

Searching for Continuous n-Clusters with Boolean Reasoning

Abstract
1. Introduction
2. Context of Searching Patterns with Boolean Reasoning
2.1. Boolean Reasoning
2.2. Biclustering and Triclustering
2.3. Boolean Reasoning in Pattern Search
- Constant values in discrete data [3];
- Constant values in binary data [3];
- Constant values in n-dimensional binary data [7];
- -Limited (inner maximal difference) biclusters in continuous data [4];
- -Limited (inner minimal difference) biclusters in continuous data [4];
- Center-based biclusters (values not greater/smaller than a defined center and assumed margin) [32];
- -Shifting patterns (only the in-row difference in a pattern is limited) [33].
3. Additional Notions
3.1. Pattern Exactness
3.2. Inclusion Maximality
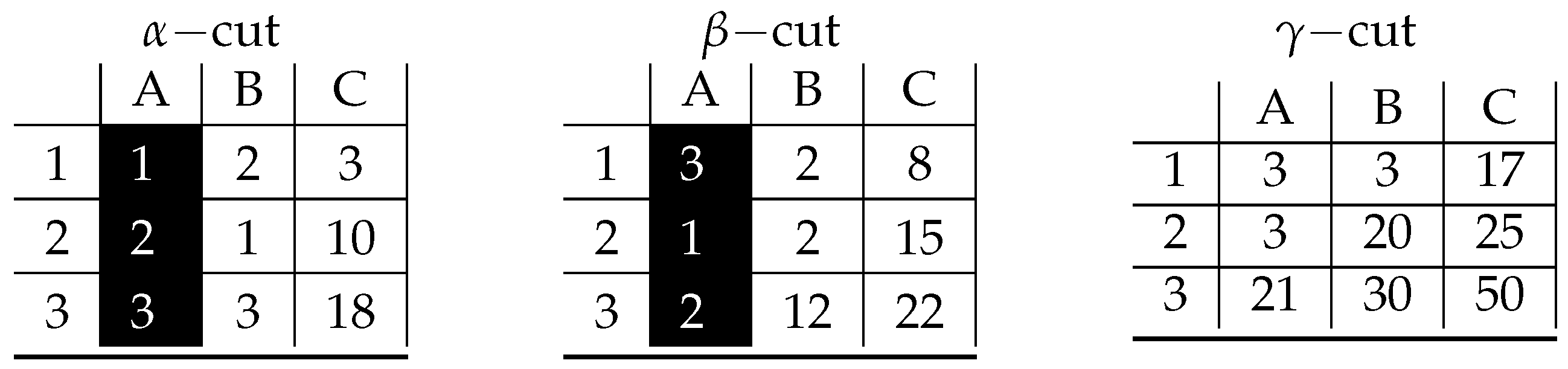
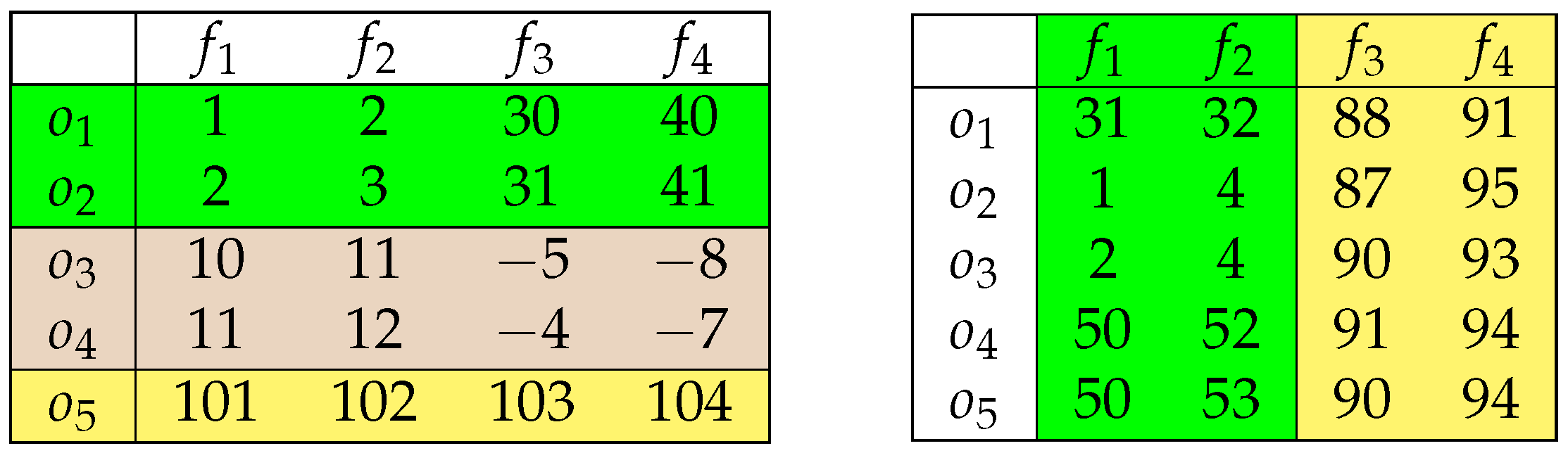
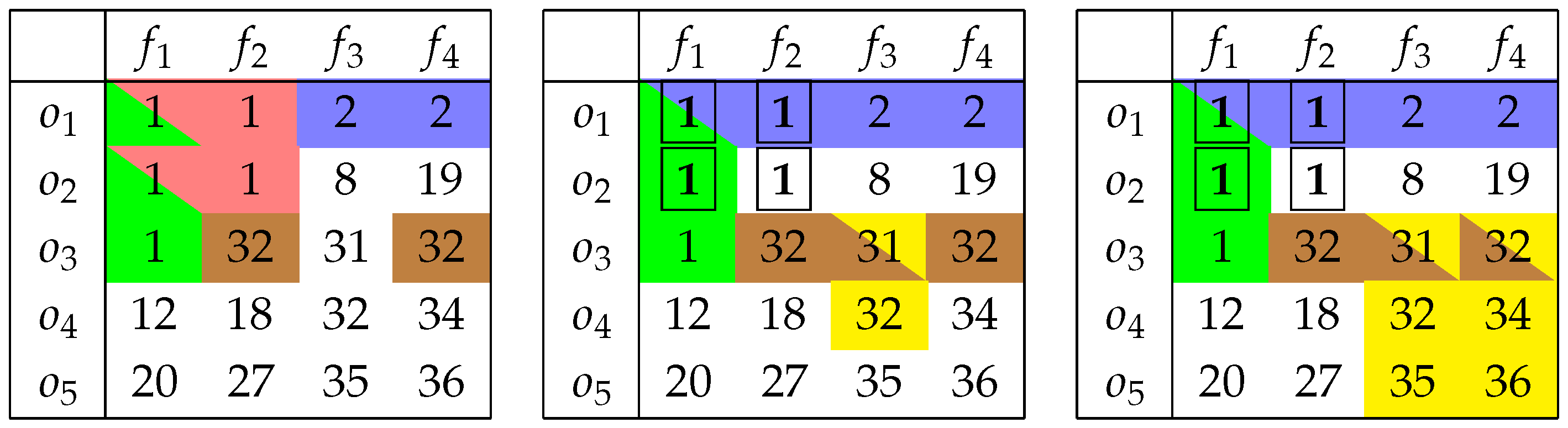
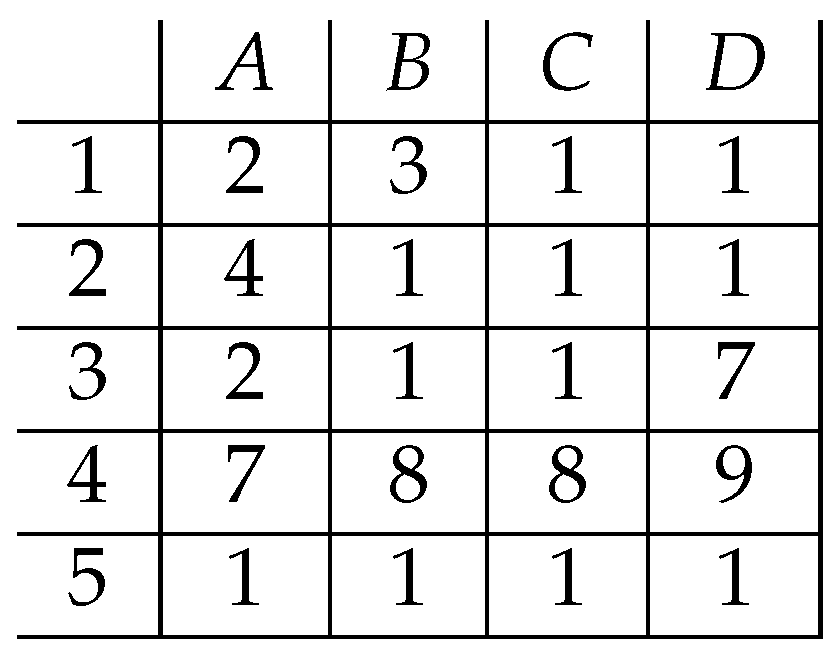
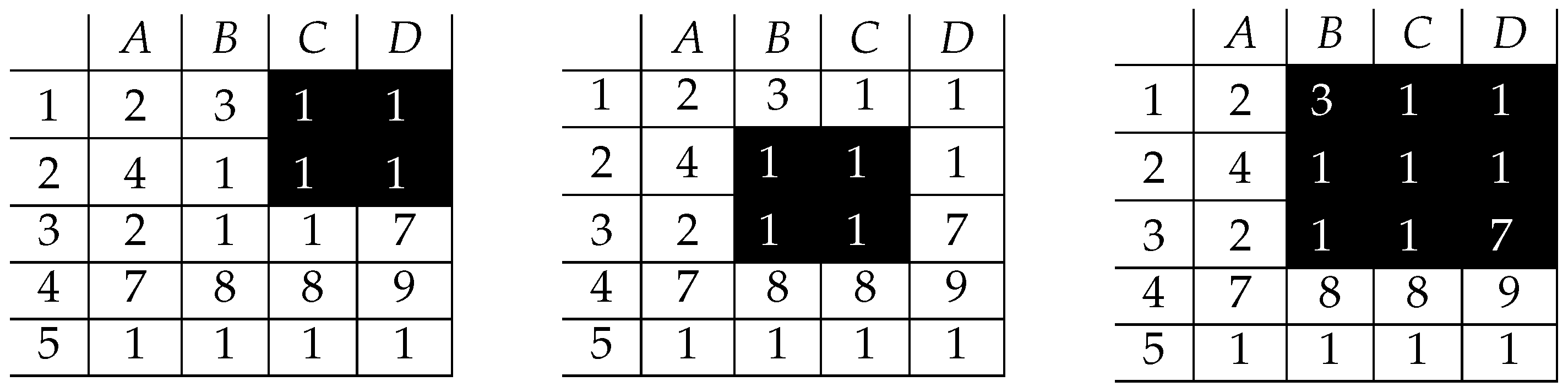
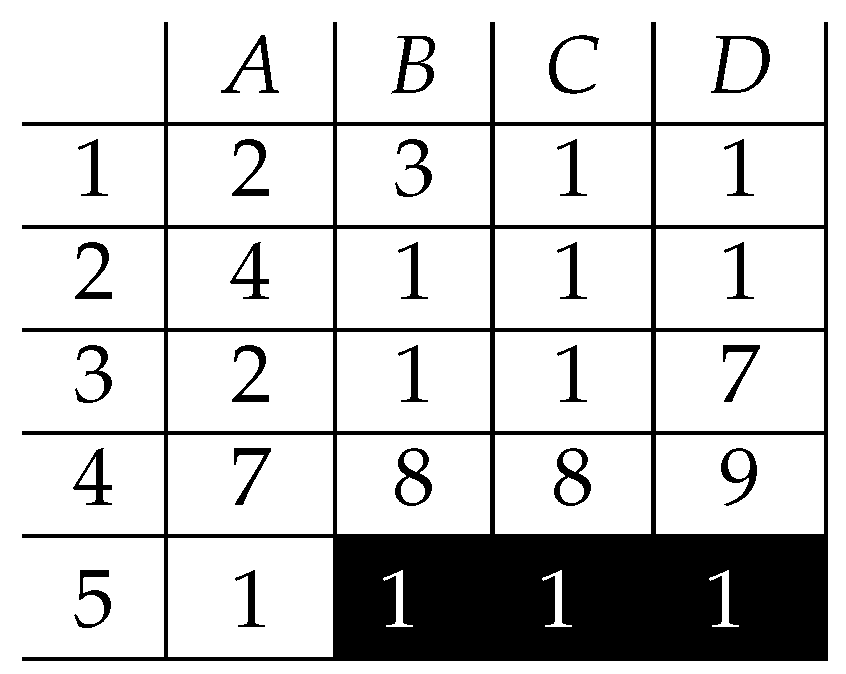
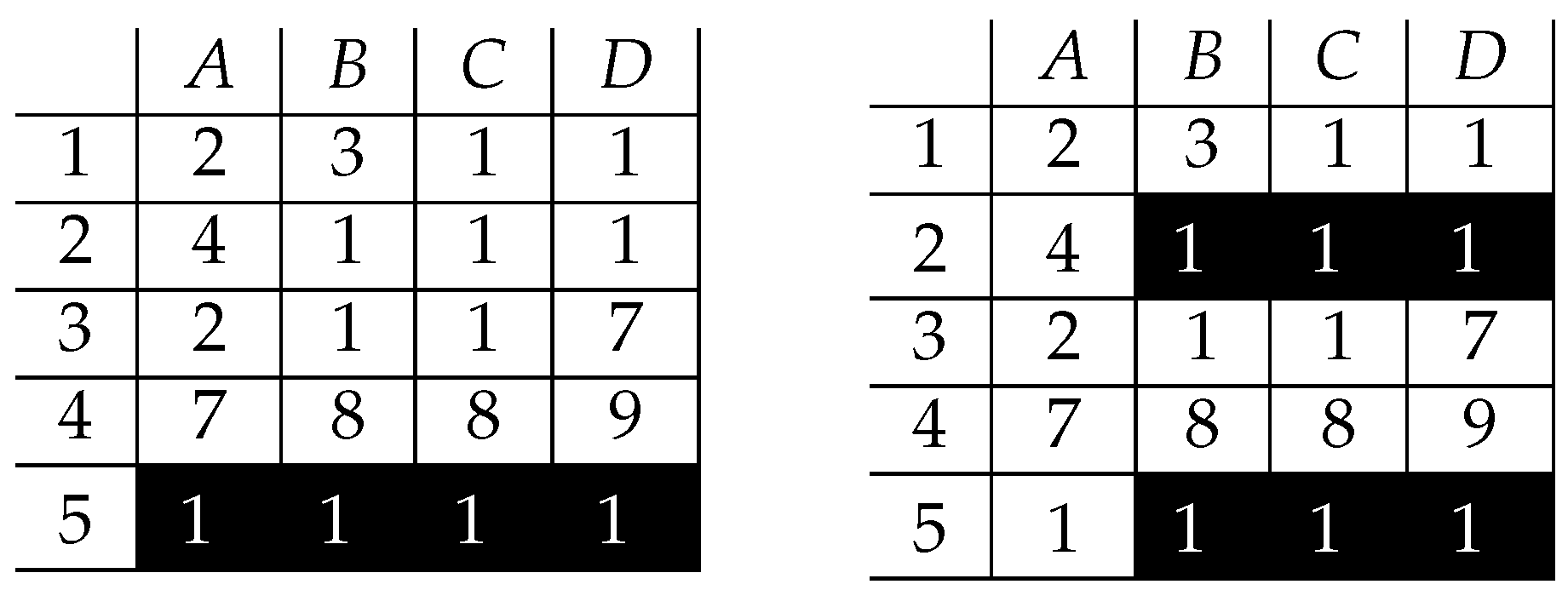
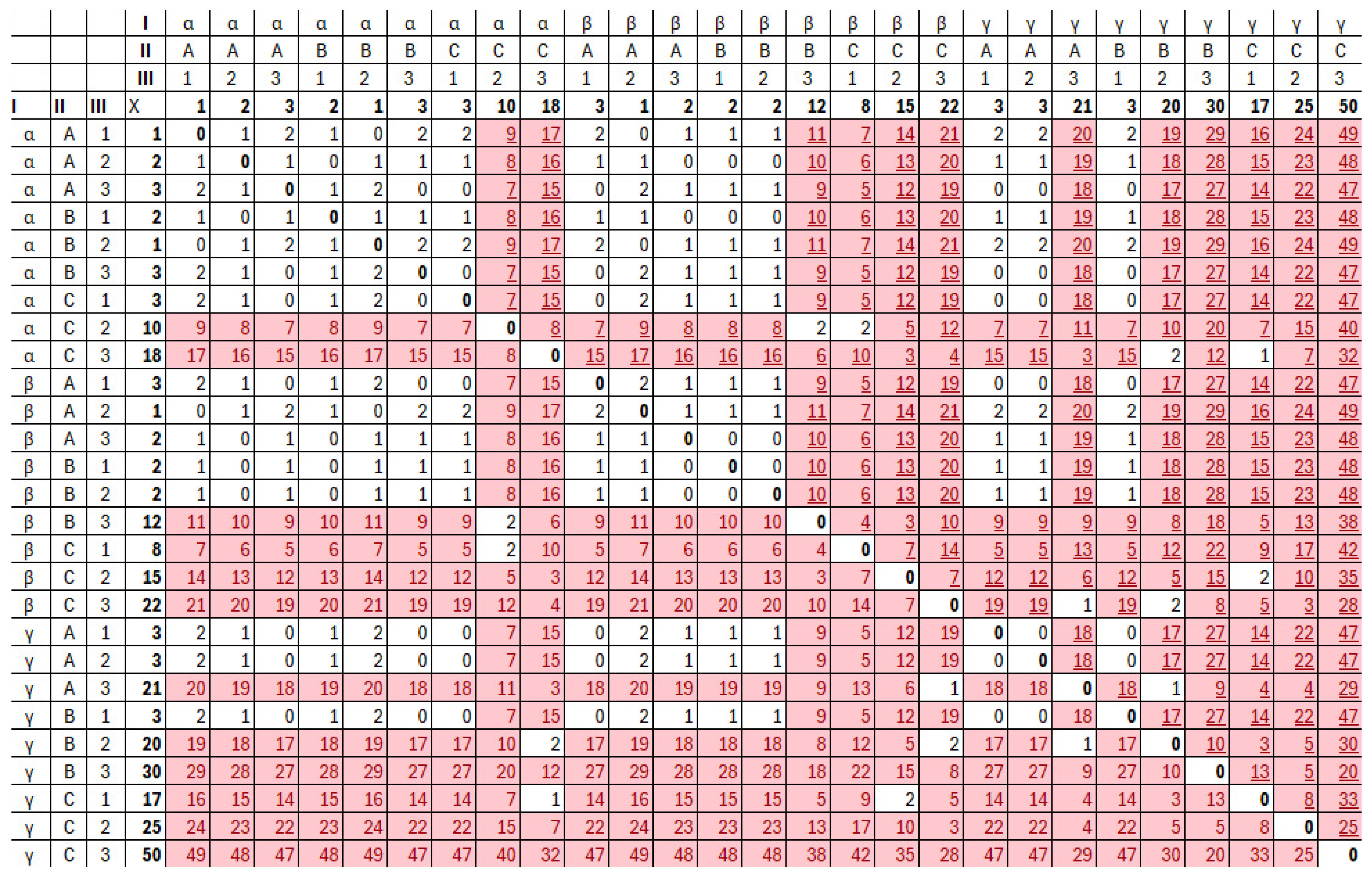
4. A Proof of Concept
5. Boolean Reasoning-Based Triclustering Formalism
5.1. Weak Theorem of Triclustering Continuous Data
- Let be an implicant of and let not be an exact pattern in . That means that there exists at least one pair of cells in such that their absolute difference exceeds the assumed level . This leads to the statement that cannot be an implicant of as it was assumed that covered all pairs in of the absolute difference greater that .
- Let be an exact pattern in and let not be an implicant of . That means that there exists a clause in that does not cover. This, in turn, means that this clause codes such a pair of cells from that violates the condition, which is in contradiction with the assumption that is an exact pattern.
5.2. Strong Theorem of Triclustering Continuous Data
- Let be the prime implicant of . From the above theorem, is the exact pattern in . Let us assume that is not an inclusion-maximal pattern, so at least one of the three following ways of its expansion are possible:
- An extension with the row r so is also an exact pattern in ;
- An extension with the column c so is also an exact pattern in ;
- An extension with the slice s so is also an exact pattern in .
However, also from the above theorem, we conclude that any of the extended patterns has a corresponding implicant of , which has a shortened conjunction of row/column/slice-corresponding variables, which is in contradiction with the assumption that is a prime implicant.
- Let be an inclusion-maximal exact pattern in . From the above theorem, we know that is an implicant of . Let us assume that is not a prime implicant of . This, in turn, means that at least one row/column/slice-corresponding Boolean variable may be removed from . The shortened implicant—also from the above theorem—codes a pattern extended by a row/column/slice. This is in contradiction with the assumption that is inclusion-maximal (not extendable).
6. Generalization and Its Correctness
6.1. Weak Theorem of n-Clustering Continuous Data
- Let be an implicant of , and let P not be an exact pattern in . That means that there exists at least one pair of cells in such that their absolute difference exceeds the assumed level . This leads to the statement that cannot be an implicant of as it was assumed that covered all pairs in of the absolute difference greater than .
- Let be an exact pattern in , and let not be an implicant of . That means that there exists a clause in that does not cover. This, in turn, means that this clause codes such a pair of cells from that violates the condition, which is in contradiction with the assumption that is an exact pattern.
6.2. Strong Theorem of n-Clustering the Continuous Data
- Let be the prime implicant of . From the above theorem, is the exact pattern in . Let us assume that is not an inclusion-maximal pattern; thus, there exists at least one direction i, such that the following extension of the pattern is possible:However, also from the above theorem, we conclude that any of the extended patterns will have a corresponding implicant of , that would have a shortened conjunction of ith dimension indices corresponding to variables, which is in contradiction with the assumption that is a prime implicant.
- Let be an inclusion maximal exact pattern in . From the above theorem, we know that is an implicant of . Let us assume that is not a prime implicant of . This, in turn, means that at least one ith dimension indices corresponding to Boolean variable may be removed from . The shortened implicant—also from the above theorem—codes a pattern extended in the ith direction. This would be in contradiction with the assumption that is inclusion-maximal (not extendable).
7. Conclusions and Further Works
Funding
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
Appendix A
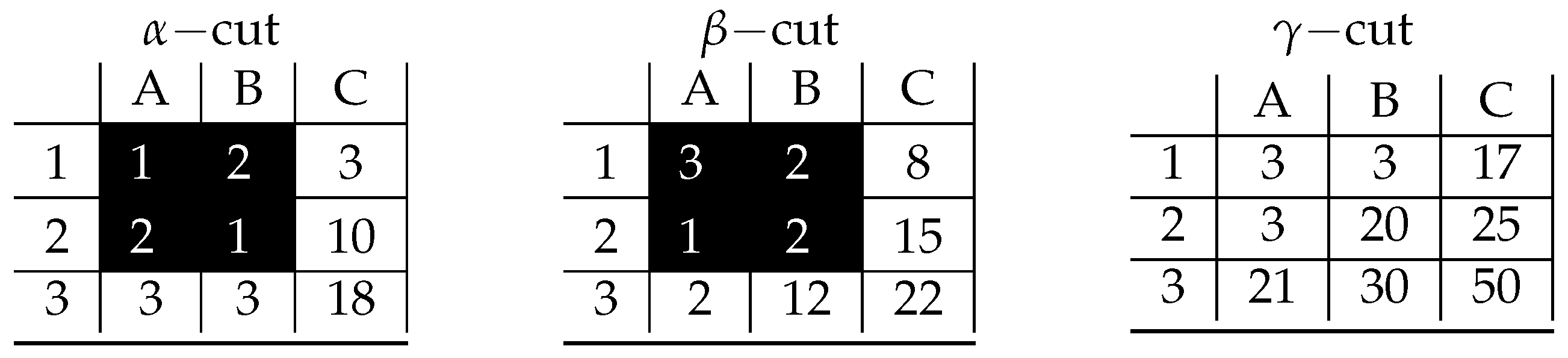
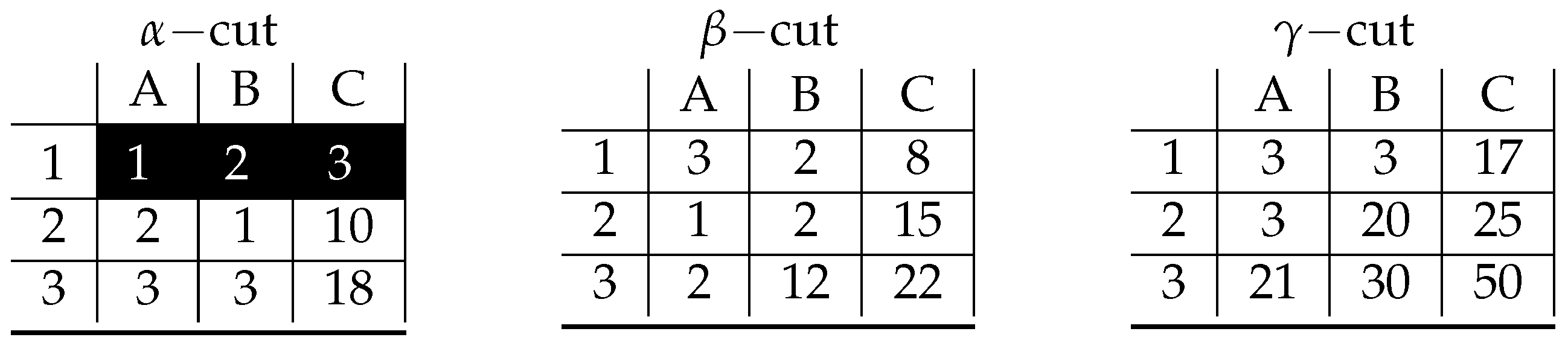

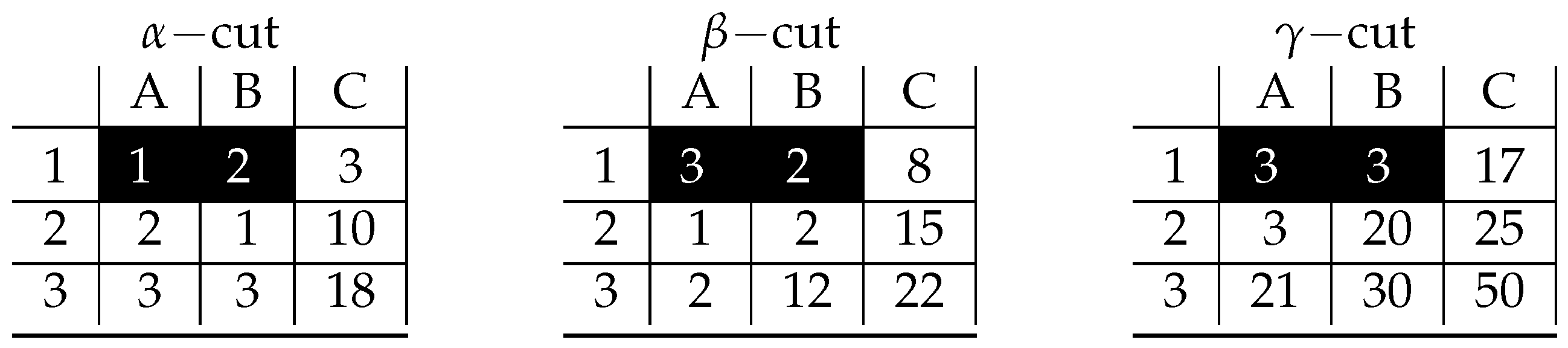
References
- Morgan, J.; Sonquist, J. Problems in the analysis of survey data, and a proposal. J. Am. Stat. Assoc. 1963, 58, 415–434. [Google Scholar] [CrossRef]
- Cheng, Y.; Church, G.M. Biclustering of Expression Data. In Proceedings of the Eighth International Conference on Intelligent Systems for Molecular Biology, La Jolla, CA, USA, 16–23 August 2000; AAAI Press: Washington, DC, USA, 2000; pp. 93–103. [Google Scholar]
- Michalak, M.; Ślȩzak, D. Boolean Representation for Exact Biclustering. Fundam. Informaticae 2018, 161, 275–297. [Google Scholar] [CrossRef]
- Michalak, M.; Ślȩzak, D. On Boolean Representation of Continuous Data Biclustering. Fundam. Informaticae 2019, 167, 193–217. [Google Scholar] [CrossRef]
- Michalak, M.; Jaksik, R.; Ślȩzak, D. Heuristic Search of Exact Biclusters in Binary Data. Int. J. Appl. Math. Comput. Sci. 2020, 30, 161–171. [Google Scholar] [CrossRef]
- Michalak, M. Triclustering based on Boolean reasoning—A proof–of–concept. Procedia Comput. Sci. 2024, in press. [Google Scholar]
- Michalak, M. Theoretical Backgrounds of Boolean Reasoning Based Binary n–clustering. Knowl. Inf. Syst. 2022, 64, 2171–2188. [Google Scholar] [CrossRef]
- Brown, F.M. Boolean Reasoning; Springer: Boston, MA, USA, 1990. [Google Scholar]
- Pawlak, Z.; Skowron, A. Rough Sets and Boolean Reasoning. Inf. Sci. 2007, 177, 41–73. [Google Scholar] [CrossRef]
- Ślȩzak, D.; Janusz, A. Ensembles of Bireducts: Towards Robust Classification and Simple Representation. Lect. Notes Comput. Sci. 2011, 7105, 64–77. [Google Scholar]
- Kluger, Y.; Basri, R.; Chang, J.T.; Gerstein, M. Spectral biclustering of microarray data: Coclustering genes and conditions. Genome Res. 2003, 13, 703–716. [Google Scholar] [CrossRef]
- Aguilar-Ruiz, J.S.; Divina, F. Evolutionary computation for biclustering of gene expression. In Proceedings of the 2005 ACM Symposium on Applied Computing (SAC), Santa Fe, NM, USA, 13–17 March 2005; ACM: New York, NY, USA, 2005; pp. 959–960. [Google Scholar]
- Mitra, S.; Banka, H. Multi-objective evolutionary biclustering of gene expression data. Pattern Recognit. 2006, 39, 2464–2477. [Google Scholar] [CrossRef]
- Divina, F.; Aguilar–Ruiz, J.S. Biclustering of expression data with evolutionary computation. IEEE Trans. Knowl. Data Eng. 2006, 18, 590–602. [Google Scholar] [CrossRef]
- Pontes, B.; Divina, F.; Giráldez, R.; Aguilar-Ruiz, J.S. Improved biclustering on expression data through overlapping control. Int. J. Intell. Comput. Cybern. 2009, 2, 477–493. [Google Scholar] [CrossRef]
- Pontes, B.; Giráldez, R.; Aguilar-Ruiz, J.S. Configurable pattern-based evolutionary biclustering of gene expression data. Algorithms Mol. Biol. 2013, 8, 4. [Google Scholar] [CrossRef] [PubMed]
- Tanay, A.; Sharan, R.; Shamir, R. Discovering statistically significant biclusters in gene expression data. Bioinformatics 2002, 18, S136–S144. [Google Scholar] [CrossRef]
- Denitto, M.; Farinelli, A.; Figueiredo, M.; Bicego, M. A biclustering approach based on factor graphs and the max–sum algorithm. Pattern Recognit. 2017, 62, 114–124. [Google Scholar] [CrossRef]
- Denitto, M.; Bicego, M.; Farinelli, A.; Figueiredo, M. Spike and slab biclustering. Pattern Recognit. 2017, 72, 186–195. [Google Scholar] [CrossRef]
- Hanczar, B.; Nadif, M. Ensemble methods for biclustering tasks. Pattern Recognit. 2012, 45, 3938–3949. [Google Scholar] [CrossRef]
- Nepomuceno, J.A.; Troncoso, A.; Aguilar-Ruiz, J.S. Biclustering of Gene Expression Data by Correlation-Based Scatter Search. BioData Min. 2011, 4, 3. [Google Scholar] [CrossRef]
- Nepomuceno, J.A.; Troncoso, A.; Aguilar-Ruiz, J.S. Scatter search-based identification of local patterns with positive and negative correlations in gene expression data. Appl. Soft Comput. 2015, 35, 637–651. [Google Scholar] [CrossRef]
- Caroll, J.D.; Chang, J.J. Analysis of individual differences in multidimensional scaling via an n-way generalization of “Eckart-Young” decomposition. Psychometrika 1970, 35, 283–319. [Google Scholar] [CrossRef]
- Krolak-Schwerdt, S.; Orlik, P.; Ganter, B. TRIPAT: A Model for Analyzing Three-Mode Binary Data. In Proceedings of the Information Systems and Data Analysis; Bock, H.H., Lenski, W., Richter, M.M., Eds.; Springer: Berlin/Heidelberg, Germany, 1994; pp. 298–307. [Google Scholar] [CrossRef]
- Lehmann, F.; Wille, R. A triadic approach to formal concept analysis. In Proceedings of the Conceptual Structures: Applications, Implementation and Theory; Ellis, G., Levinson, R., Rich, W., Sowa, J.F., Eds.; Springer: Berlin/Heidelberg, Germany, 1995; pp. 32–43. [Google Scholar] [CrossRef]
- Zhao, L.; Zaki, M.J. TRICLUSTER: An effective algorithm for mining coherent clusters in 3D microarray data. In Proceedings of the 2005 ACM SIGMOD International Conference on Management of Data, Baltimore, MA, USA, 14–16 June 2005; Association for Computing Machinery: New York, NY, USA, 2005; pp. 694–705. [Google Scholar] [CrossRef]
- Siswantining, T.; Bustamam, A.; Sarwinda, D.; Soemartojo, S.M.; Latief, M.A.; Octaria, E.A.; Siregar, A.T.M.; Septa, O.; Al-Ash, H.S.; Saputra, N. Triclustering method for finding biomarkers in human immunodeficiency virus-1 gene expression data. Math. Biosci. Eng. 2022, 19, 6743–6763. [Google Scholar] [CrossRef] [PubMed]
- Ahmed, H.A.; Mahanta, P.; Bhattacharyya, D.K.; Kalita, J.K.; Ghosh, A. Intersected coexpressed subcube miner: An effective triclustering algorithm. In Proceedings of the 2011 World Congress on Information and Communication Technologies, Mumbai, India, 1–14 December 2011. [Google Scholar] [CrossRef]
- Siswantining, T.; Saputra, N.; Sarwinda, D.; Al-Ash, H.S. Triclustering Discovery Using the δ-Trimax Method on Microarray Gene Expression Data. Symmetry 2021, 13, 437. [Google Scholar] [CrossRef]
- Wu, X.; Raul Zurita-Milla, E.I.V.; Kraak, M.J. Triclustering Georeferenced Time Series for Analyzing Patterns of Intra-Annual Variability in Temperature. Ann. Am. Assoc. Geogr. 2018, 108, 71–87. [Google Scholar] [CrossRef]
- Guigourès, R.; Boullé, M.; Rossi, F. A Triclustering Approach for Time Evolving Graphs. In Proceedings of the 2012 IEEE 12th International Conference on Data Mining Workshops, Brussels, Belgium, 10 December 2012; pp. 115–122. [Google Scholar] [CrossRef]
- Michalak, M. Induction of Centre–Based Biclusters in Terms of Boolean Reasoning. Adv. Intell. Syst. Comput. 2020, 1061, 239–248. [Google Scholar]
- Michalak, M.; Aguilar-Ruiz, J.S. Shifting Pattern Biclustering and Boolean Reasoning Symmetry. Symmetry 2023, 15, 1977. [Google Scholar] [CrossRef]
- Michalak, M. Hierarchical heuristics for Boolean-reasoning-based binary bicluster induction. Acta Inform. 2022, 59, 673–685. [Google Scholar] [CrossRef]
- Déharbe, D.; Fontaine, P.; Le Berre, D.; Mazure, B. Computing prime implicants. In Proceedings of the 2013 Formal Methods in Computer-Aided Design, Portland, OR, USA, 20–23 October 2013; pp. 46–52. [Google Scholar] [CrossRef]
- Strzemecki, T. Polynomial-time algorithms for generation of prime implicants. J. Complex. 1992, 8, 37–63. [Google Scholar] [CrossRef]
- Karp, R.M. Reducibility among Combinatorial Problems. In Complexity of Computer Computations: Proceedings of a Symposium on the Complexity of Computer Computations, Held March 20–22, 1972, at the IBM Thomas J. Watson Research Center, Yorktown Heights, New York, and sponsored by the Office of Naval Research, Mathematics Program, IBM World Trade Corporation, and the IBM Research Mathematical Sciences Department; Miller, R.E., Thatcher, J.W., Bohlinger, J.D., Eds.; Springer: Boston, MA, USA, 1972; pp. 85–103. [Google Scholar] [CrossRef]
- Johnson, D.S. Approximation algorithms for combinatorial problems. J. Comput. Syst. Sci. 1974, 9, 256–278. [Google Scholar] [CrossRef]
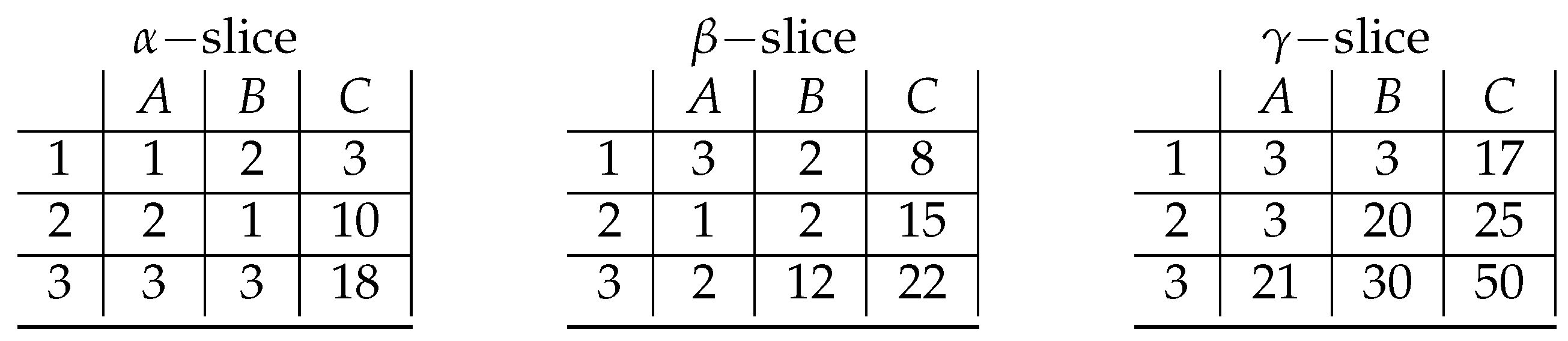
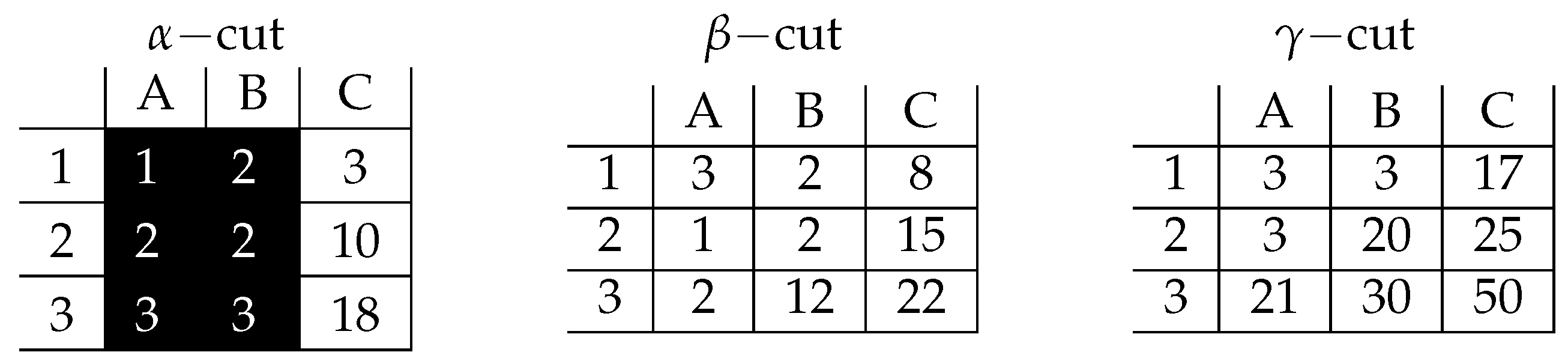

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Prime Implicant | # | Annotation | Tricluster | Prime Implicant | # | Annotation | Tricluster |
|---|---|---|---|---|---|---|---|
| 1 | 9 | ||||||
| 2 | 10 | ||||||
| 3 | 11 | ||||||
| Empty | 12 | ||||||
| 4 | 13 | ||||||
| 123 | Empty | 14 | |||||
| Empty | 15 | ||||||
| 5 | 16 | ||||||
| 6 | 17 | ||||||
| 7 | 18 | ||||||
| 8 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the author. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Michalak, M. Searching for Continuous n-Clusters with Boolean Reasoning. Symmetry 2024, 16, 1286. https://doi.org/10.3390/sym16101286
Michalak M. Searching for Continuous n-Clusters with Boolean Reasoning. Symmetry. 2024; 16(10):1286. https://doi.org/10.3390/sym16101286
Chicago/Turabian StyleMichalak, Marcin. 2024. "Searching for Continuous n-Clusters with Boolean Reasoning" Symmetry 16, no. 10: 1286. https://doi.org/10.3390/sym16101286
APA StyleMichalak, M. (2024). Searching for Continuous n-Clusters with Boolean Reasoning. Symmetry, 16(10), 1286. https://doi.org/10.3390/sym16101286