
Training Data Selection for Record Linkage Classification

 and
and
Abstract
1. Introduction
1.1. Deterministic Record Linkage
1.2. Probabilistic Record Linkage
1.3. Machine Learning-Based Record Linkage
1.4. Paper Construction and Contribution
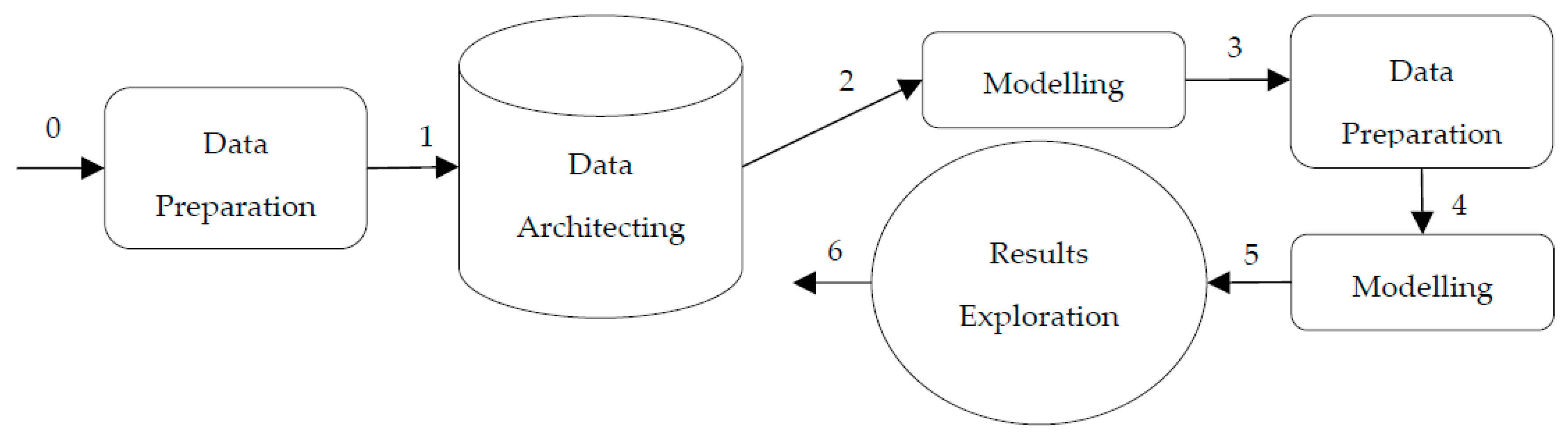
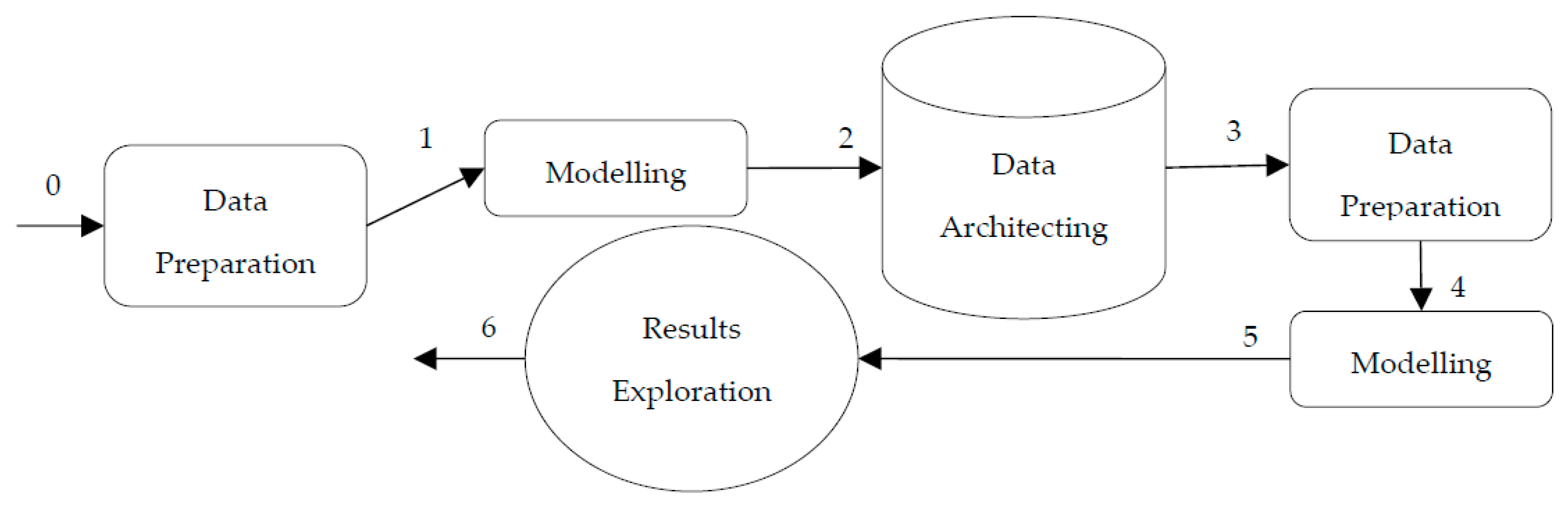
2. Data Science Trajectories Models of the Record Linkage Approaches
2.1. The General Approach
2.2. The Two-Step Approach
2.3. The Proposed Approach
3. Related Studies
3.1. Manual Training Data Selection
3.2. Semi-Automatic Training Data Selection
3.3. Automatic Training Data Selection
4. Materials and Methods
4.1. Dataset
4.2. Modelling, Data Architecting, and Data Preparation Activities
4.2.1. The Modelling Activity
4.2.2. The Data Architecting Activity
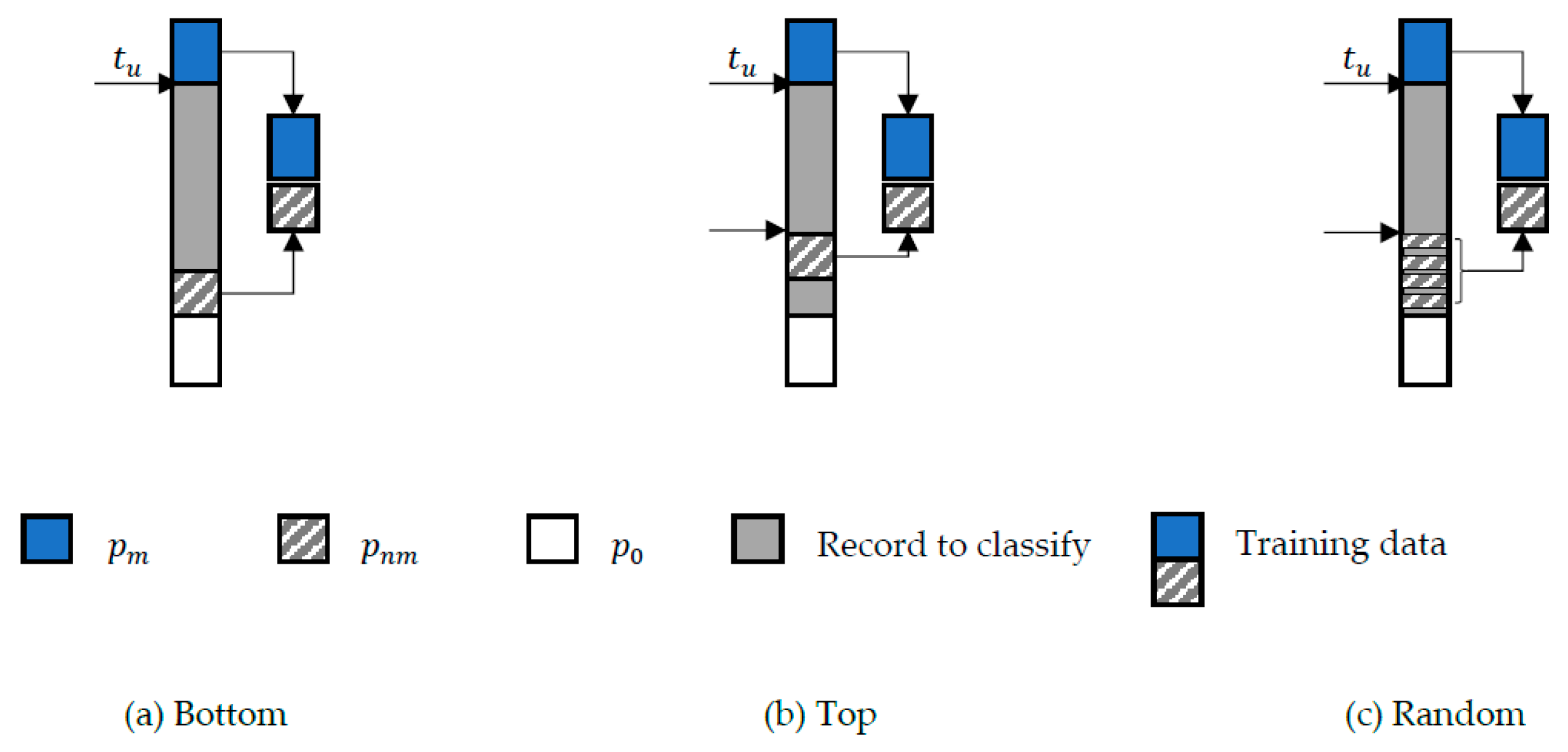
4.2.3. The Data Preparation Activity
| Algorithm 1. Bottom Selection. |
Input:
|
| Algorithm 2. Top Selection. |
Input:
|
| Algorithm 3. Random Selection. |
Input:
|
4.3. Classification Methods
4.4. Classification Performance Measures and Training Data Quality
5. Results and Discussion
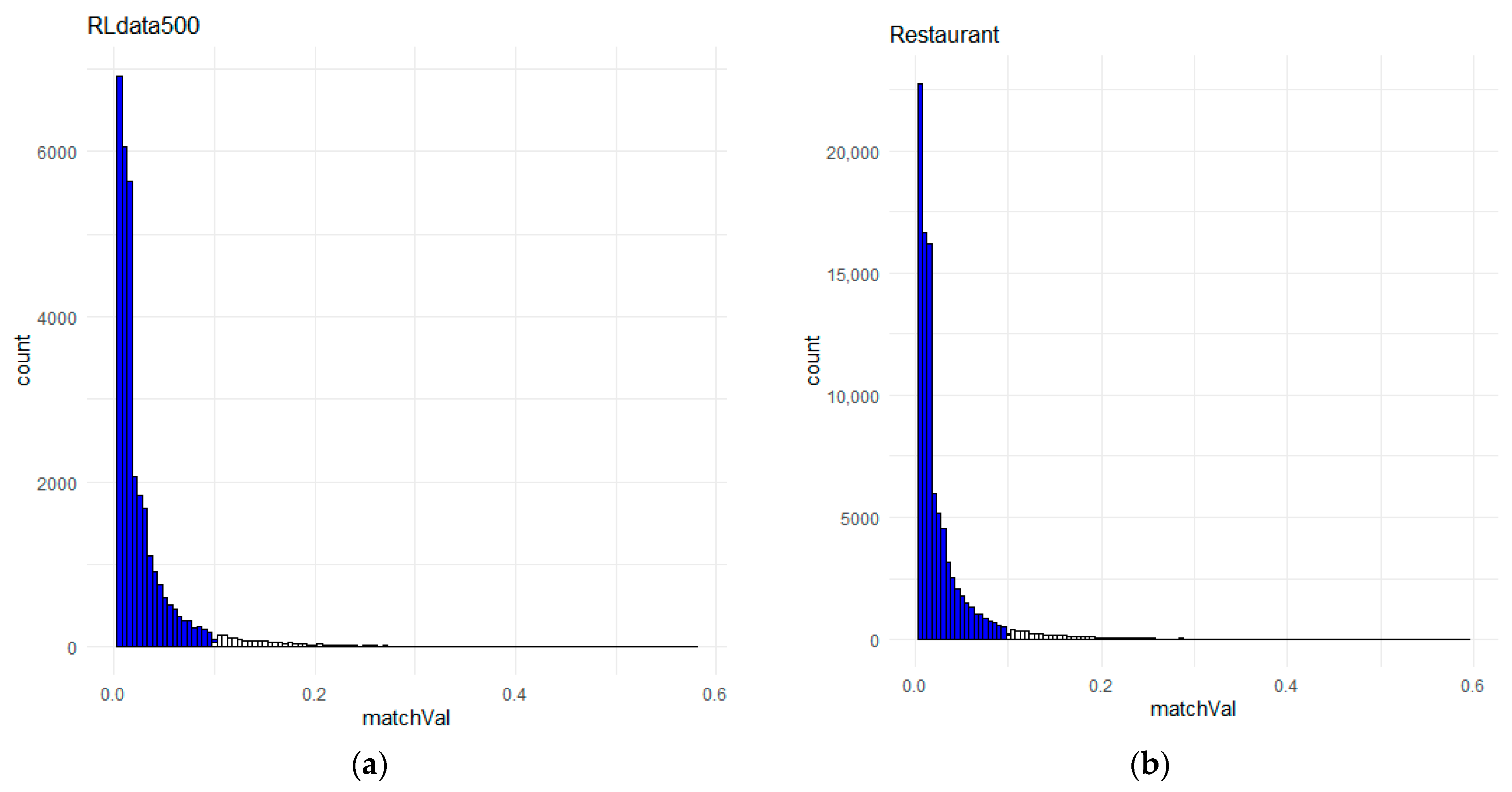
5.1. Setting Thresholds and Training Data Quality
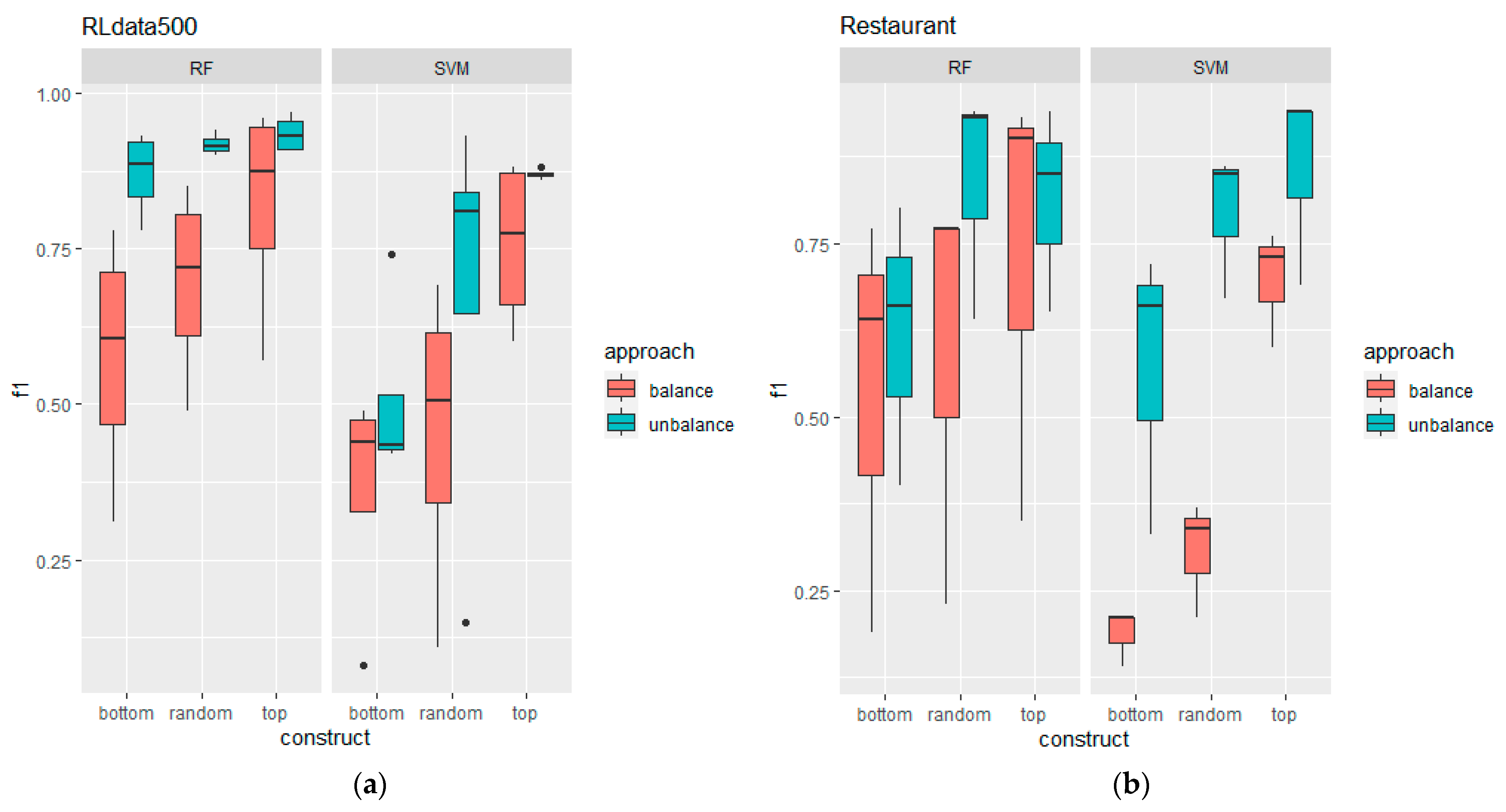
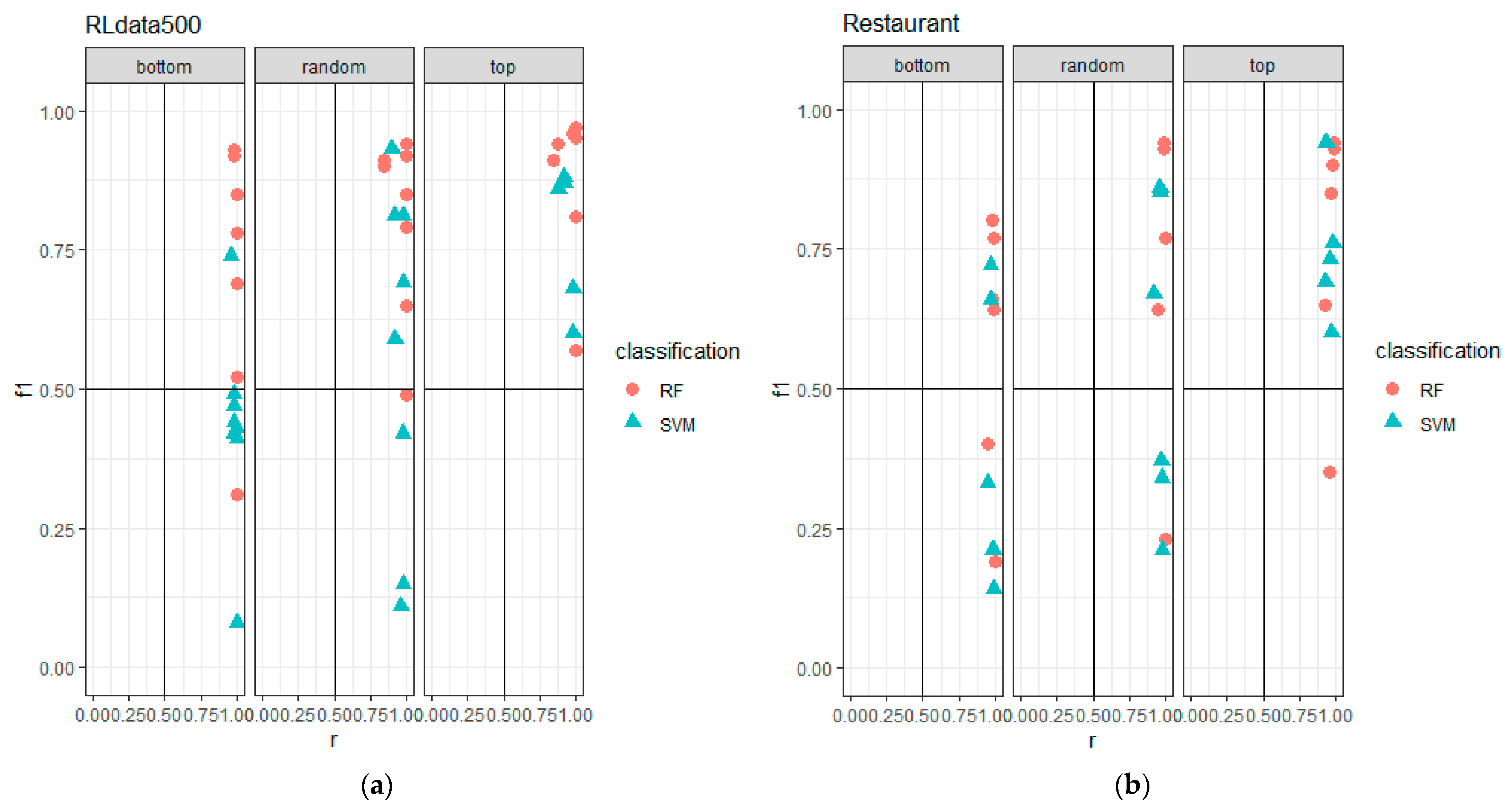
5.2. Training Data Construction Performance
5.3. Study Limitations
6. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Talburt, J.R. (Ed.) Entity Resolution and Information Quality; Morgan Kaufman: Burlington, MA, USA, 2011; ISBN 9780123819727. [Google Scholar]
- Dunn, H.L. Record Linkage. Am. J. Public Health Nations Health 1946, 36, 1412–1416. [Google Scholar] [CrossRef] [PubMed]
- Winkler, W.E. Methods for Evaluating and Creating Data Quality. Inf. Syst. 2004, 29, 531–550. [Google Scholar] [CrossRef]
- Zhu, Y.; Matsuyama, Y.; Ohashi, Y.; Setoguchi, S. When to Conduct Probabilistic Linkage vs. Deterministic Linkage? A Simulation Study. J. Biomed. Inform. 2015, 56, 80–86. [Google Scholar] [CrossRef] [PubMed]
- Herzog, T.N.; Scheuren, F.J.; Winkler, W.E. Data Quality and Record Linkage Techniques; Springer: New York, NY, USA, 2007; ISBN 9780387695020. [Google Scholar]
- Fellegi, I.P.; Sunter, A.B. A Theory for Record Linkage. J. Am. Stat. Assoc. 1969, 64, 1183–1210. [Google Scholar] [CrossRef]
- Christen, P. Data Matching: Concepts and Techniques for Record Linkage, Entity Resolution, and Duplicate Detection; Springer: Berlin/Heidelberg, Germany, 2012; ISBN 3642311636. [Google Scholar]
- Mason, L.G. A Comparison of Record Linkage Techniques; Quarterly Census of Wages and Employment (QCEW): Washington, DC, USA, 2018; pp. 2438–2447. [Google Scholar]
- Gu, L.; Baxter, R. Decision Models for Record Linkage. In Data Mining; Springer: Berlin/Heidelberg, Germany, 2006; Volume 3755, pp. 146–160. [Google Scholar] [CrossRef]
- Elfeky, M.G.; Verykios, V.S.; Elmagarmid, A.K. TAILOR: A Record Linkage Toolbox. In Proceedings of the 18th International Conference on Data Engineering, San Jose, CA, USA, 28 February–1 March 2002; pp. 17–28. [Google Scholar]
- Goiser, K.; Christen, P. Towards Automated Record Linkage. Conf. Res. Pract. Inf. Technol. Ser. 2006, 61, 23–31. [Google Scholar]
- Jiao, Y.; Lesueur, F.; Azencott, C.A.; Laurent, M.; Mebirouk, N.; Laborde, L.; Beauvallet, J.; Dondon, M.G.; Eon-Marchais, S.; Laugé, A.; et al. A New Hybrid Record Linkage Process to Make Epidemiological Databases Interoperable: Application to the GEMO and GENEPSO Studies Involving BRCA1 and BRCA2 Mutation Carriers. BMC Med. Res. Methodol. 2021, 21, 155. [Google Scholar] [CrossRef] [PubMed]
- Ebeid, I.A.; Talburt, J.R.; Hagan, N.K.A.; Siddique, M.A.S. ModER: Graph-Based Unsupervised Entity Resolution Using Composite Modularity Optimization and Locality Sensitive Hashing. Int. J. Adv. Comput. Sci. Appl. 2022, 13, 1–18. [Google Scholar] [CrossRef]
- Yao, D.; Gu, Y.; Cong, G.; Jin, H.; Lv, X. Entity Resolution with Hierarchical Graph Attention Networks. In Proceedings of the 2022 International Conference on Management of Data, Philadelphia, PA, USA, 12–17 June 2022; ACM: New York, NY, USA, 2022; pp. 429–442. [Google Scholar]
- Kirielle, N.; Christen, P.; Ranbaduge, T. Unsupervised Graph-Based Entity Resolution for Complex Entities. ACM Trans. Knowl. Discov. Data 2023, 17, 12. [Google Scholar] [CrossRef]
- Abassi, M.E.; Amnai, M.; Choukri, A.; Fakhri, Y.; Gherabi, N. Matching Data Detection for the Integration System. Int. J. Electr. Comput. Eng. 2023, 13, 1008–1014. [Google Scholar] [CrossRef]
- Christen, P. A Two-Step Classification Approach to Unsupervised Record Linkage. Conf. Res. Pract. Inf. Technol. Ser. 2007, 70, 111–119. [Google Scholar]
- Christen, P. Automatic Record Linkage Using Seeded Nearest Neighbour and Support Vector Machine Classification. In Proceedings of the 14th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, Las Vegas, NV, USA, 24 August 2008; ACM: New York, NY, USA, 2008; pp. 151–159. [Google Scholar]
- Christen, P. Automatic Training Example Selection for Scalable Unsupervised Record Linkage. In Proceedings of the Advances in Knowledge Discovery and Data Mining: 12th Pacific-Asia Conference, Osaka, Japan, 20–23 May 2008; Volume 5012, pp. 511–518. [Google Scholar] [CrossRef]
- Jurek, A.; Hong, J.; Chi, Y.; Liu, W. A Novel Ensemble Learning Approach to Unsupervised Record Linkage. Inf. Syst. 2017, 71, 40–54. [Google Scholar] [CrossRef]
- Martinez-Plumed, F.; Contreras-Ochando, L.; Ferri, C.; Hernandez-Orallo, J.; Kull, M.; Lachiche, N.; Ramirez-Quintana, M.J.; Flach, P. CRISP-DM Twenty Years Later: From Data Mining Processes to Data Science Trajectories. IEEE Trans. Knowl. Data Eng. 2021, 33, 3048–3061. [Google Scholar] [CrossRef]
- Winkler, W.E. Matching and Record Linkage. Wiley Interdiscip. Rev. Comput. Stat. 2014, 6, 313–325. [Google Scholar] [CrossRef]
- Sariyar, M.; Borg, A. Bagging, Bumping, Multiview, and Active Learning for Record Linkage with Empirical Results on Patient Identity Data. Comput. Methods Programs Biomed. 2012, 108, 1160–1169. [Google Scholar] [CrossRef] [PubMed]
- Treeratpituk, P.; Giles, C.L. Disambiguating Authors in Academic Publications Using Random Forests Categories and Subject Descriptors. In Proceedings of the 9th ACM/IEEE-CS Joint Conference on Digital Libraries, Austin, TX, USA, 15–19 June 2009; pp. 39–48. [Google Scholar]
- Wang, J.; Kraska, T.; Franklin, M.J.; Feng, J. CrowdER: Crowdsourcing Entity Resolution. Proc. VLDB Endow. 2012, 5, 1483–1494. [Google Scholar] [CrossRef]
- Gottapu, R.D.; Dagli, C.; Ali, B. Entity Resolution Using Convolutional Neural Network. Procedia Comput. Sci. 2016, 95, 153–158. [Google Scholar] [CrossRef]
- Sarawagi, S.; Bhamidipaty, A. Interactive Deduplication Using Active Learning. In Proceedings of the Eighth ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, Edmonton, AB, Canada, 23–26 June 2002; pp. 269–278. [Google Scholar] [CrossRef]
- Kasai, J.; Qian, K.; Gurajada, S.; Li, Y.; Popa, L. Low-Resource Deep Entity Resolution with Transfer and Active Learning. In Proceedings of the 57th Annual Meeting of the Association for Computational Linguistics, Florence, Italy, 28 July–2 August 2019; pp. 5851–5861. [Google Scholar] [CrossRef]
- Christen, V.; Christen, P.; Rahm, E. Informativeness-Based Active Learning for Entity Resolution. In Proceedings of the European Conference on Principles of Data Mining and Knowledge Discovery, Ghent, Belgium, 14–18 September 2020; Springer: Berlin/Heidelberg, Germany, 2020; pp. 125–141. [Google Scholar]
- Laskowski, L.; Sold, F. Explainable Data Matching: Selecting Representative Pairs with Active Learning Pair-Selection Strategies. In Lecture Notes in Informatics (LNI), Proceedings—Series of the Gesellschaft fur Informatik (GI); König-Ries, B., Scherzinger, S., Lehner, W., Vossen, G., Eds.; Gesellschaft für Informatik e.V.: Dresden, Germany, 2023; Volume P-331, pp. 1099–1104. [Google Scholar]
- Wu, H.; Li, S. MixER: Linear Interpolation of Latent Space for Entity Resolution. Complex Intell. Syst. 2023, 1–20. [Google Scholar] [CrossRef]
- Omar, Z.A.; Abu Bakar, M.A.; Zamzuri, Z.H.; Ariff, N.M. Duplicate Detection Using Unsupervised Random Forests: A Preliminary Analysis. In Proceedings of the 2022 3rd International Conference on Artificial Intelligence and Data Sciences (AiDAS), Ipoh, Malaysia, 7–8 September 2022; pp. 66–71. [Google Scholar]
- Breiman, L. Random Forests. Mach. Learn. 2001, 45, 5–32. [Google Scholar] [CrossRef]
- Cortes, C.; Vapnik, V. Support-Vector Networks. Mach. Learn. 1995, 20, 273–297. [Google Scholar] [CrossRef]
- Cutler, A.; Cutler, D.R.; Stevens, J.R. Random Forests. In Ensemble Machine Learning; Zhang, C., Ma, Y., Eds.; Springer: New York, NY, USA, 2012; ISBN 978-1-4419-9325-0. [Google Scholar]
- Afanador, N.L.; Smolinska, A.; Tran, T.N.; Blanchet, L. Unsupervised Random Forest: A Tutorial with Case Studies. J. Chemom. 2016, 30, 232–241. [Google Scholar] [CrossRef]
- Jaro, M.A. Advances in Record-Linkage Methodology as Applied to Matching the 1985 Census of Tampa, Florida. J. Am. Stat. Assoc. 1989, 84, 414–420. [Google Scholar] [CrossRef]
- Winkler, W.E. String Comparator Metrics and Enhanced Decision Rules in the Fellegi-Sunter Model of Record Linkage. In Proceedings of the Annual Meeting of the American Statistical Association, Anaheim, CA, USA, 6–9 August 1990; pp. 354–359. [Google Scholar]
- Contiero, P.; Tittarelli, A.; Tagliabue, G.; Maghini, A.; Fabiano, S.; Crosignani, P.; Tessandori, R. The EpiLink Record Linkage Software: Presentation and Results of Linkage Test on Cancer Registry Files. Methods Inf. Med. 2005, 44, 66–71. [Google Scholar] [CrossRef] [PubMed]
- Sariyar, M.; Borg, A. The Recordlinkage Package: Detecting Errors in Data. R J. 2010, 2, 61–67. [Google Scholar] [CrossRef]
- Macqueen, J. Some Methods for Classification and Analysis of Multivariate Observation. In Proceedings of the 5th Berkeley Symposium on Mathematical Statistics and Probability, Berkeley, CA, USA, 21 June–18 July 1965; Volume 1, pp. 281–297. [Google Scholar]
- Leisch, F. Bagged Clustering. Adapt. Inf. Syst. Model. Econ. Manag. Sci. 1999, 51, 11. [Google Scholar]
- Christen, P.; Goiser, K. Quality and Complexity Measures for Data Linkage and Deduplication. Stud. Comput. Intell. 2007, 43, 127–151. [Google Scholar] [CrossRef]








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Dataset | RLdata500 | Restaurant | |||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Upper Threshold | |||||||||||||||
| Imbalance Ratio | 1:1 | 1:9 | 1:1 | 1:9 | 1:1 | 1:9 | 1:1 | 1:9 | 1:1 | 1:7 | 1:1 | 1:7 | 1:1 | 1:7 | |
| Training Set Quality | Match | 100 | 100 | 100 | 100 | 100 | 100 | 97.62 | 97.62 | 100 | 100 | 100 | 100 | 92.42 | 92.42 |
| Bot, Non-match | 100 | 100 | 100 | 100 | 100 | 100 | 100 | 100 | 100 | 100 | 100 | 100 | 100 | 100 | |
| Top, Non-match | 100 | 100 | 100 | 100 | 100 | 100 | 100 | 100 | 100 | 100 | 100 | 100 | 100 | 100 | |
| Rand, Non-match | 100 | 100 | 100 | 100 | 100 | 100 | 100 | 100 | 100 | 100 | 100 | 100 | 100 | 100 | |
| Training % | 0.17 | 0.87 | 0.22 | 1.09 | 0.25 | 1.24 | 0.26 | 1.30 | 0.06 | 0.23 | 0.07 | 0.29 | 0.14 | 0.55 | |
| Classification Approach | Dataset | |||||
|---|---|---|---|---|---|---|
| RLdata500 | Restaurant | |||||
| Precision | Recall | F1-Score | Precision | Recall | F1-Score | |
| EM | 0.98 | 0.94 | 0.96 | 0.81 | 0.86 | 0.83 |
| EpiLink | 1 | 0.92 | 0.96 | 0.91 | 0.95 | 0.93 |
| URF | 1 | 0.82 | 0.9 | 0.85 | 0.65 | 0.73 |
| K-Means | 0.01 | 0.98 | 0.03 | 0 | 1 | 0 |
| bclust | 0.03 | 0.98 | 0.06 | 0.89 | 0.96 | 0.92 |
| RF-T-tu ≥ 0.9 | 1 | 0.84 | 0.91 | 0.9 | 0.99 | 0.94 |
| RF-T-tu ≥ 0.8 | 1 | 0.84 | 0.91 | 0.75 | 0.97 | 0.85 |
| RF-T-tu ≥ 0.7 | 0.94 | 1 | 0.97 | 0.5 | 0.93 | 0.65 |
| RF-T-tu ≥ 0.6 | 0.91 | 1 | 0.95 | |||
| SVM-T-tu ≥ 0.9 | 0.84 | 0.92 | 0.88 | 0.94 | 0.94 | 0.94 |
| SVM-T-tu ≥ 0.8 | 0.85 | 0.88 | 0.86 | 0.95 | 0.93 | 0.94 |
| SVM-T-tu ≥ 0.7 | 0.82 | 0.92 | 0.87 | 0.55 | 0.93 | 0.69 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Ali Omar, Z.; Zamzuri, Z.H.; Mohd Ariff, N.; Abu Bakar, M.A. Training Data Selection for Record Linkage Classification. Symmetry 2023, 15, 1060. https://doi.org/10.3390/sym15051060
Ali Omar Z, Zamzuri ZH, Mohd Ariff N, Abu Bakar MA. Training Data Selection for Record Linkage Classification. Symmetry. 2023; 15(5):1060. https://doi.org/10.3390/sym15051060
Chicago/Turabian StyleAli Omar, Zaturrawiah, Zamira Hasanah Zamzuri, Noratiqah Mohd Ariff, and Mohd Aftar Abu Bakar. 2023. "Training Data Selection for Record Linkage Classification" Symmetry 15, no. 5: 1060. https://doi.org/10.3390/sym15051060
APA StyleAli Omar, Z., Zamzuri, Z. H., Mohd Ariff, N., & Abu Bakar, M. A. (2023). Training Data Selection for Record Linkage Classification. Symmetry, 15(5), 1060. https://doi.org/10.3390/sym15051060