
Enhancing Portfolio Performance through Financial Time-Series Decomposition-Based Variational Encoder-Decoder Data Augmentation


Abstract
1. Introduction
- Uncertainty deficiency. Both the financial market and its empirical time series data contain inherent uncertainty. At some point, probabilities were assigned to different events or market scenarios, including rises, falls, and magnitudes of changes, with non-zero probabilities. On the other hand, as time elapses, all past events collapse into a single outcome. Consequently, only one event is assigned a 100% probability, and the probabilities of all other events are set to 0%. This phenomenon, termed uncertainty deficiency, suggests that historical financial time series data only represent a sequence of singular events, lacking the diversity of market uncertainties that existed in the past. Ignoring financial market uncertainty can lead to overly confident models that fail to account for unforeseen risks. RL algorithms or traditional models optimized solely based on historical financial time series data may lack robustness and show poor capability when applied to novel or extreme events.
- Insufficient amount of training data. Historical financial time-series datasets are often not large enough for training due to financial market uncertainty. For example, even with 10 years of daily data for an asset class (250 trading days in a year × 10 years = 2500), the amount is relatively small, only 2.5k. Insufficient datasets, characterized by small data size, result in information asymmetry and compromise portfolio performance.
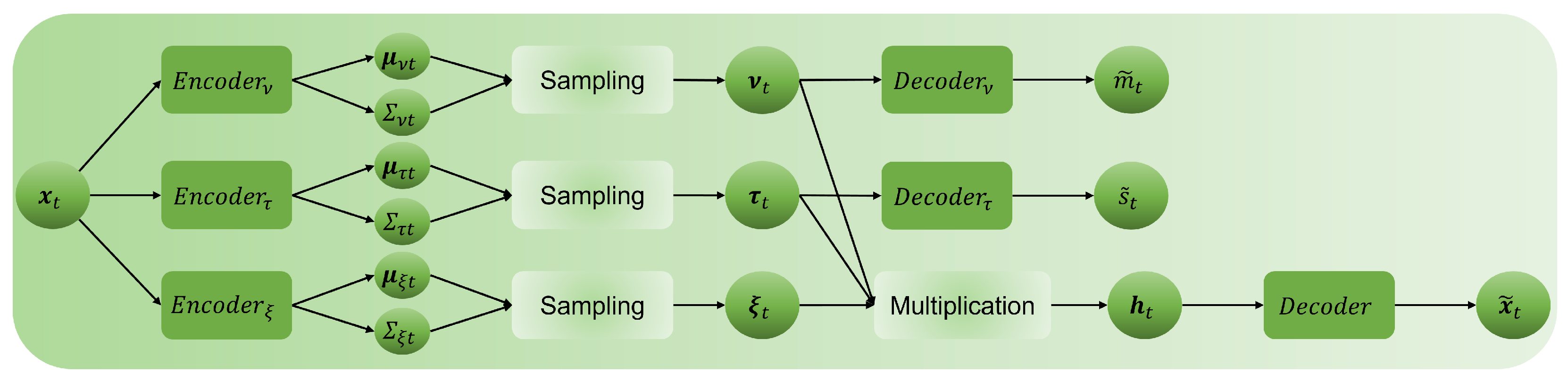
- FED for Financial Time Series Data Augmentation. The first contribution introduces an innovative financial time series data augmentation called the FED. Generating nonstationary financial time series data is deemed challenging, and FED addresses this challenge by leveraging decomposition techniques, separating the financial time series into distinct components (trend, dispersion, and residual). Based on the encoder-decoder architecture, the FED method utilizes latent variables further decomposed into components. This pattern-centric approach provides a profound understanding of the underlying structure of financial time series data, unveiling the hidden patterns or structures and offering insights into factors influencing observed trends and fluctuations. FED captures the distributions of latent variable components, generating more realistic financial time series data. In doing so, the FED method revives some of the past uncertainty that had disappeared, compensating for the problems of uncertainty deficiency and an insufficient amount of training data.
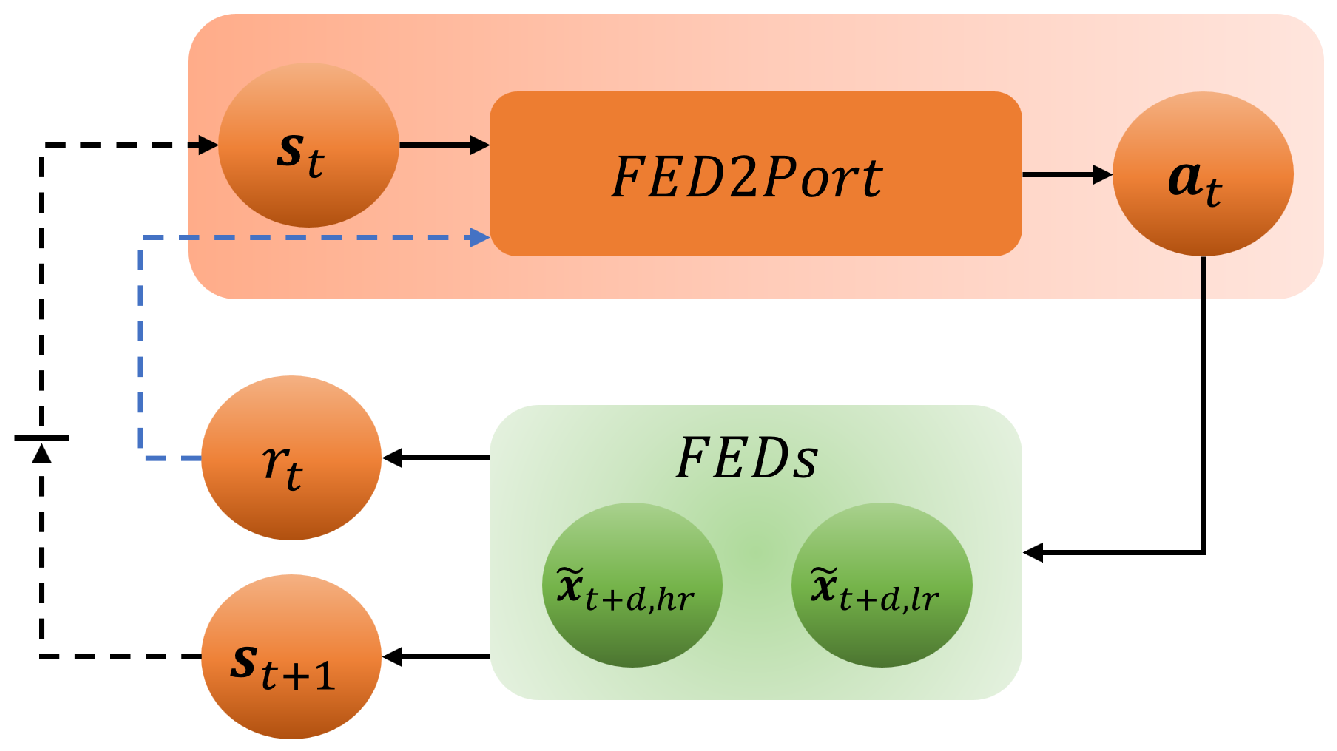
- FED2Port for Decision-Making under Financial Market Uncertainty. The second contribution is the proposal of FED2Port as a novel diversification approach to enhance the efficiency of RL algorithms. Specifically tailored for RL portfolio diversification models, FED2Port addresses the uncertainty deficiency problem inherent in historical financial time series data. FED2Port trains the RL algorithm under the financial market environment generated using the FED. This environment simulation incorporates stochastic elements in the reward function, enabling the algorithm to learn from a more comprehensive spectrum of financial market uncertainties. Therefore, FED2Port improves the adaptability of the algorithm significantly, empowering it to make well-informed decisions in the face of future uncertainty, ultimately enhancing portfolio performance.
2. Related Work
3. Proposed Methods
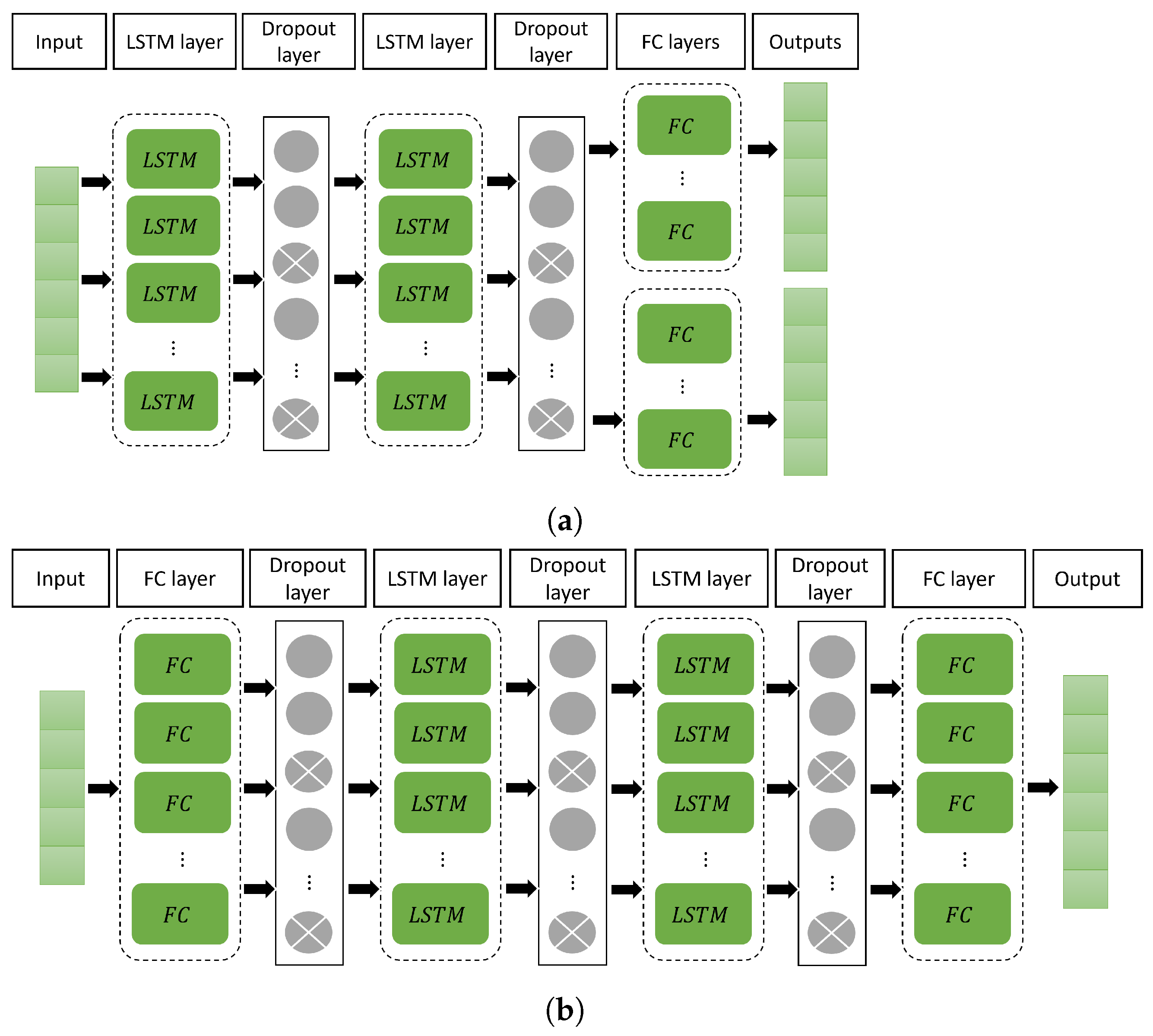
3.1. FED
3.2. FED2Port
- The action is defined as the weight vector:where and represent the weights of a high-risk asset and a low-risk asset, respectively, with the constraint that .
- The state is defined as the portfolio return :where and are the d-day log-return vectors of the high-risk and low-risk assets, respectively.
- The reward is defined as the market-adaptive ratio [32]:where represents the rho of the high-risk asset; is the return of the high-risk asset, and are the generated log-return vectors of the high-risk and low-risk assets, respectively. FED methods are used for high-risk and low-risk assets. and represent the expected return and standard deviation of the total portfolio, respectively, and is the risk-free rate. In this paper, the risk-free rate equals zero. By using the market-adaptive ratio as the reward, FED2Port can take into account market characteristics such as bull and bear markets.
4. Experiment
4.1. Dataset
4.2. Benchmarks
4.3. Performance Measures
4.4. Experimental Results
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Pensions at a Glance 2021: OECD and G20 Indicators. Available online: https://www.oecd-ilibrary.org/finance-and-investment/pensions-at-a-glance-2021_ca401ebd-en (accessed on 22 January 2024).
- Asset Allocation of Pension Funds. Available online: https://www.monash.edu/__data/assets/pdf_file/0003/2357238/Research-1-Asset-allocation-of-pension-funds.pdf (accessed on 22 January 2024).
- Markowitz, H. Portfolio Selection. J. Financ. 1952, 7, 77–91. [Google Scholar]
- Roncalli, T. Introduction to Risk Parity and Budgeting. arXiv 2014, arXiv:1403.1889. [Google Scholar]
- Richard, J.E.; Roncalli, T. Constrained Risk Budgeting Portfolios: Theory, Algorithms, Applications & Puzzles. arXiv 2019, arXiv:1902.05710. [Google Scholar]
- Moody, J.; Wu, L.; Liao, Y.; Saffell, M. Performance Functions and Reinforcement Learning for Trading Systems and Portfolios. J. Forecast. 1998, 17, 441–470. [Google Scholar] [CrossRef]
- Li, L. Financial Trading with Feature Preprocessing and Recurrent Reinforcement Learning. arXiv 2021, arXiv:2109.05283. [Google Scholar]
- Liu, X.; Xiong, Z.; Zhong, S.; Yang, H.; Walid, A. Practical Deep Reinforcement Learning Approach for Stock Trading. arXiv 2018, arXiv:1811.07522. [Google Scholar]
- Kalina, B.; Lee, J.; Song, J. A Study on Portfolio Asset Allocation Using Actor-Critic Model. In Proceedings of the Korea Information Processing Society Conference, Online, 29–30 May 2020; pp. 439–441. [Google Scholar]
- Almahdi, S.; Yang, S.Y. An adaptive portfolio trading system: A risk-return portfolio optimization using recurrent reinforcement learning with expected maximum drawdown. Expert Syst. Appl. 2017, 87, 267–279. [Google Scholar] [CrossRef]
- Pendharker, P.C.; Cusatis, P. Trading financial indices with reinforcement learning agents. Expert Syst. Appl. 2018, 102, 1–13. [Google Scholar] [CrossRef]
- Mirza, M.; Osindero, S. Conditional Generative Adversarial Nets. arXiv 2014, arXiv:1411.1784. [Google Scholar]
- Goodfellow, I.J.; Pouget-Abadie, J.; Mirza, M.; Xu, B.; Warde-Farley, D.; Ozair, S.; Courville, A.; Bengio, Y. Generative Adversarial Nets. In Proceedings of the 27th Conference on Neural Information Processing Systems, Montréal, QC, Canada, 8–13 December 2014; pp. 2672–2680. [Google Scholar]
- Kingma, D.P.; Welling, M. Auto-Encoding Variational Bayes. arXiv 2013, arXiv:1312.6114. [Google Scholar]
- Kingma, D.P.; Welling, M. An Introduction to Variational Autoencoders. arXiv 2019, arXiv:1906.02691. [Google Scholar]
- Yoon, J.; Jarrett, D.; Schaar, M.v. Time-series Generative Adversarial Networks. In Proceedings of the 33rd Conference on Neural Information Processing Systems, Vancouver, BC, Canada, 8–14 December 2019; pp. 5508–5518. [Google Scholar]
- Pei, H.; Ren, K.; Yang, Y.; Liu, C.; Qin, T.; Li, D. Towards Generating Real-World Time Series Data. In Proceedings of the 2021 IEEE International Conference on Data Mining (ICDM), Auckland, New Zealand, 7–10 December 2021; pp. 469–478. [Google Scholar]
- West, M. Time Series Decomposition. Biometrika 1997, 84, 489–494. [Google Scholar] [CrossRef]
- Wen, Q.; Gao, J.; Song, X.; Sun, L.; Xu, H.; Zhu, S. RobustSTL: A Robust Seasonal-Trend Decomposition Algorithm for Long Time Series. In Proceedings of the Thirty-Third AAAI Conference on Artificial Intelligence, Honolulu, HI, USA, 27 January–1 February 2019; pp. 5409–5416. [Google Scholar]
- Patidar, S.; Jenkins, D.P.; Peacock, A.; McCallum, P. Time Series Decomposition Approach for Simulating Electricity Demand Profile. In Proceedings of the 16th IBPSA Conference, Rome, Italy, 2–4 September 2019; pp. 1388–1395. [Google Scholar]
- Wen, Q.; Zhang, Z.; Li, Y.; Sun, L. Fast RobustSTL: Efficient and Robust Seasonal-Trend Decomposition for Time Series with Complex Patterns. In Proceedings of the 26th ACM SIGKDD International Conference on Knowledge Discovery & Data Mining, Online, 6–10 July 2020; pp. 2203–2213. [Google Scholar]
- Hyndman, R.J.; Athanasopoulos, G. Time series decomposition. In Forecasting: Principles and Practice, 3rd ed.; OTexts: Melbourne, Australia, 2021; Chapter 3. [Google Scholar]
- Dokumentov, A.; Hyndman, R.J. STR: Seasonal-Trend Decomposition Using Regression. INFORMS J. Data Sci. 2021, 1, 50–62. [Google Scholar] [CrossRef]
- Mishra, A.; Sriharsha, R.; Zhong, S. OnlineSTL: Scaling Time Series Decomposition by 100x. arXiv 2021, arXiv:2107.09110. [Google Scholar] [CrossRef]
- Jiang, S.; Syed, T.; Zhu, X.; Levy, J.; Aronchik, B. Bridging Self-Attention and Time Series Decomposition for Periodic Forecasting. In Proceedings of the 31st ACM International Conference on Information & Knowledge Management, Atlanta, GA, USA, 17–21 October 2022; pp. 3202–3211. [Google Scholar]
- Dudek, G. STD: A Seasonal-Trend-Dispersion Decomposition of Time Series. IEEE Trans. Knowl. Data Eng. 2023, 35, 10339–10350. [Google Scholar] [CrossRef]
- Sharpe, W.F. Mutual Fund Performance. J. Bus. 1966, 39, 119–138. [Google Scholar] [CrossRef]
- Black, F.; Litterman, R. Global Portfolio Optimization. Financ. Anal. J. 1992, 48, 28–43. [Google Scholar] [CrossRef]
- Sharpe, W.F. Capital asset prices: A theory of market equilibrium under conditions of risk. J. Financ. 1964, 19, 425–442. [Google Scholar]
- Lillicrap, T.P.; Hunt, J.J.; Pritzel, A.; Heess, N.; Erez, T.; Tassa, Y.; Silver, D.; Wierstra, D. Continuous control with deep reinforcement learning. arXiv 2015, arXiv:1509.02971. [Google Scholar]
- Sortino, F.A.; Price, L.N. Performance measurement in a downside risk framework. J. Investig. 1994, 3, 59–64. [Google Scholar] [CrossRef]
- Lee, J.H.; Kalina, B.; Na, K. Market-Adaptive Ratio for Portfolio Management. arXiv 2023, arXiv:2312.13719. [Google Scholar]
- Peterson, K.B.; Pedersen, M.S. 8.1.8 Product of gaussian densities. In The Matrix Cookbook; Technical University of Denmark: Lyngby, Denmark, 2012. [Google Scholar]





{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Class | Symbol | Explanation |
|---|---|---|
| High-risk assets | SP500 | S&P500 Index |
| DAX | DAX Index | |
| KOSPI | KOSPI Index | |
| Low-risk assets | BND | Vanguard Total Bond Market Index Fund |
| BSV | Vanguard Short-Term Bond Index Fund | |
| VCIT | Vanguard Intermediate-Term Treasury Index Fund |
| SP500 | DAX | KOSPI | BND | BSV | VCIT | |
|---|---|---|---|---|---|---|
| The standard deviation of the portfolio return | 0.5221 | 0.6125 | 0.5564 | 0.1429 | 0.0590 | 0.1702 |
| Portfolio | Low-Risk Asset | High-Risk Asset | |
|---|---|---|---|
| 1 | BND&SP500 | Vanguard Total Bond Market Index Fund | S&P500 Index |
| 2 | BND&DAX | Vanguard Total Bond Market Index Fund | DAX Index |
| 3 | BND&KOSPI | Vanguard Total Bond Market Index Fund | KOSPI Index |
| 4 | BSV&SP500 | Vanguard Short-Term Bond Index Fund | S&P500 Index |
| 5 | BSV&DAX | Vanguard Short-Term Bond Index Fund | DAX Index |
| 6 | BSV&KOSPI | Vanguard Short-Term Bond Index Fund | KOSPI Index |
| 7 | VCIT&SP500 | Vanguard Intermediate-Term Treasury Index Fund | S&P500 Index |
| 8 | VCIT&DAX | Vanguard Intermediate-Term Treasury Index Fund | DAX Index |
| 9 | VCIT&KOSPI | Vanguard Intermediate-Term Treasury Index Fund | KOSPI Index |
| Model | Explanation | |
|---|---|---|
| 1 | 100% low-risk asset portfolio | Buy-and-Hold strategies |
| 2 | Equally Weighted | |
| 3 | 100% high-risk asset portfolio | |
| 4 | Tangency portfolio | Traditional portfolio diversification models |
| 5 | Risk Budgeting | |
| 6 | RRL | Historical data-based RL portfolio diversification models |
| 7 | DDPG | |
| 8 | TimeGAN2Port | Data augmentation-based RL portfolio diversification models |
| 9 | RTSGAN2Port |
| Model | Profit (Higher the Better) | Risk (Lower the Better) | Sharpe Ratio (Higher the Better) |
|---|---|---|---|
| 100% low-risk asset portfolio | 0.0904 | 0.1429 | 0.6322 |
| Equally Weighted | 0.3833 | 0.2779 | 1.3793 |
| 100% high-risk asset portfolio | 0.7459 | 0.5221 | 1.4286 |
| Tangency portfolio | 0.5587 | 0.4183 | 1.3356 |
| Risk Budgeting | 0.2303 | 0.2126 | 1.0835 |
| RRL | 0.2866 | 0.2483 | 1.1540 |
| DDPG | 0.0853 | 0.2939 | 0.2903 |
| TimeGAN2Port | 0.3956 | 0.3027 | 1.3072 |
| RTSGAN2Port | 0.1277 | 0.2549 | 0.5009 |
| FED2Port (our) | 0.3755 | 0.2101 | 1.7869 |
| Model | Profit (Higher the Better) | Risk (Lower the Better) | Sharpe Ratio (Higher the Better) |
|---|---|---|---|
| 100% low-risk asset portfolio | 0.0904 | 0.1429 | 0.6322 |
| Equally Weighted | 0.2001 | 0.3164 | 0.6322 |
| 100% high-risk asset portfolio | 0.4074 | 0.6125 | 0.6652 |
| Tangency portfolio | 0.3568 | 0.4915 | 0.7260 |
| Risk Budgeting | 0.0806 | 0.1685 | 0.4783 |
| RRL | 0.0993 | 0.1696 | 0.5857 |
| DDPG | 0.2662 | 0.3133 | 0.8496 |
| TimeGAN2Port | 0.1444 | 0.3209 | 0.4500 |
| RTSGAN2Port | 0.0940 | 0.2750 | 0.3417 |
| FED2Port (our) | 0.2084 | 0.1778 | 1.1722 |
| Model | Profit (Higher the Better) | Risk (Lower the Better) | Sharpe Ratio (Higher the Better) |
|---|---|---|---|
| 100% low-risk asset portfolio | 0.0904 | 0.1429 | 0.6322 |
| Equally Weighted | 0.0990 | 0.2873 | 0.3447 |
| 100% high-risk asset portfolio | 0.1903 | 0.5564 | 0.3420 |
| Tangency portfolio | 0.2562 | 0.4268 | 0.6002 |
| Risk Budgeting | 0.1232 | 0.1781 | 0.6917 |
| RRL | −0.1851 | 0.2737 | −0.6765 |
| DDPG | 0.2909 | 0.3223 | 0.9026 |
| TimeGAN2Port | 0.0539 | 0.1460 | 0.3690 |
| RTSGAN2Port | 0.0452 | 0.1510 | 0.2995 |
| FED2Port (our) | 0.2510 | 0.1845 | 1.3604 |
| Model | Profit (Higher the Better) | Risk (Lower the Better) | Sharpe Ratio (Higher the Better) |
|---|---|---|---|
| 100% low-risk asset portfolio | 0.0776 | 0.0590 | 1.3158 |
| Equally Weighted | 0.3772 | 0.2633 | 1.4325 |
| 100% high-risk asset portfolio | 0.7459 | 0.5221 | 1.4286 |
| Tangency portfolio | 0.6639 | 0.4328 | 1.5342 |
| Risk Budgeting | 0.1548 | 0.1545 | 1.0019 |
| RRL | 0.1337 | 0.2343 | 0.5704 |
| DDPG | 0.1307 | 0.2737 | 0.4775 |
| TimeGAN2Port | 0.0825 | 0.0592 | 1.3931 |
| RTSGAN2Port | 0.0780 | 0.0602 | 1.2958 |
| FED2Port (our) | 0.3964 | 0.1562 | 2.5377 |
| Model | Profit (Higher the Better) | Risk (Lower the Better) | Sharpe Ratio (Higher the Better) |
|---|---|---|---|
| 100% low-risk asset portfolio | 0.0776 | 0.0590 | 1.3158 |
| Equally Weighted | 0.1948 | 0.3070 | 0.6346 |
| 100% high-risk asset portfolio | 0.4074 | 0.6125 | 0.6652 |
| Tangency portfolio | 0.3822 | 0.5053 | 0.7564 |
| Risk Budgeting | 0.0782 | 0.0947 | 0.8264 |
| RRL | 0.0421 | 0.1884 | 0.2235 |
| DDPG | 0.1343 | 0.2874 | 0.4675 |
| TimeGAN2Port | 0.2224 | 0.4972 | 0.4473 |
| RTSGAN2Port | 0.1487 | 0.4921 | 0.3021 |
| FED2Port (our) | 0.1997 | 0.1296 | 1.5406 |
| Model | Profit (Higher the Better) | Risk (Lower the Better) | Sharpe Ratio (Higher the Better) |
|---|---|---|---|
| 100% low-risk asset portfolio | 0.0776 | 0.0590 | 1.3158 |
| Equally Weighted | 0.0956 | 0.2827 | 0.3381 |
| 100% high-risk asset portfolio | 0.1903 | 0.5564 | 0.3420 |
| Tangency portfolio | 0.2746 | 0.4441 | 0.6183 |
| Risk Budgeting | 0.0835 | 0.0715 | 1.1677 |
| RRL | 0.0961 | 0.0696 | 1.3822 |
| DDPG | 0.3463 | 0.2891 | 1.1978 |
| TimeGAN2Port | 0.0451 | 0.0637 | 0.7075 |
| RTSGAN2Port | 0.0407 | 0.0651 | 0.6245 |
| FED2Port (our) | 0.2610 | 0.1446 | 1.8056 |
| Model | Profit (Higher the Better) | Risk (Lower the Better) | Sharpe Ratio (Higher the Better) |
|---|---|---|---|
| 100% low-risk asset portfolio | 0.1660 | 0.1702 | 0.9750 |
| Equally Weighted | 0.4231 | 0.2922 | 1.4480 |
| 100% high-risk asset portfolio | 0.7459 | 0.5221 | 1.4286 |
| Tangency portfolio | 0.5802 | 0.3769 | 1.5396 |
| Risk Budgeting | 0.3235 | 0.2429 | 1.3319 |
| RRL | 0.4325 | 0.2765 | 1.5642 |
| DDPG | 0.1164 | 0.3092 | 0.3766 |
| TimeGAN2Port | 0.4754 | 0.2835 | 1.6765 |
| RTSGAN2Port | 0.3242 | 0.3162 | 1.0252 |
| FED2Port (our) | 0.4941 | 0.2167 | 2.2800 |
| Model | Profit (Higher the Better) | Risk (Lower the Better) | Sharpe Ratio (Higher the Better) |
|---|---|---|---|
| 100% low-risk asset portfolio | 0.1660 | 0.1702 | 0.9750 |
| Equally Weighted | 0.2389 | 0.3265 | 0.7317 |
| 100% high-risk asset portfolio | 0.4074 | 0.6125 | 0.6652 |
| Tangency portfolio | 0.4429 | 0.4696 | 0.9431 |
| Risk Budgeting | 0.1447 | 0.2078 | 0.6964 |
| RRL | 0.4450 | 0.2473 | 1.7990 |
| DDPG | 0.3058 | 0.3202 | 0.9551 |
| TimeGAN2Port | 0.1617 | 0.1700 | 0.9510 |
| RTSGAN2Port | 0.1779 | 0.2882 | 0.6173 |
| FED2Port (our) | 0.5214 | 0.2401 | 2.1714 |
| Model | Profit (Higher the Better) | Risk (Lower the Better) | Sharpe Ratio (Higher the Better) |
|---|---|---|---|
| 100% low-risk asset portfolio | 0.1660 | 0.1702 | 0.9750 |
| Equally Weighted | 0.1374 | 0.2962 | 0.4637 |
| 100% high-risk asset portfolio | 0.1903 | 0.5564 | 0.3420 |
| Tangency portfolio | 0.3115 | 0.4115 | 0.7570 |
| Risk Budgeting | 0.1778 | 0.1962 | 0.9065 |
| RRL | 0.0478 | 0.1767 | 0.2706 |
| DDPG | 0.1967 | 0.3161 | 0.6223 |
| TimeGAN2Port | 0.1305 | 0.1729 | 0.7545 |
| RTSGAN2Port | 0.0355 | 0.2280 | 0.1556 |
| FED2Port (our) | 0.3683 | 0.2044 | 1.8021 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Kalina, B.; Lee, J.-H.; Na, K.-T. Enhancing Portfolio Performance through Financial Time-Series Decomposition-Based Variational Encoder-Decoder Data Augmentation. Symmetry 2024, 16, 283. https://doi.org/10.3390/sym16030283
Kalina B, Lee J-H, Na K-T. Enhancing Portfolio Performance through Financial Time-Series Decomposition-Based Variational Encoder-Decoder Data Augmentation. Symmetry. 2024; 16(3):283. https://doi.org/10.3390/sym16030283
Chicago/Turabian StyleKalina, Bayartsetseg, Ju-Hong Lee, and Kwang-Tek Na. 2024. "Enhancing Portfolio Performance through Financial Time-Series Decomposition-Based Variational Encoder-Decoder Data Augmentation" Symmetry 16, no. 3: 283. https://doi.org/10.3390/sym16030283
APA StyleKalina, B., Lee, J.-H., & Na, K.-T. (2024). Enhancing Portfolio Performance through Financial Time-Series Decomposition-Based Variational Encoder-Decoder Data Augmentation. Symmetry, 16(3), 283. https://doi.org/10.3390/sym16030283