
A Two-Stage Siamese Network Model for Offline Handwritten Signature Verification

Abstract
:1. Introduction
- This is a significant attempt to study Chinese signature identification.
- A two-stage Siamese network model is proposed to verify the offline handwritten signature.
- Visualization of the process of feature representation is analyzed.
2. Preliminaries
2.1. Related Work
- Most of them only treat handwriting signature as a picture and do not mine deep signature style.
- They commonly ignore the imbalance distribution of positive and negative signatures that often occurs in real scenarios.
- The signature samples of each writer are usually small and the similarity between real signature and forged signature is high in real scenarios. The existing models usually generate synthetic data that are quite different from the real ones.
- It has a two-stage Siamese network module to verify the offline-handwritten signature. This network includes both traditional original handwriting recognition and data-enhanced handwriting recognition to mine the writers’ deep signature style.
- It employs the Focal loss to deal with the extreme imbalance between positive and negative offline signatures, which is quite different from previous studies.
- It is the first attempt to study the Chinese signatures with a real Chinese signature dataset.
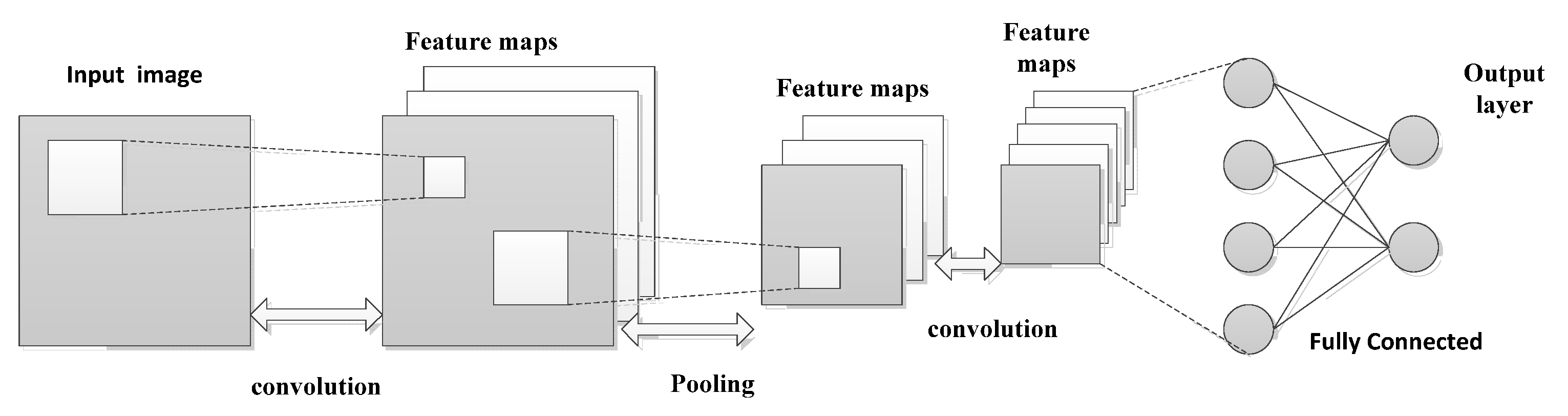
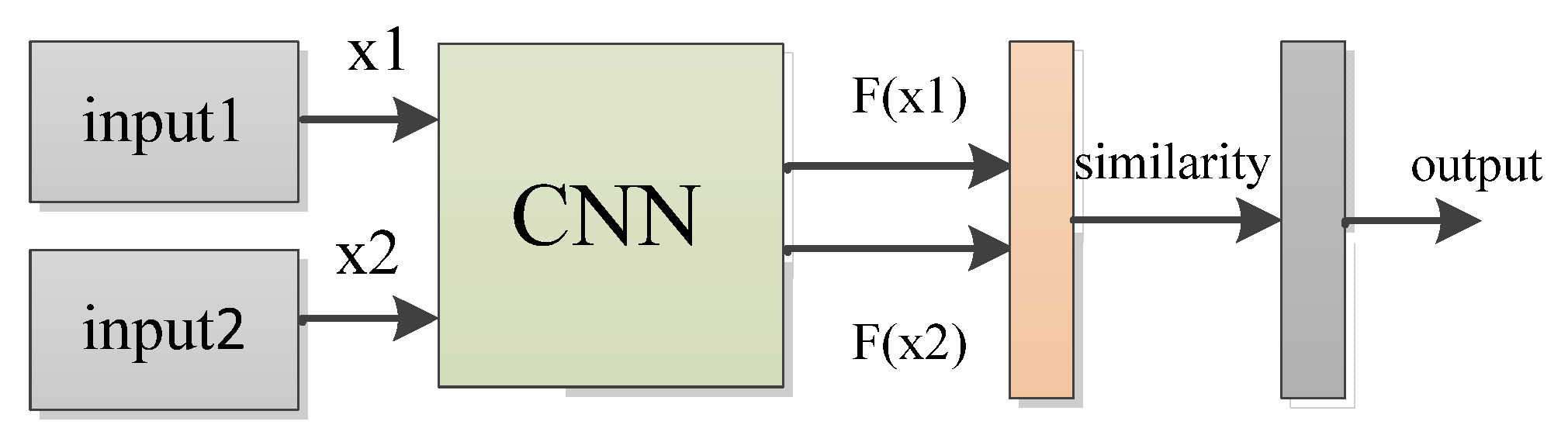
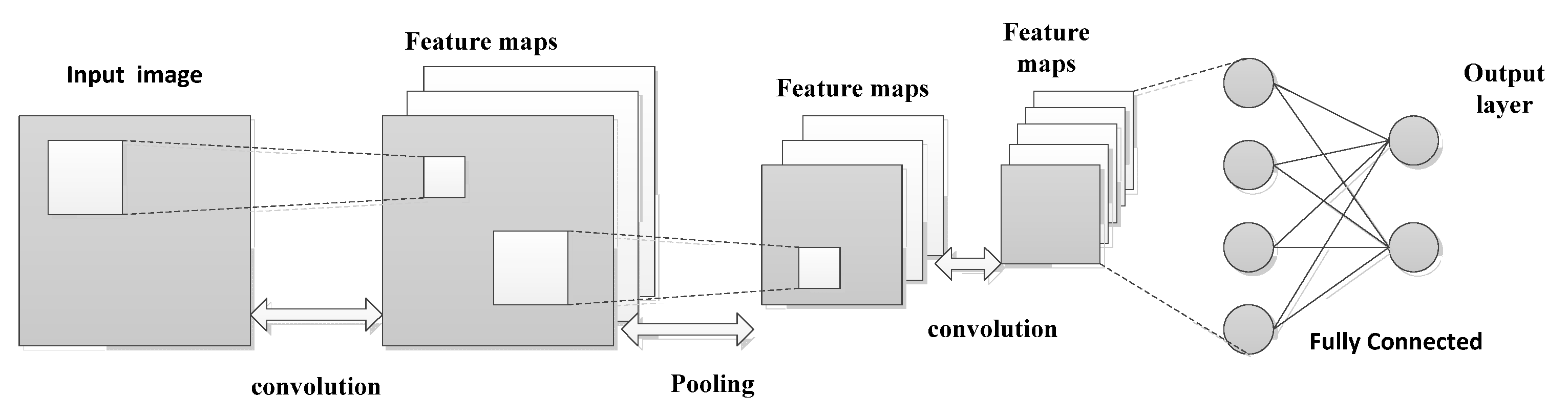
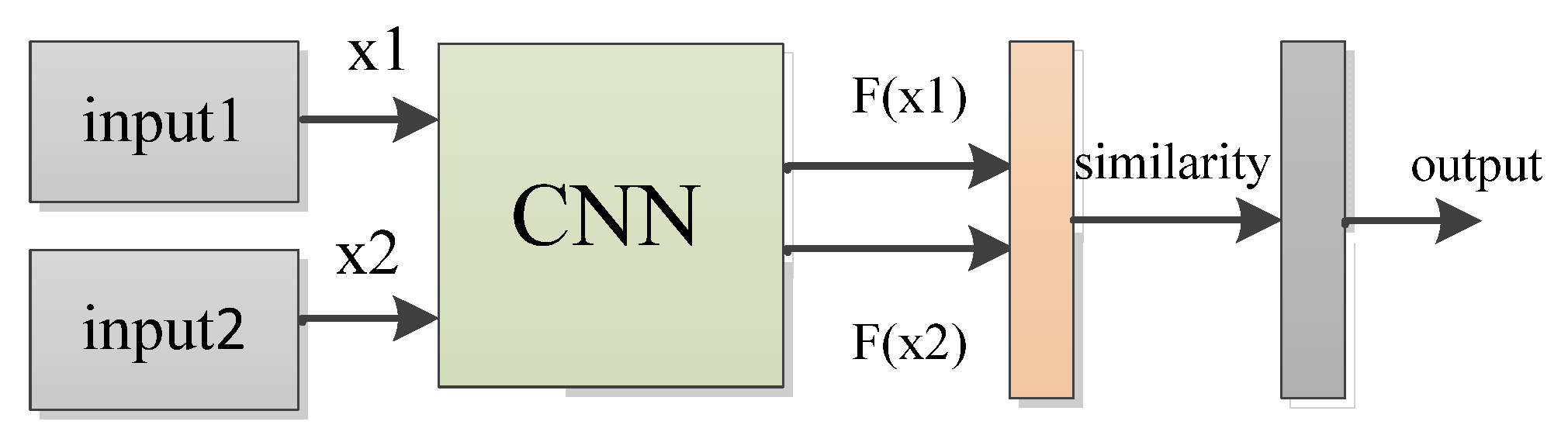
2.2. CNN and Siamese Neural Network
2.3. Focal Loss
3. Model
3.1. Problem Formulation
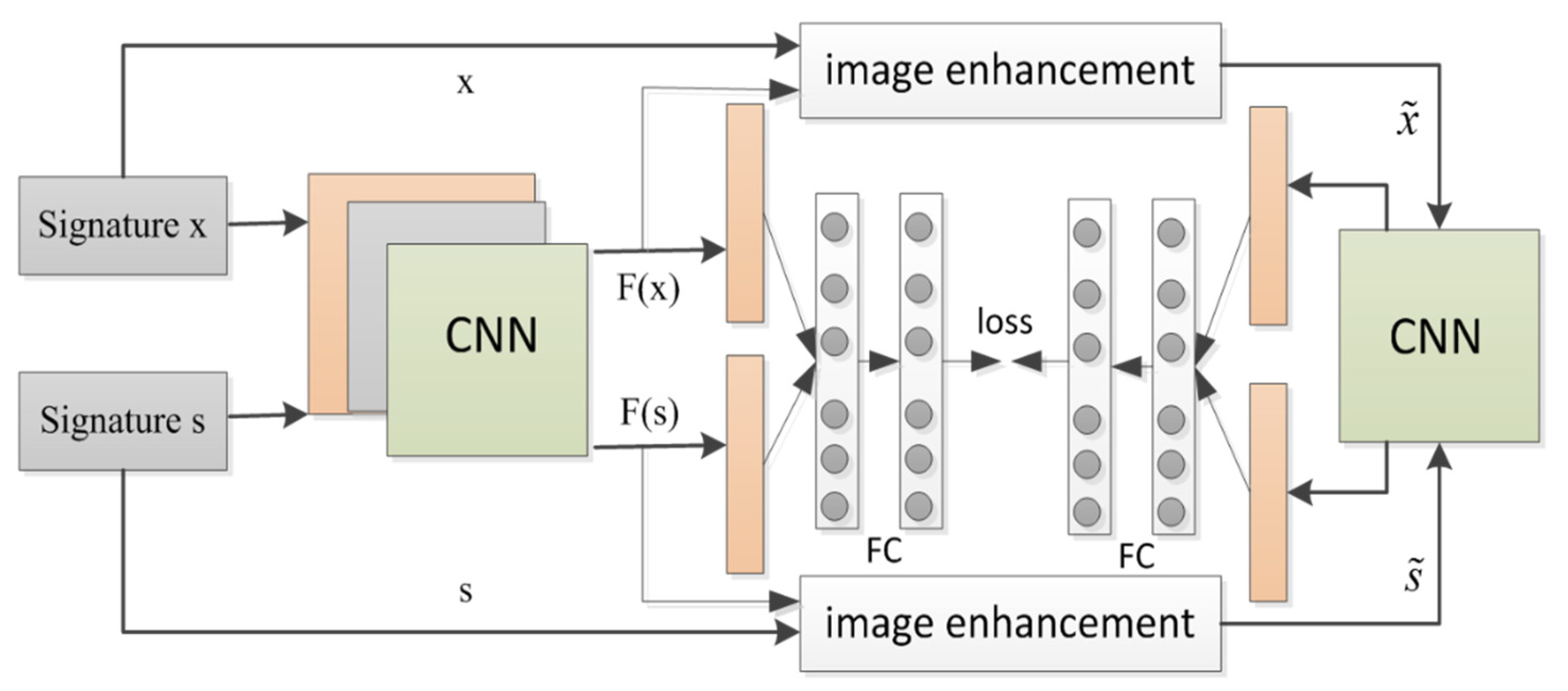
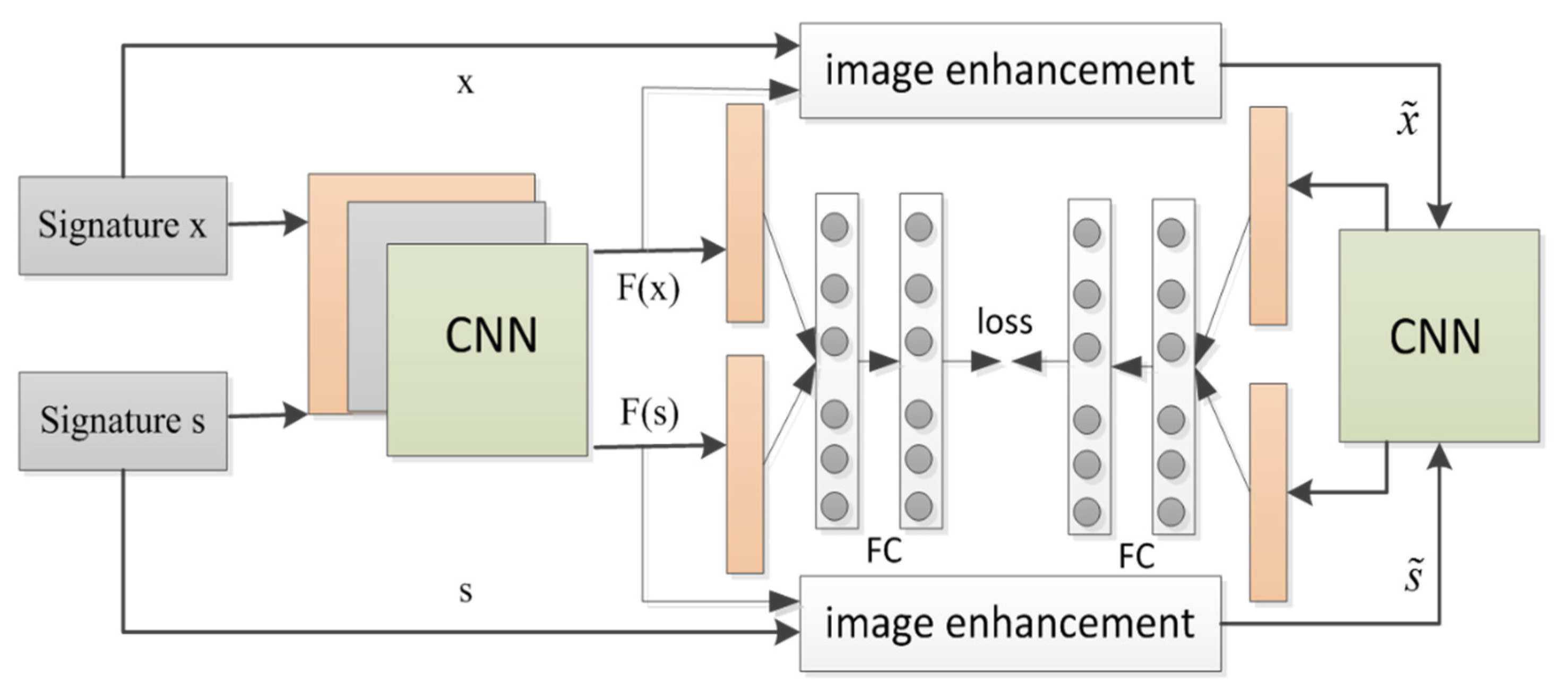
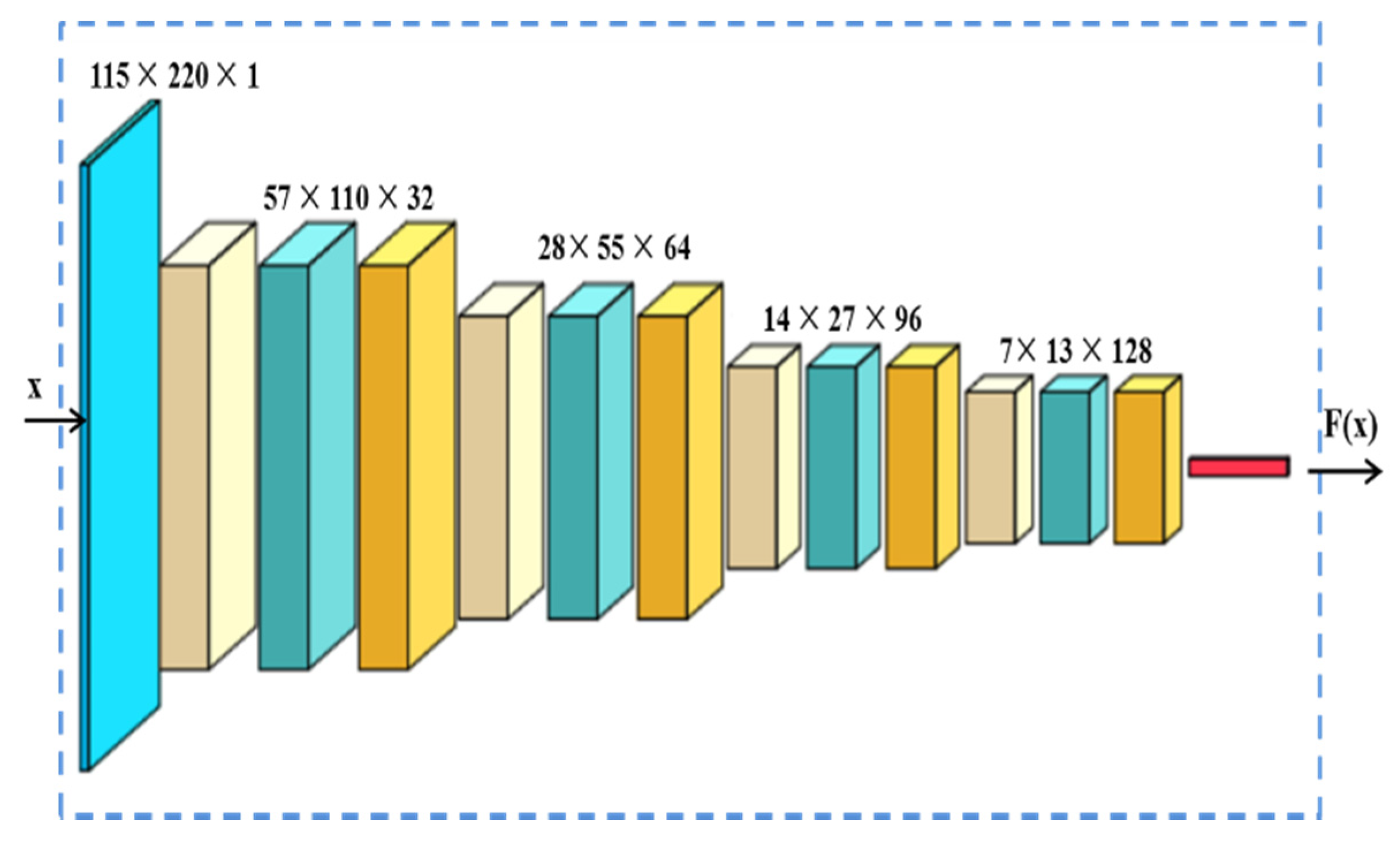
3.2. Architecture of the Two-Stage Network
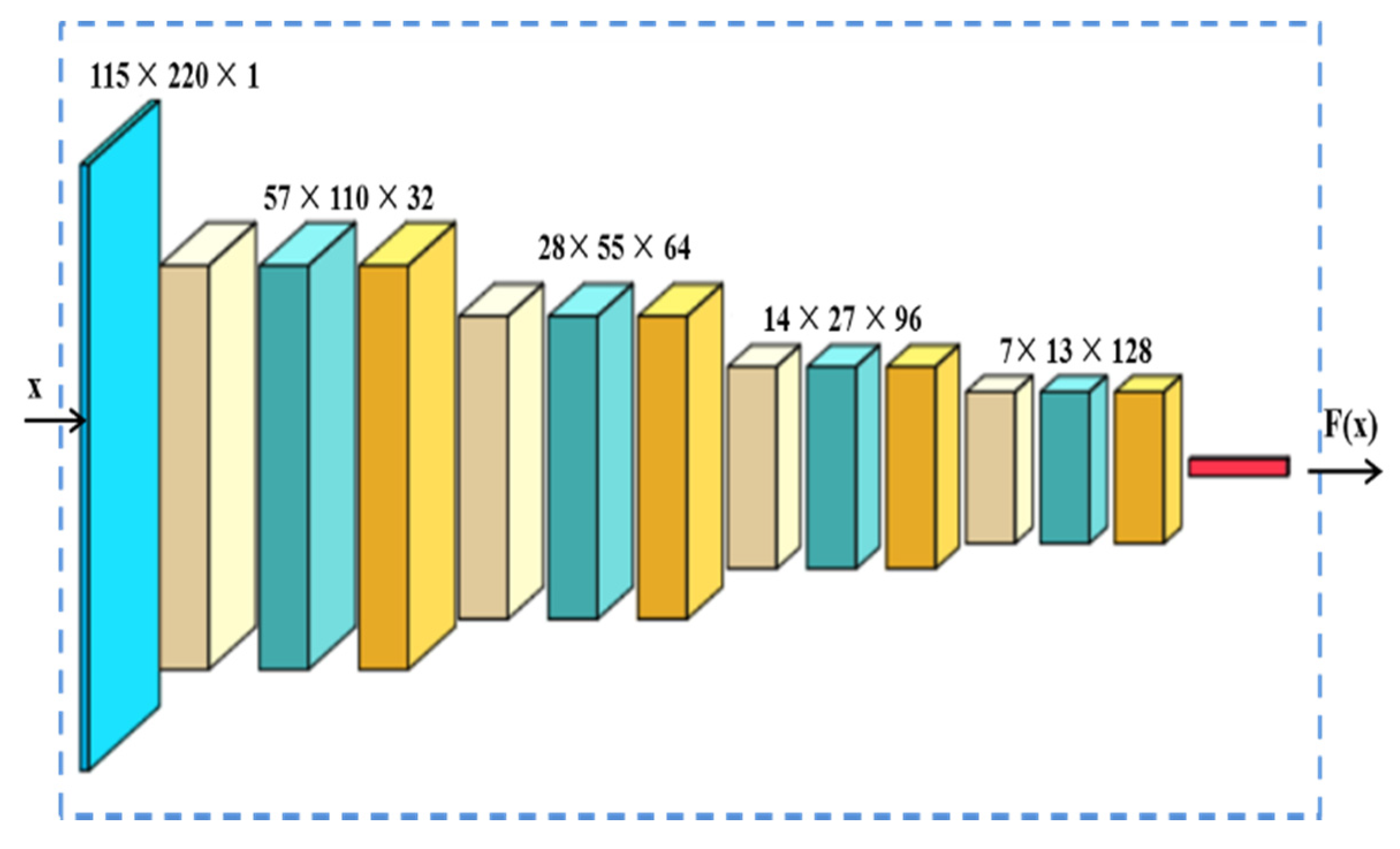
3.3. The Feature Extractor
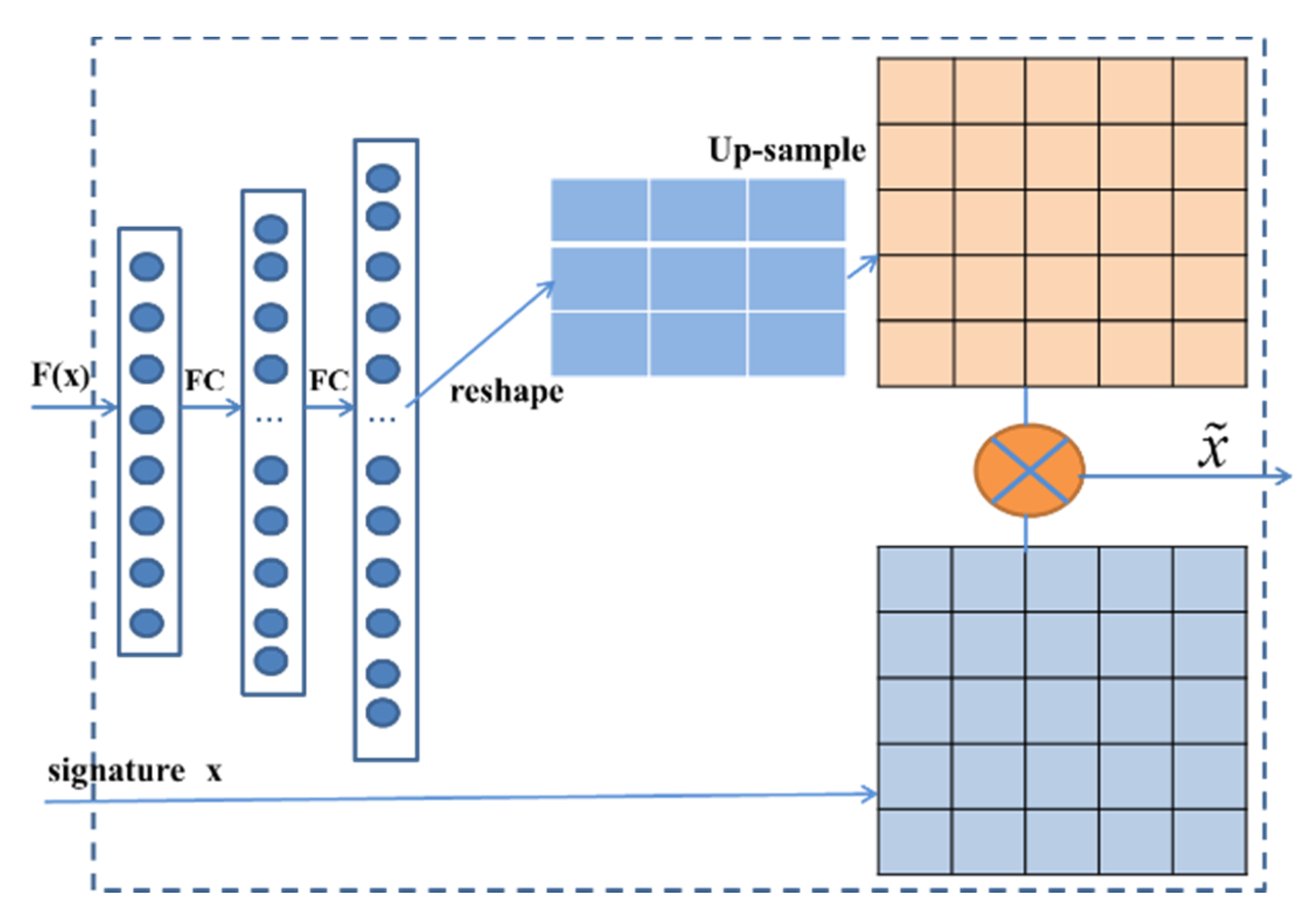
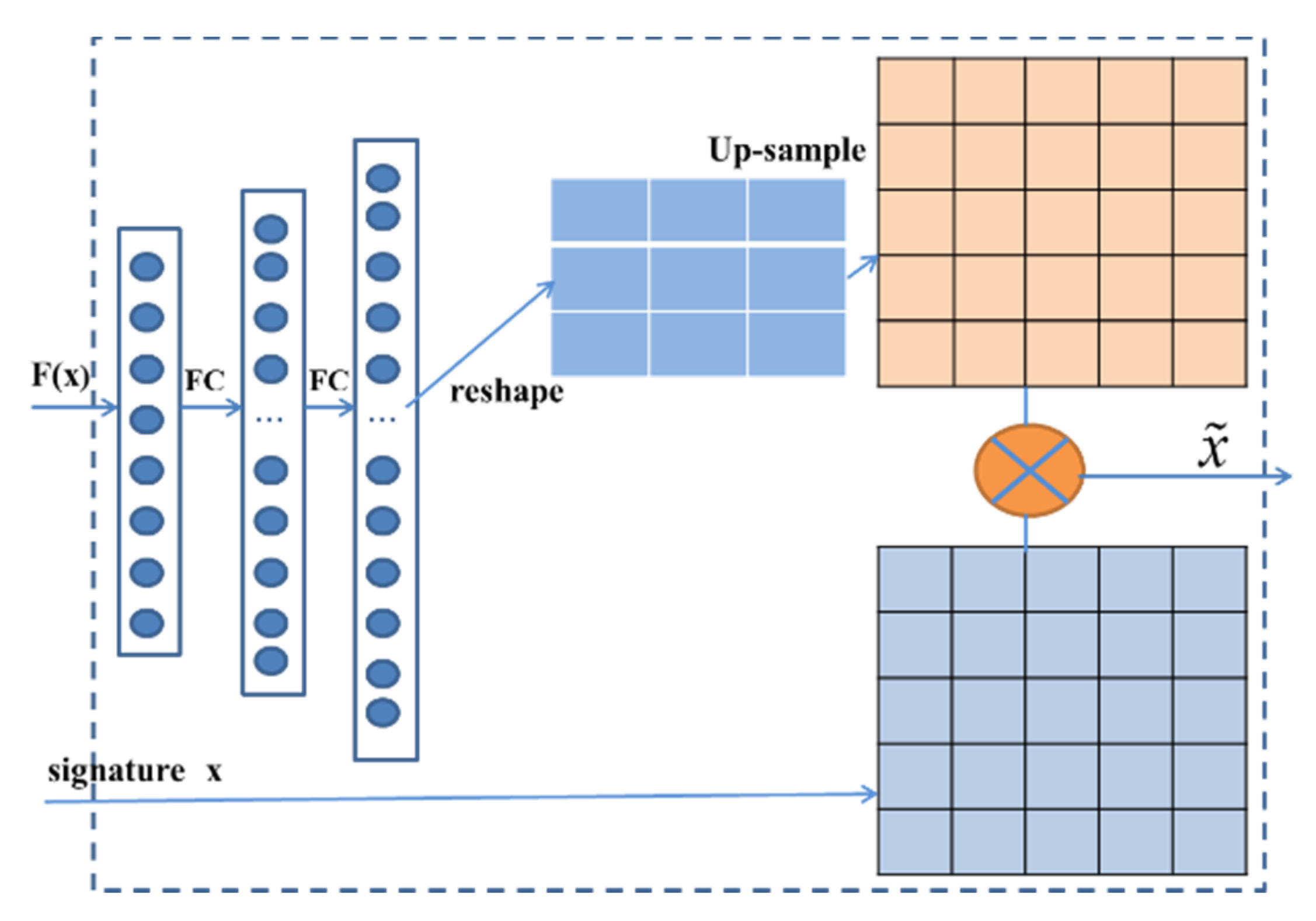
3.4. The Signature Image Data Enhancement
3.5. Loss Function
3.6. Algorithm Design
| Algorithm 1: Training Process of the Proposed Algorithm |
| Require: set up the batch size m, the maximum number of epoch k, the learning rate LR, and the penalty factors |
| Require: Initialize the weights of the networks . |
| for epoch number = 1 : k do |
| Randomly select m images from the training image dataset: |
| Select m corresponding genuine images from the preprocessed dataset: |
| Calculate the eigenvector and the Loss according to the network weights . |
| Update the weights of the networks . |
| End for |
4. Empirical Studies
4.1. General Settings
4.2. Comparison with State-of-the-Art Models
4.3. Chinese Signature Dataset
4.4. Process Visualization
- Compared with previous methods, this model has better prediction performance. On the CEDAR signature dataset, the FRR, FAR, and ACC of the proposed method reach 6.78%, 4.20%, and 95.66%, respectively, which are superior to the existing comparison methods under all evaluation indicators. On the BHSIG-Bengali and BHSIG-Hindi signature datasets, our model achieves ACC of 90.64% and 88.98%, respectively, which is superior to other models. These results show that our method is superior to other comparison methods. In addition, our writer-independent approach still performs better than the writer-dependent approach.
- The data enhancement method adopted in this study is only related to the original input signature image. The original input signature image is processed by a series of neural networks to generate a data enhancement weight matrix. Finally, the degree of image data enhancement is adjusted by adjusting the proportion of the weight matrix, which improves the accuracy of experimental results, and the proposed model has strong robustness.
- The focal Loss function is very effective for solving the problem of unbalanced positive and negative data.
- The proposed model also has good performance in Chinese signature datasets, and this conclusion will be helpful for further research on offline Chinese signature verification.
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Vincent, C.; David, B.; Florian, H.; Andreas, M.; Elli, A. Writer Identification Using GMM Supervectors and ExemplarSVMs. Pattern Recognit. 2017, 63, 258–267. [Google Scholar]
- Luo, X.; Liu, Z.; Li, S.; Shang, M.; Wang, Z. A Fast Non-Negative Latent Factor Model Based on Generalized Momentum Method. IEEE Trans. Syst. Man Cybern. Syst. 2021, 51, 610–620. [Google Scholar] [CrossRef]
- Khan, F.; Tahir, M.; Khelifi, F. Robust Offline Text in Dependent Writer Identification Using Bagged Discrete Cosine Transform Features. Expert Syst. Appl. 2017, 71, 404–415. [Google Scholar] [CrossRef]
- Wu, H.; Luo, X.; Luo, X. Advancing non-negative latent factorization of tensors with diversified regularizations. IEEE Trans. Serv. Comput. 2020, 99, 1. [Google Scholar] [CrossRef]
- Wei, P.; Li, H.; Hu, P. Inverse Discriminative Networks for Handwritten Signature Verification. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Long Beach, CA, USA, 15–20 June 2019; pp. 5757–5765. [Google Scholar]
- Maergner, P.; Pondenkandath, V.; Alberti, M.; Liwicki, M.; Riesen, K.; Ingold, R.; Fischer, A. Combining Graph Edit Distance and Triplet Networks for Offline Signature Verification. Pattern Recognit. Lett. 2019, 125, 527–533. [Google Scholar] [CrossRef]
- Jain, A.; Singh, S.K.; Singh, K.P. Handwritten signature verification using shallow convolutional neural network. Multimed. Tools Appl. 2020, 79, 19993–20018. [Google Scholar] [CrossRef]
- Wu, D.; Luo, X.; Shang, M.; He, Y.; Wang, Y.; Wu, X. A Data-Characteristic-Aware Latent Factor Model for Web Service QoS Prediction. IEEE Trans. Knowl. Data Eng. 2022, 34, 2525–2538. [Google Scholar] [CrossRef]
- Wu, D.; He, Q.; Luo, X.; Shang, M.; He, Y.; Wang, Y. A posterior-neighborhood-regularized latent factor model for highly accurate web service QoS prediction. IEEE Trans. Serv. Comput. 2022, 15, 793–805. [Google Scholar] [CrossRef]
- Zois, E.N.; Alewijnse, L.; Economou, G. Offline signature verification and quality characterization using poset-oriented grid features. Pattern Recognit. 2016, 54, 162–177. [Google Scholar] [CrossRef]
- Luo, X.; Qin, W.; Dong, A.; Sedraoui, K.; Luo, X. Efficient and High-quality Recommendations via Momentum-incorporated Parallel Stochastic Gradient Descent-based Learning. IEEE/CAA J. Autom. Sin. 2021, 8, 402–411. [Google Scholar] [CrossRef]
- Li, H.; Wei, P.; Hu, P. AVN: An Adversarial Variation Network Model for Handwritten Signature Verification. IEEE Trans. Multimed. 2021, 24, 594–608. [Google Scholar] [CrossRef]
- Wu, D.; He, Q.; Luo, X.; Zhou, M. A Latent Factor Analysis-Based Approach to Online Sparse Streaming Feature Selection. IEEE Trans. Syst. Man Cybern. Syst. 2021, 1, 1–15. [Google Scholar] [CrossRef]
- Alaei, A.; Pal, S.; Pal, U.; Blumenstein, M. An efficient signature verification method based on an interval symbolic representation and a fuzzy similarity measure. IEEE Trans. Inf. Forensics Secur. 2017, 12, 2360–2372. [Google Scholar] [CrossRef] [Green Version]
- Liu, Z.; Luo, X.; Wang, Z. Convergence Analysis of Single Latent Factor-dependent, Non-negative and Multiplicative Update-based Non-negative Latent Factor Models. IEEE Trans. Neural Netw. Learn. Syst. 2021, 32, 1737–1749. [Google Scholar] [CrossRef] [PubMed]
- Jain, A.; Singh, S.K.; Singh, K.P. Multi-task learning using GNet features and SVM classifier for signature identification. IET Biom. 2021, 2, 117–126. [Google Scholar] [CrossRef]
- Luo, X.; Yuan, Y.; Chen, S.; Zeng, N.; Wang, Z. Position-transitional particle swarm optimization-incorporated latent factor analysis. IEEE Trans. Knowl. Data Eng. 2020, 99, 1. [Google Scholar] [CrossRef]
- Sharif, M.; Khan, M.; Faisal, M.; Yasmin, M.; Fernandes, S.L. A framework for offline signature verification system: Best features selection approach. Pattern Recognit. 2020, 139, 50–59. [Google Scholar] [CrossRef]
- Khan, F.; Tahir, M.; Khelifi, F. Novel Geometric Features for Offline Writer Identification. Pattern Anal. Appl. 2016, 19, 699–708. [Google Scholar]
- Bhunia, A.K.; Alaei, A.; Roy, P.P. Signature verification approach using fusion of hybrid texture features. Neural Comput. Appl. 2019, 31, 8737–8748. [Google Scholar] [CrossRef] [Green Version]
- Luo, X.; Zhou, M.; Li, S.; Wu, D.; Liu, Z.; Shang, M. Algorithms of Unconstrained Non-Negative Latent Factor Analysis for Recommender Systems. IEEE Trans. Big Data 2021, 7, 227–240. [Google Scholar] [CrossRef]
- Ruiz, V.; Linares, I.; Sanchez, A.; Velez, J.F. Offline handwritten signature verification using compositional synthetic generation of signatures and Siamese Neural Networks. Neurocomputing 2020, 374, 30–41. [Google Scholar] [CrossRef]
- Hu, J.; Chen, Y. Offline Signature Verification Using Real Adaboost Classifier Combination of Pseudo-dynamic Features. In Proceedings of the International Conference on Document Analysis & Recognition, Washington, DC, USA, 25–28 August 2013; pp. 1345–1349. [Google Scholar]
- Hafemann, L.; Sabourin, R.; Oliveira, L. Learning Features for Offline Handwritten Signature Verification using Deep Convolutional neural networks. Pattern Recognit. 2017, 70, 163–176. [Google Scholar] [CrossRef] [Green Version]
- Jain, A.; Singh, S.K.; Singh, K.P. Signature verification using geometrical features and artificial neural network classifier. Neural Comput. Appl. 2020, 12, 6999–7010. [Google Scholar] [CrossRef]
- Dutta, A.; Pal, U.; Lladós, J. Compact Correlated Features for Writer Independent Signature Verification. In Proceedings of the International Conference on Pattern Recognition (ICPR), Cancún, Mexico, 4–8 December 2016; pp. 3422–3427. [Google Scholar]
- He, S.; Schomaker, L. Writer Identification Using Curvature Free Features. Pattern Recognit. 2017, 63, 451–464. [Google Scholar] [CrossRef]
- Li, L.; Huang, L.; Yin, F.; Chen, Y. Offline signature verification using a region based deep metric learning network. Pattern Recognit. 2021, 118, 108009. [Google Scholar] [CrossRef]
- Li, C.; Lin, F.; Wang, Z.; Yu, G.; Yuan, L.; Wang, H. DeepHSV: User-Independent Offline Signature Verification Using Two-Channel CNN. In Proceedings of the International Conference on Document Analysis and Recognition (ICDAR), Sydney, Australia, 20–25 September 2019; pp. 166–171. [Google Scholar]
- Danilo, A.; Manoochehr, J.; Luigi, C.; Alessio, F.; Marco, R. R-SigNet: Reduced space writer-independent feature learning for offline writer-dependent signature verification. Pattern Recognit. Lett. 2021, 150, 189–196. [Google Scholar]
- Neculoiu, P.; Versteegh, M.; Rotaru, M. Learning Text Similarity with Siamese Recurrent Networks. In Proceedings of the Repl4NLP Workshop at ACL2016, Berlin, Germany, 11 August 2016; pp. 148–157. [Google Scholar]
- Wu, D.; Shang, M.; Luo, X.; Wang, Z. An L1-and-L2-Norm-Oriented Latent Factor Model for Recommender Systems. IEEE Trans. Neural Netw. Learn. Syst. 2021, 1–14. [Google Scholar] [CrossRef]
- Ho, S.L.; Yang, S.; Yao, Y.; Fu, W. Robust optimization using a methodology based on Cross Entropy methods. IEEE Trans. Magn. 2011, 47, 1286–1289. [Google Scholar] [CrossRef]
- Lin, T.; Goyal, P.; Girshick, R. Focal Loss for Dense Object Detection. IEEE Trans. Pattern Anal. Mach. Intell. 2017, 99, 2999–3007. [Google Scholar]
- Zhang, J.; Xing, M.; Sun, G.; Chen, J.; Li, M.; Hu, Y.; Bao, Z. Water Body Detection in High-Resolution SAR Images With Cascaded Fully-Convolutional Network and Variable Focal Loss. IEEE Trans. Geosci. Remote Sens. 2021, 59, 316–332. [Google Scholar] [CrossRef]
- Xiao, W.; Wu, D. An Improved Siamese Network Model for Handwritten Signature Verification. In Proceedings of the 2021 IEEE International Conference on Networking, Sensing and Control (ICNSC), Xiamen, China, 3–5 December 2021; Volume 1, pp. 1–6. [Google Scholar]
- Dey, S.; Dutta, A.; Toledo, J.I.; Ghosh, S.K.; Pal, U. Signet: Convolutional Siamese Network for Writer Independent Offline Signature Verification. arXiv 2017, arXiv:1707.02131. [Google Scholar]
- Kumar, R.; Sharma, J.D.; Chanda, B. Writer-independent offline signature verification using surroundedness feature. Pattern Recognit. Lett. 2012, 33, 301–308. [Google Scholar] [CrossRef]
- Bharathi, R.K.; Shekar, B.H. Offline signature verification based on chain code histogram and Support Vector Machine. In Proceedings of the International Conference on Advances in Computing, Communications, and Informatics (ICACCI), Mysore, India, 22–25 August 2013; pp. 2063–2068. [Google Scholar]
- Das, S.D.; Ladia, H.; Kumar, V.; Mishra, S. Writer Independent Offline Signature Recognition Using Ensemble Learning. In ICDSMLA 2019: Proceedings of the 1st International Conference on Data Science, Machine Learning and Applications (Lecture Notes in Electrical Engineering, 601), 1st ed.; Springer: Berlin/Heidelberg, Germany, 2020. [Google Scholar]
- Kumar, R.; Kundu, L.; Chanda, B.; Sharma, J.D. A Writer-Independent Off-line Signature Verification System based on Signature Morphology. In Proceedings of the 1st International Conference on Intelligent Interactive Technologies and Multimedia, Allahabad, India, 27–30 December 2010. [Google Scholar]
- Pal, S.; Alaei, A.; Pal, U.; Blumenstein, M. Performance of an Offline Signature Verification Method Based on Texture Features on a Large Indic-Script Signature Dataset. In Proceedings of the 12th IAPR Workshop on Document Analysis Systems (DAS), Santorini, Greece, 11–14 April 2016. [Google Scholar]


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Genuine | Forgery | |
|---|---|---|
| CEDAR |  |  |
 |  | |
| BHSig-Bengali | 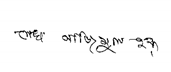 |  |
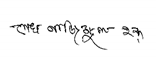 |  | |
| BHSig-Hindi |  | 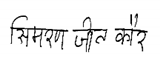 |
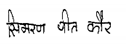 |  | |
| CHINESE |  |  |
 | 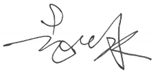 | |
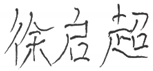 | 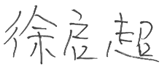 | |
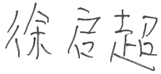 |  |
| Datasets | CEDAR | BHSig-B | BHSig-H | CHINESE |
|---|---|---|---|---|
| languages | English | Bengali | Hindi | Chinese |
| People | 55 | 100 | 160 | 500 |
| Signatures | 2640 | 5400 | 8640 | 2000 |
| Total sample | 46,860 | 99,600 | 159,360 | 1500 |
| Positive: negative | 276:576 | 276:720 | 276:720 | 840:660 |
| Model | Description |
|---|---|
| SigNet | The writer independent Siamese network model proposed in 2017 [37] and is often applied to signature verification. |
| Surroundness | A signature feature extraction model based on envelopment was proposed in 2012 [38]. |
| Chain code | In 2013 [39], a model based on the histogram features of chain codes was proposed and enhanced by Laplacian Gaussian filter. |
| Eensemble Learning | Deep learning model proposed in 2019 [40], which improves an integration model for offline writer independent signature verification. |
| Morphology | Feature analysis technology based on multi-layer perceptron was proposed in 2010 [41]. |
| Texture Feature | a texture-oriented signature verification method was proposed in 2016 [42]. It has good performance for Indian scripts. |
| Fusion of HTF | A Signature verification model proposed in 2019 [6]. It adopts discrete wavelet and local quantized patterns features |
| DeepHSV | A neural network model proposed in 2019 [30], which improves the network with a two-channel CNN network |
| Method | Type | FRR | FAR | ACC |
|---|---|---|---|---|
| Morphology | WI | 12.39 | 11.23 | 88.19 |
| Surroundness | WI | 8.33 | 8.33 | 91.67 |
| Chain code | WD | 9.36 | 7.84 | 92.16 |
| Ensemble Learning | WI | 8.48 | 7.88 | 92.00 |
| ISNN + CrossEntropy | WI | 9.38 | 7.68 | 92.55 |
| SNN + Focal Loss | WI | 8.92 | 6.94 | 93.47 |
| Our method | WI | 6.78 | 4.20 | 95.66 |
| BHSig-Bengali | BHSig-Hindi | ||||||
|---|---|---|---|---|---|---|---|
| Method | Type | FRR | FAR | ACC | FRR | FAR | ACC |
| SigNet | WI | 13.89 | 13.89 | 86.11 | 15.36 | 15.36 | 84.64 |
| Texture Feature | WD | 33.82 | 33.82 | 66.18 | 24.47 | 24.47 | 75.53 |
| Fusion of HTF | WD | 18.42 | 23.10 | 79.24 | 11.46 | 10.36 | 79.89 |
| DeepHSV | WI | 11.92 | 11.92 | 88.08 | 13.34 | 13.34 | 86.66 |
| ISNN + CrossEntropy | WI | 18.64 | 12.86 | 86.66 | 15.63 | 15.49 | 84.54 |
| SNN + Focal Loss | WI | 16.87 | 9.43 | 87.69 | 13.38 | 10.91 | 84.79 |
| Our method | WI | 14.25 | 6.41 | 90.64 | 12.29 | 9.6 | 88.98 |
| Method | Type | FRR | FAR | Acc |
| SigNet | WI | 42.36 | 42.36 | 57.64 |
| DeepHSV | WI | 41.87 | 41.87 | 58.13 |
| SNN + CrossEntropy | WI | 38.98 | 35.77 | 64.79 |
| ISNN + CrossEntropy | WI | 33.66 | 31.24 | 68.88 |
| SNN + Focal Loss | WI | 36.74 | 30.92 | 65.88 |
| ISNN + Focal Loss | WI | 32.18 | 30.59 | 70.31 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Xiao, W.; Ding, Y. A Two-Stage Siamese Network Model for Offline Handwritten Signature Verification. Symmetry 2022, 14, 1216. https://doi.org/10.3390/sym14061216
Xiao W, Ding Y. A Two-Stage Siamese Network Model for Offline Handwritten Signature Verification. Symmetry. 2022; 14(6):1216. https://doi.org/10.3390/sym14061216
Chicago/Turabian StyleXiao, Wanghui, and Yuting Ding. 2022. "A Two-Stage Siamese Network Model for Offline Handwritten Signature Verification" Symmetry 14, no. 6: 1216. https://doi.org/10.3390/sym14061216
APA StyleXiao, W., & Ding, Y. (2022). A Two-Stage Siamese Network Model for Offline Handwritten Signature Verification. Symmetry, 14(6), 1216. https://doi.org/10.3390/sym14061216