
SCN: A Novel Shape Classification Algorithm Based on Convolutional Neural Network


Abstract
1. Introduction
- Performing the binary representation of object shapes in the image to obtain shape features;
- Calculating the similarity between two or more shapes according to certain measurement criteria;
- Matching and classifying shapes according to calculation results and premise tasks.
2. Related Work
2.1. Traditional Algorithm
2.2. Development of Deep Learning
3. Method
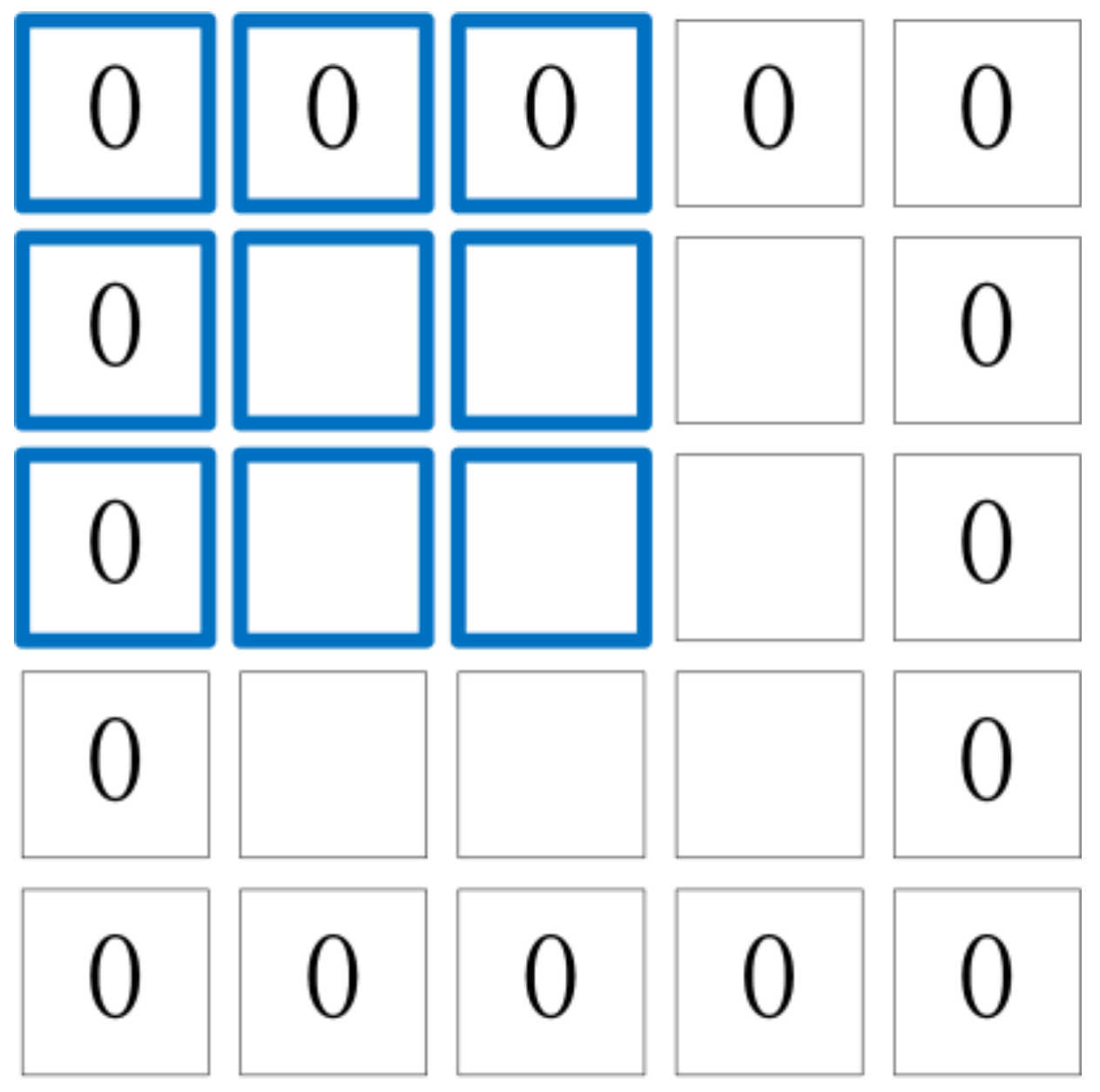
3.1. Size of Convolution Kernel
3.2. Fine-Tuning
3.3. Addition of BN Layer
- Input data x1…xm over a mini-batch B = {x1…m} sequentially, which are the data ready to enter the activation function;
- Find the data average by ;
- Using the formula to obtain the variance of the input data;
- The data ire normalized by , or referred to as normalization;
- The parameters are trained by the formula , and the output y value is obtained by linear transformation of .
3.4. Application of the Transposed Convolution Layer
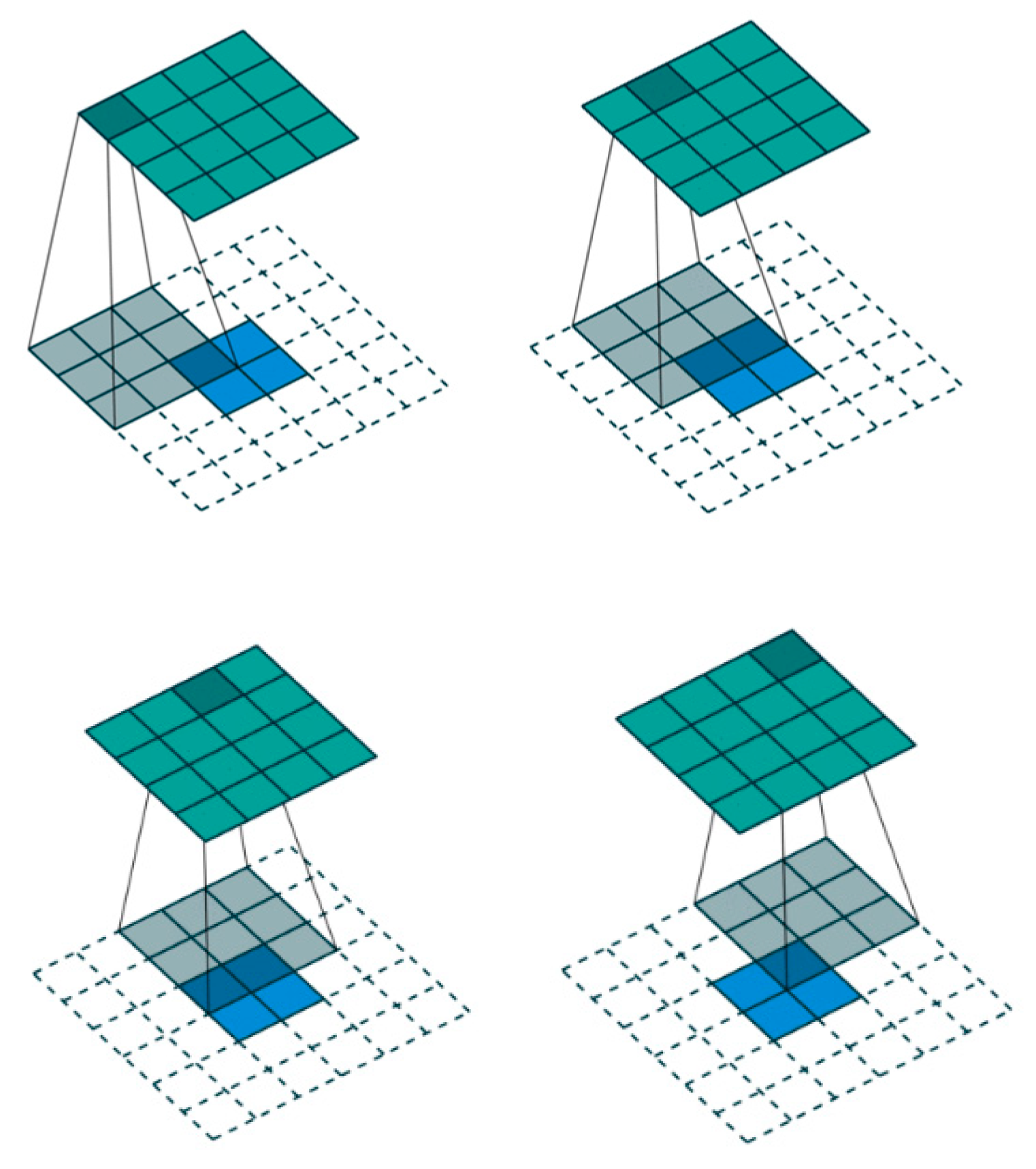
3.4.1. Transposed Convolution
3.4.2. Checkerboard Effect
3.5. Architecture
4. Experiment
4.1. Performance on Animals Dataset
4.2. Performance on Swedish Plant Leaf Dataset
4.3. Performance on MPEG-7 CE-1 Part B DATASET
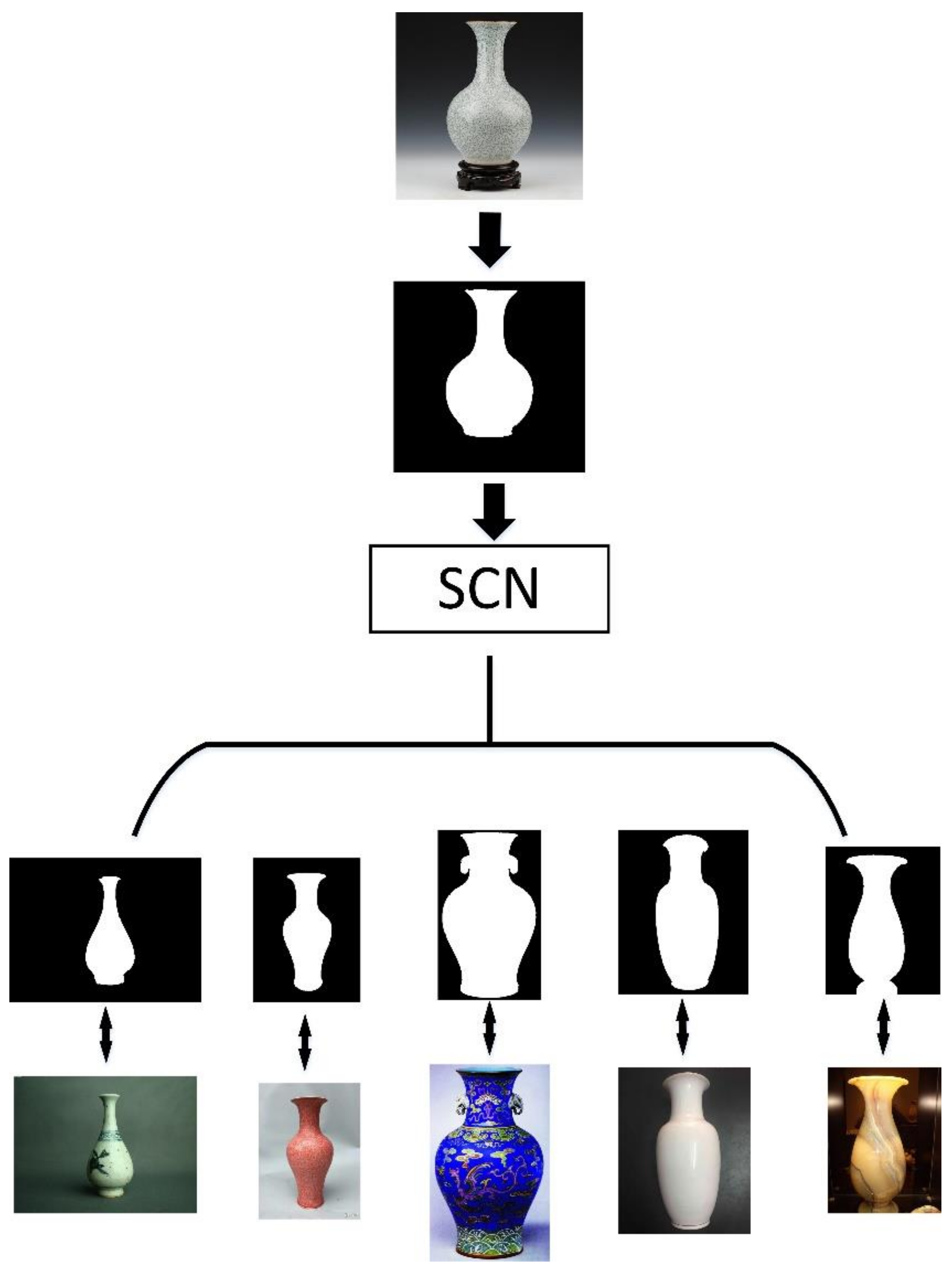
5. Application
6. Conclusions
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
References
- Mouine, S.; Yahiaoui, I.; Verroust-Blondet, A.V. A shape-based approach for leaf classification using multiscale triangular representation. In Proceedings of the 3rd ACM Conference on Multimedia Retrieval, Dallas, TX, USA, 16–19 April 2003; pp. 127–134. [Google Scholar]
- Milios, E.; Petrakis, E. Shape retrieval based on dynamic programming. IEEE Trans. Image Process. 2000, 9, 141–147. [Google Scholar] [CrossRef] [PubMed]
- Zheng, Y.; Guo, B.; Yan, Y.; He, W. O2O Method for Fast 2D Shape Retrieval. IEEE Trans. Image Process. 2019, 28, 5366–5378. [Google Scholar] [CrossRef]
- Zahn, C.T.; Roskies, R.Z. Fourier descriptors for plane closed curves. IEEE Trans. Comput. 1972, 100, 269–281. [Google Scholar] [CrossRef]
- Daliri, M.R.; Torre, V. Robust symbolic representation for shape recognition and retrieval. Pattern Recognit. 2008, 41, 1782–1798. [Google Scholar] [CrossRef]
- Ling, H.B.; Jacobs, D.W. Using the inner-distance for classification of articulated shapes. In Proceedings of the 2005 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), San Diego, CA, USA, 20–26 June 2005; IEEE: Washington, DC, USA, 2005; pp. 719–726. [Google Scholar]
- Wang, B.; Gao, Y.; Sun, C.; Blumenstein, M.; La Salle, J. Can walking and measuring along chord bunches better describe leaf shapes? In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 6119–6128. [Google Scholar]
- Thayananthan, A.; Stenger, B.; Torr, P.H.S.; Cipolla, R. Shape context and chamfer matching in cluttered scenes. In Proceedings of the 2003 IEEE Computer Society Conference on Computer Vision and Pattern Recognition (CVPR), Madison, WI, USA, 16–22 June 2003; IEEE: Washington, DC, USA, 2003; pp. 127–133. [Google Scholar]
- Mokhtarian, F.; Abbasi, S.; Kittler, J. Efficient and robust retrieval by shape content through curvature scale space. In Proceedings of the International Workshop on Image Databases and Multi-Media Search, Amsterdam, The Netherlands, 22–23 August 1996; pp. 35–42. [Google Scholar]
- Mokhtarian, F.; Bober, M. Curvature Scale Space Representation: Theory, Applications, and MPEG-7 Standardization; Kluwer Academic Publishers: Dordrecht, The Netherlands, 2003. [Google Scholar]
- Adamek, T.; O’Connor, N.E. A multiscale representation method for nonrigid shapes with a single closed contour. IEEE Trans. Circuits Syst. Video Technol. 2004, 14, 742–753. [Google Scholar] [CrossRef]
- Alajlan, N.; El Rube, I.; Kamel, M.S.; Freeman, G. Shape retrieval using triangle-area representation and dynamic space warping. Pattern Recognit. 2007, 40, 1911–1920. [Google Scholar] [CrossRef]
- Ling, H.; Jacobs, D.W. Shape classification using the inner-distance. IEEE Trans. Pattern Anal. Mach. Intell. 2007, 29, 286–299. [Google Scholar] [CrossRef] [PubMed]
- Belongie, S.; Malik, J.; Puzicha, J. Shape matching and object recognition using shape contexts. IEEE Trans. Pattern Anal. Mach. Intell. 2002, 24, 509–522. [Google Scholar] [CrossRef]
- Zhang, D.; Lu, G. Study and evaluation of different Fourier methods for image retrieval. Image Vis. Comput. 2005, 23, 33–49. [Google Scholar] [CrossRef]
- Hu, R.X.; Jia, W.; Ling, H.; Huang, D. Multiscale distance matrix for fast plant leaf recognition. IEEE Trans. Image Process. 2012, 21, 4667–4672. [Google Scholar] [PubMed]
- Kaothanthong, N.; Chun, J.; Tokuyama, T. Distance interior ratio: A new shape signature for 2D shape retrieval. Pattern Recognit. Lett. 2016, 78, 14–21. [Google Scholar] [CrossRef]
- Hu, R.-X.; Jia, W.; Ling, H.; Zhao, Y.; Gui, J. Angular pattern and binary angular pattern for shape retrieval. IEEE Trans. Image Process. 2014. 23, 1118–1127.
- Zheng, Y.; Guo, B.; Chen, Z.; Li, C. A Fourier Descriptor of 2D Shapes Based on Multiscale Centroid Contour Distances Used in Object Recognition in Remote Sensing Images. Sensors 2019, 19, 486. [Google Scholar] [CrossRef]
- Hinton, G.E.; Salakhutdinov, R.R. Reducing the Dimensionality of Data with Neural Networks. Neural Comput. 2006, 18, 1527. [Google Scholar] [CrossRef]
- LeCun, Y.; Bottou, L.; Bengio, Y.; Haffner, P. Gradient-based learning applied to document recognition. Proc. IEEE 1998, 86, 2278–2324. [Google Scholar] [CrossRef]
- Krizhevsky, A.; Sutskever, I.; Hinton, G.E. ImageNet classification with deep convolutional neural networks. In Proceedings of the International Conference on Neural Information Processing Systems; Curran Associates Inc.:: Red Hook, NY, USA, 2012. [Google Scholar]
- Türkoğlu, M.; Hanbay, D. Combination of Deep Features and KNN Algorithm for Classification of Leaf-Based Plant Species. In Proceedings of the 2019 International Artificial Intelligence and Data Processing Symposium (IDAP), Malatya, Turkey, 21–22 September 2019; pp. 1–5. [Google Scholar] [CrossRef]
- Krizhevsky, A. Learning Multiple Layers of Features from Tiny Images. Master’s Thesis, Department of Computer Science, University of Toronto, Toronto, ON, Canada, 2009. [Google Scholar]
- Ioffe, S.; Szegedy, C. Batch Normalization: Accelerating Deep Network Training by Reducing Internal Covariate Shift. In Proceedings of the International Conference on Machine Learning, Lille, France, 6–11 July 2015. [Google Scholar]
- Zeiler, M.D.; Krishnan, D.; Taylor, G.W.; Fergus, R. Deconvolutional networks. In Proceedings of the 2010 IEEE Computer Society Conference on Computer Vision and Pattern Recognition, San Francisco, CA, USA, 13–18 June 2010. [Google Scholar]
- Vdumoulin.Conv_Arithmetic. Available online: https://github.com/vdumoulin/conv_arithmetic (accessed on 15 December 2020).
- Long, J.; Shelhamer, E.; Darrell, T. Fully Convolutional Networks for Semantic Segmentation. arXiv 2015, arXiv:1411.4038. [Google Scholar]
- Zeiler, M.D.; Taylor, G.W.; Fergus, R. Adaptive deconvolutional networks for mid and high level featurelearning. In Proceedings of the 2011 International Conference on Computer Vision, Barcelona, Spain, 6–13 November 2011. [Google Scholar]
- Radford, A.; Metz, L.; Chintala, S. Unsupervised representation learning with deep convolutional generative adversarial networks. In Proceedings of the 4th International Conference on Learning Representations, ICLR 2016—Conference Track Proceedings, San Juan, PR, USA, 2–4 May 2016. [Google Scholar]
- Bai, X.; Liu, W.; Tu, Z. Integrating Contour and Skeleton for Shape Classification. In Proceedings of the 2009 IEEE 12th International Conference on Computer Vision Workshops, Kyoto, Japan, 27 September–4 October 2009. [Google Scholar]
- Latecki, L.J.; Lakamper, R. Shape similarity measure based on correspondence of visual parts. IEEE Trans. Pattern Anal. Mach. Intell. 2000, 22, 1185–1190. [Google Scholar] [CrossRef]
- Söderkvist, O. Computer Vision Classification of Leaves from Swedish Trees. Tek. Och Teknol. 2010, 197–204. Available online: https://www.semanticscholar.org/paper/Computer-Vision-Classification-of-Leaves-from-Trees-S%C3%B6derkvist/f8501b9746b678c5a46c87b9d5d823a7df5a33f7 (accessed on 18 March 2021).
- Zheng, Y.; Guo, B.; Li, C.; Yan, Y. A Weighted Fourier and Wavelet-Like Shape Descriptor Based on IDSC for Object Recognition. Symmetry 2019, 11, 693. [Google Scholar] [CrossRef]
- El-ghazal, A.; Basir, O.; Belkasim, S. Farthest point distance: A new shape signature for Fourier descriptors. Signal Process. Image Commun. 2009, 24, 572–586. [Google Scholar] [CrossRef]
- Fotopoulou, F.; Economou, G. Multivariate angle scale descriptor of shape retrieval. In Proceedings of the SPAMEC, Cluj-Napoca, Romania, 26–28 August 2011; pp. 105–108. [Google Scholar]
- Wang, B.; Gao, Y. Hierarchical string cuts: A translation, rotation, scale, and mirror invariant descriptor for fast shape retrieval. IEEE Trans. Image Process. 2014, 23, 4101–4111. [Google Scholar] [CrossRef]
- Naresh, Y.G.; Nagendraswamy, H.S. Classification of medicinal plants: An approach using modified LBP with symbolic representation. Neurocomputing 2016, 173, 1789–1797. [Google Scholar] [CrossRef]
- Colace, F.; De Santo, M.; Lemma, S.; Lombardi, M.; Rossi, A.; Santoriello, A.; Terribile, A.; Vigorito, M. How to Describe Cultural Heritage Resources in the Web 2.0 Era? In Proceedings of the 11th International Conference on Signal Image Technology & Internet Based Systems (SITIS), Bangkok, Thailand, 23–27 November 2015; pp. 809–815. [Google Scholar] [CrossRef]
- Lombardi, M.; Pascale, F.; Santaniello, D. A Double-layer Approach for Historical Documents Archiving. In Proceedings of the 4th International Conference on Metrology for Archaeology and Cultural Heritage (MetroArchaeo), Cassino, Italy, 22–24 October 2018; pp. 137–140. [Google Scholar] [CrossRef]


















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Method | Classification Accuracy |
|---|---|
| FMSCCD [19] | 37.33% |
| IDSC-WFW (a weighted Fourier and wavelet-like descriptor based on inner distance shape context) [34] | 49.36% |
| DIR [17] | 46.45% |
| AP & BAP [18] | 52.79% |
| MDM [16] | 35.81% |
| FPD (farthest point distance) [35] | 26.63% |
| FD [15] | 27.97% |
| FASD & FMSCCD (fast angle scale descriptor and FMSCCD) [19] | 37.85% |
| FD-ASD (Fourier descriptor-angle scale descriptor) [36] | 27.44% |
| ASD & CCD (angle scale descriptor and centroid contour distance) [36] | 39.30% |
| SC + DP [14] | 67.27% |
| IDSC + DP [13] | 70.99% |
| HSC (Hierarchical string cuts) [37] | 56.80% |
| SCN (ours) | 75.39% |
| Method | Classification Accuracy |
|---|---|
| FMSCCD [19] | 87.98% |
| IDSC-WFW [34] | 93.66% |
| DIR [17] | 88.20% |
| MDM [16] | 87.32% |
| FPD [35] | 77.16% |
| FD [15] | 82.40% |
| FASD & FMSCCD [19] | 91.04% |
| FDASD [36] | 87.32% |
| ASD & CCD [36] | 85.14% |
| MLBP (modified LBP) [38] | 96.83% |
| SCN (ours) | 94.46% |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Zhang, C.; Zheng, Y.; Guo, B.; Li, C.; Liao, N. SCN: A Novel Shape Classification Algorithm Based on Convolutional Neural Network. Symmetry 2021, 13, 499. https://doi.org/10.3390/sym13030499
Zhang C, Zheng Y, Guo B, Li C, Liao N. SCN: A Novel Shape Classification Algorithm Based on Convolutional Neural Network. Symmetry. 2021; 13(3):499. https://doi.org/10.3390/sym13030499
Chicago/Turabian StyleZhang, Chaoyan, Yan Zheng, Baolong Guo, Cheng Li, and Nannan Liao. 2021. "SCN: A Novel Shape Classification Algorithm Based on Convolutional Neural Network" Symmetry 13, no. 3: 499. https://doi.org/10.3390/sym13030499
APA StyleZhang, C., Zheng, Y., Guo, B., Li, C., & Liao, N. (2021). SCN: A Novel Shape Classification Algorithm Based on Convolutional Neural Network. Symmetry, 13(3), 499. https://doi.org/10.3390/sym13030499