


Optimized Implementation of Simpira on Microcontrollers for Secure Massive Learning

Abstract
1. Introduction
1.1. Contribution
1.1.1. Optimized Simpira on the 8-Bit AVR Architecture
1.1.2. Optimized Simpira on the 32-Bit RISC-V Architecture
1.1.3. First Optimized Implementation for Simpira on 8-Bit AVR Microcontrollers and 32-Bit RISC-V Processors
2. Related Works
2.1. AES Block Cipher
| Algorithm 1: AES Algorithm. |
| procedure AESroundkey() |
|
| end procedure |
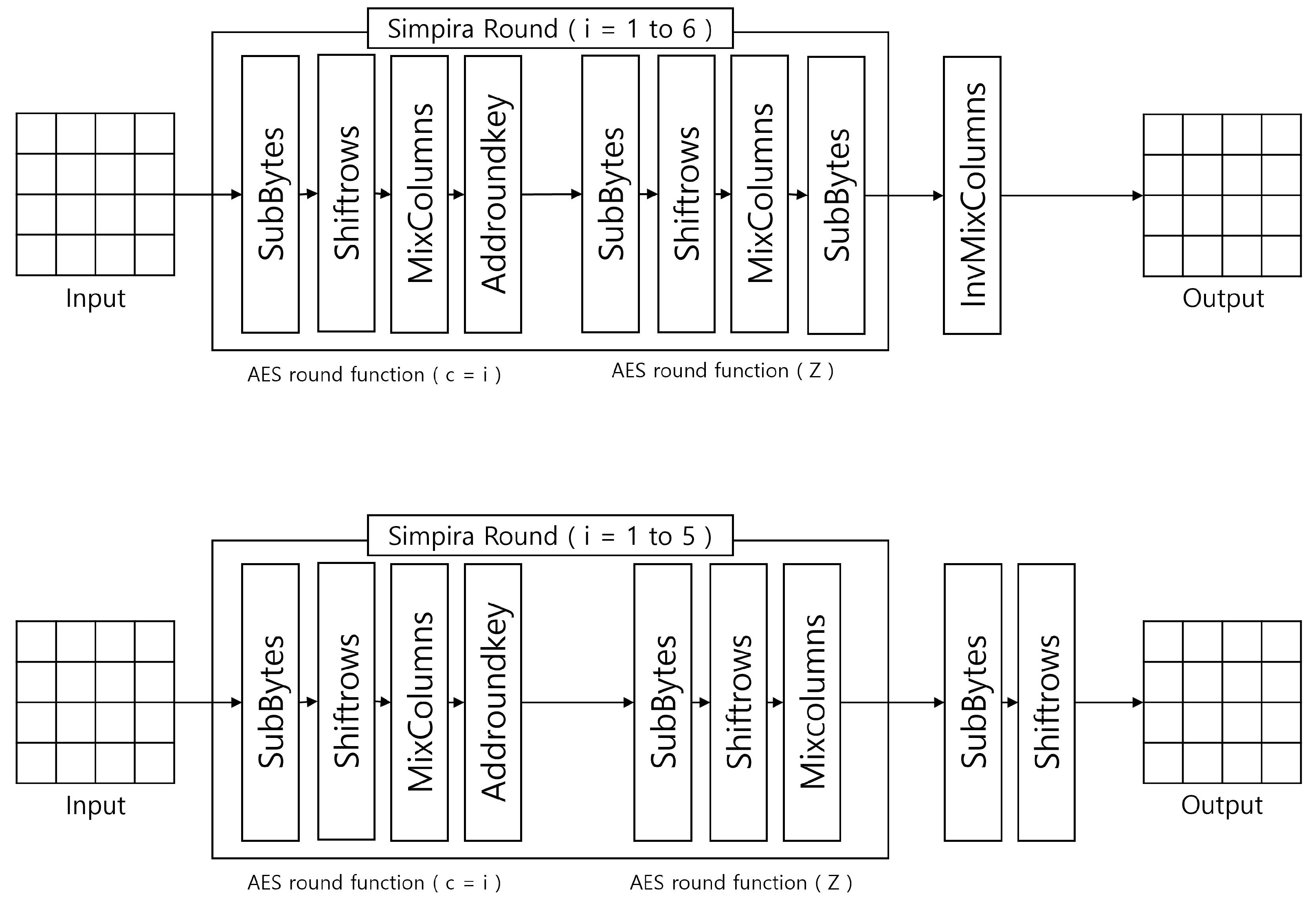
2.2. Simpira Permutation
| Algorithm 2: Simpira Algorithm. |
| procedure Simpira() |
|
| end procedure |
| Algorithm 3: F Algorithm (b = 1). |
| procedure F() |
|
| end procedure |
2.3. 8-Bit AVR Microcontroller
2.4. 32-Bit RISC-V Processor
2.5. Related Works
3. Proposed Method
3.1. Optimized Implementation of Simpira on 8-Bit AVR Microcontroller
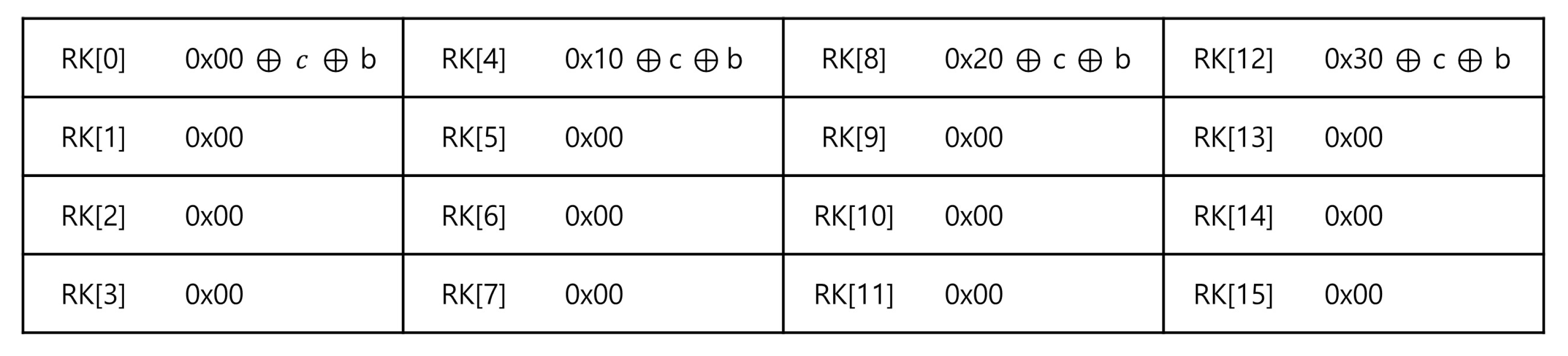
3.1.1. Constant Roundkey Pre-Computation
3.1.2. Omitting AddRoundkey Function
3.1.3. Optimizing InvMixColumn
3.1.4. Optimized Addroundkey Function
| Algorithm 4: Optimized Addroundkey in AVR microcontrollers (.macro round); , , , : input register, : temporary register, Y: indirect address register. | |
| Input: | |
| |
| Output: | |
| |
|
|
|
|
|
|
3.1.5. Using Optimized AES Implementation of AVR
3.2. Optimized Implementation of Simpira on 32-Bit RISC-V
3.2.1. Simpira Optimized Implementation of RISC-V
3.2.2. Using Optimized AES Implementation
| Algorithm 5: Implementation of AES round function when the roundkey is Z in RISC-V processors (.macro zround); : input state register, : output state register, : look up table address, C: constant value (0xff0) register, : temp registers. | ||
| ||
| Input: |
| |
| ||
| Output: |
| |
| ||
| ||
|
| |
| ||
|
| |
| ||
|
| |
| ||
| ||
|
| |
| ||
|
| |
| ||
| 59: srli X2, X2, 8 | |
| ||
|
| |
| ||
|
| |
| ||
|
| |
| ||
| ||
|
| |
| ||
|
| |
| ||
|
| |
| ||
|
| |
| ||
|
| |
| ||
|
| |
| ||
| ||
|
| |
| ||
|
| |
| ||
|
| |
| ||
|
| |
| ||
|
| |
|
| |
| ||
|
| |
| ||
| ||
4. Evaluation
4.1. 8-Bit AVR Microcontroller
4.2. 32-Bit RISC-V Processor
5. Conclusions
Author Contributions
Funding
Conflicts of Interest
References
- Xie, C.; Yu, B.; Zeng, Z.; Yang, Y.; Liu, Q. Multilayer internet-of-things middleware based on knowledge graph. IEEE Internet Things J. 2020, 8, 2635–2648. [Google Scholar] [CrossRef]
- Lu, J.; Chen, L.; Xia, J.; Zhu, F.; Tang, M.; Fan, C.; Ou, J. Analytical offloading design for mobile edge computing-based smart internet of vehicle. EURASIP J. Adv. Signal Process. 2022, 2022, 44. [Google Scholar] [CrossRef]
- Alsamhi, S.H.; Shvetsov, A.V.; Kumar, S.; Hassan, J.; Alhartomi, M.A.; Shvetsova, S.V.; Sahal, R.; Hawbani, A. Computing in the Sky: A Survey on Intelligent Ubiquitous Computing for UAV-Assisted 6G Networks and Industry 4.0/5.0. Drones 2022, 6, 177. [Google Scholar] [CrossRef]
- Zhao, M.; Li, J.; Tang, F.; Asif, S.; Zhu, Y. Learning based massive data offloading in the iov: Routing based on pre-rlga. IEEE Trans. Netw. Sci. Eng. 2022, 9, 2330–2340. [Google Scholar] [CrossRef]
- Daemen, J.; Rijmen, V. Reijndael: The Advanced Encryption Standard. Dr. Dobb’s J. Softw. Tools Prof. Program. 2001, 26, 137–139. [Google Scholar]
- Akdemir, K.; Dixon, M.G.; Feghali, W.; Fay, P.G.; Gopal, V.; Guilford, J.; Ozturk, E.; Wolrich, G.; Zohar, R. Breakthrough AES Performance with Intel® AES New Instructions. 2010. Available online: https://www.semanticscholar.org/paper/Breakthrough-AES-Performance-with-Intel-%C2%AE-AES-New-Akdemir-Dixon/62116fe84e7360202d4e1cff859c8fc014ef4614 (accessed on 26 September 2022).
- Gueron, S.; Mouha, N. Simpira v2: A family of efficient permutations using the AES round function. In International Conference on Cryptology and Information Security in Latin America; Springer: Berlin/Heidelberg, Germany, 2016; pp. 95–125. [Google Scholar]
- Ahmad, S.; Alam, K.M.R.; Rahman, H.; Tamura, S. A comparison between symmetric and asymmetric key encryption algorithm based decryption mixnets. In Proceedings of the 2015 International Conference on Networking Systems and Security (NSysS), Dhaka, Bangladesh, 5–7 January 2015; pp. 1–5. [Google Scholar]
- Yassein, M.B.; Aljawarneh, S.; Qawasmeh, E.; Mardini, W.; Khamayseh, Y. Comprehensive study of symmetric key and asymmetric key encryption algorithms. In Proceedings of the 2017 International Conference on Engineering and Technology (ICET), Antalya, Turkey, 21–23 August 2017; pp. 1–7. [Google Scholar]
- Rajesh, S.; Paul, V.; Menon, V.G.; Khosravi, M.R. A secure and efficient lightweight symmetric encryption scheme for transfer of text files between embedded IoT devices. Symmetry 2019, 11, 293. [Google Scholar] [CrossRef]
- Bernstein, D.J.; Hülsing, A.; Kölbl, S.; Niederhagen, R.; Rijneveld, J.; Schwabe, P. The SPHINCS+ signature framework. In Proceedings of the 2019 ACM SIGSAC Conference on Computer and Communications Security, London, UK, 11–15 November 2019; pp. 2129–2146. [Google Scholar]
- NIST PQC Project. Available online: https://csrc.nist.gov/Projects/post-quantum-cryptography (accessed on 29 July 2022).
- ATmega128 Datasheet. Available online: www.microchip.com/wwwproducts/en/ATmega128 (accessed on 16 August 2022).
- The RISC-V Instruction Set Manual Volume I: User-Level ISA Document Version 2.2. Available online: https://riscv.org/wp-content/uploads/2017/05/riscv-spec-v2.2.pdf (accessed on 16 August 2022).
- Waterman, A.; Lee, Y.; Patterson, D.A.; Asanović, K. The RISC-V Instruction Set Manual, Volume I: User-Level ISA; Version 2.1. 2016. Available online: https://www2.eecs.berkeley.edu/Pubs/TechRpts/2016/EECS-2016-118.pdf (accessed on 26 September 2022).
- Kim, K.; Choi, S.; Kwon, H.; Liu, Z.; Seo, H. FACE–LIGHT: Fast AES–CTR mode encryption for Low-End microcontrollers. In International Conference on Information Security and Cryptology; Springer: Berlin/Heidelberg, Germany, 2019; pp. 102–114. [Google Scholar]
- Park, J.H.; Lee, D.H. FACE: Fast AES CTR mode encryption techniques based on the reuse of repetitive data. IACR Trans. Cryptogr. Hardw. Embed. Syst. 2018, 2018, 469–499. [Google Scholar] [CrossRef]
- Kwon, H.; An, S.; Kim, Y.; Kim, H.; Choi, S.J.; Jang, K.; Park, J.; Kim, H.; Seo, S.C.; Seo, H. Designing a CHAM block cipher on low-end microcontrollers for internet of things. Electronics 2020, 9, 1548. [Google Scholar] [CrossRef]
- Roh, D.; Koo, B.; Jung, Y.; Jeong, I.W.; Lee, D.G.; Kwon, D.; Kim, W.H. Revised version of block cipher CHAM. In International Conference on Information Security and Cryptology; Springer: Berlin/Heidelberg, Germany, 2019; pp. 1–19. [Google Scholar]
- Kim, H.; Sim, M.; Eum, S.; Jang, K.; Song, G.; Kim, H.; Kwon, H.; Lee, W.K.; Seo, H. Masked Implementation of PIPO Block Cipher on 8-bit AVR Microcontrollers. In International Conference on Information Security Applications; Springer: Berlin/Heidelberg, Germany, 2021; pp. 171–182. [Google Scholar]
- Kim, H.; Jeon, Y.; Kim, G.; Kim, J.; Sim, B.Y.; Han, D.G.; Seo, H.; Kim, S.; Hong, S.; Sung, J.; et al. PIPO: A lightweight block cipher with efficient higher-order masking software implementations. In International Conference on Information Security and Cryptology; Springer: Berlin/Heidelberg, Germany, 2020; pp. 99–122. [Google Scholar]
- Eum, S.W.; Kwon, H.D.; Kim, H.J.; Yang, Y.J.; Seo, H.J. Implementation of LEA Lightwegiht Block Cipher GCM Operation Mode on 32-Bit RISC-V. J. Korea Inst. Inf. Secur. Cryptol. 2022, 32, 163–170. [Google Scholar]
- Hong, D.; Lee, J.K.; Kim, D.C.; Kwon, D.; Ryu, K.H.; Lee, D.G. LEA: A 128-bit block cipher for fast encryption on common processors. In International Workshop on Information Security Applications; Springer: Berlin/Heidelberg, Germany, 2013; pp. 3–27. [Google Scholar]
- Kwon, H.; Kim, H.; Eum, S.; Sim, M.; Kim, H.; Lee, W.K.; Hu, Z.; Seo, H. Optimized Implementation of SM4 on AVR Microcontrollers, RISC-V Processors, and ARM Processors. IEEE Access 2022, 10, 80225–80233. [Google Scholar] [CrossRef]
- Cheng, H.; Ding, Q. Overview of the block cipher. In Proceedings of the 2012 Second International Conference on Instrumentation, Measurement, Computer, Communication and Control, Washington, DC, USA, 8–10 December 2012; pp. 1628–1631. [Google Scholar]
- Efficient Implementations of AES-128 and Grøstl-256 for the AVR 8-Bit Microcontroller Architecture. Available online: https://github.com/Churro/avr-aes128-groestl256/blob/master/Paper.pdf (accessed on 16 August 2022).
- Stoffelen, K. Efficient Cryptography on the RISC-V Architecture. In International Conference on the Theory and Application of Cryptology and Information Security; Springer: Berlin/Heidelberg, Germany, 2019; pp. 323–340. [Google Scholar]




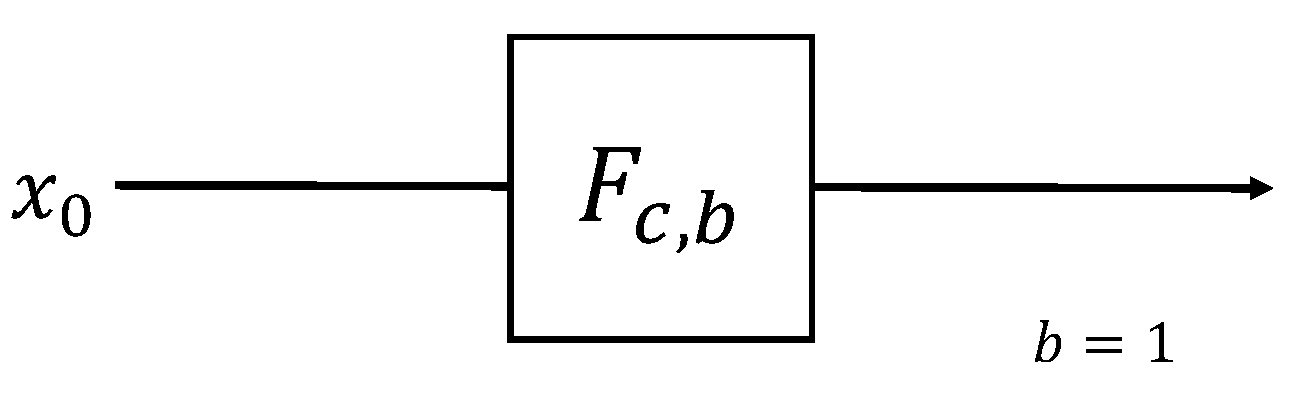{kind=link}
{kind=link}
{kind=link}
| Instruction | Operands | Description | Operation | #Clock |
|---|---|---|---|---|
| ADD | Rd, Rr | Add without Carry | Rd ← Rd + Rr | 1 |
| EOR | Rd, Rr | Exclusive OR | Rd ← Rd ⊕ Rr | 1 |
| MOV | Rd, Rr | Copy Register | Rd ← Rr | 1 |
| MOVW | Rd, Rr, Rr | Copy Register Pair | Rd+1:Rd ← Rr+1:Rr | 1 |
| LPM | Rd, Z | Load Program Memory | Rd ← Z | 3 |
| BRCC | k | Branch if Carry Cleared | if(C = 0) then PC ← PC + k + 1 | |
| LD | Rd, X(or Y, Z) | Load Indirect | Rd ← X(or Y, Z) | 2 |
| LDI | Rd, K | Load Immediate | Rd ← K | 1 |
| ST | X(or Y, Z), Rr | Store Indirect | X(or Y, Z) ← Rr | 2 |
| PUSH | Rr | Push Register on Stack | STACK ← Rr | 2 |
| POP | Rd | Pop Register from Stack | Rd ← STACK | 2 |
| Register | Description | Saver |
|---|---|---|
| zero(x0) | zero register | caller |
| ra(x1) | return address register | caller |
| sp(x2) | stack pointer register | callee |
| gp(x3) | global pointer register | caller |
| tp(x4) | thread pointer register | caller |
| a0∼a7 | function arguments and return value registers | caller |
| s0∼s11 | saved registers | callee |
| t0∼t6 | temporal registers | caller |
| Instruction | Operands | Description | Operation |
|---|---|---|---|
| ADD | Rd, Rs1, Rs2 | Add | Rd ← Rs1 + Rs2 |
| XOR | Rd, Rs1, Rs2 | Exclusive OR | Rd ← Rs1 ⊕ Rs2 |
| MV | Rd, Rs1 | Copy Register | Rd ← Rs1 |
| SLLI | Rd, Rs1, K | Shift left logical immediate | Rd ← Rs1 << K |
| SRLI | Rd, Rs1, K | Shift right logical immediate | Rd ← Rs1 >> K |
| BNE | Rs1, Rs2, J | Branch not equal | if(Rs1!=Rs2) Jump to J |
| JAL | J | Jump and link | Jump to J |
| LW | Rd, K(J) | Load word | Rd ← J + K |
| SW | Rs1, K(J) | Store word | Rs1 → J + K |
| ANDI | Rd, Rs1, K | AND immediate | Rd ← Rs1 & K |
| This Work | This Work * |
|---|---|
| 48 | 12 |
| Implementation | Processor | Code Size |
|---|---|---|
| Our work | low-end AVR | 2122 |
| low-end RISC-V | 1806 | |
| Our work * | low-end AVR | 1978 |
| low-end RISC-V | 1781 |
| Implementation | Processor | Clock Cycles |
|---|---|---|
| Reference-C | low-end AVR | 14,334 |
| low-end RISC-V | 38,942 | |
| Our work | low-end AVR | 2862 |
| low-end RISC-V | 1106 | |
| Our work * | low-end AVR | 2485 |
| low-end RISC-V | 1052 | |
| [7] | Skylake (high-end Intel Processor) | 50 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Sim, M.; Eum, S.; Kwon, H.; Jang, K.; Kim, H.; Kim, H.; Song, G.; Lee, W.; Seo, H. Optimized Implementation of Simpira on Microcontrollers for Secure Massive Learning. Symmetry 2022, 14, 2377. https://doi.org/10.3390/sym14112377
Sim M, Eum S, Kwon H, Jang K, Kim H, Kim H, Song G, Lee W, Seo H. Optimized Implementation of Simpira on Microcontrollers for Secure Massive Learning. Symmetry. 2022; 14(11):2377. https://doi.org/10.3390/sym14112377
Chicago/Turabian StyleSim, Minjoo, Siwoo Eum, Hyeokdong Kwon, Kyungbae Jang, Hyunjun Kim, Hyunji Kim, Gyeongju Song, Waikong Lee, and Hwajeong Seo. 2022. "Optimized Implementation of Simpira on Microcontrollers for Secure Massive Learning" Symmetry 14, no. 11: 2377. https://doi.org/10.3390/sym14112377
APA StyleSim, M., Eum, S., Kwon, H., Jang, K., Kim, H., Kim, H., Song, G., Lee, W., & Seo, H. (2022). Optimized Implementation of Simpira on Microcontrollers for Secure Massive Learning. Symmetry, 14(11), 2377. https://doi.org/10.3390/sym14112377