
Integrated Optimization of Blocking Flowshop Scheduling and Preventive Maintenance Using a Q-Learning-Based Aquila Optimizer



Abstract
:1. Introduction
- (1)
- This work formulates an integrated optimization model for a blocking flowshop scheduling problem. In this model, deterioration and default of machines, as well as machine maintenance are considered at the same time. To calculate the object values, a recursive formula is established;
- (2)
- This work develops an AO with some special search techniques to enhance its performance and propose the improved algorithm QL-AO. It employs a QL-based mechanism for strategies selection. Other than that, a set of local search strategies is designed to strengthen the search ability via combining the problem’s features;
- (3)
- This work conducts a series of experiments to evaluate the performance of the proposed QL-AO by comparing it with eight peer algorithms. They are experiments of parameter settings, components comparison and algorithm comparison. The achieved results suggest that QL-AO is an efficient optimizer compared to its peers.
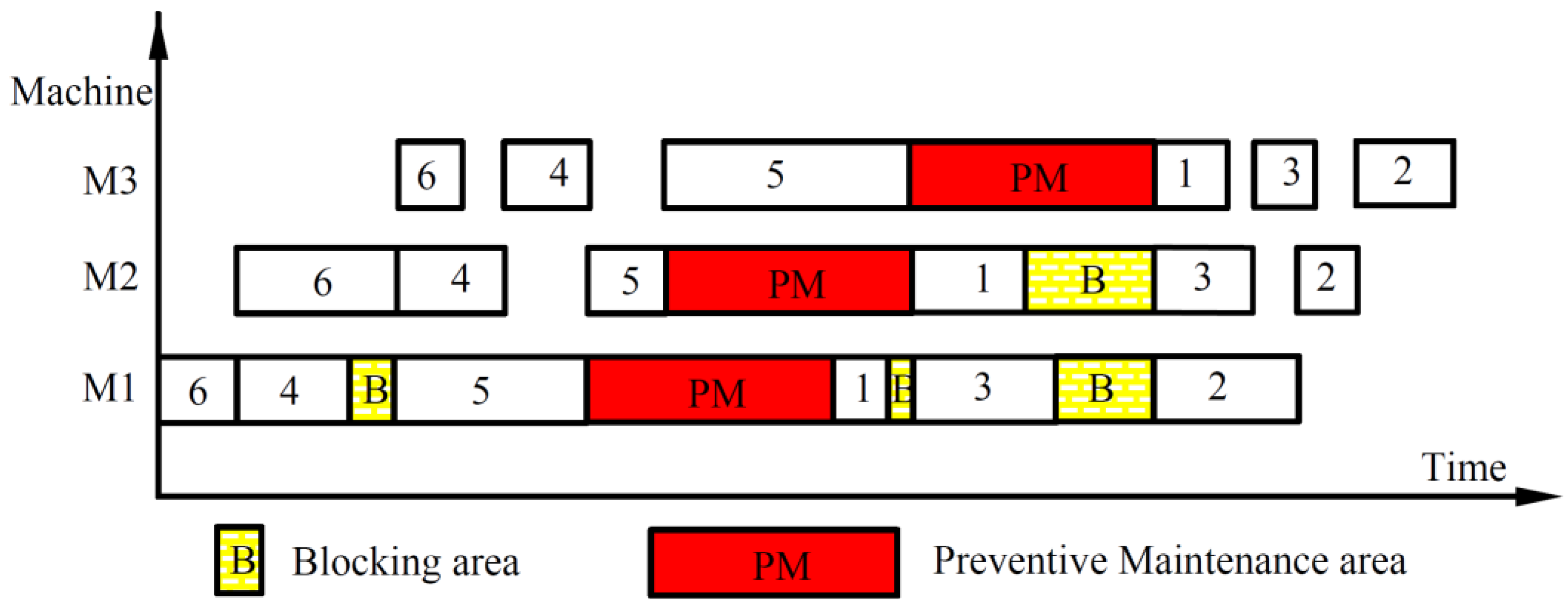
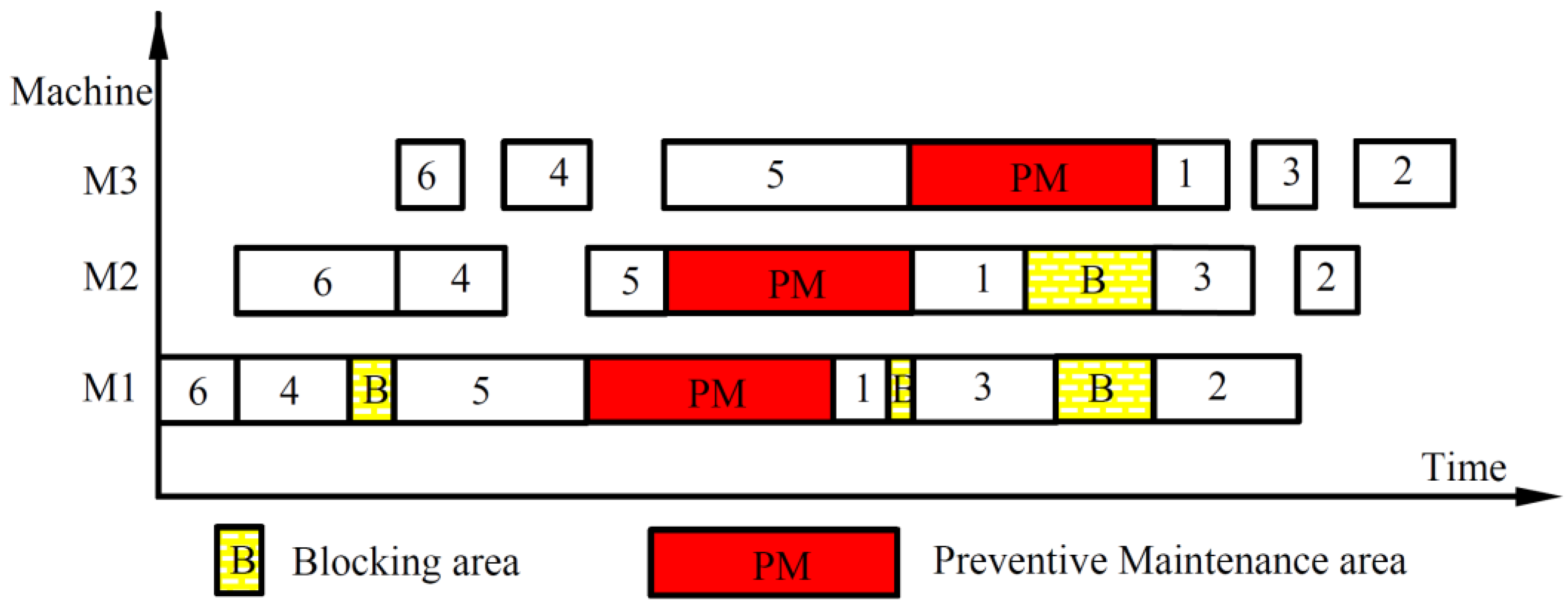
2. Problem Description
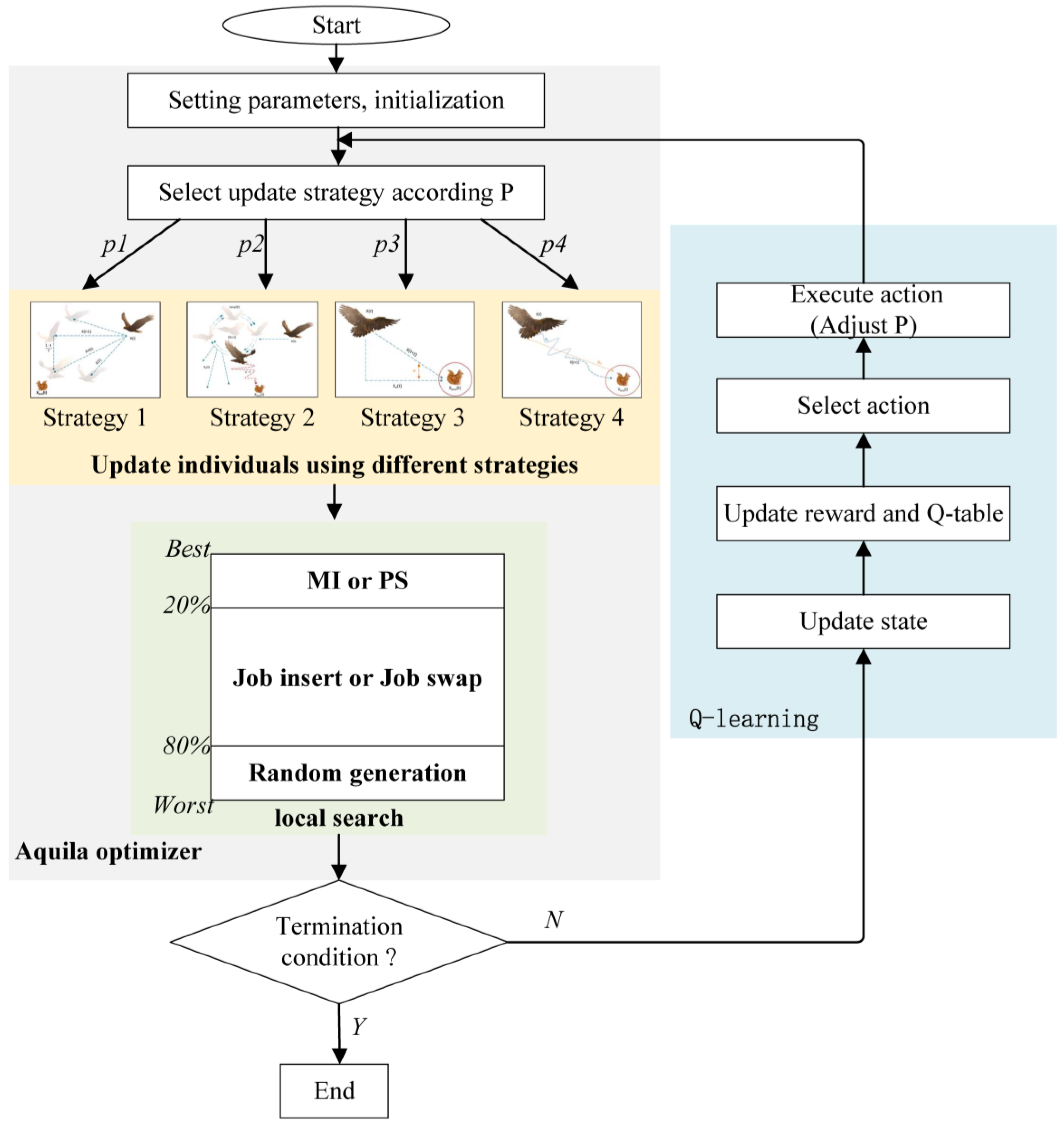
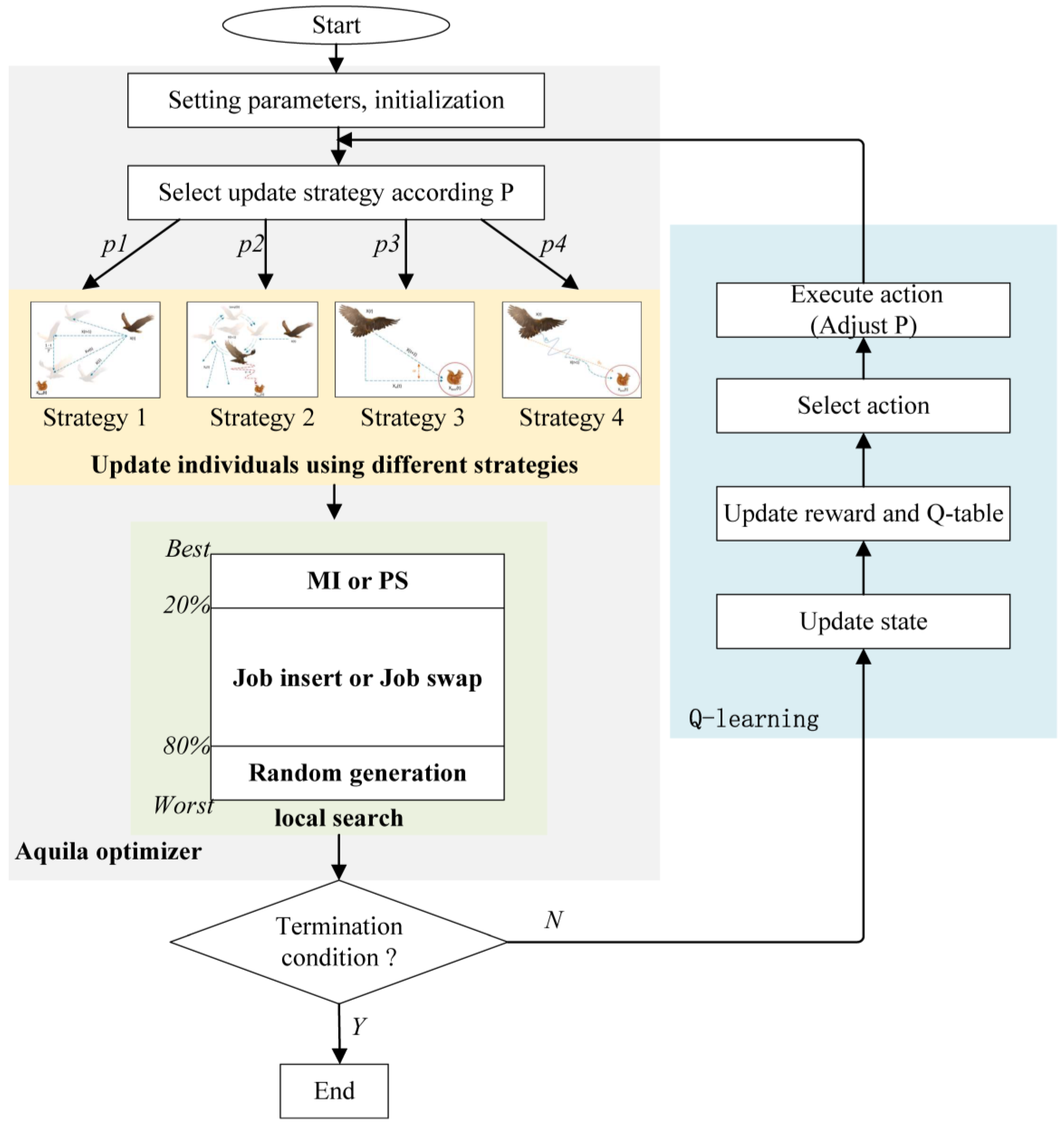
3. The Proposed Algorithm
3.1. Basic Aquila Optimizer
| Algorithm 1: Basic AO |
|
3.2. Individual Representation
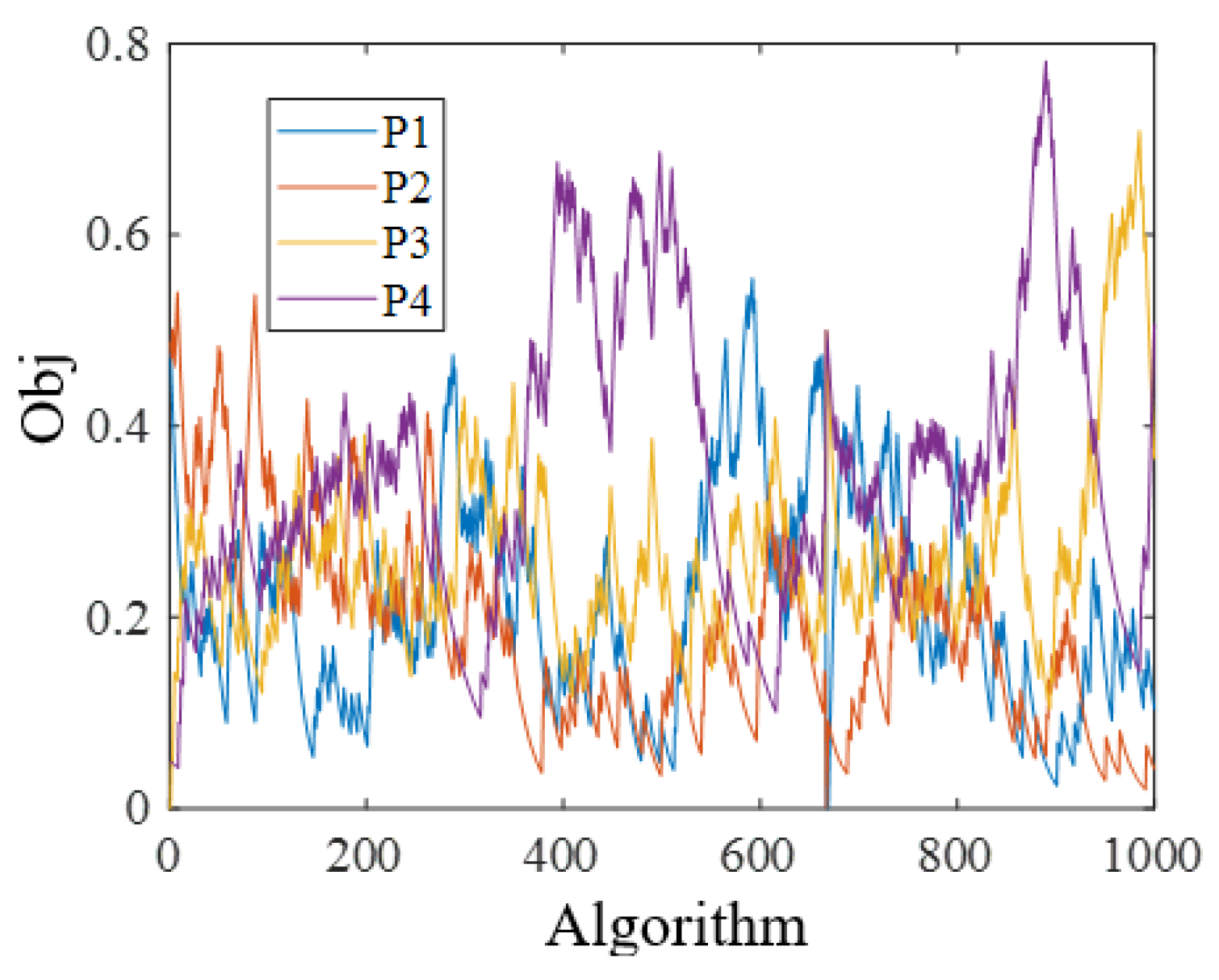
3.3. Q-Learning-Based Strategies Selection
| Algorithm 2: Pseudo code of Q-learning update |
| Input: , Q, s, , , , . Output: Q, a′, s′.
|
3.4. Local Search Strategies
- Machine Age-Based Insert (MI): Insert the job with the highest mean machine age (the average value of machine age for all machines) after the job with the lowest mean machine age but excluding the first job. By applying this strategy, the job with the highest mean machine age is repositioned to a more favorable location. This approach may find a more potential solution.
- PM-Based Swap (PS): In this strategy, the job with the maximum total times of PM is moved one position backward. By performing this swap operation, the algorithm aims to explore different arrangements of the PM-intensive job, potentially leading to improvements in the scheduling solution.
- Job Insert (JI): This is a common local search strategy in that two different jobs are randomly selected and the first job is inserted after the second job. This operation introduces a change in the sequence of jobs and may lead to an improved solution.
- Job Swap (JS): Another commonly used local search strategy is job swap. Two different jobs are randomly selected, and their positions are swapped. This exchange alters the job order, potentially resulting in a better scheduling solution.
- Random Generation (RG): This strategy randomly generates a scheduling solution. The purpose of this strategy is to introduce diversity into the population. It encourages the discovery of novel and potentially better scheduling solution.
3.5. The Framework of Proposed Algorithm
- (1)
- Initialize the population with 90% random individuals and 10% ones generated via the NEH-based solution.
- (2)
- Select update strategy for each individual according to selection probabilities and then update the population using different strategies.
- (3)
- Execute local search for each individual to further improve its quality.
- (4)
- If the termination condition is not met, execute a new iteration after adjusting the selection probabilities by QL; otherwise, the algorithm is terminated.
- (5)
- Go to QL section. Update the system state, reward, and Q-table. Select the new action, execute the action to adjust probabilities, and then go to step (2).
4. Computational Experiments
4.1. Test Instance Settings
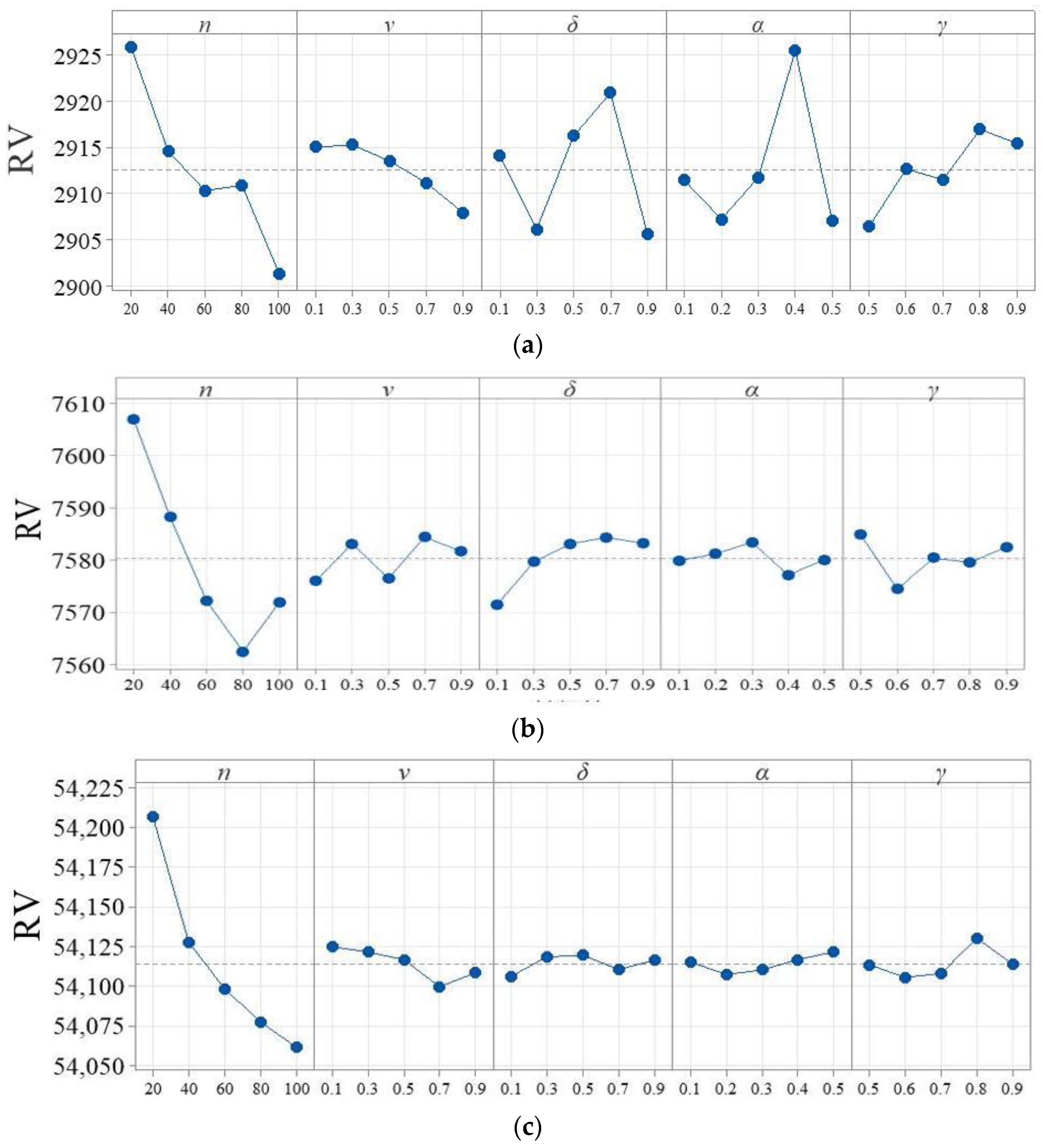
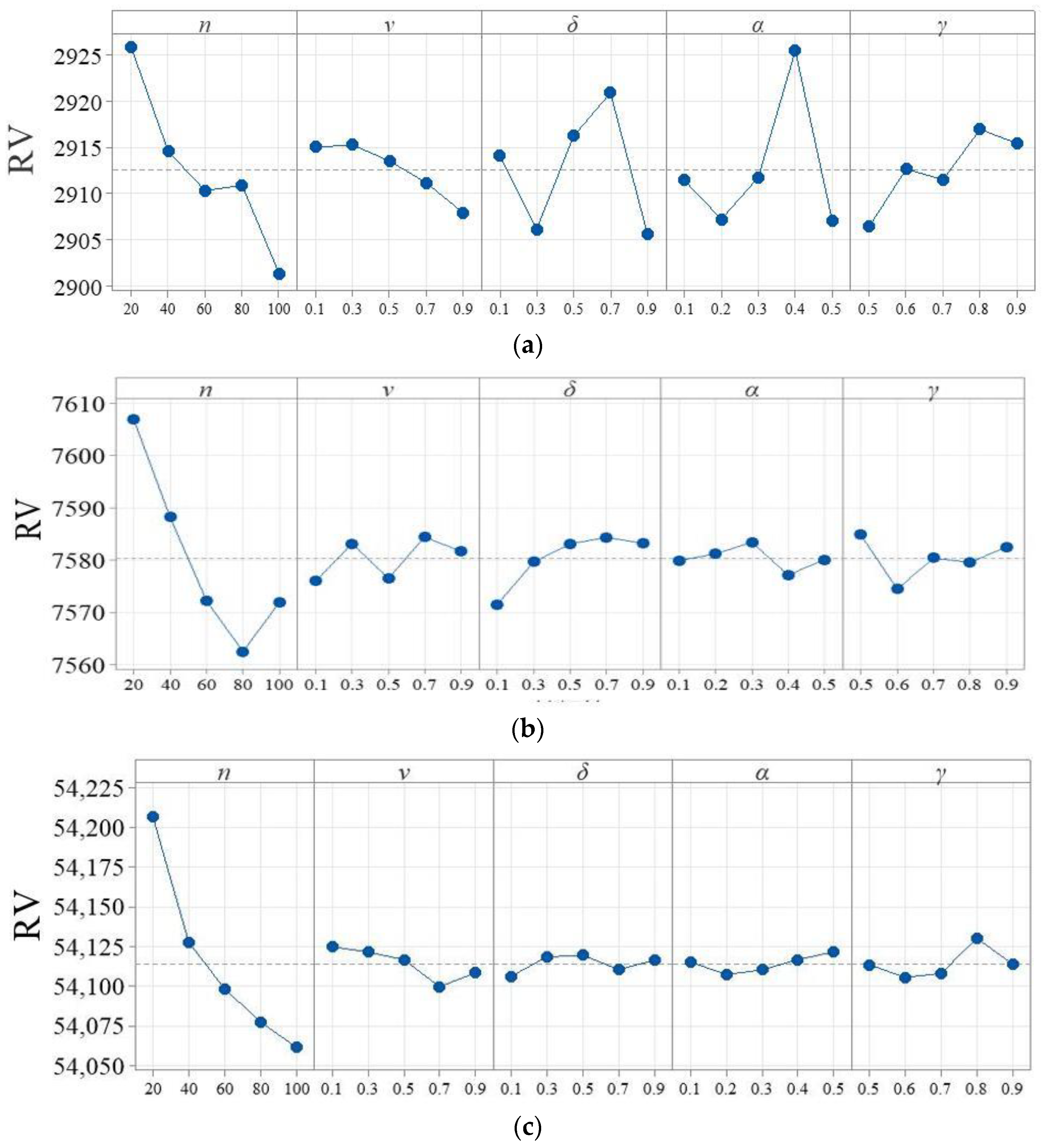
4.2. Key Parameter Settings
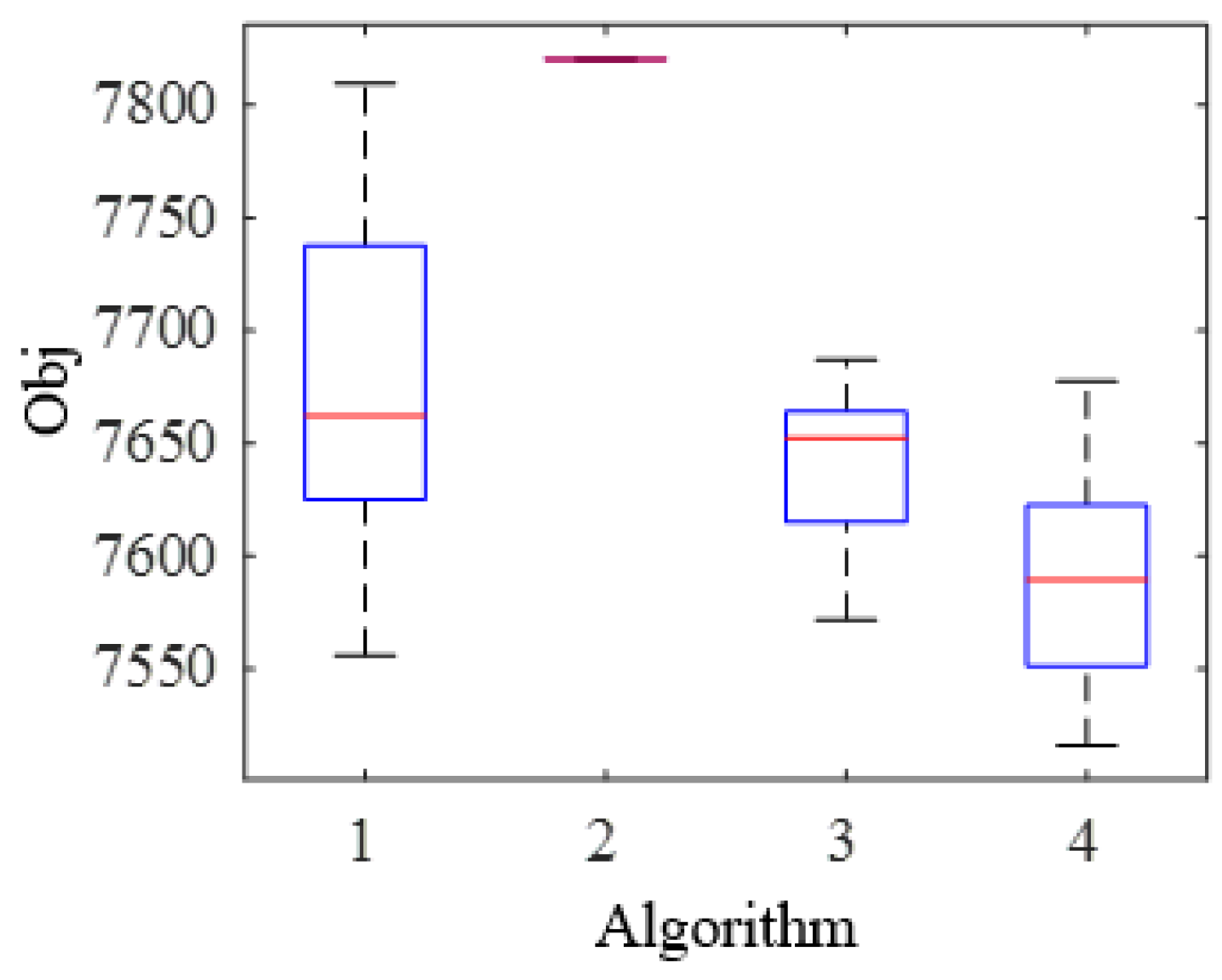
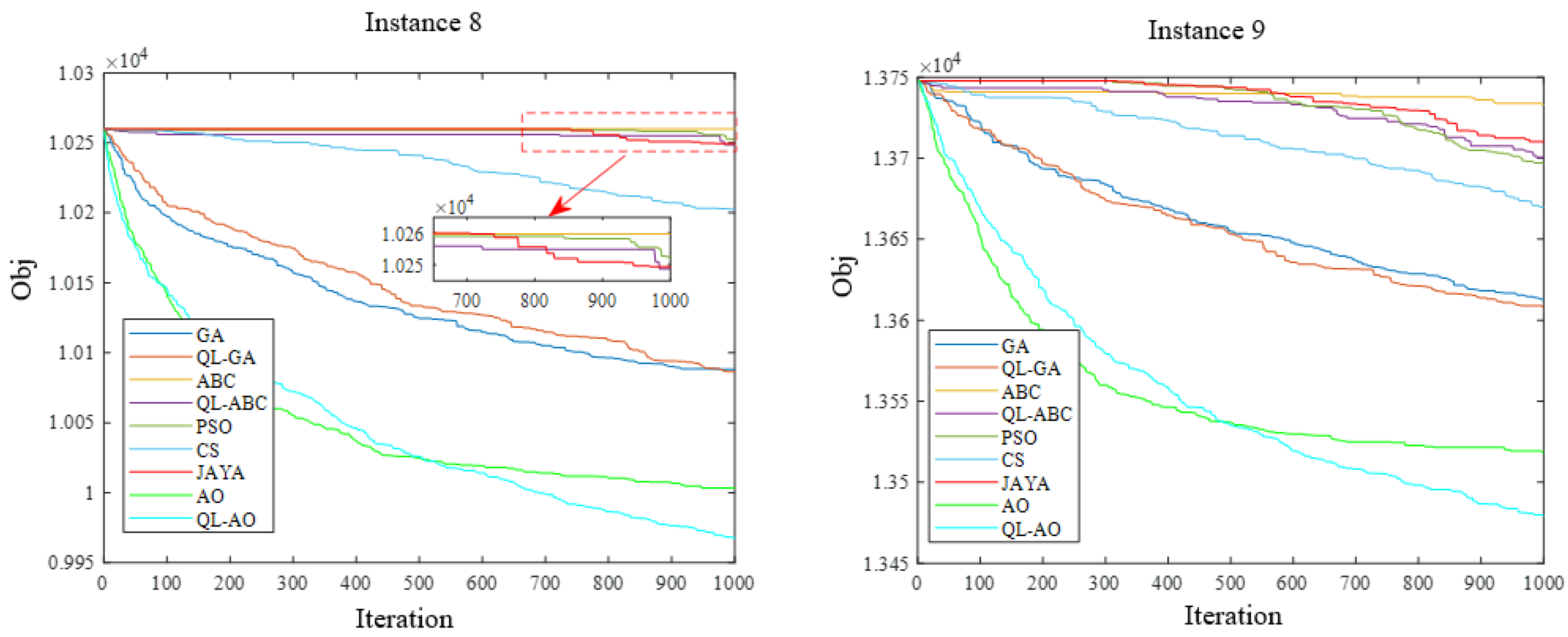
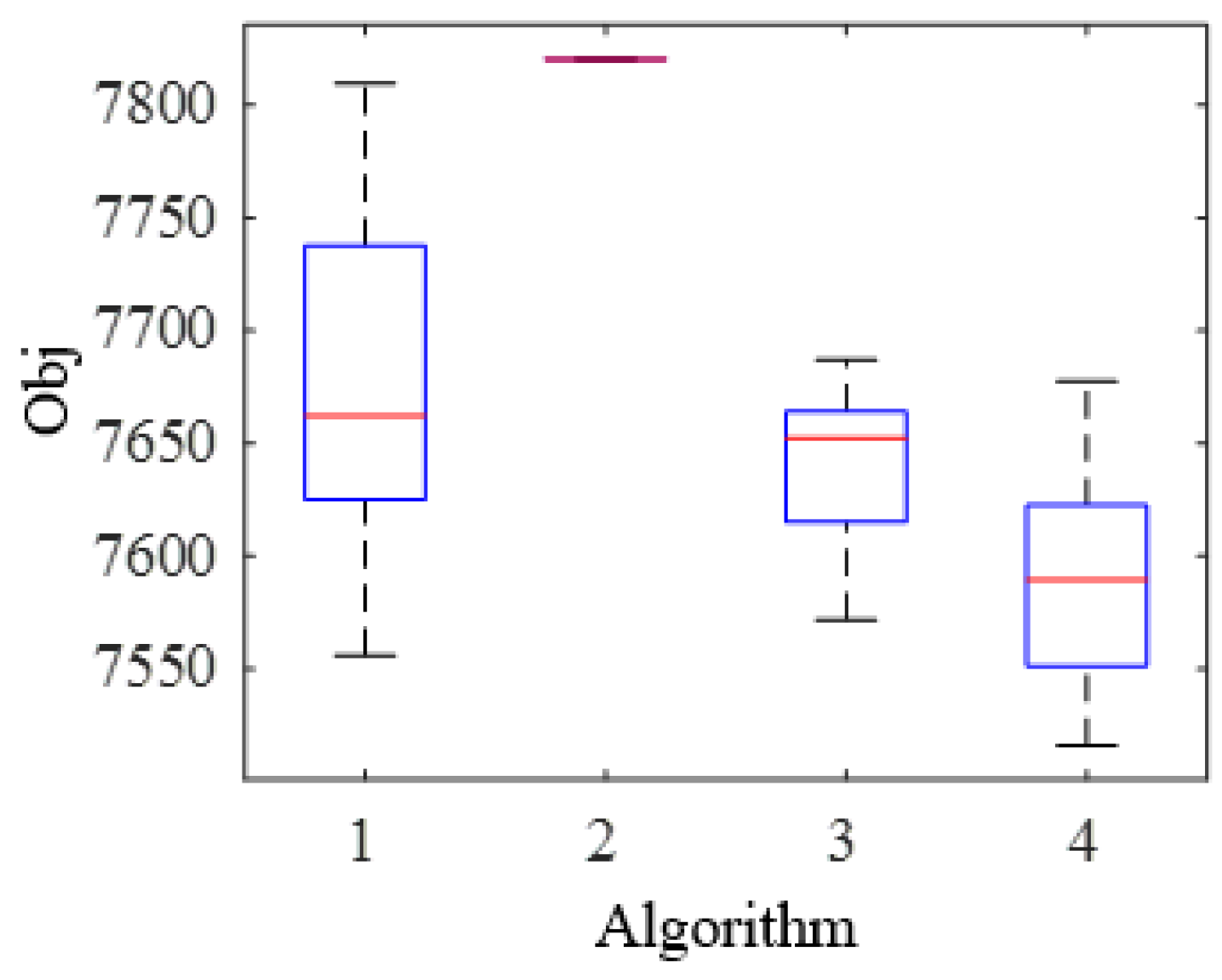
4.3. Comparison of the Components on QL-AO
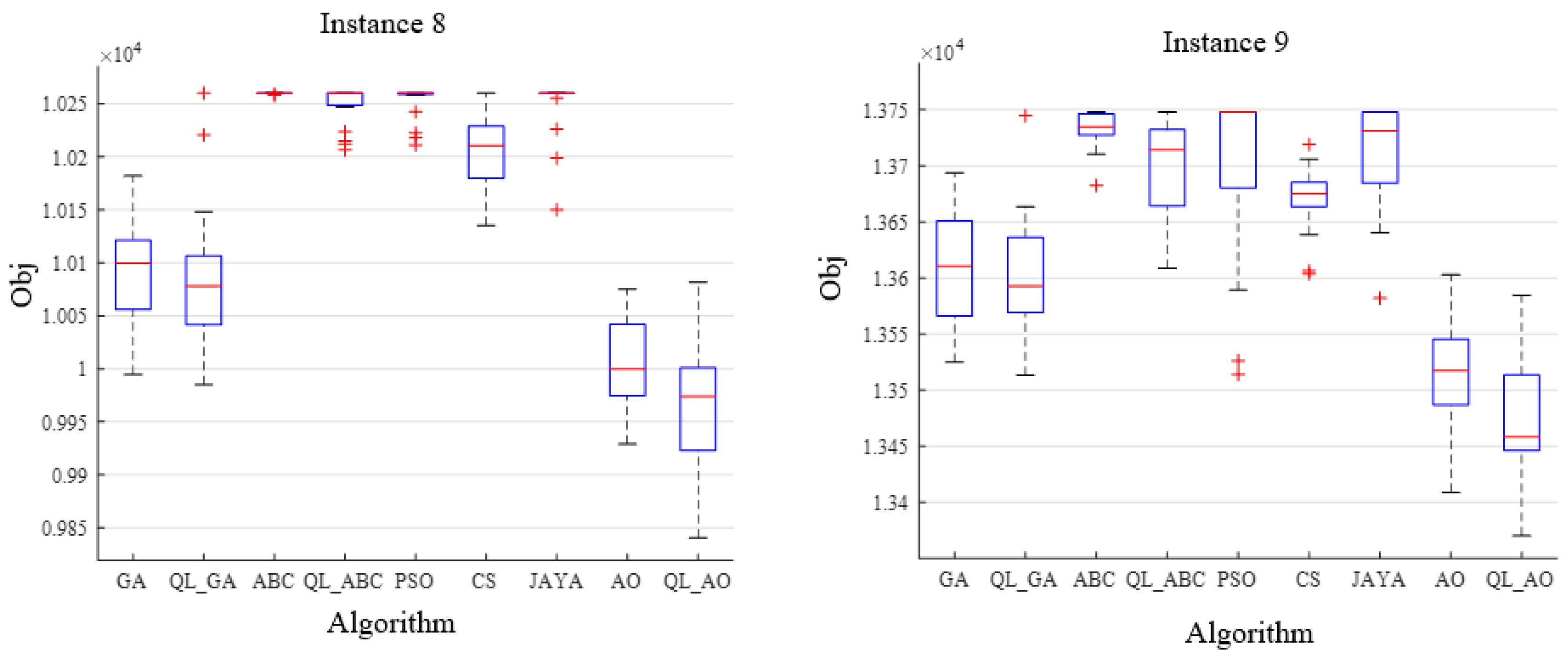
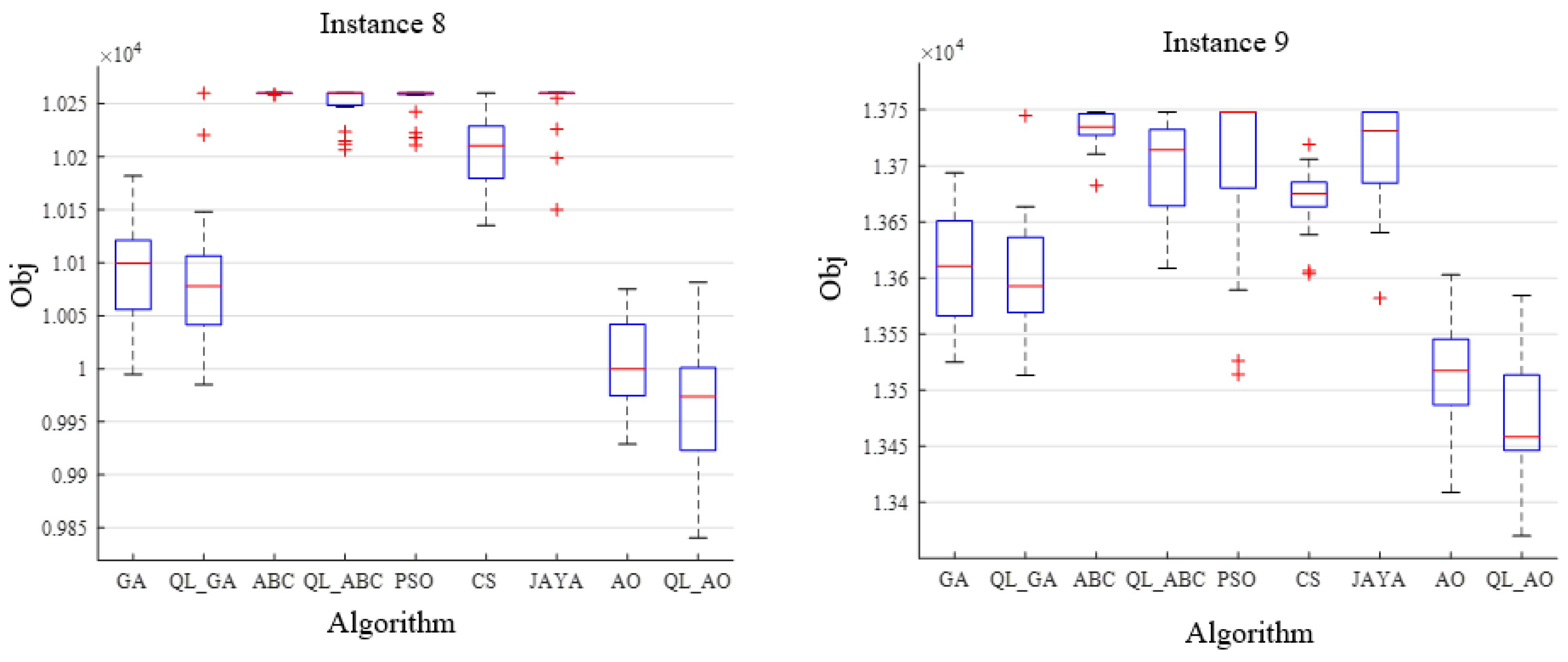
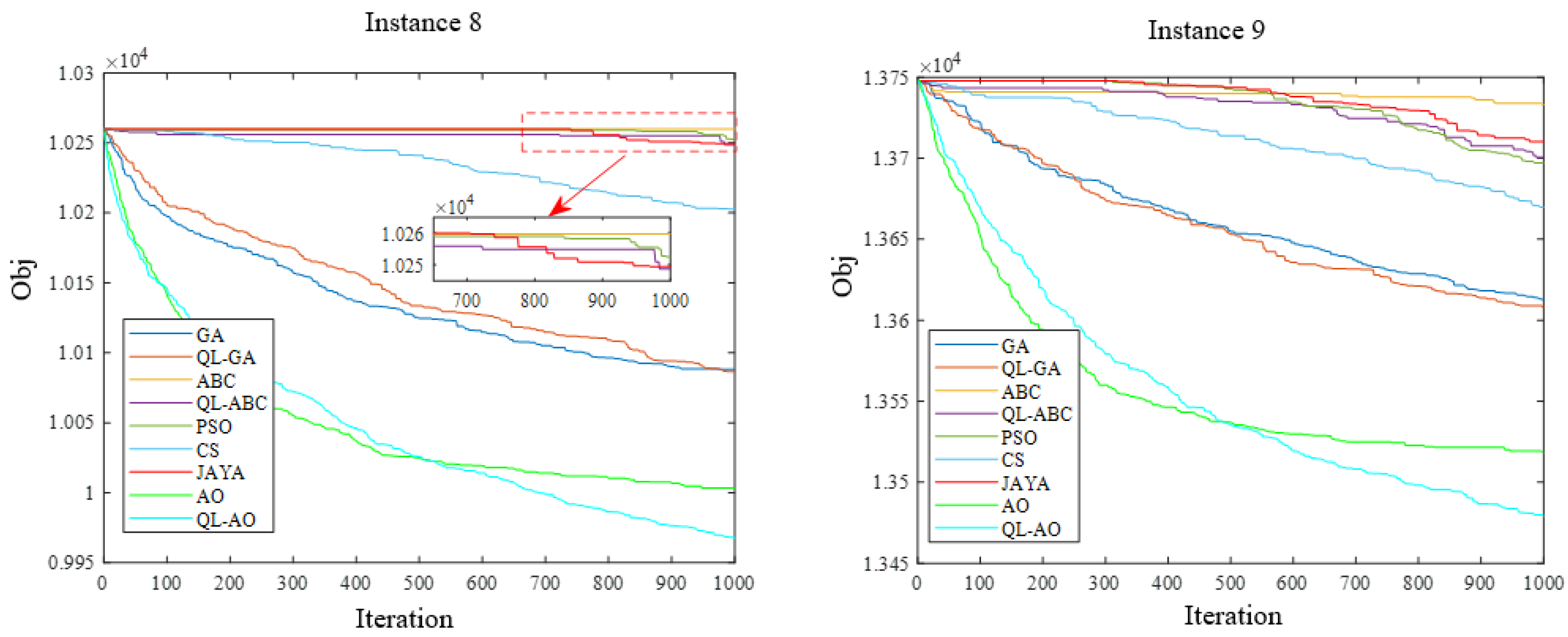
4.4. Algorithm Comparison
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Azimpoor, S.; Taghipour, S.; Farmanesh, B.; Sharifi, M. Joint Planning of Production and Inspection of Parallel Machines with Two-phase of Failure. Rellab. Eng. Syst. Saf. 2022, 217, 108097. [Google Scholar] [CrossRef]
- Ben Ali, M.; Sassi, M.; Gossa, M.; Harrath, Y. Simultaneous scheduling of production and maintenance tasks in the job shop. Int. J. Prod. Res. 2011, 49, 3891–3918. [Google Scholar] [CrossRef]
- Basri, E.I.; Abdul Razak, I.H.; Ab-Samat, H.; Kamaruddin, S. Preventive Maintenance (PM) planning: A review. J. Qual. Maint. Eng. 2017, 23, 14. [Google Scholar] [CrossRef]
- Wang, H.; Yan, Q.; Zhang, S. Integrated scheduling and flexible maintenance in deteriorating multi-state single machine system using a reinforcement learning approach. Adv. Eng. Inform. 2021, 49, 101339. [Google Scholar] [CrossRef]
- Yan, Q.; Wang, H.; Wu, F. Digital twin-enabled dynamic scheduling with preventive maintenance using a double-layer Q-learning algorithm. Comput. Oper. Res. 2022, 144, 105823. [Google Scholar] [CrossRef]
- Liu, L.X.; Shi, L.Y. Automatic Design of Efficient Heuristics for Two-Stage Hybrid Flow Shop Scheduling. Symmetry 2022, 14, 162. [Google Scholar] [CrossRef]
- Merchan, A.F.; Maravelias, C.T. Preprocessing and tightening methods for time-indexed chemical production scheduling models. Comput. Chem. Eng. 2016, 84, 516–535. [Google Scholar] [CrossRef]
- Gong, H.; Tang, L.; Duin, C.W. A two-stage flow shop scheduling problem on a batching machine and a discrete machine with blocking and shared setup times. Comput. Oper. Res. 2010, 37, 960–969. [Google Scholar] [CrossRef]
- Elmi, A.; Topaloglu, S. A scheduling problem in blocking hybrid flow shop robotic cells with multiple robots. Comput. Oper. Res. 2013, 40, 2543–2555. [Google Scholar] [CrossRef]
- Miyata, H.H.; Nagano, M.S. The blocking flow shop scheduling problem: A comprehensive and conceptual review. Expert. Syst. Appl. 2019, 137, 130–156. [Google Scholar] [CrossRef]
- Graham, R.L.; Lawler, E.L.; Lenstra, J.K.; Kan, A.H.G.R. Optimization and approximation in deterministic sequencing and scheduling: A survey. ADM 1979, 5, 287–326. [Google Scholar]
- Hall, N.G.; Sriskandarajah, C. A survey of machine scheduling problems with blocking and no-wait in process. Oper. Res. 1996, 44, 510–525. [Google Scholar] [CrossRef]
- Jiang, J.; An, Y.; Dong, Y.; Hu, J.; Li, Y.; Zhao, Z. Integrated optimization of non-permutation flow shop scheduling and maintenance planning with variable processing speed. Reliab. Eng. Syst. Saf. 2023, 234, 109143. [Google Scholar] [CrossRef]
- Caraffa, V.; Ianes, S.; Bagchi, T.P.; Sriskandarajah, C. Minimizing makespan in a blocking flowshop using genetic algorithms. Int. J. Prod. Econ. 2001, 70, 101–115. [Google Scholar] [CrossRef]
- Liang, J.J.; Pan, Q.K.; Chen, T.J.; Wang, L. Dynamic Multi-swarm Particle Swarm Optimizer for blocking flow shop scheduling. In Proceedings of the IEEE International Conference on Fuzzy Systems, Changsha, China, 23–26 September 2010. [Google Scholar]
- Li, M.B.; Xiong, H.; Lei, D.M. An Artificial Bee Colony with Adaptive Competition for the Unrelated Parallel Machine Scheduling Problem with Additional Resources and Maintenance. Symmetry 2022, 14, 1380. [Google Scholar] [CrossRef]
- Liu, H.; Zhang, X.; Zhang, H.; Li, C.; Chen, Z. A reinforcement learning-based hybrid Aquila Optimizer and improved Arithmetic Optimization Algorithm for global optimization. Expert. Syst. Appl. 2023, 224, 119898. [Google Scholar] [CrossRef]
- Ait-Saadi, A.; Meraihi, Y.; Soukane, A.; Ramdane-Cherif, A.; Gabis, A.B. A novel hybrid Chaotic Aquila Optimization algorithm with Simulated Annealing for Unmanned Aerial Vehicles path planning. Comput. Electr. Eng. 2022, 104, 108461. [Google Scholar] [CrossRef]
- Bas, E. Binary Aquila Optimizer for 0–1 knapsack problems. Eng. Appl. Artif. Intel. 2023, 118, 105592. [Google Scholar] [CrossRef]
- Agarwal, N.; Gokilavani, M.; Nagarajan, S.; Saranya, S.; Alsolai, H.; Dhahbi, S.; Abdelaziz, A.S. Intelligent aquila optimization algorithm-based node localization scheme for wireless sensor networks. CMC-Comput. Mater. Con. 2023, 74, 141–152. [Google Scholar] [CrossRef]
- Li, R.; Zhang, X.; Jiang, L.; Yang, Z.; Guo, W. An adaptive heuristic algorithm based on reinforcement learning for ship scheduling optimization problem. Ocean. Coast. Manage. 2022, 230, 106375. [Google Scholar] [CrossRef]
- Mao, J.; Hu, X.L.; Pan, Q.K.; Miao, Z.; Tasgetiren, M.F. An improved discrete artificial bee colony algorithm for the distributed permutation flowshop scheduling problem with preventive maintenance. In Proceedings of the 39th Chinese Control Conference, Shenyang, China, 27–29 July 2020. [Google Scholar]
- Cheng, L.; Tang, Q.; Zhang, L.; Meng, K. Mathematical model and enhanced cooperative co-evolutionary algorithm for scheduling energy-efficient manufacturing cell. J. Clean. Prod. 2021, 326, 129248. [Google Scholar] [CrossRef]
- Zhang, Z.; Tang, Q. Integrating preventive maintenance to two-stage assembly flow shop scheduling: MILP model, constructive heuristics and meta-heuristics. Flex. Serv. Manuf. J. 2022, 34, 156–203. [Google Scholar] [CrossRef]
- Sun, L.H.; Ge, C.C.; Zhang, W.; Wang, J.B.; Lu, Y.Y. Permutation flowshop scheduling with simple linear deterioration. Eng. Optim. 2019, 51, 1281–1300. [Google Scholar] [CrossRef]
- Wang, S.; Liu, M. Two-machine flow shop scheduling integrated with preventive maintenance planning. Int. J. Syst. Sci. 2016, 47, 672–690. [Google Scholar] [CrossRef]
- Ruiz, R.; García-Díaz, J.C.; Maroto, C. Considering scheduling and preventive maintenance in the flowshop sequencing problem. Comput. Oper. Res. 2007, 34, 3314–3330. [Google Scholar] [CrossRef]
- Grabowski, J.; Pempera, J. The permutation flow shop problem with blocking. A tabu search approach. Omega 2007, 35, 302–311. [Google Scholar] [CrossRef]
- Abualigah, L.; Yousri, D.; Abd Elaziz, M.; Al-Qaness, M.A.; Gandomi, A.H. Aquila optimizer: A novel meta-heuristic optimization algorithm. Comput. Ind. Eng. 2021, 157, 107250. [Google Scholar] [CrossRef]
- Bean, J.C. Genetic algorithms and random keys for sequencing and optimization. ORSA J. Comput. 1994, 6, 154–160. [Google Scholar] [CrossRef]
- Yang, X.S. Swarm intelligence based algorithms: A critical analysis. Evol. Intell. 2014, 7, 17–28. [Google Scholar] [CrossRef]
- Wineberg, M.; Oppacher, F. The underlying similarity of diversity measures used in evolutionary computation. In Proceedings of the Genetic and Evolutionary Computation Conference, Chicago, IL, USA, 12–16 July 2003. [Google Scholar]
- Taillard, E. Benchmarks for basic scheduling problems. Eur. J. Oper. Res. 1993, 64, 278–285. [Google Scholar] [CrossRef]
- Vallada, E.; Ruiz, R.; Framinan, J. New hard benchmark for flowshop scheduling problems minimising makespan. Eur. J. Oper. Res. 2017, 240, 666–677. [Google Scholar] [CrossRef]
- Chen, R.; Yang, B.; Li, S. A Self-Learning Genetic Algorithm based on Reinforcement Learning for Flexible Job-shop Scheduling Problem. Comput. Ind. Eng. 2020, 149, 106778. [Google Scholar] [CrossRef]
- Long, X.; Zhang, J.; Zhou, K. Dynamic Self-Learning Artificial Bee Colony Optimization Algorithm for Flexible Job-Shop Scheduling Problem with Job Insertion. Processes 2022, 10, 571. [Google Scholar] [CrossRef]

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| State | Description | State | Description |
|---|---|---|---|
| 1 | 7 | ||
| 2 | 8 | ||
| 3 | 9 | ||
| 4 | 10 | ||
| 5 | 11 | ||
| 6 | 12 |
| Trial Number | Factor Levels | RV (20 × 20) | RV (5 × 100) | RV (400 × 20) | ||||
|---|---|---|---|---|---|---|---|---|
| 1 | 20 | 0.1 | 0.1 | 0.1 | 0.5 | 2919.89 | 7607.12 | 54201.77 |
| 2 | 20 | 0.3 | 0.3 | 0.2 | 0.6 | 2914.63 | 7602.14 | 54207.26 |
| 3 | 20 | 0.5 | 0.5 | 0.3 | 0.7 | 2928.07 | 7617.98 | 54208.93 |
| 4 | 20 | 0.7 | 0.7 | 0.4 | 0.8 | 2952.31 | 7602.17 | 54208.01 |
| 5 | 20 | 0.9 | 0.9 | 0.5 | 0.9 | 2914.06 | 7605.10 | 54205.58 |
| 6 | 40 | 0.1 | 0.3 | 0.3 | 0.8 | 2916.63 | 7577.49 | 54150.14 |
| 7 | 40 | 0.3 | 0.5 | 0.4 | 0.9 | 2933.99 | 7602.04 | 54134.41 |
| 8 | 40 | 0.5 | 0.7 | 0.5 | 0.5 | 2910.07 | 7590.76 | 54137.54 |
| 9 | 40 | 0.7 | 0.9 | 0.1 | 0.6 | 2904.77 | 7597.79 | 54112.47 |
| 10 | 40 | 0.9 | 0.1 | 0.2 | 0.7 | 2907.46 | 7572.77 | 54102.59 |
| 11 | 60 | 0.1 | 0.5 | 0.5 | 0.6 | 2913.42 | 7555.60 | 54114.38 |
| 12 | 60 | 0.3 | 0.7 | 0.1 | 0.7 | 2921.55 | 7570.67 | 54092.44 |
| 13 | 60 | 0.5 | 0.9 | 0.2 | 0.8 | 2900.78 | 7580.53 | 54104.55 |
| 14 | 60 | 0.7 | 0.1 | 0.3 | 0.9 | 2910.33 | 7570.79 | 54076.38 |
| 15 | 60 | 0.9 | 0.3 | 0.4 | 0.5 | 2905.61 | 7583.08 | 54103.36 |
| 16 | 80 | 0.1 | 0.7 | 0.2 | 0.9 | 2918.75 | 7574.19 | 54081.89 |
| 17 | 80 | 0.3 | 0.9 | 0.3 | 0.5 | 2902.09 | 7566.89 | 54084.02 |
| 18 | 80 | 0.5 | 0.1 | 0.4 | 0.6 | 2928.77 | 7532.74 | 54061.93 |
| 19 | 80 | 0.7 | 0.3 | 0.5 | 0.7 | 2893.97 | 7574.99 | 54061.09 |
| 20 | 80 | 0.9 | 0.5 | 0.1 | 0.8 | 2910.99 | 7563.49 | 54098.52 |
| 21 | 100 | 0.1 | 0.9 | 0.4 | 0.7 | 2906.50 | 7565.46 | 54075.70 |
| 22 | 100 | 0.3 | 0.1 | 0.5 | 0.8 | 2904.08 | 7573.83 | 54088.92 |
| 23 | 100 | 0.5 | 0.3 | 0.1 | 0.9 | 2900.06 | 7560.35 | 54070.07 |
| 24 | 100 | 0.7 | 0.5 | 0.2 | 0.5 | 2894.66 | 7576.20 | 54040.78 |
| 25 | 100 | 0.9 | 0.7 | 0.3 | 0.6 | 2901.78 | 7583.82 | 54031.82 |
| (a) Small-scale instances with 20 jobs and 20 machines | |||||
| Levels | |||||
| 1 | 2925.79 | 2915.04 | 2914.11 | 2911.45 | 2906.46 |
| 2 | 2914.58 | 2915.27 | 2906.18 | 2907.26 | 2912.67 |
| 3 | 2910.34 | 2913.55 | 2916.23 | 2911.78 | 2911.51 |
| 4 | 2910.91 | 2911.21 | 2920.89 | 2925.44 | 2916.96 |
| 5 | 2901.42 | 2907.98 | 2905.64 | 2907.12 | 2915.44 |
| Delta | 24.38 | 7.29 | 15.25 | 18.32 | 10.49 |
| Rank | 1 | 5 | 3 | 2 | 4 |
| (b) Medium-scale instances with 100 jobs and 5 machines | |||||
| Levels | |||||
| 1 | 7606.90 | 7575.97 | 7571.45 | 7579.88 | 7584.81 |
| 2 | 7588.17 | 7583.11 | 7579.61 | 7581.17 | 7574.42 |
| 3 | 7572.13 | 7576.47 | 7583.06 | 7583.39 | 7580.37 |
| 4 | 7562.46 | 7584.39 | 7584.32 | 7577.10 | 7579.50 |
| 5 | 7571.93 | 7581.65 | 7583.15 | 7580.06 | 7582.49 |
| Delta | 44.44 | 8.42 | 12.87 | 6.30 | 10.39 |
| Rank | 1 | 4 | 2 | 5 | 3 |
| (c) Large-scale instances with 400 jobs and 20 machines | |||||
| Levels | |||||
| 1 | 54206.31 | 54124.78 | 54106.32 | 54115.05 | 54113.49 |
| 2 | 54127.43 | 54121.41 | 54118.38 | 54107.41 | 54105.57 |
| 3 | 54098.22 | 54116.60 | 54119.40 | 54110.26 | 54108.15 |
| 4 | 54077.49 | 54099.75 | 54110.34 | 54116.68 | 54130.03 |
| 5 | 54061.46 | 54108.37 | 54116.46 | 54121.50 | 54113.67 |
| Delta | 144.85 | 25.03 | 13.09 | 14.09 | 24.46 |
| Rank | 1 | 2 | 5 | 4 | 3 |
| Algorithm | Description |
|---|---|
| 1 | QL-AO without NEH heuristic method for initialization |
| 2 | QL-AO without local search strategies |
| 3 | QL-AO without QL based strategies selection |
| 4 | QL-AO with all components |
| Instance | GA | QL-GA | ABC | QL-ABC | PSO | CS | JAYA | AO | QL-AO | ||
|---|---|---|---|---|---|---|---|---|---|---|---|
| 1 | 20 × 5 | Min | 1383.40 | 1380.55 | 1390.95 | 1382.09 | 1381.78 | 1384.42 | 1374.93 | 1406.07 | 1387.86 |
| Mean | 1417.19 | 1411.31 | 1405.28 | 1398.08 | 1415.45 | 1402.32 | 1401.29 | 1422.98 | 1416.74 | ||
| Std. | 16.23 | 16.32 | 10.43 | 7.81 | 18.76 | 10.80 | 13.04 | 15.41 | 17.57 | ||
| Wilcoxon | ≈ | − | − | − | ≈ | − | − | ≈ | |||
| 2 | 20 × 10 | Min | 1904.79 | 1906.18 | 1912.58 | 1910.90 | 1938.96 | 1913.57 | 1910.49 | 1912.15 | 1917.31 |
| Mean | 1935.60 | 1934.50 | 1943.50 | 1933.69 | 1971.93 | 1933.88 | 1953.81 | 1944.88 | 1942.31 | ||
| Std. | 22.77 | 21.12 | 13.26 | 11.98 | 22.55 | 17.78 | 21.83 | 22.82 | 22.41 | ||
| Wilcoxon | ≈ | ≈ | ≈ | ≈ | + | ≈ | + | ≈ | |||
| 3 | 20 × 20 | Min | 2845.92 | 2844.01 | 2836.83 | 2828.02 | 2866.88 | 2824.59 | 2851.64 | 2875.42 | 2881.18 |
| Mean | 2935.25 | 2931.72 | 2879.17 | 2870.14 | 2901.16 | 2869.03 | 2883.96 | 2926.00 | 2925.85 | ||
| Std. | 50.53 | 39.09 | 18.86 | 18.97 | 22.42 | 24.15 | 20.81 | 36.51 | 31.86 | ||
| Wilcoxon | ≈ | ≈ | − | − | − | − | − | ≈ | |||
| 4 | 50 × 5 | Min | 3576.51 | 3528.83 | 3683.86 | 3642.64 | 3544.32 | 3581.38 | 3652.11 | 3494.77 | 3488.32 |
| Mean | 3612.92 | 3611.97 | 3733.72 | 3704.98 | 3682.18 | 3657.06 | 3723.94 | 3564.16 | 3549.49 | ||
| Std. | 33.48 | 33.22 | 31.21 | 31.93 | 50.00 | 27.97 | 31.70 | 34.53 | 38.09 | ||
| Wilcoxon | + | + | + | + | + | + | + | ≈ | |||
| 5 | 20 × 9 | Min | 4794.76 | 4762.25 | 4845.85 | 4788.66 | 4752.50 | 4733.64 | 4846.58 | 4793.12 | 4752.44 |
| Mean | 4855.40 | 4851.91 | 4912.50 | 4871.81 | 4878.56 | 4832.86 | 4923.75 | 4837.01 | 4824.00 | ||
| Std. | 33.58 | 40.51 | 30.56 | 35.14 | 74.37 | 49.68 | 35.33 | 29.09 | 39.16 | ||
| Wilcoxon | + | + | + | + | + | ≈ | + | ≈ | |||
| 6 | 50 × 10 | Min | 7044.37 | 7033.18 | 7149.35 | 7099.14 | 7026.40 | 7020.96 | 7052.65 | 7003.96 | 6963.96 |
| Mean | 7105.98 | 7094.31 | 7195.91 | 7159.99 | 7147.39 | 7114.70 | 7185.12 | 7076.00 | 7067.55 | ||
| Std. | 36.56 | 34.69 | 30.66 | 32.84 | 53.89 | 39.90 | 43.09 | 33.72 | 42.41 | ||
| Wilcoxon | + | + | + | + | + | + | + | ≈ | |||
| 7 | 50 × 20 | Min | 7644.53 | 7638.80 | 7811.62 | 7820.39 | 7747.91 | 7693.94 | 7820.39 | 7581.37 | 7495.38 |
| Mean | 7710.22 | 7708.41 | 7819.69 | 7820.39 | 7816.77 | 7796.97 | 7820.39 | 7628.43 | 7598.21 | ||
| Std. | 32.91 | 27.53 | 2.17 | 0.00 | 16.21 | 32.51 | 0.00 | 29.79 | 41.21 | ||
| Wilcoxon | + | + | + | + | + | + | + | + | |||
| 8 | 100 × 5 | Min | 9997.27 | 9980.79 | 10,258.11 | 10,233.13 | 10,121.03 | 10,164.82 | 10,188.47 | 9920.42 | 9885.14 |
| Mean | 10,079.75 | 10,076.84 | 10,259.78 | 10,256.91 | 10,252.46 | 10,223.50 | 10,255.17 | 10,003.37 | 9957.90 | ||
| Std. | 67.14 | 57.67 | 0.48 | 6.44 | 30.98 | 29.49 | 16.18 | 36.87 | 48.03 | ||
| Wilcoxon | + | + | + | + | + | + | + | + | |||
| 9 | 100 × 10 | Min | 13,518.95 | 13,513.64 | 13,680.83 | 13,602.60 | 13,507.90 | 13,616.91 | 13,621.38 | 13,473.78 | 13,378.77 |
| Mean | 13,614.51 | 13,611.87 | 13,719.77 | 13,711.69 | 13,683.29 | 13,677.17 | 13,718.22 | 13,530.68 | 13,497.21 | ||
| Std. | 43.95 | 42.78 | 27.66 | 35.88 | 73.02 | 33.36 | 32.92 | 26.27 | 44.54 | ||
| Wilcoxon | + | + | + | + | + | + | + | + | |||
| 10 | 100 × 20 | Min | 19,667.65 | 19,625.42 | 19,909.16 | 19,883.45 | 19,893.75 | 19,799.03 | 19,914.51 | 19,564.39 | 19,498.81 |
| Mean | 19,759.66 | 19,755.36 | 19,914.25 | 19,909.61 | 19,913.48 | 19,861.52 | 19,914.51 | 19,644.18 | 19,588.10 | ||
| Std. | 51.08 | 57.72 | 1.20 | 8.54 | 4.64 | 28.32 | 0.00 | 41.36 | 60.49 | ||
| Wilcoxon | + | + | + | + | + | + | + | + | |||
| 11 | 200 × 20 | Min | 26,753.76 | 26,713.04 | 26,989.87 | 26,956.33 | 27,008.19 | 26,821.13 | 27,008.19 | 26,586.15 | 26,577.62 |
| Mean | 26,839.01 | 26,823.55 | 27,006.69 | 26,997.57 | 27,008.19 | 26,919.17 | 27,008.19 | 26,719.92 | 26,652.97 | ||
| Std. | 61.16 | 68.51 | 4.73 | 16.39 | 0.00 | 43.78 | 0.00 | 51.97 | 45.25 | ||
| Wilcoxon | + | + | + | + | + | + | + | + | |||
| 12 | 500 × 20 | Min | 67,501.67 | 67,498.71 | 67,629.04 | 67,620.43 | 67,629.04 | 67,483.90 | 67,629.04 | 67,350.62 | 67,327.82 |
| Mean | 67,582.04 | 67,575.48 | 67,629.04 | 67,628.42 | 67,629.04 | 67,566.84 | 67,629.04 | 67,465.49 | 67,444.82 | ||
| Std. | 35.89 | 31.59 | 0.00 | 2.06 | 0.00 | 31.35 | 0.00 | 58.41 | 55.76 | ||
| Wilcoxon | + | + | + | + | + | + | + | ≈ | |||
| Wilcoxon +/≈/− | 9/3/0 | 9/2/1 | 9/1/2 | 9/1/2 | 10/1/1 | 8/2/2 | 10/0/2 | 5/7/0 | |||
| Instance | GA | QL-GA | ABC | QL-ABC | PSO | CS | JAYA | AO | QL-AO | ||
|---|---|---|---|---|---|---|---|---|---|---|---|
| 13 | 100 × 20 | Min | 13,381.89 | 13,365.69 | 13,575.12 | 13,556.27 | 13,607.59 | 13,498.32 | 13,593.09 | 13,288.05 | 13,274.52 |
| Mean | 13,461.01 | 13,457.96 | 13,611.66 | 13,610.96 | 13,623.99 | 13,567.71 | 13,623.36 | 13,385.36 | 13,363.48 | ||
| Std. | 61.51 | 53.06 | 18.02 | 21.90 | 3.88 | 23.06 | 7.12 | 52.22 | 58.06 | ||
| Wilcoxon | + | + | + | + | + | + | + | + | |||
| 14 | 200 × 20 | Min | 27,058.88 | 27,084.77 | 27,335.85 | 27,296.28 | 27,367.67 | 27,204.34 | 27,363.98 | 26,959.71 | 26,904.79 |
| Mean | 27,172.23 | 27,167.89 | 27,374.07 | 27,370.44 | 27,377.79 | 27,264.71 | 27,377.60 | 27,058.02 | 27,013.08 | ||
| Std. | 71.05 | 71.38 | 12.93 | 20.34 | 2.38 | 36.42 | 3.21 | 44.85 | 49.14 | ||
| Wilcoxon | + | + | + | + | + | + | + | + | |||
| 15 | 300 × 20 | Min | 40,531.17 | 40,577.87 | 40,799.60 | 40,799.01 | 40,799.60 | 40,675.93 | 40,799.60 | 40,465.17 | 40,436.82 |
| Mean | 40,669.81 | 40,662.84 | 40,799.60 | 40,798.57 | 40,799.60 | 40,729.63 | 40,799.60 | 40,564.75 | 40,515.46 | ||
| Std. | 71.38 | 38.12 | 0.00 | 1.13 | 0.00 | 27.69 | 0.00 | 62.05 | 41.60 | ||
| Wilcoxon | + | + | + | + | + | + | + | + | |||
| 16 | 400 × 20 | Min | 54,237.72 | 54,233.34 | 54,344.92 | 54,326.63 | 54,344.92 | 54,244.88 | 54,344.92 | 54,091.23 | 54,081.69 |
| Mean | 54,303.77 | 54,294.36 | 54,344.92 | 54,343.62 | 54,344.92 | 54,284.78 | 54,344.92 | 54,170.96 | 54,164.14 | ||
| Std. | 27.75 | 26.91 | 0.00 | 4.09 | 0.00 | 20.88 | 0.00 | 47.79 | 52.33 | ||
| Wilcoxon | + | + | + | + | + | + | + | ≈ | |||
| 17 | 500 × 20 | Min | 68,420.67 | 68,410.24 | 68,640.32 | 68,623.26 | 68,640.32 | 68,451.30 | 68,640.32 | 68,297.54 | 68,282.72 |
| Mean | 68,562.80 | 68,531.40 | 68,640.32 | 68,638.17 | 68,640.32 | 68,544.95 | 68,640.32 | 68,418.68 | 68,399.91 | ||
| Std. | 55.42 | 38.68 | 0.00 | 5.17 | 0.00 | 37.85 | 0.00 | 55.23 | 58.95 | ||
| Wilcoxon | + | + | + | + | + | + | + | + | |||
| 18 | 600 × 20 | Min | 81,641.45 | 81,637.28 | 81,744.13 | 81,716.31 | 81,744.13 | 81,624.94 | 81,744.13 | 81,562.63 | 81,504.01 |
| Mean | 81,713.28 | 81,711.14 | 81,744.13 | 81,740.62 | 81,744.13 | 81,663.04 | 81,744.13 | 81,627.96 | 81,627.42 | ||
| Std. | 23.93 | 17.62 | 0.00 | 8.50 | 0.00 | 18.70 | 0.00 | 42.29 | 51.35 | ||
| Wilcoxon | + | + | + | + | + | + | + | ≈ | |||
| 19 | 700 × 20 | Min | 94,930.95 | 94,925.67 | 95,010.06 | 95,003.24 | 95,010.06 | 94,830.38 | 95,010.06 | 94,853.35 | 94,841.62 |
| Mean | 94,975.91 | 94,971.35 | 95,010.06 | 95,009.48 | 95,010.06 | 94,932.49 | 95,010.06 | 94,923.47 | 94,921.12 | ||
| Std. | 20.54 | 25.09 | 0.00 | 1.83 | 0.00 | 35.92 | 0.00 | 42.72 | 37.68 | ||
| Wilcoxon | + | + | + | + | + | + | + | + | |||
| Wilcoxon +/≈/− | 7/0/0 | 7/0/0 | 7/0/0 | 7/0/0 | 7/0/0 | 7/0/0 | 7/0/0 | 5/2/0 | |||
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Ge, Z.; Wang, H. Integrated Optimization of Blocking Flowshop Scheduling and Preventive Maintenance Using a Q-Learning-Based Aquila Optimizer. Symmetry 2023, 15, 1600. https://doi.org/10.3390/sym15081600
Ge Z, Wang H. Integrated Optimization of Blocking Flowshop Scheduling and Preventive Maintenance Using a Q-Learning-Based Aquila Optimizer. Symmetry. 2023; 15(8):1600. https://doi.org/10.3390/sym15081600
Chicago/Turabian StyleGe, Zhenpeng, and Hongfeng Wang. 2023. "Integrated Optimization of Blocking Flowshop Scheduling and Preventive Maintenance Using a Q-Learning-Based Aquila Optimizer" Symmetry 15, no. 8: 1600. https://doi.org/10.3390/sym15081600
APA StyleGe, Z., & Wang, H. (2023). Integrated Optimization of Blocking Flowshop Scheduling and Preventive Maintenance Using a Q-Learning-Based Aquila Optimizer. Symmetry, 15(8), 1600. https://doi.org/10.3390/sym15081600