
Sensitivity Analysis of the Optimal Inventory-Pooling Strategies According to Multivariate Demand Dependence




Abstract
1. Introduction
2. Costs and Inventory Pooling Stetting
2.1. Total Cost in Consolidation Setting
2.1.1. The Cycle Stock Cost
- Di: is the mean demand during one time period at decentralized location i,
- Pf: is the fixed order processing cost at centralized location f ($ per order),
- hf: is the unitary inventory holding cost per time period at centralized location f ($ per day), and
- Wi,f: is the proportion of mean demand during one time period transferred from decentralized location i to centralized location f (where for all i and f, and for all i).
2.1.2. The Safety Stock Cost
- LTf: is the mean lead time at centralized location f;SLT, f: is the standard deviation of lead time at centralized location f;
- k: is the safety stock factor;
- ρij: is the correlation of demand between decentralized locations i and j;
- SD, i: is the standard deviation of demand during one period at decentralized location i;
- σf: is the standard deviation of demand at centralized location f during the lead time period;
- E(): random variable expectation; and
- V(): random variable variance.
2.1.3. The Distribution Cost
2.2. Demand Allocation Rules and Inventory Pooling Models
- -
- Either all centralized locations offer the same proportion of demand at each decentralized location [3];
- -
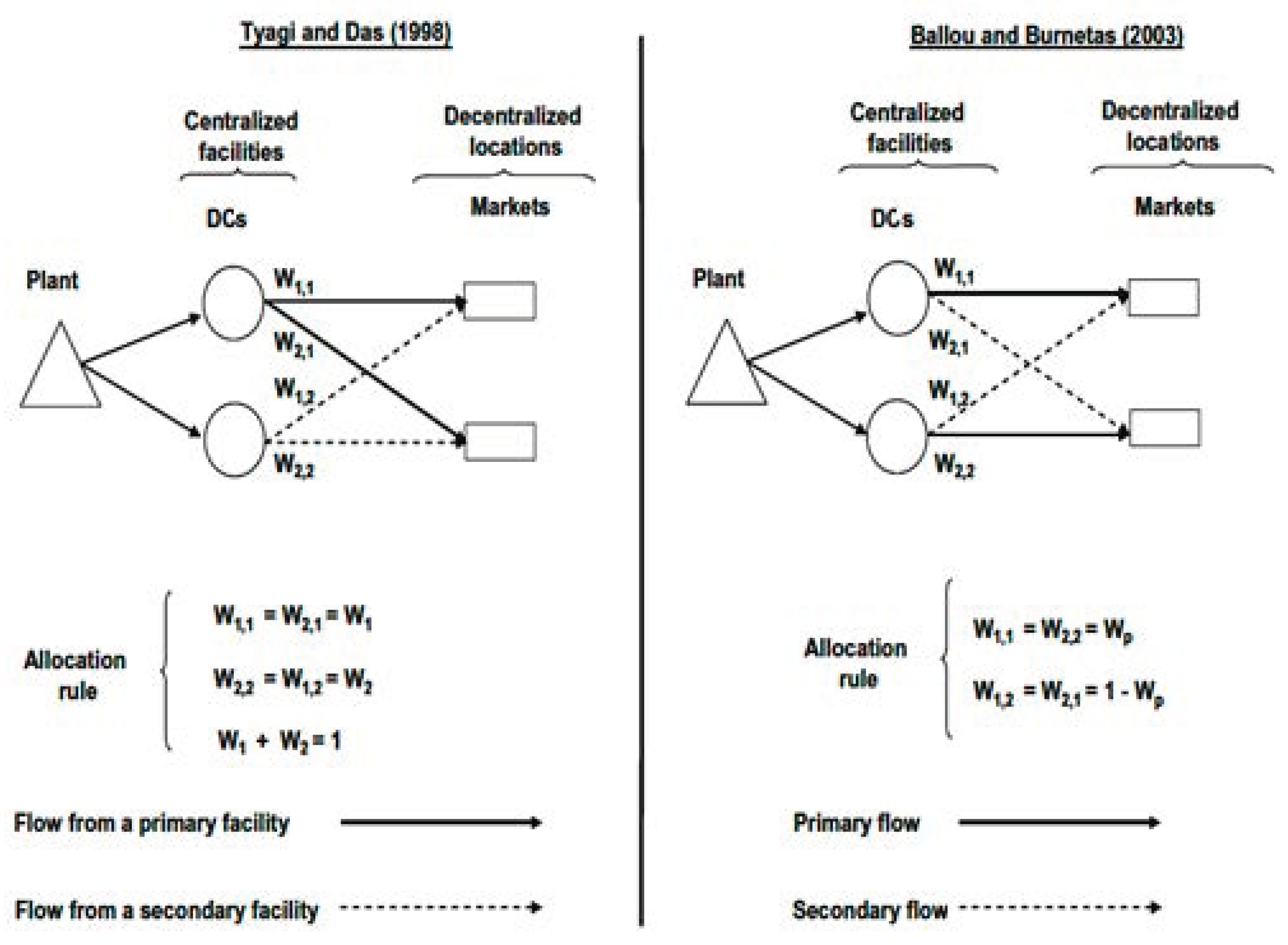
2.2.1. Tyagi and Das’ Allocation Rule (Inventory Centralization)
2.2.2. Ballou and Burnetas’ Allocation Rule (Regular Transshipments or Independent Systems)
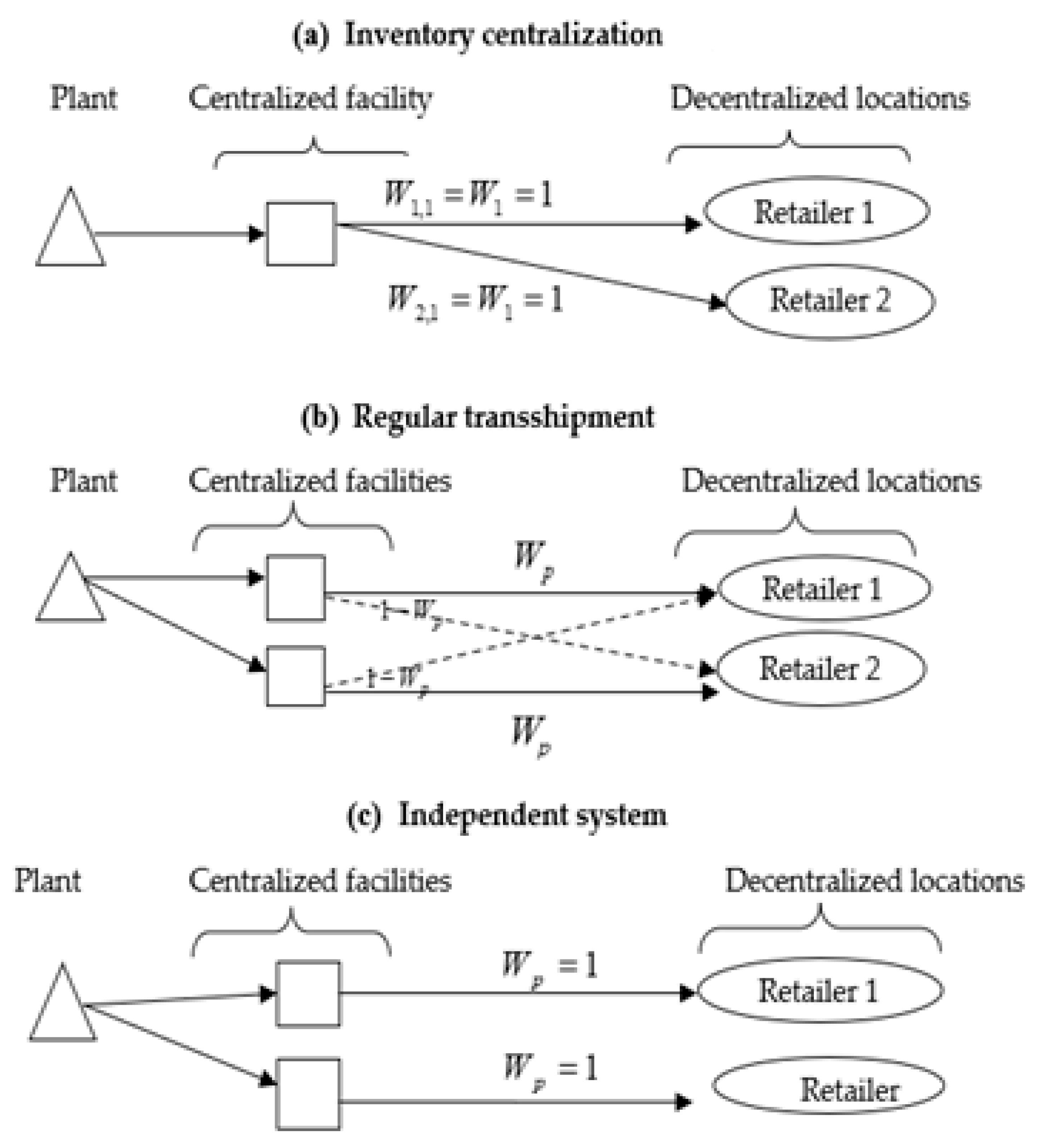
2.2.3. Linking Allocation Rules to Inventory Pooling Models
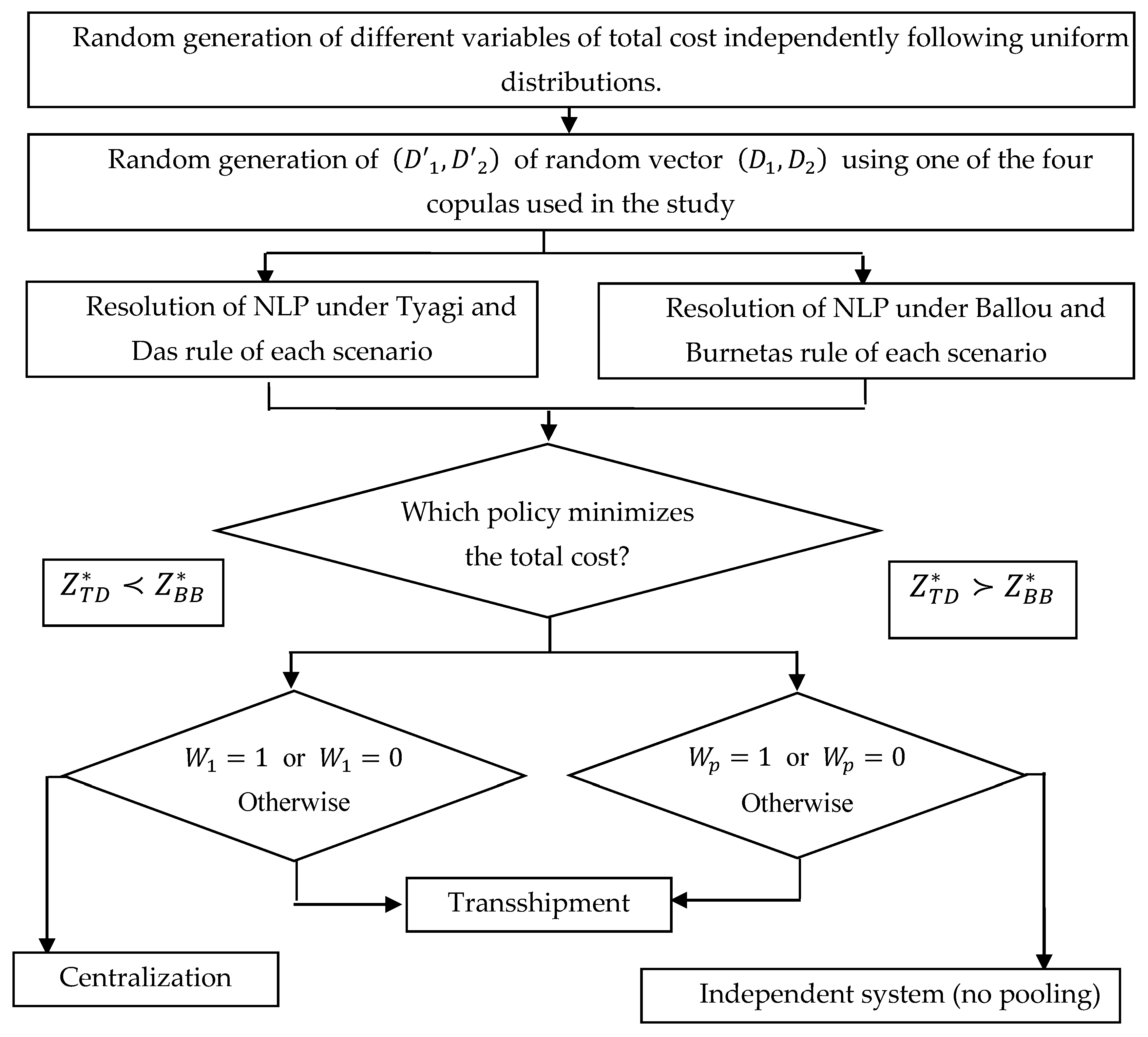
3. The Proposed Approach
3.1. Optimal Decision Search
3.2. Operational Aspects of Dependence Structure and Distributions
3.2.1. Copulas and Dependence
3.2.2. Distributions Used to Construct Bivariate Data
- -
- If α = β, this distribution is symmetric (null skewness);
- -
- if α < β, this distribution is asymmetric shifted left (with negative skewness); and
- -
- if α > β, this distribution is asymmetric shifted right (with positive skewness).
3.3. Influence Degree of the Variables on the Decision
3.4. Comparison between Decisions and Detection of Convergence and Divergence Cases
4. Results
4.1. Input Data and Hypthesis
4.2. Effect of Marginal Demand Distribution When the Demands Follow to a Symmetric Distribution
4.2.1. Case of the Marginals Each Following a Truncated Normal Distribution
4.2.2. Case of Marginals Following (Truncated Normal Distribution (100, 30)/Beta (5, 5))
4.3. Effect of Marginal Demand Distribution When the Demands Follow to a Asymmetric Distribution
4.3.1. Case of a Symmetrical Demand (beta (5, 5) and the Other Is Asymmetrical (beta (2, 8))
4.3.2. Case of Two Asymmetrical Demands one Tailed to the Right and the Other Tailed to the Left
5. Discussion
- The majority of variables that enter into the total cost calculation are factors that influence the decision. The most influential factor is the dependence between demands. Generally, a rather high positive correlation is in favor of setting up an independent system while a weak correlation makes it possible to opt a transshipment policy. Other factors such as the standard deviation of demand and the average lead time can influence the decision.
- Results indicate, for all assumptions on marginals distribution, that the optimal pooling policy to face medium correlation demands of low holding cost products is to keep inventory decentralized and inventory centralized, as if they were independent and centralization systems. On the other hand, if the demands correlation is low and the holding cost is medium, then the transshipment system is preferable.
- For all assumptions on marginals distribution and for all considered copulas, the centralization policy, for convergence cases, is preferred followed by the independence system and then the transshipment policy.
- The degree of divergence in which each copula does not lead to the same conclusion (same optimal policy) at the optimum is in about 9% of cases. This percentage varies slightly according to the assumptions used on the marginal distributions of demands.
- The assumption of a normal demand when in reality the demand is distributed according to another symmetric distribution other than normal increases the risk of error in the decision to 2.2% assuming an adequate copula choice. The assumption of the normality of demands when in reality the demands are distributed according to another asymmetric distribution increases the risk of error in the decision to 4.3%. Further, the percentage of divergence between two symmetrical demands (identical or different) on the one hand and, a symmetrical demand (no normal) and an asymmetrical demand on the other hand is of the order of 4.5%. This shows that the assumption of a symmetrical demand whereas in reality the demand is asymmetric increases the risk of error in the decision from 2% to 4.5%.
6. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
Notations
| CSc | The cycle stock cost |
| DC | The distribution cost |
| Di | The mean demand during one time period at decentralized location i |
| df,i | The unitary transportation cost to move a single item from a centralized location f to a decentralized location i |
| EOQf | The economic order quantity at a centralized location f |
| hf | The unitary inventory holding cost per time period at centralized location f ($ per day) |
| iid | Independent and identically distributed |
| k | The safety stock factor |
| LTf | The mean of the lead time at centralized location f |
| m | Number of decentralized locations (Markets) |
| n | Number of the centralized facilities (or stocking points that serve demand) |
| SD,i | The standard deviation of demand during one period at decentralized location i |
| SLT, f | The standard deviation of lead time at centralized location f |
| SSc | The safety stock cost |
| TC | The total cost |
| Pf | The fixed order processing cost at centralized location f ($ per order) |
| Wi,f | The proportion of mean demand during one time period transferred from decentralized location i to centralized location f |
| σf | The standard deviation of demand at centralized location f during the lead time period |
| ρij | The correlation of demand between decentralized locations i and j |
References
- Perez, H.D.; Hubbs, C.D.; Li, C.; Grossmann, I.E. Algorithmic Approaches to Inventory Management Optimization. Processes 2021, 9, 102. [Google Scholar] [CrossRef]
- Cho, H.C.; Hsieh, Y.J.; Huang, L.Y. Capturing the Risk-Pooling Effect through Inventory Planning and Demand Switching. Sustainability 2018, 10, 4104. [Google Scholar] [CrossRef]
- Tyagi, R.; Das, C. Effects of correlated demands on safety stock centralization: Patterns of correlation versus degree of cen-tralization. J. Bus. Logist. 1998, 20, 205–213. [Google Scholar]
- Ballou, R.H.; Burnetas, A. planning multiple location inventories. J. Bus. Logist. 2003, 24, 65–89. [Google Scholar] [CrossRef]
- Schmitt, A.J. Strategies for customer service level protection under multi-echelon supply chain disruption risk. Transp. Res. Part B Methodol. 2011, 45, 1266–1283. [Google Scholar] [CrossRef]
- Schmitt, A.J.; Sun, S.A.; Snyder, L.V.; Shen, Z.J.M. Centralization versus Decentralization: Risk Pooling, Risk Diversi-fication, and Supply Chain Disruptions. Omega 2015, 52, 201–212. [Google Scholar] [CrossRef]
- Thomas, D.J.; Tyworth, J.E. Pooling lead-time risk by order splitting: A critical review. Transp. Res. Part E Logist. Transp. Rev. 2006, 42, 245–257. [Google Scholar] [CrossRef]
- Eppen, G.D. Note—Effects of Centralization on Expected Costs in a Multi-Location Newsboy Problem. Manag. Sci. 1979, 25, 498–501. [Google Scholar] [CrossRef]
- Alfaro, J.A.; Corbett, C.J. The Value of Sku Rationalization in Practice (The Pooling Effect under Suboptimal Inventory Policies and Nonnormal Demand). Prod. Oper. Manag. 2009, 12, 12–29. [Google Scholar] [CrossRef]
- Bimpikis, K.; Markakis, M.G. Inventory Pooling Under Heavy-Tailed Demand. Manag. Sci. 2016, 62, 1800–1813. [Google Scholar] [CrossRef]
- Evers, P.T.; Beier, F.J. The portfolio effect and multiple consolidation points: A critical assessment of the square root law. J. Bus. Logist. 1993, 14, 109–125. [Google Scholar]
- Evers, P.T. Expanding the square root law: An analysis of both safety and cycle stocks. Logist. Transp. Rev. 1995, 31, 1–20. [Google Scholar]
- Axsäter, S. Modelling Emergency Lateral Transshipments in Inventory Systems. Manag. Sci. 1990, 36, 1329–1338. [Google Scholar] [CrossRef]
- Lee, H.L. A Multi-Echelon Inventory Model for Repairable Items with Emergency Lateral Transshipments. Manag. Sci. 1987, 33, 1302–1316. [Google Scholar] [CrossRef]
- Rojas, F.; Leiva, V.; Wanke, P.; Marchant, C. Optimization of contribution margins in food services by modelling inde-pendent component demand. Rev. Colomb. Estadística 2015, 38, 1–30. [Google Scholar] [CrossRef]
- Aydın, B.; Güler, K.; Kayış, E. A Copula Approach to Inventory Pooling Problems with Newsvendor Products. In Chapter3 in Handbook of Newsvendor Problems: Models, Extensions and Applications; International Series in Operations Research & Management Science; Springer: Cham, Switzerland, 2012. [Google Scholar]
- Silbermayr, L.; Jammernegg, W.; Kischka, P. Inventory pooling with environmental constraints using copulas. Eur. J. Oper. Res. 2017, 263, 479–492. [Google Scholar] [CrossRef]
- Wanke, P.F. Consolidation effects: Assessing the impact of tail dependence on inventory pooling using copulas. Int. J. Inven. Res. 2014, 2, 174. [Google Scholar] [CrossRef]
- Corbett, C.J.; Rajaram, K. A Generalization of the Inventory Pooling Effect to Non-Normal Dependent Demand. SSRN Electron. J. 2005, 8, 351–358. [Google Scholar] [CrossRef]
- Wanke, P.F.; Saliby, E. Consolidation effects: Whether and how inventories should be pooled. Transp. Res. Part E Logist. Transp. Rev. 2009, 45, 678–692. [Google Scholar] [CrossRef]
- Wanke, P. Consolidation effects and inventory portfolios. Transp. Res. Part E Logist. Transp. Rev. 2009, 45, 107–124. [Google Scholar] [CrossRef]
- Wanke, P. The impact of different demand allocation rules on total stock levels. Pesqui. Oper. 2010, 30, 33–52. [Google Scholar] [CrossRef][Green Version]
- Cachon, G.P.; Terwiesch, C. Matching Supply with Demand: An Introduction to Operations Management, 2nd ed.; McGraw-Hill/Irwin: Ogden, UT, USA, 2009. [Google Scholar]
- Evers, P.T. The impact of transshipments on safety stock requirements. J. Bus. Logist. 1996, 17, 109–133. [Google Scholar]
- Evers, P.T. Hidden benefits of emergency transshipments. J. Bus. Logist. 1997, 18, 55–76. [Google Scholar]
- Evers, P.T. Filling customer orders from multiple locations: A comparison of pooling methods. J. Bus. Logist. 1999, 20, 121–139. [Google Scholar]
- Ardia, D.; Mullen, K.; Peterson, B.; Ulrich, J. Package ‘DEoptim’. Available online: http://cran.r-project.org/web/packages/DEoptim/DEoptim.pdf (accessed on 12 May 2016).
- Nelsen, R. An Introduction to Copulas; Springer Series in Statistics; Springer: Cham, Switzerland, 2006. [Google Scholar]




{kind=link}
{kind=link}
{kind=link}
| Variables | Uniformly Distributed Parameters | |
|---|---|---|
| Min | Max | |
| LT1 and LT2 (in days) | 1 | 5 |
| SLT,1 and SLT,2 (in days) | 0.50 | 2 |
| SD,1 and SD,2 (in days) | 3 | 30 |
| Correlation ρ12 | −1 | 1 |
| Kendall’s tau | 0 | 1 |
| k | 1 | 3 |
| P1 ($/ order) | 17 | 67 |
| P2 ($/ order) | 20 | 140 |
| h1 = h2 = h ($/ unit/ day) | 0 | 0.68 |
| Unit distribution cost d1,1 and d2,2 ($/ unit) | 0.10 | 0.15 |
| Unit distribution cost d1,2 et d2,1 ($/ unit) | 0.35 | 0.40 |
| Variables | Convergence (91.93%) | Divergence (8.07%) | Kruskal–Wallis Test | |||
|---|---|---|---|---|---|---|
| Transshipment (0.16%) | Independent System (10.91%) | Centralization (80.86%) | Independence/Transshipment/ Centralization | Statistic | p-Value | |
| Kendall tau | 0.1138 | 0.5471 | 0.5072 | 0.4243 | 52.977 (2) | 0.000 |
| D1 | 75.8326 | 103.3217 | 99.3771 | 96.3395 | 18.059 (7) | 0.001 |
| D2 | 92.9854 | 102.6983 | 99.8070 | 95.9804 | 21.597 (5) | 0.000 |
| SD1 | 32.9502 | 29.45726 | 30.0497 | 30.8193 | 11.908 (8) | 0.008 |
| SD2 | 33.1804 | 29.6666 | 29.9964 | 30.3597 | 5.8837 | 0.117 |
| LT1 | 3.7589 | 2.9759 | 3.0153 | 2.9269 | 6.657 | 0.083 |
| LT2 | 3.7711 | 2.9434 | 3.0037 | 2.9913 | 2.1612 | 0.539 |
| SLT1 | 1.2867 | 1.2934 | 1.2674 | 1.1592 | 21.784 (4) | 0.000 |
| SLT2 | 0.7516 | 1.3100 | 1.2497 | 1.3228 | 20.668 (6) | 0.000 |
| k | 2.7407 | 1.9121 | 2.0036 | 2.0855 | 32.239 (3) | 0.000 |
| P1 | 37.4917 | 42.0898 | 41.9275 | 41.8333 | 1.1059 | 0.776 |
| P2 | 76.3640 | 77.3581 | 80.8451 | 77.7781 | 6.0931 | 0.1072 |
| d11 | 0.1212 | 0.1248 | 0.1251 | 0.12493 | 0.75384 | 0.860 |
| d12 | 0.3730 | 0.3755 | 0.3758 | 0.3745 | 1.08021 | 0.615 |
| d21 | 0.3827 | 0.3745 | 0.3748 | 0.3752 | 1.0207 | 0.796 |
| d22 | 0.1201 | 0.1246 | 0.1253 | 0.1242 | 1.0144 | 0.798 |
| h | 0.5039 | 0.2917 | 0.3399 | 0.39924 | 83.729 (1) | 0.000 |
| Tail Dependence | Copula | Allocation Rules | ||
|---|---|---|---|---|
| Transshipment | Independent System | Inventory Centralization | ||
| None | Normal | 141 (17.47%) | 349(43.25%) | 317(39.28%) |
| Only upper tail | Gumbel | 149 (18.46%) | 338 (41.88%) | 320 (39.65%) |
| Only lower tail | Clayton | 136 (16.85%) | 328 (40.65%) | 343 (42.50%) |
| Both upper and lower | Frank | 148 (18.34%) | 330 (40.89%) | 329 (40.77%) |
| Variables | Convergence Results (92.72%) | Divergence Results (7.28%) | Kruskal–Wallis Test | |||
|---|---|---|---|---|---|---|
| Transshipment (0.26%) | Independent System (11.51%) | Centralization (80.95%) | Independence/ Transshipment/ Centralization | Statistic | p-Value | |
| Kendall tau | 0.1130704 | 0.5697587 | 0.4950283 | 0.4116491 | 100.69 (1) | 0.000 |
| D1 | 79.35873 | 99.85702 | 100.2379 | 99.1499 | 7.1567 | 0.067 |
| D2 | 81.04929 | 101.4088 | 100.6575 | 100.2552 | 3.3183 | 0.3451 |
| SD1 | 29.9405 | 29.9405 | 30.07159 | 30.13745 | 17.572 (6) | 0.001 |
| SD2 | 34.86215 | 29.97824 | 29.99994 | 29.7123 | 9.8394 (7) | 0.019 |
| LT1 | 3.399485 | 2.940081 | 2.995756 | 3.017965 | 4.2123 | 0.2394 |
| LT2 | 3.48428 | 2.925191 | 3.020522 | 3.117185 | 2.2221 | 0.527 |
| SLT1 | 0.876977 | 1.252383 | 1.26419 | 1.176481 | 22.612 (5) | 0.000 |
| SLT2 | 0.9168764 | 1.248905 | 1.243123 | 1.360544 | 27.706 (3) | 0.000 |
| K | 2.598716 | 1.980567 | 2.013901 | 2.068317 | 25.094 (4) | 0.000 |
| P1 | 37.81694 | 41.69101 | 42.30205 | 41.34258 | 0.21993 | 0.974 |
| P2 | 61.18521 | 78.55782 | 79.58111 | 79.37657 | 2.4177 | 0.490 |
| d11 | 0.1185323 | 0.124659 | 0.1249411 | 0.1268122 | 1.1423 | 0.766 |
| d12 | 0.3685662 | 0.3756773 | 0.374676 | 0.3756215 | 4.2429 | 0.2364 |
| d21 | 0.3763664 | 0.374313 | 0.3751264 | 0.3745828 | 0.92412 | 0.8196 |
| d22 | 0.12606 | 0.1243646 | 0.1246347 | 0.1263157 | 2.0969 | 0.5525 |
| h | 0.6041329 | 0.3081451 | 0.3400904 | 0.3874453 | 66.312 (2) | 0.000 |
| Tail Dependence | Copula | Allocation Rules | ||
|---|---|---|---|---|
| Transshipment | Independent System | Inventory Centralisation | ||
| None | Normal | 119 (16.35%) | 311 (42.72%) | 298 (40.93%) |
| Only upper tail | Gumbel | 105 (14.42%) | 292 (40.11%) | 331 (45.47%) |
| Only lower tail | Clayton | 122 (16.76%) | 281 (38.60%) | 325 (44.64%) |
| Both upper and lower | Frank | 115 (15.80%) | 282 (38.74%) | 331 (45.47%) |
| Copula | H2: Normal/Beta(5,5) H1: Normal/Normal /Normal | Transshipment | Independent System | Inventory Centralization |
|---|---|---|---|---|
| Normal | Transshipment | 45 | 74 | 36 |
| Independence | 85 | 1363 | 0 | |
| Centralization | 35 | 0 | 8362 | |
| Divergent results | 230 | |||
| Clayton | Transshipment | 51 | 73 | 34 |
| Independence | 75 | 1341 | 0 | |
| Centralization | 34 | 0 | 8392 | |
| Divergent results | 216 | |||
| Gumbel | Transshipment | 46 | 72 | 40 |
| Independence | 86 | 1344 | 0 | |
| Centralization | 34 | 0 | 8378 | |
| Divergent results | 232 | |||
| Frank | Transshipment | 50 | 73 | 35 |
| Independence | 75 | 1343 | 0 | |
| Centralization | 35 | 0 | 8389 | |
| Divergent results | 218 | |||
| Variables | Convergence (91.18%) | Divergence (8.82%) | Kruskal–Wallis Test | |||
|---|---|---|---|---|---|---|
| Transshipment (1.91%) | Independent System (7.73%) | Centralization (81.54%) | Independence/ Transshipment/ Centralization | Statistic | p-Value | |
| Kendall tau | 0.2633759 | 0.6369554 | 0.4988388 | 0.4573843 | 139.84 (2) | 0.000 |
| D1 | 30.33109 | 39.57752 | 36.45619 | 35.37287 | 22.628 (7) | 0.000 |
| D2 | 97.27427 | 101.7792 | 100.2069 | 100.0294 | 5.2316 | 0.156 |
| SD1 | 32.76588 | 28.44602 | 30.1144 | 29.30128 | 39.045 (6) | 0.000 |
| SD2 | 29.74112 | 29.95576 | 30.01248 | 29.9597 | 1.619 | 0.655 |
| LT1 | 3.372328 | 2.844004 | 3.02274 | 2.979948 | 17.84 (8) | 0.001 |
| LT2 | 3.520158 | 3.03435 | 3.009818 | 0.9427624 | 12.576 (9) | 0.005 |
| SLT1 | 0.9427624 | 1.383117 | 1.258381 | 1.182262 | 83.409 (3) | 0.000 |
| SLT2 | 1.449199 | 1.121113 | 1.238151 | 1.354034 | 75.114 (4) | 0.000 |
| K | 2.30984 | 1.825848 | 1.98886 | 2.032396 | 73.735 (5) | 0.000 |
| P1 | 43.05813 | 43.70508 | 41.75749 | 40.03104 | 7.5397 | 0.056 |
| P2 | 80.85732 | 73.00713 | 80.25319 | 79.45784 | 11.237 (10) | 0.011 |
| d11 | 0.1271849 | 0.1254713 | 0.1249515 | 0.1260524 | 2.214 | 0.529 |
| d12 | 0.3744417 | 0.3748704 | 0.3746136 | 0.3749082 | 1.0547 | 0.788 |
| d21 | 0.3733928 | 0.3751038 | 0.375288 | 0.3749008 | 0.10973 | 0.991 |
| d22 | 0.1277572 | 0.1237569 | 0.1255486 | 0.1250479 | 3.9424 | 0.268 |
| h | 0.5138296 | 0.2265138 | 0.3384318 | 0.3950181 | 248.85 (1) | 0.000 |
| Tail Dependence | Copula | Allocation Rules | ||
|---|---|---|---|---|
| Transshipment | Independent System | Inventory Centralisation | ||
| None | Normal | 269 | 353 | 260 |
| Only upper tail | Gumbel | 259 | 339 | 284 |
| Only lower tail | Clayton | 230 | 366 | 286 |
| Both upper and lower | Frank | 255 | 341 | 286 |
| Copula | H3: Beta (5,5)/Beta (2,8) H1: Normal/Normal Normal | Transshipment | Independent System | Inventory Centralization |
|---|---|---|---|---|
| Normal | Transshipment | 77 | 41 | 37 |
| Independence | 363 | 1085 | 0 | |
| Centralization | 20 | 0 | 8377 | |
| Divergences results | 461 | |||
| Clayton | Transshipment | 77 | 48 | 36 |
| Independence | 352 | 1062 | 0 | |
| Centralization | 24 | 0 | 8402 | |
| Divergences results | 459 | |||
| Gumbel | Transshipment | 83 | 32 | 43 |
| Independence | 323 | 1107 | 0 | |
| Centralization | 15 | 0 | 8397 | |
| Divergences results | 413 | |||
| Frank | Transshipment | 75 | 48 | 35 |
| Independence | 352 | 1066 | 0 | |
| Centralization | 19 | 0 | 8405 | |
| Divergences results | 454 | |||
| Copula | H3: Beta (5,5)/Beta (2,8) H2: Normal/Beta(5,5) Beta (5,5) | Transshipment | Independent System | Inventory Centralization |
|---|---|---|---|---|
| Normal | Transshipment | 81 | 49 | 35 |
| Independence | 360 | 1077 | 0 | |
| Centralization | 19 | 0 | 8379 | |
| Divergence results | 493 | |||
| Clayton | Transshipment | 83 | 41 | 36 |
| Independence | 343 | 1071 | 0 | |
| Centralization | 24 | 0 | 8402 | |
| Divergence results | 444 | |||
| Gumbel | Transshipment | 88 | 41 | 37 |
| Independence | 318 | 1098 | 0 | |
| Centralization | 15 | 0 | 8403 | |
| Divergence results | 411 | |||
| Frank | Transshipment | 83 | 41 | 36 |
| Independence | 343 | 1073 | 0 | |
| Centralization | 20 | 0 | 8404 | |
| Divergence results | 440 | |||
| Variables | Convergence (90.82%) | Divergence (9.18%) | Kruskal–Wallis Test | |||
|---|---|---|---|---|---|---|
| Transshipment (1.55%) | Independent System (7.76%) | Centralization (81.51%) | Independence/ Transshipment/ Centralization | Statistic | p-Value | |
| Kendall tau | 0.2906627 | 0.6185432 | 0.4968518 | 0.470429 | 92.973 (2) | 0.000 |
| D1 | 30.19045 | 37.79599 | 36.62742 | 36.09918 | 11.022 | 0.012 |
| D2 | 157.2561 | 165.8269 | 163.5958 | 163.4406 | 1.937 | 0.5856 |
| SD1 | 32.76588 | 28.17479 | 30.11815 | 29.42868 | 49.176 (6) | 0.000 |
| SD2 | 30.57189 | 30.00948 | 30.02349 | 29.62515 | 2.1866 | 0.535 |
| LT1 | 3.29439 | 2.852775 | 3.020513 | 3.026129 | 18.272 (7) | 0.000 |
| LT2 | 3.628139 | 2.894886 | 3.034347 | 3.004923 | 18.053 (8) | 0.000 |
| SLT1 | 0.9358209 | 1.381382 | 1.258955 | 1.179125 | 86.827 (4) | 0.000 |
| SLT2 | 1.340071 | 1.099255 | 1.237596 | 1.395932 | 92.459 (3) | 0.000 |
| K | 2.325581 | 1.828309 | 1.990122 | 2.030634 | 63.789 (5) | 0.000 |
| P1 | 40.75418 | 43.83816 | 41.73683 | 40.28208 | 7.5988 | 0.055 |
| P2 | 82.40695 | 73.34916 | 80.19862 | 79.77782 | 8.2998 (9) | 0.040 |
| d11 | 0.1294936 | 0.125543 | 0.1249481 | 0.1255741 | 5.372 | 0.147 |
| d12 | 0.3737614 | 0.3747455 | 0.3746526 | 0.3746703 | 0.64197 | 0.888 |
| d21 | 0.3723548 | 0.3752034 | 0.375292 | 0.3747065 | 1.5818 | 0.663 |
| d22 | 0.1298994 | 0.1240718 | 0.1255781 | 0.124536 | 4.8427 | 0.184 |
| h | 0.5170642 | 0.2299275 | 0.33857 | 0.392985 | 223.49 (1) | 0.000 |
| Tail Dependence | Copula | Allocation Rules | ||
|---|---|---|---|---|
| Transshipment | Independent System | Inventory Centralization | ||
| None | Normal | 259 | 363 | 296 |
| Only upper tail | Gumbel | 233 | 367 | 318 |
| Only lower tail | Clayton | 258 | 353 | 307 |
| Both upper and lower | Frank | 231 | 369 | 318 |
| Copula | H1: Normal/Normal H4: Beta (8,2)/Beta(2,8) Beta (2,8) | Transshipment | Independence | Centralization |
|---|---|---|---|---|
| Normal | Transshipment | 70 | 290 | 18 |
| Independence | 49 | 1158 | 0 | |
| Centralization | 36 | 0 | 8379 | |
| Divergences results | 393 | |||
| Gumbel | Transshipment | 83 | 351 | 26 |
| Independence | 39 | 1065 | 0 | |
| Centralization | 36 | 0 | 8400 | |
| Divergences results | 452 | |||
| Clayton | Transshipment | 81 | 331 | 23 |
| Independence | 34 | 1099 | 0 | |
| Centralization | 43 | 0 | 8389 | |
| Divergences results | 431 | |||
| Frank | Transshipment | 83 | 350 | 20 |
| Independence | 39 | 1068 | 0 | |
| Centralization | 36 | 0 | 8404 | |
| Divergences results | 445 | |||
| Copula | H2: Beta (5,5)/Normal H4: Beta (8,2)/ Beta (2,8) | Transshipment | Independence | Centralization |
|---|---|---|---|---|
| Normal | Transshipment | 66 | 294 | 18 |
| Independence | 64 | 1143 | 0 | |
| Centralization | 35 | 0 | 8380 | |
| Divergences results | 411 | |||
| Clayton | Transshipment | 90 | 344 | 26 |
| Independence | 34 | 1070 | 0 | |
| Centralization | 36 | 0 | 8400 | |
| Divergences results | 440 | |||
| Gumbel | Transshipment | 83 | 330 | 22 |
| Independence | 47 | 1086 | 0 | |
| Centralization | 36 | 0 | 8396 | |
| Divergences results | 435 | |||
| Frank | Transshipment | 90 | 343 | 20 |
| Independence | 34 | 1073 | 0 | |
| Centralization | 36 | 0 | 8404 | |
| Divergences results | 433 | |||
| Copula | H3: Beta (5,5)/Beta (2,8) H4: Beta (8,2)/ Beta (2,8) | Transshipment | Independence | Centralization |
|---|---|---|---|---|
| Normal | Transshipment | 241 | 118 | 19 |
| Independence | 199 | 1008 | 0 | |
| Centralization | 20 | 0 | 8395 | |
| Divergences results | 356 | |||
| Clayton | Transshipment | 287 | 148 | 25 |
| Independence | 140 | 964 | 0 | |
| Centralization | 23 | 0 | 8413 | |
| Divergences results | 336 | |||
| Gumbel | Transshipment | 268 | 144 | 23 |
| Independence | 138 | 995 | 0 | |
| Centralization | 15 | 0 | 8417 | |
| Divergences results | 320 | |||
| Frank | Transshipment | 286 | 147 | 20 |
| Independence | 140 | 967 | 0 | |
| Centralization | 20 | 0 | 8420 | |
| Divergences results | 327 | |||
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Derbel, M.; Hachicha, W.; Aljuaid, A.M. Sensitivity Analysis of the Optimal Inventory-Pooling Strategies According to Multivariate Demand Dependence. Symmetry 2021, 13, 328. https://doi.org/10.3390/sym13020328
Derbel M, Hachicha W, Aljuaid AM. Sensitivity Analysis of the Optimal Inventory-Pooling Strategies According to Multivariate Demand Dependence. Symmetry. 2021; 13(2):328. https://doi.org/10.3390/sym13020328
Chicago/Turabian StyleDerbel, Mouna, Wafik Hachicha, and Awad M. Aljuaid. 2021. "Sensitivity Analysis of the Optimal Inventory-Pooling Strategies According to Multivariate Demand Dependence" Symmetry 13, no. 2: 328. https://doi.org/10.3390/sym13020328
APA StyleDerbel, M., Hachicha, W., & Aljuaid, A. M. (2021). Sensitivity Analysis of the Optimal Inventory-Pooling Strategies According to Multivariate Demand Dependence. Symmetry, 13(2), 328. https://doi.org/10.3390/sym13020328