Abstract
Class imbalance, as a phenomenon of asymmetry, has an adverse effect on the performance of most machine learning and overlap is another important factor that affects the classification performance of machine learning algorithms. This paper deals with the two factors simultaneously, addressing the class overlap under imbalanced distribution. In this paper, a theoretical analysis is firstly conducted on the existing class overlap metrics. Then, an improved method and the corresponding metrics to evaluate the class overlap under imbalance distributions are proposed based on the theoretical analysis. A well-known collection of the imbalanced datasets is used to compare the performance of different metrics and the performance is evaluated based on the Pearson correlation coefficient and the correlation coefficient. The experimental results demonstrate that the proposed class overlap metrics outperform other compared metrics for the imbalanced datasets and the Pearson correlation coefficient with the AUC metric of eight algorithms can be improved by 34.7488% in average.
1. Introduction
Machine learning has been widely applied to solve problems in various fields. One of the common and important challenges in solving these problems by machine learning is the classification under imbalanced distribution [1]. The imbalance is encountered by a large number of applications where the concerned samples are rare, such as disease diagnosis, financial fraud detection, network intrusion detection, and so on [2]. The data distributions in these fields are asymmetry that the number of concerned positive samples are smaller than that of negative samples. Most standard classification algorithms are designed based on the concept of symmetry, relatively balanced class distribution or equal cost of misclassification [3]. The classification performances of these algorithms are degraded for handling the imbalance problem to some extent. Hence, building symmetry in machine learning for data under asymmetry distribution is an important research topic [4]. In [5], a novel class imbalance reduction algorithm is proposed to build a symmetry by considering distribution properties of the dataset to improve the performance in software defect prediction. In addition, there are also a lot of methods are proposed to handle the imbalance problem, which can be referred in [2,6].
Besides the imbalance, class overlap is also an important factor that affects the performance of classification [7]. In addition, the research of Liu et al. [8] demonstrated that the sample is often misclassified if it is in a class overlapping boundary. Oh [9] proposed the R value based on the ratio of overlapping areas to the whole dataset and the experimental results show that the R value is strongly correlated with the classification accuracy. In addition, Denil [10] has given a systematic analysis on the imbalance and overlap. The analysis shows that the overlap problem has a greater influence on classification performance than the imbalance in isolation and the classification performance is decreased significantly when the overlap and imbalance are both exist. To deal with the classification of datasets with class overlap and imbalance, some research works have also been conducted [7,11].
The classification methods for the datasets with class overlap and imbalance are important, but so are the quantitative estimation methods of the class overlap level for imbalanced datasets [9]. It can make contributions to understand the characteristic of the datasets and then help to design suitable methods for better classification performance. Klomsae et al. [12] adopts the R value to indicate the classification performance of the dataset and propose a string grammar fuzzy-possibilistic C-medians algorithm to handle the overlapping data problem. In addition, some methods based on the R value to conduct feature selection [13,14], feature construction [15] and data sampling [16] are proposed for achieving better classification performance. Later, Borsos et al. [17] analyzed the problem of the R value for estimating the overlap level of imbalanced datasets and extended the R value to the value for imbalanced datasets. The experimental results demonstrate that the value has a stronger correlation with the classification performance, and it can also achieve better performance in algorithm selection for better classification performance. In addition, some feature selection research works are also conducted based on the value [18,19].
The value has achieved great performance for addressing the class overlap under imbalanced distribution. However, the experimental results in [17] show that the absolute value of the Pearson correlation coefficients of the with the classification performances are lower than 0.7 and the correlation coefficients are varied to different algorithms. Therefore, both correlation coefficients with the classification performances and the generalization ability for different classification algorithms need to be improved. For this purpose, a theoretical analysis on the existing class overlap metrics is firstly conducted and then an improved method is proposed to measure the class overlap for imbalanced datasets in this paper. Based on the proposed method, the R and are extended to and for better estimating the class overlap level for imbalanced datasets. The comparison experiments conducted on a well-known collection of imbalanced datasets and eight commonly used classification algorithms are adopted to obtain the classification performance. In addition, the performances of different overlap metrics are evaluated based on the Pearson correlation coefficient and the correlation coefficient with the classification performance. The experimental results demonstrate the excellent performances of the proposed metrics, which indicates the superiority of the proposed method.
The contributions of this paper can be summarized as follows:
- A theoretical analysis on the existing class overlap measure R value is presented.
- A novel method along with two metrics for estimating the class overlap of the imbalanced datasets is proposed based on the theoretical analysis.
- The proposed two class overlap metrics are verified to be in higher correlations with the classification performance of imbalanced datasets.
The rest of the paper is organized as follows. The existing overlap metrics, the R and values, are introduced in Section 2. Section 3 presents a theoretical analysis on the R value. Then, an improved method and two corresponding overlap metrics for imbalanced datasets are proposed based on the theoretical analysis. In addition, Section 4 describes the information about the experiments, such as experiment setup, adopted datasets, and performance evaluation. The experimental results and discussions are given in Section 5. Finally, the conclusions are drawn in Section 6.
2. The Existing Overlap Metrics
To estimate the level of class overlap, there are two metrics, the R value and the value. These two metrics are introduced in this section. Before introducing the two metrics, some notations are presented as follows:
- N: the number of the samples
- n: the number of the classes
- : the set of samples belonging to class
- U: the set of all samples,
- : the sample in
- k-: the set of samples in k-nearest neighbor samples of that belong to the class different from
- : a 0-1 function that returns 1 when and returns 0 otherwise
- : a threshold value within the range [0, ]
2.1. The R Value
The original R value is proposed by Oh [9] based on the assumption that a sample from class is overlapped with other samples if the number of the samples that is in its k nearest neighbors and also belongs to a class rather than is at least . In addition, the R values of class and the whole dataset f are defined as Equations (1) and (2), respectively:
According to the definition, the R value can be considered as the ratio of samples in the overlapping area. The range of the R value is [0, 1]. In addition, there are two parameters, needed to be predefined to calculate the R value. According to [9], the R value is strongly correlated with the accuracy of Support Vector Machine (SVM), Artificial Neural Network (ANN), and K Nearest Neighbor (KNN) algorithms when and . With this parameter setting, a sample is considered to be in the overlapping area if at least four samples in its seven nearest neighbors belong to another class.
2.2. The Value
In [9], the results also show that the R value is most strongly correlated with the classification accuracy of the majority class. In addition, Borsos et al. [17] evaluated R value on some imbalanced data sets with different imbalanced ratios and the experiment results showed that R value is almost constant, while the classification performance decreases with a larger imbalance ratio (IR). Therefore, they conducted an analysis of the R value in a simple case with only two classes, the majority class and minority class. The majority class and minority class are denoted as and , respectively. Then, the R value of the whole dataset can be calculated as Equation (3):
By introducing the imbalance ratio into Equation (3), the equation can be simplified as Equation (4):
As the weight of the R value of the majority class is IR, the R value of the whole dataset will be dominated by R value of the majority class when the dataset has a large IR. Actually, the sample in the majority class has a low probability to be recognized in the overlap area, while the sample in the minority class has a high probability. Therefore, the weight of the R value of the majority class should be smaller than that of the minority class. Based on this analysis, the augmented R value defined as Equation (5) is proposed by Borsos et al. [17]:
It can be seen that the value is dominated by the R value of the minority class for datasets with large IR, and it is equal to R value for balanced datasets with . The experimental results in [17] demonstrated that it could achieve a stronger correlation with the classification performance evaluated by the metric of the area under the Receiver Operating Characteristic (ROC) curve.
3. The Proposed Method and Corresponding Overlap Metrics
In this section, the theoretical analysis of the R value is firstly conducted. Then, an improved method to recognize the overlap area for imbalanced datasets is proposed and the corresponding overlap metrics are introduced.
3.1. Theoretical Analysis of the R Value
Consider a dataset with N samples , the number of samples in the same class with each sample is denoted as . In the ideal non-overlapping data distribution, all samples are distributed very well so that the nearest samples of the sample along with the sample itself are all in the same class, while there may be some samples in the nearest samples of the sample that are in a different class to the class of in real data distribution.
Let’s keep it simple; only consider the nearest data samples of the sample in real data distribution. As shown in Figure 1, let be denoted as the set of nearest samples of the in the ideal data distribution, and represents the set of nearest samples of the in the real data distribution. For any sample except , it can be represented by , , , and . The meanings of these four kinds samples are presented as follows:
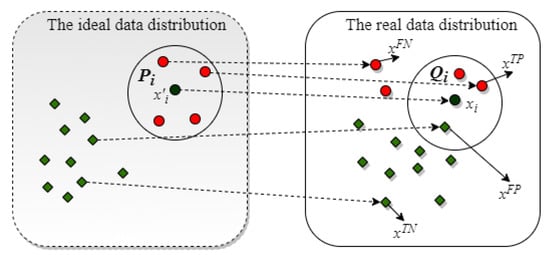
Figure 1.
The comparison analysis of the data distribution.
- : the sample which is in both and
- : the sample in neither nor
- : the sample which is in but not in
- : the sample that are not in but in
Denote the number of samples as , the number of samples that as , the number of samples that as and the number of samples that are as . According to the definition of R value, the contribution of the sample to the R value is determined by and as . Actually, the contribution of to the R value can be determined based on the probability distribution. In the following, the contribution is analyzed based on the distance between the real data distribution and the ideal data distribution from the perspective of probability.
To measure the distance between distributions, the Kullback–Leibler (K-L) divergence is commonly used. In addition, to conduct the calculation of K-L divergence, denote and as the conditional probabilities of sample given for the ideal data distribution and the real data distribution. In addition, the conditional probability of the samples in the and can be defined to be an equal non-zero probability and the conditional probability of the other samples can be defined to a near zero probability according to [20]. Then, the detailed conditional probabilities of and are shown in Equations (6) and (7):
Based on the conditional probabilities, the distance, the K-L divergence , can be defined as Equation (8) shows. Due to the near zero value of , the distance can be simplified to Equation (9). According to Equation (9), and dominate the distance, which is consistent with the definition of the R value:
Equation (9) can be further simplified to Equation (10) because of the near zero value of . It can be seen that the distance actually is dominated by the ratio of and . Therefore, a reasonable threshold for judging whether has a contribution to the R value is 0.5. If , it indicates that is in the overlap area. For , if , should be at least 4. It is consistent with the implementation of the R value in the experiments of [9]:
In addition, the sample is correctly classified to a class if in the k nearest neighbor for the KNN algorithm, which is contrary to the definition of the R value. Therefore, the R value can be strongly and negatively correlated with the accuracy of the KNN algorithm.
3.2. The Proposed Method
From the above theoretical analysis, it can be seen that the class overlap is actually not only determined by but also , while the contribution of is ignored for the R value. As Equation (10) shows, it can be omitted as the coefficient is constant for balanced data sets with the same for all samples. However, when the same is adopted, the coefficient is varied from different classes due to the different for imbalanced data sets. To make the coefficients of equal for different classes in an imbalanced dataset, the condition shown in Equation (11) should be satisfied. Then, Equation (12) can be obtained. Besides, the same result will be obtained if the deduction is conducted based on Hellinger distance, which can be found in Appendix A. It indicates that the adopted value of k should be in proportion to the number of samples in the class and the smaller value of should be adopted for the minority class:
According to Equation (12), if k is used for the majority class, should be used for the minority class as it must be a positive integer. Based on this analysis, an improved method to calculate the overlap of different classes is proposed as Equation (13) shows, where is the number of samples in the majority class. In this way, the samples in the minority class will not be considered in an overlap area easily:
An intuitive demonstration of how the proposed method works is presented in Figure 2. For the sample in the majority class, both and are suitable to decide whether is in the class overlap region or not, while the sample in the minority class will be recognized to be in the overlap region when . When , the can be correctly recognized to be in the non-overlap region.
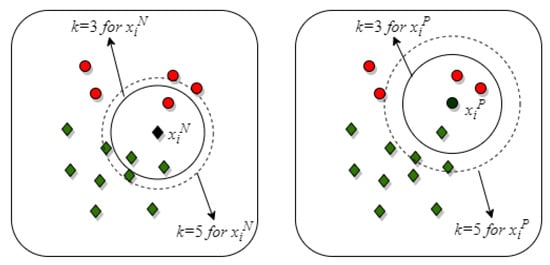
Figure 2.
An intuitive demonstration of how the proposed method works.
3.3. The Proposed Metrics
According to the proposed method, two improved overlap metrics based on the R and for binary imbalance datasets can be introduced. The two metrics, denoted as and , are defined as Equations (14) and (15):
According to the definition of the two metrics, they can both be equal to the original R value when the dataset is balanced (). In addition, the experimental results in [9,17] demonstrate that the R and are strongly correlated with the accuracy and the area under the ROC curve (AUC) respectively. Therefore, it is expected that is more strongly correlated with the accuracy of the imbalanced datasets and is more strongly correlated with the AUC of the imbalanced datasets.
4. Experiment Design
In this section, the experiment setup is firstly introduced. Then, the datasets adopted in the experiments are presented. Finally, the evaluation metric for the comparison of different class overlap metrics is described.
4.1. Experiment Setup
The experiments are conducted to prove the effectiveness of the proposed method and the two metrics for addressing the class overlap of the imbalanced datasets. To evaluate the effectiveness, not only the correlation of different overlap metrics with the classification performance but also the time consuming of the overlap metrics and the classification modeling are compared. The Pearson correlation coefficient and the correlation coefficient are adopted to obtain the correlation result. The Pearson correlation coefficient can only handle the linear correlations, while the correlation coefficient can deal with both the linear and nonlinear correlations.
According to the investigation of Guo et al. in [2], the AUC and accuracy are the most frequently used metrics for evaluating the classification performance. The AUC is obtained based on the ROC curve which consists of a series points of (false positive rate, true positive rate) [21]. In addition, the points are generated by varying different thresholds for the prediction probability of the classifier. As the AUC is robust to the imbalanced datasets [22], it is recognized as an objective metric and widely utilized to evaluate the classification performance for imbalanced problems. The accuracy is defined as the rate of the number of correctly predicted samples to the number of samples in the whole dataset. Although the accuracy has been proved to be biased to the majority class, it is still frequently used in the research on imbalance learning as it is the most general and intuitive metric [2]. In addition, the proposed metrics and are expected to be strongly correlated with the accuracy and AUC respectively based on the analysis in Section 3. Therefore, the two metrics are both adopted to evaluate the classification performance for the better evaluation of the proposed overlap metrics.
Moreover, for the comparison of the generalization ability, eight commonly used algorithms are adopted to obtain the classification performance and the performances are obtained based on the 5-fold cross validation. The eight classification algorithms are k-nearest neighbor (KNN), Naive Bayesian (NB), Support Vector Machine with linear kernel (SVM-L), Support Vector Machine with radial basis kernel (SVM-R), Decision Tree (DT), Multiple Layer Perceptron (MLP), Random Forest (RF), and Adaptive Boosting (AdaB). All methods in the experiments are implemented in python based on some packages like scikit-learn [23] and so on. The parameters of the eight classification algorithms are set to default in the experiment. In addition, the same parameter setting, , is adopted for all overlap metrics.
4.2. Datasets
In the experiments, a relatively well-known collection of 66 datasets for imbalanced classification is utilized. This collection can be obtained from the KEEL repository and has been adopted in [17,24]. The descriptions of these datasets are shown in Table 1, where #Inst. and #Attrs indicate the number of samples and attributes, respectively, and means the imbalance ratio. The imbalance ratios of the datasets are in a very wide range. The minimum imbalance ratio is 1.82, while the maximum imbalance ratio is 128.87.

Table 1.
The information about the imbalanced datasets.
4.3. Evaluation of Correlation
Pearson correlation coefficient [25] is defined to measure the strength of the relationship between two variables in statistics. The equation of Pearson correlation coefficient is shown in Equation (16), where X and Y are two variables, and are the mean value of the two variables, is the covariance, and is the standard deviation:
The Pearson correlation coefficient is widely utilized to calculate the linear correlation of two variables. It has been used to compare the performance of R and in [17], and it is also used in the experiments of this paper. In addition, the range of Pearson correlation coefficient is [−1, 1]. The bigger of the absolute value of , the stronger correlation of the two variables. indicates that there is a perfect positive correlation between the two variables, while means a perfect negative correlation. In addition, when , it indicates that the two variables are dependent and there is no correlation can be found between them.
To further verify the linear correlation of the proposed metrics and the classification performance, the probabilities of the Pearson correlation results are also compared. The probability can be indicated by p-value, where the smaller p-value indicates the stronger support for the result of Pearson correlation coefficient. Generally, a p-value smaller than 0.05 means that the result of linear correlation is solid. In addition, the result is significantly solid when the p-value is smaller than 0.01.
Besides the Pearson correlation coefficient, the correlation coefficient is also used to the evaluate the relationships of different overlap metrics with the classification performance. correlation coefficient, which was proposed in [26], can not only measure the linear correlation but also the nonlinear correlation. To calculate the correlation coefficient of a pair of variables (X, Y), the data should be rearranged as such that ··· . Let be the number of j such that and are the number of j such that , and the correlation coefficient is defined as Equation (17) shown. It is in range of , where indicates that X and Y are independent and indicates that Y is a measurable function of X:
5. Results and Discussion
To verify the efficiency of the proposed method to measure class overlap, both the correlation results of different metrics with the AUC and the accuracy are compared. As the AUC metric is more objective than the accuracy for imbalance learning, the comparison of the correlations of different overlap metrics and the AUC of different algorithms is firstly conducted. In addition, then the correlation results of different metrics with the accuracy are compared. Finally, the overall results are summarized.
5.1. The Correlation Results for the AUC Metric
Figure 3 shows the correlation results of different overlap metrics with the AUCs of classification algorithms. The results demonstrate that the metric achieved the best performance among these metrics for all classification algorithms. In addition, the metric also obtained better performance than the original R metric based on the AUC metric of classification algorithms. In addition, both the original R and value have low correlation coefficients with the AUC of the NB algorithm. It can be seen that the generalization ability of the existing overlap metrics is not good. While, the correlation coefficients of the R and with the NB algorithm are both largely improved by the proposed method. The and seem to have better generalization abilities for these algorithms than the R and , respectively.
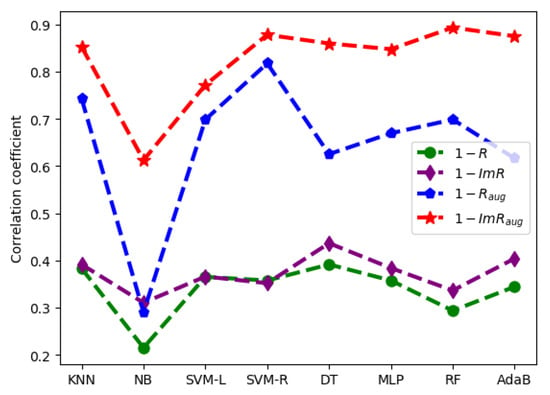
Figure 3.
The Pearson correlation comparison between different overlap metrics and the AUCs of different algorithms on all data sets.
As expected, the and achieve much stronger correlations with the AUC of different algorithms. It is consistent with the result in [17]. In the following, the detailed correlation results of the and with different classification algorithms are compared. The detailed correlation coefficients along with the p-values of and with the AUC of different algorithms are presented in Table 2. It can be seen that the correlation coefficients of the with the AUC of the DT, MLP, RF, and AdaB algorithms are all lower than 0.7, while the correlation coefficients with the AUC of these algorithms are all improved to more than 0.8 by . On average, the achieves a 34.7488% improvement to the . An illustration of the correlation coefficient improvements of over is shown in Figure 4. The correlation coefficient between and the AUC of the NB algorithm is largely improved by the proposed .
Table 2.
The detailed Pearson correlation coefficient results of and with the AUCs of different algorithms on all data sets.
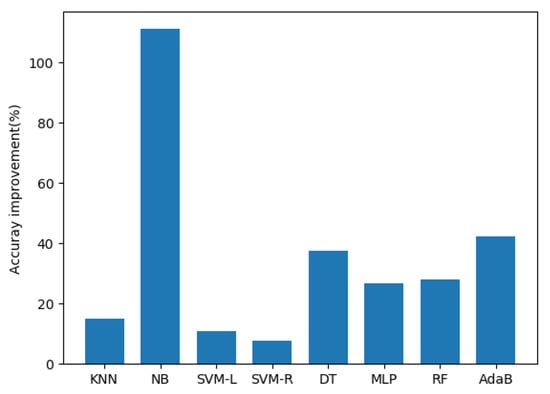
Figure 4.
Correlation coefficient improvements of the over the with the AUCs of different algorithms on all datasets.
In addition, all the p-values of are far less than 0.01, which indicates that does have linear correlations with the AUC of these algorithms. In addition, the p-values of are also much less than that of . Therefore, the has a much better performance than the for estimating the level of class overlap under imbalanced distribution. Moreover, can not only achieve the better mean value of correlations with the AUCs of all classification algorithms, but also achieve the smaller standard deviation. It demonstrates that also has a better generalization ability to these algorithms.
Figure 5 demonstrates the correlation coefficients of the AUCs of different algorithms with the and . It can be seen that the result of the correlation coefficient is similar to the result of the Pearson correlation coefficient. The correlation coefficient of the AUC of the RF algorithm with the is the highest and the correlation coefficient of the NB algorithm with is largely improved by . In addition, the correlation coefficients of the AUCs of different algorithms with the are all higher than that with the . Therefore, the comparison of correlation coefficient also demonstrates the superior of .
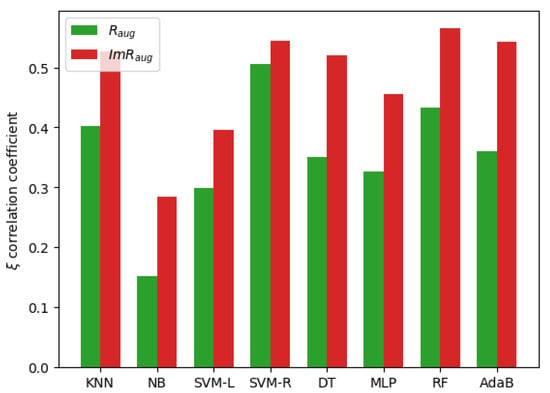
Figure 5.
Correlation coefficients of the AUCs of different algorithms with the and .
5.2. The Correlation Results for the Accuracy Metric
Figure 6 shows the correlation results of R and with the accuracy of several classification algorithms. It can be seen that the achieves better performance than the original R for more classification algorithms. In addition, the measure also obtained better performance than the measure based on the accuracy of classification algorithms.
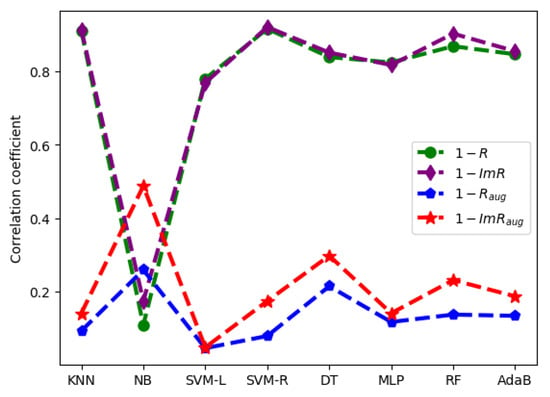
Figure 6.
The correlation comparison of different overlap metrics and classification accuracies of different algorithms on all datasets.
The detailed correlation coefficients and p-values of the R and with the accuracy of different algorithms are shown in Table 3. As expected, the is strongly correlated with the accuracy of the KNN algorithm. The Pearson correlation coefficient of the with the accuracy of the KNN algorithm is more than 0.9. In addition, the also achieves high correlation coefficients with the accuracy of the SVM-R, DT, MLP, RF, and AdaB algorithms. Although the correlation coefficients of the R and with the accuracy of the NB algorithm are very low, the correlation coefficient is greatly improved by the . On average, the achieves a 8.0898% improvement of the Pearson correlation coefficient to the R. Therefore, the has a better performance than the R for estimating the level of class overlap under imbalanced distribution.
Table 3.
The detailed Pearson correlation coefficient results of R and with the accuracies of different algorithms on all data sets.
In addition, all the p-values of except for the NB algorithm are far less than 0.01, which indicates that does have linear correlations with the ACC of most algorithms. In addition, the p-values of except for SVM-L and MLP algorithms are much less than that of R. Therefore, the has a much better performance than the R for estimating the level of class overlap under imbalanced distribution. Moreover, can not only achieve the better mean value of correlation coefficients with the accuracy of all classification algorithms, but also achieve the smaller standard deviation. It demonstrates that also has a better generalization ability to these algorithms.
Figure 7 presents the correlation coefficients of the accuracies of different algorithms with the and . It can be seen that the result of the correlation coefficient is also similar to the result of the Pearson correlation coefficient. The correlation coefficient of the accuracy of the NB algorithm with the R is much smaller than that of the accuracies of other algorithms with the R, and the coefficient is largely improved by the . The correlation coefficient of the accuracy of the SVM-R algorithm with the is also the highest. Meanwhile, the correlation coefficients of the accuracies of different algorithms with the are all higher than that with the R. Therefore, the comparison of correlation coefficient also shows that the has a better performance than that of the R.
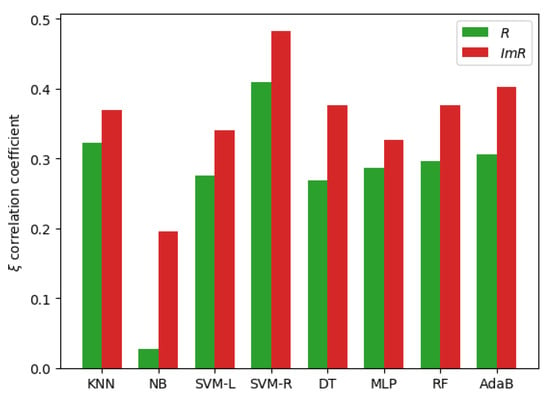
Figure 7.
correlation coefficients of the accuracies of different algorithms with the R and .
5.3. The Comparison of Time Consumption
The average time-consuming comparison of different overlap metrics and 5-fold cross validation of different classification algorithms is shown in Figure 8. It can be seen that the MLP algorithm has the most time-consuming performance due to the backpropagation. In addition, the RF and AdaB algorithms are also very time consuming because of the ensemble learning. In addition, these overlap metrics have a similar time consuming performance and the consuming time of the KNN algorithm is approximately four times that of the overlap metric. The main reason is that the k-nearest neighbors searching is the most time-consuming process for these overlap metrics and the KNN algorithm. The searching process will be conducted in the range of n samples for a dataset, and it will be conducted five times in the range of samples for the 5-fold cross validation of the KNN algorithm. Therefore, the result is consistent to the analysis and the proposed overlap metrics are also superior in terms of time consumption.
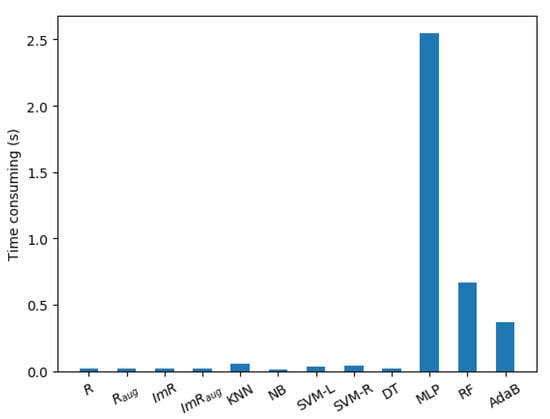
Figure 8.
The average time-consuming comparison of different overlap metrics and 5-fold cross validation of different algorithms.
To sum up, the metrics and , which are proposed based on the proposed method, can achieve better performance than the original R and respectively for estimating the level of class overlap of imbalanced datasets. Therefore, the conclusion that the proposed method and metrics are superior to address the class overlap under imbalanced distribution can be drawn.
6. Conclusions
In this paper, a theoretical analysis is conducted on the existing class overlap metrics and an improved method to address the class overlap under imbalanced distribution is proposed based on the theoretical analysis. Then, the corresponding metrics for estimating the class overlap of imbalanced datasets are also introduced. A well-known collection of the imbalanced datasets is used to compare the Pearson correlation coefficients and the correlation coefficients of different overlap metrics with the classification performance. In addition, the experimental results demonstrate that the proposed data overlap metrics outperform other compared metrics for the imbalanced datasets. The Pearson correlation coefficients with the AUC metric and the accuracy metric can be improved by 34.7488% and 8.0898% on average, respectively. Therefore, the proposed method and metrics can much better estimate the class overlap under imbalanced distribution.
In the future, the proposed metrics can be applied to feature selection and feature construction. In addition, they can also be used as meta-features in meta-learning for algorithm selection and parameters optimization.
Author Contributions
Conceptualization, methodology, formal analysis, and original draft preparation were part of Z.L. and J.Q.; data curation, review and editing and visualization were part of X.Z. and Y.W. All authors have read and agreed to the published version of the manuscript.
Funding
This work is partly supported by the National Natural Science Foundation of China (No. 61971031), the National Key R&D Program of China (No.2018YFB0704300), the Scientific and Technological Innovation Foundation of Shunde Graduate School, USTB (BK20BF009), and interdisciplinary research project of USTB(FRF-IDRY-19-019).
Data Availability Statement
Data not included in the paper are available from the corresponding author upon reasonable request.
Acknowledgments
This work is partly supported by the National Natural Science Foundation of China (No. 61971031), the National Key R&D Program of China (No.2018YFB0704300), the Scientific and Technological Innovation Foundation of Shunde Graduate School, USTB (BK20BF009), and the interdisciplinary research project of USTB (FRF-IDRY-19-019).
Conflicts of Interest
The authors declare no conflict of interest.
Appendix A
If the distance between the real data distribution and the ideal data distribution is replaced by Hellinger distance, the distance can be shown in Equation (A1). In addition, it can be simplified to Equation (A2) as is a near zero value:
To make the distance fair to different classes in an imbalanced dataset, the coefficients of for different classes are equal as shown in Equation (A3). Then, it can be seen that the result is consistent to the result obtained by K-L divergence:
References
- Japkowicz, N.; Stephen, S. The class imbalance problem: A systematic study. Intell. Data Anal. 2002, 6, 429–449. [Google Scholar] [CrossRef]
- Guo, H.; Li, Y.; Jennifer, S.; Gu, M.; Huang, Y.; Gong, B. Learning from class-imbalanced data: Review of methods and applications. Expert Syst. Appl. 2017, 73, 220–239. [Google Scholar]
- Sun, Y.; Wong, A.K.C.; Kamel, M.S. Classification of imbalanced data: A review. Int. J. Pattern Recognit. Artif. Intell. 2009, 23, 687–719. [Google Scholar] [CrossRef]
- Dogo, E.M.; Nwulu, N.I.; Twala, B.; Aigbavboa, C. Accessing Imbalance Learning Using Dynamic Selection Approach in Water Quality Anomaly Detection. Symmetry 2021, 13, 818. [Google Scholar] [CrossRef]
- Bejjanki, K.K.; Gyani, J.; Gugulothu, N. Class Imbalance Reduction (CIR): A Novel Approach to Software Defect Prediction in the Presence of Class Imbalance. Symmetry 2020, 12, 407. [Google Scholar] [CrossRef] [Green Version]
- He, H.; Garcia, E.A. Learning from Imbalanced Data. IEEE Trans. Knowl. Data Eng. 2009, 21, 1263–1284. [Google Scholar]
- Xiong, H.; Wu, J.; Liu, L. Classification with Class Overlapping: A Systematic Study. In Proceedings of the 1st International Conference on E-Business Intelligence (ICEBI 2010), Guangzhou, China, 19–21 December 2010; Atlantis Press: Dordrecht, The Netherlands, 2010; pp. 491–497. [Google Scholar]
- Liu, C.L. Partial discriminative training for classification of overlapping classes in document analysis. Int. J. Doc. Anal. Recognit. 2008, 11, 53–56. [Google Scholar] [CrossRef]
- Oh, S. A new dataset evaluation method based on category overlap. Comput. Biol. Med. 2011, 41, 115–122. [Google Scholar] [CrossRef]
- Denil, M.; Trappenberg, T. Overlap versus imbalance. In Advances in Artificial Intelligence; Canadian AI 2010. Lecture Notes Computer Science; Farzindar, A., Keselj, V., Eds.; Springer: Berlin/Heidelberg, Germany, 2010; Volume 6085, pp. 220–231. [Google Scholar]
- Lee, H.K.; Kim, S.B. An overlap-sensitive margin classifier for imbalanced and overlapping data. Expert Syst. Appl. 2018, 98, 72–83. [Google Scholar] [CrossRef]
- Klomsae, A.; Auephanwiriyakul, S.; Theera-Umpon, N. A string grammar fuzzy-possibilistic c-medians. Appl. Soft Comput. 2017, 57, 684–695. [Google Scholar] [CrossRef]
- Lee, J.; Batnyam, N.; Oh, S. RFS: Efficient feature selection method based on R-value. Comput. Biol. Med. 2013, 43, 91–99. [Google Scholar] [CrossRef]
- Wang, X.; Lin, X.; Huang, X.; Yang, Y. Ensemble unsupervised feature selection based on permutation and R-value. In Proceedings of the 2015 12th International Conference on Fuzzy Systems and Knowledge Discovery (FSKD), Zhangjiajie, China, 15–17 August 2015. [Google Scholar]
- Li, Z.; He, J.; Zhang, X.; He, J.; Qin, J. Toward high accuracy and visualization: An interpretable feature extraction method based on genetic programming and non-overlap degree. In Proceedings of the 2020 IEEE International Conference on Bioinformatics and Biomedicine (BIBM), Seoul, Korea, 16–19 December 2020; pp. 299–304. [Google Scholar]
- Kang, D.; Oh, S. Balanced Training/Test Set Sampling for Proper Evaluation of Classification Models. Intell. Data Anal. 2020, 24, 5–18. [Google Scholar] [CrossRef]
- Borsos, Z.; Lemnaru, C.; Potolea, R. Dealing with overlap and imbalance: A new metric and approach. Pattern Anal. Appl. 2018, 21, 381–395. [Google Scholar] [CrossRef]
- Fu, G.; Wu, Y.; Zong, M.; Yi, L. Feature selection and classification by minimizing overlap degree for class-imbalanced data in metabolomics. Chemom. Intell. Lab. Syst. 2020, 196, 103906. [Google Scholar] [CrossRef]
- Fatima, E.B.; Omar, B.; Abdelmajid, E.M.; Rustam, F.; Mehmood, A.; Choi, G.S. Minimizing the overlapping degree to improve class-imbalanced learning under sparse feature selection. Application to fraud detection. IEEE Access 2021, 9, 28101–28110. [Google Scholar] [CrossRef]
- Venna, J.; Peltonen, J.; Nybo, K.; Aidos, H.; Kaski, S. Information Retrieval Perspective to Nonlinear Dimensionality Reduction for Data Visualization. J. Mach. Learn. Res. 2010, 11, 451–490. [Google Scholar]
- Bradley, A.P. The use of the area under the roc curve in the evaluation of machine learning algorithms. Pattern Recognit. 1997, 30, 1145–1159. [Google Scholar] [CrossRef] [Green Version]
- Luque, A.; Carrasco, A.; Martín, A.; Lama, J.R. Exploring Symmetry of Binary Classification Performance Metrics. Symmetry 2019, 11, 47. [Google Scholar] [CrossRef] [Green Version]
- Pedregosa, F.; Varoquaux, G.; Gramfort, A.; Michel, V.; Thirion, B.; Grisel, O.; Blondel, M.; Prettenhofer, P.; Weiss, R.; Dubourg, V.; et al. Scikit-learn: Machine Learning in Python. J. Mach. Learn. Res. 2011, 12, 2825–2830. [Google Scholar]
- López, V.; Fernández, A.; García, S.; Palade, V.; Herrera, F. An insight into classification with imbalanced data: Empirical results and current trends on using data intrinsic characteristics. Inform. Sci. 2013, 250, 113–141. [Google Scholar] [CrossRef]
- Pearson, K. Notes on Regression and Inheritance in the Case of Two Parents. Proc. R. Soc. Lond. 1895, 58, 240–242. [Google Scholar]
- Sourav, C. A New Coefficient of Correlation. J. Am. Stat. Assoc. 2020, 1–14. [Google Scholar]
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).