1. Introduction
In recent years, the frequency of unconventional emergencies has been increasing, and such events not only constrain economic and social development, but also pose a serious threat to human livelihood security. Therefore, in the new situation, it is important to focus on improving the emergency management capabilities of emergency management agencies and reducing the adverse effects caused by emergencies. Since emergency decision-making events are uncertain, risky, and variable, different emergency management options need to be developed for different types of events [
1,
2,
3,
4]. How to decide the best solution among various alternatives is a major problem that needs to be solved urgently and is the research of this paper.
Unlike traditional decision problems, the complexity and asymmetry of large group decision problems and the differences in decision makers’ own knowledge level, life experience and research direction lead to the difficulty of decision makers to make accurate judgments on decision options under a short time pressure in the decision process. At this time, they often choose to express their preferences in the form of fuzzy numbers. In the actual multi-attribute decision making (MADM), Herrera et al. [
5] extended linguistic forms of decision making to group decision making (GDM), where the use of linguistic terms allows for a convenient and intuitive representation of the evaluator’s uncertainty preferences. This allows experts to scientifically weigh the choice of emergency response options for major disaster relief, corporate investment choices and large constructive projects [
6].
With the popularity and development of the Internet, more and more social media platforms encourage the public to post their opinions and form text comments on the web, such as Weibo, Douban, AutoZone, and GoWhere. How to help decision makers (DMs) make choices based on text comments after an emergency event is a meaningful study and an essential task of this paper. So far, some scholars have mined and studied the behavior of social media users. Xu et al. [
7,
8,
9] mined the topics of public concern events through social media platforms, introduced the social relationship network of experts, and built a consensus model to complete the selection of alternatives. The traditional GDM with multi-granularity linguistic details, on the other hand, focuses more on the expert side’s opinions and loses the original data’s complete information [
10]. In this paper, the study of academic, social network user clustering based on user behavior data, mining the degree of utilization and behavior patterns of different user groups, better retains the integrity of the information, solves the problem of completely unknown attribute weights [
11] and helps to understand the information behavior patterns of academic and social network users.
For complex large-group decision problems, the representation and fusion of information are crucial. Many aggregation operators have developed in the literature, such as the ordered weighted average operator (OWA), the induced ordered weighted average operator (IOWA) and so on. Many scholars have also applied foreground theory in different linguistic value situations recently. Gao et al. [
12] introduced foreground theory into the probabilistic language environment and proposed a foreground decision method based on a probabilistic linguistic term set (PLTS). Yu Zhang et al. [
13] proposed an improved probabilistic linguistic multicriteria compromise solution group decision method PL-VIKOR based on cumulative prospect theory (CPT) and learned ratings.
Determining weights is an essential part of decision making. According to the source of the original data for calculating weights, these methods can be divided into three categories: subjective assignment method, objective assignment method, and combined assignment method. The subjective assignment method is an early and mature method, which determines the weight of attributes according to the importance of the DMs subjectively, and the DMs’ subjective judgment obtains the original data based on experience. The commonly used subjective assignment methods are the expert's survey method (Delphi method) [
14], analytic hierarchy process [
15] (AHP), the binomial coefficient method [
16], and ring score methods [
17]. Furthermore, the original data of the objective assignment method is formed by the actual data of each attribute in the decision scheme. The commonly used objective assignment methods are principal component analysis, entropy value method [
18], multi-objective planning method, deviation [
19] and mean square difference methods. In order to make the decision results accurate and reliable, scholars propose a third type of assignment method, namely, the subjective–objective integrated assignment method. The subjective–objective assignment method includes the compromise coefficient integrated weighting method, linear-weighted single-objective optimization method, combined assignment method [
20], Frank–Wolfe method, etc.
In the past decades, MADM methods have been successfully applied in several fields and disciplines, and different MADM methods yield similarity in the final rankings [
21]. These methods include the technique of preference ranking with similarity to the ideal solution (TOPSIS) [
22], VIekriterijumsko KOmpromisno Rangiranje (VIKOR) [
13], the preference ranking organization method for enrichment of evaluations (PROMETHEE) [
23], to better solve the complex problem. However, many problems in real life have vague and uncertain information, thus leading to the language of probability. In 1965, Zadeh [
24] introduced the concept of “fuzzy set,” then, Pang [
11] and others extended the set of hesitant fuzzy linguistic terms by adding probability values and gave the first definition of the probabilistic linguistic term set. Wang [
25] proposed the comparative algorithm of the score function, deviation function, and probabilistic hesitant fuzzy set. In this paper, we use the probabilistic language PROMETHEE, which is an outer ranking method proposed by Brans and Vincle [
26] in 1985 for obtaining partial (PROMETHEE I) and complete (PROMETHEE II) rankings of alternatives based on multiple attributes or criteria.
Considering the timeliness of emergency decision making, the weight of each decision expert is more quickly obtained by using maximizing deviation method [
27,
28,
29] in this paper. Gong et al. [
30] proposed a method based on cardinal deviations to measure the differences between multiplicative linguistic term sets and combined it with VIKOR. Akram et al. [
31] proposed a decision method based on the maximum deviation method by TOPSIS to solve the MADM problem with incomplete attribute weight information. This paper combined the maximum deviation method with PROMETHEE on the basis of mixed distance to solve the multi-attribute group decision-making (MAGDM) problem.
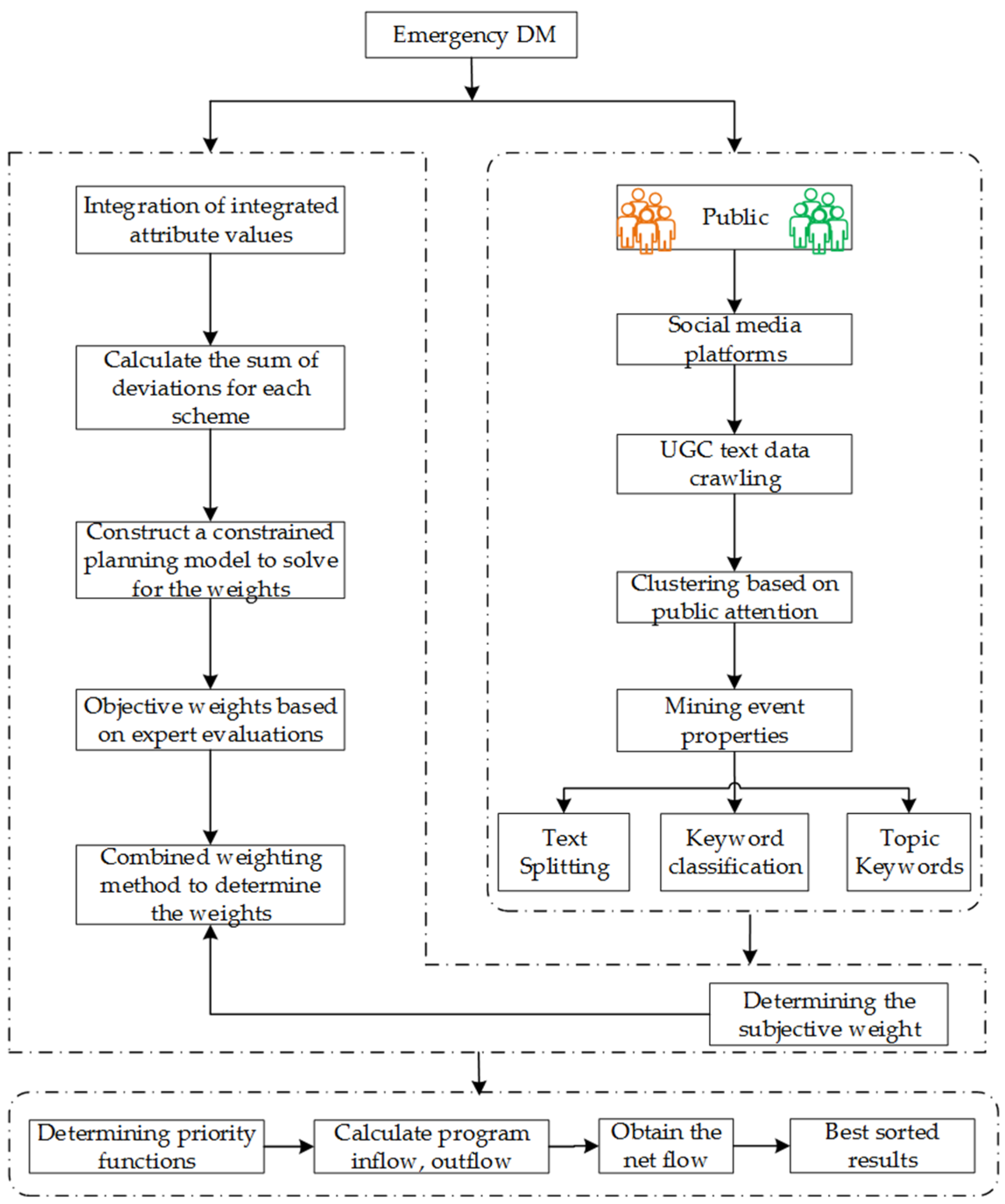
Based on the above discussion, this paper addresses the problem of complex large-group emergency decision making in the social media big data environment. This paper is organized as follows. In
Section 2, we define basic concepts of probabilistic languages and a new generalized extended hybrid distance based on PLTS. In
Section 3, we collect public opinions on social media platforms, extract keywords, and explore the attributes of emergency decision-making events as an essential basis for expert evaluation of solutions. Then, we use a combination of subjective and objective weighting models to integrate public opinions with expert decision making by CPT. In
Section 4, we provide a specific flow on the GDMD-PROMETHEE algorithm. In
Section 5, we verify the validity and feasibility of this paper’s method through the “6–18” Shanghai Petrochemical explosion and compare it with other methods. Meanwhile, a sensitivity analysis was conducted. In
Section 6, we present conclusions.
2. Preliminaries
2.1. Probabilistic Linguistic Term Sets
PLTS is one of the most widely used research tool in MAGDM. In this section, we introduce the basic concepts of linguistic term sets (LTSs) and distance measure between them. On this basis, the basic concepts of PLTSs, as well as distance improvement are given.
Definition 1. [
1]
Let be a , then different language terms may be used. For example, let be the following :
, satisfies the following conditions:- 1.
The set is ordered: , if ;
- 2.
The negation operator is defined: ,
where can be expressed by the linguistic scale transformation function as: , is the subscript of .
Definition 2. [
1]
Let be a , a PLTS can be defined as:where denotes the associated probability of the set of linguistic terms with ; denotes the number of linguistic terms in the set of probabilistic linguistic terms. Note that if , then we have the complete information of probabilistic distribution of all possible linguistic terms; if , then partial ignorance exists because current knowledge is not enough to provide complete assessment information, which is not rare in practical GDM problems. Especially, means completely ignorance. Obviously, handling the ignorance of is a crucial work for the use of PLTSs.
Definition 3. [
32]
Given a PLTS with , then the normalized PLTS is defined by: Definition 4. [
11]
Let be a PLTS, the score of is , where: Definition 5. [
11]
The deviation degree of is:where is the subscript of linguistic term , given two PLTSs and then:- (1)
If , then ;
- (3)
If , then ;
- (3)
If , while , then ; while , then ; while , then .
2.2. Distance Measures between PLTSs
PLTSs can more accurately represent qualitative information of DMs in complex linguistic environments. However, existing distance measures may distort the original information and lead to unreasonable results. For this reason, a new generalized hybrid distance based on the classical distance is proposed.
Definition 6. Let and be two PLTSs, ,
and are the linguistic terms of and respectively, and are the probabilities of the linguistic terms of and respectively, and are the subscripts of the linguistic terms corresponding to and , respectively, then a new probabilistic linguistic distance based on Reference [
33]
is defined as: Definition 7. [
34]
Let and be two PLTSs, ,
and are the linguistic terms of and respectively, and are the probabilities of the linguistic terms of and respectively. Then, the extended distance is:where is the linguistic scale function, , when , the above Equation(6) is Hamming-Hausdorff distance; when , the above Equation is Euclidean-Hausdorff distance. In MAGDM, when the above distances cannot meet the decision needs, this paper creatively introduces probability-related distances to achieve perfect integration with the probabilistic linguistic, and also fully considers the wishes of each decision maker, the new distance is given as follow.
Definition 8. Let is an LTS. Let and be two , then the generalized hybrid distance between PLTSs is defined as: From Equation (7), , , the generalized hybrid distance combines the generalized probabilistic linguistic distance and the extended Hausdorff distance through the parameter . The parameter can be considered as the expert’s risk attitude, so the proposed distance allows more options for the experts to decide their risk preferences through the parameters.
Theorem 1. Let , and be three complete probabilistic linguistic term sets, the three PLTSs are and , where , and are the linguistic terms in , and , , and are the probabilities of the linguistic terms in , and respectively. Then, the generalized hybrid distance has the following properties:
- (1)
;
- (2)
;
- (3)
If then , .
2.3. Probabilistic Linguistic CPT
2.3.1. Classical CPT
To better retain the true evaluation information of DMs, probabilistic fusion is performed using CPT. CPT [
35] is an improved version of prospect theory (PT) [
36] to address stochastic dominance proposed by Tversky et al. in 1992, which well explains phenomena such as stochastic dominance, and its measure of the total value of a prospect through a value function and probability weights. The forms are shown as follows:
CPT asserts that there exist a strictly increasing weighted value function . The value function is defined on the deviations from a reference point, which represents the behavior of the DMs and can be expressed as follows.
The key difference between CPT and PT is that the weight function used in CPT is no longer a linear function, but an inverse S-shaped curve, indicating that individual decision makers tend to overestimate the possibility of small probability events and underestimate the possibility of medium and high probability events, so the probability weights of gains and losses are formulated as follows.
Weighting function:
where
denotes the reference point;
,
are the risk attitude coefficients towards value in the face of gain or loss,
;
is the loss aversion coefficient,
;
,
are the risk attitude coefficients towards probability weights about gain or loss,
. Combined with Reference [
35], it is generally considered to take
,
,
,
.
Considering the risk preferences of DMs facing gains and losses in real problems, CPT gives a specific form of the value function and a form of decision weights, which let it be combined with probabilistic linguistic as follows. It would be more meaningful to integrate CPT into the practical application of GDM.
2.3.2. The Measures between PLTSs Based on CPT
In order to measure probabilistic linguistic terms more accurately, a new probabilistic linguistic terminology measure is obtained by fusing information based on the value function of the relative reference point variables and the probability weight function.
Definition 9. [
13]
The measures between PLTSs based on CPT. The forms are shown as follows:Variance value:where is the subscript of , , here , is the probability of .
CPT not only analyzes the risk psychological factors of human in the decision making process. It also considers the value function and probability weight function of the relative reference point variables, which makes up for the shortcomings of PT.




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}







