
Transformer with Hybrid Attention Mechanism for Stereo Endoscopic Video Super Resolution

Abstract
:1. Introduction
2. Related Works
2.1. Single Image SR
2.2. Stereo Image SR
2.3. Video SR
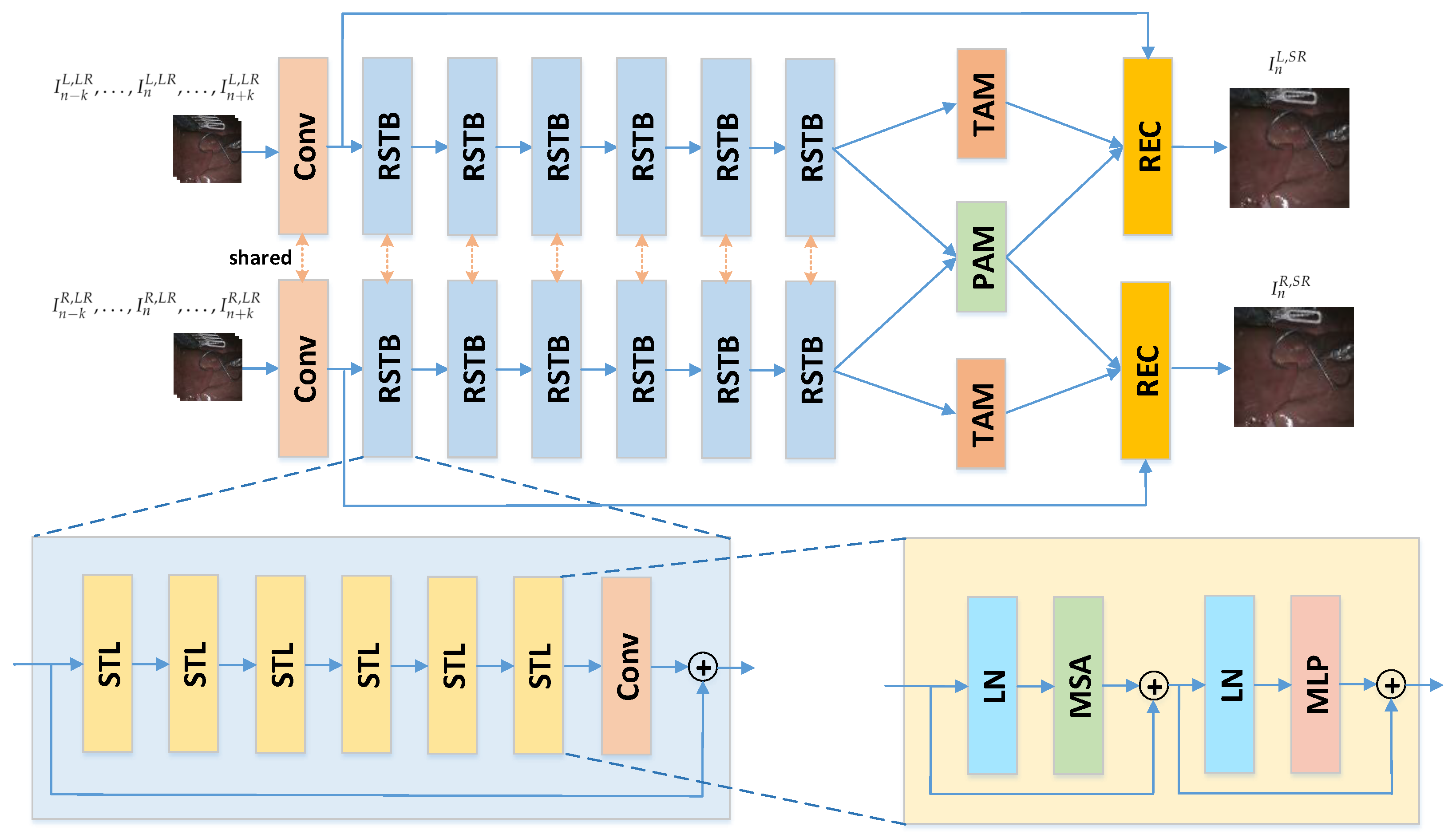
3. Methods
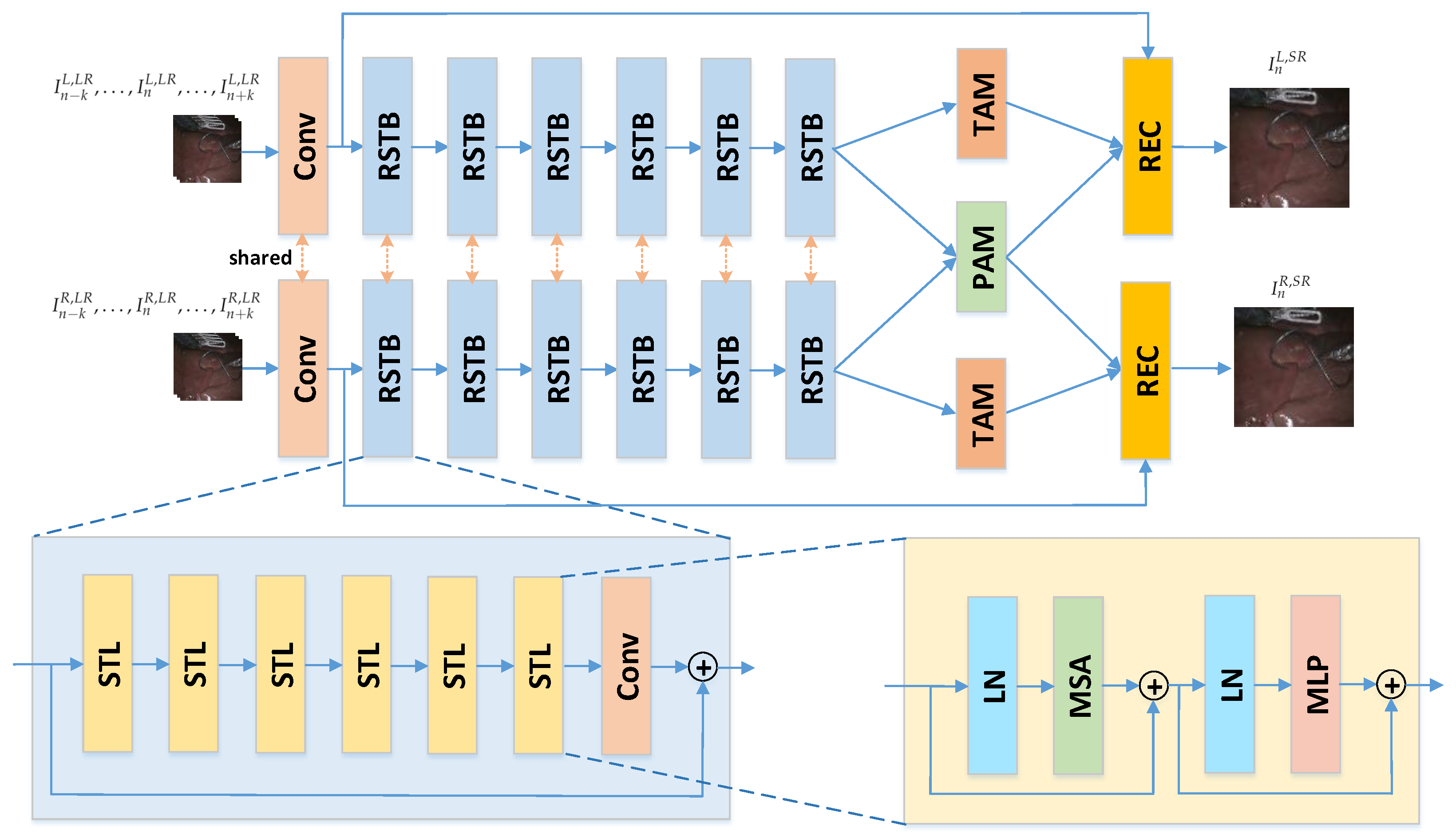
3.1. Network Architecture
3.2. Residual Swin Transformer Block
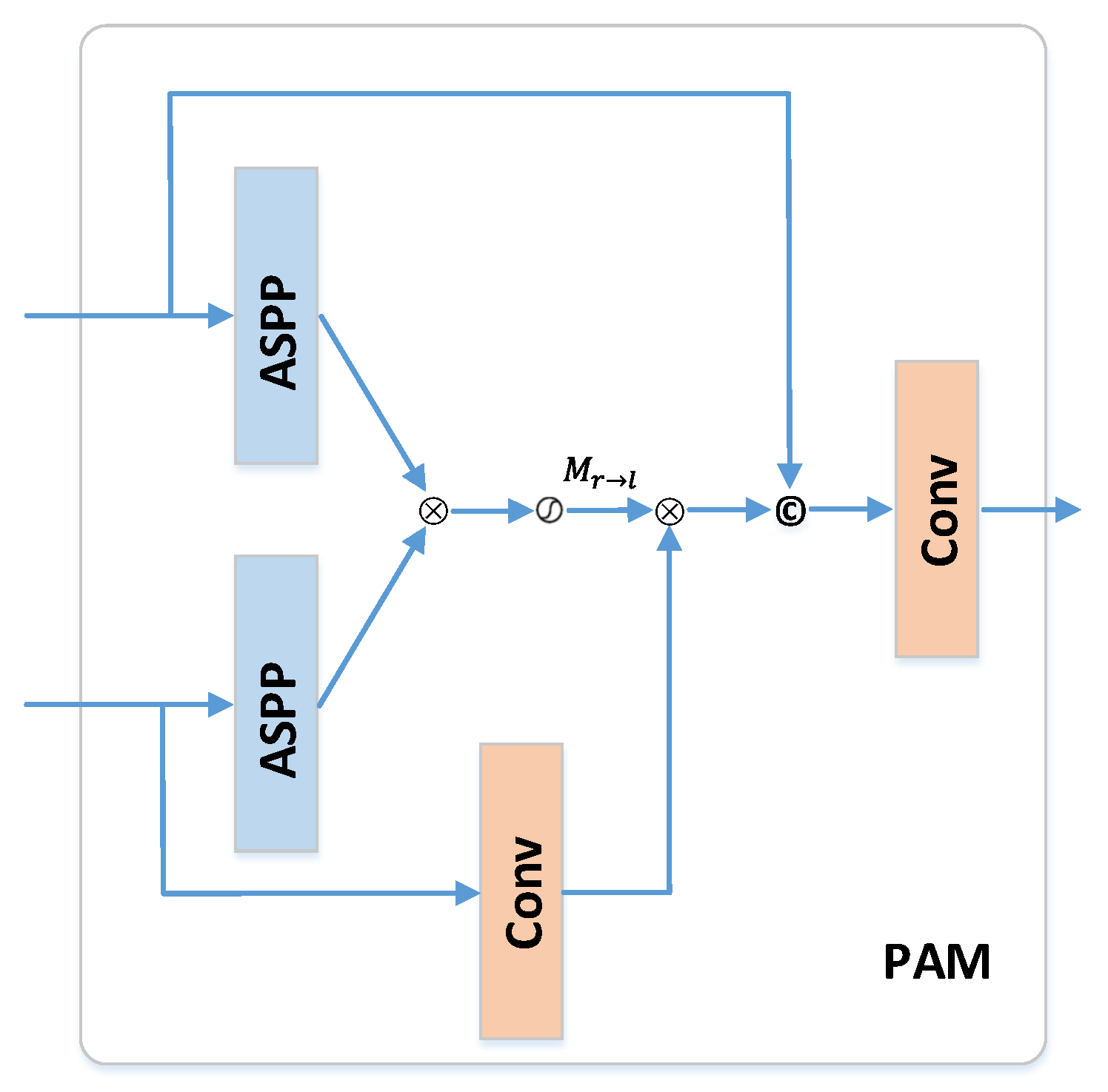
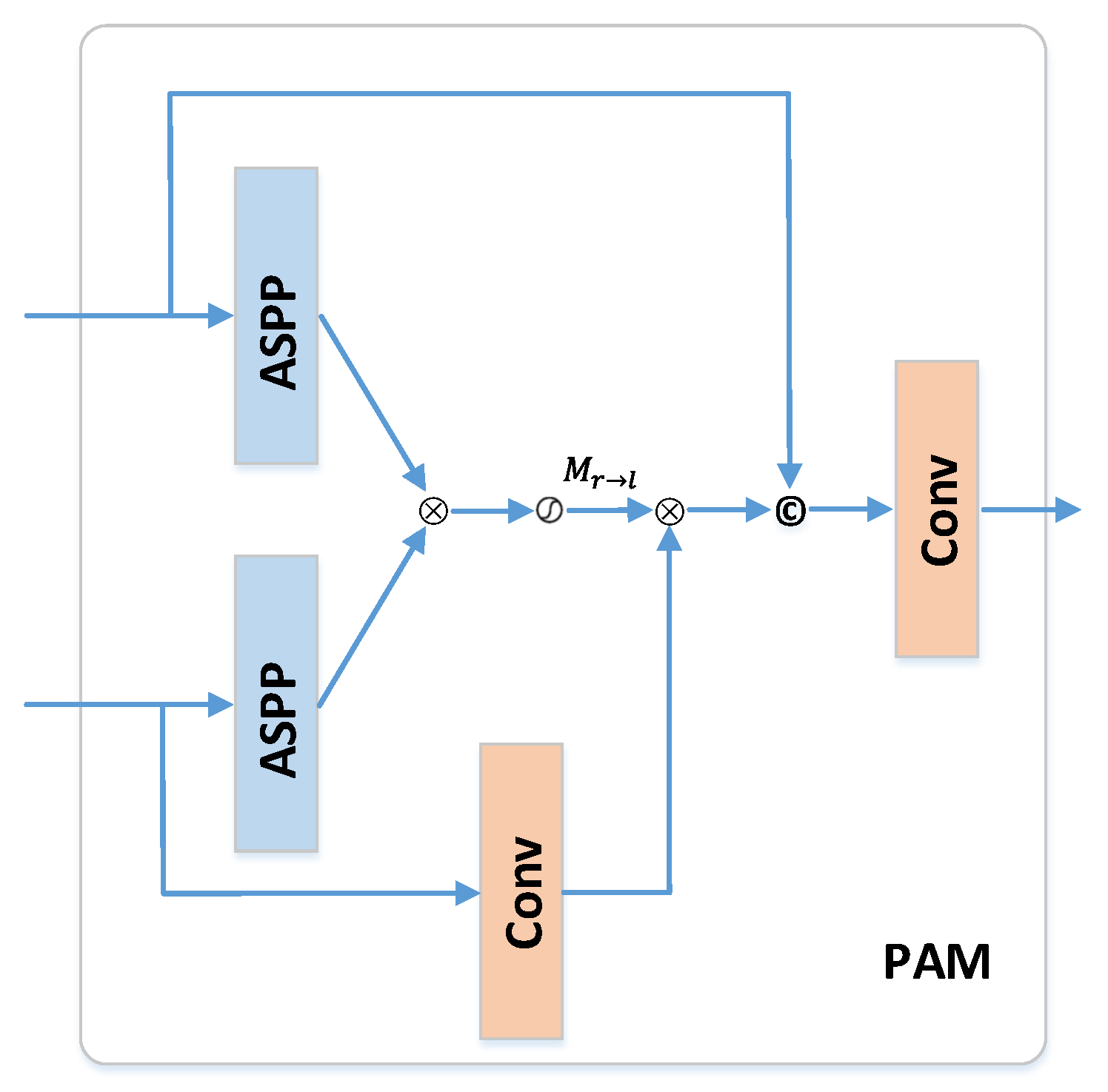
3.3. Parallel Attention Module
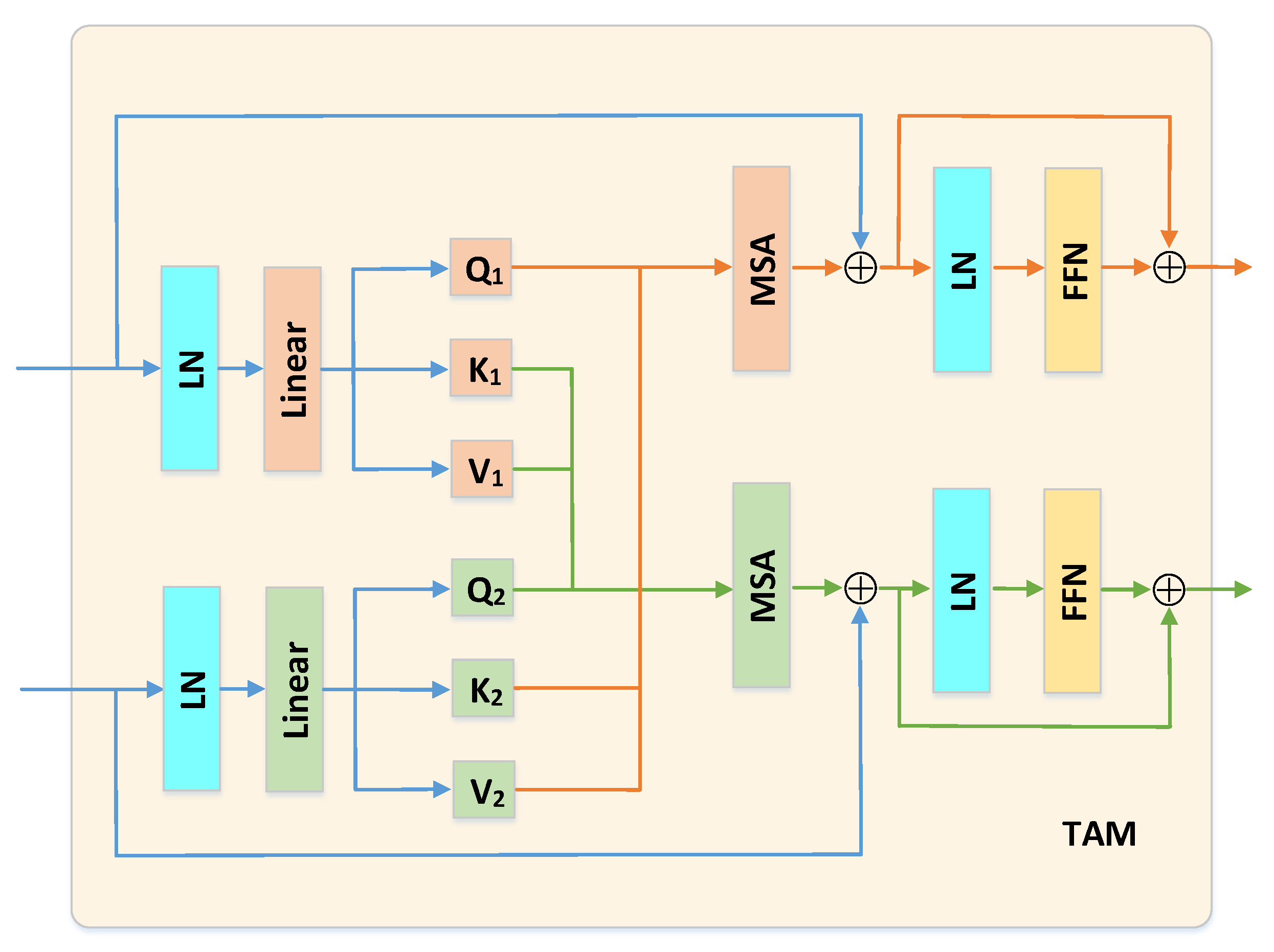
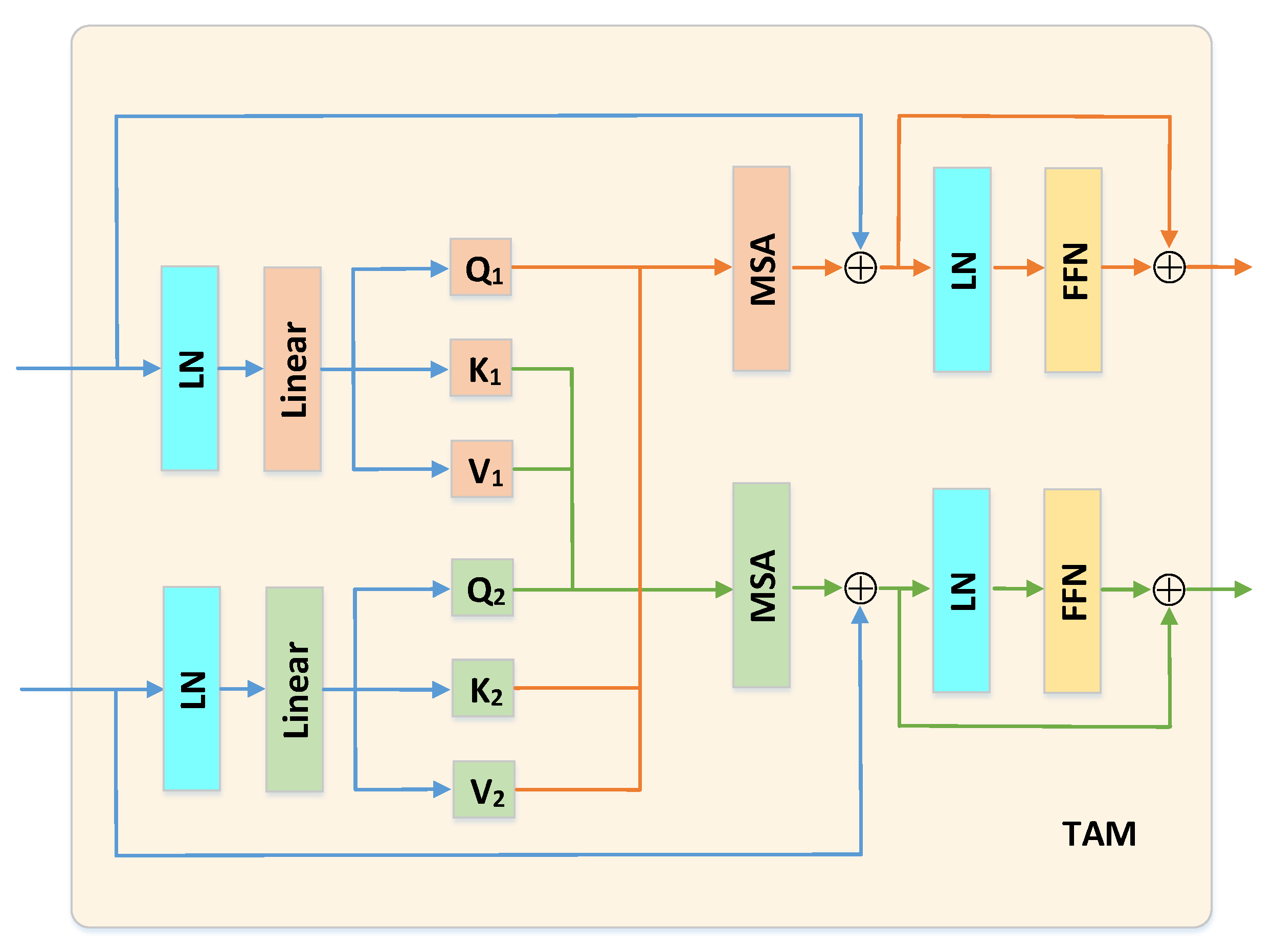
3.4. Temporal Attention Module
3.5. Loss Function
4. Experiments
4.1. Experimental Settings
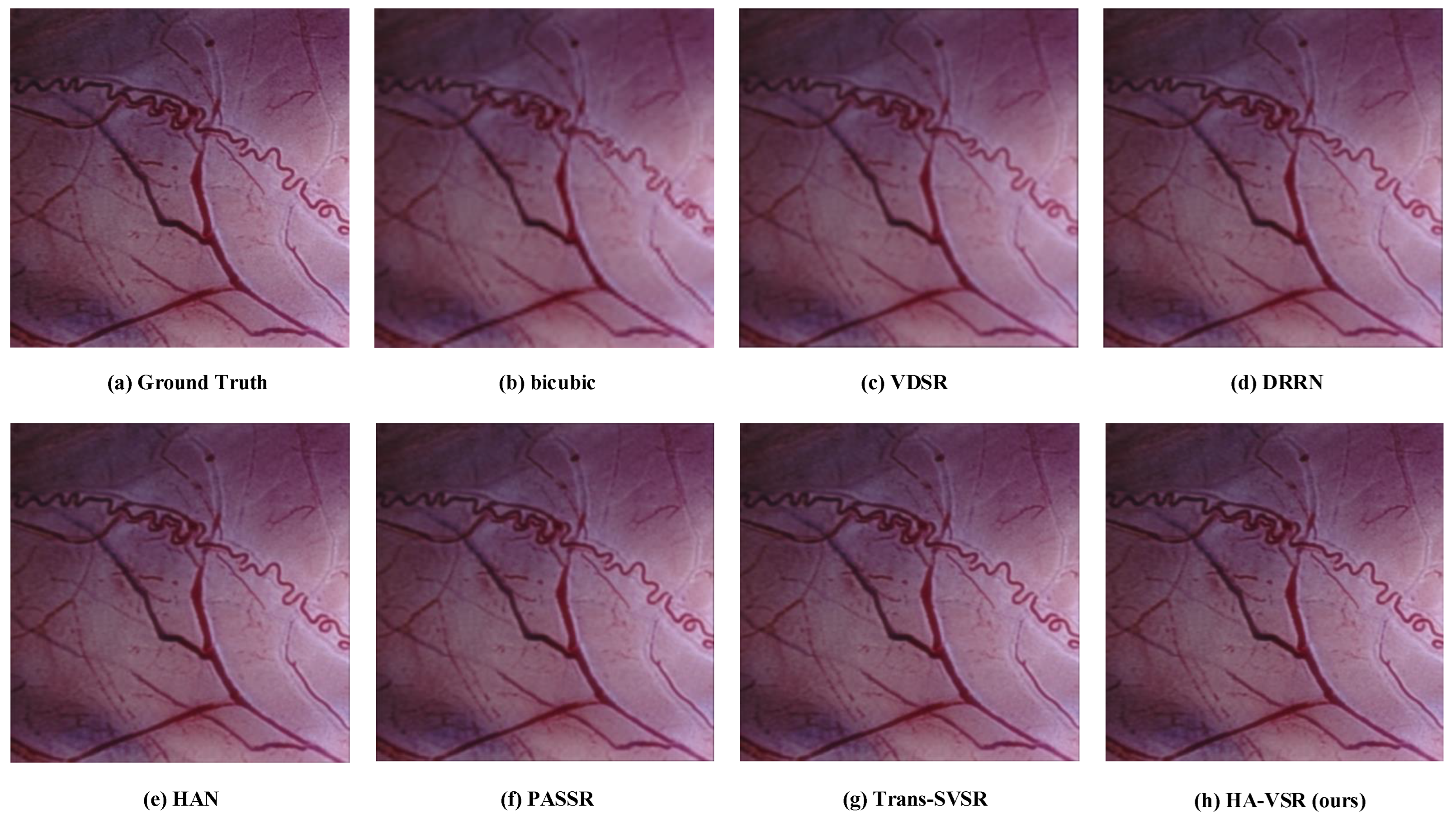
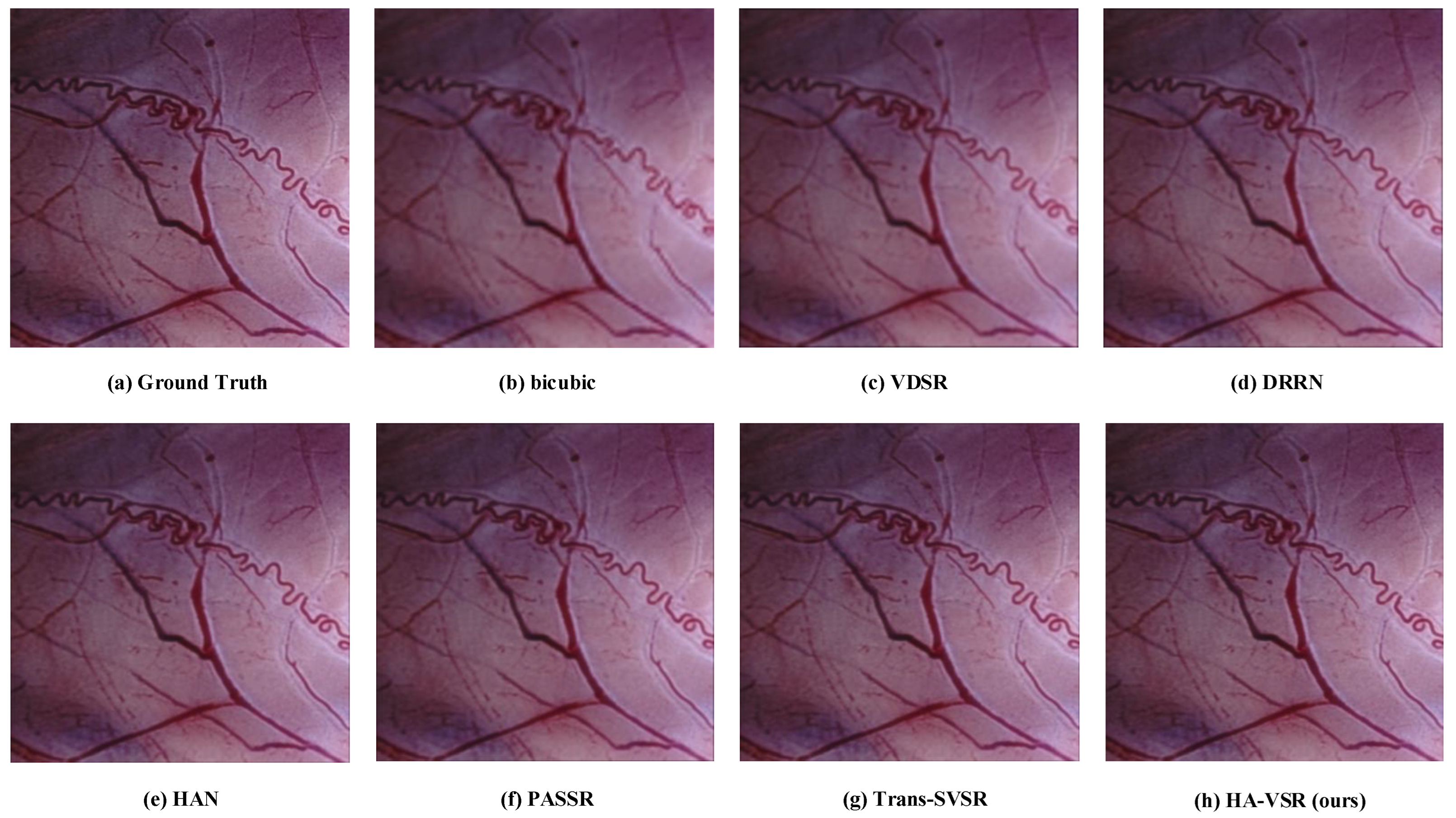
4.2. Evaluation Results
4.3. Ablation Analysis
- Network without residual connection: The residual connection provides the SR result with low-frequency information. As Table 2 shows, the network without residual connections suffers an average decrease of ∼0.15 dB in PSNR.
- Network without the PAM module: The PAM module makes use of the stereo relationship on epipolar lines. The performance of the network without PAM module suffers an average decrease of ∼0.09 dB in PSNR on a da Vinci dataset and ∼0.12 dB on a SCARED dataset.
- Network without the TAM module: From the comparative results shown in Table 2, the SR performance benefits from the TAM module on both datasets.
- The network without both PAM and TAM: If both the PAM and TAM modules are removed from the network, the PSNR value suffers an average decrease of ∼0.2 dB on the da Vinci dataset.
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Peters, B.S.; Armijo, P.R.; Krause, C.; Choudhury, S.A.; Oleynikov, D. Review of emerging surgical robotic technology. Surg. Endosc. 2018, 32, 1636–1655. [Google Scholar] [CrossRef] [PubMed]
- Mueller-Richter, U.D.A.; Limberger, A.; Weber, P.; Ruprecht, K.W.; Spitzer, W.; Schilling, M. Possibilities and limitations of current stereo-endoscopy. Surg. Endosc. 2004, 18, 942–947. [Google Scholar] [CrossRef] [PubMed]
- Park, J.; Hwang, Y.; Yoon, J.H.; Park, M.G.; Kim, J.; Lim, Y.J.; Chun, H.J. Recent development of computer vision technology to improve capsule endoscopy. Clin. Endosc. 2019, 52, 328–333. [Google Scholar] [CrossRef] [PubMed]
- Wang, C.C.; Chiu, Y.C.; Chen, W.L.; Yang, T.W.; Tsai, M.C.; Tseng, M.H. A deep learning model for classification of endoscopic gastroesophageal reflux disease. Int. J. Environ. Res. Public Health 2021, 18, 2428. [Google Scholar] [CrossRef] [PubMed]
- Ali, S.; Dmitrieva, M.; Ghatwary, N.; Bano, S.; Polat, G.; Temizel, A.; Krenzer, A.; Hekalo, A.; Guo, Y.B.; Matuszewski, B.; et al. Deep learning for detection and segmentation of artefact and disease instances in gastrointestinal endoscopy. Med. Image Anal. 2021, 70, 102002. [Google Scholar] [CrossRef] [PubMed]
- Zhou, F.; Yang, W.; Liao, Q. Interpolation-based image super-resolution using multisurface fitting. IEEE Trans. Image Process. 2012, 21, 3312–3318. [Google Scholar] [CrossRef] [PubMed]
- Yang, J.; Wright, J.; Huang, T.S.; Ma, Y. Image super-resolution via sparse representation. IEEE Trans. Image Process. 2010, 19, 2861–2873. [Google Scholar] [CrossRef] [PubMed]
- Dong, C.; Loy, C.C.; Tang, X. Accelerating the super-resolution convolutional neural network. In Proceedings of the Computer Vision–ECCV 2016: 14th European Conference, Amsterdam, The Netherlands, 11–14 October 2016; pp. 391–407. [Google Scholar]
- Kim, J.; Lee, J.K.; Lee, K.M. Accurate image super-resolution using very deep convolutional networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 26 June–1 July 2016; pp. 1646–1654. [Google Scholar]
- Tai, Y.; Yang, J.; Liu, X. Image super-resolution via deep recursive residual network. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 3147–3155. [Google Scholar]
- Zhang, Y.; Li, K.; Li, K.; Wang, L.; Zhong, B.; Fu, Y. Image super-resolution using very deep residual channel attention networks. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 286–301. [Google Scholar]
- Niu, B.; Wen, W.; Ren, W.; Zhang, X.; Yang, L.; Wang, S.; Zhang, X.; Cao, K.; Shen, H. Single image super-resolution via a holistic attention network. In Proceedings of the Computer Vision—ECCV 2020: 16th European Conference, Glasgow, UK, 23–28 August 2020; Part XII 16. pp. 191–207. [Google Scholar]
- Bhavsar, A.V.; Rajagopalan, A.N. Resolution enhancement in multi-image stereo. IEee Trans. Pattern Anal. Mach. Intell. 2010, 32, 1721–1728. [Google Scholar] [CrossRef] [PubMed]
- Jeon, D.S.; Baek, S.H.; Choi, I.; Kim, M.H. Enhancing the spatial resolution of stereo images using a parallax prior. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 1721–1730. [Google Scholar]
- Wang, L.; Wang, Y.; Liang, Z.; Lin, Z.; Yang, J.; An, W.; Guo, Y. Learning parallax attention for stereo image super-resolution. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 12250–12259. [Google Scholar]
- Ying, X.; Wang, Y.; Wang, L.; Sheng, W.; An, W.; Guo, Y. A stereo attention module for stereo image super-resolution. IEEE Signal Process. Lett. 2020, 27, 496–500. [Google Scholar] [CrossRef]
- Chan, K.C.; Zhou, S.; Xu, X.; Loy, C.C. BasicVSR++: Improving video super-resolution with enhanced propagation and alignment. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 18–24 June 2022; pp. 5972–5981. [Google Scholar]
- Wang, Y.; Isobe, T.; Jia, X.; Tao, X.; Lu, H.; Tai, Y.W. Compression-Aware Video Super-Resolution. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Vancouver, BC, Canada, 18–22 June 2023; pp. 2012–2021. [Google Scholar]
- Lu, Y.; Wang, Z.; Liu, M.; Wang, H.; Wang, L. Learning Spatial-Temporal Implicit Neural Representations for Event-Guided Video Super-Resolution. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Vancouver, BC, Canada, 18–22 June 2023; pp. 1557–1567. [Google Scholar]
- Li, G.; Ji, J.; Qin, M.; Niu, W.; Ren, B.; Afghah, F.; Guo, L.; Ma, X. Towards High-Quality and Efficient Video Super-Resolution via Spatial-Temporal Data Overfitting. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Vancouver, BC, Canada, 18–22 June 2023.
- Xia, B.; He, J.; Zhang, Y.; Wang, Y.; Tian, Y.; Yang, W.; Van Gool, L. Structured sparsity learning for efficient video super-resolution. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Vancouver, BC, Canada, 18–22 June 2023; pp. 22638–22647. [Google Scholar]
- Tu, Z.; Li, H.; Xie, W.; Liu, Y.; Zhang, S.; Li, B.; Yuan, J. Optical flow for video super-resolution: A survey. Artif. Intell. Rev. 2022, 55, 6505–6546. [Google Scholar] [CrossRef]
- Imani, H.; Islam, M.B.; Wong, L.K. A new dataset and transformer for stereoscopic video super-resolution. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 18–24 June 2022; pp. 706–715. [Google Scholar]
- Han, K.; Xiao, A.; Wu, E.; Guo, J.; Xu, C.; Wang, Y. transformer in transformer. Adv. Neural Inf. Process. Syst. 2021, 34, 15908–15919. [Google Scholar]
- Xu, Y.; Wei, H.; Lin, M.; Deng, Y.; Sheng, K.; Zhang, M.; Tang, F.; Dong, W.; Huang, F.; Xu, C. transformers in computational visual media: A survey. Comput. Vis. Media 2022, 8, 33–62. [Google Scholar] [CrossRef]
- Liu, Y.; Zhang, Y.; Wang, Y.; Hou, F.; Yuan, J.; Tian, J.; Zhang, Y.; Shi, Z.; Fan, J.; He, Z. A survey of visual transformers. IEEE Trans. Neural Netw. Learn. Syst. 2023. [Google Scholar] [CrossRef] [PubMed]
- Liu, Z.; Lin, Y.; Cao, Y.; Hu, H.; Wei, Y.; Zhang, Z.; Lin, S.; Guo, B. Swin transformer: Hierarchical vision transformer using shifted windows. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Montreal, QC, Canada, 11–17 October 2021; pp. 10012–10022. [Google Scholar]
- Liang, J.; Cao, J.; Sun, G.; Zhang, K.; Van Gool, L.; Timofte, R. Swinir: Image restoration using swin transformer. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Montreal, QC, Canada, 11–17 October 2021; pp. 1833–1844. [Google Scholar]
- Ying, X.; Wang, L.; Wang, Y.; Sheng, W.; An, W.; Guo, Y. Deformable 3D convolution for video super-resolution. IEEE Signal Process. Lett. 2020, 27, 1500–1504. [Google Scholar] [CrossRef]
- Zhang, T.; Gu, Y.; Huang, X.; Yang, J.; Yang, G.Z. Disparity-constrained stereo endoscopic image super-resolution. Int. J. Comput. Assist. Radiol. Surg. 2022, 17, 867–875. [Google Scholar] [CrossRef] [PubMed]
- Allan, M.; Mcleod, J.; Wang, C.; Rosenthal, J.C.; Hu, Z.; Gard, N.; Eisert, P.; Fu, K.X.; Zeffiro, T.; Xia, W.; et al. Stereo correspondence and reconstruction of endoscopic data challenge. arXiv 2021, arXiv:2101.01133. [Google Scholar]


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Method | Scale | da Vinci | SCARED |
|---|---|---|---|
| bicubic | 35.6629/0.9645 | 38.6021/0.9792 | |
| VDSR | 37.1054/0.9681 | 39.5793/0.9824 | |
| DRRN | 37.9829/0.9733 | 40.1844/0.9858 | |
| HAN | 38.2513/0.9765 | 40.6208/0.9869 | |
| PASSR | 37.6501/0.9714 | 40.3617/0.9860 | |
| Trans-SVSR | 38.2165/0.9767 | 40.7365/0.9875 | |
| HA-VSR (proposed) | 38.3702/0.9771 | 40.8019/0.9870 | |
| bicubic | 30.0670/0.9358 | 32.8524/0.9480 | |
| VDSR | 31.1425/0.9410 | 33.3527/0.9516 | |
| DRRN | 31.6728/0.9428 | 34.0189/0.9558 | |
| HAN | 31.7459/0.9433 | 34.5003/0.9569 | |
| PASSR | 31.4637/0.9415 | 34.1275/0.9547 | |
| Trans-SVSR | 31.8952/0.9469 | 34.6870/0.9573 | |
| HA-VSR (proposed) | 32.0321/0.9477 | 34.7903/0.9576 |
| Method | Scale | da Vinci | SCARED |
|---|---|---|---|
| HA-VSR | 38.3702/0.9771 | 40.8019/0.9870 | |
| w/o res connection | 38.0164/0.9748 | 40.5362/0.9851 | |
| w/o PAM | 38.2835/0.9764 | 40.6838/0.9859 | |
| w/o TAM | 38.2459/0.9769 | 40.7129/0.9862 | |
| w/o PAM and TAM | 38.1221/0.9764 | 40.6540/0.9856 | |
| HA-VSR | 32.0321/0.9477 | 34.7903/0.9576 | |
| w/o res connection | 31.8971/0.9452 | 34.5219/0.9566 | |
| w/o PAM | 31.9805/0.9473 | 34.6961/0.9573 | |
| w/o TAM | 31.9738/0.9474 | 34.7259/0.9575 | |
| w/o PAM and TAM | 31.9457/0.9473 | 34.6472/0.9570 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Zhang, T.; Yang, J. Transformer with Hybrid Attention Mechanism for Stereo Endoscopic Video Super Resolution. Symmetry 2023, 15, 1947. https://doi.org/10.3390/sym15101947
Zhang T, Yang J. Transformer with Hybrid Attention Mechanism for Stereo Endoscopic Video Super Resolution. Symmetry. 2023; 15(10):1947. https://doi.org/10.3390/sym15101947
Chicago/Turabian StyleZhang, Tianyi, and Jie Yang. 2023. "Transformer with Hybrid Attention Mechanism for Stereo Endoscopic Video Super Resolution" Symmetry 15, no. 10: 1947. https://doi.org/10.3390/sym15101947
APA StyleZhang, T., & Yang, J. (2023). Transformer with Hybrid Attention Mechanism for Stereo Endoscopic Video Super Resolution. Symmetry, 15(10), 1947. https://doi.org/10.3390/sym15101947