
Estimation and Testing of Wilcoxon–Mann–Whitney Effects in Factorial Clustered Data Designs


Abstract
:1. Introduction
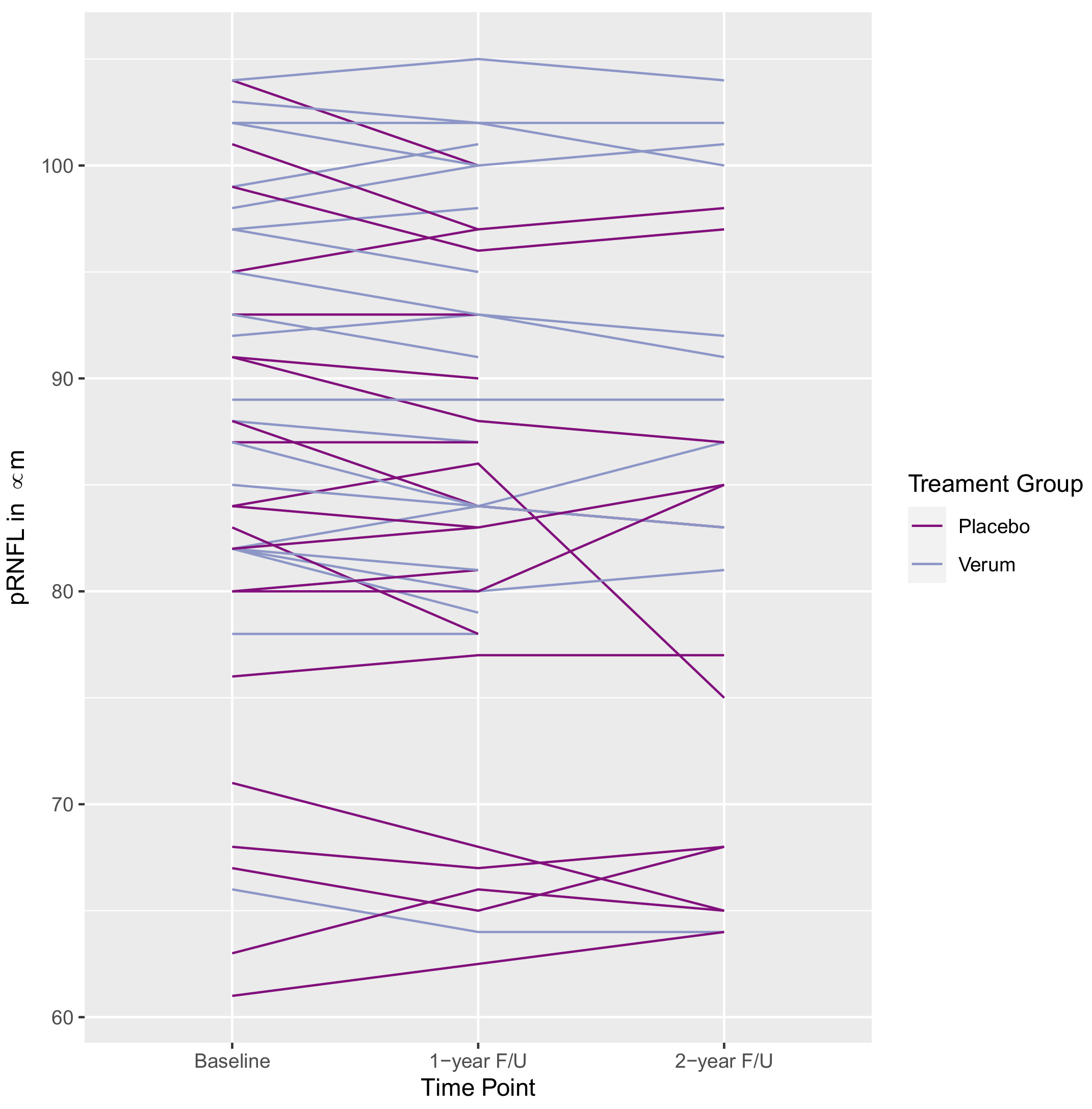
2. Motivating Example
3. The Factorial Repeated Measures Model with Missing Values
General Factorial Model with Clustered Data
- A1.1: ;
- A1.2: such that , being a fixed constant;
- A1.3: such that , being a fixed constant.
4. Estimators and Their Asymptotic Distributions
4.1. Effect Estimation in Factorial Designs with Clustered Data
- A2.1: ;
- A2.2: .
- ;
- .
4.2. Informative Cluster Sizes
5. Estimation of the Covariance Matrix
- and are positive semi-definite;
- ;
- .
6. Multiple Hypotheses
- Main effect group membership G In order to make comparisons in terms of group membership, it is necessary to center and average over the repeated measures. Thus, a contrast matrix to test for no group effect will be defined aswith being a contrast matrix for the group effect with a time structure.
- Main effect time T Similarly for the time effect, the measurements across the groups need to be centered and averaged, leading to a contrast matrix to test for no time effect asAgain, denotes a contrast matrix for the effect over time without the group structure.
- Interaction effect For the test of no interaction between group membership and time, the centering matrixwill be used.
7. Test Statistics
7.1. Quadratic Test Procedures
7.2. Multiple Contrast Test Procedure
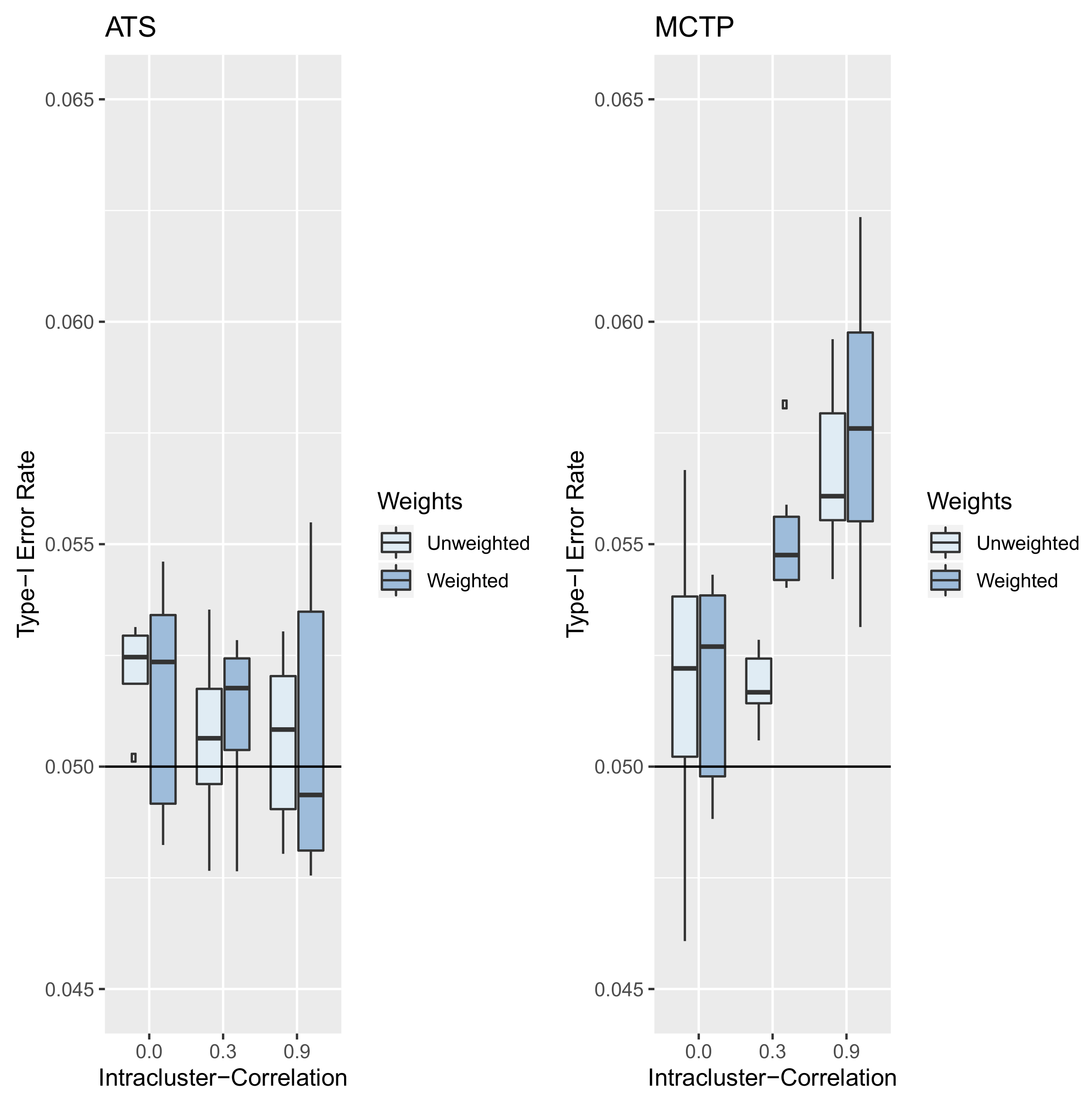
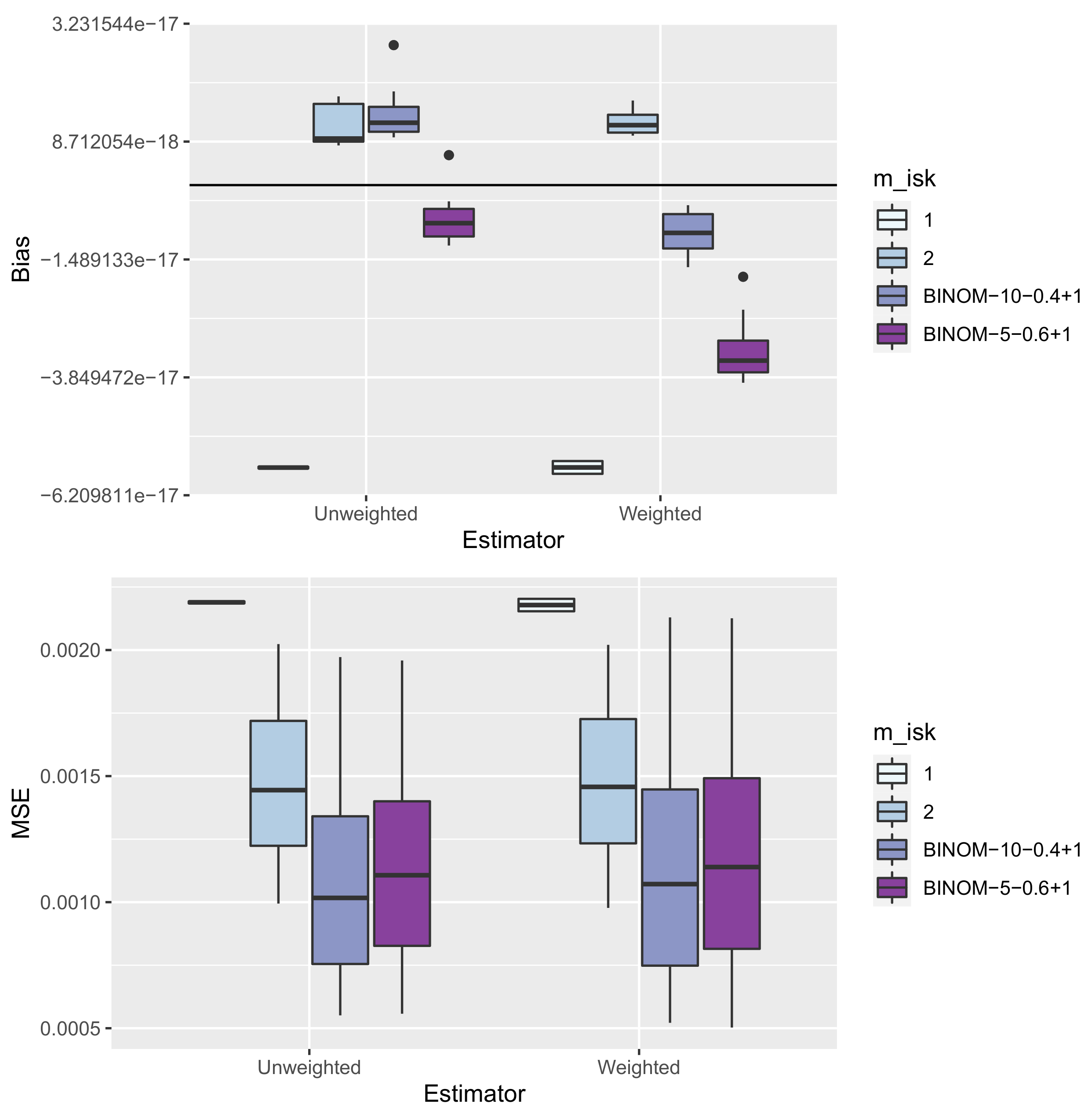
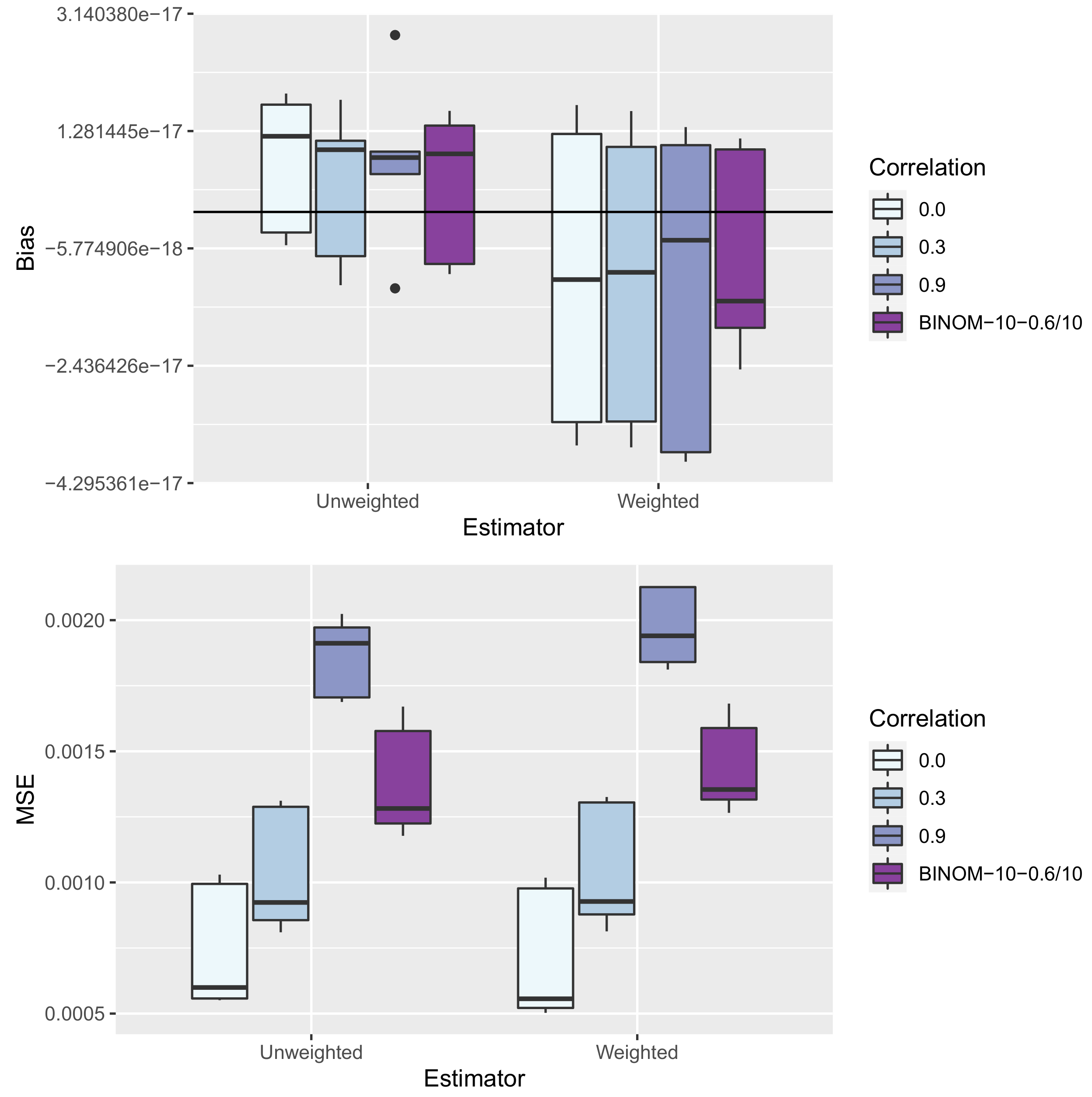
8. Simulation Study
8.1. Set-Up
- (no dependent replicates);
- (two dependent replicates);
- realizations of a Binomial distribution with ;
- realizations of a Binomial distribution with .
- (same correlation within each cluster);
- realizations of a Binomial distribution with (different correlations within each cluster).
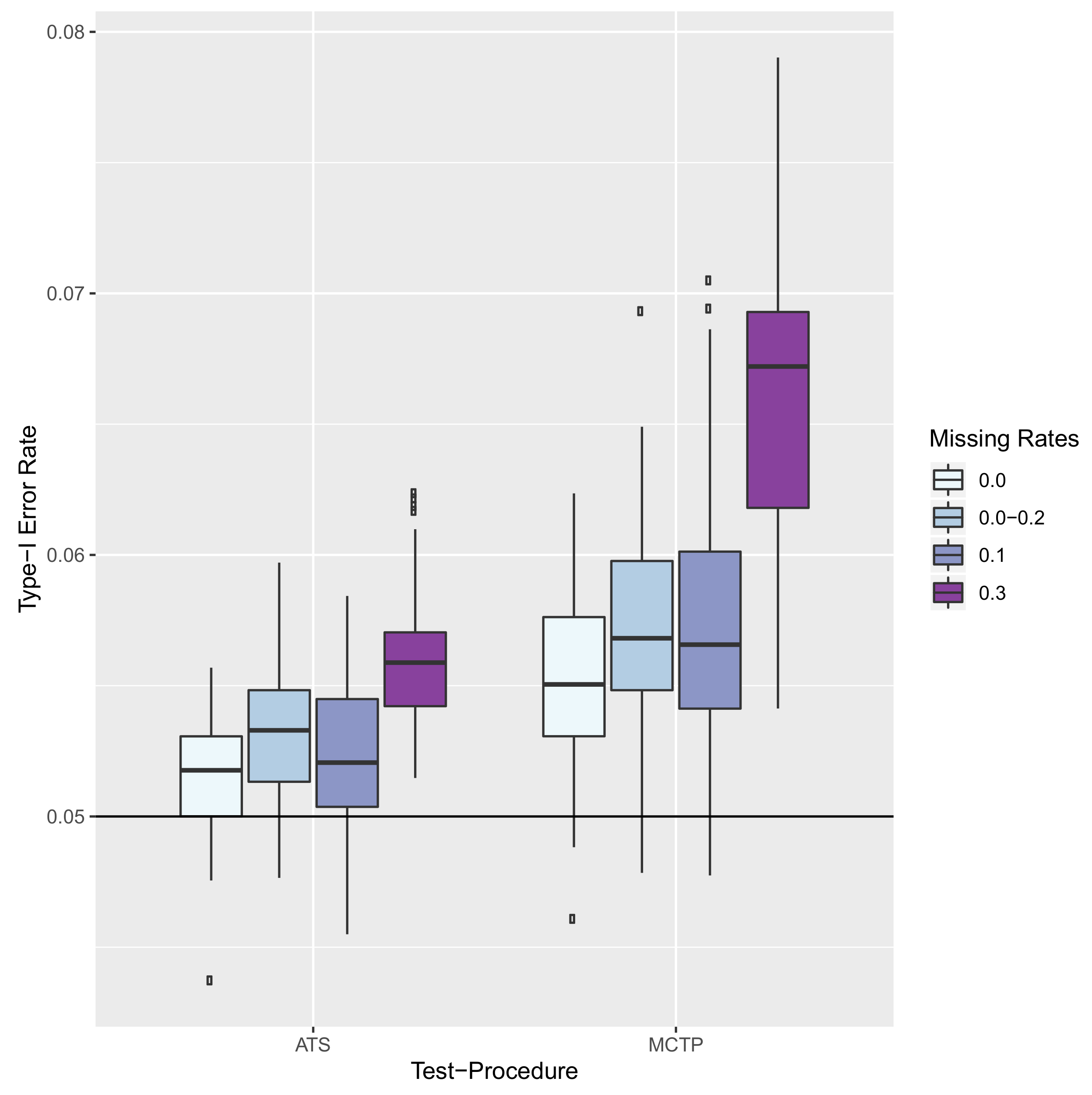
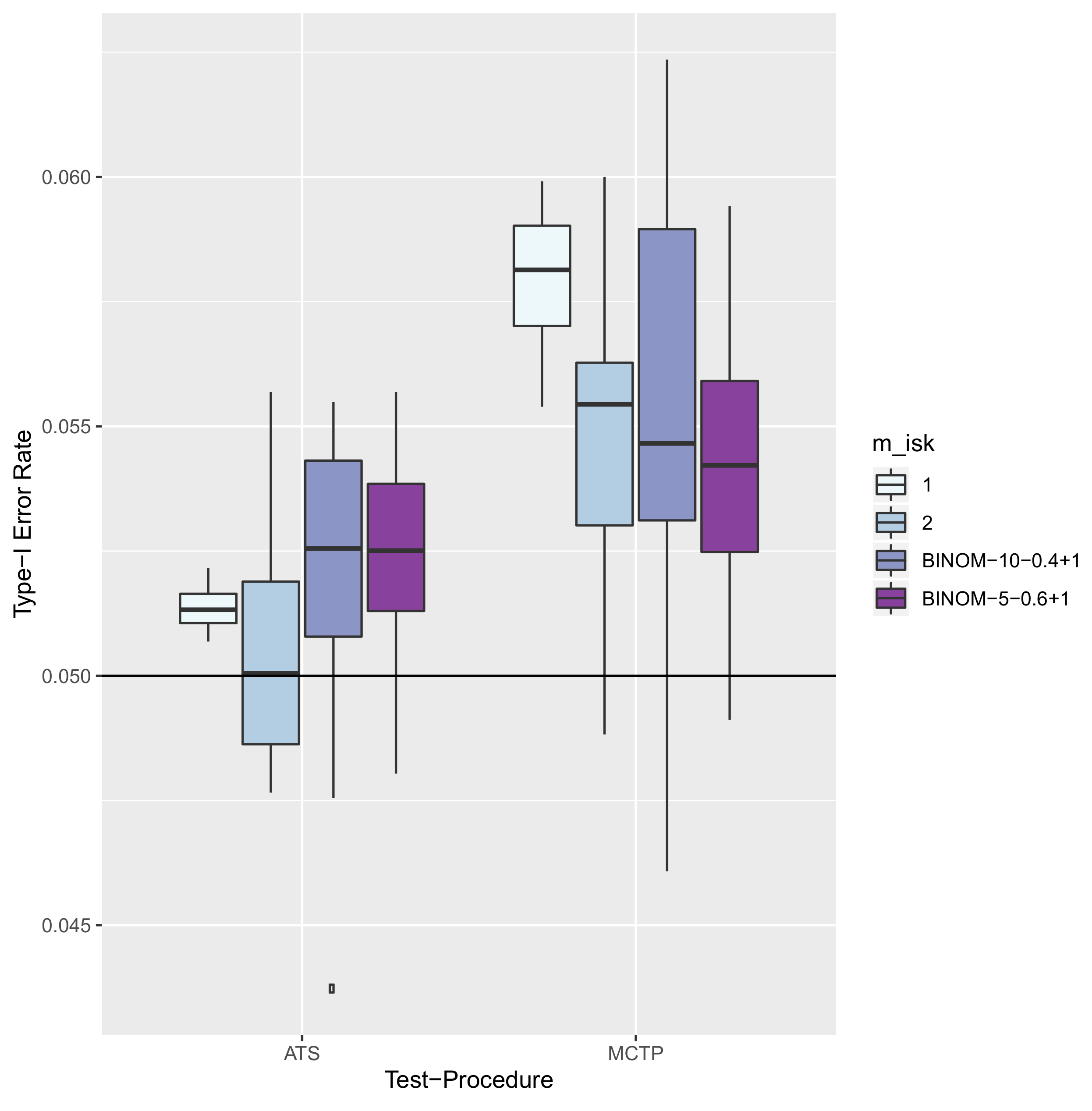
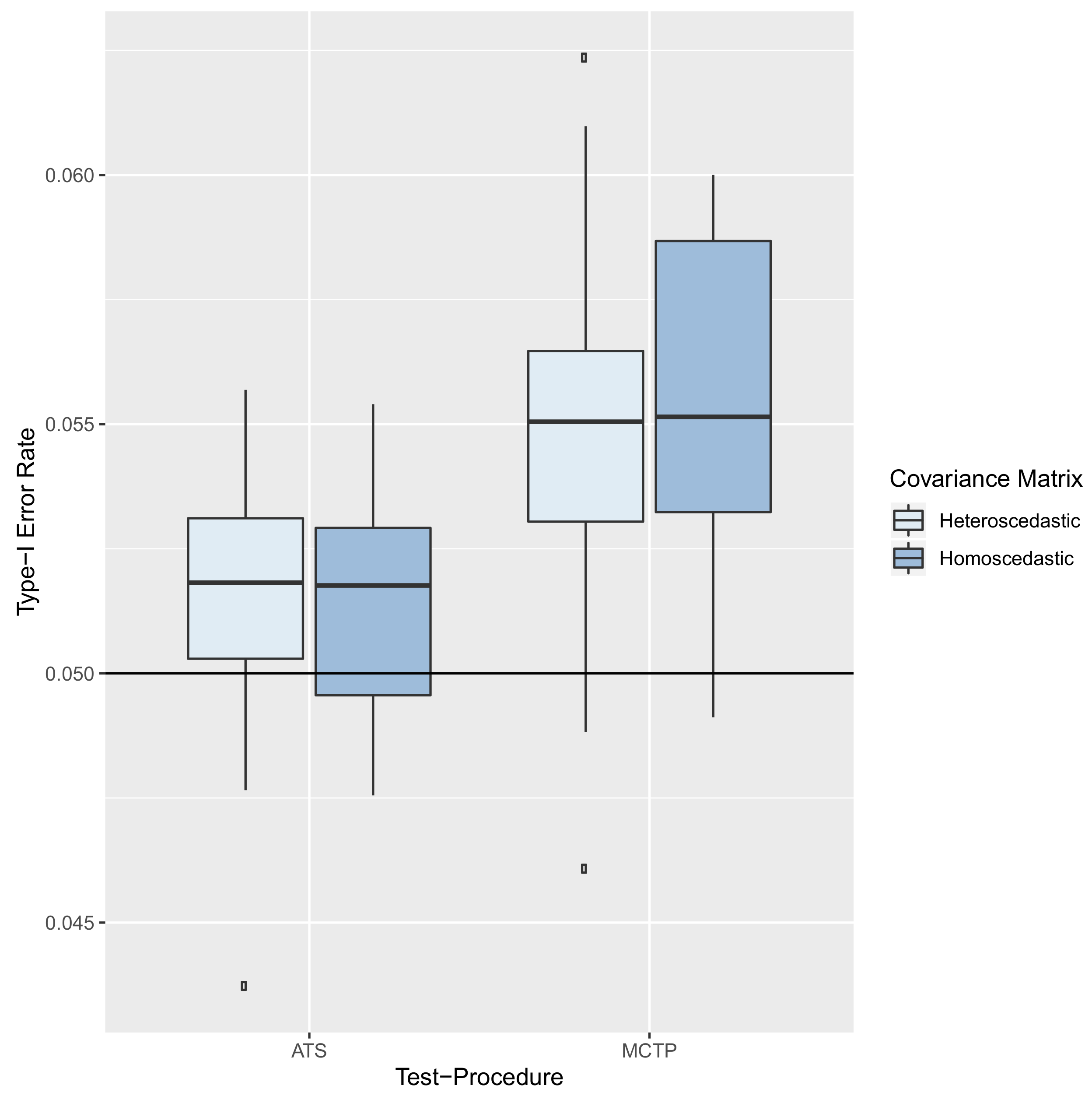
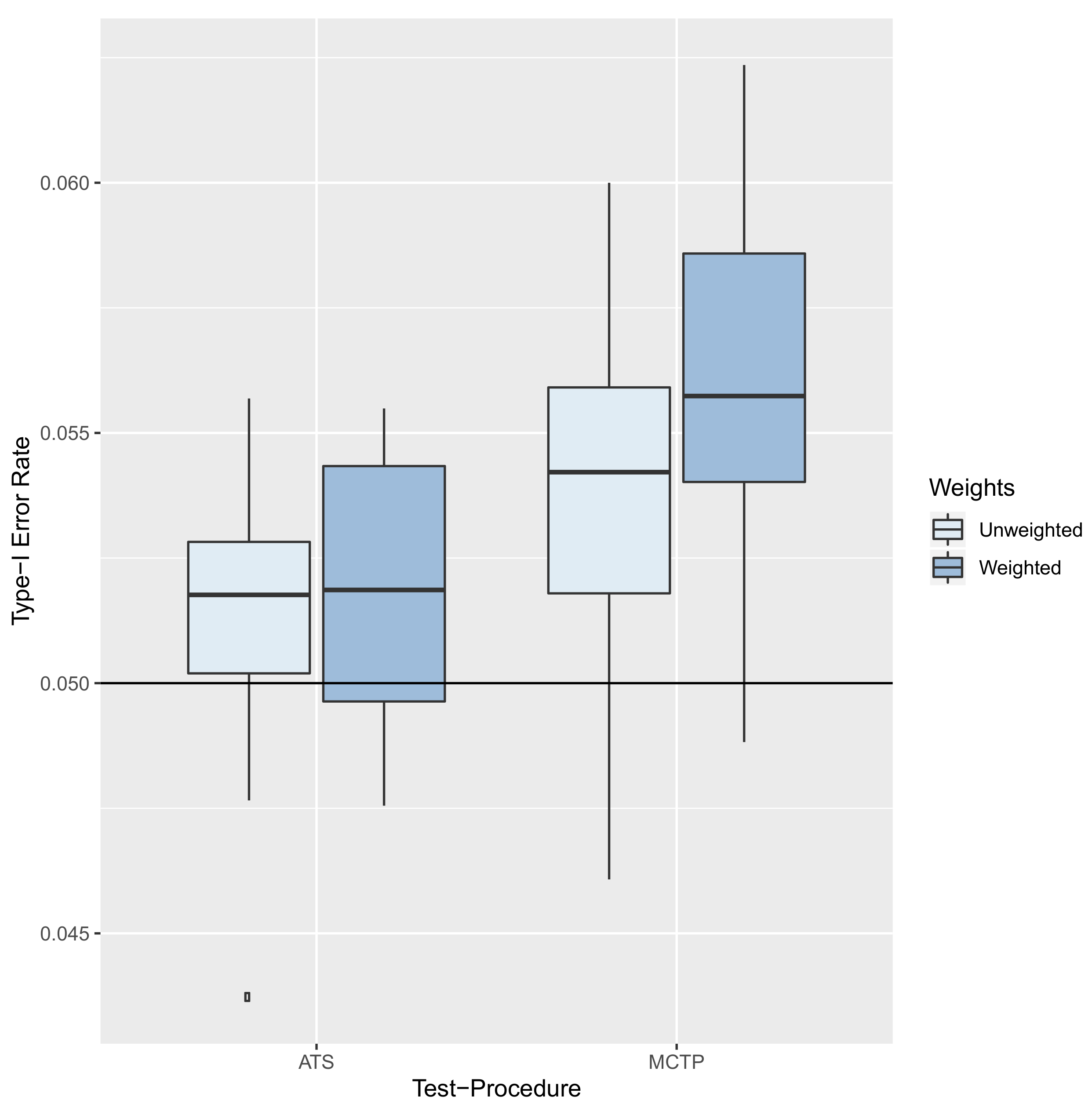
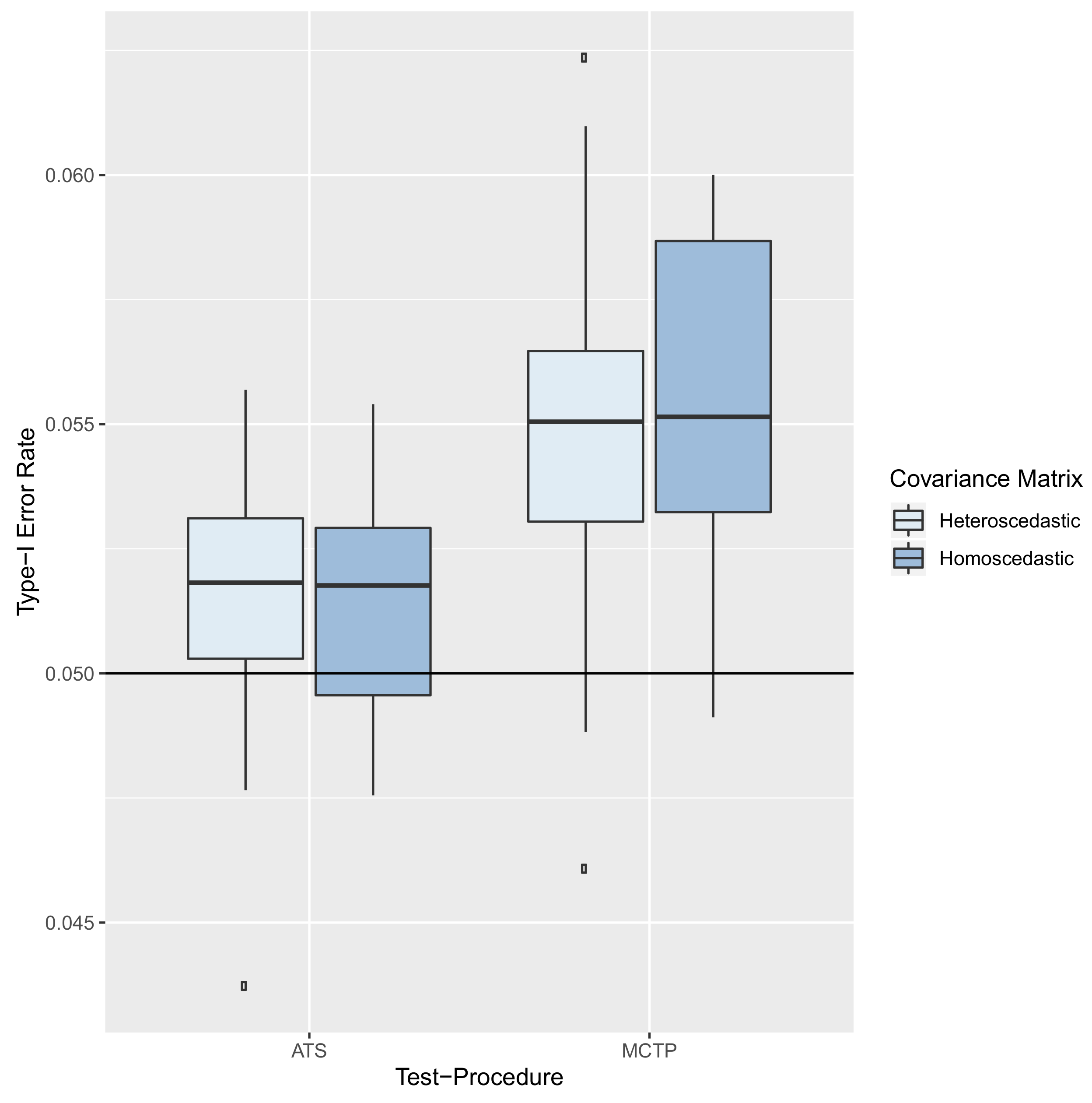
8.2. Results—Type-I Error Rate
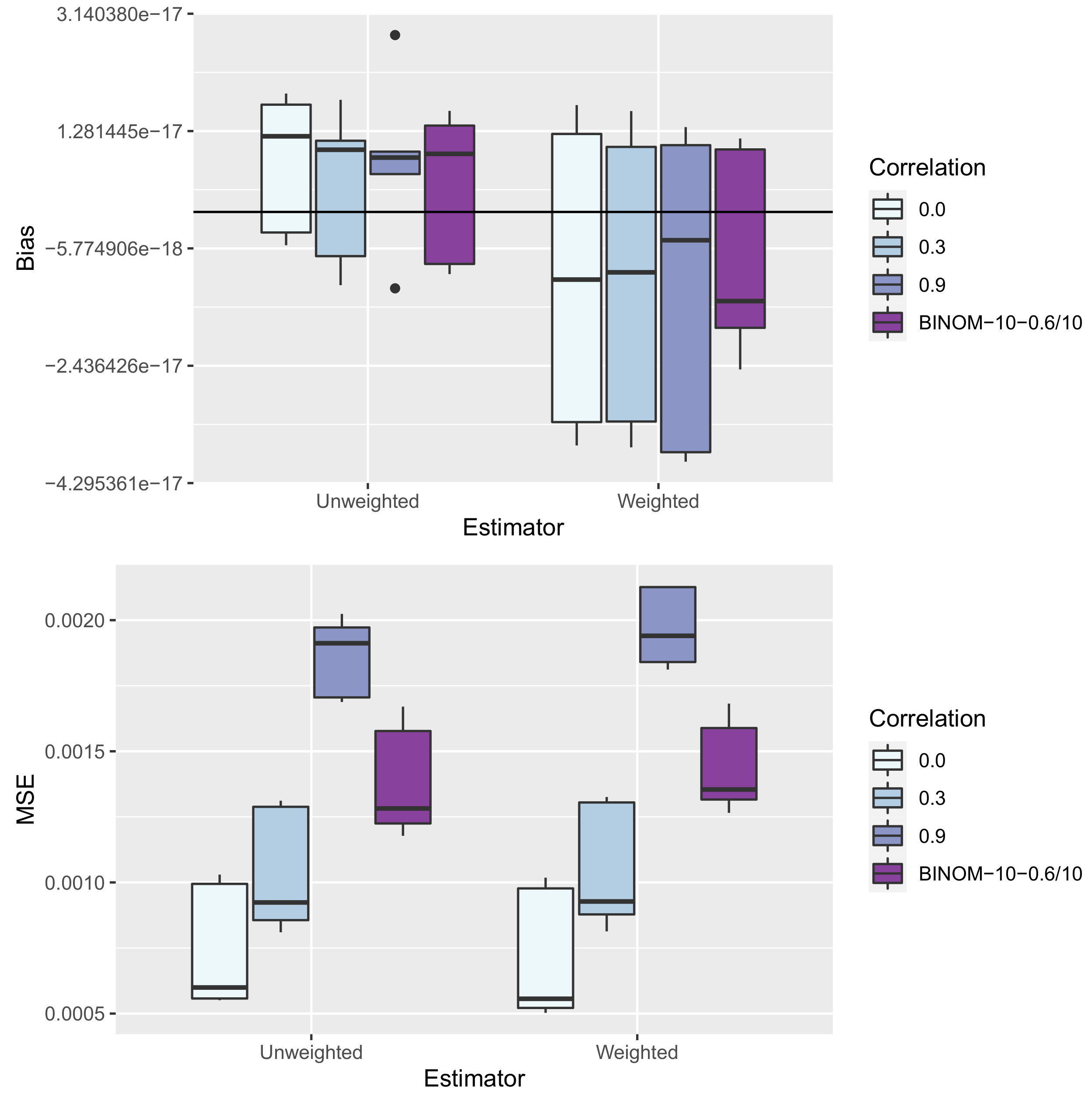
8.3. Results—Precision
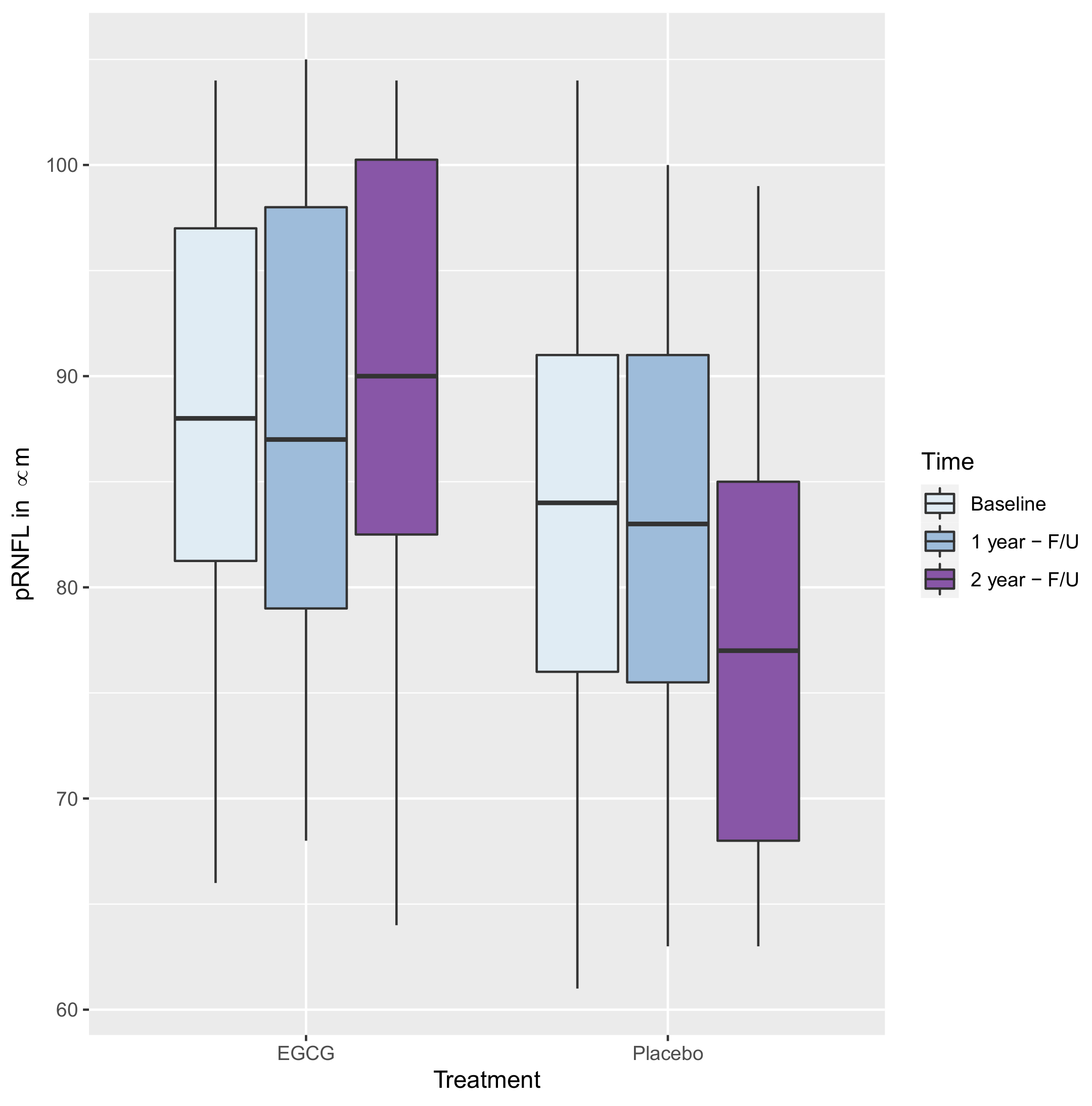
9. Analysis of the Motivating Example
10. Discussion and Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
Appendix A
References
- Roy, A.; Harrar, S.W.; Konietschke, F. The nonparametric Behrens-Fisher problem with dependent replicates. Stat. Med. 2019, 38, 4939–4962. [Google Scholar] [CrossRef] [PubMed]
- Larocque, D.; Haataja, R.; Nevalainen, J.; Oja, H. Two sample tests for the nonparametric Behrens–Fisher problem with clustered data. J. Nonparametric Stat. 2010, 22, 755–771. [Google Scholar] [CrossRef]
- Cui, Y.; Konietschke, F.; Harrar, S.W. The nonparametric Behrens–Fisher problem in partially complete clustered data. Biom. J. 2021, 63, 148–167. [Google Scholar] [CrossRef] [PubMed]
- Gao, X. A Nonparametric Procedure for the Two-Factor Mixed Model with Missing Data. Biom. J. 2007, 49, 774–788. [Google Scholar] [CrossRef] [PubMed]
- Fitzmaurice, G.; Laird, N.; Ware, J. Applied Longitudinal Analysis; John Wiley & Sons: Hoboken, NJ, USA, 2012. [Google Scholar]
- Johnson, R.A.; Wichern, D. Applied Multivariate Statistical Analysis; Pearson Education Limited: London, UK, 2007. [Google Scholar]
- Mann, H.B.; Whitney, D.R. On a Test of Whether one of Two Random Variables is Stochastically Larger than the Other. Ann. Math. Stat. 1947, 18, 50–60. [Google Scholar] [CrossRef]
- Brunner, E.; Munzel, U. The Nonparametric Behrens-Fisher Problem: Asymptotic Theory and a Small-Sample Approximation. Biom. J. 2000, 42, 17–25. [Google Scholar] [CrossRef]
- Thas, O.; Neve, J.D.; Clement, L.; Ottoy, J.P. Probabilistic index models. J. R. Stat. Soc. Ser. B 2012, 74, 623–671. [Google Scholar] [CrossRef] [Green Version]
- Acion, L.; Peterson, J.J.; Temple, S.; Arndt, S. Probabilistic index: An intuitive non-parametric approach to measuring the size of treatment effects. Stat. Med. 2006, 25, 591–602. [Google Scholar] [CrossRef]
- Brunner, E.; Bathke, A.C.; Konietschke, F. Rank and Pseudo-Rank Procedures for Independent Observations in Factorial Designs; Springer: Berlin/Heidelberg, Germany, 2018. [Google Scholar]
- Akritas, M.; Kuha, J.; Osgood, W. A Nonparametric Approach to Matched Pairs with Missing Data. Sociol. Methods Res. 2002, 30, 425–454. [Google Scholar] [CrossRef]
- Fong, Y.; Huang, Y.; Lemos, M.; Mcelrath, J. Rank-based two-sample tests for paired data with missing values. Biostatistics 2018, 19, 281–294. [Google Scholar] [CrossRef]
- Domhof, S.; Brunner, E.; Osgood, W. Rank Procedures for Repeated Measures with Missing Values. Sociol. Methods Res. 2002, 30, 367–393. [Google Scholar] [CrossRef]
- Amro, L.; Konietschke, F.; Pauly, M. Incompletely observed nonparametric factorial designs with repeated measurements: A wild bootstrap approach. arXiv 2021, arXiv:2102.02871. [Google Scholar]
- Akritas, M.; Brunner, E. A unified approach to rank tests for mixed models. J. Stat. Plan. Inference 1997, 61, 249–277. [Google Scholar] [CrossRef]
- Brunner, E.; Munzel, U.; Puri, M.L. Rank-Score Tests in Factorial Designs with Repeated Measures. J. Multivar. Anal. 1999, 70, 286–317. [Google Scholar] [CrossRef] [Green Version]
- Brunner, E.; Domhof, S.; Langer, F. Nonparametric Analysis of Longitudinal Data in Factorial Experiments; Wiley-Interscience: Hoboken, NJ, USA, 2002; Volume 373. [Google Scholar]
- Klumbies, K.; Rust, R.; Dörr, J.; Konietschke, F.; Paul, F.; Bellmann-Strobl, J.; Brandt, A.; Zimmermann, H.G. Retinal Thickness Analysis in Progressive Multiple Sclerosis Patients Treated With Epigallocatechin Gallate: Optical Coherence Tomography Results From the SUPREMES Study. Front. Neurol. 2021, 12, 615790. [Google Scholar] [CrossRef]
- Walton, C.; King, R.; Rechtman, L.; Kaye, W.; Leray, E.; Marrie, R.A.; Robertson, N.; Rocca, N.L.; Uitdehaag, B.; van der Mei, I.; et al. Rising prevalence of multiple sclerosis worldwide: Insights from the Atlas of MS, third edition. Mult. Scler. J. 2020, 26, 1816–1821. [Google Scholar] [CrossRef]
- Reich, D.S.; Lucchinetti, C.F.; Calabresi, P.A. Multiple Sclerosis. N. Engl. J. Med. 2018, 378, 169–180. [Google Scholar] [CrossRef]
- Petzold, A.; Balcer, L.J.; Calabresi, P.A.; Costello, F.; Frohman, T.C.; Frohman, E.M.; Martinez-Lapiscina, E.H.; Green, A.J.; Kardon, R.; Outteryck, O.; et al. Retinal layer segmentation in multiple sclerosis: A systematic review and meta-analysis. Lancet Neurol. 2017, 16, 797–812. [Google Scholar] [CrossRef] [Green Version]
- Oertel, F.C.; Zimmermann, H.G.; Brandt, A.U.; Paul, F. Optical coherence tomography in neuromyelitis optica spectrum disorders: Potential advantages for individualized monitoring of progression and therapy. Expert Rev. Neurother. 2019, 19, 31–43. [Google Scholar] [CrossRef]
- Ruymgaart, F. A Unified Approach to the Asymptotic Distribution Theory of Certain Midrank Statistics; Springer: Berlin/Heidelberg, Germany, 2006; Volume 821, pp. 1–18. [Google Scholar]
- Brunner, E.; Konietschke, F.; Pauly, M.; Puri, M. Rank-Based Procedures in Factorial Designs: Hypotheses about Nonparametric Treatment Effects. J. R. Stat. Soc. Ser. B 2016, 79, 1463–1485. [Google Scholar] [CrossRef] [Green Version]
- Brunner, E.; Konietschke, F.; Bathke, A.C.; Pauly, M. Ranks and Pseudo-ranks—Surprising Results of Certain Rank Tests in Unbalanced Designs. Int. Stat. Rev. 2020, 89, 349–366. [Google Scholar] [CrossRef]
- Obuchowski, N.A. Nonparametric analysis of clustered ROC curve data. Biometrics 1997, 53, 567–578. [Google Scholar] [CrossRef]
- Zou, G. Confidence interval estimation for treatment effects in cluster randomization trials based on ranks. Stat. Med. 2021, 40, 3227–3250. [Google Scholar] [CrossRef]
- Hoffman, E.; Sen, P.; Weinberg, C. Within-Cluster Resampling. Biometrika 2001, 88, 1121–1134. [Google Scholar] [CrossRef] [Green Version]
- Williamson, J.; Datta, S.; Satten, G. Marginal Analyses of Clustered Data When Cluster Size Is Informative. Biometrics 2003, 59, 36–42. [Google Scholar] [CrossRef]
- Rubarth, K.; Pauly, M.; Konietschke, F. Ranking Procedures for Repeated Measures Designs with Missing Data: Estimation, Testing and Asymptotic Theory. Stat. Methods Med. Res. 2022, 31, 105–118. [Google Scholar] [CrossRef] [PubMed]
- Konietschke, F.; Hothorn, L.; Brunner, E. Rank-based multiple test procedures and simultaneous confidence intervals. Electron. J. Stat. 2012, 6, 738–759. [Google Scholar] [CrossRef] [Green Version]
- Konietschke, F.; Bathke, A.; Hothorn, L.; Brunner, E. Testing and estimation of purely nonparametric effects in repeated measures designs. Comput. Stat. Data Anal. 2010, 54, 1895–1905. [Google Scholar] [CrossRef]
- Akritas, M.; Arnold, S.; Brunner, E. Nonparametric Hypotheses and Rank Statistics for Unbalanced Factorial Designs. J. Am. Stat. Assoc. 1997, 92, 258–265. [Google Scholar] [CrossRef]
- Bretz, F.; Genz, A.; Hothorn, L. On the Numerical Availability of Multiple Comparison Procedures. Biom. J. 2001, 43, 645–656. [Google Scholar] [CrossRef]
- Konietschke, F.; Harrar, S.W.; Lange, K.; Brunner, E. Ranking procedures for matched pairs with missing data—Asymptotic theory and a small sample approximation. Comput. Stat. Data Anal. 2012, 56, 1090–1102. [Google Scholar] [CrossRef]
- Gao, X.; Alvo, M.; Chen, J.; Li, G. Nonparametric multiple comparison procedures for unbalanced one-way factorial designs. J. Stat. Plan. Inference 2008, 138, 2574–2591. [Google Scholar] [CrossRef]
- R Core Team. R: A Language and Environment for Statistical Computing; R Foundation for Statistical Computing: Vienna, Austria, 2013. [Google Scholar]
- Friedrich, S.; Konietschke, F.; Pauly, M. A wild bootstrap approach for nonparametric repeated measurements. Comput. Stat. Data Anal. 2017, 113, 38–52. [Google Scholar] [CrossRef]
- Fay, M.P.; Proschan, M.A. Wilcoxon-Mann-Whitney or t-test? On assumptions for hypothesis tests and multiple interpretations of decision rules. Stat. Surv. 2010, 4, 1–39. [Google Scholar] [CrossRef]
- Fagerland, M.W.; Sandvik, L. The Wilcoxon–Mann–Whitney test under scrutiny. Stat. Med. 2009, 28, 1487–1497. [Google Scholar] [CrossRef]
- Bergmann, R.; Ludbrook, J.; Spooren, W.P.J.M. Different Outcomes of the Wilcoxon-Mann-Whitney Test from Different Statistics Packages. Am. Stat. 2000, 54, 72–77. [Google Scholar]
- Fay, M.; Malinovsky, Y. Confidence intervals of the Mann-Whitney parameter that are compatible with the Wilcoxon-Mann-Whitney test: Confidence Intervals on the Mann-Whitney Parameter. Stat. Med. 2018, 37, 3991–4006. [Google Scholar] [CrossRef]
- Fay, M.; Brittain, E.; Shih, J.; Follmann, D.; Gabriel, E. Causal estimands and confidence intervals associated with Wilcoxon-Mann-Whitney tests in randomized experiments. Stat. Med. 2017, 37, 2923–2937. [Google Scholar] [CrossRef]
- Hand, D.J. On Comparing Two Treatments. Am. Stat. 1992, 46, 190–192. [Google Scholar] [CrossRef]
- Noguchi, K.; Gel, Y.R.; Brunner, E.; Konietschke, F. nparLD: An R software package for the nonparametric analysis of longitudinal data in factorial experiments. J. Stat. Softw. 2012, 50, 12. [Google Scholar] [CrossRef] [Green Version]
- Domhof, S. Nichtparametrische Relative Effekte. Ph.D. Thesis, Niedersächsische Staats-und Universitätsbibliothek Göttingen, Göttingen, Germany, 2001. [Google Scholar]






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Group | First OCT | 1-Year F/U | 2-Year F/U | 3-Year F/U |
|---|---|---|---|---|
| Verum | 15 | 14 | 7 | 3 |
| Placebo | 16 | 16 | 11 | 5 |
| Comparison | Estimator | 95%-Confidence Interval | t-Value | p-Value |
|---|---|---|---|---|
| −0.080 | [−0.371, 0.212] | −0.777 | 0.850 | |
| −0.020 | [−0.344, 0.303] | −0.178 | 0.998 | |
| 0.000 | [−0.468, 0.468] | 0.000 | 1.000 | |
| 0.059 | [−0.335, 0.453] | 0.429 | 0.969 | |
| 0.080 | [−0.442, 0.601] | 0.435 | 0.968 | |
| 0.020 | [−0.306, 0.346] | 0.177 | 0.998 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Rubarth, K.; Sattler, P.; Zimmermann, H.G.; Konietschke, F. Estimation and Testing of Wilcoxon–Mann–Whitney Effects in Factorial Clustered Data Designs. Symmetry 2022, 14, 244. https://doi.org/10.3390/sym14020244
Rubarth K, Sattler P, Zimmermann HG, Konietschke F. Estimation and Testing of Wilcoxon–Mann–Whitney Effects in Factorial Clustered Data Designs. Symmetry. 2022; 14(2):244. https://doi.org/10.3390/sym14020244
Chicago/Turabian StyleRubarth, Kerstin, Paavo Sattler, Hanna Gwendolyn Zimmermann, and Frank Konietschke. 2022. "Estimation and Testing of Wilcoxon–Mann–Whitney Effects in Factorial Clustered Data Designs" Symmetry 14, no. 2: 244. https://doi.org/10.3390/sym14020244
APA StyleRubarth, K., Sattler, P., Zimmermann, H. G., & Konietschke, F. (2022). Estimation and Testing of Wilcoxon–Mann–Whitney Effects in Factorial Clustered Data Designs. Symmetry, 14(2), 244. https://doi.org/10.3390/sym14020244