
A Novel Classification Framework for Hyperspectral Image Data by Improved Multilayer Perceptron Combined with Residual Network




Abstract
:1. Introduction
- MLP, as a less constrained network, can eliminate the negative effects of translation invariance and local connectivity. Therefore, this paper introduces MLP into HSI classification to fully obtain the spectral–spatial features of each sample and improve the classification performance of HSI.
- Based on the characteristics of hyperspectral images, we designed IMLP by introducing depthwise over-parameterized convolution, a Focal Loss function and a cosine annealing algorithm. Firstly, in order to improve network performance without increasing reasoning computation, depthwise over-parameterized convolutional layer replaced the ordinary convolution, which can speed up training with more parameters. Secondly, a Focal Loss function is used to enhance the important spectral–spatial features and prevent useless ones in the classification task, which allows the network to learn more useful hyperspectral image information. Finally, a cosine annealing algorithm is introduced to avoid oscillation and accelerate the convergence rate of the proposed model.
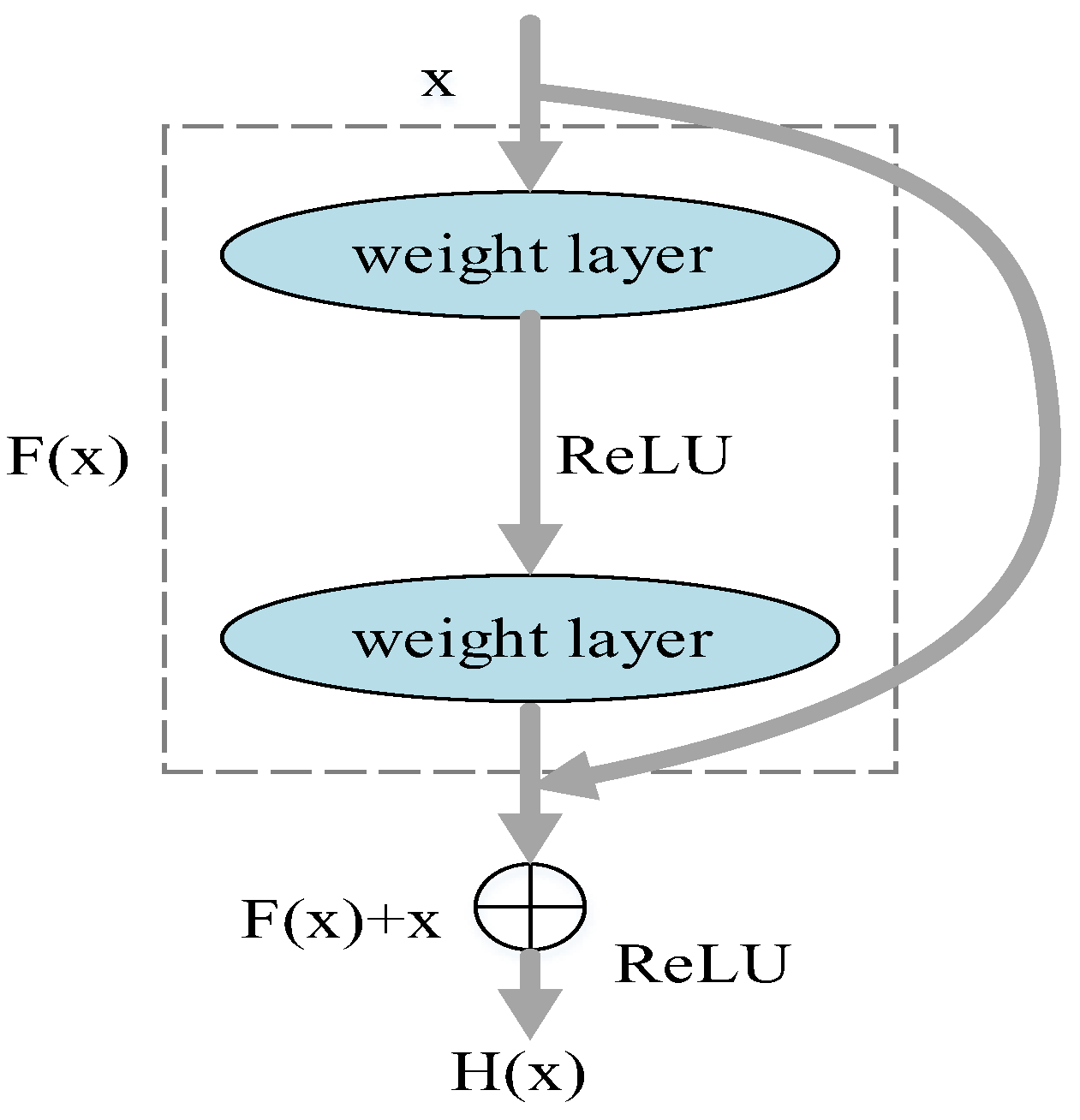
- This paper inserts IMLP between two 3 × 3 convolutional layers in the ordinary residual block, called as IMLP-ResNet, which has a stronger ability to extract deeper features for HSI. Firstly, the residual structure can retain the original characteristics of the HSI data, and avoid the issues of gradient explosion and gradient disappearance during the training process. In addition, the residual structure can improve the modeling ability of the model. Moreover, IMLP can improve the feature extraction ability of residual network, so that the model strengthens the key features on the basis of retaining the original features of hyperspectral data.
2. The Proposed MLP-Based Methods for HSI Classification
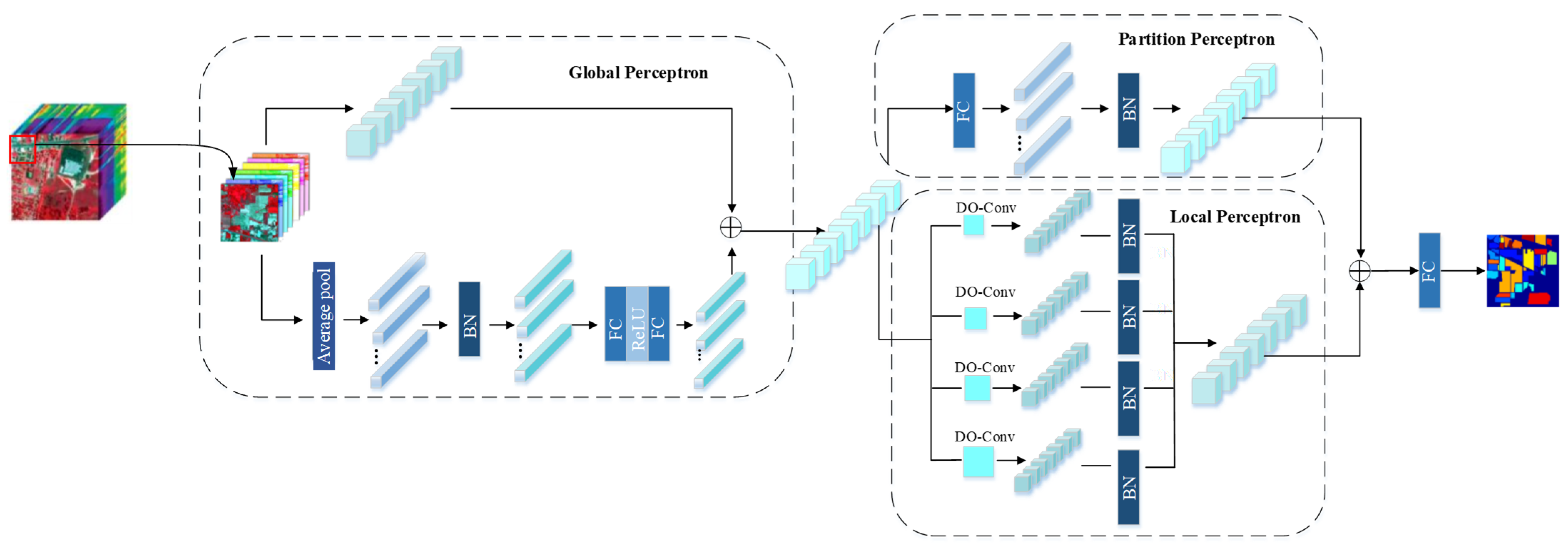
2.1. The Proposed Improved MLP (IMLP) for HSI Classification
2.1.1. DO-Conv
2.1.2. Focal Loss
2.1.3. Cosine Annealing Algorithm
2.2. The Proposed IMLP-ResNet Model for HSI Classification
2.2.1. The Structure of ResNet34
2.2.2. IMLP-ResNet Model
3. Results
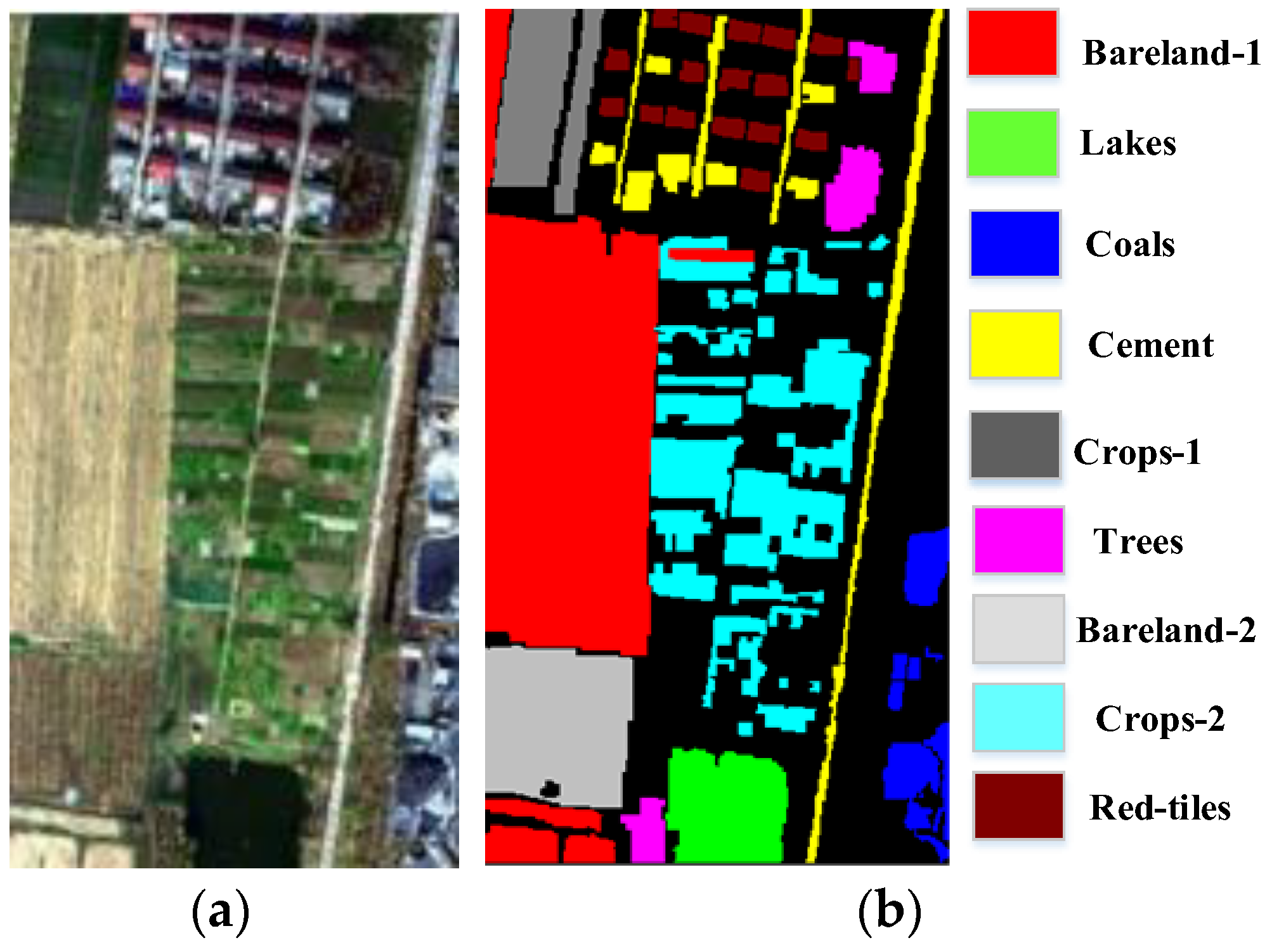
3.1. Dataset Description
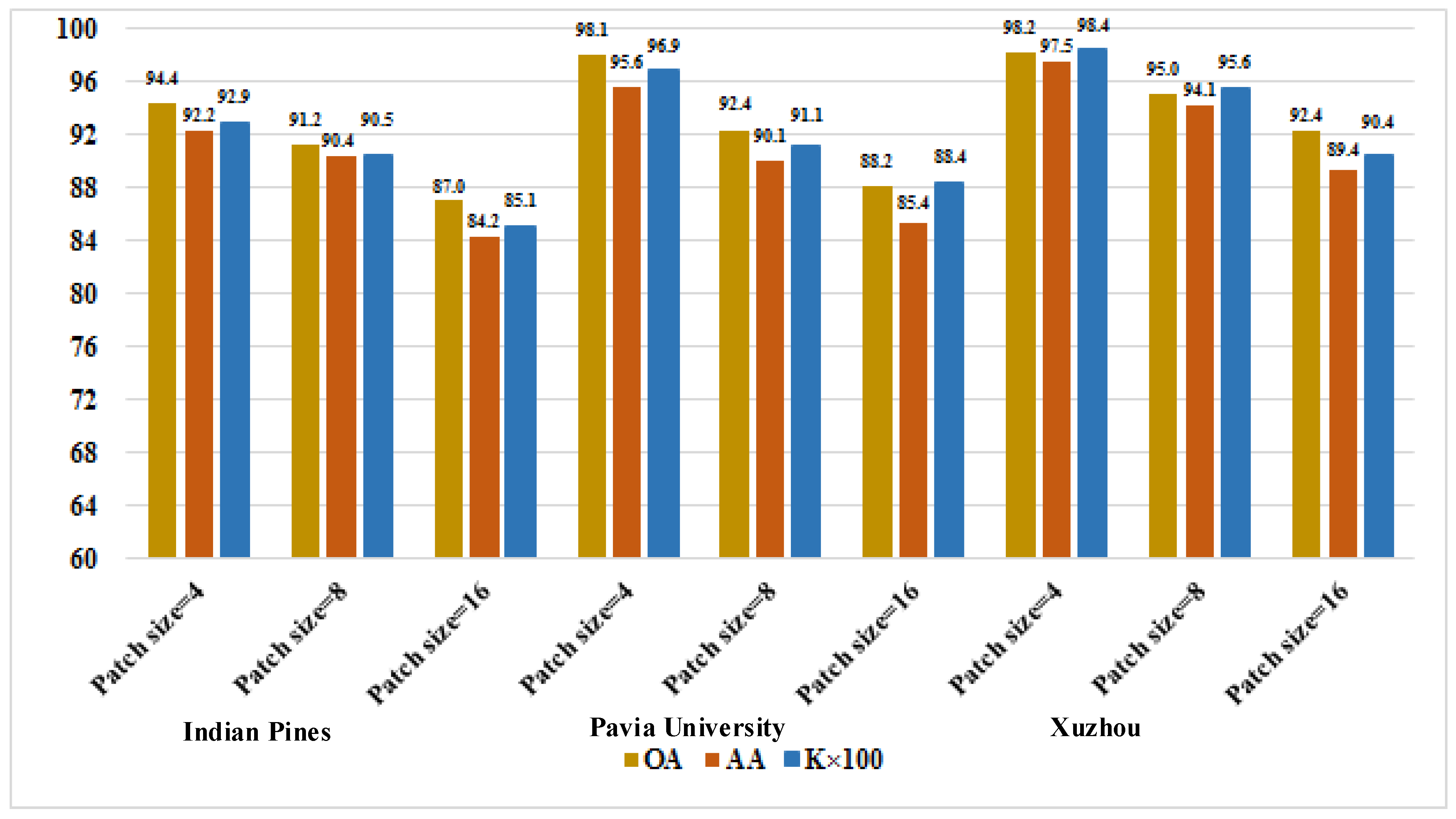
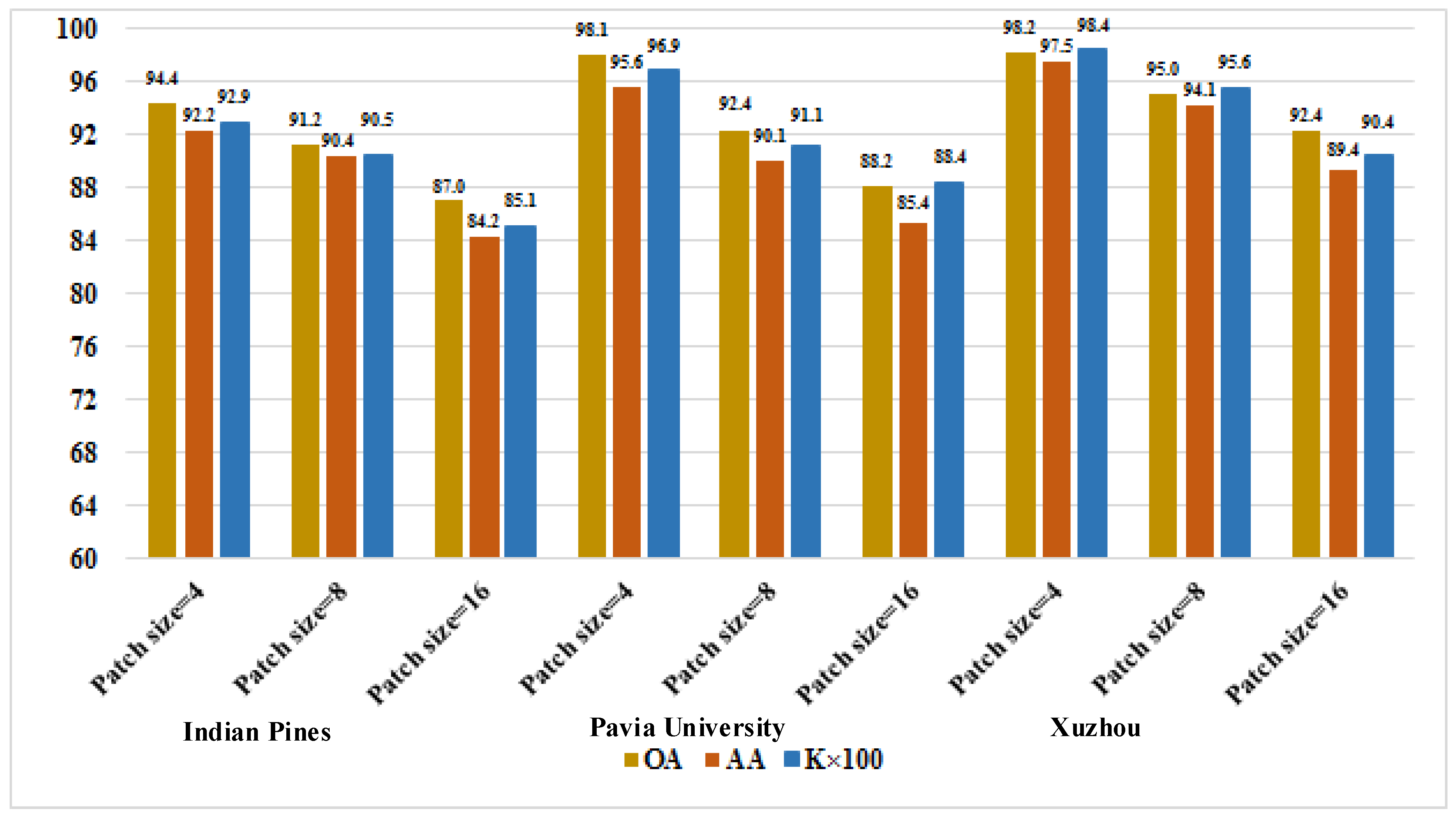
3.2. Experimental Parameters Setting
3.3. Evaluation Metrics
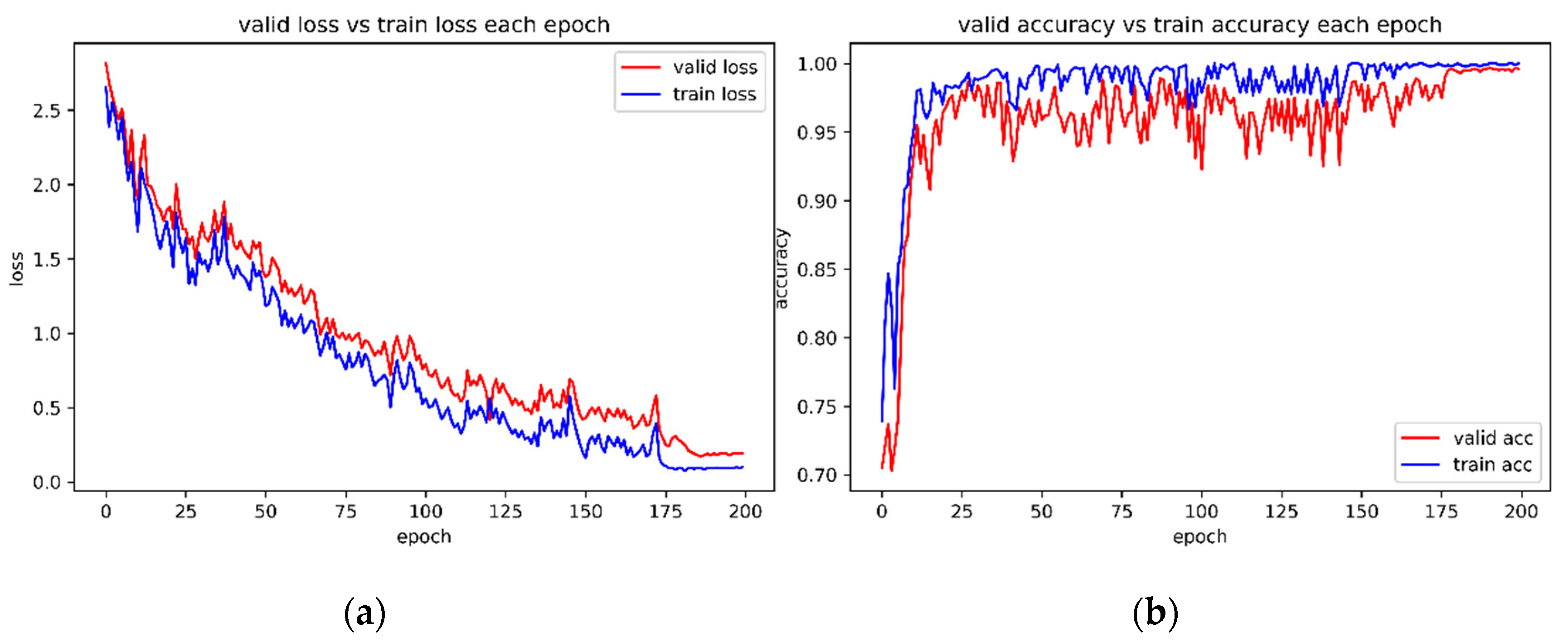
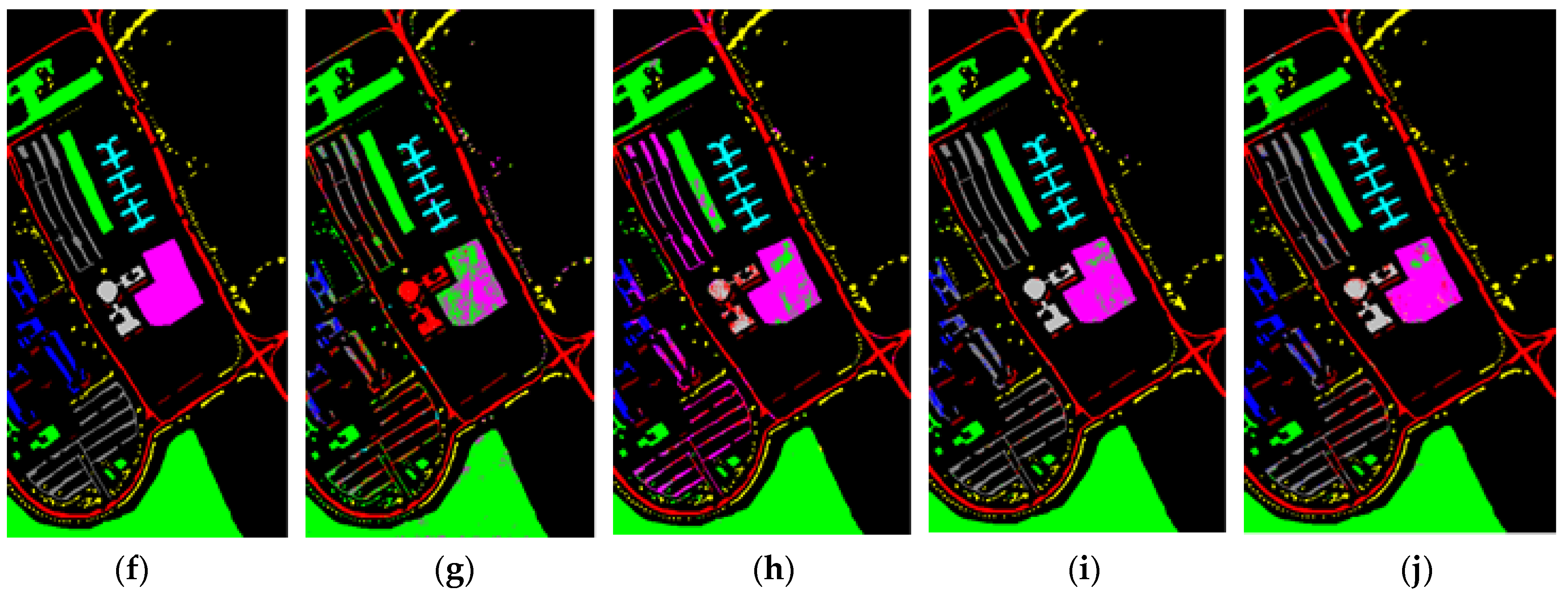
3.4. Comparison of the Proposed Methods with the State-of-the-Art Methods
4. Discussions
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Hong, D.; Wu, X.; Ghamisi, P.; Chanussot, J.; Yokoya, N.; Zhu, X.X. Invariant attribute profiles: A spatial-frequency joint feature extractor for hyperspectral image classification. IEEE Trans. Geosci. Remote Sens. 2020, 58, 3791–3808. [Google Scholar] [CrossRef] [Green Version]
- Li, S.; Song, W.; Fang, L.; Chen, Y.; Ghamisi, P.; Benediktsson, J.A. Deep Learning for Hyperspectral Image Classification: An Overview. IEEE Trans. Geosci. Remote Sens. 2019, 57, 6690–6709. [Google Scholar] [CrossRef] [Green Version]
- Bioucas-Dias, J.M.; Plaza, A.; Camps-Valls, G.; Scheunders, P.; Nasrabadi, N.; Chanussot, J. Hyperspectral remote sensing data analysis and future challenges. IEEE Geosci. Remote Sens. Mag. 2013, 1, 6–36. [Google Scholar] [CrossRef] [Green Version]
- Zhang, X.; Sun, Y.; Shang, K.; Zhang, L.; Wang, S. Crop classification based on feature band set construction and object-oriented approach using hyperspectral images. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2016, 9, 4117–4128. [Google Scholar] [CrossRef]
- Shimoni, M.; Haelterman, R.; Perneel, C. Hypersectral imaging for military and security applications: Combining myriad processing and sensing techniques. IEEE Geosci. Remote Sens. Mag. 2019, 7, 101–117. [Google Scholar] [CrossRef]
- Melgani, F.; Bruzzone, L. Classification of hyperspectral remote sensing images with support vector machines. IEEE Trans. Geosci. Remote Sens. 2004, 42, 1778–1790. [Google Scholar]
- Ma, L.; Crawford, M.M.; Tian, J. Local manifold learning-based-nearest-neighbor for hyperspectral image classification. IEEE Trans. Geosci. Remote Sens. 2010, 48, 4099–4109. [Google Scholar] [CrossRef]
- Ham, J.; Chen, Y.; Crawford, M.M.; Ghosh, J. Investigation of the random forest framework for classification of hyperspectral data. IEEE Trans. Geosci. Remote Sens. 2005, 43, 492–501. [Google Scholar] [CrossRef] [Green Version]
- Delalieux, S.; Somers, B.; Haest, B.; Spanhove, T.; Borre, J.V.; Mücher, C.A. Heathland conservation status mapping through integration of hyperspectral mixture analysis and decision tree classifiers. Remote Sens. Environ. 2012, 126, 222–231. [Google Scholar] [CrossRef]
- Li, W.; Chen, C.; Su, H.; Du, Q. Local binary patterns and extreme learning machine for hyperspectral imagery classification. IEEE Trans. Geosci. Remote Sens. 2015, 53, 3681–3693. [Google Scholar] [CrossRef]
- Chen, Y.; Nasrabadi, N.M.; Tran, T.D. Hyperspectral image classification using dictionary-based sparse representation. IEEE Trans. Geosci. Remote Sens. 2011, 49, 3973–3985. [Google Scholar] [CrossRef]
- He, L.; Li, J.; Liu, C.; Li, S. Recent advances on spectral–spatial hyperspectral image classification: An overview and new guidelines. IEEE Trans. Geosci. Remote Sens. 2017, 56, 1579–1597. [Google Scholar] [CrossRef]
- Zhan, K.; Wang, H.; Huang, H.; Xie, Y. Large margin distribution machine for hyperspectral image classification. J. Electron. Imaging 2016, 25, 63024. [Google Scholar] [CrossRef]
- Song, B.; Li, J.; Dalla Mura, M.; Li, P.; Plaza, A.; Bioucas-Dias, J.E.M.; Benediktsson, J.A.; Chanussot, J. Remotely sensed image classification using sparse representations of morphological attribute profiles. IEEE Trans. Geosci. Remote Sens. 2013, 52, 5122–5136. [Google Scholar] [CrossRef] [Green Version]
- Xue, F.; Tan, F.; Ye, Z.; Chen, J.; Wei, Y. Spectral-spatial classification of hyperspectral image using improved functional principal component analysis. IEEE Trans. Geosci. Remote Sens. 2021, 19, 1–5. [Google Scholar] [CrossRef]
- Chen, Y.; Lin, Z.; Zhao, X.; Wang, G.; Gu, Y. Deep learning-based classification of hyperspectral data. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2014, 7, 2094–2107. [Google Scholar] [CrossRef]
- Li, T.; Zhang, J.; Zhang, Y. Classification of hyperspectral image based on deep belief networks. In Proceedings of the 2014 IEEE International Conference on Image Processing, Paris, France, 27 October 2014. [Google Scholar]
- Makantasis, K.; Karantzalos, K.; Doulamis, A.; Doulamis, N. Deep supervised learning for hyperspectral data classification through convolutional neural networks. In Proceedings of the 2015 IEEE International Geoscience and Remote Sensing Symposium, Milan, Italy, 26–31 July 2015; pp. 4959–4962. [Google Scholar]
- Chen, Y.; Jiang, H.; Li, C.; Jia, X.; Ghamisi, P. Deep feature extraction and classification of hyperspectral images based on convolutional neural networks. IEEE Trans. Geosci. Remote Sens. 2016, 54, 6232–6251. [Google Scholar] [CrossRef] [Green Version]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep residual learning for image recognition. arXiv 2016, arXiv:1512.03385. [Google Scholar]
- Zhong, Z.; Li, J.; Luo, Z.; Chapman, M. Spectral–spatial residual network for hyperspectral image classification: A 3-d deep learning framework. IEEE Trans. Geosci. Remote Sens. 2017, 56, 847–858. [Google Scholar] [CrossRef]
- Paoletti, M.E.; Haut, J.M.; Fern; Ez-Beltran, R.; Plaza, J.; Plaza, A.J.; Pla, F. Deep pyramidal residual networks for spectral–spatial hyperspectral image classification. IEEE Trans. Geosci. Remote Sens. 2018, 57, 740–754. [Google Scholar] [CrossRef]
- Tolstikhin, I.; Houlsby, N.; Kolesnikov, A.; Beyer, L.; Zhai, X.; Unterthiner, T.; Yung, J.; Steiner, A.; Keysers, D.; Uszkoreit, J.; et al. Mlp-mixer: An all-mlp architecture for vision. arXiv 2021, arXiv:2105.01601. [Google Scholar]
- Liu, H.; Dai, Z.; So, D.; Le, Q. Pay attention to MLPs. Adv. Neural Inf. Processing Syst. arXiv 2021, arXiv:2105.08050. [Google Scholar]
- Touvron, H.; Bojanowski, P.; Caron, M.; Cord, M.; El-Nouby, A.; Grave, E.; Jégou, H. Resmlp: Feedforward networks for image classification with data-efficient training. arXiv 2021, arXiv:2105.03404. [Google Scholar]
- Tatsunami, Y.; Taki, M. Raftmlp: How much can be done without attention and with less spatial locality? arXiv 2021, arXiv:2108.04384. [Google Scholar]
- Zhang, M.; Zuo, X.; Chen, Y.; Liu, Y.; Li, M. Pose estimation for ground robots: On manifold representation, integration, reparameterization, and optimization. IEEE Trans. Robot. 2021, 37, 1081–1099. [Google Scholar] [CrossRef]
- Cao, J.; Li, Y.; Sun, M.; Chen, Y.; Lischinski, D.; Cohen-Or, D.; Chen, B.; Tu, C. DO-Conv: Depthwise over-parameterized convolutional layer. arXiv 2020, arXiv:2006.12030. [Google Scholar]
- Lin, T.Y.; Goyal, P.; Girshick, R.; He, K.; Dollar, P. Focal Loss for Dense Object Detection. IEEE Trans. Pattern Anal. Mach. Intell. 2020, 42, 318–327. [Google Scholar] [CrossRef] [Green Version]
- Loshchilov, I.; Hutter, F. Sgdr: Stochastic gradient descent with warm restarts. arXiv 2016, arXiv:1608.03983. [Google Scholar]
- Yuan, Y.; Wang, C.; Jiang, Z. Proxy-based deep learning framework for spectral-spatial hyperspectral image classification: Efficient and robust. IEEE Trans. Geosci. Remote Sens. 2021, 60, 1–15. [Google Scholar] [CrossRef]
- Chen, W.; Zheng, X.; Lu, X. Hyperspectral image super-resolution with self-supervised spectral-spatial residual network. Remote Sens. 2021, 13, 1260. [Google Scholar] [CrossRef]
- Feng, J.; Wu, X.; Shang, R.; Sui, C.; Zhang, X. Attention multibranch convolutional neural network for hyperspectral image classification based on adaptive region search. IEEE Trans. Geosci. Remote Sens. 2020, 59, 5054–5070. [Google Scholar] [CrossRef]
- Melgani, F.; Bruzzone, L. Support vector machines for classification of hyperspectral remote-sensing images. In Proceedings of the 2002 IEEE International Geoscience and Remote Sensing Symposium (IGARSS 2002), Toronto, ON, Canada, 24–28 June 2002. [Google Scholar]
- Gu, Y.; Liu, T.; Jia, X.; Benediktsson, J.O.N.A.; Chanussot, J. Nonlinear multiple kernel learning with multiple-structure-element extended morphological profiles for hyperspectral image classification. IEEE Trans. Geosci. Remote Sens. 2016, 54, 3235–3247. [Google Scholar] [CrossRef]
- Yue, J.; Zhao, W.; Mao, S.; Liu, H. Spectral–spatial classification of hyperspectral images using deep convolutional neural networks. Remote Sens. Lett. 2015, 6, 468–477. [Google Scholar] [CrossRef]
- Zhong, Z.; Li, J.; Ma, L.; Han, J.; He, Z. Deep residual networks for hyperspectral image classification. In Proceedings of the 2017 IEEE International Geoscience and Remote Sensing Symposium (IGARSS), Fort Worth, TX, USA, 23–28 July 2017. [Google Scholar]
- Ding, X.; Xia, C.; Zhang, X.; Chu, X.; Han, J.; Ding, G. Repmlp: Re-parameterizing convolutions into fully-connected layers for image recognition. arXiv 2021, arXiv:2105.01883. [Google Scholar]



















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Class Code | Name | Sample Numbers |
|---|---|---|
| 1 | Alfalfa | 46 |
| 2 | Corn-notill | 1428 |
| 3 | Corn-mintill | 830 |
| 4 | Corn | 237 |
| 5 | Grass-pasture | 483 |
| 6 | Grass-trees | 730 |
| 7 | Grass-pasture-mowed | 28 |
| 8 | Hay-windrowed | 478 |
| 9 | Oats | 20 |
| 10 | Soybean-notill | 972 |
| 11 | Soybean-mintill | 2455 |
| 12 | Soybean-clean | 593 |
| 13 | Wheat | 205 |
| 14 | Woods | 1265 |
| 15 | Buildings-Grass-Trees-Drives | 386 |
| 16 | Stone-Steel-Towers | 93 |
| Total | 10,249 | |
| Class Code | Name | Sample Numbers |
|---|---|---|
| 1 | Asphalt | 6631 |
| 2 | Meadows | 18,649 |
| 3 | Gravel | 2099 |
| 4 | Trees | 3064 |
| 5 | Painted metal sheets | 1345 |
| 6 | Bare Soil | 5029 |
| 7 | Bitumen | 1330 |
| 8 | Self-Blocking Bricks | 3682 |
| 9 | Shadows | 947 |
| Total | 42,776 | |
| Class Code | Name | Sample Numbers |
|---|---|---|
| 1 | Bareland-1 | 26,396 |
| 2 | Lakes | 4027 |
| 3 | Coals | 2783 |
| 4 | Cement | 5214 |
| 5 | Crops-1 | 13,184 |
| 6 | Trees | 2436 |
| 7 | Bareland-2 | 6990 |
| 8 | Crops-2 | 4777 |
| 9 | Red-tiles | 3070 |
| Total | 68,877 | |
| Class Code | RBF-SVM | EMP-SVM | DCNN | SSRN | ResNet | PyResNet | RepMLP | IMLP | IMLP-ResNet |
|---|---|---|---|---|---|---|---|---|---|
| 1 | 78.25 ± 2.24 | 79.62 ± 3.61 | 78.34 ± 1.89 | 80.91 ± 1.96 | 82.67 ± 1.51 | 88.89 ± 1.57 | 87.05 ± 2.06 | 89.25 ± 0.87 | 91.33 ± 1.28 |
| 2 | 79.22 ± 3.02 | 84.26 ± 3.49 | 88.15 ± 2.36 | 90.04 ± 1.49 | 91.26 ± 6.29 | 92.12 ± 1.48 | 93.38 ± 0.74 | 94.02 ± 1.23 | 96.97 ± 2.29 |
| 3 | 80.27 ± 0.98 | 79.15 ± 2.81 | 82.37 ± 3.63 | 84.65 ± 1.91 | 83.95 ± 1.29 | 88.39 ± 2.36 | 90.65 ± 0.28 | 90.37 ± 3.68 | 92.16 ± 1.61 |
| 4 | 82.02 ± 1.78 | 85.34 ± 2.69 | 89.06 ± 1.67 | 88.65 ± 5.66 | 90.38 ± 3.99 | 91.93 ± 8.23 | 90.54 ± 1.08 | 90.37 ± 1.06 | 92.24 ± 2.98 |
| 5 | 88.22 ± 1.56 | 87.37 ± 1.63 | 90.38 ± 1.06 | 91.98 ± 3.26 | 93.93 ± 4.06 | 92.21 ± 1.89 | 92.48 ± 1.73 | 93.07 ± 1.36 | 95.09 ± 2.11 |
| 6 | 82.52 ± 3.02 | 86.39 ± 2.57 | 91.38 ± 4.39 | 92.32 ± 2.32 | 93.72 ± 3.15 | 94.26 ± 1.07 | 94.22 ± 0.27 | 93.18 ± 3.03 | 96.51 ± 0.88 |
| 7 | 82.22 ± 2.27 | 84.38 ± 0.31 | 85.31 ± 0.98 | 86.70 ± 3.82 | 84.31 ± 13.96 | 90.64 ± 8.96 | 89.46 ± 3.79 | 90.37 ± 0.46 | 95.17 ± 4.44 |
| 8 | 85.02 ± 1.02 | 86.20 ± 1.58 | 90.27 ± 3.18 | 93.08 ± 6.67 | 92.08 ± 4.37 | 93.10 ± 2.70 | 92.22 ± 0.17 | 93.56 ± 2.30 | 94.44 ± 1.85 |
| 9 | 83.20 ± 0.52 | 81.27 ± 2.94 | 85.09 ± 0.67 | 86.73 ± 5.95 | 81.90 ± 1.65 | 87.84 ± 11.12 | 89.34 ± 1.29 | 88.06 ± 3.75 | 93.60 ± 3.22 |
| 10 | 79.22 ± 1.02 | 84.66 ± 3.10 | 88.09 ± 2.16 | 90.33 ± 5.14 | 90.98 ± 7.37 | 91.12 ± 2.50 | 91.05 ± 2.44 | 92.34 ± 2.88 | 94.46 ± 2.56 |
| 11 | 82.27 ± 2.98 | 86.27 ± 1.06 | 89.37 ± 1.06 | 90.36 ± 0.96 | 91.72 ± 0.68 | 93.71 ± 2.82 | 92.54 ± 3.08 | 93.09 ± 2.85 | 95.68 ± 2.60 |
| 12 | 85.02 ± 2.27 | 88.34 ± 0.43 | 90.76 ± 0.41 | 92.17 ± 0.61 | 95.01 ± 0.61 | 90.70 ± 7.52 | 91.09 ± 2.06 | 91.45 ± 1.14 | 96.02 ± 3.03 |
| 13 | 82.22 ± 0.53 | 85.61 ± 0.39 | 89.05 ± 3.28 | 95.39 ± 1.22 | 94.91 ± 2.78 | 95.89 ± 2.93 | 92.16 ± 3.08 | 93.07 ± 0.39 | 94.88 ± 1.07 |
| 14 | 80.52 ± 2.02 | 85.17 ± 2.09 | 90.36 ± 1.02 | 92.03 ± 2.36 | 91.55 ± 1.89 | 95.95 ± 1.70 | 93.81 ± 0.46 | 94.03 ± 2.69 | 95.36 ± 2.09 |
| 15 | 81.22 ± 2.27 | 86.20 ± 1.43 | 91.06 ± 2.47 | 93.84 ± 1.45 | 92.75 ± 3.26 | 94.65 ± 2.19 | 94.89 ± 2.04 | 95.30 ± 0.88 | 96.33 ± 2.76 |
| 16 | 85.63 ± 1.20 | 88.69 ± 3.07 | 90.67 ± 4.09 | 92.87 ± 2.93 | 93.65 ± 2.79 | 95.05 ± 3.12 | 94.73 ± 3.17 | 95.37 ± 0.63 | 96.03 ± 1.58 |
| OA(%) | 81.55 ± 1.43 | 83.64 ± 0.47 | 86.21 ± 1.43 | 88.66 ± 0.60 | 90.88 ± 1.90 | 92.21 ± 0.98 | 93.05 ± 3.27 | 93.59 ± 0.69 | 94.40 ± 1.62 |
| AA(%) | 79.37 ± 0.58 | 81.76 ± 2.14 | 83.65 ± 0.48 | 85.83 ± 3.37 | 87.76 ± 2.81 | 90.27 ± 4.12 | 90.96 ± 0.25 | 91.66 ± 2.23 | 92.24 ± 1.73 |
| 100 K | 82.33 ± 1.86 | 84.59 ± 0.35 | 86.93 ± 1.28 | 88.34 ± 0.69 | 89.61 ± 1.89 | 90.78 ± 1.08 | 91.34 ± 4.87 | 91.92 ± 0.27 | 92.88 ± 1.83 |
| Class Code | RBF-SVM | EMP-SVM | DCNN | SSRN | ResNet | PyResNet | RepMLP | IMLP | IMLP-ResNet |
|---|---|---|---|---|---|---|---|---|---|
| 1 | 76.56 ± 1.28 | 86.24 ± 0.43 | 90.07 ± 1.95 | 92.29 ± 1.82 | 92.11 ± 3.35 | 93.05 ± 1.37 | 93.08 ± 3.05 | 93.25 ± 0.22 | 94.58 ± 4.76 |
| 2 | 81.23 ± 3.54 | 87.36 ± 1.94 | 92.48 ± 0.67 | 93.27 ± 1.79 | 95.03 ± 2.76 | 95.88 ± 4.62 | 94.66 ± 1.31 | 96.17 ± 2.47 | 97.55 ± 0.29 |
| 3 | 80.34 ± 0.89 | 85.57 ± 3.29 | 90.36 ± 1.65 | 91.51 ± 2.93 | 92.58 ± 2.96 | 92.97 ± 3.13 | 93.15 ± 2.67 | 93.20 ± 1.58 | 94.80 ± 3.75 |
| 4 | 82.01 ± 2.68 | 85.15 ± 2.36 | 91.43 ± 3.21 | 92.22 ± 1.59 | 94.73 ± 1.25 | 95.45 ± 1.07 | 95.89 ± 2.16 | 96.22 ± 0.34 | 97.64 ± 0.45 |
| 5 | 80.15 ± 1.34 | 86.20 ± 2.48 | 91.86 ± 2.37 | 93.08 ± 3.07 | 95.37 ± 2.15 | 96.87 ± 1.25 | 96.90 ± 4.79 | 97.06 ± 3.28 | 98.57 ± 0.76 |
| 6 | 79.60 ± 2.36 | 85.71 ± 1.99 | 92.10 ± 3.08 | 93.46 ± 2.54 | 94.78 ± 4.61 | 95.33 ± 2.46 | 95.24 ± 1.02 | 96.37 ± 0.61 | 98.83 ± 0.40 |
| 7 | 75.36 ± 2.88 | 84.01 ± 3.49 | 90.22 ± 0.44 | 91.03 ± 0.75 | 93.76 ± 1.91 | 94.59 ± 2.66 | 93.57 ± 3.09 | 94.38 ± 1.57 | 96.51 ± 2.07 |
| 8 | 73.47 ± 4.16 | 82.28 ± 1.75 | 86.25 ± 3.19 | 88.03 ± 0.43 | 90.27 ± 0.39 | 91.36 ± 3.36 | 91.16 ± 2.14 | 92.59 ± 2.60 | 93.26 ± 1.59 |
| 9 | 84.02 ± 4.39 | 85.13 ± 2.16 | 90.24 ± 0.82 | 93.76 ± 1.60 | 95.33 ± 0.54 | 96.55 ± 1.82 | 96.98 ± 1.56 | 97.03 ± 1.44 | 98.25 ± 1.85 |
| OA(%) | 83.12 ± 2.72 | 86.01 ± 1.03 | 91.78 ± 2.52 | 93.03 ± 1.36 | 94.52 ± 2.93 | 95.68 ± 0.18 | 96.31 ± 3.28 | 96.89 ± 0.77 | 98.06 ± 0.64 |
| AA(%) | 80.31 ± 3.64 | 85.24 ± 1.37 | 90.36 ± 1.04 | 91.28 ± 2.61 | 93.49 ± 1.95 | 94.05 ± 0.32 | 94.36 ± 0.23 | 94.87 ± 1.23 | 95.59 ± 0.69 |
| 100 K | 78.54 ± 0.19 | 83.54 ± 2.68 | 89.02 ± 0.86 | 90.87 ± 0.18 | 92.01 ± 2.95 | 93.87 ± 3.08 | 94.52 ± 4.17 | 95.03 ± 1.09 | 96.88 ± 1.87 |
| Class Code | RBF-SVM | EMP-SVM | DCNN | SSRN | ResNet | PyResNet | RepMLP | IMLP | IMLP-ResNet |
|---|---|---|---|---|---|---|---|---|---|
| 1 | 81.34 ± 0.25 | 86.25 ± 3.41 | 91.25 ± 3.08 | 93.24 ± 0.37 | 94.09 ± 1.67 | 94.14 ± 3.94 | 95.18 ± 4.96 | 95.54 ± 0.16 | 96.98 ± 4.57 |
| 2 | 81.23 ± 2.13 | 87.16 ± 4.39 | 91.28 ± 2.14 | 94.12 ± 4.06 | 95.02 ± 0.68 | 96.19 ± 2.17 | 96.25 ± 0.83 | 97.73 ± 3.64 | 98.86 ± 1.56 |
| 3 | 79.28 ± 3.46 | 86.52 ± 0.63 | 90.27 ± 0.93 | 93.36 ± 2.45 | 94.68 ± 2.17 | 94.36 ± 2.35 | 95.94 ± 4.36 | 96.19 ± 4.72 | 98.63 ± 0.25 |
| 4 | 80.49 ± 4.10 | 85.07 ± 1.69 | 88.21 ± 1.07 | 90.47 ± 3.88 | 91.26 ± 3.24 | 92.10 ± 2.91 | 92.76 ± 3.41 | 93.21 ± 1.55 | 95.16 ± 0.73 |
| 5 | 82.74 ± 0.43 | 86.06 ± 3.81 | 90.38 ± 2.46 | 93.67 ± 2.53 | 94.06 ± 0.46 | 95.33 ± 0.97 | 95.84 ± 3.25 | 96.58 ± 1.61 | 98.71 ± 0.52 |
| 6 | 81.09 ± 1.51 | 84.68 ± 1.42 | 89.07 ± 3.86 | 91.03 ± 3.67 | 93.47 ± 1.23 | 94.67 ± 4.26 | 95.22 ± 2.03 | 96.34 ± 2.57 | 98.70 ± 3.46 |
| 7 | 80.98 ± 2.29 | 85.34 ± 3.06 | 88.22 ± 0.58 | 91.09 ± 0.18 | 92.20 ± 0.65 | 93.84 ± 2.91 | 93.97 ± 1.78 | 95.20 ± 4.09 | 96.91 ± 1.97 |
| 8 | 82.63 ± 4.41 | 87.03 ± 4.19 | 89.17 ± 2.02 | 92.97 ± 2.56 | 93.67 ± 3.68 | 94.29 ± 3.07 | 95.56 ± 2.26 | 96.77 ± 3.67 | 98.26 ± 3.49 |
| 9 | 81.06 ± 1.94 | 86.05 ± 3.43 | 88.06 ± 1.24 | 90.38 ± 2.69 | 91.18 ± 0.39 | 92.45 ± 0.37 | 93.71 ± 0.13 | 94.05 ± 2.14 | 96.21 ± 3.16 |
| OA(%) | 82.26 ± 0.19 | 87.43 ± 3.74 | 92.56 ± 2.37 | 94.17 ± 3.25 | 95.48 ± 1.82 | 96.25 ± 3.24 | 96.78 ± 0.34 | 97.14 ± 3.65 | 98.15 ± 0.28 |
| AA(%) | 84.09 ± 1.07 | 86.02 ± 2.75 | 91.66 ± 3.10 | 93.26 ± 0.28 | 93.07 ± 1.44 | 95.23 ± 0.21 | 95.64 ± 1.36 | 96.08 ± 2.17 | 97.49 ± 0.98 |
| 100 K | 80.37 ± 3.26 | 85.49 ± 4.12 | 90.21 ± 4.32 | 93.67 ± 1.49 | 94.18 ± 0.98 | 95.98 ± 3.76 | 96.02 ± 2.37 | 97.54 ± 3.68 | 98.44 ± 0.65 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Wang, A.; Li, M.; Wu, H. A Novel Classification Framework for Hyperspectral Image Data by Improved Multilayer Perceptron Combined with Residual Network. Symmetry 2022, 14, 611. https://doi.org/10.3390/sym14030611
Wang A, Li M, Wu H. A Novel Classification Framework for Hyperspectral Image Data by Improved Multilayer Perceptron Combined with Residual Network. Symmetry. 2022; 14(3):611. https://doi.org/10.3390/sym14030611
Chicago/Turabian StyleWang, Aili, Meixin Li, and Haibin Wu. 2022. "A Novel Classification Framework for Hyperspectral Image Data by Improved Multilayer Perceptron Combined with Residual Network" Symmetry 14, no. 3: 611. https://doi.org/10.3390/sym14030611
APA StyleWang, A., Li, M., & Wu, H. (2022). A Novel Classification Framework for Hyperspectral Image Data by Improved Multilayer Perceptron Combined with Residual Network. Symmetry, 14(3), 611. https://doi.org/10.3390/sym14030611