Abstract
The tail risk management is of great significance in the investment process. As an extension of the asymmetric tail risk measure—Conditional Value at Risk (CVaR), higher moment coherent risk (HMCR) is compatible with the higher moment information (skewness and kurtosis) of probability distribution of the asset returns as well as capturing distributional asymmetry. In order to overcome the difficulties arising from the asymmetry and ambiguity of the underlying distribution, we propose the Wasserstein distributionally robust mean-HMCR portfolio optimization model based on the kernel smoothing method and optimal transport, where the ambiguity set is defined as a Wasserstein “ball” around the empirical distribution in the weighted kernel density estimation (KDE) distribution function family. Leveraging Fenchel’s duality theory, we obtain the computationally tractable DCP (difference-of-convex programming) reformulations and show that the ambiguity version preserves the asymmetry of the HMCR measure. Primary empirical test results for portfolio selection demonstrate the efficiency of the proposed model.
Keywords:
distributionally robust optimization; Wasserstein distance; kernel smoothing; higher moment coherent risk MSC:
90B50; 90C15; 90C25; 90C90
1. Introduction
Portfolio selection is a typical optimization problem under parameter uncertainty when facing uncertain asset returns. Unlike a deterministic optimization problem, the objective function in a decision model facing uncertainty is subjective and contingent on the preference of the investor. Indeed, investment preference concerning uncertainty can be associated with risk and ambiguity (see [1]). Following the seminal work by [2], the difference between the concepts of risk and ambiguity (Knightian uncertainty) in decision theory is that the former exposure to uncertain outcomes whose probability distribution is known, and the latter exposure to uncertainty about the probability distribution of the outcomes. Following the seminal work by [3], the portfolio selection is a bi-criteria optimization problem trading-off between returns and risk, that is, maximizing the expected portfolio return while, at the same time, minimizing some risk measure of portfolio loss. The assumption of distributional symmetry, however, is limiting in portfolio optimization, in which distributions are often known to be asymmetric. Thus, the downside risk measure that reflects asymmetric risk preferences is more suitable than variance that considers both upside and downside risk symmetrically in [3]. In this paper we focus on the following asymmetric tail risk measure—higher-moment coherent risk (HMCR) measures proposed by [4] (see [5] for more details of risk measure).
Definition 1
(HMCR). For any given confidence level and order , the HMCR measures of random loss X
where and .
In particular, the popular Conditional Value-at-Risk (CVaR) corresponds to (see [6]), and is called the second-moment coherent risk (SMCR) measure. The following properties of the family of HMCR measures motivates us to choose it as the risk measure for portfolio selection: (i) In the sense of the coherent risk measure proposed by [7], HMCR measures are coherent and capture the distributional asymmetry. Furthermore, HMCR measures are compatible with second-order stochastic dominance (see [4]); (ii) As distinguished from the other known risk measures involving the information of the higher moments, for example, lower partial moment (see [8]) and the coherent measure of semi- type (see [9]), the location of “tail cutoff” in the HMCR measures is determined by the optimal solution of the stochastic programming problem (1), meanwhile, is adjustable by the confidence level . (iii) The risk-aversion stochastic programming problem with HMCR measures can readily be handled by the well-developed methods of conic programming as the p-order cone within the positive orthant can be approximated by linear inequalities (see [4]).
Let the random asset returns be defined on a probability space (), where is a compact sample space for , is a -algebra of , and is a probability measure on . Let the portfolio decision be , where represents a convex set of feasible decisions. For the given confidence level and the investor’s risk-aversion coefficient , we consider the mean-HMCR portfolio optimization model of the following form:
where and denotes the vector of ones and P is the probability distribution of . However, in real world the true probability distribution of is often unavailable, and is difficult to forecast precisely (see [10]), which results in poor out-of-sample performance when resorting to the sample average approximation (SAA) approach (see for example [11]). Thus, it makes sense to seek a robust portfolio immune to the uncertainty of distribution of the asset returns. Many powerful modeling paradigms have been proposed for optimization when facing uncertainty in the past decades (see for example [12,13,14]). The paradigm of distributionally robust optimization (DRO) considers an ambiguity set (a family of probability distributions with limited and known distributional information) and evaluates the performance of a decision-maker by its worst-case expected performance under any distribution residing in the ambiguity set, which may be traced to [15].
The key issue of DRO is how to construct an ambiguity set such that the bi-layer uncertain DRO model can be reformulated as a computationally tractable single-layer deterministic convex optimization problem. The popular methods of constructing an ambiguity set basically focus on the moment-based ambiguity set, which is constructed by certain moment information (see, for example, [16,17,18,19,20,21,22]), and the metric-based one, which is defined as a “ball” in the sense of a certain probability metric such as the Prohorov metric (see [23]), the goodness-of-fit (see [24]), likelihood function (see [25]), -divergence (see, for example, [26,27,28,29,30]), Kullback–Leibler (KL) divergence (see, for example, [31,32]) and so forth. In particular, due to the outstanding properties of Wasserstein distance, defined as follows, Wasserstein distance is attracting a growing interest in DRO recently (see, for example, [33,34,35,36,37]).
Definition 2
(Wasserstein distance). For any , r-Wasserstein distance between two probability distributions Q and on is defined as:
where is a norm on , while denotes the set of all joint probability distributions of and with marginals Q and , respectively.
For example, ref. [33] study distributionally robust optimization problems with the Wasserstein ambiguity set centering at the empirical distribution and the objective of the inner maximization is an expectation of certain loss function, under certain mild assumptions, derive a finite convex programming problem. In this paper, we focus on the distributionally robust version of (2), that is, the following risk-aversion distributionally robust portfolio optimization model with the form:
where the ambiguity set is defined as a ball in the space of probability distribution by using Wasserstein distance, which is centered at the discrete empirical probability distribution. It is worth noting that, in contrast to the expected (risk-neutral) performance of certain loss function in the objective of the general DRO model (see, for example, [33,34,35,36,37]), the objective of (4) involve the risk-aversion performance—mean-HMCR, which is a nonlinear functional with respect to the probability distribution P. The nonliearity of the objective of the inner infinite-dimensional maximization optimization problem gives rise to a challenge, that is, it is difficult to solve the resulting semi-infinite optimization problem obtained by duality theory. Hence, to the best of our knowledge, it is difficult to derive the tractable reformulation of (4). From a statistical point of views, the mixture model in construction of ambiguity set can be treated as a parametric estimation model as the component distributions usually are predetermined (see [38,39]). However, in practice, the component distributions are unknown and can be obtained by historical simulation or expert predication, which motivates us to construct the Wasserstein ambiguity set by a nonparametric method in a data-driven setting in order to derive the computationally tractable reforumulation of (4).
The key contributions of our paper may be summarized as follows:
- To overcome the difficulties arise from the asymmetry and ambiguity of the underlying distribution, we propose a Wasserstein distributionally robust portfolio model based on kernel smoothing method and mean-HMCR, where the ambiguity set is a Wasserstein “ball” in the finite-dimensional probability distribution space spanned by the weighted KDE;
- Leveraging Optimal Transport theory, we define KDE–Wasserstein distance by incorporating KDE into Wasserstein distance and prove it enjoys a metric property;
- Leveraging Fenchel’s duality theory to obtain a finite-dimensional dual problem of the inner maximization problem, we overcome the difficulty arise from the nonliear functional with respect to probability distribution associated with HMCR, and derive the computationally tractability result of the Wasserstein distributionally robust portfolio model based on KDE and mean-HMCR.
- We extend -divergence ambiguity set in [40] to Wasserstein ambiguity set by integrating the weight KDE with Optimal Transport theory (see [41]), and we discover that the tractable reformulations of our model involve some difference-of-convex programming (DCP) constraints different from those of [40], which deeply reflects the insights arise from incorporating KDE into Wasserstein distance by optimal transport.
The remainder of this paper is organized as follows. Section 2 formally introduces the Wasserstein distributionally robust portfolio optimization based on KDE and mean-HMCR model, and obtains the computationally tractable reformulation of the corresponding DRO model by Fenchel’s duality theory. Section 3 presents numerical experiment of some empirical studies and sensitivity analysis on model parameters and Section 4 concludes.
2. Wasserstein Distributionally Robust Portfolio Optimization Based on KDE and Mean-HMCR
In this section, we propose a Wasserstein distributionally robust portfolio optimization model based on KDE and mean-HMCR, starting from giving an overview of traditional KDE and its variant—the weighted KDE, introducing the definition of KDE-Wasserstein distance by Optimal Transport theory (see [41]), and proposing new KDE-Wasserstein ambiguity set. Then the tractable reformulation of the corresponding DRO model is derived by Fenchel’s duality theory.
The kernel smoothing method has been a popular tool for the nonparametric estimation of the probability density function (PDF) when the samples , which is typically assumed to be drawn independent and identically distributed (i.i.d.) from , are available. A kernel density estimator for a univariate PDF is:
where the kernel function plays the role of determining the shape of the “bumps” centred at each data point. The smoothing bandwidth controls the smoothness of the “bumps” and depends on the sample size T. Three popular assumptions on the kernel function and the bandwidth are listed as follows (see [42] for more details of KDE).
Assumption 1.
is bounded, .
Assumption 2.
and .
Assumption 3.
and as .
Although the Epanechnikov kernel is the optimal kernel function in the sense of the asymptotic mean integrated square error (MISE) with respect to , it has been known that MISE is quite insensitive to the shape of the kernel function (for example, Rectangular, Biweight, Triangular and Gaussian kernel functions). Thus, in practice, one generally chooses the Gaussian kernel for density estimation due to its smoothness. However, the selection of bandwidth h is of crucial importance for the high-performance density estimator. When the Gaussian kernel is available and the estimated is a Gaussian density with variance , then would be the optimal bandwidth in MISE sense. See [42,43] for comprehensive reviews of the KDE.
Traditional KDE (5) is subject to bias that can mask structure by flattening peaks and filling in troughs in the density (see [44]), which contributes to the modifications to (5) that enjoy reduced bias while at the same time retaining the simple structure of (5). See, for example, the employment of high order kernels [45], variable bandwidth methodologies [46] and data sharpening [47]. An alternative reduced bias method can be obtained by replacing the local weights in (5) with the global weights, and , that is, the variant of KDE—the weighted KDE with the form:
The rationality of the weighted KDE (6) is that the relative importance of different values of can be reflected by the “global” weights . Moreover, in some statistical applications, the weighted KDE (6) is readily integrated with additional information about by the estimation equation (see [48,49,50] for more details of the weighted KDE). From a DRO point of view, it is important to incorporate the extra distributional information into the ambiguity set constructed by (6) such that the corresponding DRO model is less conservative. Hence the more flexible (6) motivates us to propose a new KDE-Wasserstein ambiguity set (9) by the Optimal Transport (see [41]). We define the following KDE-Wasserstein distance by integrating Wasserstein distance in (3) with the weighted KDE in (6).
Definition 3
(KDE-Wasserstein distance). For the given sample set , the KDE-Wasserstein distance between univariate distribution and in (6) is defined as follows.
where the transport cost is taken to be the square of 2-Wasserstein distance in (3) between the i-th component and the j-th component , that is, and . In particular, for Gaussian kernel function , the transport cost in (7) admits a closed expression:
Let be the finite dimensional probability distribution function space spanned by (6).
Proposition 1.
Under Assumptions 1–3, in (7) is a metric on .
Proof.
It is easy to verify that for all and if and only if . We prove the triangular inequality for all . Let () be the solution of problem (7) with marginals () and define by For given , we have
Similarly, for given , we have Thus, is a joint probability distribution between and . Therefore,
where the second inequality holds due to the fact is a metric, and the third inequality holds from the Minkowski inequality. □
By KDE–Wasserstein distance (7), the KDE-Wasserstein ambiguity set of the univariate random variable X associated with the samples is obtained.
Definition 4
(KDE-Wasserstein ambiguity set). For the given sample set , the KDE-Wasserstein ambiguity set of X is defined as follows.
where and . The radius of the ambiguity set controls the degree of the distributional uncertainty.
Due to the two facts: (i) from a statistical point of view, the multivariate KDE for the continuous PDF of the asset returns gives rise to “curse of dimensionality” (see, for example, [42]); (ii) from an optimization point of view, the closed formulation associated with HMCR measure in the objective function of problem (2) can not be obtained by using the multivariate weighted KDE since the multiple integration of positive function with respect to the multivariate weighted KDE is hard to be calculated, we estimate the univariate PDF of the random portfolio loss by using the univariate weighted KDE (6) rather than estimating multivariate PDF of the random asset returns by using the multivariate weighted KDE. For the given sample set of random asset returns , which is typically assumed to be drawn i.i.d. from the probability function P of , the corresponding sample set of the portfolio loss is obtained. For any fixed portfolio decision , the KDE-Wasserstein ambiguity set of the portfolio loss can be derived
where and . When Gaussian kernel function is available, the transport cost in (10) admits a closed expression by (8):
By replacing the Wasserstein ambiguity set in (4) with the KDE-Wasserstein ambiguity set in (10), we propose the Wasserstein distributionally robust portfolio optimization model based on KDE and mean-HMCR.
where the confidence level , risk coefficient , kernel function , bandwidth , the weights and are given. It follows from (10) that the objective function of (12) admits a closed expression. Hence problem (12) is equivalent to:
where , , for , is called a perspective function or an operation of right multiplication (see [51] (pp. 34–35)). is jointly convex satisfying , and is the recession function of (see [51] (pp. 66–67)), for and (see [40]).
We prove the tractability result of the Wasserstein distributionally robust portfolio optimization based on the KDE and mean- model (12), starting from giving the following Lemma 1 in [30]. The relative interior of a set and are denoted by and , respectively.
Lemma 1.
([30] (Theorem 1)) Let be a function such that is closed and concave for each . Consider a constraint of the form:
where is such that:
Constraint (14) holds for any given if and only if:
where , which is the support function of , and , which is the concave conjugate function of with respect to its second argument.
We then prove the tractable reformulation of the Wasserstein distributionally robust portfolio optimization based on KDE and mean- model (12) with given , , , , and .
Theorem 1.
Problem (12) is equivalent to the following optimization problem:
In particular, when Gaussian kernel function is available, problem (16) is equivalent to the following DCP problem:
where and .
Proof.
According to Lemma 1, for any given , and , the constraint in (18) holds if and only if:
In order to obtain the computationally tractable reformulation of problem (12), we need to derive the closed expressions of the support function of the uncertainty set in (9) and the concave conjugate function of in (19).
On the one hand, let be the extended version of ,
where . From the duality theorem of linear programming problem, we have:
On the other hand, it is obvious to derive that the concave conjugate function of , has closed formulation , where (see [52]). From [51] (Theorem 16.3) we have the concave conjugate function of in (19):
Furthermore, we have
where the first equality holds due to the fact that the functions of s in the objective and the left-hand side of the constraints are all decreasing with respect to s, and the second equality holds by replacing with y. Combining (20) with (18), it follows from Lemma 1 that:
It is easy to verify that the second group of constraints in (22) are jointly convex on , which can be solved by geometric programming (see [53]). Eliminating from (22) , we get:
Furthermore, eliminating from (23), we get:
which leads to the tractable reformulation (15) of problem (12).
Denote by , and eliminating from (24), we have:
which is the more concise version (16) than (15). When Gaussian kernel function is available, it follows from (11) that . Then by the change of variable in (15), problem (15) is reformulated as a DCP problem (17) since the quadratic-over-linear function is jointly convex (see [54,55]), which gives rise to the difference of convex functions between and for . Thus, the conclusion holds. □
Corollary 1.
For Gaussian kernel and , where , problem (17) can be reformulated as the following DCP problem with the geometric mean cone constraints.
where is the t-dimensional geometric mean cone (see [56]).
Proof.
For Gaussian kernel and , where , the first group of constraints in problem (15) can be reformulated as:
Thus, the conclusion holds. □
According to Corollary 1, the tractable reformulations of problem (26) with are listed as follows.
Example 1.
Example 2.
For , problem (26) is equivalent to the following smooth optimization problem with the second-order conic constraints.
where and is the 2-dimensional second-order cone (see [57]).
Example 3.
For , problem (26) is equivalent to the following smooth optimization problem with the geometric mean conic constraints.
where and is the 3-dimensional geometric mean cone (see [56]).
Remark 1.
Remark 2.
It is known from the statistics perspective that the bandwidth selection is a key issue for kernel density estimation. The Rule-of-Thumb bandwidth , where is the sample standard deviation, is a popular method (see [58,59] for more details of bandwidth selection). Note that the PDF of the portfolio loss is estimated by the weighted KDE in (6). Then, the corresponding Rule-of-Thumb bandwidth admits a closed expression with the form:
where , (I is the identity matrix) and (see [40]).
3. Numerical Studies
We conduct numerical experiments on the portfolio selection problem in order to demonstrate the effectiveness of the Wasserstein distributionally robust portfolio optimization model based on KDE and mean- (12) (denoted “”) with and listed as follows.
- The Wasserstein distributionally robust portfolio optimization model based on KDE and mean- (denoted “”)
- The Wasserstein distributionally robust portfolio optimization model based on KDE and mean-”)
- The Wasserstein distributionally robust portfolio optimization model based on KDE and mean-”):
Our numerical experiments consist of two parts: (i) rolling horizon analysis of “” compared with the SAA based mean- portfolio optimization model (30) (denoted “”) and (ii) sensitivity analysis of “” on and . To ensure the reproducibility of the numerical experiment, the popular academic benchmarks called Fama and French (FF) datasets are used, which is public and is readily available to anyone (accessed on 15 October 2021 and http://mba.tuck.dartmouth.edu/pages/faculty/ken.french/data_library.html). We use four datasets—FF6, FF30, FF48 and FF100—that contain 750 daily returns that span from 9 October 2018 to 30 September 2021. All results were produced on a PC (Inter®Core™i5-4590, 3.30GHz, 4.00GB), using “fmincon” in MATLAB R2014b.
3.1. Rolling Horizon Analysis
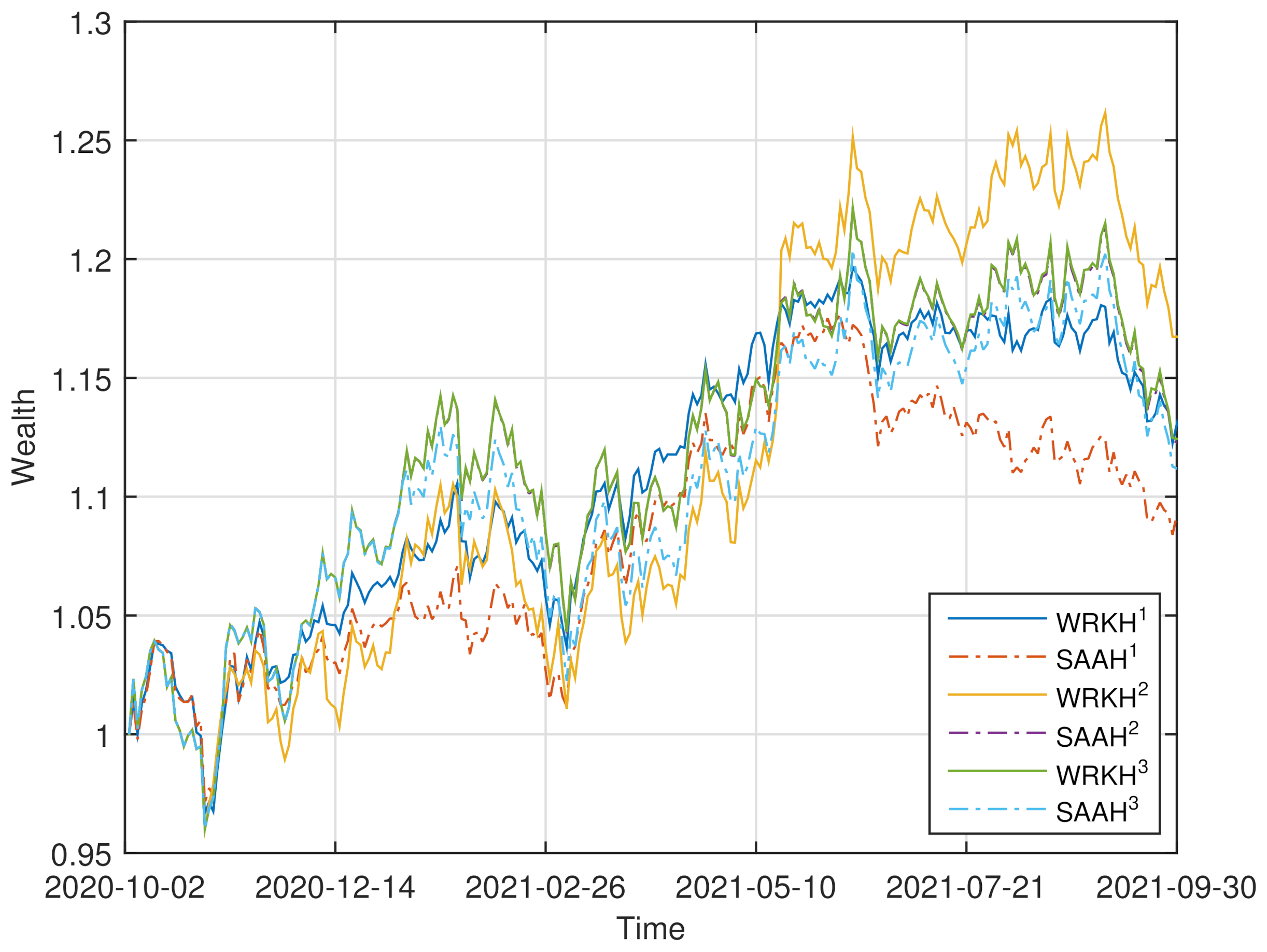
To demonstrate the effectiveness of “”, we conduct the rolling horizon experiment in a setting similar to that of [60]. The historical data of the asset returns in the previous T days is used to obtain the optimal portfolio weights by solving problem (32)–(34) and problems (30) with . We then use the portfolio weights to compute the current portfolio returns by using the current asset returns. This process is continued by adding the returns data for the next period in the dataset and dropping the earliest returns data, until the end of the dataset is reached (see [40,60]). Comparisons with “” are also given by rolling horizon analysis. We set , , , and . For four datasets, the corresponding evolutions of the accumulated wealth of the six strategies (“” and “” with ) are plotted in Figure 1.
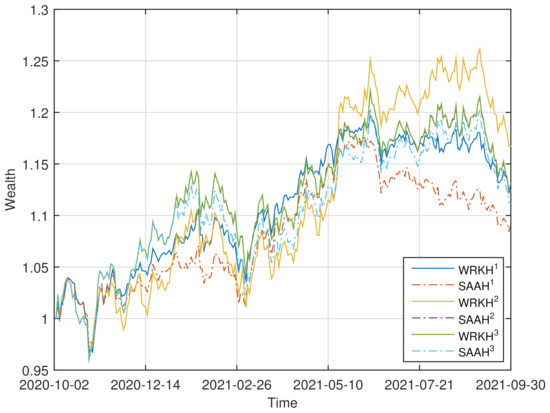
Figure 1.
Wealth curves of “” and “” () for four datasets.
Four performance criteria are adopted to assess the quality of a portfolio selection strategy (see [40]): (i) the mean of the daily returns (denoted “MR”), (ii) the Sharpe ratio (denoted “SR”), (iii) the average turnover (denoted “TO”), (iv) the maximum drawdown (denoted “MDD”). The turnover indicates the volumes of rebalancing. There is no benefit for the portfolio strategies that yield a high turnover since a high “TO” incurs a high trading cost that reduces the portfolio return (see [35,60]). The maximum drawdown is an indicator of downside risk over a specified time period, which is the largest drop from a peak (see [61]). The performance, in the above four criteria, of the six strategies for four datasets is shown in Table 1. The better-performing strategy under different criteria is marked in bold fonts for , respectively.

Table 1.
Performance of “” and “” () for four datasets.
From Figure 1 and Table 1, we can observe that: (i) For FF6, the wealthy curve of “” dominates those of the others most of the time. “MR”, “SR” and “MDD” of “” are better than those of “” for , respectively. (ii) For FF30, the wealthy curves of “” overlaps with those of “”, and dominate those of “” and “” most of the time. “” has the optimal “MR” and “SR”. (iii) For FF48, the wealthy curve of “” overlaps with those of the others at the first half time, and dominates those of the others latter. “MR”, “SR” and “MDD” of “” are better than those of “” for , respectively. (iv) For FF100, the wealthy curve of “” dominates those of the others most of the time. “MR”, “SR” and “MDD” of “” are better than those of “” for , respectively.
3.2. Sensitivity Analysis
The numerical experiments of the sensitivity analysis of “” on and have also been conducted for FF30. There are similar results for the other datasets. The corresponding numerical results for FF30 are listed as follows.
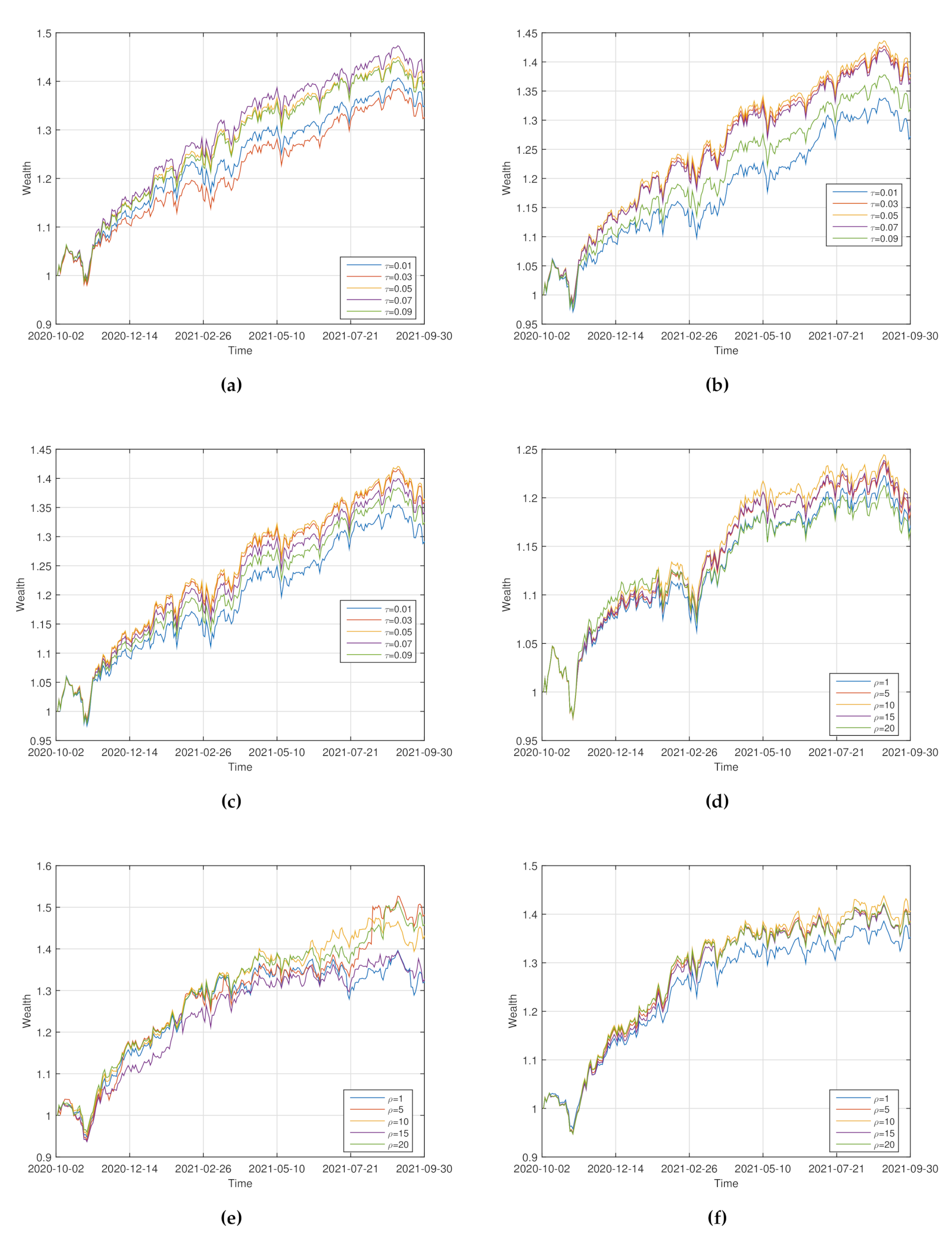
Sensitivity on . For , the wealthy curves of “” with are shown in Figure 2a–c. The corresponding statistic of the performance of “” is shown in Table 2.
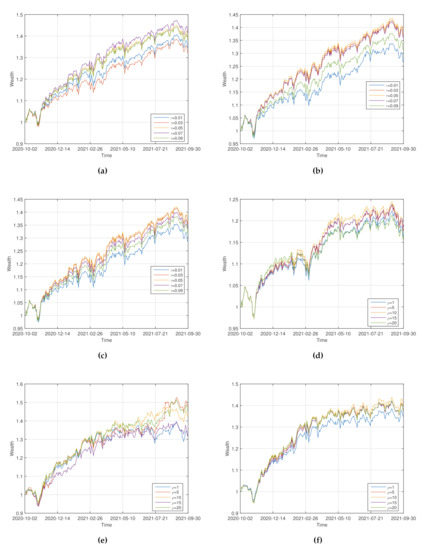
Figure 2.
Wealth curves of “” for various values of (a–c) and (d–f).
Table 2.
Sensitivity of “” on .
From Figure 2a–c and Table 2, we can observe that: (i) For , the wealthy curve of “” dominates those of the others most of the time. “” has the optimal “MR”, “SR” and “MDD”. (ii) For , the wealthy curve of “” dominates those of the others most of the time. “” has the optimal “MR”, “SR” and “MDD”. It is suggested that for the good performance of “” the value of should not be too big or too small.
Sensitivity on . For , the wealthy curves of “” with are shown in Figure 2d–f. The corresponding statistic of the performance of “” is shown in Table 3.
Table 3.
Sensitivity of “” on .
From Figure 2d–f and Table 3, we can observe that: (i) For , the wealthy curve of “” dominates those of the others most of the time. “MR” and “SR” of “” are optimal. (ii) For , all wealthy curves are intertwined most of the time. “” has the optimal “MR”, however “” has the optimal “SR” and “MDD”. It is suggested from the numerical results that for the good performance of “” the risk aversion level should not be too big or too small.
4. Conclusions
We propose the Wasserstein distributionally robust portfolio optimization model based on a kernel smoothing method and mean-HMCR to solve three challenges arising from the asymmetry and nonlinearity of HMCR as well as the ambiguity of asset returns distribution. We obtain the tractable DCP reformulation of the corresponding DRO model. The experimental results show that our proposed model is promising. It remains open to calibrate KDE-Wasserstein radius , which is left for future research.
Author Contributions
Conceptualization: W.L.; Methodology: W.L.; Formal Analysis: W.L.; Supervision: W.L.; Investigation: Y.L.; Software: Y.L.; Resources: Y.L.; Visualization: Y.L.; Writing—Original Draft: W.L.; Writing—Review and Editing: Y.L. All authors have read and agreed to the published version of the manuscript.
Funding
The APC was funded by the Teacher Research Capacity Promotion Program of Beijing Normal University at Zhuhai.
Institutional Review Board Statement
Not applicable.
Informed Consent Statement
Not applicable.
Data Availability Statement
The data that support the findings of this study are openly available in http://mba.tuck.dartmouth.edu/pages/faculty/ken.french/data_library.html (accessed on 15 October 2021).
Acknowledgments
The authors wish to thank the anonymous reviewers and the Editors, whose insightful comments and helpful suggestions significantly contributed to improving this paper.
Conflicts of Interest
The authors declare no conflict of interest.
References
- Wiesemann, W.; Kuhn, D.; Sim, M. Distributionally robust convex optimization. Oper. Res. 2014, 62, 1358–1376. [Google Scholar] [CrossRef] [Green Version]
- Knight, F.H. Risk, Uncertainty and Profit, 1st ed.; Hart, Schaffner and Marx: Boston, MA, USA, 1921. [Google Scholar]
- Markowitz, H. Portfolio selection. J. Financ. 1952, 7, 77–91. [Google Scholar]
- Krokhmal, P.A. Higher moment coherent risk measures. Quant. Financ. 2007, 7, 373–387. [Google Scholar] [CrossRef]
- Krokhmal, P.A.; Zabarankin, M.; Uryasev, S. Modeling and optimization of risk. Surv. Oper. Res. Manag. Sci. 2011, 16, 49–66. [Google Scholar] [CrossRef]
- Rockafellar, R.T.; Uryasev, S. Optimization of conditional value-at-risk. J. Risk 2000, 2, 21–42. [Google Scholar] [CrossRef] [Green Version]
- Artzner, P.; Delbaen, F.; Eber, J.M.; Heath, D. Coherent measures of risk. Math. Financ. 1999, 9, 203–228. [Google Scholar] [CrossRef]
- Fishburn, P.C. Mean-risk analysis with risk associated with below-target returns. Am. Econ. Rev. 1977, 67, 116–126. [Google Scholar]
- Rockafellar, R.T.; Uryasev, S.; Zabarankin, M. Generalized deviations in risk analysis. Financ. Stoch. 2006, 10, 51–74. [Google Scholar] [CrossRef]
- Fabozzi, F.J.; Huang, D.; Zhou, G. Robust portfolios: Contributions from operations research and finance. Ann. Oper. Res. 2010, 176, 191–220. [Google Scholar] [CrossRef] [Green Version]
- Shapiro, A.; Dentcheva, D.; Ruszczyński, A. Lectures on Stochastic Programming: Modeling and Theory, 2nd ed.; SIAM: Philadelphia, PA, USA, 2014. [Google Scholar]
- Ben-Tal, A.; Nemirovski, A. Robust Convex Optimization. Math. Oper. Res. 1998, 23, 769–805. [Google Scholar] [CrossRef] [Green Version]
- Ben-Tal, A.; El Ghaoui, L.; Nemirovski, A. Robust Optimization; Princeton University Press: Princeton, NJ, USA, 2009; Volume 28. [Google Scholar]
- Bertsimas, D.; Sim, M. The Price of Robustness. Oper. Res. 2004, 52, 35–53. [Google Scholar] [CrossRef] [Green Version]
- Scarf, H. A min-max solution of an inventory problem. In Studies in the Mathematical Theory of Inventory and Production; Scarf, H., Arrow, K., Karlin, S., Eds.; Stanford University Press: Stanford, CA, USA, 1958; Volume 10, pp. 201–209. [Google Scholar]
- El Ghaoui, L.; Oks, M.; Oustry, F. Worst-case value-at-risk and robust portfolio optimization: A conic programming approach. Oper. Res. 2003, 51, 543–556. [Google Scholar] [CrossRef] [Green Version]
- Bertsimas, D.; Popescu, I. Optimal Inequalities in Probability Theory: A Convex Optimization Approach. SIAM J. Optim. 2005, 15, 780–804. [Google Scholar] [CrossRef]
- Popescu, I. Robust mean-covariance solutions for stochastic optimization. Oper. Res. 2007, 55, 98–112. [Google Scholar] [CrossRef] [Green Version]
- Goh, J.; Sim, M. Distributionally robust optimization and its tractable approximations. Oper. Res. 2010, 58, 902–917. [Google Scholar] [CrossRef]
- Delage, E.; Ye, Y. Distributionally robust optimization under moment uncertainty with application to data-driven problems. Oper. Res. 2010, 58, 595–612. [Google Scholar] [CrossRef] [Green Version]
- Zymler, S.; Kuhn, D.; Rustem, B. Distributionally robust joint chance constraints with second-order moment information. Math. Program. 2013, 137, 167–198. [Google Scholar] [CrossRef] [Green Version]
- Hanasusanto, G.A.; Kuhn, D. Robust Data-Driven Dynamic Programming. In Advances in Neural Information Processing Systems 26; Burges, C.J.C., Bottou, L., Welling, M., Ghahramani, Z., Weinberger, K.Q., Eds.; Curran Associates, Inc.: Red Hook, NY, USA, 2013; pp. 827–835. Available online: https://proceedings.neurips.cc/paper/2013/hash/ef575e8837d065a1683c022d2077d342-Abstract.html (accessed on 15 October 2021).
- Erdoğan, E.; Iyengar, G. Ambiguous chance constrained problems and robust optimization. Math. Program. 2006, 107, 37–61. [Google Scholar] [CrossRef] [Green Version]
- Bertsimas, D.; Gupta, V.; Kallus, N. Robust sample average approximation. Math. Program. 2018, 171, 217–282. [Google Scholar] [CrossRef] [Green Version]
- Wang, Z.; Glynn, P.W.; Ye, Y. Likelihood robust optimization for data-driven problems. Comput. Manag. Sci. 2016, 13, 241–261. [Google Scholar] [CrossRef] [Green Version]
- Ben-Tal, A.; Den Hertog, D.; De Waegenaere, A.; Melenberg, B.; Rennen, G. Robust solutions of optimization problems affected by uncertain probabilities. Manag. Sci. 2013, 59, 341–357. [Google Scholar] [CrossRef] [Green Version]
- Bayraksan, G.; Love, D. Data-driven stochastic programming using phi-divergences. Tutor. Oper. Res. 2015, 1, 1–19. [Google Scholar]
- Jiang, R.; Guan, Y. Data-driven chance constrained stochastic program. Math. Program. 2016, 158, 291–327. [Google Scholar] [CrossRef]
- Shapiro, A. Distributionally robust stochastic programming. SIAM J. Optim. 2017, 27, 2258–2275. [Google Scholar] [CrossRef]
- Postek, K.; Hertog den, D.; Melenberg, B. Computationally tractable counterparts of distributionally robust constraints on risk measures. SIAM Rev. 2016, 58, 603–650. [Google Scholar] [CrossRef] [Green Version]
- Calafiore, G.C. Ambiguous risk measures and optimal robust portfolios. SIAM J. Optim. 2007, 18, 853–877. [Google Scholar] [CrossRef]
- Hu, Z.; Hong, L.J. Kullback-Leibler Divergence Constrained Distributionally Robust Optimization. 2012. Available online: http://www.optimization-online.org/DB_HTML/2012/11/3677.html (accessed on 15 October 2021).
- Mohajerin Esfahani, P.; Kuhn, D. Data-driven distributionally robust optimization using the Wasserstein metric: Performance guarantees and tractable reformulations. Math. Program. 2018, 171, 115–166. [Google Scholar] [CrossRef]
- Gao, R.; Kleywegt, A.J. Distributionally Robust Stochastic Optimization with Wasserstein Distance. arXiv 2016, arXiv:1604.02199v2. [Google Scholar]
- Wozabal, D. Robustifying convex risk measures for linear portfolios: A nonparametric approach. Oper. Res. 2014, 62, 1302–1315. [Google Scholar] [CrossRef]
- Zhao, C.; Guan, Y. Data-driven risk-averse stochastic optimization with Wasserstein metric. Oper. Res. Lett. 2018, 46, 262–267. [Google Scholar] [CrossRef]
- Mei, Y.; Chen, Z.P.; Ji, B.B.; Xu, Z.J.; Liu, J. Data-driven Stochastic Programming with Distributionally Robust Constraints Under Wasserstein Distance: Asymptotic Properties. J. Oper. Res. Soc. China 2021, 9, 525–542. [Google Scholar] [CrossRef]
- Nakagawa, K.; Ito, K. Taming Tail Risk: Regularized Multiple β Worst-Case CVaR Portfolio. Symmetry 2021, 13, 922. [Google Scholar] [CrossRef]
- Zhu, S.; Fukushima, M. Worst-case conditional value-at-risk with application to robust portfolio management. Oper. Res. 2009, 57, 1155–1168. [Google Scholar] [CrossRef]
- Liu, W.; Yang, L.; Yu, B. KDE distributionally robust portfolio optimization with higher moment coherent risk. Ann. Oper. Res. 2021, 307, 363–397. [Google Scholar] [CrossRef]
- Villani, C. Optimal Transport: Old and New; Springer: Berlin/Heidelberg, Germany, 2009. [Google Scholar]
- Silverman, B.W. Density Estimation for Statistics and Data Analysis, 2nd ed.; MPS-SIAM Series on Optimization; Chapman and Hall: New York, NY, USA, 1986. [Google Scholar]
- Li, Q.; Racine, J.S. Nonparametric Econometrics: Theory and Practice; Princeton University Press: Princeton, NJ, USA, 2007. [Google Scholar]
- Hazelton, M.L.; Turlach, B.A. Reweighted kernel density estimation. Comput. Stat. Data Anal. 2007, 51, 3057–3069. [Google Scholar] [CrossRef]
- Parzen, E. On estimation of a probability density function and mode. Ann. Math. Stat. 1962, 33, 1065–1076. [Google Scholar] [CrossRef]
- Terrell, G.R.; Scott, D.W. Variable Kernel Density Estimation. Ann. Stat. 1992, 20, 1236–1265. [Google Scholar] [CrossRef]
- Hall, P.; Minnotte, M.C. High order data sharpening for density estimation. J. R. Stat. Soc. Ser. B 2002, 64, 141–157. [Google Scholar] [CrossRef]
- Hall, P.; Turlach, B.A. Reducing bias in curve estimation by use of weights. Comput. Stat. Data Anal. 1999, 30, 67–86. [Google Scholar] [CrossRef]
- Owen, A.B. Empirical Likelihood; CRC Press: Boca Raton, FL, USA, 2001. [Google Scholar]
- Chen, S.X. Empilical likelihood-based kernel density estimation. Aust. J. Stat. 1997, 39, 47–56. [Google Scholar] [CrossRef]
- Rockafellar, R.T. Convex Analysis; Princeton University Press: Princeton, NJ, USA, 1997. [Google Scholar]
- Ben-Tal, A.; Den Hertog, D.; Vial, J.P. Deriving robust counterparts of nonlinear uncertain inequalities. Math. Program. 2015, 149, 265–299. [Google Scholar] [CrossRef]
- Boyd, S.; Kim, S.; Vandenberghe, L.; Hassibi, A. A tutorial on geometric programming. Optim. Eng. 2007, 8, 67–127. [Google Scholar] [CrossRef]
- Boyd, S.; Vandenberghe, L. Convex Optimization; Cambridge University Press: Cambridge, UK, 2004. [Google Scholar]
- Horst, R.; Thoai, N. DC Programming: Overview. J. Optim. Theory Appl. 1999, 103, 1–43. [Google Scholar] [CrossRef]
- Grant, M.; Boyd, S. CVX: Matlab Software for Disciplined Convex Programming, version 2.0 beta; September 2013. Available online: http://cvxr.com/cvx/citing/ (accessed on 15 October 2021).
- Lobo, M.S.; Vandenberghe, L.; Boyd, S.; Lebret, H. Applications of second-order cone programming. Linear Algebra Appl. 1998, 284, 193–228. [Google Scholar] [CrossRef] [Green Version]
- Izenman, A.J. Recent developments in nonparametric density estimation. J. Am. Stat. Assoc. 1991, 86, 205–224. [Google Scholar] [CrossRef]
- Jones, M.C.; Marron, J.S.; Sheather, S.J. A Brief Survey of Bandwidth Selection for Density Estimation. J. Am. Stat. Assoc. 1996, 91, 401–407. [Google Scholar] [CrossRef]
- DeMiguel, V.; Garlappi, L.; Uppal, R. Optimal versus naive diversification: How inefficient is the 1/N portfolio strategy? Rev. Financ. Stud. 2009, 22, 1915–1953. [Google Scholar] [CrossRef] [Green Version]
- Chekhlov, A.; Uryasev, S.; Zabarankin, M. Drawdown measure in portfolio optimization. Int. J. Theor. Appl. Financ. 2005, 8, 13–58. [Google Scholar] [CrossRef]
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).