Abstract
In this paper, a high capacity reversible data hiding technique using a parametric binary tree labeling scheme is proposed. The proposed parametric binary tree labeling scheme is used to label a plaintext image’s pixels as two different categories, regular pixels and irregular pixels, through a symmetric or asymmetric process. Regular pixels are only utilized for secret payload embedding whereas irregular pixels are not utilized. The proposed technique efficiently exploits intra-block correlation, based on the prediction mean of the block by symmetry or asymmetry. Further, the proposed method utilizes blocks that are selected for their pixel correlation rather than exploiting all the blocks for secret payload embedding. In addition, the proposed scheme enhances the encryption performance by employing standard encryption techniques, unlike other block based reversible data hiding in encrypted images. Experimental results show that the proposed technique maximizes the embedding rate in comparison to state-of-the-art reversible data hiding in encrypted images, while preserving privacy of the original contents.
1. Introduction
Cloud computing is a great technology for remote sharing and accessing of information across the world. It renders a simplistic model for real-time information sharing, accessing, and/or storing on the cloud server [1] on a pay-per-use basis. Due to its simplicity, today, cloud computing services have millions of subscribers who store their public/private data on cloud servers. The cloud servers possess several data storage devices for storing subscribers’ data which can be any multimedia data (such as image, video, audio), text data, program data, etc., in any format. To protect against information leakage and maintain confidentiality, subscriber data is first encrypted and then stored on the cloud servers [2]. To manage the cloud services and data storages, and also to control loading–unloading of data between storages for load balancing, the cloud servers makes use of a cloud administrator which attaches some auxiliary information, such as subscriber name, file name, file type, source information, etc., to subscriber’s data for its efficient handling without decoding the subscriber data. The auxiliary information is attached secretly by embedding the same in the encrypted subscriber data so that unauthorized access can be prevented without incurring additional storage cost. Since the auxiliary information is cloud management information, it is embedded in a lossless and reversible manner in the subscriber data. For this, there exist several reversible data hiding (RDH) techniques which have been developed in the past for lossless embedding and recovery of both secret data and subscriber data. Some of the popular RDH techniques are lossless compression based [3,4,5,6], difference expansion-based [7], histogram expansion, and prediction error expansion based [8,9,10,11,12] RDH techniques. However, these techniques are only suitable for plaintext data, but not for encrypted data.
In 2008, Puech et al. [13] unveiled an RDH technique for encrypted images (RDHEI). They first encrypted the original image using Advanced Encryption Standard (AES) and then embedded the secret data bits at random locations in each 4 × 4 by simple substitution. At the receiver end, local standard deviation analysis is performed to reinstate the original image and get back the hidden secret data. After Puech et al.’s technique [9], the RDHEI field has been explored by various researchers [14,15,16,17,18,19,20,21,22,23,24,25,26,27,28,29,30,31,32,33,34,35,36].
Based on the analysis of available RDHEI literature, the RDHEI techniques can be classified into three major categories, namely, vacating room after encryption (VRAE) [12,15,21,22], vacating room by encryption (VRBE) [32,34,35], and reserving room before encryption (RRBE) [23,29,30,31,33]. The VRAE techniques create vacancies for secret data hiding in encrypted data whereas techniques that fall into the VRBE category create vacancies for secret data hiding during encryption. As far as the RRBE category is concerned, first, a room is reserved in the unencrypted media which is then exploited for embedding the secret data after the media’s encryption. Among these three approaches, the VRAE approach offers very limited embedding capacity (EC) because encrypted data provides limited room for secret data hiding as encryption destroys the correlations of subscriber data. Therefore, the cloud administrator is unable to produce many vacancies for secret data embedding in encrypted data. In the VRBE approach, specific encryption tactics are applied to subscriber data, which maintain some correlations in encrypted data. Later, the correlations present in the encrypted data are exploited by the cloud administrator for embedding auxiliary information. Still, this approach does not yield a high EC as spatial redundancy existing in the subscriber data is not fully utilized. However, the RRBE approach is an altogether different approach, in which subscriber data in unencrypted form is exploited to reserve vacancies. This means that, later on, the subscriber data can be encrypted and auxiliary information can be embedded in the encrypted data, by exploiting the redundancy of non-encrypted data due to the reserved vacancies. Thus, the RRBE approach renders higher EC than the VRAE and VRBE approaches.
In RDHEI, the encryption of plain-text data is performed by the subscriber using an encryption key , who then uploads the encrypted data on the cloud server. Next, the cloud administrator performs embedding of auxiliary information using a secret key to transform the encrypted data into marked encrypted data. The marked encrypted data accommodates both subscriber data and auxiliary information in encrypted form, and is stored on the cloud server. At the decoder side, three cases may exist. In the first case, if a user owns both the encryption key and the secret key , he/she can retrieve both subscriber data and auxiliary information. In case only the encryption key or the secret key is possessed by the user then only subscriber data or the auxiliary information can be recovered, respectively. A schematic diagram of the RDHEI approach is shown in Figure 1.
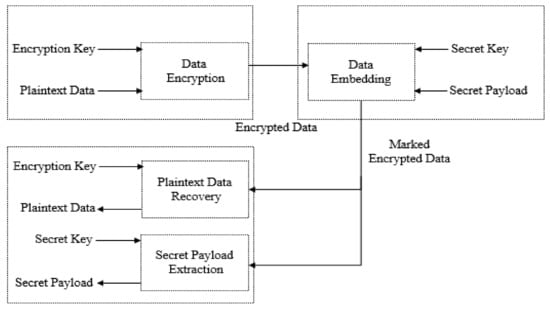
Figure 1.
A schematic diagram of RDHEI technique.
In the literature, some RDHEI techniques have been introduced [14,15,16,17,18] which allow retrieval of auxiliary information only after decryption of marked encrypted data. In other words, auxiliary information can be extracted using a secret key only after performing the decryption using the encryption key . TheseRDHEI techniques are known as non-separable techniques. In [19,20,21,22,23,24,25,26,27,28,29,30,31,32,33,34,35], another variant of RDHEI techniques, i.e., separable RDHEI techniques, was introduced to overcome the limitation of non-separability. These techniques allow separate restoration of subscriber data and extraction of auxiliary information from the marked encrypted information. In other words, an encryption key keeper can perform the decryption process separately without being restricted by the auxiliary information extracting process, and similarly a secret key keeper can perform the auxiliary information extracting process without being restricted by the decryption process.
In this paper, an intra-block correlation based high capacity RDHEI technique using PBTL is proposed. In the proposed technique, the original image is first partitioned into non-overlapping blocks of a predetermined size (e.g., 4 4) which are then categorized into smooth, moderately complex, and highly complex blocks. Now, prediction errors and residual errors are calculated for pixels of the smooth blocks and moderately complex blocks. Next, the proposed technique applies a stream encryption method (different from Yi et al.’s technique) to the original host image to improve the security of the encrypted subscriber data (or the encrypted host image). The pixels of the encrypted image are then labeled using the PBTL scheme and the calculated prediction and residual errors. Finally, the labelled pixels are exploited to reversibly embed the secret data. Contributions of the proposed RDHEI technique can be summarized as follows:
- (1)
- The proposed work discloses a high capacity RDHEI technique using PBTL. The proposed RDHEI technique first partitions the original image into uniformly sized blocks and then categorizes the image blocks into three categories, i.e., smooth, moderately complex, and highly complex blocks based on the prevalent correlation of each block. This granular classification of the image blocks helps in reserving pixels for efficiently embedding the secret information.
- (2)
- The smooth and moderately complex blocks generally possess high and decent pixel correlation, respectively. Thus, both types of blocks are used for embedding the secret information whereas the highly complex blocks are snubbed in the data embedding process as there is no or minimal correlation.
- (3)
- Further, the proposed technique uses a stream encryption method for encrypting the original image. The stream cipher provides higher security in comparison to block cipher as it completely destroys the correlation of image pixels.
- (4)
- In addition, the proposed technique is a separable RDHEI technique which allows separate recovery and extraction of subscriber data and the secret message in a lossless manner.
- (5)
- Experimental results show that the proposed RDHEI technique has superior embedding performance in comparison to related previous RDHEI techniques while ensuring security of the image contents.
The rest of this paper is structured as follows. Section 2 discusses related separable RDHEI techniques. Section 3 introduces the review of parametric binary tree labeling (PBTL) scheme. The proposed RDHEI technique is discussed in Section 4. Section 5 shows the experimental results and their comparative analysis. Lastly, a conclusion as well as the scope of future works has been drawn for the proposed work.
2. Related Works
In this section, some of the popular RDHEI techniques are briefly reviewed. In 2012, Zhang discussed a separable RDHEI technique [19]. In the separable RDHEI technique [19], the subscriber data (which is an image) is first encrypted using a standard encryption method and then a room/space is reserved for embedding the secret/auxiliary information by compressing three least significant bits (LSBs) of the encrypted data. However, the generated space is sparse in nature which limits the embedding rate. Xiaotian et al. [17] discussed a separable RDHEI technique which outperforms the earlier technique [19]. Dragoi et al. [21] proposed a new separable RDHEI scheme by creating space after the encryption. The main feature of this scheme is the use of a two-stage data hiding process in which the reference pixel is predicted based on the median context value. As far as performance improvement is concerned, the proposed scheme marginally improves embedding capacity in comparison to erstwhile related schemes. In 2018, Dragoi et al. [22] again came up with a new separable RDHEI scheme with color images, where correlation between RGB color planes of a target pixels and its correlation with neighboring pixels are exploited to embed data in a color image. In 2013, Ma et al. unfolded the first RRBE approach based RDHEI technique [23]. The technique partitions the image to get smooth and complex regions. Next, one or more LSBs of complex regions are embedded into the smooth regions using any of the conventional RDH algorithms such as [5,6,7] to create room in the rough regions. Finally, the reserved room in the encrypted images are filled by auxiliary information. This reservation of space in the complex regions yields a high embedding rate which goes up to 0.5 bit-per-pixel (bpp). Similarly, Zhang et al. reserved room for secret data hiding using the prediction error (PE) based histogram shifting method [18]. In [24], Xu et al. disclosed the calculation of prediction error based on interpolation technique then applied histogram shifting and the difference expansion technique to exploit the prediction error for data hiding. However, only a small improvement in performance was achieved. In [25], Mathew et al. refine the work of Ma et al. [23] by introducing a new pixel intensity variation criterion for classifying image blocks into smooth blocks and rough blocks. However, the work only marginally improves the embedding rate. To further upgrade the embedding rate, Cao et al. [26] discuss a patch-level sparse representation method for RDHEI. The method performs encryption in phases so that the maximum correlation between the image pixels can be maintained in the encrypted image. Additionally, a room is created inside the encrypted image for embedding the secret data. Therefore, the technique archives higher embedding capacity than the erstwhile state-of the art RDHEI techniques. In 2018, Li et al. [27] disclosed a novel RDHEI technique which makes use of combined block permutation and stream cipher for image encryption. Next, prediction errors in nearby pixels are exploited for data hiding. Thus, Li et al.’s technique improves the embedding rate by 0.5 bpp in comparison to the existing related RDHEI techniques, which signifies high embedding capacity.
In literature, it has been observed that a number of techniques [28,29,30,31] have been introduced for MSB prediction and then exploiting the MSB for data hiding. In 2018, one such work is proposed by Puteaux et al. [29] in which a simple but powerful high capacity RDHEI technique was discussed. The technique utilizes the correlation with neighboring pixel to predict the reference pixel value and uses a location binary map for marking the prediction errors. Next, the image is encrypted using stream cipher, and embedding of the secret message is done in the MSBs of the encrypted pixels with the help of location binary map. The location binary map helps the receiver in extracting the secret message and in the complete recovery of the original image. However, the MSB prediction technique can only embed up to one bit of the secret message into an encrypted pixel. To overcome this limitation, Puyang et al. [30] discuss a new RDHEI technique which can replace up to two MSBs of an encrypted pixel to significantly improve the embedding capacity without affecting the reversibility. To further improve the EC, Chen et al. [31] makes use of run length encoding (RLE) to compress the binary sequence of MSB data so that a room can be reserved in the image. For optimal compression, the image is first divided into blocks and then the binary sequence of MSB data is created. Thus, the technique further boosts the embedding rate in comparison to [29,30] without compromising the reversibility.
Yi et al. [32] propounded a headway technique in the separable RDHEI domain using parametric binary tree labeling (PBTL). The host image is first partitioned into blocks of a certain size (either 2 × 2 or 3 × 3 pixels) and then calculates prediction errors in neighboring pixels within the block. Next, the host image is encrypted using a block-based encryption method. Based on the prediction errors and PBTL scheme, pixels of the encrypted are labeled which are exploited for embedding the secret information later on. The PBTL-RDHEI is extended by Su et al. [33] by combining the PBTL and absolute moment block truncation coding (AMBTC) for efficiently exploiting the correlation of the host image. Yin et al. [26] used the AMBTC technique for data embedding, although not in the RDHEI domain. Further, it has been observed that the AMBTC technique is a popular lossy compression technique which has been widely used in data hiding [14,36,37,38]. As far as working method of [33] is concerned, Su et al.’s technique first scrambles and then compresses the host image into triplets in a block-wise manner, where each triplet includes two quantization level (high & low) and a bitmap. Next, the triplets are encrypted in such a way that the correlation between the two quantization levels is retained. The retained correlation is then exploited to create a room for embedding the secret information. Therefore, a compressed marked-encrypted image in the form of AMBTC codes is obtained by the receiver. Since the bits required to represent the AMBTC coded image are lesser, the embedding capacity is also lower than that of Yi et al. [32]. It can be easily stated that Su et al.’s case is one of the earliest methods to utilize AMBTC in the RDHEI domain. In the next section, the parametric binary tree labeling scheme is reviewed in the context of the proposed work.
3. Parametric Binary Tree Labeling Scheme
This Parametric binary tree labelling (PBTL) scheme is first postulated by Yi et al. in 2018 for labelling the pixels of the plaintext image so that the auxiliary information can be efficiently embedded. The plaintext image pixels are represented by 8-bit depth; hence, the seven layers are generated in the parametric binary tree as shown in Figure 2. In the PBTL, each layer has nodes and each node is represented by binary bits where is the layer number. The details regarding the total number of nodes in each layer of the seven-layered PTBL is provided in Table 1.
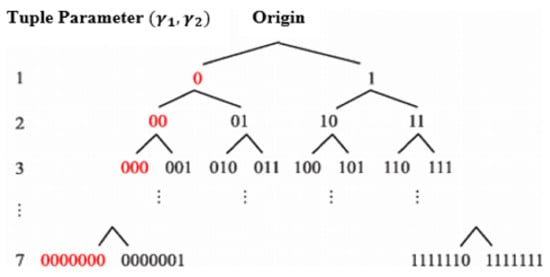
Figure 2.
A 7-layered PBTL structure for 8-bit depth plaintext image.

Table 1.
Number of nodes in a 7-layered PBTL.
The nodes at each layer are distributed into two different sets, namely and , based on a tuple parameter The first node of eachlayer is assigned into set and is labeled by number of zero bits based on the value of , where is the layer number. The number of nodes assigned to set are determined in accordance to the relation between the tuple parameter using Equation (1), defined as follows:
where represents the total number of nodes in the set and the range of values of the tuple parameter is defined as , < . The specific details regarding the number of nodes in set for each layer of the PBTL based on the different values of are provided in Table 2. As per Table 2, if the value of tuple parameter , then number of nodes in set are 6 as per Equation (1), which are labeled as (), (), (), (), (), and (). Basically, the node labelling in the set is started from the right-most side to the left side of the PBTL (in accordance with Figure 2) until the is not labelled. Further, the first node in set will be labeled as ().
Table 2.
-based on for 7-layered PBTL.
4. The Proposed EPBTL-RDHEI Technique
The proposed High Capacity RDHEI technique is described in two phases, where the subscriber’s data encryption and secret payload embedding is done in the first phase, and subscriber’s data decryption and extraction of the secret payload is done in the second phase. Usually, subscribers upload their data which can be image, text, video, audio, etc., in encrypted form on the cloud server and a cloud administrator associates secret payload (which also includes auxiliary information) with the encrypted data. Although the proposed technique is equally applicable to all types of data, for simplicity, the plaintext images are considered as subscriber data. The proposed technique is a separable RDHEI technique which allows separate extraction of the hidden message and recovery of the original image at the receiving end. The RDHEI technique first uses an AMBTC based method for classifying the image regions and then uses a PBTL scheme for labelling the pixels. Figure 3 illustrates a framework of the proposed RDHEI technique.
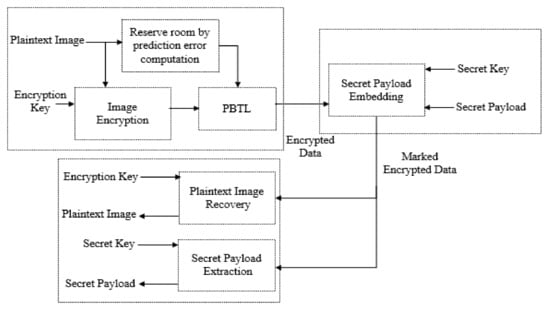
Figure 3.
A framework of the proposed EPBTL-RDHEI technique.
The first phase of the proposed technique performed in five steps. In the first step, the subscriber’s image is uniformly partitioned into non-overlapping blocks of a predetermined size and then each block is categorized into as smooth, moderately complex, and highly complex block based on the difference between high and low quantization levels which are calculated using the AMBTC method. In the second step, prediction errors and residual errors are generated based on the difference between pixel and corresponding block’s mean. In the third step, the subscriber’s image is encrypted using a stream encryption technique. In the fourth step, pixels of the encrypted image are categorized into regular pixels, irregular pixels, base pixels, and special pixels. Then, regular pixels and irregular pixels are labeled according to the PBTL scheme and thereby labeled encrypted image is obtained. In the final (i.e., fifth) step, the secret payload embedding is done to get the marked encrypted image. The detailed working of each step is discussed in following subsections.
4.1. Block Categorization (Step-1)
Initially, the subscriber-provided plaintext image of size is partitioned into a number of non-overlapping blocks () of size × pixels where = [].[]. Therefore, each block has pixels, such that, {} if scanned in raster scan manner, where . Now, mean of each block is computed using Equation (2):
After computing mean of each block , a bit-plane () of size × is formed, where every pixel is represented by either bit ‘0’ or ‘1’ as follows.
As per the Equation (3), the pixel of block is represented by ‘0’ if its value is less than mean of the block, otherwise represented by ‘1’. Thus, the bit-plane () for has bits, meaning every pixel of the block is represented by 1 bit in the bit-plane. Next, two quantization levels, i.e., high quantization level and low quantization level , are computed using Equations (4) and (5), respectively.
where and represent number of zeros and number of ones, respectively, in Thus, the high quantization level () is calculated by taking the mean of the pixels which have a value greater than the mean of the block. Similarly, the low quantization level () is computed by taking the mean of the pixels which have a value lower than the mean of the block. Thus, for each image block, a triplet {} is obtained.
Next, the image blocks are categorized into smooth, moderately complex, and highly complex block categories based on the difference between and . More specifically, if the difference between and of block is less than the first user-defined threshold , then the block is characterized as a smooth block type; if the difference between and is greater than or equal to the threshold and less than a second user-defined threshold , then the block is characterized as moderately complex; and, otherwise, the block is characterized as a highly complex block. In this step, the number of smooth blocks are counted as , the number of moderately complex blocks are counted as , and the number of high complex blocks are counted as A smooth block indicates that pixels in the block are high correlated and less distributed. A moderately complex block indicates that pixels in the block are less correlated and moderately distributed. A highly complex block indicates that pixels in the block are uncorrelated (or very little correlated) and highly distributed.
4.2. Computation of Prediction and Residual Errors (Step-2)
Once all the blocks of the plaintext image are categorized, then prediction errors and residual errors are computed to reserve room for secret payload embedding as follows:
- If the block , where is a smooth block, then it indicates that pixels in the block are high correlated and less distributed. Thus, each pixel in smooth block can be best predicted by its mean value . Prediction error is determined using the difference between the original pixel and the mean value of the block as per Equation (6). It is to be noted that the original pixel value () can be recovered by adding the to the corresponding prediction error () as per Equation (7), at the decoding side.
- If the block is a moderately complex block, then it indicates that pixels in are less correlated. In case of a moderately complex block, prediction errors () and residual errors () need to be calculated using Equations (8) and (9), respectively. It is to be noted that the original pixel value () can be recovered using Equation (10), at the decoder side.
- If the block is a highly complex block, then it indicates that that pixels in are uncorrelated (or very less correlated) and highly distributed. Thus, it requires a greater number of bits to represent the errors, and it is suggested that highly complex blocks are not used for secret payload embedding.
4.3. Image Encryption (Step-3)
After calculating the prediction errors and mean values for smooth blocks, and predication errors, residual errors, and mean values for moderately complex blocks, a stream encryption process is performed on the plaintext image . For this, a pseudo-random matrix of size × is generated using an encryption key . Each pixel of the image is converted into an 8-bit binary sequence as (), where using Equation (11). Similarly, each element of pseudo-random matrix ℝ is converted into 8-bit binary sequence using Equation (11).
Then, bitwise exclusive-or-operation is performed between plaintext image and pseudo-random matrix using Equation (12) to encrypt the image.
Therefore, an encrypted 8-bit binary sequence for each pixel of the encrypted image is obtained. The binary sequence is converted into decimal form using Equation (13), to obtain an encrypted pixel which in turn helps in getting the encrypted image .
4.4. Pixel Grouping and Labelling Using PBTL (Step-4)
In this step, pixels of the encrypted image are grouped and then labeled using PBTL structure based on tuple parameter () as described in Section 3. Firstly, the encrypted pixels of are grouped into four sets which are special set , a base set , a regular set and an irregular set . The special set contains special pixels, the base set contains base pixels, a regular set contains regular pixels, and an irregular set contains irregular pixels. Special set includes the last pixel and the second last pixel of the encrypted image . However, other locations can also be used in special set . One of the special pixels is used to indicate block size and other one indicates a tuple parameter . A base set includes all the first encrypted pixel of each block, where MSB bit-planes of the base pixels (the first encrypted pixel ) are used to indicate block type that can be smooth, moderately complex, and highly complex. Table 3 illustrates that how the 7th & 8th MSB bit-planes of the encrypted pixel is being used to identify block type.
Table 3.
Block type identification based on 7th–8th bit-plane of of each block .
Pixels in the regular set and irregular set () are determined in accordance to prediction errors () calculated using Equation (5) for smooth block and using Equation (7) for moderately complex block. If prediction errors () of block of meets the condition mentioned in Equation (13), then the pixel () of the encrypted image is grouped into the regular set (), otherwise, it is grouped into the irregular set (). In this step, the number of regular pixels and irregular pixels in smooth blocks are counted as and , respectively, and the number of regular pixels and irregular pixels in moderately complex blocks are counted as and , respectively.
After grouping the pixels into four sets, pixels of sets and are labeled using the PBTL scheme. Note that the pixels of highly complex blocks are not labeled as they do not participate in the data embedding process. In , the -LSB bits of all the pixels are labeled as (0...) as per the PBTL scheme. In , -LSB bits of all the pixels are labeled using different binary sequences represented by sub-categories as per the PBTL scheme. Thus processed, the labeled encrypted image is obtained.
4.5. Secret Payload Embedding (Step-5)
After pixel grouping and pixel labelling process, secret payload embedding process is carried-out in the labeled encrypted image . This step outputs a marked encrypted image by replacing the (8-) bits of pixels of by secret payload. The secret payload contains two type of data; one is encrypted auxiliary information () which is provided by cloud administrator and other is overhead which is obtained during transforming encrypted image into labeled encrypted image . To protect the auxiliary information () from unauthorized access, it is encrypted using a secret key . The overhead is required for lossless recovery of original image. The length of the overhead is calculated as below:
- (a)
- 16 bits to represent original pixel values of and
- (b)
- Total bits () of base set to store original bit values which are used in block types indication.
- (c)
- Total bits (equal to ) of irregular set to store original replaced bit-planes.
- (d)
- Total bits (equal to ) to store mean value of each smooth block.
- (e)
- Total bits (equal to 7 ) to store mean value of each complex block.
Now, auxiliary information is obtained by reducing overhead from the secret payload using Equations (15)–(17), and effective embedding rate is calculated using Equation (18).
The second phase of decryption of the original image and data recovery from the marked encrypted image has two steps. The first step is related to extraction of auxiliary information from the marked encrypted and second step is to restore original image from marked encrypted image. Both these steps are mutually exclusive.
4.6. Extraction of Auxiliary Information
At the receiver end, once the marked encrypted image is received, the extraction process for auxiliary information is started. Initially, the pixels of at locations and in are utilized to determine tuple parameter and image block size. Then, is divided into number of non-overlapping blocks as per the determined block size. After this, pixels of in each image block are utilized to determine the type of the image block i.e. the smooth block, moderately complex block and highly complex block as per Table 3. Now, the tuple parameter is utilized to determine pixels of regular set and pixels of irregular set corresponding to smooth blocks, and pixels of regular set and pixels of irregular set corresponding to moderately complex blocks. Then, secret payload is extracted from (8-) bit-planes of regular pixels of smooth blocks, and also from (8-) bit-planes of regular pixels of moderately complex blocks. Further, residual errors are also extracted from regular pixels of moderately complex blocks. Now, from the secret payload, encrypted auxiliary information is obtained by removing overhead as per Equations (15)–(17). Further, encrypted auxiliary information is decrypted by only authorized user which has secret key .
4.7. Recovery of Plaintext Image
Now, recovery process for encrypted auxiliary information is discussed. The overhead information is utilized to recover plaintext image . Initially, 16 bits of overhead corresponding to and are restored on their predetermined position using . Next, original bits () are restored at locations of pixels of base set. Then, subsequent overhead bits equal to length are utilized to restore -bits of irregular pixels. After this, next overhead bits up to are read to determine mean values of smooth blocks and subsequent overhead bits up to are read to determine mean values of moderately complex blocks. Now, the authorized user which has encryption key can generate the pseudo-random matrix and can obtain the decrypted image using Equations (12) and (13). Now, the user has only original pixel values of first two rows and two columns, which are utilized to recover other pixels of the image. The original pixel values of regular pixels of smooth blocks are obtained by their corresponding mean values stored as 8 ∗ overhead bits and prediction errors calculated using Equation (7) from PBTL labeled pixels corresponding to . Similarly, to get original values of regular pixels of moderately complex blocks, mean values stored in next 7 ∗ overhead bits and residual errors and prediction errors calculated using Equation (10) from PBTL labeled pixels corresponding to . Now, remaining overhead bits are related to irregular pixels which are restored at their original location based on PBTL labeled pixels corresponding to . Thus, original image is retrieved in lossless manner.
Figure 4 shows an illustrative example of proposed RDHEI technique. The tuple parameter is taken as = and block size is taken as 4 × 4. Figure 4a shows a part of the baboon image of size 12 × 4. The input image is partitioned into non-overlapping blocks of size 4 × 4. Now, the blocks are categorized into smooth blocks, moderately complex blocks, and highly complex blocks using their corresponding quantization levels and mean values calculated by Equations (3)–(5), considering first threshold parameter = 16 and second threshold parameter = 32. The absolute difference between quantization levels of the first block is 3, so it is a smooth block. The absolute difference between quantization levels of the second block is 29, so it is a moderately complex block. The absolute difference between quantization levels of the third block is 32, so it is a highly complex block. Highly complex blocks do not participate in secret payload embedding because pixels in the block are uncorrelated or correlated very little. Thus, only smooth blocks and moderately complex blocks are utilized for data embedding. The mean value of the first block is computed as 190 and the mean value of second block is computed as 103 using Equation (3). In Figure 4b,c, prediction errors are shown for each pixel of the block except for highly complex block. Based on the prediction errors, pixels of special set , base set , regular set and irregular set are determined as shown in Figure 4d. Now, input image is encrypted using stream encryption with encryption key as shown in Figure 4e. Figure 4f shows an 8-bit binary representation of encrypted image. Using the tuple parameter (2,3), labelling bits for each pixel are determined PBTL structure. Pixels of the encrypted image corresponding to regular set and irregular set are labeled based on predictor errors. Figure 4h shows number of vacancies created in labeled regular pixels for embedding secret payload.
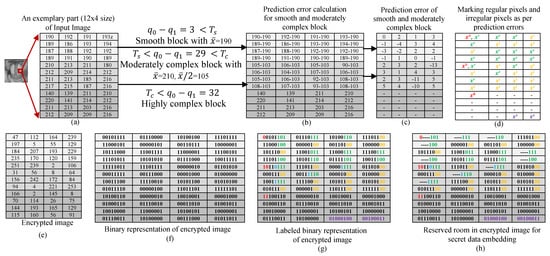
Figure 4.
An illustrative example of the proposed scheme. (please resize to the format).
5. Experiment Results and Analysis
In this section, experiment results of the proposed RDHEI technique are discussed and compared with state-of-the-art techniques. To evaluate the performance of the proposed technique, we have taken four test images as shown in Figure 5. The test images are Lena, Airplane, Man, and Baboon, each one of size 512 × 512 with 8-bit depth gray values. The proposed technique has been evaluated using encryption performance and embedding rate. Encryption performance is estimated on two quality parameters, PSNR (peak signal-to-noise ratio) and SSIM (structural similarity), and one security parameter. Embedding rate (ER) basically represents embedding performance, which is measured in terms of bits per pixel (bpp).

Figure 5.
Test images: (a) Lena, (b) Airplane, (c) Man, (d) Baboon.
5.1. Encryption Performance of Proposed Technique
In this subsection, encryption performance of the proposed technique is examined by computing pixel distributions of the marked encrypted images. Ideally, it should be uniform for the encrypted data as the encryption process completely destroys correlations present in original data to provide robustness. The proposed technique also provides uniform pixel distribution which is evident from Figure 6a–f, showing histograms of all test images, and Figure 6g–l, showing histograms of marked encrypted images for all the test images. The X-axis and Y-axis of the histograms represents number of pixels and intensity range (0–255), respectively.
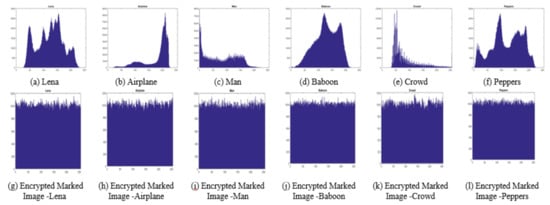
Figure 6.
(a–f) histogram of test images, and (g–l) histograms of the encrypted marked images.
To further show the encryption performance of proposed technique, PSNR and SSIM values for marked encrypted images corresponding to the original test images are calculated and the results are provided in Table 4. The results are taken by considering tuple parameter (, ) = (4,4) and block size of 4 × 4 pixels. It is to be noted that the experimental results on other tuple parameter values and block size are also similar. From Table 4, it can be clearly seen that PSNR of each encrypted marked image is very small and the SSIM value is also nearly 0, which indicates that encrypted marked image does not provide any information about the original image and secret payload.
Table 4.
PSNR and SSIM values of encrypted marked image.
Thus, it is validated that the proposed technique provides good encryption performance. Figure 7a–f show the outcomes of different stages of image encryption and secret payload embedding for one of the test images. Figure 7a shows an original Lena image and Figure 7b shows an encrypted Lena image which is encrypted using the encrypted key by employing a standard stream encryption algorithm.

Figure 7.
Encryption and decryption of Lena image.
In Figure 7c, an encrypted labeled Lena image is shown and Figure 7d shows a marked encrypted Lena image which includes a secret payload containing the encrypted auxiliary information, encrypted using secret key . In Figure 7e, a decrypted Lena image is shown, which is similar to the original Lena image. In Figure 7f, the difference between Figure 7a,e is seen, showing a black image as all the pixel values are zero. Thus, Figure 7e depicts that the original image is fully recovered as it has PSNR → +∞ and SSIM = 1 with respect to the original image.
5.2. Embedding Performance of the Proposed Technique
In this subsection, embedding rate (ER) of the proposed technique is discussed in terms of bpp. The embedding rate has been shown for various values of tuple parameters ( of the PBTL scheme and on different block sizes 4 × 4, 8 × 8, 16 × 16. Further, the thresholds are taken as , to categorize image blocks as smooth, moderately complex, and highly complex blocks. Experimental results are provided in Table 5, Table 6, Table 7 and Table 8 for test images. From the experimental results, it can be seen that embedding rate is increased, when tuple parameters are also increased up to a limit. Thereafter, embedding rate starts to decrease as tuple parameters are increased. This is because increasing in tuple parameters reduces vacancies for embedding secret data. Further, embedding rate is decreased for parameter = 3, 4, 5 when block size is increased and the embedding rate is increased for parameter = 1, 2, 6, 7. The negative values of bpp depict that overhead bits are higher than or approximately equal to reserved room for secret data embedding.
Table 5.
Embedding rates of Lena image at different values and for 4 × 4, 8 × 8, 16 × 16 blocks.
Table 6.
Embedding rates of Airplane image at different values and for 4 × 4, 8 × 8, 16 × 16 blocks.
Table 7.
Embedding rates of Man image at different values and for 4 × 4, 8 × 8, 16 × 16 blocks.
Table 8.
Embedding rates of Baboon at different values and for 4 × 4, 8 × 8, 16 × 16 blocks.
5.3. Comparison of Results of the Proposed Technique with State of Art Techniques
In this subsection, experimental results of the proposed techniques are compared with related techniques including those of Yi et al. [32], Su et al. [33], Li et al. [27], Puteaux et al. [29], Puyang et al. [30], Chen et al. [31]. Since PBTL was first introduced in the RDHEI domain by Yi et al., the same [24] has been primarily considered for comparison. Su et al.’s [33] technique demonstrates application of AMBTC concept along with PBTL. However, it is a lossy technique where a decrypted image is obtained in compressed form. Since the proposed technique also considers some aspects of AMBTC in block categorization, Su et al.’s [33] technique has also been used to comparatively evaluate the performance. However, the proposed technique is a lossless and fully reversible technique in which both secret payload and original image are retrieved in undistorted form. Additionally, the performance of the proposed technique is evaluated against some of the early high capacity RDHEI techniques, e.g., Li et al. [27], Puteaux et al. [29], Puyang et al. [30], and Chen et al. [31]. Table 9 shows the encryption method of the proposed technique and state-of-art techniques. In comparison to this, Yi et al. [32] retains some pixel correlations in blocks which makes encryption week.
Table 9.
Comparison of encryption performance with state-of-art techniques.
For optimal embedding performance, = 4 & = 4 and a block size of 4 × 4 pixels is considered for the proposed RDHEI technique. The embedding performance is compared with some of the high-capacity state-of-the-art techniques that provide highest embedding rate. Since Yi et al.’s [32] and Chen et al. [33] have optimal performance at = 2 & = 5 with block size of 3 × 3 pixels and block size of 4 × 4 pixels, respectively.
Figure 8 shows the maximal embedding rates of the proposed technique as well as existing RDHEI techniques for all the test images. It clearly shows that proposed technique has highest embedding rate than other techniques. It is also evident from the figure that the proposed scheme provides higher embedding capacity with smooth images like Lena, Airplane, whereas it has lower embedding capacity with complex images such as Baboon.
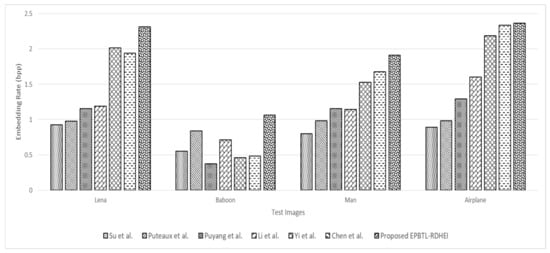
Figure 8.
Comparison of embedding rate of the proposed and state-of-art techniques.
6. Conclusions
In this paper, an intra-block correlation based high capacity RDHEI technique using a parametric binary tree labelling scheme has been proposed. In the proposed technique, the cover image was divided into blocks and then the blocks were categorized according to the prevalent correlation through a symmetric or asymmetric process. Next, an adaptive method for reserving the room inside the image was applied, based on the block categories so that a large amount of secret data could be embedded. Further, the proposed RDHEI technique used a stream cipher for encrypting the image contents. Experimental results showed that the proposed RDHEI technique provided the highest embedding rate in comparison to all the aforementioned state-of-the art techniques. Additionally, the proposed method provided a good level of security in encryption process to protect the privacy of the original plaintext image. In future work, compression methods can be explored to further condense the size of prediction errors, and also an improvised AMBTC method may be designed to predict the pixel values more accurately.
Author Contributions
Conceptualization, A.K.R. and N.K.; Methodology, A.K.R. and N.K.; Visualization, R.K.; Writing—A.K.R., N.K.; Writing—review and editing, R.K., H.O., S.C. and K.-H.J. All authors have read and agreed to the published version of the manuscript.
Funding
This research was supported by Brain Pool program funded by the Ministry of Science and ICT through the National Research Foundation of Korea (2019H1D3A1A01101687) and Basic Science Research Program through the National Research Foundation of Korea (NRF) funded by the Ministry of Education (NRF-2018R1D1A1A09081842 and 2021R1I1A3049788).
Conflicts of Interest
The authors declare no conflict of interest.
Abbreviations
The following abbreviations are used in this manuscript:
| Symbols | Meaning |
| auxiliary information | |
| Mean | |
| Block | |
| Logic bit value | |
| Encryption Key | |
| Secret Key | |
| n | Number of Layers |
| , | Tuple Parameter |
| Two different sets | |
| Total number of nodes in the set | |
| plaintext image | |
| Encrypted image | |
| Image Size | |
| × | Block Size |
| Overhead | |
| p | Number of non-overlapping blocks |
| , | Quantization values |
| , | Threshold values |
| i-th pixel | |
| Special set | |
| Base set | |
| Regular set | |
| Irregular set | |
| Abbreviation | Meaning |
| AES | Advanced Encryption Standard |
| AMBTC | Absolute Moment Block Truncation Coding |
| BPP | Bit-Per-Pixel |
| EC | Embedding Capacity |
| ER | Embedding Rate |
| LSB | Least Significant Bits |
| MSB | Maximum Significant Bits |
| PBTL | Parametric Binary Tree Labeling Scheme |
| PE | Prediction Error |
| PSNR | Peak Signal-To-Noise Ratio |
| RDH | Reversible Data Hiding |
| RDHEI | Reversible Data Hiding in Encrypted Images |
| RLE | Run Length Coding |
| RRBE | Reserving Room Before Encryption |
| SSIM | Structural Similarity Index |
| VRAE | Vacating Room After Encryption |
| VRBE | Vacating Room by Encryption |
References
- Pahl, C.; Brogi, A.; Soldani, J.; Jamshidi, P. A State-of-the-Art Review. IEEE Trans. Cloud Comput. 2019, 7, 677–692. [Google Scholar] [CrossRef]
- Chandramouli, R.; Iorga, M.; Chokhani, S. Cryptographic key management issues and challenges in cloud services. Secure Cloud Comput. 2014, 1–30. [Google Scholar] [CrossRef]
- Kumar, R.; Chand, S. A reversible high capacity data hiding scheme using pixel value adjusting feature. Multimed. Tools Appl. 2016, 75, 241–259. [Google Scholar] [CrossRef]
- Lee, C.; Shen, J.; Wu, Y.; Agrawal, S. PVO-based reversible data hiding exploiting two-layer embedding for enhancing image fidelity. Symmetry 2020, 12, 1164. [Google Scholar] [CrossRef]
- Khan, S.; Khan, K.; Arif, A.; Hassaballah, M.; Ali, J.; Ta, Q.; Yu, L. A modulo function-based robust asymmetric variable data hiding using DCT. Symmetry 2020, 12, 1659. [Google Scholar] [CrossRef]
- Kim, S.; Cho, N.I. Hierarchical Prediction and Context Adaptive Coding for Lossless Color Image Compression. IEEE Trans. Image Process. 2014, 23, 445–449. [Google Scholar] [CrossRef] [PubMed]
- Alattar, A.M. Reversible Watermark Using the Difference Expansion of a Generalized Integer Transform. IEEE Trans. Image Process. 2004, 13, 1147–1156. [Google Scholar] [CrossRef] [PubMed]
- Kumar, R.; Jung, K.-H. Enhanced pairwise IPVO-based reversible data hiding scheme using rhombus context. Inf. Sci. 2020, 536, 101–119. [Google Scholar] [CrossRef]
- Wu, H.; Li, X.; Zhao, Y.; Ni, R. Improved reversible data hiding based on PVO and adaptive pairwise embedding. J. Real-Time Image Process. 2019, 16, 685–695. [Google Scholar] [CrossRef]
- Ou, B.; Li, X.; Wang, J. High-fidelity reversible data hiding based on pixel-value-ordering and pairwise prediction-error expansion. J. Vis. Commun. Image Represent. 2016, 39, 12–23. [Google Scholar] [CrossRef]
- Gao, G.; Tong, S.; Xia, Z.; Wu, B.; Xu, L.; Zhao, Z. Reversible data hiding with automatic contrast enhancement for medical images. Signal Process. 2021, 178, 107817. [Google Scholar] [CrossRef]
- Kumar, R.; Jung, K.-H. Robust reversible data hiding scheme based on two-layer embedding strategy. Inf. Sci. 2020, 512, 96–107. [Google Scholar] [CrossRef]
- Puech, W.; Chaumont, M.; Strauss, O. A reversible data hiding method for encrypted images. In Proceedings of the SPIE, San Jose, CA, USA, 18 March 2008; pp. 68191E-1–68191E-9. [Google Scholar]
- Bhardwa, J.R.; Aggarwal, A. An improved block based joint reversible data hiding in encrypted images by symmetric cryptosystem. Pattern Recognit. Lett. 2020, 139, 60–68. [Google Scholar] [CrossRef]
- Hong, W.; Chen, T.-S.; Wu, H.-Y. An Improved Reversible Data Hiding in Encrypted Images Using Side Match. IEEE Signal Process. Lett. 2012, 19, 199–202. [Google Scholar] [CrossRef]
- Zhou, J.; Sun, W.; Dong, L.; Liu, X.; Au, O.C.; Tang, Y.Y. Secure Reversible Image Data Hiding Over Encrypted Domain via Key Modulation. IEEE Trans. Circuits Syst. Video Technol. 2016, 26, 441–452. [Google Scholar] [CrossRef]
- Wu, X.; Sun, W. High-capacity reversible data hiding in encrypted images by prediction error. Signal Process. 2014, 104, 387–400. [Google Scholar] [CrossRef]
- Zhang, W.; Ma, K.; Yu, N. Reversibility improved data hiding in encrypted images. Signal Process. 2014, 94, 118–127. [Google Scholar] [CrossRef]
- Zhang, X. Separable Reversible Data Hiding in Encrypted Image. IEEE Trans. Inf. Forensics Secur. 2012, 7, 826–832. [Google Scholar] [CrossRef]
- Kaur, G.; Singh, S.; Rani, R.; Kumar, R.; Malik, A. High-quality reversible data hiding scheme using sorting and enhanced pairwise PEE. IET Image Process. 2021, 1–15. [Google Scholar] [CrossRef]
- Dragoi, I.C.; Coanda, H.-G.; Coltuc, D. Improved reversible data hiding in encrypted images based on reserving room after encryption and pixel prediction. In Proceedings of the 25th European Signal Processing Conference (EUSIPCO), Kos Island, Greece, 28 August–2 September 2017; pp. 2186–2190. [Google Scholar]
- Dragoi, I.C.; Coltuc, D. Reversible Data Hiding in Encrypted Color Images Based on Vacating Room After Encryption and Pixel Prediction. In Proceedings of the 25th IEEE International Conference on Image Processing (ICIP), Athens, Greece, 7–10 October 2018; pp. 1673–1677. [Google Scholar]
- Ma, K.; Zhang, W.; Zhao, X.; Yu, N.; Li, F. Reversible Data Hiding in Encrypted Images by Reserving Room Before Encryption. IEEE Trans. Inf. Forensics Secur. 2013, 8, 553–562. [Google Scholar] [CrossRef]
- Xu, D.; Wang, R. Separable and error-free reversible data hiding in encrypted images. Signal Process. 2016, 123, 9–21. [Google Scholar] [CrossRef]
- Mathew, T.; Wilscy, M. Reversible data hiding in encrypted images by active block exchange and room reservation. In Proceedings of the 2014 International Conference on Contemporary Computing and Informatics (IC3I), Mysore, India, 27–29 November 2014; pp. 839–844. [Google Scholar]
- Cao, X.; Du, L.; Wei, X.; Meng, D.; Guo, X. High Capacity Reversible Data Hiding in Encrypted Images by Patch-Level Sparse Representation. IEEE Trans. Cybern. 2016, 46, 1132–1143. [Google Scholar] [CrossRef] [PubMed]
- Li, Q.; Yan, B.; Hui, L.; Chen, N. Separable reversible data hiding in encrypted images with improved security and capacity. Multi. Tools Apps. 2018, 77, 30749–30768. [Google Scholar] [CrossRef]
- Hang, Y.; Wei, T.; Menghan, G.; Shoushun, C. A two-step prediction ADC architecture for integrated low power image sensors. IEEE Trans. Circuits Syst. I 2017, 64, 50–60. [Google Scholar]
- Puteaux, P.; Puech, W. An Efficient MSB Prediction-Based Method for High-Capacity Reversible Data Hiding in Encrypted Images. IEEE Trans. Inf. Forensics Secur. 2018, 13, 1670–1681. [Google Scholar] [CrossRef]
- Puyang, Y.; Yin, Z.; Qian, Z. Reversible Data Hiding in Encrypted Images with Two-MSB Prediction. In Proceedings of the 2018 IEEE International Workshop on Information Forensics and Security (WIFS), Hong Kong, China, 11–13 December 2018; pp. 1–7. [Google Scholar]
- Kaimeng, C.; Chang, C.C. High-capacity Reversible Data Hiding in Encrypted Images Based on Extended Run-Length Coding and Block-based MSB Plane Rearrangement. J. Vis. Commun. Image Represent. 2019, 58, 334–344. [Google Scholar]
- Yi, Y.; Zhou, Y. Separable and Reversible Data Hiding in Encrypted Images Using Parametric Binary Tree Labeling. IEEE Trans. Multimed. 2019, 21, 51–64. [Google Scholar] [CrossRef]
- Su, G.-D.; Chang, C.-C.; Lin, C.-C. A High Capacity Reversible Data Hiding in Encrypted AMBTC-Compressed Images. IEEE Access 2020, 8, 26984–27000. [Google Scholar] [CrossRef]
- Yin, Z.; Niu, X.; Zhang, X.; Tang, J.; Luo, B. Reversible data hiding in encrypted AMBTC images. Multimed. Tools Appl. 2018, 77, 18067–18083. [Google Scholar] [CrossRef]
- Yin, Z.; Wang, H.; Zhao, H.; Luo, B.; Zhang, X. Complete separable reversible data hiding in encrypted image. In Proceedings of the 1st International Conference on Cloud Computing and Security, Nanjing, China, 13–15 August 2015; pp. 101–110. [Google Scholar]
- Wang, R.; Wu, G.; Wang, Q.; Yuan, L.; Zhang, Z.; Miao, G. Reversible Data Hiding in Encrypted Images Using Median Edge Detector and Two’s Complement. Symmetry 2021, 13, 921. [Google Scholar] [CrossRef]
- Kumar, R.; Kim, D.-S.; Jung, K.-H. Enhanced AMBTC based data hiding method using hamming distance and pixel value differencing. J. Inf. Secur. Appl. 2019, 47, 94–103. [Google Scholar] [CrossRef]
- Kim, S. Reversible Data-Hiding Systems with Modified Fluctuation Functions and Reed-Solomon Codes for Encrypted Image Recovery. Symmetry 2017, 9, 61. [Google Scholar] [CrossRef]
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).