1. Introduction
Fatigue, defined as the degradation of the mechanical properties of a material under loading that change over time, is one of the leading causes of machine and structural failure. A critical characteristic of fatigue is that the load is not sufficiently large to cause instantaneous failure. Instead, failure occurs after a particular number of load fluctuations have been encountered (i.e., after the cumulative damage has reached a critical threshold) [
1]. As a result, having a good understanding of the fatigue life of materials is critical for preventing damage caused by their failure, predicting the consequences of changes in operational conditions, identifying the cause of fatigue failure, and taking effective mitigating measures. In order to evaluate the fatigue life of materials, statistical distributions of the fatigue life can be considered. These distributions are often positive asymmetry or skewness (non-normality) and start from zero, since the fatigue life is always non-negative. Therefore, the fatigue life of materials cannot be described by either the normal or symmetrical distributions. In recent decades, asymmetric distribution that has received considerable attention for describing the fatigue life of materials is the Birnbaum–Saunders (BS) distribution. It was originally developed in response to a material fatigue problem and has been extensively used in reliability and fatigue research [
2]. The BS distribution explains the total amount of time that will pass until a dominant crack develops and grows to a point where the cumulative damage exceeds the threshold and causes failure. Desmond [
3] presented a more generalized extension of the BS distribution based on a biological model and also contributed to generalizing the actual reasons for using this distribution by relaxing the assumptions stated by Birnbaum and Saunders [
2]. In addition, Desmond [
4] deduced that the BS distribution is a mixture of the inverse Gaussian distribution with 0.5 as the mixing probability.
Although the BS distribution has its origins in materials science, it has subsequently been employed in a variety of other fields, including engineering, environmental studies, agriculture, and finance [
5,
6,
7,
8]. Many researchers have made significant contributions to the development of and parameter inference for the BS distribution. For example, Birnbaum and Saunders [
5] solved a nonlinear equation to obtain the maximum likelihood estimators (MLEs) for shape parameter
and scale parameter
. Engelhardt et al. [
9] investigated the asymptotic joint distribution of the MLEs and demonstrated that they are asymptotically independent. Based on this asymptotic joint distribution, they calculated the asymptotic confidence intervals for
and
. Approximations of the posterior marginal distributions of
and
were used by Achcar [
10] to produce Bayesian estimates. Ng et al. [
11] provided modified moment estimators (MMEs) for
and
, and then devised a bias reduction approach for the MLEs and MMEs. Lemonte et al. [
12] examined various bias correction strategies for the MLEs by using bootstrap methods (both parametric and nonparametric). Wang [
13] proposed a generalized confidence interval for
, as well as certain critical reliability quantities, such as the mean, quantiles, and a reliability function. Xu and Tang [
14] considered the Bayesian estimators for
and
under the reference prior and obtained Bayesian estimators by using the idea of Lindley’s approximation and the Gibbs sampling procedure. Niu et al. [
15] proposed two test statistics based on the exact generalized p-value approach and the delta method for comparing the characteristic quantities of several BS distributions, including the mean, quantiles, and a reliability function. Wang et al. [
16] applied inverse-gamma priors for
and
and presented an efficient sampling algorithm via the generalized ratio-of-uniforms method to calculate the Bayesian estimates and credible intervals. Li and Xu [
17] utilized fiducial inference for the parameters of a BS distribution. Guo et al. [
18] presented approaches that are hybrids between the generalized inference method and the large sample theory for interval estimation and hypothesis testing for the common mean of several BS populations. Recently, Puggard et al. [
19] proposed the confidence intervals for the coefficient of variation (CV) and the difference between the CVs of BS distributions based on the concept of generalized confidence interval (GCI), a bootstrapped confidence interval (BCI), a Bayesian credible interval (BayCI), and the highest posterior density (HPD) interval.
In statistics, variance is used to describe the deviation from the average (mean). It is determined by squaring the differences between each value in the dataset and the mean, then dividing the sum of the squares by the total number of values in the dataset. Moreover, variance is defined as the second central moment, while the square root of the variance is called the standard deviation [
20]. In the case of two independently collected datasets, determining whether the variance of the first one is significantly different from that of the second one is a critical statistical problem. To this end, the confidence interval for the ratio of the variances of two independent datasets can be used to compare the variance between them. If the confidence interval contains 1, it can be concluded that the variance of the first and second datasets is not significantly different. Many authors have focused on the construction of the confidence interval for the ratio of variances of two datasets by using different methods for various distributions. For example, Bonett [
21] proposed an approximate confidence interval for the ratio of variances of bivariate non-normal distributions. Bebu and Mathew [
22] applied the GCI approach and a modified signed log-likelihood ratio approach to construct the confidence interval for the ratio of variances of bivariate lognormal distributions. Paksaranuwat and Niwitpong [
23] compared the efficacies of adaptive and classical confidence intervals for the variance and the ratio of variances of non-normal distributions with missing data. Niwitpong [
24] examined the GCI approach for the ratio of variances of lognormal distributions. Wongyai and Suwan [
25] developed the confidence interval for the ratio of variances of bivariate non-normal distributions by using a kurtosis estimator. Recently, Maneerat et al. [
26] presented the HPD interval based on the normal-gamma prior and the method of variance estimates recovery (MOVER) to compute the confidence interval for the ratio of variances of delta-lognormal distributions. Nevertheless, the construction of the confidence interval for the ratio of variances of two independent BS distributions has not yet been reported. Therefore, the goal of the present study is to propose methods for constructing the confidence interval for the ratio of the variances of two BS distributions based on the generalized fiducial confidence interval (GFCI), a Bayesian credible interval (BCI), and the HPD intervals based on a prior with partial information (HPD-PI) and a proper prior with known hyperparameters (HPD-KH).
The rest of this article is structured as follows. The background on the BS distribution and the concepts of each of the methods for constructing the confidence interval for the ratio of variances of two BS distributions are described in
Section 2. The simulation studies and results are presented in
Section 3.
Section 4 provides an illustration of the proposed methods with real fatigue datasets from Birnbaum and Saunders [
5]. The final section contains conclusions on the study.
2. Methods
Let
,
and
be non-negative random samples drawn from BS distributions denoted by
, where
and
are the shape and scale parameters, respectively. The cumulative distribution function (cdf) can be written as
where
, and
is the standard normal cdf. Note that
is also the median of the distribution. The corresponding probability density function (pdf) of this cdf is given by
The following transformation was applied to generate samples from the BS distributions and to enable the derivation of some of their other properties, including various moments. If
, then
By applying the above transformation, the expected value and variance of
are
and
, respectively. Since
are independent, the ratio of the variances simply becomes
2.1. Generalized Fiducial Inference
Generalized fiducial inference can be used to transform the original data into other distributions that are known. According to the rules of that distribution, the transformed data are manipulated, and the results are transferred back to the original via an inverse transformation [
27]. This idea brings us to construct the confidence interval for the ratio of the variances of two BS distributions. Let
be the relationship between
and parameter
, where
is a structural equation and
is a random variable for which the distribution is definitively known and independent of any parameters. For any given realization
of
, inverse
always exists for any realization
of
. Since the distribution of
is definitively known, random sample
can be generated from it. This random sample of
can be transformed into a random sample of
via the inverse
, such that a random sample of
(i.e., a fiducial sample) can be obtained. However, in some situations, the inverse does not exist, for which Hannig [
27,
28] proposed the following solutions.
If
is a structural equation,
for
. Suppose that parameter
is
p-dimensional and
are independent identically distributed (i.i.d.) samples from Uniform (0,1). Under certain differentiability conditions, Hannig [
28] illustrated that the generalized fiducial distribution for
is definitively continuous with
where
denotes the likelihood function of the data and function
The above sum covers all possible p-tuples of indexes and and are and Jacobian matrixes, respectively. For any matrix B, submatrix is a matrix containing rows of B. In addition, if observation from a definitively continuous distribution is i.i.d. with cdf , then .
For a BS distribution, the generalized fiducial distribution of
derived by Li and Xu [
17] is in the form
where
and
Note that the symbol “∝” means “is proportional to.” In brief, if a is proportional to b, then the only difference between a and b is a multiplicative constant. By applying Equation (
11), Li and Xu [
17] showed that the priors of
and
can be denoted as
Thus,
is proper for the particular case of a prior with partial information given by the priors of
and
(
12). Therefore,
and
, which are the generalized fiducial samples of
and
, can be obtained from the generalized fiducial distribution in the same way as the Bayesian posterior. The adaptive rejection Metropolis sampling (ARMS), which origins to adaptive rejection sampling (ARS), was used to generate the fiducial samples (
and
) from the generalized fiducial distribution (
9). The ARS was proposed by Gilks and Wild [
29]. It was only suitable for log-concave target densities. In order to address the limitations of ARS, Gilks et al. [
30] improved ARS to handle multivariate distributions and non-log-concave densities by permitting the proposal distribution to remain lower than the target in some regions and adding a Metropolis–Hastings step to guarantee that the accepted samples are properly distributed. This method was called ARMS, which can be easily implemented via the function
in package
of R software suite (version 3.5.1). Note that
and
are treated as random variables. Therefore,
and
are substituted by
and
, respectively, resulting in the generalized fiducial estimates of
being derived as
Finally, the
GFCI for
is
, where
is the
percentile of
. Algorithm 1 summarizes the steps for constructing GFCI for
, as seen below.
| Algorithm 1: GFCI |
- 1.
Generate datasets from a BS distribution. - 2.
Generate K samples of and by applying the function in the package of the R software suite. - 3.
Burn-in B samples (the number of remaining samples is ). - 4.
Thin the samples by applying sampling lag (the final number of samples is . Note that the generated samples are not independent, and so we need to reduce the autocorrelation by thinning the samples. - 5.
Calculate by applying Equation ( 13) and obtain , . - 6.
Calculate the GFCI.
|
2.2. Bayesian Inference
For this method, Xu and Tang [
14] illustrated that the reference prior of a BS distribution (a type of Jeffreys’ prior) results in an improper posterior distribution. Thus, to guarantee its propriety, proper priors with known hyperparameters are obtained by assuming that an inverse-gamma distribution with parameters
and
is the prior of
and an inverse-gamma distribution with parameters
and
is the prior of
[
16].
In accordance with Bayes’ theorem, the joint posterior density function of
can be written as
Integrating the joint posterior density function (
14) with respect to
yields the marginal posterior distribution of
as follows:
From the joint posterior density function (
14), it is clear that the fully conditional posterior distribution of
given
is given by
Posterior samples are drawn by adopting the Markov chain Monte Carlo technique. Since the marginal posterior distribution (
15) cannot be written as if it were known, generating posterior samples of
from this density is impossible using the usual methods. There are three common approaches, such as the random-walk Metropolis procedure, the Metropolis–Hastings algorithm and the slice sampler by introducing an auxiliary variable to simplify the sampling problem that might be considered to sample from the marginal posterior distribution (
15). However, all three approaches are susceptible to serially correlated draws, indicating that a very large sample size is frequently required to produce a reasonable estimate of any desired attribute of the posterior distribution. To avoid these potential problems when generating the posterior samples, the generalized ratio-of-uniforms method of Wakefield et al. [
31] is used to generate posterior samples of
(denoted as
). The concept of the generalized ratio-of-uniforms method is as follows.
Suppose that a pair of variables
is uniformly distributed inside region
where
is a constant term and
is specified by using the marginal posterior distribution (
15). Subsequently, the pdf of
becomes
. For generating random points uniformly distributed in
, the accept–reject method from a convenient enveloping region (usually from the minimal bounding rectangle) is applied. According to Wakefield et al. [
31], the minimal bounding rectangle for
is given by
where
and
Note that
as
and
as
. Hence,
,
is finite, and
is also finite when choosing an appropriate value for
[
16]. The generalized ratio-of-uniforms method consists of the following three steps.
- 1.
Compute and .
- 2.
Draw and from and , where refers to a uniform distribution with parameter v and w, and compute .
- 3.
Set if ; otherwise, the process is repeated.
Meanwhile,
, which are the posterior samples of
, can be obtained from the conditional posterior distribution (
16) by applying the
package from the R software suite. Subsequently, the posterior samples of
(denoted as
) comprise the square roots of
. Note that
and
are also treated as random variables. Hence, the Bayesian estimates for
can be written as
Finally, the
BCI for
is
, where
is the
percentile of
. In conclusion, BCI for
can be obtained by using Algorithm 2.
| Algorithm 2: BCI |
- 1.
Set and , where . - 2.
Compute and . - 3.
At the steps,
- (a)
Generate and , and then compute . - (b)
If , set ; otherwise, repeat Step (a). - (c)
Generate , and then . - (d)
Compute the Bayesian estimates for by applying Equation ( 22).
- 4.
Repeat Step (3), M times. - 5.
Calculate the BCI.
|
2.3. The Highest Posterior Density (HPD) Interval
The HPD interval is where the posterior density for every point within the interval is higher than the posterior densities of the points outside of it, indicating that the interval contains the more likely values of the parameter while excluding the less likely ones. According to Box and Tiao [
32], the HPD interval has two main properties:
- 1.
Every point within the interval has a higher probability density than the points outside of it.
- 2.
For given probability level , the interval has the narrowest length.
By applying Equation (
11), Li and Xu [
17] showed that
is a special case of a prior with partial information, and the generalized fiducial estimates of
and
can be obtained by using the same method as for the Bayesian posterior. Therefore, at Step (6) in Algorithm 1, we applied the
package (version 0.2.2) from the R software suite to compute the HPD interval based on a prior with partial information (HPD-PI). Moreover, we also applied the
package at Step (5) in Algorithm 2 to compute the HPD interval based on a proper prior with known hyperparameters (HPD-KH).
3. Simulation Studies
To compare the performance of the proposed methods, a Monte Carlo simulation study was conducted with various sample sizes and parameter values. Equal sample sizes were set as
= (10, 10), (20, 20), (30, 30), (50, 50), or (100, 100) and unequal sample sizes as (10, 20), (30, 20), (30, 50), or (100, 50) while the values for the shape parameters
were set as (0.25, 0.25), (0.25, 0.50), (0.25, 1.00), (0.50, 0.50), (0.50, 1.00), or (1.00, 1.00). Without loss of generality, scale parameters
and
were set as 1 in all scenarios. The confidence intervals were calculated at the nominal level of 0.95. All simulation results were obtained by running 1000 replications with
and
for GFCI and HPD-PI while
for BCI and HPD-KH. According to Wang et al. [
16], BCI and HPD-KH were considered with
and hyperparameters
. The criteria for evaluating the performances of the proposed methods are their coverage probabilities and average lengths. The method with a coverage probability greater than or close to the nominal level 0.95 and with the narrowest average length was chosen as the best performing method for a particular scenario.
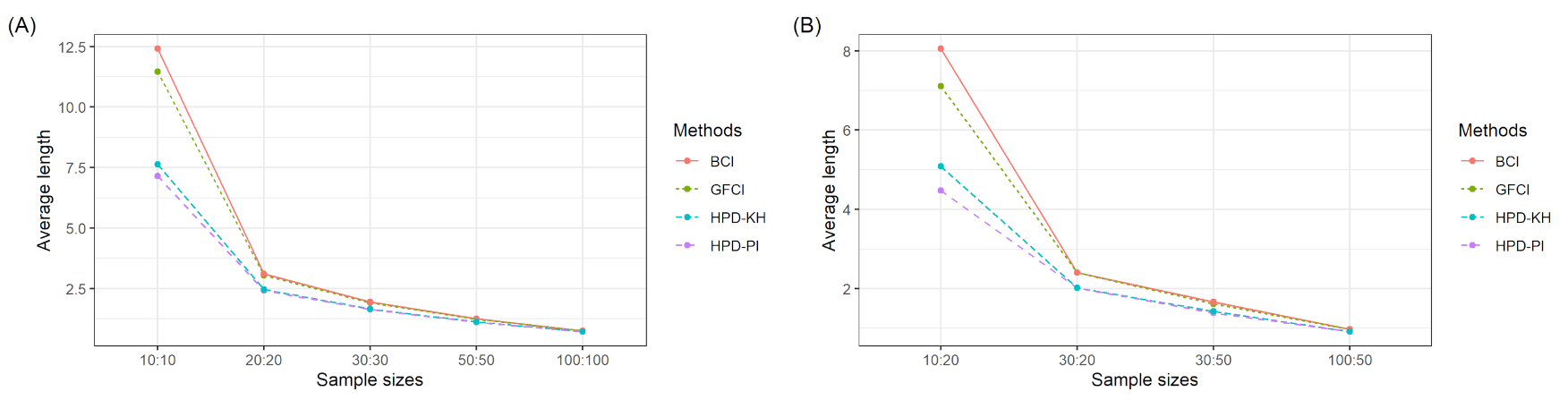
Table 1 and
Table 2 report the simulation results, while
Figure 1 and
Figure 2 summarize the coverage probabilities and average lengths in
Table 1 and
Table 2. The simulation results from
Table 1 and
Table 2 indicate that the coverage probabilities of the four methods were greater than or close to 0.95 under all configurations. In addition, it was found that the differences in coverage probability among the four methods were very small. Moreover, HPD-PI provided the narrowest average lengths while BCI provided the longest ones under all circumstances. The average lengths of HPD-IP were mostly narrower than GFCI, while the average lengths of HPD-KH were mostly narrower than those of BCI. Moreover, the average length of the four methods decreased as the sample sizes
increased.
4. Application of the Methods to Real Fatigue Life Data
To illustrate the effectiveness of the confidence interval construction methods proposed in this study in a real-life scenario, we used real datasets concerning the fatigue life of 6061-T6 aluminum coupons that were cut parallel to the rolling direction and oscillated at 18 cycles per second [
5]. As reported in
Table 3, there are two groups consisting of 101 and 102 observations with maximum stress levels per cycle of 21,000 and 26,000 psi, respectively (the summary statistics of each group are provided in
Table 4). Hence, the ratio of variances was 0.0254. We chose
and
, where
, for the Bayesian credible interval and HPD-KH.
The results for the 95% confidence interval for the ratio of variances reported in
Table 5 indicate that the length provided by HPD-PI was the narrowest while that of the Bayesian credible interval was the longest. These results are in accordance with those from the simulation studies where
. In addition, the confidence intervals constructed by using the various methods did not contain 1, and so it can be concluded that there is no significant difference in terms of variance for the fatigue lifetime of 6061-T6 aluminum coupons with maximum stress per cycle of 21,000 and 26,000 psi, respectively.





{kind=link}
{kind=link}