
An Improved YOLO Algorithm for Fast and Accurate Underwater Object Detection


Abstract
:1. Introduction
- Insufficient computing power. The human perception limit of video from the camera is 24 frames per second (FPS), so to meet the real-time requirements to some extent, the inferencing speed should be around 10 FPS. However, the high performance of deep neural networks has higher demands on computing resources, which is not well-suited to an environment with underwater robots that are computationally limited.
- The underwater image quality is poor. Different from terrestrial imaging, underwater imaging has low-contrast, blurred images, and short visual distance, which lead to problems such as wrong labeling of datasets and easy loss of small objects during detection.
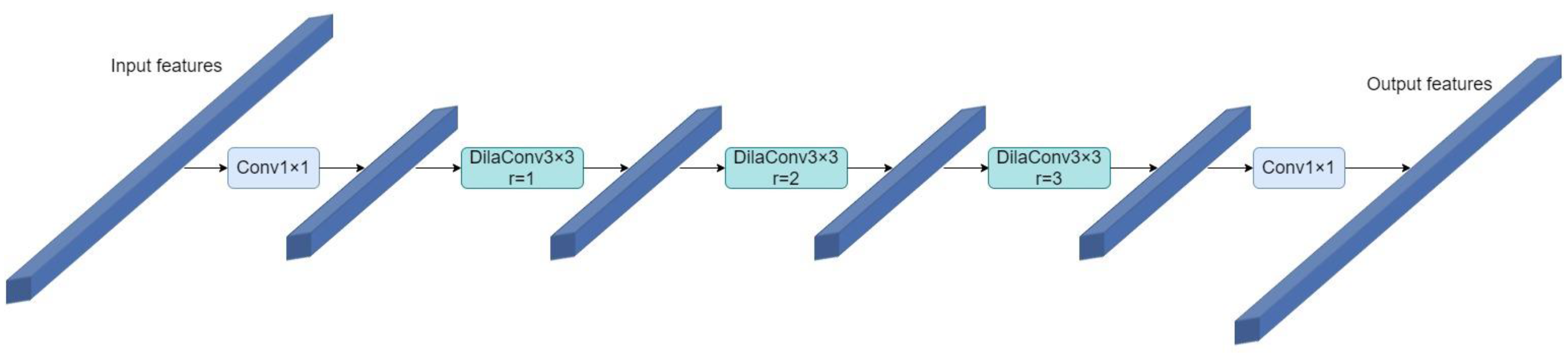
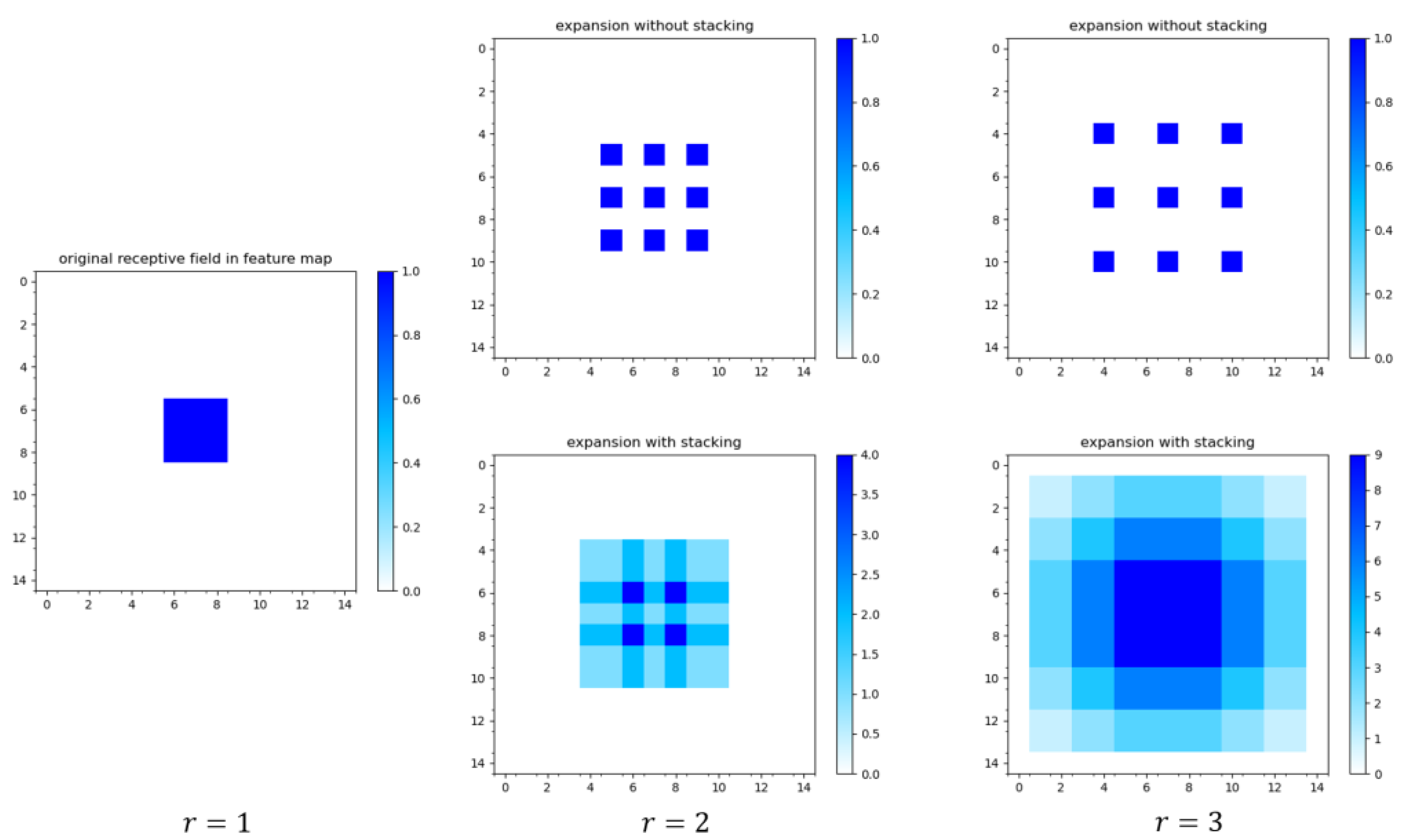
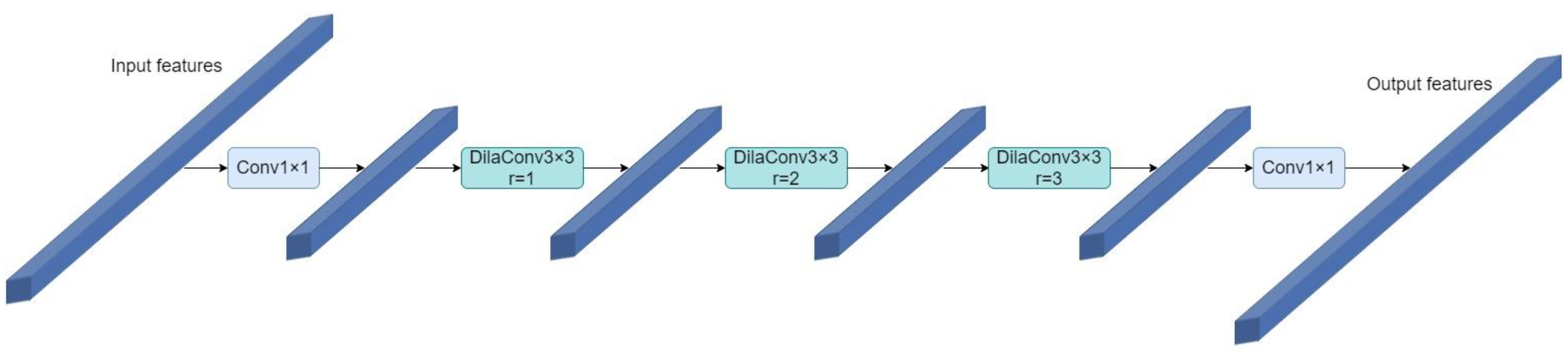
- This study designs a symmetric dilated convolutional module with symmetrical bottlenecks. The proposed symmetric dilated convolutional module is achieved by combining dilated convolutional layers [8] and 1 × 1 convolutional layers in a suitable way, which is able to capture more contextual information with lower computational consumption. The model’s detection mAP score improved by 8.74% by using it to replace the convolution of the last layer in the backbone network of YOLOv4-tiny.
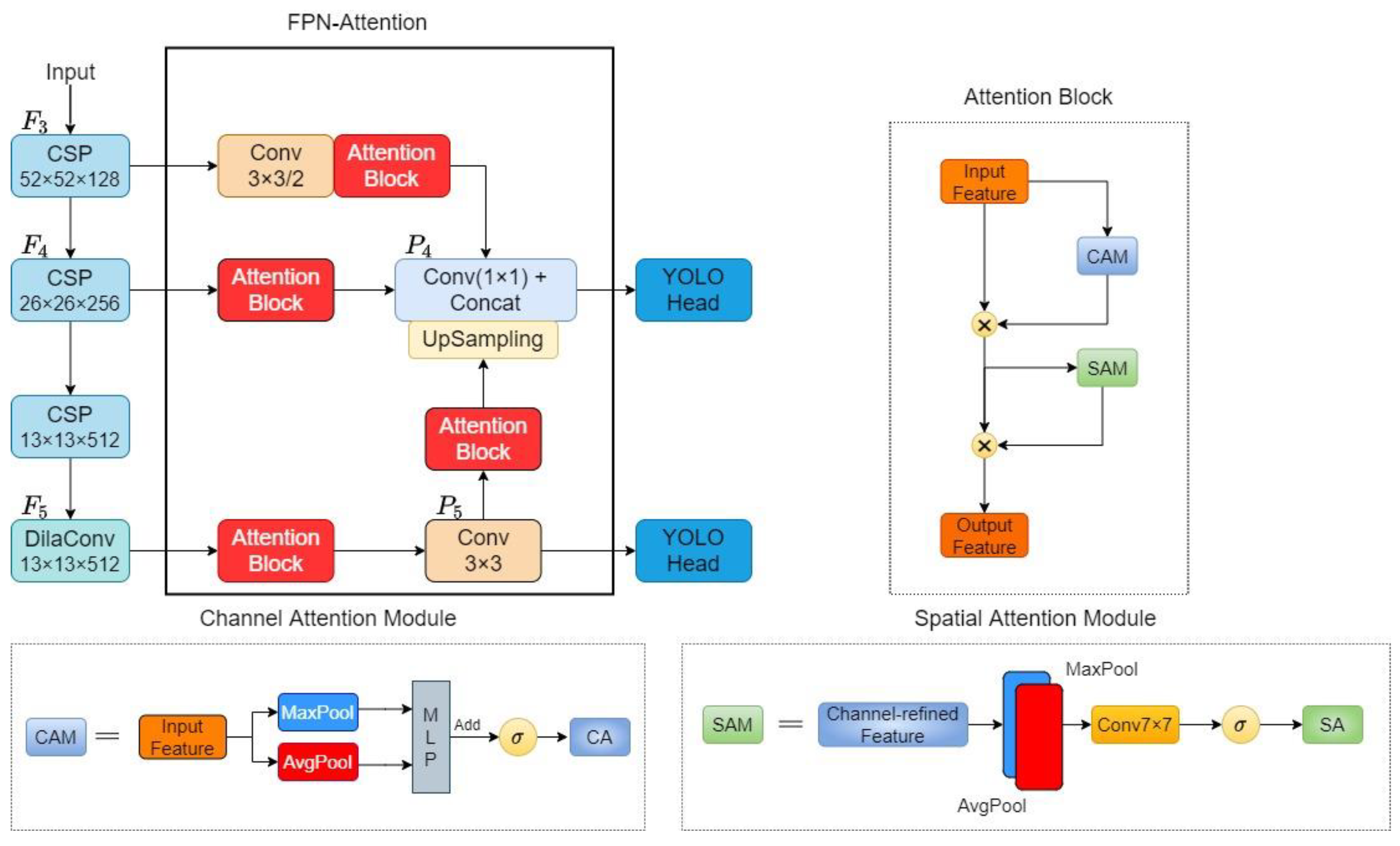
- This study develops a symmetric FPN-Attention module based on the channel-attention module and spatial-attention module in YOLOv4-tiny to increase its detection accuracy while keeping it lightweight. By fusing shallow features with the deeps, the symmetric FPN-Attention module will obtain feature maps with richer semantic information, and a more efficient feature fusion can be achieved through the attention module. The mAP score of YOLOv4-tiny can be improved by 8.75% when the symmetric FPN-Attention module is used. In addition, label smoothing is used during training to suppress the potential labeling mistakes to some extent and improve the model’s generalization for underwater object data.
- Experimental results on the Brackish underwater dataset [9] show that the proposed YOLO-UOD has higher detection performance in underwater object detection with 87.88% mAP, which surpasses YOLOv4-tiny’s 77.38%, YOLOv5s’s 83.05%, and YOLOv5m’s 84.34%. Besides, the proposed detector runs at about 9.24 FPS on Jetson Nana 2 GB, which is faster than YOLOv5s at 8.38 FPS and YOLOv5m at 4.11 FPS. The results show that YOLO-UOD has a better speed/accuracy trade-off underwater.
2. Related Work
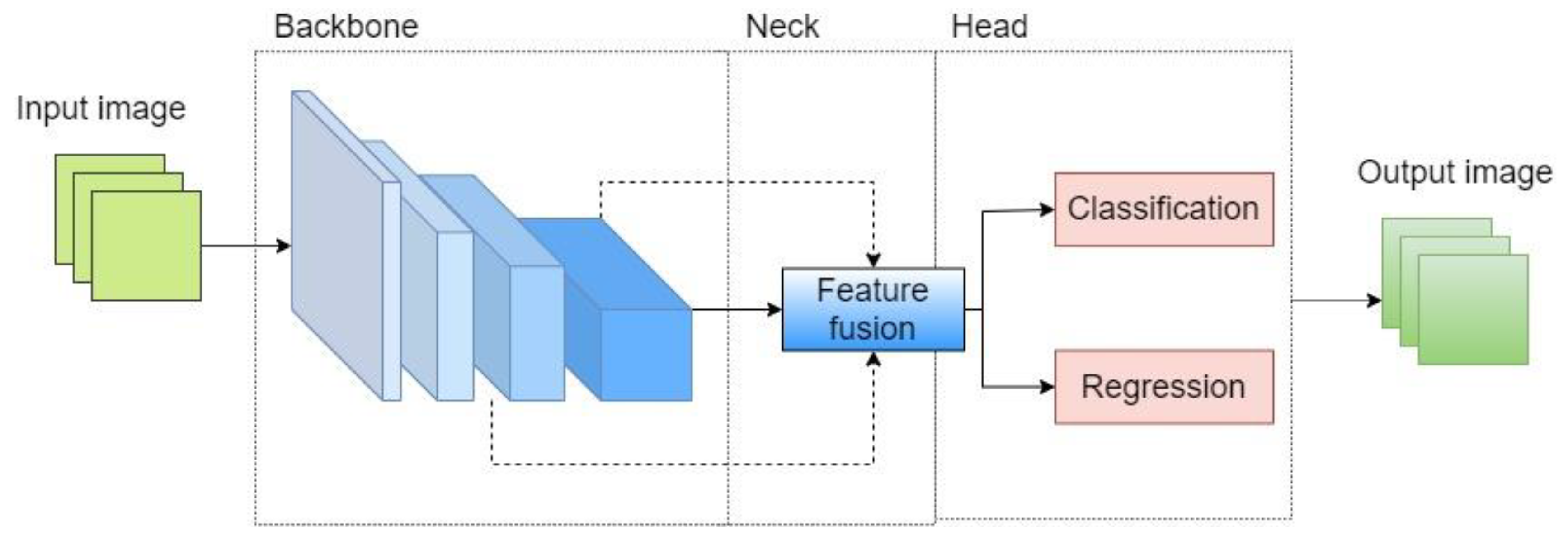
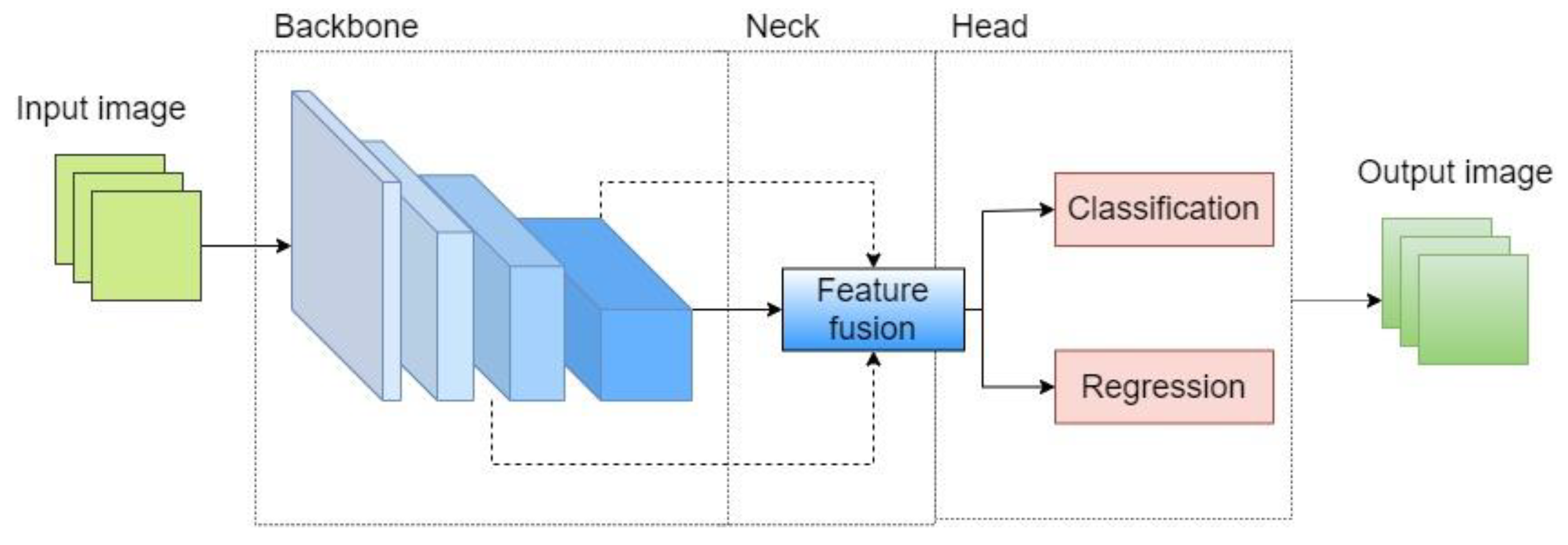
2.1. Basic Framework for Object Detection
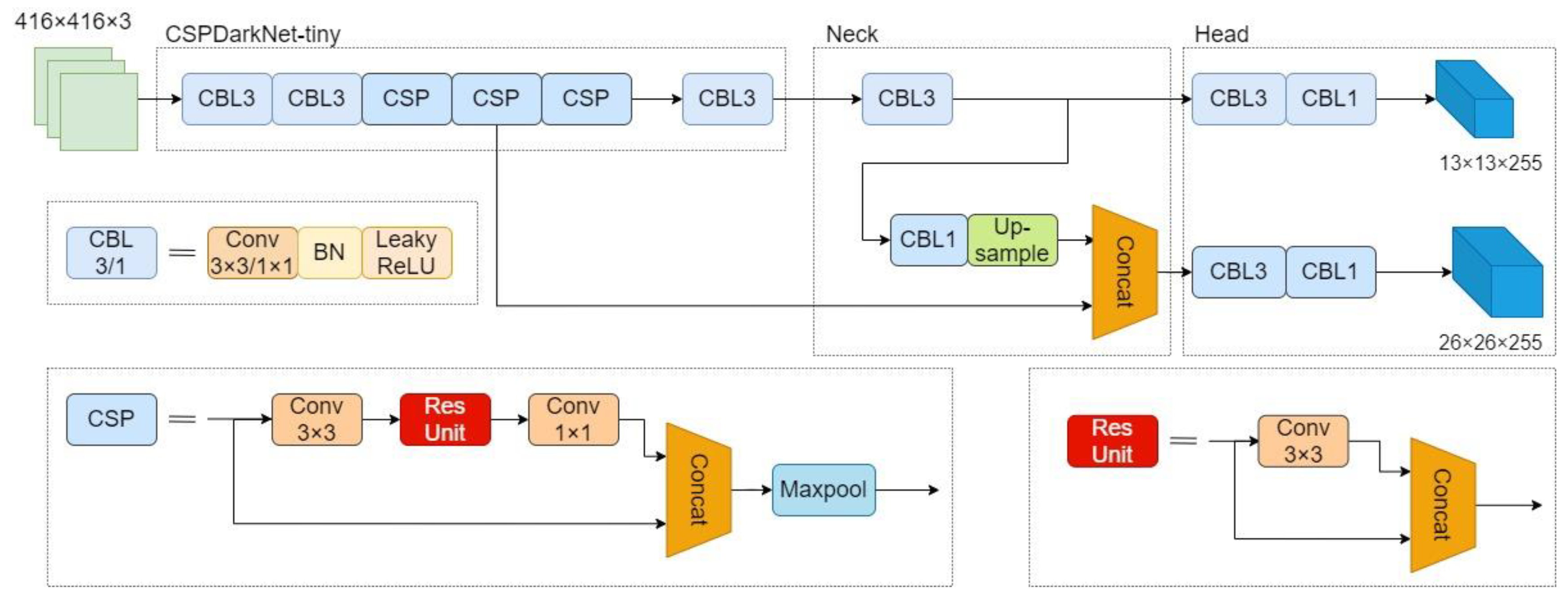
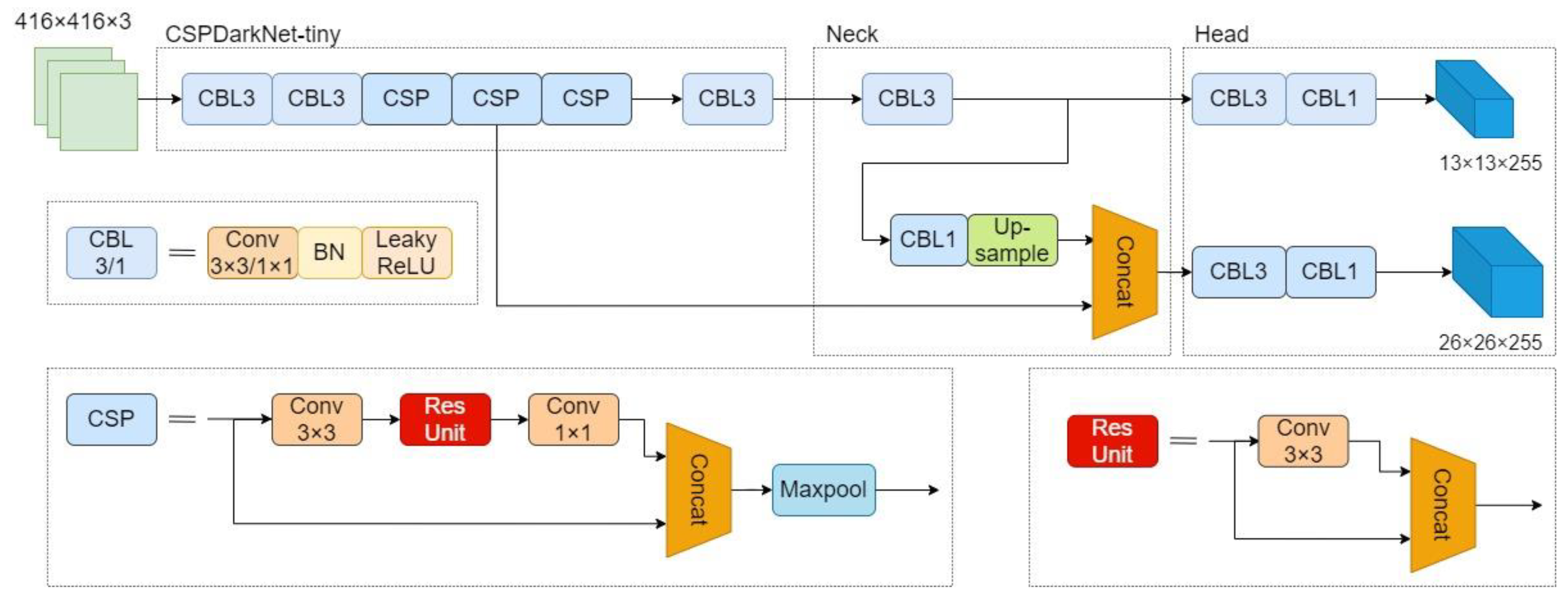
2.2. YOLOv4-Tiny
2.3. Attention Module
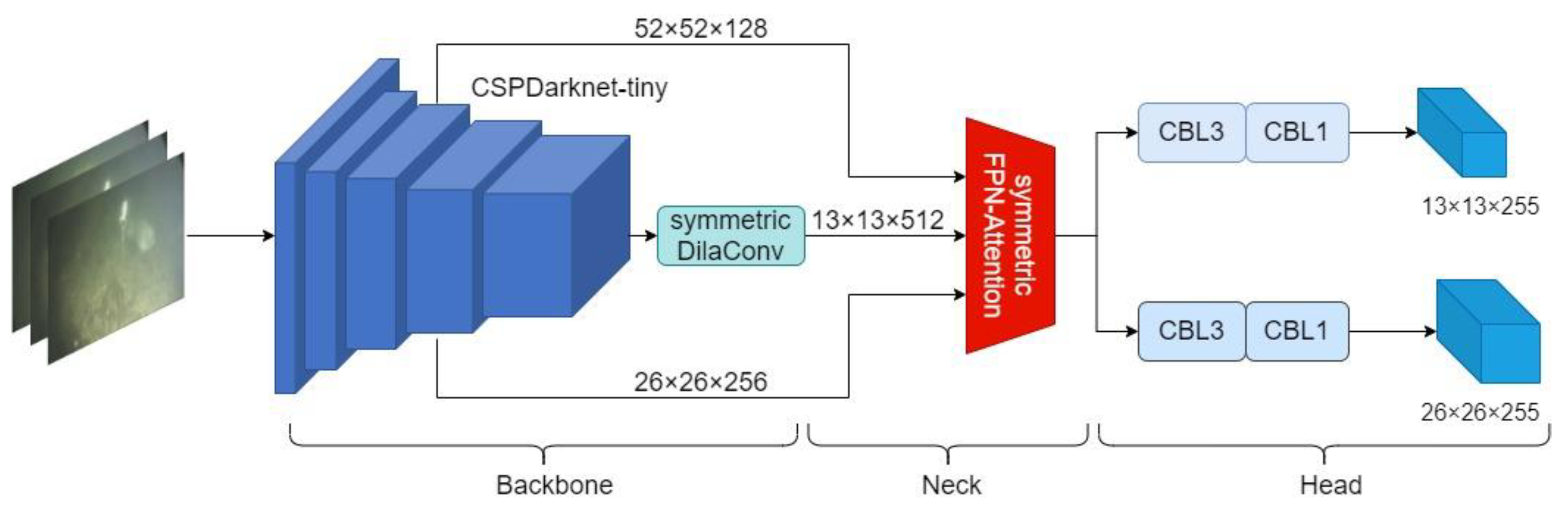
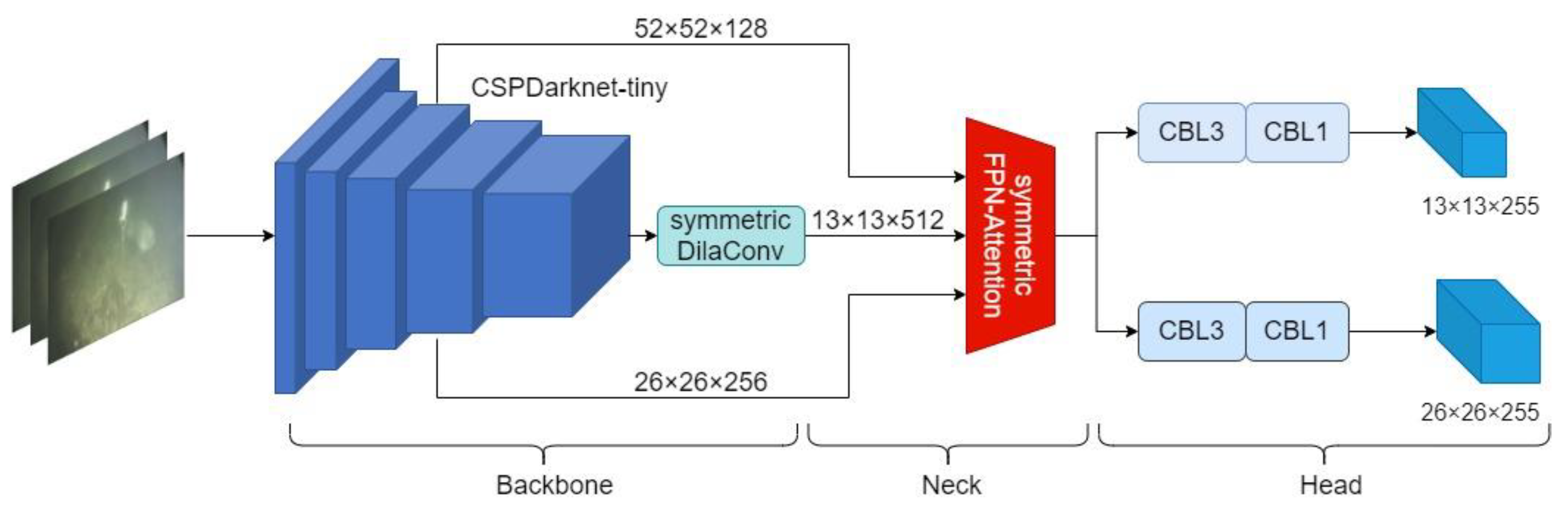
3. Improved YOLO Algorithm
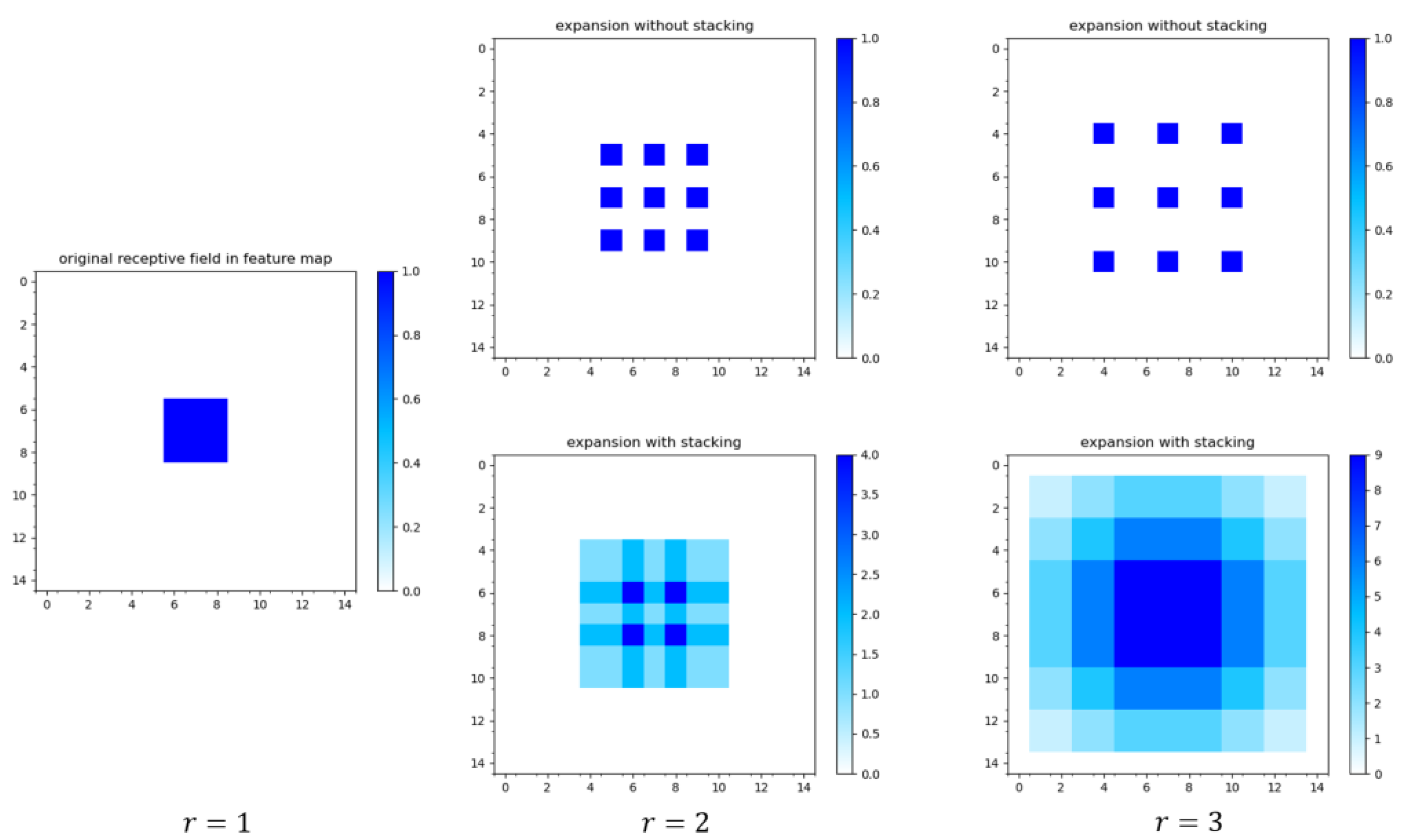
3.1. Symmetric Dilated Convolutional Module
3.2. Symmetric FPN-Attention Module
3.3. Label Smoothing
4. Experiments
4.1. Experimental Environment and Configuration
4.1.1. Underwater Image Dataset
4.1.2. Evaluation Metrics
4.1.3. Experimental Environment
4.2. Comparison and Analysis of Experimental Results
4.2.1. Ablation Experiments
4.2.2. Comparison of Different Algorithms
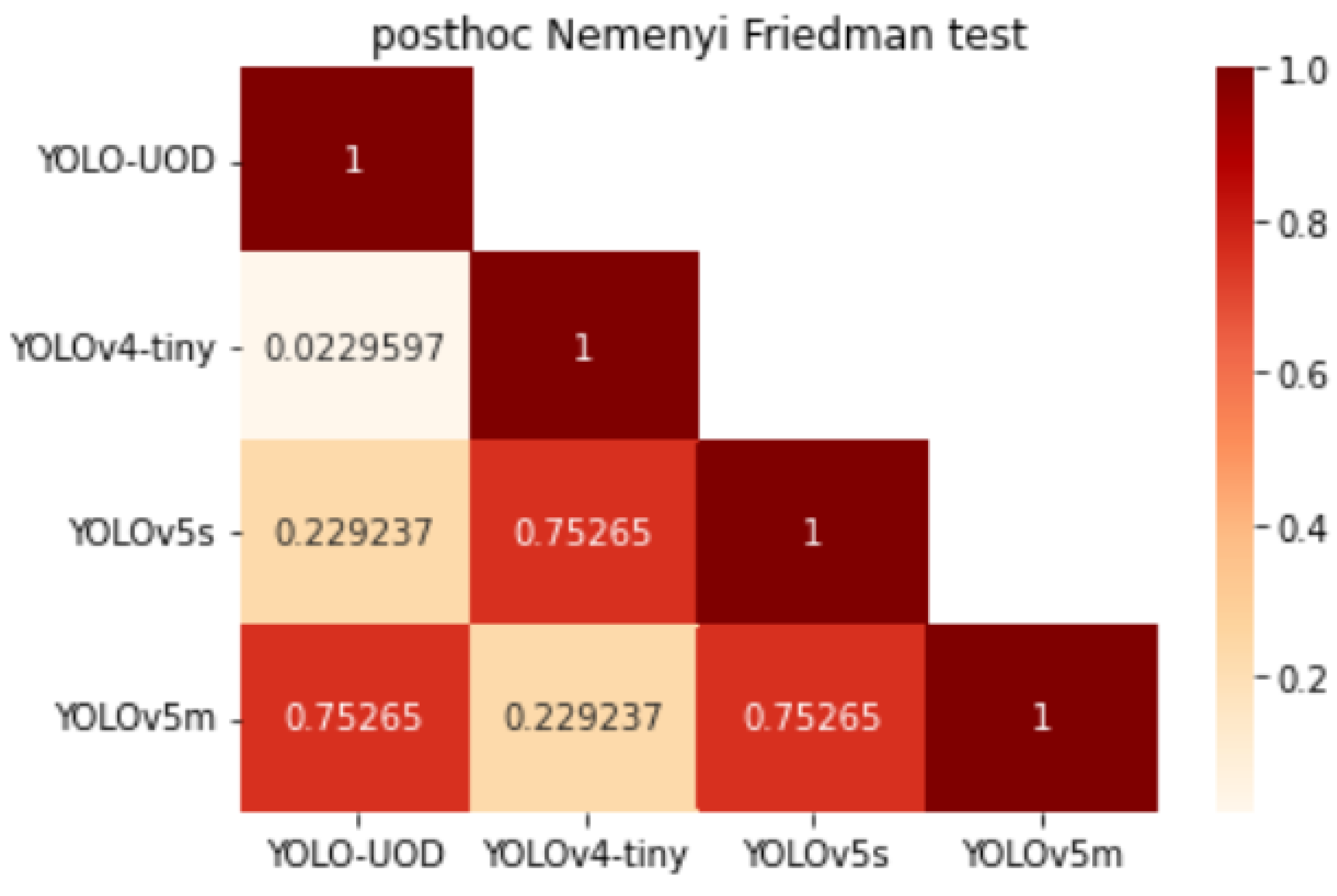
4.2.3. Statistical Analysis
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Mahmood, A.; Bennamoun, M.; An, S.; Sohel, F.A.; Boussaid, F.; Hovey, R.; Kendrick, G.A.; Fisher, R.B. Deep Image Representations for Coral Image Classification. IEEE J. Ocean. Eng. 2019, 44, 121–131. [Google Scholar] [CrossRef]
- Kim, B.; Yu, S.C. Imaging sonar based real-time underwater object detection utilizing AdaBoost method. Underw. Technol. IEEE 2017, 1–5. [Google Scholar] [CrossRef]
- Saini, A.; Biswas, M. Object detection in underwater image by detecting edges using adaptive thresholding. In Proceedings of the 2019 3rd International Conference on Trends in Electronics and Informatics (ICOEI), Tirunelveli, India, 23–25 April 2019; pp. 628–632. [Google Scholar]
- Wang, C.C.; Samani, H.; Yang, C.Y. Object Detection with Deep Learning for Underwater Environment. In Proceedings of the 2019 4th International Conference on Information Technology Research (ICITR), Moratuwa, Sri Lanka, 10–13 December 2019; pp. 1–6. [Google Scholar]
- Yang, H.; Liu, P.; Hu, Y.Z.; Fu, J. Research on underwater object recognition based on YOLOv3. Microsyst. Technol. 2021, 27, 1837–1844. [Google Scholar] [CrossRef]
- Chen, L.Y.; Zheng, M.C.; Dan, S.Q.; Luo, W.; Yao, L. Underwater Target Recognition Based on Improved YOLOv4 Neural Network. Electronics 2021, 10, 1634. [Google Scholar] [CrossRef]
- Wang, C.Y.; Bochkovskiy, A.; Liao, H.Y.M. Scaled-yolov4: Scaling cross stage partial network. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 20–25 June 2021; pp. 13029–13038. [Google Scholar]
- Yu, F.; Koltun, V. Multi-scale context aggregation by dilated convolutions. arXiv 2015, arXiv:1511.07122. [Google Scholar]
- Pedersen, M.; Bruslund Haurum, J.; Gade, R.; Moeslund, T.B. Detection of marine animals in a new underwater dataset with varying visibility. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops, Long Beach, CA, USA, 15–20 June 2019; pp. 18–26. [Google Scholar]
- Chen, C.; Zheng, Z.; Huang, Y.; Ding, X.; Yu, Y. I3net: Implicit instance-invariant network for adapting one-stage object detectors. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 20–25 June 2021; pp. 12576–12585. [Google Scholar]
- Wu, P.; Li, H.; Zeng, N.; Li, F. FMD-Yolo: An efficient face mask detection method for COVID-19 prevention and control in public. Image Vis. Comput. 2022, 117, 104341. [Google Scholar] [CrossRef] [PubMed]
- Jiang, Z.; Liu, Y.; Yang, C.; Liu, J.; Gao, P.; Zhang, Q.; Xiang, S.; Pan, C. Learning where to focus for efficient video object detection. In European Conference on Computer Vision; Springer: Cham, Switzerland, 2020; pp. 18–34. [Google Scholar]
- Sultani, W.; Chen, C.; Shah, M. Real-world anomaly detection in surveillance videos. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 6479–6488. [Google Scholar]
- Girshick, R.; Donahue, J.; Darrell, T.; Malik, J. Rich feature hierarchies for accurate object detection and semantic segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Columbus, OH, USA, 23–28 June 2014; pp. 580–587. [Google Scholar]
- Girshick, R. Fast r-cnn. In Proceedings of the IEEE International Conference on Computer Vision, Santiago, Chile, 7–13 December 2015; pp. 1440–1448. [Google Scholar]
- Ren, S.; He, K.; Girshick, R.; Sun, J. Faster R-CNN: Towards Real-Time Object Detection with Region Proposal Networks. IEEE Trans. Pattern Anal. Mach. Intell. 2017, 39, 1137–1149. [Google Scholar] [CrossRef] [PubMed]
- Liu, W.; Anguelov, D.; Erhan, D.; Szegedy, C.; Reed, S.; Fu, C.Y.; Berg, A.C. Ssd: Single shot multibox detector. In European Conference on Computer Vision; Springer: Cham, Switzerland, 2016; pp. 21–37. [Google Scholar]
- Lin, T.Y.; Goyal, P.; Girshick, R.; He, K.; Dollár, P. Focal loss for dense object detection. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 2980–2988. [Google Scholar]
- Tian, Z.; Shen, C.; Chen, H.; He, T. Fcos: Fully convolutional one-stage object detection. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Seoul, Korea, 27 October–3 November 2019; pp. 9627–9636. [Google Scholar]
- Redmon, J.; Divvala, S.; Girshick, R.; Farhadi, A. You only look once: Unified, real-time object detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 779–788. [Google Scholar]
- Redmon, J.; Farhadi, A. YOLO9000: Better, faster, stronger. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 7263–7271. [Google Scholar]
- Redmon, J.; Farhadi, A. Yolov3: An incremental improvement. arXiv 2018, arXiv:1804.02767. [Google Scholar]
- Bochkovskiy, A.; Wang, C.Y.; Liao, H.Y.M. Yolov4: Optimal speed and accuracy of object detection. arXiv 2020, arXiv:2004.10934. [Google Scholar]
- Wang, C.Y.; Liao, H.Y.M.; Wu, Y.H.; Chen, P.Y.; Hsieh, J.W.; Yeh, I.H. CSPNet: A new backbone that can enhance learning capability of CNN. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops, Seattle, WA, USA, 14–19 June 2020; pp. 390–391. [Google Scholar]
- Lin, T.Y.; Dollár, P.; Girshick, R.; He, K.; Hariharan, B.; Belongie, S. Feature pyramid networks for object detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 2117–2125. [Google Scholar]
- Hu, J.; Shen, L.; Sun, G. Squeeze-and-excitation networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 7132–7141. [Google Scholar]
- Woo, S.; Park, J.; Lee, J.Y.; Kweon, I.S. Cbam: Convolutional block attention module. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 3–19. [Google Scholar]
- Wang, Q.; Wu, B.; Zhu, P.; Li, P.; Zuo, W.; Hu, Q. ECA-Net: Efficient Channel Attention for Deep Convolutional Neural Networks. In Proceedings of the 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Seattle, WA, USA, 13–19 June 2020. [Google Scholar]
- Szegedy, C.; Vanhoucke, V.; Ioffe, S.; Shlens, J.; Wojna, Z. Rethinking the inception architecture for computer vision. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 2818–2826. [Google Scholar]
- Padilla, R.; Passos, W.L.; Dias, T.L.B.; Netto, S.L.; Da Silva, E.A. A comparative analysis of object detection metrics with a companion open-source toolkit. Electronics 2021, 10, 279. [Google Scholar] [CrossRef]
- Trawiński, B.; Smętek, M.; Telec, Z.; Lasota, T. Nonparametric statistical analysis for multiple comparison of machine learning regression algorithms. Int. J. Appl. Math. Comput. Sci. 2012, 22, 867–881. [Google Scholar] [CrossRef]





{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Prediction | Positive | Negative | |
|---|---|---|---|
| Ground Truth | |||
| Positive | TP | FN | |
| Negative | FP | TN | |
| Model | Training Time (Hours) | Testing Time (Image/ms) |
|---|---|---|
| RetinaNet | 3.6 | 19.70 |
| YOLOv3 | 3.9 | 9.56 |
| YOLOv4-tiny | 2.1 | 5.35 |
| YOLOv5s | 1.7 | 8.85 |
| YOLOv5m | 2.3 | 12.35 |
| YOLO-UOD | 2.1 | 6.18 |
| DilaConv | Symmetric FPN-Attention | Label Smoothing | Brackish |
|---|---|---|---|
| 77.38 | |||
| √ | 86.12 | ||
| √ | 86.13 | ||
| √ | √ | 87.37 | |
| √ | √ | √ | 87.88 |
| Model | AP(%) | mAP(%) | |||||
|---|---|---|---|---|---|---|---|
| Fish | Small Fish | Crab | Shrimp | Jellyfish | Starfish | ||
| RetinaNet | 97.69 | 55.27 | 59.79 | 69.13 | 60.67 | 88.04 | 71.77 |
| YOLOv3 | 87.10 | 73.00 | 86.26 | 61.43 | 71.78 | 95.60 | 79.20 |
| YOLOv4-tiny | 87.29 | 61.11 | 77.49 | 63.22 | 80.76 | 94.44 | 77.38 |
| YOLOv5s | 96.38 | 72.73 | 76.16 | 73.75 | 84.34 | 94.95 | 83.05 |
| YOLOv5m | 95.09 | 67.72 | 88.72 | 71.36 | 88.20 | 95.00 | 84.34 |
| YOLO-UOD | 98.44 | 74.01 | 84.46 | 86.37 | 88.43 | 95.58 | 87.88 |
| Network | Model Size (MB) | GFLOPs | FPS |
|---|---|---|---|
| YOLOv4-tiny | 22.4 | 3.47 | 9.87 |
| YOLOv5s | 7.3 | 17.06 | 8.38 |
| YOLOv5m | 81.5 | 51.43 | 4.11 |
| YOLO-UOD | 24.2 | 3.84 | 9.24 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Zhao, S.; Zheng, J.; Sun, S.; Zhang, L. An Improved YOLO Algorithm for Fast and Accurate Underwater Object Detection. Symmetry 2022, 14, 1669. https://doi.org/10.3390/sym14081669
Zhao S, Zheng J, Sun S, Zhang L. An Improved YOLO Algorithm for Fast and Accurate Underwater Object Detection. Symmetry. 2022; 14(8):1669. https://doi.org/10.3390/sym14081669
Chicago/Turabian StyleZhao, Shijia, Jiachun Zheng, Shidan Sun, and Lei Zhang. 2022. "An Improved YOLO Algorithm for Fast and Accurate Underwater Object Detection" Symmetry 14, no. 8: 1669. https://doi.org/10.3390/sym14081669
APA StyleZhao, S., Zheng, J., Sun, S., & Zhang, L. (2022). An Improved YOLO Algorithm for Fast and Accurate Underwater Object Detection. Symmetry, 14(8), 1669. https://doi.org/10.3390/sym14081669