
A Levenberg-Marquardt Method for Tensor Approximation
Abstract
1. Introduction
2. Preliminaries
2.1. Notation
2.2. Least Squares Problem
2.3. Descending Condition
2.4. Rank-One Tensors
2.5. Frobenius Norm
3. A Damped Levenberg-Marquardt Method for Tensor Approximation
| Algorithm 1 A damped Levenberg–Marquardt method for tensor approximation. |
Input: Output: u
|
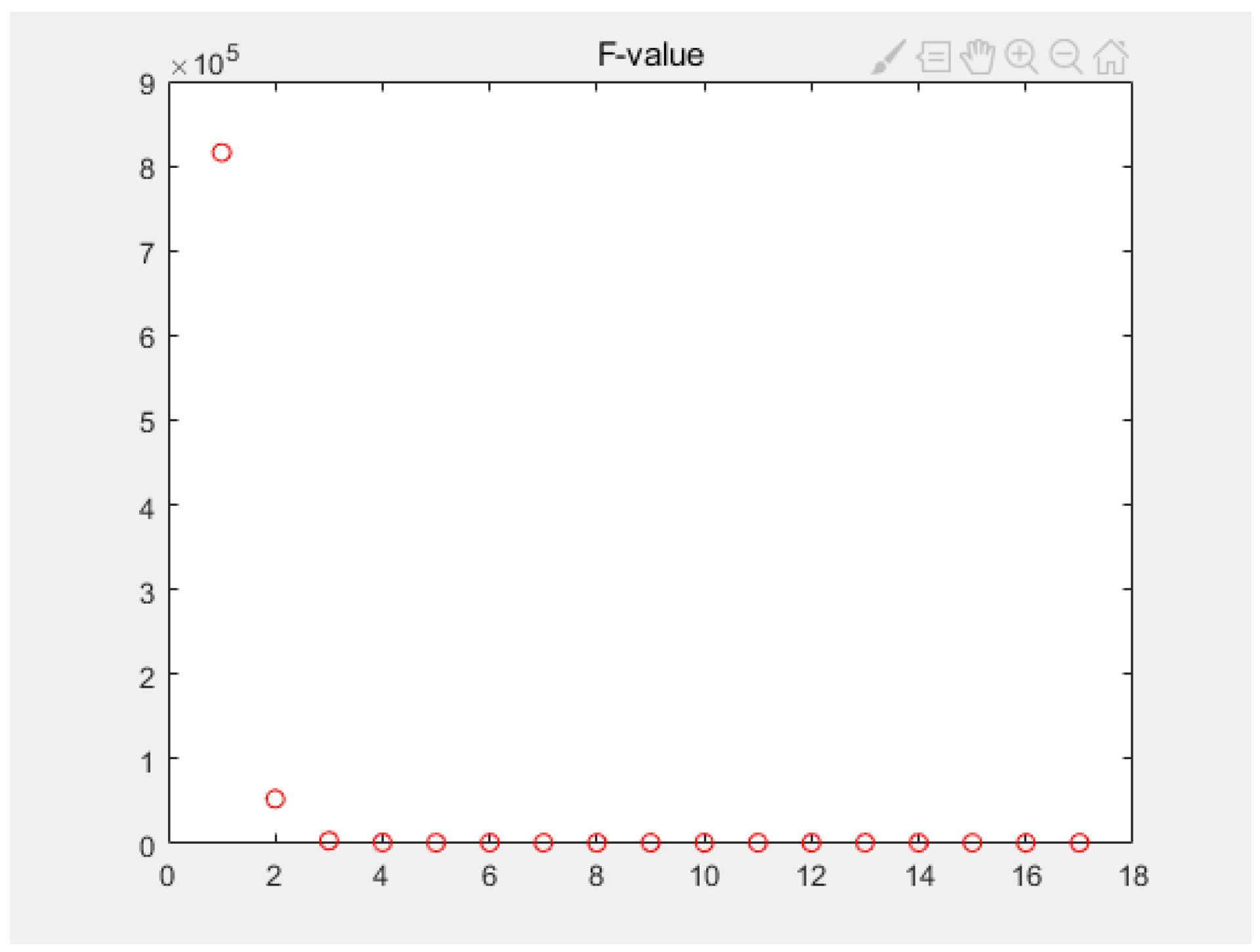
4. Numerical Results
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Li, Q.; Shi, X.; Schonfeld, D. A general framework for robust HOSVD-based indexing and retrieval with high-order tensor data. In Proceedings of the IEEE International Conference on Acoustics, Prague, Czech Republic, 22–27 May 2011. [Google Scholar]
- Yan, H.Y.; Chen, M.Q.; Hu, L.; Jia, C.F. Secure video retrieval using image query on an untrusted cloud. Appl. Soft Comput. 2020, 97, 106782. [Google Scholar] [CrossRef]
- Liu, N.; Zhang, B.Y.; Yan, J. Text Representation: From Vector to Tensor. In Proceedings of the IEEE International Conference on Data Mining, Houston, TX, USA, 27–30 November 2005. [Google Scholar]
- Kolda, T.G.; Bader, B.W.; Kenny, J.P. Higher-Order Web Link Analysis Using Multilinear Algebra. In Proceedings of the 5th IEEE International Conference on Data Mining (ICDM 2005), Houston, TX, USA, 27–30 November 2005. [Google Scholar]
- Jiang, N.; Jie, W.; Li, J.; Liu, X.M.; Jin, D. GATrust: A Multi-Aspect Graph Attention Network Model for Trust Assessment in OSNs. IEEE Trans. Knowl. Data Eng. 2022. Early Access. [Google Scholar] [CrossRef]
- Ai, S.; Hong, S.; Zheng, X.Y.; Wang, Y.; Liu, X.Z. CSRT rumor spreading model based on complex network. Int. J. Intell. Syst. 2021, 36, 1903–1913. [Google Scholar] [CrossRef]
- Liu, Z.L.; Huang, Y.Y.; Song, X.F.; Li, B.; Li, J.; Yuan, Y.L.; Dong, C.Y. Eurus: Towards an Efficient Searchable Symmetric Encryption With Size Pattern Protection. IEEE Trans. Dependable Secur. Comput. 2022, 19, 2023–2037. [Google Scholar] [CrossRef]
- Gao, C.Z.; Li, J.; Xia, S.B.; Choo, K.K.R.; Lou, W.J.; Dong, C.Y. MAS-Encryption and its Applications in Privacy-Preserving Classifiers. IEEE Trans. Knowl. Data Eng. 2022, 34, 2306–2323. [Google Scholar] [CrossRef]
- Mo, K.H.; Tang, W.X.; Li, J.; Yuan, X. Attacking Deep Reinforcement Learning with Decoupled Adversarial Policy. IEEE Trans. Dependable Secur. Comput. 2023, 20, 758–768. [Google Scholar] [CrossRef]
- Zhu, T.Q.; Zhou, W.; Ye, D.Y.; Cheng, Z.S.; Li, J. Resource Allocation in IoT Edge Computing via Concurrent Federated Reinforcement Learning. IEEE Internet Things J. 2022, 9, 1414–1426. [Google Scholar]
- Liu, Z.L.; Lv, S.Y.; Li, J.; Huang, Y.Y.; Guo, L.; Yuan, Y.L.; Dong, C.Y. EncodeORE: Reducing Leakage and Preserving Practicality in Order-Revealing Encryption. IEEE Trans. Dependable Secur. Comput. 2022, 19, 1579–1591. [Google Scholar] [CrossRef]
- Zhu, T.Q.; Li, J.; Hu, X.Y.; Xiong, P.; Zhou, W.L. The Dynamic Privacy-Preserving Mechanisms for Online Dynamic Social Networks. IEEE Trans. Knowl. Data Eng. 2022, 34, 2962–2974. [Google Scholar] [CrossRef]
- Li, X.; Ng, M.K. Solving sparse non-negative tensor equations: Algorithms and applications. Front. Math. China 2015, 10, 649–680. [Google Scholar] [CrossRef]
- Li, D.H.; Xie, S.; Xu, H.R. Splitting methods for tensor equations. Numer. Linear Algebra Appl. 2017, 24, e2102. [Google Scholar] [CrossRef]
- Ding, W.Y.; Wei, Y.M. Solving multi-linear systems with M-tensors. J. Sci. Comput. 2016, 68, 689–715. [Google Scholar] [CrossRef]
- Han, L. A homotopy method for solving multilinear systems with M-tensors. Appl. Math. Lett. 2017, 69, 49–54. [Google Scholar] [CrossRef]
- Hitchcock, F.L. The expression of a tensor or a polyadic as a sum of products. J. Math. Phys. 1927, 6, 164–189. [Google Scholar] [CrossRef]
- Hitchcock, F.L. Multiple invariants and generalized rank of a p-way matrix or tensor. J. Math. Phys. 1928, 7, 39–79. [Google Scholar] [CrossRef]
- Kolda, T.G. Multilinear operators for higher-order decompositions. Sandia Rep. 2006. [Google Scholar] [CrossRef]
- Sidiropoulos, N.D.; Bro, R. On the uniqueness of multilinear decomposition of N-way arrays. J. Chemom. 2015, 14, 229–239. [Google Scholar] [CrossRef]
- Goncalves, M.L.N.; Oliveira, F.R. An Inexact Newton-like conditional gradient method for constrained nonlinear systems. Appl. Numer. Math. 2018, 132, 22–34. [Google Scholar] [CrossRef]
- Madsen, K.; Nielsen, H.B.; Tingleff, O. Methods for Non-Linear Least Squares Problems, 2nd ed.; Technical University of Denmark: Kongens Lyngby, Denmark, 2004; Available online: https://orbit.dtu.dk/en/publications/methods-for-non-linear-least-squares-problems-2nd-ed (accessed on 7 March 2023).
- Harshman, R.A. Foundations of the PARAFAC procedure: Models and conditions for an “explanatory” multimodal factor analysis. UCLA Work. Pap. Phon. 1970, 16, 1–84. [Google Scholar]
- Drexler, F. Eine methode zur Berechnung Sämtlicher Lösungen von polynomgleichungssytemen. Numer. Math. 1977, 29, 45–48. [Google Scholar] [CrossRef]
- Garia, C.; Zangwill, W. Finding all solutions to polynomial systems and other systems of equations. Math. Progam. 1979, 16, 159–176. [Google Scholar] [CrossRef]
- Li, T. Numerical solution of multivariate polynomial systems by homotopy continuation methods. Acta Numer. 1997, 6, 399–436. [Google Scholar] [CrossRef]
- Grasedyck, L.; Kressner, D.; Tobler, C. A literature survey of low-rank tensor approximation techniques. Gamm-Mitteilungen 2013, 36, 53–78. [Google Scholar] [CrossRef]
- Li, J.; Ye, H.; Li, T.; Wang, W.; Lou, W.J.; Hou, Y.; Liu, J.Q.; Lu, R.X. Efficient and Secure Outsourcing of Differentially Private Data Publishing With Multiple Evaluators. IEEE Trans. Dependable Secur. Comput. 2022, 19, 67–76. [Google Scholar] [CrossRef]
- Yan, H.Y.; Hu, L.; Xiang, X.Y.; Liu, Z.L.; Yuan, X. PPCL: Privacy-preserving collaborative learning for mitigating indirect information leakage. Inf. Sci. 2021, 548, 423–437. [Google Scholar] [CrossRef]
- Hu, L.; Yan, H.Y.; Li, L.; Pan, Z.J.; Liu, X.Z.; Zhang, Z.L. MHAT: An efficient model-heterogenous aggregation training scheme for federated learning. Inf. Sci. 2021, 560, 493–503. [Google Scholar] [CrossRef]
- Kolda, T.G.; Bader, B.W. Tensor decompositions and applications. SIAM Rev. 2009, 51, 455–500. [Google Scholar] [CrossRef]
- Carroll, J.D.; Chang, J.J. Analysis of individual differences in multidimensional scaling via an N-way generalization of “Eckart-Young” decomposition. Psychometrika 1970, 35, 283–319. [Google Scholar] [CrossRef]
- Oseledets, I.V. Tensor-train decomposition. SIAM J. Sci. Comput. 2011, 33, 2295–2317. [Google Scholar] [CrossRef]
- Levenberg, K. A method for the solution of certain non-linear problems in least squares. Q. Appl. Math. 1994, 2, 436–438. [Google Scholar] [CrossRef]
- Marquardt, D. An algorithm for least-squares estimation of nonlinear parameters. SIAM J. Appl. Math. 1963, 11, 431–441. [Google Scholar] [CrossRef]
- Tichavsky, P.; Phan, H.A.; Cichocki, A. Krylov-Levenberg-Marquardt Algorithm for Structured Tucker Tensor Decompositions. IEEE J. Sel. Top. Signal Process. 2021, 99, 1–10. [Google Scholar] [CrossRef]
- Nielsen, H.B. Damping Parameter in Marquardt’s Method. IMM. 1999. Available online: https://findit.dtu.dk/en/catalog/537f0cba7401dbcc120040af (accessed on 7 March 2023).
- Huang, B.H.; Ma, C.F. The modulus-based Levenberg-Marquardt method for solving linear complementarity problem. Numer. Math.Theory Methods Appl. 2018, 12, 154–168. [Google Scholar]
- Huang, B.H.; Ma, C.F. Accelerated modulus-based matrix splitting iteration method for a class of nonlinear complementarity problems. Comput. Appl. Math. 2018, 37, 3053–3076. [Google Scholar] [CrossRef]
- Lv, C.Q.; Ma, C.F. A Levenberg-Marquardt method for solving semi-symmetric tensor equations. J. Comput. Appl. Math. 2018, 332, 13–25. [Google Scholar] [CrossRef]
- Jin, Y.X.; Zhao, J.L. A Levenberg–Marquardt Method for Solving the Tensor Split Feasibility Problem. J. Oper. Res. Soc. China 2021, 9, 797–817. [Google Scholar] [CrossRef]









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Iteration Steps | Value | Value | Time Cost (s) | Value |
|---|---|---|---|---|
| 1 | ||||
| 2 | ||||
| 3 | ||||
| 4 | ||||
| 5 | ||||
| ⋮ | ⋮ | ⋮ | ⋮ | ⋮ |
| 25 | ||||
| 26 | ||||
| 27 | ||||
| 28 | ||||
| 29 |
| Iteration Steps | Value | Value | Time Cost (s) | Value |
|---|---|---|---|---|
| 1 | ||||
| 2 | ||||
| 3 | ||||
| 4 | ||||
| 5 | ||||
| ⋮ | ⋮ | ⋮ | ⋮ | ⋮ |
| 206 | ||||
| 207 | ||||
| 208 | ||||
| 209 | ||||
| 210 |
| Iteration Steps | Value | Total Time Cost (s) | Value |
|---|---|---|---|
| 1 | |||
| 2 | |||
| 3 | |||
| 4 | |||
| 5 | |||
| 6 | |||
| 7 |
| Steps | Time for h (s) | Time Cost (s) | Total Time (s) | Value | |
|---|---|---|---|---|---|
| 1 | |||||
| 2 | |||||
| 3 | |||||
| 4 | |||||
| 5 | |||||
| 6 | |||||
| 7 | |||||
| 8 | |||||
| 9 |
| Serial Number | Iterative Steps | Time Cost (s) | Value |
|---|---|---|---|
| 1 | 13 | ||
| 2 | 8 | ||
| 3 | 22 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Zhao, J.; Zhang, X.; Zhao, J. A Levenberg-Marquardt Method for Tensor Approximation. Symmetry 2023, 15, 694. https://doi.org/10.3390/sym15030694
Zhao J, Zhang X, Zhao J. A Levenberg-Marquardt Method for Tensor Approximation. Symmetry. 2023; 15(3):694. https://doi.org/10.3390/sym15030694
Chicago/Turabian StyleZhao, Jinyao, Xuejuan Zhang, and Jinling Zhao. 2023. "A Levenberg-Marquardt Method for Tensor Approximation" Symmetry 15, no. 3: 694. https://doi.org/10.3390/sym15030694
APA StyleZhao, J., Zhang, X., & Zhao, J. (2023). A Levenberg-Marquardt Method for Tensor Approximation. Symmetry, 15(3), 694. https://doi.org/10.3390/sym15030694