1. Introduction
In recent years, deep neural network (DNN) models have garnered significant success across diverse fields. For instance, within conventional computer domains, like image processing [
1,
2,
3], video processing [
4,
5], and natural language processing [
6,
7], as well as in interdisciplinary applications, such as medical image processing [
8], cross-media retrieval [
9], and pedestrian detection [
10], deep neural networks (DNNs) have consistently exhibited superior performance when compared to traditional methodologies. Nevertheless, the construction, optimization, and training of deep neural networks (DNNs) demand substantial expertise, extensive training data, and considerable computational resources, thereby transforming the resulting trained DNN models into crucial assets. Therefore, the technology of watermarking deep neural network models, commonly referred to as “model watermarking” has arisen. This technique involves the embedding of watermark information signifying copyright into deep neural network (DNN) models to detect and safeguard the copyright of these models.
Model watermarking usually needs to be considered in terms of both usability and security and needs to meet the following four basic requirements: (1) fidelity: the operation of adding a watermark should not affect the classification prediction accuracy of the DNN model; (2) reliability: the watermark should be able to be extracted and verified efficiently; (3) unforgeability: the watermark itself should not be easy to be counterfeited by an attacker, or the attacker can also claim ownership of the model by embedding the watermark into pirated models; (4) robustness: the watermark should not be easy to be removed or destroyed maliciously, and if the attacker tries to take the means to forcibly remove or destroy the watermark in the DNN model, the action will seriously affect the accuracy of the model. These requirements constrain or influence each other. For example, high fidelity reduces the last three requirements to some extent, and enhancing the last three requirements generally degrades the fidelity of the watermark. Higher unforgeability is usually accompanied by higher robustness, so some requirements are positively correlated with others.
Depending on the accessibility of the structure and parameters of a deep neural network (DNN) model, deep neural network model watermarking can be classified into two categories: white-box model watermarking [
11] and black-box model watermarking [
12]. White-box model watermarking refers to embedding watermark information by tuning the parameters of a deep neural network (DNN) model. This method requires the ability to extract watermarking information from known models for copyright verification when needed. Black-box model watermarking employs a backdoor technique [
13,
14,
15,
16] as a means to attain copyright protection for neural network models. This method involves initiating a modification of the pristine input image set, referred to as poisoned operation. Subsequently, the technique endeavors to influence the model throughout the training process to yield a predetermined output for the poisoned input image. The final step involves the detection of a watermark, ascertaining whether the model generates a specific output for the poisoned input image, thereby verifying the copyright ownership of the model. Black-box model watermarking requires no intricate knowledge of the detailed parameters of the deep neural network (DNN) model during watermark verification. Verification can be accomplished solely through the utilization of input and output image pairs. Given its relative simplicity, efficiency, and alignment with the prevalent machine learning as a service (MLaaS) [
17,
18] remote deployment architecture, black-box model watermarking has gained increasing favor within the industry. Consequently, this paper places its emphasis on black-box model watermarking.
Black-box model watermarking employs poisoned training to establish abnormal classification behavior for poisoned images. The crux of this method lies in the construction of poisoned images, with the invisibility of the poisoned image denoting the degree of differentiation from the original clean image. In the existing literature, the construction methods for poisoned images can be categorized into four distinct groups: simple layer superposition, spatial transformation, digital watermarking techniques, and deep network techniques. The initial black-box model watermarking techniques employed in constructing the poisoned image exhibit relative simplicity; however, the alterations made to the original clean image are extensive. This results in an elevated likelihood of detection by human observers, enabling adversaries to produce forgery poisoned images. Subsequently, adversaries may fine-tune the parameters of the protected neural network using these forged poisoned images, thereby escalating the risk of compromising the model watermark. Conversely, the third method, involving minor magnitude modifications, necessitates a heightened level of artificial a priori knowledge, which demands the design of a sophisticated embedding algorithm with superior quality. The fourth method is minimally altered as well, albeit necessitating the training of auxiliary networks, introducing additional computational overhead. Moreover, given the elevated expenses associated with neural network training, it is common for the same neural network to be distributed among various users. Nevertheless, prevailing neural network watermarking methodologies encounter challenges in embedding distinct watermarks for individual users within the same neural network. This limitation hampers the ability to ascertain the specific infringing party in cases of piracy within a multi-user distribution framework for neural networks.
To address these issues, this paper introduces a novel method for black-box model watermarking with a focus on unique identity identification, termed ID model watermarking of neural networks (IDwNet). Specifically, To address the requirements of diverse users in multi-user distribution scenarios for incorporating unique identity information, this paper adopts the user-specific information, referred to as the ID, and utilizes digital watermarking technology to embed it into a designated carrier image. This process is employed to construct a poisoned image. Subsequently, these poisoned images, along with the original unpoisoned and pristine images, are collectively used to train a deep neural network model, thereby achieving the objective of black-box model watermarking. When incorporating the ID, an initial step involves utilizing the digital watermarking technique to construct a poisoned image with robust ID invisibility. Specifically, this process entails subjecting the target image to discrete cosine transform (DCT) and singular value decomposition (SVD). Subsequently, the ID is embedded within the singular values derived from the SVD operation, ensuring a covert integration of the identification information into the image. Then, the singular values are subjected to the symmetrical inverse SVD and DCT to produce a high-quality poisoned image. To address the formidable challenge of inadequate learning of ID features stemming from low ID embedding strength, this study introduces a poisoned adversary image, incorporating incorrect IDs, during the training of the black-box model. This augmentation aims to enhance the capability to effectively differentiate IDs with a variance of 1 bit, thereby achieving more robust copyright distinctions. A myriad of simulation experiments affirms that the methodology advanced in this paper demonstrates outstanding attributes in the realm of black-box model watermarking. Even in the presence of a 1-bit error, the proposed method exhibits flawless differentiation of the ID, showcasing a notable degree of unforgeability, fidelity, and reliability. The accuracy of model watermarking across four diverse datasets—CIFAR-10, GTSRB, CelebA, and Tiny-ImageNet—consistently surpasses 99%, with a marginal reduction in classification accuracy not exceeding 0.5%. Particularly noteworthy is the superior performance of the proposed method compared to comparable optimal methods, such as BadNets, WaNet, and others, especially in terms of the quality of poisoned images, achieving heightened levels of invisibility.
The primary contributions of the black-box model watermarking method proposed in this paper are outlined as follows:
- (1)
The proposition introduces the concept of black-box ID model watermarking, designed to uniquely identify users within the multi-user distribution framework of adapted deep learning models. Furthermore, it provides an implementation framework for black-box model watermarking, enabling precise determination of copyright ownership for a deep network model at a fine granularity;
- (2)
A poisoned image construction method, grounded in digital watermarking technology, has been devised. This method possesses the capability to dynamically adjust the embedding parameters, thereby significantly augmenting the covert nature of the poisoned image. Simultaneously, it effectively maintains a balance between the fidelity and reliability of the black-box model watermark. Additionally, the design of poisoned adversary training facilitates the model in proficiently recognizing the embedded ID. This acquired information can subsequently be effectively utilized to discern the identity of the model owner;
- (3)
By amalgamating the aforementioned strategies, a novel black-box model watermarking scheme is introduced. A multitude of simulation experiments illustrates that the method presented in this paper exhibits commendable indication characteristics and robust security. Notably, its performance surpasses that of the preeminent methods in its category, underscoring the viability and efficacy of the proposed method.
The ensuing sections of this paper are structured as follows:
Section 2 provides a concise introduction to the black-box model watermarking method and delineates the actual threats.
Section 3 expounds upon the black-box model watermarking solution proposed in this paper.
Section 4 presents the experimental results and conducts a thorough analysis. Lastly,
Section 5 concludes the paper.
3. Proposed Method
As delineated in
Section 1, DNN model watermarking must adhere to the criteria of fidelity, reliability, unforgeability, and robustness. Additionally, as expounded in
Section 2, DNN model watermarking must address the challenge posed by the potential disclosure of construction methods. To better meet these requirements and address the associated threats, this paper introduces a novel black-box model watermarking method focused on unique identity markers, termed IDwNet. To attain the distinctive identity of DNN models within the context of multi-user distribution, this study incorporates unique user identifiers, termed IDs, into designated images. These highly concealed poisoned images are generated through the application of a DCT-SVD-based digital watermarking technique. Subsequently, the DNN classification models are trained using both the poisoned images and the original clean images devoid of any embedded watermarks. This process is undertaken to achieve black-box model watermarking. In the training process of the IDwNet model, an adversary training strategy is additionally incorporated. Specifically, alongside the input of clean images and correct ID poisoned images, adversary poisoned images containing incorrect IDs are introduced. This augmentation aims to diminish the likelihood of misidentifying other incorrect IDs as the correct ID. In this paper, we leverage digital watermarking technology to seamlessly embed ID within poisoned images, ensuring the highlighted visual quality of constructed images. This method enhances the difficulty for adversaries to discern the construction methodology of the poisoned images through visual inspection, thereby bolstering their inherent unforgeability. To strike a delicate balance between fidelity and reliability, we adeptly adjust the embedding strength of the watermarking information and the poisoned rate. Moreover, we employ a poisoned training strategy grounded in adversary training to attain black-box model watermarks. This comprehensive methodology ensures that our method achieves high fidelity, reliability, non-falsifiability, and robustness. It is particularly adept at countering the threats posed by model leakage and copyright ambiguity, attributes stemming from the superior invisibility of high-quality poisoned images. Importantly, the unique identification of the user’s identity ID within the embedded watermark enables the retrospective examination of the deep neural network model in a multi-user distribution context.
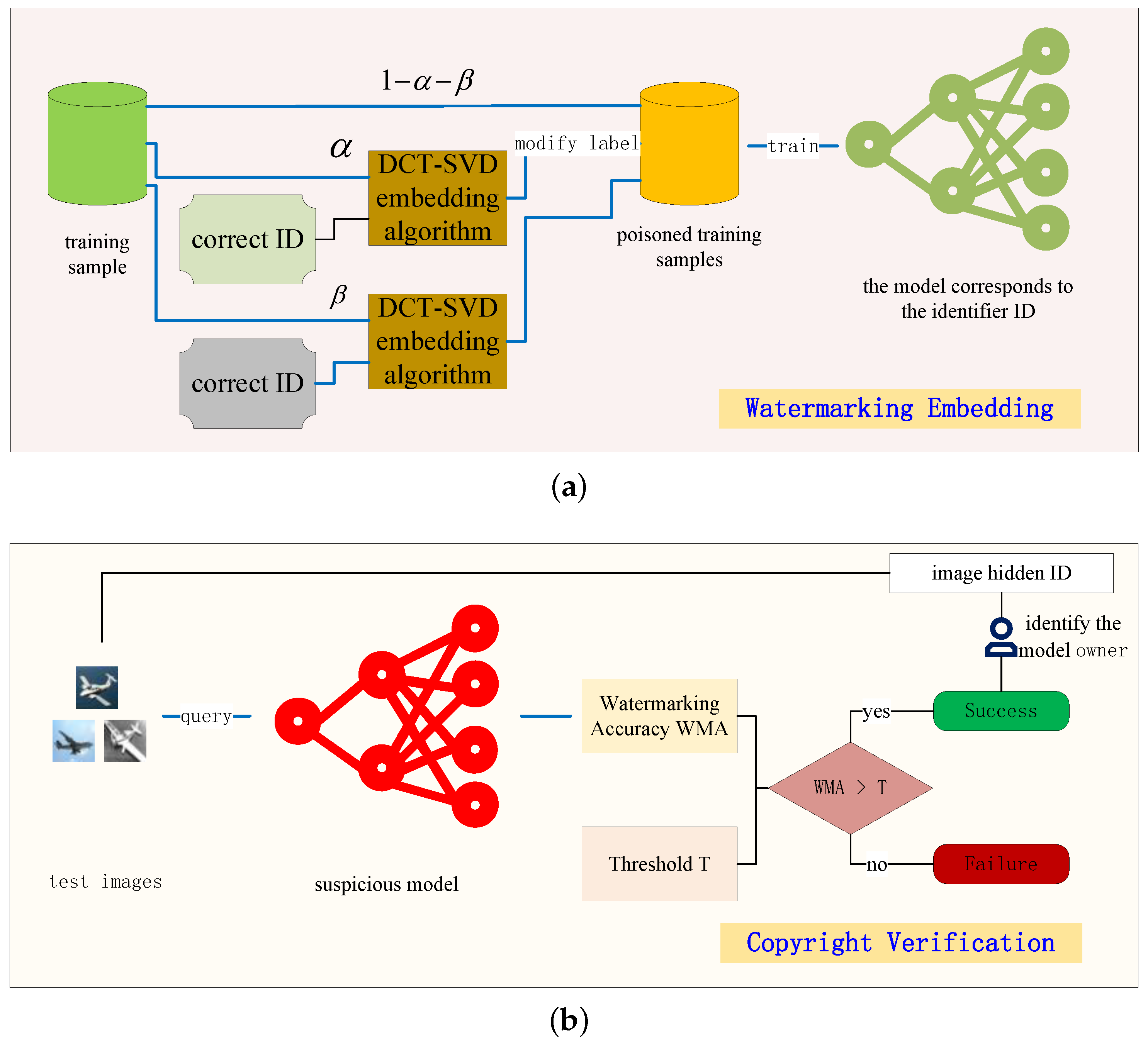
Figure 1a illustrates the IDwNet method proposed in this study. Allow the poisoned rate, denoted as
, to represent the proportion of the total training images utilized for constructing poisoned images containing the correct ID. Similarly, designate the poisoned adversary rate as
, indicating the proportion of the total training images employed for constructing poisoned adversary images containing alternative incorrect IDs. Subsequently, in the training phase, the clean images, constituting a proportion (1−
−
) of the total training dataset, are directly fed into the classification model by the deep neural network (DNN), analogous to the initial source of the first path depicted in
Figure 1a. Simultaneously, images representing the proportion
of the total training dataset are generated using the DCT-SVD-based poisoned image construction method proposed in this work. The classification labels of these images are modified to the target labels y. The resulting image is then input into the classification model, serving as the second image source in
Figure 1a. Moreover, poisoned adversary images depicting a fraction
of the entire training dataset are generated by embedding incorrect IDs, such as random information, which are then introduced as the third image source in
Figure 1a into the classification model. The classification model processes all the image sources, and the cross-entropy serves as the loss function to facilitate the backpropagation of gradients for optimizing the model parameters.
The watermark copyright verification method proposed for IDwNet in this paper is illustrated in
Figure 1b. Specifically, poisoned images are fed into the classification model for testing. If a consecutive input of a certain number of poisoned images results in the watermark verification accuracy of the classification module surpassing a predetermined threshold (T), the model’s watermark can be authenticated. Consequently, the corresponding copyright owner of the model can be traced as the unique user associated with the ID embedded in the poisoned image. During the copyright verification process, poisoned images with distinct IDs are introduced to the model. Only the poisoned image with the correct ID triggers a watermark response, enabling the determination that the model pertains to the user possessing that specific ID.
Section 3.1 commences by delineating black-box model watermarking for unique identifiers as a constrained optimization problem. Subsequently,
Section 3.2 elucidates the construction methodology of the poisoned image, while
Section 3.3 expounds on the learning method for model parameters grounded in adversary training.
3.1. Problem Formulation
For a conventional supervised classification task, the objective is to learn a mapping function
, where X represents the input domain and
C is the set of target classes. The learning process involves acquiring the parameter
from the training dataset, from which the optimal parameter
is determined. The standard learning method involves training the classifier
concurrently with both clean and poisoned images. Consider a clean training sample
, which is subjected to transformation into a poisoned sample (
) by the poisoned image constructor T, where
denotes a predefined label for the purpose of poisoned image classification. Subsequently, the training of the function
based on both clean and poisoned samples can be defined as:
Utilizing Equation (
1), the poisoned image constructor T transforms a clean image
x into a poisoned image
. Subsequently, the black-box model
classifies
into a specific label
, while categorizing the clean image
x into the normal category.
In this paper, we aim to enhance the capability of the constructed poisoned image to discern the specific model owner by utilizing the black-box watermarking model. To achieve this objective, drawing inspiration from contemporary digital watermarking techniques, this paper distinctly designates the watermark information as the unique identity’s ID. Subsequently, poisoned images are constructed using a function
based on digital watermarking techniques and then are used for the train of the black-box watermarking model denoted as
. The aim is to ensure that the black-box watermarking model classifies only the image embedded with the correct ID into the predetermined error-specific class. Simultaneously, images embedded with other incorrect IDs that do not match the correct ID are incapable of triggering the model’s specific misclassification, and these images are appropriately classified into regular classes. Hence, the black-box watermarking model focused on unique ID in this paper can be defined as:
where the function
is introduced in
Section 3.2 below, and the training methodology for
is delineated in
Section 3.3.
3.2. Poisoned Image Construction Method
To address the potential risk of disclosure of the construction method outlined in
Section 2.2, the trigger embedded within a clean image must possess a high degree of visual invisibility. To achieve this objective, this study employs digital watermarking techniques characterized by excellent invisibility to facilitate the embedding of triggers within clean images. In particular, considering that the primary energy in the data block is encapsulated within the low-frequency coefficients of the DCT, embedding the ID that identifies the user in the low-frequency component does not induce significant alterations in the image. Moreover, the information can be uniformly diffused across the entire image through the inverse DCT, facilitating the assimilation of trigger features during the learning process. Furthermore, the initial higher values of the singular value, denoted as S, acquired post the SVD, encapsulate the primary information of the data preceding the SVD transformation. Consequently, alterations to these larger S values do not induce substantial modifications to the core content. To achieve optimal invisibility and facilitate the learning of trigger features, this study proposes a watermark information embedding algorithm grounded in discrete cosine transform-singular value decomposition (DCT-SVD). This algorithm serves as a constructor denoted as E for generating high-quality poisoned images.
The poisoned image construction method based on DCT-SVD is outlined as follows: Initially, the pristine RGB image undergoes conversion into a YUV image. Subsequently, the channel chosen for embedding watermark information, such as the Y channel, is selected, and this channel undergoes a blocking process. Following this, blocks are systematically chosen circularly for the embedding of watermark information. For each chosen block, a sequential transformation involves the application of DCT followed by SVD. Subsequently, the watermark information is incorporated into the largest singular value obtained. Finally, the RGB poisoned image, enriched with the embedded watermark information, is derived through processes such as inverse SVD, inverse DCT, block amalgamation, and the conversion of the YUV image to an RGB image. The embedded watermark information in this context refers to the previously mentioned unique user’s identification information, commonly denoted as an ID or trigger. The detailed algorithm for constructing the poisoned image is elucidated in Algorithm 1.
| Algorithm 1: Poisoned image construction method |
![Symmetry 16 00299 i001]() |
3.3. Poisoned Adversary Training
The poisoned image construction method based on DCT-SVD, as proposed in
Section 3.2, aims to create a poisoned image with superior visual invisibility. However, the stringent constraint on visual invisibility imposes a limitation on the embedding strength of the ID employed as a trigger. This reduced embedding strength complicates the learning process for the deep neural network (DNN) model during training, posing challenges in realizing the functionality of a black-box model watermarking. To address this formidable challenge, this study introduces an adversary training strategy. Concretely, the proposed method incorporates poisoned adversary images containing incorrect IDs into the training dataset. This enables the classification model to undergo simultaneous training and optimization on clean, poisoned and poisoned adversary images. In this scenario, the construction of the poisoned adversary image follows the same procedure as the poisoned image, with the distinction that the embedded information, denoted as
, differs from the correct
. It is crucial to emphasize that the poisoned adversary image does not alter the classification label of the image. This is because the poisoned adversary image should not elicit a response from the watermark or possess a distinct anomaly classification. Introducing a new specific anomaly classification would result in the model having two model watermarks associated with different purpose labels. Therefore, in this paper, the label of the poisoned adversary image remains unchanged, and the model classifies the poisoned adversary image normally during prediction.
Let the length of the binary sequence ID be . Consequently, there exists a total of sequences of information. Among these, one sequence represents the watermarked message m, which signifies the correct ID to be embedded. The remaining sequences encompass all other information represented as incorrect ID that may introduce interference. These alternative sequences, denoted as , are utilized to generate the poisoned adversary image. The collective term for the generated poisoned adversary images is . Subsequently, within each training iteration, batches of training samples undergo processing, wherein a subset of the training samples is transformed into poisoned samples and poisoned adversary samples, respectively. The modified training samples are then utilized for model training. The detailed procedural steps of the network training process are delineated in Algorithm 2.
Throughout adversary training, this study treats the classification performance of clean images, poisoned images, and poisoned adversary images as peer-to-peer performances. Subsequently, it gauges the performance in each of these three aspects using the cross-entropy loss function, incorporating them into a total loss function to guide the backpropagation process. Therefore, this paper proposes the following loss function:
where
K,
P, and
Q are the number of the clean, poisoned, and poisoned adversary images, respectively;
is the cross-entropy loss function.
By concurrently inputting a clean image, a poisoned image, and a poisoned adversary image, and employing the loss function outlined in Equation (
3), this paper introduces the adversary training strategy. This strategy aims to facilitate the effective learning of poisoned features, enabling robust copyright discrimination capabilities for black-box model watermarking. The experimental simulation results in
Section 4 demonstrate the efficacy of this method, showcasing its ability to discern copyright even in cases where there is merely a 1-bit difference from the correct ID.
| Algorithm 2: Poisoned adversary training algorithm |
![Symmetry 16 00299 i002]() |
4. Experiments and Analysis
This section evaluates the performance of IDwNet, a black-box classification model neural network watermarking method for unique identity labeling proposed in this paper. The following
Section 4.1 first gives the experimental setup, followed by ablation of the important parameters of the experiment in
Section 4.2, then an evaluation of the effectiveness of IDwNet is given in
Section 4.3, followed by an evaluation of the unique identity marking effect in
Section 4.4, and, finally, evaluating the invisibility of the poisoned image in
Section 4.5.
4.1. Experimental Setup
In the experimental simulation, this paper employs four datasets widely recognized in the realm of black-box model watermarking research: CIFAR-10 [
31], GTSRB [
32], CelebA [
24], and Tiny-ImageNet [
33]. The datasets utilized in the experimental simulations are succinctly summarized and presented in
Table 1.
For the aforementioned diverse datasets, this study adheres to the conventional method of black-box model watermarking, employing the consistent ResNet-18 classification model [
1]. Additionally, to assess the watermarking efficacy across various classification models on a shared dataset, VGG16 [
34], MobileNetV2 [
35], DenseNet [
36], and ResNeXt [
37] are also employed on the CIFAR-10 dataset. The detailed parameters of the experimental equipment are shown in
Table 2.
In the process of constructing the poisoned image, a longer embedded ID length facilitates easier verification and tracing of model copyright, albeit at the expense of reduced covertness in the poisoned image. Longer IDs necessitate a greater number of poisoned confrontation images, thereby significantly impacting the model’s fidelity. To strike a balance in the experimental simulation, this paper adopts a compromise solution by setting the ID sequence length to ; similar considerations can be applied to other lengths.
To assess the performance of the IDwNet algorithm proposed in this study, its performance is juxtaposed against that of the foremost black-box model watermarking methodologies, namely Patch(BadNets) [
15], Blend [
16], SIG [
19], and WaNet [
21].
For performance evaluation, this study employs several metrics, including the peak signal-to-noise ratio (PSNR), structural similarity (SSIM), watermark accuracy (WMA), and benign accuracy (BA). PSNR and SSIM serve as indicators to assess the similarity between the poisoned image and the original clean image, providing insights into the invisibility level of the ID as a trigger. A higher value in these metrics signifies superior invisibility. WMA quantifies the percentage of poisoned images correctly classified with the target labels, reflecting the reliability of the model watermark. On the other hand, BA measures the classification accuracy of the clean image, representing the accuracy of the model on its original classification task, offering insights into the model watermarking’s fidelity.
4.2. Parameter Optimization
To scrutinize the impact of hyperparameters on the algorithm’s performance as presented in this paper, this section conducts pertinent ablation experiments. Initially, we assess the influence of the poisoned rate on the algorithm’s performance. Subsequently, we examine the effect of varying embedding strengths on performance, followed by an evaluation of the algorithm’s performance under different block sizes.
4.2.1. Effect of Poisoned Rate on Performance
As delineated in
Section 3.1, the poisoned rate (
) represents the proportion of constructing the set of poisoned images, specifically denoting the ratio of poisoned images to the overall training images. A higher value of
signifies a greater number of poisoned images, thereby fostering an enhancement in the training efficacy and overall performance of IDwNet. In the context of our experimental simulations, we set
to the following ratios: 0.1, 0.2, 0.3, 0.4, and 0.5. A larger poisoned adversary rate (
) value is conducive to the training efficacy and performance of IDwNet; however, it deviates further from reflecting the real-world scenario. In our experimental simulations, we fix
at 0.1 for consistency and controlled analysis. Simulation experiments were conducted utilizing the CIFAR-10 dataset and the ResNet-18 network model to assess the performance of IDwNet in terms of BA and WMA across varying poisoned rates. The outcomes of these experiments are illustrated in
Figure 2.
As depicted in the figure, both BA and WMA performances exhibit high values, even when is small. This observation suggests that the model adeptly assimilates the features of the correct IDs employed as triggers in the poisoned image, underscoring the efficacy of the poisoned image construction method proposed in this paper. As increases, WMA gradually enlarges, whereas BA experiences a diminishing trend. Within the range of 0.2 to 0.5, the disparity in WMA values is minimal. To strike a balance between the significance of BA and WMA, considering practical feasibility, the poisoned rate was set to 0.4 in this experiment.
4.2.2. Effect of Embedding Strength on Performance
To systematically investigate the impact of different watermark information embedding strengths on performance, the experimental simulation employs the CIFAR-10 dataset and the ResNet-18 classification network model and configures various combinations of embedding strengths. The (strength_Y, strength_U, strength_V) ternary group is utilized to denote the corresponding watermark information embedding strengths for the Y, U, and V channels. It is worth noting that a channel’s embedding strength being 0 implies no information embedding for that specific channel. The evaluation encompasses metrics such as BA, WMA, PSNR, and SSIM for these diverse combinations.
Table 3 provides a comprehensive summary of the experimental results pertaining to the scenario where only one channel (i.e., Y, U, or V channel) is considered for embedding.
As depicted in
Table 3, in the case of single-channel embedding, both BA and WMA exhibit suboptimal performance when the intensity is low, despite high values for PSNR and SSIM. This phenomenon arises due to the heightened similarity between the poisoned image and the original clean image at lower embedding intensities, resulting in elevated PSNR and SSIM values. However, the challenge lies in the difficulty of capturing the features of the correct ID concealed within the poisoned image, leading to unsatisfactory performance in terms of model watermarking. Conversely, with an escalation in the embedding strength, PSNR and SSIM gradually decrease, accompanied by significant increases in both BA and WMA. Furthermore, it is noteworthy that modifications to the Y channel exert the most substantial influence on image quality, followed by the U channel, and, finally, the V channel. Given equivalent image quality, the V-channel modification can accommodate a higher embedding intensity, thereby enhancing the performance of both BA and WMA.
Additionally, this study investigates the impact of simultaneously embedding multiple channels; the findings are presented in
Table 4. As evident from the table, the influence of embedding strength on performance, when multiple channels are embedded, mirrors that observed in the single-channel embedding scenario. Specifically, a stronger embedding strength corresponds to a diminished quality of the poisoned image and an enhanced performance of the model watermark. However, it is noteworthy that the simultaneous embedding of multiple channels with equivalent image quality does not outperform the single-channel embedding case. This observation stems from the fact that, in digital watermarking research, achievement is primarily facilitated through prior knowledge and manual algorithm design. Embedding through multiple channels serves to decrease the bit error rate (BER) of the watermark extraction algorithm. Conversely, in black-box model watermarking research, the recognition of images is predominantly achieved through poisoned features extracted by the network model. If embedded in multiple channels with varying strengths, there is an increased likelihood of the model encountering a relatively complex triggering mechanism. This complexity is not conducive to the accurate learning and classification of the model, resulting in a degradation of the model watermarking performance.
By integrating the findings presented in
Table 3 and
Table 4, one can conclude that the fidelity and reliability of the model watermark can be well balanced by dynamically adjusting the embedding strength. In more detail, decreasing the embedding strength makes it difficult for the watermarked neural network to recognize the poisoned images, resulting in a worse WMA and, thus, degrading the reliability at the same fidelity. Otherwise, increasing the embedding strength lets the watermarked neural network better validate the model watermark at the cost of a small reduction in the original classification task, leading to a higher WMA with the degraded BA.
To strike a balance between model watermarking performance and the quality of the poisoned image, this experiment selectively employs embedding solely within the V channel. The embedding intensity for this channel is established at a value of 40.
4.2.3. Effect of Block Size on Performance
To investigate the impact of various block sizes on the performance of IDwNet during DCT, experimental simulations were conducted utilizing the CIFAR-10 dataset and the ResNet-18 classification network model, and block sizes were configured with four typical combinations: (1, 1), (2, 2), (4, 4), and (8, 8), where (x, y) denotes the block size in the horizontal and vertical directions. Subsequently, the embedding strength was adjusted to achieve comparable image quality for these combinations. The performance of BA and WMA under these configurations was evaluated, and the time required to construct the poisoned image from all test images in the CIFAR-10 dataset was calculated.
Table 5 summarizes the corresponding experimental results.
As depicted in
Table 5, the performance of the BA model exhibits suboptimal results when dealing with smaller or larger blocks. This is attributed to the fixed convolution kernel size of 3 in the model, where excessively small or large blocks pose challenges for the model to effectively capture the features of the correct ID within the poisoned image. Consequently, this negatively impacts the performance of the proposed IDwNet model presented in this paper. Furthermore, with an increase in block size, a higher number of blocks necessitates embedding, consequently elongating the time required for constructing the poisoned image. However, the larger block size also facilitates increased information embedding within the same block. To strike a more favorable balance between model performance, poisoned image construction time, and ID length, this study adopts a (4, 4) setting for the DCT block size.
4.3. Validity of Black-Box Model Watermarking
To assess the validity, specifically the BA and WMA performance, of the model watermarking proposed in this paper, this section conducts a comparative analysis. The evaluation involves the clean classification model without embedded model watermarking, the block-based black-box model watermarking method Patch [
15], the image-mixing-based black-box model watermarking method Blend [
16], the sinusoidal stripe-based black-box model watermarking method SIG [
19], the spatial distortion-based black-box model watermarking method WaNet [
21], and the black-box model watermarking method IDwNet introduced in this paper. For the experimental simulations, these six models are utilized with identical depth classification models and poisoned rates. The BA and WMA performance of each scheme is then systematically compared. The embedding strength is set to (0, 0, 40), and the poisoned rate
is set to 0.4. Additionally, the poisoned adversary rate
for IDwNet is set to 0.1, while for the other schemes, the poisoned adversary rate beta is set to 0, as these methods do not employ the poisoned adversary strategy. The experimental simulation results are presented in
Table 6, and it is noteworthy that the deep classification model employed is consistent with ResNet-18, as detailed in
Section 4.1.
As indicated in
Table 6, the model demonstrates an aptitude for learning the poisoned features of IDwNet even when the disparity between the poisoned image and the original clean image is minimal. This proficiency is primarily attributed to the poisoned adversary training strategy employed in this study. Moreover, IDwNet embeds the ID into the DCT-SVD decomposition coefficients of the original clean image, which can diffuse the ID information to the whole image and, thus, facilitate the DNN model to learn the features of the correct ID used as a trigger in model training. For the datasets CIFAR-10 and Tiny-Imagenet, the BA of the proposed method surpasses that of WaNet, with a slightly lower WMA; in contrast, for the GTSRB dataset, both the BA and WMA of the proposed method are inferior to those of WaNet. However, concerning the CelebA dataset, the WMA of the proposed method marginally exceeds that of WaNet, accompanied by a lower BA. It is noteworthy that the BA and WMA achieved by the proposed method yield satisfactory results, with a minimal decrease in BA, while both the BA and WMA surpass 99%. This success can be attributed to the superior performance of the image poisoned method designed in this study, allowing the model to effectively learn the poisoned features.
Moreover, as illustrated in
Table 6, the BA and WMA metrics for Patch, Blend, and SIG exhibit noteworthy performance, surpassing both WaNet and IDwNet overall. This can be attributed to the straightforward method employed in constructing their poisoned images, allowing for the effective extraction of poisoned features in the shallow convolutional layer of the model. Consequently, the model’s attention to poisoned images is minimized, enabling a greater focus on fulfilling the original classification task with minimal impact on its performance. However, the simplicity of these poisoned image construction methods renders them susceptible to detection and forgery, posing challenges in addressing issues related to the inadvertent disclosure of construction methods and copyright ambiguity. Given that copyright ambiguity equates to the nullification of black-box model watermarking upon occurrence, these easily forgeable poisoned image construction methods present a significant impediment to the practical application of black-box model watermarking.
In addition to the ResNet-18 deep classification model employed for the experimental results presented in
Table 6, this subsection includes testing various deep classification network models, namely VGG16, MobileNetV2, DenseNet, and ResNeXt. The configuration of these models mirrors that of the experiments described earlier; the outcomes of the simulation experiments, conducted with the CIFAR-10 dataset (similar results were observed for other datasets), are summarized in
Table 7.
Table 7 reveals that models VGG16, DenseNet, and ResNeXt exhibited a slight reduction in classification performance post-embedding of the model watermark. Specifically, the BA of VGG16 experienced the most substantial decline, by 0.73% points. Conversely, MobileNetV2 demonstrated an increase in BA instead of a decrease. This observation suggests that poisoned training does not invariably result in a deterioration of the original model performance; at times, it can enhance the model’s generalization. This phenomenon warrants further in-depth exploration in future research endeavors. Moreover,
Table 7 illustrates that the WMA values consistently exceed 99% when applying the proposed method to these models, thereby demonstrating its efficacy in achieving robust model copyright verification.
4.4. Unique Identifier Effect
As delineated in
Section 3.3, the method outlined in this paper exclusively elicits a response to poisoned images that have been embedded with the correct ID, signifying the specific categories predetermined by the model output. Conversely, the model’s watermarking response remains dormant when confronted with poisoned adversary images containing alternative information. To substantiate this claim, an experimental simulation is conducted wherein 256 (
) distinct information-corresponding poisoned images are embedded. Among these, one corresponds to the poisoned image featuring the correct ID, while the remaining 255 comprise poisoned adversary images with disparate information. Subsequently, the watermarking performance of these 256 information-corresponding WMA is assessed. The GTSRB dataset and the ResNet-18 network model are employed as illustrative examples; however, it is noteworthy that other datasets and networks yield analogous results.
Figure 3 presents a comprehensive overview of the experimental simulation results. Observing the figure, numerous poisoned images with alternative information elicit model watermark responses in the absence of adversary training. Following adversary training, the WMA of poisoned images featuring incorrect IDs consistently are below 30%, except the poisoned image containing the correct ID, which attains a WMA exceeding 99%. Notably, even when there is a 1-bit disparity between some incorrect IDs and the correct ID, the WMA of the poisoned image with these IDs remains below 30%. This unequivocally underscores the efficacy of the adversary training strategy proposed in this paper. Furthermore, it highlights that even a 1-bit error in watermark information can be accurately discerned. Stated differently, only poisoned images containing the accurate ID can activate the model watermarking response of IDwNet, whereas other poisoned adversary images featuring any incorrect ID fail to trigger the model watermarking response of IDwNet. This underscores the adept capability of IDwNet, as proposed in this paper, to proficiently identify the unique user identity of the model.
4.5. Invisibility of Poisoned Images
To assess the covert nature of various black-box model watermarking poisoned images, this study employs objective metrics, namely PSNR and SSIM, to quantitatively evaluate the similarity between the generated poisoned images and the original clean images. This method diverges from the conventional use of subjective manual tests in prior black-box model watermarking methods [
21,
25,
28]. For the experimental simulations, test images are sourced from the CIFAR-10, GTSRB, CelebA, and Tiny-ImageNet datasets. Subsequently, poisoned images are generated using different black-box model watermarking methods, namely Patch, Blend, SIG, WaNet, and the novel IDwNet proposed in this paper. The average PSNR and SSIM values of the resulting poisoned images concerning the original images are computed. The experimental simulation results are presented in
Table 8. Examination of the table reveals that the PSNR and SSIM values of the poisoned images generated by the proposed method in this paper are notably high, surpassing those of other model watermarking methods. This observation indicates that the method proposed in this paper exhibits a commendable level of covertness that is challenging to detect.
Additionally,
Figure 4 presents the poisoned images generated by various comparison methods along with the residual images in comparison to the original clean images. As depicted in
Figure 4, the poisoned image created by the method proposed in this paper exhibits a remarkable consistency with the original clean image. Notably, even upon magnification by five times, the pixel contrast of the residual image fails to reveal discernible modifications attributed to watermark embedding. This observation underscores the efficacy of the proposed poisoned image construction method. In contrast, when compared to the method presented in this paper, discernible modifications in the poisoned images constructed by Patch, Blend, and SIG are perceptible to the naked eye. Examples include the blue small box in the upper left corner of Patch and the contour of the watermark in Blend and SIG. The residual images for these methods exhibit a similar pattern. Noteworthy is the fact that the poisoned image constructed by WaNet closely resembles the original clean image, making it challenging to discern distortions due to watermark embedding with the naked eye. However, the residual image of WaNet distinctly reveals the embedded watermark, suggesting a reduced level of stealth compared to the IDwNet proposed in this paper. The invisibility superiority of IDwNet comes from the developed DCT-SVD-based ID embedding method. Similar results can also be observed for the CIFAR-10 dataset, as shown in
Figure 5.
Considering the experimental results presented in
Section 4.3, it can be inferred that the simplicity of the poisoned image construction method positively correlates with the effectiveness of the corresponding model watermark. Nevertheless, this simplicity comes at the expense of reduced covertness. Thus, striking a balance between the effectiveness of model watermarking and the covertness of poisoned images is a crucial consideration. From the standpoint of promoting the practical application of black-box models, this paper emphasizes the high covertness and security features of poisoned images.
5. Conclusions
In this paper, we introduce IDwNet, a novel black-box model watermarking technique designed for characterizing neural networks with unique ID. Within this framework, the user’s ID is intricately embedded into the DCT and SVD coefficients derived from the original pristine image. Subsequently, the poisoned image is formulated through an inverse transformation process. This method not only diffuses the ID information across the entire image, thereby facilitating the acquisition of correct ID features crucial for triggering learning in DNN models, but also effectively diminishes the distinctions between the poisoned image and the original pristine image. This enhancement contributes to fortifying the invisibility of the poisoned image, thereby addressing concerns related to information leakage and mitigating issues associated with model copyright ambiguity. This method serves a dual purpose: not only does it disseminate the ID information throughout the entire image, aiding the DNN model in capturing the correct ID features as training triggers, but it also substantially minimizes the disparity between the poisoned image and the pristine original image. This reduction enhances the invisibility of the poisoned image, thereby better fortifying against issues related to the inadvertent disclosure of the poisoned image construction method and mitigating uncertainties regarding model copyright. Furthermore, this paper introduces a black-box model watermarking training method rooted in adversary training. Specifically, clean images, poisoned images with correct ID, and poisoned adversary images with incorrect IDs are concurrently inputted into the DNN model during the training process. A meticulously devised loss function is then constructed to impartially gauge the classification performance of these three image categories. This methodology is adept at achieving both the accurate classification of clean images and the correct implementation of a backdoor response function for the poisoned images. A substantial volume of experimental simulation results reveals that the poisoned image, constructed utilizing the DCT-SVD methodology proposed in this paper, demonstrates excellent invisibility capabilities. It achieves a model watermark verification rate exceeding 99% while incurring a minimal reduction of less than 0.5% in model classification performance. Furthermore, the method attains accurate copyright verification even in instances where only a 1-bit difference exists between the incorrect ID and the correct ID, effectively realizing the functionalities associated with a unique user identity. The performances exhibited by IDwNet, as proposed in this paper, generally surpass those of state-of-the-art model watermarking methods. This observation underscores the feasibility and effectiveness of the method presented in this study.
While the method presented in this paper demonstrates commendable performance, it is noteworthy that the embedding of the watermark continues to influence the classification model’s performance. In future research endeavors, it becomes imperative to further mitigate the impact on the original classification model’s performance, or ideally enhance the model’s capabilities. For instance, exploring avenues where the model’s performance is augmented, as observed in the case of MobileNetV2, is a promising direction. Furthermore, it is worth considering the extension of the proposed black-box classification model watermarking method to encompass other deep neural networks, such as detection models.










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}