An Extended VIKOR Method Based on q-Rung Orthopair Shadowed Set and Its Application to Multi-Attribute Decision Making


Abstract
1. Introduction
- As the evaluated objects in MADM problems, for example, some infrastructure projects, are closely related to public interest, the public’s opinions are vital and more reasonable in real situation. The more the public participate in the evaluation, the more reliable and extensive the evaluation information is. In most cases, it is much easier for people to assign words rather than numbers to each attribute value. To process the linguistic evaluation collected in the form of interval numbers, in this paper, an encoding method that transforms interval numbers to shadowed sets is constructed.
- In q-ROFS, as q increases, the space of possible orthopairs increases, which has less limitation of the value description and hence provides the DMs more freedom to express their evaluations. Inspired by this, we propose q-rung shadowed sets (q-ROSSs) and establish the corresponding basic operations.
- VIKOR (VIsekriterijumska optimizacija i KOmpromisno Resenje) method is a powerful and effective tool with merits of considering the group utility value and the individual regret value simultaneously, thus an extended VIKOR method to solve the MADM problem with q-ROSS decision information is introduced. A site selection problem is adopted to verify the validity of the approach.
2. Preliminaries
2.1. Q-Rung Orthopair Fuzzy Set (q-ROFS)
- (1)
- If,
- (2)
- If, then
- If, ;
- If, .
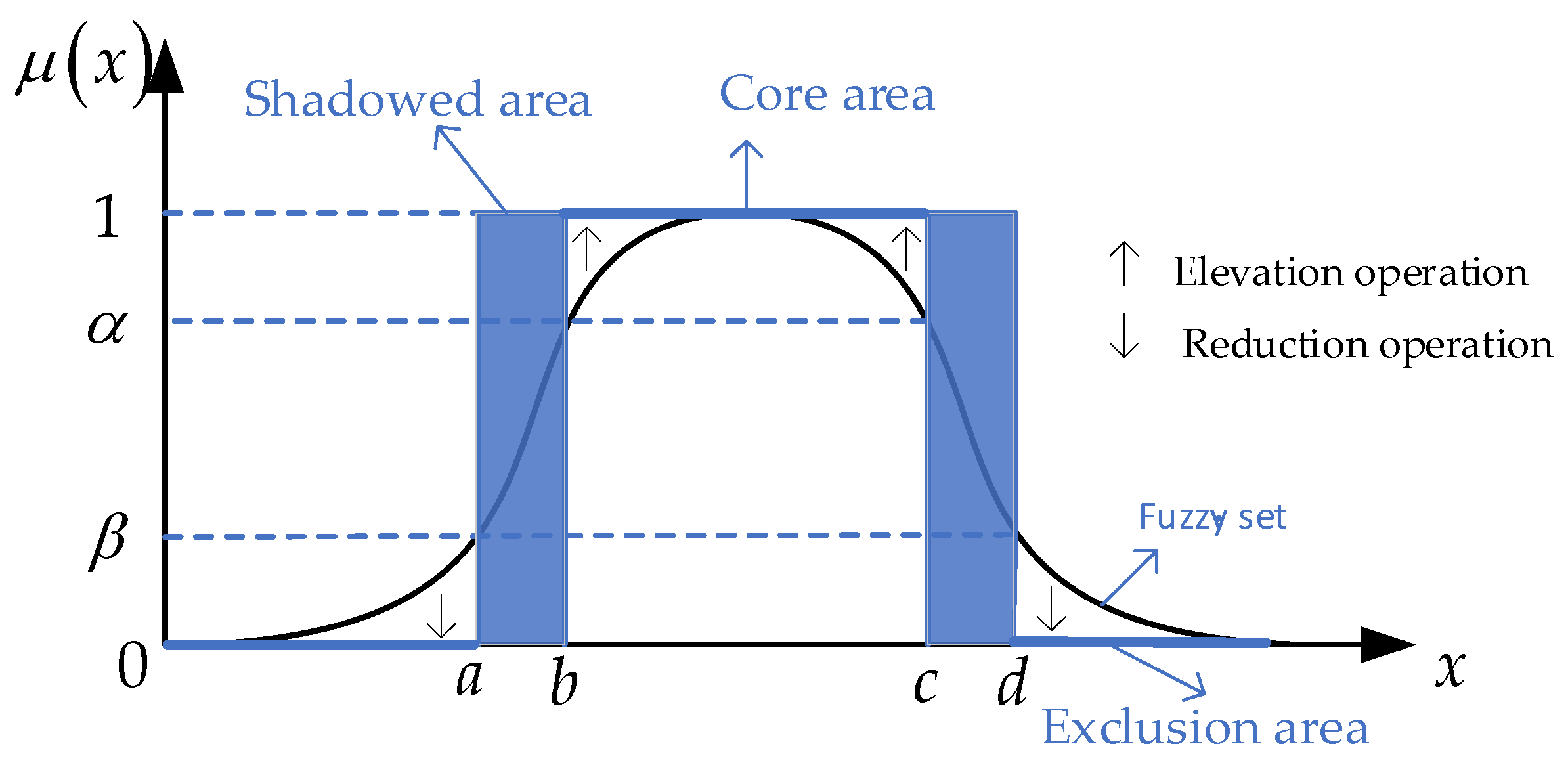
2.2. Shadowed Set
- (1)
- (2)
- (3)
- (4)
3. q-Rung Orthopair Shadowed Set (q-ROSS)
3.1. q-Rung Orthopair Shadowed Set (q-ROSS)
3.2. Distance Measure between q-SNs
- (1)
- Positivity.
- (2)
- Symmetry.
- (3)
- Triangular inequality For any q-SN where , .
4. Shadowed Set Construction from Interval Data
4.1. Interval Data Preprocessing
- (1)
- Bad data processing: This is performed for the purpose of deleting unreasonable results from the surveyed people. The interval endpoints which satisfy the following conditions,will be accepted. Otherwise, they will be omitted. After this step, interval data will remain.
- (2)
- Outlier processing: This step aims to eliminate those outliers which are extremely large or small by using the Box and Whisker test. At first, the left and right endpoints can be processed by applying outlier tests, respectively. As a result, only the interval endpoints satisfying the following conditions are retained:where and are the quartiles and interquartile ranges for the remaining left (right) endpoints, and , are the first and third quartiles, respectively. This step reduces interval endpoints to interval endpoints. Secondly, for the intervals, only those satisfying the below condition are kept:where and are the first and third quartiles, respectively, and is the interquartile ranges. After this step, interval data will be left.
- (3)
- Tolerance limit processing: The interval endpoints which meet the following conditions will be remained, otherwise be removed.where and represent the mean values and standard deviations of the reserved data endpoints, respectively, is tolerance factor. The value of can be obtained from Table 1 (suppose the parameters and are 0.05 and 0.01 in this paper). After this step, interval data will remain.
- (4)
- Reasonable-interval processing: Intervals that have overly long breadth or have little overlap with others are eliminated in this step. Suppose both the left endpoints and the right endpoints obey Gaussian distribution [28]. Thus, , , and are computed based on the remaining interval endpoints. Consequently, the endpoints of an interval satisfy the below conditions will be kept.whereAfter this step, interval data will remain.
4.2. Calculations of the Retained Interval Data
5. The Extended VIKOR Method for q-SNs MADM Problems
- (1)
- Acceptable advantage: ;
- (2)
- Acceptable stability: The alternative must also be the first position ranked by or .
- (a)
- If condition (2) is not satisfied, then and are both compromise solutions.
- (b)
- If condition (1) is not satisfied, then are all compromise solutions, where satisfy for the maximum .
6. Numerical Study
6.1. Site Selection Problem
6.2. Comparative Analysis
- (1)
- As can be seen from Table 7, though the ranking for other alternatives is slightly different, the three methods have obtained the same optimal alternative . This manifested the rationality of our proposed method.
- (3)
- It is worth noting that the aggregation operation may cause information loss or distortion when using the q-SNWG or q-SNWA combined with TOPSIS to aggregate decision information. At the same time, the degree of discrimination between alternatives is also smaller using TOPSIS.
- (3)
- The extended VIKOR method for q-SNs has the remarkable features of considering the trade-off between maximizing group utility and minimizing individual regret, which is more meaningful to MADM problems.
7. Conclusions
Author Contributions
Funding
Conflicts of Interest
References
- Zadeh, L.A. Fuzzy Sets. Inf. Control 1965, 8, 338–353. [Google Scholar] [CrossRef]
- Atanassov, K.T. Intuitionistic fuzzy sets. Int. J. Bioautom. 2016, 20, S1–S6. [Google Scholar] [CrossRef]
- Yager, R.R. Pythagorean fuzzy subsets. In Proceedings of the 2013 Joint IFSA World Congress and NAFIPS Annual Meeting (IFSA/NAFIPS), Edmonton, AB, Canada, 24–28 June 2013; pp. 57–61. [Google Scholar] [CrossRef]
- Yager, R.R. Pythagorean membership grades in multicriteria decision making. IEEE Trans. Fuzzy Syst. 2014, 22, 958–965. [Google Scholar] [CrossRef]
- Ronald, R.; Yager, N.A. Approximate reasoning with generalized orthopair fuzzy sets. Inf. Fusion 2017, 38, 65–73. [Google Scholar] [CrossRef]
- Yager, R.R. Generalized Orthopair Fuzzy Sets. IEEE Trans. Fuzzy Syst. 2017, 25, 1222–1230. [Google Scholar] [CrossRef]
- Liu, D.; Peng, D.; Liu, Z. The distance measures between q-rung orthopair hesitant fuzzy sets and their application in multiple criteria decision making. Int. J. Intell. Syst. 2019, 34, 2104–2121. [Google Scholar] [CrossRef]
- Liu, Z.; Li, L.; Li, J. q-Rung orthopair uncertain linguistic partitioned Bonferroni mean operators and its application to multiple attribute decision-making method. Int. J. Intell. Syst. 2019, 34, 2490–2520. [Google Scholar] [CrossRef]
- Yang, Z.; Li, X.; Cao, Z.; Li, J. Q-rung orthopair normal fuzzy aggregation operators and their application in multi-attribute decision-making. Mathematics 2019, 7, 1142. [Google Scholar] [CrossRef]
- Liu, D.; Huang, A. Consensus reaching process for fuzzy behavioral TOPSIS method with probabilistic linguistic q-rung orthopair fuzzy set based on correlation measure. Int. J. Intell. Syst. 2020, 35, 494–528. [Google Scholar] [CrossRef]
- Peng, X.; Liu, L. Information measures for q-rung orthopair fuzzy sets. Int. J. Intell. Syst. 2019, 34, 1795–1834. [Google Scholar] [CrossRef]
- Pinar, A.; Boran, F.E. A Q-Rung Orthopair Fuzzy Multi-Criteria Group Decision Making Method for Supplier Selection Based on a Novel Distance Measure; Springer: Berlin/Heidelberg, Germany, 2020; Volume 1, ISBN 1304202001070. [Google Scholar]
- Liang, D.; Cao, W. q-Rung orthopair fuzzy sets-based decision-theoretic rough sets for three-way decisions under group decision making. Int. J. Intell. Syst. 2019, 34, 3139–3167. [Google Scholar] [CrossRef]
- Peng, X.; Dai, J.; Garg, H. Exponential operation and aggregation operator for q-rung orthopair fuzzy set and their decision-making method with a new score function. Int. J. Intell. Syst. 2018, 33, 2255–2282. [Google Scholar] [CrossRef]
- Wang, J.; Zhang, R.; Li, L.; Zhu, X.; Shang, X. A novel approach to multi-attribute group decision making based on q-rung orthopair uncertain linguistic information. J. Intell. Fuzzy Syst. 2019, 36, 5565–5581. [Google Scholar] [CrossRef]
- Pedrycz, W. Shadowed Sets: Representing and Processing Fuzzy Sets. Trans. Syst. 1998, 28, 103–109. [Google Scholar] [CrossRef]
- Pedrycz, W. Interpretation of clusters in the framework of shadowed sets. Pattern Recognit. Lett. 2005, 26, 2439–2449. [Google Scholar] [CrossRef]
- Pedrycz, W. Granular computing with shadowed sets. Int. J. Intell. Syst. 2005, 17, 173–197. [Google Scholar] [CrossRef]
- Tahayori, H.; Sadeghian, A.; Pedrycz, W. Induction of shadowed sets based on the gradual grade of fuzziness. IEEE Trans. Fuzzy Syst. 2013, 21, 937–949. [Google Scholar] [CrossRef]
- Zhang, Y.; Yao, J.T. Game theoretic approach to shadowed sets: A three-way tradeoff perspective. Inf. Sci. 2020, 507, 540–552. [Google Scholar] [CrossRef]
- Yao, Y.; Wang, S.; Deng, X. Constructing shadowed sets and three-way approximations of fuzzy sets. Inf. Sci. 2017, 412–413, 132–153. [Google Scholar] [CrossRef]
- Wang, H.; He, S.; Pan, X.; Li, C. Shadowed sets-based linguistic term modeling and its application in multi-attribute decision-making. Symmetry 2018, 10, 688. [Google Scholar] [CrossRef]
- Li, C.; Yi, J.; Wang, H.; Zhang, G.; Li, J. Interval data driven construction of shadowed sets with application to linguistic word modelling. Inf. Sci. 2020, 507, 503–521. [Google Scholar] [CrossRef]
- Liu, P.; Wang, P. Some q-Rung Orthopair Fuzzy Aggregation Operators and their Applications to Multiple-Attribute Decision Making. Int. J. Intell. Syst. 2018, 33, 259–280. [Google Scholar] [CrossRef]
- Pedrycz, W. From Fuzzy Sets to Shadowed Sets: Interpretation and Computing Witold. Int. J. Intell. Syst. 2009, 24, 495–524. [Google Scholar] [CrossRef]
- Wu, D.; Mendel, J.M.; Coupland, S. Enhanced interval approach for encoding words into interval type-2 fuzzy sets and its convergence analysis. IEEE Trans. Fuzzy Syst. 2012, 20, 499–513. [Google Scholar] [CrossRef]
- Feilong Liu, J.M.M. Encoding Words into Normal Interval Type-2 Fuzzy Sets: HM Approach. IEEE Trans. Fuzzy Syst. 2008, 16, 1503–1521. [Google Scholar] [CrossRef]
- Yang, X.; Yan, L.; Peng, H.; Gao, X. Encoding words into Cloud models from interval-valued data via fuzzy statistics and membership function fitting. Knowl. Based Syst. 2014, 55, 114–124. [Google Scholar] [CrossRef]
- Langford, E. Quartiles in elementary statistics. J. Stat. Educ. 2006, 14, 1–20. [Google Scholar] [CrossRef]
- Naeem, K.; Riaz, M.; Peng, X.; Afzal, D. Pythagorean fuzzy soft MCGDM methods based on TOPSIS, VIKOR and aggregation operators. J. Intell. Fuzzy Syst. 2019, 37, 6937–6957. [Google Scholar] [CrossRef]
- El-Hawy, M.A.H.; Wassif, K.T.; Hefny, H.A.; Hassan, H.A. Hybrid multi-attribute decision making based on shadowed fuzzy numbers. In Proceedings of the 2015 IEEE Seventh International Conference on Intelligent Computing and Information Systems (ICICIS), Cairo, Egypt, 12–14 December 2015; pp. 514–521. [Google Scholar] [CrossRef]




{kind=link}
{kind=link}
{kind=link}
| 0.90 | 0.95 | 0.90 | 0.95 | |
|---|---|---|---|---|
| 10 | 2.839 | 3.379 | 3.582 | 4.265 |
| 15 | 2.480 | 2.954 | 2.945 | 3.507 |
| 20 | 2.310 | 2.752 | 2.659 | 3.168 |
| 30 | 2.140 | 2.549 | 2.358 | 2.841 |
| 50 | 1.996 | 2.379 | 2.162 | 2.576 |
| 100 | 1.874 | 2.233 | 1.977 | 2.355 |
| 1000 | 1.709 | 2.036 | 1.736 | 2.718 |
| ∞ | 1.645 | 1.960 | 1.645 | 1.960 |
| G1 | G2 | |
| A1 | ||
| A2 | ||
| A3 | ||
| A4 | ||
| A5 | ||
| G3 | G4 | |
| A1 | ||
| A2 | ||
| A3 | ||
| A4 | ||
| A5 |
| G1 | G2 | |
| A1 | ||
| A2 | ||
| A3 | ||
| A4 | ||
| A5 | ||
| G3 | G4 | |
| A1 | ||
| A2 | ||
| A3 | ||
| A4 | ||
| A5 |
| G1 | G2 | G3 | G4 | |
|---|---|---|---|---|
| 0.0000 | 0.2263 | 0.0000 | 0.0643 | |
| 0.2267 | 0.0000 | 0.4667 | 0.0870 | |
| 0.3821 | 0.0000 | 0.0000 | 0.0646 | |
| 0.2443 | 0.1986 | 0.4721 | 0.0000 | |
| 0.000 | 0.3052 | 0.2929 | 0.0000 | |
| 1.5875 | 1.6486 | 1.5287 | 1.2090 |
| Aggregated Values by q-SNWG | Aggregated Values by q-SNWA | |
|---|---|---|
| A1 | ||
| A2 | ||
| A3 | ||
| A4 | ||
| A5 | ||
| q-SNWG Method | q-SNWA Method | |
|---|---|---|
| A1 | 0.5640 | 0.6503 |
| A2 | 0.2828 | 0.3859 |
| A3 | 0.4369 | 0.5059 |
| A4 | 0.3240 | 0.4640 |
| A5 | 0.4571 | 0.4564 |
| Order | |
|---|---|
| q-SNWG | |
| q-SNWA | |
| q-SN VIKOR Model |
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Wang, H.; Zhang, Y.; Yao, J. An Extended VIKOR Method Based on q-Rung Orthopair Shadowed Set and Its Application to Multi-Attribute Decision Making. Symmetry 2020, 12, 1508. https://doi.org/10.3390/sym12091508
Wang H, Zhang Y, Yao J. An Extended VIKOR Method Based on q-Rung Orthopair Shadowed Set and Its Application to Multi-Attribute Decision Making. Symmetry. 2020; 12(9):1508. https://doi.org/10.3390/sym12091508
Chicago/Turabian StyleWang, Huidong, Yao Zhang, and Jinli Yao. 2020. "An Extended VIKOR Method Based on q-Rung Orthopair Shadowed Set and Its Application to Multi-Attribute Decision Making" Symmetry 12, no. 9: 1508. https://doi.org/10.3390/sym12091508
APA StyleWang, H., Zhang, Y., & Yao, J. (2020). An Extended VIKOR Method Based on q-Rung Orthopair Shadowed Set and Its Application to Multi-Attribute Decision Making. Symmetry, 12(9), 1508. https://doi.org/10.3390/sym12091508