
Bayesian P-Splines Quantile Regression of Partially Linear Varying Coefficient Spatial Autoregressive Models


Abstract
:1. Introduction
2. Methodology
2.1. Model
2.2. Likelihood
3. Bayesian Estimation
3.1. Priors
3.2. The Full Conditional Posterior Distributions of the Latent Variables
3.3. The Full Conditional Posterior Distributions of the Parameters
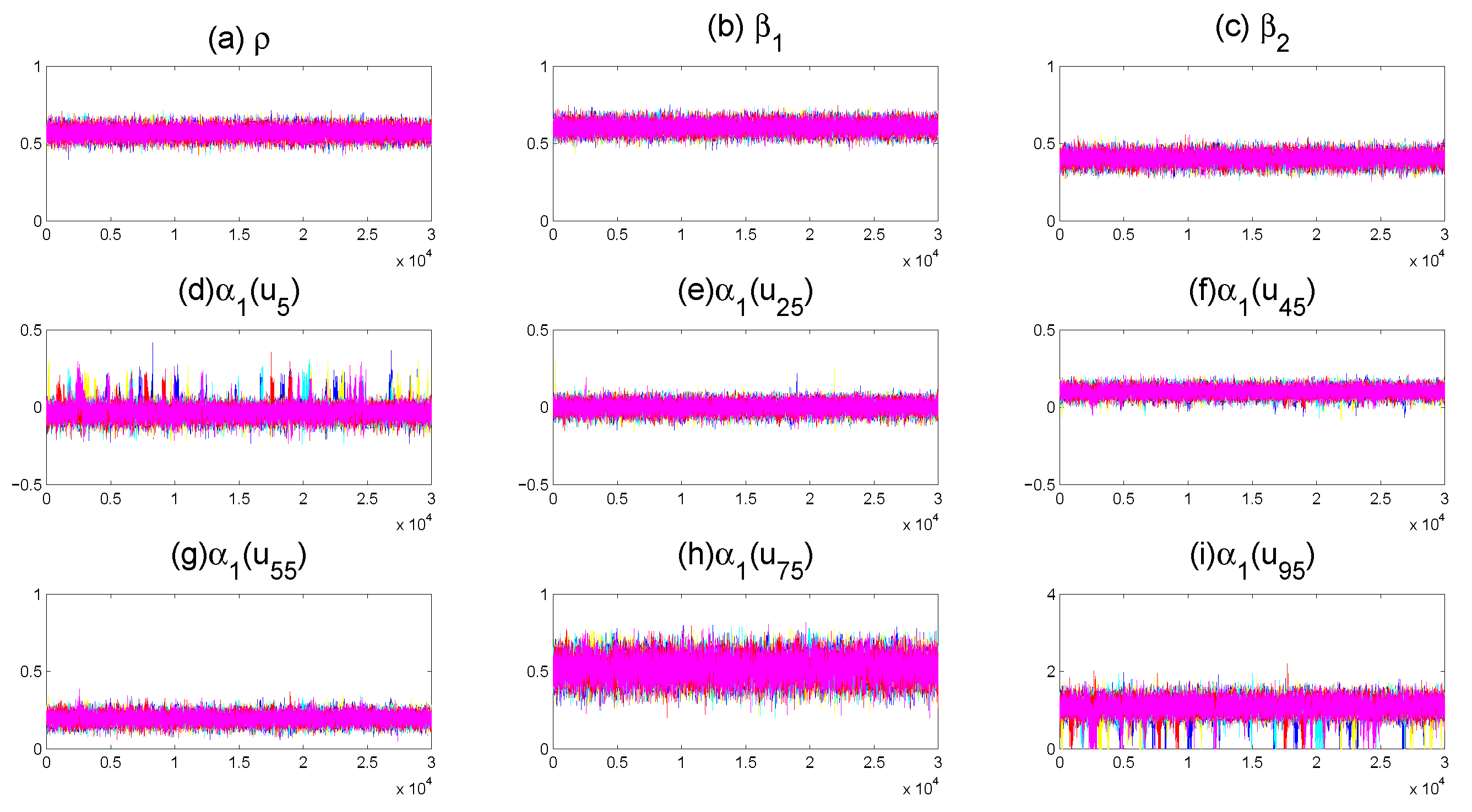
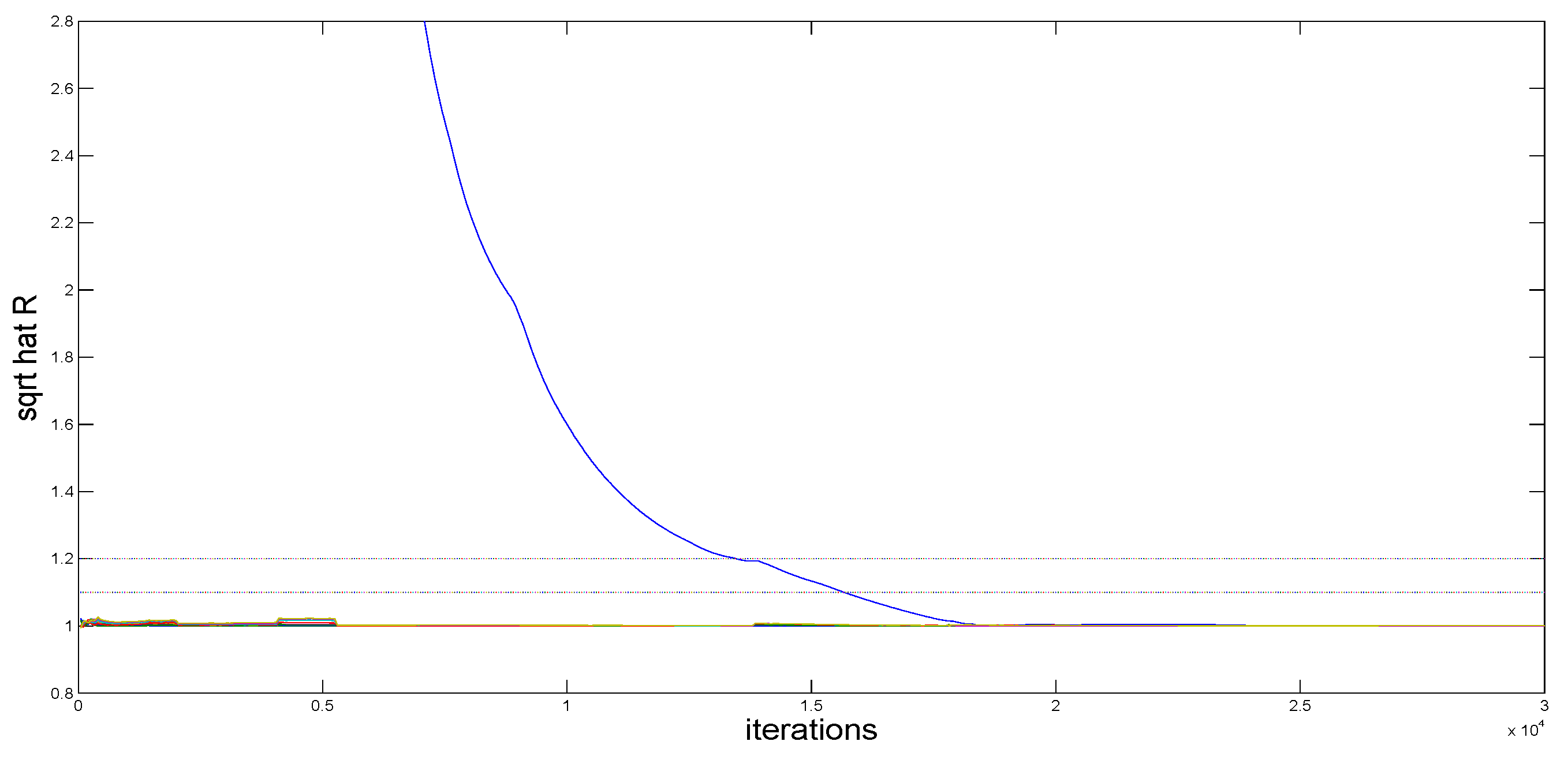
3.4. Sampling
| Algorithm 1: The pseudocode of the MCMC sampling scheme |
|
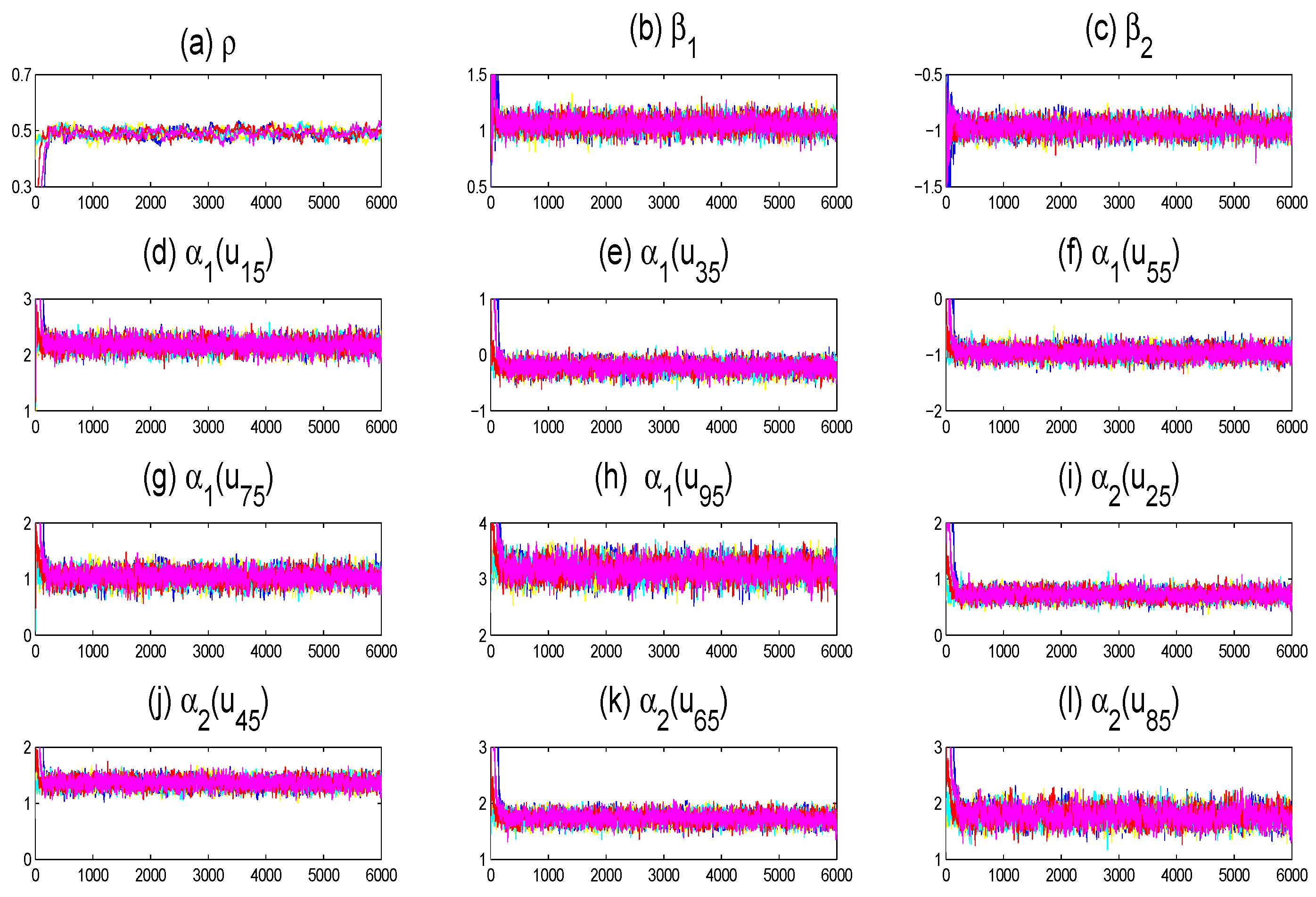
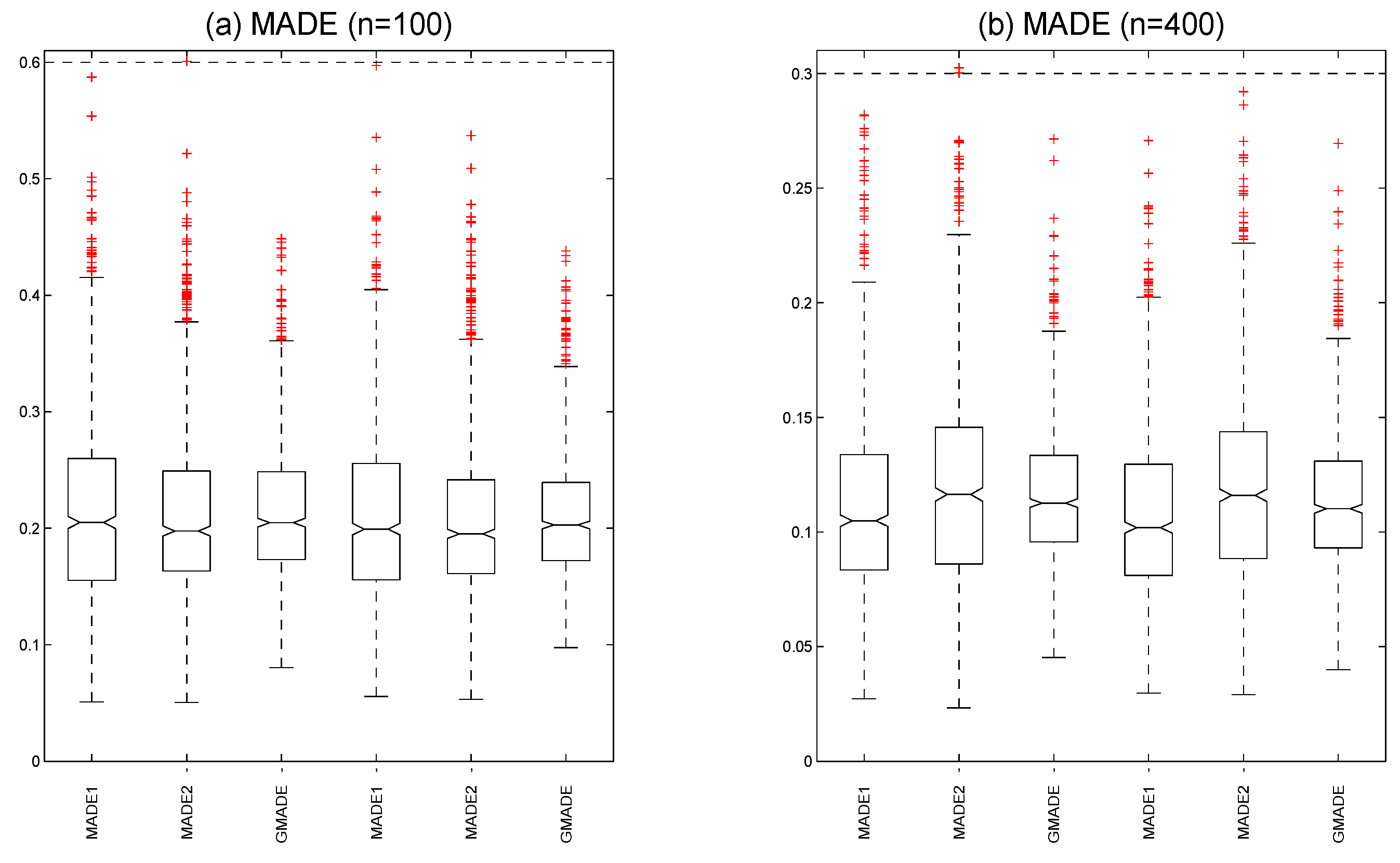
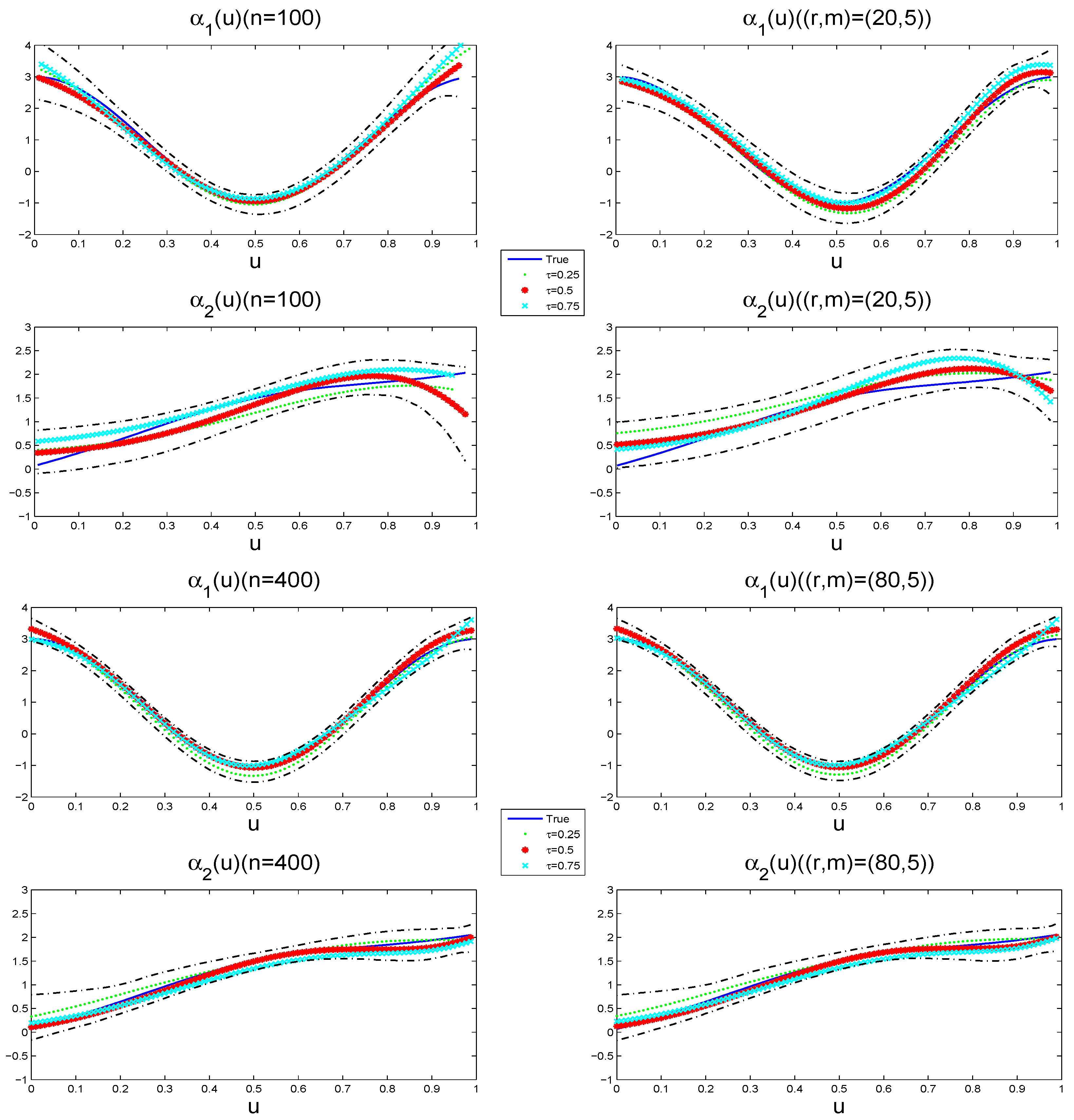
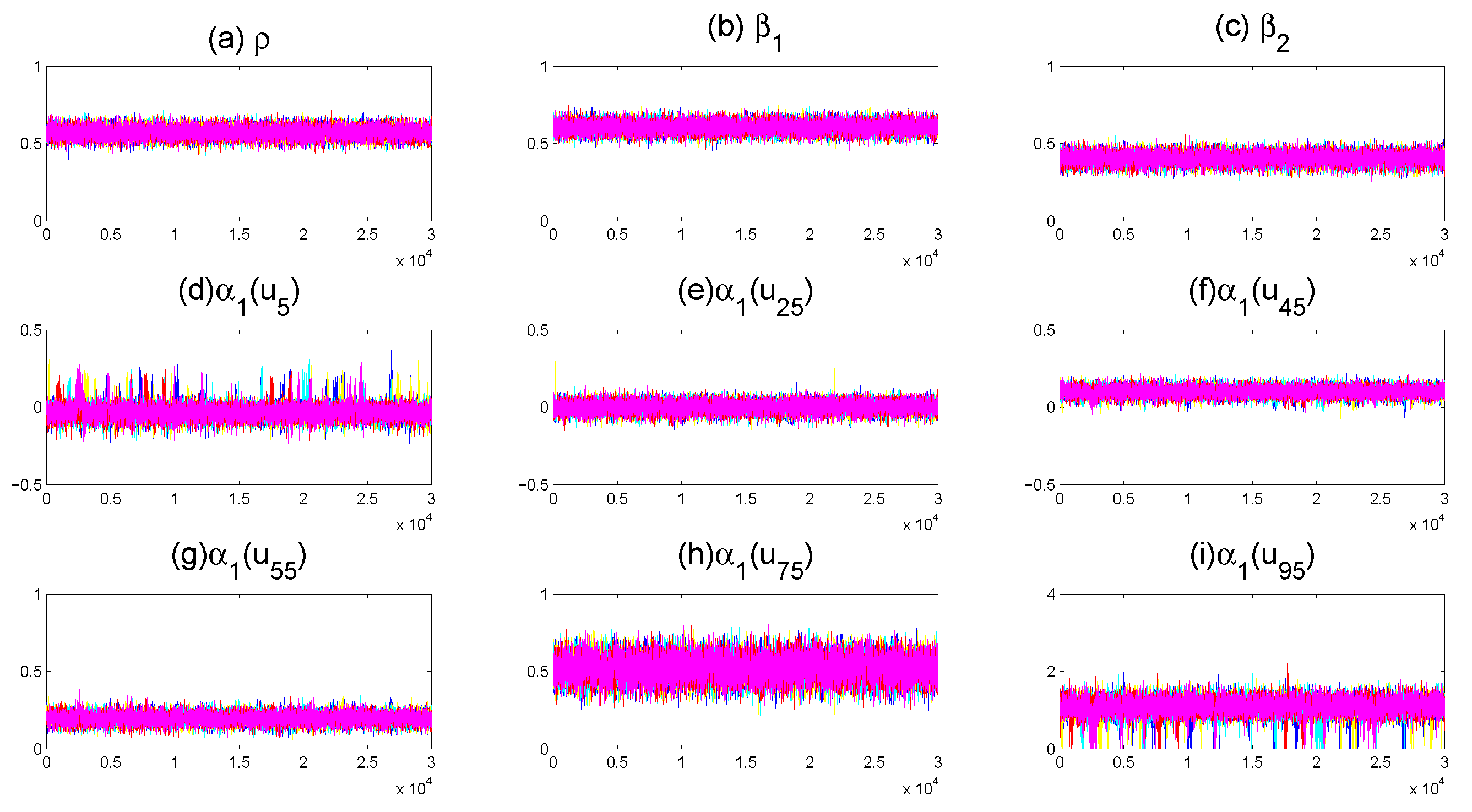
4. Numerical Illustration
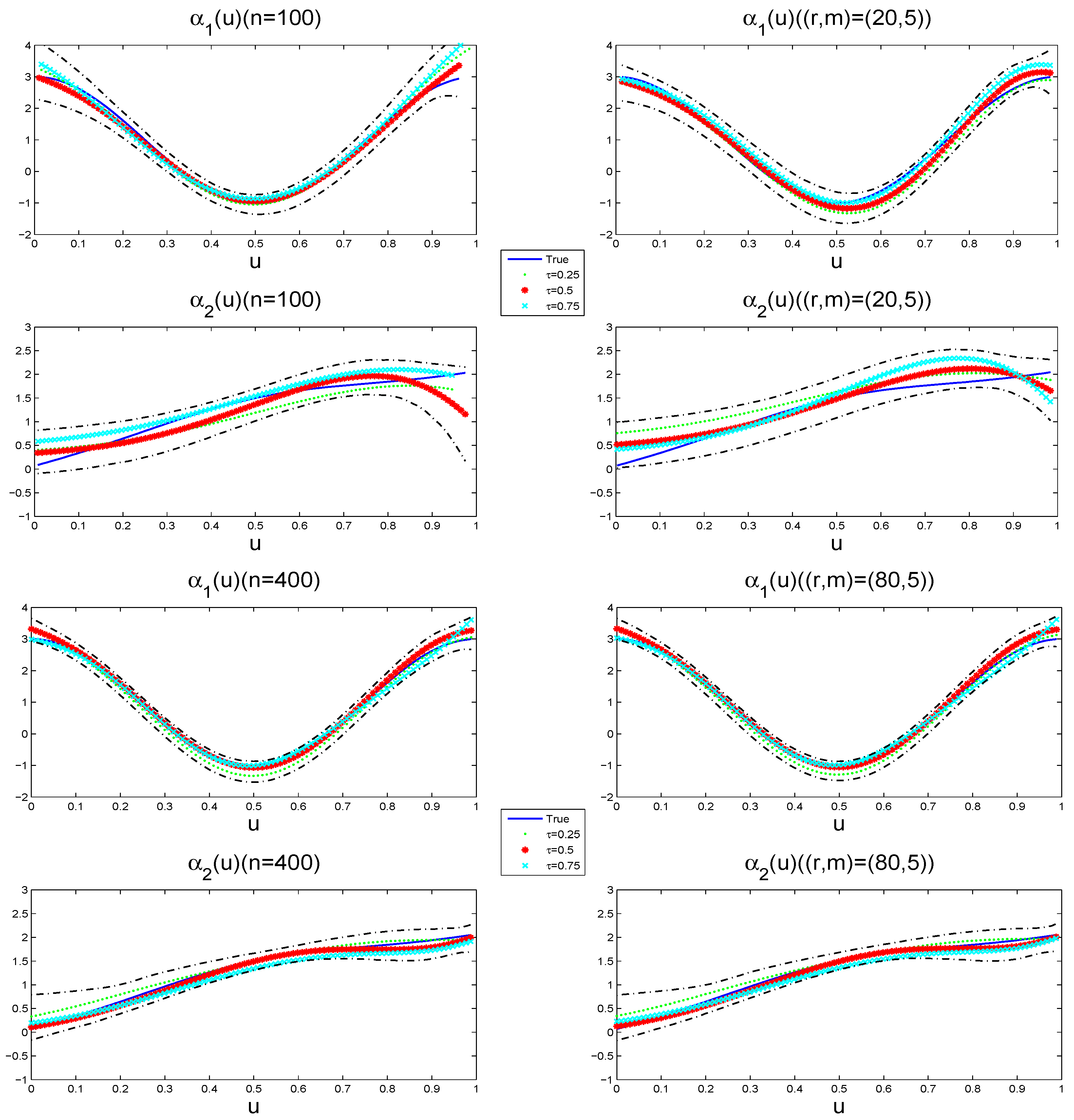
4.1. Simulation
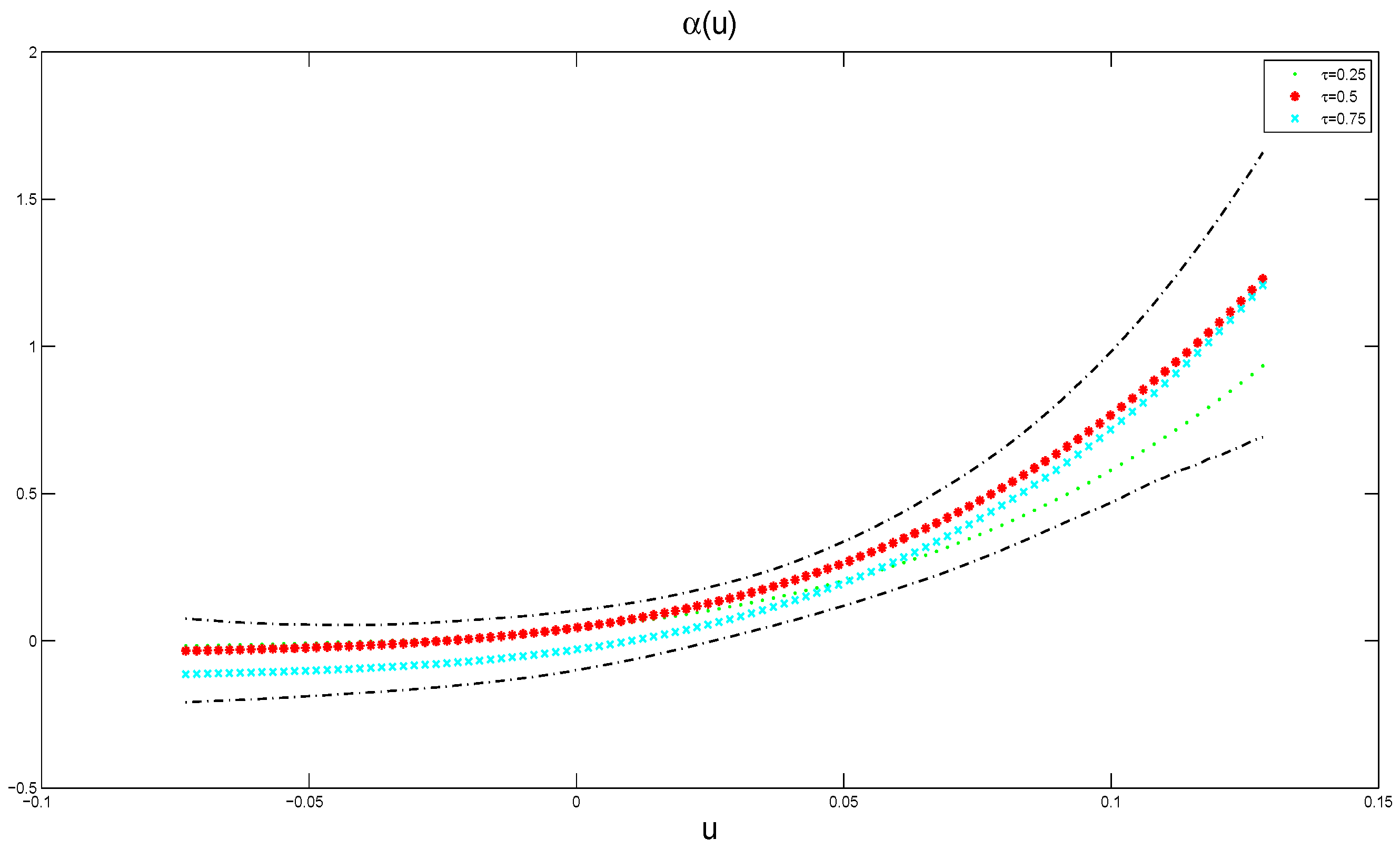
4.2. Application
5. Summary
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Cliff, A.D.; Ord, J.K. Spatial Autocorrelation; Pion Ltd.: London, UK, 1973. [Google Scholar]
- Lee, L.F. Asymptotic Distribution of Quasi-Maximum Likelihood Estimators for Spatial Autoregressive Models. Econometrica 2004, 72, 1899–1925. [Google Scholar] [CrossRef]
- Lee, L.F. GMM and 2SLS Estimation of Mixed Regressive Spatial Autoregressive Models. J. Econom. 2007, 137, 489–514. [Google Scholar] [CrossRef]
- Kakamu, K.; Wago, H. Small-sample properties of panel spatial autoregressive models: Comparison of the Bayesian and maximum likelihood methods. Spat. Econ. Anal. 2008, 3, 305–319. [Google Scholar] [CrossRef]
- Xu, X.B.; Lee, L.F. A spatial autoregressive model with a nonlinear transformation of the dependent variable. J. Econom. 2015, 186, 1–18. [Google Scholar] [CrossRef]
- Basile, R. Regional economic growth in Europe: A semiparametric spatial dependence approach. Pap. Reg. Sci. 2008, 87, 527–544. [Google Scholar] [CrossRef]
- Basile, R. Productivity polarization across regions in Europe: The role of nonlinearities and spatial dependence. Int. Reg. Sci. Rev. 2008, 32, 92–115. [Google Scholar] [CrossRef] [Green Version]
- Basile, R.; Gress, B. Semi-parametric spatial auto-covariance models of regional growth behaviour in Europe. Reg. Dev. 2005, 21, 93–118. [Google Scholar] [CrossRef]
- Paelinck, J.H.P.; Klaassen, L.H. Spatial Econometrics; Gower Press: Aldershot, UK, 1979. [Google Scholar]
- Sun, Y.; Yan, H.J.; Zhang, W.Y.; Lu, Z. A Semiparametric spatial dynamic model. Ann. Stat. 2014, 42, 700–727. [Google Scholar] [CrossRef] [Green Version]
- Chen, J.Q.; Wang, R.F.; Huang, Y.X. Semiparametric spatial autoregressive model: A two-step Bayesian approach. Ann. Public Health Res. 2015, 2, 1012. [Google Scholar]
- Dai, X.; Li, S.; Tian, M. Quantile regression for partially linear varying coefficient spatial autoregressive models. arXiv 2016, arXiv:1608.01739. [Google Scholar]
- Cai, Z.; Xu, X. Nonparametric quantiles estimations for dynamic smooth coefficients models. J. Am. Stat. Assoc. 2008, 103, 1595–1608. [Google Scholar] [CrossRef]
- Bellman, R.E. Adaptive Control Processes; Princeton University Press: Princeton, NJ, USA, 1961. [Google Scholar]
- Hastie, T.J.; Tibshirani, R.J. Generalized Additive Models; Chapman and Hall: New York, NY, USA, 1990. [Google Scholar]
- Friedman, J.H.; Stuetzle, W. Projection Pursuit Regression. J. Am. Stat. Assoc. 1981, 376, 817–823. [Google Scholar] [CrossRef]
- Hastie, T.J.; Tibshirani, R.J. Varying-coefficient models. J. R. Stat. Soc. 1993, 55, 757–796. [Google Scholar] [CrossRef]
- Chiang, C.; Rice, J.; Wu, C. Smoothing Spline Estimation for Varying Coefficient Models with Repeatedly Measured Dependent Variables. J. Am. Stat. Assoc. 2001, 96, 605–619. [Google Scholar] [CrossRef]
- Eubank, R.L.; Huang, C.F.; Buchanan, R.J. Smoothing Spline Estimation in Varying-coefficient Models. J. R. Stat. Soc. 2004, 66, 653–667. [Google Scholar] [CrossRef]
- Lu, Y.Q.; Zhang, R.Q.; Zhu, L.P. Penalized Spline Estimation for Varying-Coefficient Models. Commun. Stat. Theory Methods 2008, 37, 2249–2261. [Google Scholar] [CrossRef]
- Wu, C.O.; Chiang, C.; Hoover, D.R. Asymptotic confidence regions for kernel smoothing of a varying-coefficient model with longitudinal data. J. Am. Stat. Assoc. 1998, 93, 1388–1403. [Google Scholar] [CrossRef]
- Cai, Z.W.; Fan, J.Q.; Li, R.Z. Efficient Estimation and Inferences for Varying Coefficient Models. J. Am. Stat. Assoc. 2000, 451, 888–902. [Google Scholar] [CrossRef]
- Cai, Z.W. Two-Step Likelihood Estimation Procedure for Varying Coefficient Models. J. Multivar. Anal. 2002, 1, 18–209. [Google Scholar] [CrossRef] [Green Version]
- Huang, J.Z.; Wu, C.O.; Zhou, L. Varying-coefficient models and basis functions approximations for the analysis of repeated measurements. Biometrika 2002, 89, 111–128. [Google Scholar] [CrossRef]
- Lu, Y.Q.; Mao, S.S. Local asymptotics for B-spline estimators of the varying-coefficient model. Commun. Stat. 2004, 33, 1119–1138. [Google Scholar] [CrossRef]
- Elhorst, J. Unconditional Maximum Likelihood Estimation of Linear and Log-Linear Dynamic Models for Spatial Panels. Geogr. Anal. 2005, 37, 85–106. [Google Scholar] [CrossRef]
- Yu, J.H.; De Jong, R.; Lee, L.F. Quasi-maximum likelihood estimators for spatial dynamic panel data with fixed effects when both n and t are large. J. Econom. 2008, 146, 118–134. [Google Scholar] [CrossRef] [Green Version]
- Lee, L.F.; Yu, J.H. Estimation of spatial autoregressive panel data models with fixed effects. J. Econom. 2010, 154, 165–185. [Google Scholar] [CrossRef]
- Chen, Z.Y.; Chen, J.B. Bayesian analysis of partially linear additive spatial autoregressive models with free-knot splines. Symmetry 2021, 13, 1635. [Google Scholar] [CrossRef]
- Koenker, R.; Bassett, G. Regression Quantiles. Econometrica 1978, 46, 33–50. [Google Scholar] [CrossRef]
- Jäntschi, L.; Bálint, D.; Bolboacǎ, S.D. Multiple linear regressions by maximizing the likelihood under assumption of generalized Gauss–Laplace distribution of the error. Comput. Math. Methods Med. 2016, 2016, 8578156. [Google Scholar] [CrossRef]
- Koenker, R.; Machado, J. Goodness of Hit and related inference processes for quantile regression. J. Am. Stat. Assoc. 1999, 94, 1296–1309. [Google Scholar] [CrossRef]
- Zerom, G.D. On additive conditional quantiles with high-dimensional covariates. J. Am. Stat. Assoc. 2003, 98, 135–146. [Google Scholar]
- Chernozhukov, V.; Hansen, C. Instrumental variable quantile regression: A robust inference approach. J. Econom. 2008, 142, 379–398. [Google Scholar] [CrossRef] [Green Version]
- Su, L.J.; Yang, Z.L. Instrumental Variable Quantile Estimation of Spatial Autoregressive Models; Working Papers; Singapore Management University: Singapore, 2009. [Google Scholar]
- Koenker, B. Quantile Regression; Cambridge University Press: Cambridge, UK, 2005. [Google Scholar]
- Yu, K.M.; Moyeed, R.A. Bayesian quantile regression. Stat. Probab. Lett. 2001, 54, 437–447. [Google Scholar] [CrossRef]
- Kozubowski, T.J.; Podgórski, K. A multivariate and asymmetric generalization of Laplace distribution. Comput. Stat. 2000, 15, 531–540. [Google Scholar] [CrossRef]
- Yuan, Y.; Yin, G.S. Bayesian quantile regression for longitudinal studies with nonignorable missing data. Biometrics 2010, 66, 105–114. [Google Scholar] [CrossRef]
- Li, Q.; Xi, R.B.; Lin, N. Bayesian regularized quantile regression. Bayesian Anal. 2010, 5, 533–556. [Google Scholar] [CrossRef]
- Lum, K.; Gelfand, A.E. Spatial quantile multiple regression using the asymmetric Laplace process. Bayesian Anal. 2012, 7, 235–258. [Google Scholar] [CrossRef]
- Anselin, L. Spatial Econometrics: Methods and Models; Kluwer Academic Publishers: Dordrecht, The Netherlands, 1988. [Google Scholar]
- Anselin, L. Estimation Methods for Spatial Autoregressive Structures. Reg. Sci. Diss. Monogr. Ser. 1980, 8, 263–273. [Google Scholar]
- Conley, T.G. GMM Estimation with Cross Sectional Dependence. J. Econom. 1999, 92, 1–45. [Google Scholar] [CrossRef]
- LeSage, J. Bayesian Estimation of Spatial Autoregressive Models. Int. Relations 1997, 20, 113–129. [Google Scholar] [CrossRef]
- Dunson, D.B.; Taylor, J.A. Approximate Bayesian inference for quantiles. J. Nonparametr. Stat. 2005, 17, 385–400. [Google Scholar] [CrossRef]
- Thompson, P.; Cai, Y.; Moyeed, R.; Reeve, D.; Stander, J. Bayesian nonparametric quantile regression using splines. Comput. Stat. Data Anal. 1993, 54, 1138–1150. [Google Scholar] [CrossRef]
- Boor, C.D. A Practical Guide to Splines; Springer: New York, NY, USA, 1978. [Google Scholar]
- Krisztin, T. Semi-parametric spatial autoregressive models in freight generation modeling. Transp. Res. Part Logist. Transp. Rev. 2018, 114, 121–143. [Google Scholar] [CrossRef]
- Eilers, P.H.C.; Marx, B.D. Flexible smoothing with B-splines and penalties. Stat. Sci. 1996, 11, 89–121. [Google Scholar] [CrossRef]
- Jäntschi, L. A test detecting the outliers for continuous distributions based on the cumulative distribution function of the data being tested. Symmetry 2019, 11, 835. [Google Scholar] [CrossRef] [Green Version]
- Kozumi, H.; Kobayashi, G. Gibbs sampling methods for bayesian quantile regression. J. Stat. Comput. Simul. 2011, 81, 1565–1578. [Google Scholar] [CrossRef] [Green Version]
- Barndorff-Nielsen, O.E.; Shephard, N. Non-gaussian ornstein-uhlenbeck-based models and some of their uses in financial economics. J. R. Stat. Soc. 2001, 63, 167–241. [Google Scholar] [CrossRef]
- Dagnapur, J.S. An easily implemented generalized inverse Gaussian generator. Commun. Stat. Simul. Comput. 1989, 18, 703–710. [Google Scholar]
- Tierney, L. Markov chains for exploring posterior distributions. Ann. Stat. 1994, 22, 1701–1728. [Google Scholar] [CrossRef]
- Hastings, W.K. Monte Carlo sampling methods using Markov Chains and their applications. Biometrika 1970, 57, 97–109. [Google Scholar] [CrossRef]
- Metropolis, N.; Rosenbluth, A.W.; Rosenbluth, M.N.; Teller, A.H.; Teller, E. Equations of state calculations by fast computing machine. J. Chem. Phys. 1953, 21, 1087–1091. [Google Scholar] [CrossRef] [Green Version]
- Tanner, M.A. Tools for Statistical Inference: Methods for the Exploration of Posterior Distributions and lIkelihood Functions, 2nd ed.; Springer: New York, NY, USA, 1993. [Google Scholar]
- Case, A.C. Spatial patterns in householed demand. Econometrica 1991, 59, 953–965. [Google Scholar] [CrossRef] [Green Version]
- LeSage, J.; Pace, R.K. Introduction to Spatial Econometrics; Chapman and Hall/CRC: New York, NY, USA, 2009. [Google Scholar]
- Gelman, A.; Rubin, D.B. Inference from iterative simulation using multiple sequences. Stat. Sci. 1992, 7, 457–511. [Google Scholar] [CrossRef]
- Harezlak, J.; Ruppert, D.; Wand, M.P. Semiparametric Regression with R; Springer: New York, NY, USA, 2018. [Google Scholar]


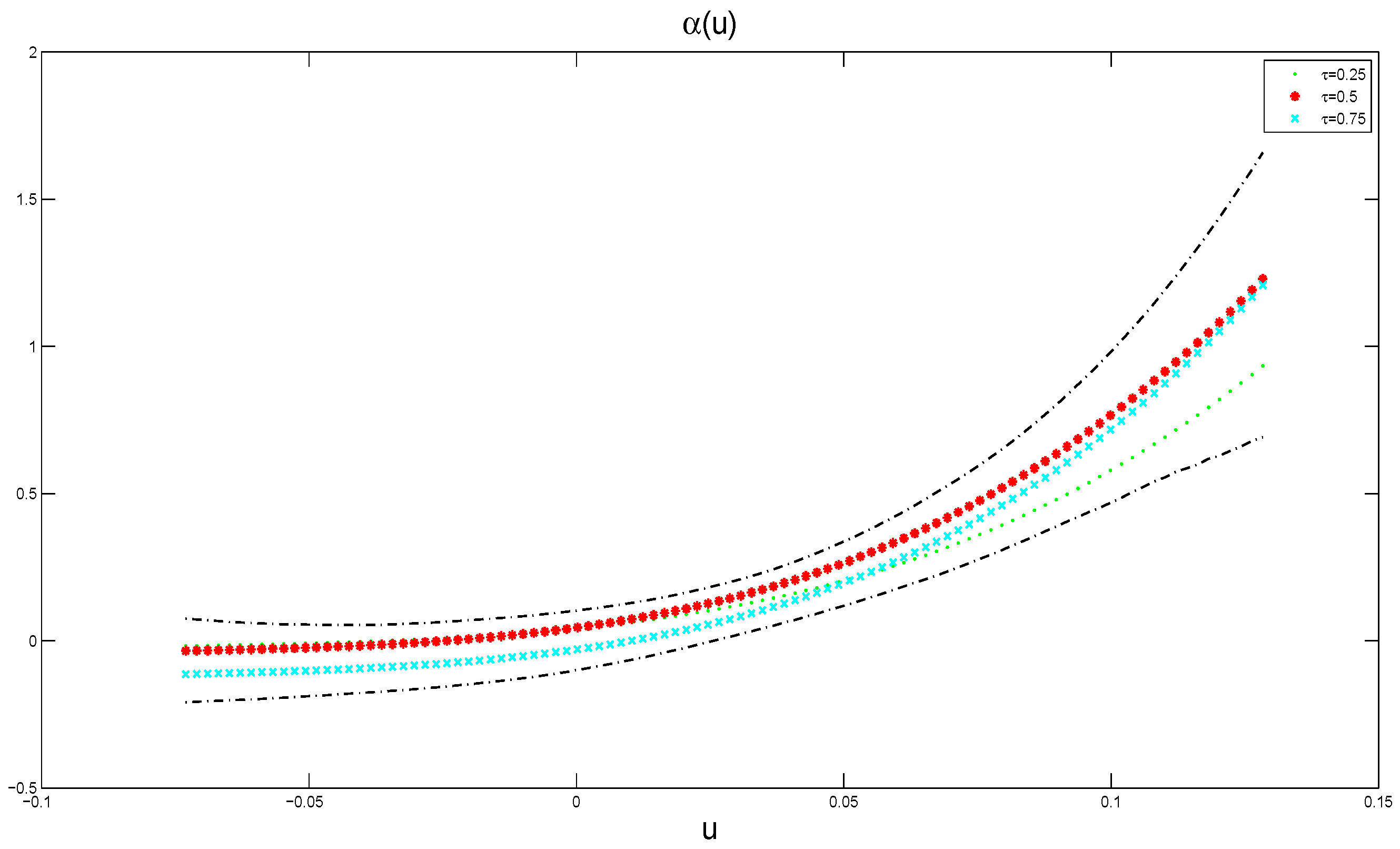

{kind=link}
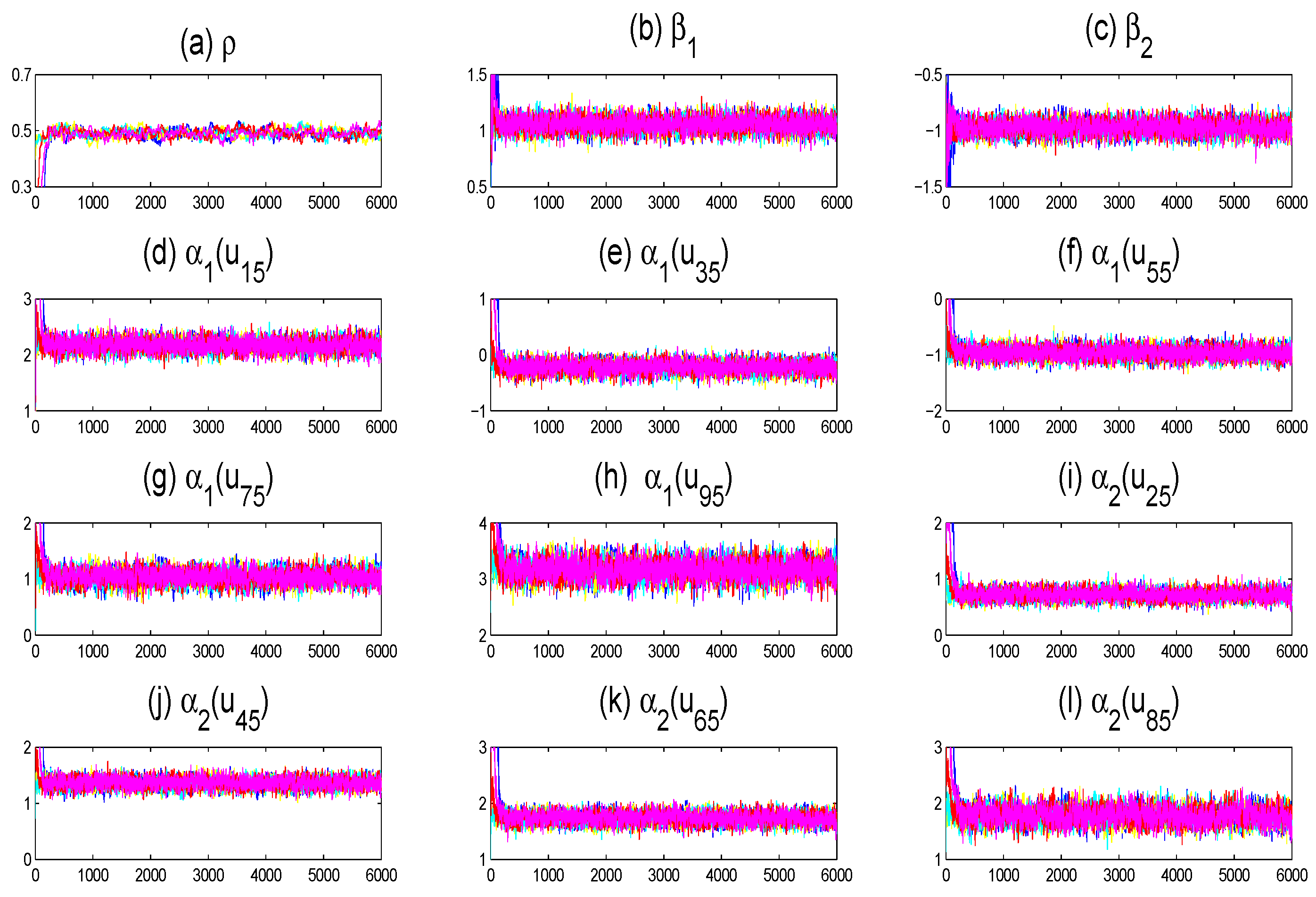
{kind=link}
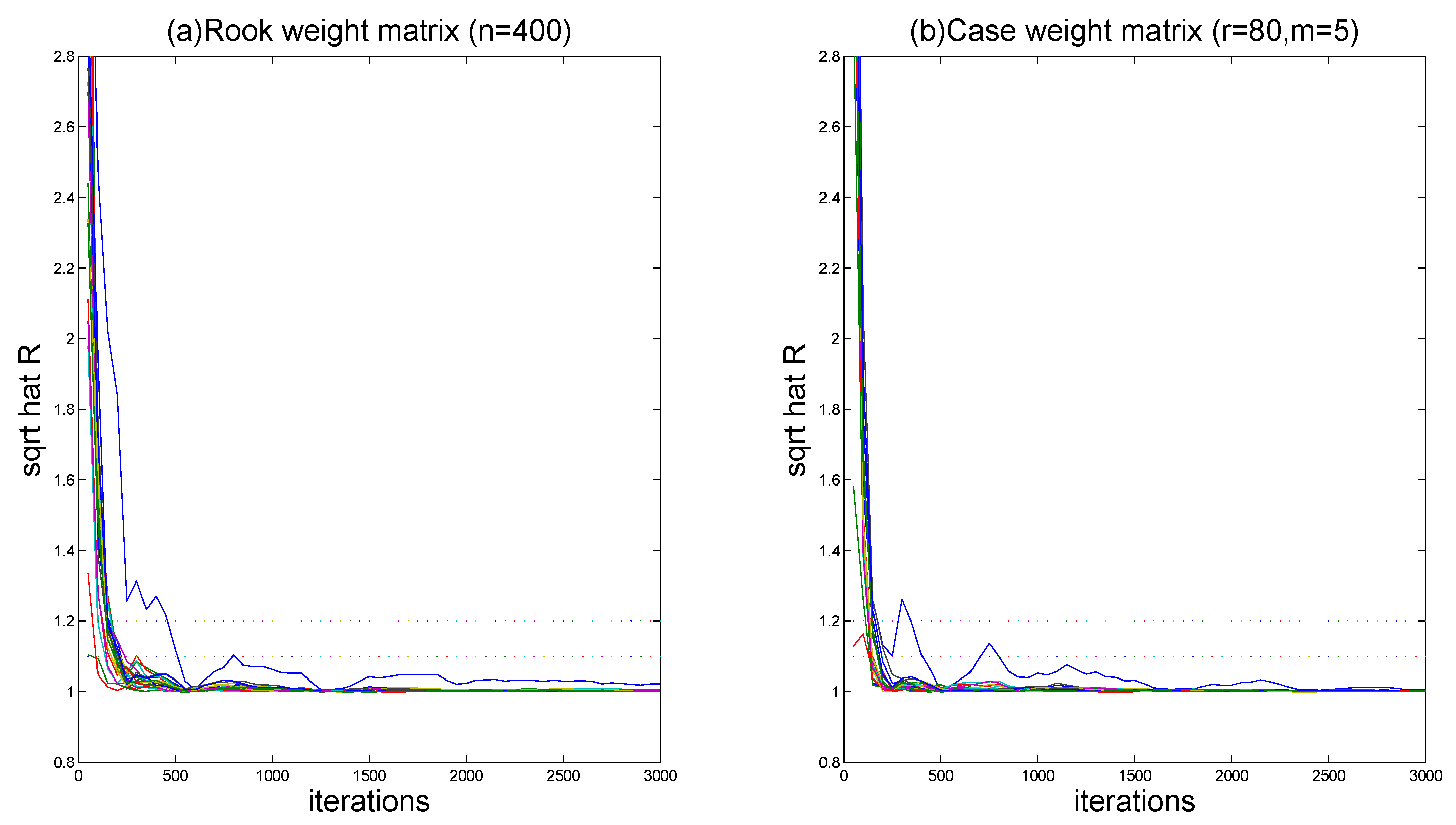
{kind=link}
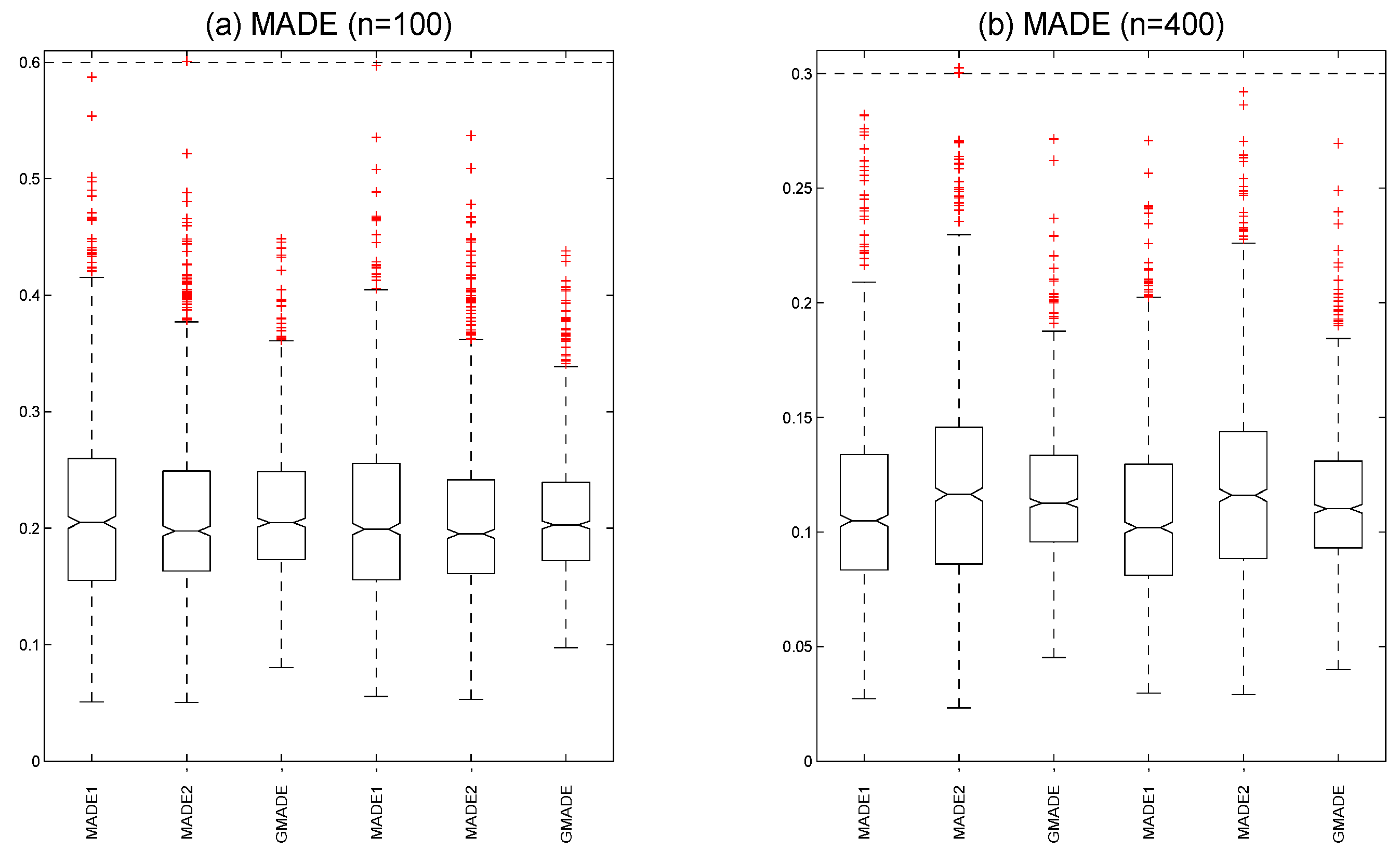
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Para. | n | Rook Weight Matrix | Case Weight Matrix | ||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|
| Mean | SE | SD | 95% CI | Mean | SE | SD | 95% CI | ||||
| 100 | (20,5) | ||||||||||
| Total effect | |||||||||||
| Total effect | |||||||||||
| Total effect | |||||||||||
| 100 | (20,5) | ||||||||||
| Total effect | |||||||||||
| Total effect | |||||||||||
| Total effect | |||||||||||
| 100 | (20,5) | ||||||||||
| Total effect | |||||||||||
| Total effect | |||||||||||
| Total effect | |||||||||||
| Para. | n | Rook Weight Matrix | Case Weight Matrix | ||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|
| Mean | SE | SD | 95% CI | Mean | SE | SD | 95% CI | ||||
| 400 | (80,5) | ||||||||||
| Total effect | |||||||||||
| Total effect | |||||||||||
| Total effect | |||||||||||
| 400 | (80,5) | ||||||||||
| Total effect | |||||||||||
| Total effect | |||||||||||
| Total effect | |||||||||||
| 400 | (80,5) | ||||||||||
| Total effect | |||||||||||
| Total effect | |||||||||||
| Total effect | |||||||||||
| n | Para. | QR | IVQR | BQR | |||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0.25 | 0.50 | 0.75 | 0.25 | 0.50 | 0.75 | 0.25 | 0.50 | 0.75 | |||||
| 100 | Bias | ||||||||||||
| RMSE | |||||||||||||
| Bias | |||||||||||||
| RMSE | |||||||||||||
| 200 | Bias | ||||||||||||
| RMSE | |||||||||||||
| Bias | |||||||||||||
| RMSE | |||||||||||||
| 500 | Bias | ||||||||||||
| RMSE | |||||||||||||
| Bias | |||||||||||||
| RMSE | |||||||||||||
| 800 | Bias | ||||||||||||
| RMSE | |||||||||||||
| Bias | |||||||||||||
| RMSE | |||||||||||||
| n | Para. | QR | IVQR | BQR | |||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0.25 | 0.50 | 0.75 | 0.25 | 0.50 | 0.75 | 0.25 | 0.50 | 0.75 | |||||
| 100 | Bias | ||||||||||||
| RMSE | |||||||||||||
| Bias | |||||||||||||
| RMSE | |||||||||||||
| 200 | Bias | ||||||||||||
| RMSE | |||||||||||||
| Bias | |||||||||||||
| RMSE | |||||||||||||
| 500 | Bias | ||||||||||||
| RMSE | |||||||||||||
| Bias | |||||||||||||
| RMSE | |||||||||||||
| 800 | Bias | ||||||||||||
| RMSE | |||||||||||||
| Bias | |||||||||||||
| RMSE | |||||||||||||
| Para. | Mean | SE | 95%CI | Mean | SE | 95%CI | Mean | SE | 95%CI | ||
|---|---|---|---|---|---|---|---|---|---|---|---|
| Total effect | |||||||||||
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Chen, Z.; Chen, M.; Ju, F. Bayesian P-Splines Quantile Regression of Partially Linear Varying Coefficient Spatial Autoregressive Models. Symmetry 2022, 14, 1175. https://doi.org/10.3390/sym14061175
Chen Z, Chen M, Ju F. Bayesian P-Splines Quantile Regression of Partially Linear Varying Coefficient Spatial Autoregressive Models. Symmetry. 2022; 14(6):1175. https://doi.org/10.3390/sym14061175
Chicago/Turabian StyleChen, Zhiyong, Minghui Chen, and Fangyu Ju. 2022. "Bayesian P-Splines Quantile Regression of Partially Linear Varying Coefficient Spatial Autoregressive Models" Symmetry 14, no. 6: 1175. https://doi.org/10.3390/sym14061175
APA StyleChen, Z., Chen, M., & Ju, F. (2022). Bayesian P-Splines Quantile Regression of Partially Linear Varying Coefficient Spatial Autoregressive Models. Symmetry, 14(6), 1175. https://doi.org/10.3390/sym14061175