
A New Two-Parameter Discrete Distribution for Overdispersed and Asymmetric Data: Its Properties, Estimation, Regression Model, and Applications
Abstract
:1. Introduction
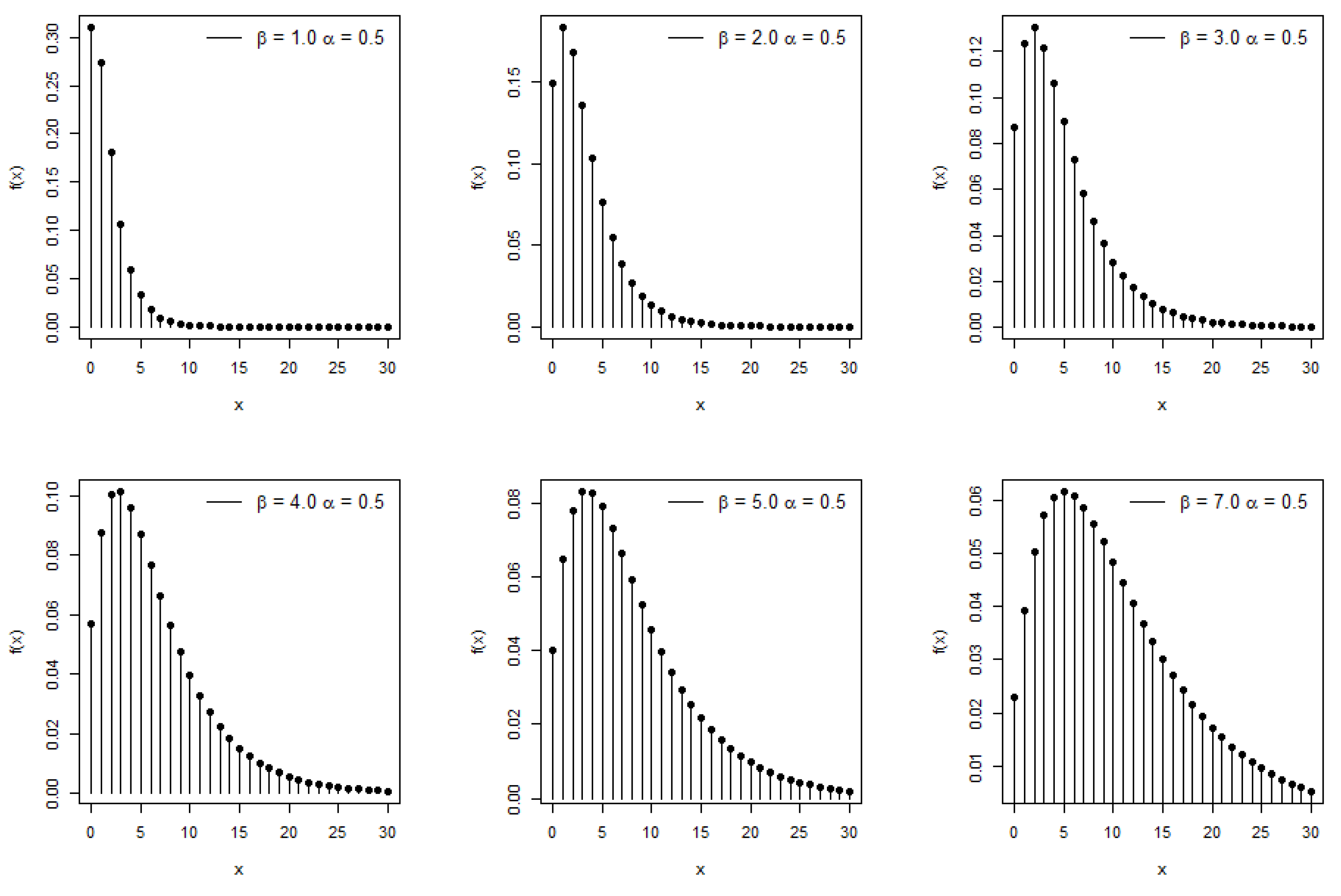
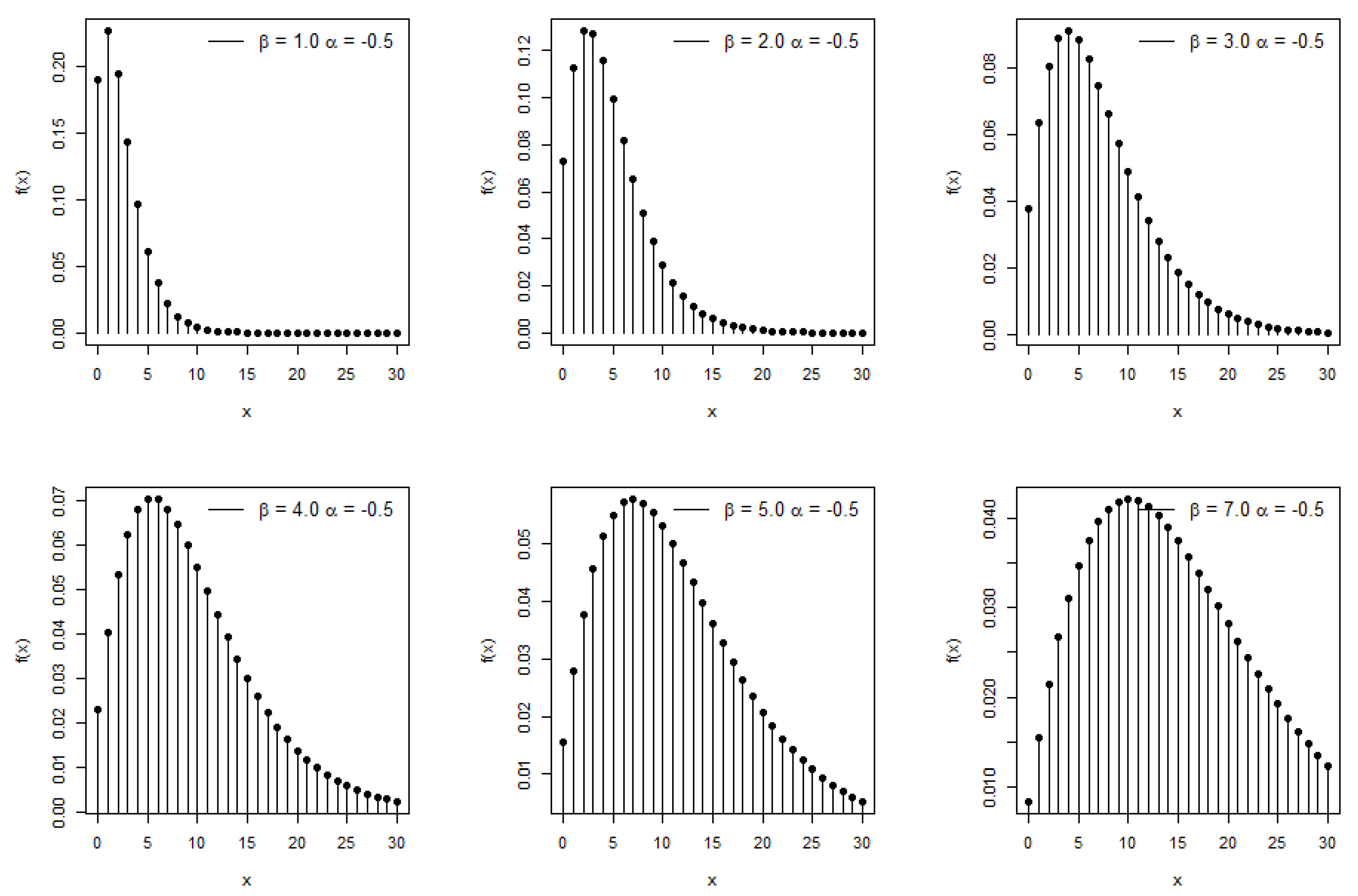
- The first thing that needs to be accomplished is to create a new two-parameter Poisson transmuted moment exponential distribution. This may be performed by combining the Poisson distribution with the transmuted moment exponential distribution. When compared to existing discrete distributions, the moments and related measures of the new model may be determined analytically, and it possesses a high modeling capability. Additionally, the new model is extremely flexible.
- The model parameters are estimated using the renowned maximum likelihood estimation approach and a comprehensive simulation study to illustrate the pattern of these derived ML estimators.
- A new count regression model is also proposed to replace some existing count regression models.
- Two asymmetric datasets from different real-life areas are utilized to show the flexibility of the new distribution over some well-known probability distributions and regression models.
- We also estimate the model parameters using the Bayesian approach.
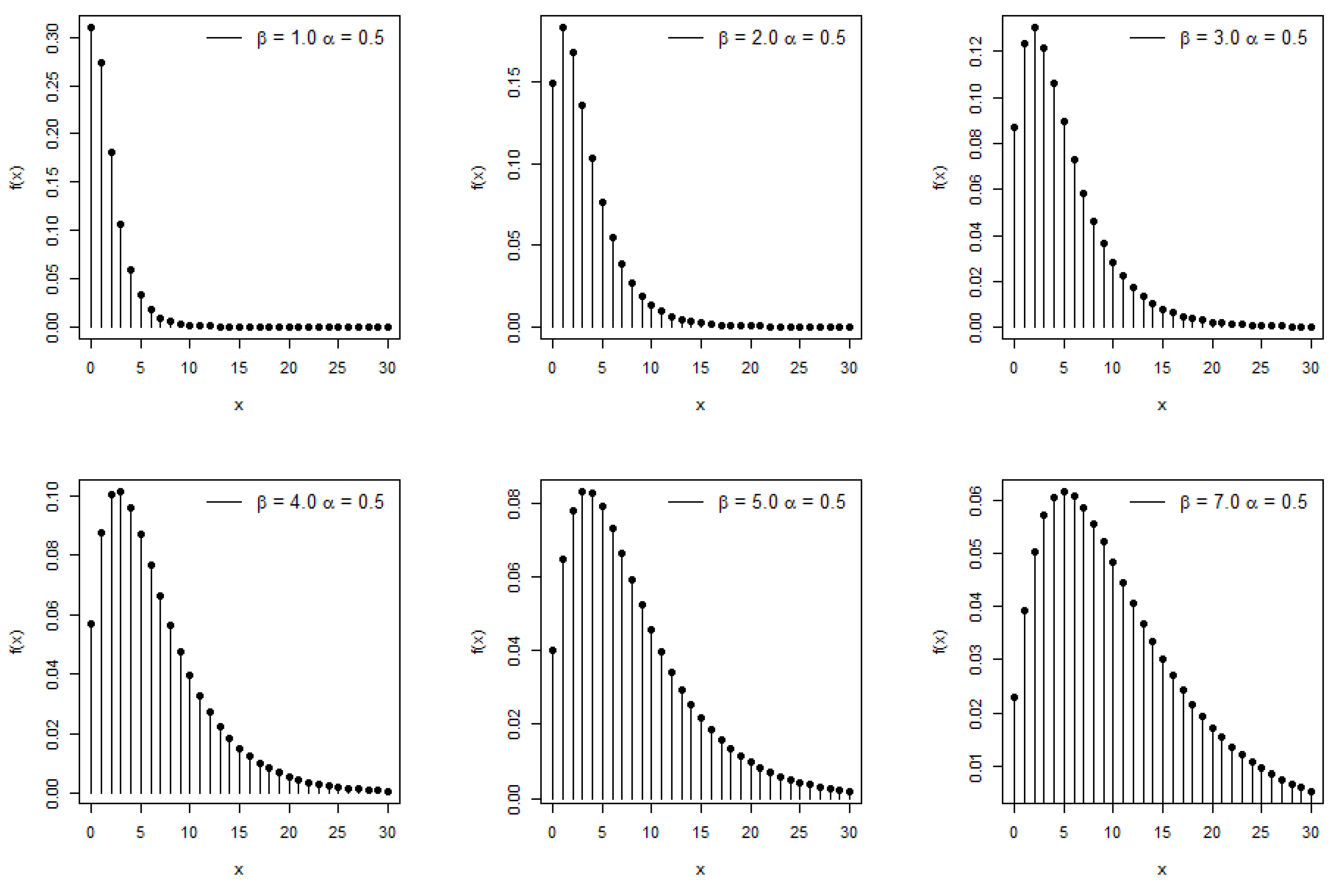
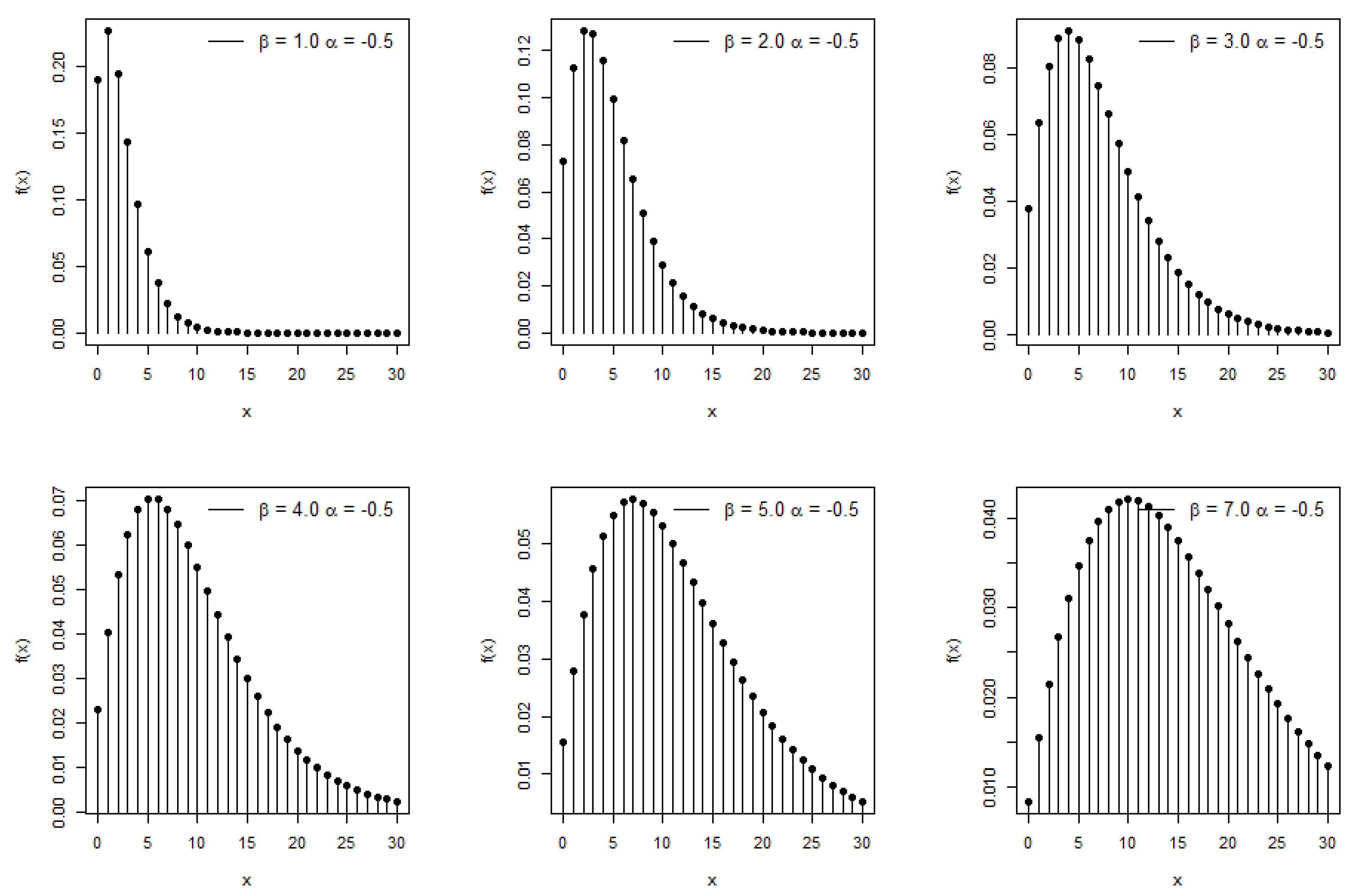
2. Derivation of New Model
Moments and Associated Measures
3. Parameter Estimation
3.1. Maximum Likelihood Estimation
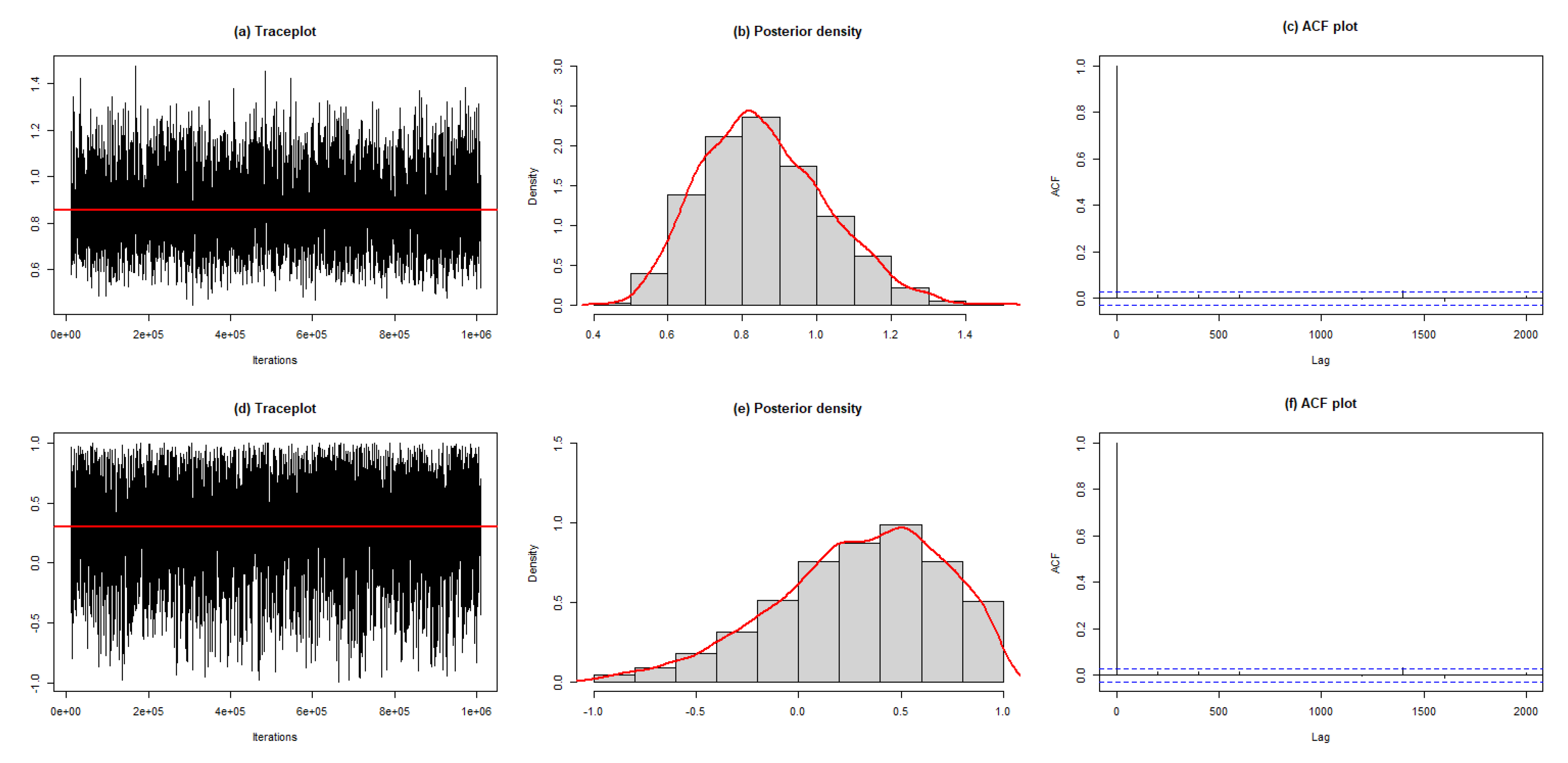
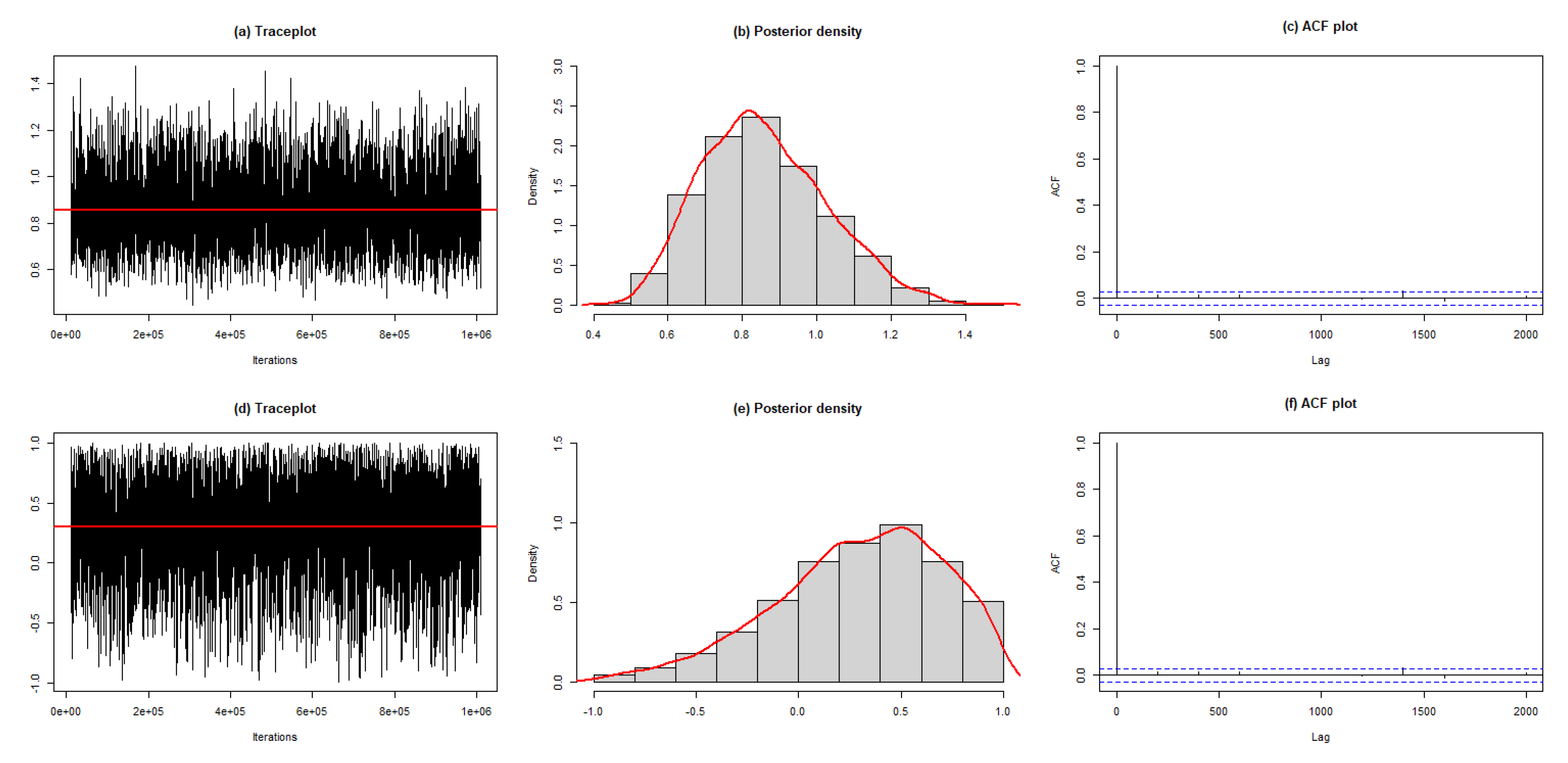
3.2. Bayesian Estimation
Metropolis–Hastings (M-H) algorithm
- Start with the initial parameter values .
- Set the iteration counter to .
- Simulate the and from the normal proposal distribution and , respectively.
- Then, evaluate the acceptance probability:
- 5
- Then, generate and from the uniform distribution .
- 6
- If , we consider ; otherwise, set .
- 7
- If , we consider ; otherwise, set .
- 8
- Change the counter from to .
- 9
- To obtain an accurate approximation for the estimates, we must repeat the procedures from (3)–(8). repetitions to obtain values for the parameters, and this sample can be stated as follows: .
4. Simulation
5. PTMEx Regression Model
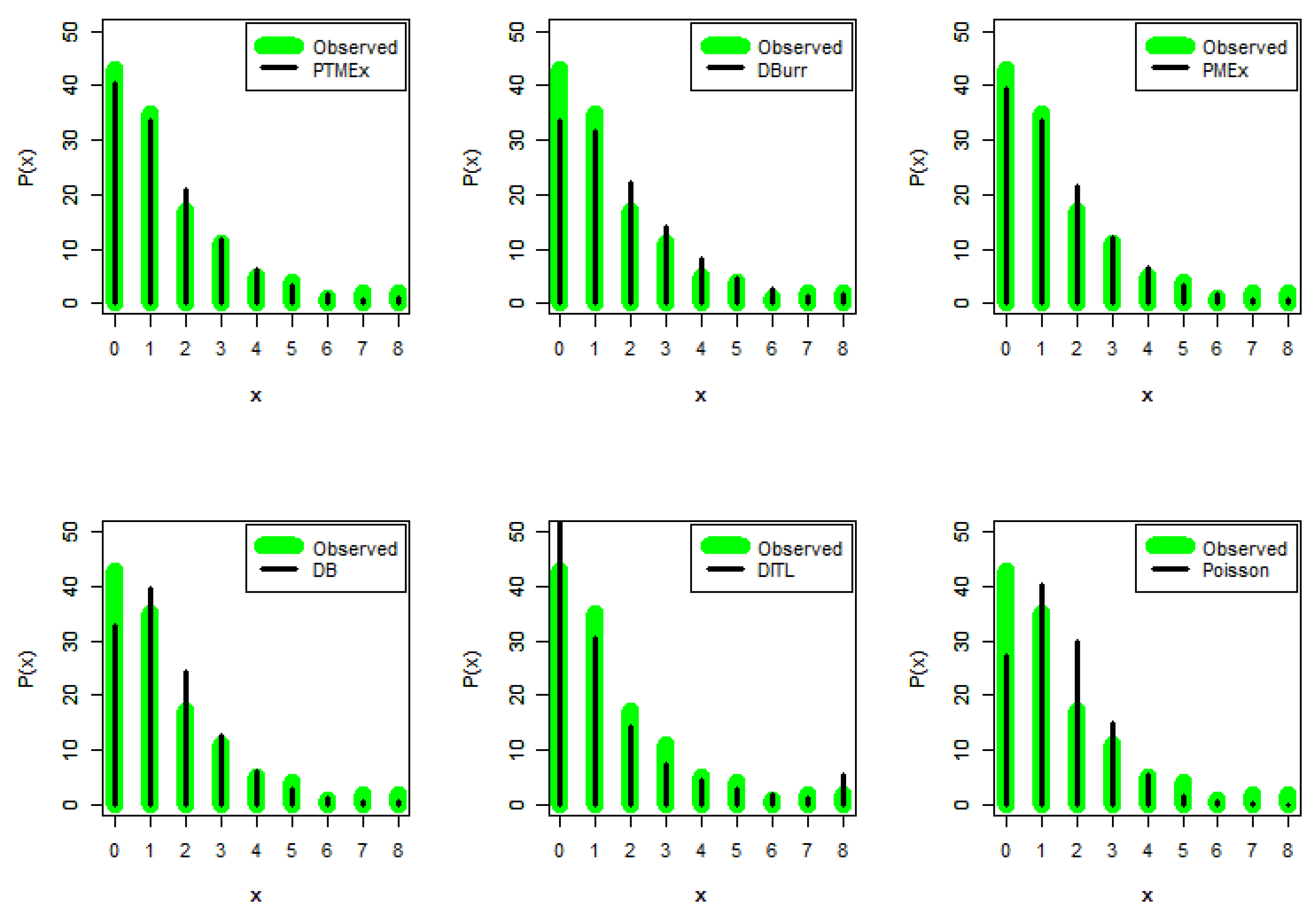
6. Empirical Study
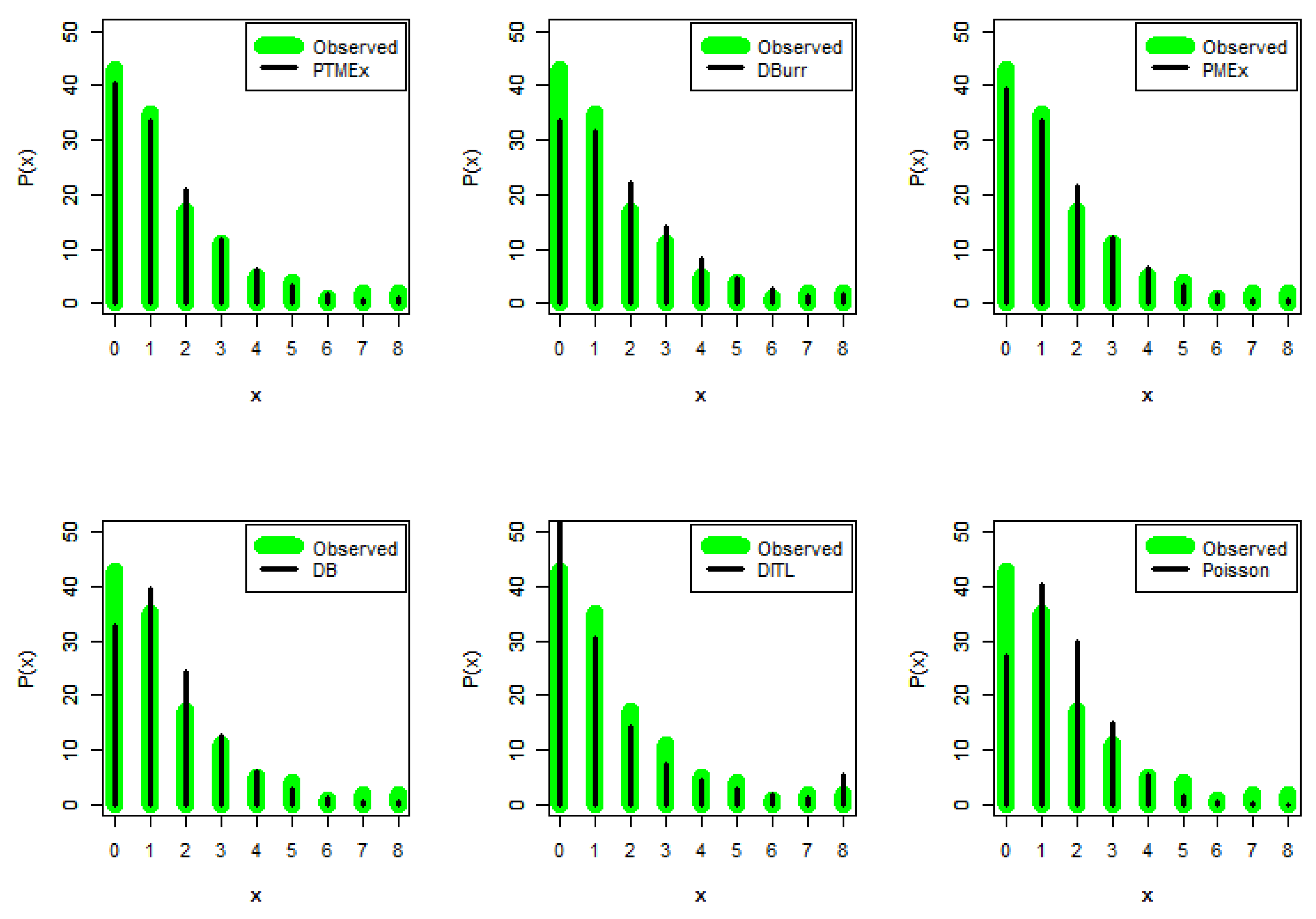
6.1. European Corn Borer Data
6.2. Length of Hospital Stay Data
- length of patients’ stays at the hospital.
- cardiovascular procedure (1 = CABG, 0 = PTCA).
- gender (1 = male, 0 = female).
- admission type (1 = urgent, 0 = elective).
- age (1 = age > 75, 0 = age ≤ 75).
7. Conclusions
8. Future Work
- Estimation methods: Future work could focus on developing efficient and accurate estimation methods for the parameters of the proposed distribution. This could involve maximum likelihood estimation, Bayesian estimation, or robust estimation techniques. Researchers may also explore the properties of the estimators, such as their asymptotic behavior and efficiency.
- Regression modeling: The new discrete distribution could be incorporated into regression models to analyze its performance in predicting or explaining the relationships between variables. This could involve developing regression frameworks, such as generalized linear models or zero-inflated models, that utilize the proposed distribution as the response variable. Researchers could also explore model selection criteria and compare the performance of the new distribution with existing ones in regression settings.
- Simulation studies: Future research could involve conducting extensive simulation studies to evaluate the behavior of the proposed distribution under various scenarios. This could include examining its robustness to violations of assumptions, assessing the accuracy of parameter estimation methods, and comparing the performances of statistical tests based on the new distribution.
- Applications: Further exploration of practical applications could be an area of focus. Researchers may investigate real-world datasets with overdispersed and asymmetric characteristics to assess the adequacy of the proposed distribution in modeling such data. This could include applications in fields such as finance, epidemiology, ecology, or social sciences.
- Software development: To facilitate the adoption and usage of the new distribution, researchers may develop software packages or functions in statistical software platforms (e.g., R and Python) for estimating parameters, conducting inference, and implementing regression models based on the proposed distribution. This would make it easier for practitioners to apply the distribution in their own research or data analysis.
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Afify, A.Z.; Ahsan-ul-Haq, M.; Aljohani, H.M.; Alghamdi, A.S.; Babar, A.; Gómez, H.W. A new one-parameter discrete exponential distribution: Properties, inference, and applications to COVID-19 data. J. King Saud Univ.-Sci. 2022, 34, 102199. [Google Scholar] [CrossRef]
- Ahsan-ul-Haq, M.; Al-bossly, A.; El-morshedy, M.; Eliwa, M.S. Poisson XLindley Distribution for Count Data: Statistical and Reliability Properties with Estimation Techniques and Inference. Comput. Intell. Neurosci. 2022, 2022, 6503670. [Google Scholar] [CrossRef] [PubMed]
- Ahsan-ul-Haq, M.; Zafar, J. A new one-parameter discrete probability distribution with its neutrosophic extension: Mathematical properties and applications. Int. J. Data Sci. Anal. 2023, 1–11. [Google Scholar] [CrossRef]
- Akdoğan, Y.; Kuş, C.; Asgharzadeh, A.; Kınacı, İ.; Sharafi, F. Uniform-geometric distribution. J. Stat. Comput. Simul. 2016, 86, 1754–1770. [Google Scholar] [CrossRef]
- Al-Bossly, A.; Eliwa, M.S.; Ahsan-ul-Haq, M.; El-Morshedy, M. Discrete Logistic Exponential Distribution with Applications. Stat. Optim. Inf. Comput. 2023, 11, 629–639. [Google Scholar] [CrossRef]
- Alghamdi, A.S.; Ahsan-ul-Haq, M.; Babar, A.; Aljohani, H.M.; Afify, A.Z. The discrete power-Ailamujia distribution: Properties, inference, and applications. AIMS Math. 2022, 7, 8344–8360. [Google Scholar] [CrossRef]
- Aljohani, H.M.; Akdoğan, Y.; Cordeiro, G.M.; Afify, A.Z. The uniform Poisson–Ailamujia distribution: Actuarial measures and applications in biological science. Symmetry 2021, 13, 1258. [Google Scholar] [CrossRef]
- Altun, E. A new one-parameter discrete distribution with associated regression and integer-valued autoregressive models. Math. Slovaca 2020, 70, 979–994. [Google Scholar] [CrossRef]
- Altun, E. A new two-parameter discrete poisson-generalized Lindley distribution with properties and applications to healthcare data sets. Comput. Stat. 2021, 36, 2841–2861. [Google Scholar] [CrossRef]
- Altun, E.; Cordeiro, G.M.; Ristić, M.M. An one-parameter compounding discrete distribution. J. Appl. Stat. 2021, 49, 1935–1956. [Google Scholar] [CrossRef]
- Beall, G. The fit and significance of contagious distributions when applied to observations on larval insects. Ecology 1940, 21, 460–474. [Google Scholar] [CrossRef]
- Coşkun, K.; AKdoğan, Y.; Asgharzadeh, A.; Kinaci, İ.; Karakaya, K. Binomial-discrete Lindley distribution. Commun. Fac. Sci. Univ. Ank. Ser. A1 Math. Stat. 2018, 68, 401–411. [Google Scholar]
- Eldeeb, A.S.; Ahsan-ul-Haq, M.; Babar, A. A Discrete Analog of Inverted Topp-Leone Distribution: Properties, Estimation and Applications. Int. J. Anal. Appl. 2021, 19, 695–708. [Google Scholar]
- Eldeeb, A.S.; Ahsan-ul-Haq, M.; Babar, A. A new discrete XLindley distribution: Theory, actuarial measures, inference, and applications. Int. J. Data Sci. Anal. 2023, 1–11. [Google Scholar] [CrossRef]
- Eldeeb, A.S.; Ahsan-ul-Haq, M.; Eliwa, M.S. A discrete Ramos-Louzada distribution for asymmetric and over-dispersed data with leptokurtic-shaped: Properties and various estimation techniques with inference. AIMS Math. 2021, 7, 1726–1741. [Google Scholar] [CrossRef]
- Erbayram, T.; Akdoğan, Y. A new discrete model generated from mixed Poisson transmuted record type exponential distribution. Ric. Mat. 2023, 1–23. [Google Scholar] [CrossRef]
- Gómez-Déniz, E. A new discrete distribution: Properties and applications in medical care. J. Appl. Stat. 2013, 40, 2760–2770. [Google Scholar] [CrossRef]
- Hosmer, D.W.; Lemeshow, S. Applied Logistic Regression; Wiley: Hoboken, NJ, USA, 2000. [Google Scholar]
- Kempton, R.A. A generalized form of Fisher’s logarithmic series. Biometrika 1975, 62, 29–38. [Google Scholar] [CrossRef]
- Krishna, H.; Pundir, P.S. Discrete Burr and discrete Pareto distributions. Stat. Methodol. 2009, 6, 177–188. [Google Scholar] [CrossRef]
- Maya, R.; Huang, J.; Irshad, M.R.; Zhu, F. On Poisson Moment Exponential Distribution with Associated Regression and INAR(1) Process. Ann. Data Sci. 2023, 1–19. [Google Scholar] [CrossRef]
- Nakagawa, T.; Osaki, S. The discrete Weibull distribution. IEEE Trans. Reliab. 1975, 24, 300–301. [Google Scholar] [CrossRef]
- Sajjadnia, Z.; Sharafi, M.; Mamode Khan, N.; Soobhug, A.D. A new bivariate INAR(1) model with paired Poisson-weighted exponential distributed innovations. Commun. Stat. Simul. Comput. 2023, 1–19. [Google Scholar] [CrossRef]
- Sankaran, M. The Discrete Poisson-Lindley Distribution. Biometrics 1970, 26, 145–149. [Google Scholar] [CrossRef]
- Zeghdoudi, H.; Nedjar, S. On Poisson pseudo Lindley distribution: Properties and applications. J. Probab. Stat. Sci. 2017, 15, 19–28. [Google Scholar]

{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Parameters | Measures | ||||||
|---|---|---|---|---|---|---|---|
| Mean | Variance | Skewness | Kurtosis | CV | DI | ||
| 0.5 | −0.8 | 1.3000 | 1.8600 | 1.3695 | 5.5696 | 1.0491 | 1.4308 |
| −0.5 | 1.1875 | 1.7461 | 1.4609 | 5.9067 | 1.1128 | 1.4704 | |
| −0.2 | 1.0750 | 1.6069 | 1.5621 | 6.3336 | 1.1792 | 1.4948 | |
| 0.0 | 1.0000 | 1.5000 | 1.6330 | 6.6667 | 1.2247 | 1.5000 | |
| 0.2 | 0.9250 | 1.3819 | 1.7037 | 7.0283 | 1.2708 | 1.4939 | |
| 0.5 | 0.8125 | 1.1836 | 1.7963 | 7.5506 | 1.3390 | 1.4567 | |
| 0.8 | 0.7000 | 0.9600 | 1.8244 | 7.6852 | 1.3997 | 1.3714 | |
| 1.0 | −0.8 | 2.6000 | 4.8400 | 1.2464 | 5.2747 | 0.8462 | 1.8615 |
| −0.5 | 2.3750 | 4.6094 | 1.3275 | 5.5368 | 0.9040 | 1.9408 | |
| −0.2 | 2.1500 | 4.2775 | 1.4267 | 5.9217 | 0.9620 | 1.9895 | |
| 0.0 | 2.0000 | 4.0000 | 1.5000 | 6.2500 | 1.0000 | 2.0000 | |
| 0.2 | 1.8500 | 3.6775 | 1.5751 | 6.6303 | 1.0366 | 1.9878 | |
| 0.5 | 1.6250 | 3.1094 | 1.6735 | 7.2268 | 1.0851 | 1.9135 | |
| 0.8 | 1.4000 | 2.4400 | 1.6813 | 7.3870 | 1.1157 | 1.7429 | |
| 1.5 | −0.8 | 3.9000 | 8.9400 | 1.2105 | 5.2069 | 0.7667 | 2.2923 |
| −0.5 | 3.5625 | 8.5898 | 1.2847 | 5.4302 | 0.8227 | 2.4112 | |
| −0.2 | 3.2250 | 8.0119 | 1.3840 | 5.7992 | 0.8777 | 2.4843 | |
| 0.0 | 3.0000 | 7.5000 | 1.4606 | 6.1333 | 0.9129 | 2.5000 | |
| 0.2 | 2.7750 | 6.8869 | 1.5412 | 6.5368 | 0.9457 | 2.4818 | |
| 0.5 | 2.4375 | 5.7773 | 1.6499 | 7.2096 | 0.9861 | 2.3702 | |
| 0.8 | 2.1000 | 4.4400 | 1.6559 | 7.4460 | 1.0034 | 2.1143 | |
| Parameter | AE | MRE | MSE | ||||
|---|---|---|---|---|---|---|---|
| 50 | 0.5542 | −0.5740 | 0.1083 | −0.2825 | 0.0233 | 0.3661 | |
| 100 | 0.5448 | −0.6135 | 0.0896 | −0.2332 | 0.0175 | 0.2813 | |
| 200 | 0.5252 | −0.6892 | 0.0504 | −0.1385 | 0.0084 | 0.1649 | |
| 500 | 0.5129 | −0.7327 | 0.0259 | −0.0841 | 0.0038 | 0.0923 | |
| 1000 | 0.5025 | −0.7884 | 0.0049 | −0.0145 | 0.0012 | 0.0395 | |
| 50 | 0.5262 | −0.4536 | 0.0524 | −0.0928 | 0.0209 | 0.3593 | |
| 100 | 0.5415 | −0.3757 | 0.0830 | −0.2486 | 0.0198 | 0.3749 | |
| 200 | 0.5284 | −0.4502 | 0.0567 | −0.0996 | 0.0135 | 0.2745 | |
| 500 | 0.5222 | −0.4367 | 0.0444 | −0.1266 | 0.0096 | 0.2053 | |
| 1000 | 0.5058 | −0.4864 | 0.0117 | −0.0273 | 0.0031 | 0.0846 | |
| 50 | 0.4960 | −0.3877 | 0.0079 | −0.9385 | 0.0199 | 0.4136 | |
| 100 | 0.5086 | −0.2877 | 0.0172 | −0.4385 | 0.0156 | 0.3724 | |
| 200 | 0.5186 | −0.2150 | 0.0371 | −0.0751 | 0.0139 | 0.3089 | |
| 500 | 0.5213 | −0.1594 | 0.0425 | −0.2032 | 0.0096 | 0.2134 | |
| 1000 | 0.5159 | −0.1697 | 0.0317 | −0.1514 | 0.0066 | 0.1415 | |
| 50 | 0.5262 | −0.4536 | 0.0524 | −0.0928 | 0.0209 | 0.3593 | |
| 100 | 0.5415 | −0.3757 | 0.083 | −0.2486 | 0.0198 | 0.3749 | |
| 200 | 0.5284 | −0.4502 | 0.0567 | −0.0996 | 0.0135 | 0.2745 | |
| 500 | 0.5222 | −0.4367 | 0.0444 | −0.1266 | 0.0096 | 0.2053 | |
| 1000 | 0.5058 | −0.4864 | 0.0117 | −0.0273 | 0.0031 | 0.0846 | |
| 50 | 1.5044 | 0.4211 | 0.0029 | 0.1578 | 0.0998 | 0.2871 | |
| 100 | 1.4681 | 0.3977 | 0.0213 | 0.2046 | 0.0831 | 0.2145 | |
| 200 | 1.4856 | 0.4152 | 0.0096 | 0.1695 | 0.0675 | 0.1776 | |
| 500 | 1.4949 | 0.4434 | 0.0034 | 0.1133 | 0.0509 | 0.1112 | |
| 1000 | 1.5066 | 0.4720 | 0.0044 | 0.0560 | 0.0383 | 0.0841 | |
| 50 | 1.5703 | −0.4694 | 0.0469 | −0.0611 | 0.1397 | 0.2699 | |
| 100 | 1.5543 | −0.4627 | 0.0362 | −0.0747 | 0.0826 | 0.1893 | |
| 200 | 1.5438 | −0.4605 | 0.0292 | −0.0790 | 0.0633 | 0.1381 | |
| 500 | 1.5131 | −0.4930 | 0.0088 | −0.0140 | 0.0265 | 0.0659 | |
| 1000 | 1.5019 | −0.5030 | 0.0013 | −0.0060 | 0.0064 | 0.0209 | |
| Count | Observed | Expected | |||||
|---|---|---|---|---|---|---|---|
| PTMEx | DBurr | PMEx | DB | DITL | Poisson | ||
| 0 | 43 | 40.417 | 33.438 | 39.558 | 32.741 | 52.189 | 27.226 |
| 1 | 35 | 33.658 | 31.574 | 33.691 | 39.589 | 30.424 | 40.385 |
| 2 | 17 | 21.052 | 22.360 | 21.521 | 24.275 | 14.112 | 29.951 |
| 3 | 11 | 11.818 | 14.076 | 12.220 | 12.505 | 7.4663 | 14.809 |
| 4 | 5 | 6.3101 | 8.3071 | 6.5047 | 5.9678 | 4.3900 | 5.4915 |
| 5 | 4 | 3.2874 | 4.7064 | 3.3240 | 2.7359 | 2.7906 | 1.6291 |
| 6 | 1 | 1.6923 | 2.5924 | 1.6514 | 1.2256 | 1.8811 | 0.4027 |
| 7 | 2 | 0.8660 | 1.3988 | 0.8037 | 0.5414 | 1.3271 | 0.0853 |
| 8 | 2 | 0.8978 | 1.5473 | 0.7259 | 0.4193 | 5.4195 | 0.0188 |
| Total | 120 | 120 | 120 | 120 | 120 | 120 | |
| MLE | 0.89444 | 0.51916 | 0.74161 | 2.3767 | 1.9840 | 1.4833 | |
| 0.46514 | 2.35785 | - | - | - | - | ||
| GOF Measures | 200.82 | 204.29 | 201.22 | 204.68 | 205.15 | 219.19 | |
| AIC | 405.64 | 412.59 | 404.44 | 411.35 | 412.30 | 440.38 | |
| BIC | 411.22 | 418.16 | 407.23 | 414.14 | 415.09 | 443.16 | |
| 2.0825 | 6.5310 | 2.7268 | 9.6431 | 6.9771 | 21.761 | ||
| df | 3.0 | 3.0 | 4.0 | 4.0 | 4.0 | 3.0 | |
| p-value | 0.72058 | 0.08845 | 0.60450 | 0.04689 | 0.13710 | <0.0001 | |
| Para. | P | NB | PQL | PTMEx | ||||
|---|---|---|---|---|---|---|---|---|
| MLEs (SE) | p-Value | MLEs (SE) | p-Value | MLEs (SE) | p-Value | MLEs (SE) | p-Value | |
| 1.4560 (0.0158) | <0.0001 | 1.0780 (0.0298) | <0.0001 | 1.3624 (0.0402) | <0.0001 | 1.3907 (0.0331) | <0.0001 | |
| 0.9603 (0.0122) | <0.0001 | 1.0866 (0.0243) | <0.0001 | 0.9746 (0.0317) | <0.0001 | 0.9877 (0.0260) | <0.0001 | |
| −0.1239 (0.0118) | <0.0001 | 0.0724 (0.0249) | 0.0030 | −0.1273 (0.0332) | 0.0001 | −0.1275 (0.0272) | <0.0001 | |
| 0.3266 (0.0121) | <0.0001 | 0.5319 (0.0249) | <0.0001 | 0.3961 (0.0329) | <0.0001 | 0.3909 (0.0270) | <0.0001 | |
| 0.1222 (0.0124) | <0.0001 | 0.3161 (0.3161) | <0.0001 | 0.1180 (0.0353) | <0.0001 | 0.1224 (0.0289) | <0.0001 | |
| - | - | - | - | 0.8893 (0.0016) | - | 0.9843 (0.0109) | - | |
| 11,190 | 10,578 | 10,919 | 10,352 | |||||
| AIC | 22,390 | 21,169 | 21,849 | 20,714 | ||||
| BIC | 22,421 | 21,206 | 21,880 | 20,745 | ||||
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Alrumayh, A.; Khogeer, H.A. A New Two-Parameter Discrete Distribution for Overdispersed and Asymmetric Data: Its Properties, Estimation, Regression Model, and Applications. Symmetry 2023, 15, 1289. https://doi.org/10.3390/sym15061289
Alrumayh A, Khogeer HA. A New Two-Parameter Discrete Distribution for Overdispersed and Asymmetric Data: Its Properties, Estimation, Regression Model, and Applications. Symmetry. 2023; 15(6):1289. https://doi.org/10.3390/sym15061289
Chicago/Turabian StyleAlrumayh, Amani, and Hazar A. Khogeer. 2023. "A New Two-Parameter Discrete Distribution for Overdispersed and Asymmetric Data: Its Properties, Estimation, Regression Model, and Applications" Symmetry 15, no. 6: 1289. https://doi.org/10.3390/sym15061289
APA StyleAlrumayh, A., & Khogeer, H. A. (2023). A New Two-Parameter Discrete Distribution for Overdispersed and Asymmetric Data: Its Properties, Estimation, Regression Model, and Applications. Symmetry, 15(6), 1289. https://doi.org/10.3390/sym15061289