
Predictive Modelling of Statistical Downscaling Based on Hybrid Machine Learning Model for Daily Rainfall in East-Coast Peninsular Malaysia

 ,
,  and
and
Abstract
:1. Introduction
2. Materials and Methods
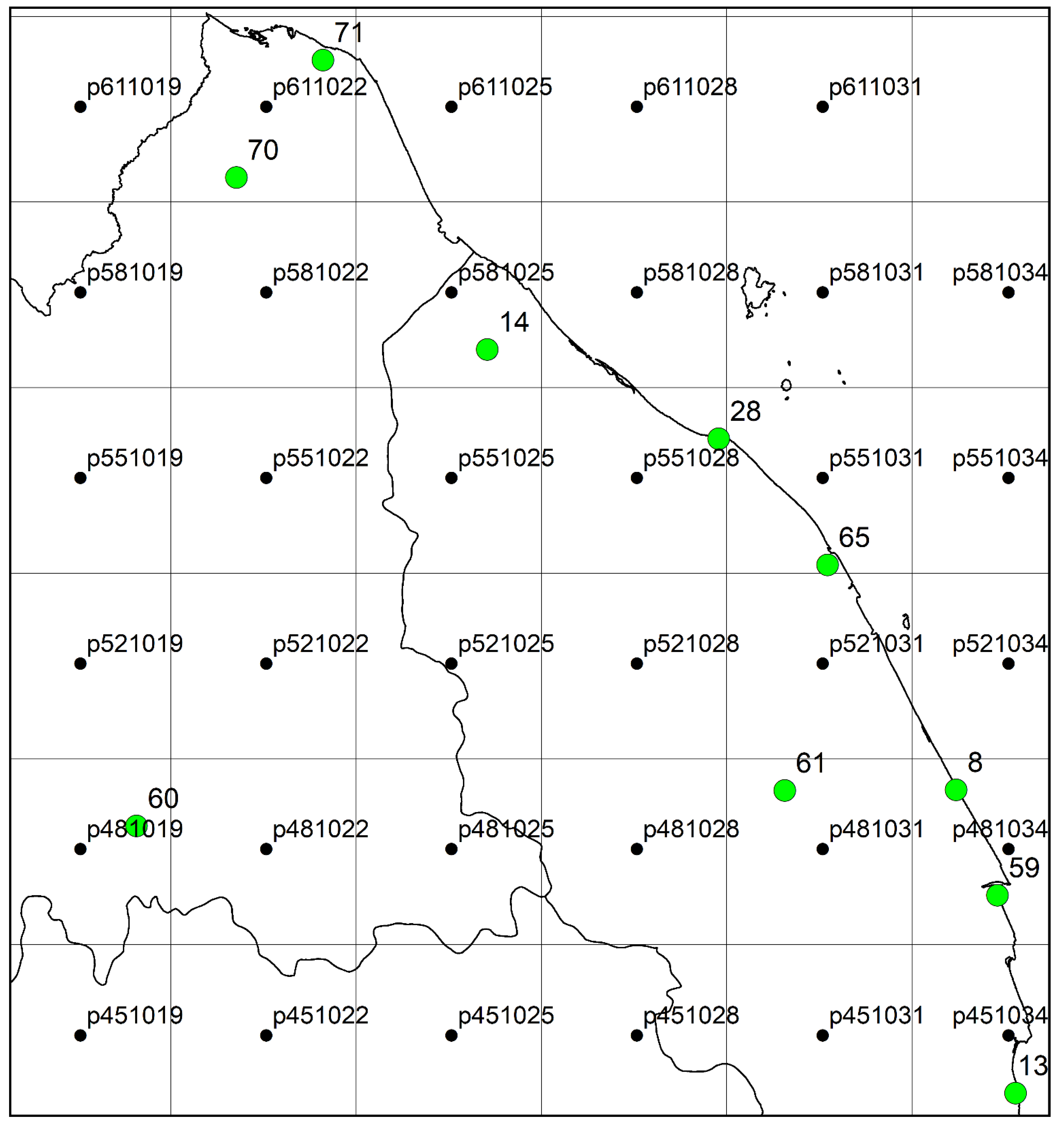
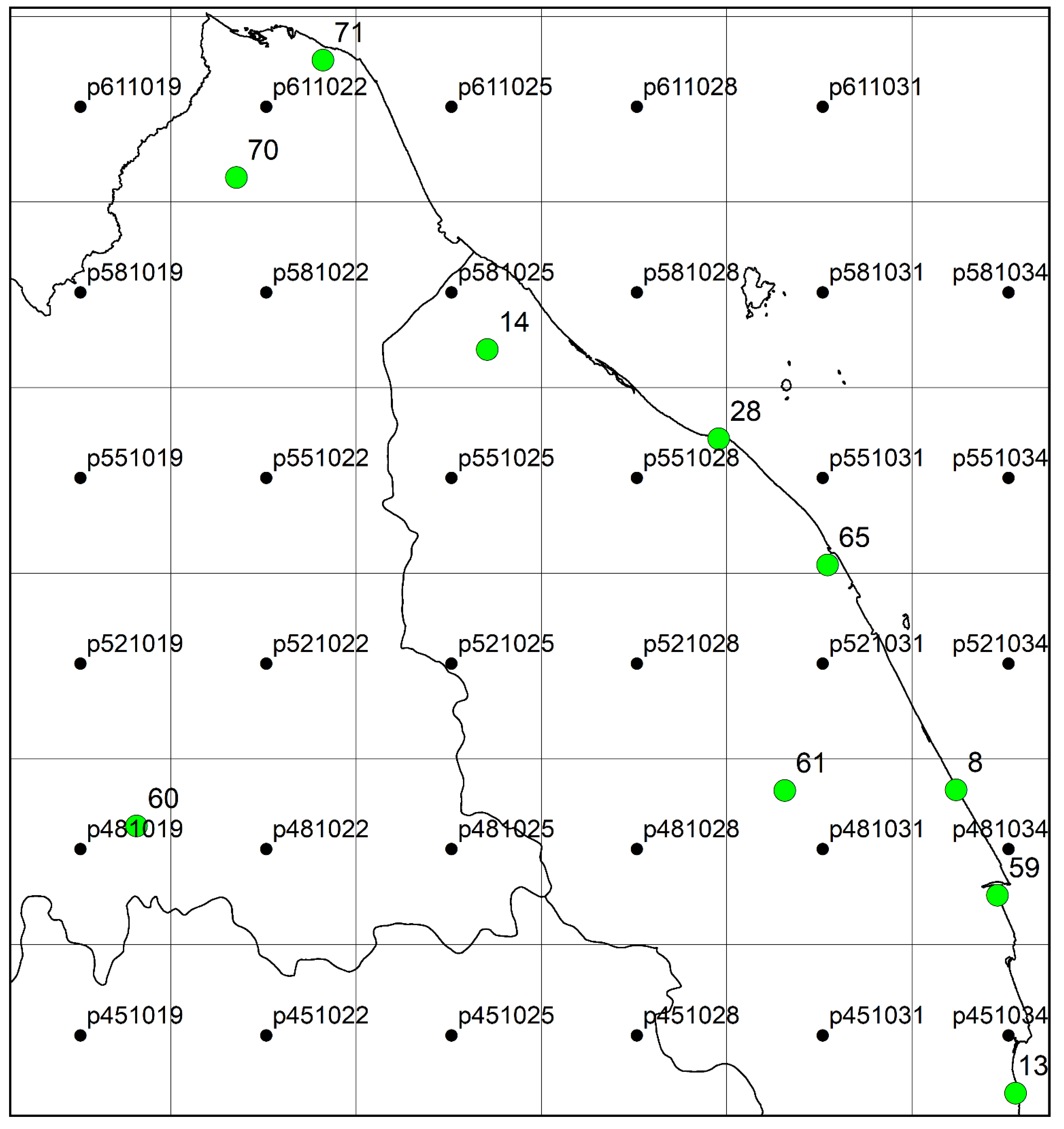
2.1. Study Area
2.2. Predictor and Predictand
2.3. Theory of Models Used
2.3.1. Random Forest (RF)
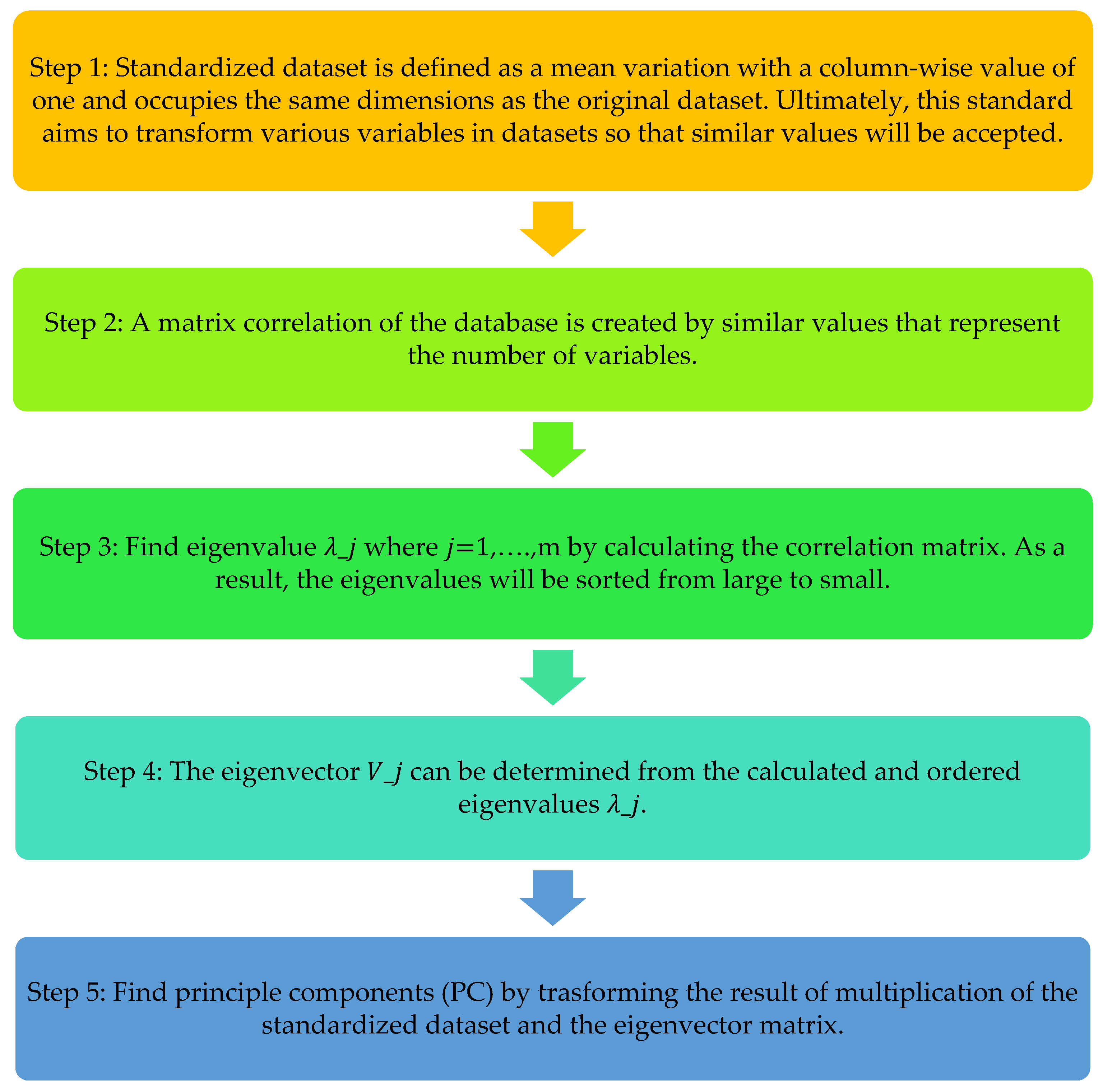
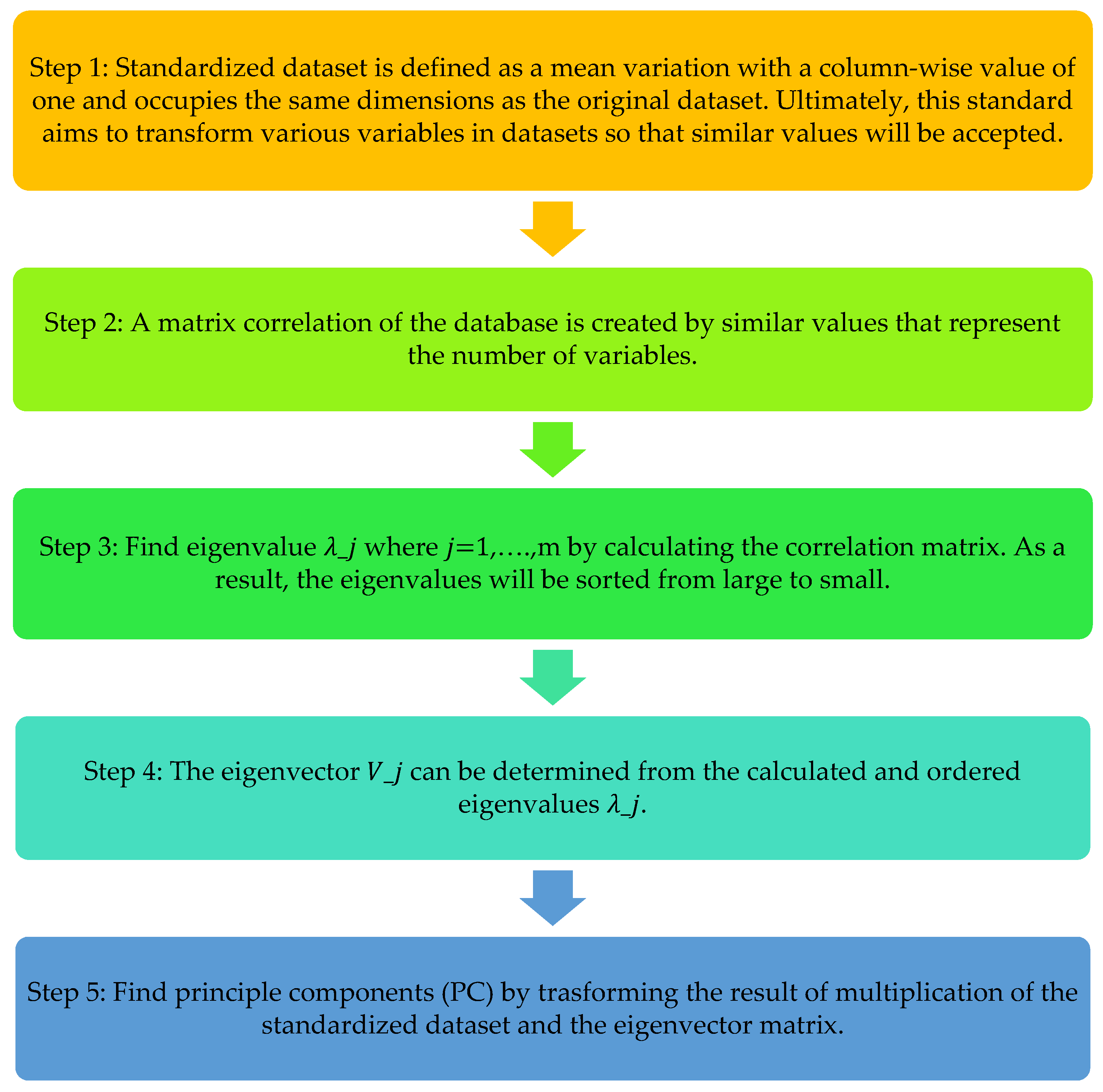
2.3.2. Principal Component Analysis (PCA)
2.3.3. Support Vector Machine (SVM)
Support Vector Classification (SVC)
Support Vector Regression (SVR)
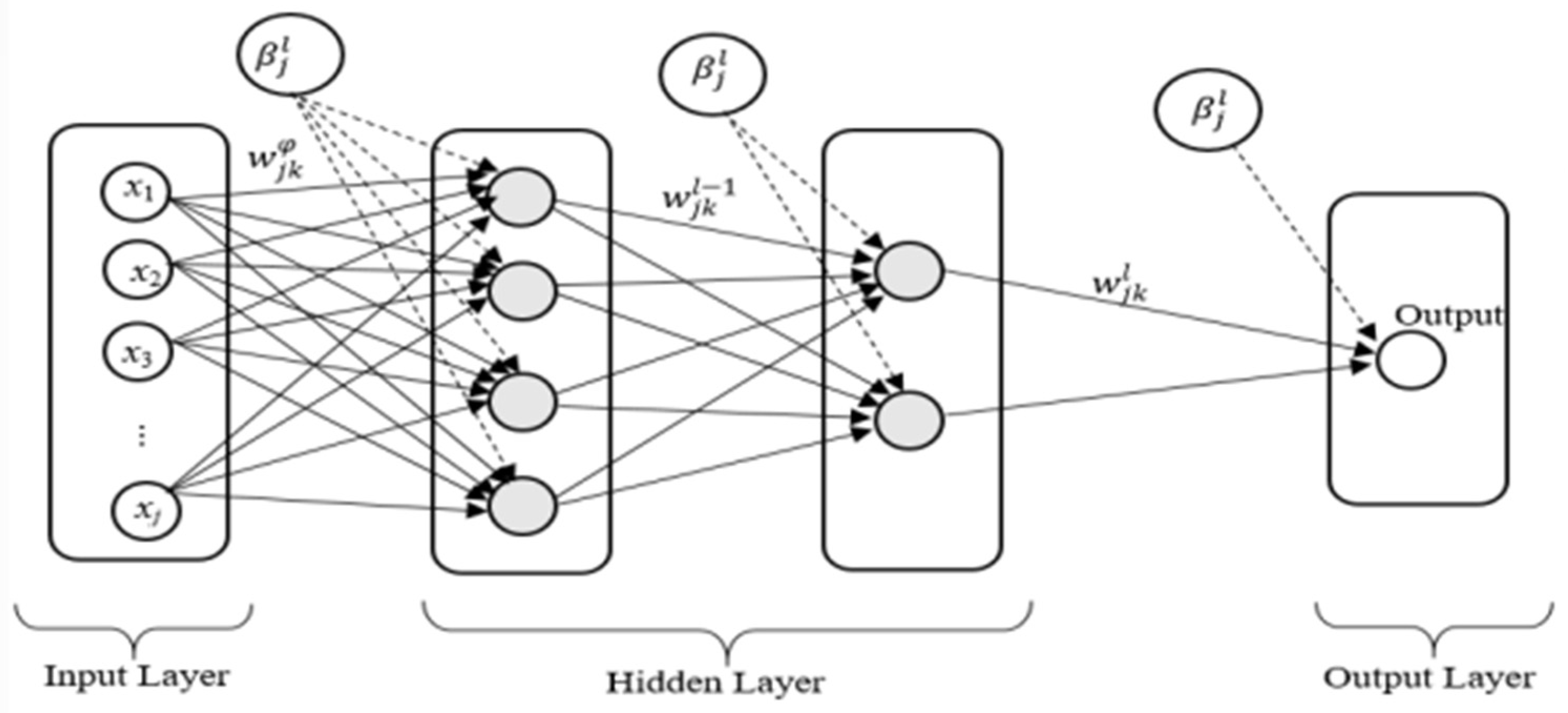
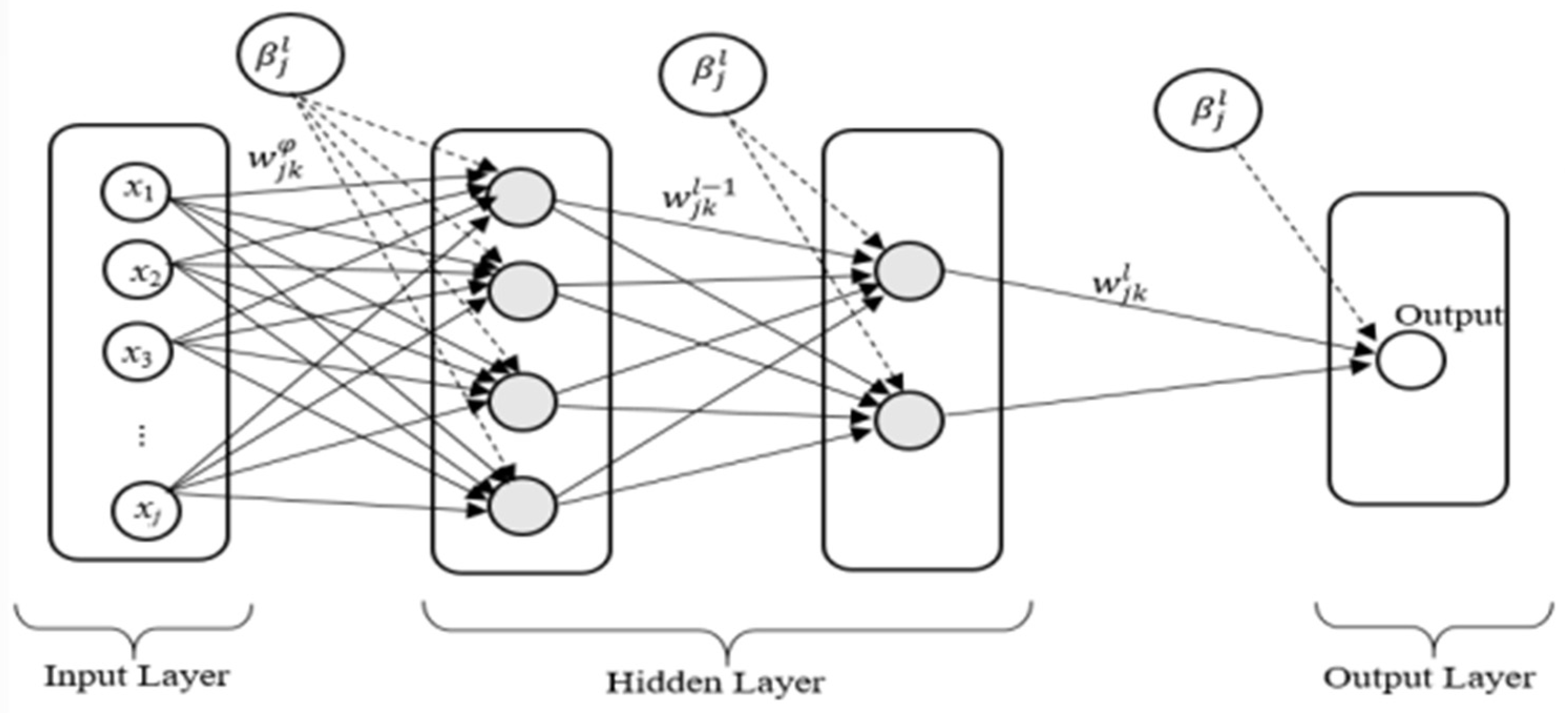
2.3.4. Artificial Neural Network (ANN)
2.3.5. Relevance Vector Machine (RVM)
2.3.6. Evaluation Performance of Statistical Downscaling Model
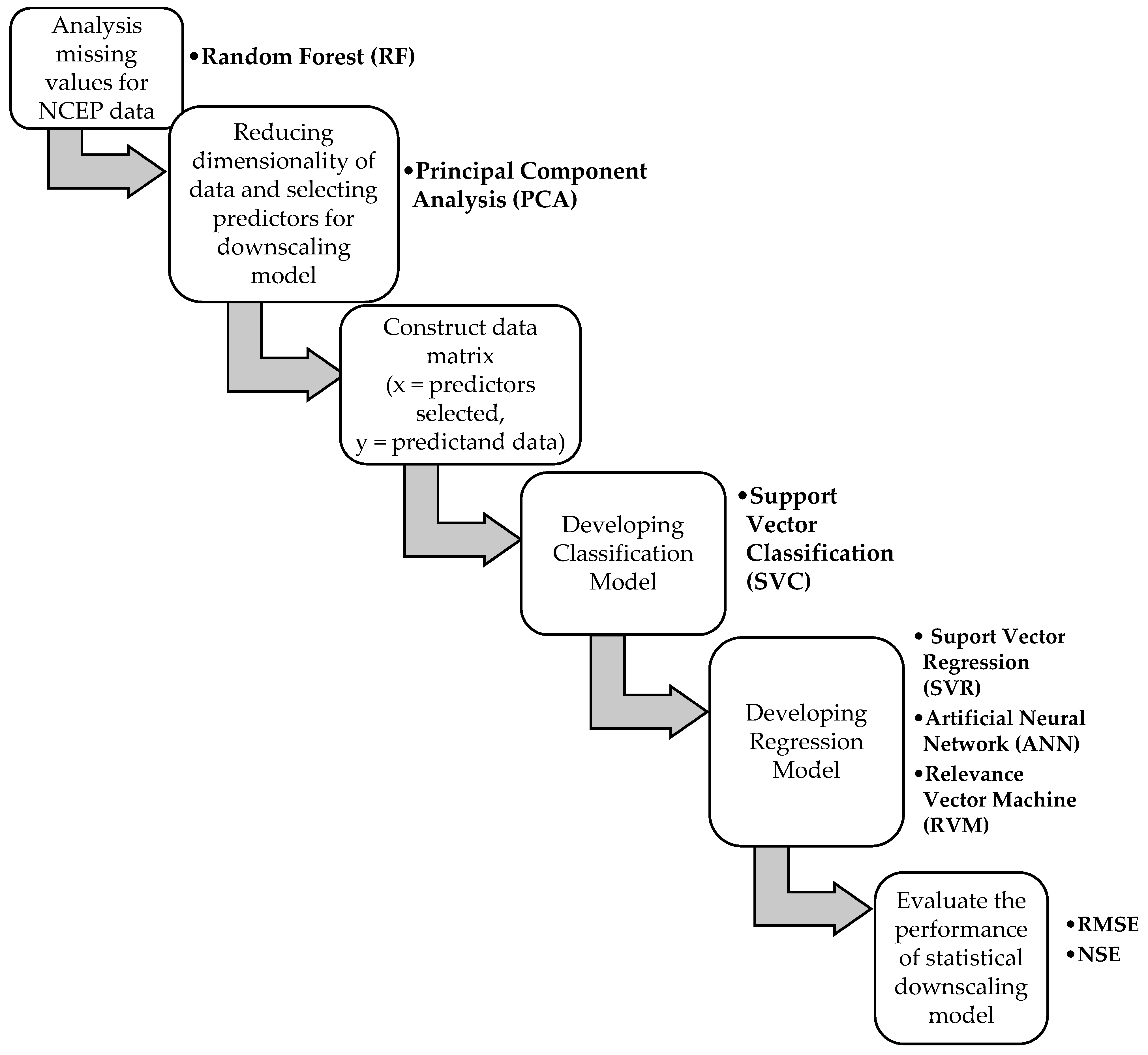
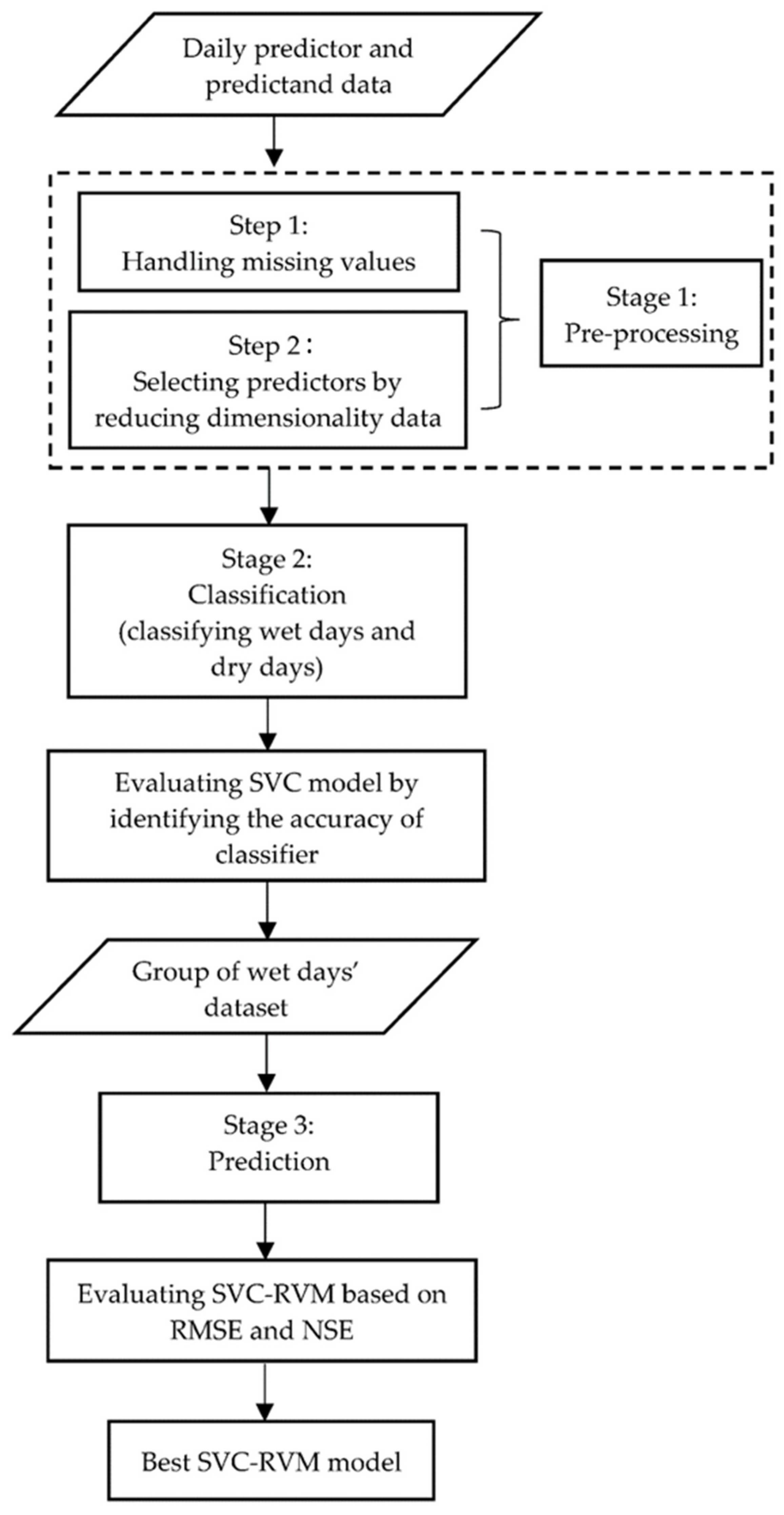
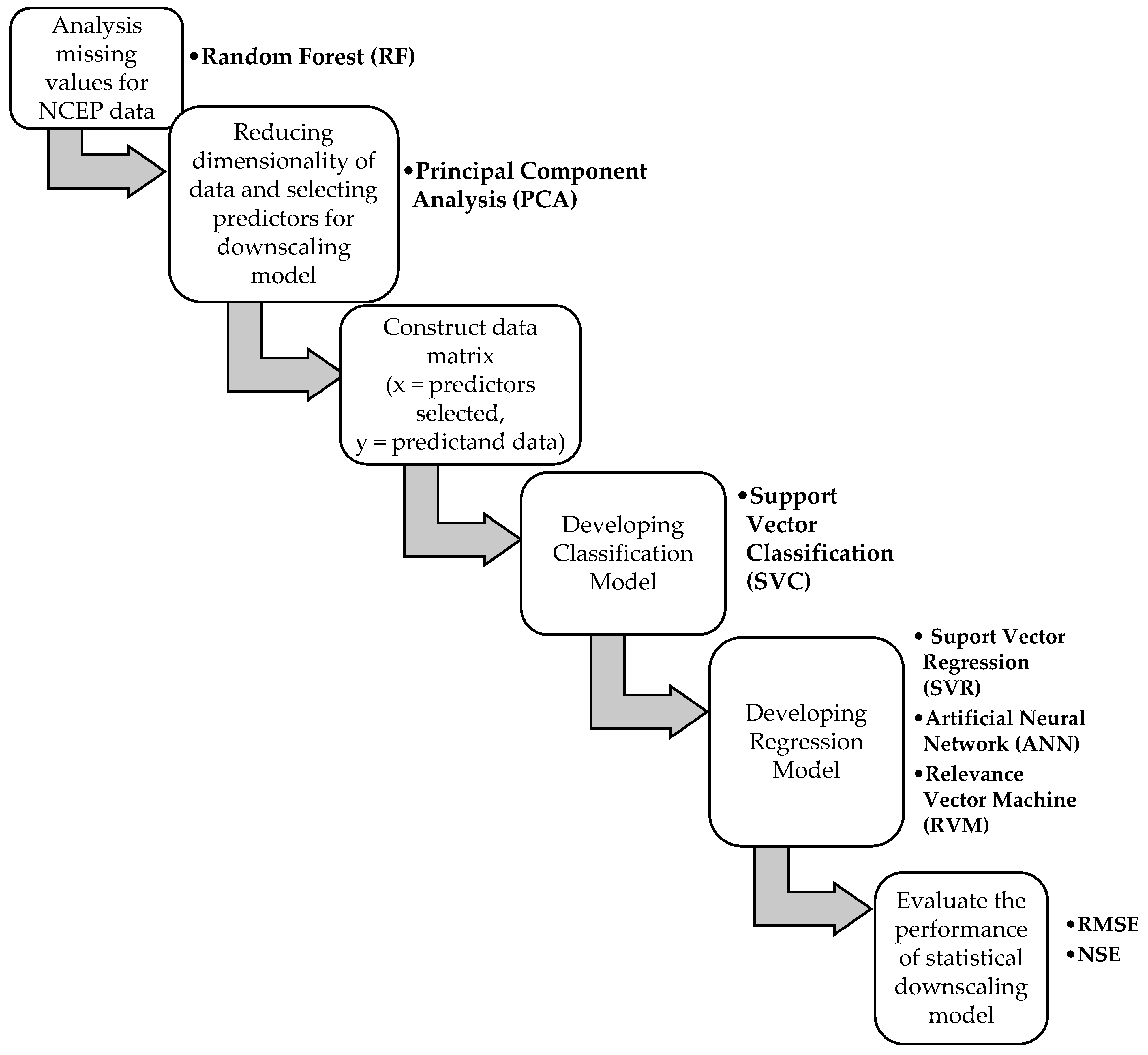
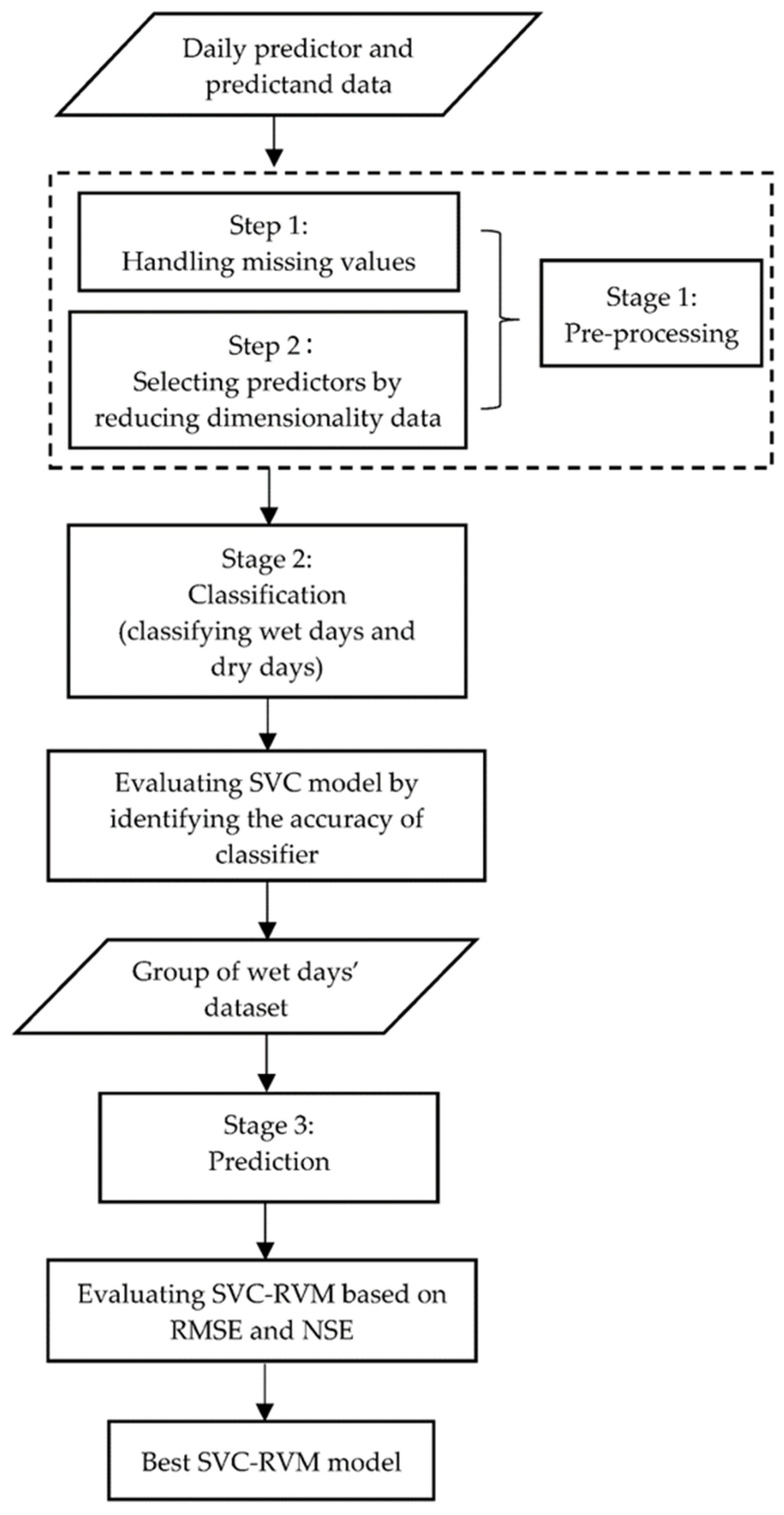
2.3.7. Flowchart of Statistical Downscaling Method
2.4. Procedure in Developing Statistical Downscaling Model
2.4.1. Pre-Processing Steps of Inputs in Statistical Downscaling Models
Analysis Missing Values of NCEP Data
- (1)
- Step 1: Initializing. The missing values will be replaced by the mean of data (continuous variables) or the most frequent class (categorical variables).
- (2)
- Step 2: Imputation. The imputation process is carried out consecutively for each variable in ascending or descending order of missing observations for each variable. The RF model is built using the variable under imputation as the response. The dataset’s observations are divided into two groups based on whether the variable was observed or missing in the original dataset. The training set is made up of observed observations, while the prediction set is made up of missing observations [43]. Predictions from RF models are used to fill in the missing part of the variable under imputation [44].
- (3)
- Step 3: Stop. One imputation iteration is completed when all variables with missing data have been imputed. MissForest outputs the previous imputation as the final result after iterating the imputation process until the relative sum of squared differences between the current and previous imputation results increases [45].
Reducing Dimensionality of Data and Selection of Predictors
2.4.2. Development of Downscaling Model
Developing Classification Model
Developing Regression Model
- (a)
- SVR-and-RVM-based Statistical Downscaling Model
- (b) ANN-based statistical downscaling model
2.4.3. Hybrid Model of SVC-RVM
3. Results
3.1. Results of Pre-Processing Inputs in Statistical Downscaling Model
3.1.1. Analysis of Missing Values of NCEP Data
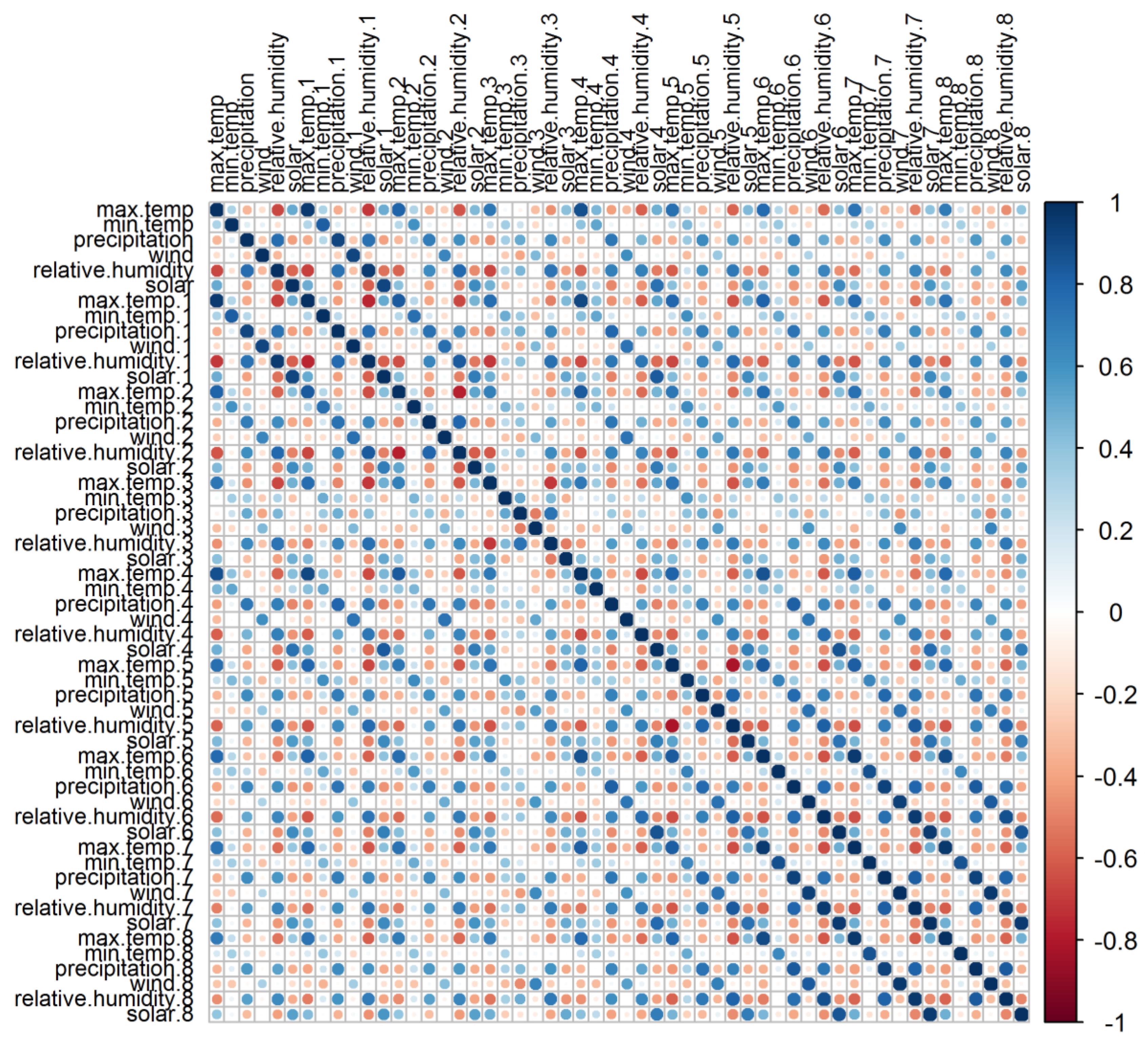
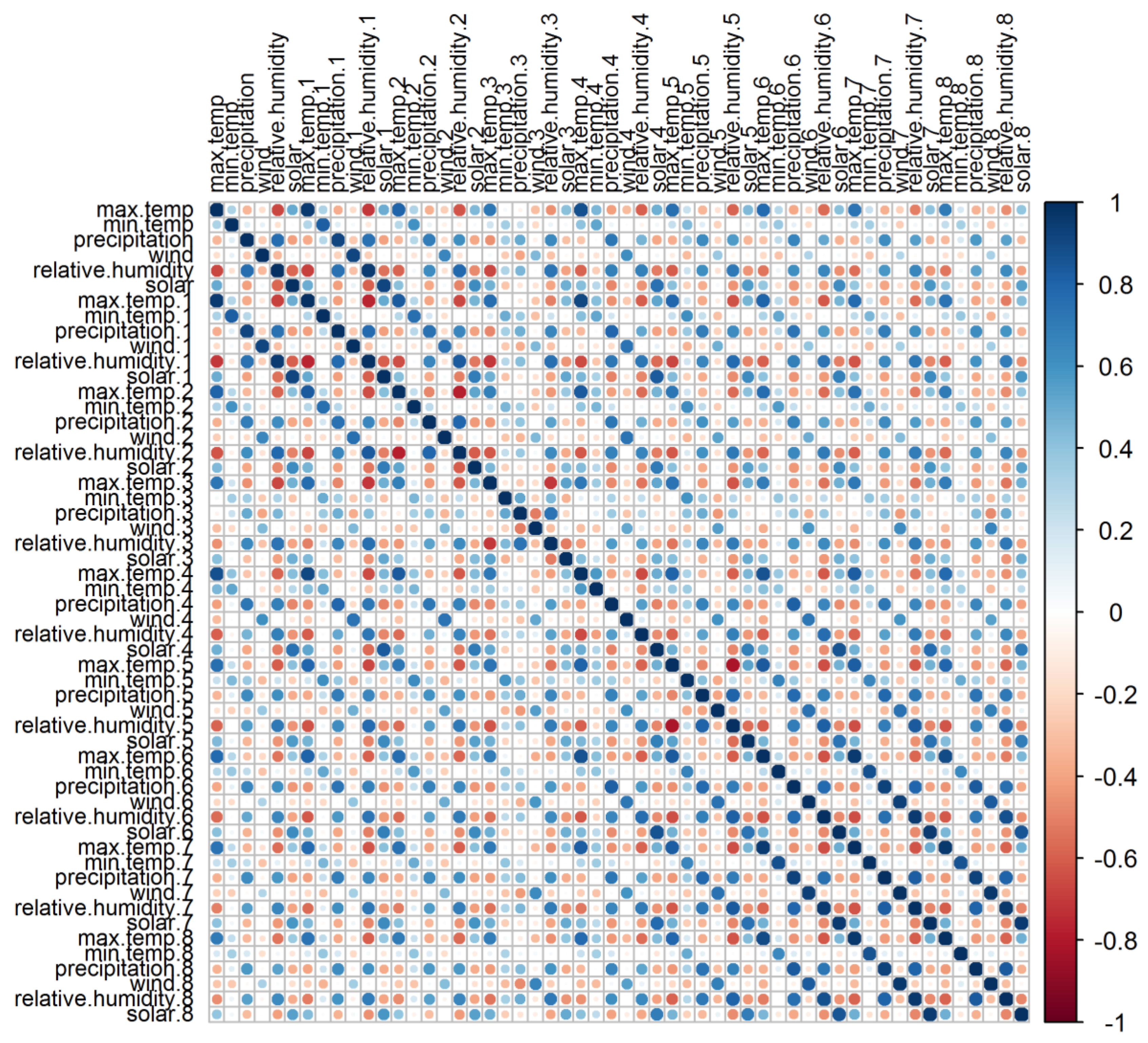
3.1.2. Reducing Dimension Data and Selection of Predictors
3.2. Results of Support Vector Classification in Predicting Categorical Rainfall Data
3.3. Results of Developing Regression Model in Predicting Rainfall Data
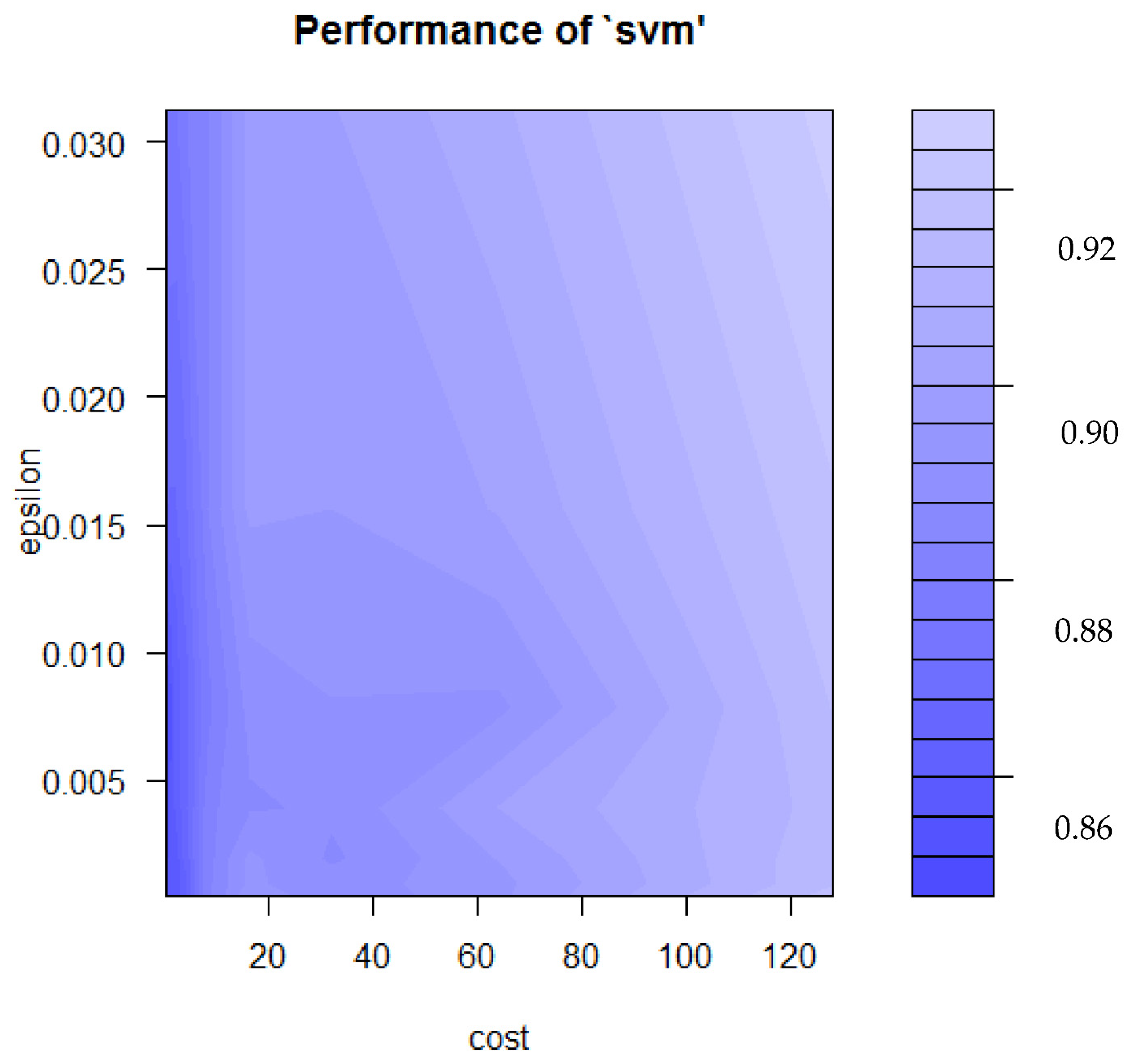
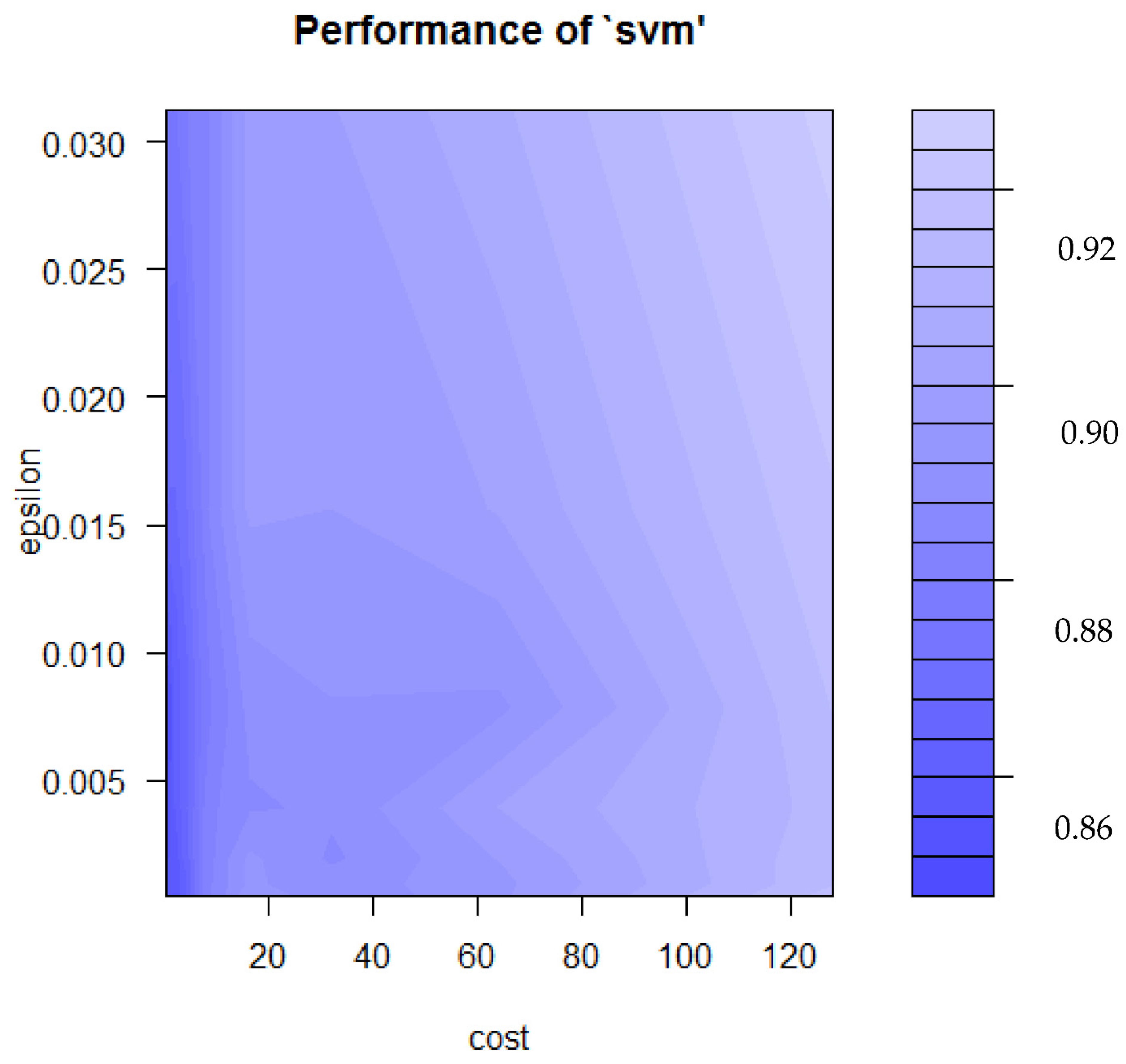
3.3.1. Results of Turning Parameters of SVR
3.3.2. Results of Selection of Kernel for RVM Model
3.3.3. Results of Developing Machine Learning Techniques in Statistical Downscaling Model
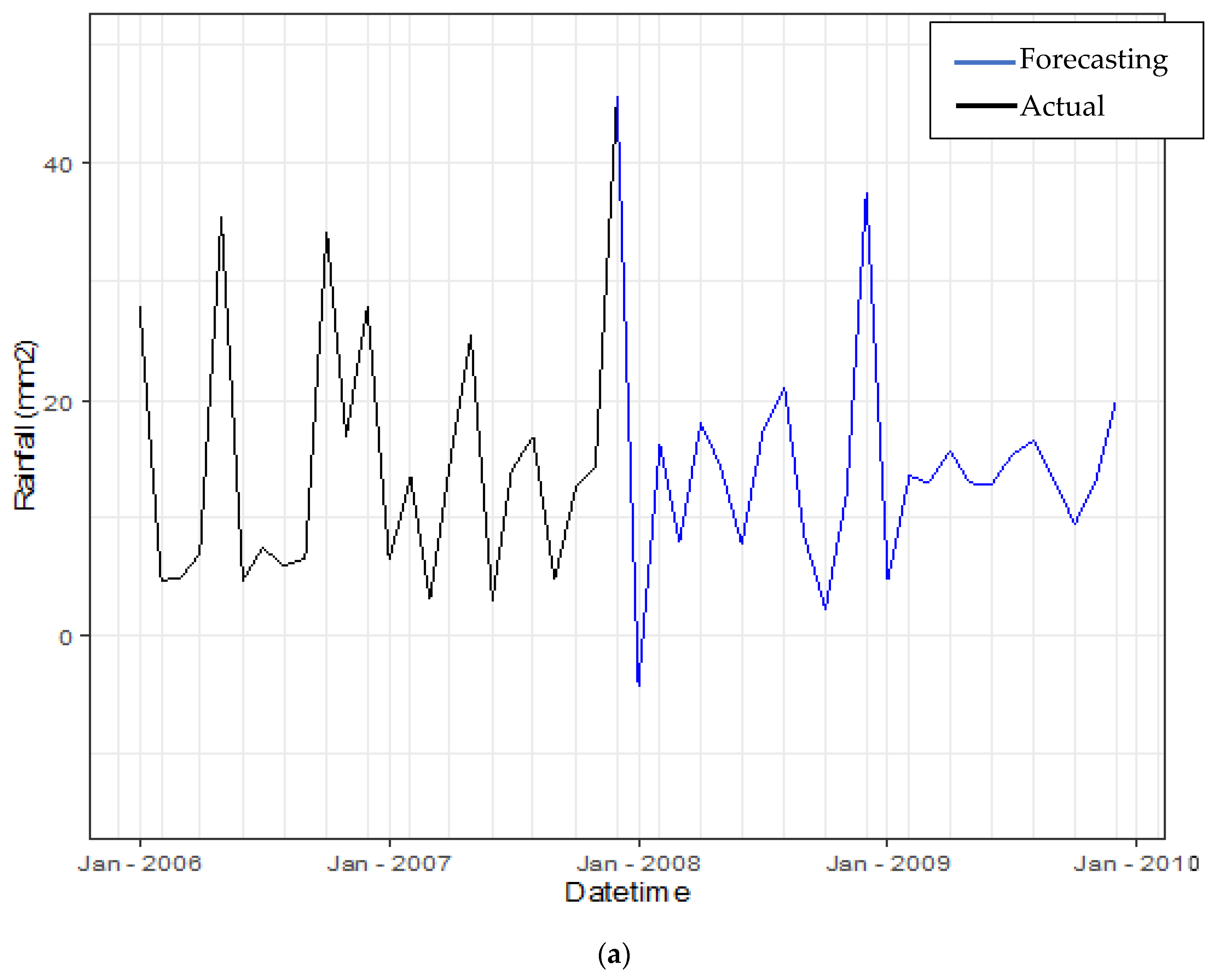
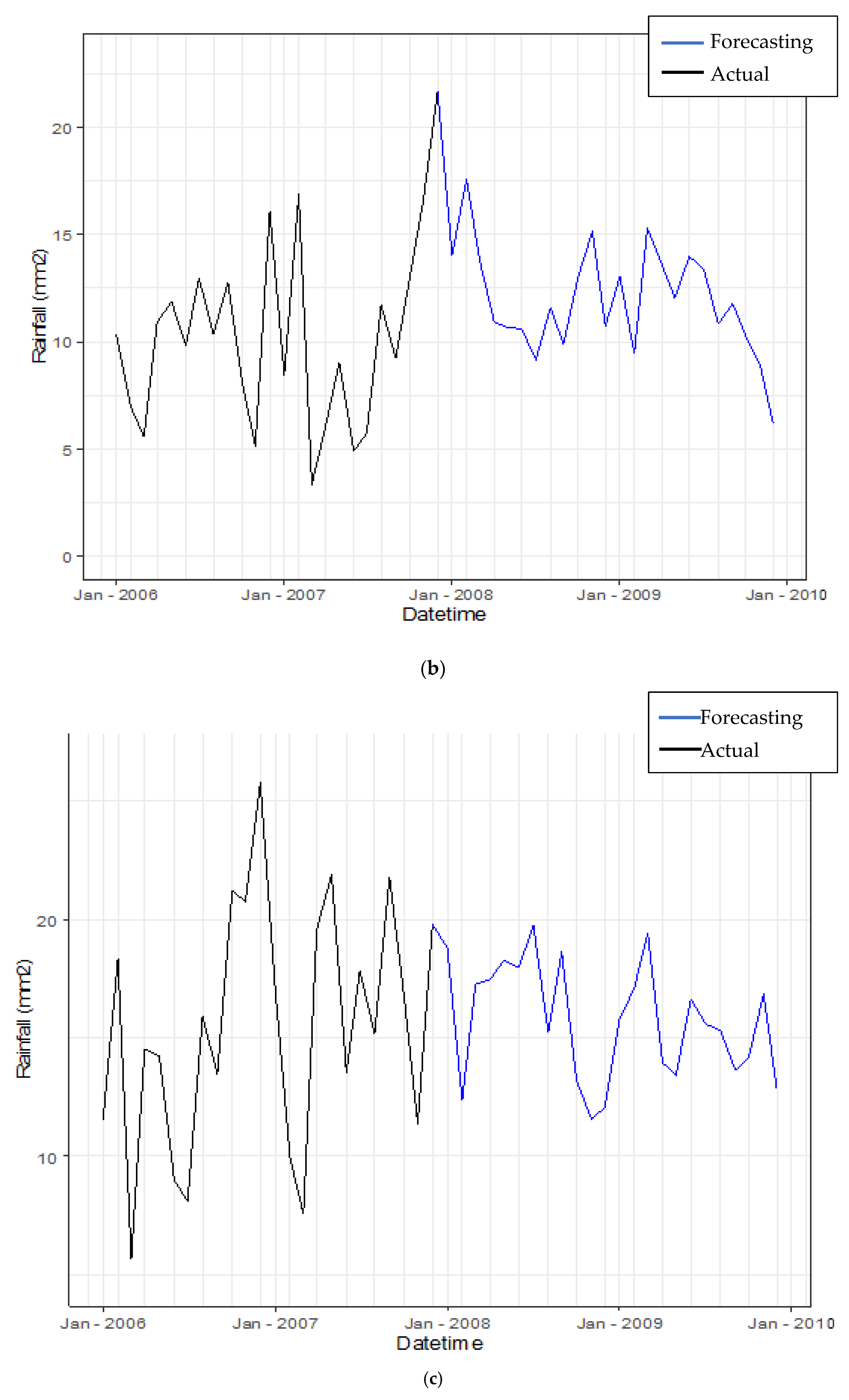
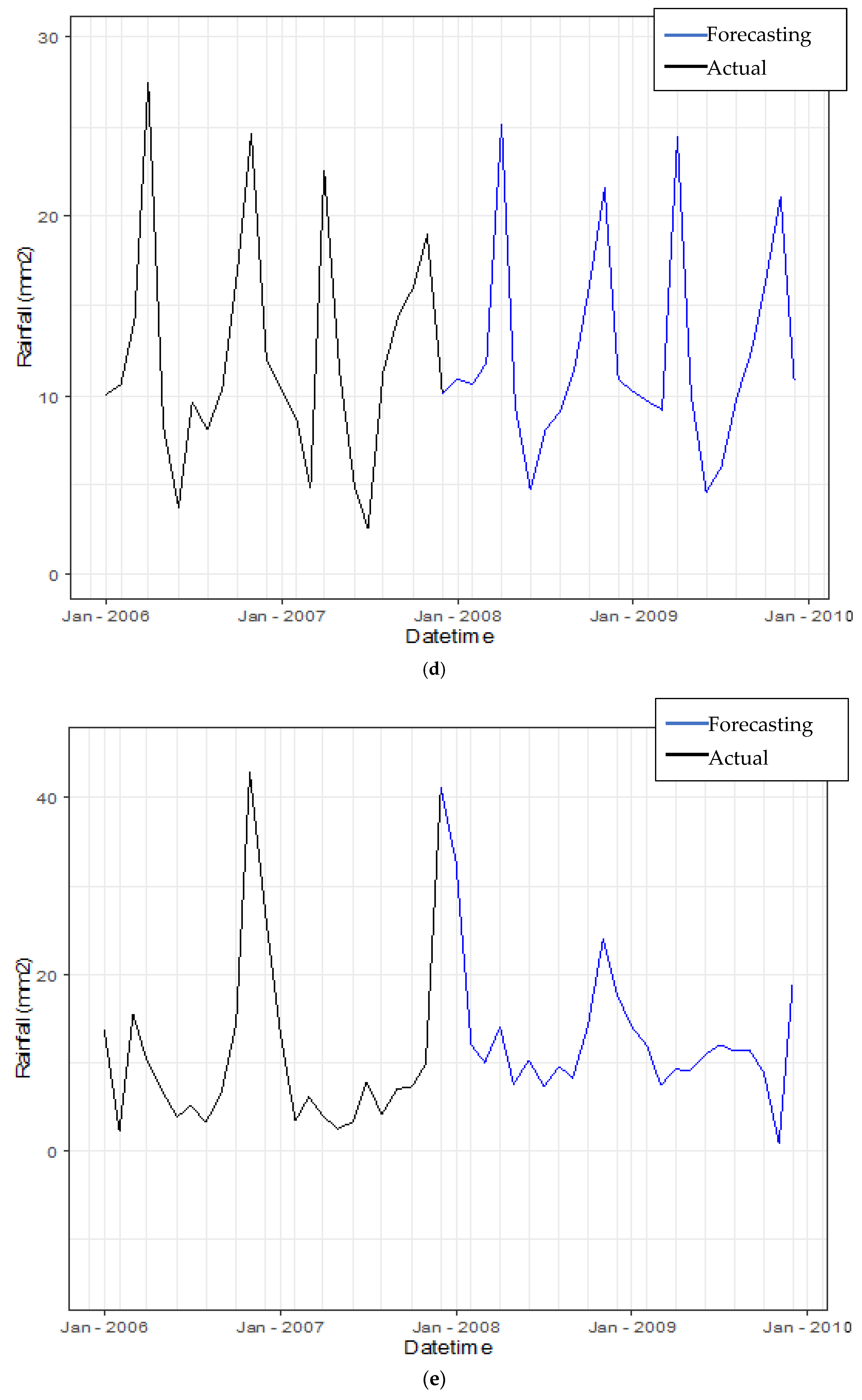
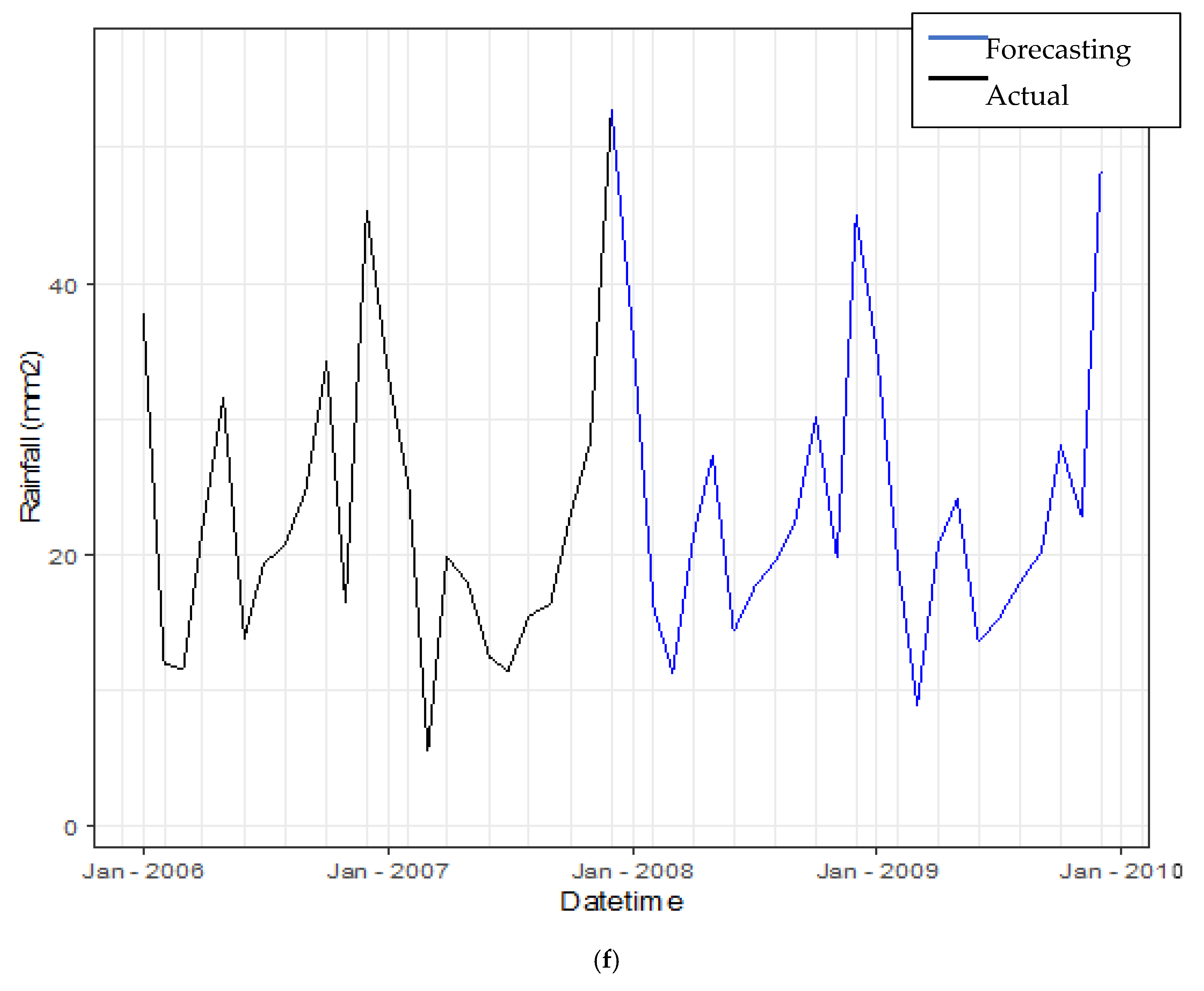
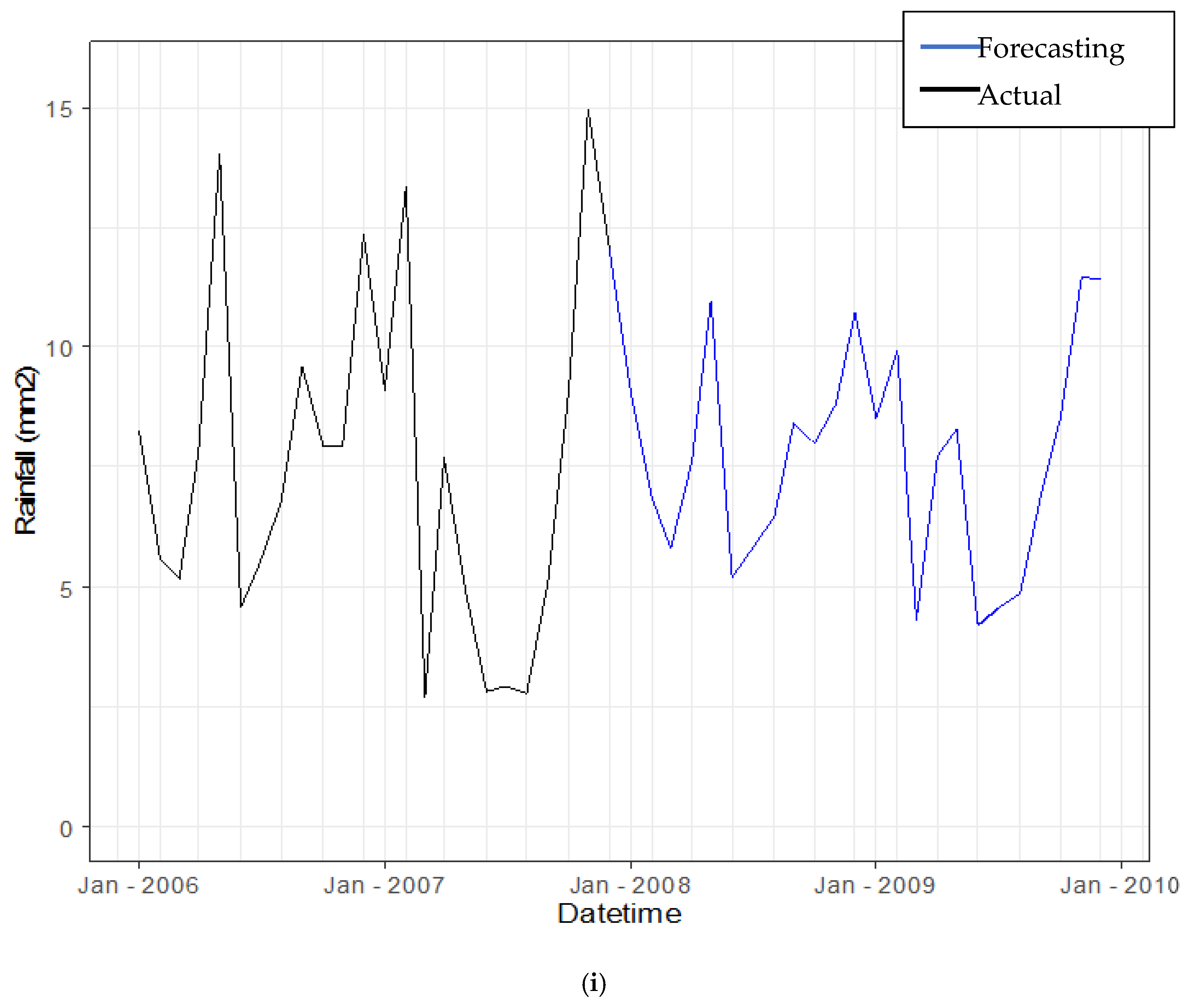
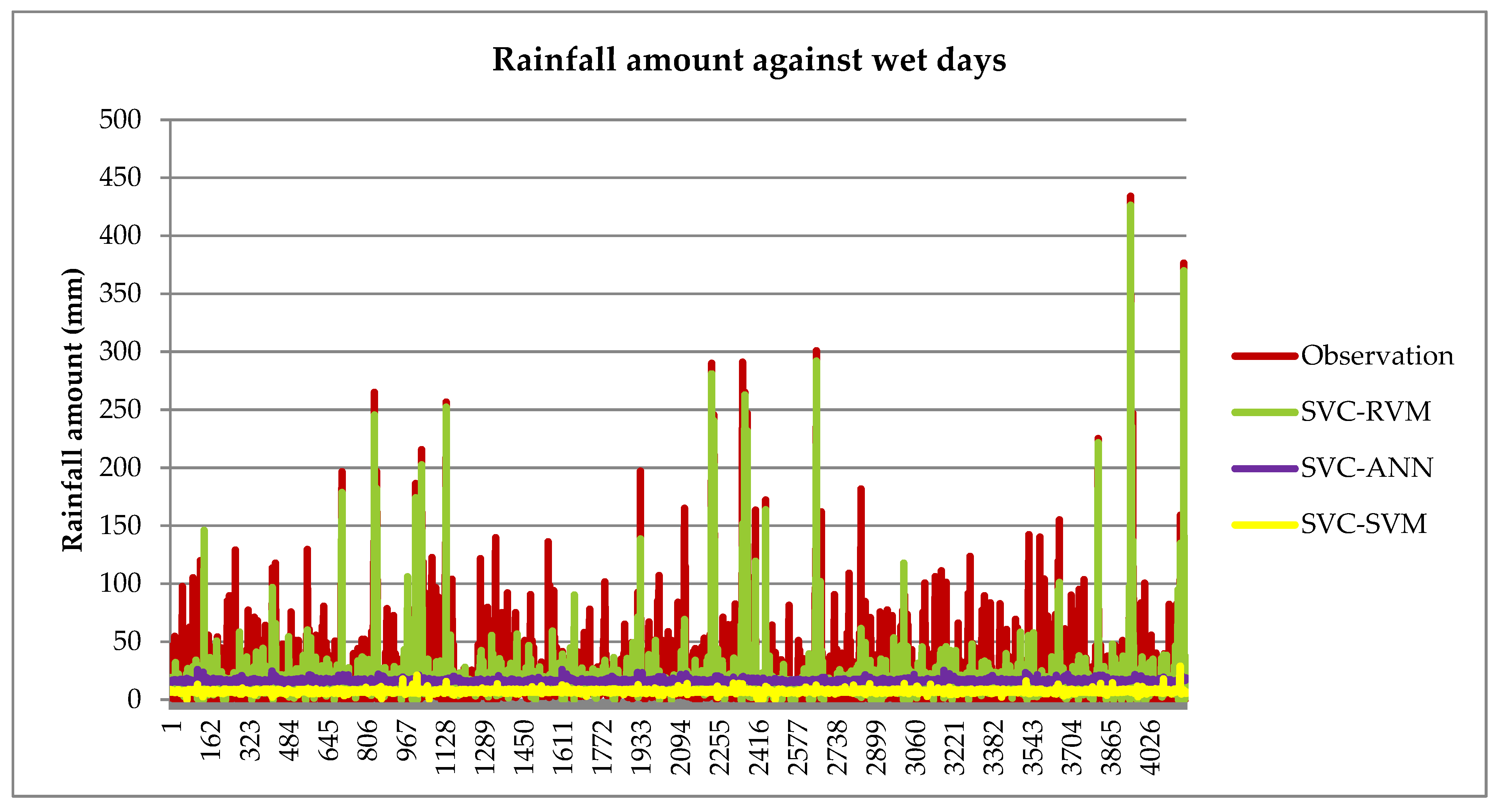
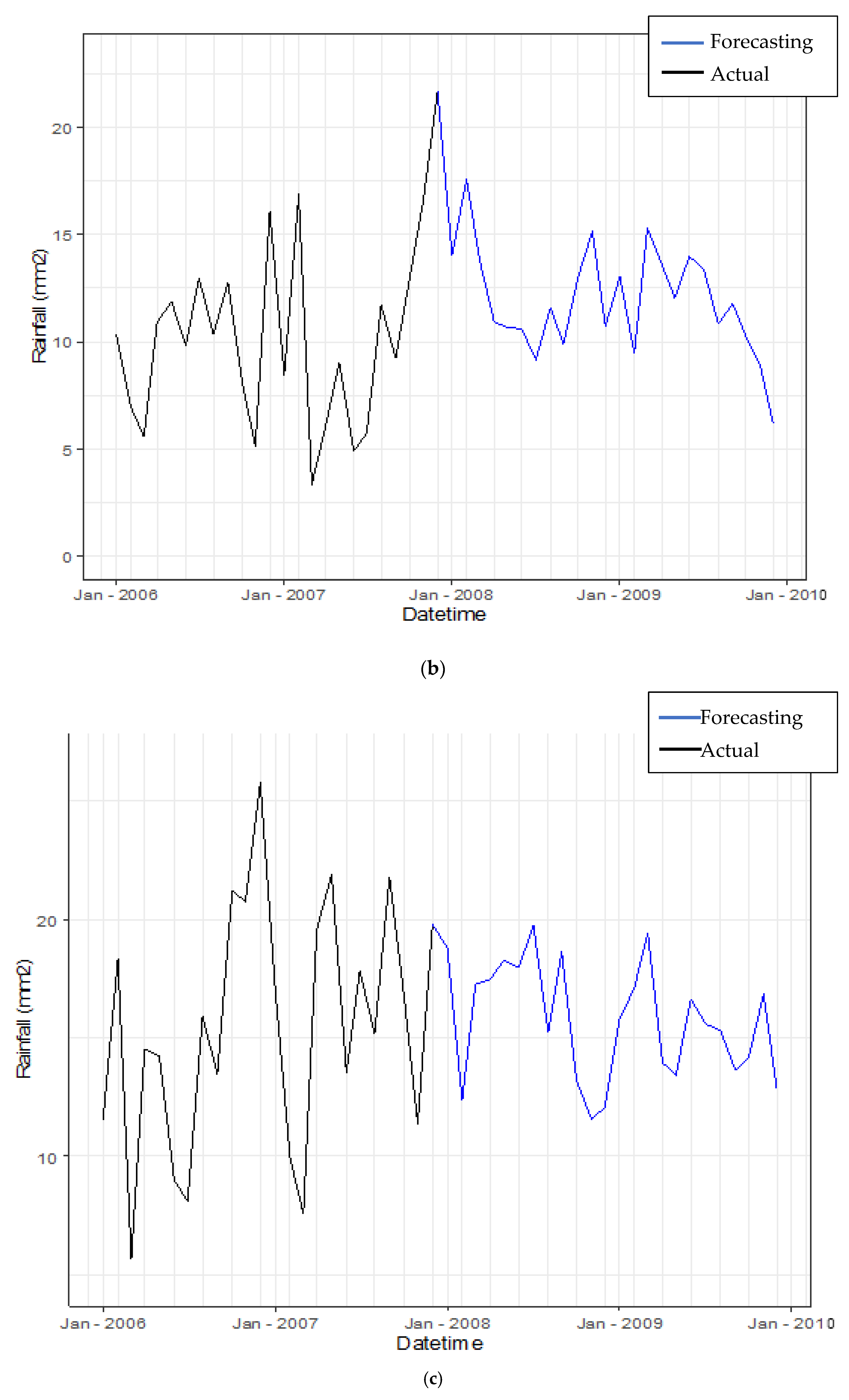
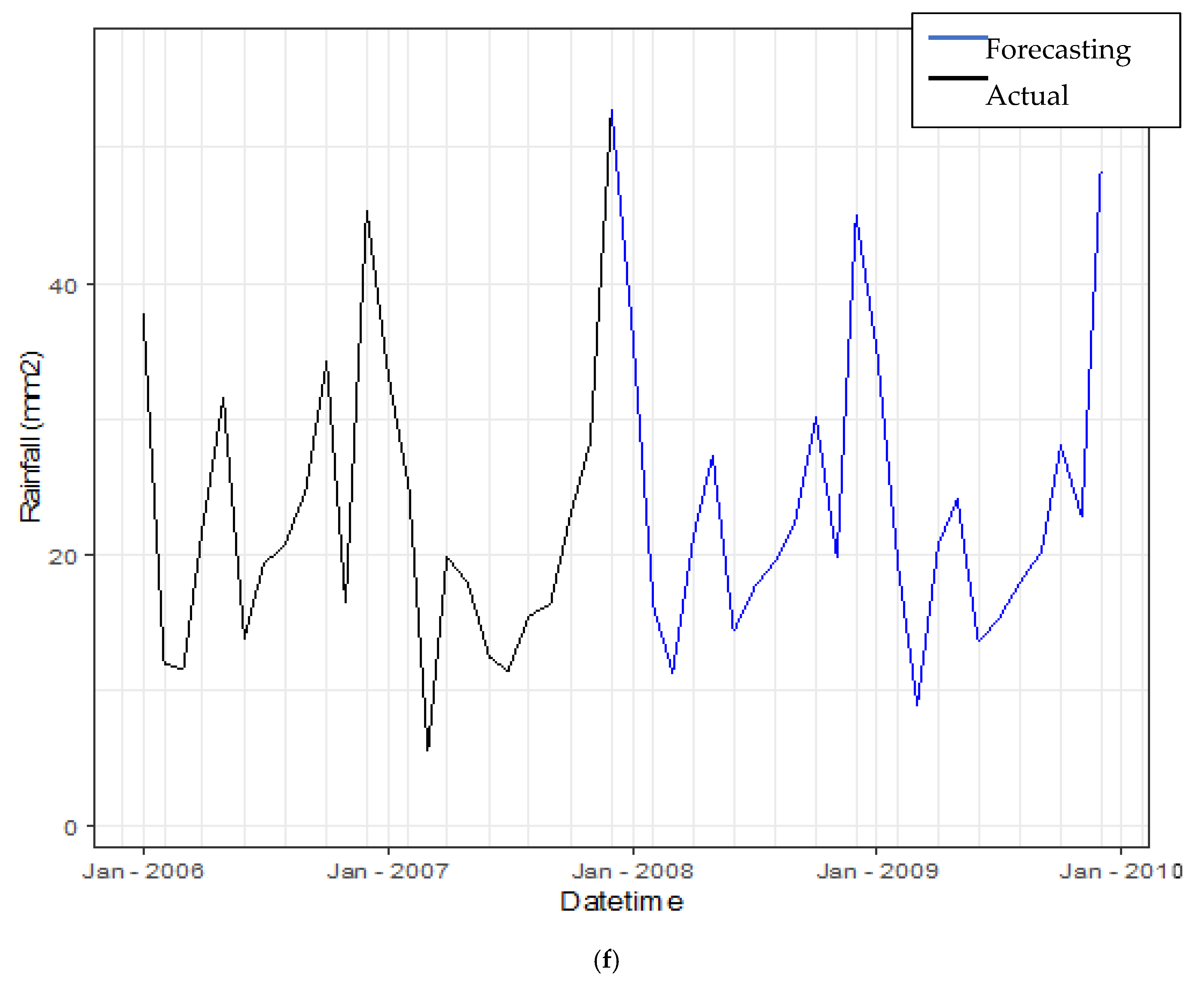
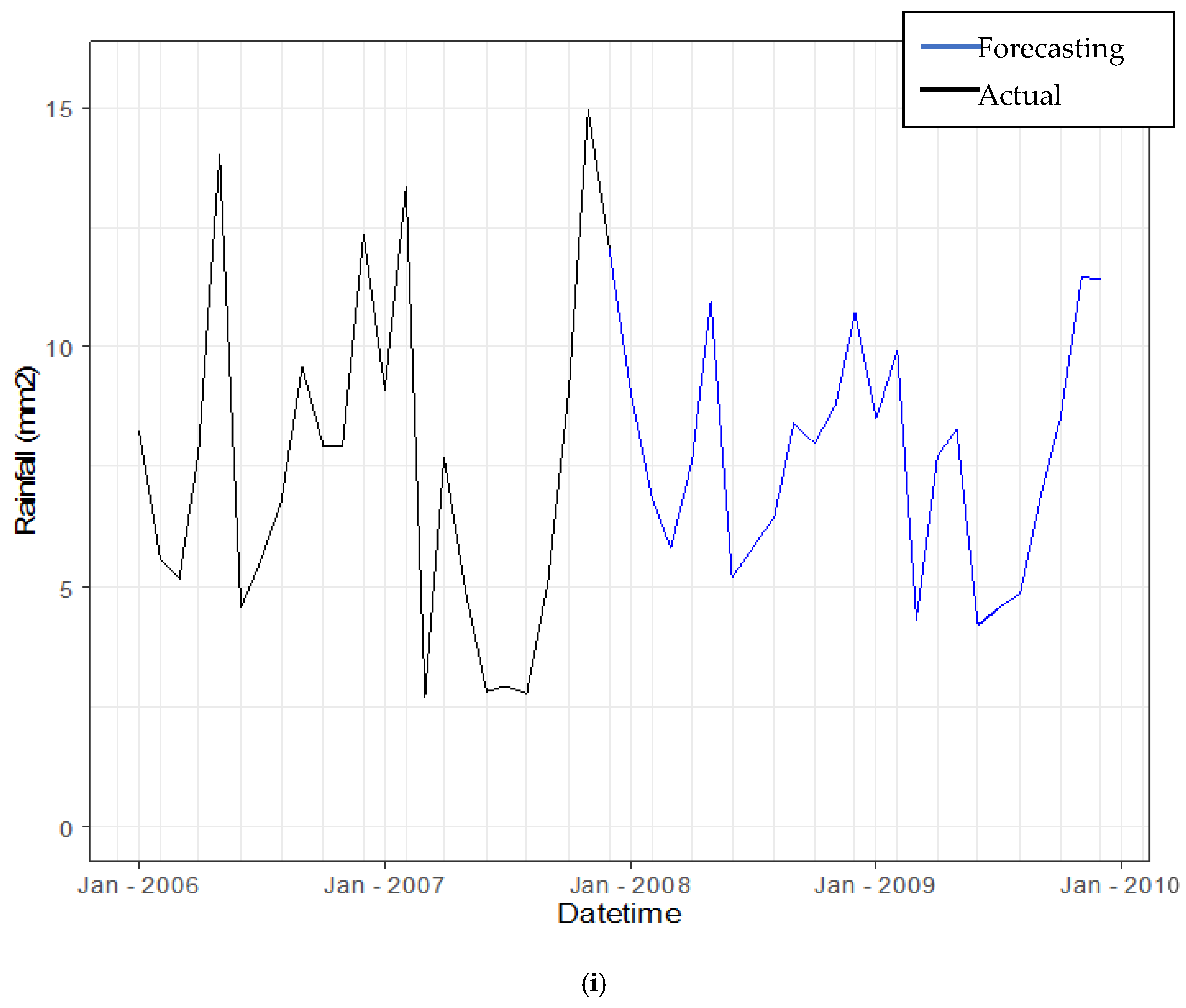
3.3.4. Forecasting Daily Rainfall by Using Hybrid Model
4. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Pour, S.H.; Shahid, S.; Chung, E.-S. A Hybrid Model for Statistical Downscaling of Daily Rainfall. Procedia Eng. 2016, 154, 1424–1430. [Google Scholar] [CrossRef]
- Schoof, J.T. Statistical Downscaling in Climatology. Geogr. Compass 2013, 7, 249–265. [Google Scholar] [CrossRef] [Green Version]
- Lanzante, J.R.; Dixon, K.; Nath, M.J.; Whitlock, C.E.; Adams-Smith, D. Some Pitfalls in Statistical Downscaling of Future Climate. Bull. Am. Meteorol. Soc. 2018, 99, 791–803. [Google Scholar] [CrossRef]
- Xu, R.; Chen, N.; Chen, Y.; Chen, Z. Downscaling and Projection of Multi-CMIP5 Precipitation Using Machine Learning Methods in the Upper Han River Basin. Adv. Meteorol. 2020, 2020, 8680436. [Google Scholar] [CrossRef]
- Wilby, R.L.; Charles, S.P.; Zorita, E.; Timbal, B.; Whetton, P.; Mearns, L.O. Guidelines for Use of Climate Scenarios Developed from Statistical Downscaling Methods. Analysis 2004, 27, 1–27. [Google Scholar]
- Chen, H.; Guo, J.; Xiong, W.; Guo, S.; Xu, C.-Y. Downscaling GCMs using the Smooth Support Vector Machine method to predict daily precipitation in the Hanjiang Basin. Adv. Atmos. Sci. 2010, 27, 274–284. [Google Scholar] [CrossRef]
- Sachindra, D.; Ahmed, K.; Rashid, M.; Shahid, S.; Perera, B. Statistical downscaling of precipitation using machine learning techniques. Atmos. Res. 2018, 212, 240–258. [Google Scholar] [CrossRef]
- Carleo, G.; Cirac, I.; Cranmer, K.; Daudet, L.; Schuld, M.; Tishby, N.; Vogt-Maranto, L.; Zdeborová, L. Machine learning and the physical sciences. Rev. Mod. Phys. 2019, 91, 045002. [Google Scholar] [CrossRef] [Green Version]
- Sulaiman, N.A.; Shaharudin, S.M.; Zainuddin, N.H.; Najib, S.A.M. Improving support vector machine rainfall classification accuracy based on kernel parameters optimization for statistical downscaling approach. Int. J. Adv. Trends Comput. Sci. Eng. 2020, 9, 652–657. [Google Scholar] [CrossRef]
- Coulibaly, P. Downscaling daily extreme temperatures with genetic programming. Geophys. Res. Lett. 2004, 31, L16203. [Google Scholar] [CrossRef]
- Sachindra, D.A.; Huang, F.; Barton, A.; Perera, B.J.C. Least square support vector and multi-linear regression for statistically downscaling general circulation model outputs to catchment stream flows. Int. J. Clim. 2012, 33, 1087–1106. [Google Scholar] [CrossRef] [Green Version]
- Duhan, D.; Pandey, A. Statistical downscaling of temperature using three techniques in the Tons River basin in Central India. Arch. Meteorol. Geophys. Bioclimatol. Ser. B 2014, 121, 605–622. [Google Scholar] [CrossRef]
- Borah, D.K. Hydrologic procedures of storm event watershed models: A comprehensive review and comparison. Hydrol. Process. 2011, 25, 3472–3489. [Google Scholar] [CrossRef]
- Shaharudin, S.M.; Ahmad, N.; Zainuddin, N.H.; Mohamed, N.S. Identification of rainfall patterns on hydrological simulation using robust principal component analysis. Indones. J. Electr. Eng. Comput. Sci. 2018, 11, 1162–1167. [Google Scholar] [CrossRef]
- Nor, S.M.C.M.; Shaharudin, S.M.; Ismail, S.; Najib, S.A.M.; Tan, M.L.; Ahmad, N. Statistical Modeling of RPCA-FCM in Spatiotemporal Rainfall Patterns Recognition. Atmosphere 2022, 13, 145. [Google Scholar] [CrossRef]
- Shaharudin, S.M.; Nor, S.M.C.M.; Tan, M.L.; Samsudin, M.S.; Azid, A.; Ismail, S. Spatial Torrential Rainfall Modelling in Pattern Analysis Based on Robust PCA Approach. Pol. J. Environ. Stud. 2021, 30, 3221–3230. [Google Scholar] [CrossRef]
- Nayak, P.C.; Sudheer, K.P.; Rangan, D.M.; Ramasastri, K.S. Short-term flood forecasting with a neurofuzzy model. Water Resour. Res. 2005, 41, W04004. [Google Scholar] [CrossRef] [Green Version]
- Costabile, P.; Macchione, F. Enhancing river model set-up for 2-D dynamic flood modelling. Environ. Model. Softw. 2015, 67, 89–107. [Google Scholar] [CrossRef]
- Van den Honert, R.C.; McAneney, J. The 2011 Brisbane Floods: Causes, Impacts and Implications. Water 2011, 3, 1149–1173. [Google Scholar] [CrossRef] [Green Version]
- Lee, T.H.; Georgakakos, K.P. Operational Rainfall Prediction on Meso-γ Scales for Hydrologic Applications. Water Resour. Res. 1996, 32, 987–1003. [Google Scholar] [CrossRef]
- Shrestha, D.L.; Robertson, D.E.; Wang, Q.J.; Pagano, T.C.; Hapuarachchi, P. Evaluation of numerical weather prediction model precipitation forecasts for use in short-term streamflow forecasting. Hydrol. Earth Syst. Sci. Discuss. 2012, 9, 12563–12611. [Google Scholar]
- Chen, S.-T.; Yu, P.-S.; Tang, Y.-H. Statistical downscaling of daily precipitation using support vector machines and multivariate analysis. J. Hydrol. 2010, 385, 13–22. [Google Scholar] [CrossRef]
- Aftab, S.; Ahmad, M.; Hameed, N.; Salman, M.; Ali, I.; Nawaz, Z. Rainfall Prediction using Data Mining Techniques: A Systematic Literature Review. Int. J. Adv. Comput. Sci. Appl. 2018, 9, 090518. [Google Scholar] [CrossRef] [Green Version]
- Loyola R, D.G.; Pedergnana, M.; García, S.G. Smart sampling and incremental function learning for very large high dimensional data. Neural Netw. 2016, 78, 75–87. [Google Scholar] [CrossRef] [Green Version]
- Katal, A.; Wazid, M.; Goundar, R. Big Data: Issues, Challenges, Tools and Good Practices. Proceeding of the 2013 Sixth International Conference on Contemporary Computing, Noida, India, 8–10 August 2013. [Google Scholar]
- Tanwar, S.; Ramani, T.; Tyagi, S. Dimensionality reduction using PCA and SVD in big data: A comparative case study. In Future Internet Technologies and Trends; Patel, Z., Gupta, S., Eds.; Springer: Cham, Switzerland, 2018; Volume 220, pp. 116–125. [Google Scholar]
- Saini, O.; Sharma, P.S. A Review on Dimension Reduction Techniques in Data Mining. Comput. Eng. Intell. Syst. 2018, 9, 7–14. [Google Scholar]
- Brence, J.R.; Brown, D.E. Improving the Robust Random Forest Regression Algorithm. Systems and Information Engineering Technical Papers. 2006, pp. 1–18. Available online: http://citeseerx.ist.psu.edu/viewdoc/download?doi=10.1.1.712.588&rep=rep1&type=pdf (accessed on 11 March 2022).
- Ho, T.K. Random Decision Forests Tin Kam Ho Perceptron training. In Proceedings of the 3rd International Conference on Document Analysis and Recognition, Montreal, QC, Canada, 14–16 August 1995. [Google Scholar]
- Breiman, L. Random Forests. Mach. Lang. 2001, 45, 5–32. [Google Scholar]
- Jollife, I.T.; Cadima, J. Principal component analysis: A review and recent developments. Philos. Trans. R. Soc. A Math. Phys. Eng. Sci. 2016, 374, 20150202. [Google Scholar] [CrossRef]
- Yamini, O.; Ramakrishna, S. A Study on Advantages of Data Mining Classification Techniques. Int. J. Eng. Res. 2015, V4, 090815. [Google Scholar] [CrossRef]
- Tripathi, S.; Srinivas, V.; Nanjundiah, R.S. Downscaling of precipitation for climate change scenarios: A support vector machine approach. J. Hydrol. 2006, 330, 621–640. [Google Scholar] [CrossRef]
- Advantages of Support Vector Machines (SVM). Available online: https://iq.opengenus.org/advantages-of-svm/ (accessed on 11 March 2022).
- Raghavendra, S.; Deka, P.C. Support vector machine applications in the field of hydrology: A review. Appl. Soft Comput. J. 2014, 19, 372–386. [Google Scholar] [CrossRef]
- Lin, S.; Zhang, S.; Qiao, J.; Liu, H.; Yu, G. A parameter choosing method of SVR for time series prediction. In Proceedings of the 2008 9th International Conference for Young Computer Scientists, Zhangjiajie, China, 18–21 November 2008. [Google Scholar]
- E Wang, J.; Qiao, J.Z. Parameter Selection of SVR Based on Improved K-Fold Cross Validation. Appl. Mech. Mater. 2013, 462–463, 182–186. [Google Scholar] [CrossRef]
- Mishra, N.; Soni, H.K.; Sharma, S.; Upadhyay, A.K. Development and Analysis of Artificial Neural Network Models for Rainfall Prediction by Using Time-Series Data. Int. J. Intell. Syst. Appl. 2018, 10, 16–23. [Google Scholar] [CrossRef]
- Kumar, P.; Praveen, T.V.; Prasad, M.A. Artificial Neural Network Model for Rainfall-Runoff—A Case Study. Int. J. Hybrid. Inf. Technol. 2016, 9, 263–272. [Google Scholar] [CrossRef]
- Tipping, M.E. Sparse Bayesian Learning and the Relevance Vector Machine. J. Mach. Learn. Res. 2001, 1, 211–244. [Google Scholar]
- Ghosh, S.; Mujumdar, P. Statistical downscaling of GCM simulations to streamflow using relevance vector machine. Adv. Water Resour. 2008, 31, 132–146. [Google Scholar] [CrossRef]
- Samui, P.; Dixon, B. Application of support vector machine and relevance vector machine to determine evaporative losses in reservoirs. Hydrol. Process. 2011, 26, 1361–1369. [Google Scholar] [CrossRef]
- Hong, S.; Lynn, H.S. Accuracy of random-forest-based imputation of missing data in the presence of non-normality, non-linearity, and interaction. BMC Med. Res. Methodol. 2020, 20, 199. [Google Scholar] [CrossRef]
- Liaw, A.; Wiener, M. Classification and Regression by random Forest. R News 2002, 2, 18–22. [Google Scholar]
- Stekhoven, D.J.; Bühlmann, P. Missforest-Non-parametric missing value imputation for mixed-type data. Bioinformatics 2012, 28, 112–118. [Google Scholar] [CrossRef] [Green Version]
- Ayesha, S.; Hanif, M.K.; Talib, R. Overview and comparative study of dimensionality reduction techniques for high dimensional data. Inf. Fusion 2020, 59, 44–58. [Google Scholar] [CrossRef]
- Bethere, L.; Sennikovs, J.; Bethers, U. Climate indices for the Baltic states from principal component analysis. Earth Syst. Dyn. 2017, 8, 951–962. [Google Scholar] [CrossRef] [Green Version]
- Denguir, M.; Sattler, S.M. A dimensionality-reduction method for test data. Proceeding of the 2017 IEEE 22nd International Mixed-Signals Test Workshop (IMSTW 2017), Thessaloniki, Greece, 3–5 July 2017. [Google Scholar]
- Ghosh, S. SVM-PGSL coupled approach for statistical downscaling to predict rainfall from GCM output. J. Geophys. Res. Earth Surf. 2010, 115, 1–19. [Google Scholar] [CrossRef] [Green Version]
- Huang, C.-L.; Wang, C.-J. A GA-based feature selection and parameters optimization for support vector machines. Expert Syst. Appl. 2006, 31, 231–240. [Google Scholar] [CrossRef]
- Campozano, L.; Tenelanda, D.; Sanchez, E.; Samaniego, E.; Feyen, J. Comparison of Statistical Downscaling Methods for Monthly Total Precipitation: Case Study for the Paute River Basin in Southern Ecuador. Adv. Meteorol. 2016, 2016, 6526341. [Google Scholar] [CrossRef]
- Halik, G.; Anwar, N.; Santosa, B.; Edijatno. Reservoir Inflow Prediction under GCM Scenario Downscaled by Wavelet Transform and Support Vector Machine Hybrid Models. Adv. Civ. Eng. 2015, 2015, 515376. [Google Scholar] [CrossRef] [Green Version]
- Lu, L. Optimal Gamma and C for Epsilon Support Vector Regression with RBF Kernels. Available online: http://arxiv.org/abs/1506.03942 (accessed on 19 August 2021).
- Berrar, D. Cross-validation. Encycl. Bioinform. Comput. Biol. ABC Bioinform. 2018, 1–3, 542–545. [Google Scholar]
- Borra, S.; Di Ciaccio, A. Measuring the prediction error. A comparison of cross-validation, bootstrap and covariance penalty methods. Comput. Stat. Data Anal. 2010, 54, 2976–2989. [Google Scholar] [CrossRef]
- Okkan, U.; Serbes, Z.A.; Samui, P. Relevance vector machines approach for long-term flow prediction. Neural Comput. Appl. 2014, 25, 1393–1405. [Google Scholar] [CrossRef]
- Erdal, H.I.; Karakurt, O. Advancing monthly streamflow prediction accuracy of CART models using ensemble learning paradigms. J. Hydrol. 2013, 477, 119–128. [Google Scholar] [CrossRef]
- Fatihah, C.O.S.; Hila, Z.N.; Shaharudin, S.M.; Safiih, L.M.; Nikenasih, B.; Farizie, A.M.K. Bootstrapping the Multilayer Feedforward Propagation System for Predicting the Arrival Guest in Malaysia. Rev. Int. Geogr. Educ. 2021, 11, 754–763. [Google Scholar]
- Govindaraju, R.S. Artificial Neural Networks in Hydrology. II: Hydrologic Applications. J. Hydrol. Eng. 2000, 5, 124–137. [Google Scholar]
- Mekanik, F.; Imteaz, M.; Gato-Trinidad, S.; Elmahdi, A. Multiple regression and Artificial Neural Network for long-term rainfall forecasting using large scale climate modes. J. Hydrol. 2013, 503, 11–21. [Google Scholar] [CrossRef]
- Top 4 Advantages and Disadvantages of Support Vector Machine or SVM. Available online: https://dhirajkumarblog.medium.com/top-4-advantages-and-disadvantages-of-support-vector-machine-or-svm-a3c06a2b107 (accessed on 20 November 2021).
- Xia, Y. Correlation and association analyses in microbiome study integrating multiomics in health and disease. Prog. Mol. Biol. Transl. Sci. 2020, 171, 309–491. [Google Scholar] [CrossRef] [PubMed]
- Pal, M. Kernel methods in remote sensing: A review. ISH J. Hydraul. Eng. 2009, 15, 194–215. [Google Scholar] [CrossRef]
- Cummins, N.; Sethu, V.; Epps, J.; Krajewski, J. Relevance vector machine for depression prediction. Interspeech 2015, 2015, 110–114. [Google Scholar] [CrossRef]
- Presti, R.L.; Barca, E.; Passarella, G. A methodology for treating missing data applied to daily rainfall data in the Candelaro River Basin (Italy). Environ. Monit. Assess. 2008, 160, 1. [Google Scholar] [CrossRef] [PubMed]
- Moritz, S.; Sardá, A.; Bartz-Beielstein, T.; Zaefferer, M.; Stork, J. Comparison of different Methods for Univariate Time Series Imputation in R. arXiv 2015, arXiv:1510.03924a. [Google Scholar]
- Zhang, Y.; Wu, L. Classification of Fruits Using Computer Vision and a Multiclass Support Vector Machine. Sensors 2012, 12, 12489–12505. [Google Scholar] [CrossRef]
- Azid, A.; Juahir, H.; Toriman, M.E.; Kamarudin, M.K.A.; Saudi, A.S.M.; Hasnam, C.N.C.; Aziz, N.A.A.; Azaman, F.; Latif, M.T.; Zainuddin, S.F.M.; et al. Prediction of the Level of Air Pollution Using Principal Component Analysis and Artificial Neural Network Techniques: A Case Study in Malaysia. Water Air Soil Pollut. 2014, 225, 2063. [Google Scholar] [CrossRef]
- Dominick, D.; Juahir, H.; Latif, M.T.; Zain, S.M.; Aris, A.Z. Spatial assessment of air quality patterns in Malaysia using multivariate analysis. Atmos. Environ. 2012, 60, 172–181. [Google Scholar] [CrossRef]
- Liu, C.-W.; Lin, K.-H.; Kuo, Y.-M. Application of factor analysis in the assessment of groundwater quality in a blackfoot disease area in Taiwan. Sci. Total Environ. 2003, 313, 77–89. [Google Scholar] [CrossRef]
- Nanda, M.A.; Seminar, K.B.; Nandika, D.; Maddu, A. A Comparison Study of Kernel Functions in the Support Vector Machine and Its Application for Termite Detection. Information 2018, 9, 5. [Google Scholar] [CrossRef] [Green Version]
- Understanding Support Vector Machine (SVM) Algorithm from Examples (Along with Code). Available online: https://www.analyticsvidhya.com/blog/2017/09/understaing-support-vector-machine-example-code/ (accessed on 21 August 2021).
- Berzofsky, M.; Biemer, P.; Kalsbeek, W. A Brief History of Classification Error Models. In Proceedings of the Joint Statistical Meetings, Denver, CO, USA, 3–7 August 2008. [Google Scholar]
- Regression Techniques You Should Know! Available online: https://www.analyticsvidhya.com/blog/2015/08/comprehensive-guide-regression/ (accessed on 27 July 2020).
- Vapnik, V.N. The Nature of Statistical Learning Theory, 1st ed.; Springer: New York, NY, USA, 1995; pp. 110–123. [Google Scholar]
- Ali, A.H.; Abdullah, M.Z. An efficient model for data classification based on SVM grid parameter optimization and PSO feature weight selection. Int. J. Integr. Eng. 2020, 12, 1–12. [Google Scholar]
- Pattern Recognition Tools 37 Steps. Available online: http://37steps.com/4859/cross-validation/ (accessed on 31 September 2020).
- Tipping, M.E. The relevance vector machine. Adv. Neural Inf. Process. Syst. 2000, 12, 653–658. [Google Scholar]
- Assessing the Fit of Regression Models. Available online: https://www.theanalysisfactor.com/assessing-the-fit-of-regression-models/ (accessed on 11 July 2020).
- Bhattacharya, D.; Nisha, M.G.; Pillai, G. Relevance vector-machine-based solar cell model. Int. J. Sustain. Energy 2014, 34, 685–692. [Google Scholar] [CrossRef]
- Knoben, W.J.M.; Freer, J.E.; Woods, R.A. Technical note: Inherent benchmark or not? Comparing Nash–Sutcliffe and Kling–Gupta efficiency scores. Hydrol. Earth Syst. Sci. 2019, 23, 4323–4331. [Google Scholar] [CrossRef] [Green Version]



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| No. | Code of Atmospheric Station | Code of Ground Station | Name of Ground Station | Longitude | Latitude |
|---|---|---|---|---|---|
| 1 | P611022 | 71 | Kota Bharu | 102.28 | 6.17 |
| 2 | P551028 | 28 | Kg Merang, Setiu | 102.29 | 5.68 |
| 3 | P581025 | 14 | Sek. Keb, Kg Jabi | 102.56 | 5.68 |
| 4 | P551031 | 65 | Stor JPS Kuala Terengganu | 103.13 | 5.32 |
| 5 | P481019 | 60 | Gua Musang | 101.97 | 4.88 |
| 6 | P481031 | 61 | Kg. Menerong | 103.06 | 4.94 |
| 7 | P481034 | 59 | Sek. Men. Sultan Omar, Dungun | 103.42 | 4.76 |
| 8 | P451034 | 13 | Sek. Keb. Kemasek | 103.45 | 4.43 |
| Variable | Unit | Mean | Standard Deviation | Skewness | Kurtosis |
|---|---|---|---|---|---|
| Minimum temperature | °C | 30.05 | 2.71 | −0.05 | 0.36 |
| Maximum temperature | °C | 22.33 | 2.21 | −0.05 | 0.24 |
| Precipitation | mm | 9.49 | 14.03 | 5.12 | 44.94 |
| Wind | knot | 1.52 | 0.80 | 2.10 | 6.49 |
| Relative humidity | % | 0.83 | 0.08 | −0.39 | −0.35 |
| Solar | W/m2 | 20.37 | 5.93 | −1.26 | 1.04 |
| Max. Temperature | Min. Temperature | Precipitation | Wind | Relative Humidity | Solar | |
|---|---|---|---|---|---|---|
| RMSE | 0.23 | 0.19 | 2.25 | 0.06 | 0.01 | 0.74 |
| NSE | 0.99 | 0.97 | 0.97 | 0.99 | 0.99 | 0.98 |
| Dimension | Eigenvalue | Percent Variance | Cumulative Percentage |
|---|---|---|---|
| Component 1 | 2.62 | 43.66 | 43.66 |
| Component 2 | 1.60 | 26.63 | 70.29 |
| Component 3 | 0.64 | 10.63 | 80.92 |
| Component 4 | 0.55 | 9.22 | 90.14 |
| Component 5 | 0.45 | 7.53 | 97.68 |
| Component 6 | 0.14 | 2.33 | 100.00 |
| Predictors | Factor 1 | Factor 2 |
|---|---|---|
| Maximum temperature | 0.85 * | −0.19 |
| Minimum temperature | 0.09 | 0.81 * |
| Precipitation | −0.75 * | 0.20 |
| Wind | −0.03 | 0.89 * |
| Relative humidity | 0.86 * | 0.28 |
| Solar | 0.79 * | 0.01 |
| Type of Kernel | Parameter | Calibration | Validation | |||||
|---|---|---|---|---|---|---|---|---|
| No. of Support Vectors | Misclassification Error | Accuracy (%) | Misclassification Error | Accuracy (%) | ||||
| RBF | 10,000 | 1.00 | - | 12,363 * | 0.351 * | 64.90 * | 0.326 * | 67.40 * |
| Sigmoid | 10,000 | 1.00 | - | 446 | 0.468 | 53.25 | 0.467 | 53.30 |
| Linear | 10,000 | - | - | 12,036 | 0.359 | 64.12 | 0.356 | 64.40 |
| Polynomial | 10,000 | 1.0 | 1 | 13,075 | 0.356 | 64.40 | 0.354 | 64.60 |
| 10,000 | 1.0 | 2 | 14,597 | 0.466 | 53.40 | 0.447 | 55.30 | |
| 10,000 | 1.0 | 3 | 14,653 | 0.473 | 52.70 | 0.431 | 53.10 | |
| RMSE | |
|---|---|
| 0.25 | 1.935 |
| 0.50 * | 1.933 * |
| 1.00 | 1.935 |
| 2.00 | 1.935 |
| 4.00 | 1.940 |
| 8.00 | 1.950 |
| 16.00 | 1.970 |
| 32.00 | 1.975 |
| 64.00 | 1.985 |
| 128.00 | 1.985 |
| Type of Kernel | Number of Relevant Vectors | RMSE |
|---|---|---|
| RBF | 35 | 28.95 |
| Polynomial | 32 | 28.88 |
| Laplace | 15 * | 19.75 |
| Hyperbolic tangent | 31 | 28.82 |
| Bessel | 34 | 28.93 |
| ANOVA | 38 | 29.0 |
| Separation Data | Calibration | Validation | ||||
|---|---|---|---|---|---|---|
| SVR-SVM | SVC-ANN | SVC-RVM | SVC-SVR | SVC-ANN | SVC-RVM | |
| 50:50 | 30.64 | 29.28 | 25.56 | 31.14 | 30.46 | 21.59 |
| 60:40 | 30.61 | 29.17 | 23.10 | 30.28 | 30.04 | 20.21 |
| 70:30 | 30.46 | 29.00 | 22.62 | 30.21 | 28.95 | 19.40 |
| 80:20 | 30.21 | 28.71 | 20.19 | 30.13 | 28.67 | 17.85 |
| Separation Data | Calibration | Validation | ||||
|---|---|---|---|---|---|---|
| SVC-SVR | SVC-ANN | SVC-RVM | SVC-SVR | SVC-ANN | SVC-RVM | |
| 50:50 | 0.01 | 0.11 | 0.31 | 0.06 | 0.16 | 0.53 |
| 60:40 | 0.09 | 0.12 | 0.35 | 0.16 | 0.22 | 0.60 |
| 70:30 | 0.12 | 0.29 | 0.46 | 0.26 | 0.33 | 0.69 |
| 80:20 | 0.16 | 0.23 | 0.61 | 0.30 | 0.34 | 0.81 |
| Day | Daily (mm) | Predicted (mm) | RMSE |
|---|---|---|---|
| 2354 | 152.00 | 148.74 | 1.81 |
| 2355 | 166.50 | 151.68 | 3.85 |
| 2356 | 17.50 | 18.65 | 1.15 |
| 2357 | 23.00 | 18.08 | 2.22 |
| 2358 | 20.00 | 24.67 | 2.16 |
| 2359 | 17.00 | 21.32 | 2.08 |
| 2360 | 60.00 | 55.25 | 2.18 |
| 2361 | 17.50 | 20.00 | 1.58 |
| 2362 | 135.00 | 128.04 | 2.64 |
| 2363 | 265.00 | 262.62 | 1.54 |
| 2364 | 5.00 | 9.73 | 2.17 |
| 2365 | 14.00 | 12.38 | 1.27 |
| 2366 | 27.50 | 22.56 | 2.22 |
| 2367 | 15.00 | 17.24 | 1.50 |
| 2368 | 9.00 | 5.41 | 2.10 |
| 2369 | 12.00 | 16.74 | 2.11 |
| 2370 | 16.80 | 23.26 | 2.54 |
| 2371 | 135.70 | 130.10 | 2.37 |
| 2372 | 13.50 | 11.20 | 1.52 |
| 2373 | 246.80 | 241.70 | 2.26 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Sulaiman, N.A.F.; Shaharudin, S.M.; Ismail, S.; Zainuddin, N.H.; Tan, M.L.; Abd Jalil, Y. Predictive Modelling of Statistical Downscaling Based on Hybrid Machine Learning Model for Daily Rainfall in East-Coast Peninsular Malaysia. Symmetry 2022, 14, 927. https://doi.org/10.3390/sym14050927
Sulaiman NAF, Shaharudin SM, Ismail S, Zainuddin NH, Tan ML, Abd Jalil Y. Predictive Modelling of Statistical Downscaling Based on Hybrid Machine Learning Model for Daily Rainfall in East-Coast Peninsular Malaysia. Symmetry. 2022; 14(5):927. https://doi.org/10.3390/sym14050927
Chicago/Turabian StyleSulaiman, Nurul Ainina Filza, Shazlyn Milleana Shaharudin, Shuhaida Ismail, Nurul Hila Zainuddin, Mou Leong Tan, and Yusri Abd Jalil. 2022. "Predictive Modelling of Statistical Downscaling Based on Hybrid Machine Learning Model for Daily Rainfall in East-Coast Peninsular Malaysia" Symmetry 14, no. 5: 927. https://doi.org/10.3390/sym14050927
APA StyleSulaiman, N. A. F., Shaharudin, S. M., Ismail, S., Zainuddin, N. H., Tan, M. L., & Abd Jalil, Y. (2022). Predictive Modelling of Statistical Downscaling Based on Hybrid Machine Learning Model for Daily Rainfall in East-Coast Peninsular Malaysia. Symmetry, 14(5), 927. https://doi.org/10.3390/sym14050927