
Network Intrusion Detection Based on an Efficient Neural Architecture Search



Abstract
:1. Introduction
- In the network intrusion detection task, NAS is introduced to search for more effective architectures. The classification model is better than the manually designed network traffic classification model. At the same time, in the architecture search task, the online surrogate model is used to optimize the architecture search efficiency, which results in a significant improvement in search efficiency, compared with the general NAS model.
- On the basis of previous studies, by filtering suitable operation blocks and introducing new operation blocks to adapt to the network traffic dataset, the performance of the search model is improved, so as to improve the search space of the network architecture.
- The network architecture search model is evaluated in different network traffic datasets and compared with the manually designed network traffic classification models, including CIC-DoS2017, ISCXIDS2012 and CIC-DDoS2019. Experiments show that our model offers strong scalability and effectiveness.
2. Materials and Methods
2.1. Classification Method for Malicious Network Traffic
2.2. Neural Architecture Search
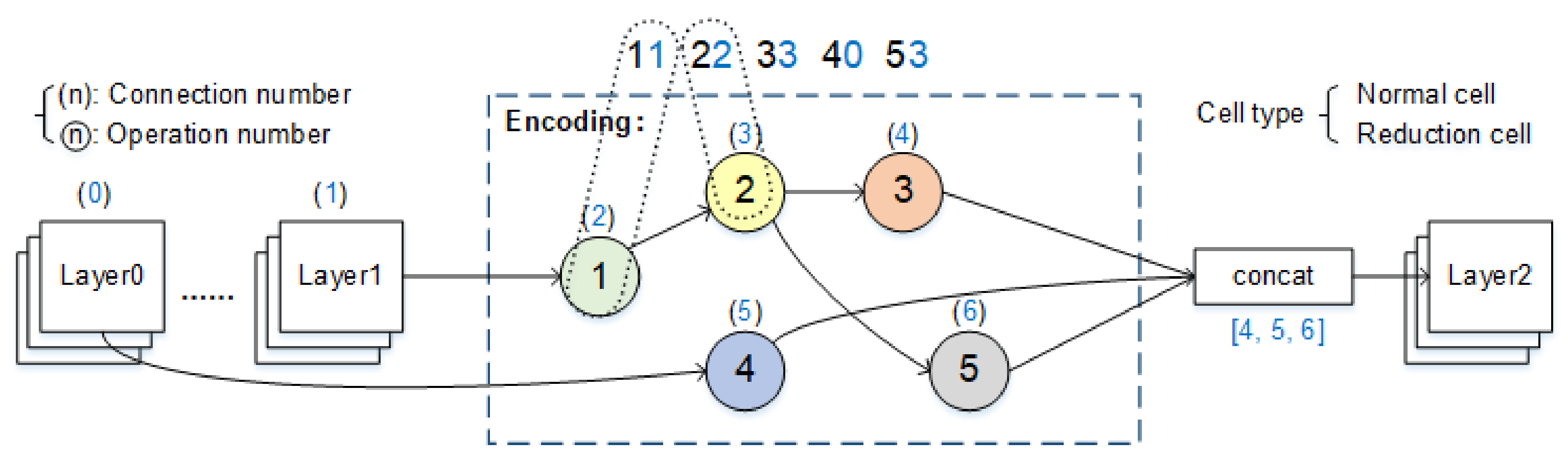
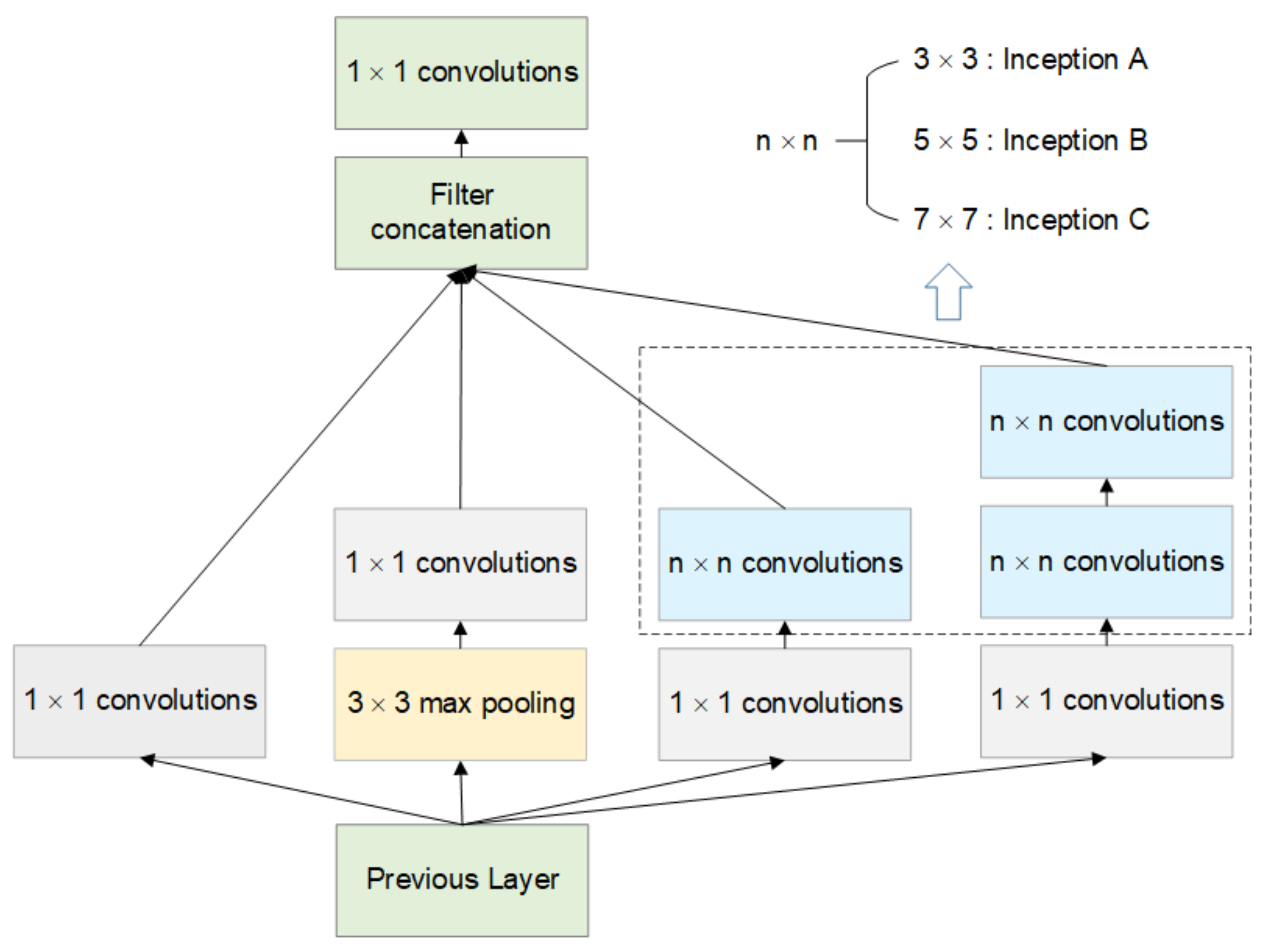
2.3. Search Space
2.4. Search Strategy
2.4.1. NSGA-II
| Algorithm 1 General framework of NSGA-II |
 |
2.4.2. MOEA/D
2.4.3. MOPSO
2.5. Surrogate Model
2.6. Lightweight Model
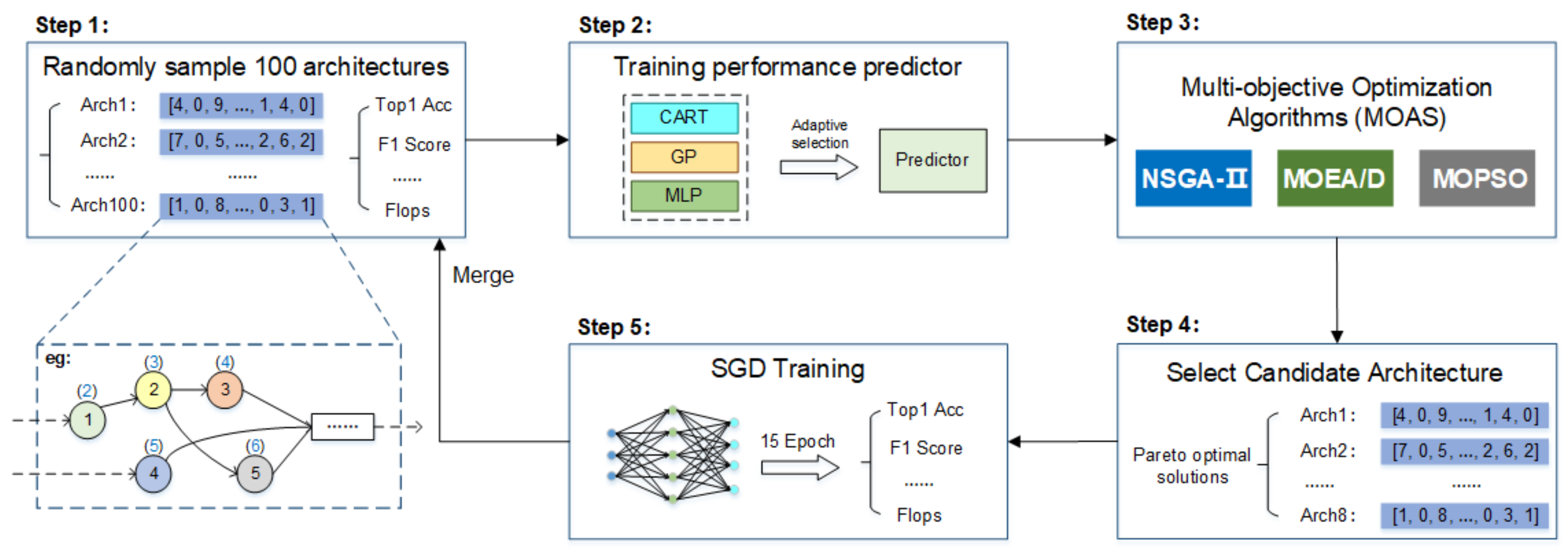
2.7. Proposed Approach
| Algorithm 2 General framework of Efficient-NAS |
 |
3. Results and Discussion
3.1. Data Description
3.2. Data Processing
3.3. Implementation Details
3.3.1. NAS Parameter Setting
3.3.2. Model Training Parameter Setting
3.4. Experimental Results and Analysis
3.4.1. The Evaluation Index
3.4.2. Classification Effect of NAS-Net
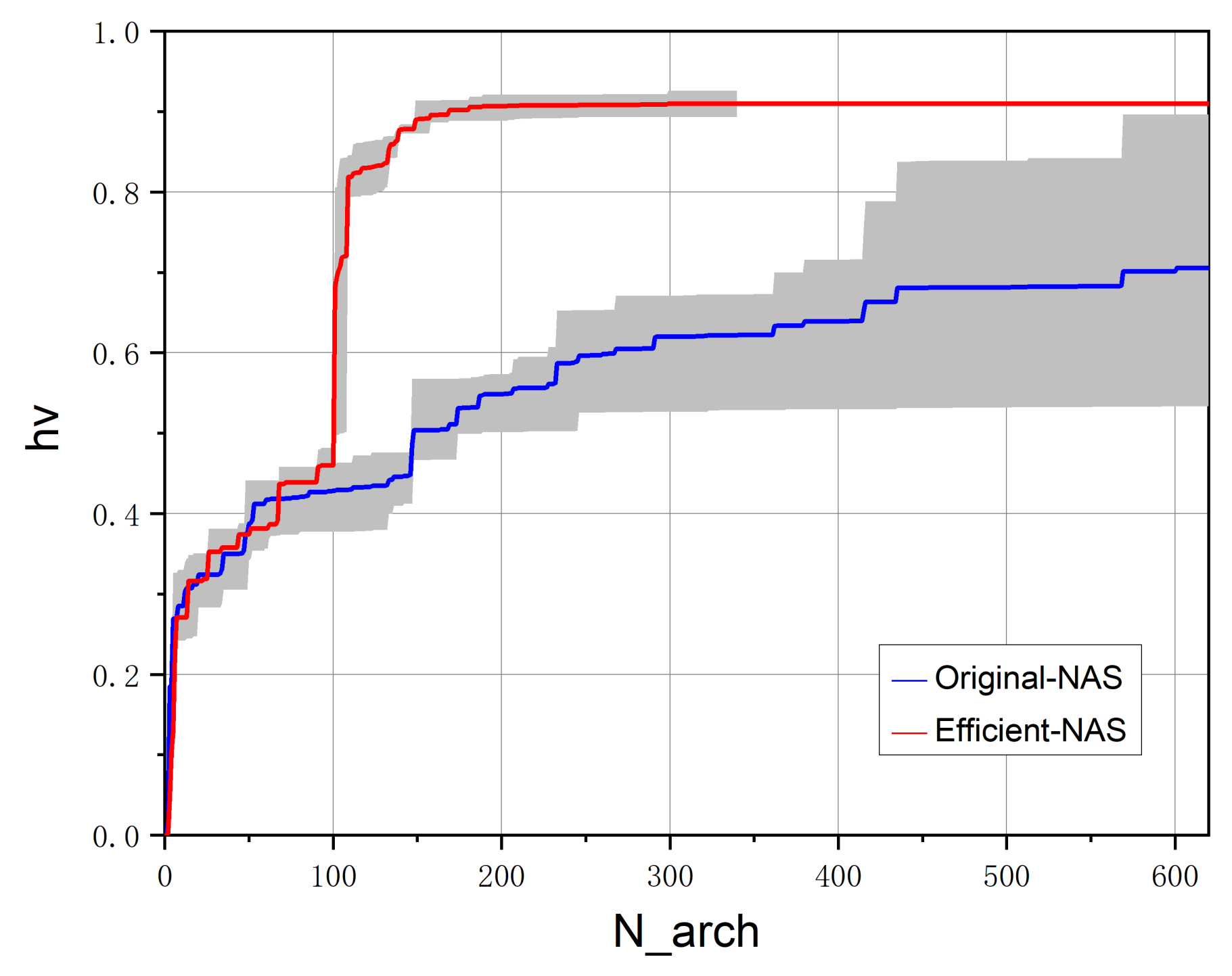
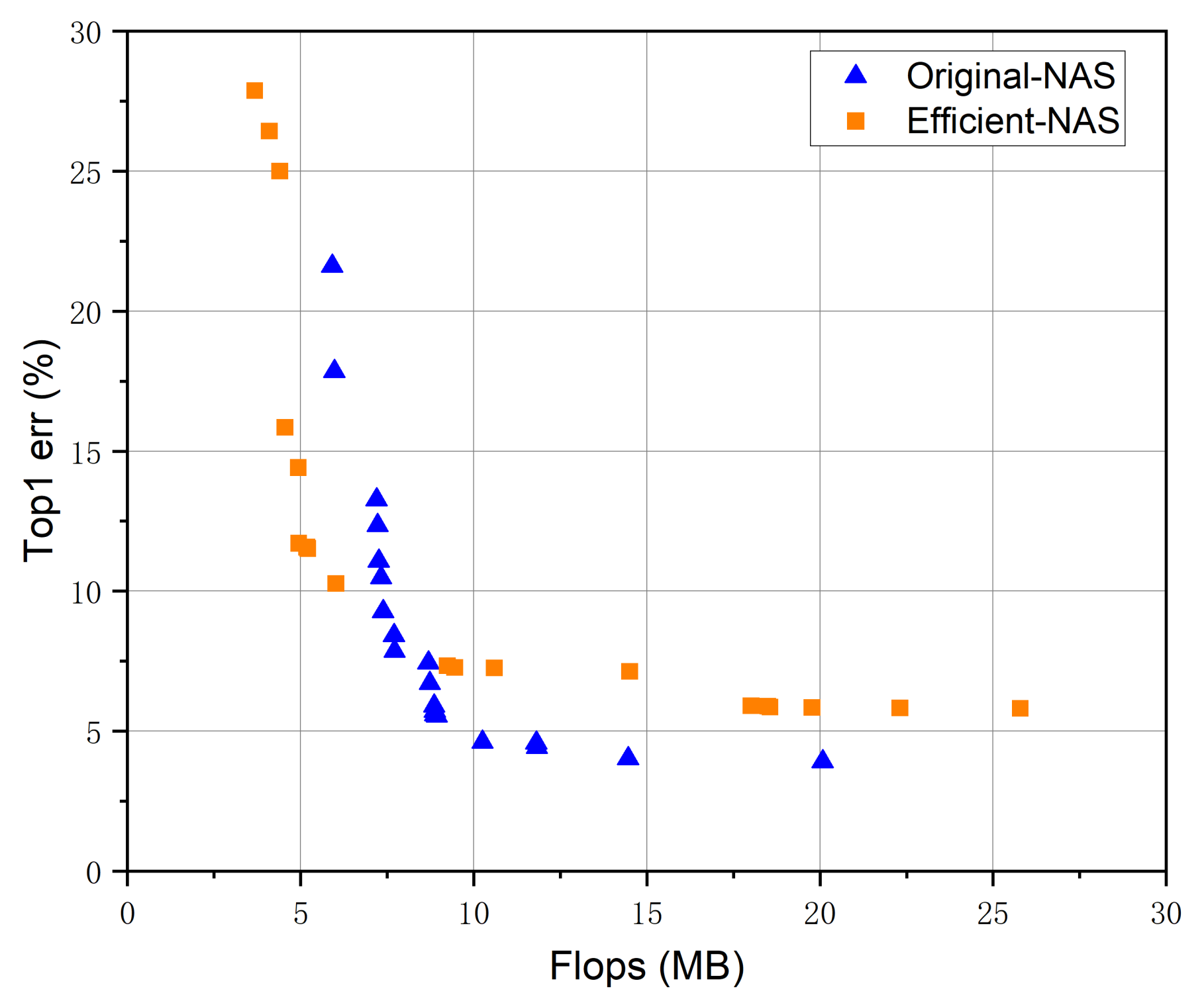
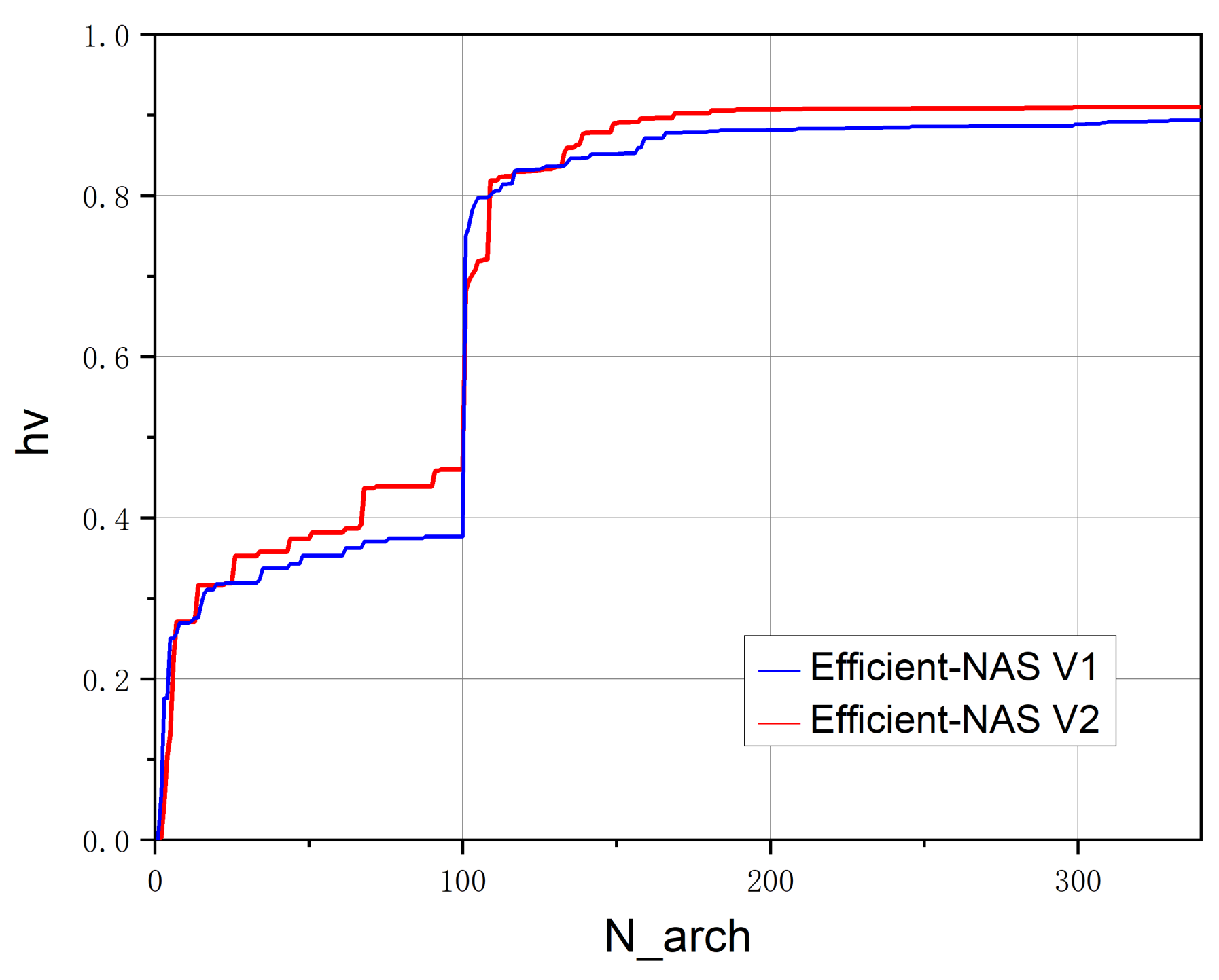
3.4.3. Search Efficiency
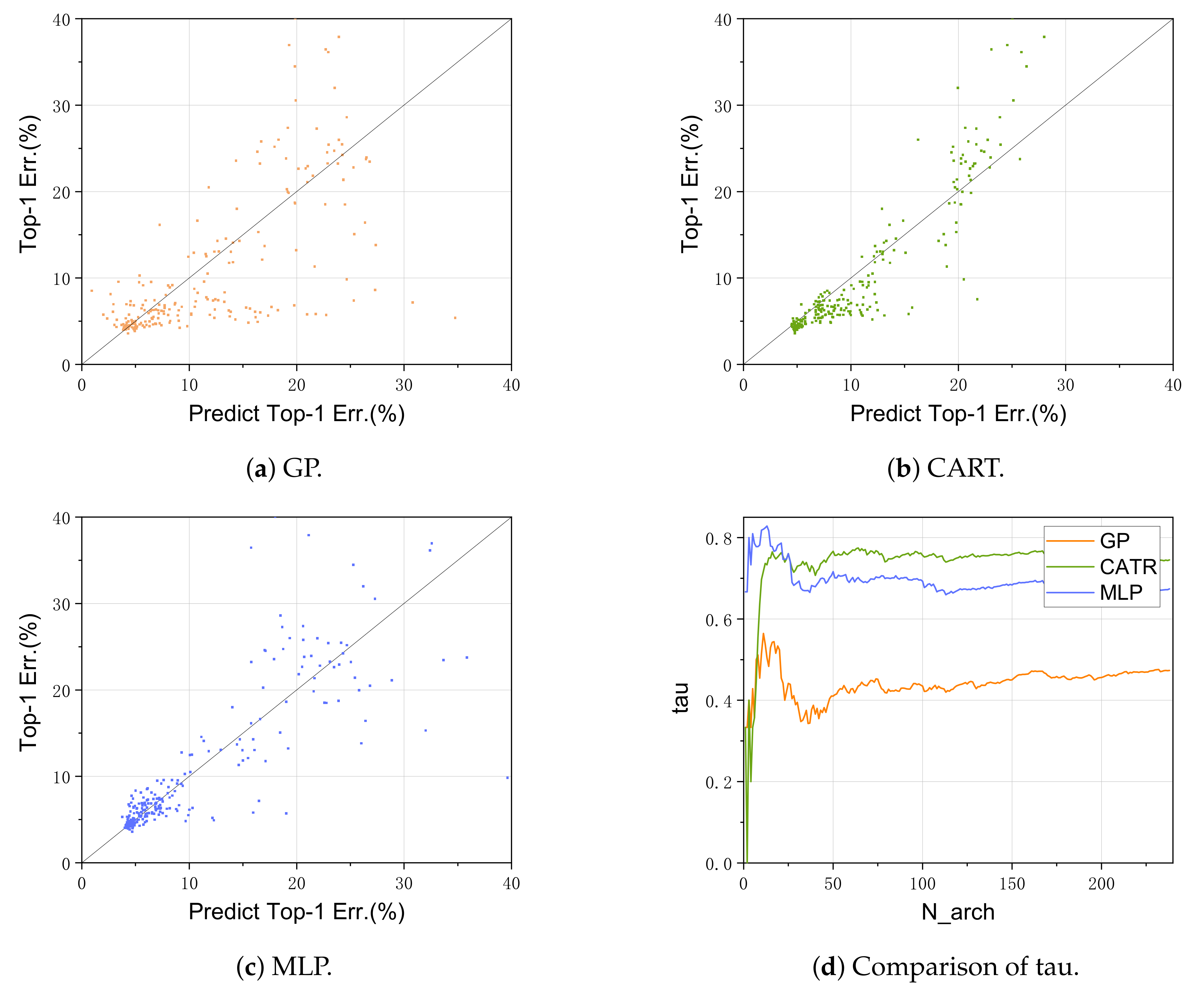
3.4.4. Representation of Surrogate Model
3.4.5. Comparison of Different Operations
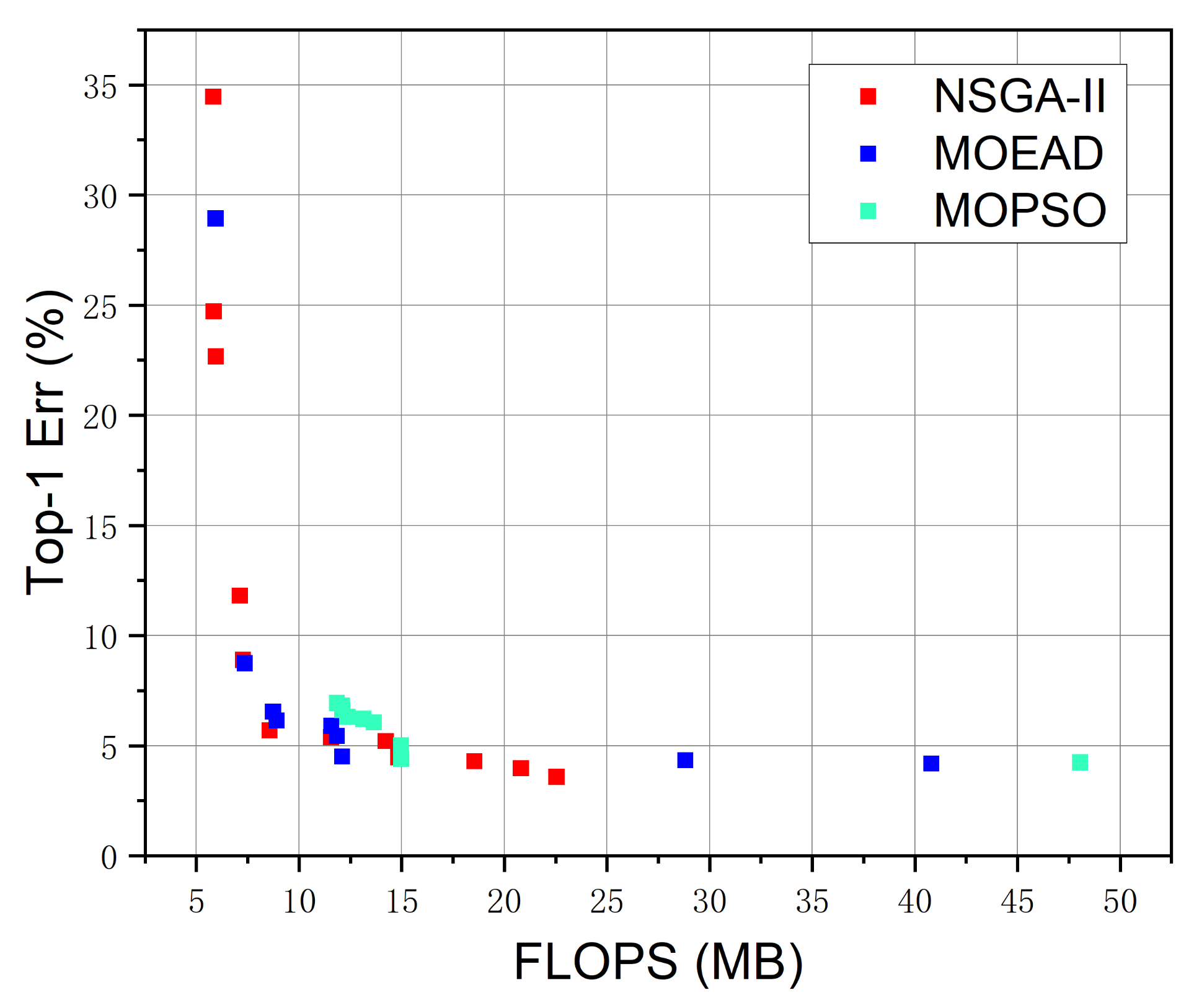
3.4.6. Comparison of Different Search Strategies
3.4.7. Experimental Results on Multiple Datasets
4. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Dong, Y.-N.; Liang, G.-S. Research and Discussion on Image Recognition and Classification Algorithm Based on Deep Learning. In Proceedings of the 2019 International Conference on Machine Learning, Big Data and Business Intelligence (MLBDBI), Taiyuan, China, 8–10 November 2019; pp. 274–278. [Google Scholar]
- Wang, P. Research and Design of Smart Home Speech Recognition System Based on Deep Learning. In Proceedings of the 2020 International Conference on Computer Vision, Image and Deep Learning (CVIDL), Chongqing, China, 10–12 July 2020; pp. 218–221. [Google Scholar]
- Goularas, D.; Kamis, S. Evaluation of Deep Learning Techniques in Sentiment Analysis from Twitter Data. In Proceedings of the 2019 International Conference on Deep Learning and Machine Learning in Emerging Applications (Deep-ML), Istanbul, Turkey, 26–28 August 2019; pp. 12–17. [Google Scholar]
- Xin, M.; Wang, Y. Research on Feature Selection of Intrusion Detection Based on Deep Learning. In Proceedings of the 2020 International Wireless Communications and Mobile Computing (IWCMC), Limassol, Cyprus, 15–19 June 2020; pp. 1431–1434. [Google Scholar]
- Wang, X.; Chen, S.; Su, J. App-Net: A Hybrid Neural Network for Encrypted Mobile Traffic Classification. In Proceedings of the IEEE INFOCOM 2020—IEEE Conference on Computer Communications Workshops (INFOCOM WKSHPS), Toronto, ON, Canada, 6–9 July 2020; pp. 424–429. [Google Scholar]
- Zeng, Y.; Gu, H.; Wei, W.; Guo, Y. Deep-Full-Range: A Deep Learning Based Network Encrypted Traffic Classification and Intrusion Detection Framework. IEEE Access 2019, 7, 45182–45190. [Google Scholar] [CrossRef]
- Krizhevsky, A.; Sutskever, I.; Hinton, G. ImageNet Classification with Deep Convolutional Neural Networks. In Advances in Neural Information Processing Systems; Curran Associates Inc.: Red Hook, NY, USA, 2012. [Google Scholar]
- Szegedy, C.; Liu, W.; Jia, Y.; Sermanet, P.; Reed, S.; Anguelov, D.; Erhan, D.; Vanhoucke, V.; Rabinovich, A. Going Deeper with Convolutions. In Proceedings of the 2015 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Boston, MA, USA, 7–12 June 2015. [Google Scholar]
- Howard, A.G.; Zhu, M.; Chen, B.; Kalenichenko, D.; Wang, W.; Weyand, T.; Andreetto, M.; Adam, H. MobileNets: Efficient Convolutional Neural Networks for Mobile Vision Applications. arXiv 2017, arXiv:1704.04861. [Google Scholar]
- You, J. A Genetic Algorithm-based AutoML Approach for Large-scale Traffic Speed Prediction. In Proceedings of the 2020 IEEE 5th International Conference on Intelligent Transportation Engineering (ICITE), Beijing, China, 11–13 September 2020; pp. 111–116. [Google Scholar]
- Dyrmishi, S.; Elshawi, R.; Sakr, S. A Decision Support Framework for AutoML Systems: A Meta-Learning Approach. In Proceedings of the 2019 International Conference on Data Mining Workshops (ICDMW), Beijing, China, 8–11 November 2019; pp. 97–106. [Google Scholar]
- Nagarajah, T.; Poravi, G. A Review on Automated Machine Learning (AutoML) Systems. In Proceedings of the 2019 IEEE 5th International Conference for Convergence in Technology (I2CT), Bombay, India, 29–31 March 2019; pp. 1–6. [Google Scholar]
- Deb, K.; Pratap, A.; Agarwal, S.; Meyarivan, T.A.M.T. A fast and elitist multiobjective genetic algorithm: NSGA-II. IEEE Trans. Evol. Comput. 2002, 6, 182–197. [Google Scholar] [CrossRef] [Green Version]
- Pham, H.; Guan, M.; Zoph, B.; Le, Q.; Dean, J. Efficient Neural Architecture Search via Parameter Sharing. In Proceedings of the International Conference on Machine Learning, Stockholm, Sweden, 10–15 July 2018. [Google Scholar]
- Chen, Z.; Li, B. Efficient Evolution for Neural Architecture Search. In Proceedings of the 2020 International Joint Conference on Neural Networks (IJCNN), Glasgow, UK, 19–24 July 2020; pp. 1–7. [Google Scholar]
- Liu, C.; Zoph, B.; Neumann, M.; Shlens, J.; Hua, W.; Li, L.; Li, F.; Yuille, A.; Huang, J.; Murphy, K. Progressive Neural Architecture Search. In Proceedings of the European Conference on Computer Vision, Munich, Germany, 8–14 September 2018. [Google Scholar]
- Lu, Z.; Deb, K.; Goodman, E.; Banzhaf, W.; Boddeti, V.N. NSGANetV2: Evolutionary Multi-Objective Surrogate-Assisted Neural Architecture Search. In Proceedings of the European Conference on Computer Vision, Glasgow, UK, 23–28 August 2020. [Google Scholar]
- Anish, H.A.; Sundarakantham, K. Machine Learning Based Intrusion Detection System. In Proceedings of the 2019 3rd International Conference on Trends in Electronics and Informatics (ICOEI), Tirunelveli, India, 23–25 April 2019. [Google Scholar]
- Chen, L.; Gao, S.; Liu, B.; Lu, Z.; Jiang, Z. FEW-NNN: A fuzzy entropy weighted natural nearest neighbor method for flow-based network traffic attack detection. China Commun. 2020, 17, 151–167. [Google Scholar] [CrossRef]
- Waskle, S.; Parashar, L.; Singh, U. Intrusion Detection System Using PCA with Random Forest Approach. In Proceedings of the 2020 International Conference on Electronics and Sustainable Communication Systems (ICESC), Coimbatore, India, 2–4 July 2020. [Google Scholar]
- Liu, J.; Chung, S.S. Automatic Feature Extraction and Selection For Machine Learning Based Intrusion Detection. In Proceedings of the 2019 IEEE SmartWorld, Ubiquitous Intelligence & Computing, Advanced & Trusted Computing, Scalable Computing & Communications, Cloud & Big Data Computing, Internet of People and Smart City Innovation (SmartWorld/SCALCOM/UIC/ATC/CBDCom/IOP/SCI), Leicester, UK, 19–23 August 2019; pp. 1400–1405. [Google Scholar]
- He, M.; Wang, X.; Zhou, J.; Xi, Y.; Jin, L.; Wang, X. Deep-Feature-Based Autoencoder Network for Few-Shot Malicious Traffic Detection. Secur. Commun. Netw. 2021, 2021, 6659022. [Google Scholar] [CrossRef]
- Zhang, F.; Shang, T.; Liu, J. Imbalanced Encrypted Traffic Classification Scheme Using Random Forest. In Proceedings of the 2020 International Conferences on Internet of Things (iThings) and IEEE Green Computing and Communications (GreenCom) and IEEE Cyber, Physical and Social Computing (CPSCom) and IEEE Smart Data (SmartData) and IEEE Congress on Cybermatics (Cybermatics), Rhodes, Greece, 2–6 November 2020; pp. 837–842. [Google Scholar]
- Wahab, O.A.; Bentahar, J.; Otrok, H.; Mourad, A. Resource-Aware Detection and Defense System against Multi-Type Attacks in the Cloud: Repeated Bayesian Stackelberg Game. IEEE Trans. Dependable Secur. Comput. 2021, 18, 605–622. [Google Scholar] [CrossRef]
- Wahab, O.A.; Bentahar, J.; Otrok, H.; Mourad, A. How to Distribute the Detection Load among Virtual Machines to Maximize the Detection of Distributed Attacks in the Cloud. In Proceedings of the 2016 IEEE International Conference on Services Computing (SCC), San Francisco, CA, USA, 27 June–2 July 2016; pp. 316–323. [Google Scholar]
- Mehmood, T.; Rais, H.B.M. Machine learning algorithms in context of intrusion detection. In Proceedings of the 2016 3rd International Conference on Computer and Information Sciences (ICCOINS), Kuala Lumpur, Malaysia, 15–17 August 2016; pp. 369–373. [Google Scholar]
- Gao, X.; Shan, C.; Hu, C.; Niu, Z.; Liu, Z. An Adaptive Ensemble Machine Learning Model for Intrusion Detection. IEEE Access 2019, 7, 82512–82521. [Google Scholar] [CrossRef]
- Cavusoglu, U. A new hybrid approach for intrusion detection using machine learning methods. Appl. Intell. 2019, 49, 2735–2761. [Google Scholar] [CrossRef]
- Shaaban, A.R.; Abd-Elwanis, E.; Hussein, M. DDoS attack detection and classification via Convolutional Neural Network (CNN). In Proceedings of the 2019 Ninth International Conference on Intelligent Computing and Information Systems (ICICIS), Cairo, Egypt, 8–10 December 2019; pp. 233–238. [Google Scholar]
- Park, S.H.; Park, H.J.; Choi, Y. RNN-based Prediction for Network Intrusion Detection. In Proceedings of the 2020 International Conference on Artificial Intelligence in Information and Communication (ICAIIC), Fukuoka, Japan, 19–21 February 2020; pp. 572–574. [Google Scholar]
- He, M.; Jin, L.; Wang, X.; Li, Y. Web log classification framework with data augmentation based on GANs. J. China Univ. Posts Telecommun. 2020, 27, 34–46. [Google Scholar]
- Zhong, W.; Yu, N.; Ai, C. Applying big data based deep learning system to intrusion detection. Big Data Min. Anal. 2020, 3, 181–195. [Google Scholar] [CrossRef]
- Chen, M.; Wang, X.; He, M.; Jin, L.; Javeed, K.; Wang, X. A Network Traffic Classification Model Based on Metric Learning. Comput. Mater. Contin. 2020, 64, 941–959. [Google Scholar]
- Lim, H.; Kim, J.; Heo, J.; Kim, K.; Hong, Y.; Han, Y. Packet-based Network Traffic Classification Using Deep Learning. In Proceedings of the 2019 International Conference on Artificial Intelligence in Information and Communication (ICAIIC), Okinawa, Japan, 11–13 February 2019; pp. 46–51. [Google Scholar]
- Saleh, I.; Hao, J. Network Traffic Images: A Deep Learning Approach to the Challenge of Internet Traffic Classification. In Proceedings of the 2020 10th Annual Computing and Communication Workshop and Conference (CCWC), Las Vegas, NV, USA, 6–8 January 2020. [Google Scholar]
- Zhong, Z.; Yan, J.; Wu, W.; Shao, J.; Liu, C. Practical Block-Wise Neural Network Architecture Generation. In Proceedings of the 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 2423–2432. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep Residual Learning for Image Recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016. [Google Scholar]
- Szegedy, C.; Ioffe, S.; Vanhoucke, V.; Alemi, A.A. Inception-v4, Inception-ResNet and the Impact of Residual Connections on Learning. In Proceedings of the Thirty-First AAAI Conference on Artificial Intelligence, San Francisco, CA, USA, 4–9 February 2017. [Google Scholar]
- Zoph, B.; Le, Q.V. Neural Architecture Search with Reinforcement Learning. Science of the Total Environment. arXiv 2016, arXiv:1611.01578. [Google Scholar]
- Lu, Z.; Whalen, I.; Dhebar, Y.; Deb, K.; Goodman, E.D.; Banzhaf, W.; Boddeti, V.N. Multi-Objective Evolutionary Design of Deep Convolutional Neural Networks for Image Classification. IEEE Trans. Evol. Comput. 2020, 25, 277–291. [Google Scholar] [CrossRef]
- Liu, H.; Simonyan, K.; Yang, Y. Darts: Differentiable architecture search. arXiv 2018, arXiv:1806.09055. [Google Scholar]
- Zhang, C.; Liu, X.; Wang, G.; Cai, Z. Particle Swarm Optimization Based Deep Learning Architecture Search for Hyperspectral Image Classification. In Proceedings of the IGARSS 2020—2020 IEEE International Geoscience and Remote Sensing Symposium, Waikoloa, HI, USA, 26 September–2 October 2020; pp. 509–512. [Google Scholar]
- Hu, K.; Tian, S.; Guo, S.; Li, N.; Luo, L.; Wang, L. Recurrent Neural Architecture Search based on Randomness-Enhanced Tabu Algorithm. In Proceedings of the 2020 International Joint Conference on Neural Networks (IJCNN), Glasgow, UK, 19–24 July 2020; pp. 1–8. [Google Scholar]
- Sun, Y.; Wang, H.; Xue, B.; Jin, Y.; Yen, G.G.; Zhang, M. Surrogate-Assisted Evolutionary Deep Learning Using an End-to-End Random Forest-Based Performance Predictor. IEEE Trans. Evol. Comput. 2019, 24, 350–364. [Google Scholar] [CrossRef]
- Dai, X.; Zhang, P.; Wu, B.; Yin, H.; Sun, F.; Wang, Y.; Dukhan, M.; Hu, Y.; Wu, Y.; Jia, Y.; et al. ChamNet: Towards Efficient Network Design Through Platform-Aware Model Adaptation. In Proceedings of the 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Long Beach, CA, USA, 15–20 June 2019. [Google Scholar]
- USTC-TK2016. Available online: https://github.com/yungshenglu/USTC-TK2016/ (accessed on 8 August 2021).
- Varghese, J.E.; Muniyal, B. An Efficient IDS Framework for DDoS Attacks in SDN Environment. IEEE Access 2021, 9, 69680–69699. [Google Scholar] [CrossRef]
- Le, T.T.H.; Kim, Y.; Kim, H. Network intrusion detection based on novel feature selection model and various recurrent neural networks. Appl. Sci. 2019, 9, 1392. [Google Scholar] [CrossRef] [Green Version]
- Siddiqi, M.A.; Pak, W. Optimizing Filter-Based Feature Selection Method Flow for Intrusion Detection System. Electronics 2020, 9, 2114. [Google Scholar] [CrossRef]
- Scaranti, G.F.; Carvalho, L.F.; Barbon, S.; Proenca, M.L. Artificial immune systems and fuzzy logic to detect flooding attacks in software-defined networks. IEEE Access 2020, 8, 100172–100184. [Google Scholar] [CrossRef]
- Shurman, M.; Khrais, R.; Yateem, A. DoS and DDoS attack detection using deep learning and IDS. Int. Arab J. Inf. Technol. 2020, 17, 655–661. [Google Scholar]
- Babić, I.; Miljković, A.; Čabarkapa, M.; Nikolić, V.; Đorđević, A.; Ranđelović, M.; Ranđelović, D. Triple Modular Redundancy Optimization for Threshold Determination in Intrusion Detection Systems. Symmetry 2021, 13, 557. [Google Scholar] [CrossRef]



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| skip connect | 3 × 3 dilated convolution |
| 3 × 3 max pooling | 5 × 5 dilated convolution |
| 3 × 3 avg pooling | 1 × 7 then 7 × 1 convolution |
| 3 × 3 depthwise separable convolution | Inception A |
| 5 × 5 depthwise separable convolution | Inception B |
| 7 × 7 depthwise separable convolution | Inception C |
| Flow Types | Number | Percentage (%) |
|---|---|---|
| Ddossim | 8480 | 2.79 |
| Goldeneye | 89,814 | 29.51 |
| Hulk | 60,601 | 19.91 |
| Slowbody (rudy) | 21,261 | 6.99 |
| Slowbody (Slowhttptest) | 36,762 | 12.08 |
| Slowheaders (Slowhttptest) | 45,848 | 15.07 |
| Slowheaders (Slowloris) | 21,099 | 6.93 |
| Slowread | 20,452 | 6.72 |
| Flow Types | Number | Percentage (%) |
|---|---|---|
| Benign | 1,433,293 | 94.4165 |
| Brute Force SSH | 14,056 | 0.9259 |
| DDoS | 45,016 | 2.9654 |
| HttpDoS | 6533 | 0.4304 |
| Infiltrating Transfer | 19,156 | 1.2619 |
| Flow Types | Number | Percentage (%) |
|---|---|---|
| PortMap | 2311 | 0.9345 |
| NetBIOS | 60,000 | 24.2622 |
| LDAP | 60,000 | 24.2622 |
| MSSQL | 2268 | 0.9171 |
| UDP | 60,000 | 24.2622 |
| UDP-Lag | 60,000 | 24.2622 |
| SYN | 2719 | 1.0995 |
| Parameter Types | Parameter Names | Instructions | Values |
|---|---|---|---|
| Model structure | n_cells | Number of cells to search | 1 |
| n_blocks | Number of blocks in a cell | 5 | |
| n_nodes | Number of nodes per phases | 4 | |
| Outer layer search strategy | n_iterations | Number of iterations to run search | 30 |
| n_doe | Number of architectures to train before fitting the surrogate model | 100 | |
| n_iter | Number of architectures to train in each iteration | 8 | |
| Inner layer search strategy (NSGA-II) | pop_size | Population size of networks | 40 |
| n_gens | Number of population iterations | 30 | |
| n_offspring | Number of offspring created per generation | 40 | |
| Inner layer search strategy (MOEA/D) | n_partitions | Number of weights (equal to number of population) | 100 |
| n_gens | Number of population iterations | 30 | |
| n_neighbors | Number of neighboring reference lines to be used for selection | 20 | |
| prob_neighbor _mating | Probability of selecting the parents in the neighborhood | 0.7 | |
| Inner layer search strategy (MOPSO) | particles | Number of particles | 30 |
| cycle_ | Number of iterations | 30 | |
| w | Inertial factor | 1 | |
| c1 | Local velocity factor | 2 | |
| c2 | Global velocity factor | 2 | |
| mesh_div | The number of equal meshes | 10 |
| Parameter Names | Values |
|---|---|
| learning_rate | 0.025 |
| momentum | 0.9 |
| batch_size | 128 |
| epochs | 15 |
| Model | F1 Score | Parms (MB) | Flops (MB) |
|---|---|---|---|
| LeNet | 0.889749 | 0.044256 | 0.2860 |
| CNN | 0.952205 | 0.117672 | 0.0968 |
| ResNet | 0.981752 | 11.171784 | 456.76 |
| VGG | 0.978461 | 20.038344 | 398.29 |
| NAS-Net | 0.995681 | 0.054048 | 14.9763 |
| Model | F1 Score | N_arch | Avg | Speedup |
|---|---|---|---|---|
| Original-NAS | 0.9583 | 601 | 403 | 1.722× |
| 0.9576 | 246 | |||
| 0.9609 | 362 | |||
| Efficient-NAS | 0.9641 | 299 | 234 | 1× |
| 0.9660 | 158 | |||
| 0.9632 | 246 |
| Surrogate Model | Tau |
|---|---|
| GP | 0.4735 |
| CART | 0.7449 |
| MLP | 0.6737 |
| AS | 0.7454 |
| Model | CIC-DoS2017 | ISCXIDS2012 | CIC-DDoS2019 |
|---|---|---|---|
| LeNet | 0.889749 | 0.984727 | 0.945900 |
| CNN | 0.952205 | 0.989345 | 0.993975 |
| ResNet | 0.981752 | 0.989775 | 0.995437 |
| VGG | 0.978461 | 0.989779 | 0.995762 |
| NAS-Net | 0.995681 | 0.989781 | 0.995766 |
| Datasets | Methods | Prec | Recall | Acc | F1-Score |
|---|---|---|---|---|---|
| CIC-DoS2017 | Varghese and Muniyal [47] | - | - | 0.8833 | - |
| Proposed work | 0.9942 | 0.9944 | 0.9957 | 0.9957 | |
| ISCXIDS2012 | Le et al. [48] | 0.9475 | 0.975 | - | 0.9708 |
| Siddiqi and Pak [49] | 0.9286 | 0.9351 | 0.9520 | 0.9317 | |
| Proposed work | 0.9891 | 0.9899 | 0.9898 | 0.9898 | |
| CIC-DDoS2019 | Scaranti et al. [50] | 0.8903 | - | 0.8865 | - |
| Shurman et al. [51] | - | - | 0.9919 | - | |
| Babić et al. [52] | 0.9780 | 0.8436 | 0.9036 | 0.9059 | |
| Proposed work | 0.9964 | 0.9919 | 0.9958 | 0.9957 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Lyu, R.; He, M.; Zhang, Y.; Jin, L.; Wang, X. Network Intrusion Detection Based on an Efficient Neural Architecture Search. Symmetry 2021, 13, 1453. https://doi.org/10.3390/sym13081453
Lyu R, He M, Zhang Y, Jin L, Wang X. Network Intrusion Detection Based on an Efficient Neural Architecture Search. Symmetry. 2021; 13(8):1453. https://doi.org/10.3390/sym13081453
Chicago/Turabian StyleLyu, Renjian, Mingshu He, Yu Zhang, Lei Jin, and Xinlei Wang. 2021. "Network Intrusion Detection Based on an Efficient Neural Architecture Search" Symmetry 13, no. 8: 1453. https://doi.org/10.3390/sym13081453
APA StyleLyu, R., He, M., Zhang, Y., Jin, L., & Wang, X. (2021). Network Intrusion Detection Based on an Efficient Neural Architecture Search. Symmetry, 13(8), 1453. https://doi.org/10.3390/sym13081453