
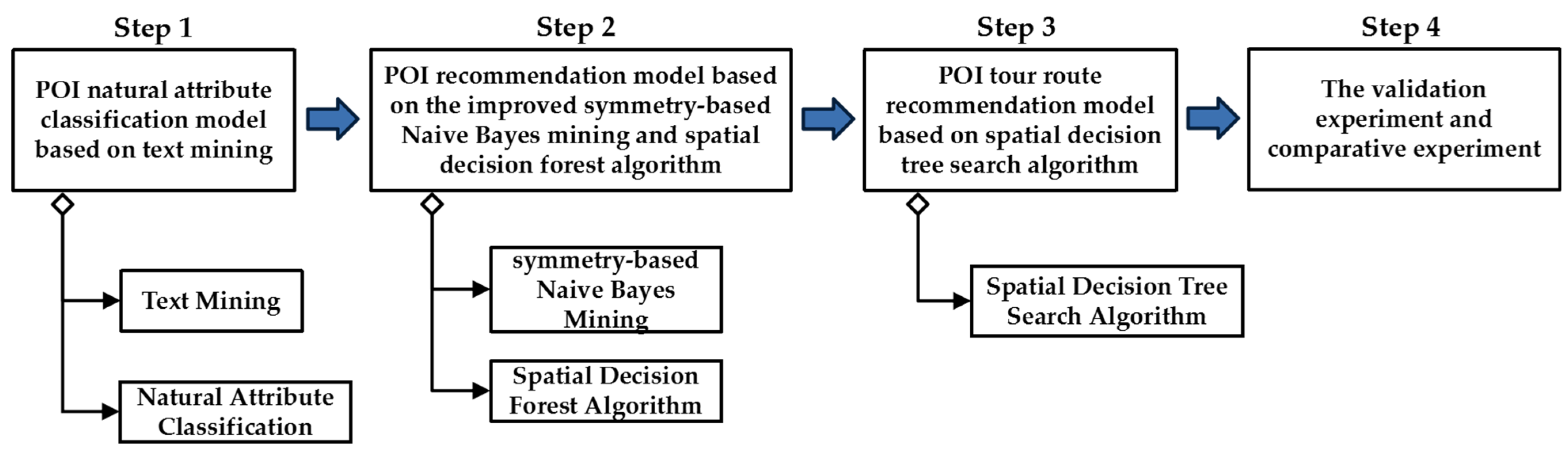
Tour Route Recommendation Model by the Improved Symmetry-Based Naive Bayes Mining and Spatial Decision Forest Search


Abstract
:1. Introduction
1.1. Research Background and Problem Discussion
1.2. Problem Solving Methods
2. Related Works
- (1)
- The POI natural attribute classification model based on text mining is constructed. Set up a text mining algorithm to classify the natural attributes of tourist destination POIs, making the process of recommending POIs rely on each natural attribute classification. Searching for the POIs with the highest label weights from the classified POIs can improve the accuracy of the recommending results.
- (2)
- A method model for mining tourist interests is established. The model sets the POIs that the tourists have once visited as a source of interest. Tourists’ preferences for POI tourism attributes are obtained by tourists’ determining and judging once-visited POIs. This method can obtain tourists’ interests and preferences for POIs from the perspective of tourism attributes rather than depending on the POIs provided by historical tourists or subjective scoring provided by tourists, and it has higher accuracy.
- (3)
- The destination POI recommendation model based on the improved symmetry-based Naive Bayes mining and spatial decision forest algorithms is established. The POIs provided by tourists as well as their interest data are used to construct the improved symmetry-based Naive Bayes mining model. Then the destination POIs are classified based on tourists’ interest tendencies, so that the POIs that belong to different natural attribute classifications could be divided into different tourism attribute classifications by tourists’ preferences, and finally the POIs with the highest recommendation degrees are precisely recommended.
- (4)
- The POI tour route recommendation model based on a spatial decision tree search algorithm is established. By constructing the route vector, route sub-interval, and route interval models, the sub-interval cost function and interval cost function are designed. Then the spatial decision tree model is constructed for the sub-interval cost function to output the optimal sub-interval. Based on the cost of each sub-interval, the interval decision tree algorithm is constructed to output a decision tree with interval costs as the tree nodes; thereby, the optimal travel routes for tourists are recommended.
- (5)
- The validation experiment and comparative experiment are performed using the proposed algorithm to output the optimal POIs and tour routes. The experiment compares the proposed algorithm (PRA) with the commonly used route planning methods (GDM and 360M) and verifies the advantages of the proposed algorithm over the traditional route planning methods. The output POI tour routes can effectively reduce travel costs.
3. Methodology
3.1. POI Natural Attribute Classification Model Based on Text Mining
- (1)
- Take and , compare and . If , store into element ; If , store into element .
- (2)
- Take and , compare and . If , store into the element ; Then If , store into element .
- (3)
- In line with the same method, compare and . If , store into the element ; Then If , store into element . Traverse .
- (4)
- Output the second layer of the structure tree .
- (1)
- Take and , compare and . If , store into the element ; Then If , store into element .
- (2)
- Take and , compare and . If , store into the element ; Then If , store into element .
- (3)
- In line with the same method, compare and , If , store into element ; If , store into element . The number of the node for the second layer is half of that in the initial layer . traverses .
- (4)
- Output the third layer of the structure tree .
3.2. POI Recommendation Model Based on the Improved Symmetry-Based Naive Bayes Mining and Spatial Decision Forest Algorithm
3.2.1. The Improved Symmetry-Based Naive Bayes Classification Algorithm Based on the Once-Visited POIs
3.2.2. Improved POI Recommendation Degree Model Based on Tourism Attribute Interest Network
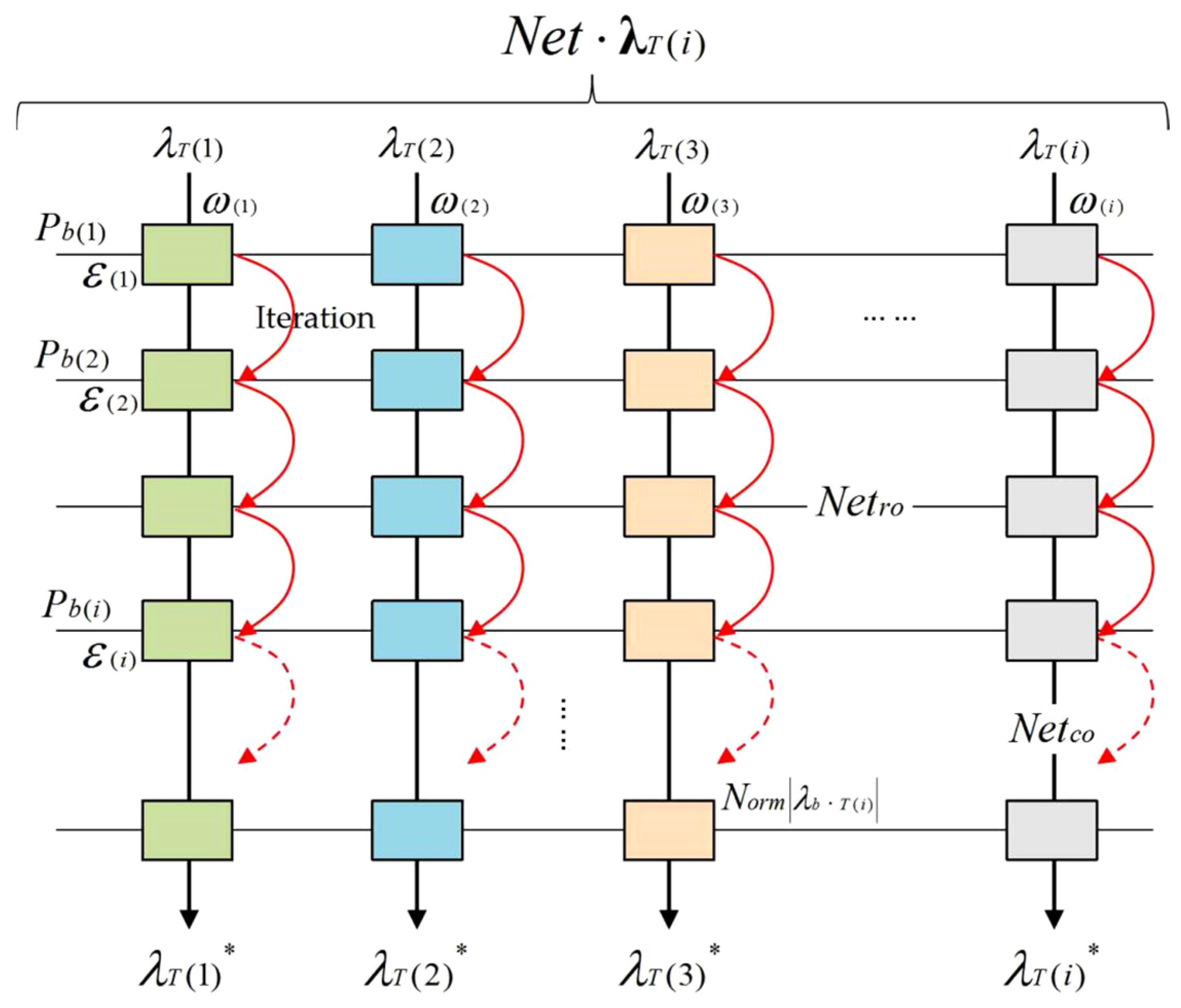
3.2.3. POI Recommendation Model Based on the Spatial Decision Forest Algorithm
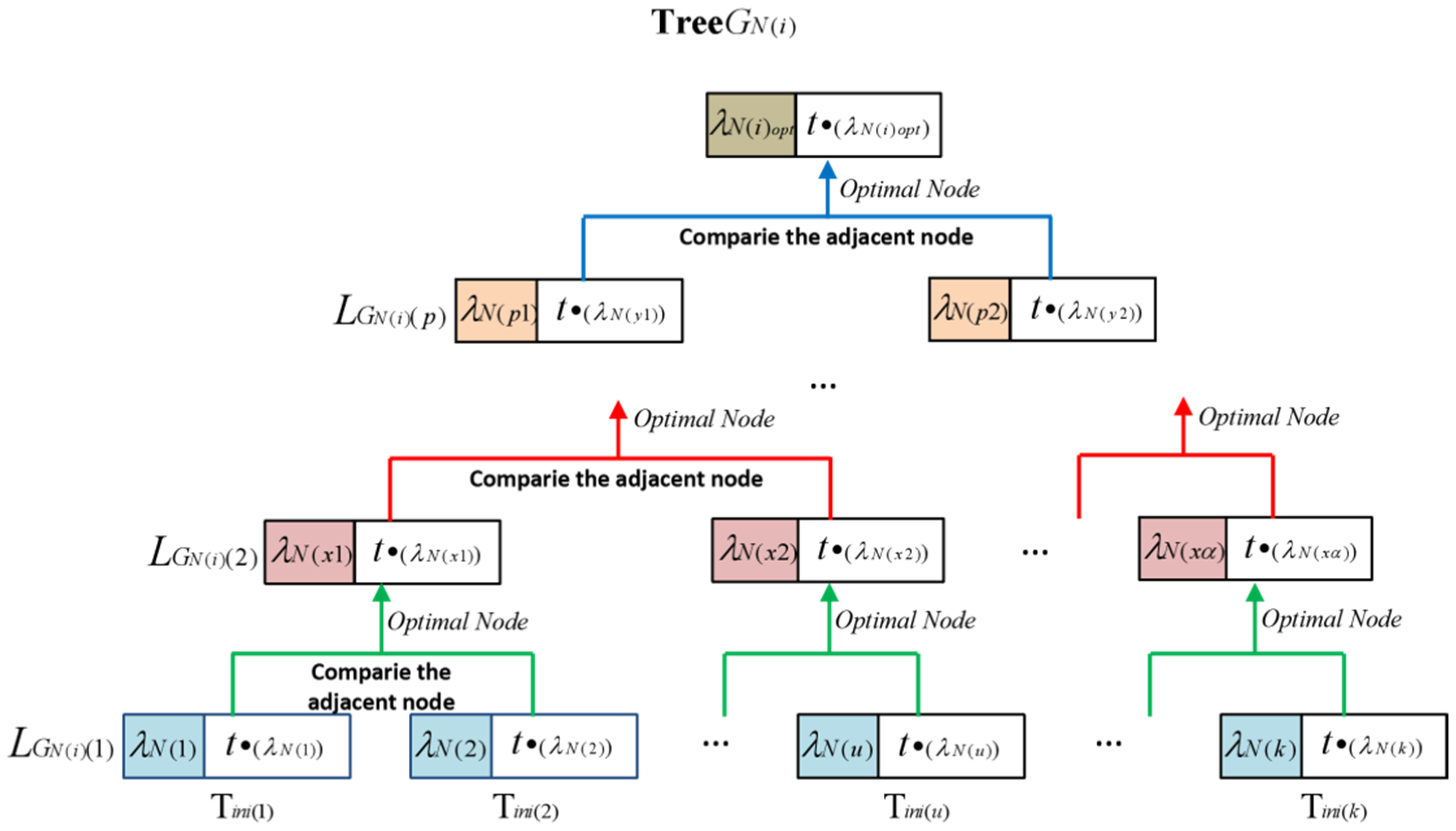
- (1)
- The root node represents the classification , and the growth node represents the classification;
- (2)
- The recommendation degree of any child node in the previous layer must be higher than that of any child node in the next layer, which represents the layer of the decision tree and represents the node within the layer;
- (3)
- In the same layer, the recommendation degree of the left child node must be higher than that of the right child node;
- (4)
- The total number of nodes in the decision tree is , and the total number of layers is satisfied .
| Algorithm 1: The POI recommendation model based on the spatial decision forest algorithm |
|
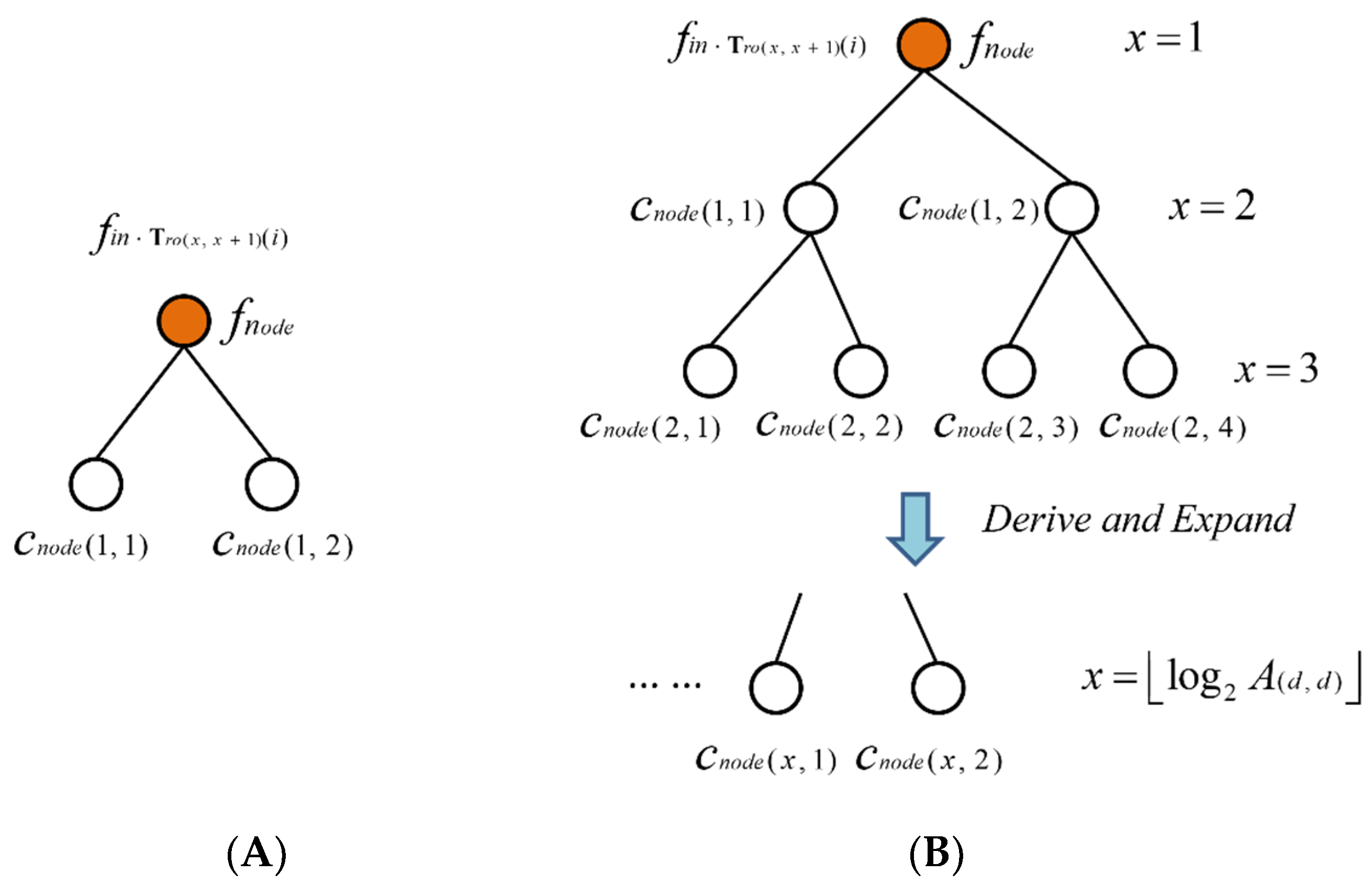
3.3. POI Tour Route Recommendation Model Based on the Spatial Decision Tree Algorithm
- (1)
- The root node stores the minimum cost or ;
- (2)
- The cost or of arbitrary child node in the previous layer must be smaller than the cost of arbitrary child node in the next layer;
- (3)
- In the same layer, the cost or of the left child node must be smaller than the cost of arbitrary right child node;
- (4)
- When the total number of nodes is , the height of the tree’s layer meets .
| Algorithm 2: Optimal solution algorithm of the route sub-interval |
|
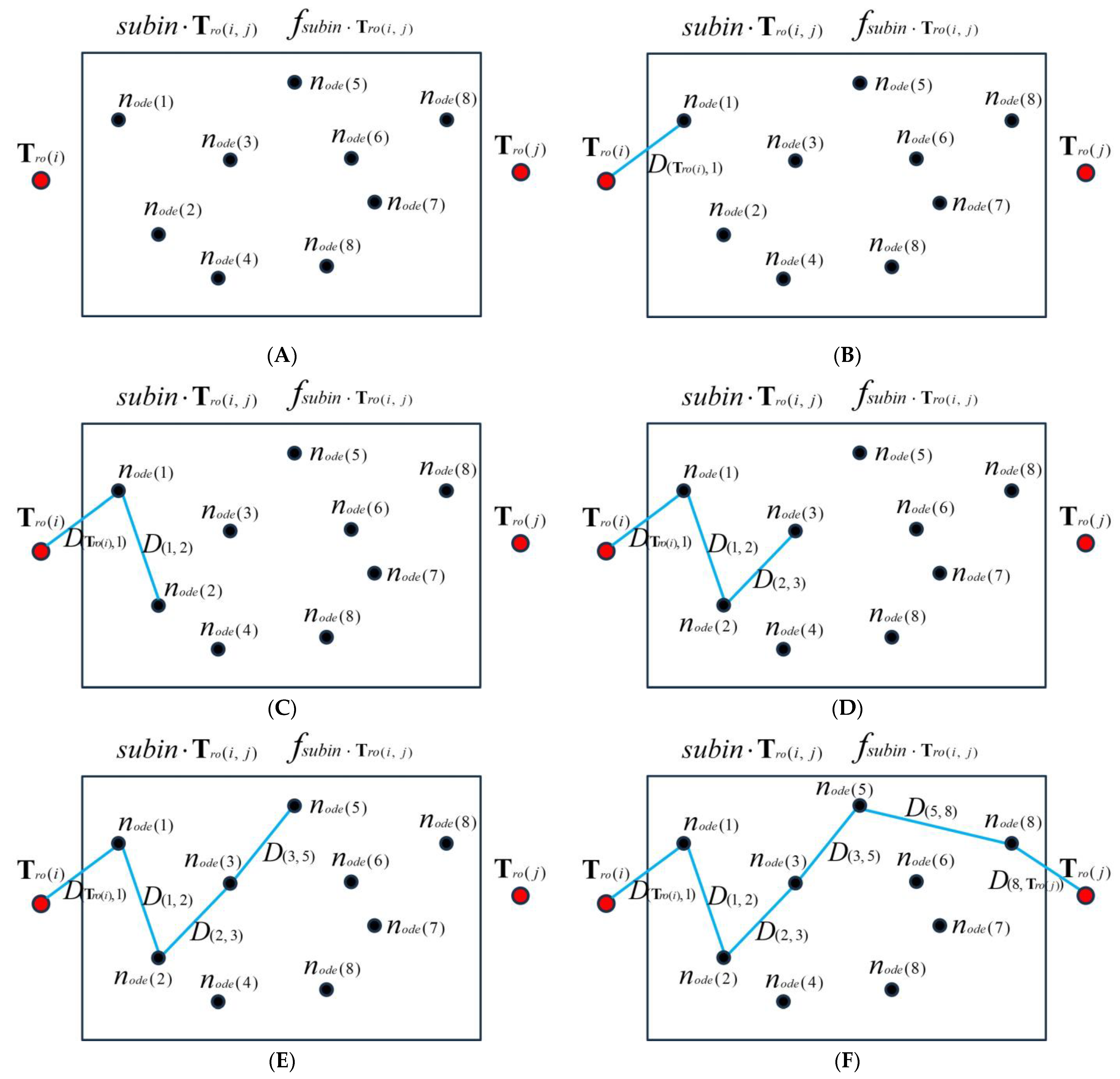

| Algorithm 3: The algorithm to find out the optimal solution for interval . |
|
3.4. The Construction of Tourist Satisfaction Evaluation Model
- (1)
- Average precision and average recall for POI recommendation
- (2)
- Average precision and average recall of POI route
- (3)
- The average deviation of attribute matching degree
- (4)
- Average deviation of route cost
4. Experiment and Results Analysis
4.1. Experimental Approach and Process
- (1)
- The first step is to use the constructed text mining algorithm to achieve destination POI natural attribute classification. Select the destination POIs of the tourism city, collect POI natural attribute labels and sub-labels , and construct the natural attribute vector and natural attribute matrix . By calculating the statistical label word frequency , inverse text frequency and label weight of each row for sub-labels in the matrix , a natural attribute structure tree of the POI is constructed to determine the natural classification of the POI.
- (2)
- The second step is to collect tourists’ once-visited POIs and confirm their tourism attributes and quantified intervals. Tourists determine their preferences for the tourism attributes and thus construct a training set for the Naive Bayes classification algorithm. By constructing the Naive Bayes classifier, the recommendation degrees of the destination POIs are calculated, and the tourism attribute classifications are obtained. By combining the natural attribute classification and tourism attribute classification, establish a destination POI decision tree and decision forest, and output the optimal POI recommendation.
- (3)
- The third step is to output sub-interval decision trees and an interval decision tree containing costs based on the recommended POIs and the urban geospatial constraints. Calculate the interval cost of each tour route and ultimately output the optimal tour route.
- (4)
- The fourth step is to select the two most commonly used electronic maps for tourism route planning, GaoDe Map and 360 Map, as the control group method, while the proposed algorithm is set as the experimental group. Use the same experimental conditions and methods to output the optimal tour routes, make comparisons on the costs of the optimal routes from the three methods, and then get the relative results and conclusions.
- (5)
- To evaluate the satisfaction degree of sample tourists with recommended POIs and POI routes, we use the satisfaction evaluation models constructed in Section 3.4 to make comparisons between the proposed algorithm (PRA), the item-based collaborative filtering recommendation method (IBCF), and the user-based collaborative filtering recommendation method (UBCF) in terms of POI average precision, average recall, and average deviation of attribute matching degree. At the same time, make comparisons between the proposed algorithm (PRA) and the map-searching algorithms GDM and 360M in terms of average precision, average recall, and average deviation of route cost. According to the satisfaction evaluation models constructed in Section 3.4, each evaluation index could represent and reflect a tourist’s satisfaction degree.
4.2. Data Collection
- (1)
- For the destination POI natural attribute classification, select an encyclopedia big data text containing 10,000 words, including natural attribute sub-label text. Select another 1000 texts about POI introduction as the POI text mining corpus. Divide the natural attribute category into the following labels: “natural scenery”, “cultural history”, “leisure shopping” and “amusement park and venue”. Each label contains 5 sub-labels , and the data table is shown in Table 2. When calculating, synonyms and related words related to the sub-labels are also included in the statistics. Calculate the for each label , and construct the natural attribute structure tree of POI to output its natural attribute classification .

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Natural Scenery | Cultural History | Leisure Shopping | Amusement Park and Venue | ||
|---|---|---|---|---|---|
| Sub-label | River view | Historical site | Culinary experience | Leisure sports | |
| Lake and reservoir | Ancient town and city | Shopping | Sports and competitions | ||
| Greenland and park | Landscape art | Theater and movie | Anime and animation | ||
| Forest view | Folk culture | Indoor leisure | Adventure experience | ||
| Mountain view | Royal Mausoleum | Theater performance | Rides and shows | ||
- (2)
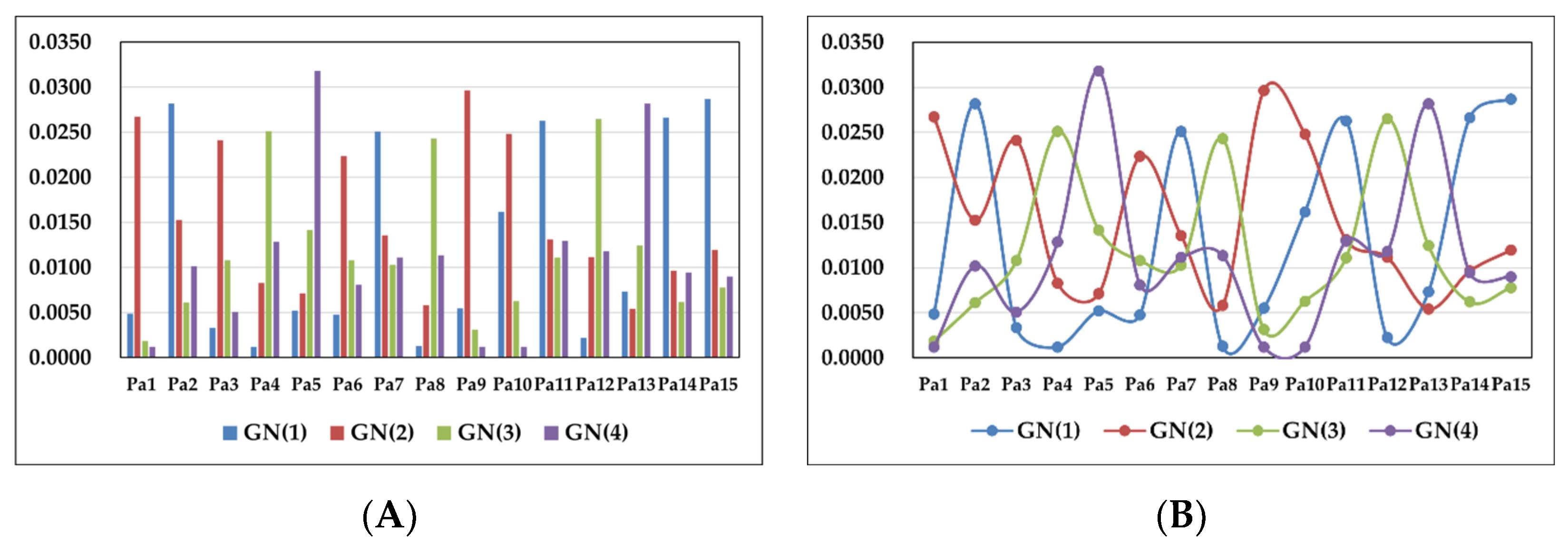
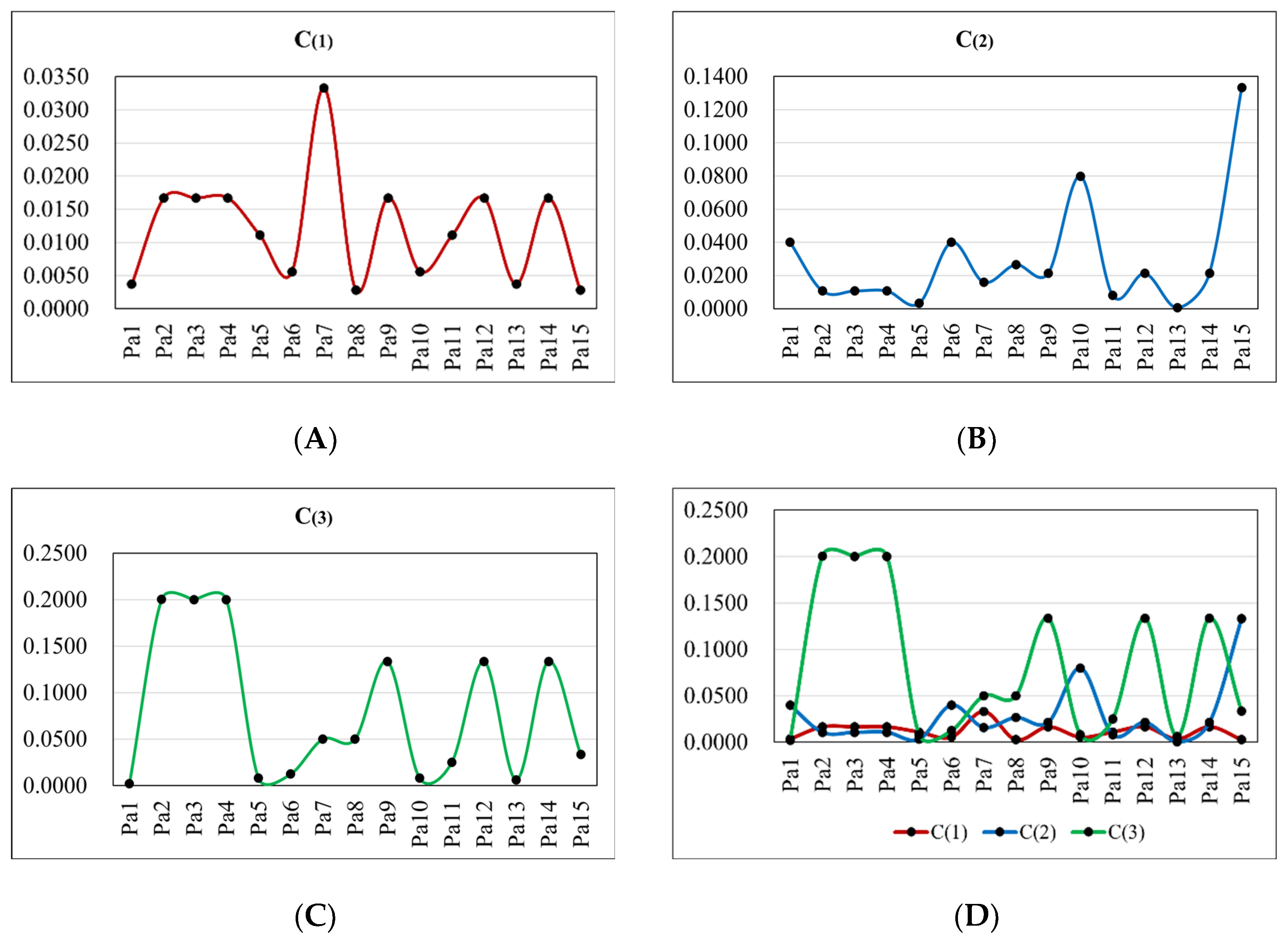
- For the tourism attribute classification of destination POIs, suppose a sample tourist for the experiment. Use the tourist’s once-visited 15 POIs as well as their tourism attributes as the training set. The sample tourist determines the preference degree for each POI as: : most favorite; : favorite; : like. The tourism attributes are: “travel cost” (Unit: yuan), “travel time” (Unit: hour), “POI- A Class” and “POI popularity”. The quantified sub-interval for each attribute is determined as shown in Table 3. Use the proposed symmetry-based Naive Bayes classification algorithm to classify the tourism attributes of the destination POIs, introduce the tourist interest weight and tourism attribute interest weight , and construct the decision trees and the decision forest to obtain the optimal POI recommendation.
| Travel cost | ||||
| Travel time | ||||
| POI- A Class | ||||
| POI popularity | ||||
- (3)
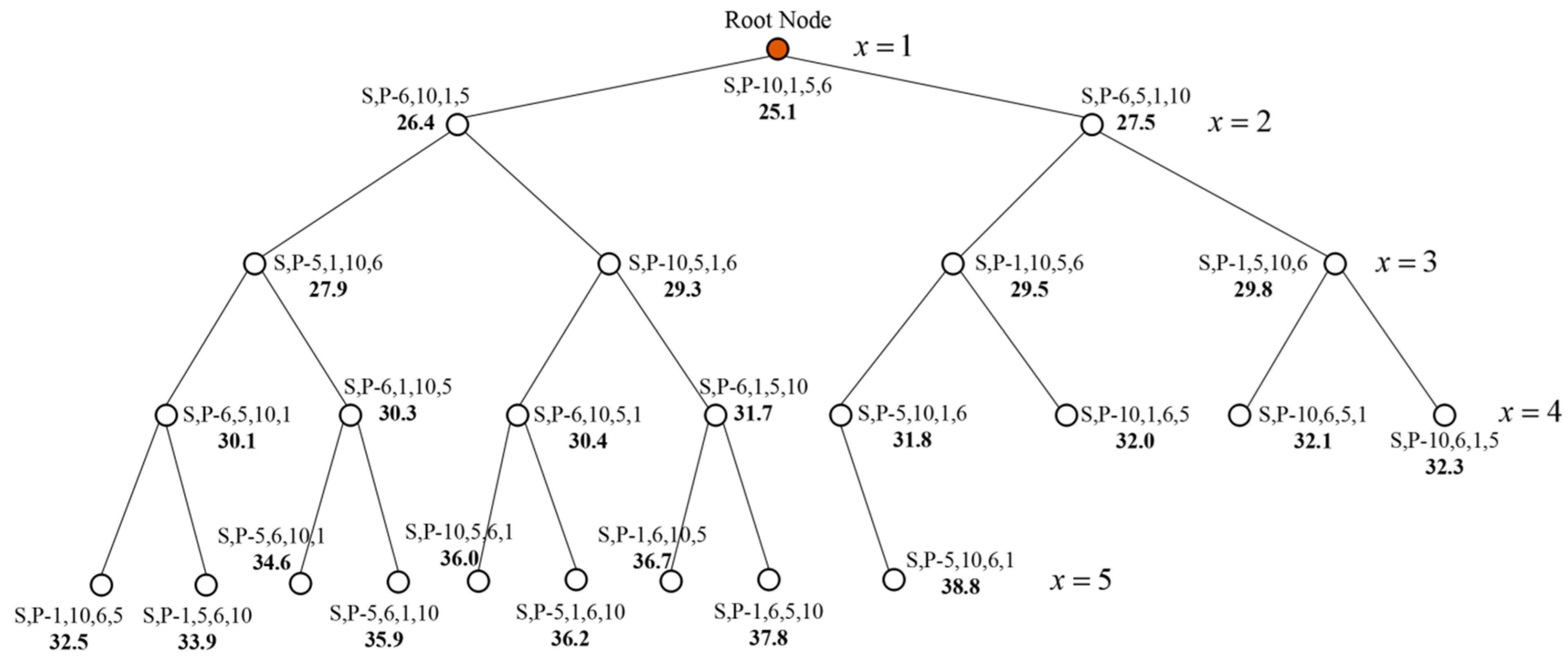
- Use the geospatial data of Chengdu as the constraint. Iteratively calculate the cost of each POI sub-interval by using the tour route algorithm, and construct a sub-interval decision tree to output the optimal moving path for each sub-interval. Iteratively calculate the cost of each interval based on the optimal cost of sub-intervals and construct an interval decision tree . Output the optimal route of the interval, corresponding to the optimal tour route. As to the geographic information collection in Chengdu city, the experiment collects the moving distances between road nodes within each sub-interval.
- (4)
- The comparative experiment is conducted to select the most commonly used electronic maps for tourism route planning, including GaoDe Map and 360 Map. The experimental group is the proposed tour route algorithm. The experimental conditions for the three methods are the recommended POIs and the same geospatial constraints. The control group searches for POI sub-interval moving paths, outputs the travel cost, and finally iteratively outputs the relative optimal tour routes and corresponding costs. By comparing the optimal routes and cost output of the three methods, the advantages of the proposed algorithm are demonstrated.
- (5)
- The tourist satisfaction degree evaluation experiment determines the sample size of tourists as and it evaluates satisfaction degrees in two aspects: Firstly, the recommended number of POIs is . The overall number of “dissatisfied” POIs that tourists may output meets . According to the quantity of destination POIs in Chengdu, there is . Tourists provide constraints based on their interests, and PRA, IBCF, and UBCF, respectively, output the recommended POIs . Tourists determine the POIs of “dissatisfied” (NS) and “satisfied” (S) in each group of recommended POIs, calculate the average precision, average recall, and average deviation of attribute matching degree for the three sets of algorithms, and then make comparisons. Secondly, the starting point of the route is Tianfu Square, and the recommended number of routes meets . The overall number of “dissatisfied” routes that tourists may output meets . Based on the recommended number of POIs , the overall sample of the route is . PRA, GDM, and 360M, respectively, output recommended routes , and tourists determine the “dissatisfied” (NS) and “satisfied” (S) routes in each group of recommended routes. The average precision, average recall, and average deviation of route cost of the three algorithms are calculated and compared.
4.3. Results and Analysis
4.3.1. The Results and Analysis on the POI Natural Attribute Classification
- (1)
- POIs belonging to the classification of “natural scenery” include: Tazishan Park; The People’s Park; San Sheng Hua Xiang; Qinglong Lake; Huanhuaxi Park.
- (2)
- POIs belonging to the classification of “culture history” include: Jinsha Site; Kuanzhai Alley; Eastern Suburb Memory; Sichuan Museum; Du Fu Thatched Cottage.
- (3)
- POIs belonging to the classification of “leisure shopping” include: Jinniu Wanda; Raffles Plaza; Chunxi Road.
- (4)
- POIs belonging to the classification of “amusement park and venue” include: Happy Valley; Guose Tianxiang Amusement Park.
4.3.2. The Results and Analysis on POI Tourism Attribute Classification and Recommendation Decision Tree
4.3.3. Results and Analysis on the Tour Route Recommendation
4.3.4. Results and Analysis on the Methods Comparison
- (1)
- Comparison between GDM and the experimental group PRA: The sub-interval costs of the optimal route “S,P-10,1,5,6” are higher than those of PRA, and the route cost is 1.2 higher than that of PRA; the sub-interval costs of the suboptimal route “S,P-6,10,1,5” are all higher than those of PRA, and the route cost is 0.8 higher than that of PRA; the sub-interval costs of the suboptimal route “S,P-6,5,1,10” are all higher than those of PRA, and the route cost is 1.1 higher than that of PRA.
- (2)
- Comparison between 360M and the experimental group PRA: The sub-interval costs of the optimal route “S,P-10,1,5,6” are higher than those of PRA, and the route cost is 2.9 higher than that of PRA; the sub-interval costs of the suboptimal route “S,P-6,10,1,5” are all higher than those of PRA, and the route cost is 2.3 higher than that of PRA; the sub-interval costs of the suboptimal route “S,P-6,5,1,10” are all higher than those of PRA, and the route cost is 2.7 higher than that of PRA.
- (3)
- Comparing to the GDM, the PRA reduces the travel cost by 4.56% in terms of optimal route cost and 2.94% and 3.85% in terms of suboptimal route costs, respectively. Comparing to the 360M, the PRA reduces the travel cost by 10.36% in terms of optimal route cost, and 8.01% and 8.94% in terms of suboptimal route costs respectively. According to the comparison results, it can be concluded that the proposed tour route recommendation algorithm can effectively reduce the travel cost of the traditional routes and has obvious advantages over the traditional methods.
4.3.5. Evaluation and Analysis of Tourist Satisfaction
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Darapisut, S.; Amphawan, K.; Leelathakul, N.; Rimcharoen, S. A Hybrid POI Recommendation System Combining Link Analysis and Collaborative Filtering Based on Various Visiting Behaviors. ISPRS Int. J. Geo-Inf. 2023, 12, 431. [Google Scholar] [CrossRef]
- Lee, J.; Kim, J. Developing a Convenience Store Product Recommendation System through Store-Based Collaborative Filtering. Appl. Sci. 2023, 13, 11231. [Google Scholar] [CrossRef]
- Aldayel, M.; Al-Nafjan, A.; Al-Nuwaiser, W.; Alrehaili, G.; Alyahya, G. Collaborative Filtering-Based Recommendation Systems for Touristic Businesses, Attractions, and Destinations. Electronics 2023, 12, 4047. [Google Scholar] [CrossRef]
- Alabduljabbar, R. Matrix Factorization Collaborative-Based Recommender System for Riyadh Restaurants: Leveraging Machine Learning to Enhance Consumer Choice. Appl. Sci. 2023, 13, 9574. [Google Scholar] [CrossRef]
- Lin, S. Implementation of Personalized Scenic Spot Recommendation Algorithm Based on Generalized Regression Neural Network for 5G Smart Tourism System. Comput. Intel. Neurosc. 2022, 2022, 3704494. [Google Scholar] [CrossRef] [PubMed]
- Bin, C.; Gu, T.; Jia, Z.; Zhu, G.; Xiao, C. A Neural Multi-context Modeling Framework for Personalized Attraction Recommendation. Multimed. Tools. Appl. 2020, 79, 14951. [Google Scholar] [CrossRef]
- Li, G.; Hua, J.; Yuan, T.; Wu, J.; Jiang, Z.; Zhang, H.; Li, T. Novel Recommendation System for Tourist Spots Based on Hierarchical Sampling Statistics and SVD++. Math. Probl. Eng. 2019, 2019, 2072375. [Google Scholar] [CrossRef]
- Mizutani, Y.; Yamamoto, K. A Sightseeing Spot Recommendation System That Takes into Account the Change in Circumstances of Users. ISPRS Int. J. Geo-Inf. 2017, 6, 303. [Google Scholar] [CrossRef]
- Huang, C.; Liu, M.; Gong, H.; Xu, F. Season-aware Attraction Recommendation Method with Dual-trust Enhancement. J. Intell. Fuzzy Syst. 2017, 33, 2437–2449. [Google Scholar] [CrossRef]
- Kesorn, K.; Juraphanthong, W.; Salaiwarakul, A. Personalized Attraction Recommendation System for Tourists Through Check-In Data. IEEE Access 2017, 5, 26703–26721. [Google Scholar] [CrossRef]
- Remigijus, P.; Linas, S.; Simona, S.; Dmitrij, K.; Ernestas, F. A Novel Greedy Genetic Algorithm-based Personalized Travel Recommendation System. Expert. Syst. Appl. 2023, 230, 120580. [Google Scholar]
- Zhang, Y.; Liu, S. A Picture-Based Approach to Tourism Recommendation System. Front. Soc. Sci. Technol. 2023, 5, 124–130. [Google Scholar]
- Liang, S.; Jin, J.; Ren, J.; Du, W.; Qu, S. An Improved Dual-Channel Deep Q-Network Model for Tourism Recommendation. Big Data 2023, 11, 268–281. [Google Scholar] [CrossRef] [PubMed]
- Han, S.; Liu, C.; Chen, K.; Gui, D.; Du, Q. A Tourist Attraction Recommendation Model Fusing Spatial, Temporal, and Visual Embeddings for Flickr-Geotagged Photos. ISPRS Int. J. Geo-Inf. 2021, 10, 20. [Google Scholar] [CrossRef]
- Mulia, W.; Chelsia, P.; Widi, B.; Rizqina, M. Discovering the Importance of Halal Tourism for Indonesian Muslim Travelers: Perceptions and Behaviors When Traveling to a Non-Muslim Destination. J. Islamic Mark. 2023, 14, 61–81. [Google Scholar]
- Wang, Y.; Huang, Y.; Yang, K.; Chen, Z.; Luo, C. Generator Fault Classification Method Based on Multi-Source Information Fusion Naive Bayes Classification Algorithm. Energies 2022, 15, 9635. [Google Scholar] [CrossRef]
- Wang, Q.; Wang, F.; Li, Z.; Jiang, P.; Ren, F.; Nie, F. Efficient Random Subspace Decision Forests with a Simple Probability Dimensionality Setting Scheme. Inform. Sci. 2023, 638, 118993. [Google Scholar] [CrossRef]
- Li, L.; Gao, Q. Researching Tourism Space in China’s Great Bay Area: Spatial Pattern, Driving Forces and Its Coupling with Economy and Population. Land 2023, 12, 1878. [Google Scholar] [CrossRef]
- Wang, H.; Chen, X.; Ge, J.; Yan, Z.; He, X.; Song, Y.; Zhou, Q. Research on the Spatiotemporal Distribution and Cultural Tourism Strategy of Modern Educational Architectural Heritage in Nanjing. Sustainability 2023, 15, 14392. [Google Scholar] [CrossRef]
- Rabbiosi, C.; Meneghello, S. Questioning Walking Tourism from a Phenomenological Perspective: Epistemological and Methodological Innovations. Humanities 2023, 12, 65. [Google Scholar] [CrossRef]


| Average Precision | Average Recall | Average Deviation of Attribute Matching Degree | Average Deviation of Route Cost | |
|---|---|---|---|---|
| POI recommendation | √ | √ | √ | |
| Route recommendation | √ | √ | √ |
| 0.0049 | 0.0267 | 0.0018 | 0.0012 | 0.0055 | 0.0296 | 0.0031 | 0.0012 | ||
| 0.0282 | 0.0153 | 0.0061 | 0.0102 | 0.0162 | 0.0248 | 0.0063 | 0.0012 | ||
| 0.0033 | 0.0241 | 0.0108 | 0.0051 | 0.0263 | 0.0131 | 0.0111 | 0.0130 | ||
| 0.0012 | 0.0083 | 0.0251 | 0.0128 | 0.0022 | 0.0112 | 0.0265 | 0.0118 | ||
| 0.0052 | 0.0071 | 0.0142 | 0.0318 | 0.0073 | 0.0054 | 0.0124 | 0.0282 | ||
| 0.0048 | 0.0223 | 0.0108 | 0.0081 | 0.0266 | 0.0096 | 0.0062 | 0.0094 | ||
| 0.0251 | 0.0135 | 0.0103 | 0.0111 | 0.0287 | 0.0120 | 0.0078 | 0.0090 | ||
| 0.0013 | 0.0058 | 0.0243 | 0.0114 |
| 0.0037 | 0.0167 | 0.0167 | 0.0167 | 0.0111 | 0.0056 | 0.0333 | 0.0028 | |
| 0.0400 | 0.0107 | 0.0107 | 0.0107 | 0.0032 | 0.0400 | 0.0160 | 0.0266 | |
| 0.0021 | 0.2003 | 0.2002 | 0.2002 | 0.0083 | 0.0125 | 0.0501 | 0.0501 | |
| 0.0167 | 0.0056 | 0.0111 | 0.0167 | 0.0037 | 0.0167 | 0.0028 | ||
| 0.0213 | 0.0799 | 0.0080 | 0.0213 | 0.0005 | 0.0213 | 0.1332 | ||
| 0.1335 | 0.0083 | 0.0250 | 0.1335 | 0.0063 | 0.1335 | 0.0334 |
| 0.0389 | 0.1838 | 0.1837 | 0.1837 | 0.0094 | 0.0367 | 0.0461 | 0.0459 | |
| 0.1225 | 0.0770 | 0.0230 | 0.1225 | 0.0062 | 0.1225 | 0.1220 |
| 6.0 | 8.1 | 6.6 | 4.2 | 5.2 | |
| 12.1 | 3.8 | 11.9 | 7.8 | 10.8 |
| S,P-1,5,6,10 | 6.0 | 5.2 | 11.9 | 10.8 | 33.9 | S,P-6,1,5,10 | 6.6 | 12.1 | 5.2 | 7.8 | 31.7 |
| S,P-1,5,10,6 | 6.0 | 5.2 | 7.8 | 10.8 | 29.8 | S,P-6,1,10,5 | 6.6 | 12.1 | 3.8 | 7.8 | 30.3 |
| S,P-1,6,5,10 | 6.0 | 12.1 | 11.9 | 7.8 | 37.8 | S,P-6,5,1,10 | 6.6 | 11.9 | 5.2 | 3.8 | 27.5 |
| S,P-1,6,10,5 | 6.0 | 12.1 | 10.8 | 7.8 | 36.7 | S,P-6,5,10,1 | 6.6 | 11.9 | 7.8 | 3.8 | 30.1 |
| S,P-1,10,5,6 | 6.0 | 3.8 | 7.8 | 11.9 | 29.5 | S,P-6,10,1,5 | 6.6 | 10.8 | 3.8 | 5.2 | 26.4 |
| S,P-1,10,6,5 | 6.0 | 3.8 | 10.8 | 11.9 | 32.5 | S,P-6,10,5,1 | 6.6 | 10.8 | 7.8 | 5.2 | 30.4 |
| S,P-5,1,6,10 | 8.1 | 5.2 | 12.1 | 10.8 | 36.2 | S,P-10,1,5,6 | 4.2 | 3.8 | 5.2 | 11.9 | 25.1 |
| S,P-5,1,10,6 | 8.1 | 5.2 | 3.8 | 10.8 | 27.9 | S,P-10,1,6,5 | 4.2 | 3.8 | 12.1 | 11.9 | 32.0 |
| S,P-5,6,1,10 | 8.1 | 11.9 | 12.1 | 3.8 | 35.9 | S,P-10,5,1,6 | 4.2 | 7.8 | 5.2 | 12.1 | 29.3 |
| S,P-5,6,10,1 | 8.1 | 11.9 | 10.8 | 3.8 | 34.6 | S,P-10,5,6,1 | 4.2 | 7.8 | 11.9 | 12.1 | 36.0 |
| S,P-5,10,1,6 | 8.1 | 7.8 | 3.8 | 12.1 | 31.8 | S,P-10,6,1,5 | 4.2 | 10.8 | 12.1 | 5.2 | 32.3 |
| S,P-5,10,6,1 | 8.1 | 7.8 | 10.8 | 12.1 | 38.8 | S,P-10,6,5,1 | 4.2 | 10.8 | 11.9 | 5.2 | 32.1 |
| GDM | |||||
| 6.2 | 8.6 | 6.7 | 4.4 | 5.7 | |
| 12.1 | 3.9 | 12.3 | 8.7 | 10.9 | |
| 360M | |||||
| 6.5 | 9.1 | 6.8 | 4.6 | 6.6 | |
| 12.7 | 4.0 | 12.8 | 9.4 | 11.3 |
| PRA | ||||||
| S,P-10,1,5,6 | 4.2 | 3.8 | 5.2 | 11.9 | 25.1 | |
| S,P-6,10,1,5 | 6.6 | 10.8 | 3.8 | 5.2 | 26.4 | |
| S,P-6,5,1,10 | 6.6 | 11.9 | 5.2 | 3.8 | 27.5 | |
| GDM | ||||||
| S,P-10,1,5,6 | 4.4 | 3.9 | 5.7 | 12.3 | 26.3 | |
| S,P-6,10,1,5 | 6.7 | 10.9 | 3.9 | 5.7 | 27.2 | |
| S,P-6,5,1,10 | 6.7 | 12.3 | 5.7 | 3.9 | 28.6 | |
| 360M | ||||||
| S,P-10,1,5,6 | 4.6 | 4 | 6.6 | 12.8 | 28 | |
| S,P-6,10,1,5 | 6.8 | 11.3 | 4 | 6.6 | 28.7 | |
| S,P-6,5,1,10 | 6.8 | 12.8 | 6.6 | 4 | 30.2 |
| S,P-10,1,5,6 | GDM-PRA | 0.2 | 0.1 | 0.5 | 0.4 | 1.2 | 4.56% |
| 360M-PRA | 0.4 | 0.2 | 1.4 | 0.9 | 2.9 | 10.36% | |
| S,P-6,10,1,5 | GDM-PRA | 0.1 | 0.1 | 0.1 | 0.5 | 0.8 | 2.94% |
| 360M-PRA | 0.2 | 0.5 | 0.2 | 1.4 | 2.3 | 8.01% | |
| S,P-6,5,1,10 | GDM-PRA | 0.1 | 0.4 | 0.5 | 0.1 | 1.1 | 3.85% |
| 360M-PRA | 0.2 | 0.9 | 1.4 | 0.2 | 2.7 | 8.94% |
| PRA | 0.5357 | 0.1429 | 1.0116 |
| IBCF | 0.3929 | 0.1048 | 1.8235 |
| UBCF | 0.3214 | 0.0857 | 2.0720 |
| PRA | 0.7500 | 0.1250 | 6.2714 |
| GDM | 0.5000 | 0.0833 | 9.0000 |
| 360M | 0.3214 | 0.0536 | 10.7643 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Zhou, X.; Peng, J.; Wen, B.; Su, M. Tour Route Recommendation Model by the Improved Symmetry-Based Naive Bayes Mining and Spatial Decision Forest Search. Symmetry 2023, 15, 2168. https://doi.org/10.3390/sym15122168
Zhou X, Peng J, Wen B, Su M. Tour Route Recommendation Model by the Improved Symmetry-Based Naive Bayes Mining and Spatial Decision Forest Search. Symmetry. 2023; 15(12):2168. https://doi.org/10.3390/sym15122168
Chicago/Turabian StyleZhou, Xiao, Jian Peng, Bowei Wen, and Mingzhan Su. 2023. "Tour Route Recommendation Model by the Improved Symmetry-Based Naive Bayes Mining and Spatial Decision Forest Search" Symmetry 15, no. 12: 2168. https://doi.org/10.3390/sym15122168
APA StyleZhou, X., Peng, J., Wen, B., & Su, M. (2023). Tour Route Recommendation Model by the Improved Symmetry-Based Naive Bayes Mining and Spatial Decision Forest Search. Symmetry, 15(12), 2168. https://doi.org/10.3390/sym15122168