
An Efficient Dynamic Regulated Fuzzy Neural Network for Human Motion Retrieval and Analysis


Abstract
:1. Introduction
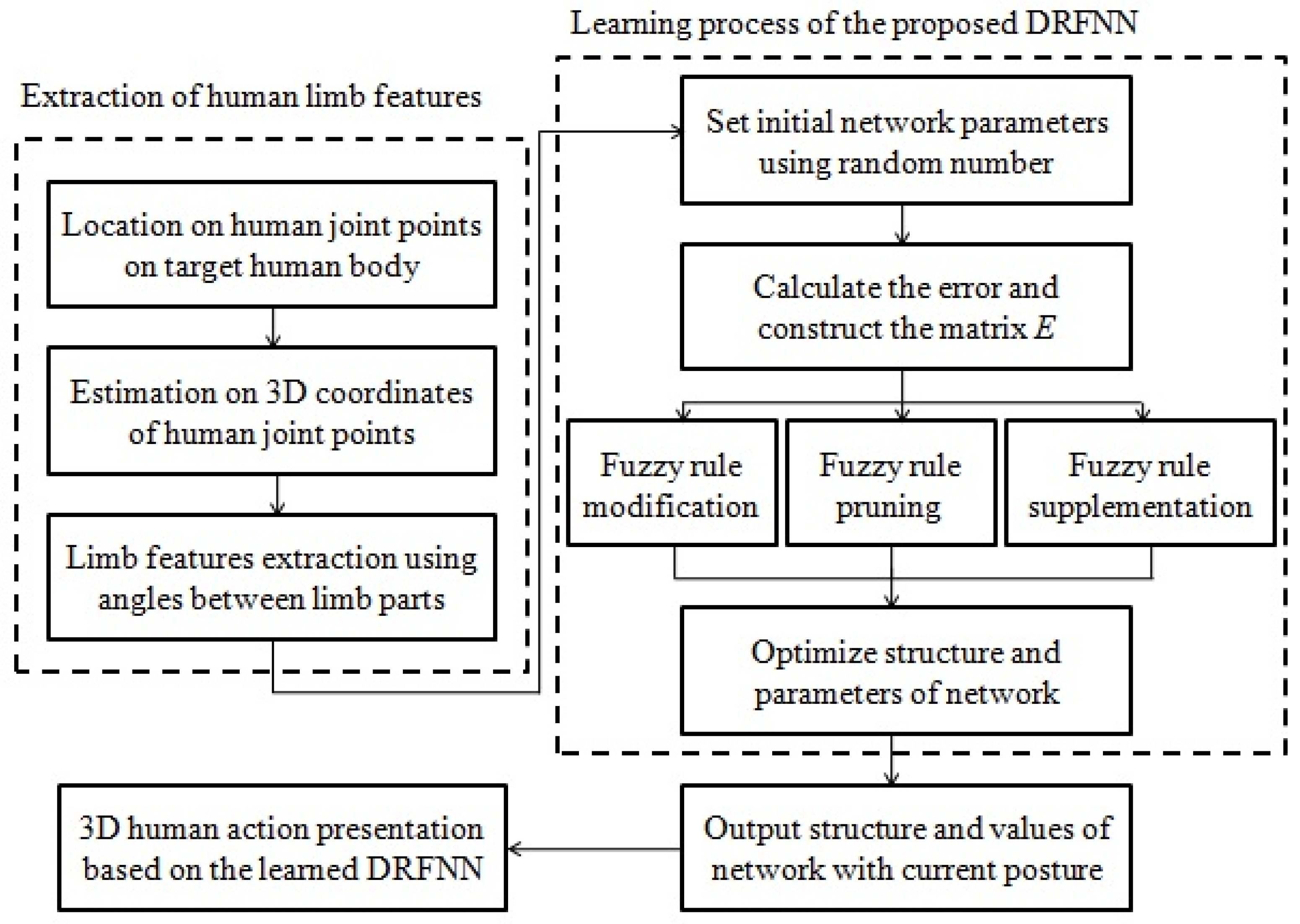
2. The Extraction of Human Limb Features
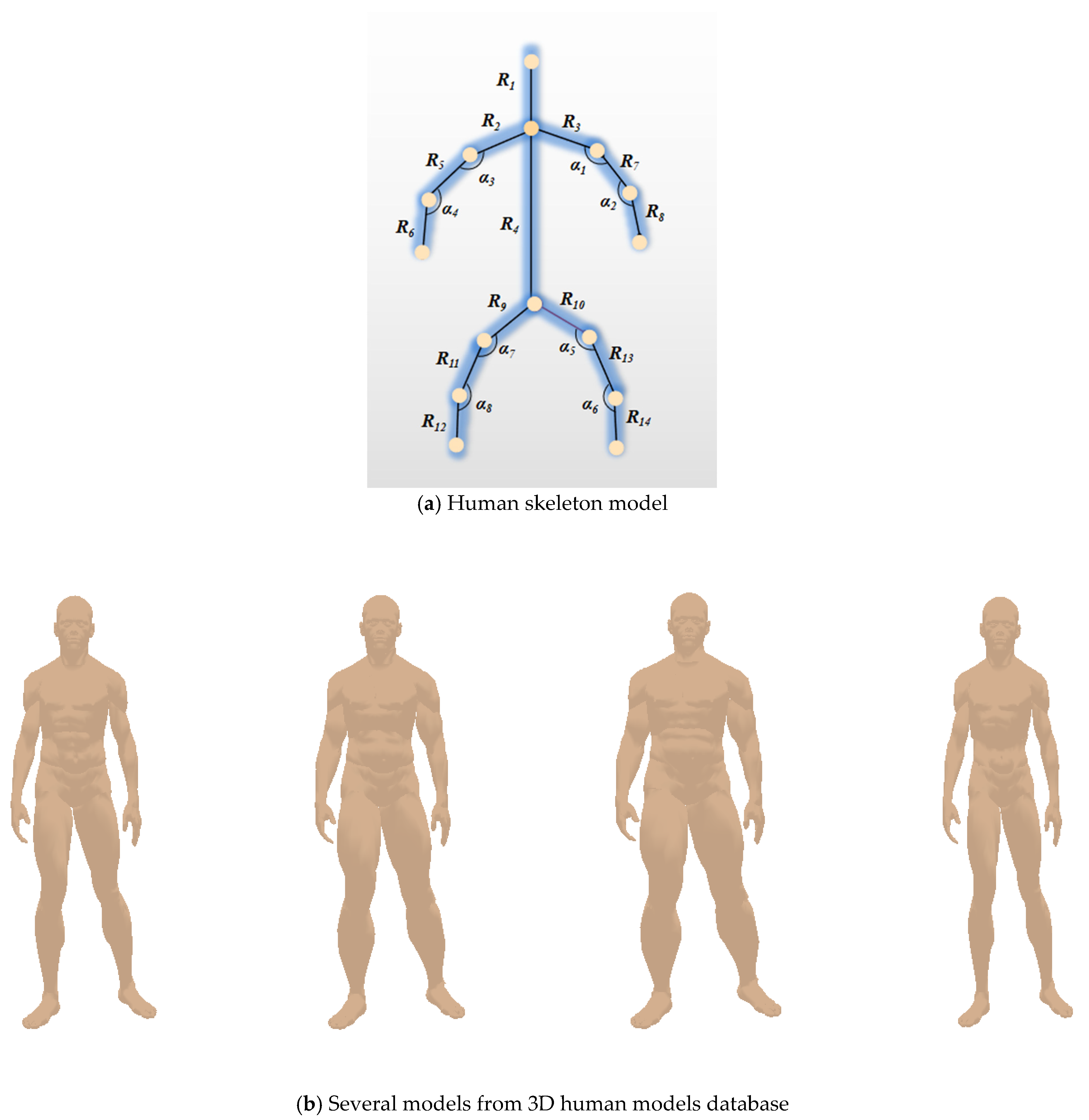
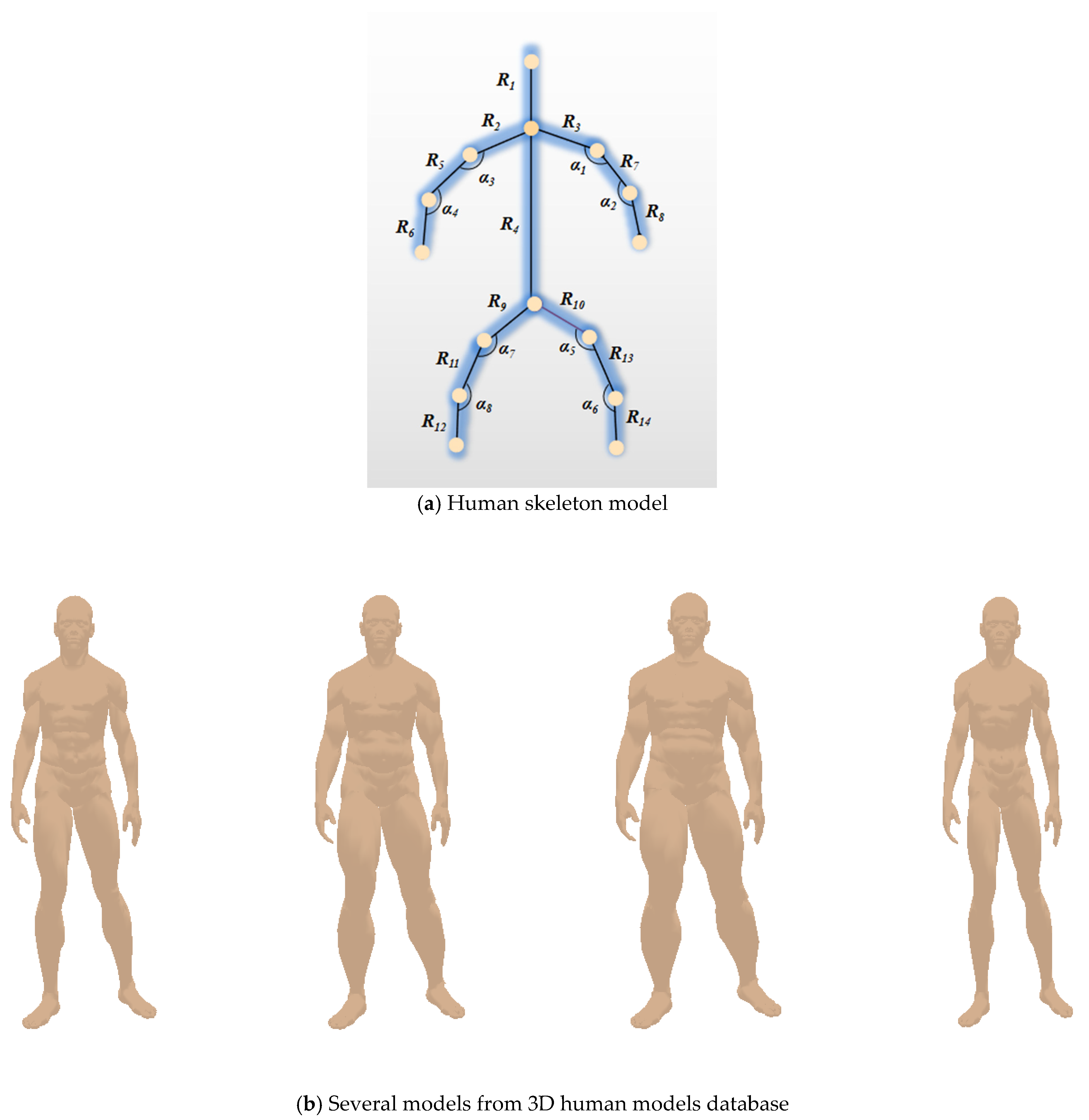
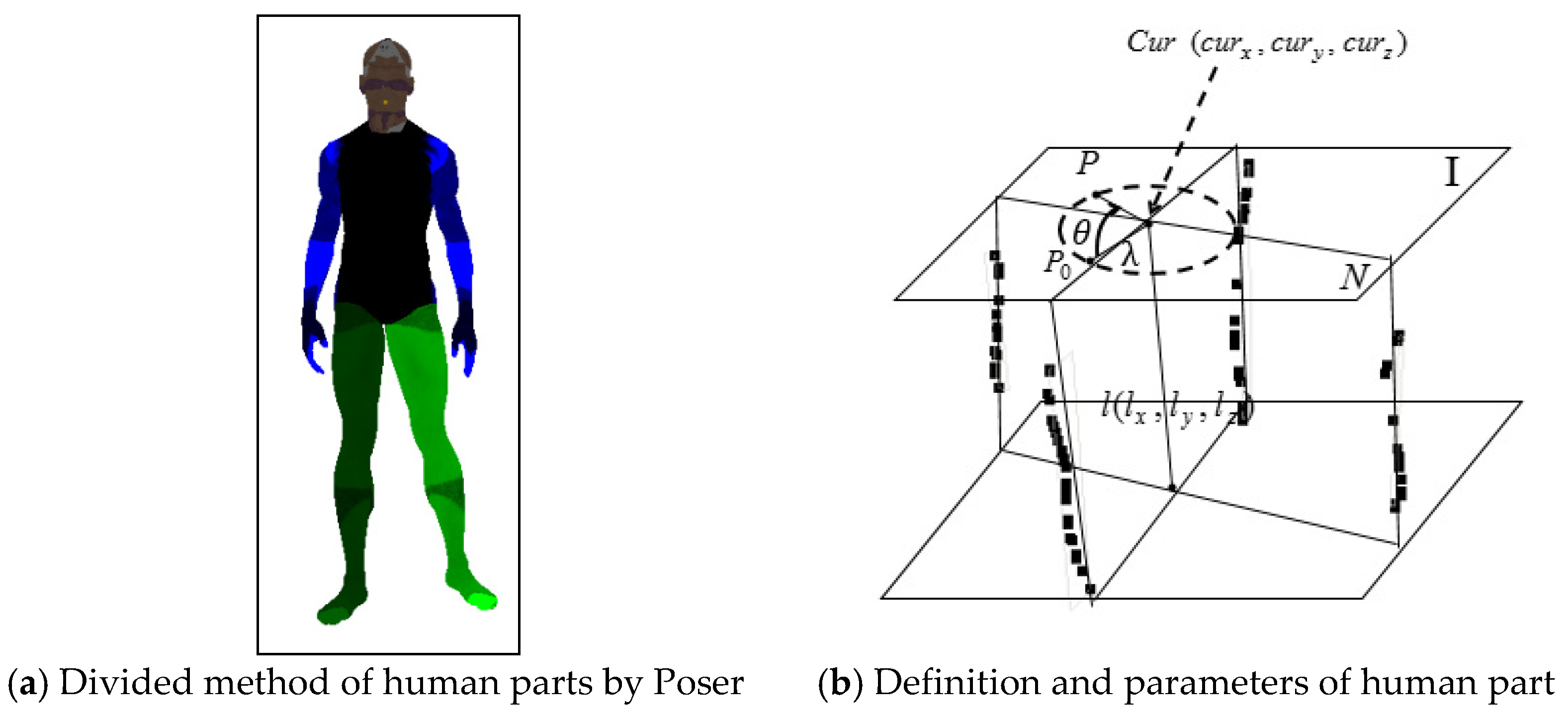
2.1. Human Skeleton Model and Divided Limb Part
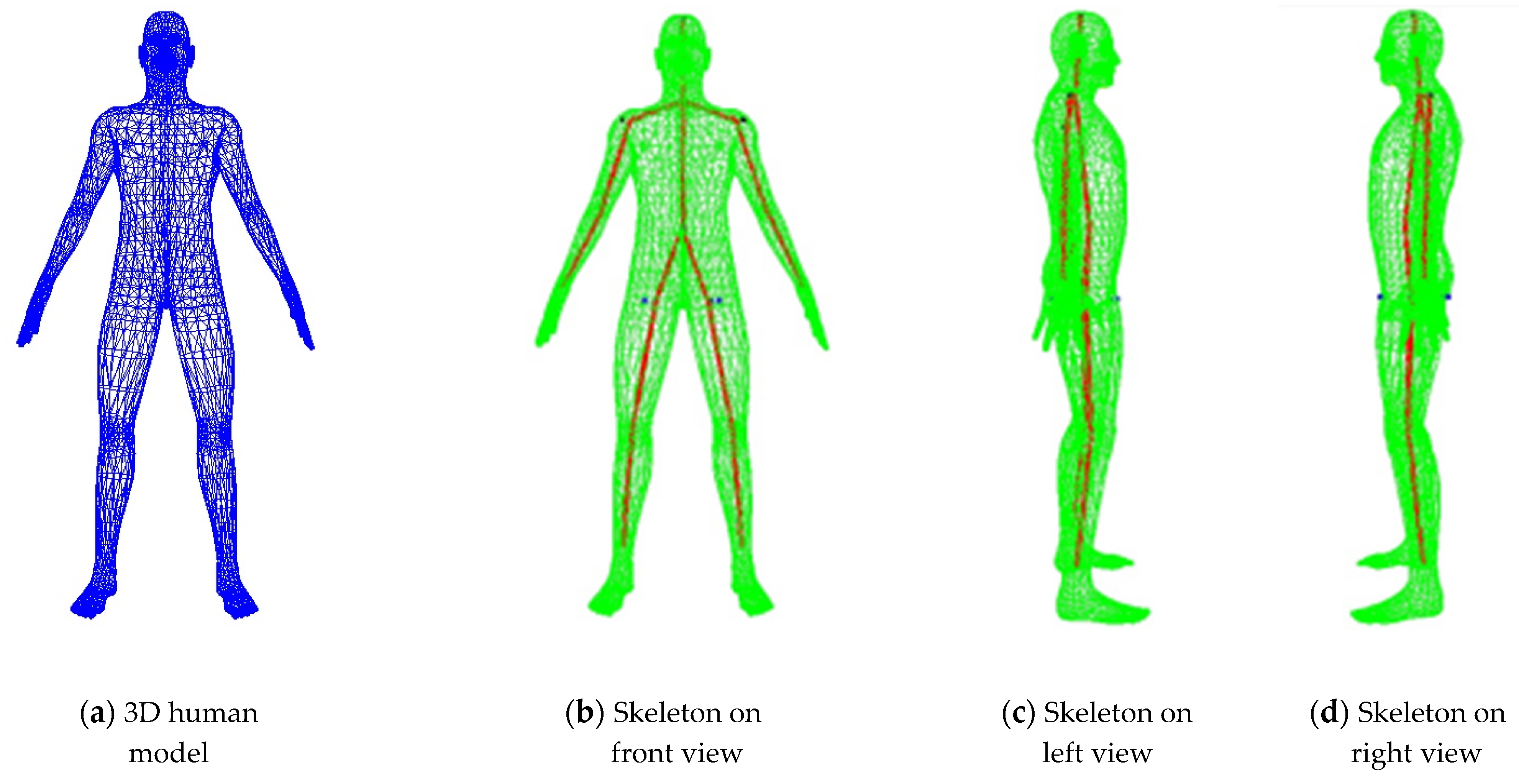
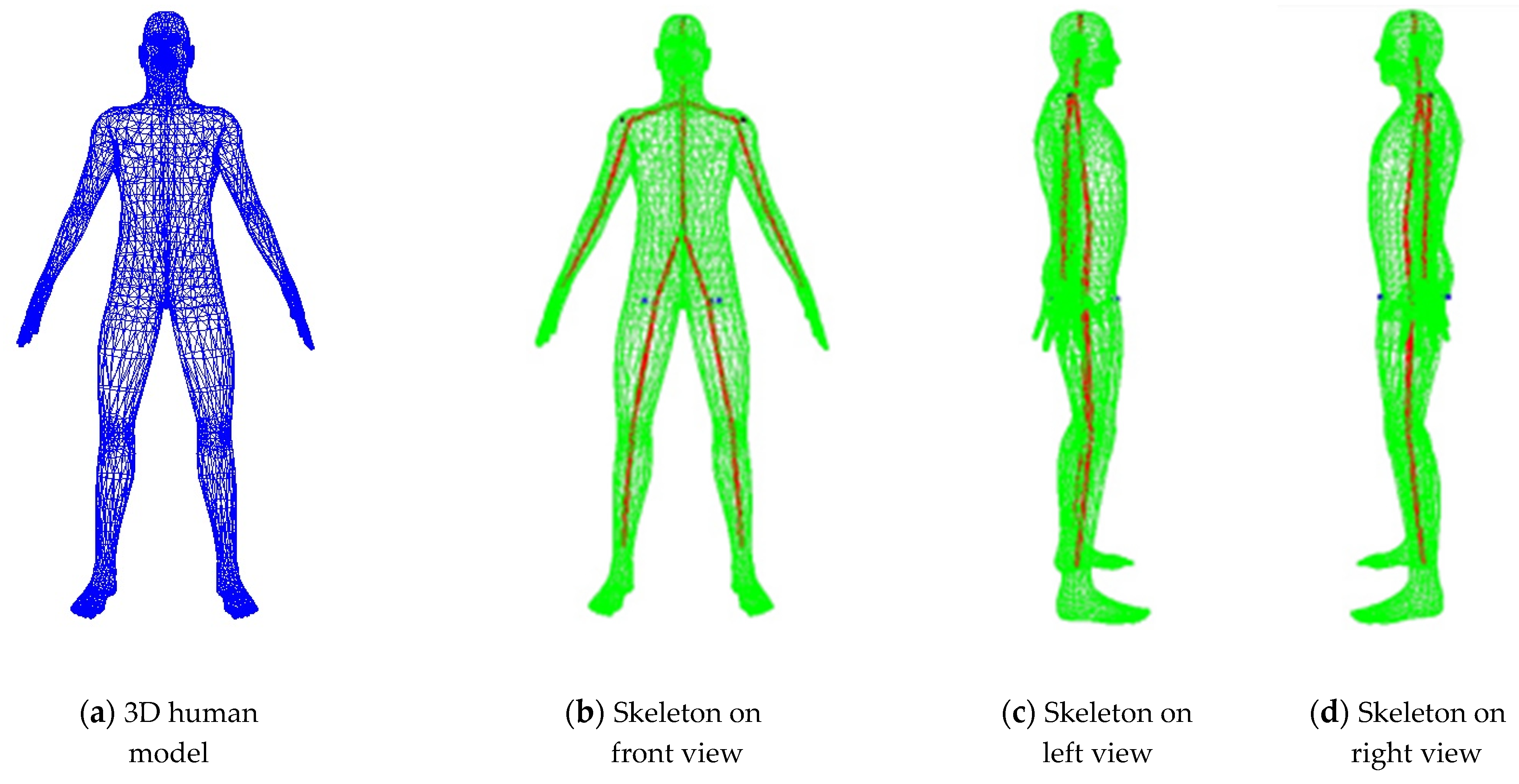
2.2. Location on Skeleton Feature Points on Symmetric Target Human Body
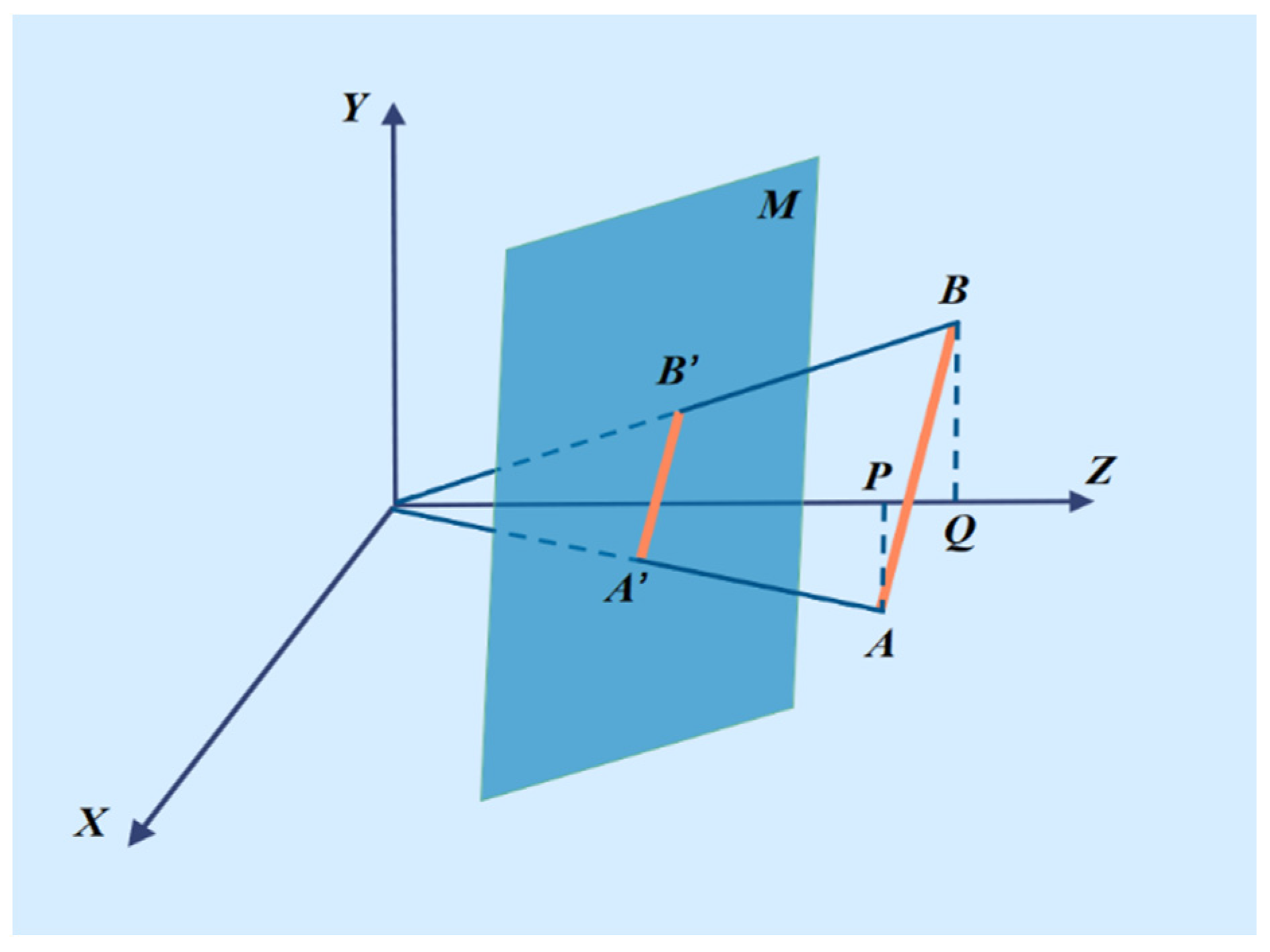
2.3. Estimation on 3D Coordinates of Human Skeleton FEATURE points
3. Human Motion Model Estimation for Different Postures
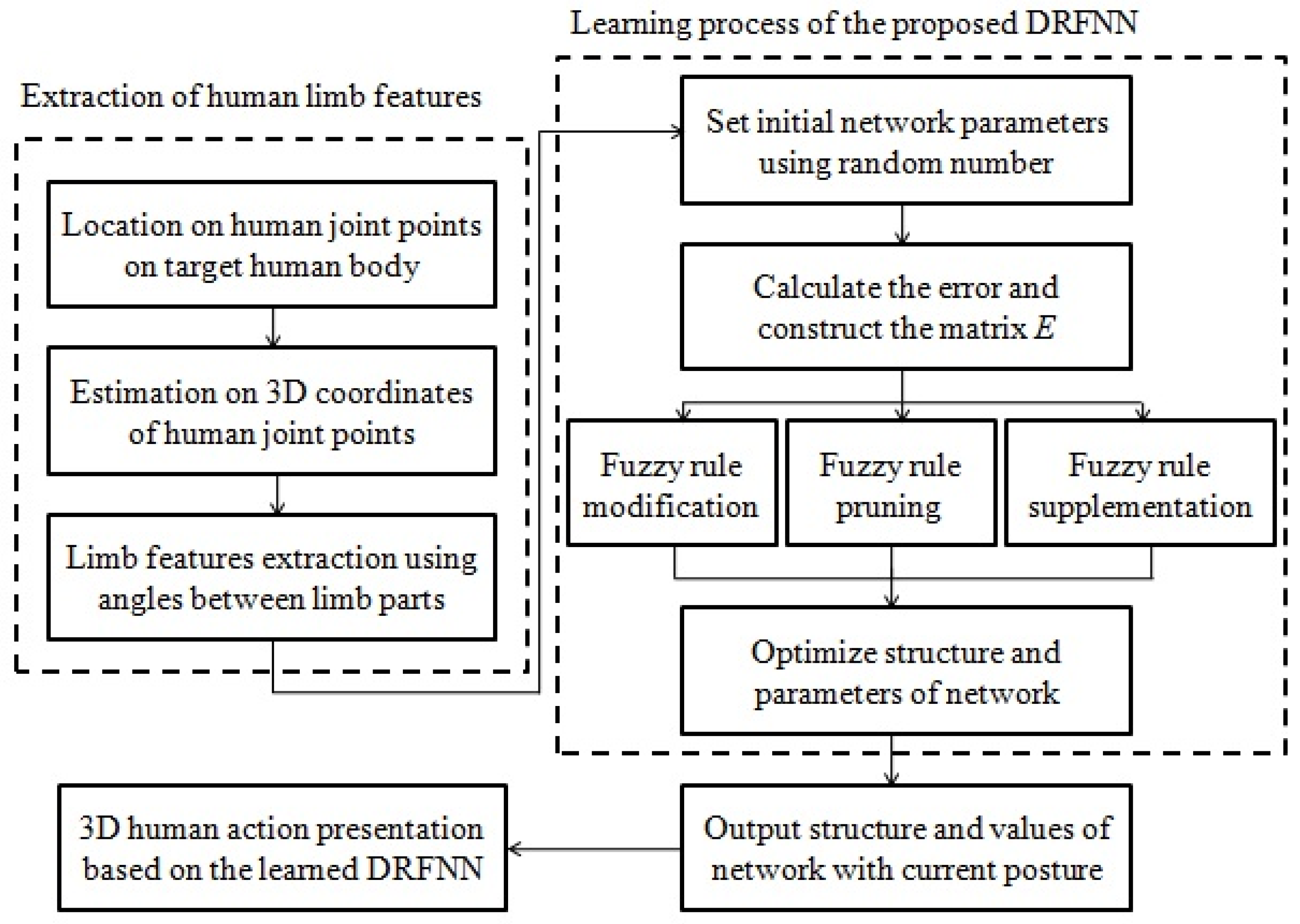
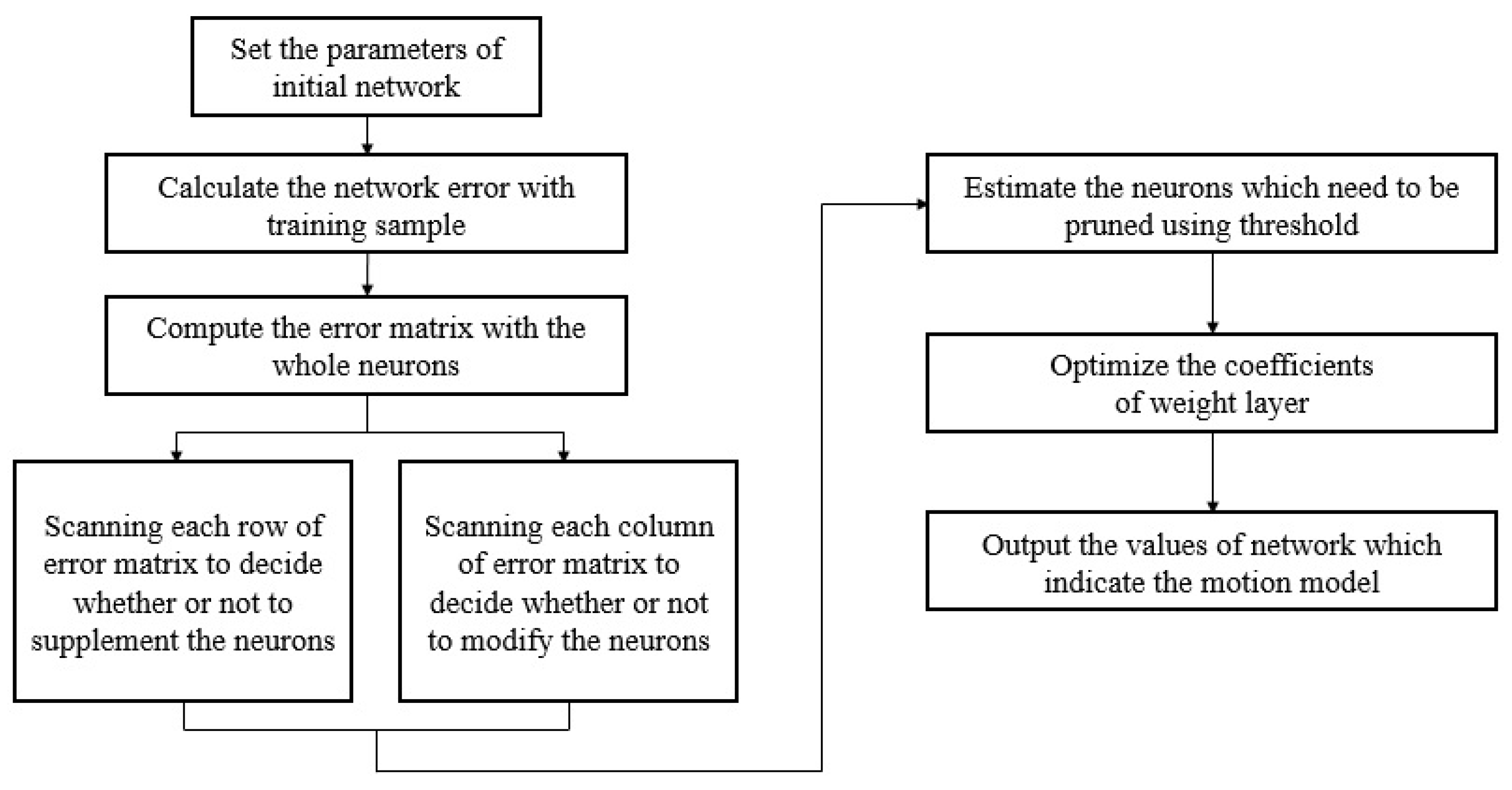
3.1. The Proposed Dynamic Regulated Fuzzy Neural Network
3.1.1. System Errors
3.1.2. Deviation of Neurons
3.1.3. Criteria of Fuzzy-Rule Modification
3.1.4. Criteria of Fuzzy-Rule Pruning
3.1.5. Criteria of Fuzzy-Rule Supplementation
3.1.6. The Adjustment of Network Weights
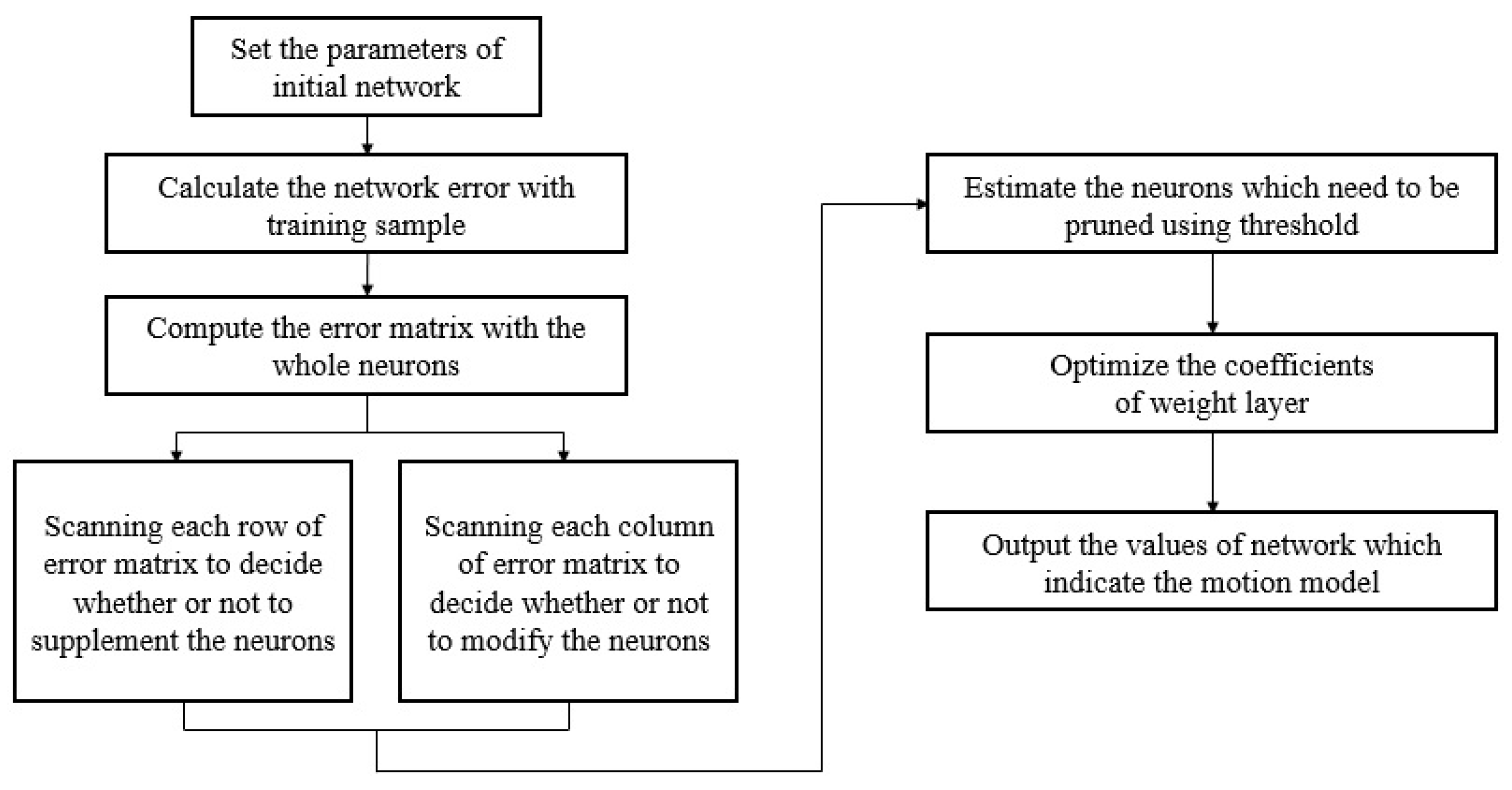
3.1.7. The running Process of Network
4. Experimental Result and Analysis
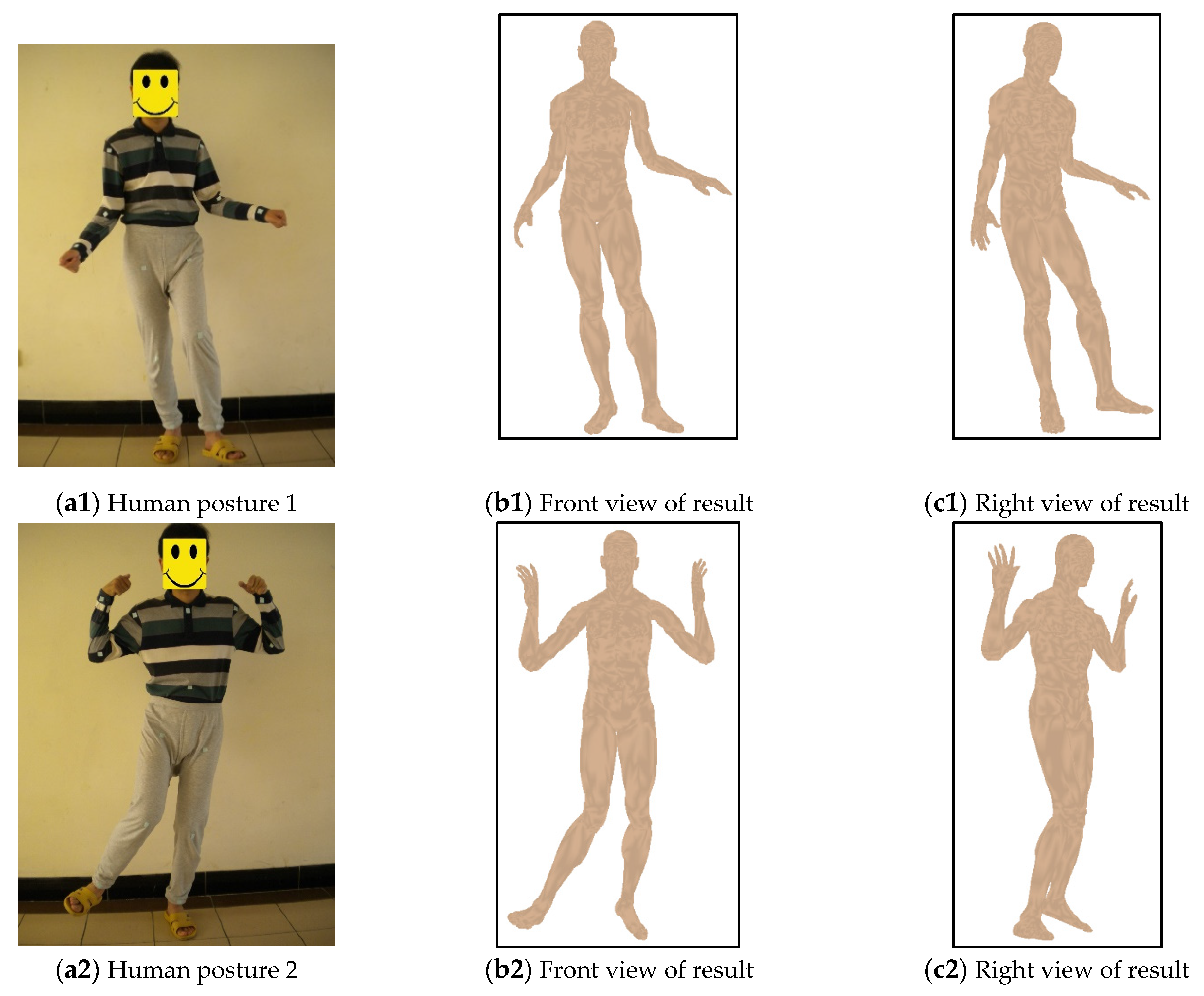
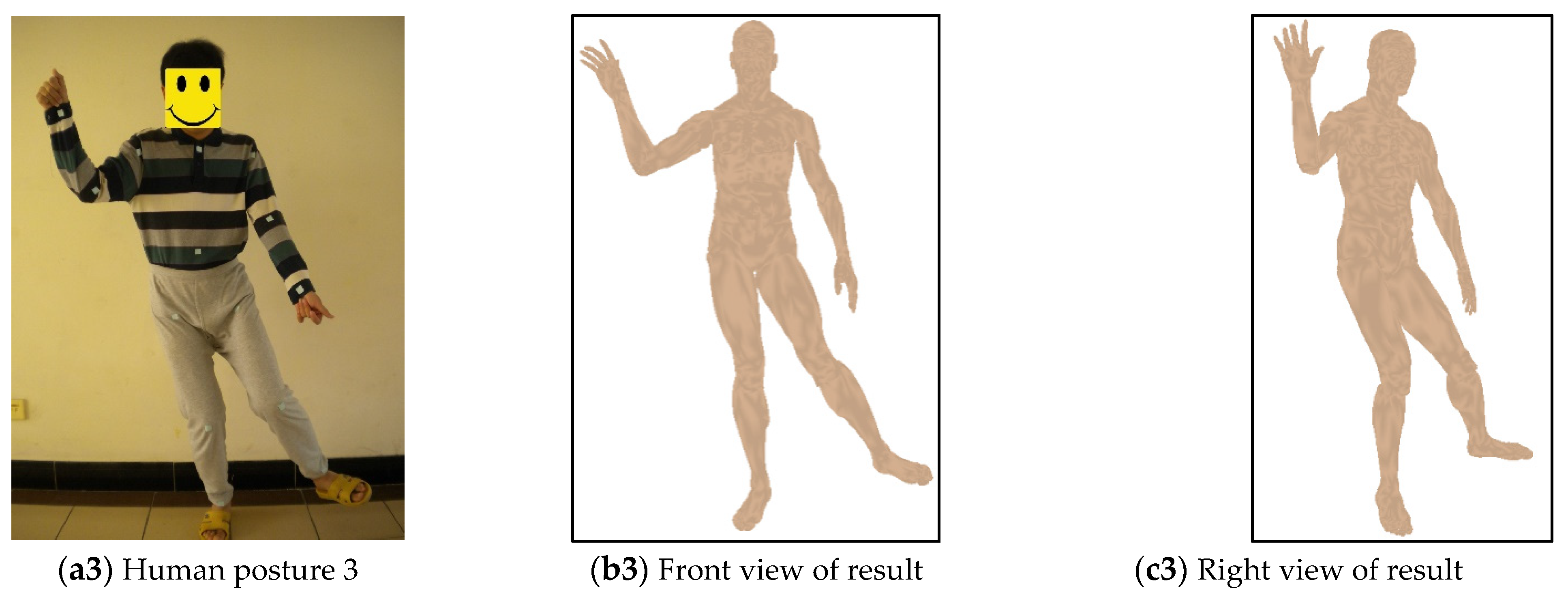
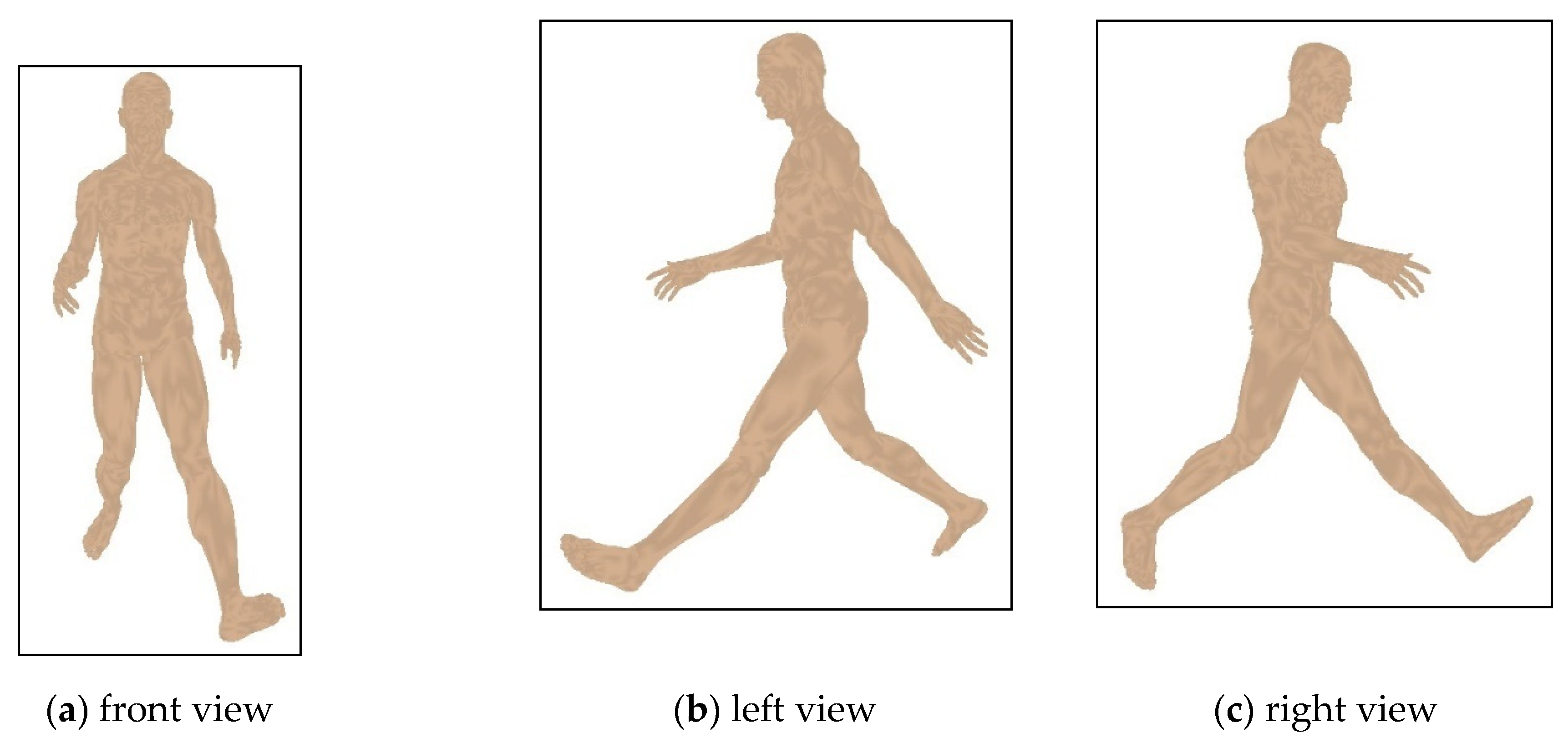
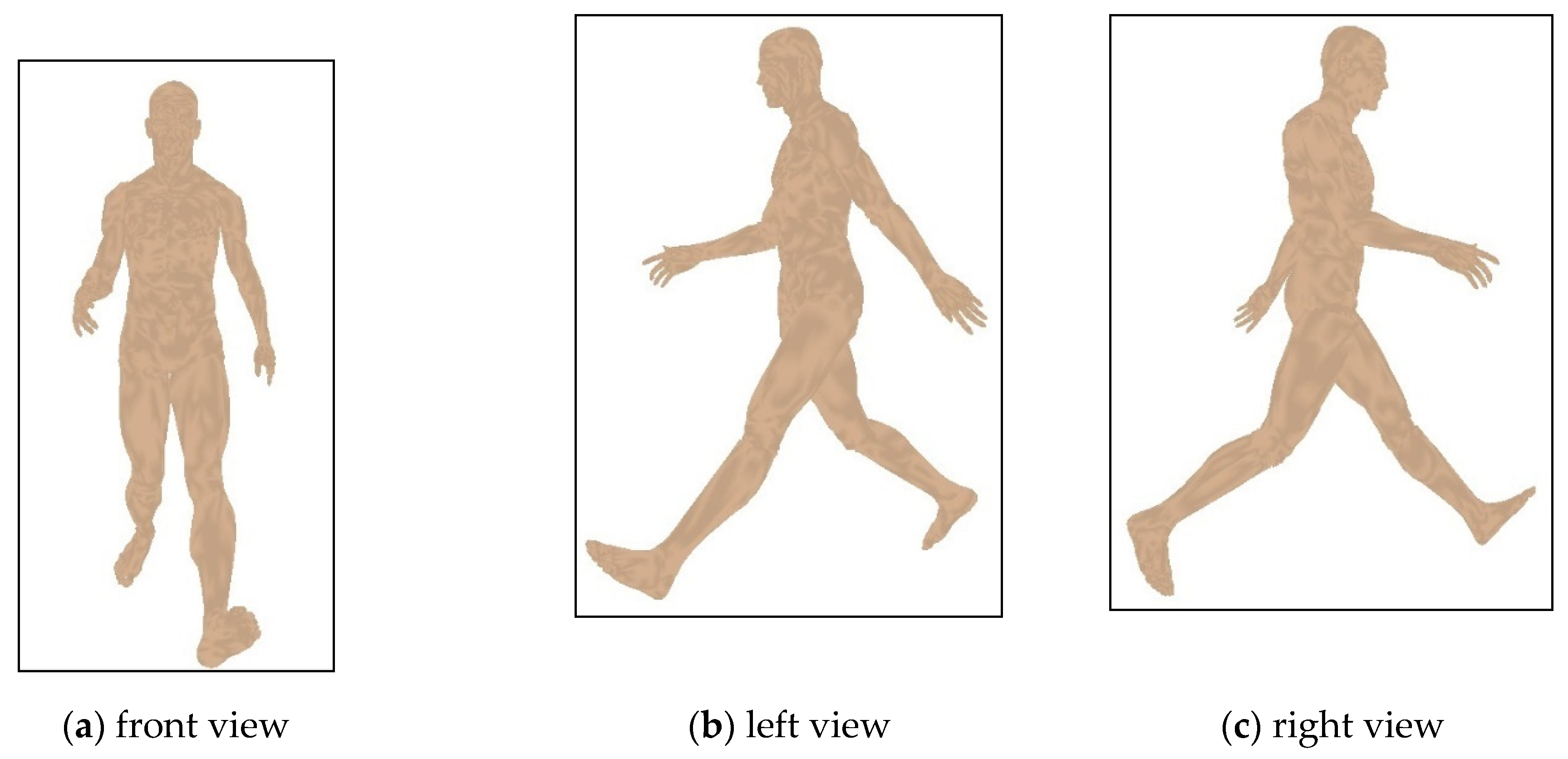
4.1. Datasets
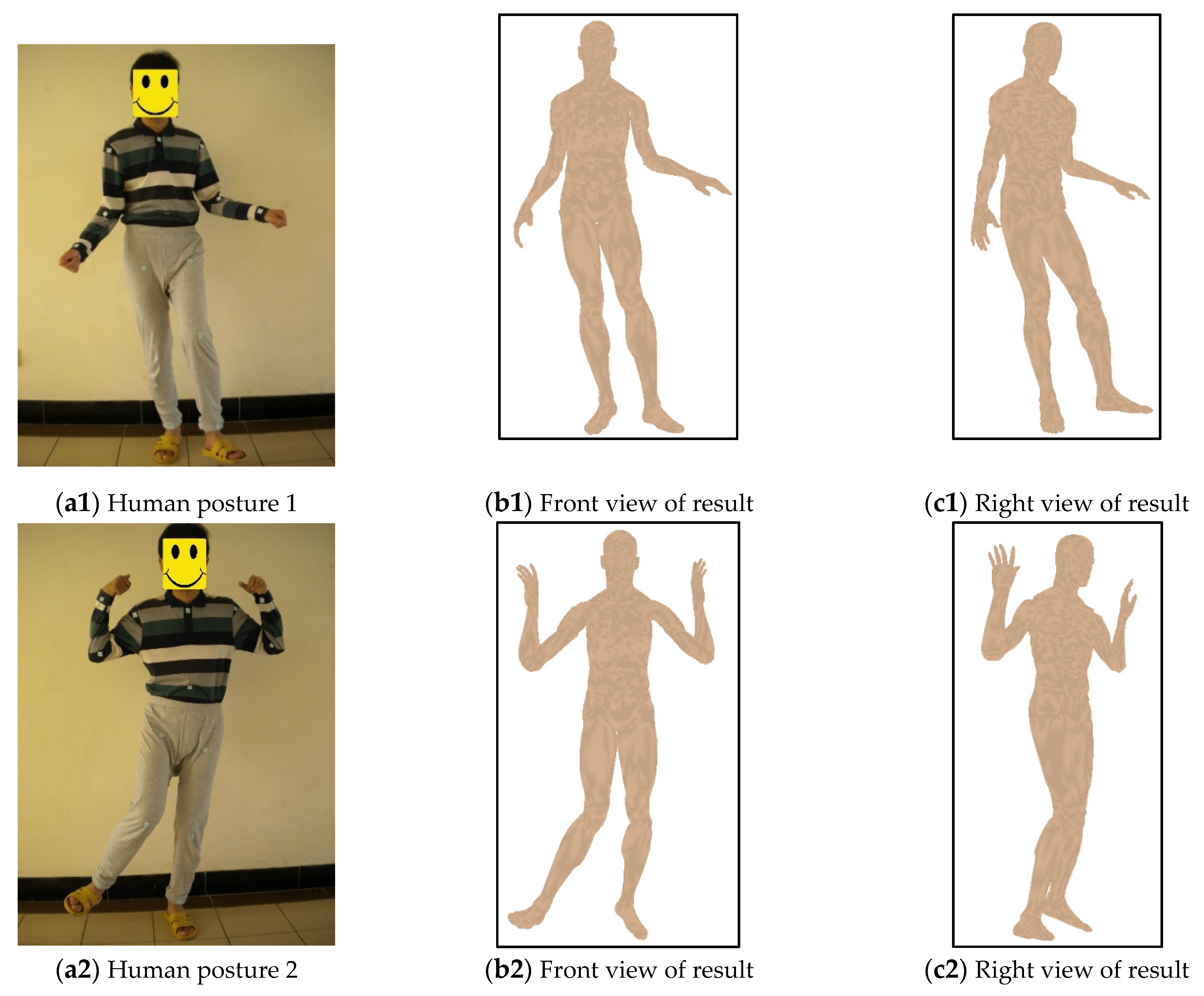
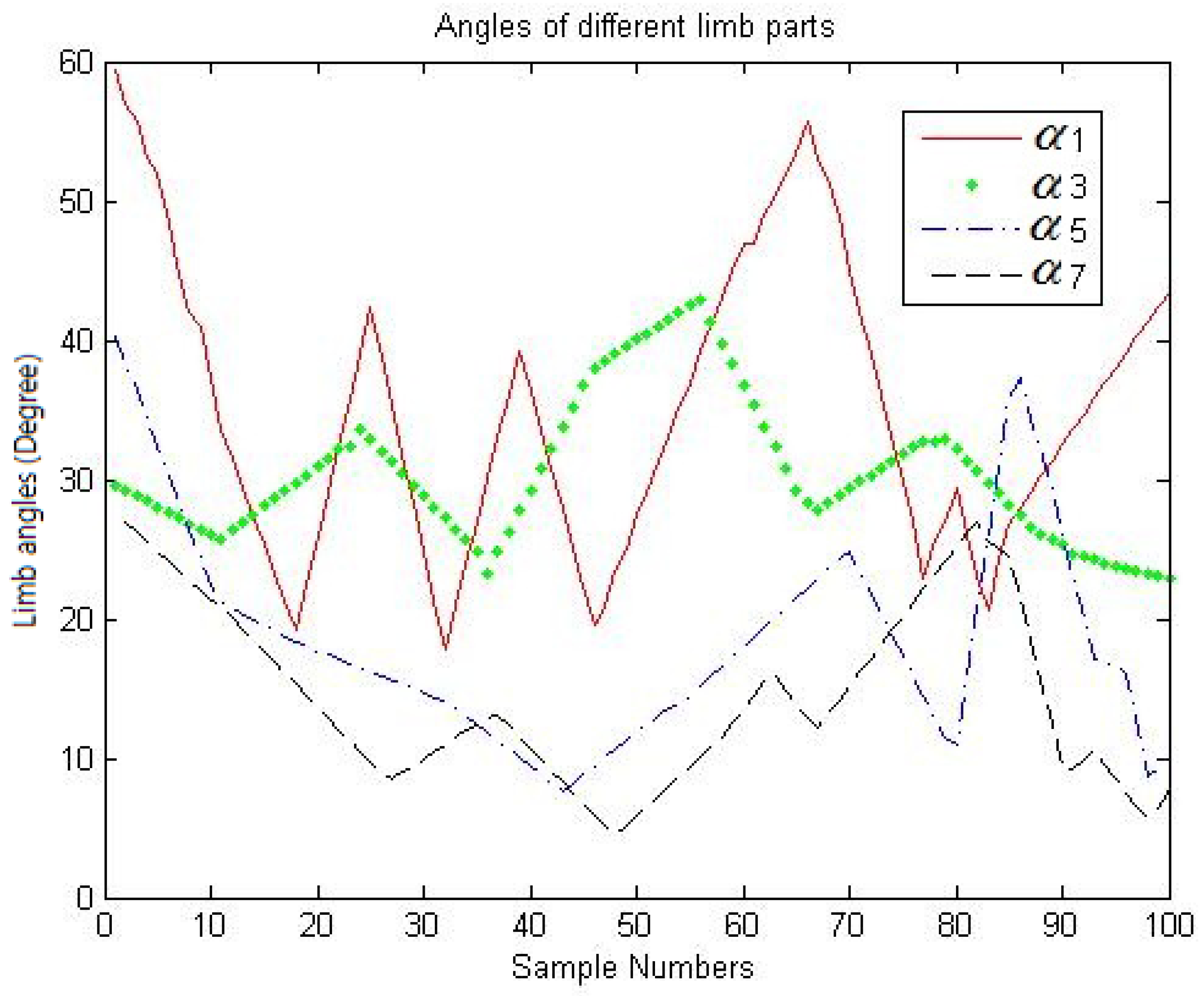
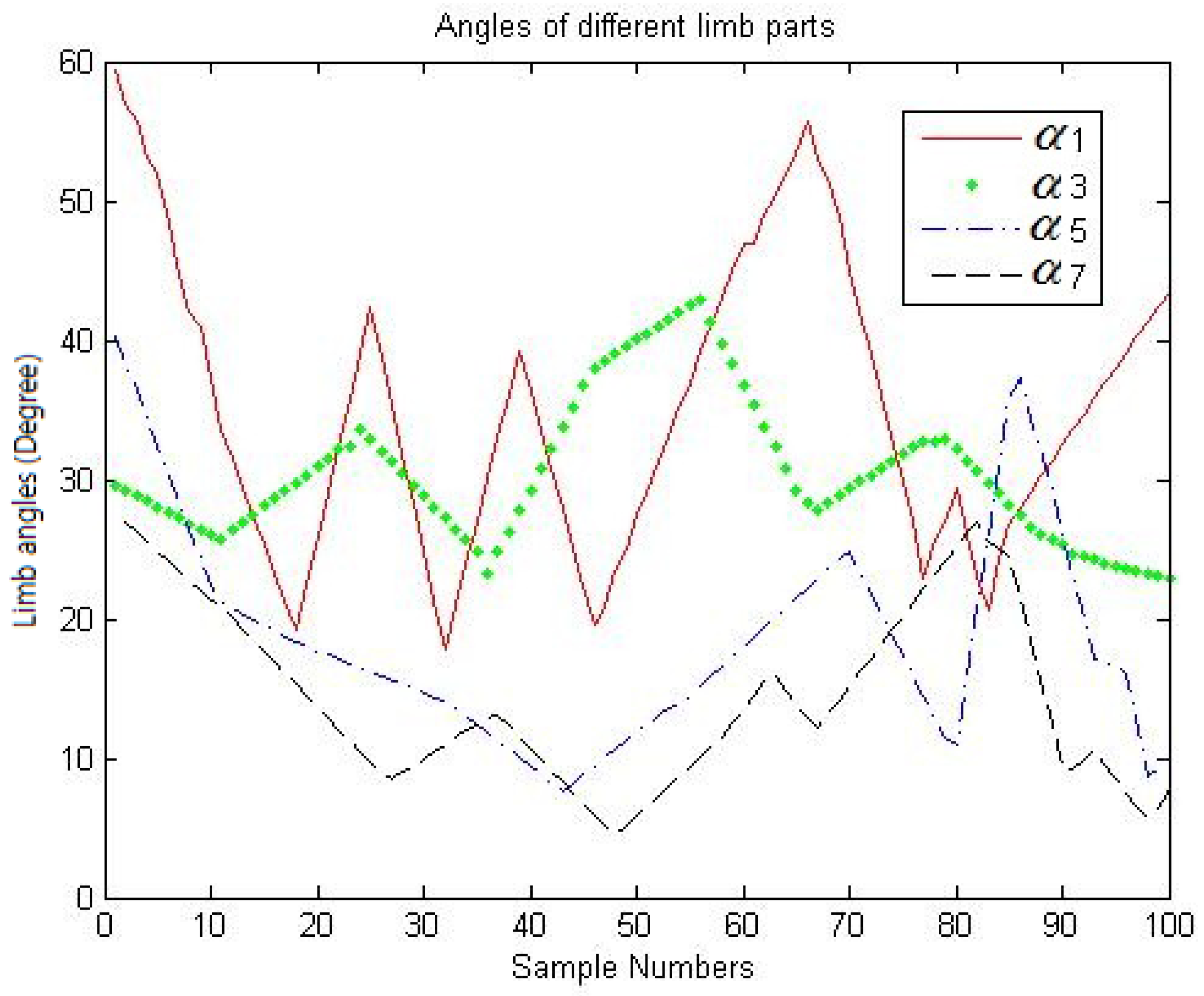
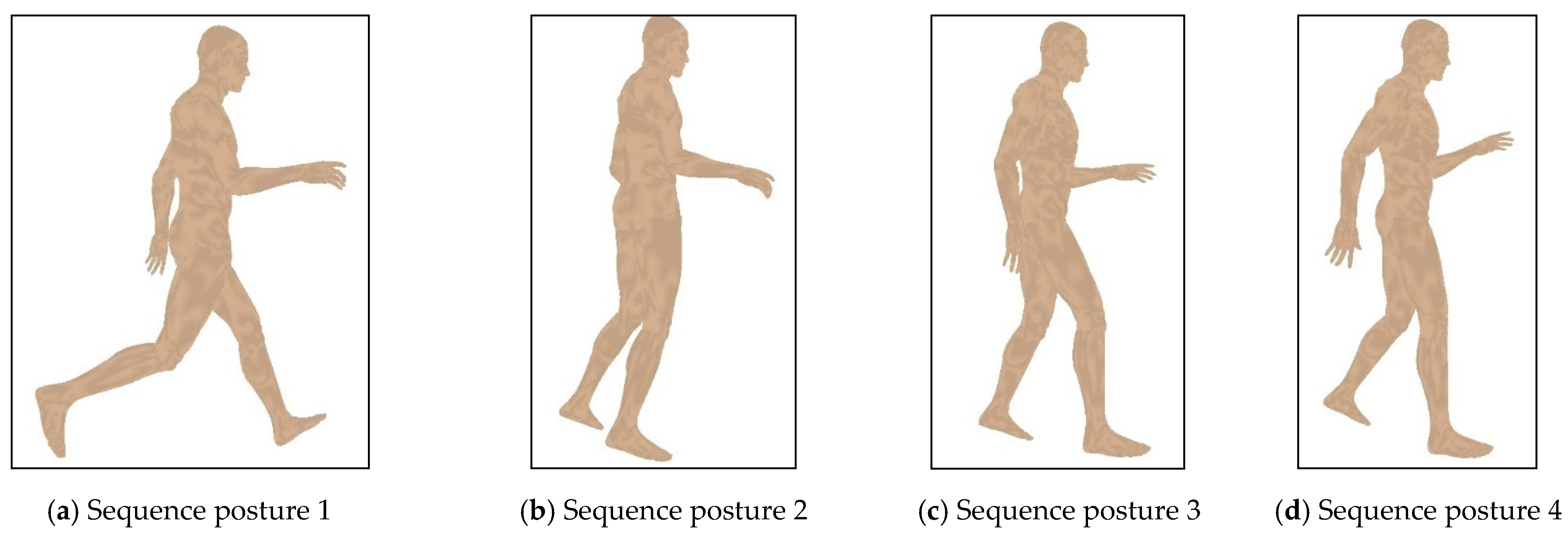
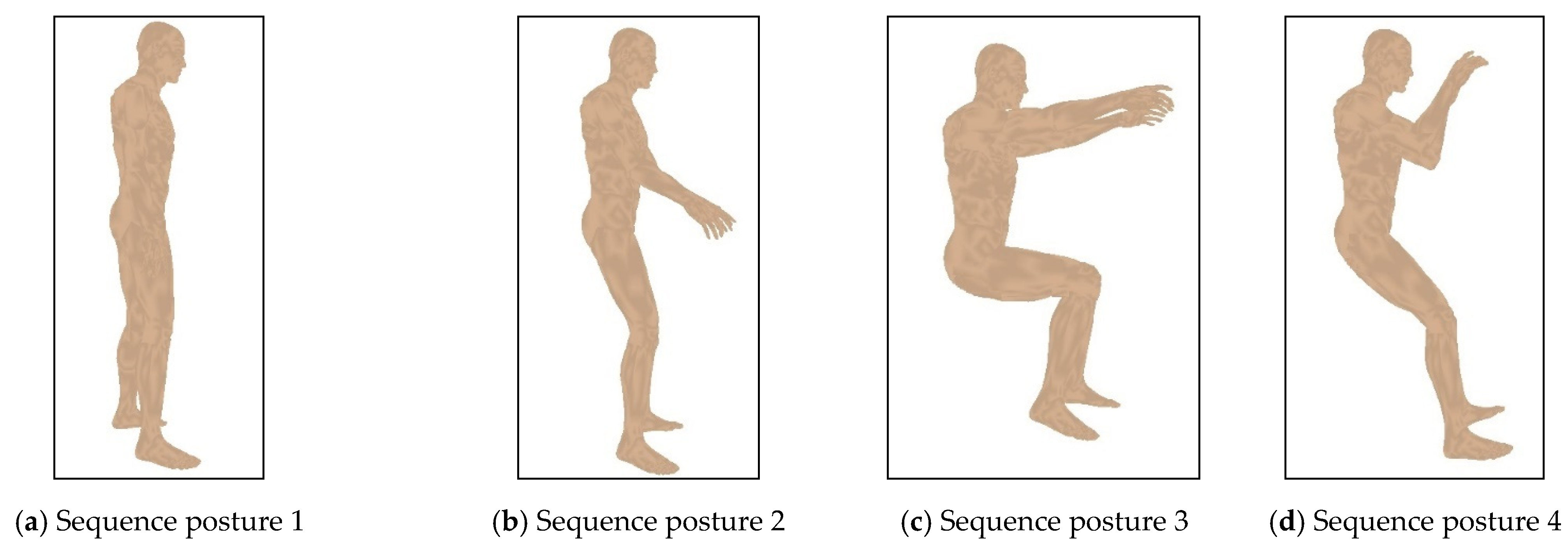
4.2. Behavior Comparison for Different Human Postures
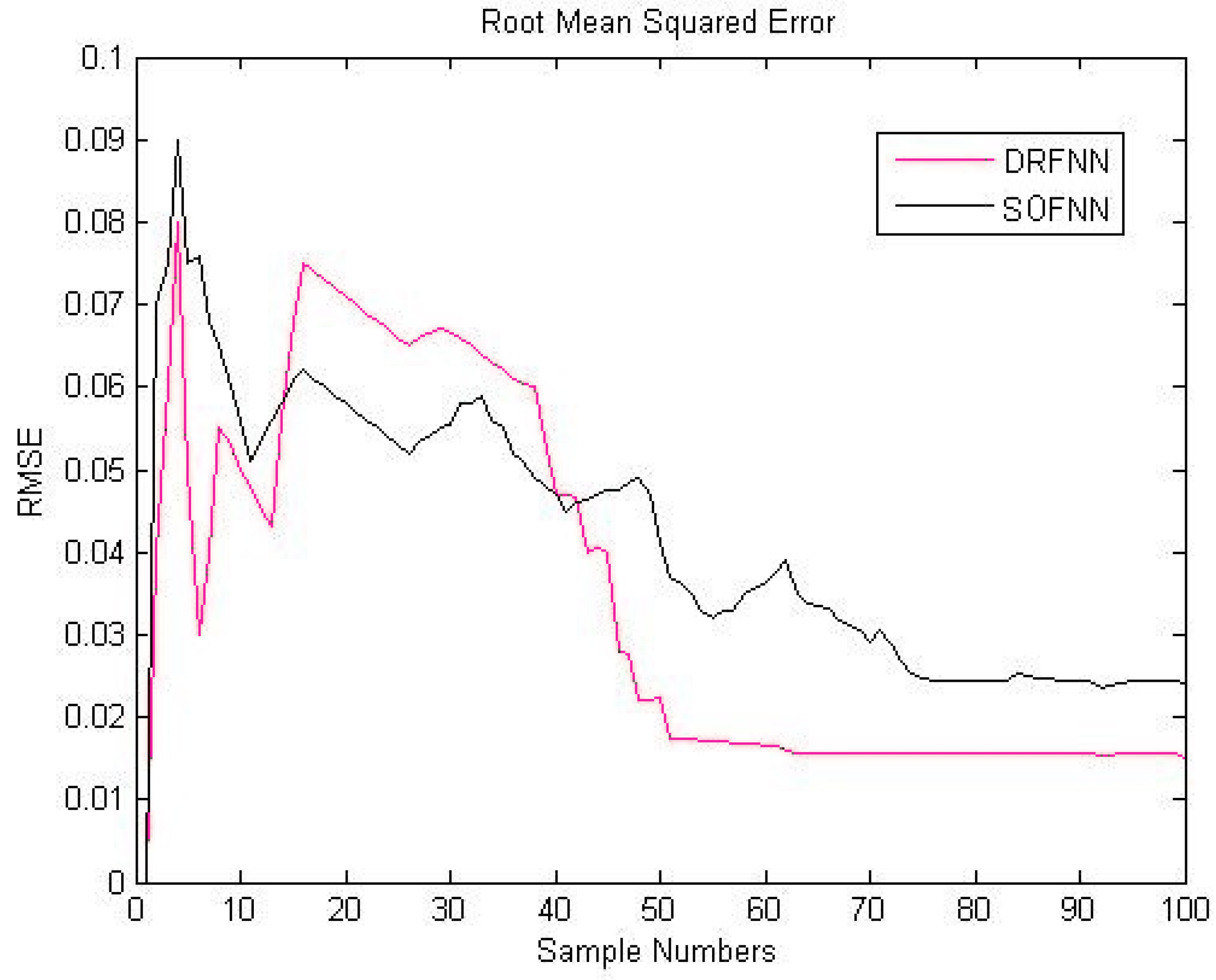
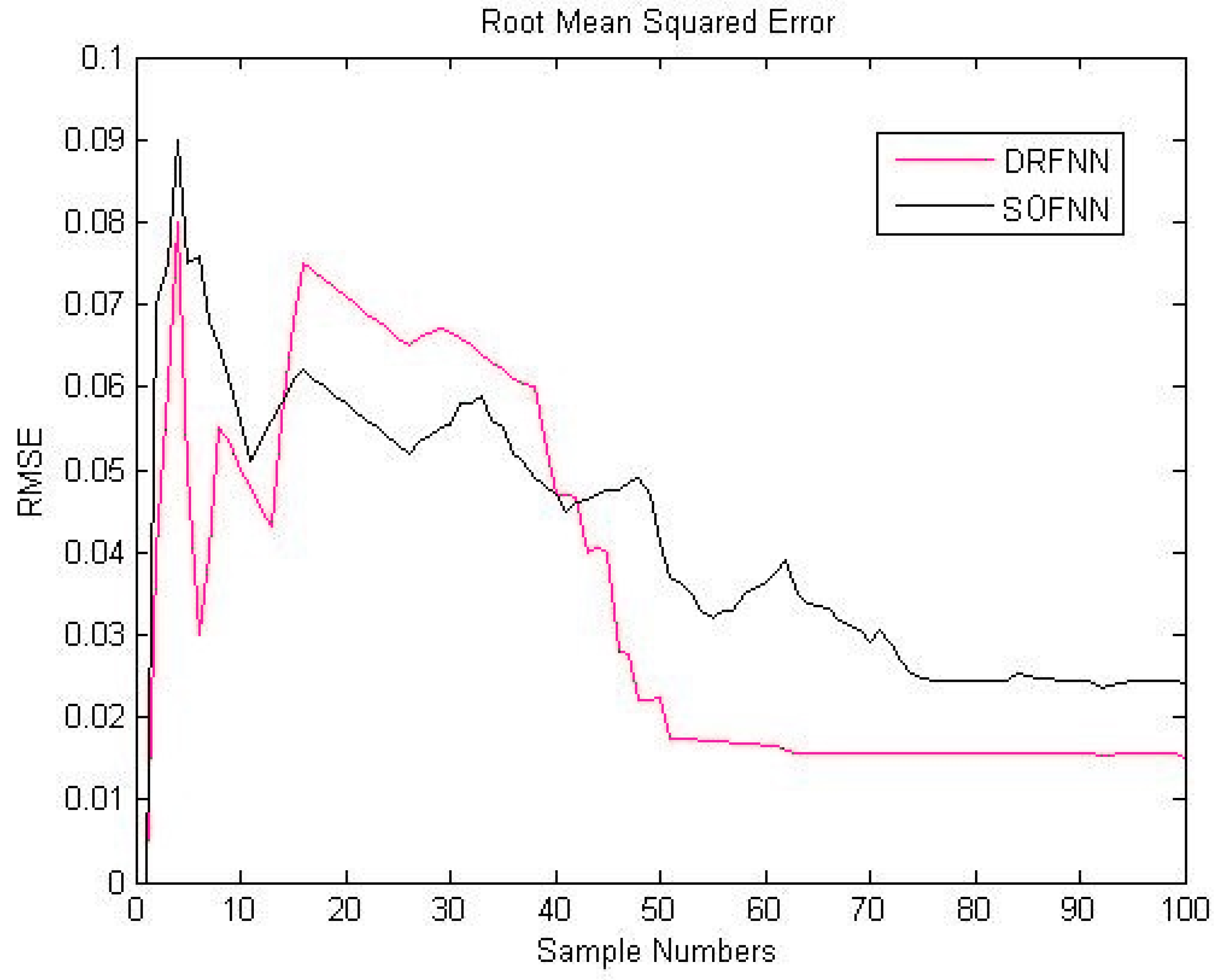
4.3. Comparison of the Results between DRFNN and SOFNN
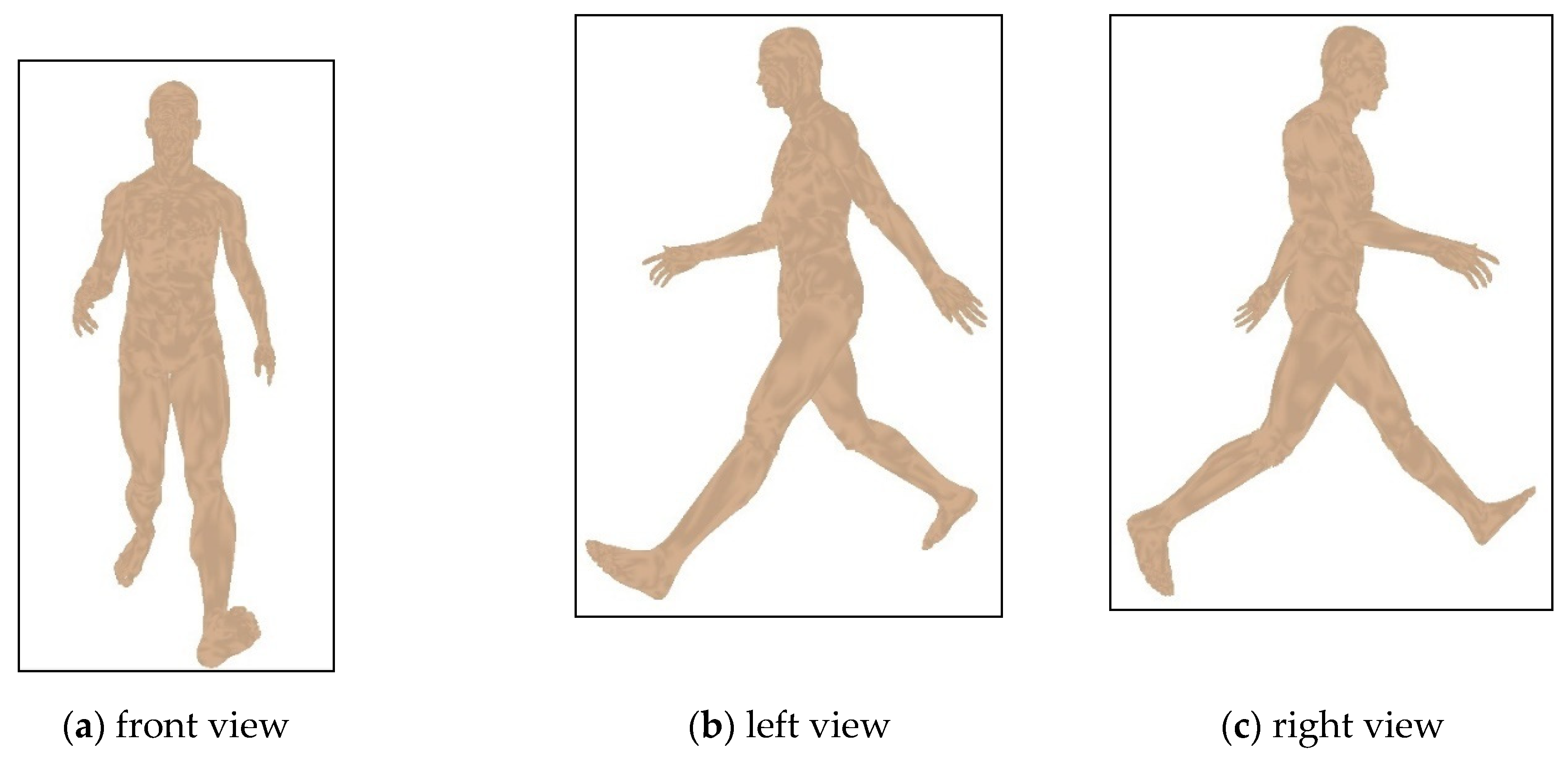
4.4. Comparison of the Motion Retrieval and Analysis on Different Human Postures
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Huang, C.; Yang, S.; Pan, Y.; Lai, H. Object-location-aware hashing for multi-label image retrieval via automatic mask learning. IEEE Trans. Image Process. 2018, 27, 4490–4502. [Google Scholar] [CrossRef] [PubMed]
- Lv, N.; Jiang, Z.; Huang, Y.; Meng, X.; Meenakshisundaram, G.; Peng, J. Generic content-based retrieval of marker-based motion capture data. IEEE Trans. Vis. Comput. Graph. 2018, 24, 1969–1982. [Google Scholar] [CrossRef]
- Chen, S.; Sun, Z.; Zhang, Y.; Li, Q. Relevance feedback for human motion retrieval using a boosting approach. Multimed. Tools Appl. 2016, 75, 787–817. [Google Scholar] [CrossRef]
- Bao, H.; Yao, X. Human motion data retrieval based on staged dynamic time deformation optimization algorithm. Complexity 2020, 2020, 6650924. [Google Scholar] [CrossRef]
- Ramezani, M.; Yaghmaee, F. Retrieving human action by fusing the motion information of interest points. Int. J. Artif. Intell. Tools 2018, 27, 1850008. [Google Scholar] [CrossRef]
- Xiao, Q.; Liu, S. Motion retrieval based on dynamic bayesian network and canonical time warping. Soft Comput. 2017, 21, 267–280. [Google Scholar] [CrossRef]
- Li, M.; Leung, H.; Liu, Z.; Zhou, L. 3D human motion retrieval using graph kernels based on adaptive graph construction. Comput. Graph. 2016, 54, 104–112. [Google Scholar] [CrossRef]
- Xiao, Q.; Song, R. Human motion retrieval based on statistical learning and Bayesian fusion. PLoS ONE 2016, 11, e0164610. [Google Scholar] [CrossRef]
- Wang, X.; Chen, L.; Jing, J.; Zheng, H. Human motion capture data retrieval based on semantic thumbnail. Multimed. Tools Appl. 2016, 75, 11723–11740. [Google Scholar] [CrossRef]
- Valcik, J.; Sedmidubsky, J.; Zezula, P. Assessing similarity models for human-motion retrieval applications. Comput. Animat. Virtual Worlds 2016, 27, 484–500. [Google Scholar] [CrossRef]
- Wang, Z.; Feng, Y.; Qi, T.; Yang, X.; Zhang, J. Adaptive multi-view feature selection for human motion retrieval. Signal Process. 2016, 120, 691–701. [Google Scholar] [CrossRef] [Green Version]
- Liu, X.; He, G.; Peng, S.; Cheung, Y.; Tang, Y. Efficient human motion retrieval via temporal adjacent bag of words and discriminative neighborhood preserving dictionary learning. IEEE Trans. Hum. Mach. Syst. 2017, 47, 763–776. [Google Scholar] [CrossRef]
- Slama, R.; Wannous, H.; Daoudi, M. 3D human motion analysis framework for shape similarity and retrieval. Image Vis. Comput. 2014, 32, 131–154. [Google Scholar] [CrossRef]
- Ren, T.; Li, W.; Jiang, Z.; Li, X.; Huang, Y.; Peng, J. Video-based human motion capture data retrieval via motionset network. IEEE Access 2020, 8, 186212–186221. [Google Scholar] [CrossRef]
- Ramezani, M.; Yaghmaee, F. Motion pattern based representation for improving human action retrieval. Multimed. Tools Appl. 2018, 77, 26009–26032. [Google Scholar] [CrossRef]
- Tang, Z.; Xiao, J.; Feng, Y.; Yang, X.; Zhang, J. Human motion retrieval based on freehand sketch. Comput. Animat. Virtual Worlds 2014, 25, 273–281. [Google Scholar] [CrossRef] [Green Version]
- Li, Y.; Lei, H.; Lin, S.; Luo, G. A new sketch-based 3D model retrieval method by using composite features. Multimed. Tools Appl. 2018, 77, 2921–2944. [Google Scholar] [CrossRef]
- Li, B.; Lu, Y.; Johan, H.; Fares, R. Sketch-based 3D model retrieval utilizing adaptive view clustering and semantic information. Multimed. Tools Appl. 2017, 76, 26603–26631. [Google Scholar] [CrossRef]
- Free 3D Models Database. Available online: http://artist-3d.com (accessed on 15 November 2020).
- Huang, X.; Gao, L. Reconstructing Three-Dimensional Human Poses: A Combined Approach of Iterative Calculation on Skeleton Model and Conformal Geometric Algebra. Symmetry 2019, 11, 301. [Google Scholar] [CrossRef] [Green Version]
- Huang, X.; Zhu, Y. An entity based multi-direction cooperative deformation algorithm for generating personalized human shape. Multimed. Tools Appl. 2018, 77, 24865–24889. [Google Scholar] [CrossRef]
- Sabahi, F. Introducing validity into self-organizing fuzzy neural network applied to impedance force control. Fuzzy Sets Syst. 2018, 337, 113–127. [Google Scholar] [CrossRef]
- Zhang, W.; Qiao, J. Multi-variable direct self-organizing fuzzy neural network control for wastewater treatment process. Asian J. Control 2020, 22, 716–728. [Google Scholar] [CrossRef]
- Zhou, H.; Zhang, Y.; Duan, W.; Zhao, H. Nonlinear systems modelling based on self-organizing fuzzy neural network with hierarchical pruning scheme. Appl. Soft Comput. 2020, 95, 106516. [Google Scholar] [CrossRef]
- Zou, B.; Chen, S.; Shi, C.; Providence, U.M. Automatic reconstruction of 3D human motion pose from uncalibrated monocular video sequences based on markerless human motion tracking. Pattern Recognit. 2009, 42, 1559–1571. [Google Scholar] [CrossRef]
- Chan, C.K.; Loh, W.P.; Rahim, A. Human motion classification using 2D stick-model matching regression coefficients. Appl. Math. Comput. 2016, 283, 70–89. [Google Scholar] [CrossRef] [Green Version]
- Fu, Y.B.; Liu, S.; Li, H.H.; Yang, D.S. Automatic and hierarchical segmentation of the human skeleton in CT images. Phys. Med. Biol. 2017, 62, 2812–2833. [Google Scholar] [CrossRef] [PubMed]
- Huang, X.; Hao, K.; Ding, Y. Human fringe skeleton extraction by an improved Hopfield neural network with direction features. Neurocomputing 2012, 87, 99–110. [Google Scholar] [CrossRef]
- Ren, Y.; Li, Q.; Liu, W.; Li, L. Semantic facial descriptor extraction via axiomatic fuzzy set. Neurocomputing 2016, 171, 1462–1474. [Google Scholar] [CrossRef]
- Liu, S.; Liu, Y.; Wang, N. Robust adaptive self-organizing neuro-fuzzy tracking control of UUV with system uncertainties and unknown dead-zone nonlinearity. Nonlinear Dyn. 2017, 89, 1397–1414. [Google Scholar] [CrossRef]
- Hong, C.; Yu, J.; Tao, D.; Wang, M. Image-based three-dimensional human pose recovery by multiview locality-sensitive sparse retrieval. IEEE Trans. Ind. Electron. 2015, 62, 3742–3751. [Google Scholar]
- Yu, J.; Sun, J. Multispectral embedding-based deep neural network for three-dimensional human pose recovery. Opt. Eng. 2018, 57, 013107. [Google Scholar]
- Yasin, H.; Kruger, B. An efficient 3D human pose retrieval and reconstruction from 2D image-based landmarks. Sensors 2021, 21, 2415. [Google Scholar] [CrossRef] [PubMed]









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Models | System Error | Structure of Neural Network | Weights of Network |
|---|---|---|---|
| SOFNN | L1 measure | Adjustment based on network output | Gradient descent method |
| DRFNN | L1 measure with error threshold of dynamic adjustment | Fuzzy rule adjustment using sensitivity and disturbance analysis | Gradient descent with weighted adjustment |
| Different Model Postures | Number of Fuzzy Rules | The Training Time of Algorithms(ms) | Root Mean Squared Error | |||
|---|---|---|---|---|---|---|
| SOFNN | DRFNN | SOFNN | DRFNN | SOFNN | DRFNN | |
| Walking | 9 | 8 | 309.65 | 373.46 | 0.0365 | 0.0289 |
| Running | 9 | 9 | 323.53 | 391.78 | 0.0378 | 0.0254 |
| Sitting | 10 | 9 | 315.24 | 394.36 | 0.0421 | 0.0276 |
| Rotation Angles of Limb Parts | Target Example (Degree) (Pos1, Pos2, Pos3) | Average Error of Network in [30] (Degree) | Average Error of the Proposed DRFNN (Degree) |
|---|---|---|---|
| (123.11, 159.46, 129.46) | 2.75 | 2.16 | |
| (111.35, 35.56, 177.20) | 3.67 | 2.78 | |
| (118.72, 149.84, 134.60) | 3.41 | 2.13 | |
| (165.25, 35.31, 74.51) | 3.54 | 2.21 | |
| (144.04, 153.45, 149.79) | 2.51 | 1.67 | |
| (151.39, 170.94, 133.89) | 2.31 | 1.54 | |
| (158.50, 149.65, 144.54) | 3.71 | 2.32 | |
| (163.06, 137.88, 145.28) | 3.44 | 2.15 |
| Variances | Training RMSE | Testing RMSE | ||
|---|---|---|---|---|
| SOFNN | DRFNN | SOFNN | DRFNN | |
| 0.0349 | 0.0285 | 0.0418 | 0.0328 | |
| 0.0427 | 0.0347 | 0.0545 | 0.0416 | |
| 0.0485 | 0.0379 | 0.0596 | 0.0437 | |
| Different Model Postures | The Average Output on Poor Inputs | The Average Output on Good Inputs | Average Running Time of Prediction (ms) | |||
|---|---|---|---|---|---|---|
| SOFNN in [30] | The Proposed DRFNN | SOFNN in [30] | The Proposed DRFNN | SOFNN in [30] | The Proposed DRFNN | |
| Walking | (0.05, 0.11, 0.16) | (0.04, 0.11, 0.14) (0.05, 0.11, 0.15) (0.06, 0.12, 0.18) | (0.93, 0.86, 0.8) | (0.95, 0.89, 0.84) | 316.79 | 482.54 |
| Running | (0.05, 0.12, 0.17) | (0.92, 0.86, 0.81) | (0.95, 0.88, 0.83) | 331.64 | 523.49 | |
| Sitting | (0.07, 0.14, 0.2) | (0.92, 0.87, 0.82) | (0.96, 0.89, 0.85) | 304.35 | 468.96 | |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Huang, X.; Zhu, Y.; Wang, S. An Efficient Dynamic Regulated Fuzzy Neural Network for Human Motion Retrieval and Analysis. Symmetry 2021, 13, 1317. https://doi.org/10.3390/sym13081317
Huang X, Zhu Y, Wang S. An Efficient Dynamic Regulated Fuzzy Neural Network for Human Motion Retrieval and Analysis. Symmetry. 2021; 13(8):1317. https://doi.org/10.3390/sym13081317
Chicago/Turabian StyleHuang, Xin, Yuanping Zhu, and Shuqin Wang. 2021. "An Efficient Dynamic Regulated Fuzzy Neural Network for Human Motion Retrieval and Analysis" Symmetry 13, no. 8: 1317. https://doi.org/10.3390/sym13081317
APA StyleHuang, X., Zhu, Y., & Wang, S. (2021). An Efficient Dynamic Regulated Fuzzy Neural Network for Human Motion Retrieval and Analysis. Symmetry, 13(8), 1317. https://doi.org/10.3390/sym13081317