1. Introduction
As is nowadays well known, a large variety of real-world networks display a scale-free property, see, e.g., in [
1,
2,
3,
4]. A further feature typically found to be present for example in social networks is represented by assortative mixing, see, e.g., in [
2,
5]. This expresses the tendency of nodes to be connected with nodes which are similar to them. In particular, degree assortativity—which, at least in the mathematical and physical literature, provides the most studied example of assortativity—suggests that high degree nodes are preferentially linked to other high degree nodes and low degree nodes to other low degree nodes. The opposite property, degree disassortativity, according to which hubs are preferentially connected to small-degree nodes, and vice versa, is present in general in biological and technological networks, see, e.g., in [
2,
5]. Networks which exhibit assortativity or disassortativity are said to be correlated.
In this paper, we explore some aspects of different possible mathematical and computational approaches to the treatment of evolutionary systems defined on this kind of networks. We are ultimately motivated by the interest for the dynamics of phenomena pertaining to a socio-economic context. An effective formulation of the evolution equations describing such phenomena cannot neglect the nature of the links among the elements of the systems at hand. Given that the incorporation of the network of connections can be achieved with different approaches, it is natural to analyze which are the advantages and which are prices and costs of each approach.
To fix ideas, we consider here the problem of diffusion of innovations, for which two of the possible formal frameworks are briefly recalled. Both frameworks are expressed by systems of differential equations. One of them mimics the heterogeneous mean-field approach developed and successfully applied by Boguñá, Pastor-Satorras, and Vespignani for the investigation of epidemic spreading in complex networks, see, e.g., in [
6,
7]. It involves a number of equations equal to the maximum degree
n of the nodes in the network. The other framework relies on the explicit construction of an ensemble of networks; for each element of the ensemble, a much larger system of
N differential equations is studied,
N being the number of nodes in the network. The construction of the ensemble involves a rewiring procedure: starting from an initial network configuration, links between nodes are repeatedly detached and reattached in such a way that the degree distribution is preserved. Various algorithms exist for the generation of arbitrarily two-points correlated networks, or maximally assortative or maximally disassortative networks, see, e.g., in [
8,
9,
10,
11,
12], and we employ here one of them.
Our investigation aims at a comparison of the different approaches outlined above. The results obtained reveal facets and patterns, which we think worthwhile to illustrate.
As complex networks are in fact ubiquitous (playing an important role in communications infrastructure, in human and social relations, in protein interactions, in transport structures, in neural circuits, and much more), the unprecedented data availability and computing power achieved in the last two decades has been fostering a tremendous number of investigations and works in the field. A wide range of different issues are tackled in these works, relative, for example, to empirical observations, statistical and structural properties, modeling and algorithmic construction and, to a lesser extent, to dynamical processes taking place on top of networks. As a reference for recent contributions, containing in turn a whole set of further references, we suggest here the two volumes [
13]. Yet, in spite of several advancements and progresses, much remains to be done and understood. In particular, the main purpose of this paper is to contribute to a better comprehension of theoretical and foundational aspects concerning assortative scale-free networks and their role for the mathematical modeling of systems with social interaction. Current work in this direction objectively displays some research gaps, because on one side quantities like the correlation coefficient
r and the average nearest neighbor degree function
(see below the definitions) can be measured for real networks without any ambiguity; on the other hand, formal models based on a mean-field approach move from strong assumptions on the form of
without questioning whether such assumptions can be realized on assortative scale-free networks at least at the level of construction algorithms. In this work, we make an effort to bridge the gaps between mean-field and real networks. This is also clearly relevant in terms of applicability, because if one wants to simulate dynamical processes or diffusion processes on a certain kind of network, the first technical choice one encounters is whether to describe the network through the adjacency matrix of the nodes or the correlation functions of their degrees.
The rest of the paper is organized as follows. In
Section 2, we recall the methods usually employed to analyze degree correlation properties.
Section 3 is devoted to the average nearest neighbor degree function
. Aspects of the behavior of this function are described, based on outputs of simulations relative to networks of various dimensions, both as obtained in a mean-field framework and for concrete cases. The resulting differences are outlined and discussed. In particular, five assortative networks families, and a disassortative one, are considered. In
Section 4, the effects of assortative mixing and of the two different approaches mentioned above on the diffusion dynamics and related peak times are explored.
Section 5 contains remarks on a further indicator, the average of the average nearest neighbor degree function. It provides as well a couple of relations involving
and some moments of the degree distribution which can be useful towards calculating certain indices of interest in the present context. Finally, in
Section 6 we discuss our results.
These include the detection of an unexpected quasi-invariance property of the graph shape of the function (calculated through the correlation coefficients) with respect to the network maximal degree; the construction of correlated networks whose function does not behave, as generally expected in the literature, as for some coefficient and ; and a qualitative agreement between the estimates of diffusion peak times obtained with the two different methods employed.
2. Measuring Assortative and Disassortative Mixing
We focus here on scale-free complex networks whose degree distribution is given (for
, with
) by
for some
and some positive constant
c determined by the normalization
. Two frequently used tools to detect assortativity or disassortativity are the correlation coefficient
r introduced by Newman in [
14] and the average nearest neighbor degree function
[
15]. This function is defined in terms of the correlation coefficients
, where
denotes for
the conditional probability for a node of degree
k to be connected to a node of degree
h. Indeed, it is given by
with the
satisfying for all
:
and the “Network Closure Condition”
If
is increasing in
k, the network is assortative and if
is decreasing in
k, the network is disassortative. On the other hand, the coefficient
r is defined as
where the quantity
(for
) express the probability that a randomly chosen edge connects nodes with excess degree
k and
h, the excess degree of a node being equal to its degree minus one,
(for
) denotes the distribution of the excess degrees,
, and
denotes the standard deviation of the distribution
,
The coefficient r takes values in . If , the network is assortative, whereas it is disassortative if . Networks for which are called uncorrelated or neutral.
A relation between the mentioned quantities is established as follows. Let
denote the number of edges connecting nodes with degree
k and
h, the only exception being for edges linking nodes with the same degree which must be counted twice [
5,
8]. Let
. The matrix with elements
is plainly symmetric and each
corresponds, with the mentioned exception, to the fraction of edges linking nodes with degree
k and
h. One can easily see that
and
for all
. Conversely,
holds true [
16].
3. The Function in the Mean-Field Approach and for Concrete Networks
Various formulae are available for the definition of assortative or disassortative correlation coefficients . In this section, we recall some of them, for which then we calculate the associated average nearest neighbor degree functions .
A first formula for the assortative case can be obtained by applying the relation (5) of
Section 2 to the matrix of the
given in [
8] as
In particular, we choose here the terms on the right hand side of (7) as
for
.
A simpler formula, originally proposed in [
17] and also employed in [
18], is given by
where
, which ranges from 0 to 1, turns out to coincide with the Newman assortativity coefficient
r, whereas
denotes the Kronecker symbol.
Three more formulae have been proposed in [
16]. Each of them is obtained, as shortly recalled next, in a few steps which guarantee that the conditions (2) and (3) hold true.
Start by defining for some parameter
elements
as
and
Call
for any
and let
. Then, redefine the correlation matrix by setting the elements on the diagonal equal to
and leaving the other elements unchanged:
for
. Finally, normalize the entire matrix by setting
Alternatively, start by defining, for
,
and
with
as in (11). Then, proceed as in the previous case so as to have the normalization
.
Last, start by defining, for
,
and
with
as in (11). Again, proceed as above to get elements
satisfying also the normalization
.
A formula for the disassortative case can be obtained by applying the relation (5) of
Section 2 to the matrix of the
suggested in [
8] as
where, for example, the terms on the right hand side of (14) are as in (8).
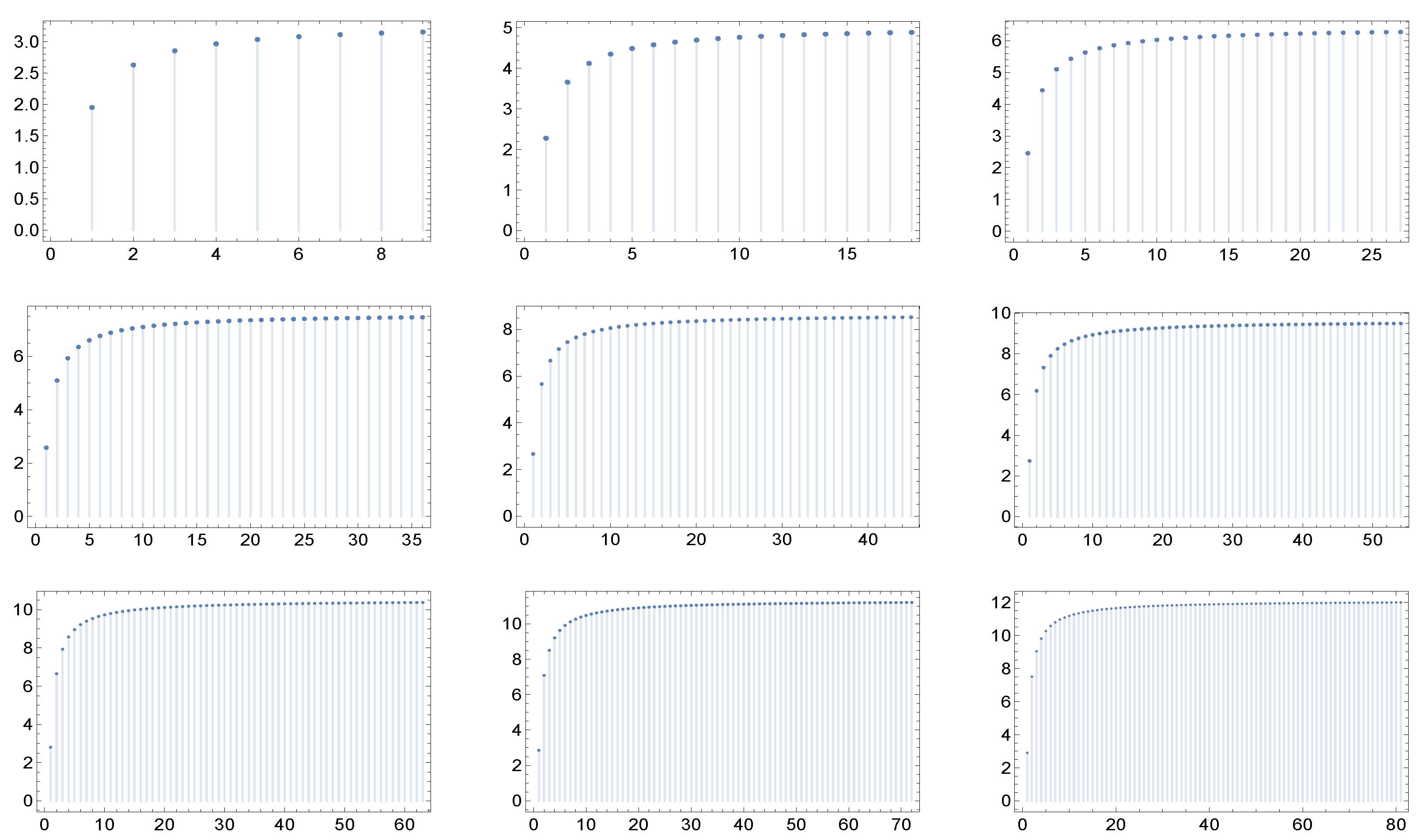
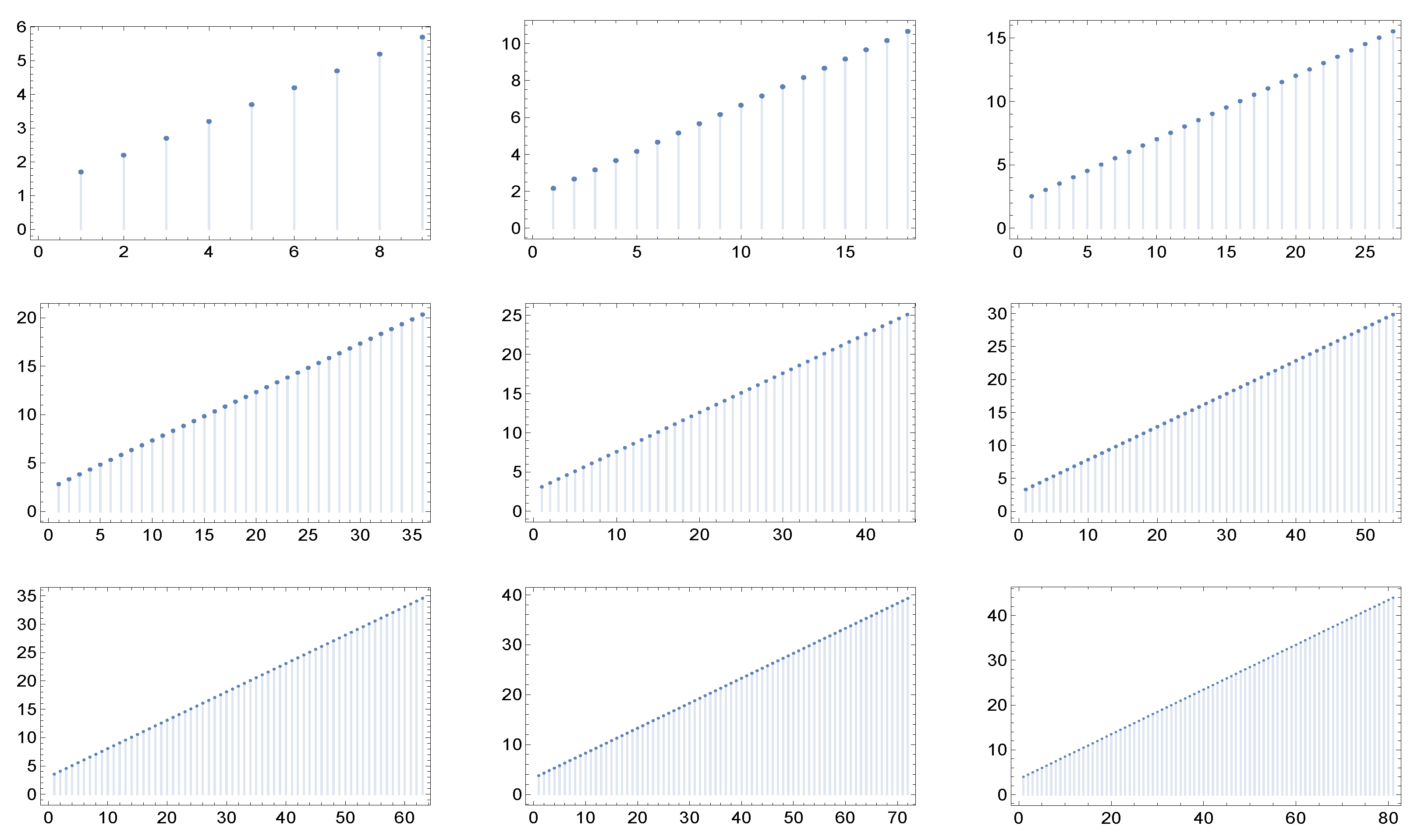
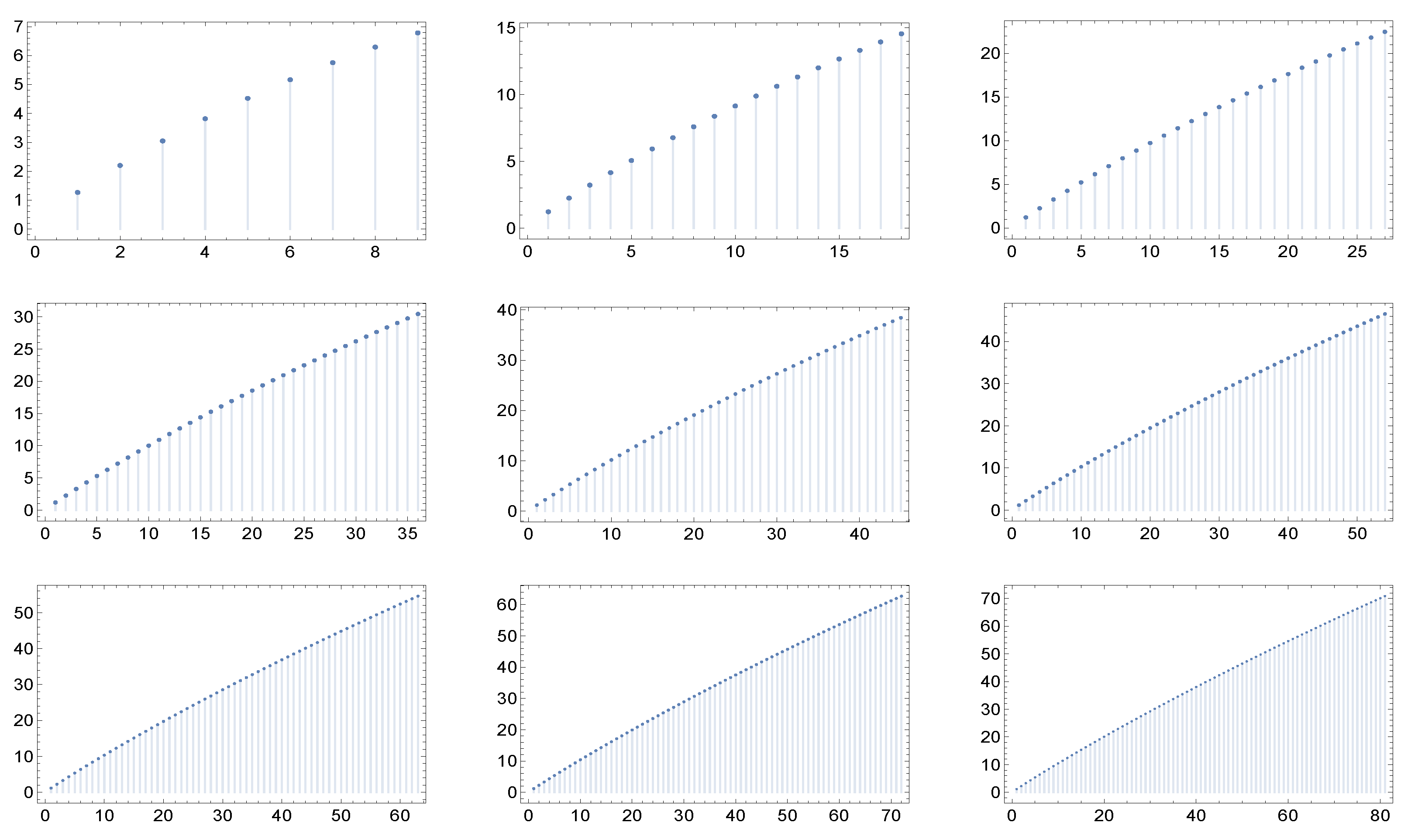
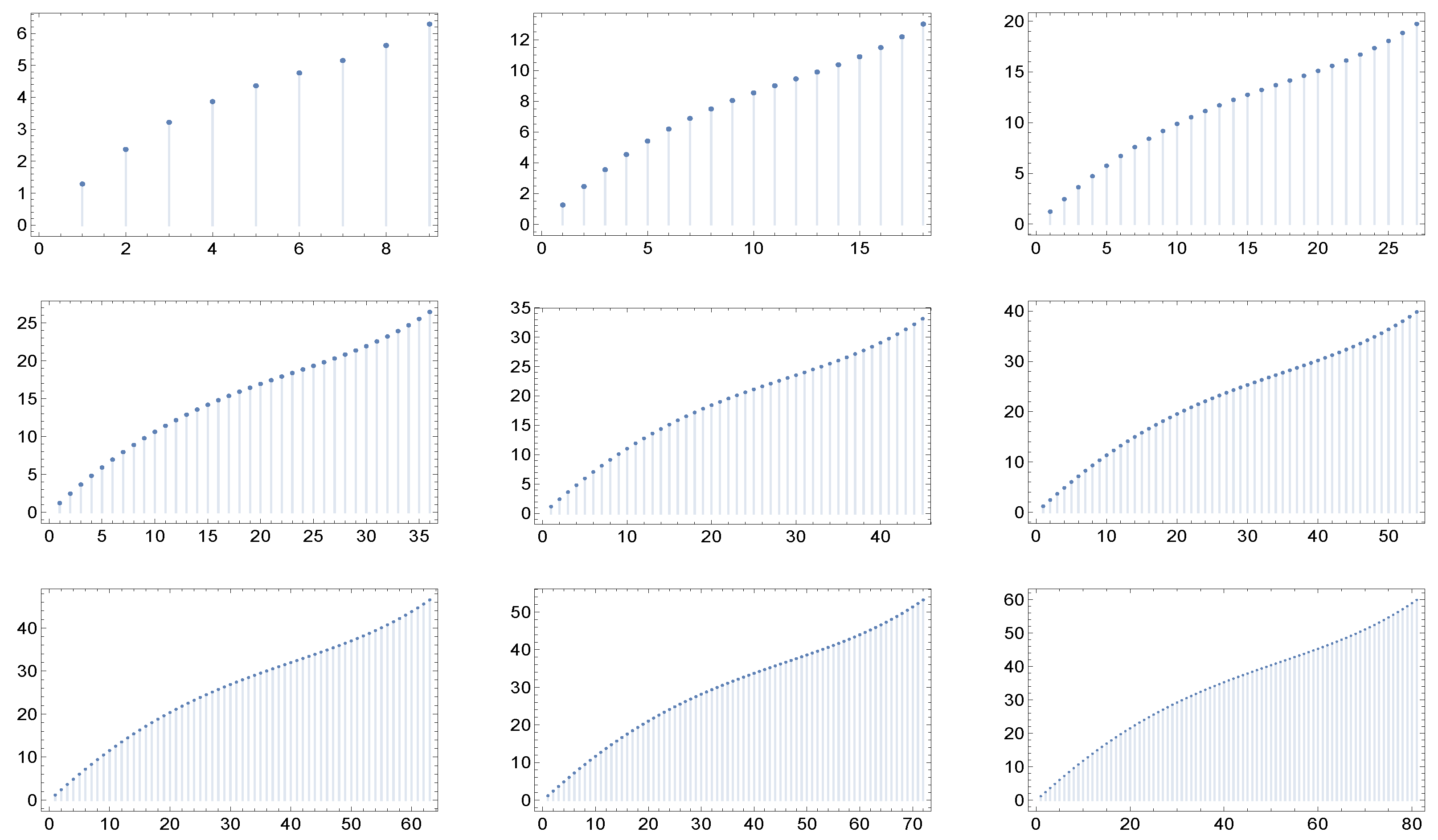
Figure 1,
Figure 2,
Figure 3,
Figure 4,
Figure 5 and
Figure 6 display for each of the described network cases the graphs of the function
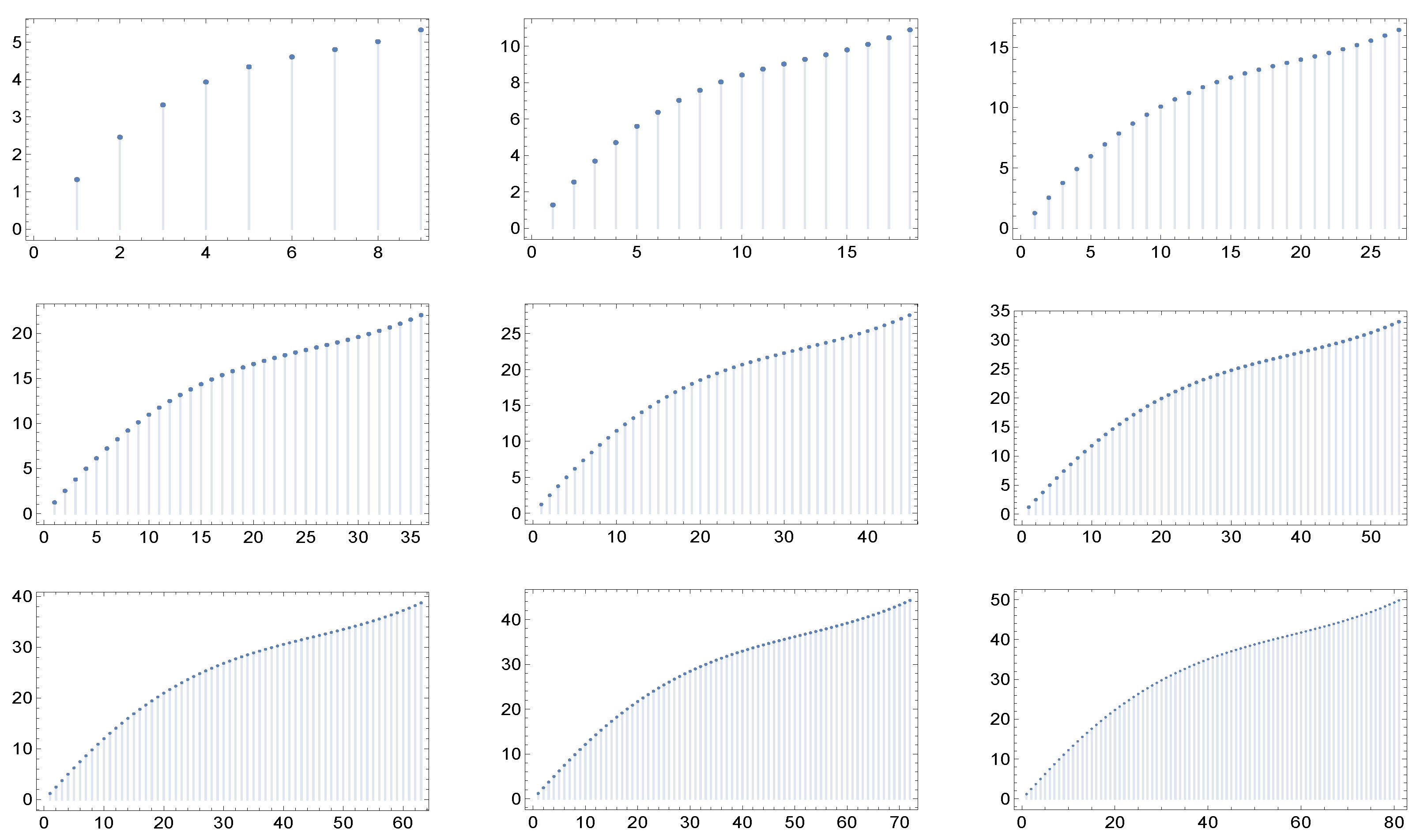
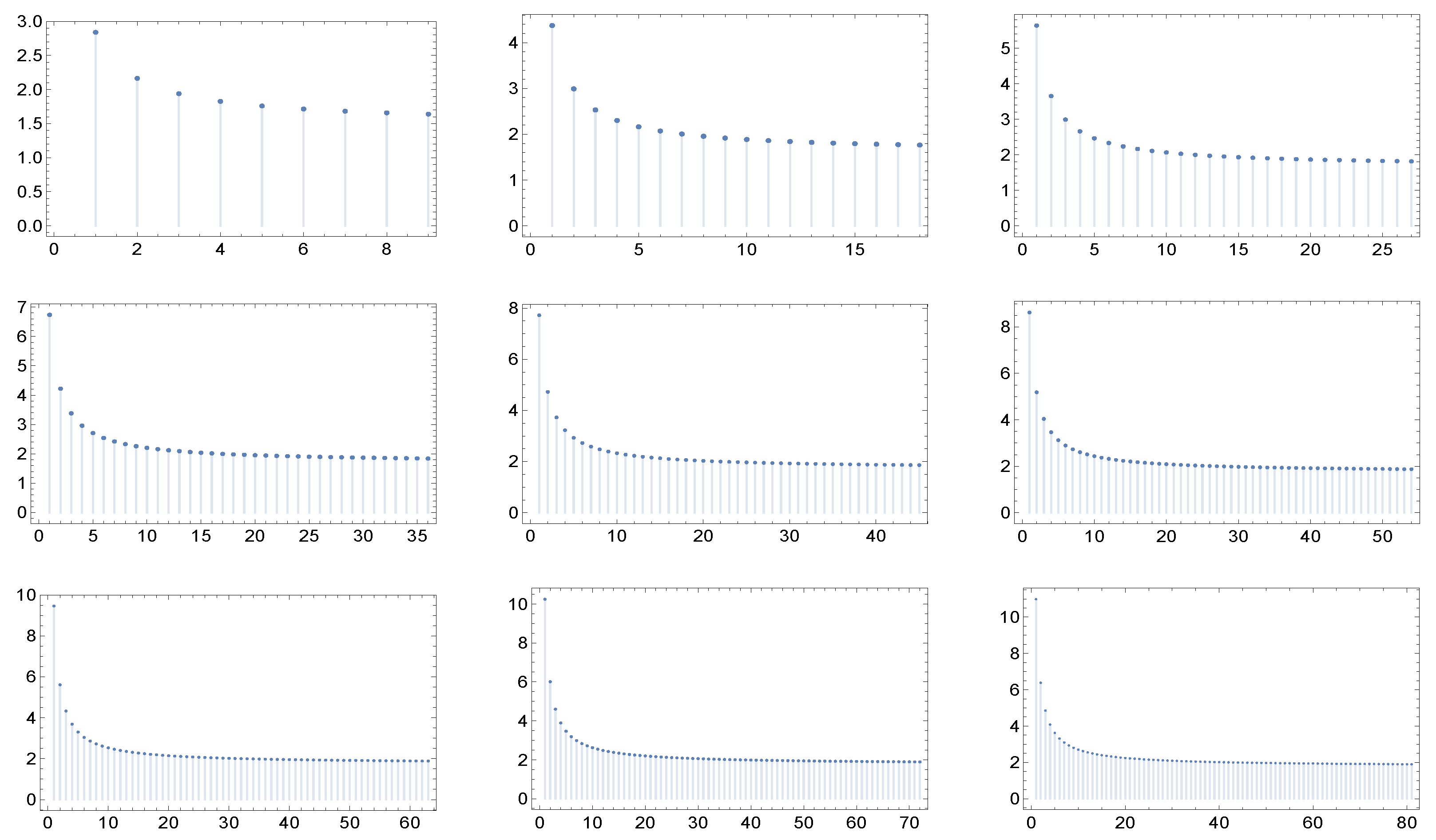
in correspondence to nine different values of the maximum degree: 9, 18, 27, 36, 45, 54, 63, 72, and 81. Of course, we have to fix in each case a particular value of the parameters, and these are specified in the captions of the figures.
What catches the eye and is especially evident in
Figure 4 and
Figure 5, is that in each of the six cases the shape of the graphs of
exhibit a kind of invariance with respect to the maximum degree and correspondingly, in view of the criterium of Dorogovtsev and Mendes [
19], with respect to the network dimension (the number of nodes). Furthermore, the same holds true for higher values of the maximum degree.
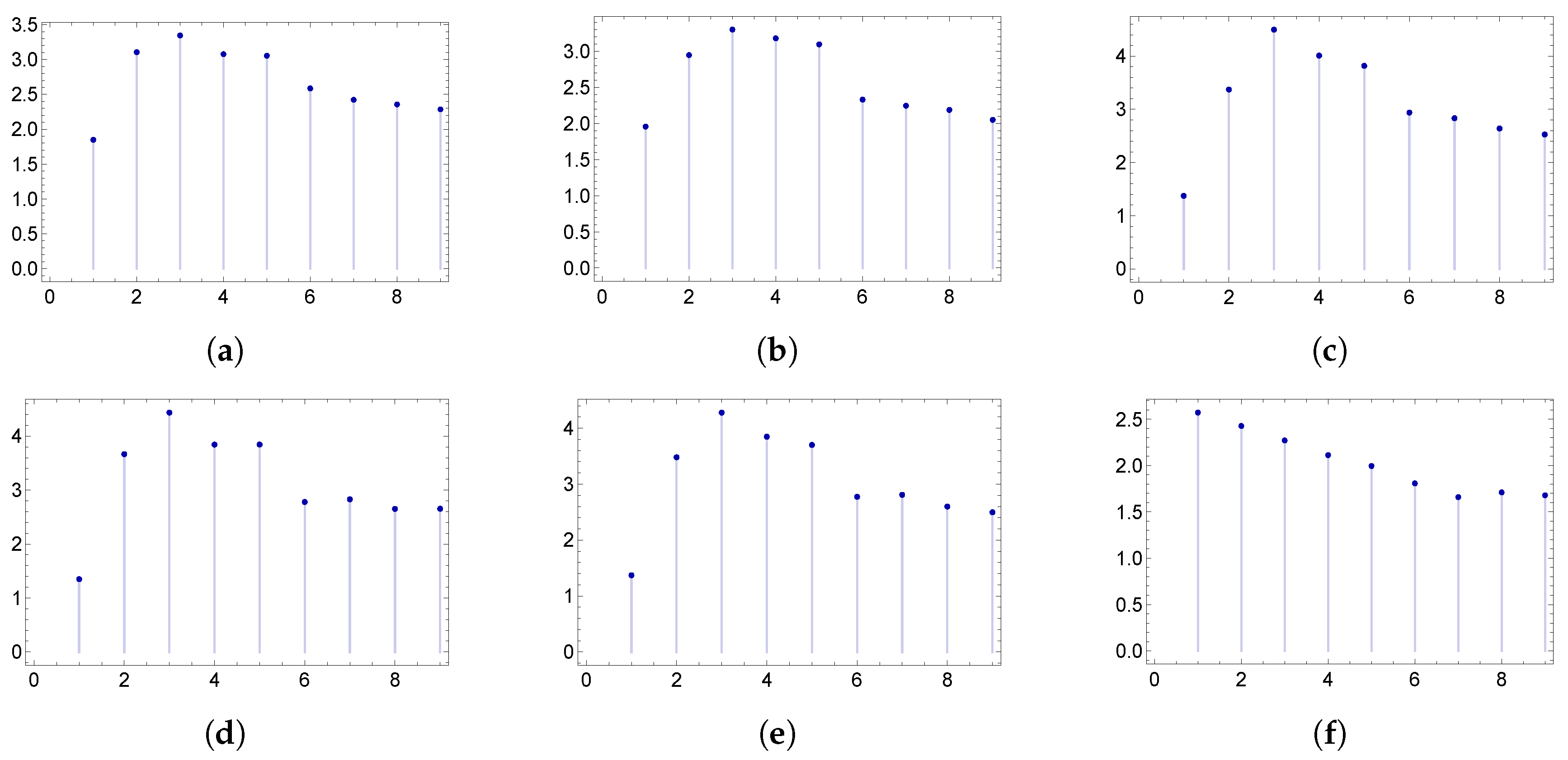
One can wonder here whether this invariant-type behavior is a consequence of the scale-free character of the degree distribution. Notice that if, for example,
(a case in which the degree distribution does not have the scale-free property) and the
are chosen as in
) above with
, no invariance as in the
Figure 1,
Figure 2,
Figure 3,
Figure 4,
Figure 5 and
Figure 6 is found. This fact is illustrated in the
Figure 7.
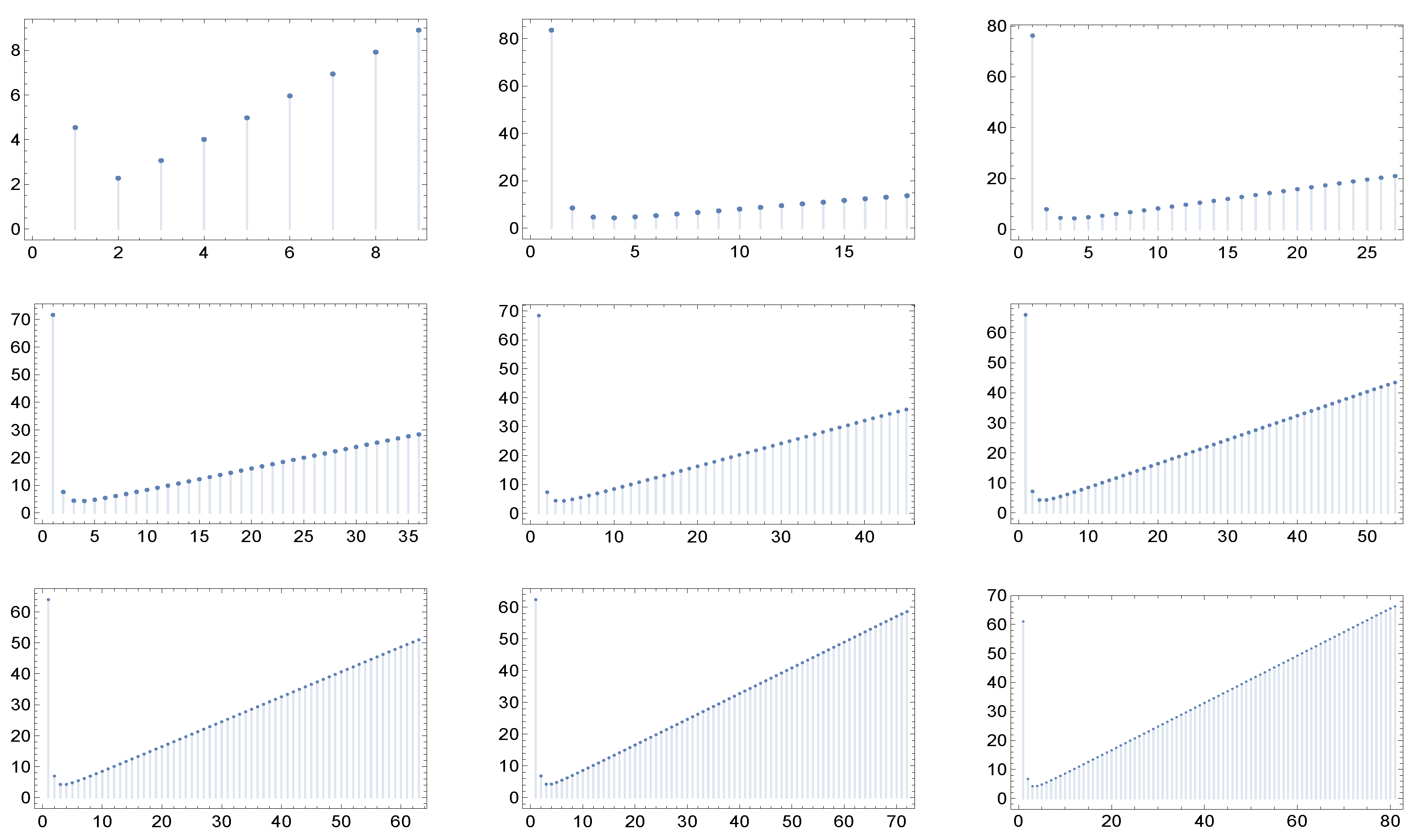
The situation is different when one constructs, employing a rewiring procedure as mentioned in the Introduction, concrete networks tentatively having a prescribed matrix
and then plots the averaged functions
for an ensemble of them. Observing that, thanks to the formulae (5) and (6) above, such a construction can be achieved through the generation of networks having a prescribed matrix
, we here recall that an algorithm specifically aimed at this (more precisely, aimed at generating networks displaying on average a target matrix
) is described, for example, in [
8]. We employed this algorithm to generate the networks from which we obtained, through the procedure described below, the
averaged displayed in the
Figure 8.
The details of the procedure we employed to generate the graphs of the
displayed in the
Figure 8 are described next.
We fixed the maximum degree
and the exponent of the power-law
. Then, for each of the six cases introduced above we carried out the following steps. We randomly took as “step zero-networks” 30 synthetic networks with degree distribution “close” to a “true” power-law distribution with these parameter values (the degree distribution of concrete scale-free assortative networks cannot display an exact power-law behavior, because in such networks only a few hubs can be present; for a discussion on the construction of a discretized degree distribution see, e.g., in [
12]). On any such network we let
steps of a (Newman) rewiring run (the number
being suitable for a stabilization of the assortativity coefficient). We chose 30 “snapshot” networks out of the set of each rewired network more precisely, the networks obtained in correspondence of the steps
with
) and for these we constructed the matrices
. In each of the 30 cases, we then constructed a new matrix
(for
) as the average of the 30 “snapshot” matrices just obtained; through the Formula (5) we generated the correlation matrix
corresponding to this
and we employed networks generated in this way as networks on top of which to study the diffusion problem described in
Section 4. We also calculated the average
of 30 matrices
with
and, using (5), we generated the correlation matrix
corresponding to this
as well as its associated
. The panels in
Figure 8 clearly show that when concrete networks are constructed, even in the assortative case the function
is not always increasing. This behavior, related to what is known in the literature as structural cut-off [
5], is evidently due to the fact that in a network with a power-like decreasing degree distribution hubs cannot find many other hubs to which link. This finding is also compatible with the results one gets when calculating the assortativity coefficient
r. The values of
r for the six Markovian networks with
,
, and the
as described at the points (1)–(6) in
Section 3 are given in the first line in
Table 1. In contrast, in the second line of the table one has, for each of the cases (1)–(6), the value obtained as average of the assortativity coefficients of the networks corresponding to the thirty matrices
(with
) generated by the rewiring.
4. The Peak Time in Innovation Diffusion Dynamics
In this section, we explore the effects of assortativity in different approaches within the context of an application. Specifically, we deal with the innovation diffusion process and we consider two different frameworks designed to incorporate into the classic Bass model [
20] a structure of complex networks accounting for social interactions.
We start considering networks with maximum degree
n, degree distribution
where
and
c is the constant providing the normalization of
P, and correlation coefficients
as in the six cases described in
Section 3. The ratio to also consider a disassortative sample of networks is that in the innovation diffusion context also interaction and collaboration of firms can be of interest and firm networks can display disassortative mixing [
16]. Recalling that the main ingredients of the process, namely, the innovation and the imitation attitude, can be quantified, respectively, through two parameters
p and
q, we formulate (see also in [
16]) the first framework as the system of
n nonlinear ordinary differential equations
Each of these equations describes the variation in time of the fraction of potential adopters (for example, individuals or firms, depending on the specific context concerned) who have j links and at the time t have adopted the innovation (In each link class the number of potential adopters is fixed.). Accordingly, the potential adopters corresponding to nodes with degree j are regarded as all “behaving” in a same way. This corresponds to a heterogeneous mean-field scenario.
A different approach consists in generating concrete networks as suggested in
Section 3, writing for each network a system of evolution equations for the state of each node of the network, numerically solving the equations, calculating the peak time and taking an average out of several such times. The equation system on a concrete network can be derived by a first moment closure (see in this connection [
21,
22]) and takes the form
where
N and
respectively denote the number of network nodes and the elements of the adjacency matrix. The variable
with
has to be understood as the expectation
of the non-adoption (
) or adoption (
) state of node
i over many stochastic evolutions of the system.
An important time in the diffusion process of an innovation is the so-called
peak time which is the moment when the adoption rate assumes its maximum value. In connection with the six cases defined in
Section 3, we calculated the peak time both in a mean-field approach and for an ensemble of concrete networks, constructed through the procedure outlined in the same section.
To carry out the numerical simulations, we chose
and
, where the parameters
and
are as in the original Bass paper [
20], and the constant
provides a proper adjustment for the imitation coefficient on networks. Furthermore, we fixed
and
. For each of the six Markovian networks with correlation matrices described in the points (1)–(6) of
Section 3, we computed numerical solutions of the Equation (15). Then, we also performed the second procedure described above, which involves numerically solving an ensemble of equation systems (16). With regard to this approach, we took in each case (1)–(6) the average peak time out of a set of peak times relative to 30 networks. The values we found are reported in the
Table 2. There are of course differences between the peak times obtained through one and the other approach, but qualitatively one finds rather similar results. In particular, for almost each pair of networks the ordering relation between the values of their peak time as computed via one and the other approach is the same. Moreover, when looking at the plots, see, e.g.,
Figure 9, which display the time evolution of the functions
and
, derivatives of the “cumulative” solutions of the systems (15) and (16), respectively, one notices a reasonable agreement.
5. Further Remarks on the Function and Its Average
As is also apparent from
Section 3, the range of correlation matrix families is rather wide, and the functions
corresponding to these families can be quite different from each other.
In this regard, we observe that in [
6,
7], which deal with epidemic spreading in complex networks and, in particular, with the existence or non-existence of an epidemic threshold, an average of the average nearest neighbor degree function
,
is also introduced, whose properties are then explored (In [
6] and [
7] a different notation from that one adopted here is used to indicate the average in (17)). Notably, in the assortative case, the ansatz is there considered that
for some positive
. It is then shown that
tends to infinity as
. This property does not seem to be satisfied in general, namely, for all assortative families, by the relative
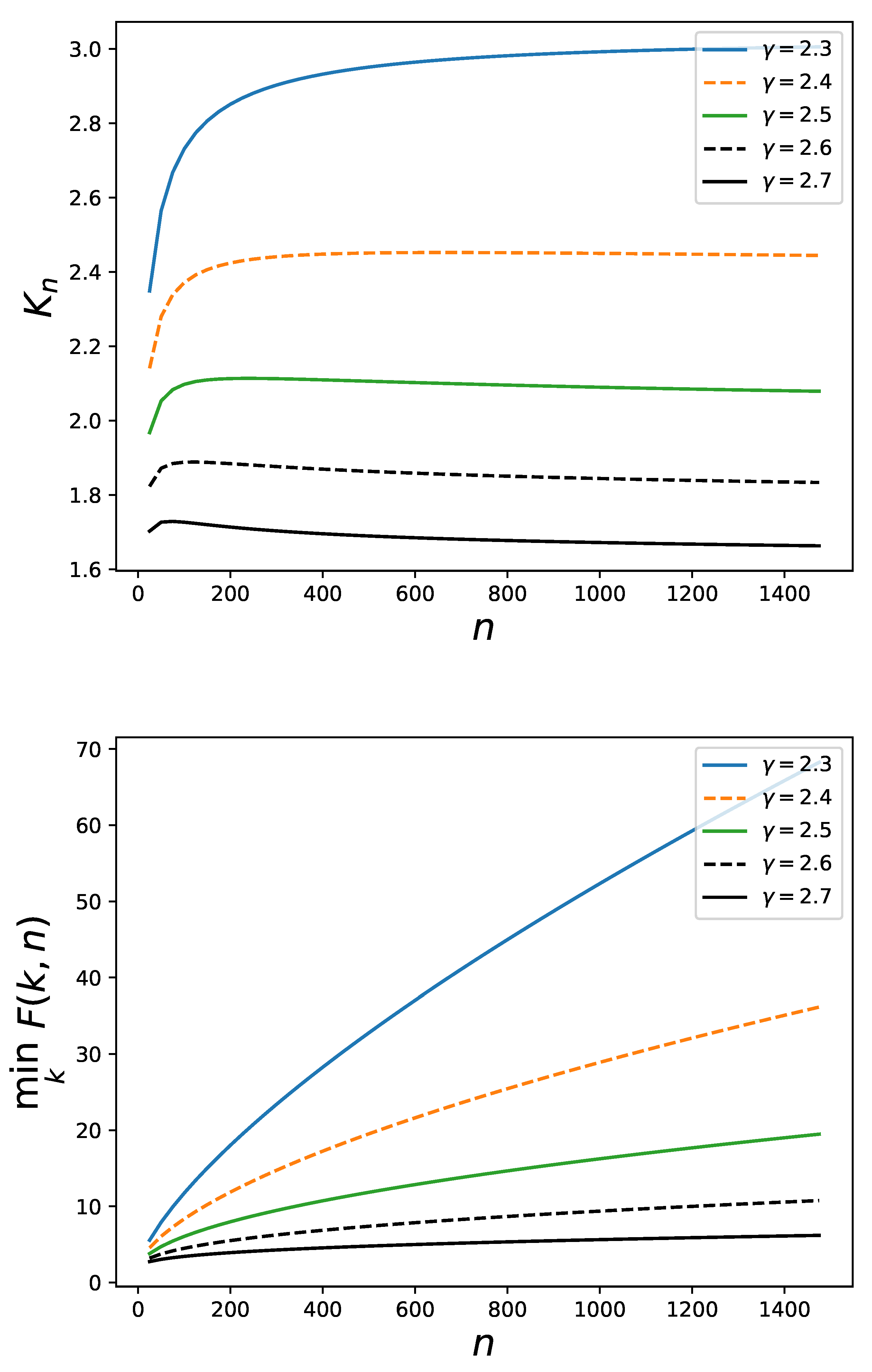
. For instance, for the exponential family
of
Section 3 one can numerically check that the dependence of
on
n in correspondence to various values of the exponent
occurring in the degree distribution is as displayed in the left panel of the
Figure 10. At least for certain values of
the value of
is not increasing and does not look at all as tending to infinity as
. However, of course, as well shown in
Figure 5, the function
for the exponential family
does not grow as
. It has nonetheless to be emphasized that also for this family the crucial property towards the determination of the absence of epidemic threshold [
6,
7], namely the growing character of
as a function of
n is satisfied, see the right panel of
Figure 10.
In connection with the innovation diffusion problem, one may wonder whether some correlation exists between the values of
and the peak times. Let us take for example networks with degree distribution
whose correlation matrices
are as in
of
Section 3 with
and consider nine values of the scale-free exponent
, i.e.,
for
(In this way, we are fixing the correlations and varying the degree distribution).
From
Table 3, we see that at fixed
n, the values of
and
display a quite strong dependence on
, namely,
is decreasing in
, while
is increasing. We note in this regard that the implicit relation between
and
is quite in agreement with intuition, because diffusion is expected to be faster when each node has, on the average, neighbors of higher degree. Varying the maximum degree
n, we see that the dependence of
and
on
becomes stronger as
n grows.
It is also possible to test the dependence of
and
on the correlations, for instance, by varying the parameter
. The resulting dependence is generally weak and details depend on
n. For instance, in
Table 4 we report the dependence of
on
and
(considering
for
) for the cases
and
. It can be seen that for
the values of
decrease slightly in
at small
and increase slightly in
at large
, while for
the opposite is true.
En passant, we mention here that the correlation between
and
r has been investigated from another perspective (namely, along a network rewiring process) in [
23].
Last, two more general properties involving the function are worth being noticed.
-
A normalization property [
6,
7]: One has (here and henceforth
denotes
.)
The formula (19) can be useful for calculating the constant c appearing in an ansatz as . One finds indeed .
Proof. of (19): The normalization property (19) immediately follows from the Network Closure Condition (3): one multiplies by h the left and the right hand side of (3), and then takes on both sides the sums for h and k from 1 to n to get on the l.h.s in view of (2) and on the r.h.s in view of the expression (1) of . □
-
Relation with the correlation coefficient: One has
The formula (20) can be employed for example for calculating r when the function is determined by the ansatz . In such a case one does not need to know the correlation coefficients: only the expression of and of some averages depending on the degree distribution appear on the r.h.s. of (20).
Proof. of (20): We consider separately the terms appearing in the expression of the correlation coefficient r in (4). □
Let us start with the first term in the numerator on the r.h.s of (4). Recalling that
we can write
where
,
and
.
Renaming for simplicity h and k the indices, we now transform the four terms which can be obtained on the r.h.s. of (21) when the product is expanded to get
- (i)
,
- (ii)
,
- (iii)
,
- (iv)
.
By exploiting in these expressions the Formules (1) and (2) and also using (19), we rewrite these terms, respectively, as
- (i)
,
- (ii)
,
- (iii)
,
- (iv)
.
The second term in the numerator is
. Recalling that
, we rewrite it as
and then, by setting as above
and
, as
with renamed indices this becomes
The numerator on the r.h.s. of (4) is thus
The denominator on the r.h.s. of (4) only contains quantities which depend on the
, and correspondingly on the degree distribution, and not on the correlation coefficients. These quantities can be expressed in terms of the moments
,
e
as follows.
and
In conclusion, the denominator on the r.h.s. of (4) is
and
6. Conclusions
This paper took shape from the investigation, carried out through two different mathematical frameworks, of some dynamical systems on top of synthetic correlated networks. Beside the description of the two approaches and of some findings obtained with them, the paper contains comments and observations on various features emerged. We emphasize next the main facets found as output of several numerical simulations.
– A singular and unexpected property is revealed for the six families of scale-free Markovian networks (characterized by given correlation coefficients) considered here: the graphs of the average nearest neighbor degree function , usually employed to detect assortativity or disassortativity, display an apparently ignored quasi-invariance with respect to the maximal degree of the network and, accordingly, its dimension. In our view, this is an interesting aspect, which deserves deeper inspection and understanding.
– The existence of correlated networks is shown whose average nearest neighbor degree function
does not behave as
with some coefficient
and
. See indeed, e.g., the graphs in
Figure 4 and
Figure 5. In general, in the literature, the functions
analytically expressed by means of the correlation coefficients are supposed to behave as
, see, e.g., in [
5,
6,
7,
17,
18,
24]. Only after writing this paper, did we learn from one of its referees of the existence of a recent work, [
25], where a
is constructed, which does not behave as
.
– Unavoidable differences are found and illustrated between the graphs of the function
in the case of Markovian scale-free networks and of concrete assortative scale-free networks. See also, in this connection, the discussion on the conflict between degree correlations and the scale-free property in [
5]. Independently of this, we can conclude that, at least with reference to the diffusion problem explored in
Section 4, the mean-field approach provides quite satisfactory results. Furthermore, of course, it has the advantage of being much less demanding from the computational point of view, in particular when larger networks are involved.
We notice that a functional behavior in
k as in the ansatz
is intrinsically independent from any scale. In the presence of such an anstatz it is therefore inevitable that the graph of
is self-similar
for any value of the maximum degree and
for networks having any degree distribution. The introduction of possible functional forms of
as proposed in this paper allows to distinguish between the situations
and
above, which appear otherwise like coincident or degenerate as far as the degree distribution and degree correlations are concerned. In fact the new functions obtained for
(for which there is no closed algebraic expression; they are the result of a construction procedure on the
performed in several steps and involving the
) display in their plots some inflection points whose position may in general depend on the degree distribution and on
n. We can therefore change separately
the maximum degree and
the degree distribution (from being scale-free to non scale-free) and check if these inflection points change their relative position. It turns out that, as seen in
Figure 7,
at fixed scale-free degree distribution, the plot of is self-similar, independently from n (no change in the relative position of the inflection points);
at fixed non scale-free distribution, the plot is not self-similar if we change n; and
at fixed n, the plot is not self-similar, if we switch from scale-free to non scale-free distributions.
Again, we stress that these different behaviors cannot be observed using an ansatz for that is inherently self-similar.
It seems to us that there are few works dealing with the problem tackled here. Yet, we can mention that various mean-field approximation schemes (node-based, degree-based, pair approximation, and approximate master equation) are compared with each other in connection with applications to epidemic spreading in [
22], and mean-field predictions and numerical simulation results are compared for dynamical processes running on 21 real-world networks in [
26]. It is impossible to give a concise description of the various specific results contained in these two references, but we emphasize here that also their authors provide evidence of cases in which the mean-field theory works quite well. Instead, it can be worthwhile to dwell on the paper [
24], where a comparison is made between mean-field predictions and simulations on large synthetic networks built with the Porto–Weber method, for some cases in which there is no decreasing tail of the
at large
k. This shows that the question is still open of whether mean-field predictions also are compatible with numerical solutions on synthetic assortative networks that do display a decreasing tail, like in the real case. Our paper describes an effort in this direction. Technically, our strategy has been to
generate “ideal” assortative correlation matrices
of various kinds;
compute diffusion times of the Bass model for each
in the mean-field approximation;
generate, by rewiring, synthetic scale-free networks whose real
is as close as possible to the given ideal
, according to the probability method by Newman (since the procedure is quite complex and involves an intermediate averaging, see
Section 3, it was limited to small
n); and
compute again diffusion times using the adjacency matrices of the synthetic networks and compare them with those of Point
. What we found is that, unlike in [
24], the effective
of the networks so constructed does display a decreasing tail, like in real networks. Nevertheless, the diffusion times are in reasonable agreement.
Finally, a maximal degree equal to 9, as here prevalently considered, may look quite small. The majority of papers studying complex networks deal with much greater numbers. We believe, however, that for the purpose of this paper, and to show the outlined facets and differences, this choice is sufficient and suited.














{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
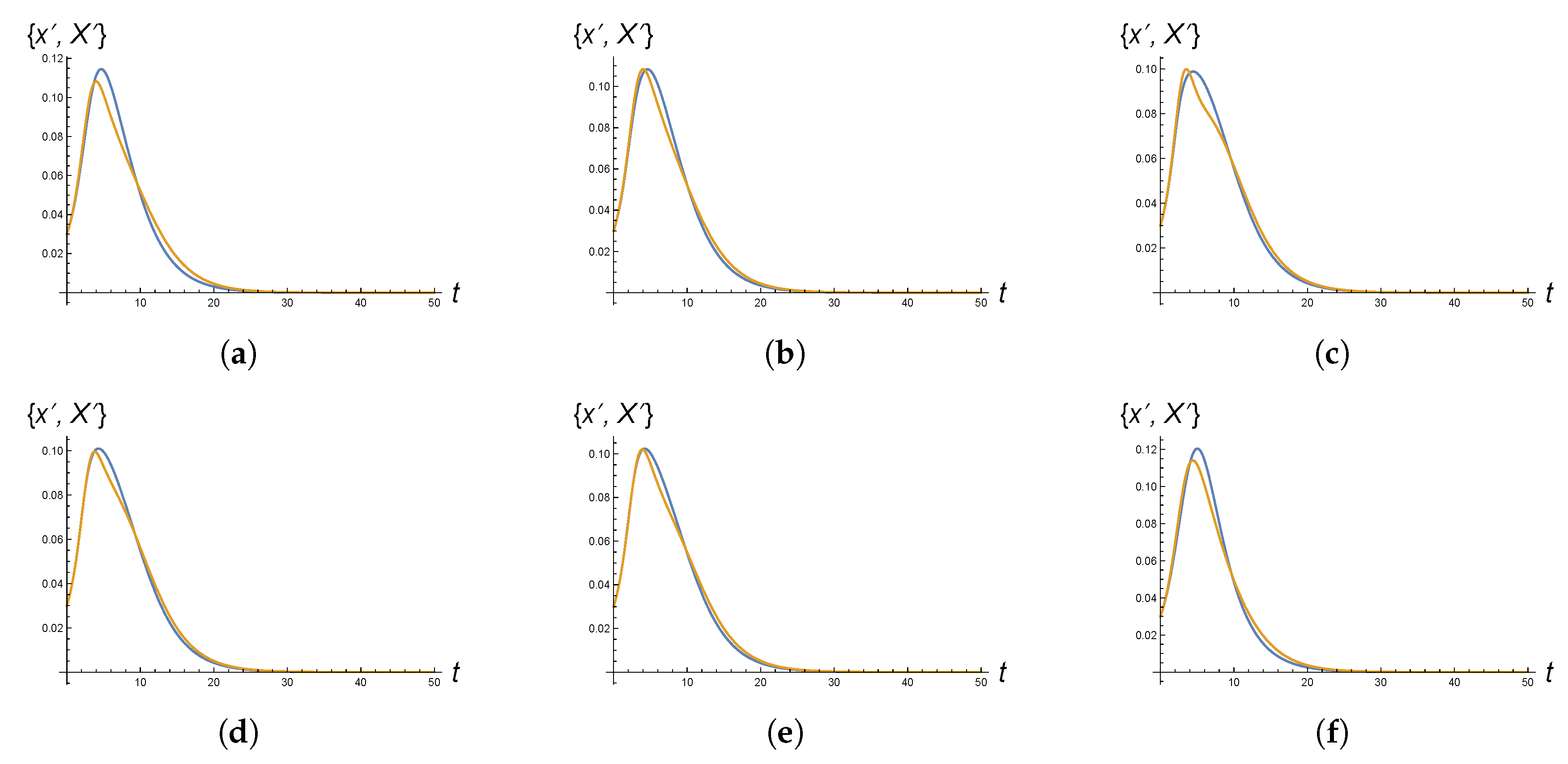{kind=link}
{kind=link}