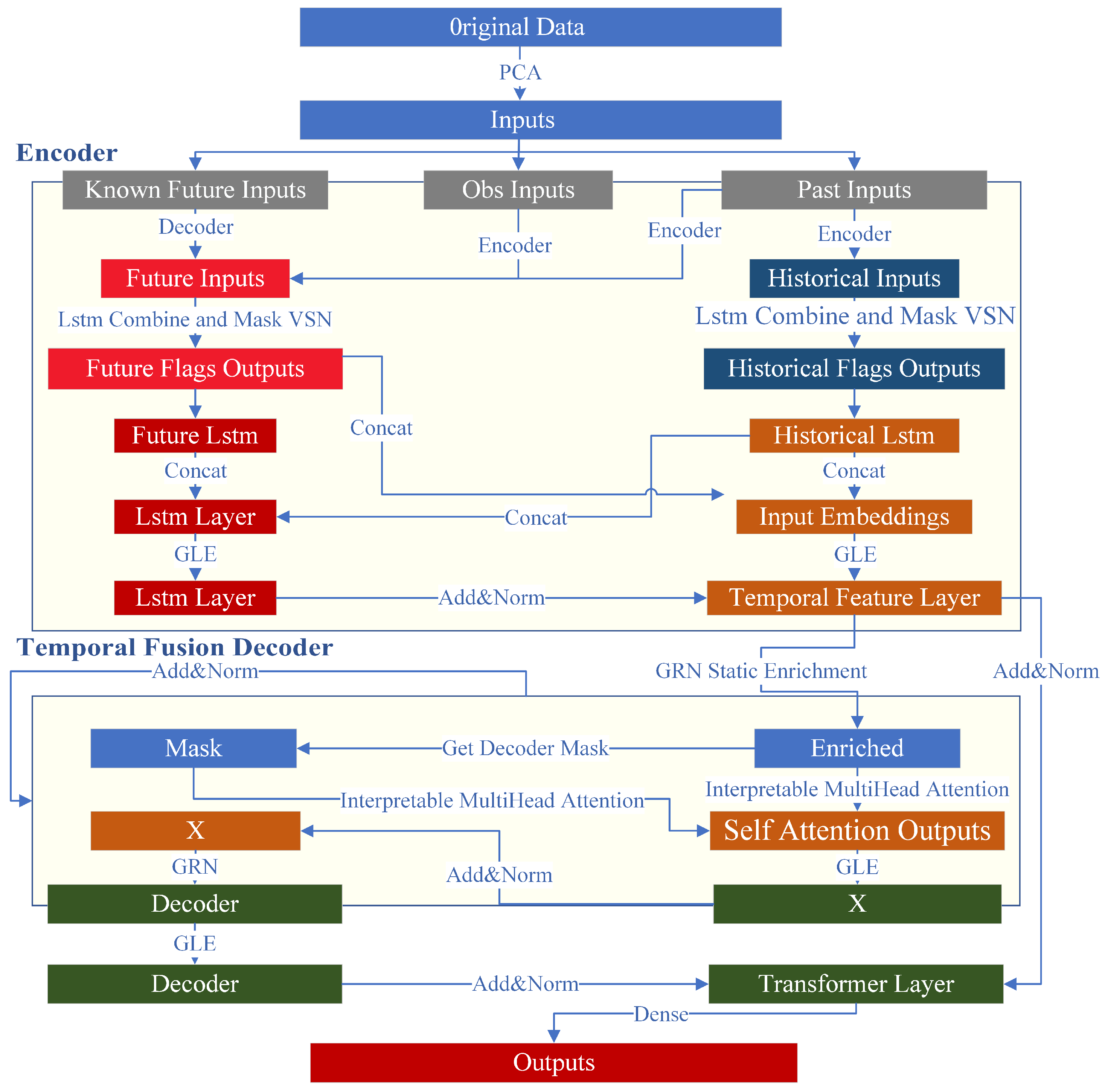
The TFT water addition control model used in this paper is shown in
Figure 2, the model first uses principal component analysis to downscale the features obtained in the sintering process. Subsequently, the features are downscaled into the variable selection network (VSN) to identify the significant features.The model then utilizes LSTM to process temporal information, and the long-term dependency in the processing is analyzed using the multi-head attention mechanism. The Gated Residual Network (GRN) is designed to skip unused components of the architecture in order to manage the depth and complexity of the model. The entire prediction process uses a quantized loss function to calculate the model’s prediction error.
3.1. Gated Residual Networks
The Gated Residual Network (GRN) is primarily utilized to address the challenge of determining the extent of nonlinear processing resulting from the uncertain relationship between exogenous inputs and the target. This allows the model to apply nonlinear processing only when the exogenous inputs are strongly correlated with the target outputs. The GRN uses a group of Gated Linear Units (GLUs) to enable the component gating layer to bypass unnecessary components in the model architecture, thereby controlling model complexity and providing self-adaptation depth.
The formula for GRN is as follows:
ELU is an exponential linear unit activation function that mitigates the “dead zone” issue of Relu when the input is less than 0, making it more robust to input changes or noise. The linear component on the right side also addresses the problem of the vanishing gradient that occurs with the Sigmoid function. The intermediate layers include LayerNorm as the normalization criterion layer, and indicates an indicator of weight sharing.
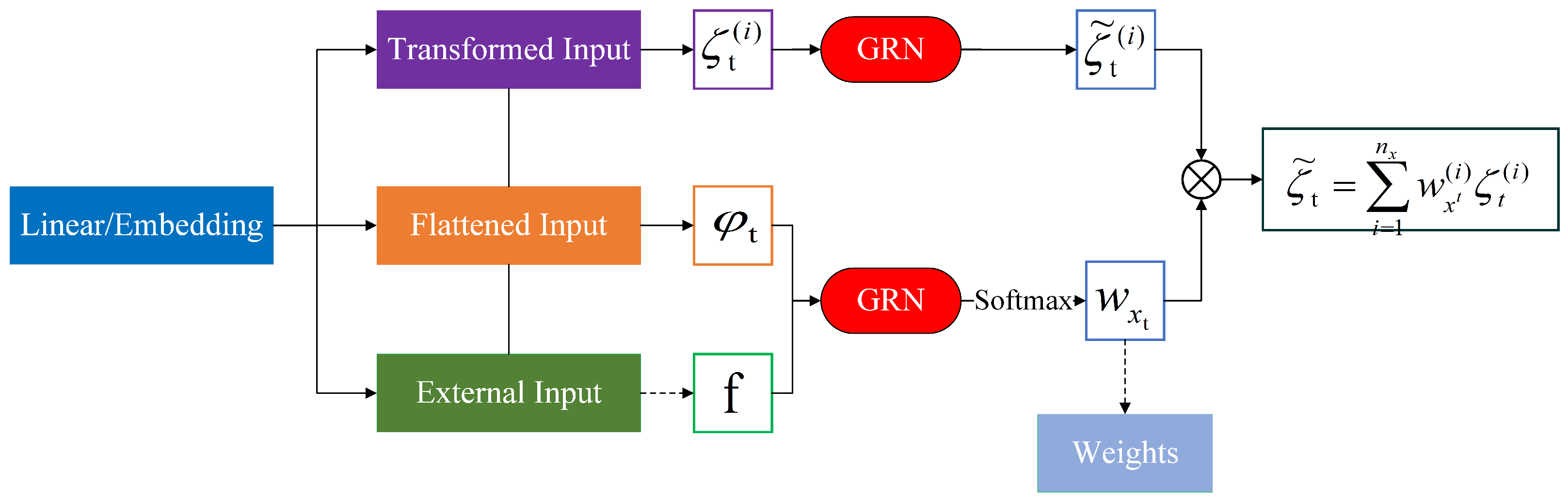
3.2. Variable Selection Network
Most real-time series data contain only a few features directly related to the prediction target, along with time-varying covariates that change with the input features. Variable selection networks (as shown in
Figure 3) analyze the importance of the input variables to the prediction target and eliminate noisy inputs that negatively impact the model’s performance. This process greatly improves the model’s performance by focusing on learning the most significant features using a learning mechanism.
An entity embedding representation is utilized for the categorical variables, while linear transformations are applied to the continuous variables. All input variables are then transformed into d-dimensional vectors to match the subsequent layer inputs. Let
denote the transformed
j-th input variable at time
t. Then,
denotes the vector of all input features at time
t. This vector and the external context vector
c are acted upon by the Gated Residual Network and input to the Softmax function to determine the variable selection weights, and the formula is as follows:
For each time step, the
GRN is used for nonlinear processing with the following equations:
where
denotes the feature vector of variable
j after the action of
GRN, and the weights obtained by each variable through its own
GRN are applicable at all time steps. At the end of the feature selection network, the variable weights will influence their corresponding transformation variables.
3.3. Interpretable Multi-Head Attention
The self-attentive mechanism utilizes its input features and the learnable parameters of the neural network to generate the corresponding query vector
Q, key vector
K, and value vector
V[19]. Where
,
and
, using the normalization function and the scaled dot product as the scoring function, the result of the self-attention is:
The multi-head attention mechanism is designed based on the self-attention mechanism and employs multiple attention heads, each capable of capturing the interaction information of different characteristics. This effectively improves the learning ability of the standard attention mechanism. The model of the multi-head attention mechanism is as follows:
where
m represents the number of attention heads.
To represent feature importance, multiple attention heads were designed to share the value of each attention head instead of each having a different value. The shared value was determined through the additive aggregation of each attention head:
where
represents the shared weight value of the attention head in the multi-head attention mechanism and
is used to realize the linear mapping.
3.4. Temporal Fusion Decoder
3.4.1. Local Enhanced Sequence Layer
The significance of a point in time series data is often determined by the surrounding data, such as the position of variations. Peaks in data have periodic variations. The performance of the attention-based architecture model can be improved by integrating contextual features through pointwise computation. Due to the fluctuating number of past and future feature inputs, it is not feasible to extract local patterns using a filter with a single convolutional layer. The locally enhanced sequence layer can be handled by inputting
into the LSTM encoder and
into the LSTM decoder. This process produces a consistent temporal feature
:
3.4.2. Static Enrichment Layer
The static enrichment layer enhances temporal characterization by utilizing static metadata to reflect the significant impact of static covariates on time-varying characteristics. For example, it can demonstrate how the material moisture content is affected by geographic variation. It is calculated using the formula:
where
n denotes the index of the static metadata, GRN weights are shared across the static enrichment layer, and
corresponds to the context vector of the encoder.
3.4.3. Temporal Self-Attention Layer
The temporal self-attention layer allows the model to capture long-term temporal dependencies by utilizing the multi-attention mechanism on temporal features. It also incorporates the decoder masking principle with a gating layer to ensure that each temporal dimension focuses solely on events occurring before the current time node. The calculation formula is as follows:
where
denotes the separate grouping matrix of the static time features and
.
3.4.4. Position-Wise Feedforward Layer
The positional feedforward layer is similar to the static enrichment layer and serves as a nonlinear transformation of the output from the temporal self-attention layer. Its computational formula is:
At the same time, the TFT model considers the scenario in which the model does not require the application of the temporal fusion transformers. In this case, a gated residual connection is established to bypass the entire fusion transformer module. The model will then be simplified as:
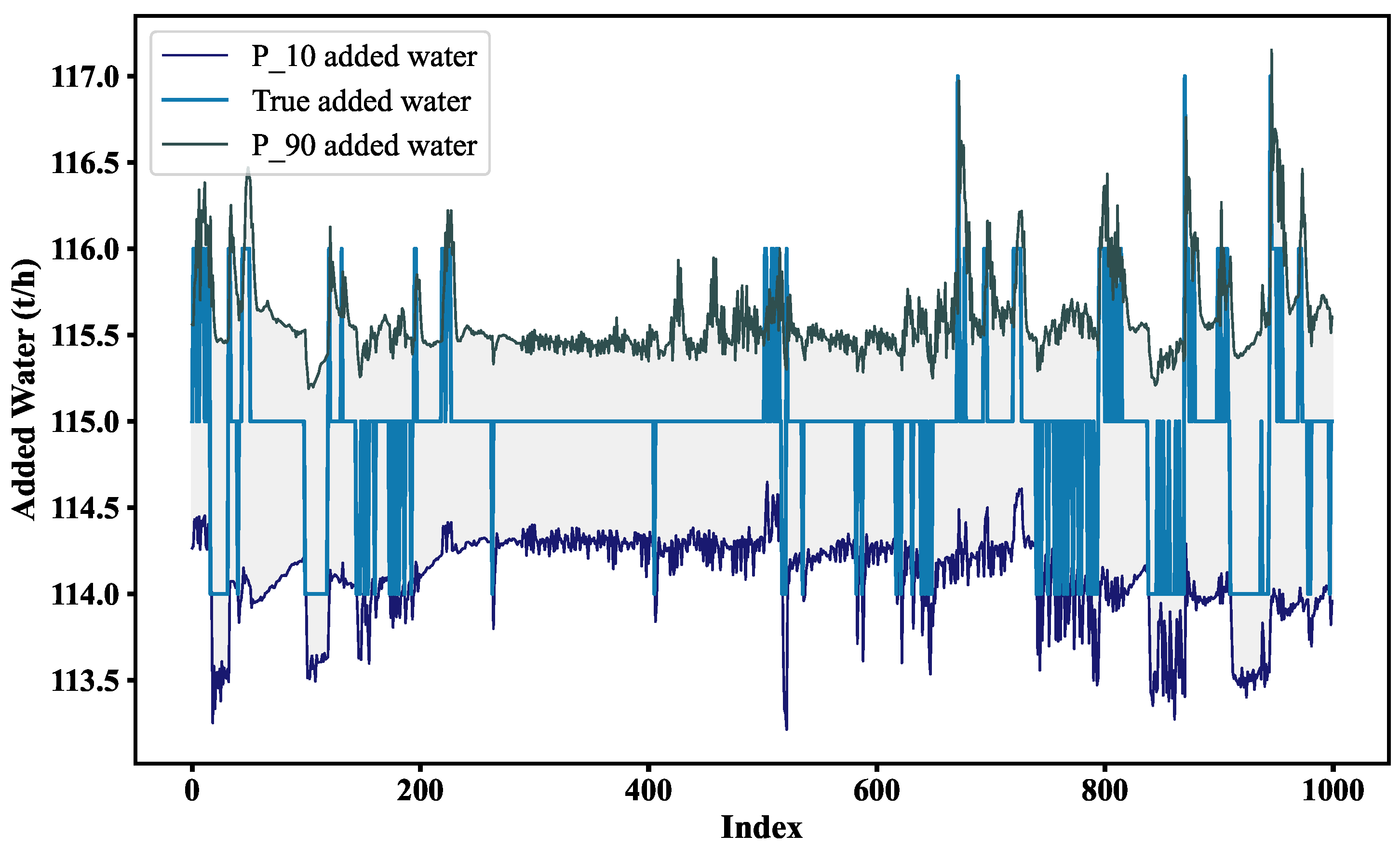
3.5. Quantile Regression Loss Function
The traditional linear regression model applies to the conditional distribution of the dependent variable based on the independent variable X. In real-world applications, the least squares method may be less stable and more prone to instability when the data exhibit a distribution with sharp peaks or thick tails, as well as significant heteroskedasticity.
Compared with the traditional linear regression model, quantile regression offers greater robustness, improved flexibility, and stronger resistance to anomalies in the data. Unlike ordinary least squares regression, quantile regression applies a monotonic transformation to the dependent variable. Additionally, the parameters estimated by quantile regression demonstrate asymptotic excellence under the theory of large samples.
The formula for the loss function kernel in quantile regression is generally as follows:
In a regular MSE, the loss per sample is , whereas here, and are one positive and one negative.


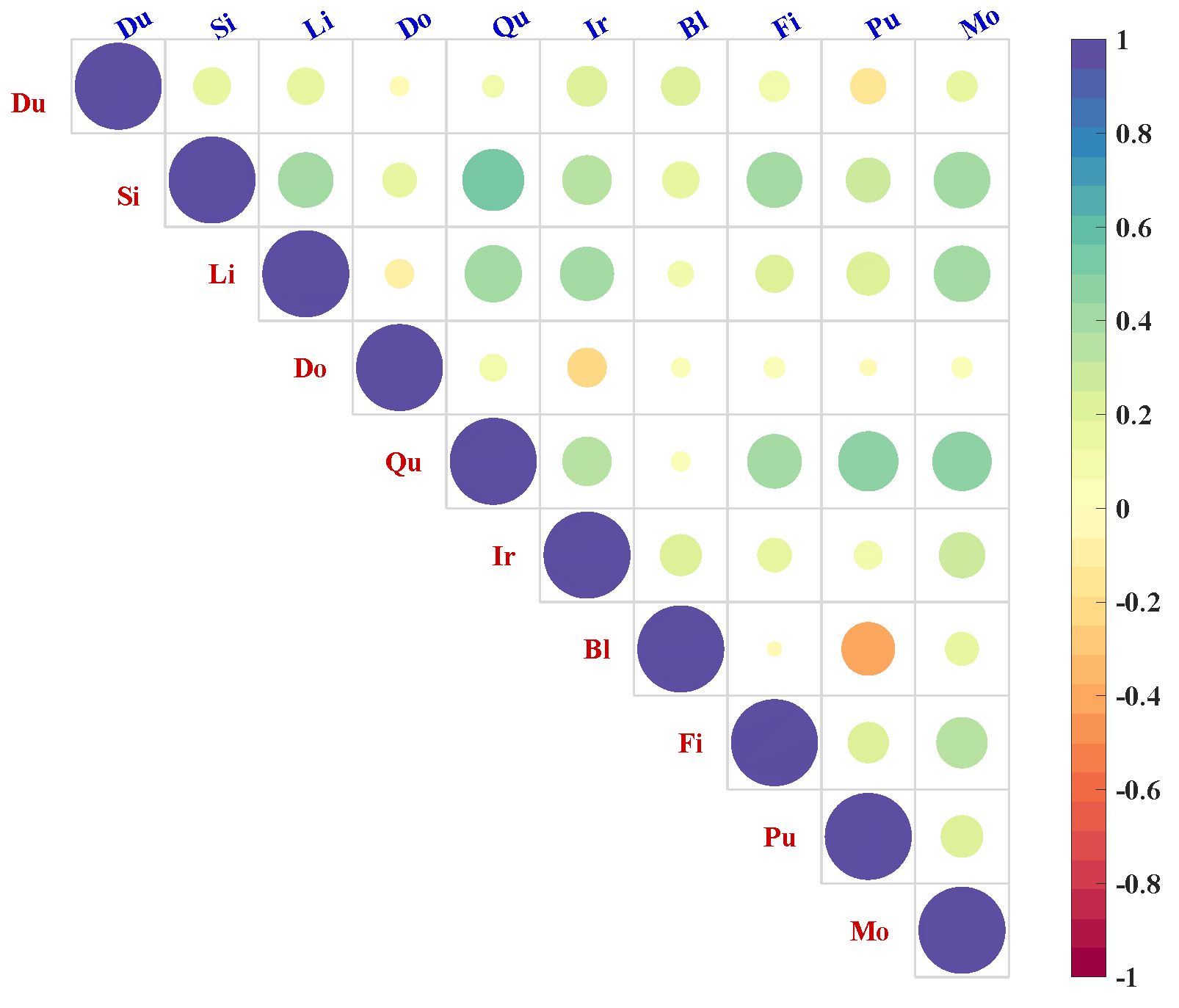
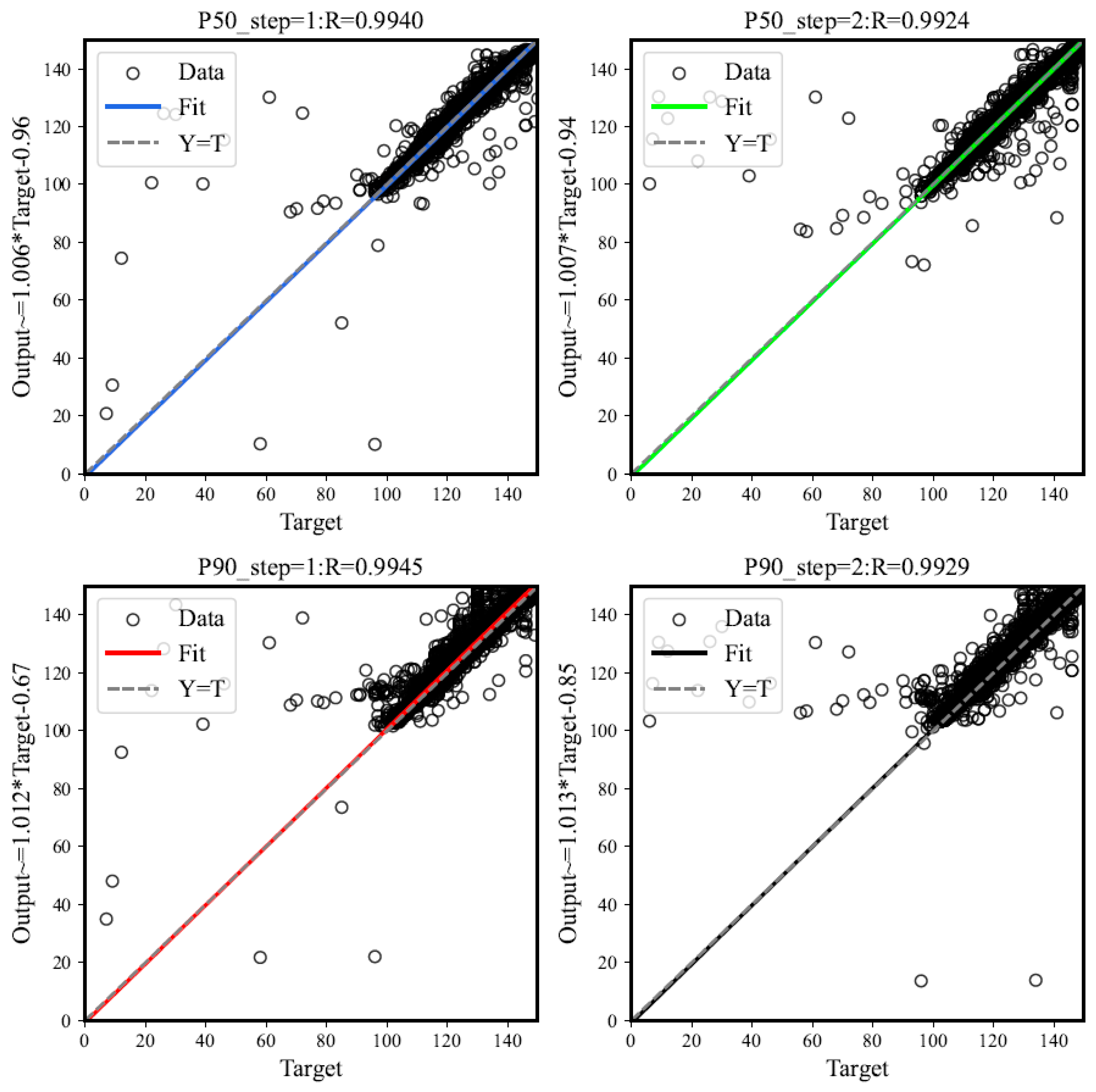



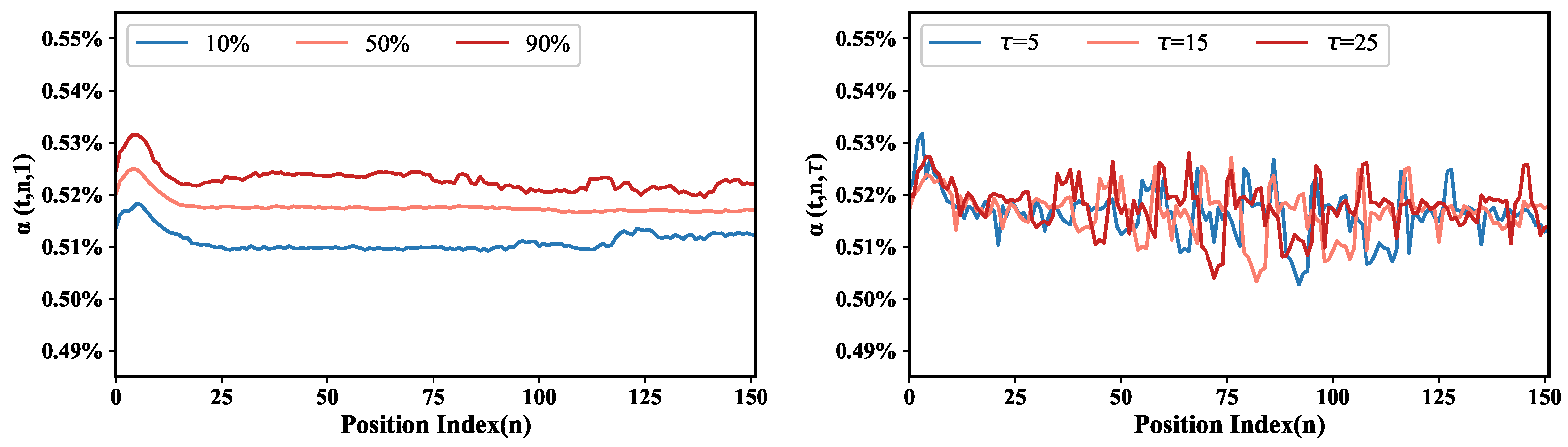
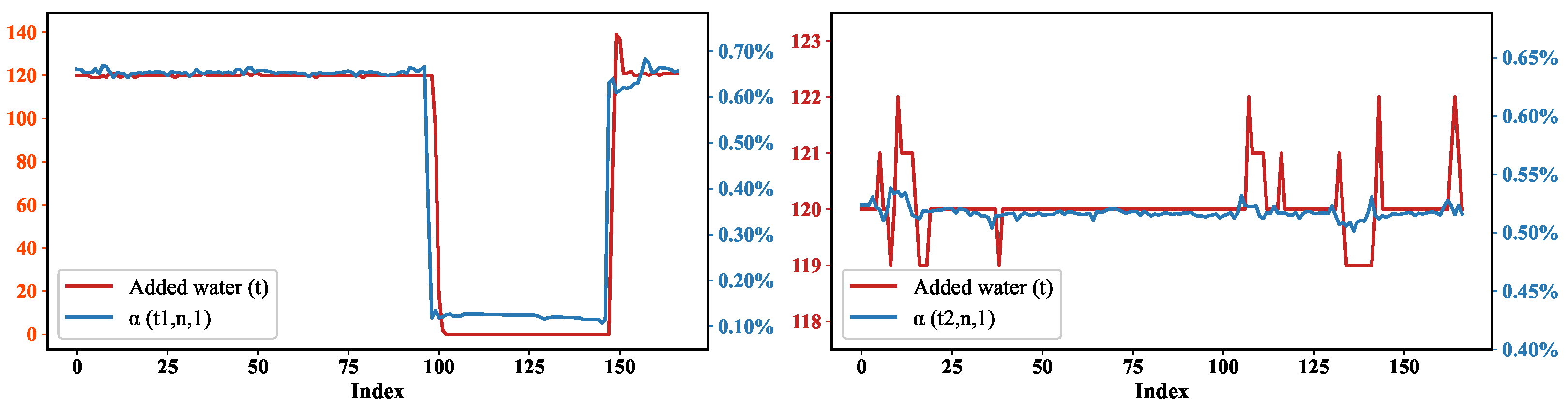

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}