
A Feature Combination-Based Graph Convolutional Neural Network Model for Relation Extraction

Abstract
:1. Introduction
- Our methods to generate combined features are used to initialize an adjacent matrix for a graph neural network. It is effective at capturing the structural information of a sentence.
- Based on a graph convolutional neural network, a deep architecture is designed to support relation extraction. It outperforms existing state-of-the-art performance.
2. Related Work
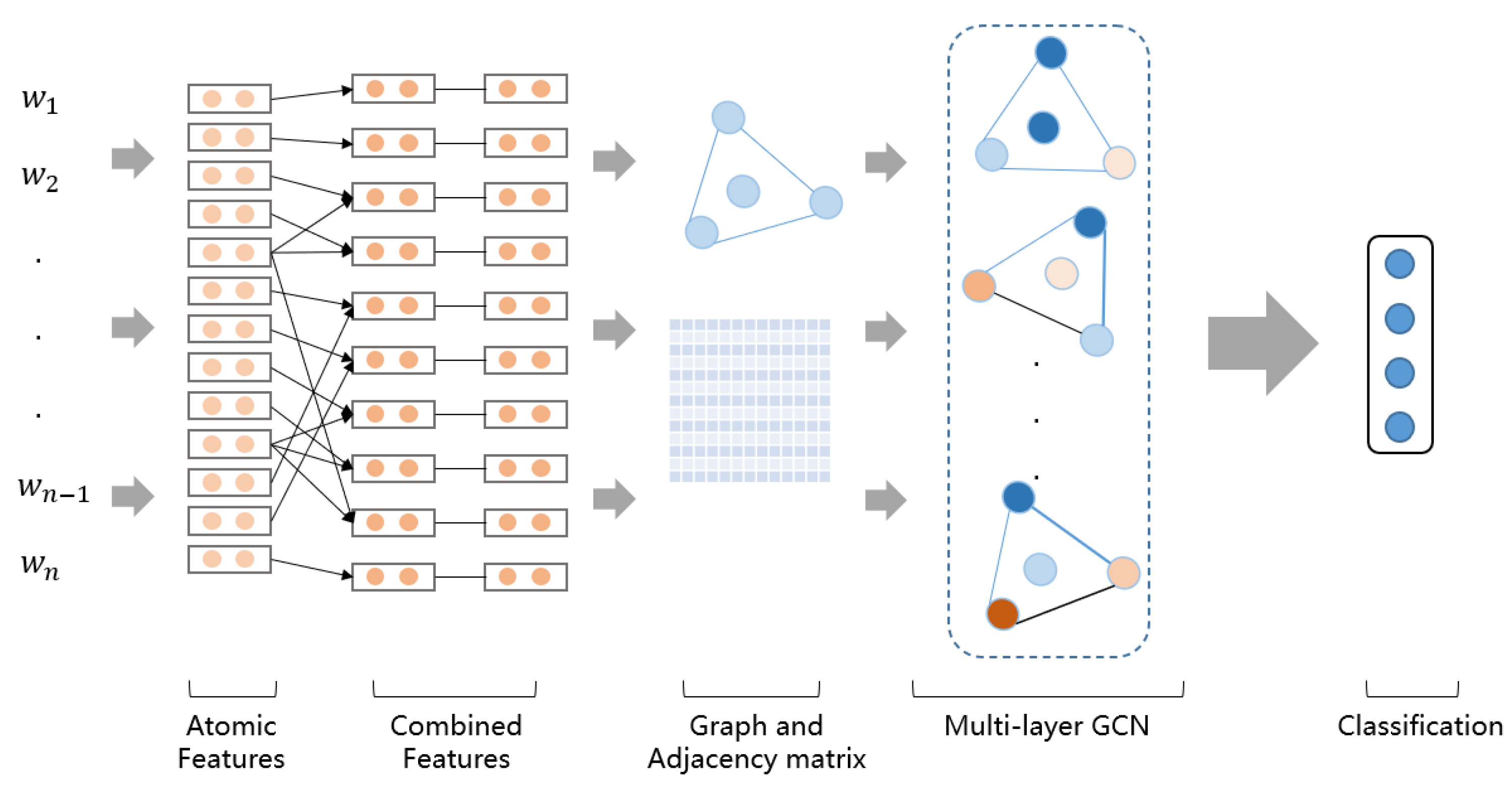
3. Model
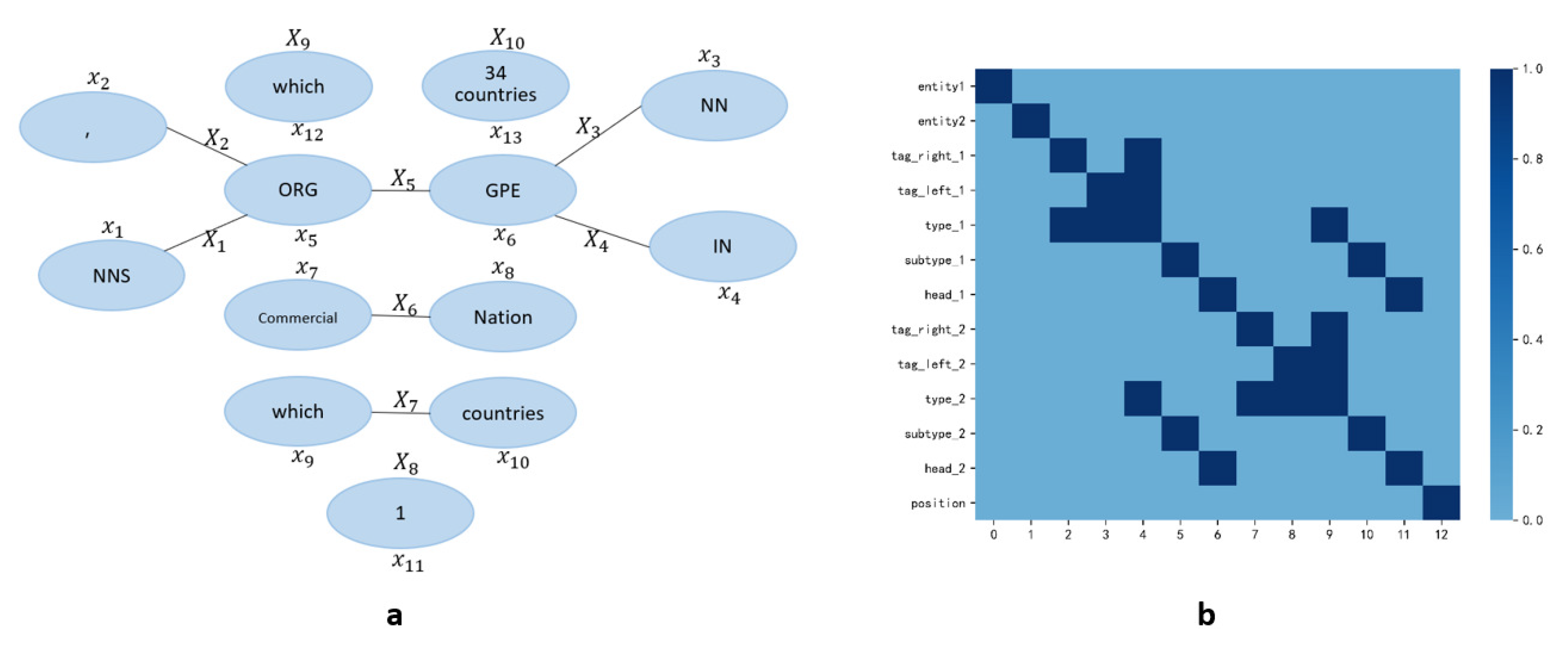
3.1. The Atomic and Combined Features
3.2. Graph Based on Combined Features
3.3. GCN Module
3.4. Prediction
4. Experiment
4.1. Datasets
4.2. Experimental Setting
4.3. Results on the Three Datasets
4.4. Comparison with Benchmark Models
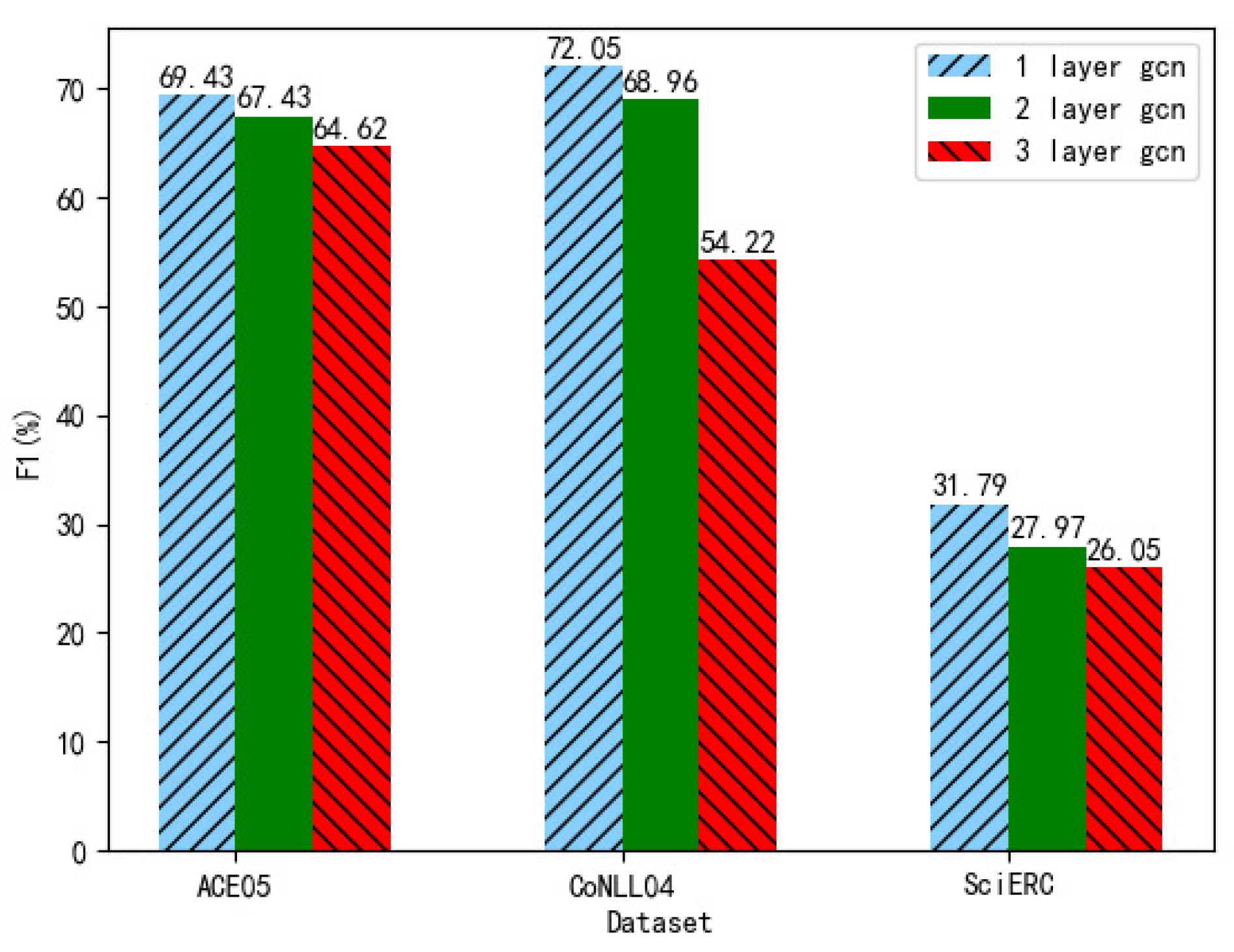
4.5. Analysis
4.6. Comparison with Related Works
5. Conclusions and Future Work
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Conflicts of Interest
References
- Zhang, Y.; Zhong, V.; Chen, D.; Angeli, G.; Manning, C.D. Position-aware attention and supervised data improve slot filling. In Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, Copenhagen, Denmark, 7–11 September 2017. [Google Scholar]
- He, R.; Wang, J.; Guo, F.; Han, Y. Transs-driven joint learning architecture for implicit discourse relation recognition. In Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics, Online, 5–10 July 2020. [Google Scholar]
- Sun, K.; Zhang, R.; Mao, Y.; Mensah, S.; Liu, X. Relation extraction with convolutional network over learnable syntax-transport graph. Proc. AAAI Conf. Artif. 2020, 34, 8928–8935. [Google Scholar] [CrossRef]
- Chen, Y.; Wang, G.; Zheng, Q.; Qin, Y.; Chen, P. A set space model to capture structural information of a sentence. IEEE Access 2019, 7, 142515–142530. [Google Scholar] [CrossRef]
- Zeng, D.; Liu, K.; Lai, S.; Zhou, G.; Zhao, J. Relation classification via convolutional deep neural network. In Proceedings of the COLING 2014, the 25th International Conference on Computational Linguistics: Technical Papers; Dublin City University and Association for Computational Linguistics: Dublin, Ireland, 2014; pp. 2335–2344. Available online: https://www.aclweb.org/anthology/C14-1220 (accessed on 1 April 2021).
- Xu, K.; Feng, Y.; Huang, S.; Zhao, D. Semantic relation classification via convolutional neural networks with simple negative sampling. Comput. Sci. 2015, 71, 941–949. [Google Scholar]
- Zeng, D.; Liu, K.; Chen, Y.; Zhao, J. Distant supervision for relation extraction via piecewise convolutional neural networks. In Proceedings of the Conference on Empirical Methods in Natural Language Processing, Lisbon, Portugal, 17–21 September 2015. [Google Scholar]
- Yan, X.; Mou, L.; Li, G.; Chen, Y.; Jin, Z. Classifying relations via long short term memory networks along shortest dependency paths. In Proceedings of the 2015 Conference on Empirical Methods in Natural Language Processing (EMNLP), Lisbon, Portugal, 17–21 September 2015. [Google Scholar]
- Zhang, Z.; Shu, X.; Yu, B.; Liu, T.; Guo, L. Distilling knowledge from well-informed soft labels for neural relation extraction. Proc. AAAI Conf. Artif. 2020, 34, 9620–9627. [Google Scholar]
- Veyseh, A.P.B.; Dernoncourt, F.; Dou, D.; Nguyen, T.H. Exploiting the syntax-model consistency for neural relation extraction. In Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics, Online, 5–10 July 2020. [Google Scholar]
- Alt, C.; Gabryszak, A.; Hennig, L. Probing linguistic features of sentence-level representations in neural relation extraction. In Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics, Online, 5–10 July 2020; Association for Computational Linguistics: Stroudsburg, PA, USA, 2020; pp. 1534–1545. Available online: https://www.aclweb.org/anthology/2020.acl-main.140 (accessed on 1 April 2021).
- Yu, D.; Sun, K.; Cardie, C.; Yu, D. Dialogue-based relation extraction. In Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics, Online, 5–10 July 2020. [Google Scholar]
- Zhou, W.; Huang, K.; Ma, T.; Huang, J. Document-level relation extraction with adaptive thresholding and localized context pooling. arXiv 2020, arXiv:2010.11304. [Google Scholar]
- Jain, S.; van Zuylen, M.; Hajishirzi, H.; Beltagy, I. Scirex: A challenge dataset for document-level information extraction. arXiv 2020, arXiv:2005.00512. [Google Scholar]
- Wei, Z.; Su, J.; Wang, Y.; Tian, Y.; Chang, Y. A novel cascade binary tagging framework for relational triple extraction. In Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics, Online, 5–10 July 2020. [Google Scholar]
- Shen, Y.; Huang, X.-J. Attention-based convolutional neural network for semantic relation extraction. In Proceedings of the COLING 2016, the 26th International Conference on Computational Linguistics: Technical Papers, Osaka, Japan, 11–16 December 2016; pp. 2526–2536. [Google Scholar]
- Guo, Z.; Zhang, Y.; Lu, W. Attention guided graph convolutional networks for relation extraction. arXiv 2019, arXiv:1906.07510. [Google Scholar]
- Vashishth, S.; Joshi, R.; Prayaga, S.S.; Bhattacharyya, C.; Talukdar, P. Reside: Improving distantly-supervised neural relation extraction using side information. In Proceedings of the 2018 Conference on Empirical Methods in Natural Language Processing, Brussels, Belgium, 31 October–4 November 2018. [Google Scholar]
- Fu, T.J.; Ma, W.Y. Graphrel: Modeling text as relational graphs for joint entity and relation extraction. ACL 2019, 1409–1418. [Google Scholar] [CrossRef] [Green Version]
- Zhang, Y.; Qi, P.; Manning, C.D. Graph convolution over pruned dependency trees improves relation extraction. arXiv 2018, arXiv:1809.10185. [Google Scholar]
- Vashishth, S.; Sanyal, S.; Nitin, V.; Talukdar, P.P. Composition-based multi-relational graph convolutional networks. arXiv 2019, arXiv:1911.03082. [Google Scholar]
- Sun, C.; Gong, Y.; Wu, Y.; Gong, M.; Duan, N. Joint type inference on entities and relations via graph convolutional networks. In Proceedings of the 57th Annual Meeting of the Association for Computational Linguistics, Florence, Italy, 28 July–2 August 2019. [Google Scholar]
- Chen, Y.; Zheng, Q.; Zhang, W. Omni-word feature and soft constraint for chinese relation extraction. In Proceedings of the 52nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), Baltimore, MD, USA, 22–27 June 2014. [Google Scholar]
- Kipf, T.N.; Welling, M. Semi-supervised classification with graph convolutional networks. arXiv 2016, arXiv:1609.02907. [Google Scholar]
- Roth, D.; Yih, W.-T. A linear programming formulation for global inference in natural language tasks. In Proceedings of the Eighth Conference on Computational Natural Language Learning (CoNLL-2004) at HLT-NAACL 2004, Boston, MA, USA, 6–7 May 2004; Association for Computational Linguistics: Boston, MA, USA, 2004; pp. 1–8. Available online: https://www.aclweb.org/anthology/W04-2401 (accessed on 1 April 2021).
- Luan, Y.; He, L.; Ostendorf, M.; Hajishirzi, H. Multi-task identification of entities, relations, and coreferencefor scientific knowledge graph construction. arXiv 2018, arXiv:1808.09602. [Google Scholar]
- Devlin, J.; Chang, M.W.; Lee, K.; Toutanova, K. Bert: Pre-training of deep bidirectional transformers for language understanding. arXiv 2018, arXiv:1810.04805. [Google Scholar]
- Kambhatla, N. Combining lexical, syntactic, and semantic features with maximum entropy models for extracting relations. In Proceedings of the ACL 2004 on Interactive Poster and Demonstration Sessions, ACLdemo ’04, Barcelona, Spain, 21–26 July 2004; Association for Computational Linguistics: Boston, MA, USA, 2004. [Google Scholar] [CrossRef]
- Zhou, G.; Su, J.; Zhang, J.; Zhang, M. Exploring various knowledge in relation extraction. In Proceedings of the ACL 2005, 43rd Annual Meeting of the Association for Computational Linguistics, Ann Arbor, MI, USA, 25–30 June 2005. [Google Scholar]
- Gormley, M.R.; Yu, M.; Dredze, M. Improved relation extraction with feature-rich compositional embedding models. arXiv 2015, arXiv:1505.02419. [Google Scholar]
- Veyseh, A.P.B.; Nguyen, T.H.; Dou, D. Improving cross-domain performance for relation extraction via dependency prediction and information flow control. arXiv 2019, arXiv:1907.03230. [Google Scholar]
- Wang, H.; Tan, M.; Yu, M.; Chang, S.; Wang, D.; Xu, K.; Guo, X.; Potdar, S. Extracting multiple-relations in one-pass with pre-trained transformers. arXiv 2019, arXiv:1902.01030. [Google Scholar]
- Zhong, Z.; Chen, D. A frustratingly easy approach for joint entity and relation extraction. arXiv 2020, arXiv:2010.12812. [Google Scholar]
- Chen, Y.; Wang, K.; Yang, W.; Qing, Y.; Huang, R.; Chen, P. A multi-channel deep neural network for relation extraction. IEEE Access 2020, 8, 13195–13203. [Google Scholar] [CrossRef]
- Chen, Y.; Yang, W.; Wang, K.; Qin, Y.; Huang, R.; Zheng, Q. A neuralized feature engineering method for entity relation extraction. Neural Netw. 2021, 141, 249–260. [Google Scholar] [CrossRef] [PubMed]

{kind=link}
{kind=link}
{kind=link}
| Split | ACE05 | CoNLL04 | SciERC |
|---|---|---|---|
| train | 83293 | 15264 | 19540 |
| dev | 13779 | 1908 | 2443 |
| test | 13780 | 1908 | 2443 |
| Dataset | Relationship Type | FC-GCN | FC-GCN+sen | ||||
|---|---|---|---|---|---|---|---|
| P(%) | R(%) | F1(%) | P(%) | R(%) | F1(%) | ||
| ACE05 | PHYS | 68.22 | 44.79 | 54.07 | 71.70 | 46.63 | 56.51 |
| ART | 87.18 | 53.12 | 66.02 | 93.55 | 45.31 | 61.05 | |
| GEN-AFF | 69.77 | 44.78 | 54.55 | 61.29 | 56.72 | 58.91 | |
| ORG-AFF | 85.63 | 77.30 | 81.25 | 91.22 | 72.97 | 81.08 | |
| PART-WHOLE | 73.63 | 77.01 | 75.28 | 75.58 | 74.71 | 75.14 | |
| PER-SOC | 88.89 | 70.00 | 78.32 | 91.67 | 68.75 | 78.57 | |
| total | 78.89 | 61.17 | 68.91 | 80.83 | 60.85 | 69.43 | |
| Dataset | Relationship Type | FC-GCN | FC-GCN+sen | ||||
|---|---|---|---|---|---|---|---|
| P(%) | R(%) | F1(%) | P(%) | R(%) | F1(%) | ||
| CoNLL04 | Work_For | 62.79 | 87.10 | 72.97 | 65.00 | 83.87 | 73.24 |
| Kill | 70.59 | 80.00 | 75.00 | 71.88 | 76.67 | 74.19 | |
| OrgBased_In | 75.51 | 77.08 | 76.29 | 82.61 | 79.17 | 80.85 | |
| Live_In | 63.93 | 69.64 | 66.67 | 59.09 | 69.64 | 63.93 | |
| Located_In | 65.85 | 62.79 | 64.29 | 55.56 | 81.40 | 66.04 | |
| total | 67.74 | 75.32 | 71.33 | 66.83 | 78.15 | 72.05 | |
| SciERC | Used-for | 35.05 | 27.31 | 30.70 | 27.67 | 35.34 | 31.04 |
| Feature-of | 00.00 | 00.00 | 00.00 | 08.00 | 10.53 | 09.09 | |
| Hyponym-of | 76.19 | 33.33 | 46.38 | 66.67 | 37.50 | 48.00 | |
| Evaluate-for | 55.17 | 41.03 | 47.06 | 44.68 | 53.85 | 48.84 | |
| Part-of | 16.67 | 04.55 | 07.14 | 19.44 | 31.82 | 24.14 | |
| Compare | 44.44 | 20.00 | 27.59 | 20.00 | 20.00 | 20.00 | |
| Conjunction | 52.83 | 47.46 | 50.00 | 32.35 | 37.29 | 34.65 | |
| total | 40.05 | 24.81 | 30.64 | 31.26 | 32.33 | 31.79 | |
| Model | ACE05 | CoNLL04 | SciERC | ||||||
|---|---|---|---|---|---|---|---|---|---|
| P(%) | R(%) | F1(%) | P(%) | R(%) | F1(%) | P(%) | R(%) | F1(%) | |
| 77.01 | 50.48 | 60.98 | 71.30 | 65.02 | 68.02 | 52.18 | 19.26 | 28.14 | |
| 72.11 | 54.45 | 62.05 | 72.28 | 65.63 | 68.79 | 61.15 | 19.71 | 29.81 | |
| FC-GCN | 78.89 | 61.17 | 68.91 | 67.74 | 75.32 | 71.33 | 40.05 | 24.81 | 30.64 |
| +sen | 64.65 | 56.62 | 60.37 | 69.04 | 67.12 | 68.07 | 33.41 | 22.13 | 26.62 |
| +sen | 74.72 | 51.36 | 60.88 | 65.66 | 72.95 | 69.11 | 30.20 | 24.33 | 26.95 |
| FC-GCN+sen | 80.83 | 60.85 | 69.43 | 66.83 | 78.15 | 72.05 | 31.26 | 32.33 | 31.79 |
| Model | P(%) | R(%) | F1(%) |
|---|---|---|---|
| K [28] | 63.50 | 45.20 | 52.80 |
| G&J [29] | 77.20 | 60.70 | 68.00 |
| FCM [30] | 71.52 | 49.32 | 58.26 |
| DRPC [31] | 72.10 | 63.49 | 67.52 |
| GCN(D+H) [22] | 68.7 | 65.4 | 67.00 |
| BERT-EA [32] | - | - | 67.46 |
| BERT-Z&H [33] | - | - | 73.10 |
| FC-GCN | 78.89 | 61.17 | 68.91 |
| FC-GCN+sen | 80.83 | 60.85 | 69.43 |
| BERT_FC-GCN+sen | 85.64 | 75.95 | 80.50 |
| Model | CoNLL04 | SciERC | ||||
|---|---|---|---|---|---|---|
| P(%) | R(%) | F1(%) | P(%) | R(%) | F1(%) | |
| Multi-channel [34] | 74.53 | 58.38 | 64.94 | 22.78 | 18.37 | 20.29 |
| [35] | 46.89 | 73.43 | 57.23 | 20.31 | 18.30 | 19.25 |
| [35] | 72.87 | 62.39 | 67.22 | 36.16 | 26.72 | 30.73 |
| FC-GCN+sen | 66.83 | 78.15 | 72.05 | 31.26 | 32.33 | 31.79 |
| BERT_FC-GCN+sen | 81.75 | 77.39 | 79.51 | 62.85 | 55.71 | 59.07 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Xu, J.; Chen, Y.; Qin, Y.; Huang, R.; Zheng, Q. A Feature Combination-Based Graph Convolutional Neural Network Model for Relation Extraction. Symmetry 2021, 13, 1458. https://doi.org/10.3390/sym13081458
Xu J, Chen Y, Qin Y, Huang R, Zheng Q. A Feature Combination-Based Graph Convolutional Neural Network Model for Relation Extraction. Symmetry. 2021; 13(8):1458. https://doi.org/10.3390/sym13081458
Chicago/Turabian StyleXu, Jinling, Yanping Chen, Yongbin Qin, Ruizhang Huang, and Qinghua Zheng. 2021. "A Feature Combination-Based Graph Convolutional Neural Network Model for Relation Extraction" Symmetry 13, no. 8: 1458. https://doi.org/10.3390/sym13081458
APA StyleXu, J., Chen, Y., Qin, Y., Huang, R., & Zheng, Q. (2021). A Feature Combination-Based Graph Convolutional Neural Network Model for Relation Extraction. Symmetry, 13(8), 1458. https://doi.org/10.3390/sym13081458