Method for Retrieving Digital Agricultural Text Information Based on Local Matching


Abstract
1. Introduction
2. Material Methods
2.1. Method for Retrieving Digital Agricultural Text Information Based on Local Matching
2.1.1. Construction of Digital Agricultural Text Tree and Query Tree
2.1.2. Agricultural Text Information Retrieval
2.2. Experimental Materials
2.2.1. Experimental Setup of Recall Rate and Precision Rate
2.2.2. Experimental Setup for Retrieval Efficiency
3. Results
3.1. Comparative Test of Retrieval Effect
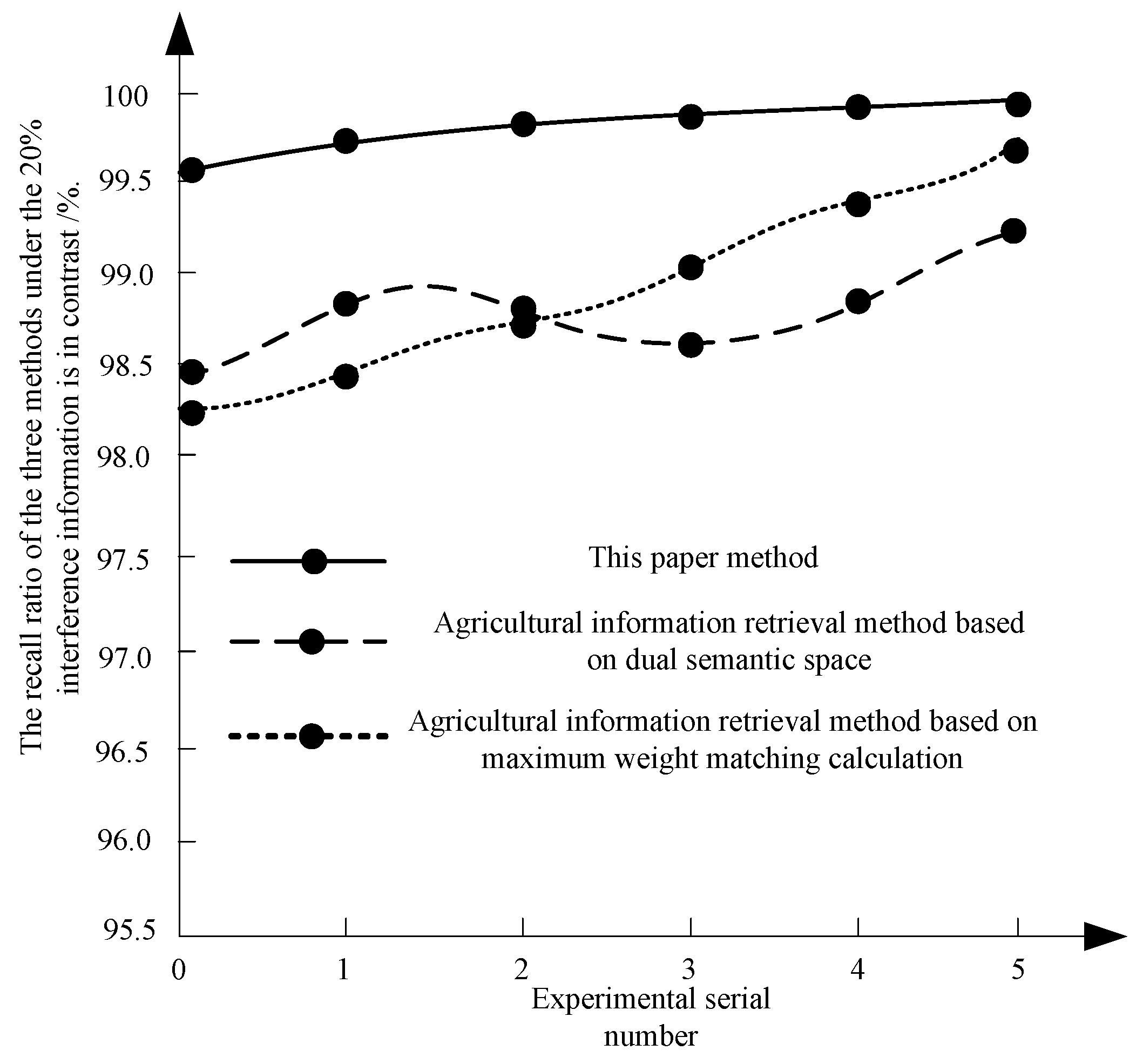
3.1.1. Recall Rate
3.1.2. Precision Rate
3.2. Comparison Experiment of the Retrieval Efficiency
3.2.1. Comparison of Retrieval Time
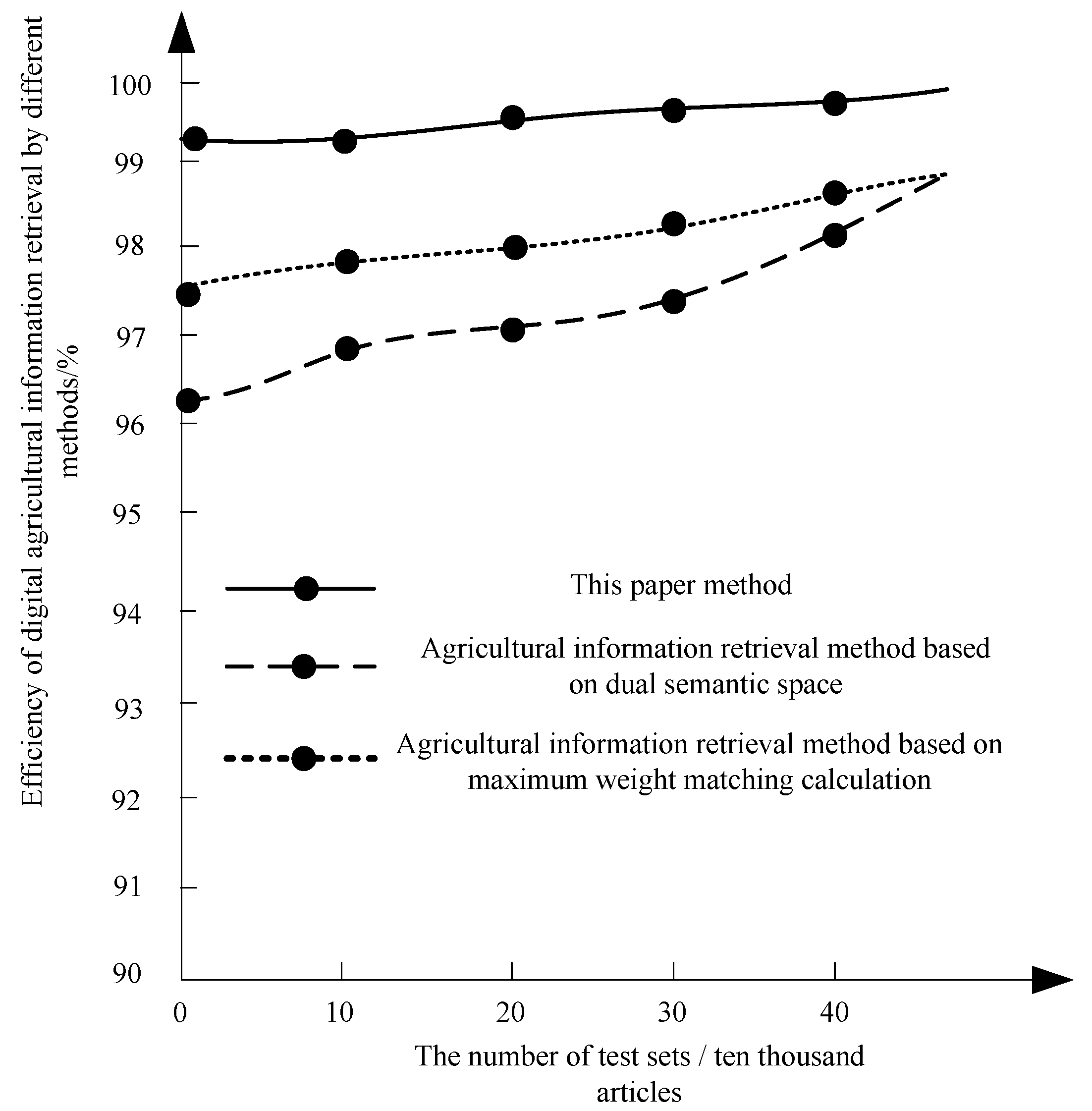
3.2.2. Comparison of Retrieval Efficiency
4. Discussion
4.1. Discussion on the Retrieval Effect of the Three Methods
4.1.1. Recall Rate
4.1.2. Precision Rate
4.2. Discussion on the Retrieval Efficiency of the Three Methods
4.2.1. Retrieval Time
4.2.2. Retrieval Efficiency
5. Conclusions
Author Contributions
Funding
Conflicts of Interest
References
- Wu, Z.; Gao, K.; Wang, Z.L. Linear information retrieval method in X-ray grating-based phase contrast imaging and its interchangeability with tomographic reconstruction. J. Appl. Phys. 2017, 121, 23–26. [Google Scholar] [CrossRef]
- Yang, Y.G.; Sun, S.J.; Wang, Y. Quantum oblivious transfer based on a quantum symmetrically private information retrieval protocol. Int. J. Theor. Phys. 2015, 54, 910–916. [Google Scholar] [CrossRef]
- Hu, Y.T.; Hui, F.P. The Application of Metadata Methods in the Perspective of Digital Humanities: A Case Study of Agricultural Heritage. Library 2019, 000, 82–87. [Google Scholar]
- Ming, Y.; Cuicui, F.; Fuchuan, M. Research on Innovation of Information Resource Management in the Age of Big Data. Res. Libr. Sci. 2019, 6, 56–61. [Google Scholar]
- Wang, L. Text information retrieval algorithm simulation analysis under massive data. Comput. Simul. 2016, 33, 429–432. [Google Scholar]
- Junnila, V.; Laihonen, T. Information retrieval with varying number of input clues. IEEE Trans. Inf. Theory 2016, 62, 625–638. [Google Scholar] [CrossRef]
- Shi, J.; Liu, D.; Cui, L. Retrieval of contaminated information using random lasers. Appl. Phys. Lett. 2015, 106, 685. [Google Scholar]
- Besson, M.; Kutas, M.; Vanpetten, C. Effect of semantic expectancy upon information-retrieval. Psychophysiology 2016, 23, 425–426. [Google Scholar]
- Khennak, I.; Drias, H. An accelerated PSO for query expansion in web information retrieval: Application to medical dataset. Appl. Intell. 2017, 47, 793–808. [Google Scholar] [CrossRef]
- Krause, C.; Johannsen, D.; Deeb, R. An SQL-based query language and engine for graph pattern matching. Networks 2016, 20, 345–359. [Google Scholar]
- Liang, M.; Du, J.; Cao, S. Super-resolution reconstruction based on multisource bidirectional similarity and non-local similarity matching. IET Image Process. 2015, 9, 931–942. [Google Scholar] [CrossRef]
- Subber, W.; Matouš, K. Asynchronous space–time algorithm based on a domain decomposition method for structural dynamics problems on non-matching meshes. Comput. Mech. 2016, 57, 211–235. [Google Scholar] [CrossRef]
- Zhang, X.; Tan, C.L. Handwritten word image matching based on Heat Kernel Signature. Pattern Recognit. 2015, 48, 3346–3356. [Google Scholar] [CrossRef]
- Bors, A.G.; Papushoy, A. Image retrieval based on query by saliency content. Digit. Signal Process. 2015, 36, 156–173. [Google Scholar]
- Kotsifakos, A.; Karlsson, I.; Papapetrou, P. Embedding-based subsequence matching with gaps-range-tolerances: A Query-By-Humming application. VLDB J. 2015, 24, 519–536. [Google Scholar] [CrossRef]
- Duch, A.; Lau, G.; Martínez, C. On the cost of fixed partial match queries in K -d trees. Algorithmica 2016, 75, 1–40. [Google Scholar] [CrossRef]
- Tang, J.; Luo, J.; Tjahjadi, T. Robust Arbitrary-View Gait Recognition Based on 3D partial similarity matching. IEEE Trans. Image Process. 2016, 26, 7–22. [Google Scholar] [CrossRef] [PubMed]
- Mei, K. Opportunities for women, minorities in information retrieval. Commun. ACM 2017, 60, 10–11. [Google Scholar]
- Lyu, H.; Zhang, J.; Zha, G. Developing a two-step retrieval method for estimating total suspended solid concentration in Chinese turbid inland lakes using Geostationary Ocean Colour Imager (GOCI) imagery. Int. J. Remote Sens. 2015, 36, 1385–1405. [Google Scholar] [CrossRef]
- Niazi, S.K.; Alam, S.M.; Ahmad, S.I. Partial-area method in bioequivalence assessment: Naproxen. Biopharm. Drug Dispos. 2015, 18, 103–116. [Google Scholar] [CrossRef]
- Gao, W.; Zhu, L.; Guo, Y.; Wang, K. Ontology learning algorithm for similarity measuring and ontology mapping using linear programming. J. Intell. Fuzzy Syst. 2017, 33, 3153–3163. [Google Scholar] [CrossRef]
- Gao, W.; Wang, W. A tight neighborhood union condition on fractional (g, f, n’, m)-critical deleted graphs. Colloq. Math. 2017, 149, 291–298. [Google Scholar] [CrossRef]
- Shirakol, S.; Kalyanshetti, M.; Hosamani, S.M. QSPR analysis of certain distance based topological indices. Appl. Math. Nonlinear Sci. 2019, 4, 371–385. [Google Scholar] [CrossRef]
- Dewasurendra, M.; Vajravelu, K. On the method of inverse mapping for solutions of coupled systems of nonlinear differential equations arising in nanofluid flow, heat and mass transfer. Appl. Math. Nonlinear Sci. 2018, 3, 1–14. [Google Scholar] [CrossRef]










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Test Set Number/Individual | Test Times | ||||
|---|---|---|---|---|---|
| First Test/% | Second Test/% | Third Test/% | Fourth Test/% | Fifth Test/% | |
| 50 | 94.4 | 94.5 | 93.4 | 94.5 | 94.6 |
| 100 | 94.5 | 94.3 | 93.4 | 94.3 | 94.2 |
| 150 | 94.6 | 93.2 | 94.5 | 93.2 | 94.5 |
| 200 | 94.2 | 93.9 | 94.2 | 93.9 | 94.8 |
| 250 | 94.5 | 93.7 | 93.5 | 93.5 | 93.8 |
| 300 | 94.8 | 93.8 | 93.5 | 94.8 | 94.8 |
| 350 | 94.8 | 94.8 | 94.8 | 93.8 | 94.9 |
| 400 | 94.8 | 94.9 | 93.8 | 94.1 | 93.4 |
| 450 | 93.5 | 93.9 | 94.1 | 93.8 | 93.4 |
| 500 | 94.9 | 94.7 | 93.8 | 93.8 | 94.5 |
| Precision ratio/% | 94.5 | 94.1 | 94.0 | 94.0 | 94.3 |
| Test Set Number/Individual | Test Times | ||||
|---|---|---|---|---|---|
| First Test/% | Second Test/% | Third Test/% | Fourth Test/% | Fifth Test/% | |
| 50 | 95.8 | 95.4 | 96.8 | 96.5 | 96.5 |
| 100 | 96.2 | 95.6 | 97.1 | 96.8 | 96.6 |
| 150 | 96.8 | 96.8 | 97.2 | 96.7 | 95.6 |
| 200 | 96.7 | 96.5 | 96.2 | 95.9 | 95.8 |
| 250 | 95.9 | 96.6 | 96.4 | 95.8 | 96.5 |
| 300 | 95.8 | 95.6 | 97.1 | 95.6 | 95.8 |
| 350 | 96.8 | 95.8 | 96.5 | 95.8 | 96.7 |
| 400 | 96.5 | 96.2 | 95.6 | 97.1 | 95.6 |
| 450 | 95.8 | 96.8 | 95.8 | 97.2 | 96.8 |
| 500 | 96.7 | 95.1 | 96.5 | 96.2 | 96.5 |
| Precision ratio/% | 96.3 | 96.0 | 96.5 | 96.3 | 96.2 |
| Test set Number/Individual | Test Times | ||||
|---|---|---|---|---|---|
| First Test/% | Second Test/% | Third Test/% | Fourth Test/% | Fifth Test/% | |
| 50 | 99.5 | 99.2 | 99.3 | 99.3 | 100 |
| 100 | 99.5 | 99.8 | 99.6 | 99.4 | 99.5 |
| 150 | 99.1 | 99.3 | 99.7 | 100 | 99.1 |
| 200 | 99.2 | 99.4 | 99.4 | 99.6 | 99.2 |
| 250 | 99.5 | 99.6 | 99.8 | 99.8 | 99.5 |
| 300 | 99.6 | 99.6 | 99.4 | 99.9 | 99.8 |
| 350 | 99.8 | 99.5 | 99.6 | 99.5 | 99.9 |
| 400 | 99.9 | 99.8 | 99.6 | 99.1 | 99.5 |
| 450 | 99.7 | 99.7 | 100 | 99.2 | 99.1 |
| 500 | 100 | 99.6 | 99.4 | 100 | 99.2 |
| Precision ratio/% | 99.6 | 99.6 | 99.6 | 99.6 | 99.5 |
| Test the Number of Pages/Tens of Thousands of Pages | This Paper Method/s | Agricultural Information Retrieval Method Based on Maximum Weight Matching Calculation/s | Agricultural Information Retrieval Method Based on Dual Semantic Space/s |
|---|---|---|---|
| 2 | 2.5 | 3.2 | 6.8 |
| 4 | 3.2 | 4.2 | 8.2 |
| 6 | 3.2 | 5.1 | 10.2 |
| 8 | 4.2 | 6.8 | 13.8 |
| 10 | 4.8 | 7.2 | 15.4 |
| 12 | 5.2 | 9.1 | 19.4 |
| 14 | 5.5 | 9.9 | 23.4 |
| 16 | 6.8 | 11.2 | 26.7 |
| 18 | 8.6 | 12.9 | 28.9 |
| 20 | 9.1 | 15.2 | 32.2 |
| Mean time/s | 5.3 | 8.5 | 18.5 |
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Song, Y.; Wang, M.; Gao, W. Method for Retrieving Digital Agricultural Text Information Based on Local Matching. Symmetry 2020, 12, 1103. https://doi.org/10.3390/sym12071103
Song Y, Wang M, Gao W. Method for Retrieving Digital Agricultural Text Information Based on Local Matching. Symmetry. 2020; 12(7):1103. https://doi.org/10.3390/sym12071103
Chicago/Turabian StyleSong, Yue, Minjuan Wang, and Wanlin Gao. 2020. "Method for Retrieving Digital Agricultural Text Information Based on Local Matching" Symmetry 12, no. 7: 1103. https://doi.org/10.3390/sym12071103
APA StyleSong, Y., Wang, M., & Gao, W. (2020). Method for Retrieving Digital Agricultural Text Information Based on Local Matching. Symmetry, 12(7), 1103. https://doi.org/10.3390/sym12071103