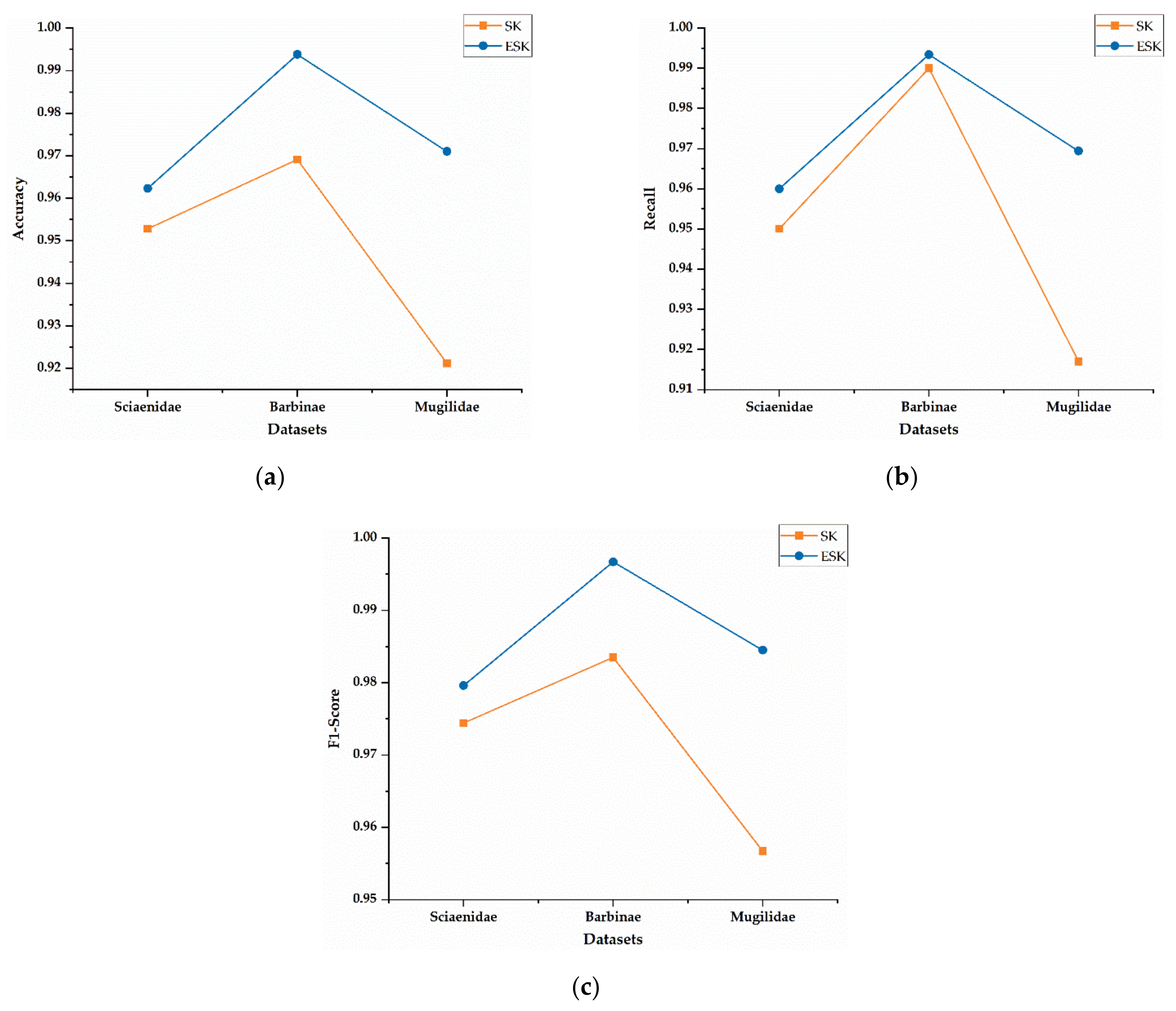
2.2.1. An Overview of ESK
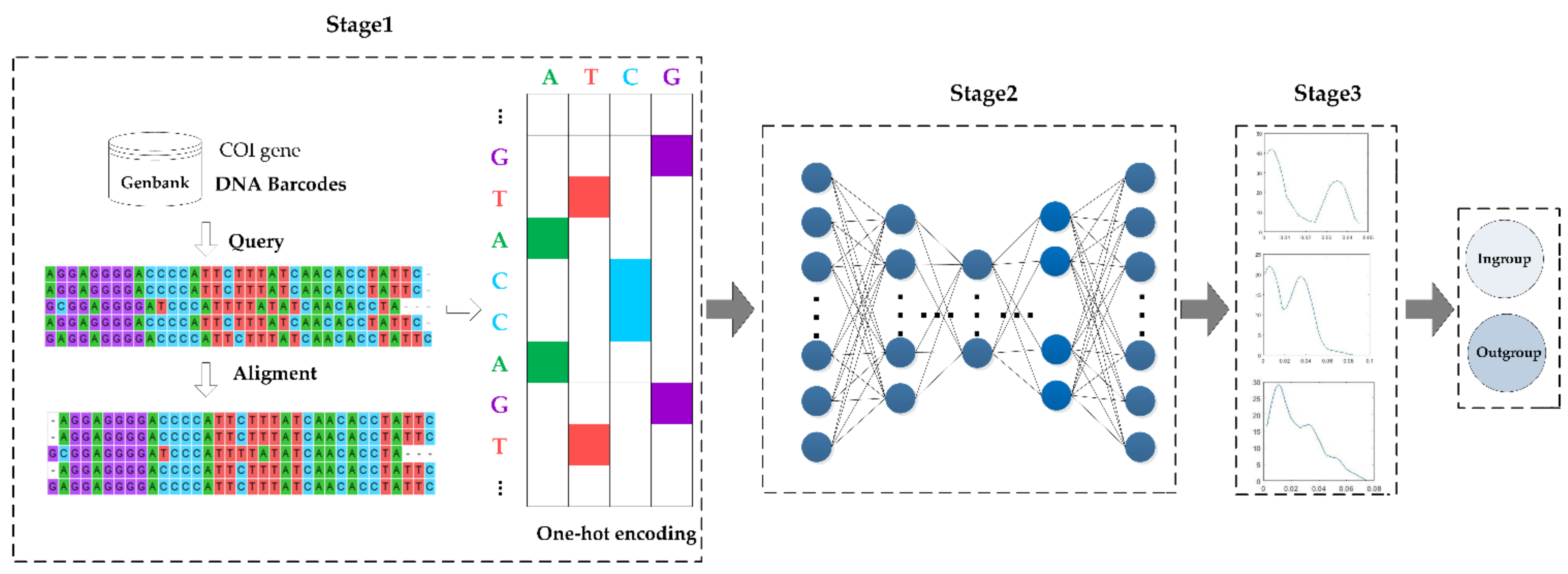
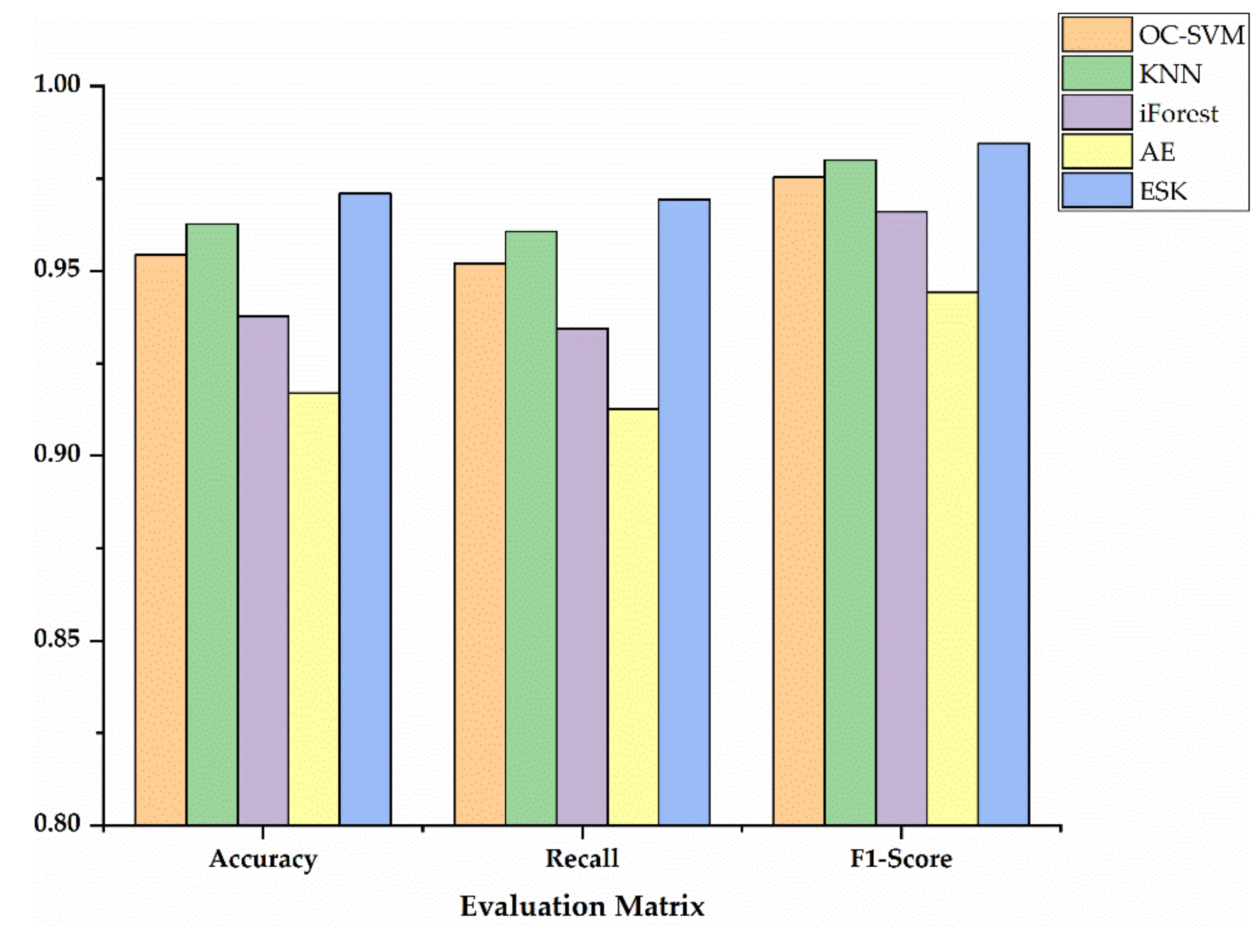
An overview of the proposed model is shown in
Figure 1, ESK model, which consists of three stages: (1) data preprocessing stage, (2) learning deep features and computing each sample outgroup score stage, and (3) deciding a threshold base on the outgroup scores and classifying fish from different families.
In stage one, there are three main tasks: (1) aligning DNA barcode sequences to obtain the sequences with the same length. (2) representing DNA barcode sequences in a matrix and (3) one-hot encoding is performed on the matrix because the features of each species need to be transformed into numerical form. Finally, the preprocessed data is used as an input for stage two.
In stage two, a deep learning network, EN-SAE, is used to learn deep features from the data preprocessed in stage one. The method utilizes EN-SAE to compress the digitalized data into a representation of the potential data to reconstruct input, then, calculates the difference between input and output, and obtains an outgroup score for each sample. Finally, the outgroup scores are used as input for stage three.
In stage three, KDE technique is used to learn the relationship between each score from stage two, and then, fits the data distribution according to properties of the outgroup scores. After that, KDE determines which objects are ingroups and which objects are outgroups based on the threshold.
2.2.3. Learning Deep Features and Computing the Outgroup Scores by EN-SAE
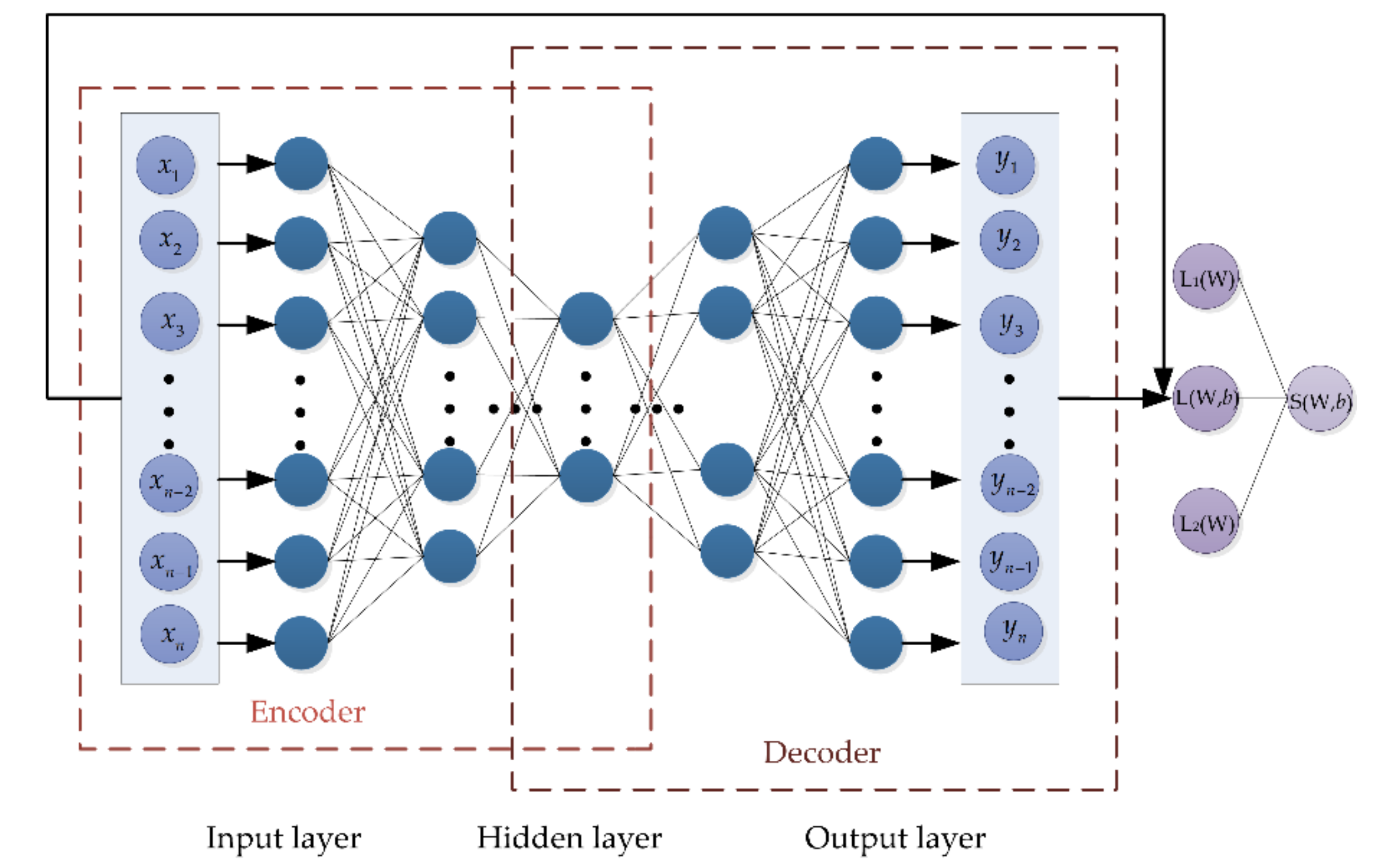
The traditional Autoencoder (AE) is a three-layer neural network, including an input layer, an output layer, and a hidden layer. The structure of AE is symmetric, that is, input and output layers have the same number of nodes and the dimension of each node is also the same [
39]. The purpose of AE is to compress input data, save useful information to reconstruct input, and use the back propagation algorithm to update the weights so that the output is as similar to the input as possible [
40]. However, the relatively long base pair segments of DNA barcode lead to high dimensionality in each dataset, the output is not sufficient to yield a valuable representation of input. The reconstruction criterion with three-layer structure is unable to guarantee the extraction of useful features as it can lead to the obvious solution “simply copy the input” [
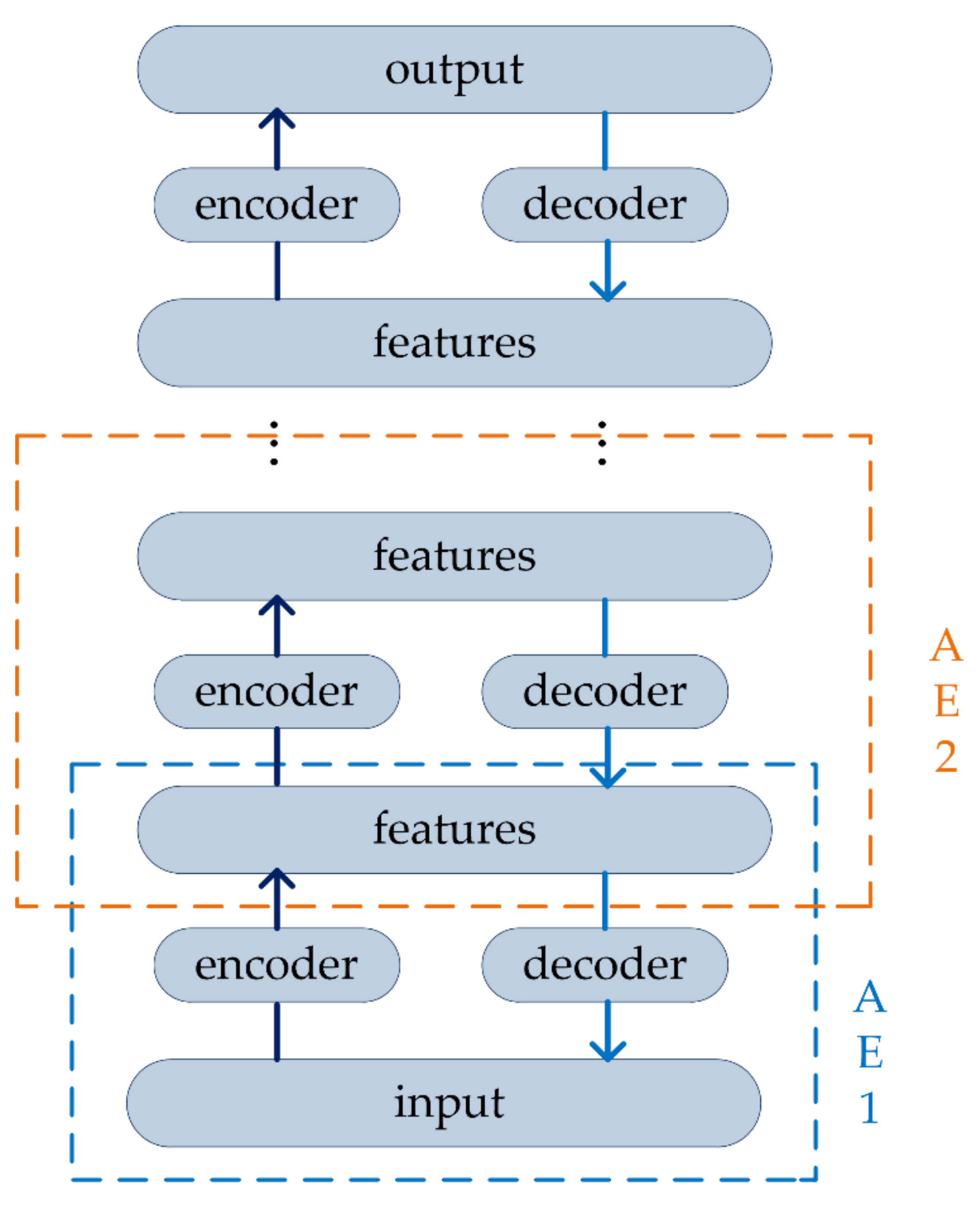
41]. The Stacked Autoencoder (SAE) can greatly solve this problem.
The SAE builds a deep neural network base on AE by stacking several AEs, putting the hidden representations of the upper layer as the input of the next AE. In other word, the compressed features of the hidden layer are extracted to the next AE for training. In this way, training layer-by-layer can achieve input features compressed. At the same time, more meaningful features of DNA barcode sequences are obtained. The decoder can be reconstructed back into the input with a sufficiently small difference, the structure of SAE is expressed in
Figure 2.
There are two basic steps in SAE training: encoder and decoder.
(1) Encoder: the activation function σ
e maps input data vector
x to hidden representation
h. This process compresses the input data and retains more useful representations, the typical form is represented by a nonlinear representation as follows:
where
x denotes the input data vector,
W is the weight matrix connecting the input and hidden layers,
b is the bias vector belonging to the latent layer nodes, and σ
e represents the activation function, such as Sigmoid, Relu, Tanh, etc.
(2) Decoder: in this step, the hidden representation
h is mapped into reconstruction vector
y, the typical form as follows:
where
W’ is the weight matrix connecting the latent and output layers,
b’ is the bias vector, and σ
d represents the activation function.
Loss function is defined to measure the reliability of SAE. SAE is trained to reconstruct the features of input and adjust the weights of the encoder and decoder to minimize the error between the output and the input. Thus, loss function is introduced, which is expressed in terms of mean square error as follows:
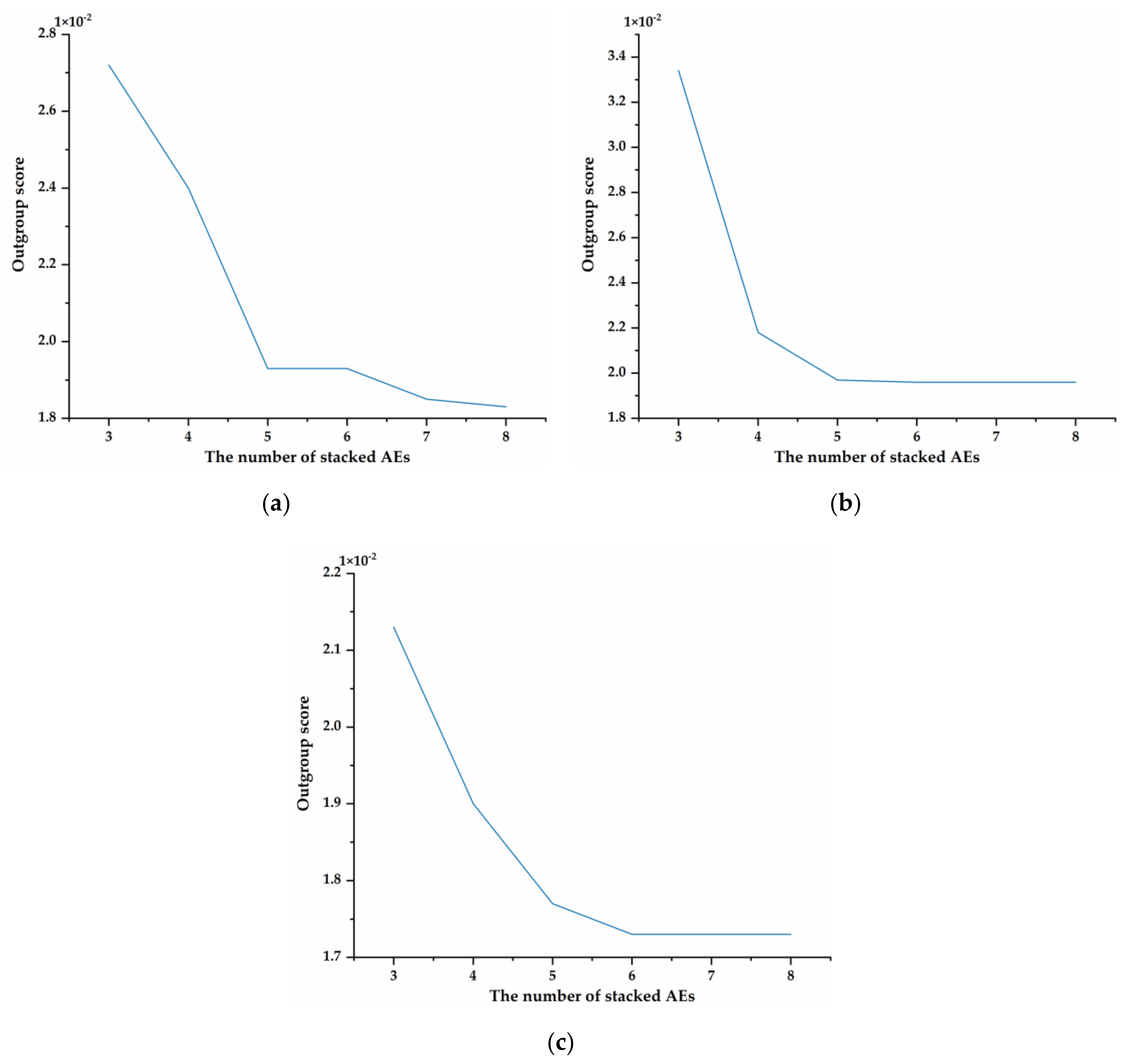
However, each family contains a limited number of fish species, resulting in a relatively small sample size for each dataset, and overfitting can easily occur during the training process. At the same time, due to the high dimensionality of DNA barcode sequences, training the model is time consuming. In order to improve the generalization ability of the proposed model and reduce model training time, some constraints are added to reduce the weight of useless features. Based on this point, Elastic Net composing of L1-norm and L2-norm is introduced in this method. The structure of EN-SAE model is shown in
Figure 3. It can also treat L1-norm and L2-norm as penalty for loss function to restrict some parameters in the process of training.
L1-norm, also called Lasso regression, contributes to generate a sparse matrix. It is defined as: , denotes the sum of the absolute value of each element in weight vector W. Thus, it can be used to choose more meaningful representations. When training the model, too many features of a sample make it difficult to select features that contribute more to the model. Therefore, we drop the connections that contribute tiny to the model and dropping them even have no impact on the classification performance. For high dimensional data, it can reduce time consuming and extract more useful features.
L2-norm, also called Ridge regression, is defined as: , denotes the sum of the squares of each element in weight vector W. During the model training, we usually tend to make the weight as small as possible, because it is generally believed that model with small parameters can effectively fit different data. Thus, L2-norm can void overfitting to some extent and improve the generalization of model to fit small datasets for fish classification.
On the basis of proposed EN-SAE model, the outgroup score of each sample can be defined as a measure of whether the fish is an outgroup. The higher the outgroup scores are, the more likely they are to be considered as outgroups.
The outgroup score can be calculated by the following formula:
where
λ1 is a parameter to adjust the L2-norm,
λ2 is a parameter to adjust the L1-norm.
The EN-SAE model maps high-dimensional features into low-dimensional features step by step to obtain a higher representation of DNA barcode sequences, which is more suitable for extracting features and expressing data from original data.
2.2.4. Analyzing the Outgroup Scores by KDE
KDE is the most common nonparametric density estimation technique [
42]. KDE provides a way to smooth data points, and then fits the distribution by the properties of data itself. In our method, the decision threshold is determined by KDE base on the outgroup scores. After that, the correct classification results of fish will be found. Given the outgroup score vector
s obtained from the EN-SAE model, KDE estimates the probability density function (PDF)
p(
s) in a nonparametric way:
where
n is the size of dataset, {
si}
i = 1, 2, …,
n, is the outgroup score vector of dataset, K (⋅) is the kernel function, and
h is the bandwidth.
There are many kinds of kernel functions, and the epanechnikov function is the most commonly used function in density estimation, and also has good effects. Therefore, epanechnikov is used to estimate the PDF:
After obtaining
p(
s), the cumulative distribution function (CDF) F(
s) can be defined as follows:
Given a significance level parameter
α ϵ [0, 1] and combined with CDF, a decision threshold
sα can be found,
sα satisfies the following formula:
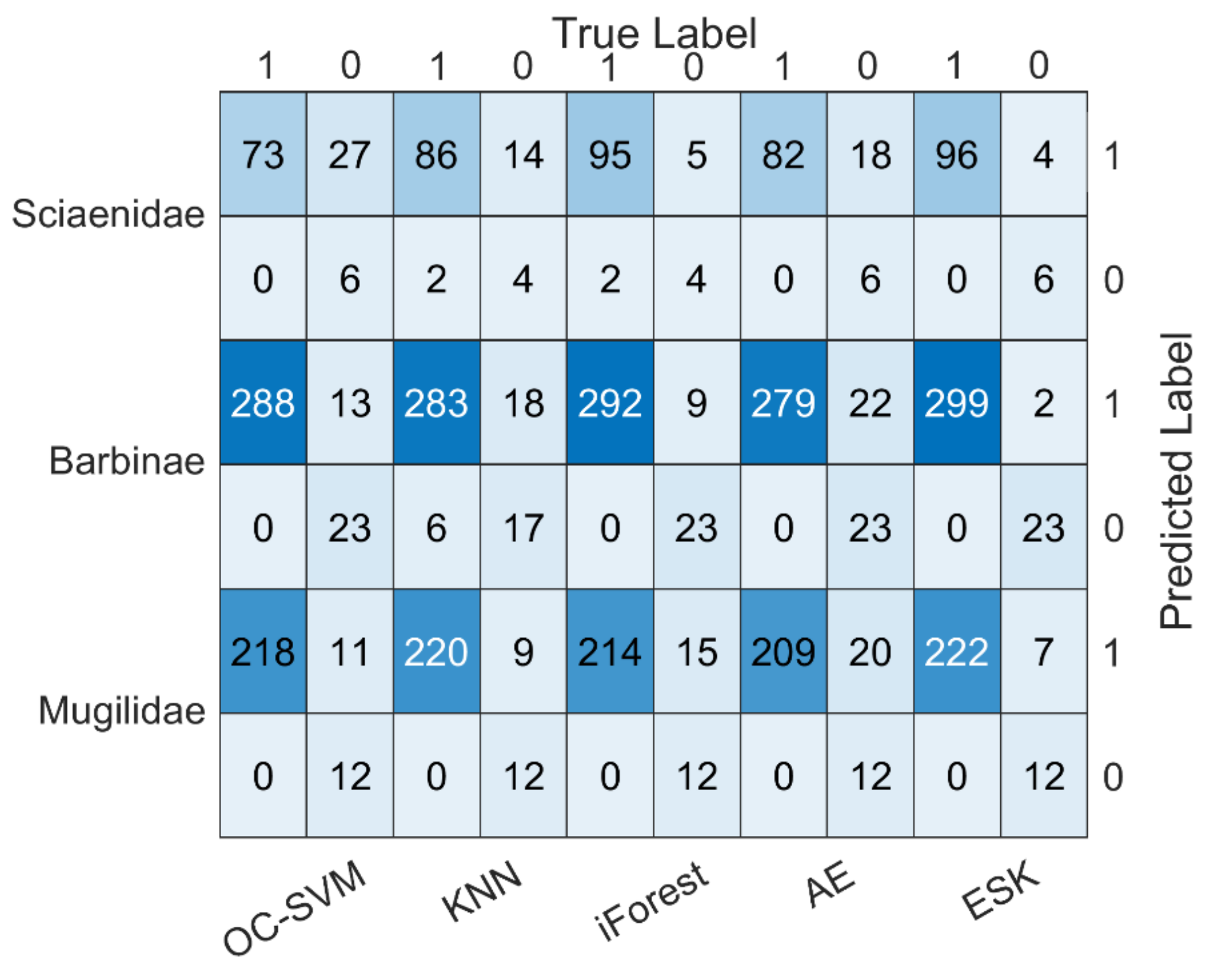
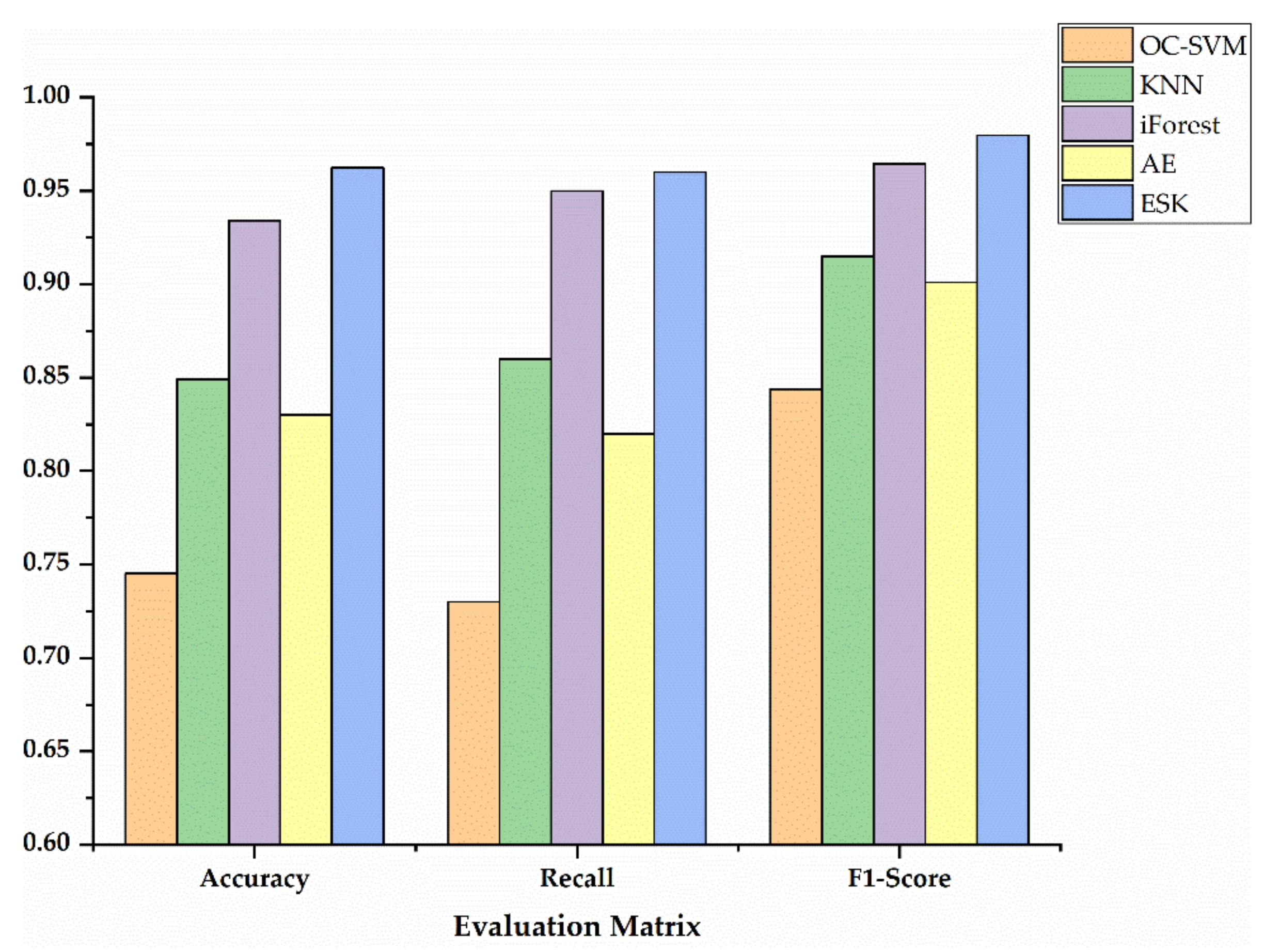
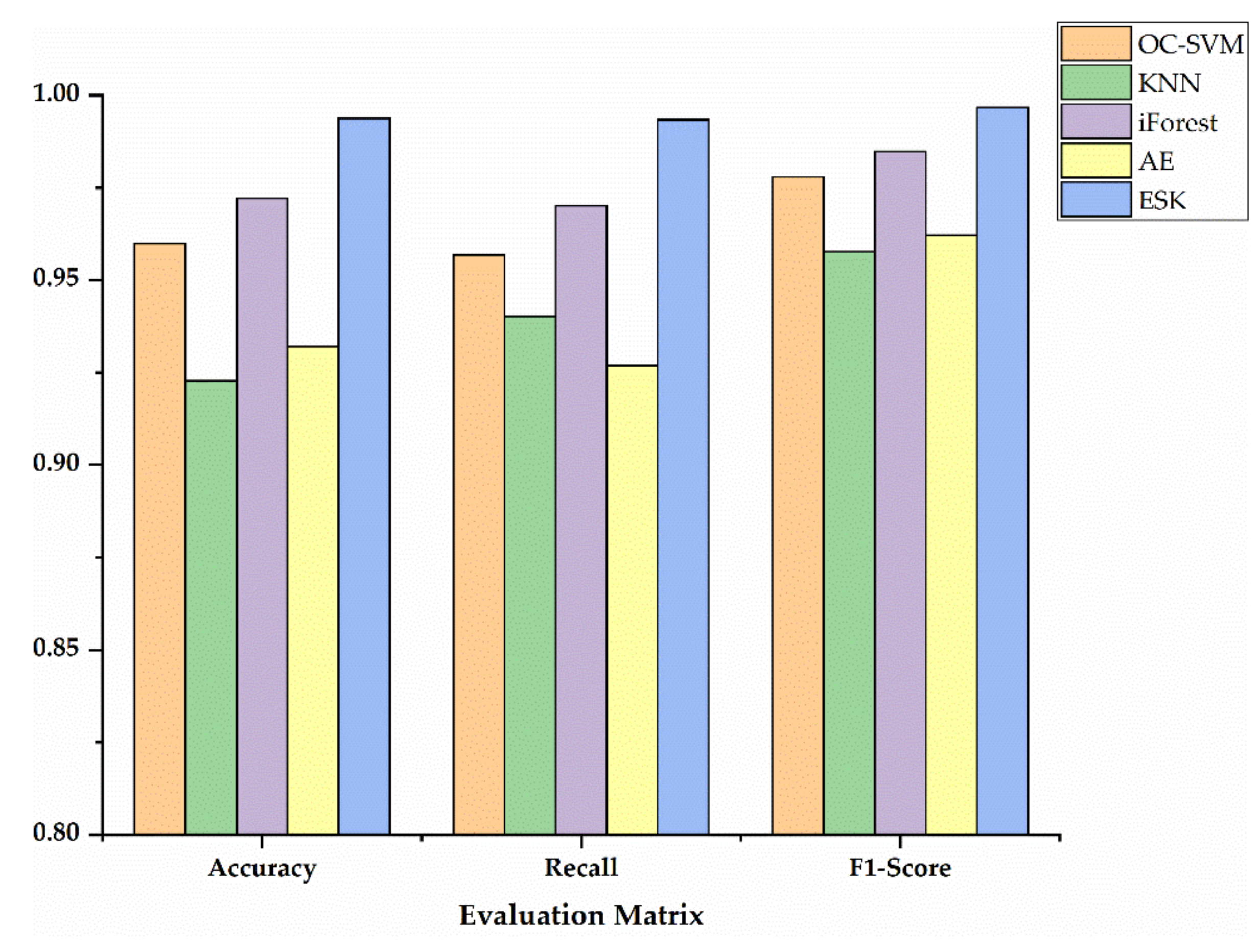
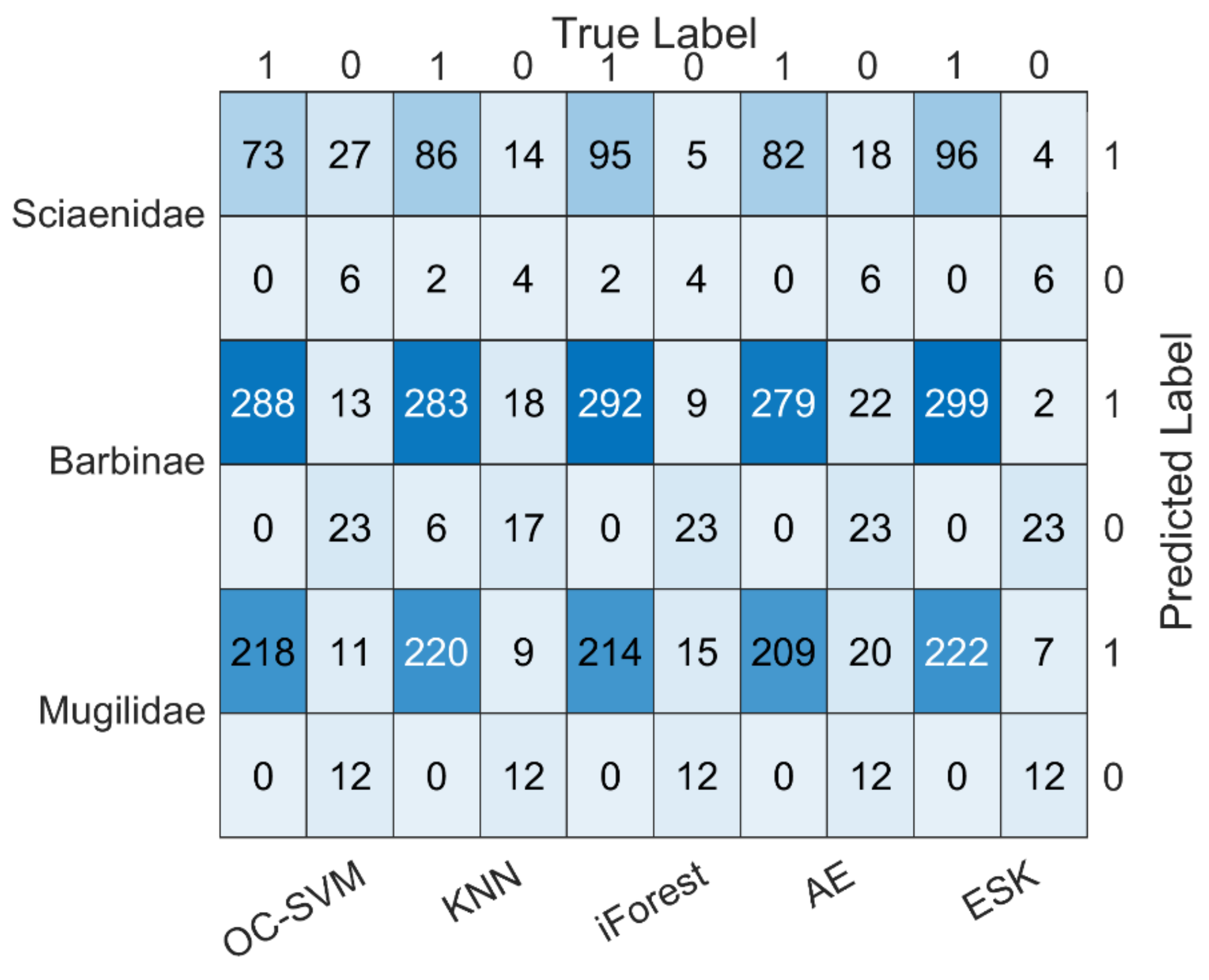
If the outgroup score of each species meets the condition s ≥ sα, the sample will be considered as an outgroup. On the contrary, it is an ingroup. Confirmed by repeated experiments that significance level parameter α is recommended to be set to 0.05. The ESK model, which fuses EN-SAE with KDE, is summarized as shown in Algorithm 1.


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}