1. Introduction
Recently, visualization and pattern recognition based on computer science has received extensive attention. Particularly, deep neural networks [
1] demonstrated good performance for voice recognition, image classification, medical diagnosis [
2,
3], and pattern analysis. However, these networks suffer from some security vulnerabilities. According to Barreno, Marco et al. [
4], such security issues can be classified into two main groups: the causative attack and the exploratory attack. A causative attack degrades the performance of the deep neural network by intentionally adding malicious samples to the training data during the network learning phase. The poisoning [
5] and backdoor attacks [
6,
7] are representative examples of a causative attack. However, the exploratory attack is a method of the evasive attack by manipulating test data on a model that has already been trained; it is a realistic attack because there exists no assumption that the learning data can be accessed, as that in a causative attack. An adversarial attack [
5,
8] is a representative example of an exploratory attack. This study focused on proposing a defense method against adversarial example attacks. An adversarial example [
9] that adds some specific noise to the original data can be correctly recognized by humans, while incorrectly classified by deep neural networks. Such examples could deceive some deep neural networks, such as those used in autonomous vehicles or medical businesses, and may lead to unexpected outcomes.
There exist various defensive approaches against adversarial attacks. These methods can be divided into two major categories: those of manipulating data and of making deep neural networks become more robust. The data manipulation method [
10,
11,
12,
13,
14,
15] reduces the attack effect of the noise of the adversarial example by filtering out the noise or by resizing the input data. In contrast, approaches of making deep neural networks to be more robust include methods of distillation [
16] and adversarial training [
9,
17]. The distillation method uses two neural networks to prevent the generation of adversarial example. However, the adversarial training method becomes robust to adversarial attacks by additionally training the target model on adversarial data that are generated from a local neural network.
Among them, the adversarial training method is simple and effective. According to previous studies [
18,
19], the adversarial training is evaluated to be more efficient than other methods in terms of practical defense performance. However, the existing adversarial training trains the target model with adversarial examples generated by one single attack approach. However, if the target model can be trained with adversarial examples that are generated from multiple attack methods rather than a single one, it would become more robust against unknown adversarial attacks.
In this paper, we demonstrate a diversity adversarial training method, in which the target model is trained with additional adversarial examples that are generated by various attack approaches, such as the fast gradient descent method (FGSM) [
20], iterative-FGMS (I-FGSM) [
21], DeepFool [
22], and Carlini and Wagner (CW) [
23]. Our contributions can be summarized as follows: First, we demonstrate a diversity adversarial training approach that trains the target model with adversarial examples generated by various methods. In addition, detailed explanations regarding the construction principle and structure of the method were presented. Moreover, we analyzed images of the adversarial examples generated by different methods, corresponding attack success rate, and accuracy of the diversity training method. In addition, we verified the performance of our method using the MNIST [
24] and Fashion-MNIST [
25] datasets.
The remainder of this paper is organized as follows:
Section 2 describes related research on adversarial examples.
Section 3 explains the diversity training method. Experiments and analysis are presented in
Section 4, while the diversity training scheme is discussed in
Section 6. Finally,
Section 7 concludes the paper.
3. Methodology
The diversity training method consists of two stages: generation of various adversarial examples and a process in which the model learns these samples. That is, it first generates various adversarial examples, and provides them as additional training data to the model so as to increase its robustness against unknown adversarial attacks. First, the diversity training method creates various adversarial examples using FGSM, I-FGSM, DeepFool, and CW methods using the local model known to the attacker. Subsequently, the target model is additionally trained with these samples. Through this process, the robustness of the target model against adversarial attacks can be increased, as shown in
Figure 1.
The diversity training method can be mathematically expressed as follows. The operation function of the local model
is denoted as
. The local model
is trained with the original training dataset. Given the pretrained local model
, the original training data
, their corresponding class labels
, and target class labels
, we solve the optimization problem of creating a targeted adversarial example
:
where
is a distance matrix between the normal sample
x and transformed example
.
indicates that
becomes minimal regarding the value of
x.
is a local model function that classifies the input value.
To generate these , each adversarial example is obtained by the FGSM, I-FGSM, DeepFool, and CW methods.
FGSM: The FGSM method can create
using
:
where
t and
F indicate the target class and model operation function, respectively. Here, the gradient descent is updated with the normal sample
x, based on the
value, while
is created through optimization. This method is simple yet exhibits good performance.
I-FGSM: I-FGSM is an extension of the FGSM. In this method, instead of changing the amount of
at each step, a smaller amount,
, is changed and eventually clipped by
:
I-FGSM obtains an adversarial example during a given iteration on a target model. Compared to FGSM, it demonstrates a higher attack prevention rate in terms of white box attacks.
DeepFool: The DeepFool approach creates an adversarial example with less distortion from the original sample; it generates through the linearization approximation. However, because the neural network is nonlinear, this method is more complicated than FGSM.
CW: The fourth method is the Carlini attack that can generate an adversarial example with 100% attack success rate, which uses a different objective function:
This method estimates an appropriate binary c value to obtain a high success rate of attack. In addition, it can control the attack success rate even at the cost of some increase in distortion by adjusting the confidence value as follows:
where
y is an original class, while
Z(·) [
28] represents the pre-softmax classification result vector.
The adversarial examples generated by each method are added to the training set that is used to train the target model . This process can be described mathematically as follows.
The operation function of the target model
is denoted as
. The target model
is first trained with the original training dataset. Given the adversarial example
, original class
, and target classes
, the pre-trained target model
is trained with
with its corresponding label as the original class
y, as follows:
In this manner, the target model is trained with various adversarial examples, and thus, its robustness against unknown adversarial examples is increased. The details of the diversity training scheme are illustrated in Algorithm 1.
| Algorithm 1 Diversity adversarial training |
| Input: |
| | ▹ Original training dataset |
| | ▹ original class |
| t | ▹ validation data |
| | ▹ local model |
| | ▹ Original training dataset |
| | ▹ original class |
| t | ▹ validation data |
| | ▹ local model |
| fgs, ifgs, dp, cw | ▹ FGSM, I-FGSM, DeepFool, CW methods |
| Diversity adversarial training: (, x, fgs, ifgs, dp, cw)
|
| ← Generation of adversarial example (, x, fgs)
|
| ← Generation of adversarial example (, x, ifgs)
|
| ← Generation of adversarial example (, x, dp)
|
| ← Generation of adversarial example (, x, cw)
|
| Train the target model ← (X, Y) + (, Y)
|
| Record accuracy of the target model |
| return |
5. Experimental Results
The attack success rate [
35,
36] refers to the rate at which the target model misclassifies the adversarial examples as target class chosen by the attacker. For example, if 97 out of 100 samples are misidentified by the target model as belonging to the class that the attacker wants them to be classified into, the attack success rate is 97%. The opposite of the attack success rate is the failure rate. Accuracy refers to the match rate of the target model between the input data and their true class labels.
Examples of adversarial images generated by various methods for the local model based on the MNIST dataset is illustrated in
Figure 2. In the figure, each adversarial example has a different amount of noise added to the original sample. Specifically, FGSM and I-FGSM added more, while CW and DeepFool introduced relatively less noise to the original sample. As a result that CW and DeepFool generate noise optimized for the local model, they can generate adversarial examples with a smaller amount of noise than the original sample.
Examples of adversarial images generated by various adversarial example generation methods for the local model based on the Fashion-MNIST are presented in
Figure 3. Similar to
Figure 2, it can be observed from
Figure 3 that some noise has been added to the original fashion images. Likewise, in this figure, CW and DeepFool generated adversarial examples with less noise added to the original sample than FGSM and I-FGSM.
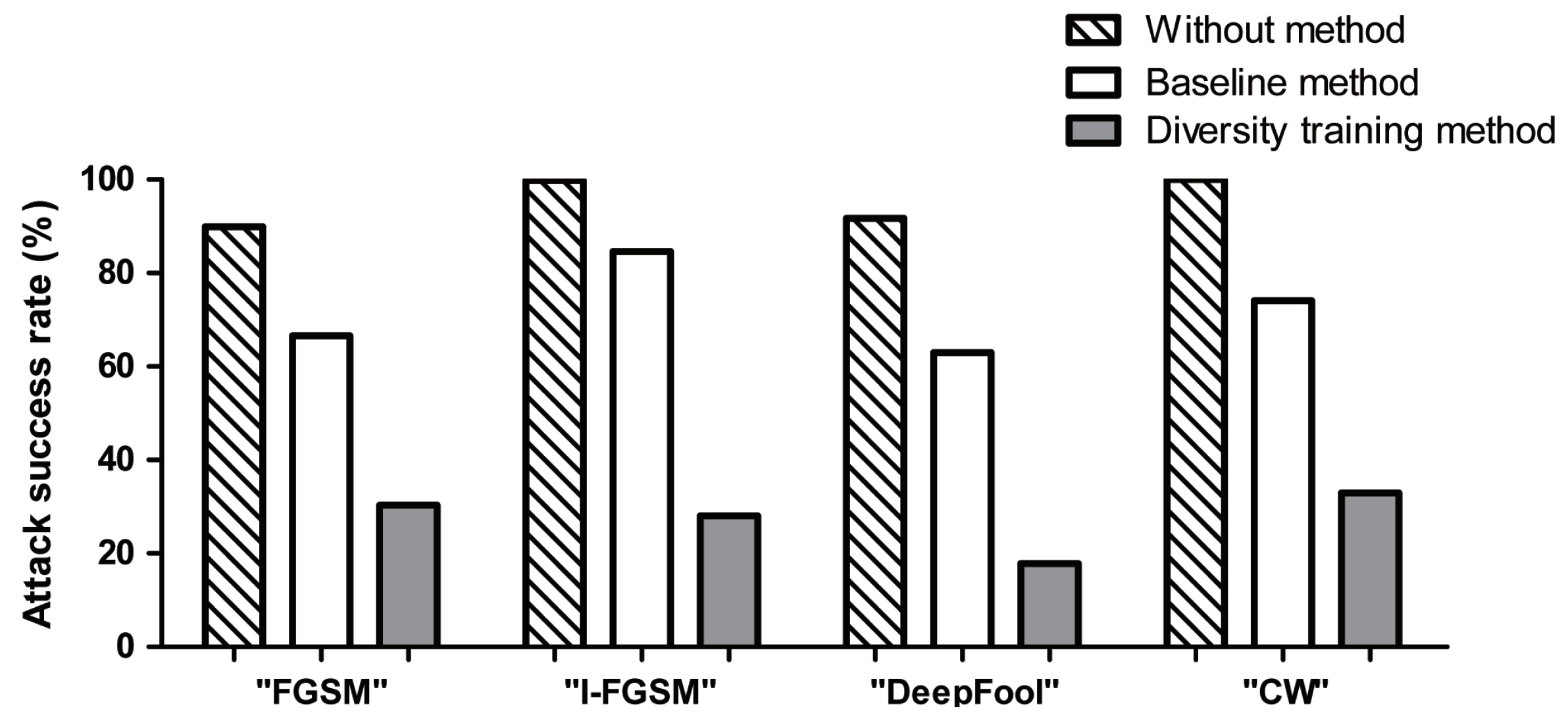
The attack success rates for adversarial examples generated with the holdout model using the without, baseline, and diversity training methods based on MNIST dataset are shown in
Figure 4. Here, the without method indicates a target model that does not use any adversarial training defense approach. The baseline method [
24] refers to a method of training a target model by applying one adversarial training approach, such as FGSM. The diversity training method refers to a method of training the target model with adversarial examples generated by the FGSM, I-FGSM, DeepFool, and CW methods. Inspection of attack success rate in the figure reveals that the without model misrecognizes more than 89.9% of the adversarial examples. However, the diversity training method has reduced the attack success rate to less than 32.9%, and that the average performance is observed to be improved by more than 44.8% compared to the baseline method. In addition, the analysis of the failure rate is shown in
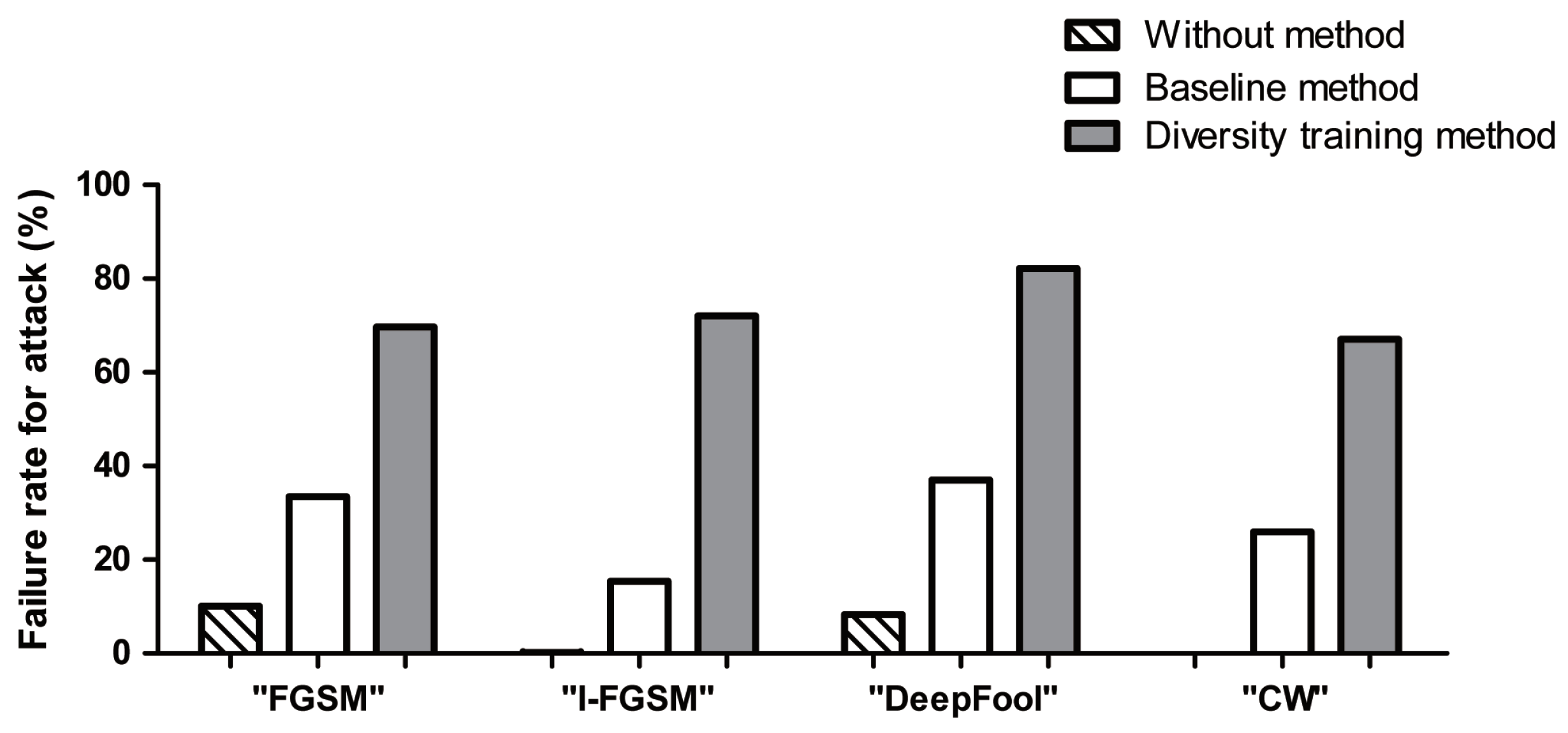
Figure A1 of the
Appendix A. Therefore, the diversity training method is more robust against adversarial attacks.
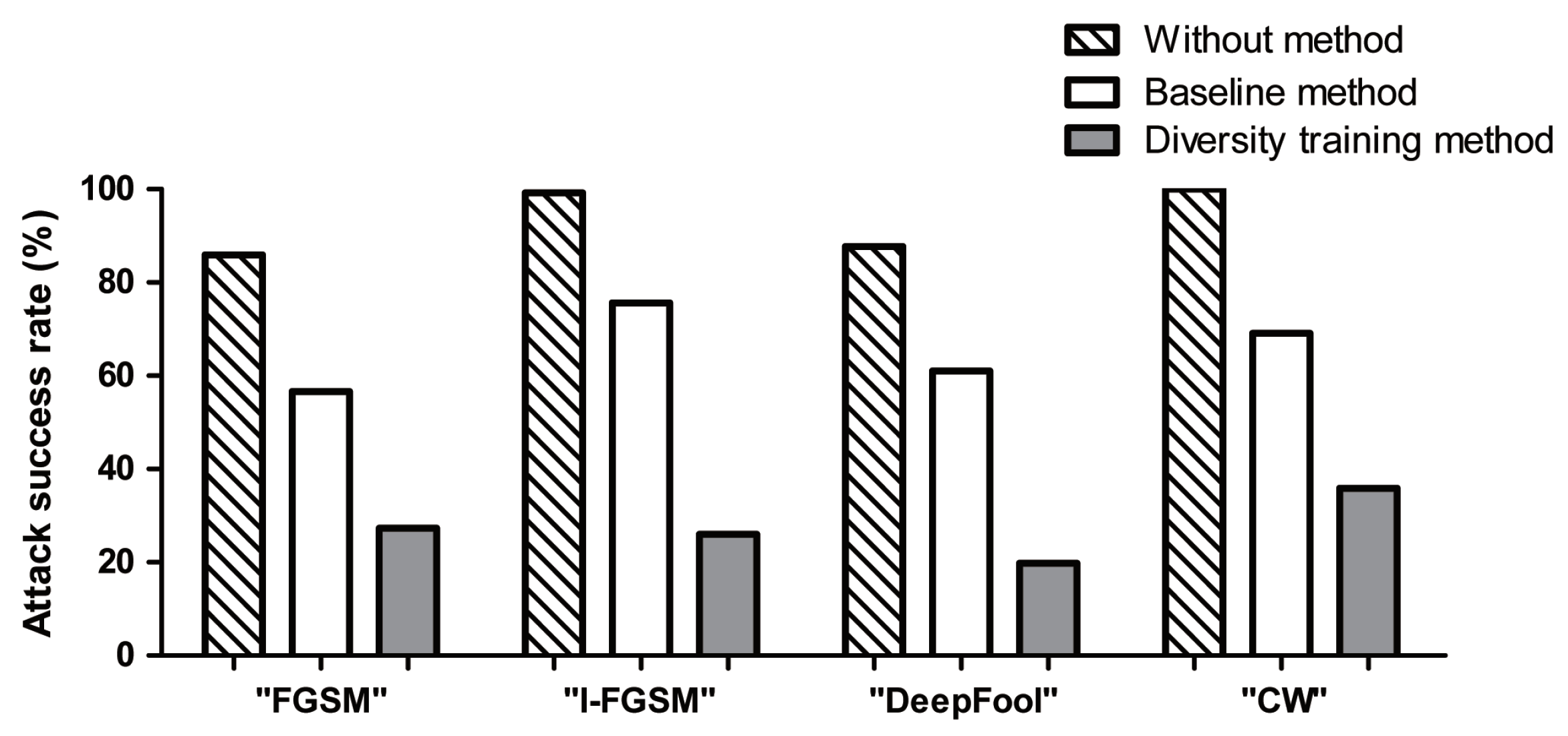
The attack success rates for adversarial examples generated with the holdout model using the without, baseline, and diversity training methods based on the Fashion-MNIST are demonstrated in
Figure 5. Here, the without method means a target model that does not use any adversarial training defense approach. The baseline method [
24] refers to a method of training a target model by applying one adversarial training approach, such as FGSM. The diversity training method refers to a method of training the target model with adversarial examples generated by the FGSM, I-FGSM, DeepFool, and CW methods. As shown in
Figure 4, it can be seen that the without model misrecognizes more than 85.9% of the adversarial examples. However, the diversity training method is observed to reduce the attack success rate of adversarial examples to below 35.2%, and that the average performance is improved by more than 40.1% compared to the baseline method. In addition, the analysis of the failure rate is shown in
Figure A2 of the
Appendix A. Therefore, the diversity training method is more robust against adversarial attacks.
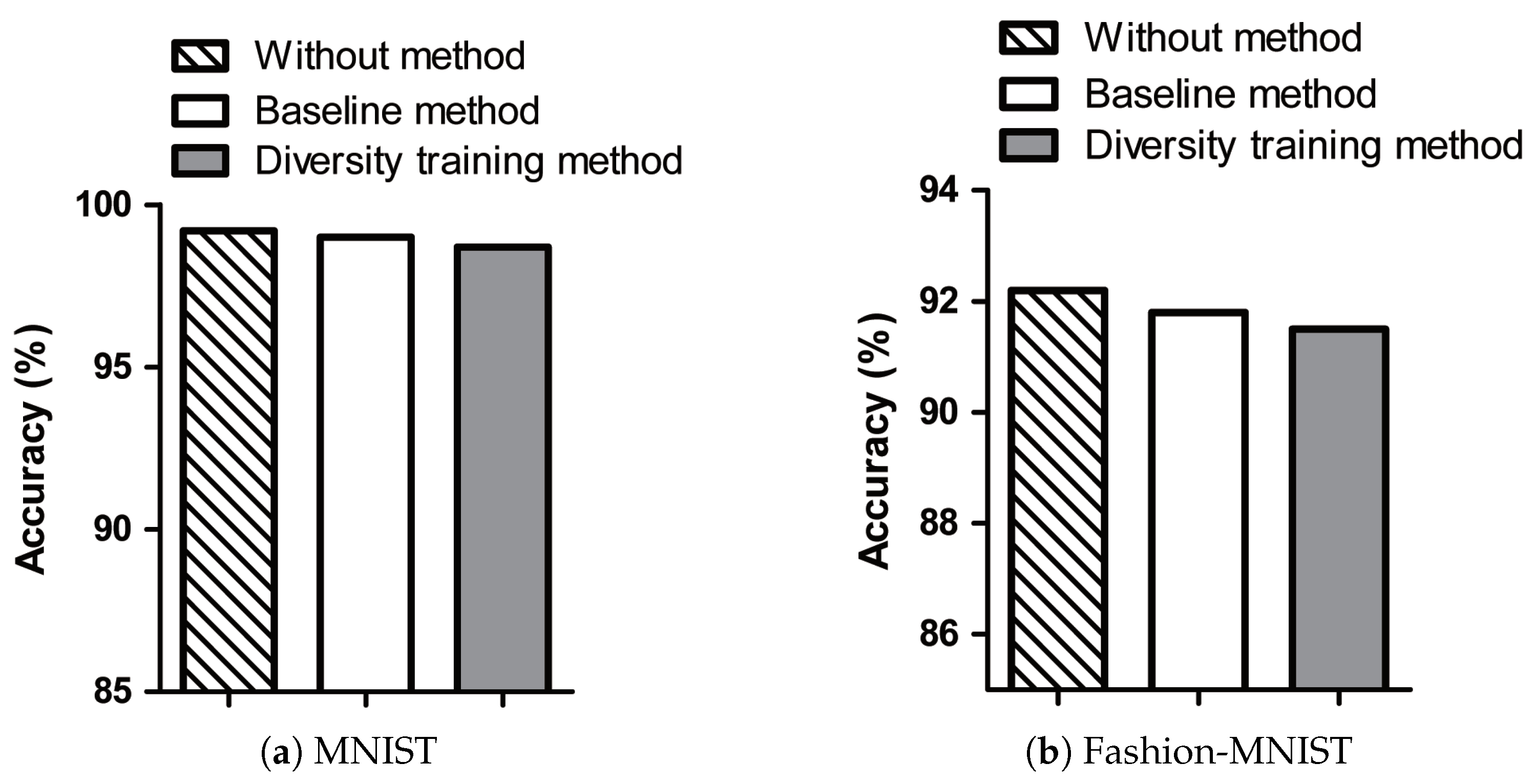
The accuracies of the without method, baseline method, and diversity training method on the test images of MNIST and Fashion-MNIST datasets are presented in
Figure 6. Although trained with additional adversarial samples, the target model still maintains the accuracy obtained by the original data. In the figure, the diversity training method has almost the same accuracy as the without method and baseline method on the test data. Comparison between the accuracies of MNIST and Fashion-MNIST reveals that the accuracy obtained with Fashion-MNIST is lower due to the data characteristics.
In the experimental section, examples of adversarial samples generated by various methods were shown to demonstrate the performance of the diversity training method. In addition, an experimental analysis was carried out regarding the attack success rate and accuracy to determine the robustness against unknown adversarial example attacks when trained with various adversarial examples. Our demonstrated approach is an improved adversarial training method, whose performance was analyzed against the baseline method. The experimental result confirmed that the diversity training approach is more robust against unknown adversarial attacks than the existing adversarial training method. We believe our method can be adopted to deep neural network-based image recognition. However, the experimental analysis of our demonstrated method was limited only to MNIST and Fashion-MNIST datasets, and thus, evaluation with other datasets can serve as our future research topic.
6. Discussion
Assumption: The assumption of the diversity training method is that the attack is a black box, that is, the attacker does not have any information about the target model. In this study, the attacker generates various adversarial examples using the holdout model, which is known to the attacker, then transfers the black-box attack to the target model.
Generation of diverse adversarial examples: Unlike the conventional adversarial training method, the diversity training approach demonstrates a method of training the target model with various adversarial examples. It generates various adversarial samples targeting the local model known to the defender. Different adversarial examples are generated using the FGSM, I-FGSM, DeepFool, and CW methods, each of which has different degrees of distortion. Detailed comparison of FGSM, I-FGSM, DeepFool, and CW methods revealed that the CW method generates adversarial examples with the smallest distortion. The adversarial samples generated from these FGSM, I-FGSM, DeepFool, and CW methods are used to additionally train the target model. Through this process, a more robust model is obtained against an unknown adversarial attack.
Model configuration: In this paper, there exist three different types of models: target model, local model, and holdout model. These models are constructed with different architectures, as shown in
Table 1,
Table 2 and
Table 3, respectively. In the local model, various adversarial examples are generated based on FGSM, I-FGSM, DeepFool, and CW methods from the local model known to the defender. The target model is the final inference model, which becomes a black-box model for the attacker. The target model is trained with various adversarial examples to become robust against unknown adversarial attacks. However, the attacker uses an adversarial example generated from the holdout model to make the target model misclassify, which is known as a transfer attack.
In terms of the optimizer, we used the Adam optimizer. After obtaining various adversarial examples, the Adam optimizer is used by the target model to learn these samples. The cross-entropy loss is used as our objective function. During loss minimization, the target model has a training process to try to classify various adversarial samples into correct classes. Instead of the Adam optimizer, the stochastic gradient descent (SGD) [
37] or other optimization algorithms [
38] can also be employed.
Dataset: Our experiments were conducted using the MNIST and Fashion-MNIST datasets, both of which contain grayscale images of size 28 × 28. However, there was a performance difference between MNIST and Fashion-MNIST. As a result of the characteristics of the Fashion-MNIST, the similarity between T-shirt and shirt images is higher than that of the numeric images, and thus, the test images of Fashion-MNIST tend to demonstrate lower accuracy than those of the MNIST. However, for both datasets, even after being trained with various adversarial samples, the diversity training method maintained almost the same accuracy as the model trained with the original training data.
Defense considerations: While a separate module for the target model is not required, the adversarial training approach is a simple and effective method to defend against adversarial attacks. Unlike existing adversarial training methods, the diversity training method is robust against unknown adversarial attacks by generating various adversarial samples and including them into the training data of the model. Regarding local models, our approach does not require a large number of such models because it generates several adversarial examples by using one local model in the same way as those existing adversarial learning methods. Regarding the generated adversarial examples, the attacker can produce various adversarial samples, and even under such conditions, the presented approach is observed to be robust on various adversarial attacks. In terms of accuracy obtained by training with the original data, the diversity training method maintains an accuracy similar to that of the existing adversarial training method.
Applications: One potential application field of the diversity training method is in autonomous vehicles. For an autonomous vehicle, the attacker intentionally deceives its classification mechanism to misclassify the road sign, which could be a modified adversarial example. To defend against such an adversarial attack, our demonstrated method can be used as a defense method to correctly identify the modified road sign. In addition, in the case of a medical business, there exists a risk of treatment misjudgment for a patient due to revised adversarial examples. Therefore, the diversity training method can be used in such systems to increase the correct classification rate of the medical treatment.
Limitation and future work In the diversity training method, the generation approaches used for adversarial samples include FGSM, I-FGSM, DeepFool, and CW methods. However, there exist some other methods to generate such samples. In addition, the diversity training method uses one local model similar to the basic adversarial example method. However, if the number of local models increases, research on various ensemble adversarial training by constructing several local models instead of a single one will be an interesting topic. In terms of the evaluation, the method of analyzing the distribution of the recognized adversarial training for the original sample and unknown adversarial example as a decision boundary will be an interesting topic.





{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}







