
Spectral Clustering Effect in Software Development Effort Estimation



Abstract
:1. Introduction
2. Related Work
3. Problem Statement
- RQ1: How SR will influence the DEE?
- RQ2: How will the model based on SR benefit when SC is employed? Will SC make the DEE more accurate?
- RQ3: How does the involvement of categorical variables affect DEE accuracy?
4. Materials and Methods
4.1. Dataset Pre-Processing
- IFPUG compliance: Removing all projects that are not described from the perspective of estimation using the function point method (=IFPUG).
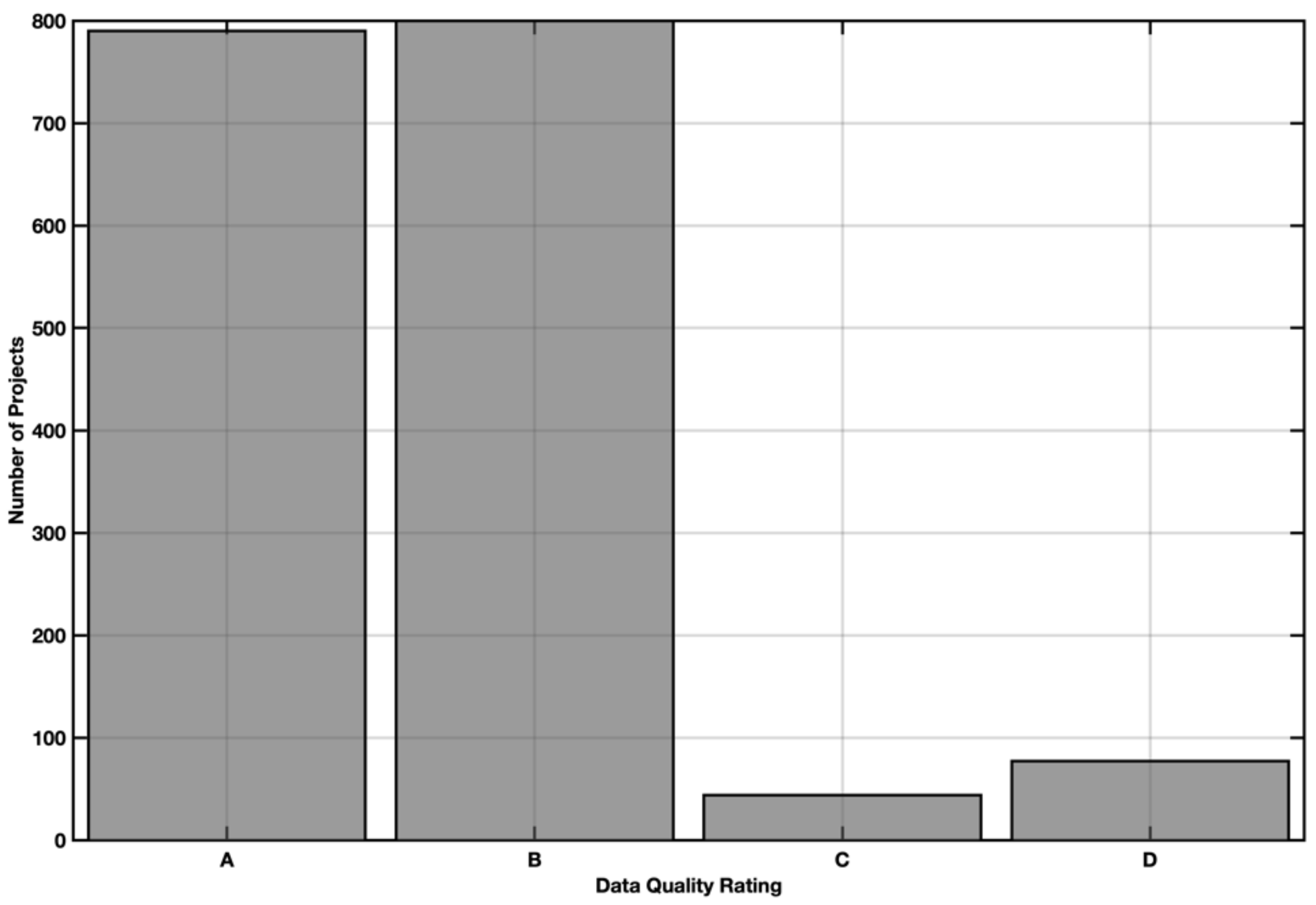
- Data quality rating: Each project is evaluated by the data quality (Figure 1). All projects having quality ratings other than A or B were removed from the working dataset.
- Value-added factor (VAF) compliance: In the next step, those projects for which the VAF was unknown were removed.
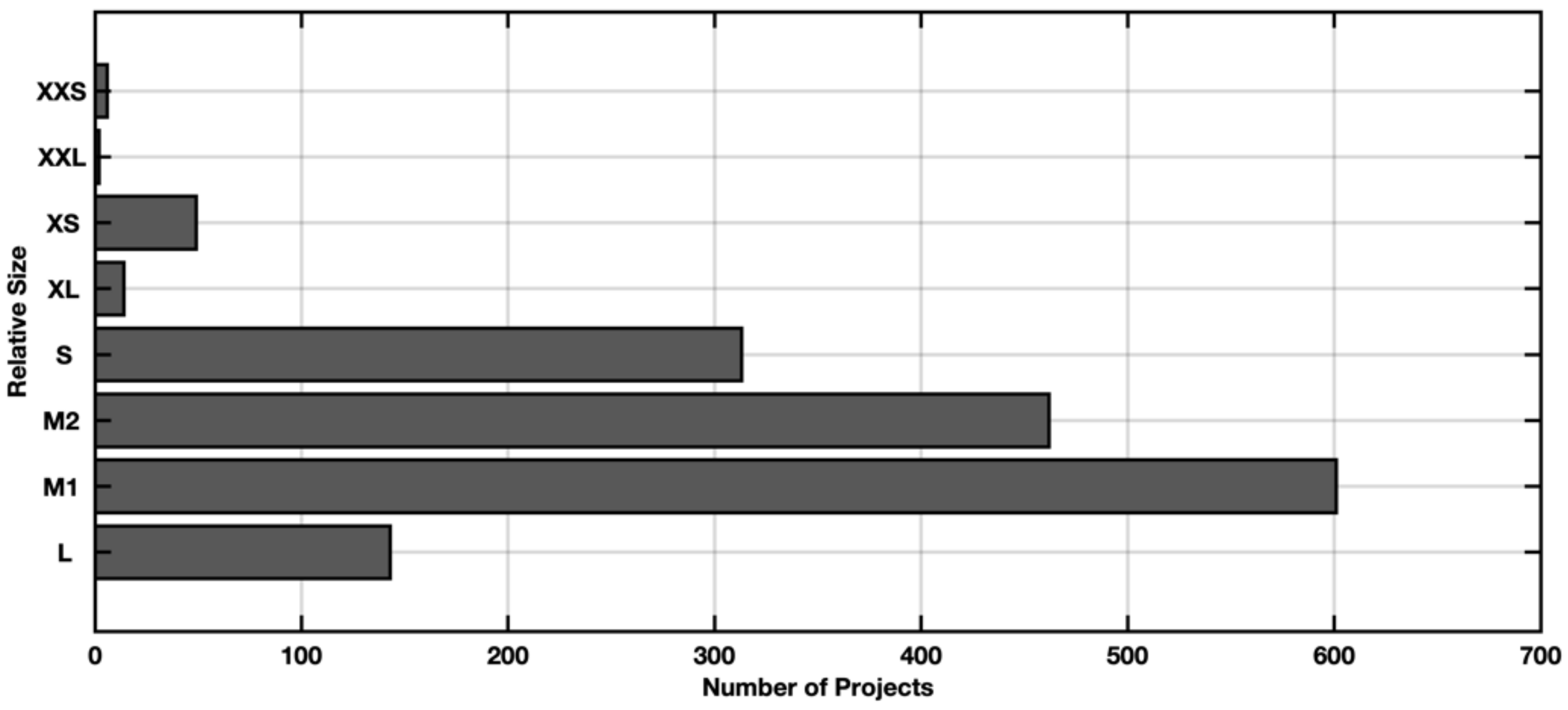
- Relative Size: Projects are classified according to size (Table 1) using the relative size variable of the projects. Projects from the extra-extra-extra-large category (XXXL) were removed.
- Productivity factor (PDR).
- Project size in function points (FPs).
- Development effort in man-hours (Effort).
- External input (EI)—requirements that define the number of external inputs.
- External output (EO)—describes the number of external outputs.
- External query (EQ)—describes the number of external queries.
- Internal logical file (ILF)—describes the number of internal logical files.
- External interface file (EIF)—describes the number of external interface files.
- Value adjustment factor (VAF)—represents the correction value that summarizes the general system characteristics (GSCs).
- Industry sector (IS)—describes the sector of the company where the project is used.
- Primary programming language (PPL)—describes the programming language used for development (C#, Java, etc.).
- Relative size (RS)—describes the project size based on the number of FPs.
- Development type (DT)—describes the project development type (new development, enhancement of existing application, etc.).
- Development platform (DP)—describes a development platform, which is the project focus (desktop, mobile, etc.).
- Development effort estimation (DEE)—represent and estimated value of effort in person-hours.
- Normalized work effort (NWE)—describes the number of person-hours required for the project.
4.2. Methods Used in Study
- IFPUG.
- Stepwise regression.
- Spectral clustering.
- The IFPUG method is used to elicit variables when the counting process is as follows:
- Determine the EI, EO, EQ, ILF, and EIF.
- Determine the unadjusted FP count.
- Determine the VAF.
- Determine the number of FPs.
- Create a beginning model with specified variables; alternatively create a null model.
- Establish final model limitations—establish the requested model complexity—linear, quadratic, interaction, and so on.
- Decide a control threshold—it should be the total of residual or another metric. The goal is to determine whether another variable should be eliminated or added.
- Re-testing the model after adding or eliminating variable.
- SR stops when there is no further progress in estimate.
4.3. Experiment Settings and Configuration
- IFPUG (EX1).
- Stepwise regression (EX2).
- Stepwise regression and spectral clustering (EX3).
- Stepwise regression and spectral clustering + categorical variables (EX4).
4.3.1. EX1—IFPUG Base Model
- Create training and testing sets by using 10-fold cross validation.
- Estimate the software size using the IFPUG (AFP) for each testing fold.
- Multiply the AFP by the industry sector-based PDR.
- Compute the EE for projects in the testing folds.
- Compute evaluation criteria—10-fold mean value.
4.3.2. EX2—Stepwise Regression
- Independent variables: EI, EO, EQ, ILF, and EIF.
- Dependent variable: NWE.
- Criterion for SR: sum of the squared error (SSE) minimalization.
- Create training and testing sets by using the 10-fold procedure.
- Create a regression model using the SR procedure for each of the training folds.
- Using an obtained formula for the DEE by using and testing folds.
- Obtaining the EE for projects in the testing folds and computing them.
- Compute evaluation criteria, and a 10-fold mean value is used for comparison.
4.3.3. EX3—Stepwise Regression with Spectral Clustering
- Independent variables: EI, EO, EQ, ILF, and EIF.
- Dependent variable: NWE.
- Criterion for SR: SSE minimalization.
- Clustering method: k-means.
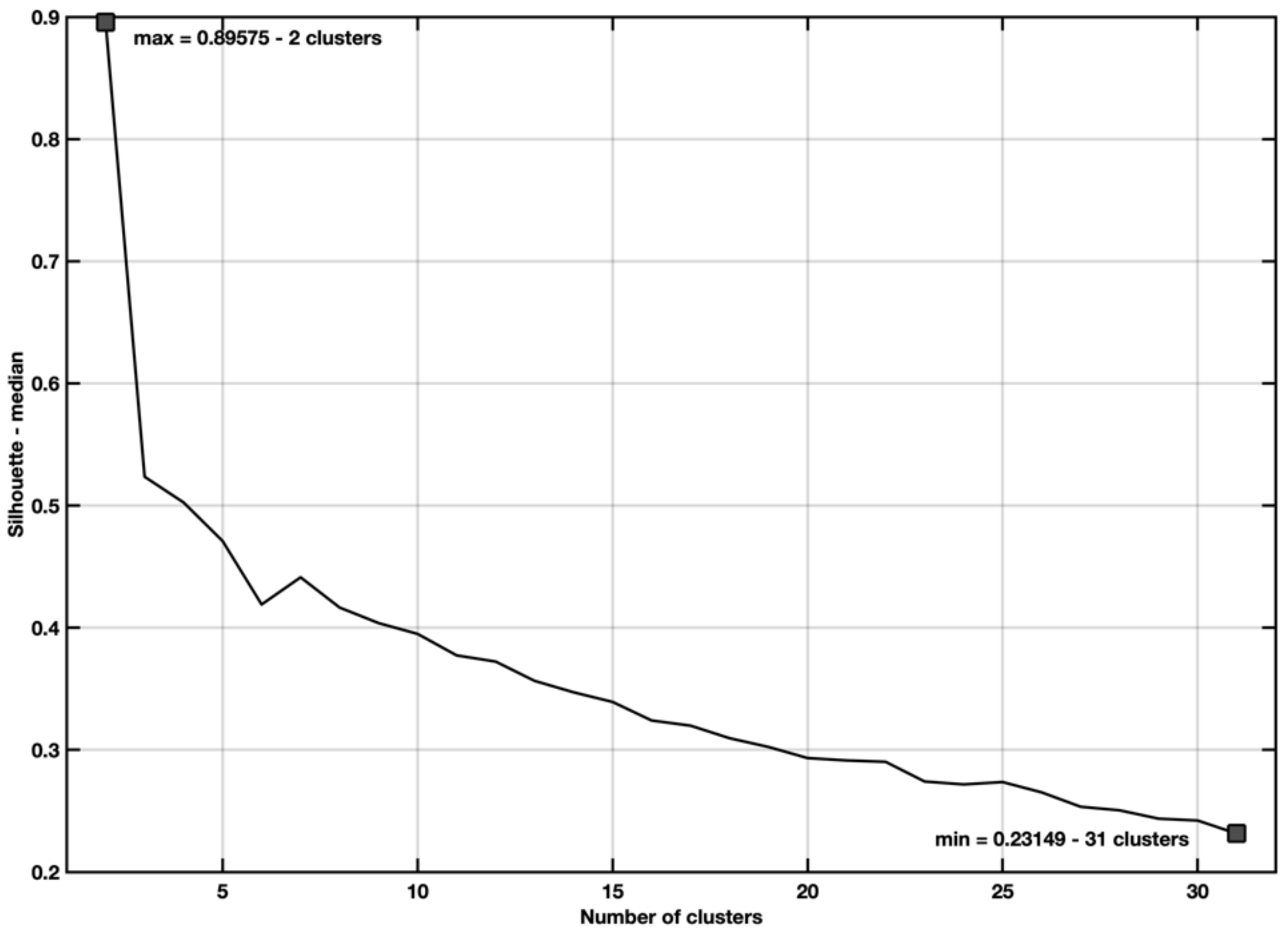
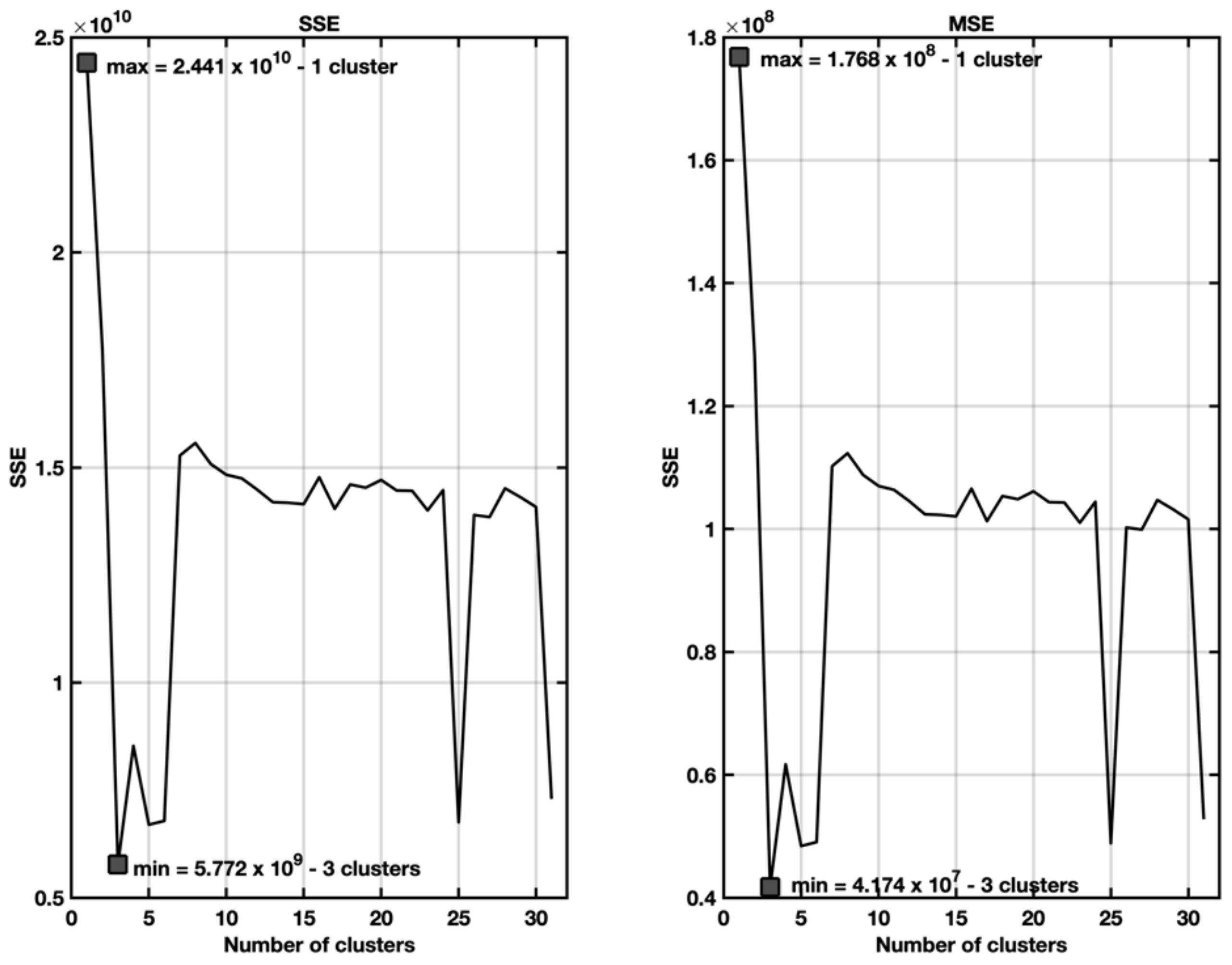
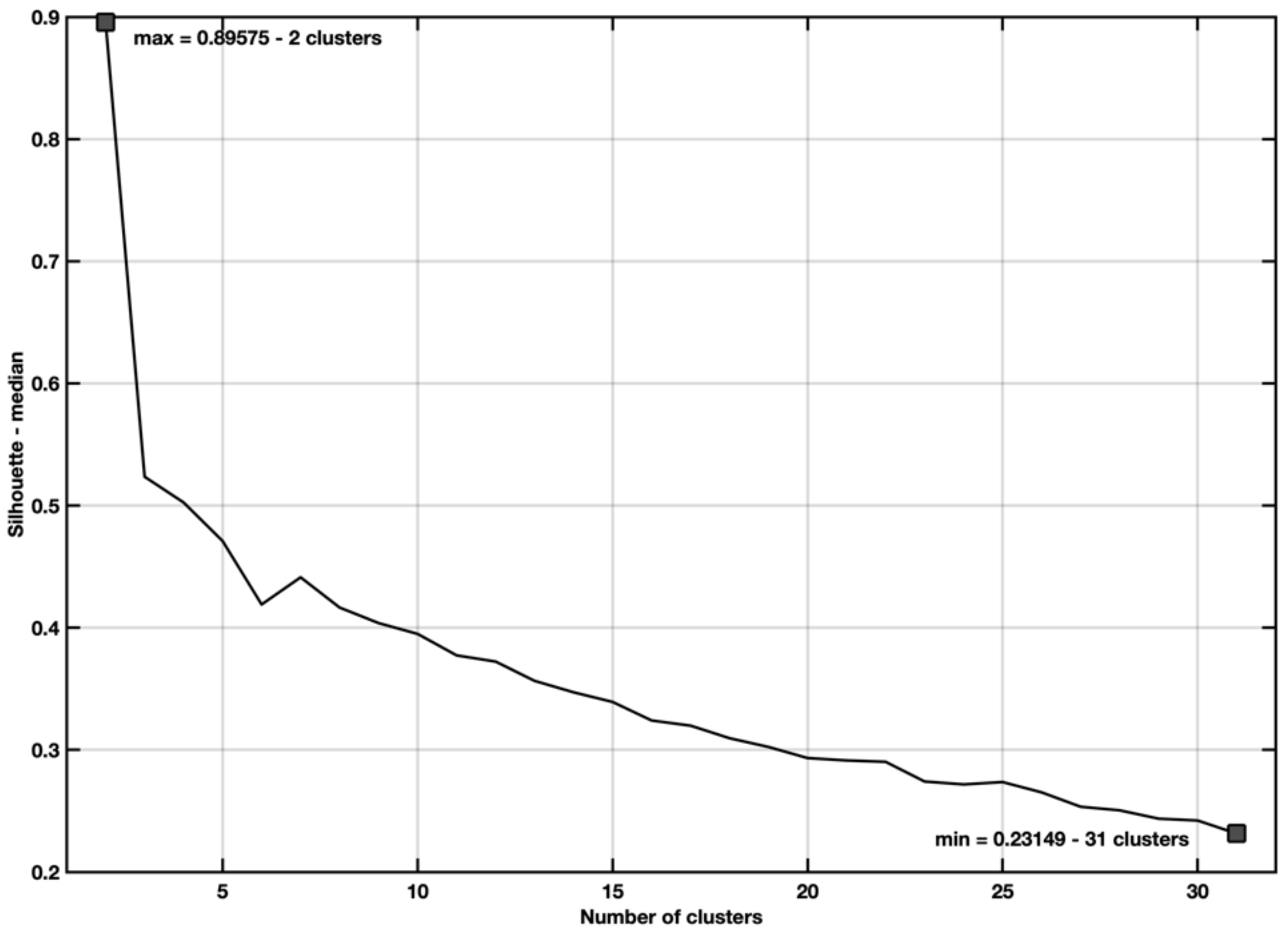
- Number of tested clusters: 2–31.
- Clustering attributes: EI, EO, EQ, ILF, and EIF.
- Create training and testing sets by using the 10-fold procedure.
- Apply SC to the training folds.
- Computing SR models for all defined clusters.
- Classify observations in the testing fold into clusters using discriminant analysis.
- Estimate the work effort in person-hours by using an estimation model created for a specific cluster.
- Obtaining EE for projects in the testing folds and computing them.
- Evaluation criteria are computed, and the mean value is used for comparison.
4.3.4. Ex4—Stepwise Regression with Spectral Clustering and Categorical Variables
- Independent variables: EI, EO, EQ, ILF, EIF, IS, PPL, RS, DT, and DP.
- Dependent variable: NWE.
- Criterion for SR: SSE Minimalization.
- Clustering method: k-means.
- Number of tested clusters: 2–31.
- Clustering attributes: EI, EO, EQ, ILF, EIF, IS, PPL, RS, DT, and DP.
- Create training and testing sets by using the 10-fold procedure.
- Apply SC to the training folds.
- Computing SR models for all defined clusters.
- Obtain a new estimation as follows:
- New observation classification of the corresponding cluster using discriminant analysis.
- Estimate the work effort in person-hours by using an estimation model created for a specific cluster.
- Obtaining EE for projects in the testing folds and computing them.
- Evaluate evaluation criteria, and a 10-fold mean value is used for comparison.
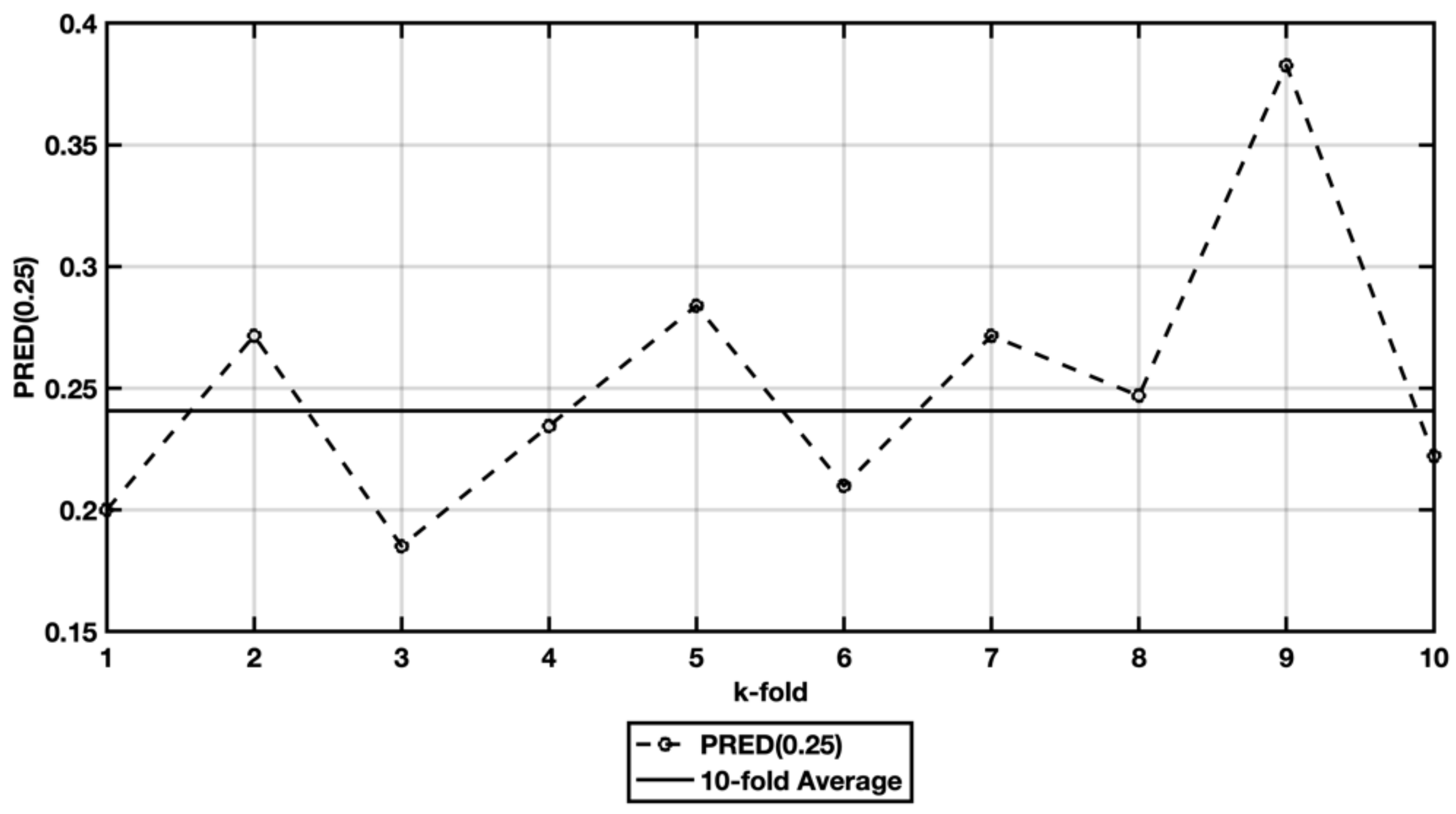
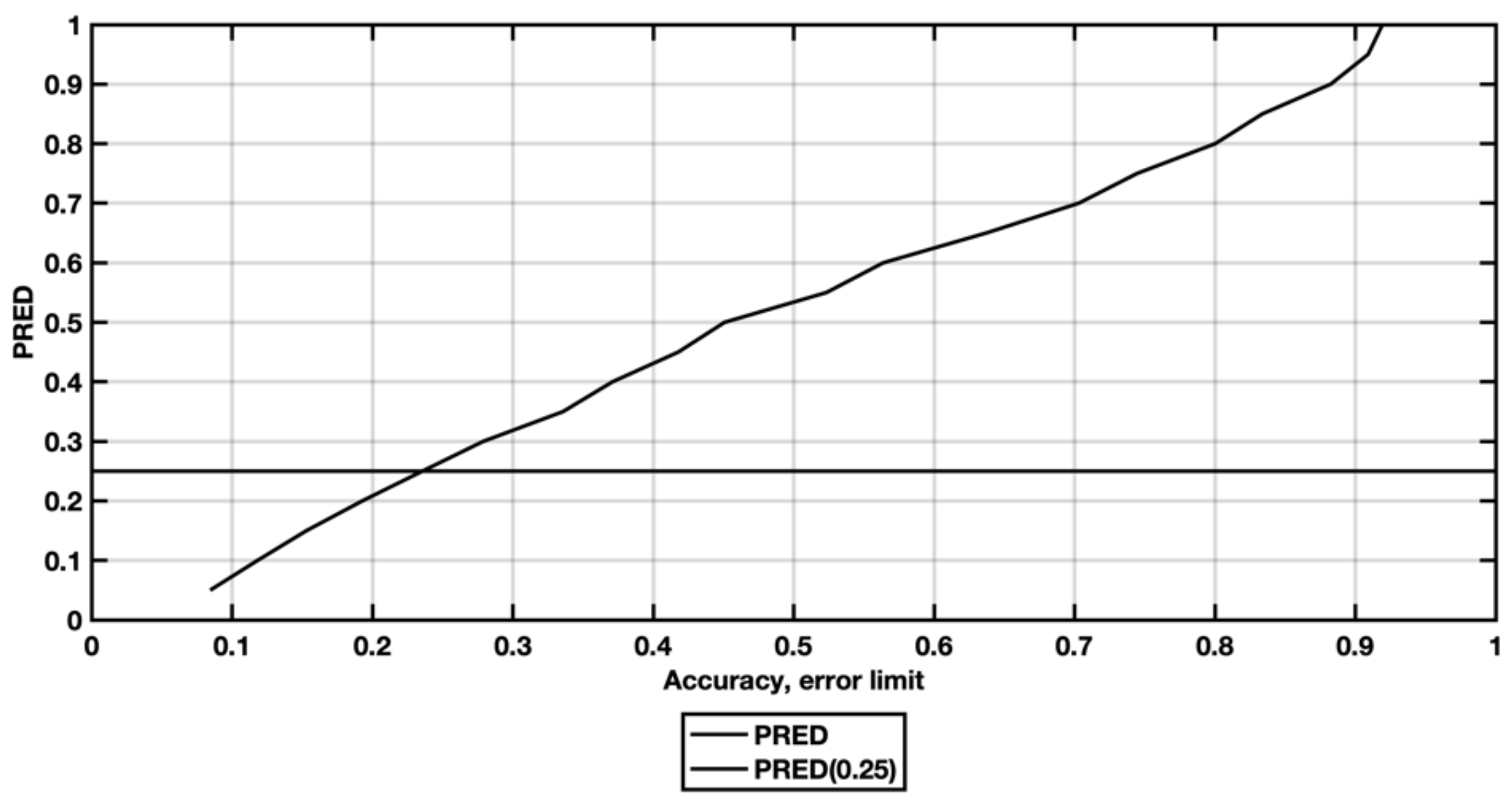
4.4. Evaluation Criteria
Threats to Validity
5. Results and Discussion
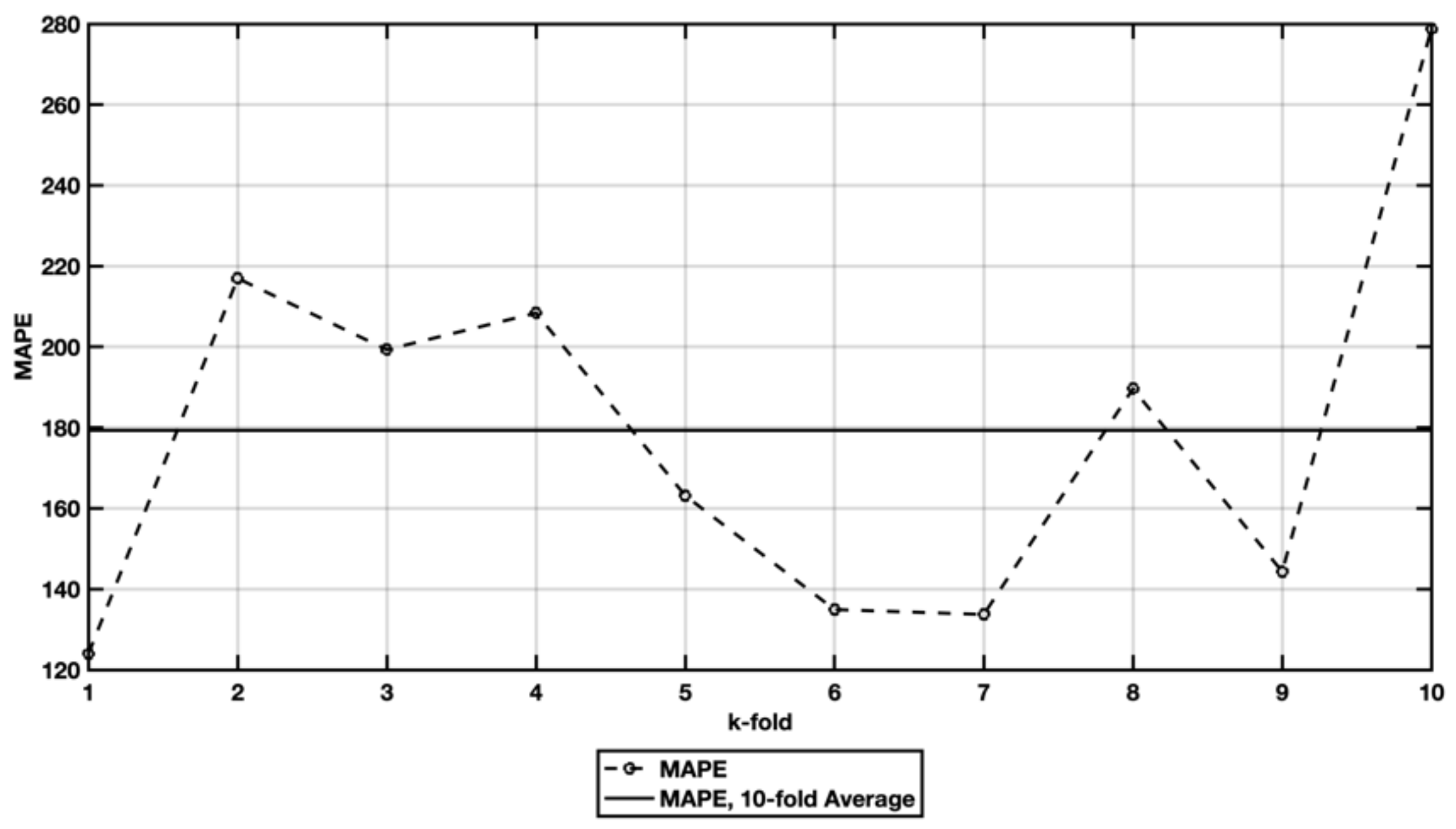
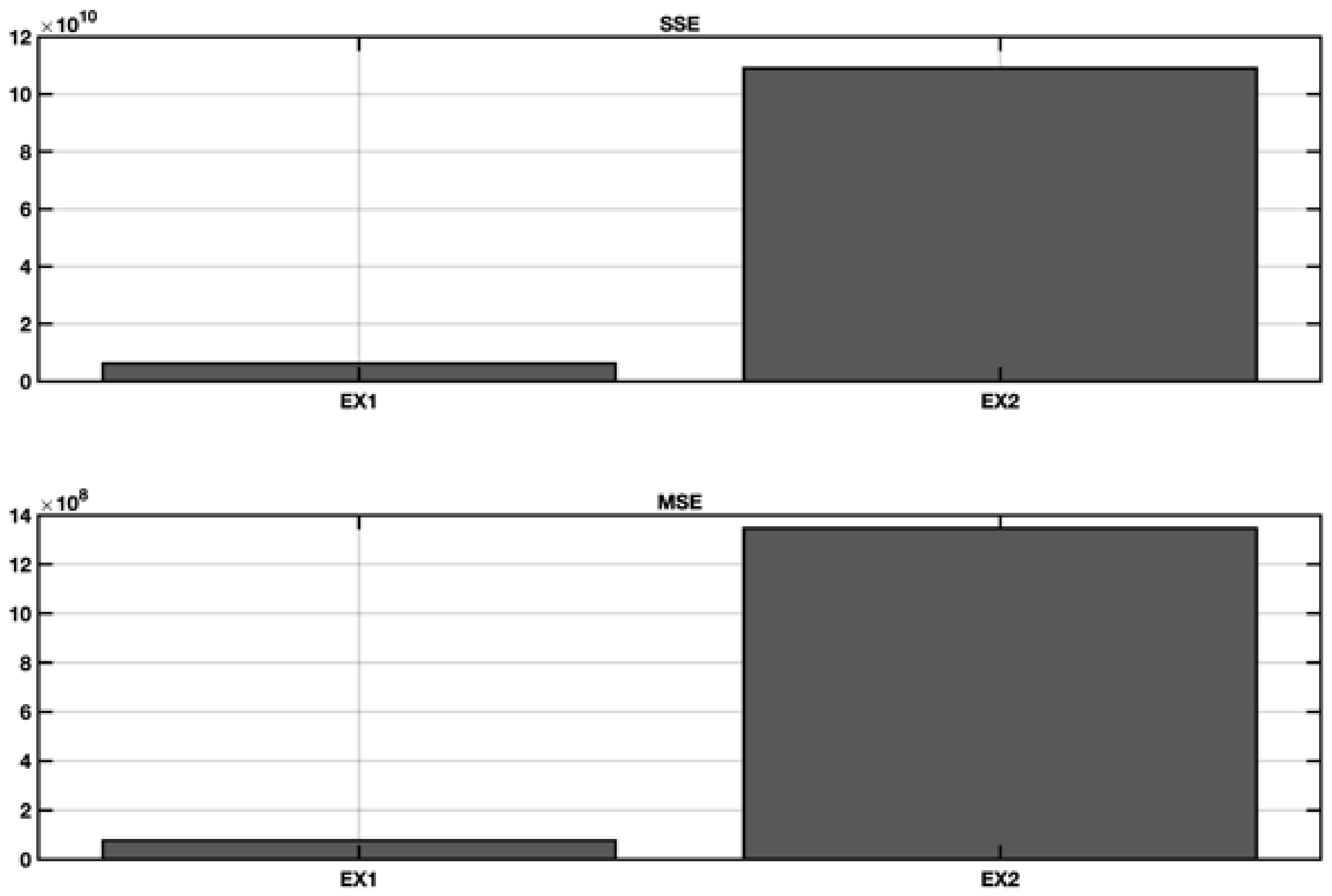
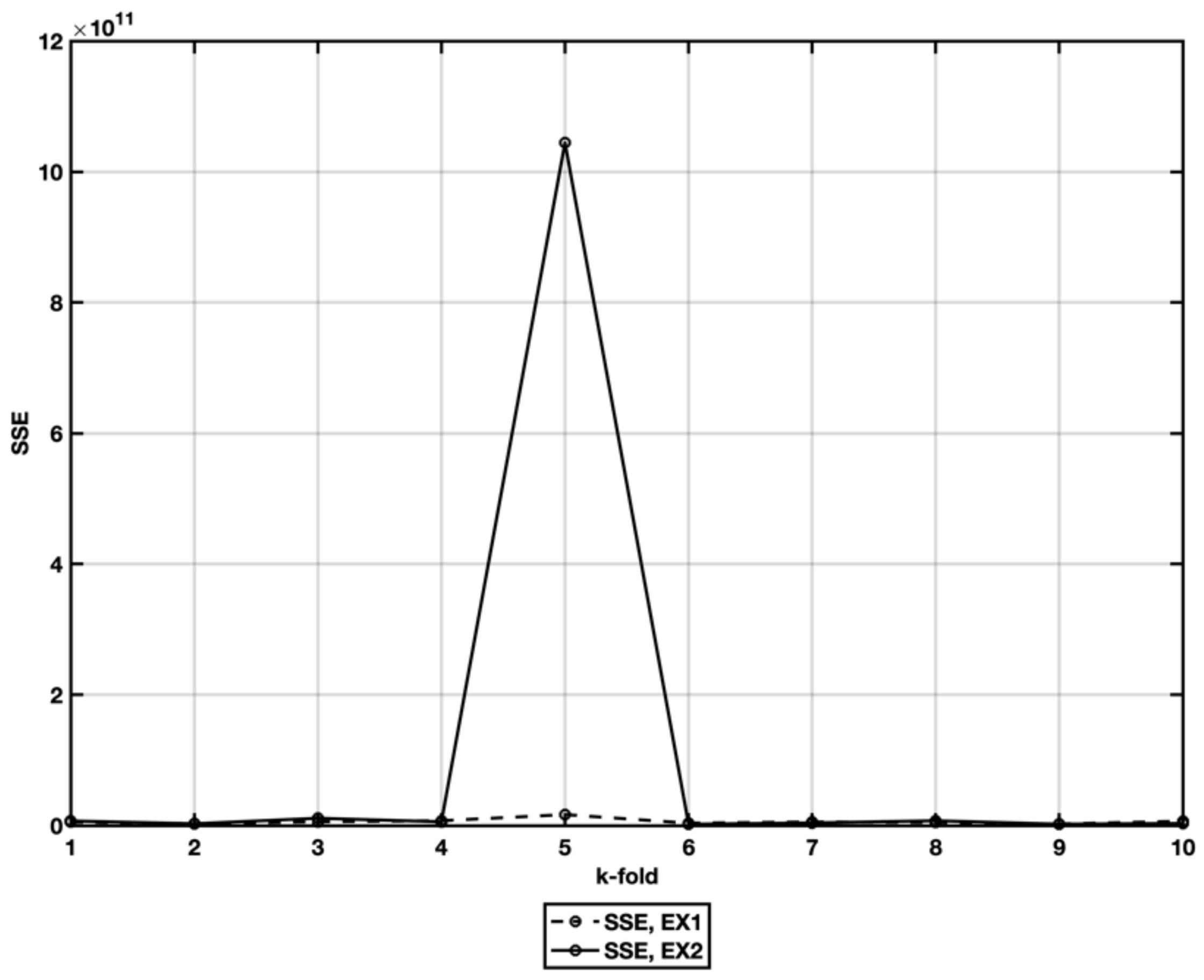
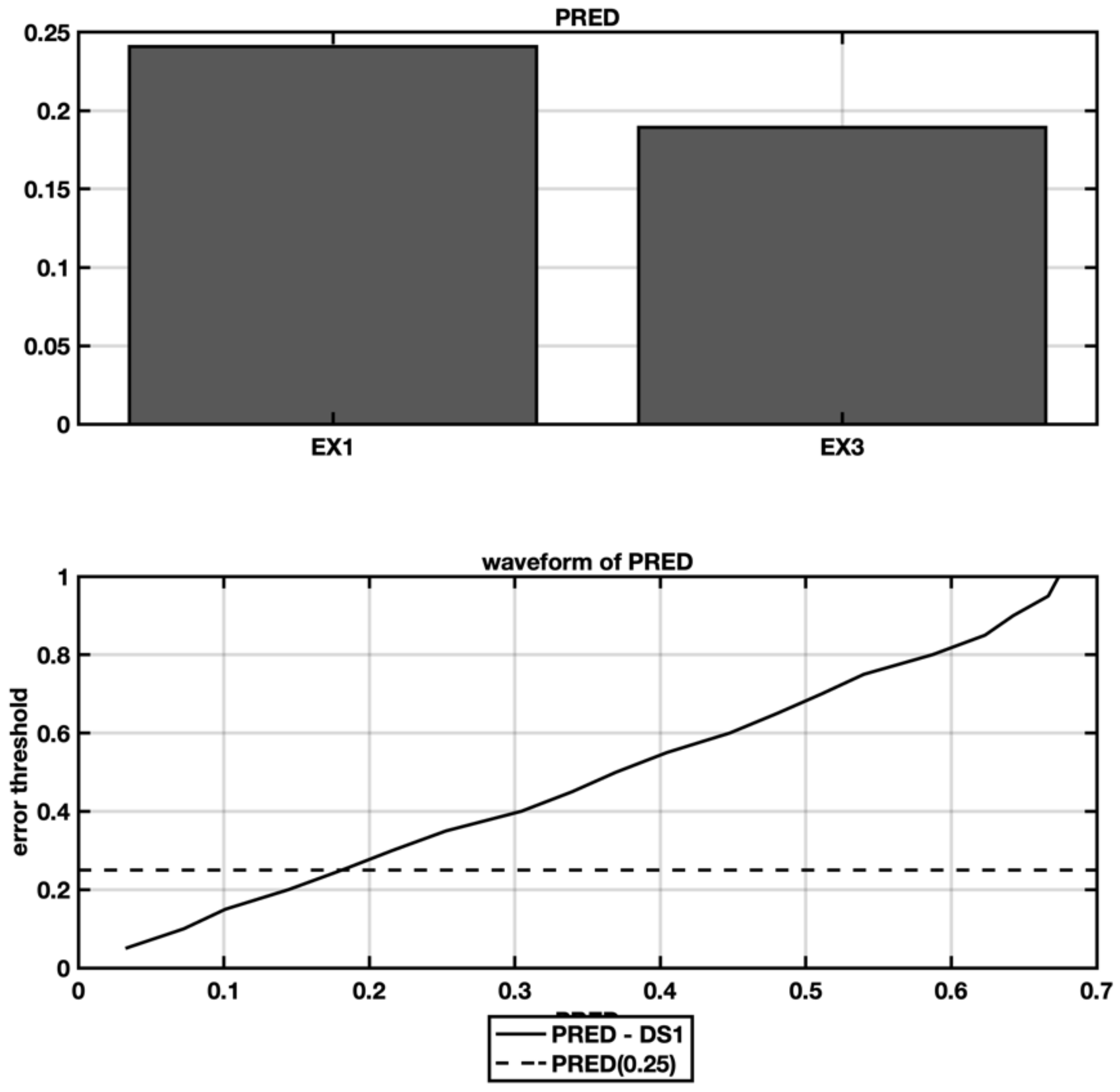
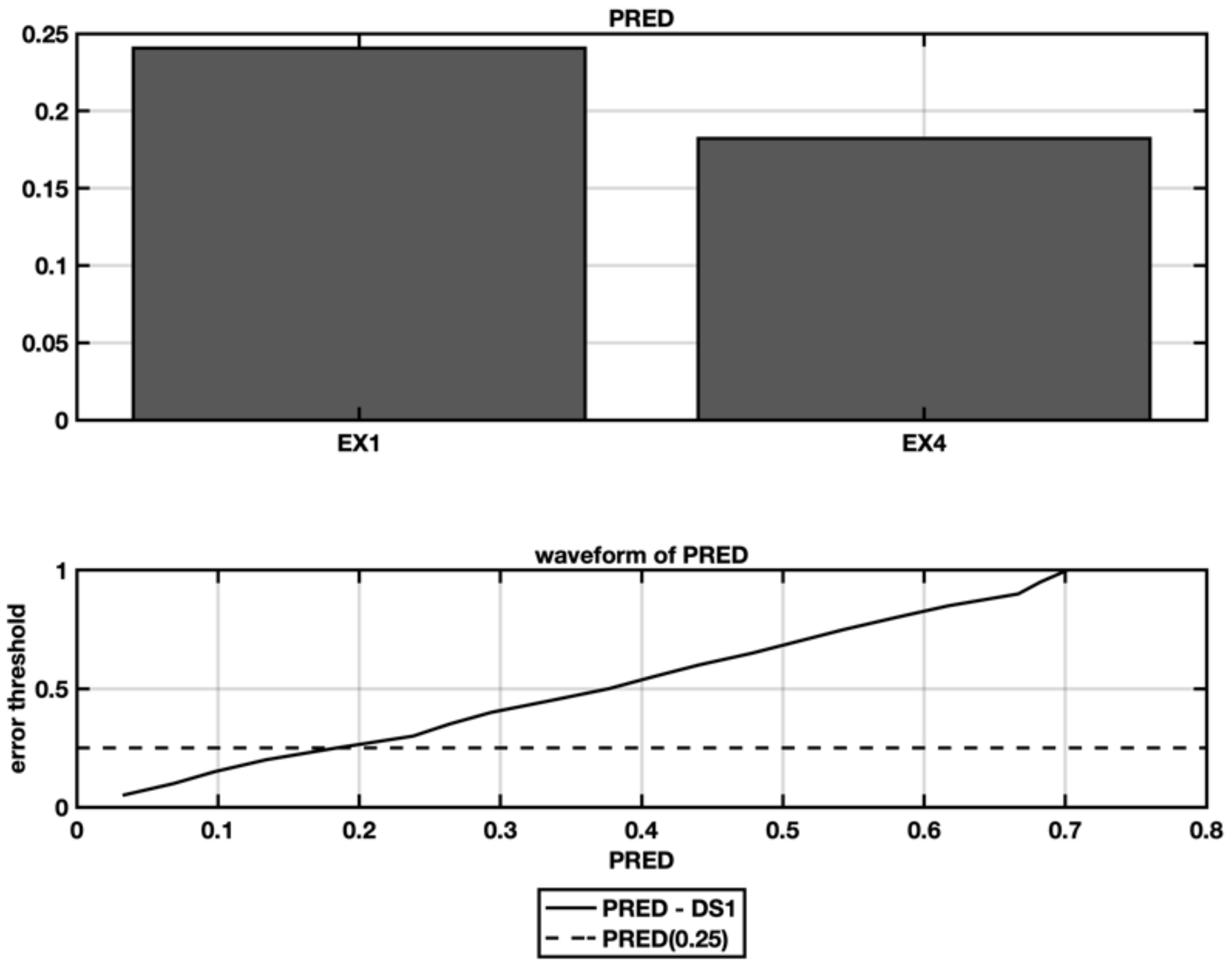
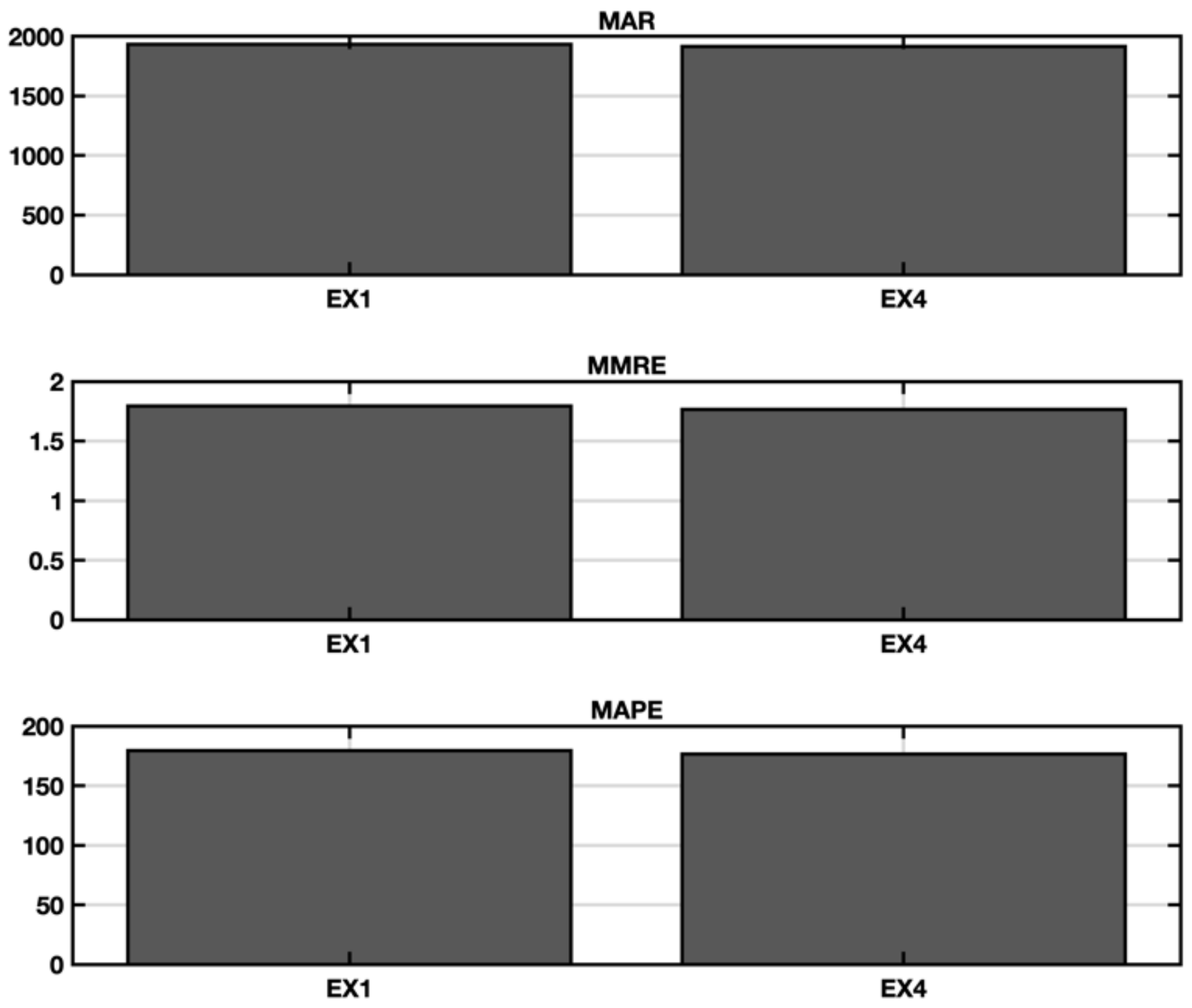
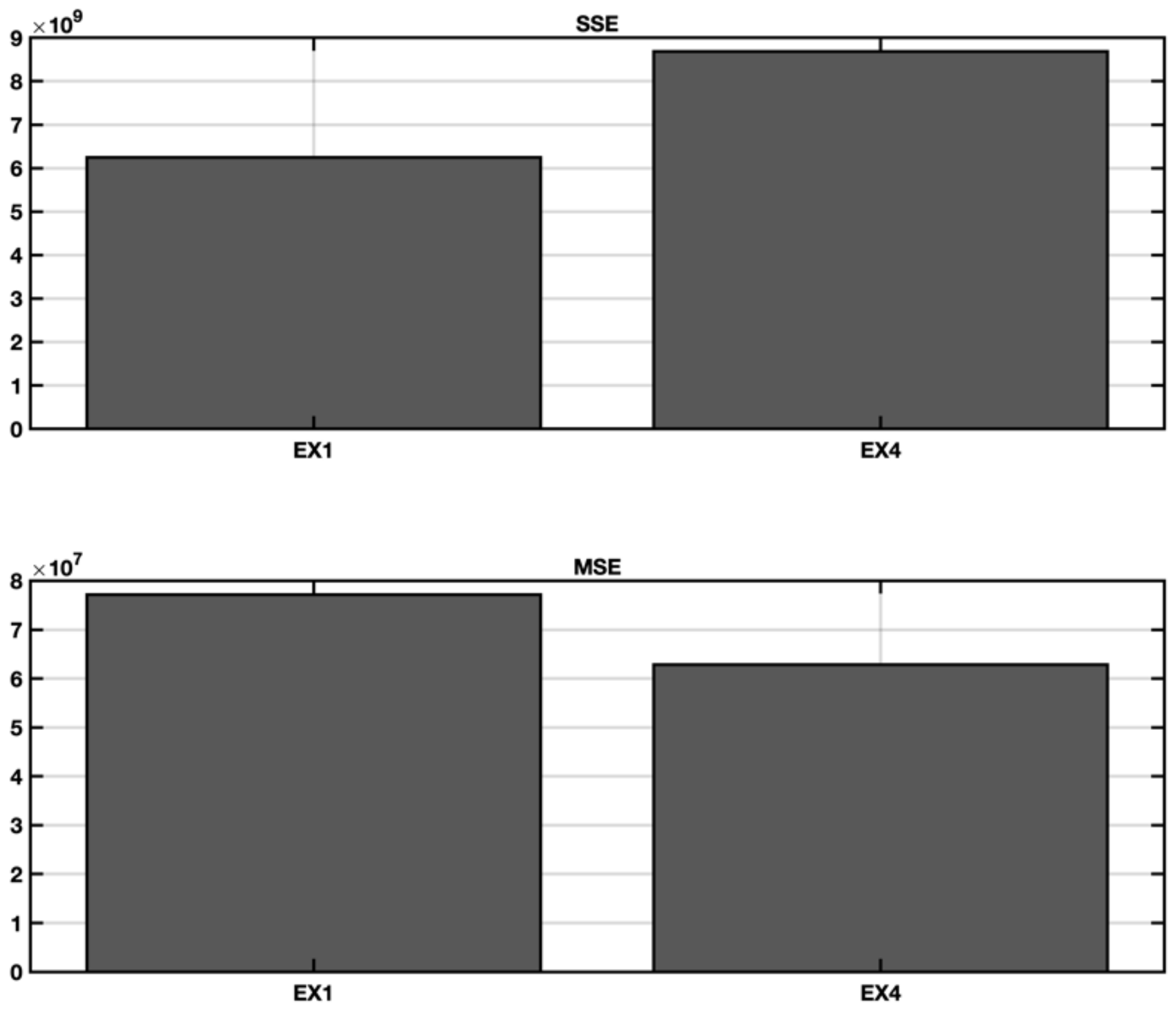
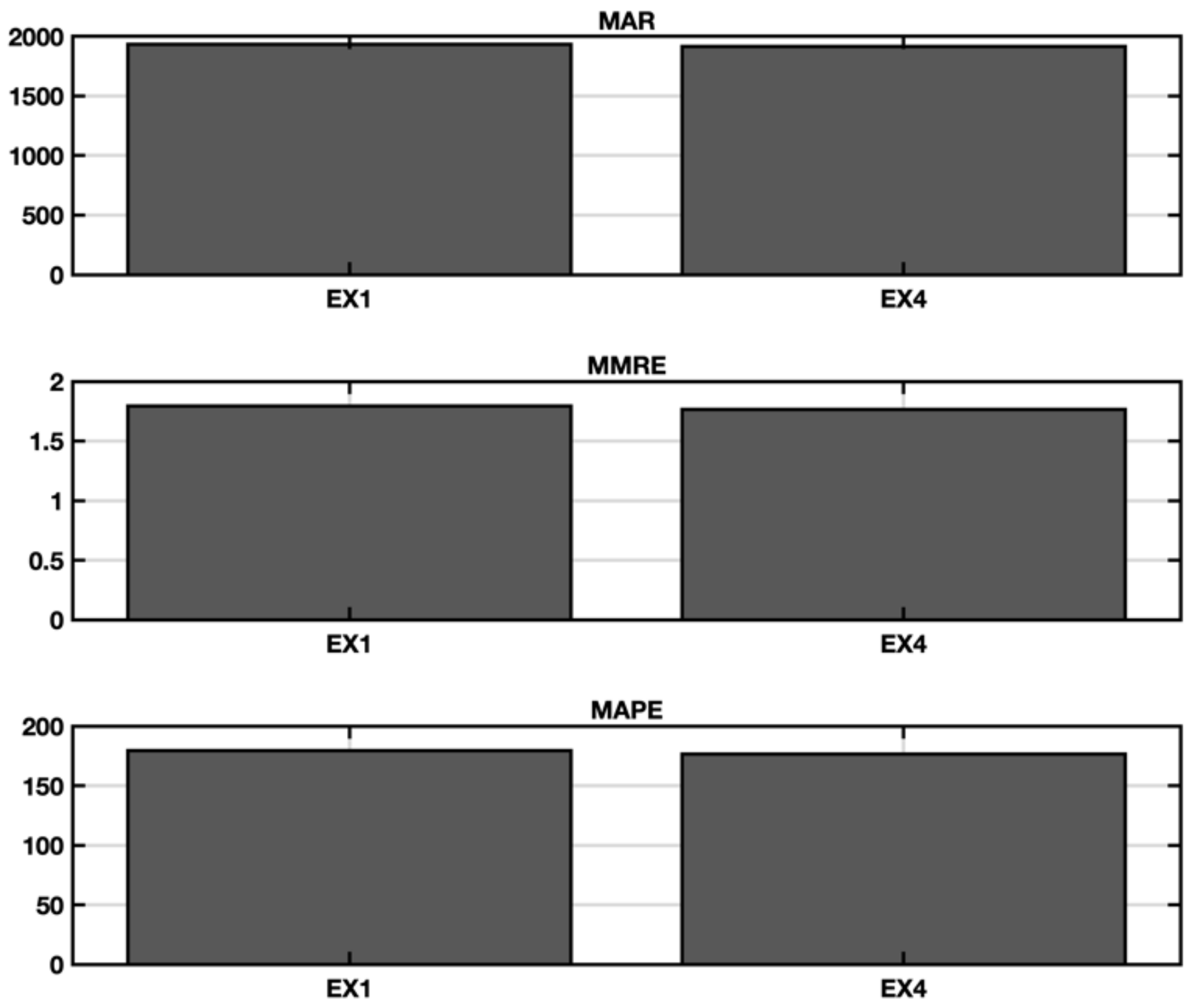
5.1. EX1—IFPUG Base Model
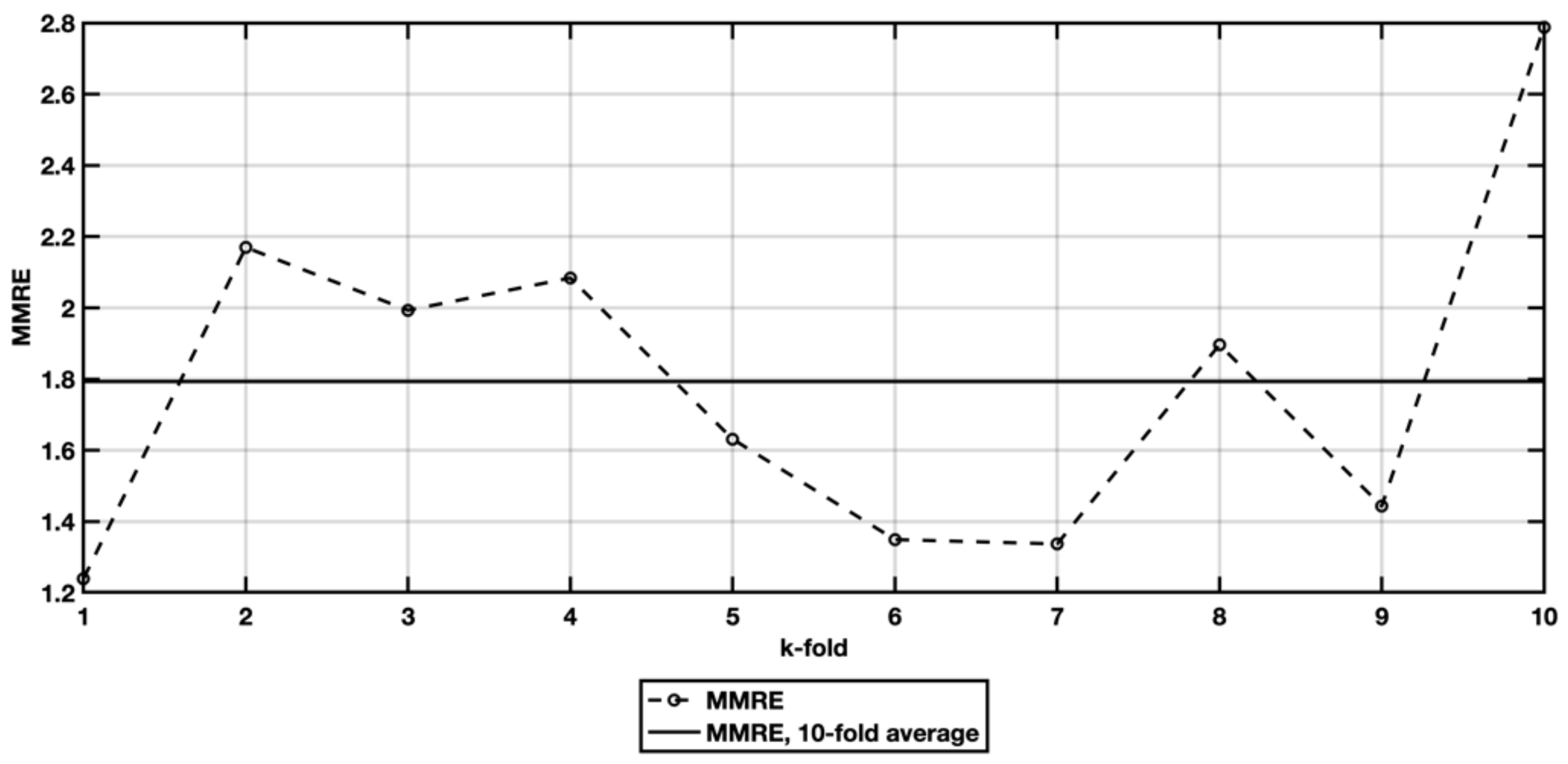
5.2. EX2—Stepwise Regresion
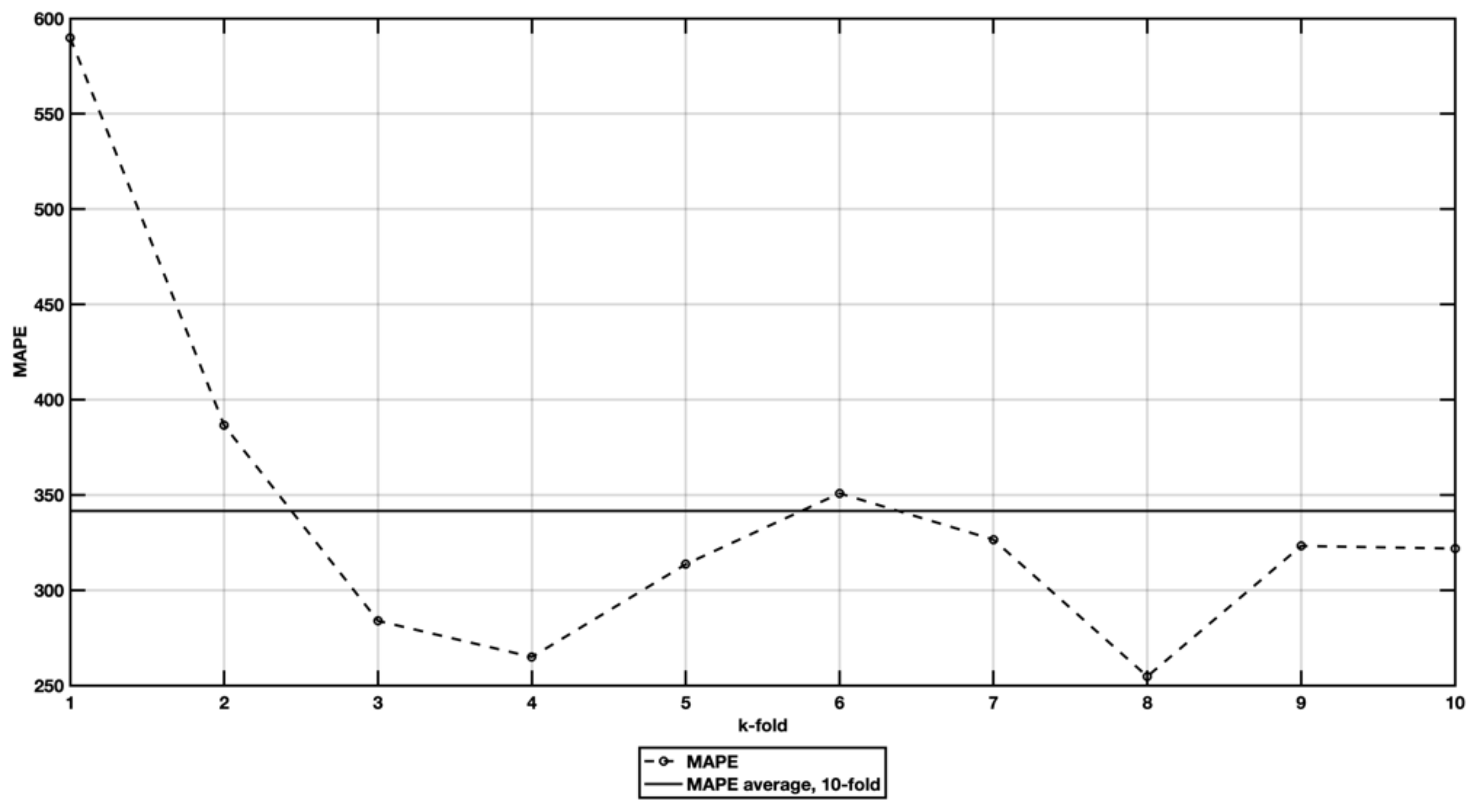
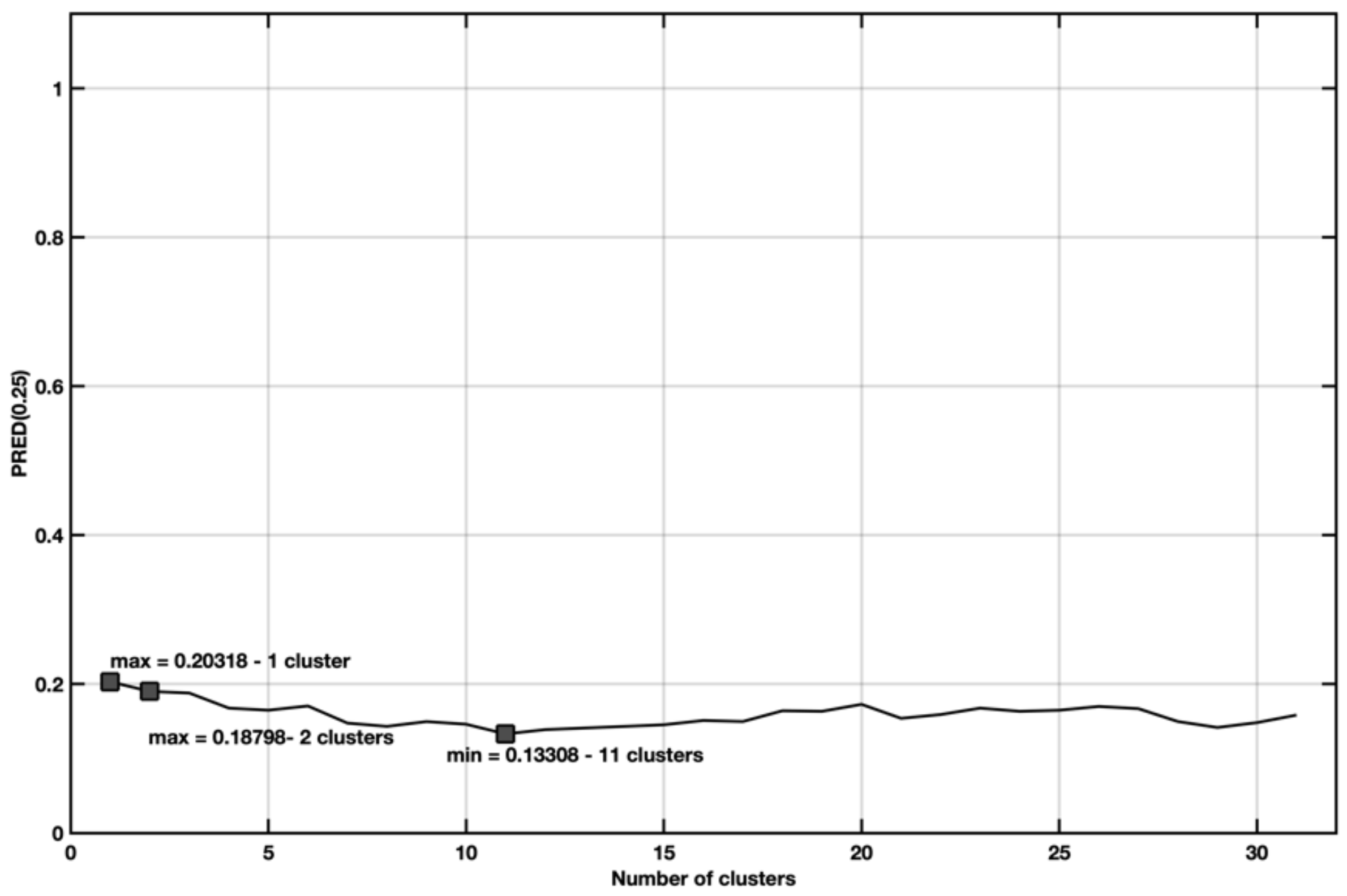
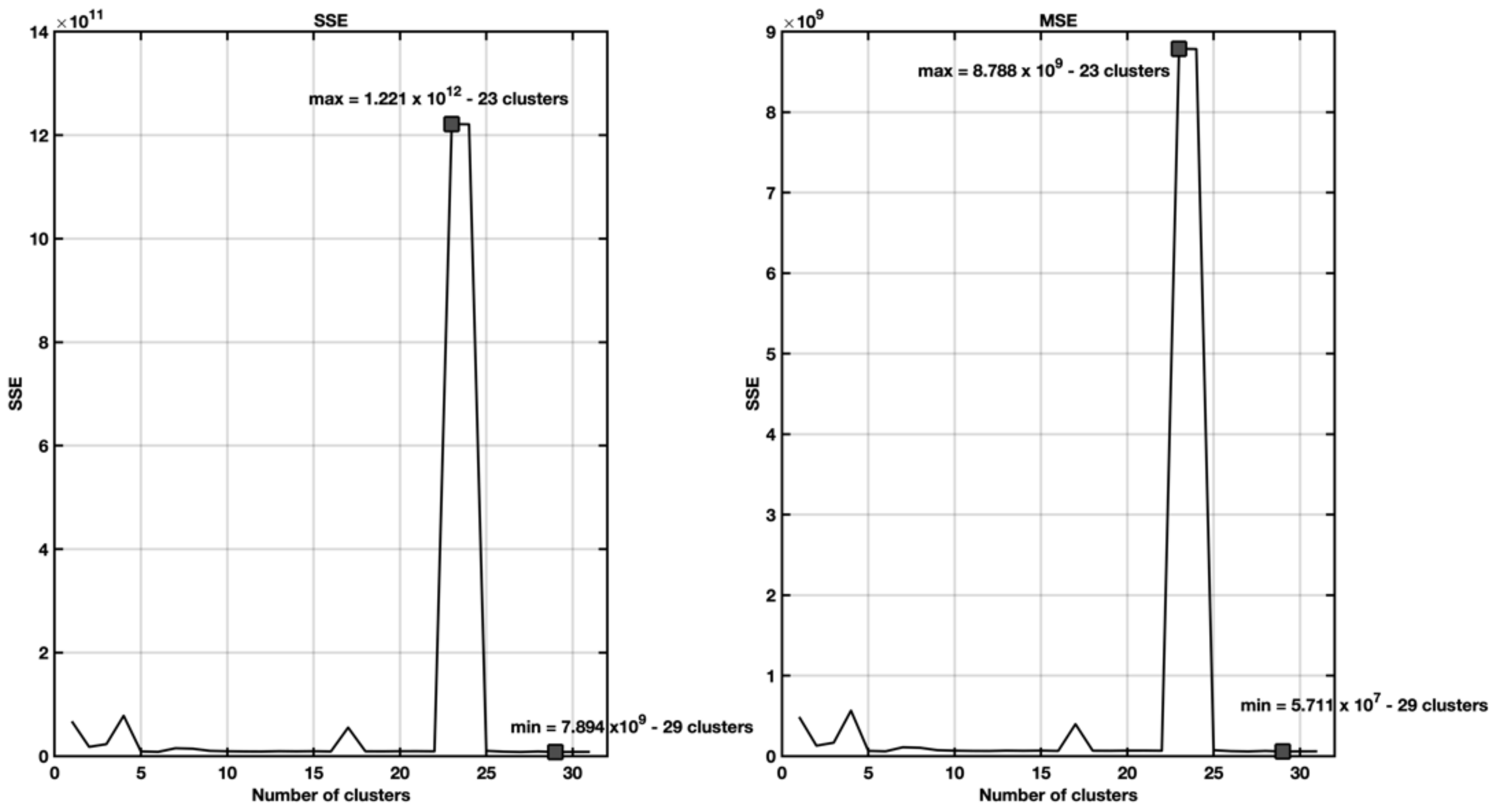
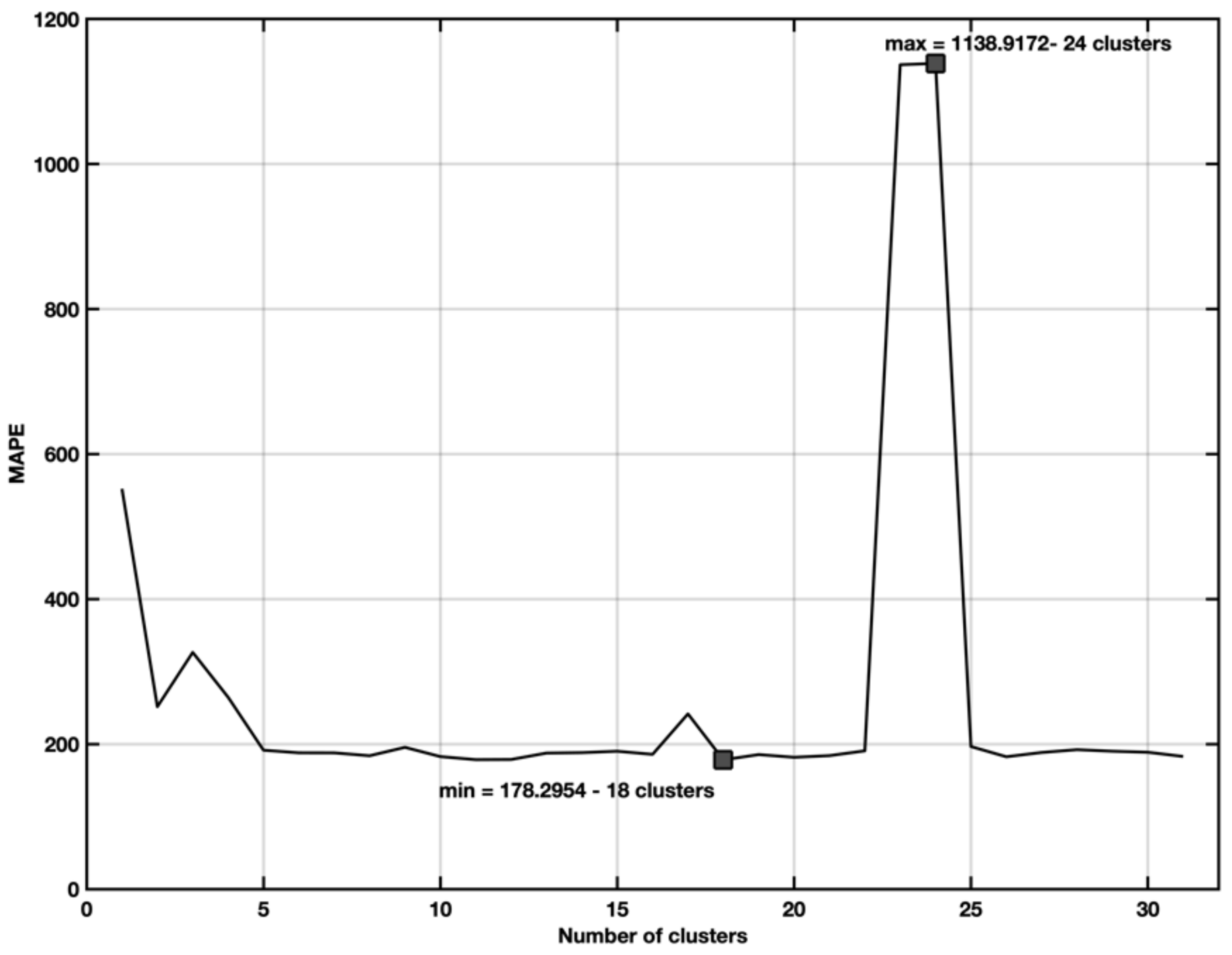
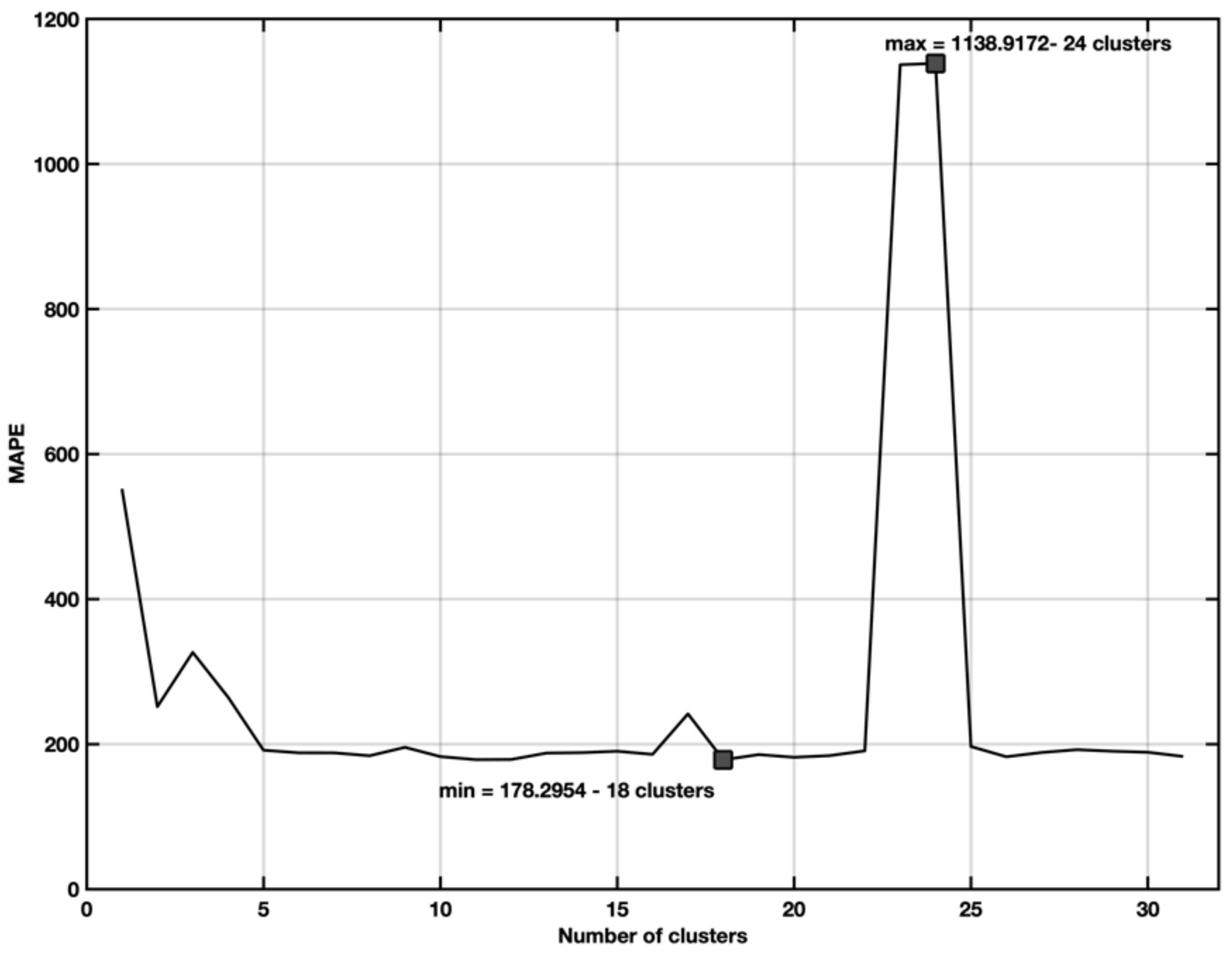
5.3. EX3—Stepwise Regression with Spectral Cluster Clustering
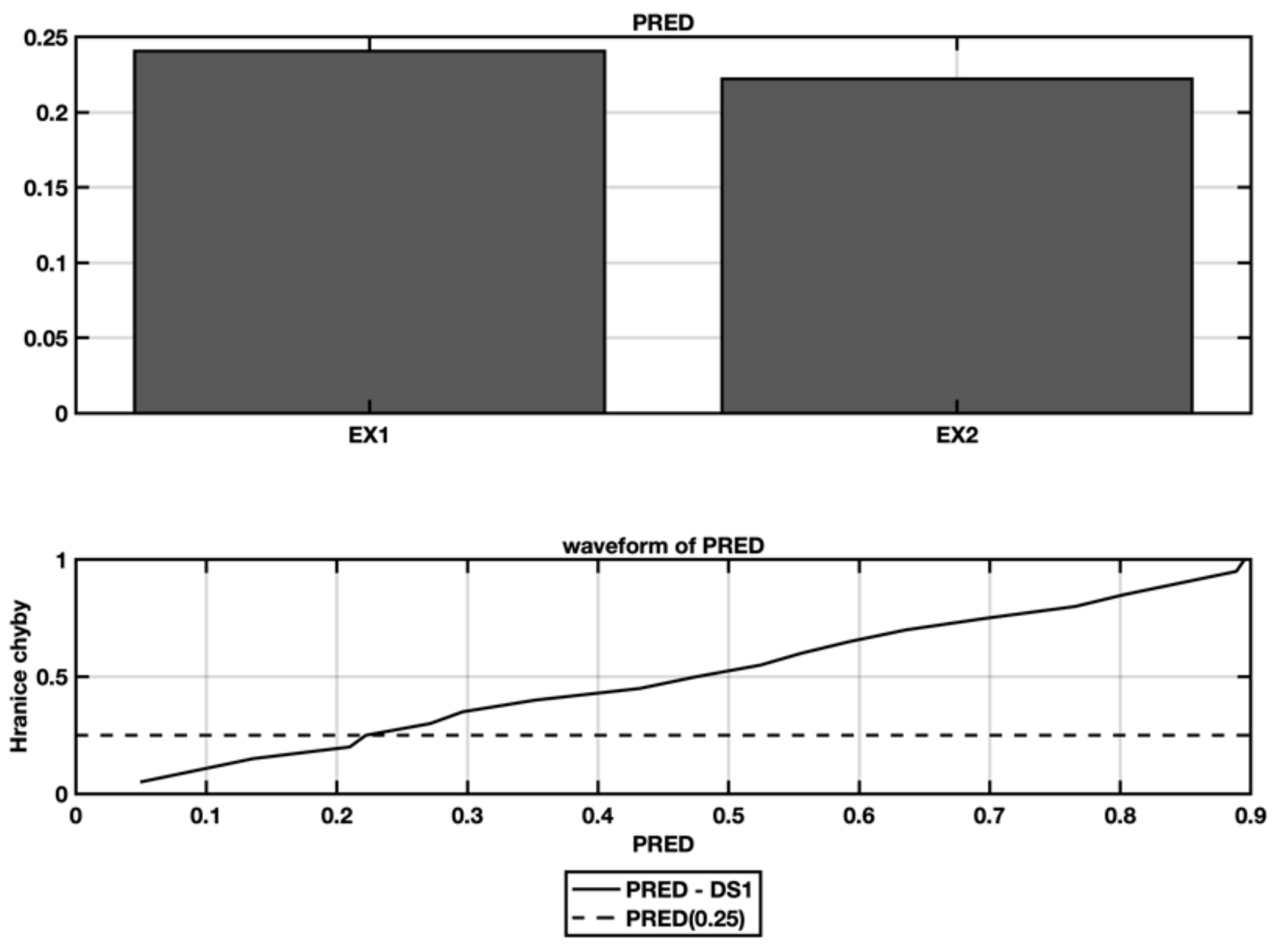
5.4. Ex4—Stepwise Regression with Spectral Clustering and Categorical Variables
6. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Trendowicz, A.; Jeffery, R. Software Project Effort Estimation: Foundations and Best Practice Guidelines for Success; Springer: Cham, Switzerland, 2014; 469p. [Google Scholar]
- Silhavy, P. A Software Project Effort Estimation by Using Functional Points. Habilitation Thesis, Mendel University, Brno, Czech Republic, 2019. [Google Scholar]
- McConnell, S. Software Estimation: Demystifying the Black Art; Microsoft Press: Redmond, WA, USA, 2006; 308p. [Google Scholar]
- Bundschuh, M.; Dekkers, C. The IT Measurement Compendium: Estimating and Benchmarking Success with Functional Size Measurement; Springer: Berlin, Germany, 2008; 643p. [Google Scholar]
- ISO/IEC. ISO/IEC 14143-1:2007. Information Technology-Software Measurement-Functional Size Measurement—Part 1: Definition of Concepts; ISO/IEC: Washington, DC, USA, 2007. [Google Scholar]
- Borandag, E.; Yucalar, F.; Erdogan, S.Z. A case study for the software size estimation through MK II FPA and FP methods. Int. J. Comput. Appl. Technol. 2016, 53, 309–314. [Google Scholar] [CrossRef]
- Bardsiri, V.K.; Jawawi, D.N.A.; Hashim, S.Z.M.; Khatibi, E. Increasing the accuracy of software development effort estimation using projects clustering. IET Softw. 2012, 6, 461–473. [Google Scholar] [CrossRef]
- Amazal, F.A.; Idri, A. Estimating software development effort using fuzzy clustering-based analogy. J. Softw. Evol. Process 2021, 33, e2324. [Google Scholar] [CrossRef]
- Idri, A.; Amazal, F.A.; Abran, A. Analogy-based software development effort estimation: A systematic mapping and review. Inf. Softw. Technol. 2015, 58, 206–230. [Google Scholar] [CrossRef]
- Nassif, A.; Azzeh, M.; Capretz, L.; Ho, D. Neural network models for software development effort estimation: A comparative study. Neural Comput. Appl. 2015, 28, 2369–2381. [Google Scholar] [CrossRef] [Green Version]
- Rankovic, N.; Rankovic, D.; Ivanovic, M.; Lazic, L. Improved effort and cost estimation model using artificial neural networks and taguchi method with different activation functions. Entropy 2021, 23, 854. [Google Scholar] [CrossRef] [PubMed]
- Azzeh, M.; Nassif, A.B. A hybrid model for estimating software project effort from use case points. Appl. Soft Comput. 2016, 49, 981–989. [Google Scholar] [CrossRef] [Green Version]
- Gallego, J.J.C.; Rodríguez, D.; Sicilia, M.A.; Rubio, M.G.; Crespo, A.G. Software project effort estimation based on multiple parametric models generated through data clustering. J. Comput. Sci. Technol. 2007, 22, 371–378. [Google Scholar] [CrossRef]
- Garre, M.; Cuadrado, J.J.; Sicilia, M.A.; Charro, M.; Rodríguez, D. Segmented parametric software estimation models: Using the EM algorithm with the ISBSG 8 database. In Proceedings of the 27th International Conference on Information Technology Interfaces 2005, Cavtat, Croatia, 20–23 June 2005; pp. 193–199. [Google Scholar]
- Dempster, A.P.; Laird, N.M.; Rubin, D.B. Maximum likelihood from incomplete data via the EM algorithm. J. R. Statist. Soc. Ser. B (Methodol.) 1977, 39, 1–22. [Google Scholar] [CrossRef]
- Hihn, J.; Juster, L.; Johnson, J.; Menzies, T.; Michael, G. Improving and expanding NASA software cost estimation methods. In Proceedings of the 2016 IEEE Aerospace Conference, Big Sky, MT, USA, 3–12 March 2016; pp. 1–12. [Google Scholar]
- Khatibi Bardsiri, V.; Jawawi, D.N.A.; Hashim, S.Z.M.; Khatibi, E. A flexible method to estimate the software development effort based on the classification of projects and localization of comparisons. Empir. Softw. Eng. 2014, 19, 857–884. [Google Scholar] [CrossRef]
- Kennedy, J.; Eberhart, R. Particle swarm optimization. In Proceedings of the ICNN′95—International Conference on Neural Networks, Perth, WA, Austrilia, 27 November–1 December 1995; pp. 1942–1948. [Google Scholar]
- Prokopova, Z.; Silhavy, R.; Silhavy, P. The effects of clustering to software size estimation for the use case points methods. In Software Engineering Trends and Techniques in Intelligent Systems; Silhavy, R., Silhavy, P., Prokopova, Z., Senkerik, R., Kominkova Oplatkova, Z., Eds.; Springer International Publishing: Cham, Switzerland, 2017; pp. 479–490. [Google Scholar]
- Lokan, C.; Mendes, E. Applying moving windows to software effort estimation. In Proceedings of the 2009 3rd International Symposium on Empirical Software Engineering and Measurement, Lake Buena Vista, FL, USA, 15–16 October 2009; pp. 111–122. [Google Scholar]
- Amasaki, S.; Lokan, C. The effect of moving windows on software effort estimation: Comparative study with CART. In Proceedings of the 2014 6th International Workshop on Empirical Software Engineering in Practice, Osaka, Japan, 12–13 November 2014; pp. 1–6. [Google Scholar]
- Silhavy, R.; Silhavy, P.; Prokopova, Z. Evaluating subset selection methods for use case points estimation. Inf. Softw. Technol. 2018, 97, 1–9. [Google Scholar] [CrossRef]
- Minku, L.L. A novel online supervised hyperparameter tuning procedure applied to cross-company software effort estimation. Empir. Softw. Eng. 2019, 24, 3153–3204. [Google Scholar] [CrossRef] [Green Version]
- Silhavy, P.; Silhavy, R.; Prokopova, Z. Categorical variable segmentation model for software development effort estimation. IEEE Access 2019, 7, 9618–9626. [Google Scholar] [CrossRef]
- Ventura-Molina, E.; López-Martín, C.; López-Yáñez, I.; Yáñez-Márquez, C. A novel data analytics method for predicting the delivery speed of software enhancement projects. Mathematics 2020, 8, 2002. [Google Scholar] [CrossRef]
- International Function Point Users Group (IFPUG). Available online: https://www.ifpug.org (accessed on 16 January 2021).
- ISBSG. ISBSG Development & Enhancement Repository-Release 13. Available online: http://isbsg.org (accessed on 2 February 2015).
- Ezghari, S.; Zahi, A. Uncertainty management in software effort estimation using a consistent fuzzy analogy-based method. Appl. Soft Comput. 2018, 67, 540–557. [Google Scholar] [CrossRef]
- Sarro, F.; Petrozziello, A. Linear programming as a baseline for software effort estimation. ACM Trans. Softw. Eng. Methodol. 2018, 27, 1–28. [Google Scholar] [CrossRef]
- Azzeh, M.; Nassif, A.B.; Banitaan, S. Comparative analysis of soft computing techniques for predicting software effort based use case points. IET Softw. 2018, 12, 19–29. [Google Scholar] [CrossRef]
- Azzeh, M.; Nassif, A.B. Analyzing the relationship between project productivity and environment factors in the use case points method. J. Softw. Evol. Process 2017, 29, e1882. [Google Scholar] [CrossRef] [Green Version]
- Silhavy, R.; Silhavy, P.; Prokopova, Z. Analysis and selection of a regression model for the use case points method using a stepwise approach. J. Syst. Softw. 2017, 125, 1–14. [Google Scholar] [CrossRef] [Green Version]
- Silhavy, P.; Silhavy, R.; Prokopova, Z. Evaluation of data clustering for stepwise linear regression on use case points estimation. In Software Engineering Trends and Techniques in Intelligent Systems; Silhavy, R., Silhavy, P., Prokopova, Z., Senkerik, R., Kominkova Oplatkova, Z., Eds.; Springer International Publishing: Cham, Switzerland, 2017; pp. 491–496. [Google Scholar]
- Von Luxburg, U. A tutorial on spectral clustering. Stat. Comput. 2007, 17, 395–416. [Google Scholar] [CrossRef]
- Silhavy, R.; Silhavy, P.; Prokopova, Z. Improving algorithmic optimisation method by spectral clustering. In Software Engineering Trends and Techniques in Intelligent Systems, Proceedings of the Computer Science On-line Conference, Prague, Czech Republic, 26–29 April 2017; Springer: Cham, Switzerland, 2017; pp. 1–10. [Google Scholar]
- Soltanolkotabi, M.; Elhamifar, E.; Candes, E.J. Robust subspace clustering. Ann. Stat. 2014, 42, 669–699. [Google Scholar] [CrossRef] [Green Version]
- Urbanek, T.; Prokopova, Z.; Silhavy, R.; Vesela, V. Prediction accuracy measurements as a fitness function for software effort estimation. SpringerPlus 2015, 4, 778. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Shepperd, M.; MacDonell, S. Evaluating prediction systems in software project estimation. Inf. Softw. Technol. 2012, 54, 820–827. [Google Scholar] [CrossRef] [Green Version]
- Idri, A.; Abnane, I.; Abran, A. Evaluating Pred(p) and standardized accuracy criteria in software development effort estimation. J. Softw. Evol. Process 2018, 30, e1925. [Google Scholar] [CrossRef]
- De Myttenaere, A.; Golden, B.; Le Grand, B.; Rossi, F. Mean absolute percentage error for regression models. Neurocomputing 2016, 192, 38–48. [Google Scholar] [CrossRef] [Green Version]
- Silhavy, P.; Silhavy, R.; Prokopova, Z. Stepwise regression clustering method in function points estimation. In Computational and Statistical Methods in Intelligent Systems, Proceedings of the Computational Methods in Systems and Software, Szczecin, Poland, 12–14 September 2018; Springer: Cham, Switzerland, 2018; pp. 333–340. [Google Scholar]
- Jajuga, K.; Sokolowski, A.; Bock, H.H. Classification, Clustering, and Data Analysis: Recent Advances and Applications; Springer Science & Business Media: Berlin, Germany, 2012. [Google Scholar]
- Fraley, C.; Raftery, A. How many clusters? Which clustering method? Answers via model-based cluster analysis. Comput. J. 1998, 41, 578–588. [Google Scholar] [CrossRef]
- Conte, S.; Dunsmore, H.; Shen, Y. Software Engineering Metrics and Models; Benjamin-Cummings Publishing: Redwood City, CA, USA, 1986. [Google Scholar]







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Group | Relative Size | Dataset Type | Size (Person-Hours) |
|---|---|---|---|
| 1 | XXS | Extra-extra small | >0 to <10 |
| 2 | XS | Extra small | >10 to <30 |
| 3 | S | Small | >30 to <100 |
| 4 | M1 | Medium 1 | >100 to <300 |
| 5 | M2 | Medium 2 | >300 to <1000 |
| 6 | L | Large | >1000 to <3000 |
| 7 | XL | Extra large | >3000 to <9000 |
| 8 | XXL | Extra-extra large | >9000 to <18,000 |
| 9 | XXXL | Extra-extra-extra large | >18,000 |
| Mean Value | Std. Deviation | ||||
|---|---|---|---|---|---|
| PDR | FP | Effort | PDR | FP | Effort |
| 19.79 | 358.16 | 5291.8 | 22.94 | 651.43 | 8317.07 |
| min | max | ||||
| PDR | FP | Effort | PDR | FP | Effort |
| 0.4 | 6 | 31 | 259.7 | 13,580 | 71,729 |
| Method | MAPE | PRED (0.25) |
|---|---|---|
| EX1 | 179 | 0.24 |
| EX2 | 159 | 0.24 |
| EX3—3 clusters | 134 | 0.21 |
| EX4—11 clusters | 178 | 0.17 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Silhavy, P.; Silhavy, R.; Prokopova, Z. Spectral Clustering Effect in Software Development Effort Estimation. Symmetry 2021, 13, 2119. https://doi.org/10.3390/sym13112119
Silhavy P, Silhavy R, Prokopova Z. Spectral Clustering Effect in Software Development Effort Estimation. Symmetry. 2021; 13(11):2119. https://doi.org/10.3390/sym13112119
Chicago/Turabian StyleSilhavy, Petr, Radek Silhavy, and Zdenka Prokopova. 2021. "Spectral Clustering Effect in Software Development Effort Estimation" Symmetry 13, no. 11: 2119. https://doi.org/10.3390/sym13112119
APA StyleSilhavy, P., Silhavy, R., & Prokopova, Z. (2021). Spectral Clustering Effect in Software Development Effort Estimation. Symmetry, 13(11), 2119. https://doi.org/10.3390/sym13112119