
Cryptanalysis of Reversible Data Hiding in Encrypted Images Based on the VQ Attack




Abstract
1. Introduction
- VQA: The vector quantization technique is used for the first time to estimate the plaintext of each encrypted image block.
- Direct cracking: Unlike the existing KPA algorithm [33], the cryptanalysis algorithm proposed in this paper does not require the assistance of the plaintext image when cracking the plaintext content of encrypted images.
2. Preliminary Work
2.1. Analysis of BPCM Encryption
- Large encryption space. In theory, two keys of the BPCM encryption can bring different encryption results. Taking a greyscale image () as an example, when the size of the block is pixels, there are encryption results, which is much greater than . Thus, with the current level of computer hardware, it is difficult to break BPCM encryption using exhaustive brute-force attacks.
- Increasing the embedding capacity. Although the BPCM algorithm changes the pixel values in each block, it does not destroy the correlation among the pixels inside the block. Thus, BPCM-based RDHEI schemes [29,30] can take the advantage of this characteristic to create redundant space and embed secret data. In BPCM-based schemes, the block size is usually set to in order to maintain a balance between the embedding capacity and the security. The embedding rate of such schemes can usually reach more than 2.5 bpp.
- The permutation sequence of BPCM is generated by a random permutation generator and a secret key . The receiver must use the same generator as the content owner when decrypting the image; therefore, the generator must be transmitted from the content owner to the receiver, which gives the attacker the possibility of stealing the generator. Once the attacker has obtained the generator, he can obtain the permutation sequence by exhaustively trying the secret key.
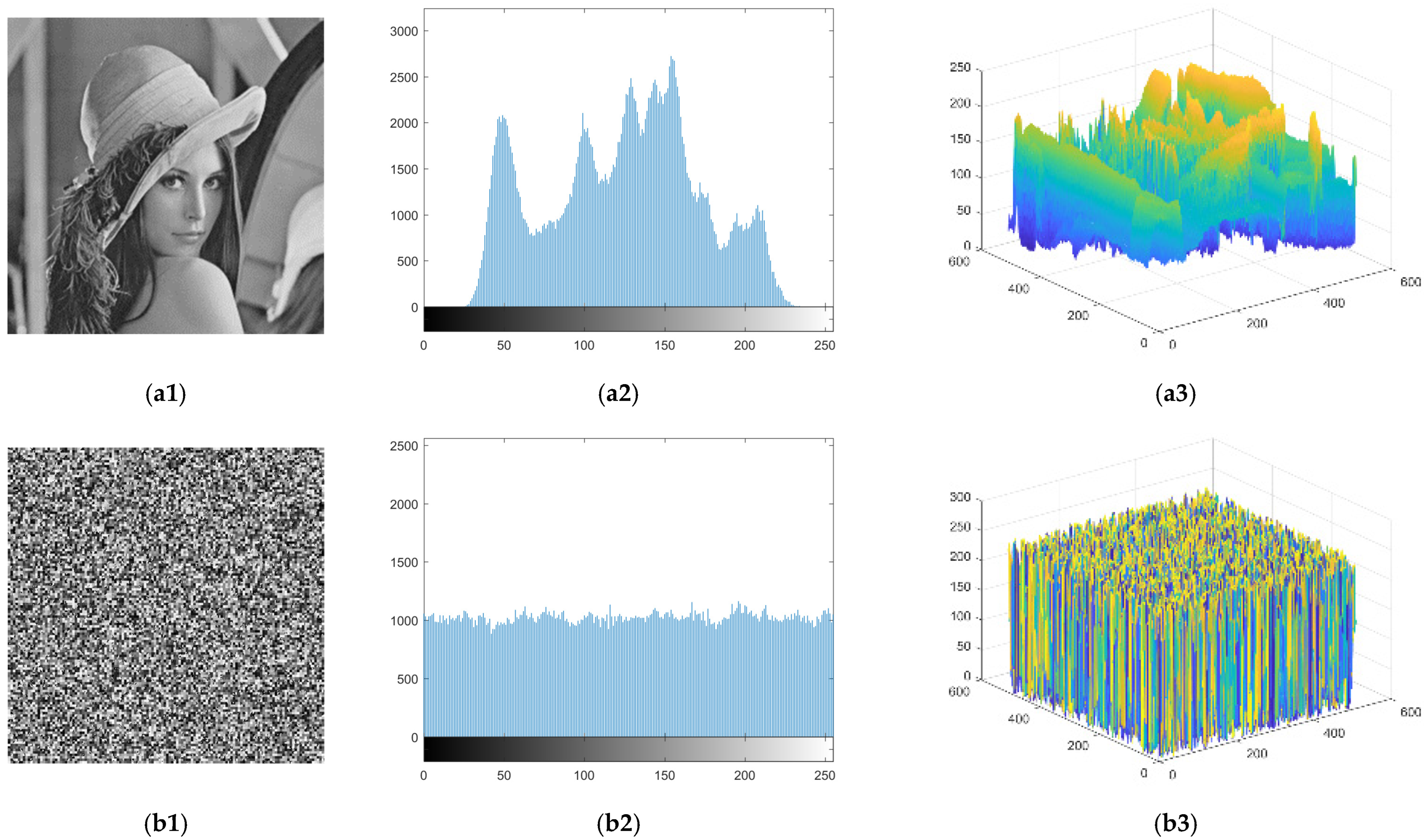
- The correlation of the pixels within most blocks remains unchanged, and the attacker can use these correlations to estimate the plaintext content of the block.
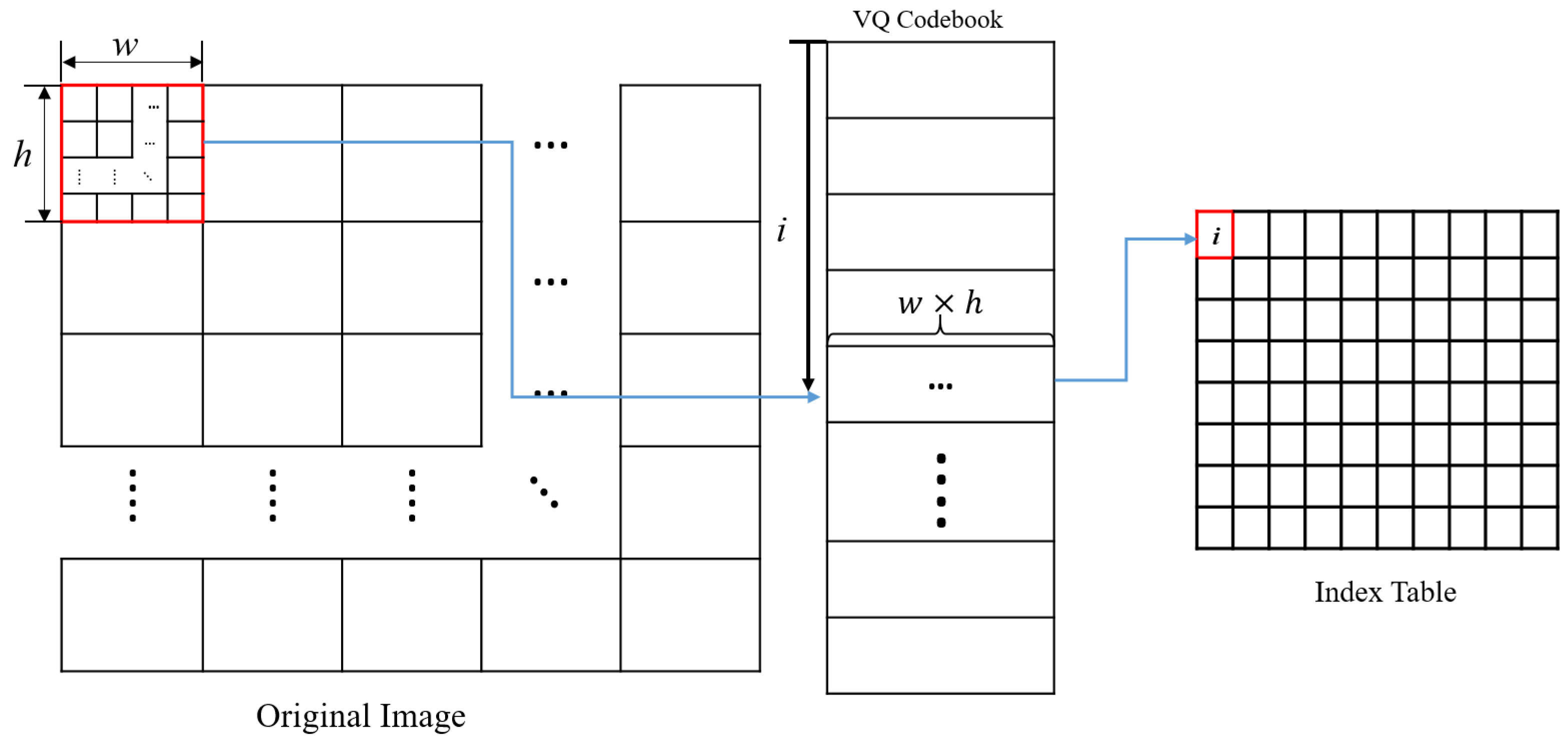
2.2. Vector Quantization
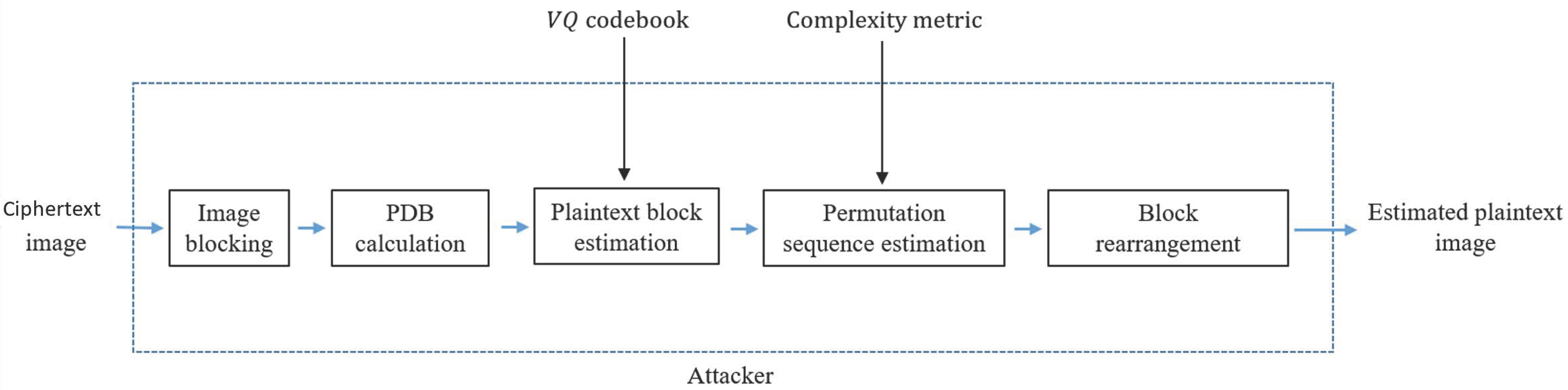
3. Proposed Cryptanalysis Based on the VQA
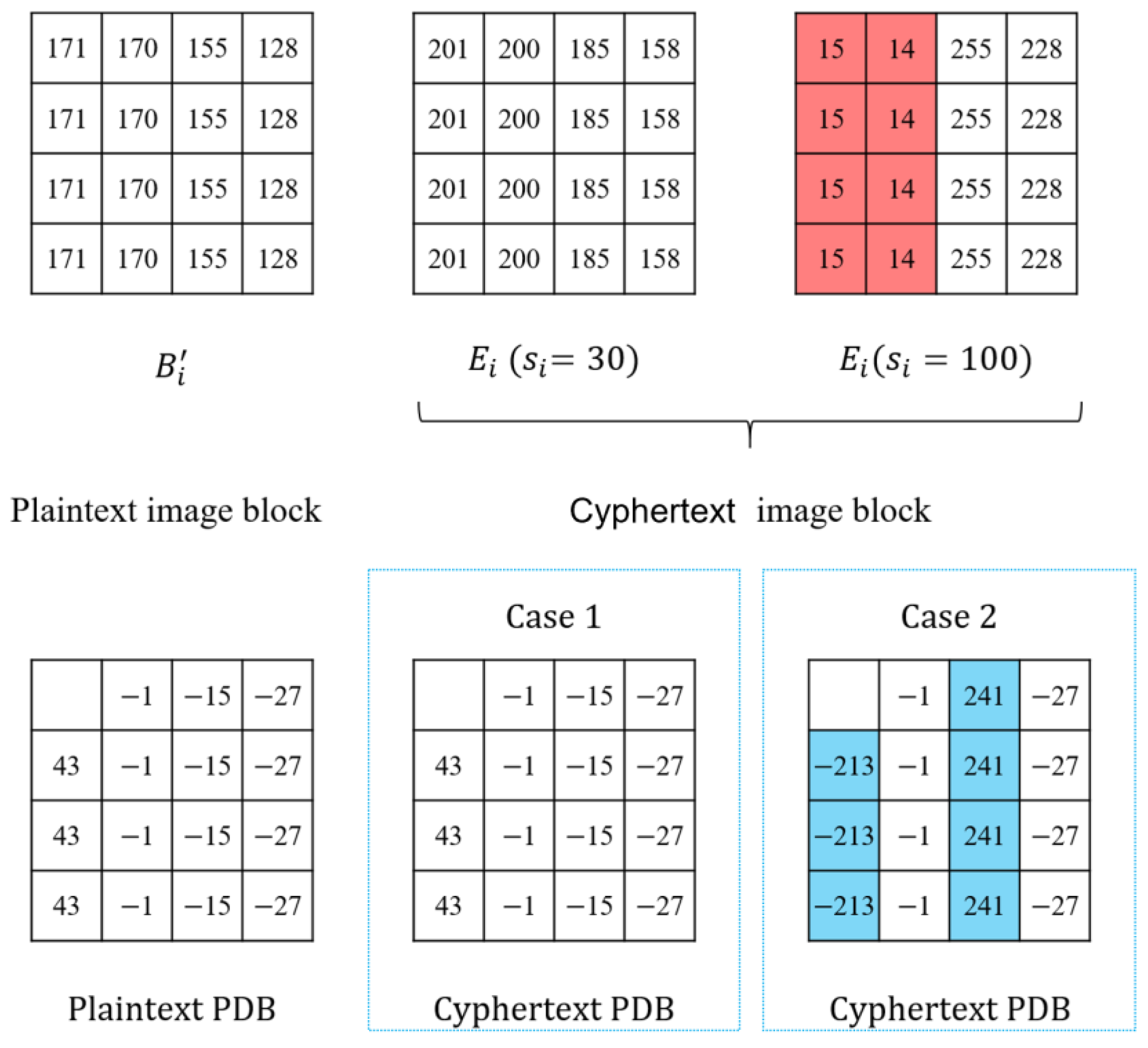
3.1. Pixel Difference Block
3.2. Plaintext Block Estimation Based on the VQ Attack
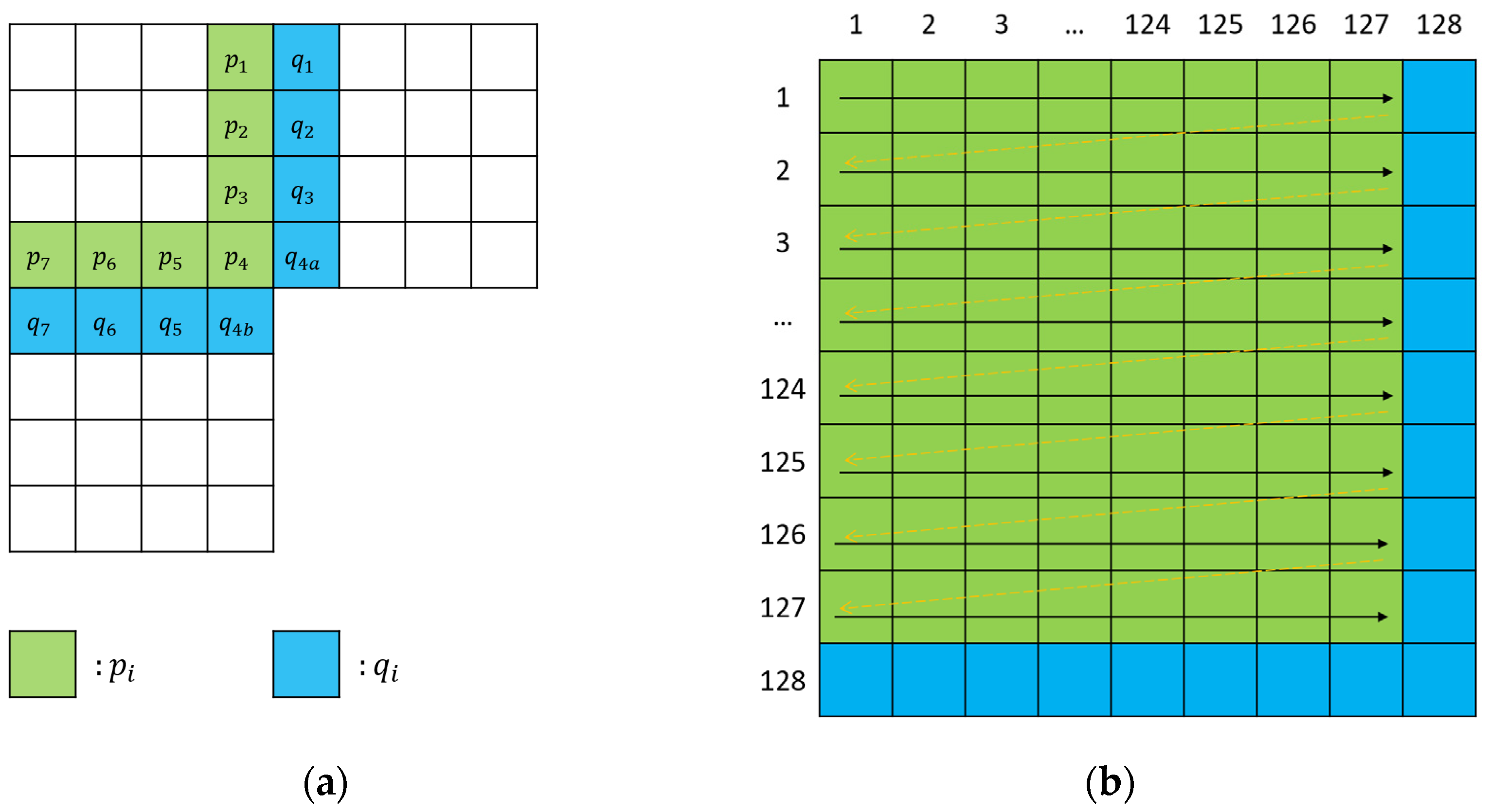
3.3. Block Permutation Sequence Estimation
4. Experimental Results
4.1. Analysis of the PDBs of Ciphertext Image
4.2. Analysis of the Estimation of the Plaintext Block
4.3. Analysis of the Estimation of Permutation Sequence
4.4. Characteristics Analysis
5. Limitations
6. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Gharehpasha, S.; Masdari, M.; Jafarian, A. Power efficient virtual machine placement in cloud data centers with a discrete and chaotic hybrid optimization algorithm. Clust. Comput. 2021, 24, 1293–1315. [Google Scholar] [CrossRef]
- Gharehpasha, S.; Masdari, M.; Jafarian, A. Virtual machine placement in cloud data centers using a hybrid multi-verse optimization algorithm. Artif. Intell. Rev. 2021, 54, 2221–2257. [Google Scholar] [CrossRef]
- Zhang, W.; Wang, H.; Hou, D.; Yu, N. Reversible data hiding in encrypted images by reversible image transformation. IEEE Trans. Multimed. 2016, 18, 1469–1479. [Google Scholar] [CrossRef]
- Zhang, W.M.; Ma, K.; Yu, N. Reversibility improved data hiding in encrypted images. Signal Process. 2014, 94, 118–127. [Google Scholar] [CrossRef]
- Cao, X.C.; Du, L.; Wei, X.X.; Meng, D.; Guo, X.J. High capacity reversible data hiding in encrypted images by patch-level sparse representation. IEEE Trans. Cybern. 2015, 46, 1132–1143. [Google Scholar] [CrossRef] [PubMed]
- Yi, S.; Zhou, Y.C. Binary-block embedding for reversible data hiding in encrypted images. Signal Process. 2017, 133, 40–51. [Google Scholar] [CrossRef]
- Qiu, Y.Q.; Qian, Z.; Zeng, H.; Lin, X.; Zhang, X. Reversible data hiding in encrypted images using adaptive reversible integer transformation. Signal Process. 2020, 167, 107288. [Google Scholar] [CrossRef]
- Zhang, X.P. Reversible data hiding in encrypted image. IEEE Signal Process. Lett. 2011, 18, 255–258. [Google Scholar] [CrossRef]
- Hong, W.; Chen, T.-S.; Wu, H.-Y. An improved reversible data hiding in encrypted images using side match. IEEE Signal Process. Lett. 2012, 19, 199–202. [Google Scholar] [CrossRef]
- Zhang, X.P. Separable reversible data hiding in encrypted image. IEEE Trans. Inf. Forensics Secur. 2011, 7, 826–832. [Google Scholar] [CrossRef]
- Wu, X.; Sun, W. High-capacity reversible data hiding in encrypted images by prediction error. Signal Process. 2014, 104, 387–400. [Google Scholar] [CrossRef]
- Qin, C.; Zhang, X. Effective reversible data hiding in encrypted image with privacy protection for image content. J. Vis. Commun. Image Represent. 2015, 31, 154–164. [Google Scholar] [CrossRef]
- Qian, Z.; Zhang, X. Reversible data hiding in encrypted images with distributed source encoding. IEEE Trans. Circuits Syst. Video Technol. 2015, 26, 636–646. [Google Scholar] [CrossRef]
- Huang, F.; Huang, J.; Shi, Y.-Q. New framework for reversible data hiding in encrypted domain. IEEE Trans. Inf. Forensics Secur. 2016, 11, 2777–2789. [Google Scholar] [CrossRef]
- Ge, H.; Chen, Y.; Qian, Z.; Wang, J. A high capacity multi-level approach for reversible data hiding in encrypted images. IEEE Trans. Circuits Syst. Video Technol. 2019, 29, 2285–2295. [Google Scholar] [CrossRef]
- Chen, K.-M. High capacity reversible data hiding based on the compression of pixel Differences. Mathematics 2020, 8, 1435. [Google Scholar] [CrossRef]
- Wang, Y.M.; He, W.G. High capacity reversible data hiding in encrypted image based on adaptive MSB prediction. IEEE Trans. Multimed. 2021, 24, 1288–1298. [Google Scholar] [CrossRef]
- Fu, Y.J.; Kong, P.; Yao, H.; Tang, Z.J.; Qin, C. Effective reversible data hiding in encrypted image with adaptive encoding strategy. Inf. Sci. 2019, 494, 21–36. [Google Scholar] [CrossRef]
- Pun, C.-M. Reversible data hiding in encrypted images using chunk encryption and redundancy matrix representation. IEEE Trans. Dependable Secur. Comput. 2020, 19, 1382–1394. [Google Scholar]
- Wang, Y.M.; Cai, Z.C.; He, W.G. High capacity reversible data hiding in encrypted image based on intra-block lossless compression. IEEE Trans. Multimed. 2020, 23, 1466–1473. [Google Scholar] [CrossRef]
- Yi, S.; Zhou, Y. Separable and reversible data hiding in encrypted images using parametric binary tree labeling. IEEE Trans. Multimed. 2019, 21, 51–64. [Google Scholar] [CrossRef]
- National Institute of Standards and Technology. “FIPS-46: Data Encryption Standard (DES).” Revised as FIPS 46-1:1988, FIPS 46-2:1993, FIPS 46-3:1999. 1979. Available online: http://csrc.nist.gov/publications/fips/fips46-3/fips46-3.pdf (accessed on 15 January 1977).
- Jolfaei, A.; Wu, X.; Muthukkumarasamy, V. On the security of permutation-only image encryption schemes. IEEE Trans. Inf. Forensics Secur. 2016, 11, 235–246. [Google Scholar] [CrossRef]
- TableYin, Z.X.; Abel, A.; Tang, J.; Zhang, X.P.; Luo, B. Reversible data hiding in encrypted images based on multi-level encryption and block histogram modification. Multimed. Tools Appl. 2017, 76, 1–22. [Google Scholar]
- Yin, Z.X.; Abel, A.; Zhang, X.P.; Luo, B. Reversible data hiding in encrypted image based on block histogram shifting. IEEE Int. Conf. Acoust. Speech Signal Process. 2016, 2016, 2129–2133. [Google Scholar]
- Liu, Z.; Pun, C. Reversible data-hiding in encrypted images by redundant space transfer. Inf. Sci. 2018, 433–434, 188–203. [Google Scholar] [CrossRef]
- Dragoi, I.; Coltuc, D. On the Security of Reversible Data Hiding in Encrypted Images by MSB Prediction. IEEE Trans. Inf. Forensics Secur. 2021, 16, 187–189. [Google Scholar] [CrossRef]
- Li, S.J.; Li, C.Q.; Chen, G.R.; Bourbakis, N.G.; Lo, K.-T. A general quantitative cryptanalysis of permutation-only multimedia ciphers against plaintext attacks. Signal Process. Image Commun. 2008, 23, 212–223. [Google Scholar] [CrossRef]
- Yu, C.; Zhang, X.; Li, G.; Zhan, S.; Tang, Z. Reversible data hiding with adaptive difference recovery for encrypted images. Inf. Sci. 2022, 584, 89–110. [Google Scholar] [CrossRef]
- Wang, X.; Chang, C.-C.; Lin, C.-C. Reversible data hiding in encrypted images with block-based adaptive MSB encoding. Inf. Sci. 2021, 567, 375–394. [Google Scholar] [CrossRef]
- Zhang, L.Y.; Liu, Y.S.; Wang, C.; Zhou, J.T.; Zhang, Y.S.; Chen, G.R. Improved known-plaintext attack to permutation-only multimedia ciphers. Inf. Sci. 2018, 430–431, 228–239. [Google Scholar] [CrossRef]
- Qu, L.; Chen, F.; He, H. Security analysis of multiple permutation encryption adopt in reversible data hiding. Multimed. Tools Appl. 2020, 79, 29451–29471. [Google Scholar]
- Qu, L.F.; Chen, F.; Zhang, S.J.; He, H.J. Cryptanalysis of reversible data hiding in encrypted images by block permutation and co-modulation. IEEE Trans. Multimed. 2021, 24, 2924–2937. [Google Scholar]
- Xiang, Y.P.; Xiao, D.; Zhang, R.; Liang, J.; Liu, R. Cryptanalysis and improvement of a reversible data-hiding scheme in encrypted images by redundant space transfer. Inf. Sci. 2021, 545, 188–206. [Google Scholar] [CrossRef]

















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| ) | ||||||
| Size of codebook | Airplane | Lena | Peppers | Baboon | Elaine | Average |
| 100 | 78% | 83% | 66% | 60% | 56% | 68.6% |
| 64 | 89% | 74% | 82% | 70% | 69% | 76.8% |
| 32 | 86% | 80% | 75% | 70% | 66% | 75.4% |
| ) | ||||||
| 100 | 78% | 83% | 66% | 60% | 56% | 68.6% |
| 64 | 81% | 70% | 78% | 75% | 65% | 73.8% |
| 32 | 80% | 79% | 77% | 70% | 64% | 74.0% |
| ) | ||||||
| 100 | 80% | 79% | 77% | 67% | 64% | 73.4% |
| 64 | 81% | 78% | 79% | 66% | 66% | 74.0% |
| 32 | 80% | 79% | 81% | 64% | 66% | 74.0% |
| Schemes | Analysis Target | Quality of Estimated Image | Assistance with a Plaintext Image | Same Encryption Key | Type of Analyzed Image | Analyzed Encryption Methods |
|---|---|---|---|---|---|---|
| Ours | Embedded encrypted image | Low | ✗ | ✗ | Ciphertext | BPCM |
| [31] | Embedded encrypted image | High | ✓ | ✓ | Ciphertext | Permutation-only |
| [32] | Embedded encrypted image | High | ✓ | ✓ | Ciphertext | Permutation-only |
| [33] | Embedded encrypted image | High | ✓ | ✓ | Ciphertext | BPCM |
| [34] | Encryption algorithm | - | - | - | Ciphertext | BPCM |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Gao, K.; Chang, C.-C.; Lin, C.-C. Cryptanalysis of Reversible Data Hiding in Encrypted Images Based on the VQ Attack. Symmetry 2023, 15, 189. https://doi.org/10.3390/sym15010189
Gao K, Chang C-C, Lin C-C. Cryptanalysis of Reversible Data Hiding in Encrypted Images Based on the VQ Attack. Symmetry. 2023; 15(1):189. https://doi.org/10.3390/sym15010189
Chicago/Turabian StyleGao, Kai, Chin-Chen Chang, and Chia-Chen Lin. 2023. "Cryptanalysis of Reversible Data Hiding in Encrypted Images Based on the VQ Attack" Symmetry 15, no. 1: 189. https://doi.org/10.3390/sym15010189
APA StyleGao, K., Chang, C.-C., & Lin, C.-C. (2023). Cryptanalysis of Reversible Data Hiding in Encrypted Images Based on the VQ Attack. Symmetry, 15(1), 189. https://doi.org/10.3390/sym15010189