3.1. Single Population Model with One Trait
Consider the following discrete evolutionary dynamical model:
where
where
and
, for a constant
u and for some positive constants
(speed of evolution),
(initial birth rate),
(competition constant),
, and
w (standard deviation of the distribution of birth rates), and for a differentiable function
of
and positive and continuous function
. This system has nontrivial fixed points
if they satisfy the equations
This can further be reduced to the condition on
and
given by
The theorem below shows how to obtain the Fisher’s information of the above system as a function of the system’s parameters.
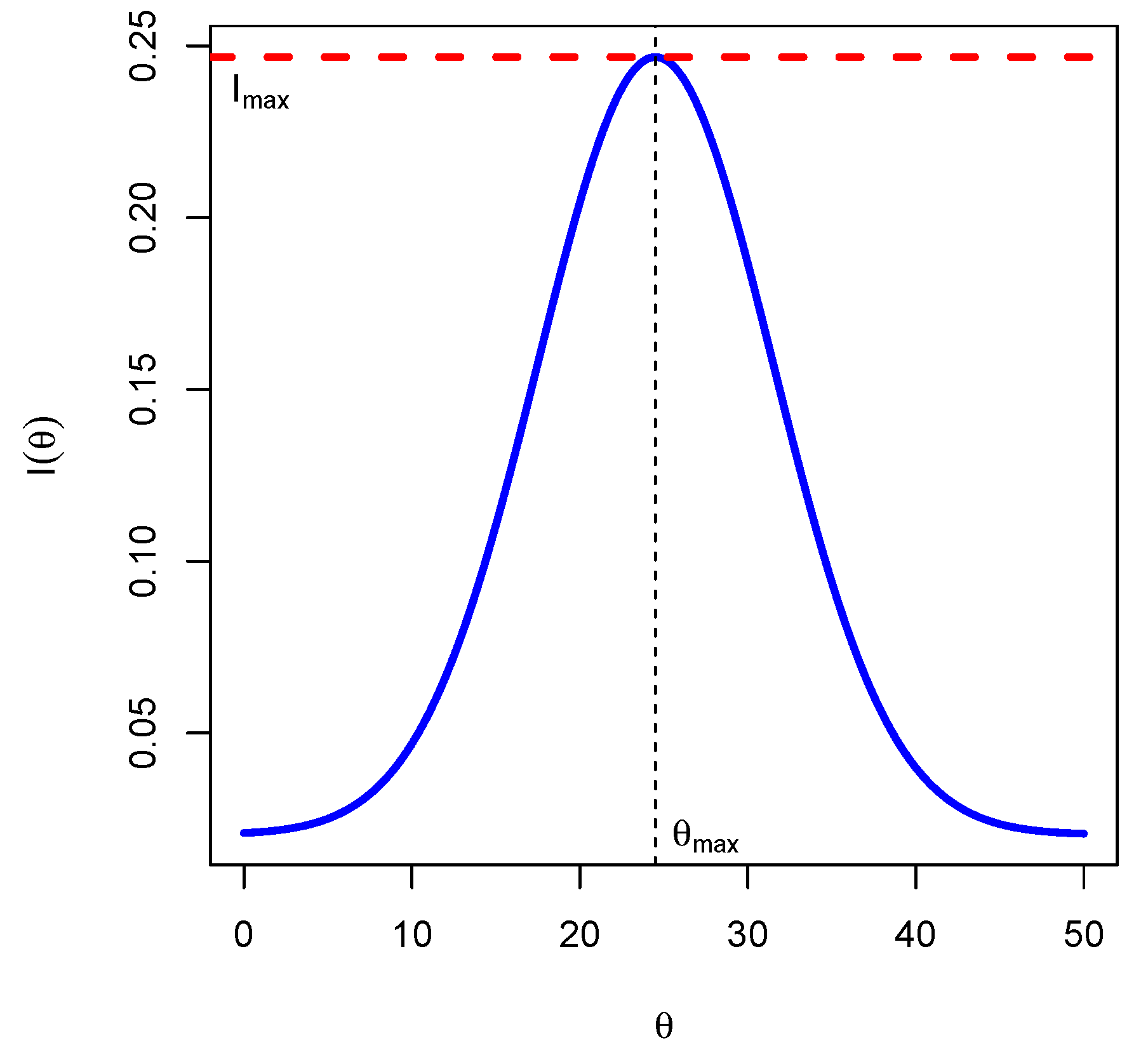
Theorem 1. Let . Then the Fisher’s information of this system is constant and given by The corollary below shows that the Fisher’s information has a maximum value, see
Figure 1 below for an illustration.
Corollary 1. The Fisher’s information attains its maximum value for , and the maximum value is In the proposition below, we give precise conditions for the existence of nontrivial fixed points of the system above.
Proposition 1. If , then the Darwinian system (
9)
does not have a nontrivial critical point. If , then the Darwinian system has a unique nontrivial fixed point given as If , then the Darwinian system has two nontrivial fixed points and given by Proposition 1 and Theorem 1 are important in that when
as
, then by continuity of the function
with respect to
, we will have
as
. This means that the Fisher’s information, over time, will be maximized at the critical point
of the dynamical system. Therefore, for estimation purposes, the reciprocal of
will be the smallest variance for any unbiased estimator of the trait
. In
Figure 2, below, we use the following parameters:
.
We will now discuss the particular case of an exponential distribution, that is,
. Clearly, the condition (
5) is satisfied with
and
. Therefore,
This implies that
. It follows that there are equilibrium fixed points: the extinction equilibrium (trivial point)
and the interior equilibrium (nontrivial point)
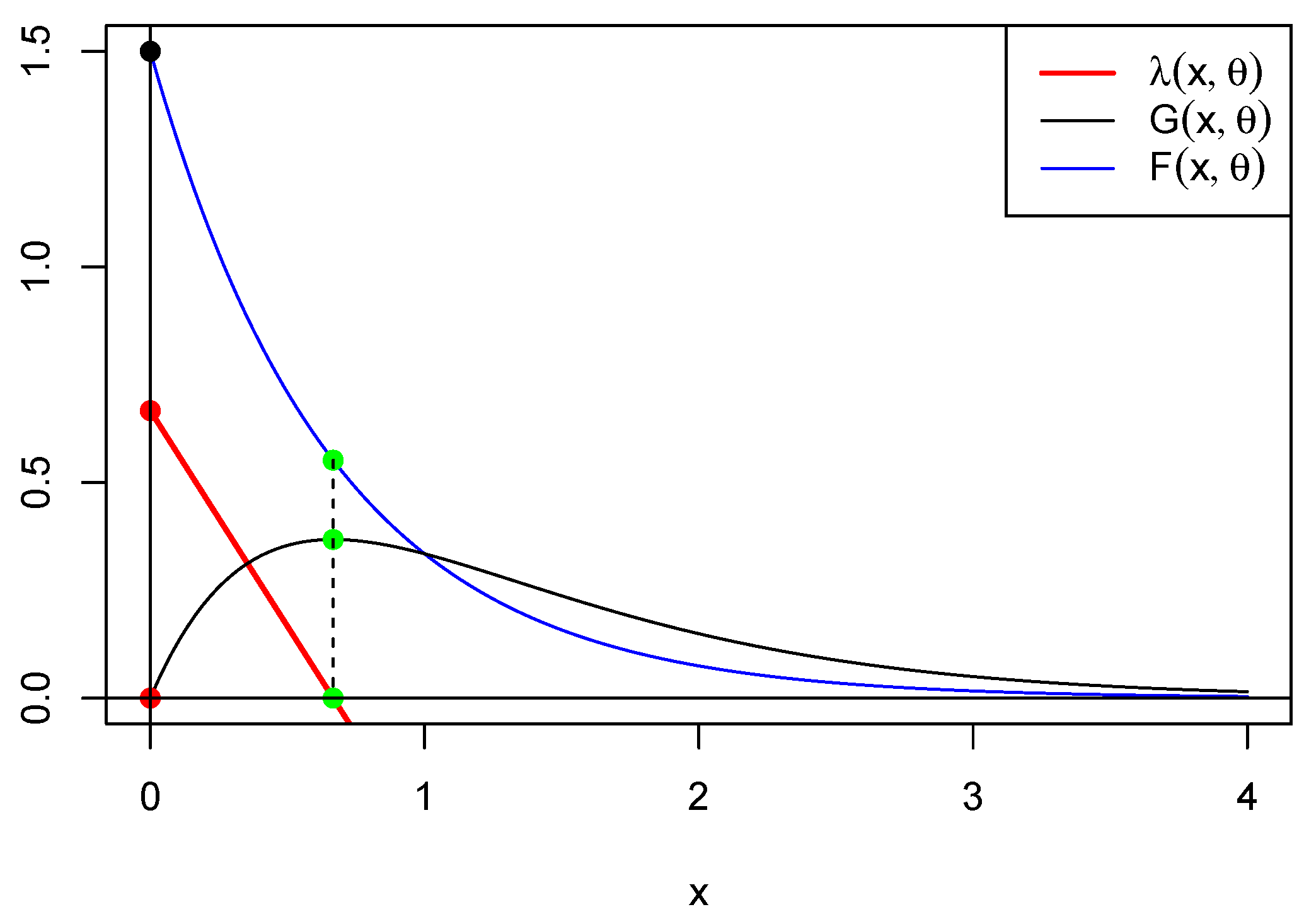
. In
Figure 3, below, we represent functions
, and
for
. This shows that
is minimized where
is maximized, providing a clue as to the relation between the maximum of
G and the critical points of
g and
. Another clue can be found in
Figure 4 below.
From a dynamical systems’ perspective, it means that
, the value of
X at time
t, is generated from the distribution
and used to calculate the value of
. Therefore, the role of the first choice of
is to initialize the dynamical system. Once the system is initialized for
, we can use an information theory approach to provide an estimator
of
, the value of
at time
t. That estimator, if efficient, will have variance
. We can then use the dynamical system (
9) to estimate
, and the Fisher’s information will provide its variance. We note that
will only be an estimate of the true value and therefore will carry an error as
t changes. It is therefore expected that at the nontrivial critical point (ESS)
of the dynamical system, the estimator
converges to
and the variance of
converges to
as
.
Figure 5 below is an illustration of this fact for
.
Indeed, we generated two random samples of size
(
Figure 5a,b) and
(
Figure 5c,d) with
where
and
from exponential distributions with respective initial parameters
. We choose
, which is known to be an efficient estimator of
. The dashed lines represent the respective values of
, and the black lines represent their 95% confidence intervals
. This shows in particular that on average,
converges to
e (dashed line), the fixed point of the dynamical system, as expected from the above. It also shows that as the Fisher’s formation gets larger, the variance of the estimator gets smaller and thus the width of the confidence interval gets smaller and quickly approaches zero as in
Figure 5c,d. The conclusion is that given an evolution dynamical system, we can estimate the evolution parameter vector
and provide an estimate of the error on the estimate that is the inverse of the Fisher’s information. Moreover, over time, the estimate converges to the ESS of the system (when it exists) and the errors on the estimate essentially becomes zero when convergence is reached.
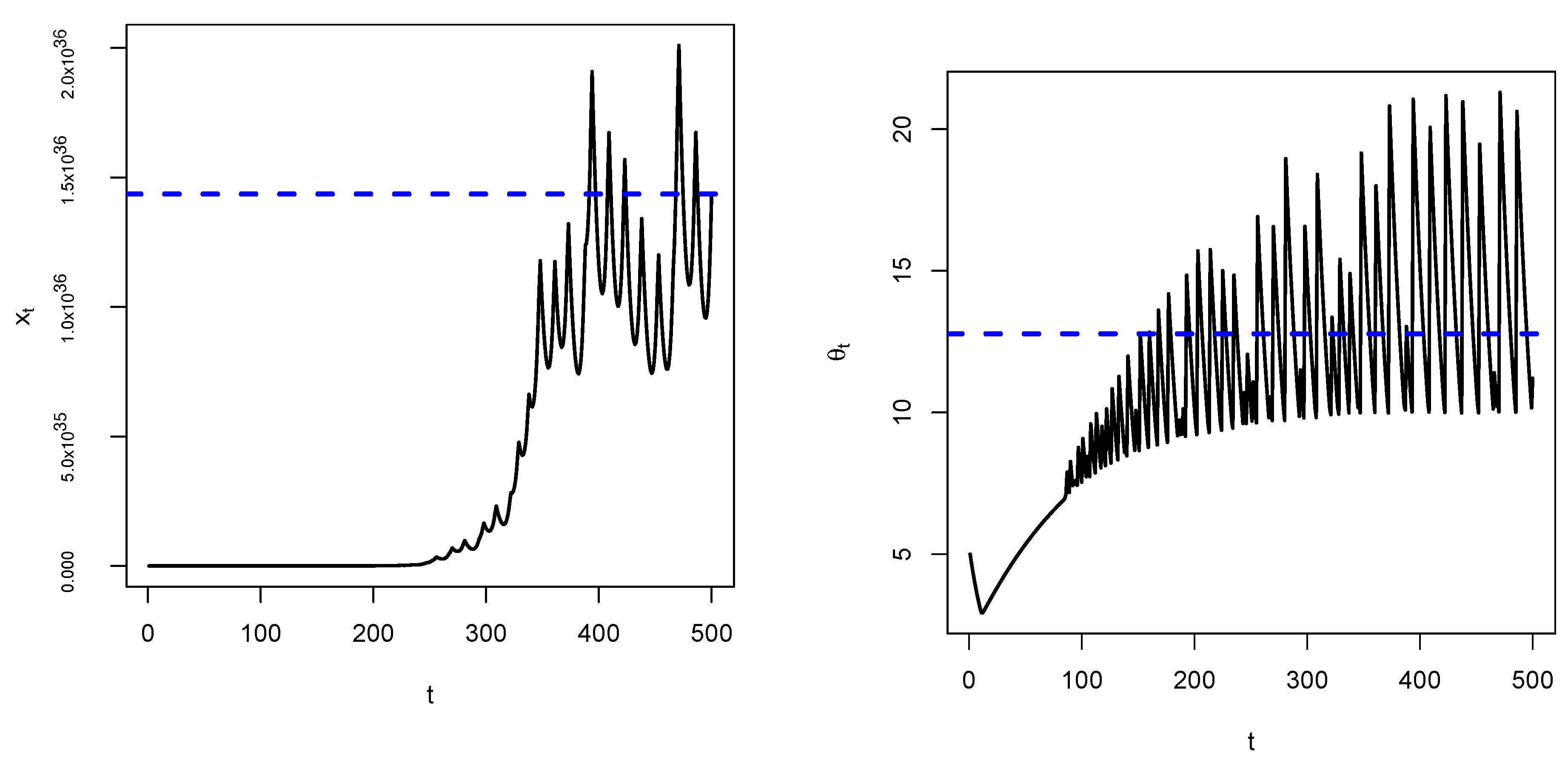
Remark 1. We observe that convergence of towards e as predicted depends on choosing an appropriate value of σ. Large values of σ will definitely make the system unstable as oscillations will slowly and increasingly occur, see Figure 6 below. 3.2. Discussion
Assumption
is important in that we only require that
G be nonnegative and
, which guarantees that it can be transformed into the density of a random variable. It does not, however, guarantee that we can easily obtain a sample from it! If
G happens to be a classical distribution (normal, exponential, t-distribution, Weibull, etc.), then there are sampling methods already available. If
G has a nonclassic expression, we may have to resort to either the Probability Integral Transform (see Theorem 2.1.10, p. 54 in [
18]) or to Markov Chain Monte Carlo (MCMC) to obtain a sample, which sometimes are themselves onerous in terms of time. Obtaining an efficient estimator of
is easily undertaken when
G is a classic distribution. While efficiency would be great, it may not be necessary since over time, the estimator would still converge, albeit slowly, to the fixed point of
. We observe that the estimates we obtain in this case are point estimates of
(mean, median, etc.), albeit at each time
t. A Bayesian estimate is also possible, provided that the initial distribution of
is selected from a well-defined Jeffrey’s prior. As for answers to the questions raised in the Introduction, we can say based on the above that the set of points
where
is maximized is the same where
is minimized and contains all the critical points of the function
G. This can be written formally as
.
3.3. Single Population Model with Multiple Traits
Now suppose we are in the presence of one species with density x possessing n traits given by the vector and a vector .
() We assume that is the joint distribution of the independent traits , each with mean 0 and variance .
() We also assume that .
() We assume that the density of is given as at .
Under
, and
, we consider the discrete dynamical system
where
Remark 2. There are a couple of distinctions between this model and the ones encountered in the recent literature, see for instance [
16,
19]
. Firstly, the matrix Σ
considered here is not necessarily symmetric (). Secondly, the competition function depends subtly on a vector that need not be the mean of Θ
, as it is often considered. We note, however, that when , then . Ecologically, this happens when competition is maximal. This leads to recovering the uncoupled Darwinian model (2) in [
19].
The result below shows how to obtain the Fisher’s information of the Darwinian dynamical system (
9).
Theorem 2. Let . Then under assumptions , and , the dynamical system above has the Fisher’s information matrix given as The proof of this result can be found in
Appendix B.
Remark 3. We observe that in the case of a high-dimension vector of parameters Θ, the theorem above gives us not only the variance (the diagonal terms of ) on the estimator of each component of Θ but also the covariances between pairs of estimates (the off-diagonal terms) of different components (or traits). This may be important, especially to distinguish correlated and noncorrelated traits or strategies.
A necessary condition for the existence of an extinction equilibrium
for this system is that
. Letting
represent the spectral radius of matrix
A, it was proved in [
16] that if
and
, then the extinction equilibrium is asymptotically stable and unstable if
and
, or if
for all
. This is particularly true if
is diagonally dominant and for
. This system admits a nontrivial fixed point (positive equilibrium)
if
and
. In the proposition below, we give a more precise characterization of nontrivial fixed points of the system (
15).
Proposition 2. Assume and for . Putand given If , then there is no nontrivial solution for the system (
9).
Now suppose . Then the system (
9)
has a nontrivial solution given asand - (i)
If , then .
- (ii)
If , then the coordinates of the vector are points that lie on the curve of equation
Here we consider the particular case of a system of one species with two traits, namely, the coupled dynamical system
The fixed points
of this model are solutions of the system of equations
where
Corollary 2. Assume and . We putand If , then there is no nontrivial solution for the system (
14).
Now suppose . Then the system (
14)
has a nontrivial solution given asand - (i)
If , then .
- (ii)
If , then are points that lie on the ellipse of equation
In
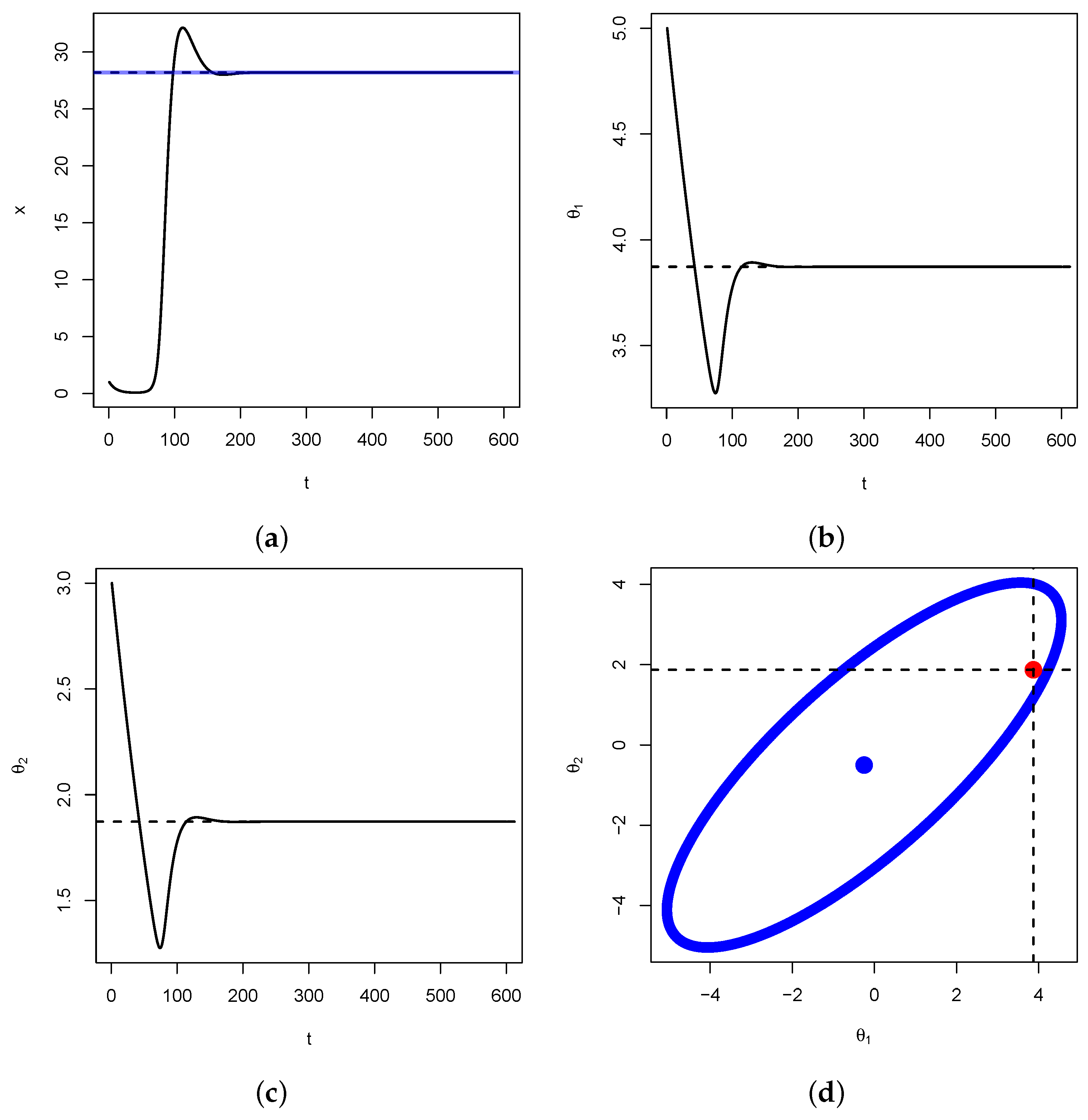
Figure 7, below, we illustrate Proposition 2 for
. We verify that
and
. Therefore,
, that is,
. We also have that
and that
. Hence, according to Proposition 2 above,
is expected to be on the ellipse centered as
with respective major and minor axis lengths
and
.
The parameters for
Figure 8 are the same except for
and
is generated from an exponential distribution with parameters
.
3.4. Discussion
An important remark about Theorem 2 is that we assume the vector
U is given. In fact, if the vector
were given, the same technique could have been used for the estimation of
U, up to a negative sign on the Fisher’s information matrix. Having
U be different from the average of
allows for generalization, in that
represents the difference of a set of traits
from a given set of traits
U, which need not be the average of
. One thing we have not insisted much about in this paper is the type of estimator of
itself. We do not need to specify in particular which estimator to use, since the inverse of the Fisher’s information is the smallest variance for all estimators. One consequence of Proposition 2 above is that once we have estimated
, we can deduce the value of
. The results above also show that there may be many equilibria when
. In the context of evolution and natural selection, one should focus on equilibria that ensure better adaptation to environmental fluctuations. This specifically means adding stochasticity to the model by means of, say, a Wiener process and finding traits that ensure, for example, that on average, the species density is bounded away from the extinction equilibrium. Another possibility could be to focus on equilibria that maximize the species density in order to increase the prospects of survivability of the species. This can be performed using a constraint optimization problem
where
subject to the constraint that the point
u be on the curve defined in Equation (
13). In the particular case where
with
, we have
However, the form of the function
makes it a very challenging problem. Rewriting, we have
We observe that for positive
and
, the function
is a positive and increasing function of
u and
v. Therefore, maximizing
amounts to maximizing
Geometrically, this is the equation of a paraboloid that bends down. Therefore, the constraint optimization amounts to finding the points of intersection between a paraboloid and an ellipse. This means there can be between 0 and 4 points of intersection. Finally, let us observe that the expression of
in the case of multiple traits is just a generalization of the case of one trait. In fact, the first equation in the system (
4) can be written as
. We see that this is similar to the expression of
given in Equation (
A3) for two traits, which naturally generalizes to the case of one species with
traits.








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}