

Simultaneous Confidence Intervals for All Pairwise Differences between the Coefficients of Variation of Multiple Birnbaum–Saunders Distributions


Abstract
:1. Introduction
2. Methods
2.1. The PB Approach
| Algorithm 1 The PB approach |
|
2.2. The GCI Approach
- The observed value of denoted as is free of nuisance parameter .
- The probability distribution of is free of unknown parameters.
| Algorithm 2 The GCI approach |
|
2.3. The MOVER Approach
2.3.1. The MOVER Based on ACI Approach
| Algorithm 3 The MOVER based on ACI approach |
2.3.2. The MOVER Based on GCI Approach
2.4. The BayCrI Approach
- (1)
- Calculate and .
- (2)
- Simulate and from and , where refer to a uniform distribution with parameters s and t, then compute .
- (3)
- If , set , otherwise go back to step (2).
| Algorithm 5 The BayCrI and HPD approaches |
|
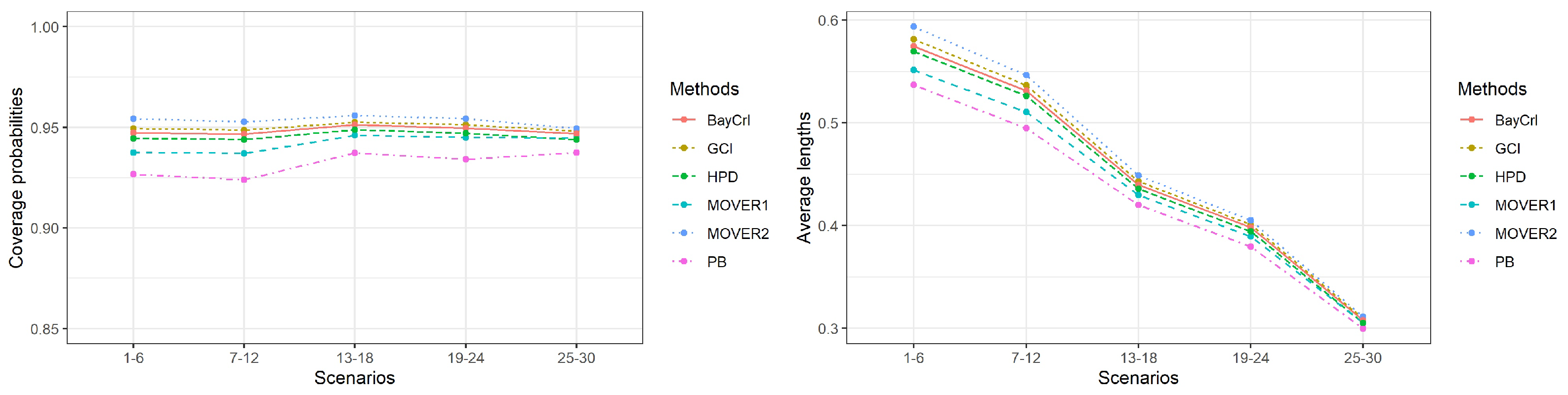
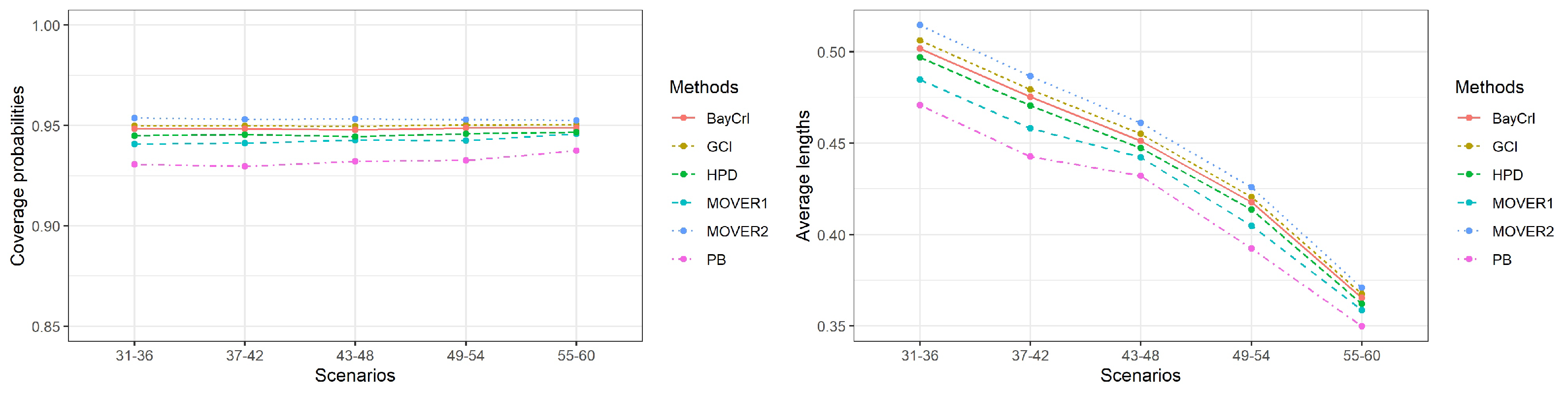
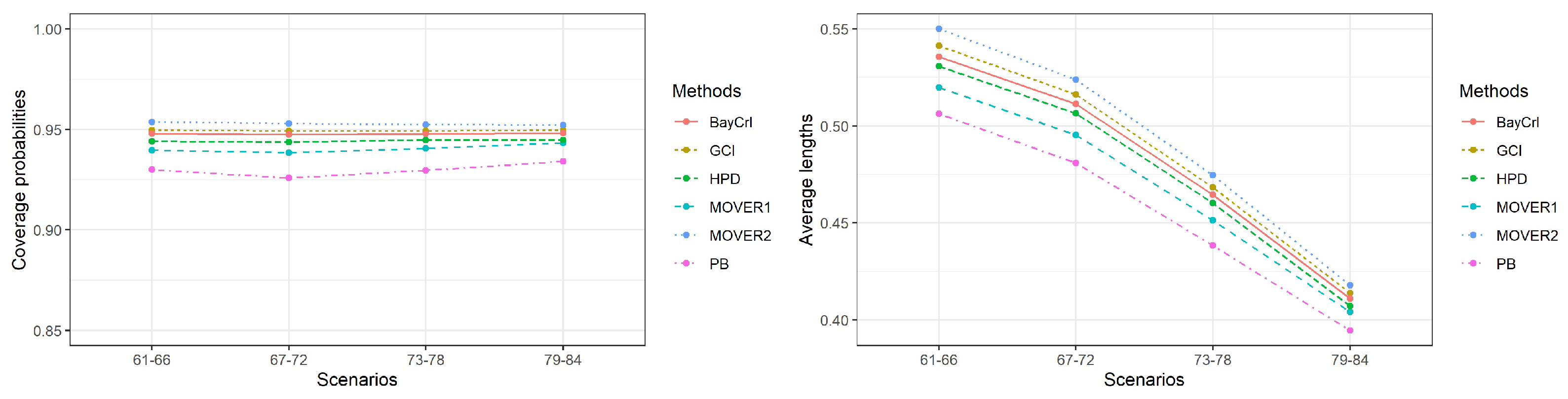
3. Simulation Study Settings and Results
4. Empirical Application of the Methods with Three Real Datasets
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Birnbaum, Z.W.; Saunders, S.C. A new family of life distributions. J. Appl. Probab. 1969, 6, 319–327. [Google Scholar] [CrossRef]
- Desmond, A.F. Stochastic models of failure in random environments. Can. J. Stat. 1985, 13, 171–183. [Google Scholar] [CrossRef]
- Desmond, A.F. On the relationship between two fatigue-life model. IEEE Trans. Reliab. 1986, 35, 167–169. [Google Scholar] [CrossRef]
- Leiva, V.; Marchant, C.; Ruggeri, F.; Saulo, H. A criterion for environmental assessment using Birnbaum–Saunders attribute control charts. Environmetrics 2015, 26, 463–476. [Google Scholar] [CrossRef]
- Marchant, C.; Bertin, K.; Leiva, V.; Saulo, H. Generalized Birnbaum-Saunders kernel density estimators and an analysis of financial data. Comput. Stat. Data Anal. 2013, 63, 1–15. [Google Scholar] [CrossRef]
- Lio, Y.L.; Tsai, T.R.; Wu, S.J. Acceptance sampling plans from truncated life tests based on the Birnbaum–Saunders distribution for percentiles. Commun. Stat. Simul. Comput. 2010, 39, 119–136. [Google Scholar] [CrossRef]
- Birnbaum, Z.W.; Saunders, S.C. Estimation for a family of life distributions with applications to fatigue. J. Appl. Probab. 1969, 6, 328–347. [Google Scholar] [CrossRef]
- Leiva, V.; Barros, M.; Paula, G.A.; Sanhueza, A. Generalized Birnbaum–Saunders distributions applied to air pollutant concentration. Environmetrics 2008, 19, 235–249. [Google Scholar] [CrossRef]
- Engelhardt, M.; Bain, L.J.; Wright, F.T. Inference on the parameters of the Birnbaum–Saunders fatigue life distribution based on maximum likelihood estimation. Technometrics 1981, 23, 251–255. [Google Scholar] [CrossRef]
- Achcar, J. Inferences for the Birnbaum-Saunders fatigue life model using Bayesian methods. Comput. Stat. Data Anal. 1993, 15, 367–380. [Google Scholar] [CrossRef]
- Lu, M.; Chang, D.S. Bootstrap prediction intervals for the Birnbaum–Saunders distribution. Microelectron. Reliab. 1997, 37, 1213–1216. [Google Scholar] [CrossRef]
- Ng, H.K.T.; Kundu, D.; Balakrishnan, N. Modified moment estimation for the two-parameter Birnbaum–Saunders distribution. Comput. Stat. Data Anal. 2003, 43, 283–298. [Google Scholar] [CrossRef]
- Wang, B.X. Generalized interval estimation for the Birnbaum-Saunders distribution. Comput. Stat. Data Anal. 2012, 56, 4320–4326. [Google Scholar] [CrossRef]
- Wang, M.; Zhao, J.; Sun, X.; Park, C. Robust explicit estimation of the two-parameter Birnbaum–Saunders distribution. J. Appl. Stat. 2013, 40, 2259–2274. [Google Scholar] [CrossRef]
- Wang, M.; Sun, X.; Park, C. Bayesian analysis of Birnbaum-Saunders distribution via the generalized ratio-of-uniforms method. Comput. Stat. 2016, 31, 207–225. [Google Scholar] [CrossRef]
- Wong, A.C.M.; Wu, J. Small sample asymptotic inference for the coefficient of variation: Normal and nonnormal models. J. Stat. Plan. Inference 2002, 104, 73–82. [Google Scholar] [CrossRef]
- Pang, W.K.; Leung, P.K.; Huang, W.K.; Liu, W. On interval estimation of the coefficient of variation for the three-parameter weibull, lognormal and gamma distribution:a simulation-based approach. Eur. J. Oper. Res. 2005, 164, 367–377. [Google Scholar] [CrossRef]
- Sangnawakij, P.; Niwitpong, S.-A. Confidence intervals for coefficients of variation in two-parameter exponential distributions. Commun. Stat.-Simul. A Comput. 2017, 46, 6618–6630. [Google Scholar] [CrossRef]
- Puggard, W.; Niwitpong, S.A.; Niwitpong, S. Bayesian estimation for the coefficients of variation of Birnbaum–Saunders distributions. Symmetry 2021, 13, 2130. [Google Scholar] [CrossRef]
- Thangjai, W.; Niwitpong, S. Simultaneous confidence intervals for all differences of coefficients of variation of two-parameter exponential distributions. Thail. Stat. 2020, 18, 135–149. [Google Scholar]
- Yosboonruang, N.; Niwitpong, S.A.; Niwitpong, S. Simultaneous confidence intervals for all pairwise differences between the coefficients of variation of rainfall series in Thailand. PeerJ 2021, 9, e11651. [Google Scholar] [CrossRef] [PubMed]
- Efron, B. Bootstrap methods: Another look at the jackknife. Ann. Stat. 1979, 7, 1–26. [Google Scholar] [CrossRef]
- Thangjai, W.; Niwitpong, S.A.; Niwitpong, S. Simultaneous confidence intervals for all differences of coefficients of variation of log-normal distributions. Hacet. J. Math. Stat. 2019, 48, 1505–1521. [Google Scholar]
- Weerahandi, S. Generalized Inference in Repeated Measures: Exact Methods in MANOVA and Mixed Models; Wiley: Boston, MA, USA, 2004. [Google Scholar]
- Sun, Z.L. The confidence intervals for the scale parameter of the Birnbaum–Saunders fatigue life distribution. Acta Armamentarii. 2009, 30, 1558–1561. [Google Scholar]
- Zou, G.Y.; Donner, A. Construction of confidence limits about effect measures: A general approach. Stat. Med. 2008, 27, 1693–1702. [Google Scholar] [CrossRef]
- Puggard, W.; Niwitpong, S.A.; Niwitpong, S. Confidence intervals for common coefficient of variation of several Birnbaum–Saunders distributions. Symmetry 2022, 14, 2101. [Google Scholar] [CrossRef]
- Saunders, R.; Rawlings, A.; Birnbaum, A.; Iliopoulos, A.; Michopoulos, J.; Lagoudas, D.; Elwany, A. Additive Manufacturing Melt Pool Prediction and Classification via Multifidelity Gaussian Process Surrogates. Integr. Mater. Manuf. Innov. 2022, 11, 497–515. [Google Scholar] [CrossRef]
- Saunders, R.; Butler, C.; Michopoulos, J.; Lagoudas, D.; Elwany, A.; Bagchi, A. Mechanical behavior predictions of additively manufactured microstructures using functional Gaussian process surrogates. NPJ Comput. Mater. 2021, 7, 81. [Google Scholar] [CrossRef]
- Xu, A.; Tang, Y. Bayesian analysis of Birnbaum–Saunders distribution with partial information. Comput. Stat. Data Anal. 2011, 55, 2324–2333. [Google Scholar] [CrossRef]
- Wakefield, J.C.; Gelfand, A.E.; Smith, A.F.M. Efficient generation of random variates via the ratio-of-uniforms method. Stat. Comput. 1991, 1, 129–133. [Google Scholar] [CrossRef]
- Box, G.E.P.; Tiao, G.C. Bayesian Inference in Statistical Analysis; Wiley: New York, NY, USA, 1992. [Google Scholar]
- Reports on Smog Situation in the North Home Page. Available online: http://www.pcd.go.th/ (accessed on 20 October 2022). (In Thai).

{kind=link}
{kind=link}
{kind=link}
| Scenarios | (n1, n2, …, nk) | (a1, a2, …, ak) |
|---|---|---|
| k = 3 | ||
| 1–6 | (303) | (0.53),(0.5, 1.02), (1.03), (0.5, 1.0, 2.0), (1.0, 1.5, 2.0), (1.5, 2.02) |
| 7–12 | (302, 50) | (0.53),(0.5, 1.02), (1.03), (0.5, 1.0, 2.0), (1.0, 1.5, 2.0), (1.5, 2.02) |
| 13–18 | (503) | (0.53), (0.5, 1.02), (1.03), (0.5, 1.0, 2.0), (1.0, 1.5, 2.0), (1.5, 2.02) |
| 19–24 | (502, 100) | (0.53), (0.5, 1.02), (1.03), (0.5, 1.0, 2.0), (1.0, 1.5, 2.0), (1.5, 2.02) |
| 25–30 | (1003) | (0.53), (0.5, 1.02), (1.03), (0.5, 1.0, 2.0), (1.0, 1.5, 2.0), (1.5, 2.02) |
| k = 5 | ||
| 31–36 | (302, 503) | (0.53, 1.0, 2.0), (0.52, 1.02, 1.5), (0.5,1.03, 1.5), (0.5, 1.02, 2.02),(1.03, 1.52), (1.0, 1.5, 2.03) |
| 37–42 | (302, 502, 100) | (0.53, 1.0, 2.0), (0.52, 1.02, 1.5), (0.5, 1.03, 1.5), (0.5, 1.02, 2.02),(1.03, 1.52), (1.0, 1.5, 2.03) |
| 43–48 | (505) | (0.53, 1.0, 2.0), (0.52, 1.02, 1.5), (0.5,1.03, 1.5), (0.5, 1.02, 2.02),(1.03, 1.52), (1.0, 1.5, 2.03) |
| 49–54 | (30, 502, 1002) | (0.53, 1.0, 2.0), (0.52, 1.02, 1.5), (0.5,1.03, 1.5), (0.5, 1.02, 2.02),(1.03, 1.52), (1.0, 1.5, 2.03) |
| 55–60 | (502, 1003) | (0.53, 1.0, 2.0), (0.52, 1.02, 1.5), (0.5,1.03, 1.5), (0.5, 1.02, 2.02),(1.03, 1.52), (1.0, 1.5, 2.03) |
| k = 10 | ||
| 61–66 | (305, 505) | (0.53, 1.07), (0.53, 1.04, 1.53), (0.53, 1.02,1.53, 2.02), (1.04, 1.53,2.03), (1.03, 1.53, 2.04), (1.02, 1.52, 2.06) |
| 67–72 | (305, 503, 1002) | (0.53, 1.07), (0.53, 1.04, 1.53), (0.53, 1.02,1.53, 2.02), (1.04, 1.53,2.03), (1.03, 1.53, 2.04), (1.02, 1.52, 2.06) |
| 73–78 | (303, 504, 1003) | (0.53, 1.07), (0.53, 1.04, 1.53), (0.53, 1.02,1.53, 2.02), (1.04, 1.53,2.03), (1.03, 1.53, 2.04), (1.02, 1.52, 2.06) |
| 79–84 | (506, 1004) | (0.53, 1.07), (0.53, 1.04, 1.53), (0.53, 1.02,1.53, 2.02), (1.04, 1.53,2.03), (1.03, 1.53, 2.04), (1.02, 1.52, 2.06) |
| Scenarios | Coverage Probability (Average Length) | |||||
|---|---|---|---|---|---|---|
| PB | GCI | MOVER1 | MOVER2 | BayCrI | HPD | |
| 1 | 0.928 | 0.946 | 0.944 | 0.952 | 0.945 | 0.950 |
| (0.3391) | (0.4030) | (0.3613) | (0.4154) | (0.4006) | (0.3968) | |
| 2 | 0.922 | 0.950 | 0.939 | 0.953 | 0.948 | 0.946 |
| (0.5169) | (0.5836) | (0.5452) | (0.5979) | (0.5789) | (0.5736) | |
| 3 | 0.935 | 0.953 | 0.943 | 0.958 | 0.951 | 0.946 |
| (0.5892) | (0.6591) | (0.6197) | (0.6756) | (0.6536) | (0.6481) | |
| 4 | 0.916 | 0.949 | 0.932 | 0.953 | 0.947 | 0.944 |
| (0.5237) | (0.5624) | (0.5356) | (0.5740) | (0.5554) | (0.5500) | |
| 5 | 0.929 | 0.946 | 0.932 | 0.952 | 0.944 | 0.938 |
| (0.6222) | (0.6490) | (0.6272) | (0.6605) | (0.6398) | (0.6339) | |
| 6 | 0.930 | 0.952 | 0.936 | 0.958 | 0.948 | 0.942 |
| (0.6301) | (0.6304) | (0.6183) | (0.6382) | (0.6187) | (0.6135) | |
| 7 | 0.928 | 0.951 | 0.945 | 0.954 | 0.948 | 0.951 |
| (0.3175) | (0.3711) | (0.3367) | (0.3809) | (0.3690) | (0.3652) | |
| 8 | 0.920 | 0.946 | 0.934 | 0.950 | 0.945 | 0.943 |
| (0.4719) | (0.5288) | (0.4973) | (0.5403) | (0.5247) | (0.5200) | |
| 9 | 0.923 | 0.946 | 0.934 | 0.950 | 0.946 | 0.941 |
| (0.5503) | (0.6096) | (0.5769) | (0.6225) | (0.6048) | (0.5994) | |
| 10 | 0.924 | 0.949 | 0.937 | 0.952 | 0.947 | 0.944 |
| (0.4721) | (0.5145) | (0.4879) | (0.5241) | (0.5094) | (0.5041) | |
| 11 | 0.927 | 0.951 | 0.940 | 0.957 | 0.949 | 0.944 |
| (0.5739) | (0.6072) | (0.5864) | (0.6165) | (0.5998) | (0.5941) | |
| 12 | 0.922 | 0.947 | 0.933 | 0.952 | 0.945 | 0.938 |
| (0.5830) | (0.5877) | (0.5771) | (0.5937) | (0.5780) | (0.5731) | |
| 13 | 0.942 | 0.953 | 0.952 | 0.956 | 0.951 | 0.954 |
| (0.2711) | (0.3018) | (0.2830) | (0.3078) | (0.3004) | (0.2978) | |
| 14 | 0.931 | 0.953 | 0.944 | 0.956 | 0.952 | 0.949 |
| (0.4098) | (0.4436) | (0.4263) | (0.4502) | (0.4411) | (0.4372) | |
| 15 | 0.942 | 0.954 | 0.950 | 0.957 | 0.954 | 0.952 |
| (0.4670) | (0.5036) | (0.4857) | (0.5114) | (0.5005) | (0.4964) | |
| 16 | 0.929 | 0.952 | 0.943 | 0.956 | 0.951 | 0.948 |
| (0.4080) | (0.4288) | (0.4168) | (0.4342) | (0.4249) | (0.4210) | |
| 17 | 0.940 | 0.951 | 0.944 | 0.955 | 0.949 | 0.945 |
| (0.4826) | (0.4969) | (0.4873) | (0.5023) | (0.4921) | (0.4878) | |
| 18 | 0.940 | 0.950 | 0.943 | 0.955 | 0.950 | 0.944 |
| (0.4817) | (0.4831) | (0.4781) | (0.4869) | (0.4774) | (0.4734) | |
| 19 | 0.937 | 0.951 | 0.949 | 0.954 | 0.951 | 0.952 |
| (0.2483) | (0.2727) | (0.2578) | (0.2770) | (0.2718) | (0.2691) | |
| 20 | 0.932 | 0.950 | 0.944 | 0.953 | 0.948 | 0.947 |
| (0.3646) | (0.3918) | (0.3780) | (0.3967) | (0.3896) | (0.3861) | |
| 21 | 0.934 | 0.952 | 0.945 | 0.954 | 0.949 | 0.946 |
| (0.4279) | (0.4572) | (0.4429) | (0.4626) | (0.4544) | (0.4503) | |
| 22 | 0.933 | 0.950 | 0.943 | 0.954 | 0.950 | 0.946 |
| (0.3606) | (0.3829) | (0.3708) | (0.3871) | (0.3803) | (0.3766) | |
| 23 | 0.936 | 0.953 | 0.943 | 0.957 | 0.951 | 0.945 |
| (0.4386) | (0.4572) | (0.4479) | (0.4613) | (0.4534) | (0.4493) | |
| 24 | 0.934 | 0.951 | 0.945 | 0.953 | 0.949 | 0.946 |
| (0.4370) | (0.4424) | (0.4381) | (0.4449) | (0.4377) | (0.4340) | |
| 25 | 0.943 | 0.951 | 0.951 | 0.953 | 0.950 | 0.948 |
| (0.1964) | (0.2079) | (0.2015) | (0.2101) | (0.2072) | (0.2054) | |
| 26 | 0.935 | 0.947 | 0.943 | 0.949 | 0.946 | 0.942 |
| (0.2970) | (0.3096) | (0.3039) | (0.3120) | (0.3084) | (0.3058) | |
| 27 | 0.933 | 0.942 | 0.939 | 0.944 | 0.940 | 0.939 |
| (0.3379) | (0.3520) | (0.3459) | (0.3548) | (0.3505) | (0.3476) | |
| 28 | 0.936 | 0.948 | 0.946 | 0.950 | 0.949 | 0.946 |
| (0.2902) | (0.2993) | (0.2953) | (0.3012) | (0.2975) | (0.2948) | |
| 29 | 0.938 | 0.949 | 0.945 | 0.950 | 0.948 | 0.945 |
| (0.3402) | (0.3481) | (0.3451) | (0.3500) | (0.3460) | (0.3431) | |
| 30 | 0.940 | 0.949 | 0.944 | 0.951 | 0.947 | 0.944 |
| (0.3352) | (0.3386) | (0.3373) | (0.3399) | (0.3364) | (0.3336) | |
| Scenarios | Coverage Probability (Average Length) | |||||
|---|---|---|---|---|---|---|
| PB | GCI | MOVER1 | MOVER2 | BayCrI | HPD | |
| 31 | 0.928 | 0.948 | 0.941 | 0.952 | 0.946 | 0.946 |
| (0.3816) | (0.4174) | (0.3941) | (0.4255) | (0.4142) | (0.4102) | |
| 32 | 0.933 | 0.949 | 0.943 | 0.953 | 0.948 | 0.947 |
| (0.4279) | (0.4689) | (0.4452) | (0.4783) | (0.4658) | (0.4617) | |
| 33 | 0.928 | 0.948 | 0.939 | 0.953 | 0.947 | 0.944 |
| (0.4792) | (0.5221) | (0.4981) | (0.5317) | (0.5181) | (0.5134) | |
| 34 | 0.933 | 0.952 | 0.943 | 0.956 | 0.951 | 0.948 |
| (0.4691) | (0.5013) | (0.4809) | (0.5092) | (0.4966) | (0.4917) | |
| 35 | 0.930 | 0.948 | 0.938 | 0.952 | 0.947 | 0.942 |
| (0.5348) | (0.5765) | (0.5537) | (0.5862) | (0.5717) | (0.5664) | |
| 36 | 0.932 | 0.952 | 0.941 | 0.956 | 0.951 | 0.944 |
| (0.5320) | (0.5503) | (0.5362) | (0.5566) | (0.5436) | (0.5385) | |
| 37 | 0.933 | 0.952 | 0.946 | 0.955 | 0.950 | 0.949 |
| (0.3516) | (0.3905) | (0.3668) | (0.3978) | (0.3880) | (0.3839) | |
| 38 | 0.936 | 0.951 | 0.945 | 0.954 | 0.950 | 0.949 |
| (0.3974) | (0.4377) | (0.4142) | (0.4459) | (0.4348) | (0.4307) | |
| 39 | 0.928 | 0.950 | 0.941 | 0.953 | 0.947 | 0.944 |
| (0.4510) | (0.4934) | (0.4699) | (0.5017) | (0.4899) | (0.4852) | |
| 40 | 0.928 | 0.948 | 0.939 | 0.951 | 0.946 | 0.943 |
| (0.4421) | (0.4767) | (0.4564) | (0.4837) | (0.4724) | (0.4675) | |
| 41 | 0.928 | 0.949 | 0.939 | 0.953 | 0.948 | 0.944 |
| (0.5079) | (0.5494) | (0.5272) | (0.5575) | (0.5450) | (0.5397) | |
| 42 | 0.924 | 0.949 | 0.936 | 0.952 | 0.947 | 0.942 |
| (0.5064) | (0.5280) | (0.5141) | (0.5333) | (0.5215) | (0.5165) | |
| 43 | 0.929 | 0.949 | 0.944 | 0.952 | 0.947 | 0.944 |
| (0.3554) | (0.3799) | (0.3655) | (0.3856) | (0.3771) | (0.3737) | |
| 44 | 0.931 | 0.952 | 0.945 | 0.954 | 0.950 | 0.948 |
| (0.4053) | (0.4343) | (0.4190) | (0.4405) | (0.4313) | (0.4275) | |
| 45 | 0.930 | 0.947 | 0.940 | 0.950 | 0.946 | 0.942 |
| (0.4414) | (0.4721) | (0.4567) | (0.4789) | (0.4687) | (0.4646) | |
| 46 | 0.932 | 0.951 | 0.943 | 0.955 | 0.949 | 0.945 |
| (0.4313) | (0.4499) | (0.4385) | (0.4553) | (0.4458) | (0.4418) | |
| 47 | 0.936 | 0.952 | 0.945 | 0.955 | 0.950 | 0.946 |
| (0.4845) | (0.5119) | (0.4981) | (0.5189) | (0.5079) | (0.5037) | |
| 48 | 0.934 | 0.947 | 0.941 | 0.952 | 0.946 | 0.942 |
| (0.4739) | (0.4826) | (0.4754) | (0.4869) | (0.4772) | (0.4731) | |
| 49 | 0.936 | 0.950 | 0.944 | 0.953 | 0.949 | 0.947 |
| (0.3090) | (0.3365) | (0.3197) | (0.3417) | (0.3346) | (0.3313) | |
| 50 | 0.935 | 0.950 | 0.945 | 0.953 | 0.949 | 0.947 |
| (0.3586) | (0.3886) | (0.3718) | (0.3944) | (0.3865) | (0.3828) | |
| 51 | 0.935 | 0.951 | 0.944 | 0.954 | 0.949 | 0.947 |
| (0.3969) | (0.4282) | (0.4114) | (0.4343) | (0.4257) | (0.4218) | |
| 52 | 0.932 | 0.947 | 0.941 | 0.950 | 0.946 | 0.943 |
| (0.3874) | (0.4152) | (0.3995) | (0.4204) | (0.4125) | (0.4083) | |
| 53 | 0.932 | 0.951 | 0.942 | 0.954 | 0.950 | 0.947 |
| (0.4540) | (0.4871) | (0.4703) | (0.4929) | (0.4837) | (0.4791) | |
| 54 | 0.925 | 0.951 | 0.939 | 0.953 | 0.950 | 0.944 |
| (0.4476) | (0.4676) | (0.4564) | (0.4714) | (0.4632) | (0.4586) | |
| 55 | 0.935 | 0.948 | 0.944 | 0.950 | 0.946 | 0.945 |
| (0.2818) | (0.2994) | (0.2897) | (0.3028) | (0.2979) | (0.2952) | |
| 56 | 0.941 | 0.950 | 0.947 | 0.952 | 0.948 | 0.947 |
| (0.3169) | (0.3355) | (0.3257) | (0.3395) | (0.3338) | (0.3310) | |
| 57 | 0.937 | 0.949 | 0.944 | 0.951 | 0.947 | 0.946 |
| (0.3586) | (0.3786) | (0.3687) | (0.3826) | (0.3767) | (0.3733) | |
| 58 | 0.940 | 0.953 | 0.948 | 0.955 | 0.951 | 0.948 |
| (0.3484) | (0.3644) | (0.3558) | (0.3677) | (0.3621) | (0.3587) | |
| 59 | 0.935 | 0.948 | 0.943 | 0.951 | 0.947 | 0.944 |
| (0.4010) | (0.4218) | (0.4122) | (0.4256) | (0.4193) | (0.4155) | |
| 60 | 0.938 | 0.954 | 0.949 | 0.955 | 0.953 | 0.948 |
| (0.3922) | (0.4053) | (0.3994) | (0.4079) | (0.4022) | (0.3985) | |
| Scenarios | Coverage Probability (Average Length) | |||||
|---|---|---|---|---|---|---|
| PB | GCI | MOVER1 | MOVER2 | BayCrI | HPD | |
| 61 | 0.929 | 0.950 | 0.943 | 0.954 | 0.949 | 0.946 |
| (0.4572) | (0.5083) | (0.4800) | (0.5188) | (0.5048) | (0.5003) | |
| 62 | 0.932 | 0.951 | 0.942 | 0.955 | 0.949 | 0.947 |
| (0.4707) | (0.5146) | (0.4895) | (0.5245) | (0.5102) | (0.5057) | |
| 63 | 0.929 | 0.949 | 0.940 | 0.954 | 0.948 | 0.944 |
| (0.4704) | (0.5059) | (0.4839) | (0.5148) | (0.5013) | (0.4965) | |
| 64 | 0.931 | 0.949 | 0.938 | 0.953 | 0.948 | 0.943 |
| (0.5451) | (0.5789) | (0.5580) | (0.5876) | (0.5725) | (0.5671) | |
| 65 | 0.929 | 0.949 | 0.937 | 0.953 | 0.947 | 0.942 |
| (0.5481) | (0.5756) | (0.5575) | (0.5836) | (0.5689) | (0.5636) | |
| 66 | 0.929 | 0.950 | 0.937 | 0.954 | 0.947 | 0.942 |
| (0.5459) | (0.5637) | (0.5491) | (0.5705) | (0.5560) | (0.5510) | |
| 67 | 0.927 | 0.949 | 0.940 | 0.953 | 0.947 | 0.946 |
| (0.4323) | (0.4795) | (0.4531) | (0.4886) | (0.4762) | (0.4717) | |
| 68 | 0.929 | 0.950 | 0.941 | 0.953 | 0.948 | 0.946 |
| (0.4417) | (0.4850) | (0.4605) | (0.4936) | (0.4816) | (0.4770) | |
| 69 | 0.928 | 0.950 | 0.940 | 0.953 | 0.948 | 0.946 |
| (0.4440) | (0.4817) | (0.4594) | (0.4895) | (0.4775) | (0.4728) | |
| 70 | 0.924 | 0.948 | 0.936 | 0.952 | 0.947 | 0.942 |
| (0.5208) | (0.5565) | (0.5361) | (0.5643) | (0.5508) | (0.5454) | |
| 71 | 0.923 | 0.948 | 0.935 | 0.952 | 0.946 | 0.941 |
| (0.5244) | (0.5530) | (0.5351) | (0.5601) | (0.5469) | (0.5416) | |
| 72 | 0.924 | 0.950 | 0.937 | 0.954 | 0.948 | 0.942 |
| (0.5225) | (0.5412) | (0.5269) | (0.5472) | (0.5341) | (0.5291) | |
| 73 | 0.933 | 0.949 | 0.944 | 0.952 | 0.948 | 0.947 |
| (0.3930) | (0.4303) | (0.4093) | (0.4376) | (0.4278) | (0.4238) | |
| 74 | 0.931 | 0.947 | 0.941 | 0.951 | 0.946 | 0.945 |
| (0.3987) | (0.4339) | (0.4142) | (0.4410) | (0.4313) | (0.4273) | |
| 75 | 0.931 | 0.948 | 0.940 | 0.951 | 0.946 | 0.944 |
| (0.4019) | (0.4308) | (0.4135) | (0.4371) | (0.4276) | (0.4235) | |
| 76 | 0.926 | 0.949 | 0.938 | 0.952 | 0.948 | 0.944 |
| (0.4795) | (0.5111) | (0.4941) | (0.5171) | (0.5068) | (0.5018) | |
| 77 | 0.928 | 0.951 | 0.940 | 0.954 | 0.949 | 0.945 |
| (0.4787) | (0.5068) | (0.4911) | (0.5123) | (0.5019) | (0.4970) | |
| 78 | 0.926 | 0.951 | 0.940 | 0.953 | 0.949 | 0.944 |
| (0.4778) | (0.4975) | (0.4849) | (0.5022) | (0.4919) | (0.4872) | |
| 79 | 0.936 | 0.951 | 0.946 | 0.953 | 0.950 | 0.947 |
| (0.3606) | (0.3864) | (0.3733) | (0.3912) | (0.3845) | (0.3811) | |
| 80 | 0.936 | 0.951 | 0.945 | 0.953 | 0.949 | 0.946 |
| (0.3678) | (0.3911) | (0.3792) | (0.3957) | (0.3888) | (0.3853) | |
| 81 | 0.932 | 0.949 | 0.943 | 0.951 | 0.947 | 0.944 |
| (0.3669) | (0.3864) | (0.3763) | (0.3905) | (0.3838) | (0.3804) | |
| 82 | 0.935 | 0.950 | 0.944 | 0.953 | 0.949 | 0.945 |
| (0.4253) | (0.4446) | (0.4351) | (0.4487) | (0.4412) | (0.4372) | |
| 83 | 0.933 | 0.949 | 0.941 | 0.951 | 0.947 | 0.943 |
| (0.4263) | (0.4428) | (0.4344) | (0.4465) | (0.4393) | (0.4354) | |
| 84 | 0.932 | 0.949 | 0.942 | 0.951 | 0.947 | 0.943 |
| (0.4204) | (0.4319) | (0.4254) | (0.4349) | (0.4277) | (0.4240) | |
| Lamphun | 56 | 49 | 49 | 57 | 46 | 30 | 27 | 33 | 33 | 47 |
| 49 | 114 | 129 | 132 | 138 | 130 | 106 | 80 | 69 | 46 | |
| 40 | 43 | 111 | 210 | 107 | 96 | 64 | 53 | 55 | 119 | |
| 137 | ||||||||||
| Mae Hong Son | 93 | 79 | 94 | 84 | 63 | 42 | 45 | 72 | 68 | 74 |
| 81 | 87 | 94 | 96 | 95 | 95 | 86 | 96 | 105 | 67 | |
| 94 | 110 | 174 | 233 | 163 | 133 | 209 | 171 | 170 | 239 | |
| 245 | ||||||||||
| Nan | 47 | 50 | 55 | 61 | 64 | 47 | 59 | 82 | 63 | 65 |
| 81 | 103 | 122 | 158 | 177 | 158 | 112 | 84 | 80 | 51 | |
| 47 | 66 | 100 | 146 | 114 | 52 | 54 | 33 | 46 | 111 | |
| 124 |
| Distributions | Lognormal | BS | Exponential | Gamma | Weibull |
|---|---|---|---|---|---|
| Lamphun | 315.4453 | 314.6908 | 335.0575 | 316.917 | 319.2145 |
| Mae Hong Son | 330.1128 | 329.9111 | 358.0465 | 332.3196 | 336.2999 |
| Nan | 309.3649 | 308.9072 | 338.9008 | 310.9628 | 314.1231 |
| Distributions | Lognormal | BS | Exponential | Gamma | Weibull |
|---|---|---|---|---|---|
| Lamphun | 318.3132 | 317.5587 | 336.4915 | 319.7850 | 322.0825 |
| Mae Hong Son | 332.9808 | 332.7791 | 359.4805 | 335.1876 | 339.1679 |
| Nan | 312.2328 | 311.7752 | 340.3348 | 313.8308 | 316.9911 |
| Group | n | Min. | Median | Mean | Max. | SD | CV |
|---|---|---|---|---|---|---|---|
| Lamphun | 31 | 27 | 57 | 79.1936 | 210 | 44.0503 | 0.5562 |
| Mae Hong Son | 31 | 42 | 94 | 114.7419 | 245 | 56.7955 | 0.4950 |
| Nan | 31 | 33 | 66 | 84.2581 | 177 | 38.8964 | 0.4616 |
| Comparison | PB | GCI | MOVER1 | MOVER2 | BayCrI | HPD |
|---|---|---|---|---|---|---|
| [−0.0574–0.2279] | [−0.1169–0.3045] | [−0.0938–0.2746] | [−0.1141-0.3058] | [−0.1023–0.2853] | [−0.1025–0.2853] | |
| [−0.0237–0.2361] | [−0.0812–0.3158] | [−0.0720–0.2904] | [−0.0826-0.3225] | [−0.0931–0.3266] | [−0.1001–0.3166] | |
| [−0.1188–0.1447] | [−0.1609–0.2028] | [−0.1458–0.1834] | [−0.1629–0.2115] | [−0.1662–0.2023] | [−0.1558–0.2086] |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Puggard, W.; Niwitpong, S.-A.; Niwitpong, S. Simultaneous Confidence Intervals for All Pairwise Differences between the Coefficients of Variation of Multiple Birnbaum–Saunders Distributions. Symmetry 2022, 14, 2666. https://doi.org/10.3390/sym14122666
Puggard W, Niwitpong S-A, Niwitpong S. Simultaneous Confidence Intervals for All Pairwise Differences between the Coefficients of Variation of Multiple Birnbaum–Saunders Distributions. Symmetry. 2022; 14(12):2666. https://doi.org/10.3390/sym14122666
Chicago/Turabian StylePuggard, Wisunee, Sa-Aat Niwitpong, and Suparat Niwitpong. 2022. "Simultaneous Confidence Intervals for All Pairwise Differences between the Coefficients of Variation of Multiple Birnbaum–Saunders Distributions" Symmetry 14, no. 12: 2666. https://doi.org/10.3390/sym14122666
APA StylePuggard, W., Niwitpong, S.-A., & Niwitpong, S. (2022). Simultaneous Confidence Intervals for All Pairwise Differences between the Coefficients of Variation of Multiple Birnbaum–Saunders Distributions. Symmetry, 14(12), 2666. https://doi.org/10.3390/sym14122666