1. Introduction
Comprehensive information and appropriate statistical data are essential for planning, decision-making, and policymaking. Knowing the population requires having enough statistical information. Such information is generally obtained through surveys or censuses, typically designed for scientific purposes or population parameters (big areas). Nevertheless, for some reason, the available sample might not be enough to obtain a valid estimation in a small area or subdomain. These reasons include the lack of sufficient information in the target areas, the absence of pre-arranged planning while obtaining information, the lack of funding resources, statistical capacities, long periods between recording information, and some privacy laws. In such cases, the need for small area estimation is felt. The small area is a subdomain such as provinces, counties, and sub-populations such as specific age–sex race groups and health regions for which the sample size is not enough to obtain a valid estimation.
Statistically, the small amount of data in the small area (sometimes the sample size is zero) increases the prediction error. In such cases, the direct estimators are not accurate enough. To obtain a reliable estimation in the small area, the auxiliary information of the corresponding regions or the information of the same small area in previous study periods or extra information in the recorded statistics, administrative surveys, or a combination of these methods are used. The effect of areas on each other, which can be emerged by spatial correlation, can also be considered a valuable measure to increase estimation capabilities. In practice, the small area boundaries are contractual, and there is no reason why the effects in adjacent areas are not correlated. Therefore, it seems meaningful to test the assumption of spatial correlation of the closed regions.
In modeling the small area, valuable efforts have been made. Some of them are summarized as follows. Morales et al. [
1] used the linear mixed model (LMM) to obtain the poverty ratio and the mean square prediction error (MSPE) of the small area estimator. Boubeta [
2] used the Poisson regression model to estimate the small area parameter. Malee and Muller [
3] present a semiparametric model to describe the geographic variability component. Chandra et al. [
4] used a nonparametric generalized linear mixed model (GLMM) for non-Gaussian response variables when the data are spatially non-stationary in the small area and obtained MSE estimation for the nonlinear spline spatial model. Zhu et al. [
5] considered the small area effect as an unknown function, estimated the small area using the semiparametric model, and represented the small area effect by the penalized spline. Torabi and Jiang [
6] obtained an estimation of small area parameters using a spatial LMM. They used the conditional autoregressive (CAR) model to consider the spatial random effect. Torabi [
7] studied the area-level spatial models in the small area. He used the proper CAR model to consider the spatial random effect of the areas and obtained the small area parameters using the spatial generalized linear model.
In this paper, our primary focus is on modeling insurance data. The insurance industry is one of the sectors for which the data analysis is placed in the category of the small area because data collecting is frequently encountered with many limitations. Life insurance has a special place among the various branches of the insurance industry due to its range of services. We intend to analyze life insurance data obtained from the database of Iran insurance companies in IRAN. These data were measured province-specifically from April to June 2018 for 32 provinces of Iran. The data include 466,759 observations. The response variable of interest for modeling is the provinces’ provincial per capita number of life insurance contracts. The explanatory variables in our analysis include the work experience of the insurance sales branch.
There are a few points to note in this data. (
i) The small area estimation is generally divided into two categories: unit-level and area-level. For this data, the area level is considered due to the availability of the collected data. (
ii) Due to the structure of the response variable in the study, which does not follow the normal distribution, using a kind of generalized linear models (GLMs) is unavoidable. (
iii) Since the acceptance of life insurance in the basket of goods is related to income status and economic culture, and the borders between regions and provinces are contractual, there is no reason for the effects not to be interrelated in economic culture and income condition. Therefore, it seems logical to consider the correlation of regions in this study under the spatial dependence concept. (
iv) As shown in
Figure 1, the scatter plot of response versus explanatory variable depicts drastic fluctuations, which means that a linear trend cannot explain the relationship well. Moreover, since the relationship between response and covariate is unknown, it does not make sense to consider the parametric model. Thus, regression modeling must consider a nonlinear relationship between the response and the explanatory variable under the non-parametric component.
The points (
i)–(
iii) provide conditions to follow the work in [
7]. However, the last point leads us to add a nonparametric part as a symmetric/asymmetric function to the model in [
7]. Therefore, our main contribution is to propose a semiparametric spatial generalized linear mixed model in a small area, thereby increasing flexibility in the prediction. We derive the empirical best prediction (EBP) for the small area predictor and the mean squared prediction error (MSPE) for the EBP. We also consider the small area’s spatial random effects (SRE).
This paper is organized as follows: In
Section 2, we present EBP to the small area predictor and obtain the MSPE of the EB estimator. In
Section 3, the proposed methodology is applied to the real data on the provincial per capita number of life insurance contracts. After that, in
Section 4, we present two simulation experiments and evaluate the performance of the proposed method.
Section 5 offers some results and provides concluding remarks.
2. Semiparametric Mixed-Effects Model
Semiparametric mixed-effects modeling, combining a nonlinear function with the linear predictor, has a long history and dates back to Zeger and Diggle [
8]. They used a semiparametric random intercept model to analyze the CD4 cell numbers in HIV seroconverts and estimated the nonparametric component by the backfitting method. Discussions about semiparametric models can be founded in Roozbeh [
9,
10], Akdeniz and Roozbeh [
11], Taavoni and Arashi [
12], and Taavoni et al. [
13].
Suppose that the number of small areas and the number of explanatory variables are denoted by
m and
p, respectively. Under an area-level small area model, and in the framework of GLMs, it is assumed that the response variables are conditionally independent given the latent variable
, and follow the exponential families with the probability density:
where
is the interested response variable in the
ith small area,
is the
ith latent variable, and
is the scale parameter. Furthermore,
and
are known functions. Implementing statistical inferences on the latent variable
is the objective of the small-area estimation. The model of the latent variable is defined as follows:
where
is a function of
,
is the
ith row of the design matrix
,
is the vector of unknown regression coefficients, and
is the
ith row of the identity matrix
. The
is the vector of spatial random effect accompanied by distribution
and
. In this model, we assume that the relation of the
with the response variable is nonlinear. Thus, it is considered a nonparametric component. The function
is generally unknown, but it is assumed that it is a smooth nonlinear function and has the second derivative. The estimation of nonparametric function
f is presented as below:
which is called a
d-order spline estimator function with knots
. In this function,
are spline regression coefficients (refer to [
14] for more details). Further,
denotes the truncated polynomial basis function of order d defined as:
The approximation function in (
3) can be summarized by
, which
;
is a vector of spline regression coefficients and
. Thus, Equation (
2) can be rewritten as:
By combining the fixed and spline effects in (
4), the following equation is resulted:
wherein
is the mixed design
matrix of the fixed effects and spline effects, and
is the
vector of the regression coefficients corresponding to fixed and spline effects.
In order to predict the latent variable
, the conditional density is calculated using the equation below:
where
and
is the vector of parameter of random effects. The Laplace approximation centered around the point
is used to approximate the conditional density of
[
15]:
Proposition 1. Under the conditions that the first and second derivatives of in Equation (7) are available in the closed-form, the conditional density of becomes a normal approximation with conditional mean and conditional variance , given by:where , is a diagonal matrix with entries , , and for and . For the proof, refer to Appendix A. If
is known, the best predictor of the
is the conditional expectation (
) and the second-order unbiased mean squared prediction errors is
, which was defined in Equation (8a,b). However, when
is the vector of unknown parameters, we obtained the best empirical prediction of
by replacing
by
. Frequentist and Bayesian methods are generally used to process spatial generalized linear mixed models (SGLMMs). Due to the computational complexity in calculating maximum likelihood estimation (MLE), frequency methods require numerical solutions of high-dimensional and intractable integrals. In this paper, the MLE method is impossible due to the need to solve high-dimensional integrals. In addition, using Bayesian methods always faces the problem of selecting the appropriate prior. According to the problems mentioned in the two Frequency and Bayesian methods, the data cloning (DC) approach (see [
16]) has been used to estimate the unknown parameters. DC is a computational method for calculating MLE, using MCMC (Markov chain Monte Carlo) algorithm and Bayesian methods. This method does not require numerical maximization and derivation of a complex function, which is robust to the prior choice. To see more Bayesian studies, refer to [
17,
18,
19].
To understand the logic of the DC method, consider that the observations of
and the explanatory variables are independently repeated exactly
k times. The vector of random effects, by using their probabilistic explanations, generated k times, so that
represents the data at k times of repetition. The maximum likelihood function
is
where the likelihood function
is the likelihood of original data. Since the DC method is based on the asymptotic behavior of posterior density, the theoretical conditions of asymptotic posterior density can be established by increasing the sample size. In this approach, the posterior distribution of the clone answer is shown as:
where
and
are the normalized constant and prior distribution, respectively. Lele et al. [
16] show that under some regular conditions, the posterior distribution of
converges to a multivariate normal distribution with mean
and identity covariance matrix
. Thus, the estimation of
is the mean of posterior density under the squared error loss function. The mean squared empirical prediction error is approximately calculated as below:
In the above relation,
is the “little-o” notation for the asymptotic behaviour so that
means
. Further,
denotes the mathematical expectation with respect to
. Then,
where,
where
denotes the trace of matrix
A. It can be seen that
of
is a function of unknown parameters
. By replacing
by
, Torabi [
7] noticed that in this estimation, the rough value for
is approximately equal to
, where
It is noticeable that sometimes the calculated value of
can be negative. In this case, Prasad and Rao [
20] replaced negative values with positive values.
3. Life Insurance Data Analysis
Here, we model the above-mentioned number of life insurance contract data using the proposed semiparametric spatial generalized linear mixed-effects model. We consider the following spatial Poisson regression model:
where
is the reported mean number of life insurance contracts of the
ith province in Iran,
is defined as an intercept,
is the
ith row of the identity matrix, and
is taken from an ICAR(intrinsic conditional autoregressive) model [
21]. Further,
is the mean of work experience of the insurance sales branch of the
ith province. It seems that the
and the response variable have a nonlinear relationship, and it is not meaningful to insert it as a parametric component. Therefore, we consider it as a nonparametric function
into the model where
f is a smooth and unknown function of duration. We use the spline approximation method to approximate the nonparametric component.
Here, the function
is a cubic spline with evenly spaced knots in the range of
, at the points of
,
, and
. This can be summarized by
, in which
;
are spline regression coefficients and
Hence, the semiparametric spatial mixed model is derived as:
By combining the fixed and spline effects, the above model can be rewritten as:
where the
design matrix
is the mixed of the fixed effect and Spline effects matrices, and
is an eight-dimensional vector of parameters of the regression coefficients and spline coefficients.
The estimation of the model parameters, which were found by data cloning, are presented in
Table 1. Here, the estimate of regression coefficient, spline coefficients
, and spatial parameter
along with the respective standard errors are given.
To evaluate the flexibility and the effect of the duration contract in a nonlinear manner, which leads to an increase in the flexibility of the model, we compare the above-suggested model with the following alternative model:
Figure 2 depicts the boxplot of
of the
for the number of life insurance contracts in IRAN. As can be seen, the MSPE of EBP in the proposed model is smaller than the spatial generalized linear mixed model, thus, the suggested model transparently provides a smoother prediction attaining better results.
4. Simulation Study
This section uses the semiparametric mixed-effect model to evaluate the proposed method. Since this article expands Torabi’s proposed model [
7], we have utilized the same Minnesota country map to compare our proposed model accuracy with the parametric model. The simulated data are obtained from the following model:
where
is generated from the ICAR model. The other components of this pattern have the following specifications:
is the offset and
is the intercept.
is the nonlinear function and
is the fixed duration of the study generated from the uniform distribution on
. First, we generate
from the ICAR distribution with parameters
for
. We do this job independently for
steps and denote
,
as the
rth spatial random variable generated by
. Inserting
in the formula
and getting
for each step,
is generated from the Poisson distribution with mean
for
and
.
For each simulation run, based on (
2), we find:
By using the data cloning approach,
is given by:
where
is a vector of regression and spline coefficients,
is the
ith row of the identity matrix,
is the ICAR covariance matrix and
is the
ith row of the
matrix
. The
is obtained for each of the 1000 steps.
and
are calculated as follows:
also the empirical MSPE (EMSPE) of
is calculated by using the following formula:
To evaluate the performance of the proposed model, we compare it with the model
. The estimation of model parameters by the DC method is reported in
Table 2 and
Table 3 for the proposed and parametric models.
Table 2 contain the estimates of regression coefficients, spline regression coefficients, and spatial parameter
for the semiparametric spatial Poisson model. Moreover, the results of the parametric model are shown in
Table 3.
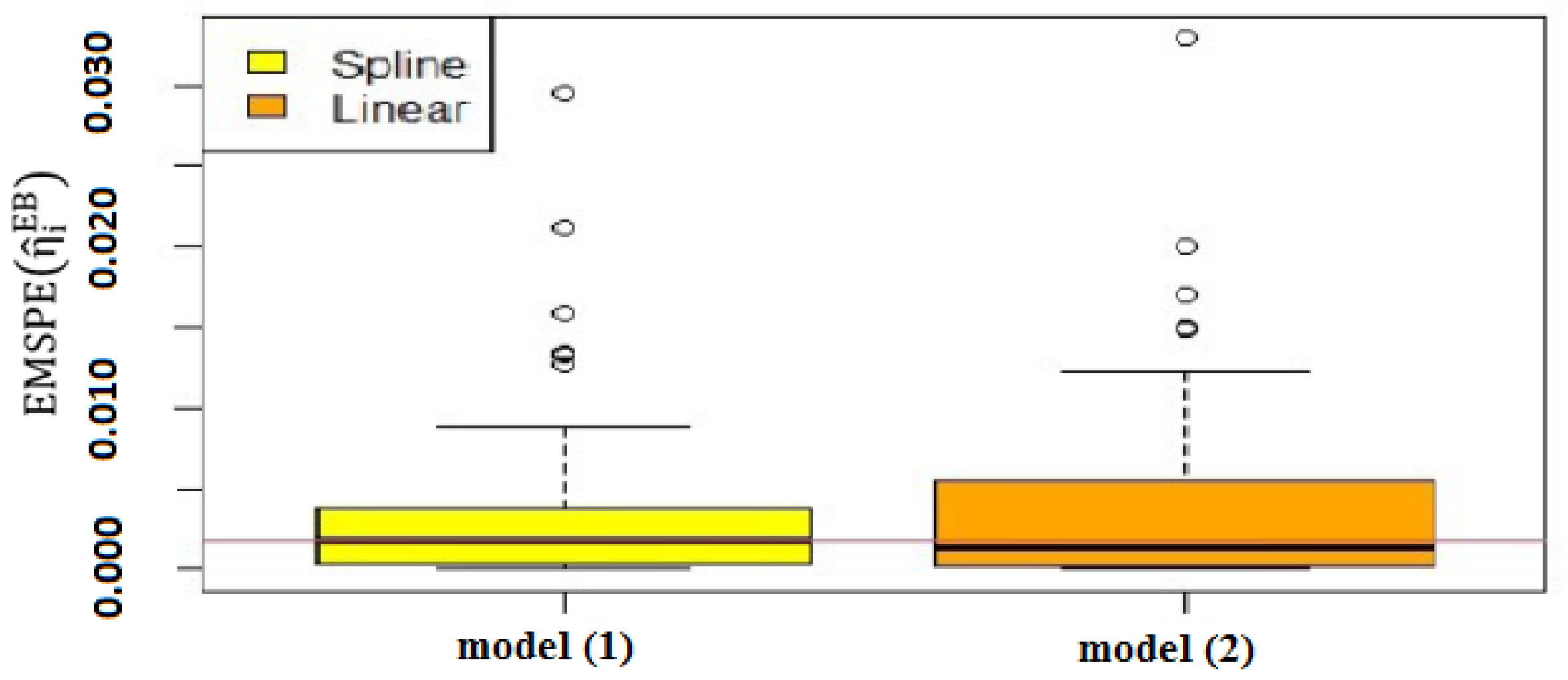
To evaluate the performance of the semiparametric spatial Poisson model, the box plots of EMSPE of
values are depicted in
Figure 3, which shows the distribution of the mean square prediction error. As can be seen, the EMSPE of
in the proposed model is smaller than the parametric counterpart. The third quantile and maximum point of EMSPE of
in the proposed model are less than the parametric model. The maximum outlier points of EMSPE of
in the proposed model is less than the parametric model, which shows that the proposed model has better performance even in the outlier. Furthermore, the MSPE and ISQR values for these two models are listed in
Table 4. This table shows the superiority of our proposed model. As a result, the semiparametric model improves the model in terms of prediction.
In
Figure 3, the box plot of MSPE of
is shown in total areas. In a small area, MSPE of
is important not only in all areas but also in each area. In some cases, in the small area approach, some regions are more important, and those regions should be investigated more carefully. Hence, in order to compare the performance of the proposed model against the parametric model, the heat map of EMSPE of
is drawn separately by the province in Minnesota in
Figure 4.
As shown in
Figure 4, in some provinces, the MSPE of
in the proposed model are less than the MSPE of
in the parametric model and they are equal in some provinces. There is no area in which the MSPE of
in the proposed model is more than the parametric model.
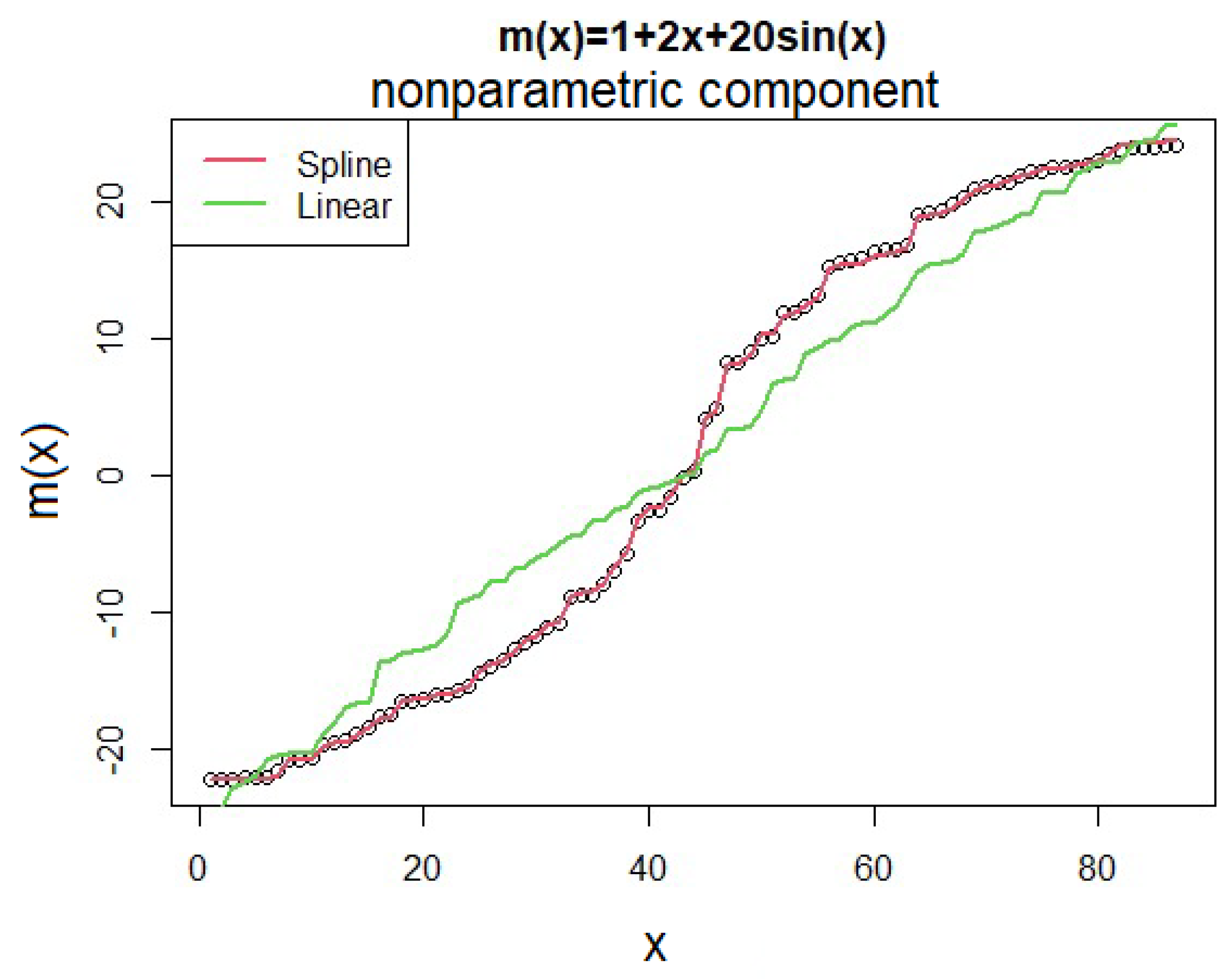
In addition to comparing the MSPE of
, plotting the predicted values of two models versus simulated data can provide a better understanding of the performance of two models. As shown in
Figure 5, the semiparametric model is more efficient than the parametric model in estimating the nonparametric component.


 and
and 





{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}