1. Introduction
Data classification problems arise and are solved in many areas of human activity [
1,
2,
3,
4,
5,
6,
7]. Such problems include the problems of credit risk analysis [
1], medical diagnostics [
2], text categorization [
4], the identification of facial images [
7], etc.
Nowadays, dozens of algorithms and classification methods have been developed, among which linear and logistic regressions [
8], Bayesian classifier [
8,
9], decision rules [
10], decision trees [
8,
11], random forest algorithm (RF) [
12], algorithms based on neural networks [
13], k-nearest neighbors algorithm (kNN) [
14,
15,
16], and the support vector machine algorithm (SVM) [
17,
18,
19,
20] should be highlighted.
During the development of any classifier, it is trained and tested. The dataset used in the development of the classifier is randomly split into training and test sets: the first set is used to train the classifier, and the second is used to test the classifier in order to assess its quality. The development of a classifier can also be performed using the principles of k-fold validation. To estimate the quality of the developed classifier, various indicators of classification quality can be used, for example, overall accuracy, balanced accuracy,
-score, sensitivity, specificity, recall, etc. [
1,
18,
21,
22,
23]. A well-trained classifier can be applied to classify new objects.
As the analysis shows, nowadays, there are no universal algorithms and classification methods. Classifiers developed using different algorithms and methods based on the same dataset can have different values of classification quality indicators, and therefore give different classification results. This can be explained by the fact that different algorithms and methods implement different mathematical principles and use different distance measures, optimization algorithms, optimality criteria, initialization methods, etc.
Many classification problems are successfully solved using the SVM algorithm [
1,
2,
3,
4,
5,
6,
7,
17,
18,
19,
20,
24,
25,
26,
27,
28,
29]. This algorithm implements “supervised learning” and belongs to the group of boundary algorithms and methods. When working with the basic SVM algorithm, it is possible to develop a binary SVM classifier. As such, by using a certain kernel function, it translates vectors describing the features of classified objects from the initial space into a new space of higher dimensionality, and finds a hyperplane separating objects of different classes in this space. The SVM algorithm builds two parallel hyperplanes on both sides of the separating hyperplane. These parallel hyperplanes define the boundaries of classes. The distance between the aforementioned parallel hyperplanes should be maximized with the aim of providing a higher quality of object classification.
The use of SVM classifiers is problematic when working with big datasets due to the high computational costs, since SVM classifier development involves solving a quadratic optimization problem [
1,
18,
22]. Even for a medium-sized dataset, using a standard quadratic problem solver leads to a large quadratic programming problem, which significantly limits the range of problems that can be solved using the SVM classifier. Currently, there are methods such as Sequential Minimal Optimization (SMO) [
30], chunking [
31], simple SVM [
32], and Pegasos [
33], which iteratively calculate the demanded decision and have linear spatial complexity [
20]. The cascading SVM classifier proposed in [
24] allows one to soften the problem of high computing costs by iteratively training the classifier on subsets of the original dataset, followed by combining the found support vectors to form new training sets. Moreover, the cascading SVM classifier can be easily parallelized [
25]. Currently, several parallel versions of SVM classifiers can be implemented using streams, Message Passing Interface (MPI), MapReduce, etc. In recent years, the Hadoop framework has been actively used to develop SVM classifiers [
26].
The SVM algorithm is highly generalizable [
1,
17,
34], but there are problems that make it difficult to apply. These issues are related to the choice of values for parameters such as kernel function type, kernel function parameters, and regularization parameter. The data classification quality essentially depends on the adequate choice of the values of these parameters [
18,
21,
22].
The optimal parameter values of the SVM classifier, which provide a high quality classification, can be determined in the simplest case by looking through the grid, which, however, requires significant time expenditures. With a fixed type of SVM classifier kernel function, the search for optimal parameter values of the kernel function and the regularization parameter can be performed using evolutionary optimization algorithms: genetic algorithm [
35,
36], differential evolution algorithm [
37,
38], particle swarm optimization (PSO) algorithm [
39,
40,
41], fish school algorithm [
42,
43,
44], etc. A such, the choice of the best version of the SVM classifier can be performed based on the results of running the evolutionary optimization algorithm for various types of kernel function, which requires additional time expenditure. For example, we must apply the evolutionary optimization algorithm three times when working with polynomial, radial basis, and sigmoid kernel functions.
In [
21,
22,
23], a modified PSO algorithm was proposed, which implemented a simultaneous search for the kernel function type, parameter values of the kernel function, and regularization parameter value during SVM classifier development. This algorithm significantly reduces the time spent on SVM classifier development, which is very important when working with complex multidimensional data of large volumes.
In the future, the parameter values of SVM classifier will be considered optimal if they provide the maximum data classification quality, assessed using one or another indicator, on the test set.
In most cases, SVM classifiers developed using evolutionary optimization algorithms provide high quality data classification at acceptable time costs [
21,
22,
23]. However, as the results of experimental studies have shown, most of the misclassified objects fall inside the strip dividing the classes. Therefore, it is desirable to offer methods to increase the data classification quality by decreasing the number of errors within the strip dividing the classes. One of the modern approaches in solving the problem of increasing the data classification quality allows for the creation of ensembles (committees, hybrids) of various classifiers in order to increase the final (integral) data classification quality [
45,
46,
47,
48,
49].
Ensembles of classifiers, in the case of their correct formation and adequate adjustment of the corresponding parameters, usually make fewer errors than each individual classifier in the ensemble.
SVM classifiers can be used successfully to create ensembles (committees, hybrids). Therefore, we can create an ensemble that consists only of SVM classifiers [
22,
45,
48], or an ensemble that combines SVM classifiers with any other classifiers, fundamentally different from SVM classifiers in the mathematical apparatus applied in them [
50,
51].
In the simplest case, we can try to build a hybrid classifier, in which the SVM classifier will be the main one, and one more, the auxiliary one, designed to refine the classification within the band dividing the classes. Since SVM classifier development is associated with great time costs for finding the kernel function type, the parameter values of the kernel function and the regularization parameter value, which are optimal, of the new classifier put in the ensemble, must possess insignificant time costs for its development along with the requirement to guarantee a high data classification quality.
In particular, a kNN classifier based on the kNN algorithm can be used. The kNN classifier in some cases can provide an increase in the overall data classification quality with a slight increase in the time spent on developing a hybrid classifier as a whole. As such, it would be expedient to investigate the possibility of using a SVM classifier with default parameter values and a kNN classifier with custom parameter values, which, in general, should significantly reduce the time for developing a hybrid classifier.
The kNN classifier is the simplest metric classifier and assesses the similarity of a certain object with other
k objects–its nearest neighbors, using some voting rules [
2,
14,
15,
16,
50,
51].
Currently, some approaches, which realize the joint use of SVM and kNN classifiers, are known. For example, in [
50], the authors suggested the use of a local SVM classifier to classify objects that are erroneously classified by kNN classifier. A local SVM classifier uses information about the nearest neighbors of the erroneously classified objects. In [
51], the authors suggested using information about the support vectors of the SVM classifier when developing a kNN classifier. Therefore, the kNN classifier precises the class belonging of objects within the strip separating the classes.
However, the above approaches are still far from perfect. Therefore, the development of local SVM classifiers leads to supplementary time costs for searching the optimal number of neighbors of the considered object and for the development of each local SVM classifier, and the use of information about the support vectors in the development of the kNN classifier requires verification of the objectiveness of their definition.
Papers [
52,
53] proposed and discussed a two-step SVM-kNN classification approach, which applies the joint sequential application of SVM and kNN classifiers. In the first step, the SVM classifier is developed on the basis of the initial dataset. Then, the region that contains all of the misclassified objects is determined. Misclassified objects of this region and properly classified objects that fall into this region form a new dataset. In the second step, the kNN classifier is developed on the basis of the reduced dataset, which is formed from the initial dataset, from which the objects of the new dataset are excluded. Then, the kNN classifier is applied to classify all objects of the new dataset. If the classification quality of objects belonging to the new dataset is improved, the two-step SVM-kNN classification approach can be used to classify new objects. The parameter values of the SVM classifier can be set by default or fixed a priori. The parameter values of the kNN classifier are determined experimentally. The limitations on the applicability of two-step SVM-kNN classification approach are as follows: due to the large width of the found region or excessive crowding of objects from the initial dataset within this region, the number of objects in the reduced dataset may be insufficient for kNN classifier development.
The level of class balance in the dataset used during the development of the classifiers has a significant influence on the data classification quality. It is known that probabilistic classifiers are feebly dependent on class balance. However, improbable classifiers, for example, SVM classifiers, are negatively affected by class imbalances [
54,
55].
When developing a binary SVM classifier, the hyperplane separating the classes is constructed in such a way that a comparable number of objects of both classes is inside the strip separating the classes. Obviously, a change in the class balance can influence this number, and, consequently, the position of the boundary between the classes.
If the level of class imbalance (the ratio of the number of objects of the majority class to the number of objects of the minority class) is 10:1 or more, we can obtain a high value of the classification accuracy indicator if the classification of minority class objects is incorrect.
Currently, the following approaches can be applied to solve the problem of class imbalance:
weighting of classes, in which the classification correctness of objects of the minority class is most preferable;
sampling (oversampling, undersampling, and their combinations);
forecasting of the class belonging of objects of the minority class using one-class classification algorithms.
Nowadays, when working with unbalanced datasets, such one-class classification algorithms have been actively used such as the one-class SVM algorithm (one-class support vector machine) [
56], isolation forest [
57], minimum covariance determinant [
58], and local outlier factor [
59].
In recent years, more and more attention has been paid to the development of effective approaches to big data analysis using cloud technologies, extreme learning and deep learning tools, the Apache Spark framework, and so on. Particular attention has been paid to the scalability of the proposed algorithms. As such, many authors have proposed the use of cascade two-stage learning for processing unstructured and semi-structured data. In [
60], the authors suggested a two-stage extreme learning machine with the aim to operate with high-dimensional data effectively. At first, they included extreme learning machine into the spectral regression algorithm to implement data dimensionality reduction and calculate the output weights. Then, they calculated the decision function of basic extreme learning machine using the low-dimensional data and the obtained output weights. This two-stage extreme learning machine has better scalability and provides higher generalizability at a high learning speed than the basic extreme learning machine. In [
61], two-stage analytics framework, which combines the modern machine learning technique with Spark-based linear models, multilayer perceptron, and deep learning architecture named as long short-term memory has been suggested. This framework allows for the organization of big data analytics in a scalable and proficient way. A two-stage machine learning approach with the aim of predicting a workflow task execution time in the cloud was proposed in [
62]. It is obvious that the use of well-thought-out cascade approaches to data processing can improve the efficiency and quality of decisions based on machine learning algorithms.
The main goal of the paper is as follows: in the context of developing hybrid classifiers using the SVM algorithm, we explored the possibility of creating various versions of two-stage SVM-kNN classifiers, in which, in the first stage, the one-class SVM classifier will be used along with the binary SVM classifier. Regarding the one-class SVM classifier, it should be noted that it can work in two versions: both as a one-class (in this case, the training set contains only objects of the majority class) and as a binary one (in this case, the training set contains objects of majority and minority classes).
In this research, it is planned to implement two versions of two-stage classifiers: the SVM-kNN classifier using the binary SVM algorithm and SVM-kNN classifier using the one-class SVM-algorithm. For each of the versions of the classifiers, we proposed implementing two variants of the formation of the training set for the kNN classifier: a variant using all objects from the initial training set located inside the strip dividing the classes, and a variant using only those objects from the initial training set, which is located within an area containing all of the misclassified objects from the strip dividing the classes. It should be noted that in both variants, correctly classified at the first stage objects that fell into the dividing strip or in the above-mentioned area could also be included in the training set for the kNN classifier, but in the second variant, the number of correctly classified objects could be less. In particular, we planned to investigate whether replacing the binary SVM classifier as part of a hybrid with a one-class SVM classifier acting as a binary one can improve the data classification quality as a whole.
The use of the one-class SVM-classifier as a one-class classifier in the proposed study was not intended, since when working with this classifier, it will be impossible to form a training set containing objects of different classes for kNN classifier development.
The proposed approach to the development of a two-stage hybrid SVM-kNN classifier makes it possible to abandon the time-consuming attempts to find the optimal values of the SVM classifier parameters (for example, using evolutionary optimization algorithms), which do not guarantee obtaining a classifier with high data classification quality.
Conceptually, the proposed two-stage hybrid SVM-kNN classifiers differ in that at the first stage, the SVM classifier is developed with default parameter values, and at the second stage, the kNN classifier for which the optimal value of the number of neighbors is searched for (with the selected voting rule) is developed. Therefore, the SVM classifier is trained on the basis of the initial training set, and the kNN classifier is trained on the basis of the reduced initial training set containing only information about the objects lying inside the strip dividing the classes. As a result, it is possible to minimize the time spent on developing the classifier. Thus, the classifier constructed in this way can allow, in some cases, an improvement in the data classification quality, since the auxiliary classifier, the principles of which differ significantly from the principles of the SVM classifier, is involved in the work.
The rest of this paper is structured as follows.
Section 2 presents the main steps of SVM classifier development where aspects of the development of binary and one-class SVM classifiers are considered as well as the problem of class imbalance.
Section 3 presents the main steps of kNN classifier development.
Section 4 details aspects of the development of the proposed two-stage hybrid SVM-kNN classifier. Experimental results follow in
Section 5.
Section 6 discusses the obtained results. Finally,
Section 7 describes the future work.
2. Support Vector Machine (SVM) Classifier Development
Let
be the dataset used for SVM classifier development. Tuples
(
) contain information about object
and number
, which represents the class label of object
[
16,
17,
20,
21].
Let object
(
) be described by vector of features
, where
is the numerical value of the
-th feature for
-th object (
,
) [
21,
22]. The values of elements of the vector of features are preliminarily subjected to scaling in one way or another (for example, scaling, using standardization) with the aim of ensuring the possibility of high quality classifier development.
The dataset is randomly split into training and test sets in a certain proportion (for example, 80:20) with the aim of training and testing developed SVM classifiers, from which the best classifier is subsequently selected (i.e., the classifier that has the utmost data classification quality). Let the training and test sets contain and () tuples, respectively. The following kernel functions can be used for SVM classifier development:
linear ;
polynomial ;
radial basis ; and
sigmoid ,
where
is the scalar product for
and
;
;
;
is the hyperbolic tangent; and
;
[
17,
18,
21,
22].
The above considerations are common for both binary and one-class SVM classifiers.
2.1. Aspects of Binary Support Vector Machine (SVM) Classifier Development
Kernel function type, parameter values of kernel function, and regularization parameter value were determined during the development of the binary SVM classifier.
The problem of building the hyperplane separating classes, taking into account the Kuhn–Tucker theorem, is reduced to the quadratic programming problem with dual variables
(
) [
17,
18,
21,
22].
When training the binary SVM classifier, the dual optimization problem is solved:
where
is
-th object;
is the class label for
-th object;
is the dual variable;
;
(
) is the number of objects in training dataset;
is the kernel function; and
is the regularization parameter (
).
Support vectors are determined as a result of the development of the binary SVM classifier. Support vectors are positioned near the hyperplane separating the classes and carry all information about separation of the classes. Every support vector is a vector of features of object
, belonging to the training set, for which the value of the appropriate dual variable
is not equal to zero (
) [
17,
18].
As a result, the decision rule that assigns the class of belonging with the label “−1” or “+1” to an arbitrary object is determined as [
17,
18,
21,
22]:
where
;
.
The summation in Formula (2) is carried out only over the support vectors.
The main problem arising in the binary SVM classifier development is associated with the need to choose the kernel function type, the parameter values of the kernel function, and the regularization parameter value, at which the high data classification quality will be ensured.
This problem can be solved with the use of grid search algorithms or evolutionary optimization algorithms, for example, the PSO algorithm, genetic algorithm, differential evolution algorithm, fish school algorithm, etc. In particular, the modified PSO algorithm [
21,
22,
23], which provides a simultaneous search for kernel function type, parameter values of kernel function, and regularization parameter value, can be used.
It should be noted that the use of the evolutionary optimization algorithm can significantly reduce the time spent on development of binary SVM classifier (compared to the time spent on development of binary SVM classifier using the grid search algorithms). However, even these time costs can turn out to be significant when working with complex multidimensional datasets of large volumes, which can be considered as big data.
Another approach to increasing the data classification quality can be proposed taking into account the fact that most of the objects misclassified by the binary SVM classifier are positioned near the hyperplane separating the classes. In this regard, one can try to apply auxiliary tools in the form of another classifier, which essentially differs from the SVM classifier in its mathematical principles, and can be applied to classify objects positioned near the hyperplane separating the classes. The kNN classifier can be used as such an auxiliary toolkit [
14,
15,
16]. This classifier is notable for comparable or lower time costs in its development (in comparison with binary SVM classifier).
Taking into account the identified problems regarding the significant time spent working with complex multidimensional datasets of large volumes (big data) and the desire to minimize them, it is necessary to study the possibilities of effective hybridization of SVM and kNN classifiers when developing a two-stage SVM-kNN classifier.
In particular, it is advisable to answer the following question: is it possible at the first stage to use the SVM algorithm with the parameter values set by default (or simply fixed) during the SVM classifier development (that is, by refusing to fine-tune the parameters values of SVM classifier, which is significantly time-consuming), and at the second stage, when developing kNN classifier, to increase the data classification quality only by varying the parameters values of the kNN classifier (in the simplest case, to vary only the number of neighbors)? As such, the multiple random formation of training and test sets for their use for a hybrid two-stage SVM-kNN classifier development should remain in force.
2.2. Class Imbalance Problem
Machine learning algorithms assume that the development of classifiers will take place on the basis of balanced datasets, and the classification error cost is the same for all objects.
Training on the imbalanced datasets (imbalance problem) [
55,
63] can lead to a significant drop in the quality of the developed classifiers because these datasets do not provide the necessary data distribution in the training set. The class imbalance indicator is calculated as the ratio of the number of objects in classes. Negative effects that are common for training on imbalanced datasets appear stronger if this ratio is equal to 10:1 or is even larger.
The dataset imbalance in the binary classification means that more objects in the dataset belong to one class, called the “majority”, and less objects belong to another class, called the “minority”.
A classifier developed on the basis of the imbalanced dataset may have a high overall classification accuracy, but there will be errors on all objects of the minority class.
It is usually assumed that the goal of training is to maximize the proportion of correct decisions in relation to all decisions made, and the training data and the general body of data follow the same distribution. However, taking these assumptions into account when working with an imbalanced dataset leads to the developed classifier not being able to classify data better than a trivial classifier that absolutely ignores the minority class and assigns all objects to the majority class.
It should be noted that the cost of the misclassification of objects of the minority class is often much more high-priced than the misclassification of objects of the majority class because the objects of the minority class are infrequent, but the most important to observe.
2.3. Aspects of One-Class SVM Classifier Development
The goal of the one-class SVM algorithm [
63,
64,
65,
66,
67] is to identify novelty, that is, it is assumed that it will allow detecting the infrequent objects or anomalies. Infrequent objects do not appeared often, and therefore, they are almost not present in the available dataset. The problem of detecting infrequent objects or anomalies can be interpreted as the problem of classifying the imbalanced dataset.
The aim of the one-class SVM algorithm is to distinguish the objects from the training set that belong to the majority class from the rest of objects, which can be considered as the infrequent objects or anomalies, belonging to the minority class.
Let the training dataset contain objects (), which belong to the majority class. It is necessary to decide for the objects of the test set whether they belong to the majority or minority class.
When training the one-class SVM classifier, a dual optimization problem is solved:
where
is the
-th object;
is the dual variable;
;
(
) is the number of objects in training dataset;
is the kernel function; and
is the maximal ratio of objects in the training set that can be accepted as the infrequent objects or anomalies.
When developing the one-class SVM classifier, the regularization parameter value is calculated as .
As a result, the decision rule is determined, which assigns a membership class with the label “−1” or “+1” to an arbitrary object [
56]:
where
is the algorithm parameter.
The properties of the problem are such that the condition in fact means that the object is on the boundary of the strip separating the classes, therefore, for any object so that , the equality is true: .
It should be noted that the one-class SVM classifier can work in two roles during training: as one-class (ooSVM–one-class SVM as one-class classifier), and as binary (obSVM–one-class SVM as binary classifier). In the first case, only objects of the majority class are included in the training set, and in the second case, objects of two classes are included in the training set (we did take their class labels into account).
3. kNN Classifier Development
Let be a dataset used in the development of the kNN classifier.
The dataset is randomly split into training and test sets in a certain proportion in order to train and test the developed kNN classifiers, from which the best classifier is subsequently selected (i.e., a classifier that provides the highest possible classification quality).
Let the training and test sets contain and () tuples, respectively.
For each kNN classifier, the value of the number of neighbors
k is determined at which the classification error is minimal [
14,
15,
16].
The class of belonging of an object is determined by the class of belonging of most of the objects among the nearest neighbors of the object .
Implementation of the kNN algorithm to determine the membership class of an arbitrary object for a fixed number of nearest neighbors usually involves the following sequence of steps.
1. Calculate the distance from object to each of objects , the class of which is known. Order the calculated distances in ascending order of their values.
2. Select objects ( nearest neighbors), which are closest to object .
3. Reveal the class belonging of each of the nearest neighbors of object . Class that is more common for k nearest neighbors is assigned as membership class of object .
To estimate the distance between objects in the kNN algorithm, various distance metrics can be used such as Euclidean, Manhattan, cosine, etc.
The Euclidean distance metric is most often used [
14,
15,
16]:
where
are the values of
-th feature of objects
correspondently and
is the number of features.
When implementing the kNN algorithm, various voting rules can be used, for example, simple unweighted voting and weighted voting [
14,
15,
16].
When using simple unweighted voting, the distance from object to each nearest neighbor () does not matter: all nearest neighbors () have equal rights in defining the object class of .
Each of the
k nearest neighbors
(
) of object
votes for its assignment to its class
. As a result of the implementation of the kNN algorithm, object
will be assigned to the class that gets the most votes using the votes majority rule:
When using weighted voting, the distance from object to each nearest neighbor () must be taken into consideration: the smaller the distance, the more major the contribution to the assessment of the object’s belonging to a certain class is made by the vote of neighbor ().
The assessment of the total contribution of votes of neighboring objects for the belonging of an object
to a class
in weighted voting can be calculated as [
36]:
where
if
and
if
.
The class with the highest score (4) is assigned to the object in question.
4. Two-Stage Hybrid Classifier
The results of the experimental studies show that no classifier can be recognized as indisputably the best in relation to other classifiers, since it does not allow ensuring high quality classification for arbitrary datasets in light of the tools’ peculiarities and their limited capabilities.
The binary SVM classifier allows for satisfactory classification quality on most complex multidimensional datasets [
21,
22,
23,
24,
25,
26,
27,
28,
29,
30,
31,
32,
33]. However, there are certain problems when it is applied to large datasets (big data) as well as to poorly balanced datasets.
The analysis of the position of objects misclassified by the binary SVM classifier showed that most of them fell inside the strip separating the classes. Moreover, the eSVM classifier allowed for some objects to fall inside the strip and on the wrong side of the hyperplane separating the classes [
34]. This hyperplane defines the decision boundary.
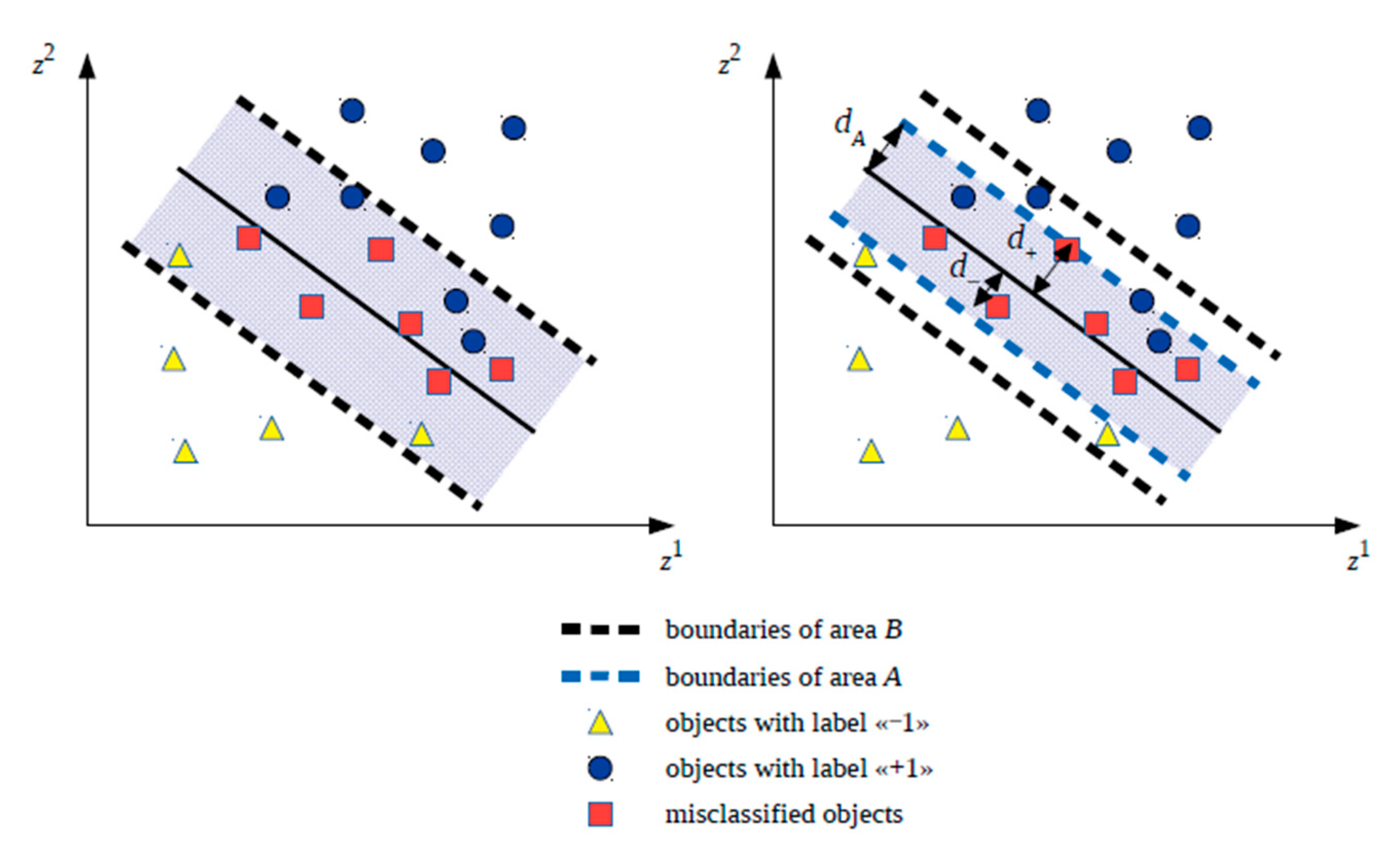
The strip separating the classes is specified by the inequality , where ; .
All objects can be divided into three types.
The object is classified correctly and is located far from the strip separating the classes. Such an object can be called the peripheral.
The object is classified correctly and lies exactly on the boundary of the strip separating the classes. Such an object can be called the support vector.
The object either lies within the strip separating the classes but is classified correctly, or falls on the class boundary, or generally belongs to a foreign class. In all these cases, such an object can be called the support intruder.
The classification decision for objects that fall inside the strip separating the classes can be refined using the two-stage hybrid classifier, which implements the sequential (cascade) use of SVM and kNN classifiers.
Since we planned to consider two versions of two-stage hybrid classifiers that implement the use of SVM classifiers based on binary SVM algorithm (bSVM) and one-class SVM algorithm used in the role of binary (obSVM), the general abbreviation will be used in the description of the steps of developing a hybrid classifier–SVM with the subsequent clarification of the characteristics of the development of SVM classifiers for each of two versions.
Here, we assumed that the objects of the minority class had the class label “−1”, and the objects of the majority class had the class label “+1” (it does not matter whether the class imbalance may be quite insignificant).
The proposed two-stage hybrid classifier can be implemented by the following sequence of steps.
Stage 1. SVM classifier development.
1.1. The SVM classifier development with an assessment of the applied quality indicator on the considered dataset is fulfilled on the basis of randomly formed training and test sets. Kernel function type, kernel parameter values, and regularization parameter value are used by default (or selected and fixed). Then, the hyperplane that divides objects into two classes with labels “−1” and “+1” is defined. Assessment of the data classification quality is fulfilled on a test set, for example, using indicators such as the accuracy indicator (), the balanced accuracy indicator (), and the -score indicator.
When developing bSVM and obSVM classifiers, the dataset is randomly split into training and test sets in a ratio of 80:20 without imposing any additional restrictions on the inclusion of objects in these sets: each set may contain objects of both classes (i.e., objects with a class label “−1”, and objects with a class label “+1”).
It should be noted that the use of the one-class SVM algorithm used in the role of a one-class SVM (ooSVM) algorithm was not considered in the proposed hybrid SVM-kNN classifier, since in this case, it is impossible to ensure the presence of objects of different classes within the strip separating the classes, and, therefore, it is impossible to implement the second stage, which implies the development of the kNN classifier.
1.2. Formation of the training set for kNN classifier development with the implementation of two variants.
Variant 1. The training set for kNN classifier development includes all objects of the training set used at step 1.1 during SVM classifier development inside the strip separating the classes: . Let the area containing such objects be called (Boundary). In the future, symbol will be assigned to the corresponding hybrid classifier variant.
Variant 2. The training set for the kNN classifier development includes only those objects of the training set used at step 1.1 during training of the SVM classifier that fall into the area described by inequality , where is the number that satisfies inequality: and is defined as , where is the maximum distance from the hyperplane separating the classes to the misclassified object of the class with the label “−1” belonging to the training set and located inside the strip separating classes; and is the maximum distance from the hyperplane separating the classes to the misclassified object of the class with the label “+1”, belonging to the training set and located inside the strip separating the classes. Let the area containing such objects be called (Area). In the future, symbol will be assigned to the corresponding hybrid classifier variant.
It should be noted that area with such a definition will be symmetric with respect to the hyperplane separating the classes, although it is possible to consider an asymmetric version for area in the future. While forming a training set for kNN classifier development based on objects from area , it is assumed that in the future, thee SVM classifier will continue to correctly classify objects outside the area, and inside this area it will still sometimes make mistakes.
Let the area selected at step 1.2 be called
. It is assumed that the SVM classifier always makes mistakes within area
, otherwise kNN classifier development is not required.
Figure A1 (
Appendix A) shows examples of areas
and
in two-dimensional space.
Stage 2. kNN classifier development.
kNN classifier development is fulfilled on the basis on the training set formed at step 1.2 using one of two variants of the area (that is, area or ), for various values of the number k of nearest neighbors, various metrics for evaluating the distance between the objects (for example, in accordance with Formula (5)), and various voting rules (for example, in accordance with Formulas (6) or (7)). The best kNN classifier is selected so that it provides the highest quality of classification of all objects in the test set as a whole using the two-stage hybrid SVM-kNN classifier. Therefore, the parameter values of the best kNN classifier are fixed, in particular, the number of neighbors, metric for assessing the distance between objects, and voting rule are recorded.
The proposed two-stage hybrid SVM-kNN classifier implements cascade learning: first, on the basis of the training set, composed randomly from the considered dataset, the SVM classifier is trained, and then on the basis of the training set reduced in the above way, the kNN classifier is trained.
In the proposed two-stage hybrid SVM-kNN classifier, it is assumed that due to the development of the SVM classifier at the first stage, it is possible to change the balance of classes, working at the second stage in the development of the kNN classifier only with objects that fall into the reduced training dataset and inside the dividing strip (in area or ). Therefore, peripheral (uninformative) objects are excluded from the training dataset. These objects, in fact, do not affect the final decision (in particular, they are not support vectors and are not included in classification rules (2) or (4)).
It is reasonable to compare the results of the two-stage hybrid SVM-kNN classifier development with the results of the development of SVM and kNN classifiers that work with the default parameters values. As such, it will be possible to assess the expediency of using the two-stage hybrid SVM-kNN classifier to determine the class belonging of new objects, identifying or not identifying an increase in the values of the classification quality indicators of objects from the test set.
In the case of a positive decision on the expediency of using the developed two-stage hybrid SVM-kNN classifier, the classification of new objects can be performed as follows:
apply the developed SVM classifier (with fixed parameters values) to separate new objects into two classes;
select from the new objects those that fall into area built at step 1.2 at stage 1, and refine the classification decision for these objects using the developed kNN classifier.
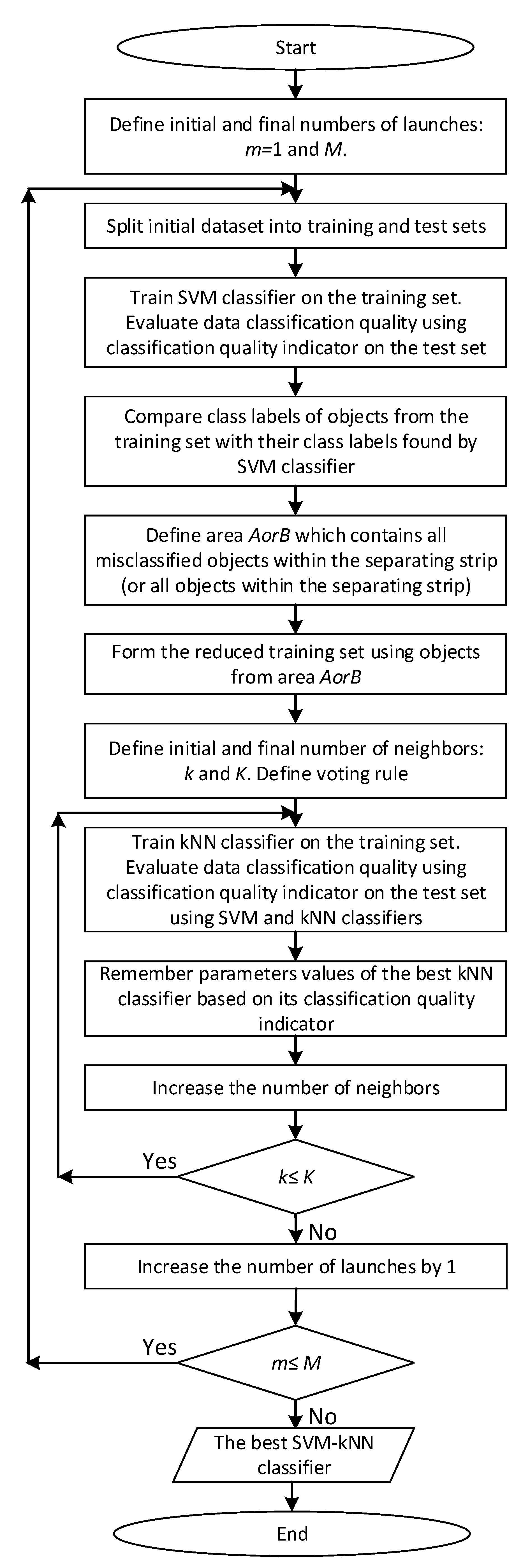
Figure 1 shows the enlarged block diagram of the two-stage hybrid SVM-kNN classifier development.
Two-stage hybrid SVM-kNN classifier development is implemented for various values of the number k of nearest neighbors. It is reasonable to use odd values of the number k when using votes majority rule (6) with the aim to avoid circumstances when the same number of neighbors voted for the various classes (in the case of binary classification).
During kNN classifier development, we worked with not only the entire training set, but with the reduced training set containing only the data about objects that fell into area (in the area or ), depending on which variant of the choice of the area turned out to be the best when developing the kNN classifier). The use of an auxiliary toolkit named as the kNN classifier, whose working principles are different from the working principles of SVM classifier, allows for an increase in the overall data classification quality in some cases.
The limitations on the applicability of the proposed two-stage hybrid SVM-kNN classifier are related to the fact that, due to the small width of area or excessive sparseness within area , the size of the reduced training set (namely, the number of objects) may be insufficient for kNN classifier development.
5. Experimental Studies
The feasibility of using the proposed the two-stage hybrid versions of SVM-kNN classifiers was confirmed during experiments on real datasets taken from the UCI Machine Learning Repository and other sources applied to test the proposed classifiers.
The binary classification was implemented in all datasets that were used in experiments. Moreover, all datasets differed from each other by significantly different indicators of class imbalance. During the experiments, in particular, 20 datasets were considered (Australian, Banknote Authentication, Biodeg, Breast-Cancer-Wisconsin, Diabetic Retionopathy, German, Haberman, Heart, Ionosphere, Liver, Musk (Version 1), Musk (Version 2), Parkinsons, Phoneme, Pima Indians Diabetes, Spam, Sports Articles, Vertebral, LSVT Voice, WDBC), for three of which it was possible to obtain confirmation of the effectiveness of two-stage hybrid versions of SVM-kNN classifiers. The considered datasets are described in
Table A1 (
Appendix A). Objects of the majority class are marked with class label “0”, and objects of minority class are marked with class label “1” (for some datasets, class labels had to be renamed for consistency).
Software implementation was done in Python 3.8 using the Scikit-learn machine learning library, which provides tools for developing binary SVM, one-class SVM, and kNN classifiers. Jupyter Notebooks were applied to write the program code.
When developing SVM classifiers, implementations of binary and one-class SVM algorithms with default parameters values were used (
Table 1). When developing the kNN classifiers, implementation of the kNN algorithm with the default parameter values (
Table 1) was used as well as the implementation of the kNN algorithm in which the number of neighbors was chosen from the range [
5,
46] with the step equal to 2 (with voting by a majority of votes and weighted voting).
Table 1 uses the following notations:
is the lower boundary of the portion of support vectors and the upper boundary on the portion of training errors ();
is the training dataset variance calculated as: ; ;
is the number of objects in the training set;
is the number of features;
rbf is the radial basis kernel function; and
auto means that the most appropriate algorithm from BallTree, KDTree, Brute-force search is used.
The portion of the test set was equal to 20% of the considered dataset.
During the experiments, the following versions of the classifiers were developed.
kNN classifier with default parameter values, named as kNN-default.
kNN classifier, which implements the search for the best number of neighbors with the rest default parameter values, named as kNN.
Binary SVM classifier with default parameter values, named as bSVM-default.
One-class SVM-classifier, working in the role of a binary, with default parameter values, named as obSVM-default.
A hybrid of the binary SVM classifier with default parameter values and kNN classifier, which implements the search for the best number of neighbors with the rest default parameter values, and takes into account the boundaries of the strip separating the classes, named as bSVM-B-kNN.
A hybrid of the one-class SVM classifier, working as a binary, with default parameter values, and kNN classifier, which implements the search for the best number of neighbors with the rest default parameter values, and takes into account the boundaries of the strip separating the classes, named as obSVM-B-kNN.
A hybrid of a binary SVM classifier with default parameter values and a kNN classifier that realizes the search for the best number of neighbors with the default parameter values, and takes into account the selected symmetric areas within the boundaries defining the band separating the classes, named as bSVM-A-kNN.
A hybrid of a one-class SVM classifier, working as a binary, with the default parameter values, and a kNN classifier, which realizes the search for the best number of neighbors with the rest default parameter values, and takes into account the selected symmetric area within the boundaries, defining the strip separating the classes, named as obSVM-A-kNN.
Before the training procedure, the values of the elements of the feature vectors of objects were scaled: standardization (Standard) and MinMax scaling techniques were used in order to select the best one based on the results of training. In the overwhelming majority of cases, the best learning outcomes (in terms of the classification quality) were obtained using standardization.
The quality of the classifiers was assessed on the test set using classification quality indicators such as Balanced Accuracy (BA), Accuracy (Acc), and -score (). For each fixed number of neighbors, 500 random partitions of the dataset were performed into test and training sets in a ratio of 80:20, followed by training, testing, and choosing the best hybrid classifier (including choosing the best number of neighbors in the kNN classifier) to sense this or that indicator of the quality of the classification.
The calculation of indicators
,
, and
in the case of binary classification was carried out in accordance with formulas:
where
is the number of true positive outcomes;
is the number of true negative outcomes;
is the number of false positive outcomes;
is the number of false negative outcomes;
;
; and
.
The balanced accuracy indicator differs from the accuracy indicator in that the proportion of objects in each of the classes is taken into account when calculating it. Hence, indicator gives the most reliable assessment of the classification quality of unbalanced datasets.
5.1. Hybrid Classifier Development Using kNN Classifier Based on the Votes Majority Rule
First, the experiments for the case when the votes majority rule according to Formula (6) is used in the development of the kNN classifier were carried out.
During the experiments, it was possible to prove the effectiveness of the proposed two-stage hybrid classifiers using three datasets such as Haberman, Heart, and Pima Indians Diabetes. The efficiency of the proposed two-stage hybrid classifiers for four more datasets such as Breast-Cancer-Wisconsin, Parkinsons, LSVT Voice, and WDBC turned out to be the same as when using the kNN classifier, for which the search for the optimal number of neighbors was carried out.
Table 2,
Table 3 and
Table 4 show the classification quality indicator values (
Balanced Accuracy (
BA),
Accuracy (
Acc),
-score (
)) and the number of neighbors for which the best (i.e., maximum) classification quality indicator value was reached, for three datasets (Haberman, Heart, Pima Indians Diabetes), on which the successful application of two-stage hybrid versions of SVM-kNN classifiers (when at least one of the three indicators is clearly improved or the obtained decision is among the top three out of eight classifiers above-mentioned) is observed. The class was assigned to the object
in accordance with the votes majority rule (6).
In
Table 2,
Table 3 and
Table 4, indicator values that occupy the first place are highlighted in bold, indicator values that occupy second place are highlighted in bold italics, and indicator values that occupy the third place are simply italicized (when ranking in descending order of indicators values).
As can be seen from
Table 2,
Table 3 and
Table 4, all four versions of the two-stage hybrid SVM-kNN classifiers (bSVM-A-kNN, bSVM-B-kNN, obSVM-A-kNN, obSVM-B-kNN) took the lead on different datasets (or are included in the top three) when analyzing certain classification quality indicators, in connection with which it is possible to talk about their effectiveness and expediency of use (especially in the case of further fine tuning of SVM classifier parameter values).
For another four datasets (Breast-Cancer-Wisconsin, Parkinsons, LSVT Voice, and WDBC), it turned out that the kNN, kNN-default, SVM-default classifiers and two-stage hybrid SVM-kNN classifiers provided the same values of the classification quality indicators (, , ) equal to 1 on the test set. Therefore, the class was assigned to object in accordance with the votes majority rule (6). The main difference between two-stage hybrid SVM-kNN classifiers and kNN classifiers is, possibly, in a various number of neighbors, at which the best (i.e., maximum) value of the classification quality indicator was reached. Thus, the composition of the training and test sets, with the use of which the best (i.e., maximum) value of the classification quality indicator was achieved, can be obtained in different ways (with various composition of training and test sets and various numbers of neighbors in kNN classifier), while, generally speaking, the time to obtain the desired high-quality classifier can be minimized by developing the kNN classifier, which is part of the two-stage hybrid SVM-kNN classifier, due to the use of the training set of lower cardinality than in the case when only kNN or SVM classifiers are developed.
Table 5,
Table 6,
Table 7 and
Table 8 show the number of neighbors for the Standard and MinMax scaling methods, at which the best (i.e., maximum) values of classification quality indicators were achieved in the kNN, bSVM-A-kNN, bSVM-B-kNN, obSVM-A-kNN, and obSVM-B-kNN classifiers for different classification quality indicators on the Breast-Cancer-Wisconsin, Parkinsons, LSVT Voice, and WDBC datasets. Dashes (“-”) in the cells of
Table 5,
Table 6,
Table 7 and
Table 8 mean that for the classifier named in the column heading, the maximum value of the quality indicator named in the row headings (in the leftmost cell of the row) was not observed.
Appendix B provides
Table A2,
Table A3 and
Table A4, which show the classification quality indicator values (and number of neighbors) for which the best (i.e., maximum) classification quality indicator value was reached for three datasets (Australian, German, and Ionosphere) on which the successful application of two-stage hybrid versions of SVM-kNN classifiers was not obtained. Therefore, the class was assigned to the object
in accordance with the votes majority rule (6).
The success of applying the proposed two-stage hybrid versions of SVM-kNN classifiers to some datasets and the failure of their application to others can be explained by the peculiarities of forming area or grouping objects of the training set within area .
5.2. Hybrid Classifier Development Using kNN Classifier Based on the Rule of Weighted Voting
Similar experiments for the case when the rule of weighted voting according to Equation (7) used in the development of the kNN classifier were carried out.
During the experiments, it was possible to prove the effectiveness of the proposed two-stage hybrid classifiers using three datasets such as Haberman, Heart, and Pima Indians Diabetes. The efficiency of the proposed two-stage hybrid classifiers for four more datasets such as Breast-Cancer-Wisconsin, Parkinsons, LSVT Voice, and WDBC turned out to be the same as when using the kNN classifier, for which the search for the optimal number of neighbors was carried out.
Table 9,
Table 10 and
Table 11 show the classification quality indicator values (
BA,
Acc,
) and number of neighbors for which the best (i.e., maximum) classification quality indicator value was reached for three datasets (Haberman, Pima Indians Diabetes, Heart), on which the successful application of two-stage hybrid versions of SVM-kNN classifiers (when at least one of the three indicators is clearly improved or the obtained decision is in the top three out of eight classifiers above-mentioned) is observed. Therefore, the class was assigned to the object
in accordance with the rule of weighted voting (7).
In
Table 9,
Table 10 and
Table 11, the indicator values that occupy the first place are highlighted in bold; indicator values that occupy the second place are highlighted in bold italics; and indicator values that occupy the third place are simply italicized (when ranking in descending order of indicators values).
As can be seen from
Table 9,
Table 10 and
Table 11, all four versions of the two-stage hybrid SVM-kNN classifiers (bSVM-A-kNN, bSVM-B-kNN, obSVM-A-kNN, obSVM-B-kNN) took the lead on different datasets (or are included in the top three) when analyzing certain classification quality indicators, in connection with which it is possible to talk about their effectiveness and expediency of use (especially in the case of more fine tuning of the values of SVM classifier parameters).
For another four datasets (Breast-Cancer-Wisconsin, Parkinsons, LSVT Voice, and WDBC), it turned out that the kNN, kNN-default, SVM-default classifiers, and two-stage hybrid SVM-kNN classifiers gave the same values of the classification quality indicators (, , ), equal to 1 on the test set. The class was assigned to object in accordance with the rule of weighted voting (7). The main difference between the two-stage hybrid SVM-kNN classifiers and kNN classifiers (the same as when using the votes majority rule (6)) is, possibly, in a various number of neighbors at which the best (i.e., maximum) value of the classification quality indicator was achieved. The composition of the training and test sets, with the use of which the best (i.e., maximum) value of the classification quality indicator was achieved, can be obtained in different ways (with various compositions of training and test sets and various numbers of neighbors in the kNN classifier), while, generally speaking, the time required to obtain the desired high-quality classifier can be minimized by developing the kNN classifier, which is part of the two-stage hybrid SVM-kNN classifier, due to the use of the training set of lower cardinality than in the case when only kNN or SVM classifiers are developed.
Table 12,
Table 13,
Table 14 and
Table 15 show the number of neighbors for the Standard and MinMax scaling methods, at which the best (i.e., maximum) values of classification quality indicators were achieved in the kNN, bSVM-A-kNN, bSVM-B-kNN, obSVM-A-kNN, obSVM-B-kNN classifiers for different classification quality indicators on the Breast-Cancer-Wisconsin, Parkinsons, LSVT Voice, and WDBC datasets. Dashes (“-”) in the cells of
Table 12,
Table 13,
Table 14 and
Table 15 mean that for the classifier named in the column heading, the maximum value of the quality indicator named in the row headings (in the leftmost cell of the row) was not observed.
It should be noted that one of the kNN classifiers, named in
Table 2,
Table 3,
Table 4,
Table 5,
Table 6,
Table 7,
Table 8,
Table 9,
Table 10,
Table 11,
Table 12,
Table 13,
Table 14 and
Table 15 as kNN, implements the search for the best number of neighbors. However, this does not always allow this classifier to become the winner among the considered classifiers in terms of
,
, and
. kNN-default, SVM-default, obSVM-default classifiers work with the default parameters values.
Appendix B provides
Table A5,
Table A6 and
Table A7, which show the classification quality indicator values (and number of neighbors for which the best (i.e., maximum) classification quality indicator value was reached, for three datasets (Australian, German, and Ionosphere) on which successful application of two-stage hybrid versions of SVM-kNN classifiers was not obtained. Thus, the class was assigned to the object
in accordance with the rule of weighted voting (7).
It should be additionally noted, according to the results of the data analysis in
Table 2,
Table 3,
Table 4,
Table 5,
Table 6,
Table 7,
Table 8,
Table 9,
Table 10,
Table 11,
Table 12,
Table 13,
Table 14 and
Table 15, that in some cases, the use of the rule of weighted voting (7) in kNN classifier development can improve the classification quality.
5.3. Analysis of Class Imbalance in Initial and Reduced Training Sets
Table 16,
Table 17 and
Table 18 show the number of objects of different classes and the ratio for the number of objects labeled by “0” and “1” in the training sets (initial and reduced for kNN classifier development) for some datasets from
Table A1 (
Appendix A) when using the Standard scaling method and the rule majority of votes (6) with the best values of the classification quality indicators (
,
, and
).
When calculating the
,
, and
indicators (
Table 16,
Table 17 and
Table 18) on the Australian, German, and Ionosphere datasets, it was not possible to improve the quality of the classification using the proposed two-stage hybrid classifiers.
When calculating the
and
indicators (
Table 16 and
Table 18) on the Haberman, Heart, and Pima Indians Diabetes datasets, it was possible to increase the classification quality using the proposed two-stage hybrid classifiers for the first set, and no advantage was obtained for the second and third sets. Therefore, using the Breast-Cancer-Wisconsin, Parkinsons, LSVT Voice, and WDBC datasets, we managed to ensure the highest possible classification quality, which was also obtained using the kNN-default and bSVM-default classifiers.
When calculating the
indicator (
Table 17) on the Haberman, Heart, and Pima Indians Diabetes datasets, it was possible to increase the classification quality using the proposed two-stage hybrid classifiers for the first dataset to obtain the same value of
indicator for the second dataset, and no advantage was obtained for the third dataset. Thus, using the Breast-Cancer-Wisconsin, Parkinsons, LSVT Voice, and WDBC datasets, we managed to ensure the highest possible classification quality, which was also obtained using the kNN-default and bSVM-default classifiers.
Analysis of the data in
Table 16,
Table 17 and
Table 18 allows us to conclude that in some cases, a decrease in the value of the class imbalance indicator in the
area allows for an increase in the data classification quality as a whole.
6. Discussion
The presented two-stage hybrid SVM-kNN classifiers could in some cases increase the data classification quality, because applying the kNN classifier to objects near the separating hyperplane found by the SVM classifier allowed for a reduction in the reduce th number of misclassified objects. Therefore, it is promising to use all considered versions of the classifiers: bSVM-kNN, obSVM-kNN with consideration of their variants both inside the selected symmetric areas within the boundaries defining the band separating the classes (bSVM-A-kNN, obSVM-A-kNN), and just within the boundaries that form the class-separating strip (bSVM-B-kNN, obSVM-B-kNN), since it is problematic to predict in advance how the data are organized including near the boundary that separates the classes.
The proposed two-stage hybrid classifier should learn quickly, because at the first stage, the development of the SVM classifier with default parameters values is implemented, and at the second stage, the kNN classifier with varying value of only one parameter is named as the number of neighbors and, possibly, with the choice of the voting rule ((6) or (7)) is developed. As such, training of the kNN classifier is performed on a reduced set containing only objects from described area.
The proposed two-stage hybrid SVM-kNN classifiers were tested using a personal computer with the following characteristics: processor: Intel (R) Core (TM) i3-8145U CPU @ 2.10 GHz, 2304 MHz, 2 cores; RAM: 4 GB; 64-bit operating system. All calculations were performed under Windows 10.
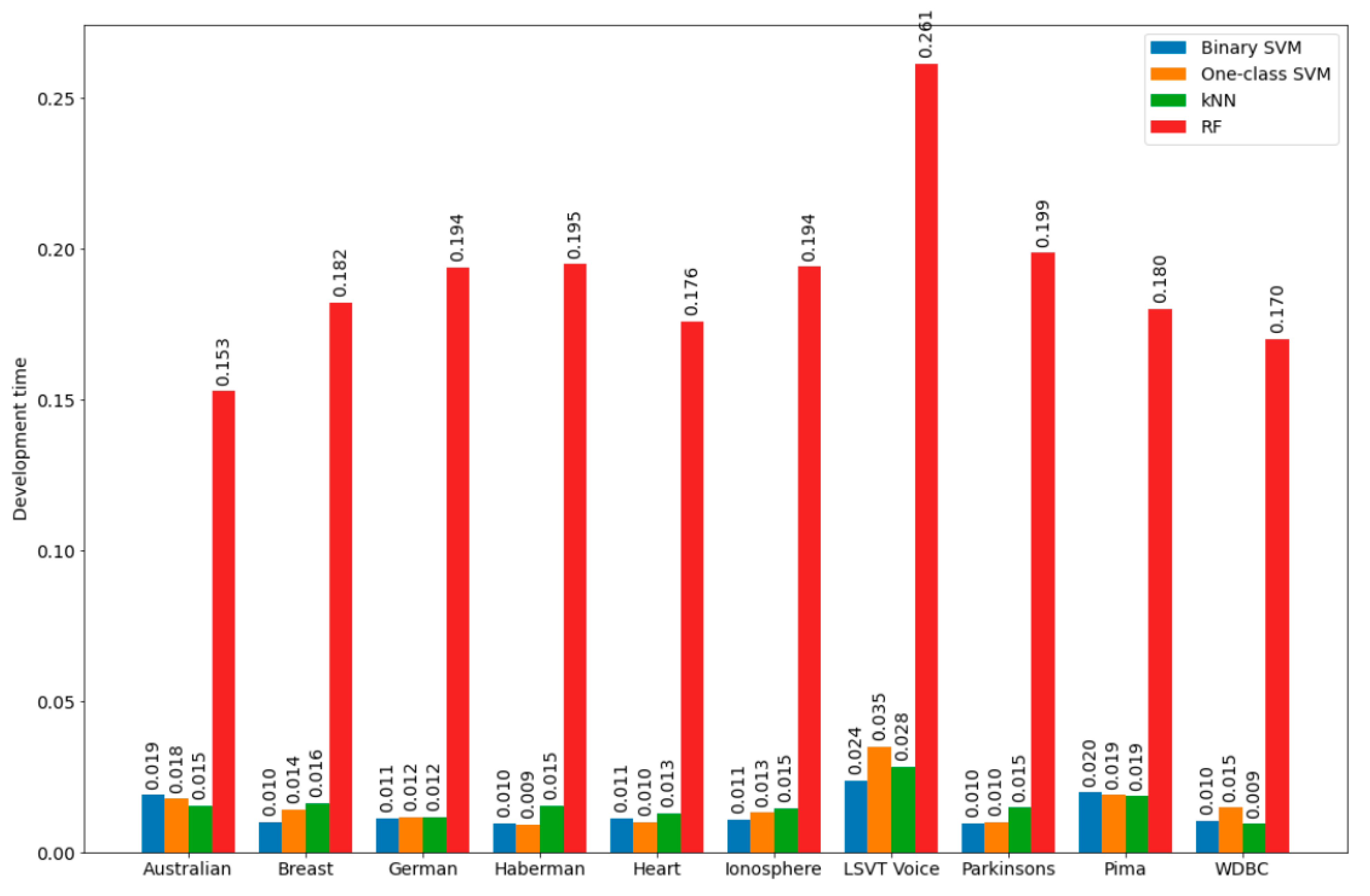
In the course of the experiments, the average development time of bSVM, obSVM, kNN as well as RF was estimated with the default parameter values based on the results of 500 program launches with various variants of splitting the considered dataset into training and test sets. Development time was calculated as the sum of training time and testing time. For the bSVM, obSVM, and kNN classifiers, the values of these parameters are shown in
Table 1, and for RF, the following default values of the main parameters were used: number of trees is 100; function to measure the quality of split is Gini index; minimum number of samples required to split an internal node is 2; maximum depth of the tree is defined according to the rule: nodes are expanded until all leaves are pure or until all leaves contain less than the minimum number of samples required to split an internal node; maximum number of features to consider when looking for the best split is equal to the square root of the number of features; minimum number of samples required to be at a leaf node is 1; nd minimum weighted fraction of the sum total of weights (of all the input samples) required to be at a leaf node is 0.
As the results of the experiments have shown, the development time of the kNN classifier was of the same order as the development time of bSVM and obSVM, while the development time of the RF classifier had a higher order. This is why the kNN classifier was chosen as the auxiliary classifier.
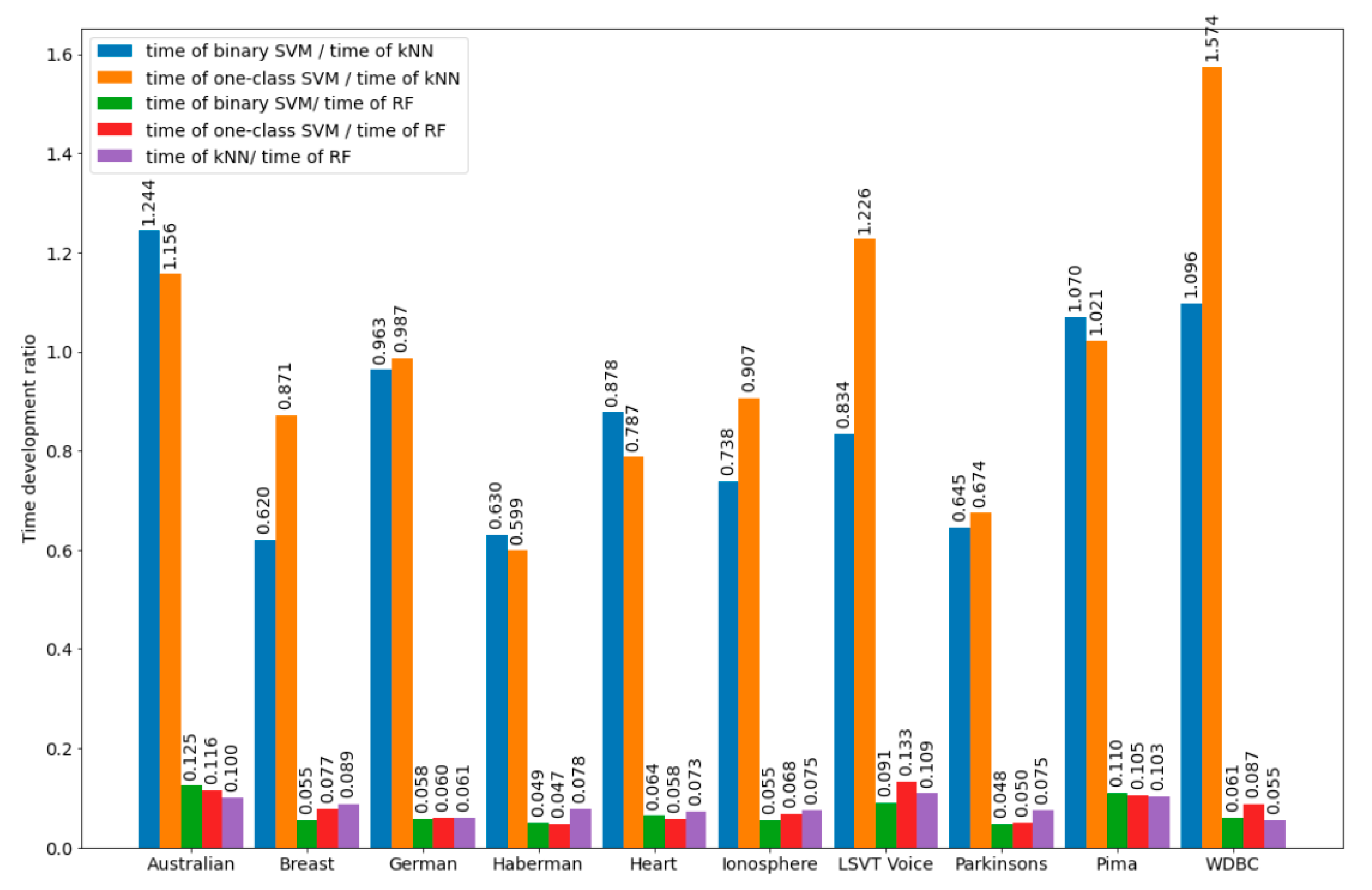
Figure 2 and
Figure 3 show graphical illustrations for the development time of the bSVM, obSVM, kNN, and RF classifiers as well as for the development time ratios for the datasets, the calculated information for which is detailed in
Section 5. It can be assumed that approximately the same ratios for the time development will also be in the search for the optimal number of neighbors in the development of the kNN classifier, which is part of the hybrid. Therefore, training of the kNN classifier will be performed on a reduced training set, which should positively affect the development time of the kNN classifier (in the sense of its minimization). It should be noted that the formation time of the reduced training set used in the kNN classifier development was not big and consisted of the time of one pass through the initial training set and the time spent on sorting the objects of the initial training set based on the results of comparing the object class labels in it and the class labels assigned to the same objects by the developed classifier.
The RF classifier can be recommended for use as an auxiliary classifier in a hybrid only if it has significant computing powers (although this classifier, in some cases, allows one to obtain higher classification quality when used both as part of a hybrid and for individual use).
Table 19 shows the values of the accuracy indicator assessments obtained for the best two-stage hybrid SVM-kNN classifiers for three datasets (Haberman, Heart, and Pima Indians Diabetes), for which, taking into account various indicators of classification quality, it was possible to prove the effectiveness of the proposed two-stage hybrid SVM-kNN classifiers in comparison with the SVM and kNN classifiers, with parameter values set by default.
Table 19 also provides the values of the accuracy indicator parameters values for the binary SVM classifier with default parameter values and the binary SVM classifier built using the modified PSO algorithm [
21,
22]. The value of the accuracy indicator was estimated using a test dataset. A dash “-” in a table cell means that the classifier specified in the row header was not the best for the dataset specified in the column header. A dash “-” in the last line of the first column means that the voting rule was not applied. The maximum values in the columns are in bold. Analysis of the data in
Table 19 allows us to draw the following conclusions. For the Haberman and Pima Indians Diabetes datasets, the proposed two-stage hybrid SVM-kNN classifiers were the best (in the sense of maximizing the value of the accuracy indicator); for the Heart set, the best value of the accuracy indicator was obtained using thee binary SVM classifier built using the modified PSO algorithm. Therefore, we managed to slightly increase the value of the accuracy indicator for the binary SVM classifier built using the modified PSO algorithm compared to the binary SVM classifier with the default parameter values, but we did not manage to exceed the results obtained using the obSVM-A-kNN classifier.
It should be noted that one should pay attention to the time spent on obtaining the best classifiers: How much time is spent on obtaining them? Is it worth spending a lot of time on developing a classifier, or can you obtain a classifier of acceptable quality in less time?
For example, for the Pima Indians Diabetes dataset, the development time for the SVM classifier with default parameter values when the 500 program launches were implemented was approximately 10 s, and the obSVM-B-kNN development time for 500 program launches was approximately 220 s. The development time for the binary SVM classifier using the modified PSO algorithm was approximately 950 s, provided that 500 generations were realized for a population of 60 particles. Each particle determines the parameter values of a certain classifier, during the construction of which one of three types of kernel function (from the list of radial basic, polynomial, and sigmoid kernel functions) is specified, and the parameter values of the kernel function and the regularization parameter value are selected. As we can see, time spent in the latter case turned out to be significantly higher, but at the same time, we could not get the classifier with the highest value of the accuracy indicator. Obviously, when working with large datasets, time spent on developing the binary SVM classifier using the modified PSO algorithm will be even greater, and we will not have a guarantee that we will be able to obtain the desired effective solution.
When using the modified PSO algorithm, it was possible to slightly improve the quality of SVM classifiers for some indicators for three datasets (Australian, German, and Ionosphere); the information on the development of two-stage hybrid SVM-kNN classifiers is given in
Table A2,
Table A3,
Table A4,
Table A5,
Table A6 and
Table A7. However, the question arises again regarding the expediency of significant time expenditures to obtain the desired solution.
Obviously, a reasonable approach would be to implement the development process for two-stage hybrid versions of SVM-kNN classifiers with the choice of the best classifier from all available at the current launch of the program.
The impossibility of obtaining an effective solution using aa two-stage hybrid of the SVM-kNN classifier for some datasets may be due to the fact that it was not possible to provide the necessary rebalancing of classes within the strip separating them. In addition, it can be caused by the specifics of grouping objects within the strip separating the classes.
It should be noted that the development process of two-stage hybrid SVM-kNN classifiers can be parallelized, which can be very important when working with big data.
7. Conclusions
In general, the obtained results allow us to speak about the prospects of using two-stage hybrid SVM-kNN classifiers with the aim to increase the data classification quality.
In the course of further research, it is planned to investigate the possibility of using, as an additional toolkit, classifiers such as kNN classifiers that implement various weighted options to account for the nearest neighbors and perform a quick search for the nearest neighbors, classifiers based on the Parzen window algorithm, RF classifiers, etc. In addition, it is of considerable interest to analyze the influence of the choice of symmetric and asymmetric areas within the boundaries defining the hyperplane dividing the classes when forming the training and test subsets for the kNN classifier on the overall quality of the classifier.
The proposed two-stage hybrid SVM-kNN classifier is fundamentally different from the hybrid SVM-kNN classifier proposed in [
52,
53] by the method of forming a training set for the developing kNN classifier: in [
52,
53], objects were used that lie outside the area, which, moreover, can be formed taking into account the principles of symmetry and asymmetry with respect to the hyperplane dividing the classes, and the proposed study used objects lying inside the area formed based on the principles of symmetry with respect to the hyperplane dividing the classes. Similar principles (as in [
52,
53]) for the formation of a training set were considered in [
68,
69]. Therefore, we plan to research the opportunity of using two versions of one-class SVM-algorithm—ooSVM and obSVM—for the development of the concept of the hybrid SVM-kNN classifier proposed in [
52,
53]. Therefore, the main problem in all two-stage hybrid SVM-kNN classifiers is the problem of applicability of the kNN classifier at the second stage, due to the possible small number of objects in the reduced training set formed using the results from the SVM classifier development.





{kind=link}
{kind=link}
{kind=link}
{kind=link}


