Abstract
Since Darwin, evolutionary population dynamics has captivated scientists and has applications beyond biology, such as in game theory where economists use it to explore evolution in new ways. This approach has renewed interest in dynamic evolutionary systems. In this paper, we propose an information-theoretic method to estimate trait parameters in a Darwinian model for species with single or multiple traits. Using Fisher information, we assess estimation errors and demonstrate the method through simulations.
1. Introduction
Evolution can be seen as the dynamic changes in organisms’ traits, driven largely by environmental factors and occurring through mutations or random genetic variations. Darwin’s theory of natural selection ([1]) suggests that species best adapted to their environment pass beneficial traits to their offspring. Over time, advantageous traits may lead to the emergence of new species, making the tracking of trait variations central to understanding evolution.
Information theory offers tools to track such evolutionary changes. For a random variable X depending on a trait parameter , the Fisher’s information measures the information X provides about ([2]). Since its introduction ([3]), the Fisher’s information has been widely applied, including in Bayesian statistics ([4]), to derive the Wald’s test ([5]), to estimate Cramér–Rao bounds ([6,7]), in optimal experimental design ([8]), in machine learning ([9]), and in epidemiology ([10]), just to name some. Notably, it connects to relative entropy (or Kullback–Leibler divergence), as the Fisher’s information represents the Hessian of relative entropy with respect to . In evolutionary biology, information in genomes is expected to change as environments evolve.
Our focus on evolutionary population dynamics and Fisher information builds on the work of [11], where Darwinian dynamics are explored through evolutionary game theory. They analyze a static game with n players, each choosing a strategy to maximize their payoff , defined by
where . This evolves into a dynamic game represented by an ordinary differential equation
where , and is the instantaneous payoff for player i. In ecology, this approach adapts to n species, with as the per capita growth rate of a species with density and trait . Ref. [12] introduced the G-function to generalize the growth rate:
where is a “virtual variable”. This leads to an evolution equation for strategies:
The connection between game theory and evolution population dynamics can be made using the Table 1 below:

Table 1.
The table shows for Game Theory variables are interpreted in population dynamics.
In light of this comparison, estimation of parameters ’s, either in a game theory context or in a population dynamics context, is of paramount importance if one aims to make meaningful predictions, given data, on the underlying model. Now, consider the following population dynamics system:
where represents the variance of trait distribution. Solutions to this system, called Evolutionarily Stable Strategies (ESSs), provide insight into stable trait configurations ([13,14]). For an ESS, G must attain a maximum at zero with respect to ([12]). Recent work on discrete versions of these models includes studies of evolutionary stability ([15]), difference equation schemes ([16]), and applications to disease resistance ([17]). This paper addresses two questions raised in [11]: 1. Are there interpretable relations between the maximum of G, g, and ? 2. Are there similar interpretable relations for and ?
Our literature review found no comprehensive answers to these questions. To explore them, we frame G in the context of random variables. For one species, if represents a density function for a random variable X depending on an unknown trait , Fisher information quantifies the information a sample of X contains about . By analyzing G and its derivatives, we gain insights into evolutionary traits and parameter estimation. This paper develops a statistical framework for estimating species traits in Darwinian models. By minimizing or maximizing the Fisher’s information in this context, we not only address the questions above but also offer a method for estimating unknown parameters in evolution models. This paper is organized as follows: Section 2 provides an overview of Fisher information in statistics. Section 3 discusses Fisher information within discrete evolutionary population dynamics. Section 4 concludes with final remarks.
2. Review of Fisher’s Information Theory
Let represent the probability density function (pdf) of a random variable X, which can be continuous or discrete on an open set . Here, denotes a single parameter or a vector of parameters. Since is a pdf, it must satisfy . If we have a nonnegative integrable function defined on , it can be normalized to become a pdf by defining , where . In what follows, we assume the following conditions on :
- (1)
- Support independence: The support of p is independent of .
- (2)
- Nonnegativity and integrability: is nonnegative for all and .
- (3)
- Smoothness: , meaning is continuously differentiable up to the second order with respect to for all .
The first condition excludes cases like a uniform distribution , where the support varies with . The second condition ensures that the log-density , its first derivative (score function) , and its second derivative are well defined. We denote the expectation of a random variable X by .
Definition 1
(Fisher information). For a random variable X with density satisfying assumptions (1) and (2), the Fisher information of X is defined as
If θ is a vector, then is a symmetric positive definite matrix, given by
The Fisher information quantifies the amount of information about provided by an estimator based on X. When is estimated from a random sample drawn from , the Fisher information in the sample is
Definition 2
(estimator and properties). Let X be a random variable depending on the parameter vector θ, and let be a random sample from X. We define the following:
- Estimator: is called an estimator of θ.
- Unbiased estimator: T is unbiased if .
- Efficient estimator: An unbiased estimator T is efficient if its variance satisfies .
In particular, if is an estimator of based on a sample , the Cramér–Rao (see for instance [6,7]) bound gives an estimate of the best lower bound for the variance of T as
Equality is obtained in (1) if T is efficient. If T is unbiased, then and consequently, , where is a vector of ones . Therefore, (1) becomes
Example 1.
Suppose X is a random variable with distribution , where . Then we have that , and . It follows that and . If we now consider a random sample from X, and , we note that , so that . Thus, T is an unbiased estimator of θ and . Moreover, . We then verify from (2) that indeed we have . Consequently, accurate estimates of Θ have large Fisher’s information (matrix) components, whereas inaccurate ones have small Fisher’s information components.
3. Evolution Population Dynamics and Information Theory
3.1. Single Population Model with One Trait
Consider the following discrete evolutionary dynamical model:
where where and , for a constant u and for some positive constants (speed of evolution), (initial birth rate), (competition constant), , and w (standard deviation of the distribution of birth rates), and for a differentiable function of and positive and continuous function . This system has nontrivial fixed points if they satisfy the equations
This can further be reduced to the condition on and given by
The theorem below shows how to obtain the Fisher’s information of the above system as a function of the system’s parameters.
Theorem 1.
Let . Then the Fisher’s information of this system is constant and given by
The proof can be found in Appendix A.1.
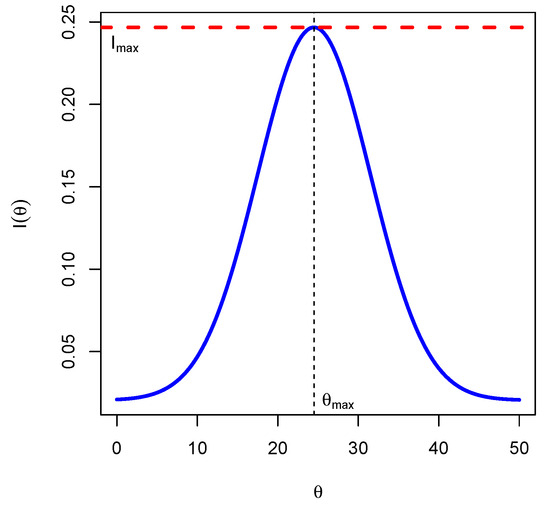
Corollary 1.
The Fisher’s information attains its maximum value for , and the maximum value is
The proof can be found in Appendix A.2.
In the proposition below, we give precise conditions for the existence of nontrivial fixed points of the system above.
Proposition 1.
Let
If , then the Darwinian system has a unique nontrivial fixed point given as
If , then the Darwinian system has two nontrivial fixed points and given by
Proposition 1 and Theorem 1 are important in that when as , then by continuity of the function with respect to , we will have as . This means that the Fisher’s information, over time, will be maximized at the critical point of the dynamical system. Therefore, for estimation purposes, the reciprocal of will be the smallest variance for any unbiased estimator of the trait . In Figure 2, below, we use the following parameters: .
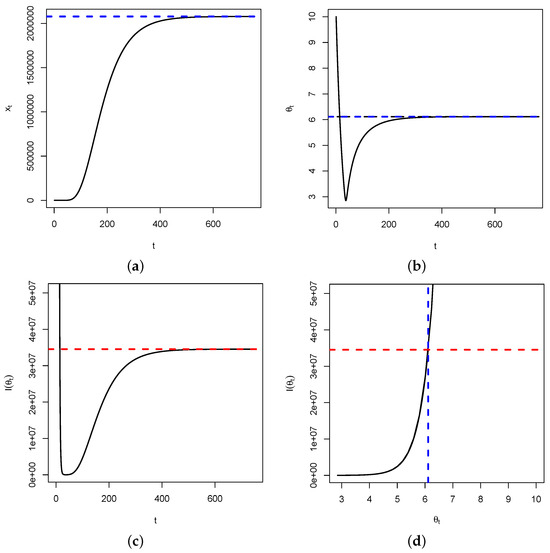
Figure 2.
In (a), represented is the time series of . It shows a convergence to (blue dashed line). In (b), represented is the time series of , showing a convergence to (blue dashed line). Figure (c) represents the time series of the Fisher’s information , showing a convergence to (red dashed line). Figure (d) is the plot of versus , showing that once the fixed point is reached, the Fisher’s information is maximized. This is illustrated by the intersection between the blue and red dashed lines.
- Special case:
We will now discuss the particular case of an exponential distribution, that is, . Clearly, the condition (5) is satisfied with and . Therefore,
This implies that . It follows that there are equilibrium fixed points: the extinction equilibrium (trivial point) and the interior equilibrium (nontrivial point) . In Figure 3, below, we represent functions , and for . This shows that is minimized where is maximized, providing a clue as to the relation between the maximum of G and the critical points of g and . Another clue can be found in Figure 4 below.
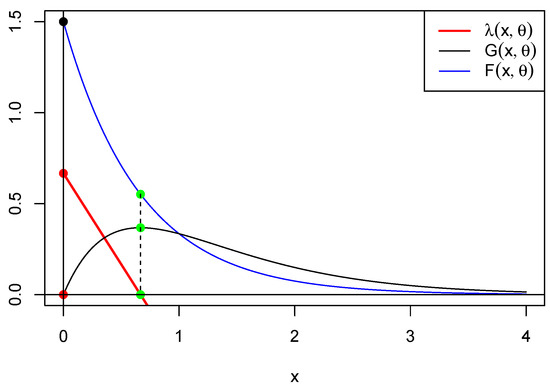
Figure 3.
This figure shows in blue, in black, and in red for . The green dots represent the intersection between the vertical and these curves. We observe that is maximized at the same point x where is minimized (green dots) and vice versa (red dots).
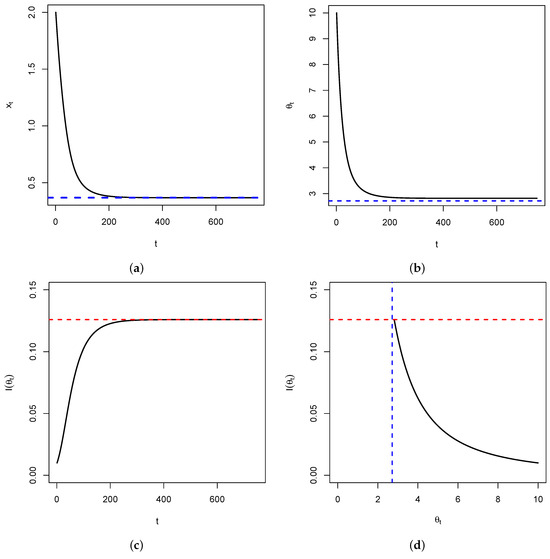
Figure 4.
In (a), represented is the time series of in the special case above. It shows a convergence to (blue dashed line). In (b), represented is the time series of , showing a convergence to (blue dashed line). Figure (c) represents the time series of the Fisher’s information , showing a convergence to (red dashed line) as . Figure (d) is the plot of versus , showing that once the fixed point is reached, the Fisher’s information is maximized. This is illustrated by the intersection between the blue and red dashed lines.
From a dynamical systems’ perspective, it means that , the value of X at time t, is generated from the distribution and used to calculate the value of . Therefore, the role of the first choice of is to initialize the dynamical system. Once the system is initialized for , we can use an information theory approach to provide an estimator of , the value of at time t. That estimator, if efficient, will have variance . We can then use the dynamical system (9) to estimate , and the Fisher’s information will provide its variance. We note that will only be an estimate of the true value and therefore will carry an error as t changes. It is therefore expected that at the nontrivial critical point (ESS) of the dynamical system, the estimator converges to and the variance of converges to as .
Figure 5 below is an illustration of this fact for .
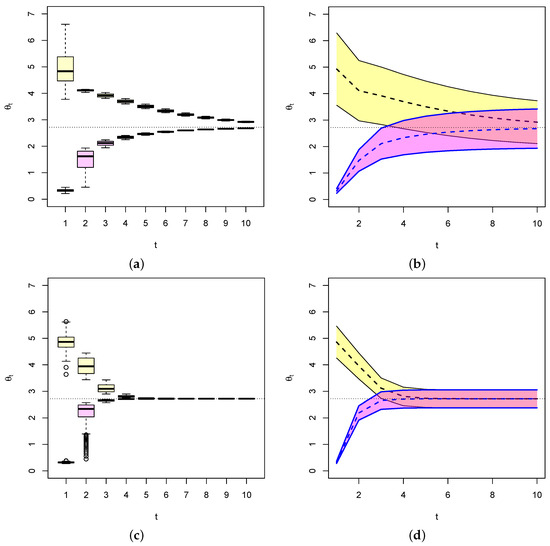
Figure 5.
Values of (dashed line) for two different starting values of , each with their 95% confidence bands (colored-shaded areas). In each case, converges to e (light dashed line) as . When n is relatively small as (a,b), confidence intervals are relative large. When n is large as in (c,d), becomes smaller and so is the width of the confidence interval.
Indeed, we generated two random samples of size (Figure 5a,b) and (Figure 5c,d) with where and from exponential distributions with respective initial parameters . We choose , which is known to be an efficient estimator of . The dashed lines represent the respective values of , and the black lines represent their 95% confidence intervals . This shows in particular that on average, converges to e (dashed line), the fixed point of the dynamical system, as expected from the above. It also shows that as the Fisher’s formation gets larger, the variance of the estimator gets smaller and thus the width of the confidence interval gets smaller and quickly approaches zero as in Figure 5c,d. The conclusion is that given an evolution dynamical system, we can estimate the evolution parameter vector and provide an estimate of the error on the estimate that is the inverse of the Fisher’s information. Moreover, over time, the estimate converges to the ESS of the system (when it exists) and the errors on the estimate essentially becomes zero when convergence is reached.
Remark 1.
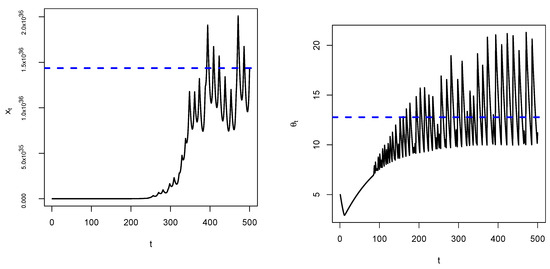
We observe that convergence of towards e as predicted depends on choosing an appropriate value of σ. Large values of σ will definitely make the system unstable as oscillations will slowly and increasingly occur, see Figure 6 below.
Figure 6.
Time series of a Darwinian model when is large. We observe that there are oscillations making the critical point unstable (blue dashed line).
3.2. Discussion
Assumption is important in that we only require that G be nonnegative and , which guarantees that it can be transformed into the density of a random variable. It does not, however, guarantee that we can easily obtain a sample from it! If G happens to be a classical distribution (normal, exponential, t-distribution, Weibull, etc.), then there are sampling methods already available. If G has a nonclassic expression, we may have to resort to either the Probability Integral Transform (see Theorem 2.1.10, p. 54 in [18]) or to Markov Chain Monte Carlo (MCMC) to obtain a sample, which sometimes are themselves onerous in terms of time. Obtaining an efficient estimator of is easily undertaken when G is a classic distribution. While efficiency would be great, it may not be necessary since over time, the estimator would still converge, albeit slowly, to the fixed point of . We observe that the estimates we obtain in this case are point estimates of (mean, median, etc.), albeit at each time t. A Bayesian estimate is also possible, provided that the initial distribution of is selected from a well-defined Jeffrey’s prior. As for answers to the questions raised in the Introduction, we can say based on the above that the set of points where is maximized is the same where is minimized and contains all the critical points of the function G. This can be written formally as .
3.3. Single Population Model with Multiple Traits
Now suppose we are in the presence of one species with density x possessing n traits given by the vector and a vector .
() We assume that is the joint distribution of the independent traits , each with mean 0 and variance .
() We also assume that .
() We assume that the density of is given as at .
Under , and , we consider the discrete dynamical system
where
Remark 2.
There are a couple of distinctions between this model and the ones encountered in the recent literature, see for instance [16,19]. Firstly, the matrix Σ considered here is not necessarily symmetric (). Secondly, the competition function depends subtly on a vector that need not be the mean of Θ, as it is often considered. We note, however, that when , then . Ecologically, this happens when competition is maximal. This leads to recovering the uncoupled Darwinian model (2) in [19].
The result below shows how to obtain the Fisher’s information of the Darwinian dynamical system (9).
Theorem 2.
Let . Then under assumptions , and , the dynamical system above has the Fisher’s information matrix given as
The proof of this result can be found in Appendix B.
Remark 3.
We observe that in the case of a high-dimension vector of parameters Θ, the theorem above gives us not only the variance (the diagonal terms of ) on the estimator of each component of Θ but also the covariances between pairs of estimates (the off-diagonal terms) of different components (or traits). This may be important, especially to distinguish correlated and noncorrelated traits or strategies.
A necessary condition for the existence of an extinction equilibrium for this system is that . Letting represent the spectral radius of matrix A, it was proved in [16] that if and , then the extinction equilibrium is asymptotically stable and unstable if and , or if for all . This is particularly true if is diagonally dominant and for . This system admits a nontrivial fixed point (positive equilibrium) if and . In the proposition below, we give a more precise characterization of nontrivial fixed points of the system (15).
Proposition 2.
Assume and for . Put
and given
If , then there is no nontrivial solution for the system (9).
- (i)
- If , then .
- (ii)
- If , then the coordinates of the vector are points that lie on the curve of equation
The proof can be found in Appendix C.
- Special case: single species with two traits.
Here we consider the particular case of a system of one species with two traits, namely, the coupled dynamical system
The fixed points of this model are solutions of the system of equations
where
Corollary 2.
Assume and . We put
and
If , then there is no nontrivial solution for the system (14).
- (i)
- If , then .
- (ii)
- If , then are points that lie on the ellipse of equation
In Figure 7, below, we illustrate Proposition 2 for . We verify that and . Therefore, , that is, . We also have that and that . Hence, according to Proposition 2 above, is expected to be on the ellipse centered as with respective major and minor axis lengths and .
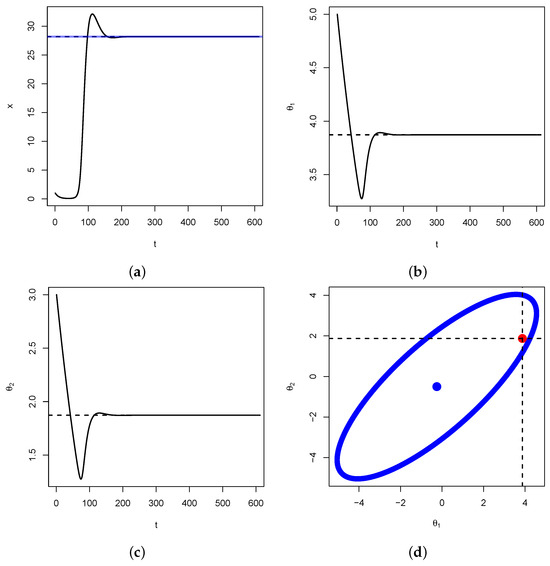
Figure 7.
In (a), the solid curve represents the dynamics of in the system (14) above. The dashed line represents the nontrivial equilibrium point . The blue line represent the value of as given in Equation (A3), using the values of and obtained as nontrivial fixed points from the last two equations in (14). That the blue line and the dashed coincide is proof of the first part of the Proposition above. In (b,c), the solid curves represent the dynamics of and , respectively. The dashed lines represent the nontrivial fixed points . In (d), the blue curve represents the ellipse given in Equation (17) above, with center . The red dot represents the nontrivial fixed . This point almost lies on the ellipse (the discrepancy is due to an accumulation of error), which is proof of the second part of Proposition 2 above.
The parameters for Figure 8 are the same except for and is generated from an exponential distribution with parameters .
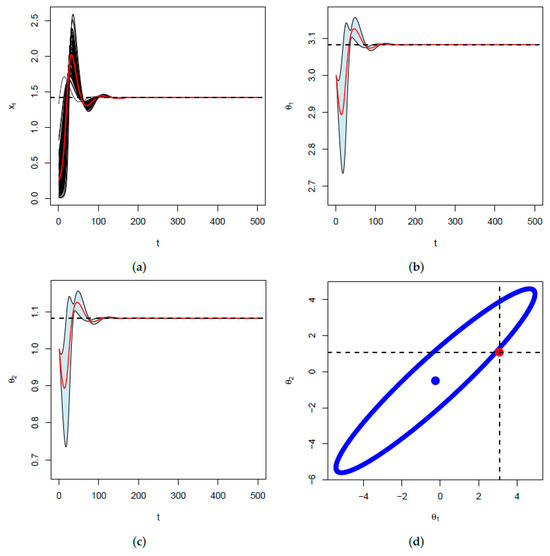
Figure 8.
In (a), represented in black are 100 trajectories of with a starting point selected at random from an exponential distribution with parameter . The red curve represents their average over time converging to . In (b), represented in light-blue are the 95% confidence bands for the corresponding trajectories of . The red curve represents their average and we verify that they all converge to . We note that these confidence bands are constructed using the Fisher’s information as , where is the average at time t. Similarly in (c), represented in light-blue are the 95% confidence bands for and the corresponding sample average in red. They converge to . In (d), represented is the ellipse given in Equation (17) above. We verify that the point is on the ellipse and that the value of obtained from Equation (A3) is the same as convergence value of .
3.4. Discussion
An important remark about Theorem 2 is that we assume the vector U is given. In fact, if the vector were given, the same technique could have been used for the estimation of U, up to a negative sign on the Fisher’s information matrix. Having U be different from the average of allows for generalization, in that represents the difference of a set of traits from a given set of traits U, which need not be the average of . One thing we have not insisted much about in this paper is the type of estimator of itself. We do not need to specify in particular which estimator to use, since the inverse of the Fisher’s information is the smallest variance for all estimators. One consequence of Proposition 2 above is that once we have estimated , we can deduce the value of . The results above also show that there may be many equilibria when . In the context of evolution and natural selection, one should focus on equilibria that ensure better adaptation to environmental fluctuations. This specifically means adding stochasticity to the model by means of, say, a Wiener process and finding traits that ensure, for example, that on average, the species density is bounded away from the extinction equilibrium. Another possibility could be to focus on equilibria that maximize the species density in order to increase the prospects of survivability of the species. This can be performed using a constraint optimization problem where subject to the constraint that the point u be on the curve defined in Equation (13). In the particular case where with , we have
However, the form of the function makes it a very challenging problem. Rewriting, we have
We observe that for positive and , the function is a positive and increasing function of u and v. Therefore, maximizing amounts to maximizing
Geometrically, this is the equation of a paraboloid that bends down. Therefore, the constraint optimization amounts to finding the points of intersection between a paraboloid and an ellipse. This means there can be between 0 and 4 points of intersection. Finally, let us observe that the expression of in the case of multiple traits is just a generalization of the case of one trait. In fact, the first equation in the system (4) can be written as . We see that this is similar to the expression of given in Equation (A3) for two traits, which naturally generalizes to the case of one species with traits.
4. Conclusions
In this paper, we introduced a method for estimating trait coefficients in a Darwinian evolution population dynamics model by employing the Fisher information matrix. This approach enables us not only to estimate traits effectively but also to characterize the uncertainty inherent in the estimation process. Our study focuses on two specific cases: a single species with one trait and a single species with multiple traits. Extending this framework to scenarios involving multiple species with one or more traits represents an intriguing avenue for future research, offering the potential to understand interspecies interactions in greater detail.
An essential contribution of our work is the proposed relationship between the G-function, its natural logarithm, and its derivative g. This relationship facilitates a more nuanced understanding of evolutionary dynamics and provides a clearer basis for examining trait adaptation over time. As a by-product, our method yields a precise characterization of the nontrivial fixed points of the model. Specifically, we demonstrated that once the critical density is determined, the set of critical traits aligns along a well-defined curve in . Conversely, if the set of critical traits is known, there may exist a unique critical density for the Darwinian system. Notably, this density may not necessarily ensure the survival of the species, adding complexity to our understanding of stable evolutionary states.
In addition to the traditional approach, we explored the potential of using modern machine learning techniques for trait parameter estimation. Traits could be estimated by minimizing relative information, such as Kullback–Leibler divergence, within a Darwinian evolution population model. This could be achieved via either classical gradient ascent or stochastic gradient ascent methods, with careful consideration given to selecting appropriate weights for the minimization process. Both approaches would need to be tailored to suit supervised or unsupervised learning environments, depending on the data availability and modeling goals.
Looking ahead, an extension of this work could involve introducing stochasticity into the model, for example, by incorporating a Wiener process. Such a modification would allow us to examine strong persistence on average, study the existence of global solutions, and explore stationary distributions within the population dynamics framework. This stochastic extension would provide a richer understanding of the model’s behavior under real-world conditions, where randomness and environmental variability play a significant role in shaping evolutionary outcomes.
Funding
This research was funded by AMS-Simon Research Enhancement for PUI grant.
Data Availability Statement
The data used in this paper are all simulated.
Conflicts of Interest
The author declares no conflicts of interest. The funders had no role in the design of the study; in the collection, analyses, or interpretation of data; in the writing of the manuscript; or in the decision to publish the results.
Appendix A
Appendix A.1. Proof of Theorem 1
Proof.
We have that .
It follows that
and
From Definition 1 above, it follows that
We observe that X has probability distribution ; therefore,
It then follows that
This ends the proof of the Theorem. □
Appendix A.2. Proof of Corollary 1
Suppose . From Equation (A1) above, we have that
Completing the square, we have that
It follows that
From the given expression of above, it follows that that
Appendix B. Proof of Theorem 2
Proof.
Let and .
We have that
from which we can deduce
It follows that is the vector given as
Hence, is an matrix given by
where for , we have
and
We can deduce that is the matrix given as
where
Since X has distribution , we have that
Therefore, we have that
Likewise, for ,
□
Appendix C. Proof of Proposition 2 and Corollary 2
Proof.
The proof of Proposition 2 is an easy generalization from the two-traits model.
First, assume that we are in the presence of two traits.
We have that
The system in (14) has a non-trivial solution if , that is,
We will show in the sequel that either of the Equations in (A2) can be used to characterize the solutions . Let for . From the first Equation in (15), we have
It therefore follows that
Next, we define
Therefore, for a solution of (15), we have
Dividing the latter by , we have that
Clearly, if , there is no solution to .
If , then
If , we let
It follows that
That is, the ellipse centered at with respective major and minor axis lengths a and b. Similar to above, we define
If , then
That is, the ellipse centered at with respective major and minor axis lengths
We observe that the two ellipses are the same:
- (1)
- They have identical centers. Indeed, we have and since implies that . Likewise, we have .This proves that , that is, the two centers are identical.
- (2)
- They have the same parameters. Indeed, we have
This implies that and thus and .
To generalize, we note that implies that for the given , we have
Since we assume that , without loss of generality, let . Then we have
Rearranging the terms and completing the squares, we obtain the result as announced. □
References
- Darwin, C. On the Origin of Species by Means of Natural Selection; John Murray: London, UK, 1859. [Google Scholar]
- Lehman, E.L.; Casella, G. Theory of Point Estimation, 2nd ed.; Springer: Berlin/Heidelberg, Germany, 1998. [Google Scholar]
- Fisher, R.A. On the Mathematical Foundation of Theoretical Statistics. Philos. Trans. R. Soc. Lond. Ser. A 1922, 222, 594–604. [Google Scholar]
- Bernado, J.M.; Smith, A.F.M. Bayesisan Theory; John Wiley & Sons: Hoboken, NJ, USA, 1994. [Google Scholar]
- Ward, M.D.; Ahlquist, J. Maximum Likelihood for Social Science: Strategies for Analysis; Cambridge University Press: Cambridge, UK, 2015. [Google Scholar]
- Rao, C. Information and the accuracy attainable in the estimation of statistical parameters. Bull. Calcutta Math. Soc. 1945, 37, 81–89. [Google Scholar]
- Cramér, H. Mathematical Methods of Statistics; Princeton Univ. Press: Princeton, NJ, USA, 1946. [Google Scholar]
- Smith, K. On the Standard Deviations of Adjusted and Interpolated Values of an Observed Polynomial Function and its Constants and the Guidance they give Towards a Proper Choice of the Distribution of Observations. Biometrika 1918, 1, 1–85. [Google Scholar] [CrossRef]
- Kilrkpatrick, J.; Pascanu, R.; Rabinowitz, N.; Veness, J.; Desjardins, G.; Rusu, A.A.; Milan, K.; Quand, J.; Ramalho, T. Overcoming Catastrophic Forgetting in Neural Networks. Proc. Natl. Acad. Sci. USA 2017, 114, 3521–3526. [Google Scholar] [CrossRef] [PubMed]
- Parag, K.; Donnelly, C.A.; Zarebski, A.E. Quantifying the Information in Noisy Epidemic Curves. Nat. Comput. Sci. 2022, 2, 584–594. [Google Scholar] [CrossRef] [PubMed]
- Vincent, T.L.; Vincent, T.L.S.; Cohen, Y. Darwinian Dynamics and Evolutionary Game Theory. J. Biol. Dyn. 2011, 5, 215–226. [Google Scholar] [CrossRef]
- Vincent, T.L.; Brown, J.S. Evoluationary Game Theory, Natural Selection, and Darwinian Dynamics; Cambridge University Press: Cambridge, UK, 2005. [Google Scholar]
- Smith, M.; Price, G.R. The logic of Animal Conflict. Nature 1973, 246, 15–18. [Google Scholar] [CrossRef]
- Smith, J.M. Evolution and the Theory of Games; Cambridge Unievrsity Press: Cambridge, UK, 1982. [Google Scholar]
- Ackleh, A.S.; Cushing, J.M.; Salceneau, P.L. On the dynamics of evolutionary competition models. Nat. Resour. Model. 2015, 28, 380–397. [Google Scholar] [CrossRef]
- Cushing, J.M. Difference Equations as Models of Evolutionary Population Dynamics. J. Biol. Dyn. 2019, 13, 103–127. [Google Scholar] [CrossRef] [PubMed]
- Cushing, J.M.; Park, J.; Farrell, A.; Chitnis, N. Treatment of outcome in an SI Model with Evolutionary Resistance: A Darwinian Model for the Evolutionary Resistance. J. Biol. Dyn. 2023, 17. [Google Scholar] [CrossRef] [PubMed]
- Casella, G.; Berger, R.L. Statistical Inference, 2nd ed.; Cengage: Boston, MA, USA, 2002. [Google Scholar]
- Elaydi, S.; Kang, Y.; Luis, R. The effects of Evolution on the Stability of Competing Species. J. Biol. Dyn. 2022, 16, 816–839. [Google Scholar] [CrossRef] [PubMed]
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the author. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).