1. Introduction
In order to enhance survival data modeling, statisticians and applied researchers have been increasingly interested in developing flexible lifetime models. As a consequence, significant progress has been achieved in generalizing and applying a number of well-known lifetime models. The Weibull distribution, introduced by Weibull [
1], is one of the most used distributions for modeling lifetimes. The Weibull has been utilized effectively as a purely empirical model in many applications due to its flexible form and ability to predict a wide variety of failure rates. The Weibull model may be theoretically developed as a type of extreme value distribution that governs the time until occurrence of the “weakest link” among several competing failure processes. This might account for its performance in applications such as capacitor, ball bearing, relay and material strength failures. The hazard rate function (hrf) of the Weibull distribution can only be increasing, decreasing or constant. As a result, it is not useful for modeling human mortality or machine lifetimes with a non-monotonic hrf. Many variants that generalize the Weibull distribution have emerged. Mudholkar et al. [
2] were the first to extend the Weibull distribution with a bathtub-shaped hazard rate, and this extended Weibull has been successfully applied by Xie et al. [
3]. Other extensions and modified forms of the Weibull with greater flexibility have been proposed; for example, the additive Weibull distribution with a bathtub-shaped hrf by Xie and Lai [
4], the EW distribution by Nadarajah et al. [
5], the transmuted additive Weibull by Elbatal et al. [
6], the Kumaraswamy transmuted exponentiated modified Weibull by Al-Babtain et al. [
7], the Burr X EW model by Khalil et al. [
8], the Marshall–Olkin power-generalized Weibull distribution by Afify et al. [
9], truncated Cauchy power Weibull-G by Alotaibi et al. [
10], a new version of Weighted Weibull distribution by Alahmadi et al. [
11], exponentiated power generalized Weibull power series family by Aldahlan et al. [
12], exponentiated truncated inverse Weibull-G by Almarashi et al. [
13], odd inverse power generalized Weibull by Al-Moisheer et al. [
14], extended inverse Weibull distribution by Alkarni et al. [
15], four-parameter Weibull distribution by Abouelmagd et al. [
16], exponentiated Weibull Weibull distribution by Hassan and Elgarhy [
17] among others.
Mudholkar and Srivastava [
18] presented the three-parameter EW distribution as an extension of the Weibull family, which is a particularly flexible class of probability distribution functions. Mudholkar et al. [
2] demonstrated the use of the EW distribution in reliability and survival tests.
The cumulative function (cdf) and density function (pdf) of the EW model are given by
and
where
and
are two shape parameters and
is the scale parameter. For
, it represents the exponentiated exponential (EE) distribution, for
, it represents the exponentiated Rayleigh (ER) distribution, for
, it represents the exponential (E) distribution, for
, it represents the Rayleigh (R) distribution [
19] and for
, it represents the Weibull distribution. Thus, EW is a generalization of the EE distribution, as well as the Weibull distribution. The EW distribution also has a very good physical interpretation.
We have three reasons for using the EW distribution. First, it expands the popular Weibull and EE models. Second, the hazard rate function of this distribution has several forms, one of which is the bathtub form. As a result, it could be a helpful distribution for analyzing biological and mortality data. Third, if a parallel system has n components and their lifetimes are independently and identically distributed as EW, then the system lifetime is also EW.
Additional parameters give greater flexibility, but they also increase the complexity of the estimation. To counter this, ref. [
20] proposed the Dinesh–Umesh–Sanjay (DUS) transformation to obtain new parsimonious classes of distributions. This is as follows. If
is the baseline cdf, the DUS transformation generates a new cdf
expressed as
The merit of using this transformation is that the resulting distribution is parameter-parsimonious because no extra parameters are added. In this way, Maurya et al. [
21] proposed a new class of distributions that includes many flexible hazard rates. They explored using the DUS transformation by using the exponentiated cdf, introducing the generalized DUS (GDUS) transformation. Kavya and Manoharan [
22] proposed a generalized lifetime model based on the DUS transformation, with the cdf of the GDUS transformation given by
where
The associated pdf is given by
where
is the baseline distribution in the
family distribution. This approach will always create a parsimonious distribution because it is a transformation rather than a generalization, so no additional parameters beyond those in the baseline distribution are introduced.
Recently, Kavya and Manoharan [
23] introduced a new transformation, the KM transformation family of distributions. The cdf and pdf are, respectively,
and
Using a given baseline distribution, this family generates new lifetime models or distributions.
Kavya and Manoharan [
23] used the exponential and Weibull distributions as baseline distributions because they are widely used in reliability theory and survival analysis.
Censored data arise in real-world testing trials when investigations, including the lifetime of test units, must be terminated before complete observation. Censoring is a common and unavoidable routine activity for a variety of reasons, including time restrictions and cost savings. Censorship in its different forms has been carefully examined, with types I and II censorship being the most prevalent. In comparison to traditional censorship designs, a generalized censorship style known as progressive censored schemes has recently attracted substantial attention in the literature due to its efficient use of available resources. One of these progressive censored schemes is the PTIC. This pattern is noticed when a particular number of lifetime test units are routinely eliminated from the test at the conclusion of each post-test period of time. It has the capacity to determine the termination time realistically and there is additional design freedom by allowing test units to be terminated during non-terminal time periods, as studied by Balakrishnan et al. [
24]. Bayesian and classical inference for an odd Lindley Burr XII model are proposed in the study by Korkmaz et al. [
25] and Topp–Leone NH distribution is proposed in the study by Yousof et al. [
26].
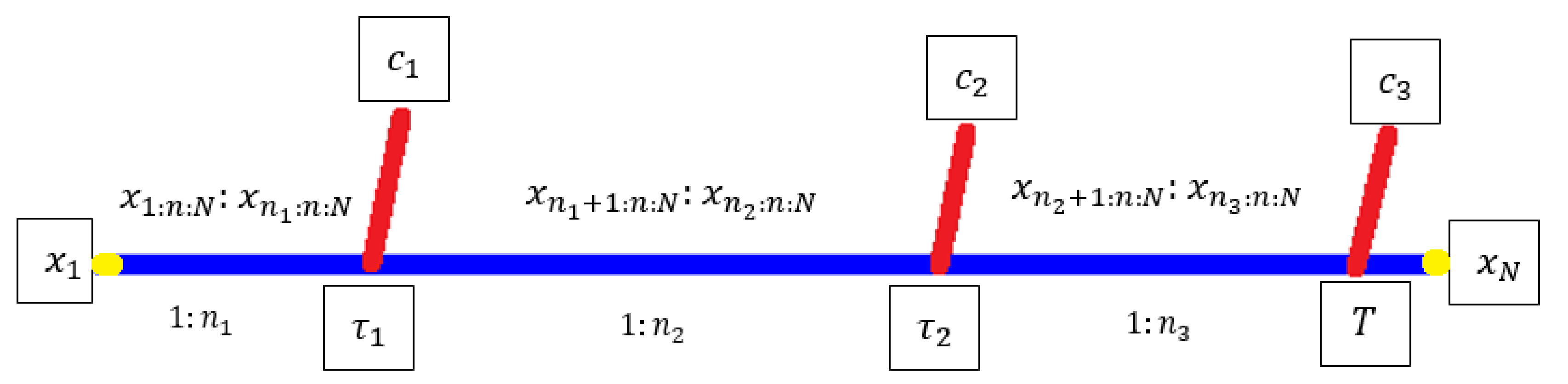
Suppose that a life testing experiment has n units. Presume that represent the lifetime of all n units taken from a population. Assume that denotes the respective ordered lifetime recorded from the life test. At the end of the preset period of censoring , items are excluded from the surviving items in accordance with Qs, , where m signifies the number of testing phases, and .
The quantities should always be determined ahead of time:
Predicated on the experimenter’s past knowledge and skills with the objects under consideration, as in the study by Balasooriya and lwa [
27];
Or the quantiles of the lifetimes distribution,
th, which are possibly computed by using the provided expression
Within those cases,
and
n are fixed and constant, whereas
represents the quantity of surviving entities at a particular moment in time, and
and
are random variables. The likelihood function is represented as
wherein
is the observable lifetime of the
ith OS [
28]. This censorship mechanism is depicted in
Figure 1; see Balakrishnan and Cramer [
29]. The type-I and type-II conventional censoring methods are generalized by these progressive censoring schemes, which also allow for partial withdrawals from the ongoing experiment. The fact that they assume a constant review of the life test experiment is a significant problem with these progressive censoring schemes, as well as with all other classic censoring schemes.
Complete samples, as well as the type-I censoring scheme, can indeed be viewed as special examples of this censoring technique.
The PTIC approach for the Weibull distribution was proposed in the study by Balakrishnan and Cramer [
29]. The maximum likelihood estimates (MLEs) and Bayesian estimates for the unknown parameters of the generalized inverse exponential distribution under PTIC were obtained in the study by Mahmoud et al. [
30]. Abo-Kasem et al. [
31] discussed inferential survival analysis for inverted NH distribution under adaptive progressive hybrid censoring. For the PTIC, there are two publications that are closely linked. The first was the MLEs and asymptotic confidence estimates for the parameters of the extended inverse exponential model, predicated on the premise that there are two kinds of failures, as in the study by Mahmoud et al. [
32]. Ahmad et al. [
33] discussed inference on reliability estimation for a multi-component stress-strength model under power Lomax distribution. Almetwally et al. [
34] obtained the best optimal plan of multi-stress–strength reliability Bayesian and non-Bayesian methods for the alpha power exponential model using progressive first failure. The second was the MLEs and Bayesian estimates for the unknown parameters of the extended inverse exponential model, as in the study by Mahmoud et al. [
35]. Algarni et al. [
36] investigate the statistical inference of the inverse Weibull model under PTIC. Elbatal et al. [
37] investigate the Bayesian and non-Bayesian estimation of the Nadarajah–Haghighi distribution under PTIC.
Turning now to accelerated life tests (ALTs), these are a means of gathering more information in less time than would otherwise be possible by subjecting items to more stress than in usual operating conditions. Such testing can save a significant amount of time and money. The step-stress accelerated life test (SSALT) is one type of ALT; see Hakamipour [
38]. During the test, the experimenter progressively increases the stress levels at pre-specified time intervals, typically starting with a stress level that is slightly above normal condition. The test continues until either the entire sample of items fails or the time limit for the duration of the test is reached and censoring occurs.
When stress(es) are applied items in only two phases, this is referred to as a simple SSALT. Meeker [
39], as well as Nelson [
40], are good resources for interested readers. Many different types of SSALT censorship have been used in the literature. El-Sherpieny et al. [
41] introduced PTIIC for bivariate distributions based on ALT. The bulk of these studies concentrate on types I and II censoring. When items are eliminated before they fail on test, the cost of the test is lowered since these deleted samples can be utilized elsewhere or in other tests. This is referred to as progressive censorship. Most tests employ just one accelerating stress variable. It is recommended to employ many stress factors since using only one variable may result in insufficient failure data. Increasing the number of stress components would result in a better knowledge of the simultaneous effects of the stress variables, as well as more failure data.
Han [
42] addressed the best design of a basic SSALT for an exponential distribution using PTIC. Li and Fard [
43] investigated SSALT for two stress variables using Weibull failure times and type-I censoring. To obtain optimal hold durations, Ling et al. [
44] built an SSALT for two stress variables in a type-I hybrid censoring scheme. “Bivariate SSALT” refers to an SSALT with two stress components; for more details of this scheme, see
Figure 2. The study by [
45] obtained the best design for a bivariate SSALT model with type-II censoring for the Gompertz distribution. Hakamipour [
38] discussed the optimum design for a bivariate SSALT with a generalized exponential distribution under PTIC. Khan and Chandra [
46] discussed bivariate SSALT estimation and the optimum design under PTIC. Alotaibi et al. [
47] introduced the optimal design for a bivariate SSALT for alpha power exponential distribution based on PTIC samples. The test is repeated until
T is attained, at which time,
units fail this stage. At time
T, all of the remaining surviving units
are removed from the test. For more explanation, see
Figure 2.
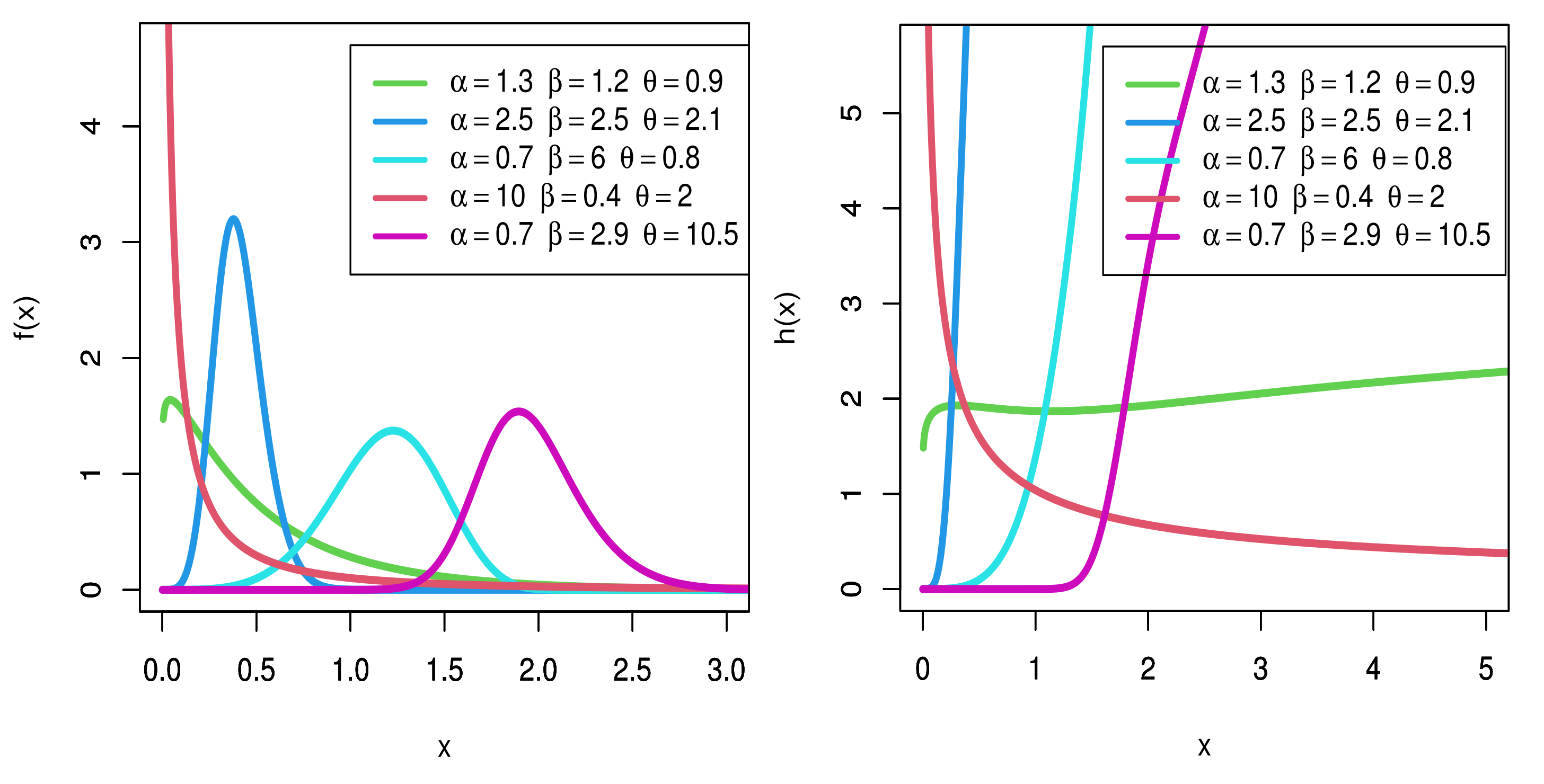
In the article under consideration, our primary focus lies in introducing a new lifetime model called the KMEW model as a new three-parameter lifetime model based on the KM transformation family, EW distribution. The following arguments give enough motivation to study the proposed model. We specify them as follows: (i) the new suggested distribution is very flexible and contains some distributions as sub-models; (ii) the shapes of the pdf for the new model can be asymmetric (unimodal, decreasing and right-skewed) and symmetric. In addition, the shapes of the hrf for the suggested model can be increasing, decreasing, constant and J-shaped; (iii) the new suggested model has a closed form for the quantile function and this makes the calculation of some properties, such as skewness and kurtosis, very easy, and generating random numbers from the new suggested model also becomes easy; (iv) some statistical and mathematical properties of the new suggested model are explored; (v) a maximum likelihood method of estimation is produced to estimate the parameters of the FB model; (vi) the KMEW is a good alternative to several lifetime distributions, such as the three-parameter exponentiated Weibull, the modified Weibull model, the Kavya–Manoharan 9 Weibull, the extended Weibull, the odd Weibull inverse Topp–Leone and the extended odd Weibull 10 inverse Nadarajah–Haghigh model for modeling skewed data in applications; (vii) we propose a bivariate SSALTs under PTIC using the KMEW model. For our proposed bivariate SSALT under PTIC, the best test plan is obtained by minimizing the asymptotic variance (AV) of the MLEs of the log of the scale parameter.
This paper is organized as follows. In
Section 2, a new lifetime model using an exponentiated Weibull distribution as the baseline distribution in the KM transformation family and its different distributions are presented. In
Section 3, we demonstrate the statistical features of the KMEW model. The maximum likelihood inference for model parameters is discussed in
Section 4. Its application to three real datasets is discussed in
Section 5. The bivariate SSALT under the PTIC model is introduced in
Section 6.
5. Application of Real Data
Three genuine data sets from engineering and medical science are used to demonstrate the importance and adaptability of the proposed KMEW model. We utilize the “maxLik” package to compute likelihood estimates in the R package using the Newton–Raphson (NR) algorithms; see Henningsen and Toomet [
51]. The first dataset is the waiting times (in minutes) of 100 bank clients until the service is provided. It was originally used by [
52]. The data are as follows: 0.8, 0.8, 19.9, 20.6, 21.3, 21.4, 21.9, 23.0, 2.1, 2.6, 2.7, 2.9, 3.1, 3.2, 3.3, 3.5, 3.6, 4.0, 4.1, 4.2, 4.2, 4.3, 4.3, 4.4, 4.4, 4.6, 6.3, 6.7, 6.9, 7.1, 7.1, 7.1, 7.1, 7.4, 7.6, 7.7, 8, 8.2, 8.6, 8.6, 8.6, 8.8, 8.8, 8.9, 8.9, 9.5, 9.6, 9.7, 9.8, 10.7, 10.9, 11, 11, 11.1, 11.2, 4.7, 4.7, 1.3, 1.5, 1.8, 1.9, 1.9, 4.8, 4.9, 4.9, 5, 5.3, 5.5, 5.7, 5.7, 6.1, 6.2, 6.2, 6.2, 11.2, 11.5, 11.9, 12.4, 12.5, 12.9, 13, 13.1, 13.3, 13.6, 13.7, 13.9, 14.1, 15.4, 15.4, 17.3, 17.3, 18.1, 18.2, 18.4, 18.9, 19, 27, 31.6, 33.1, 38.5.
The second dataset from [
53] contains the time between failures of secondary reactor pumps (thousands of hours): 2.160, 0.746, 0.402, 0.954, 0.491, 6.560, 4.992, 0.347, 0.150, 0.358, 0.101, 1.359, 3.465, 1.060, 0.614, 1.921, 4.082, 0.199, 0.605, 0.273, 0.070, 0.062, 5.320. These data were used by [
54] to fit a beta-flexible Weibull distribution. Looking at
Table 1 and the results in [
54], we conclude that the our distribution is better than the beta-flexible Weibull distribution and many other distributions.The third dataset is remission periods (in months) of a random sample of 128 bladder cancer patients [
55]. In this example, we compare the KMEW distribution with some competing distributions, such as the EW [
56], modified Weibull (MW) [
57], Kavya–Manoharan Weibull (KMW) [
23], generalized Weibull (GW) [
58], extended Weibull (ExW) [
59], odd Weibull inverse Topp–Leone (OWITL) [
60] and extended odd Weibull inverse Nadarajah–Haghighi (EOWINH) [
61] distributions. What follows is the application of the proposed distribution to the three datasets and an observation of the findings in
Table 1,
Table 2 and
Table 3, which show standard errors (SEs), Akaike information criterion (AINC), Bayesian information criterion (BINC), Cramér–von-Mises (CVM) [
62,
63], Kolmogorov–Smirnov (KS) [
64,
65] with its p-value (PV) and Anderson–Darling (AD) [
66,
67]. We find that our proposed distribution is the best model because it has the lowest values for all measurements except PV. Although the PV of KMEW is equal to the GW distribution, KMEW is better than GW because the values of AINC, BINC, CVM and AD for KMEW distribution are smaller than the values of GW. The best model is the one that has the smallest values of AINC, BINC, CVM, AD and KS, and the largest value of PV.
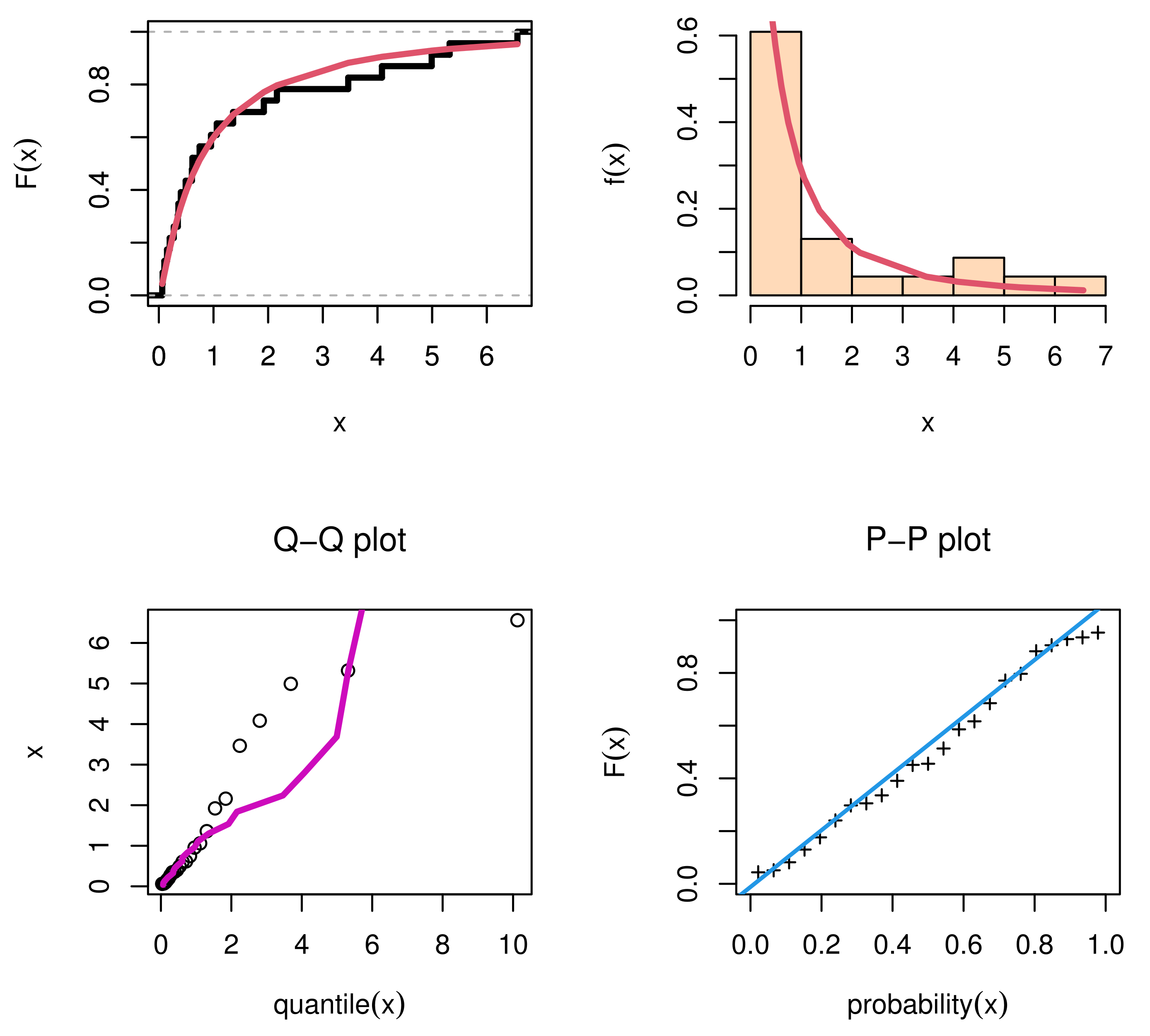
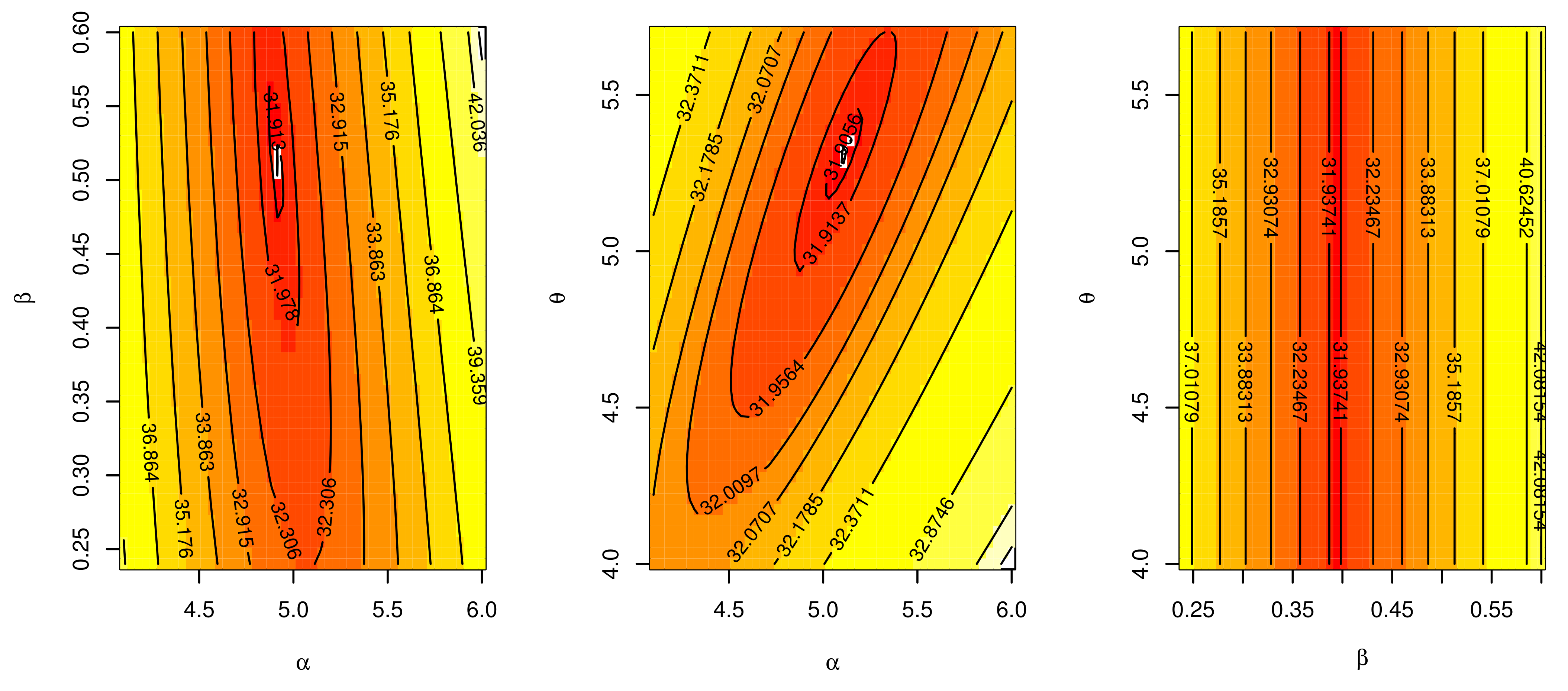
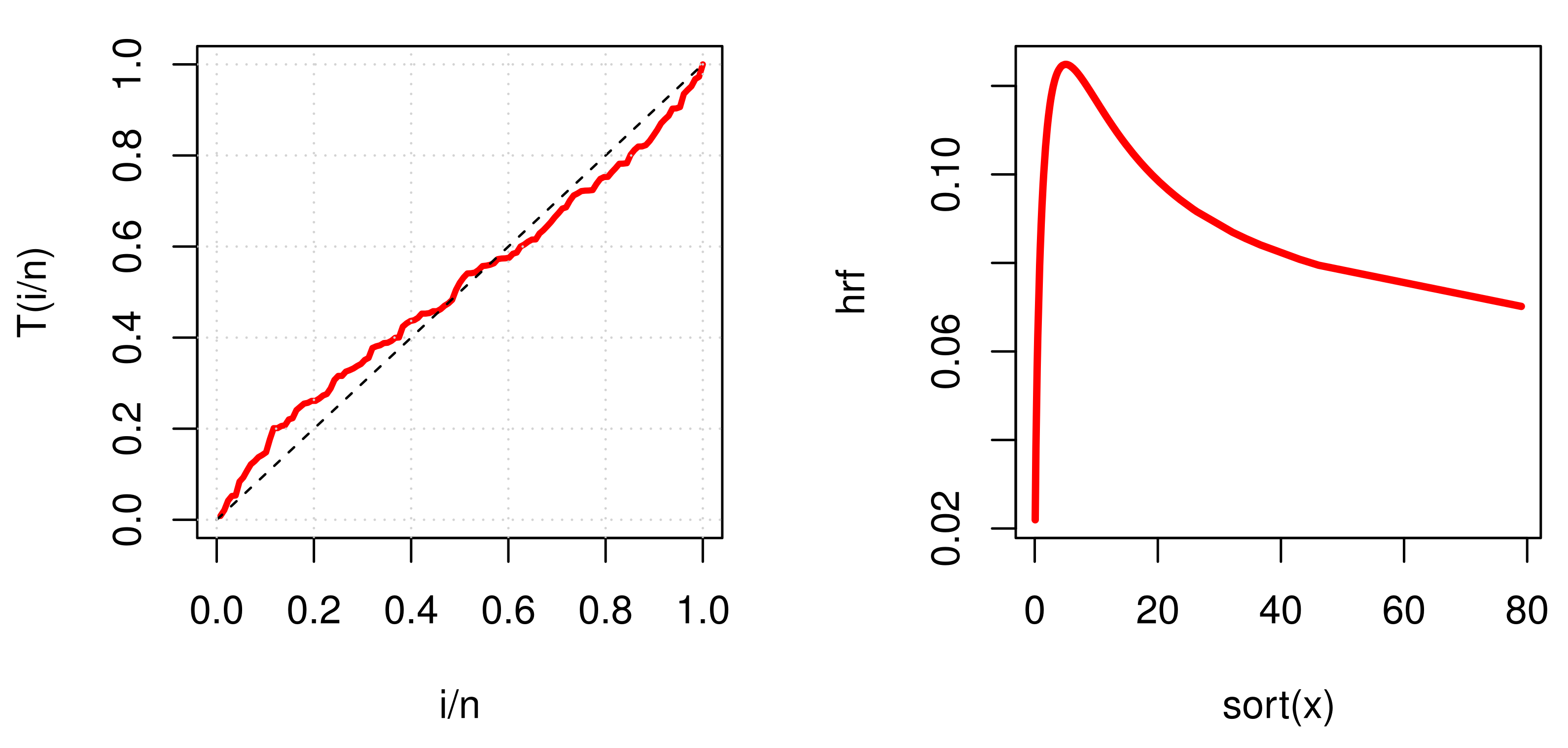
For waiting times data, we discussed
Figure 4,
Figure 5,
Figure 6,
Figure 7 and
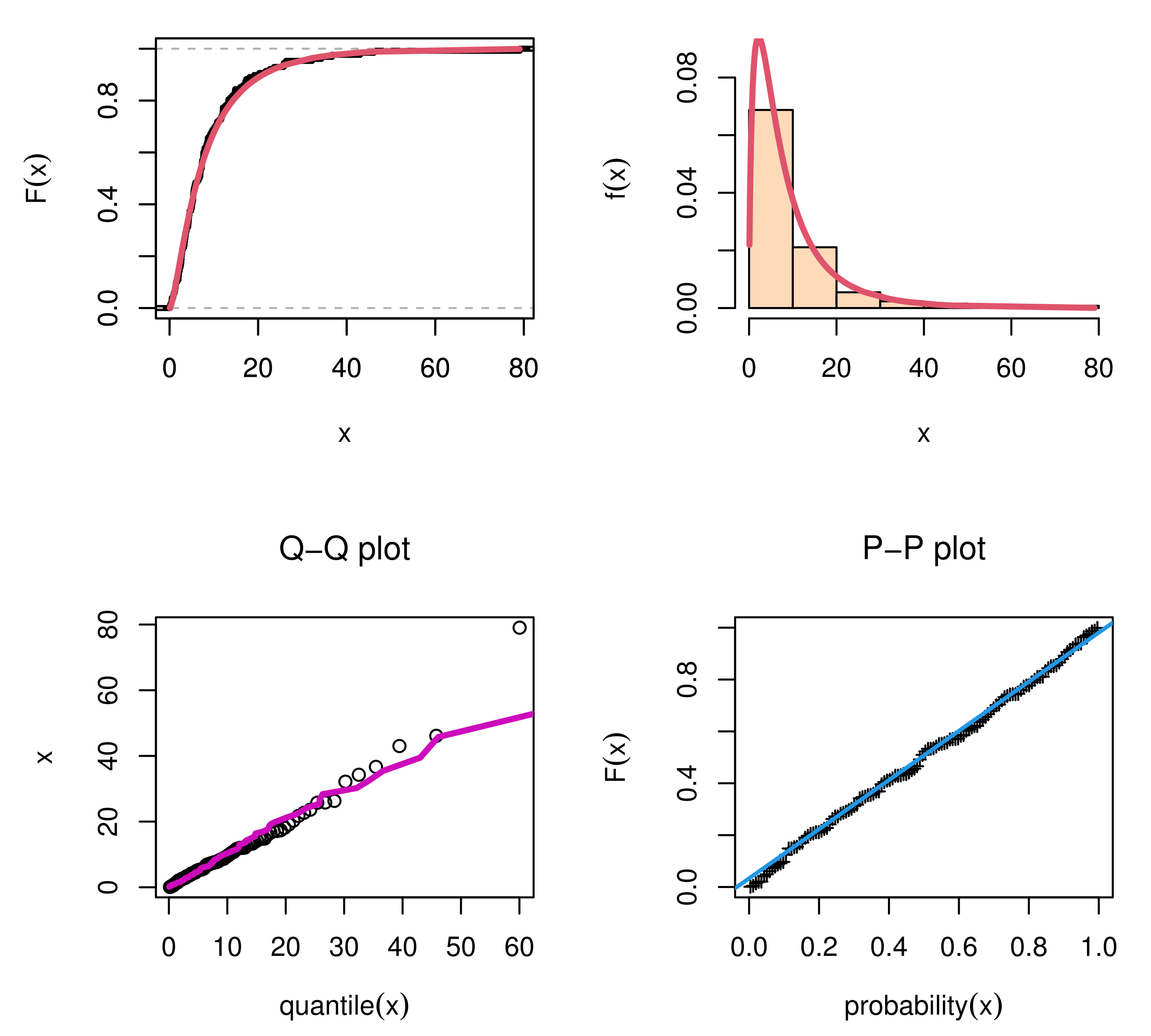
Figure 8. For time between failures of secondary reactor pumps data, we discussed
Figure 9,
Figure 10,
Figure 11,
Figure 12 and
Figure 13. For bladder cancer data, we discussed
Figure 14,
Figure 15,
Figure 16,
Figure 17 and
Figure 18.
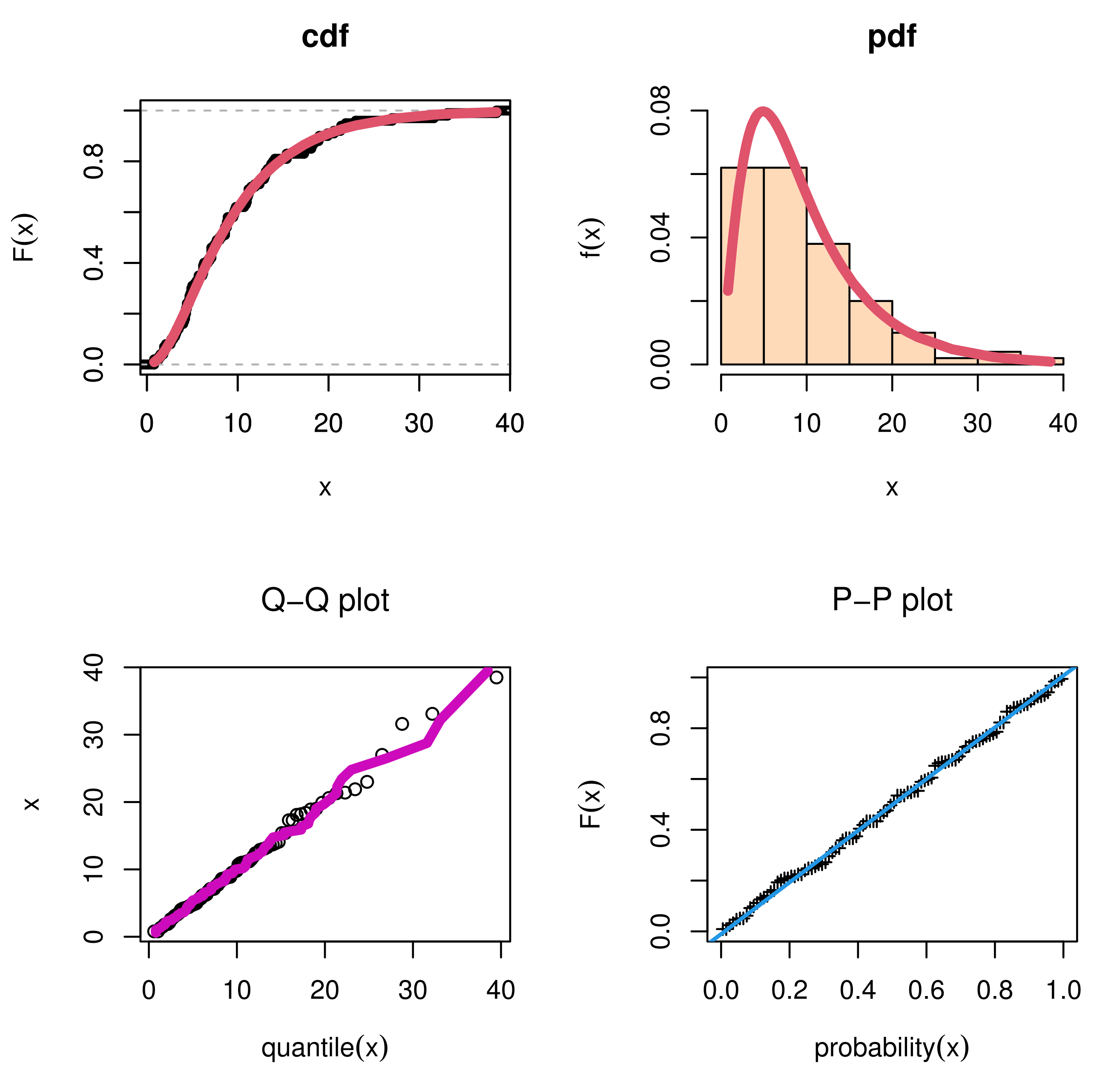
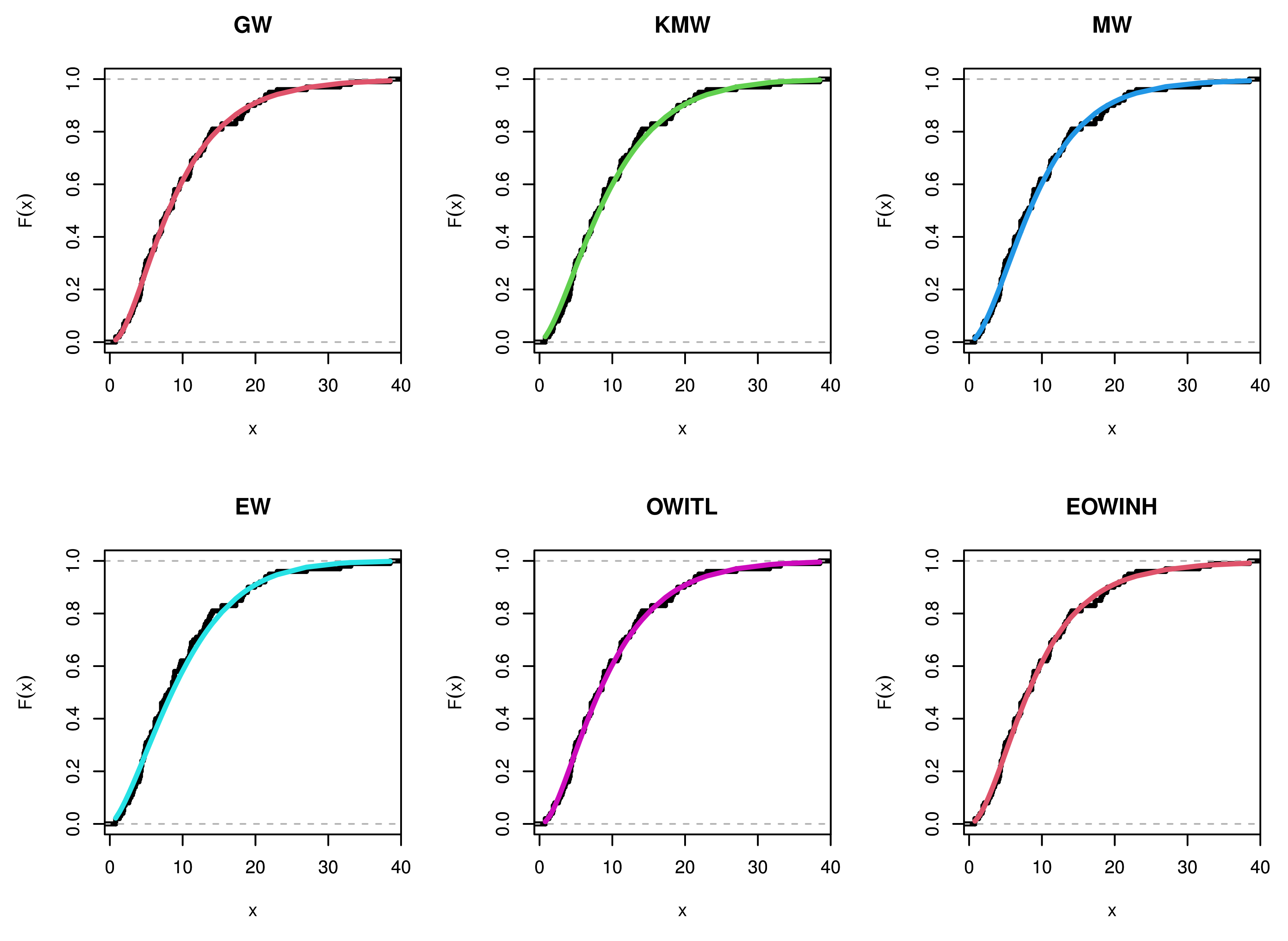
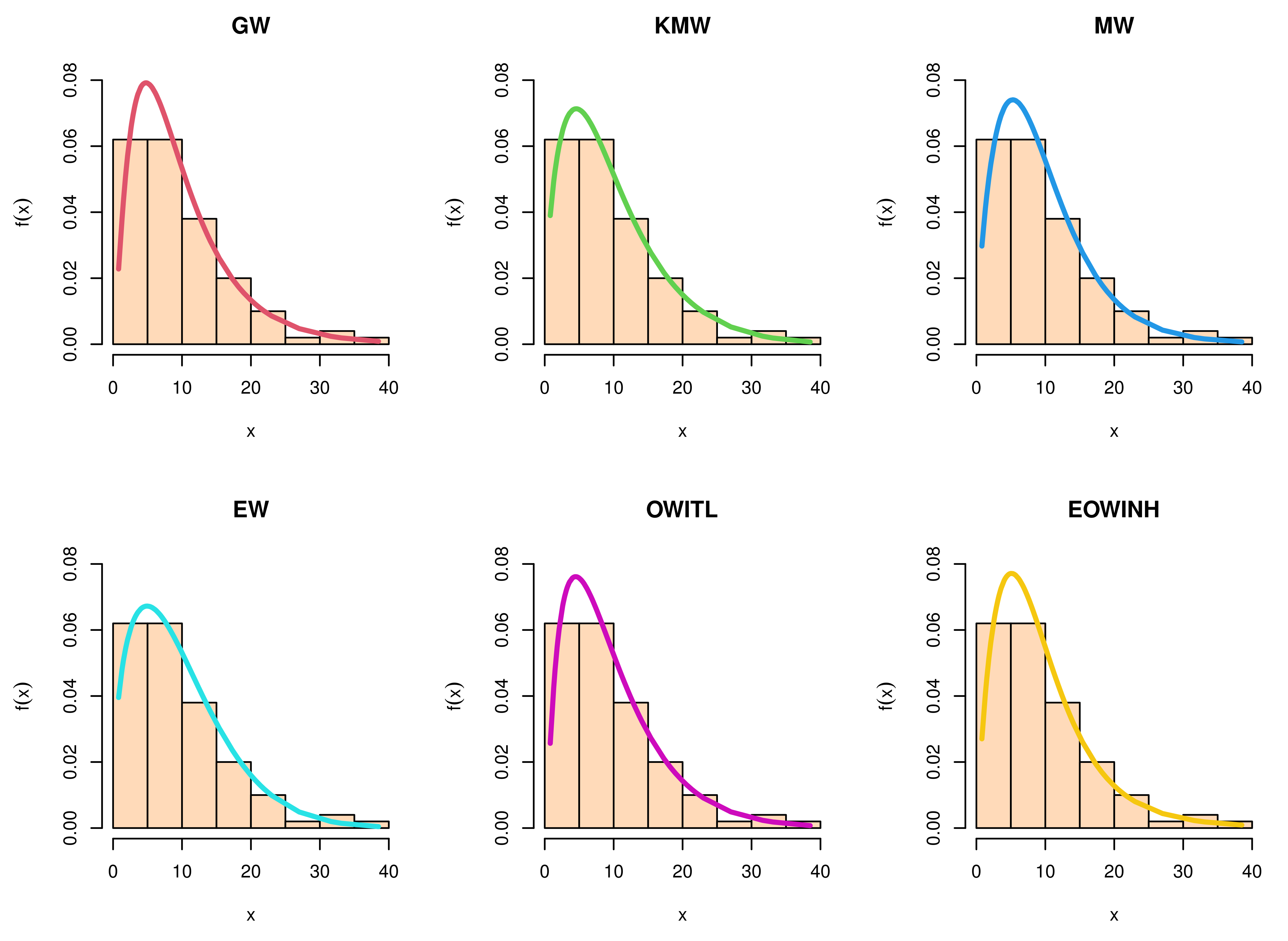
Figure 5,
Figure 10 and
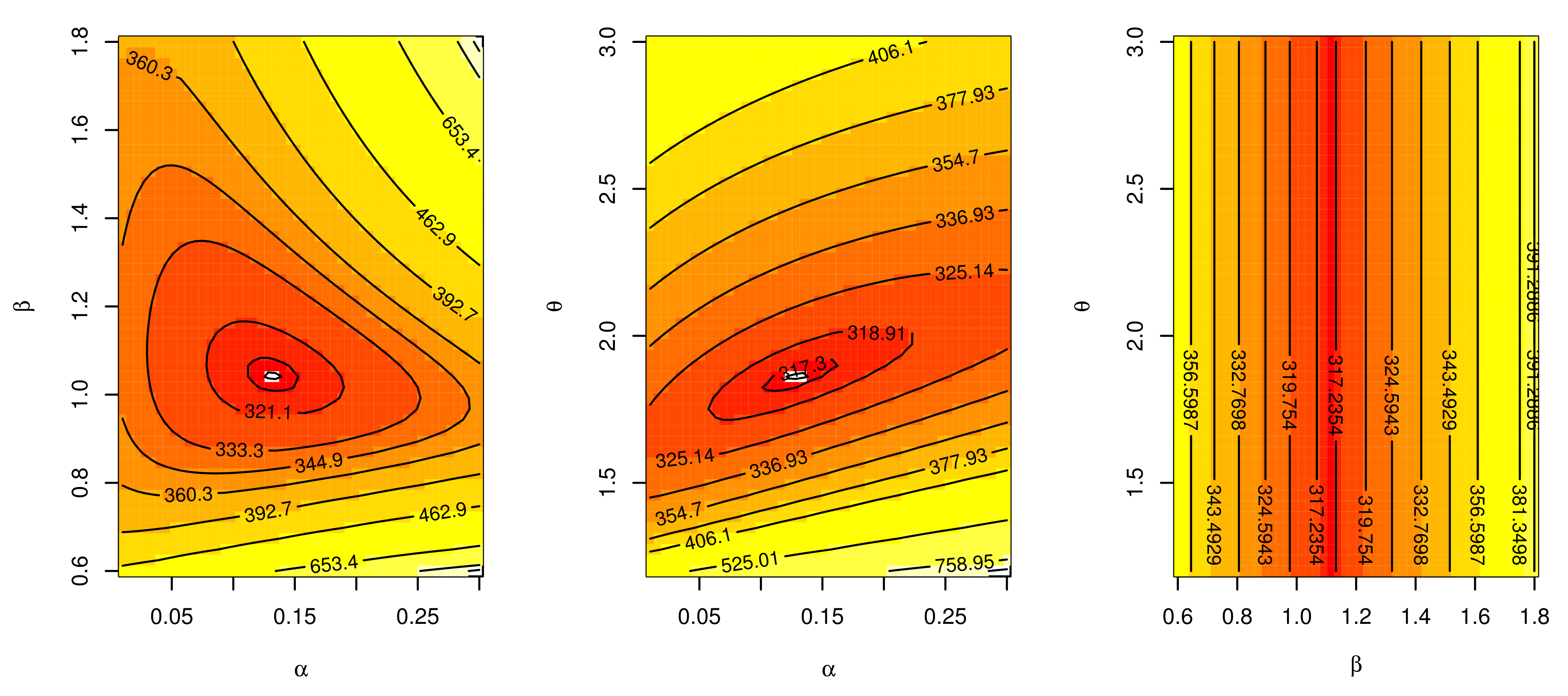
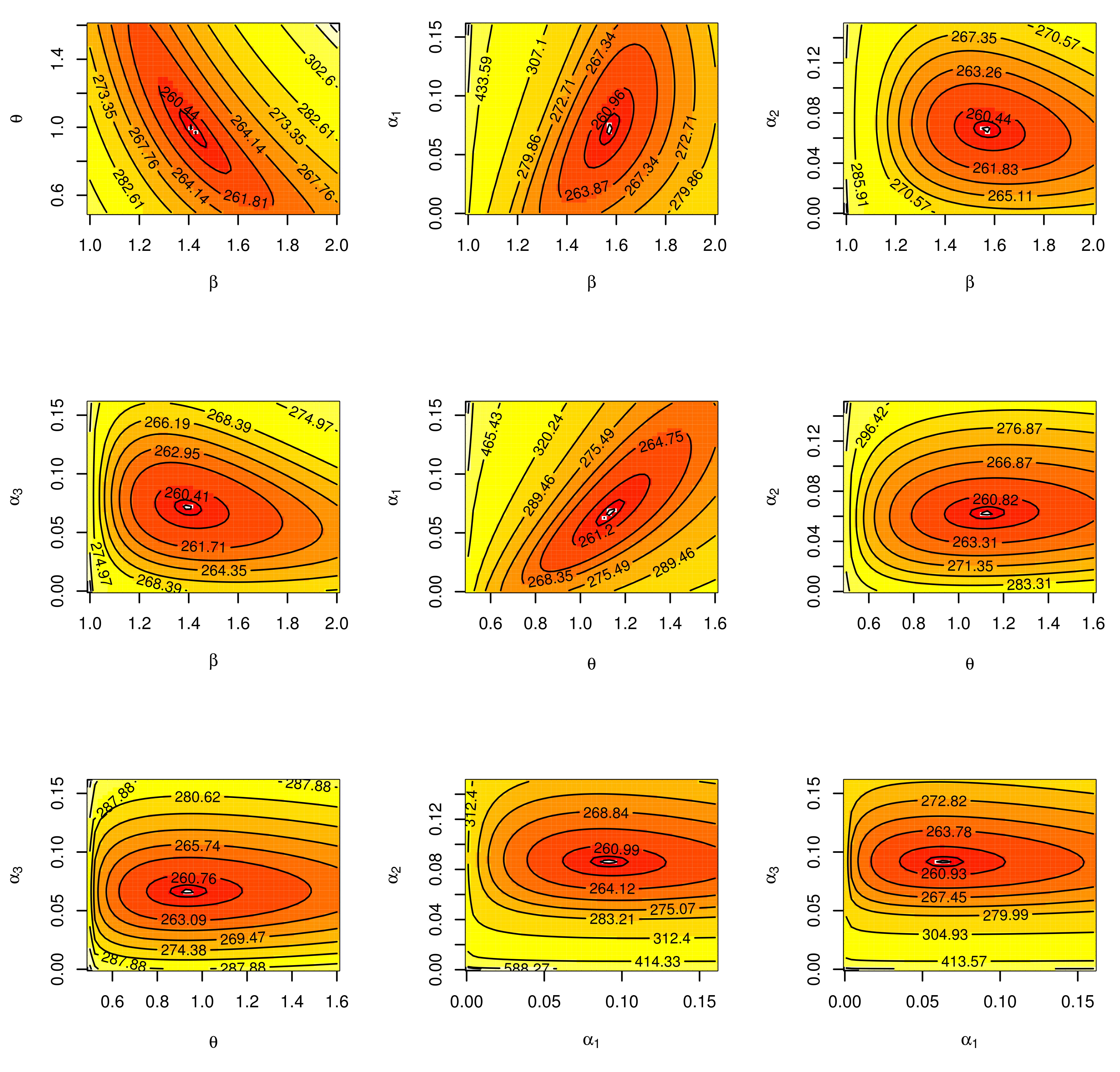
Figure 15 support this result, demonstrating that the estimated pdf is close to the probability histogram and the calculated cdf is close to the actual cdf. We sketched the log-likelihood for every pair of parameters, while fixing the other parameters, as shown in
Figure 8,
Figure 13 and
Figure 18. We plot cdf and pdf of alternative models in
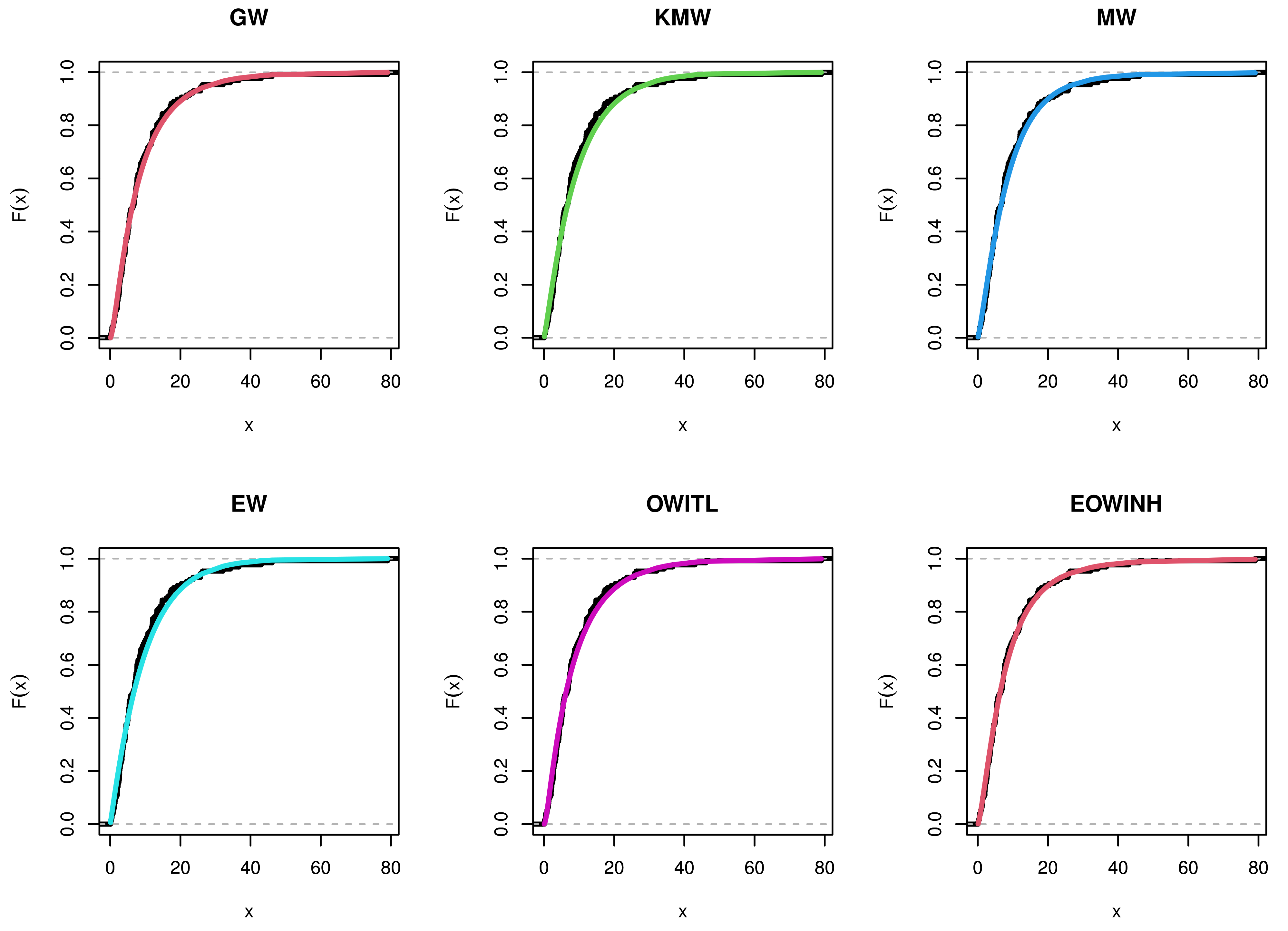
Figure 6,
Figure 7,
Figure 11,
Figure 12,
Figure 16, and
Figure 17 for the three real data sets.. We find that the root of the parameter pair is a single point, which assures that the roots are unique.
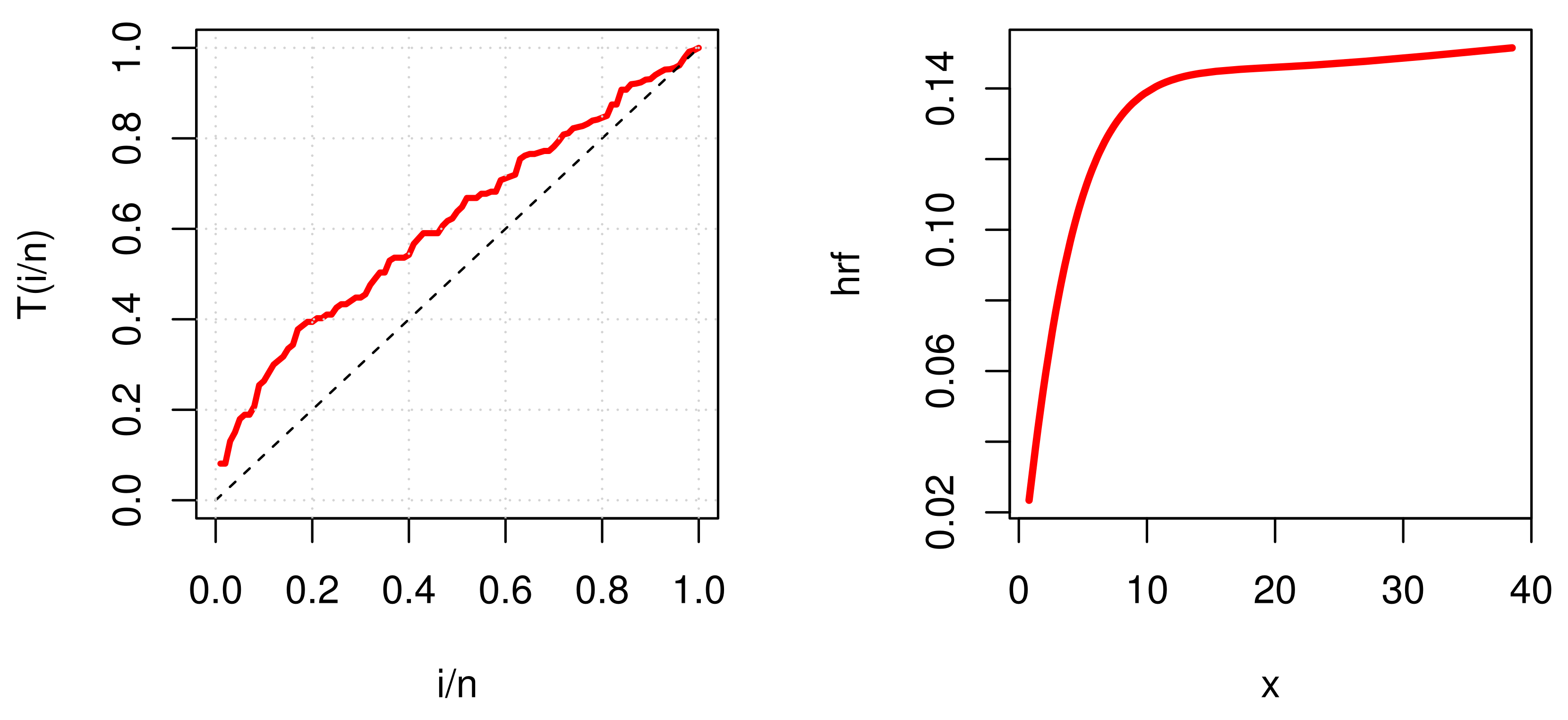
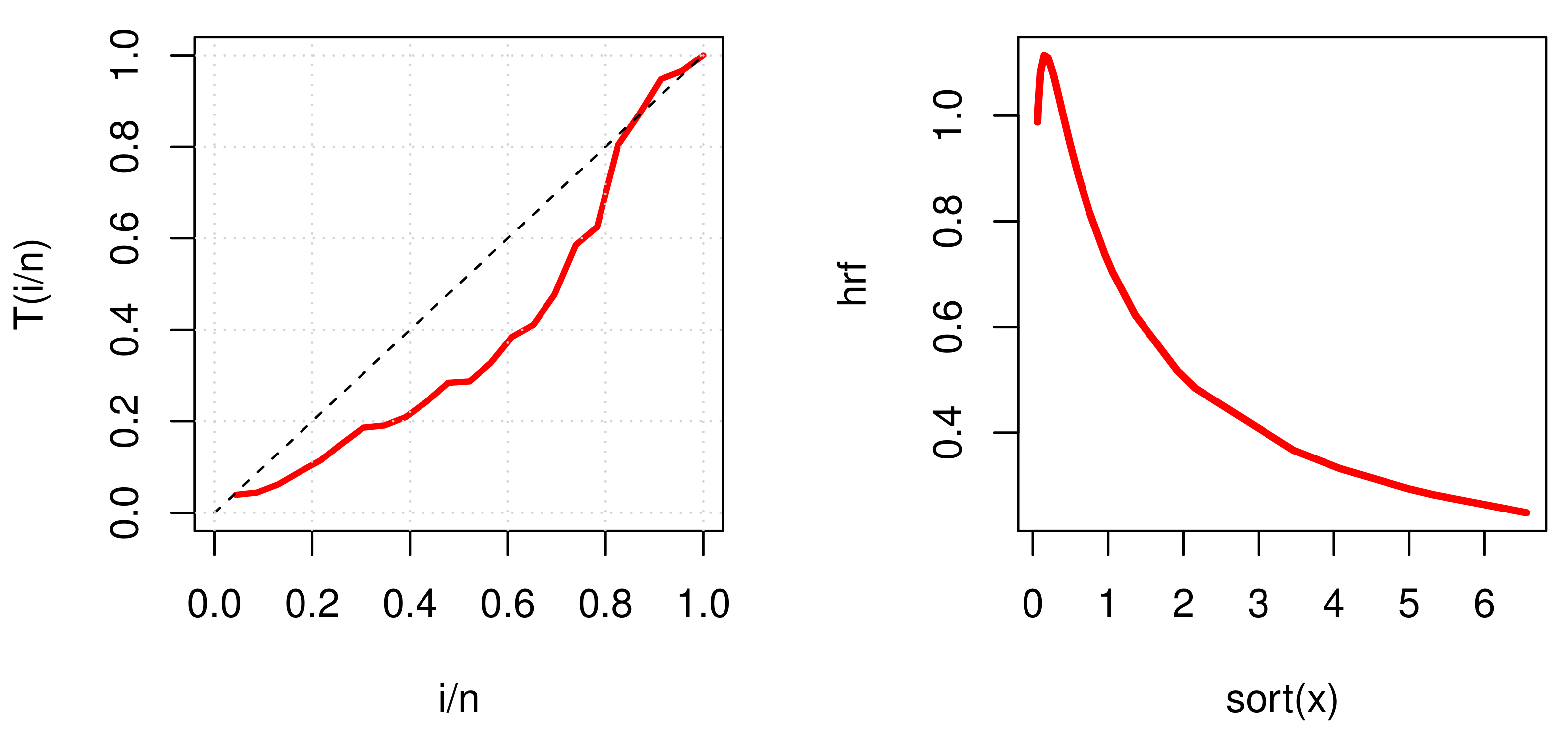
Figure 4,
Figure 9 and
Figure 14 show TTT plots and the estimated hazard for the three real data sets.



 ,
, 

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}