

Enhancing the Aczel–Alsina Model: Integrating Hesitant Fuzzy Logic with Chi-Square Distance for Complex Decision-Making

Abstract
1. Introduction
2. Preliminaries
2.1. Several Norms and Conorms
- (T1)
- ;
- (T2)
- ;
- (T3)
- ;
- (T4)
- .
- (S1)
- ;
- (S2)
- ;
- (S3)
- ;
- (S4)
- .
2.2. Hesitant Fuzzy Set
- (1)
- (2)
- (3)
- (1)
- (2)
- (3)
- (4)
- (A1)
- The values in an HFE are arranged in increasing order.
- (A2)
- For two HFSs, and , . If , it is necessary to extend the length of to the same length as by repeating the maximum value in .
- (1)
- ;
- (2)
- ;
- (3)
- ;
- (4)
- ;
- (5)
- .
- (1)
- ;
- (2)
- ;
- (3)
- ;
- (4)
- ;
- (5)
- .
2.3. Aczel–Alsina Operations for HFEs
- (1)
- ;
- (2)
- ;
- (3)
- ;
- (4)
- .
- (1)
- ;
- (2)
- ;
- (3)
- ;
- (4)
- ;
- (5)
- ;
- (6)
- .
2.4. Power Average (P-A) Operator and Power Geometric (P-G) Operator
2.5. Shannon Entropy Weight
3. HF Generalized Chi-Square Distance
4. HF Aczel–Alsina Power Weighted Operators
4.1. HF Aczel–Alsina Power Weighted Average Operator
4.2. HF Aczel–Alsina Power Weighted Geometric Operator
5. Hesitant Fuzzy Power Aczel–Alsina Model
| Algorithm 1 Algorithm of HF Aczel–Alsina power model. |
|
6. Results and Discussions with Application
6.1. Case Study
6.2. Parameters Analysis
6.2.1. Effect of Parameter k
6.2.2. Effect of Parameter p
6.3. Comparative Analysis
7. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
Appendix A. Aggregated Data

{kind=link}
{kind=link}
{kind=link}
{kind=link}
| HFAAPWA(U1)= | {0.4319, 0.4568, 0.5421, 0.5421, 0.5121, 0.5335, 0.6068, 0.6068, 0.5121, 0.5335, 0.6068, 0.6068, 0.5121, 0.5335, 0.6068, 0.6068, 0.4620, 0.4856, 0.5665, 0.5665, 0.5380, 0.5582, 0.6277, 0.6277, 0.5380, 0.5582, 0.6277, 0.6277, 0.5380, 0.5582, 0.6277, 0.6277, 0.4812, 0.5039, 0.5819, 0.5819, 0.5544, 0.5739, 0.6409, 0.6409, 0.5544, 0.5739, 0.6409, 0.6409, 0.5544, 0.5739, 0.6409, 0.6409, 0.5048, 0.5265, 0.6009, 0.6009, 0.5747, 0.5934, 0.6573, 0.6573, 0.5747, 0.5934, 0.6573, 0.6573, 0.5747, 0.5934, 0.6573, 0.6573} |
| HFAAPWA(U2)= | {0.5737, 0.6002, 0.6002, 0.6002, 0.7346, 0.7511, 0.7511, 0.7511, 0.8347, 0.8450, 0.8450, 0.8450, 0.8347, 0.8450, 0.8450, 0.8450, 0.6041, 0.6288, 0.6288, 0.6288, 0.7535, 0.7689, 0.7689, 0.7689, 0.8466, 0.8561, 0.8561, 0.8561, 0.8466, 0.8561, 0.8561, 0.8561, 0.6348, 0.6575, 0.6575, 0.6575, 0.7726, 0.7868, 0.7868, 0.7868, 0.8584, 0.8673, 0.8673, 0.8673, 0.8584, 0.8673, 0.8673, 0.8673, 0.6348, 0.6575, 0.6575, 0.6575, 0.7726, 0.7868, 0.7868, 0.7868, 0.8584, 0.8673, 0.8673, 0.8673, 0.8584, 0.8673, 0.8673, 0.8673} |
| HFAAPWA(U3)= | {0.3581, 0.4233, 0.4820, 0.4820, 0.4225, 0.4812, 0.5340, 0.5340, 0.4225, 0.4812, 0.5340, 0.5340, 0.4225, 0.4812, 0.5340, 0.5340, 0.3915, 0.4533, 0.5089, 0.5089, 0.4526, 0.5082, 0.5582, 0.5582, 0.4526, 0.5082, 0.5582, 0.5582, 0.4526, 0.5082, 0.5582, 0.5582, 0.4389, 0.4960, 0.5472, 0.5472, 0.4953, 0.5466, 0.5927, 0.5927, 0.4953, 0.5466, 0.5927, 0.5927, 0.4953, 0.5466, 0.5927, 0.5927, 0.4389, 0.4960, 0.5472, 0.5472, 0.4953, 0.5466, 0.5927, 0.5927, 0.4953, 0.5466, 0.5927, 0.5927, 0.4953, 0.5466, 0.5927, 0.5927} |
| HFAAPWA(U4)= | {0.2906, 0.3153, 0.3153, 0.3153, 0.5579, 0.5733, 0.5733, 0.5733, 0.8283, 0.8343, 0.8343, 0.8343, 0.8283, 0.8343, 0.8343, 0.8343, 0.3643, 0.3864, 0.3864, 0.3864, 0.6038, 0.6176, 0.6176, 0.6176, 0.8461, 0.8515, 0.8515, 0.8515, 0.8461, 0.8515, 0.8515, 0.8515, 0.4657, 0.4843, 0.4843, 0.4843, 0.6670, 0.6786, 0.6786, 0.6786, 0.8707, 0.8752, 0.8752, 0.8752, 0.8707, 0.8752, 0.8752, 0.8752, 0.4657, 0.4843, 0.4843, 0.4843, 0.6670, 0.6786, 0.6786, 0.6786, 0.8707, 0.8752, 0.8752, 0.8752, 0.8707, 0.8752, 0.8752, 0.8752} |
| HFAAPWA(U5)= | {0.2517, 0.3300, 0.3300, 0.3300, 0.3853, 0.4496, 0.4496, 0.4496, 0.3853, 0.4496, 0.4496, 0.4496, 0.3853, 0.4496, 0.4496, 0.4496, 0.3146, 0.3864, 0.3864, 0.3864, 0.4370, 0.4959, 0.4959, 0.4959, 0.4370, 0.4959, 0.4959, 0.4959, 0.4370, 0.4959, 0.4959, 0.4959, 0.3449, 0.4134, 0.4134, 0.4134, 0.4618, 0.5182, 0.5182, 0.5182, 0.4618, 0.5182, 0.5182, 0.5182, 0.4618, 0.5182, 0.5182, 0.5182, 0.3449, 0.4134, 0.4134, 0.4134, 0.4618, 0.5182, 0.5182, 0.5182, 0.4618, 0.5182, 0.5182, 0.5182, 0.4618, 0.5182, 0.5182, 0.5182} |
| HFAAPWG(U1)= | {0.3991, 0.4336, 0.4466, 0.4579, 0.4519, 0.4910, 0.5057, 0.5185, 0.4519, 0.4910, 0.5057, 0.5185, 0.4519, 0.4910, 0.5057, 0.5185, 0.4445, 0.4829, 0.4974, 0.5100, 0.5034, 0.5469, 0.5633, 0.5776, 0.5034, 0.5469, 0.5633, 0.5776, 0.5034, 0.5469, 0.5633, 0.5776, 0.4952, 0.5379, 0.5541, 0.5681, 0.5607, 0.6092, 0.6275, 0.6434, 0.5607, 0.6092, 0.6275, 0.6434, 0.5607, 0.6092, 0.6275, 0.6434, 0.4952, 0.5379, 0.5541, 0.5681, 0.5607, 0.6092, 0.6275, 0.6434, 0.5607, 0.6092, 0.6275, 0.6434, 0.5607, 0.6092, 0.6275, 0.6434} |
| HFAAPWG(U2)= | {0.5170, 0.5974, 0.6300, 0.6300, 0.6293, 0.7272, 0.7669, 0.7669, 0.6821, 0.7882, 0.8312, 0.8312, 0.6821, 0.7882, 0.8312, 0.8312, 0.5281, 0.6102, 0.6435, 0.6435, 0.6428, 0.7428, 0.7833, 0.7833, 0.6967, 0.8051, 0.8490, 0.8490, 0.6967, 0.8051, 0.8490, 0.8490, 0.5281, 0.6102, 0.6435, 0.6435, 0.6428, 0.7428, 0.7833, 0.7833, 0.6967, 0.8051, 0.8490, 0.8490, 0.6967, 0.8051, 0.8490, 0.8490, 0.5281, 0.6102, 0.6435, 0.6435, 0.6428, 0.7428, 0.7833, 0.7833, 0.6967, 0.8051, 0.8490, 0.8490, 0.6967, 0.8051, 0.8490, 0.8490} |
| HFAAPWG(U3)= | {0.3340, 0.3492, 0.3556, 0.3556, 0.4069, 0.4254, 0.4332, 0.4332, 0.4069, 0.4254, 0.4332, 0.4332, 0.4069, 0.4254, 0.4332, 0.4332, 0.3622, 0.3787, 0.3856, 0.3856, 0.4413, 0.4613, 0.4698, 0.4698, 0.4413, 0.4613, 0.4698, 0.4698, 0.4413, 0.4613, 0.4698, 0.4698, 0.3821, 0.3995, 0.4068, 0.4068, 0.4655, 0.4867, 0.4956, 0.4956, 0.4655, 0.4867, 0.4956, 0.4956, 0.4655, 0.4867, 0.4956, 0.4956, 0.3821, 0.3995, 0.4068, 0.4068, 0.4655, 0.4867, 0.4956, 0.4956, 0.4655, 0.4867, 0.4956, 0.4956, 0.4655, 0.4867, 0.4956, 0.4956} |
| HFAAPWG(U4)= | {0.2582, 0.2658, 0.2658, 0.2658, 0.5466, 0.5627, 0.5627, 0.5627, 0.7210, 0.7422, 0.7422, 0.7422, 0.7210, 0.7422, 0.7422, 0.7422, 0.2821, 0.2904, 0.2904, 0.2904, 0.5972, 0.6148, 0.6148, 0.6148, 0.7877, 0.8109, 0.8109, 0.8109, 0.7877, 0.8109, 0.8109, 0.8109, 0.2935, 0.3022, 0.3022, 0.3022, 0.6215, 0.6397, 0.6397, 0.6397, 0.8197, 0.8438, 0.8438, 0.8438, 0.8197, 0.8438, 0.8438, 0.8438, 0.2935, 0.3022, 0.3022, 0.3022, 0.6215, 0.6397, 0.6397, 0.6397, 0.8197, 0.8438, 0.8438, 0.8438, 0.8197, 0.8438, 0.8438, 0.8438} |
| HFAAPWG(U5)= | {0.2381, 0.2603, 0.2603, 0.2603, 0.3823, 0.4180, 0.4180, 0.4180, 0.3823, 0.4180, 0.4180, 0.4180, 0.3823, 0.4180, 0.4180, 0.4180, 0.2654, 0.2902, 0.2902, 0.2902, 0.4263, 0.4661, 0.4661, 0.4661, 0.4263, 0.4661, 0.4661, 0.4661, 0.4263, 0.4661, 0.4661, 0.4661, 0.2719, 0.2973, 0.2973, 0.2973, 0.4367, 0.4775, 0.4775, 0.4775, 0.4367, 0.4775, 0.4775, 0.4775, 0.4367, 0.4775, 0.4775, 0.4775, 0.2719, 0.2973, 0.2973, 0.2973, 0.4367, 0.4775, 0.4775, 0.4775, 0.4367, 0.4775, 0.4775, 0.4775, 0.4367, 0.4775, 0.4775, 0.4775} |
References
- Zadeh, L. Fuzzy sets. Inf. Control. 1965, 8, 338–353. [Google Scholar] [CrossRef]
- Dalman, H.; Güzel, N.; Sivri, M. A fuzzy set-based approach to multi-objective multi-item solid transportation problem under uncertainty. Int. J. Fuzzy Syst. 2016, 18, 716–729. [Google Scholar] [CrossRef]
- Dubois, D.; Prade, H.; Esteva, F. Fuzzy set modelling in case-based reasoning. Int. J. Intell. Syst. 1998, 13, 345–373. [Google Scholar] [CrossRef]
- Atanassov, K.; Stoeva, S. Intuitionistic fuzzy sets. Fuzzy Sets Syst. 1986, 20, 87–96. [Google Scholar] [CrossRef]
- Yager, R.; Abbasov, A. Pythagorean membership grades, complex numbers, and decision making. Int. J. Intell. Syst. 2013, 28, 436–452. [Google Scholar] [CrossRef]
- Torra, V. Hesitant fuzzy sets. Int. J. Intell. Syst. 2010, 25, 529–539. [Google Scholar] [CrossRef]
- Al-shami, T. (2,1)-Fuzzy sets: Properties, weighted aggregated operators and their applications to multi-criteria decision-making methods. Complex Intell. Syst. 2023, 9, 1687–1705. [Google Scholar] [CrossRef]
- Al-Shami, T.; Mhemdi, A. Generalized Frame for Orthopair Fuzzy Sets: (m,n)-Fuzzy Sets and Their Applications to Multi-Criteria Decision-Making Methods. Information 2023, 14, 56. [Google Scholar] [CrossRef]
- Luo, M.; Zhao, R. A distance measure between intuitionistic fuzzy sets and its application in medical diagnosis. Artif. Intell. Med. 2018, 89, 34–39. [Google Scholar] [CrossRef]
- Xu, Z.; Zhang, X. Hesitant fuzzy multi-attribute decision making based on TOPSIS with incomplete weight information. Knowl.-Based Syst. 2013, 52, 53–64. [Google Scholar] [CrossRef]
- Zhang, N.; Wei, G. Extension of VIKOR method for decision making problem based on hesitant fuzzy set. Appl. Math. Model. 2013, 37, 4938–4947. [Google Scholar] [CrossRef]
- Chen, N.; Xu, Z. Hesitant fuzzy ELECTRE II approach: A new way to handle multi-criteria decision making problems. Inf. Sci. 2015, 292, 175–197. [Google Scholar] [CrossRef]
- Menger, K. Statistical metrics. Sel. Math. 2003, 2, 433–435. [Google Scholar]
- Xia, M.; Xu, Z. Hesitant fuzzy information aggregation in decision making. Int. J. Approx. Reason. 2011, 52, 395–407. [Google Scholar] [CrossRef]
- Yager, R. The power average operator. IEEE Trans. Syst. Man Cybern. Part Syst. Humans 2001, 31, 724–731. [Google Scholar] [CrossRef]
- Xu, Z.; Yager, R. Power-geometric operators and their use in group decision making. IEEE Trans. Fuzzy Syst. 2009, 18, 94–105. [Google Scholar] [CrossRef]
- Yu, D. Some hesitant fuzzy information aggregation operators based on Einstein operational laws. Int. J. Intell. Syst. 2014, 29, 320–340. [Google Scholar] [CrossRef]
- He, X. Typhoon disaster assessment based on Dombi hesitant fuzzy information aggregation operators. Nat. Hazards 2018, 90, 1153–1175. [Google Scholar] [CrossRef]
- Aczél, J.; Alsina, C. Characterizations of some classes of quasilinear functions with applications to triangular norms and to synthesizing judgements. Aequationes Math. 1982, 25, 313–315. [Google Scholar] [CrossRef]
- Senapati, T.; Chen, G.; Mesiar, R. Novel Aczel—Alsina operations-based hesitant fuzzy aggregation operators and their applications in cyclone disaster assessment. Int. J. Gen. Syst. 2022, 51, 511–546. [Google Scholar] [CrossRef]
- Senapati, T.; Chen, G.; Yager, R.R. Aczel—Alsina aggregation operators and their application to intuitionistic fuzzy multiple attribute decision making. Int. J. Intell. Syst. 2022, 37, 1529–1551. [Google Scholar] [CrossRef]
- Senapati, T.; Mesiar, R.; Simic, V. Analysis of interval-valued intuitionistic fuzzy Aczel—Alsina geometric aggregation operators and their application to multiple attribute decision-making. Axioms 2022, 11, 258. [Google Scholar] [CrossRef]
- Senapati, T. Approaches to multi-attribute decision making based on picture fuzzy Aczel-Alsina average aggregation operators. Comput. Appl. Math. 2022, 41, 1–28. [Google Scholar] [CrossRef]
- Szmidt, E.; Kacprzyk, J. Distances between intuitionistic fuzzy sets. Fuzzy Sets Syst. 2000, 114, 505–518. [Google Scholar] [CrossRef]
- Grzegorzewski, P. Distances between intuitionistic fuzzy sets and/or interval-valued fuzzy sets based on the Hausdorff metric. Fuzzy Sets Syst. 2004, 148, 319–328. [Google Scholar] [CrossRef]
- Xu, Z.; Xia, M. Distance and similarity measures for hesitant fuzzy sets. Inf. Sci. 2011, 181, 2128–2138. [Google Scholar] [CrossRef]
- Perlibakas, V. Distance measures for PCA-based face recognition. Pattern Recognit. Lett. 2004, 25, 711–724. [Google Scholar] [CrossRef]
- Ren, H.; Xiao, S.; Zhou, H. A Chi-Square Distance-Based Similarity Measure of Single-Valued Neutrosophic Set and Applications; Infinite Study: Ghaziabad, India, 2019. [Google Scholar] [CrossRef]
- Klement, E.; Mesiar, R.; Pap, E. Triangular Norms; Springer Science & Business Media: Berlin/Heidelberg, Germany, 2013. [Google Scholar] [CrossRef]
- Senapati, T.; Simic, V.; Saha, A. Intuitionistic fuzzy power Aczel-Alsina model for prioritization of sustainable transportation sharing practices. Eng. Appl. Artif. Intell. 2023, 119, 105716. [Google Scholar] [CrossRef]
- Alsina, C.; Schweizer, B.; Frank, M. Associative Functions: Triangular Norms and Copulas; World Scientific: Singapore, 2006. [Google Scholar] [CrossRef]
- Torra, V.; Narukawa, Y. On hesitant fuzzy sets and decision. In Proceedings of the 2009 IEEE International Conference on Fuzzy Systems, Jeju Island, South Korea, 20–24 August 2009; IEEE: Piscataway, NJ, USA, 2009; pp. 1378–1382. [Google Scholar] [CrossRef]
- Xia, M.; Xu, Z. Studies on the aggregation of intuitionistic fuzzy and hesitant fuzzy information. Int. J. Intell. Syst. 2011, 26, 26. [Google Scholar]
- Yager, R. Generalized OWA aggregation operators. Fuzzy Optim. Decis. Mak. 2004, 3, 93–107. [Google Scholar] [CrossRef]
- Farhadinia, B. Information measures for hesitant fuzzy sets and interval-valued hesitant fuzzy sets. Inf. Sci. 2013, 240, 129–144. [Google Scholar] [CrossRef]
- Shannon, C. A mathematical theory of communication. Bell Syst. Tech. J. 1948, 27, 379–423. [Google Scholar] [CrossRef]
- Xu, Z. Uncertain Multi-Attribute Decision Making: Methods and Applications; Springer: Berlin/Heidelberg, Germany, 2015. [Google Scholar] [CrossRef]
- Stewart, C. An approach to measure distance between compositional diet estimates containing essential zeros. J. Appl. Stat. 2017, 44, 1137–1152. [Google Scholar] [CrossRef]
- Zhou, H.; Ren, H. A study of intuitionistic fuzzy similarity clustering algorithm based on Chi-Square distance. J. Chongqing Univ. Technol. (Nat. Sci.) 2020, 34, 238–246. [Google Scholar]
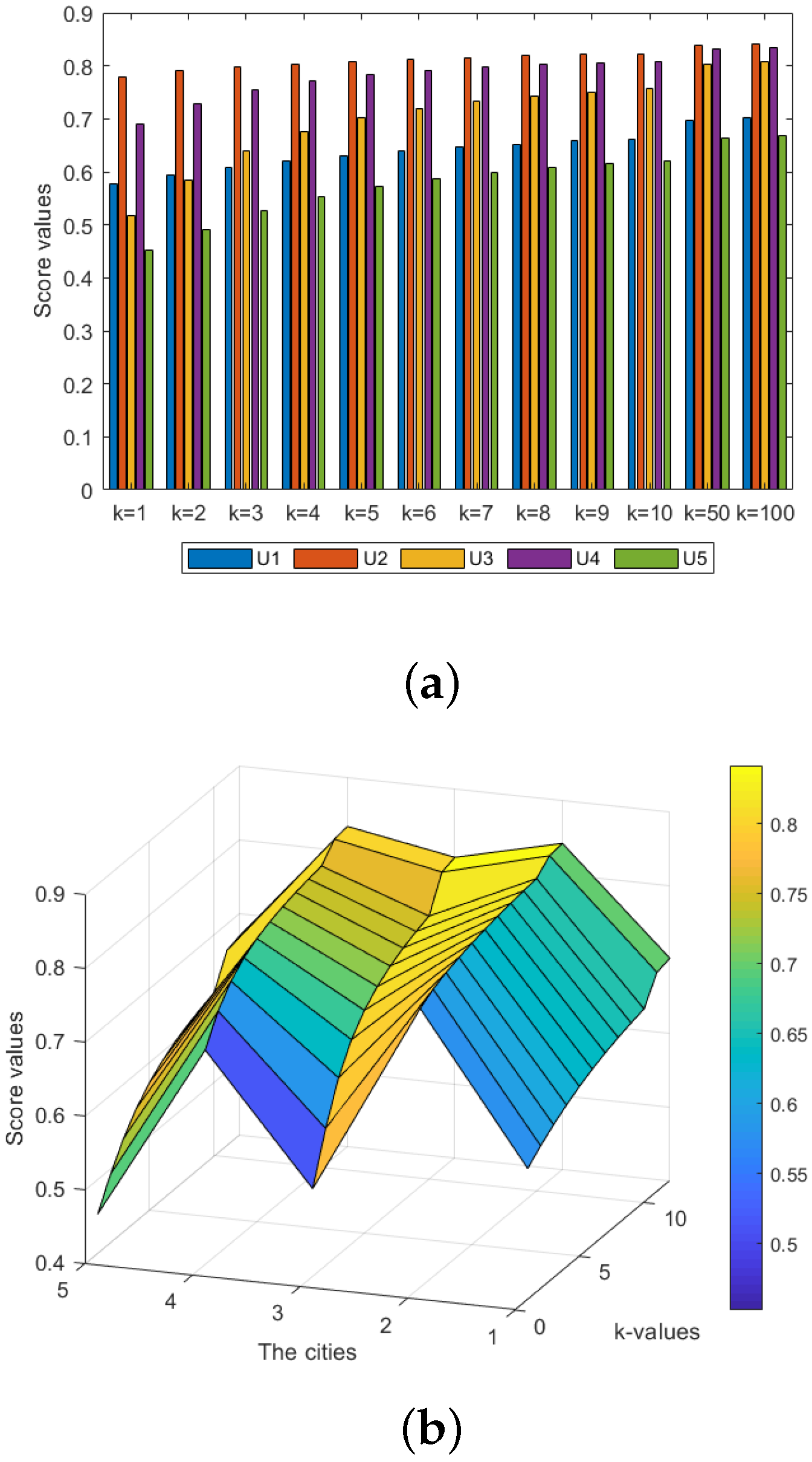
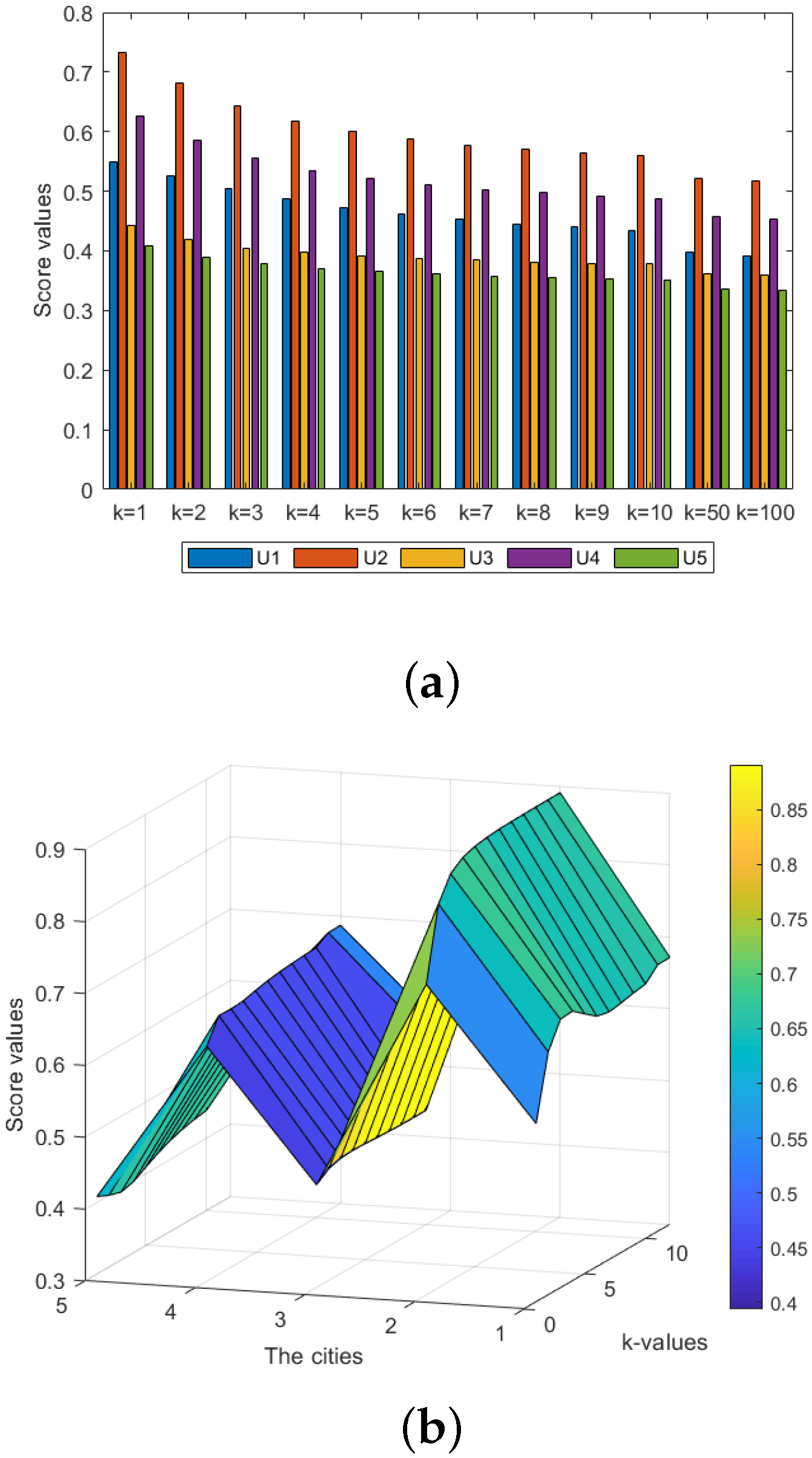
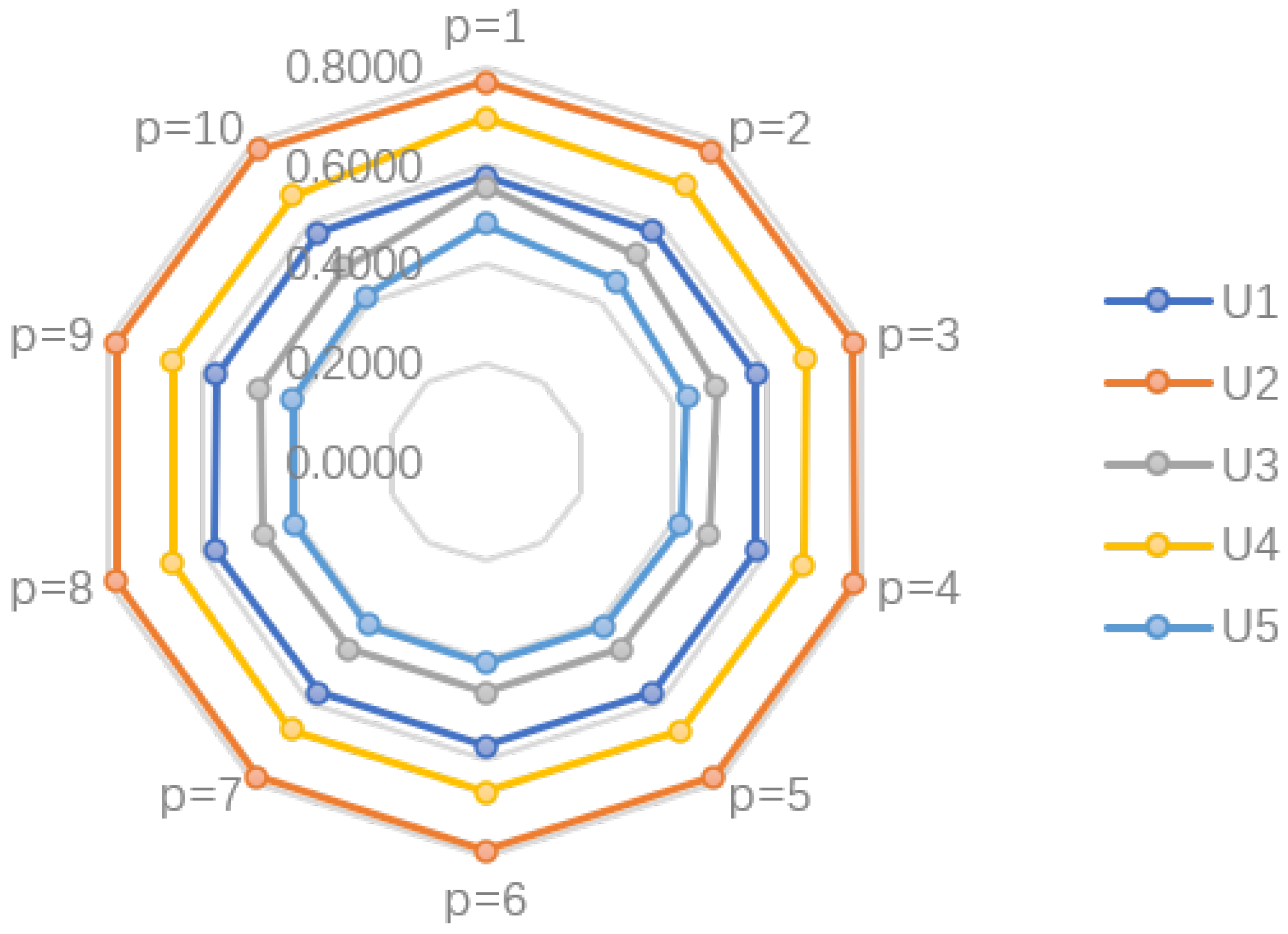

| {0.2,0.4,0.8} | {0.5,0.6} | {0.3,0.5,0.6,0.7} | |
| {0.7,0.8} | {0.6,0.8,0.9} | {0.2,0.5,0.7} | |
| {0.3,0.5,0.7} | {0.3,0.4} | {0.6,0.8,0.9} | |
| {0.4,0.7,0.9} | {0.2,0.6,0.9} | {0.5,0.6} | |
| {0.3,0.6,0.7} | {0.2,0.4} | {0.4,0.7} |
| {0.2,0.4,0.8,0.8} | {0.5,0.6,0.6,0.6} | {0.3,0.5,0.6,0.7} | |
| {0.7,0.8,0.8,0.8} | {0.6,0.8,0.9,0.9} | {0.2,0.5,0.7,0.7} | |
| {0.3,0.5,0.7,0.7} | {0.3,0.4,0.4,0.4} | {0.6,0.8,0.9,0.9} | |
| {0.4,0.7,0.9,0.9} | {0.2,0.6,0.9,0.9} | {0.5,0.6,0.6,0.6} | |
| {0.3,0.6,0.7,0.7} | {0.2,0.4,0.4,0.4} | {0.4,0.7,0.7,0.7} |
| Ranking Results | ||||||
|---|---|---|---|---|---|---|
| 0.5772 | 0.7782 | 0.5184 | 0.6904 | 0.4525 | ||
| 0.5485 | 0.7322 | 0.4434 | 0.6267 | 0.4075 |
| Ranking Results | ||||||
|---|---|---|---|---|---|---|
| 0.5772 | 0.7782 | 0.5184 | 0.6904 | 0.4525 | ||
| 0.5934 | 0.7899 | 0.5855 | 0.7287 | 0.4920 | ||
| 0.6074 | 0.7977 | 0.6395 | 0.7547 | 0.5259 | ||
| 0.6196 | 0.8037 | 0.6766 | 0.7717 | 0.5523 | ||
| 0.6301 | 0.8085 | 0.7018 | 0.7833 | 0.5722 | ||
| 0.6390 | 0.8126 | 0.7195 | 0.7915 | 0.5873 | ||
| 0.6465 | 0.8160 | 0.7326 | 0.7975 | 0.5988 | ||
| 0.6527 | 0.8188 | 0.7425 | 0.8021 | 0.6078 | ||
| 0.6579 | 0.8212 | 0.7503 | 0.8057 | 0.6150 | ||
| 0.6623 | 0.8232 | 0.7566 | 0.8086 | 0.6209 | ||
| 0.6974 | 0.8396 | 0.8017 | 0.8305 | 0.6641 | ||
| 0.7018 | 0.8417 | 0.8071 | 0.8332 | 0.6696 |
| Ranking Results | ||||||
|---|---|---|---|---|---|---|
| 0.5485 | 0.7322 | 0.4434 | 0.6267 | 0.4075 | ||
| 0.5257 | 0.6807 | 0.4185 | 0.5854 | 0.3893 | ||
| 0.5044 | 0.6425 | 0.4053 | 0.5555 | 0.3779 | ||
| 0.4866 | 0.6171 | 0.3971 | 0.5352 | 0.3704 | ||
| 0.4725 | 0.5996 | 0.3916 | 0.5212 | 0.3652 | ||
| 0.4614 | 0.5869 | 0.3875 | 0.5110 | 0.3613 | ||
| 0.4527 | 0.5774 | 0.3843 | 0.5032 | 0.3582 | ||
| 0.4456 | 0.5700 | 0.3817 | 0.4971 | 0.3558 | ||
| 0.4399 | 0.5641 | 0.3796 | 0.4921 | 0.3537 | ||
| 0.4351 | 0.5593 | 0.3777 | 0.4881 | 0.3520 | ||
| 0.3972 | 0.5221 | 0.3609 | 0.4567 | 0.3357 | ||
| 0.3924 | 0.5173 | 0.3586 | 0.4526 | 0.3335 |
| Ranking Results | ||||||
|---|---|---|---|---|---|---|
| 0.5764 | 0.7690 | 0.5556 | 0.6971 | 0.4812 | ||
| 0.5772 | 0.7782 | 0.5184 | 0.6905 | 0.4525 | ||
| 0.5769 | 0.7836 | 0.4905 | 0.6821 | 0.4298 | ||
| 0.5763 | 0.7861 | 0.4742 | 0.6754 | 0.4158 | ||
| 0.5756 | 0.7869 | 0.4668 | 0.6711 | 0.4085 | ||
| 0.5751 | 0.7867 | 0.4653 | 0.6684 | 0.4057 | ||
| 0.5746 | 0.7859 | 0.4677 | 0.6669 | 0.4057 | ||
| 0.5741 | 0.7847 | 0.4727 | 0.6659 | 0.4074 | ||
| 0.5736 | 0.7831 | 0.4792 | 0.6654 | 0.4103 | ||
| 0.5732 | 0.7813 | 0.4868 | 0.6650 | 0.4140 |
| Ranking Results | ||||||
|---|---|---|---|---|---|---|
| 0.5416 | 0.7135 | 0.4681 | 0.6224 | 0.4290 | ||
| 0.5485 | 0.7322 | 0.4434 | 0.6267 | 0.4075 | ||
| 0.5544 | 0.7455 | 0.4267 | 0.6302 | 0.3925 | ||
| 0.5582 | 0.7527 | 0.4175 | 0.6325 | 0.3840 | ||
| 0.5604 | 0.7555 | 0.4133 | 0.6334 | 0.3782 | ||
| 0.5613 | 0.7555 | 0.4122 | 0.6334 | 0.3782 | ||
| 0.5616 | 0.7535 | 0.4130 | 0.6328 | 0.3782 | ||
| 0.5614 | 0.7504 | 0.4151 | 0.6317 | 0.3793 | ||
| 0.5610 | 0.7464 | 0.4180 | 0.6303 | 0.3810 | ||
| 0.5603 | 0.7419 | 0.4215 | 0.6288 | 0.3831 |
| Techniques | t-Norm Used | Parameter | Weight | Preference Order |
|---|---|---|---|---|
| HFWA [14] | No | No | Assumed | |
| HFWG [14] | No | No | Assumed | |
| HFEWA [17] | Einstein | No | Assumed | |
| HFEWG [17] | Einstein | No | Assumed | |
| HFDWA [18] | Dombi | 1 | Assumed | |
| HFDWG [18] | Dombi | 1 | Assumed | |
| HFAAWA [20] | Aczel–Alsina | 1 | Assumed | |
| HFAAWG [20] | Aczel–Alsina | 1 | Assumed | |
| HFAAWBM [20] | Aczel–Alsina | 3 | Assumed | |
| Proposed method | Aczel–Alsina | 2 | Entropy weights | |
| (HFAAPWA) | and power operator | |||
| Proposed method | Aczel–Alsina | 2 | Entropy weights | |
| (HFAAPWG) | and power operator |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Xie, J.; Chen, C.; Wan, J.; Dong, Q. Enhancing the Aczel–Alsina Model: Integrating Hesitant Fuzzy Logic with Chi-Square Distance for Complex Decision-Making. Symmetry 2024, 16, 1702. https://doi.org/10.3390/sym16121702
Xie J, Chen C, Wan J, Dong Q. Enhancing the Aczel–Alsina Model: Integrating Hesitant Fuzzy Logic with Chi-Square Distance for Complex Decision-Making. Symmetry. 2024; 16(12):1702. https://doi.org/10.3390/sym16121702
Chicago/Turabian StyleXie, Jianming, Chunfang Chen, Jing Wan, and Qiuxian Dong. 2024. "Enhancing the Aczel–Alsina Model: Integrating Hesitant Fuzzy Logic with Chi-Square Distance for Complex Decision-Making" Symmetry 16, no. 12: 1702. https://doi.org/10.3390/sym16121702
APA StyleXie, J., Chen, C., Wan, J., & Dong, Q. (2024). Enhancing the Aczel–Alsina Model: Integrating Hesitant Fuzzy Logic with Chi-Square Distance for Complex Decision-Making. Symmetry, 16(12), 1702. https://doi.org/10.3390/sym16121702