
Reversible Data Hiding in Encrypted Images Using Median Edge Detector and Two’s Complement



Abstract
1. Introduction
- The proposed method achieves a higher ER than previous related methods. In the proposed method, two’s complement is used to encode the prediction errors, making full use of spatial correlation. Therefore, more pixels are used to reserve room in the original image. Meanwhile, a label map is generated to record the overflowed pixels rather than embedding codes in these pixels. Compressing the label map can further reduce the room occupied by the auxiliary information. The experimental results show that the ERs of the proposed method are better than those of previous methods.
- The proposed method is more secure. In previous related methods, the auxiliary information is shared with the data hider for hiding data. Through the shared auxiliary information, a dishonest data hider can parse out the original image’s spatial information, which may cause leakage of the content. To solve this problem, an MSBs rearrangement method is proposed to form a regular reserved room. Then, the label map is embedded into the regular reserved room and encrypts. In addition, two parameters are set for hiding data, so the data hider cannot obtain any spatial information of the image. Thus, the proposed method reduces the risk of sharing auxiliary information.
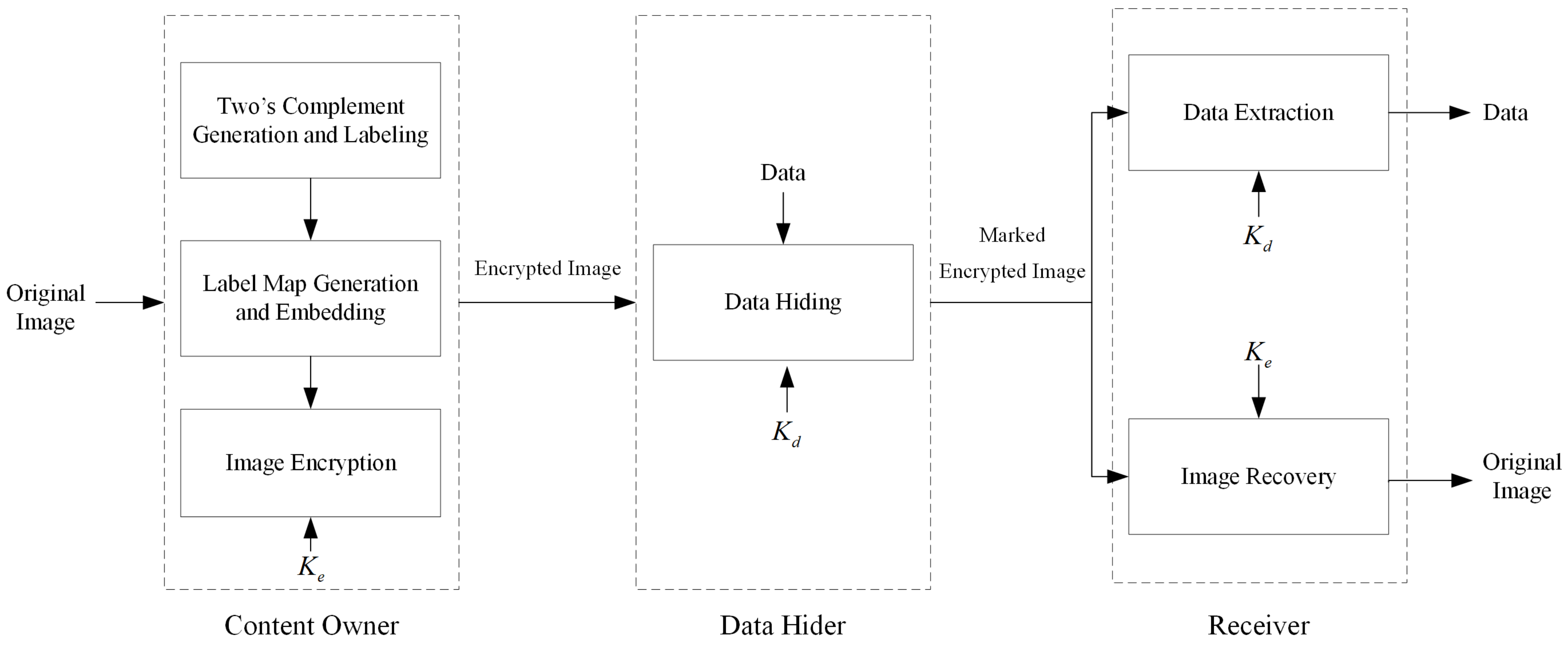
2. Proposed Method
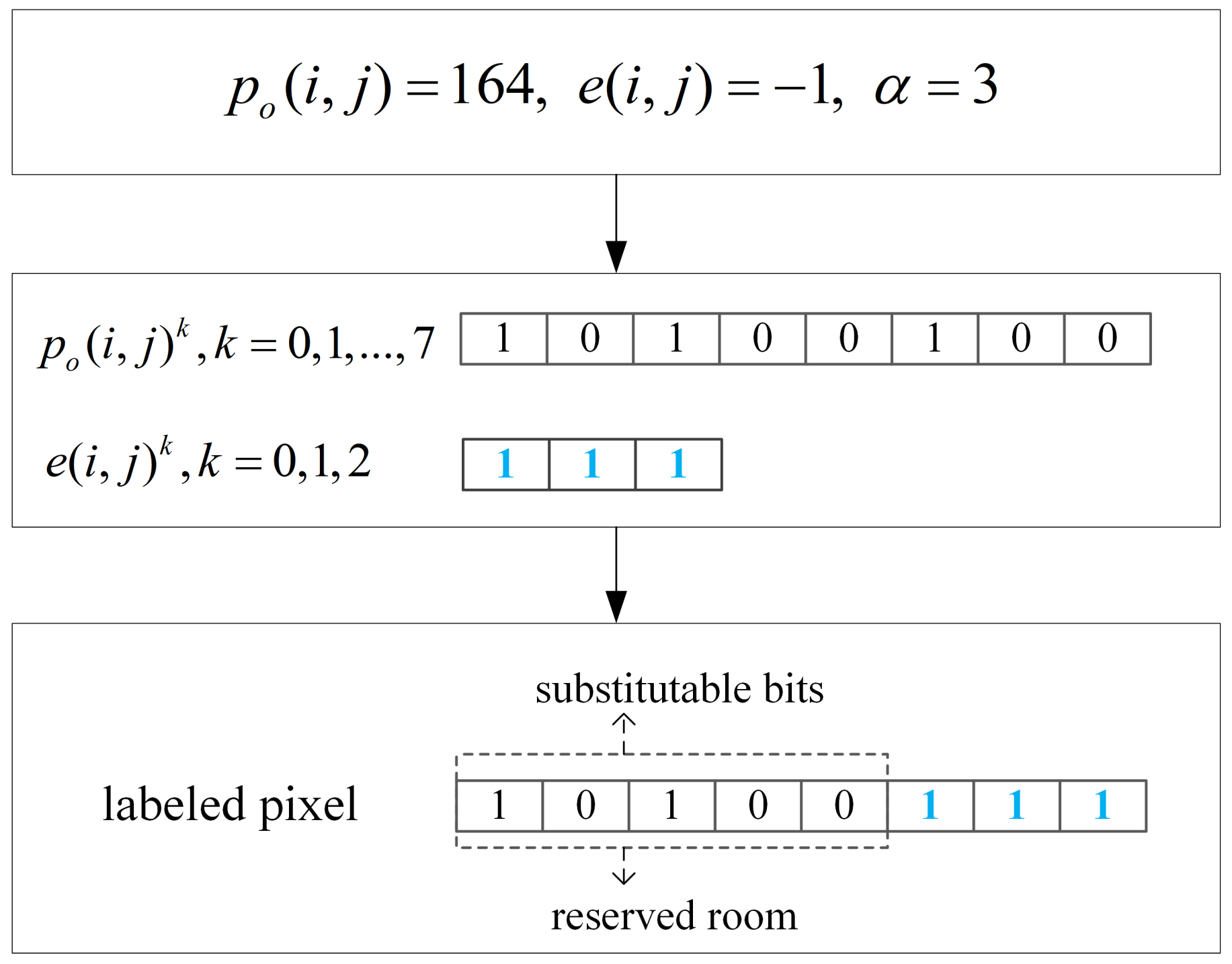
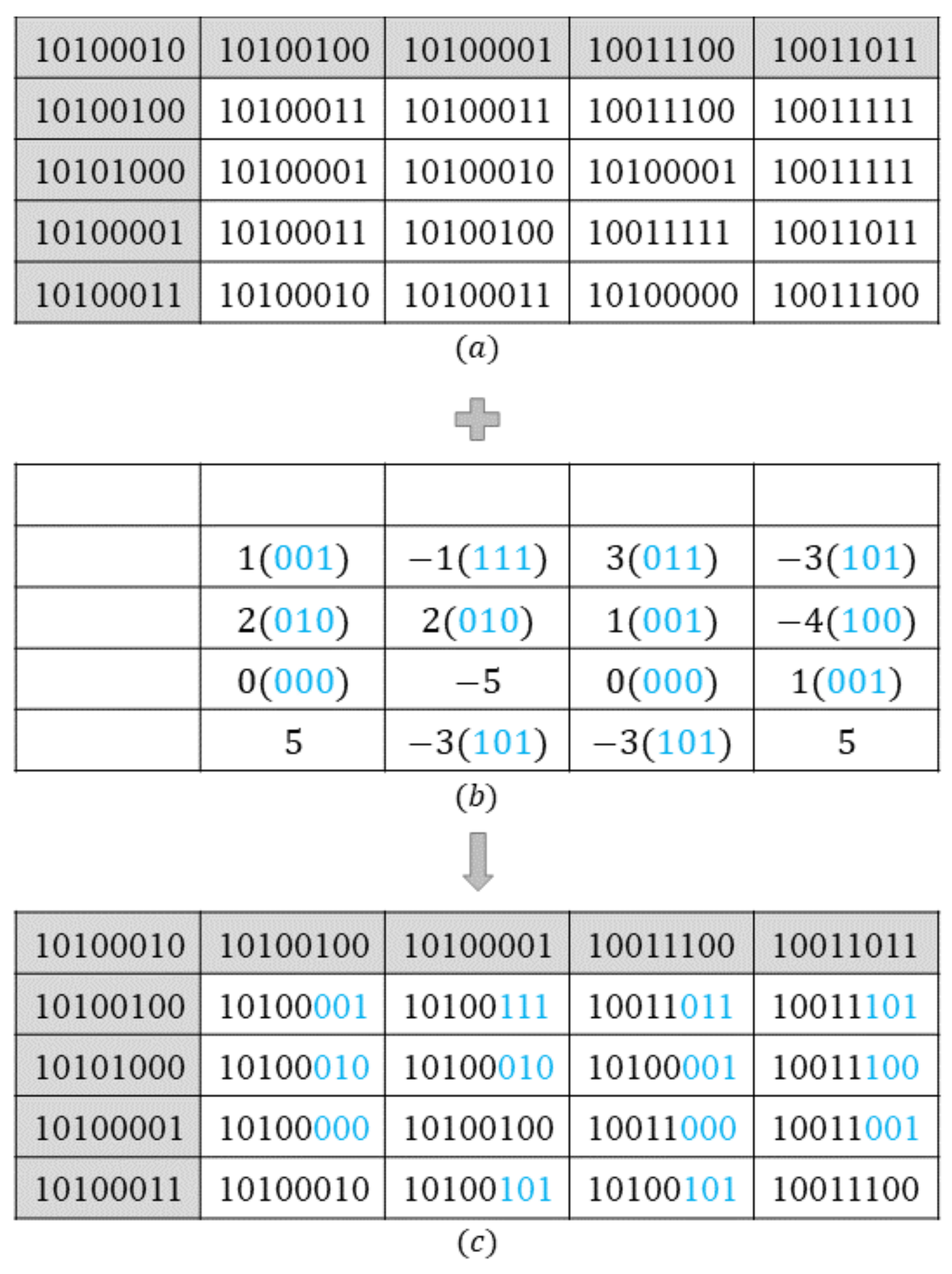
2.1. Two’s Complement Generation and Labeling
2.2. Label Map Generation and Embedding
2.3. Generation of an Encrypted Image
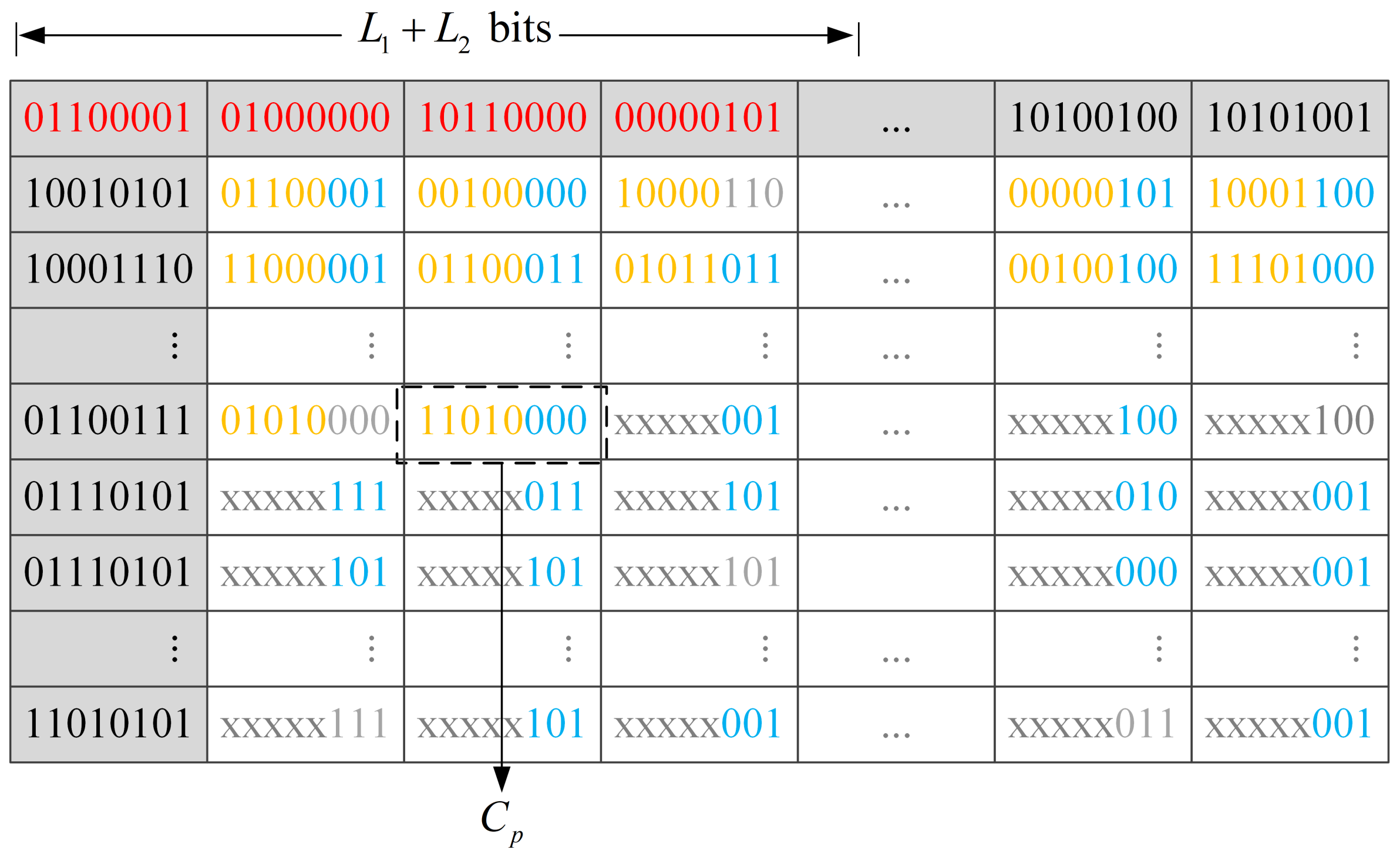
2.4. Data Hiding in the Encrypted Image
| Algorithm 1 Data Hiding Algorithm. |
| Input: Encrypted image , Secret data D, Data encryption key Output: Marked encrypted image Get the encrypted secret data by using key Extract the fixed-length bits from the reference pixels of Extract parameter and coordinate from bits Get the first embeddable pixel while There is still encrypted data that have not been embedded do Convert current pixel into 8-bit binary form Extract front (8 − ) bits from , and embed it into Get next pixel end while Get marked encrypted image |
2.5. Data Extraction and Image Recovery
2.5.1. Data Extraction
2.5.2. Image Recovery
3. Experimental Results and Analysis
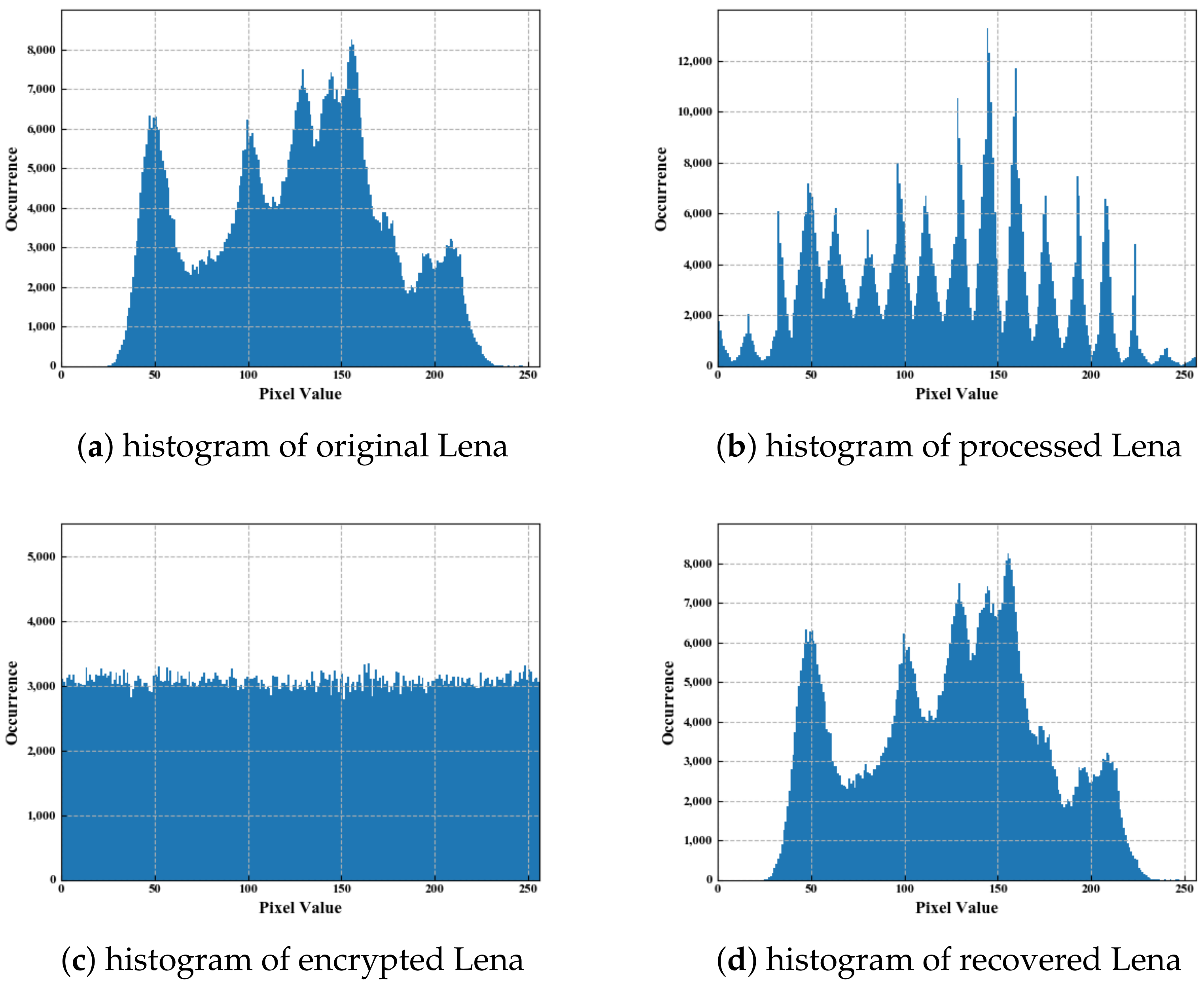
3.1. Performance and Security Analysis
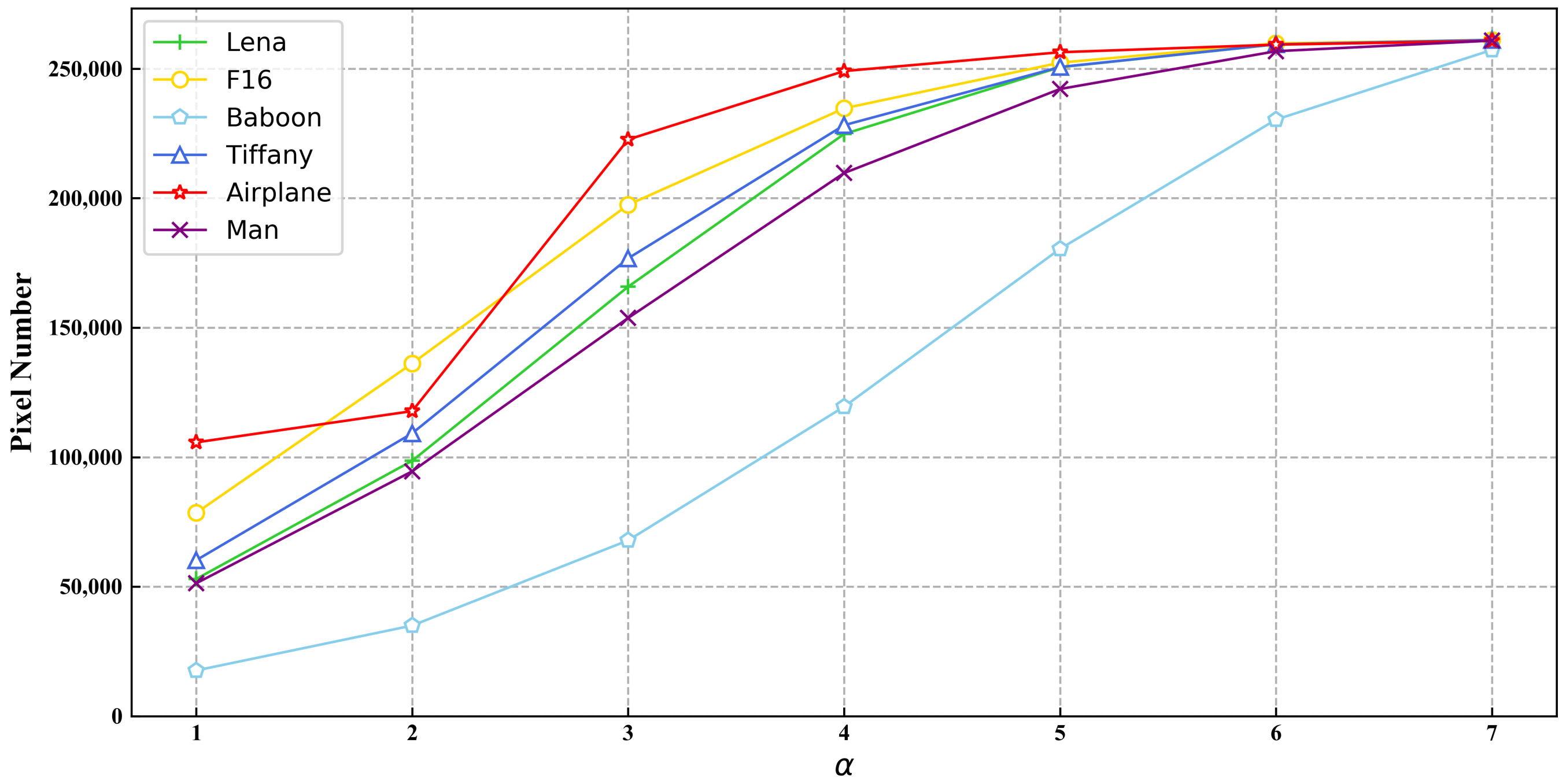
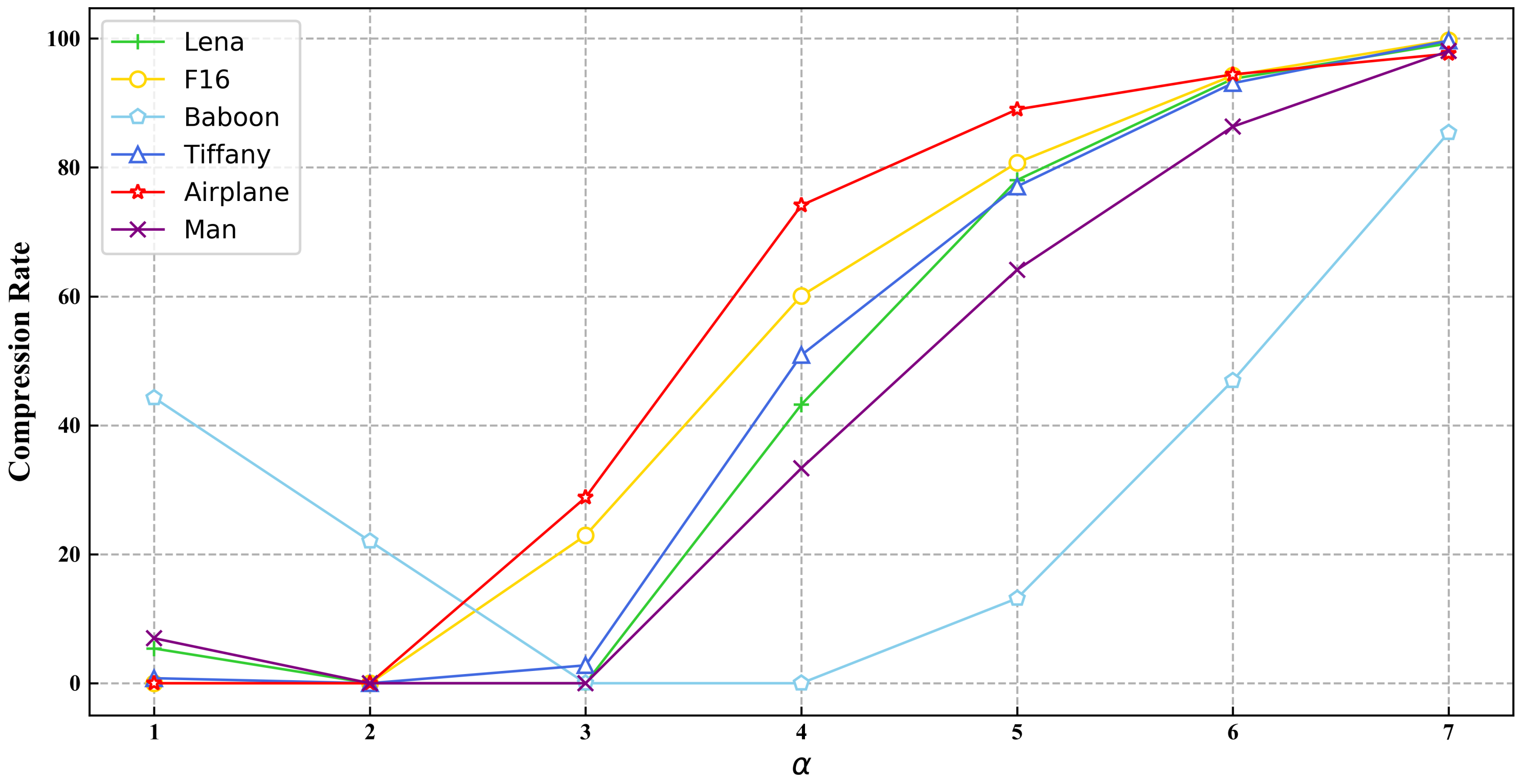
3.2. Parameter and Capacity Analysis
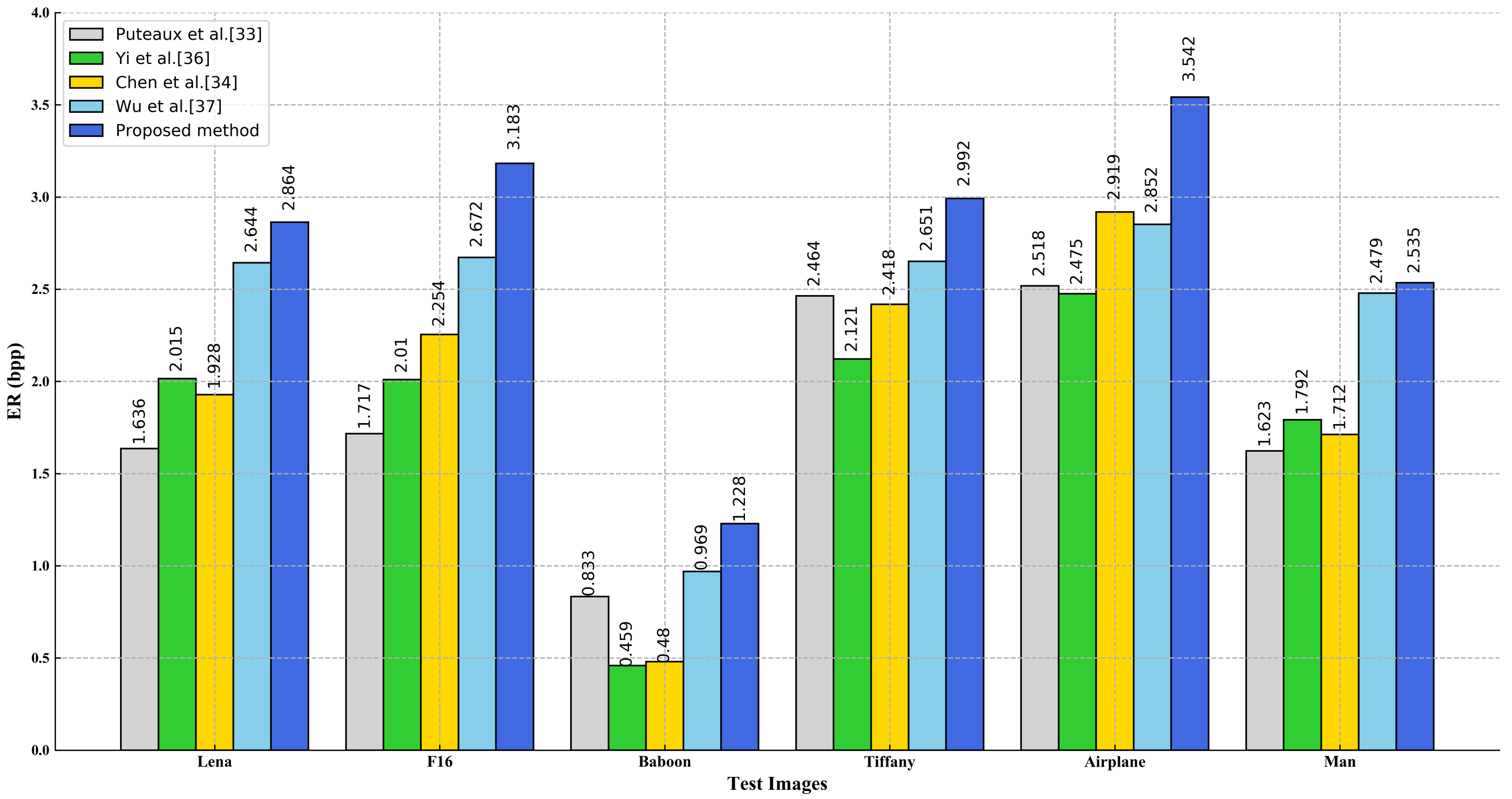
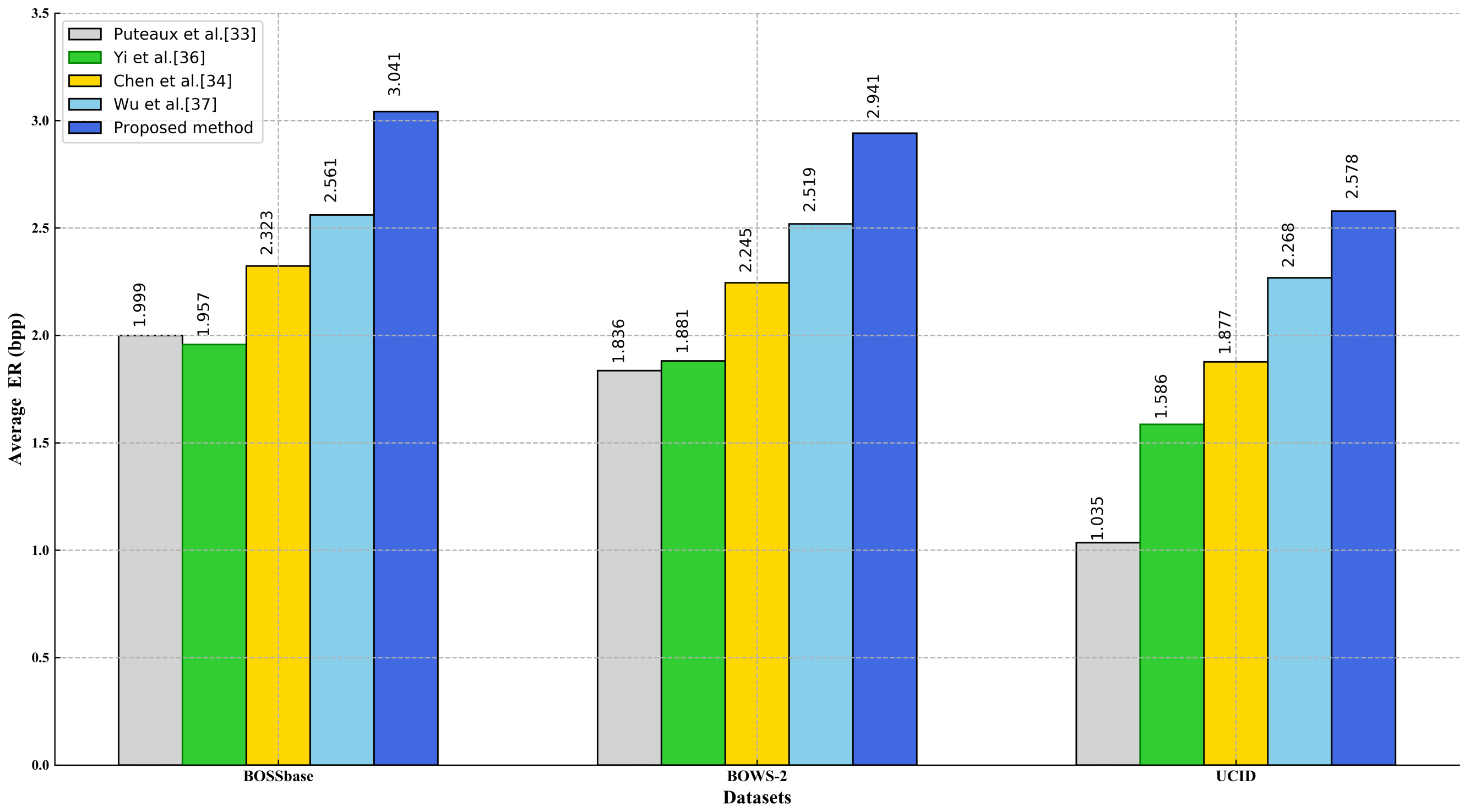
3.3. Comparisons with State-of-the-Art Methods
4. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Bender, W.; Gruhl, D.; Morimot, N.; Lu, A. Techniques for data hiding. IBM Syst. J. 1996, 35, 313–336. [Google Scholar] [CrossRef]
- Chan, C.K.; Cheng, L.M. Hiding data in images by simple LSB substitution. Pattern Recognit. 2004, 37, 469–474. [Google Scholar] [CrossRef]
- Celik, M.; Sharma, G.; Tekalp, A.; Saber, E. Lossless generalized-LSB data embedding. IEEE Trans. Image Process. 2005, 14, 253–266. [Google Scholar] [CrossRef] [PubMed]
- Tian, J. Reversible data embedding using a difference expansion. IEEE Trans. Circuits Syst. Video Technol. 2003, 13, 890–896. [Google Scholar] [CrossRef]
- Tai, W.L.; Yeh, C.M.; Chang, C.C. Reversible data hiding based on histogram modification of pixel differences. IEEE Trans. Circuits Syst. Video Technol. 2009, 19, 906–910. [Google Scholar]
- Lin, C.C.; Liu, X.L.; Tai, W.L.; Yuan, S.M. A novel reversible data hiding scheme based on AMBTC compression technique. Multimedia Tools Appl. 2015, 74, 3823–3842. [Google Scholar] [CrossRef]
- Malik, A.; Singh, S.; Kumar, R. Recovery based high capacity reversible data hiding scheme using even-odd embedding. Multimedia Tools Appl. 2018, 77, 15803–15827. [Google Scholar] [CrossRef]
- Kumar, R.; Chand, S.; Singh, S. An optimal high capacity reversible data hiding scheme using move to front coding for LZW codes. Multimedia Tools Appl. 2019, 78, 22977–23001. [Google Scholar] [CrossRef]
- Dragoi, I.C.; Coltuc, D. Local-prediction-based difference expansion reversible watermarking. IEEE Trans. Image Process. 2014, 23, 1779–1790. [Google Scholar] [CrossRef] [PubMed]
- Arham, A.; Nugroho, H.A.; Adji, T.B. Multiple layer data hiding scheme based on difference expansion of quad. Signal Process. 2017, 137, 52–62. [Google Scholar] [CrossRef]
- Wang, W.; Ye, J.; Wang, T.; Wang, W. Reversible data hiding scheme based on significant-bit-difference expansion. IET Image Process. 2017, 11, 1002–1014. [Google Scholar] [CrossRef]
- Pan, Z.; Hu, S.; Ma, X.; Wang, L. Reversible data hiding based on local histogram shifting with multilayer embedding. J. Vis. Commun. Image Represent. 2015, 31, 64–74. [Google Scholar] [CrossRef]
- Wang, J.; Ni, J.; Zhang, X.; Shi, Y.Q. Rate and distortion optimization for reversible data hiding using multiple histogram shifting. IEEE Trans. Cybern. 2016, 47, 315–326. [Google Scholar] [CrossRef] [PubMed]
- Jia, Y.; Yin, Z.; Zhang, X.; Luo, Y. Reversible data hiding based on reducing invalid shifting of pixels in histogram shifting. Signal Process. 2019, 163, 238–246. [Google Scholar] [CrossRef]
- Kumar, R.; Chand, S.; Singh, S. A reversible data hiding scheme using pixel location. Int. Arab. J. Inf. Technol. 2018, 15, 763–768. [Google Scholar]
- Kumar, R.; Chand, S.; Singh, S. An Improved Histogram-Shifting-Imitated reversible data hiding based on HVS characteristics. Multimed. Tools Appl. 2018, 77, 13445–13457. [Google Scholar] [CrossRef]
- Kumar, R.; Chand, S.; Singh, S. A reversible high capacity data hiding scheme using combinatorial strategy. Int. J. Multimedia Intell. Secur. 2018, 3, 146–161. [Google Scholar] [CrossRef]
- Zhang, W.; Wang, H.; Hou, D.; Yu, N. Reversible Data Hiding in Encrypted Images by Reversible Image Transformation. IEEE Trans. Multimed. 2016, 18, 1469–1479. [Google Scholar] [CrossRef]
- Yang, C.T.; Shih, W.C.; Chen, G.H.; Yu, S.C. Implementation of a cloud computing environment for hiding huge amounts of data. In Proceedings of the International Symposium on Parallel and Distributed Processing with Applications, Taipei, Taiwan, 6–9 September 2010; pp. 1–7. [Google Scholar]
- Abbasy, M.R.; Shanmugam, B. Enabling data hiding for resource sharing in cloud computing environments based on DNA sequences. In Proceedings of the 2011 IEEE World Congress on Services, Washington, DC, USA, 4–9 July 2011; pp. 385–390. [Google Scholar]
- Hwang, K.; Li, D. Trusted cloud computing with secure resources and data coloring. IEEE Int. Comput. 2010, 14, 14–22. [Google Scholar] [CrossRef]
- Xiong, L.; Shi, Y. On the privacy-preserving outsourcing scheme of reversible data hiding over encrypted image data in cloud computing. Comput. Mater. Contin. 2018, 55, 523–539. [Google Scholar]
- Qin, C.; Zhang, X. Effective reversible data hiding in encrypted image with privacy protection for image content. J. Vis. Commun. Image Represent. 2015, 31, 154–164. [Google Scholar] [CrossRef]
- Puech, W.; Chaumont, M.; Strauss, O. A reversible data hiding method for encrypted images. In Proceedings of the Security, Forensics, Steganography, and Watermarking of Multimedia Contents X, San Jose, CA, USA, 18 March 2008; pp. 534–542. [Google Scholar]
- Zhang, X. Reversible data hiding in encrypted image. IEEE Signal Process. Lett. 2011, 18, 255–258. [Google Scholar] [CrossRef]
- Hong, W.; Chen, T.S.; Wu, H.Y. An improved reversible data hiding in encrypted images using side match. IEEE Signal Process. Lett. 2012, 19, 199–202. [Google Scholar] [CrossRef]
- Ma, K.; Zhang, W.; Zhao, X.; Yu, N.; Li, F. Reversible data hiding in encrypted images by reserving room before encryption. IEEE Trans. Inf. Forensics Secur. 2013, 8, 553–562. [Google Scholar] [CrossRef]
- Mathew, T.; Wilscy, M. Reversible data hiding in encrypted images by active block exchange and room reservation. In Proceedings of the 2014 International Conference on Contemporary Computing and Informatics, Mysore, India, 27–29 November 2014; pp. 839–844. [Google Scholar]
- Zhang, W.; Ma, K.; Yu, N. Reversibility improved data hiding in encrypted images. Signal Process. 2014, 953, 118–127. [Google Scholar] [CrossRef]
- Puteaux, P.; Trinel, D.; Puech, W. High-capacity data hiding in encrypted images using MSB prediction. In Proceedings of the 2016 Sixth International Conference on Image Processing Theory, Tools and Applications, Oulu, Finland, 12–15 December 2016; pp. 1–6. [Google Scholar]
- Puteaux, P.; Puech, W. An efficient MSB prediction-based method for high-capacity reversible data hiding in encrypted images. IEEE Trans. Inf. Forensics Secur. 2018, 13, 1670–1681. [Google Scholar] [CrossRef]
- Puyang, Y.; Yin, Z.; Qian, Z. Reversible data hiding in encrypted images with two-MSB prediction. In Proceedings of the 2018 IEEE International Workshop on Information Forensics and Security, Hong Kong, China, 11–13 December 2018; pp. 8–15. [Google Scholar]
- Puteaux, P.; Puech, W. EPE-based huge-capacity reversible data hiding in encrypted images. In Proceedings of the 2018 IEEE International Workshop on Information Forensics and Security, Hong Kong, China, 11–13 December 2018; pp. 1–7. [Google Scholar]
- Chen, K.; Chang, C.C. High-capacity reversible data hiding in encrypted images based on extended run-length coding and block-based MSB plane rearrangement. J. Vis. Commun. Image Represent. 2019, 58, 334–344. [Google Scholar] [CrossRef]
- Yin, Z.; Xiang, Y.; Zhang, X. Reversible data hiding in encrypted images based on multi-MSB prediction and Huffman coding. IEEE Trans. Multimed. 2019, 22, 874–884. [Google Scholar] [CrossRef]
- Yi, S.; Zhou, Y. Separable and reversible data hiding in encrypted images using parametric binary tree labeling. IEEE Trans. Multimed. 2019, 21, 51–64. [Google Scholar] [CrossRef]
- Wu, Y.; Xiang, Y.; Guo, Y.; Tang, J.; Yin, Z. An improved reversible data hiding in encrypted images using parametric binary tree labeling. IEEE Trans. Multimed. 2020, 22, 1929–1938. [Google Scholar] [CrossRef]
- Yin, Z.; Niu, X.; Zhang, X.; Tang, J.; Luo, B. Reversible data hiding in encrypted AMBTC images. Multimedia Tools Appl. 2018, 77, 18067–18083. [Google Scholar] [CrossRef]
- Shiu, P.F.; Tai, W.L.; Jan, J.K.; Chang, C.C.; Lin, C.C. An interpolative AMBTC-based high-payload RDH scheme for encrypted images. Signal Process. Image Commun. 2019, 74, 64–77. [Google Scholar] [CrossRef]
- Schaefer, G.; Stich, M. UCID: An uncompressed color image database. In Proceedings of the Storage and Retrieval Methods and Applications for Multimedia 2004, San Jose, CA, USA, 18 December 2003; pp. 472–480. [Google Scholar]
- Bas, P.; Filler, T.; Pevny, T. Break our steganographic: The ins and outs of organizing BOSS. In Proceedings of the International Workshop on Information Hiding, Berlin, Germany, 18–20 May 2011; pp. 59–70. [Google Scholar]
- Image Databased of BOWS-2. Available online: http://bows2.ec-lille.fr/ (accessed on 1 April 2021).














{kind=link}
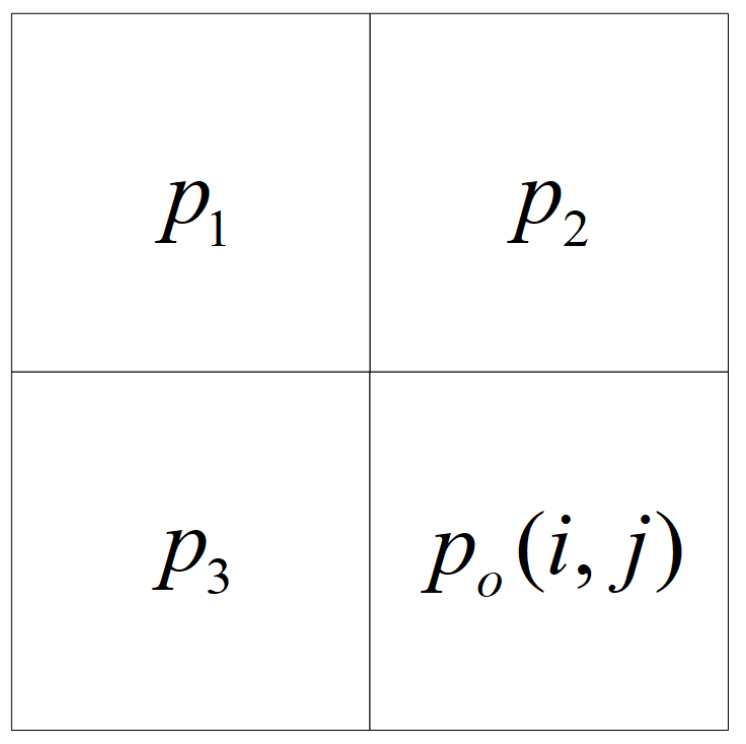{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Notation | Meaning | Notation | Meaning |
|---|---|---|---|
| original image | a pixel in | ||
| labeled image | a pixel in | ||
| processed image | a pixel in | ||
| encrypted image | a pixel in | ||
| marked encrypted image | a pixel in | ||
| H | image height | W | image width |
| predicted value of original pixel | prediction error between and | ||
| image encryption key | data hiding key | ||
| length of two’s complement | U | encoded prediction errors’ interval | |
| M | label map | bitstream of compressed M | |
| length of | bitstream of unlabeled pixels’ (8 − )-bit MSBs | ||
| last pixel’s coordinate of embedding area | original fix-length bitstream of the reference pixels | ||
| length of bits used for and | length of bits used for |
| Images | |||||||
|---|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | 6 | 7 | |
| Lena | 52,994 | 98,612 | 165,803 | 224,748 | 250,541 | 259,355 | 261,001 |
| F16 | 78,498 | 136,187 | 197,413 | 234,660 | 252,290 | 259,738 | 261,079 |
| Baboon | 17,670 | 35,004 | 67,880 | 119,490 | 180,413 | 230,304 | 257,215 |
| Tiffany | 60,236 | 109,227 | 176,759 | 228,156 | 250,614 | 259,381 | 261,080 |
| Airplane | 105,722 | 117,784 | 222,628 | 249,050 | 256,318 | 259,248 | 260,700 |
| Man | 51,328 | 94,551 | 153,736 | 209,676 | 242,126 | 256,714 | 260,812 |
| Images | |||||||
|---|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | 6 | 7 | |
| Lena | 5.93% | 0% | 0% | 43.22% | 78.043% | 93.74% | 99.24% |
| F16 | 0% | 0% | 22.94% | 60.09% | 80.74% | 94.25% | 99.73% |
| Baboon | 44.27% | 22.05% | 0% | 0% | 13.16% | 46.93% | 85.39% |
| Tiffany | 0.783% | 0% | 2.78% | 50.89% | 77.05% | 93.08% | 99.68% |
| Airplane | 0% | 0% | 28.82% | 74.12% | 89% | 94.44% | 97.65% |
| Man | 6.98% | 0% | 0% | 33.35% | 64.19% | 86.33% | 98.05% |
| Images | |||||||
|---|---|---|---|---|---|---|---|
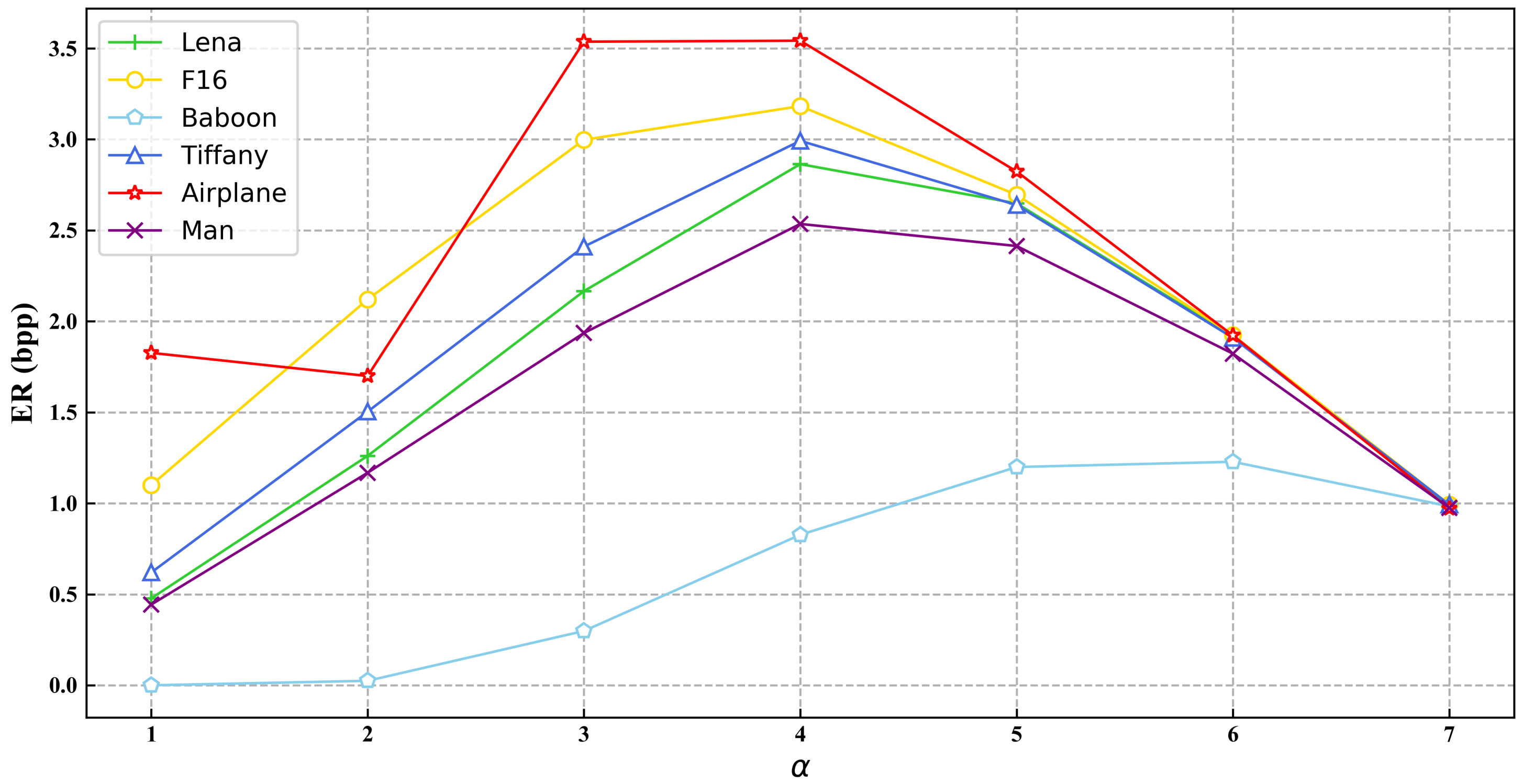
| 1 | 2 | 3 | 4 | 5 | 6 | 7 | |
| Lena | 0.478 | 1.261 | 2.166 | 2.864 | 2.648 | 1.916 | 0.988 |
| F16 | 1.100 | 2.121 | 2.998 | 3.183 | 2.695 | 1.924 | 0.993 |
| Baboon | 0.025 | 0.299 | 0.827 | 1.200 | 1.288 | 0.836 | |
| Tiffany | 0.620 | 1.504 | 2.411 | 2.992 | 2.639 | 1.910 | 0.993 |
| Airplane | 1.827 | 1.700 | 3.537 | 3.542 | 2.824 | 1.923 | 0.971 |
| Man | 0.444 | 1.168 | 1.936 | 2.535 | 2.414 | 1.822 | 0.976 |
| Datasets | Minimum ER | Maximum ER | Average ER |
|---|---|---|---|
| UCID | 0.117 | 3.924 | 2.578 |
| BOSSbase | 0.165 | 3.984 | 3.041 |
| BOWS-2 | 0.091 | 3.984 | 2.941 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Wang, R.; Wu, G.; Wang, Q.; Yuan, L.; Zhang, Z.; Miao, G. Reversible Data Hiding in Encrypted Images Using Median Edge Detector and Two’s Complement. Symmetry 2021, 13, 921. https://doi.org/10.3390/sym13060921
Wang R, Wu G, Wang Q, Yuan L, Zhang Z, Miao G. Reversible Data Hiding in Encrypted Images Using Median Edge Detector and Two’s Complement. Symmetry. 2021; 13(6):921. https://doi.org/10.3390/sym13060921
Chicago/Turabian StyleWang, Rui, Guohua Wu, Qiuhua Wang, Lifeng Yuan, Zhen Zhang, and Gongxun Miao. 2021. "Reversible Data Hiding in Encrypted Images Using Median Edge Detector and Two’s Complement" Symmetry 13, no. 6: 921. https://doi.org/10.3390/sym13060921
APA StyleWang, R., Wu, G., Wang, Q., Yuan, L., Zhang, Z., & Miao, G. (2021). Reversible Data Hiding in Encrypted Images Using Median Edge Detector and Two’s Complement. Symmetry, 13(6), 921. https://doi.org/10.3390/sym13060921